Discovering Emerging Topics in Social Streams via Link Anomaly Detection
Detection of emerging topics are now receiving renewed interest motivated by the rapid growth of social networks. Conventional term-frequency-based approaches may not be appropriate in this context, because the information exchanged are not only text…
Authors: Toshimitsu Takahashi, Ryota Tomioka, Kenji Yamanishi
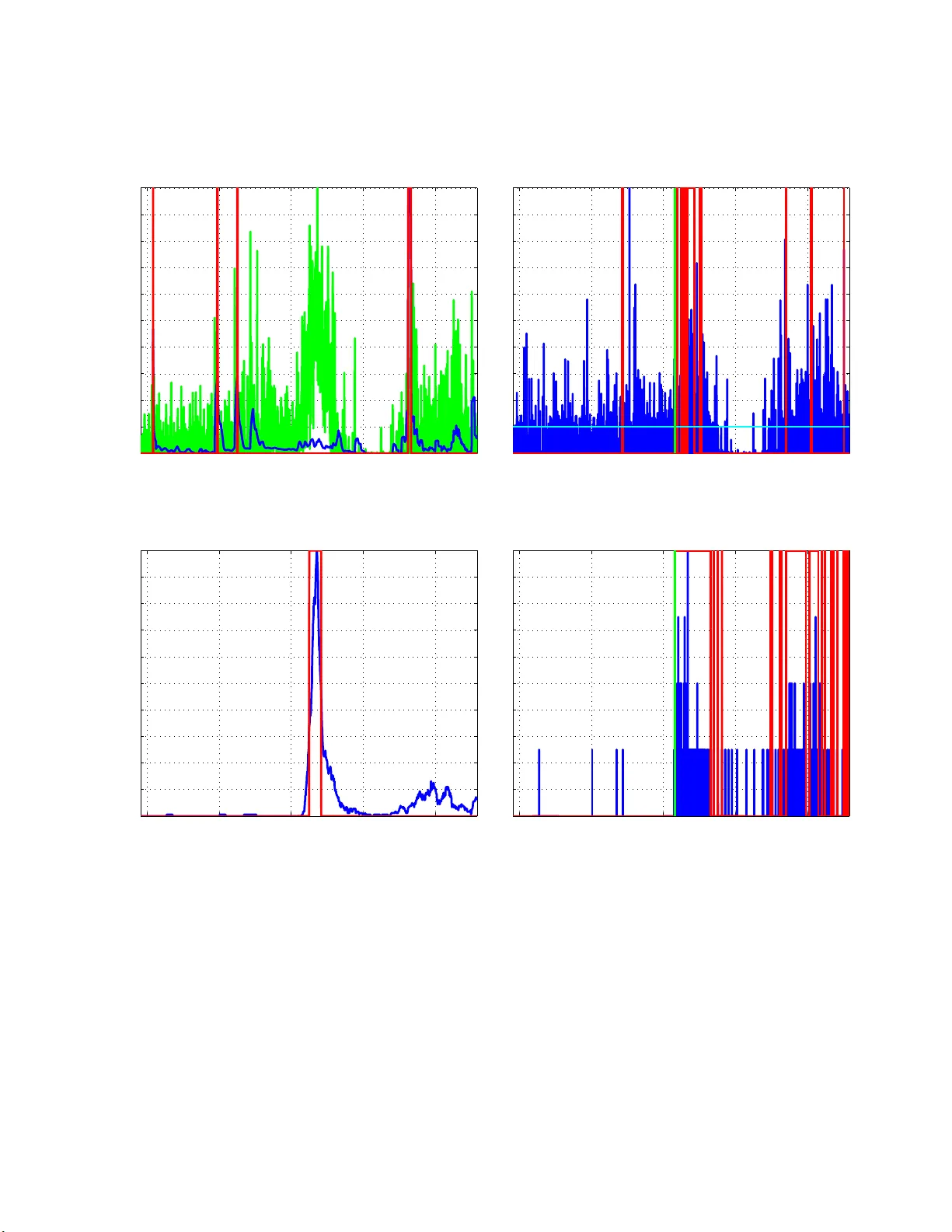
Disco v ering Emerging T opics in S o cial Streams via L ink Anomaly Detection T oshimitsu T ak ahashi Institute of Industrial Science The Univ ersit y of T oky o T oky o, Japan Email: tak ahashi@tauhat.com Ry ota T omiok a Departmen t of Mathematical Informatics The Univ ersit y of T oky o T oky o, Japan Email: tomiok a@mist.i.u-toky o.ac.jp Kenji Y amanishi Departmen t of Mathematical Informatics The Univ ersit y of T oky o T oky o, Japan Email: yamanis hi@mist.i.u-tokyo.ac.jp No v em b er 27 , 2024 Abstract Detection o f emerging topics are now receiving renewed in terest motiv ated by the rapid gro wth of social netw orks. Con ven tional term-frequency-based approac hes ma y not b e appropriate in this con text, b ecause the information exc hanged are not only texts but also imag es, URLs, and videos. W e focus on the so cial asp ects of theses n etw orks. That is, the links b etw een users that are generated dynamically inten tionally or uninten tionally through replies, mentions, and retw eets. W e p rop ose a probabilit y mod el of the mentioning b ehaviour of a social netw ork user, and p ropose to d etect t h e emergence of a new topic from t he anomaly measured through the mod el. W e com bine the proposed mention anomaly score with a recently p roposed c hange-p oint detection technique based on the Sequ entia lly Discounting Normalized Maxim um Likel iho o d (SDNML), or with K lein b erg’s b urst mo del. Aggregating anomaly scores from hundreds of u sers, we show that we can detect emerging topics only based on the reply/men tion relation- ships in social net wo rk p osts. W e demonstrate our technique in a n umber of real data sets we gathered from Twitter. The experiments show that the proposed men tion-anomaly-based approac hes can detect new topics at least as early as the conv entio nal term- frequency-based approach, and sometimes m uch earlier when the keyw ord is ill-defined. Keyw ords : T opic Detection, Anomaly Detection, So c ia l Netw orks, Sequentially Discounted Maximum Likelihoo d Co ding, Burst detection 1 In tro duction Communication through so cial netw or k s, such a s F aceb o o k and Twitter, is increasing its imp ortance in our daily life. Since the infor ma tion exc hanged ov er s o cial net works a re not only texts but also URLs, images, and videos, they are c hallenging test beds for the study of data mining. 1 !"#$%&' (()*&+,(,&)((-& ./0 1&+ 0)2'$3 4 &5 (1*&/6# ! 7 (/8 ! + 7 (/8&)((-&./0 1& +0)2'$3 4 &5 (1*&/6#9::; ! ,(, ! <=&+7(/89&!"#$%&' (()*& +,(,&)((-&./01&+0)2'$ ! >0? $ ! Figure 1: Example of the emergence of a topic in socia l streams. There is another type of information that is in tentionally or unint entionally exchanged o ver socia l net- works: mentions. Here we mean by men tions links to other users of the same so cial netw ork in the form of messag e-to, reply-to , retw eet-of, or e xplicitly in the text. One p ost ma y contain a num be r of mentions. Some users may include men tions in their p osts rar e ly ; other users may be men tioning their friends all the time. Some users (lik e celebrities) may rec eive men tions every min ute; for others, being mentioned might b e a r are o ccasion. In this sense, mention is like a language with the n umber of words equal to the n umber of users in a so cial net work. W e are interested in detecting emer ging topics from s o cial netw ork strea ms based o n monitoring the men tioning b ehaviour of users . Our bas ic assumption is that a new (emer ging) topic is something p eople feel like discussing ab out, commenting ab out, or forwarding the information further to their friends. Conven tio nal approaches for topic detection hav e mainly b een conce r ned with the freq uencies of (textual) words [1, 2]. A term fr e q uency based approach could suffer fr om the am biguity caused by syno nyms or homonyms. It ma y also requir e complica ted prepro ces sing (e.g., seg men tation) dep ending on the tar get lang ua ge. Moreov er, it cannot b e applied when the con tents of the messag e s are mostly non-textual informatio n. On the other hands, the “words” for med by mentions ar e unique, requires little prep os sessing to obtain (the infor mation is often separated from the conten ts ), and are av ailable regardless of the nature of the con tents. Figure 1 sho ws a n example of the emerg ence of a topic thr o ugh p osts on so cial netw or ks. The first po st by Bob c o nt ains men tions to Alice and John, which are b oth probably friends of Bob’s; so there is nothing un usual her e. The sec o nd p ost by Jo hn is a reply to B o b but it is also visible to many fr iends of John’s that a re not direct friends o f Bo b’s. Then in the third p o st, Dav e, o ne o f Jo hn’s friends, forwards (called retw eet in Twitter) the information fur ther down to his own friends. It is w orth mentioning that it is not clear what the topic of this conv ers ation is ab out fro m the textual informa tion, b eca use they are talk ing ab out s o mething (a new gadget, car, or jew elry ) that is sho wn a s a link in the text. In this pap er, w e prop ose a probability mo del that can capture the normal mentioning b ehaviour of a user, which consists of both the num ber of mentions p er po st and the freq uency of user s o ccurring in the mentions. Then this model is use d to measure the anomaly of future user b ehaviour. Using the pro po sed probability mo del, we can quantitativ ely meas ur e the novelt y or p ossible impact o f a p ost reflected in the men tioning 2 behaviour of the user. W e aggre g ate the anomaly scores obtained in this w ay over h undreds of users and apply a r ecently prop osed change-po in t detection tech nique based on the Sequentially Disco un ting Normalized Maximum Lik eliho o d (SDNML) co ding [3]. This technique can detect a change in the statistical dep endence structure in the time series of a ggreg a ted ano maly scores , and pin-po int where the topic emerge nc e is ; see Figure 2 . The effectiveness of the prop os e d approa ch is demonstra ted on four data sets we hav e collected from Twitter. W e show that our appro ach can detect the emerg ence of a new topic at least as fast as using the bes t term that was not ob vious at the moment. F urthermore, we show that in tw o out of fo ur data sets, the prop osed link-anomaly ba sed metho d can detect the emergence of the topics earlier than keyw ord- frequency based metho ds, whic h can be explained by the keyw or d ambiguity we mentioned ab ov e. 2 Related w ork Detection a nd tracking of to pic s hav e b e en studied extensively in the area of topic detection and tra cking (TDT) [1]. In this context, the main task is to either class ify a new do cument in to one of the kno wn topics (tracking) o r to detect that it b elong s to none of the known ca tegories. Subsequently , temp oral structur e of topics hav e b een mo deled a nd analyzed thro ugh dynamic mo del selection [4], tempo ral text mining [5], and factorial hidden Marko v mo de ls [6]. Another line of research is concerned with formalizing the notion of “bursts” in a stream of do cuments. In his se mina l pap er, Kleinberg mo deled bursts using time v ar ying Poisson pro c e ss with a hidden discrete pro cess that controls the firing rate [2]. Recently , He and Parker developed a physics inspir ed mo del of bur sts based on the change in the momen tum o f topics [7]. All the ab ov e mentioned studies make use of textual cont ent o f the do cuments, but not the so cia l con tent of the do cumen ts. The so cial conten t (links) hav e been utilized in the study of citatio n netw orks [8]. How ever, citation netw orks a re often analyzed in a stationary setting. The nov elty of the curr ent pap er lies in fo cusing on the s o cial con tent of the documents (posts) and in combining this with a c hange- po int analysis . 3 Prop osed Metho d The ov era ll flow of the prop os ed method is shown in Figure 2. W e assume that the da ta ar r ives from a so c ia l net work service in a sequential manner through so me API. F o r each new p os t we use samples within the past T time interv al for the co rresp onding user for training the men tion mo del we prop os e below. W e assign anomaly score to eac h po st based on the learned probability distribution. The score is then aggregated over users a nd further fed in to a c hange- po in t analys is. 3.1 Probabilit y Mo del W e characterize a pos t in a social netw ork stream b y the num ber of men tions k it con tains, and the set V of na mes (IDs) of the users men tioned in the po st. F ormally , we consider the following joint pr o bability distribution P ( k , V | θ , { π v } ) = P ( k | θ ) Y v ∈ V π v . (1) Here the joint dis tr ibution consists of tw o parts: the probability o f the num b er of mentions k and the probability of each mention g iven the n umber o f mentions. The probability of the num b er of mentions 3 !"#$%&' ()*+",-' !),.$#) ! /$0) ! 1"23 4' 5)+'6"4* ! 7"853 4' 5)+'6"4* ! 9"06:* )'$5;$.$ ;:%&' %5"0%&<'4#",)4 ! => >, )> % * ) ! 98%5>)?6"$5*'%5%&< 4$4' @!A(BCD ! /$0) ! /$0) ! /$0) ! / ! / ! / ,%$5$5> ! 1"23 4'6"4*4 ! 7"853 4'6"4*4 ! C)%,5' 0)5E"5' ;$4 *,$2:E"5' "F'1"2 ! C)%,5' 0)5E"5' ;$4 *,$2:E"5' "F'7"85 ! =GH ! Figure 2: Overall flow o f the propo sed metho d. P ( k | θ ) is defined as a geometric distribution with parameter θ a s follows: P ( k | θ ) = (1 − θ ) k θ. (2) On the o ther hand, the probability of ment ioning users in V is defined as indep endent, identical m ultinomial distribution with parameters π v ( P v π v = 1). Suppo se that we ar e g iven n training ex amples T = { ( k 1 , V 1 ), . . . , ( k n , V n ) } from which we w ould like to learn the predictive dis tribution P ( k , V |T ) = P ( k |T ) Y v ∈ V P ( v |T ) . (3) First we co mpute the predictive distribution with resp ect to the the num b er of mentions P ( k |T ). This can be obtained by assuming a b eta distribution as a prior and in tegra ting out the pa r ameter θ . The densit y 4 function of the b eta prior distribution is written as fo llows: p ( θ | α, β ) = (1 − θ ) β − 1 θ α − 1 B ( α, β ) , where α a nd β ar e parameters of the b eta distribution and B ( α, β ) is the beta function. By the Bayes rule, the predic tive distribution can b e obta ined as follows: P ( k |T , α, β ) = P ( k | k 1 , . . . , k n , α, β ) = P ( k , k 1 , . . . , k n | α, β ) P ( k 1 , . . . , k n | α, β ) = R 1 0 (1 − θ ) P n i =1 k i + k + β − 1 θ n +1+ α − 1 d θ R 1 0 (1 − θ ) P n i =1 k i + β − 1 θ n + α − 1 d θ . Both the in tegra ls on the numerator and deno minator ca n b e obtained in closed forms as b eta functions and the predic tive distribution can b e re written as fo llows: P ( k |T , α, β ) = B ( n + 1 + α, P n i =1 k i + k + β ) B ( n + α, P n i =1 k i + β ) . Using the relatio n b etw een b eta function a nd gamma function, we can further simplify the express ion as follows: P ( k |T , α, β ) = n + α m + k + β k Y j =0 m + β + j n + m + α + β + j , (4) where m = P n i =1 k i is the total num ber of mentions in the training set T . Next, w e derive the pr edictive distribution P ( v |T ) of men tioning user v . The maximum likelihoo d (ML) estimator is given as P ( v |T ) = m v /m , where m is the num ber of total mentions and m v is the num b er of men tions to us e r v in the data set T . The ML estimator, how e ver, ca nnot handle users that did not appea r in the training set T ; it would assign proba bility zer o to all these user s, which would app ear infinitely anoma lous in our fra mework. Instead we us e the Chinese Restaura nt Pro cess (CRP; se e [9]) based estimation. The CRP based estimator as signs pro bability to each user v that is propo rtional to the num b er of mentions m v in the training set T ; in addition, it k eeps probability prop ortional to γ for mentioning someo ne who was not mentioned in the training set T . Acco r dingly the pr obability of known users is g iven as follows: P ( v |T ) = m v m + γ (for v : m v ≥ 1) . (5) On the other hand, the probability of ment ioning a new user is given as follows: P ( { v : m v = 0 }|T ) = γ m + γ . (6) 3.2 Computing the link-anom aly score In or der to compute the anomaly s core o f a new p ost x = ( t, u, k , V ) by user u at time t containing k men tions to users V , we compute the pr obability (3) with the tr aining set T ( t ) u , which is the co lle c tion of 5 po sts by user u in the time p erio d [ t − T , t ] (we use T = 30 days in this paper ). Accor dingly the link-anomaly score is defined as follo ws: s ( x ) = − log P ( k |T ( t ) u ) Y v ∈ V P ( v |T ( t ) u ) ! = − log P ( k |T ( t ) u ) − X v ∈ V log P ( v |T ( t ) u ) . (7) The tw o ter ms in the a bove equation can b e computed via the predic tive distribution of the n umber o f men tions (4), and the predictive distribution of the men tionee (5)–(6), resp ectively . 3.3 Com bining Anomaly Scores from Differen t Users The anomaly score in (7) is co mputed for each user dep ending on the curr en t p ost of user u and his/ he r past behaviour T ( t ) u . In o r der to measure the general trend of user b e haviour, w e prop ose to a ggreg ate the anomaly scor es obtained for po sts x 1 , . . . , x n using a discretization of windo w size τ > 0 as follows: s ′ j = 1 τ X t i ∈ [ τ ( j − 1) ,τ j ] s ( x i ) , (8) where x i = ( t i , u i , k i , V i ) is the po st at time t i by us er u i including k i men tions to users V i . 3.4 Change-point detection via Sequen tially Discoun ting Normalized Maxim um Lik eliho o d Co ding Given a n a ggreg a ted mea sure o f anomaly (8), we a pply a ch ang e-p oint detectio n technique based on the SDNML c o ding [3]. This tech nique detects a c hange in the statistical dependence structure of a time ser ies by mo nitoring the compressibilit y o f the new piece of data. The s equential v ersio n o f normalized maximum likelihoo d (NML) co ding is employ ed as a co ding criterion. More precisely , a change p oint is detected through t wo la yers of scoring pro cesses (see also [10, 11]); in each lay er, the SDNML code length based on an autoregr essive (AR) mo del is used as a cr iterion for s coring. Although the NML co de length is known to be o ptimal [12], it is often hard to compute. The SNML propos ed in [13] is an a pproximation to the NML co de length that can b e computed in a s equential manner. The SDNML prop osed in [3 ] further employs discounting in the learning of the AR mo dels. Algorithmically , the change p oint detection pr o cedure can be o utlined as follows. F or conv enience, we denote the aggregate anomaly score as x j instead of s ′ j . 1. 1st la y er learning Let x j − 1 := { x 1 , . . . , x j − 1 } b e the collection o f aggreg ate anomaly scores from dis- crete time 1 to j − 1. Sequentially le a rn the SDNML density function p SDNML ( x j | x j − 1 ) ( j = 1 , 2 , . . . ); see App endix A for details. 2. 1st la y er scoring Compute the intermediate change-po int sco re by smoo thing the log los s of the SD- NML density function with windo w siz e κ as follows: y j = 1 κ j X j ′ = j − κ +1 − log p SDNML ( x j | x j − 1 ) . 6 Algorithm 1 Dynamic Threshold Optimization (DTO) [14] Given: { S cor e j | j = 1 , 2 , . . . } : scores , N H : tota l num b er of cells, ρ : parameter for threshold, λ H : estimatio n parameter, r H : discounting p arameter, M : data size Initialization: Let q (1) 1 ( h ) ( a w eigh ted sufficient statistics ) b e a uniform distribution. for j = 1 , . . . , M − 1 do Threshold optimization: Let l be the least ind ex such that P l h =1 q ( j ) ( h ) ≥ 1 − ρ . The threshold at time j is giv en as η ( j ) = a + b − a N H − 2 ( l + 1) . Alarm output: R aise an alarm if S cor e j ≥ η ( j ). Histogram update: q ( j +1) 1 ( h ) = (1 − r H ) q ( j ) 1 ( h ) + r H if S cor e j falls into the h th cell, (1 − r H ) q ( j ) 1 ( h ) otherwise. q ( j +1) ( h ) =( q ( j +1) 1 ( h ) + λ H ) / ( P h q ( j +1) 1 ( h ) + N H λ H ). end for 4. 2nd la y er learning Let y j − 1 := { y 1 , . . . , y j − 1 } be the co llection of smo othed change-p o int sc o re o b- tained as ab ov e. Sequentially learn the seco nd lay er SDNML density function p SDNML ( y j | y j − 1 ) ( j = 1 , 2 , . . . ); see Appendix A for details . 5. 2nd la y er scoring Compute the final change-p oint score by smo othing the log loss of the SDNML density function as follows: S core ( y j ) = 1 κ j X j ′ = j − κ +1 − log p SDNML ( y j | y j − 1 ) . (9) 3.5 Dynamic Threshold Opt imization (DTO) W e make an alarm if the change-p o int scor e exceeds a threshold, which was determined ada ptively using the metho d of dynamic threshold o ptimization (DTO), prop osed in [1 4]. In DTO, we use a 1-dimensional histog ram for the r epresentation of the score distribution. W e learn it in a seq uen tial and disco un ting wa y . Then, for a sp ecified v alue ρ , to deter mine the thresho ld to be the largest score v alue suc h tha t the tail probability beyond the v alue does not e xceed ρ . W e call ρ a thr eshold p ar ameter . The details of DTO ar e summarized as follows: Let N H be a given p o sitive integer. Let { q ( h )( h = 1 , . . . , N H ) : P N H h =1 q ( h ) = 1 } be a 1- dimensional histogram with N H bins wher e h is an index of bins, with a smaller index indicating a bin having a s maller sc o re. F o r given a, b such that a < b , N H bins in the histogram are set as: { ( − ∞ , a ); [ a + { ( b − a ) / ( N H − 2) } ℓ, [ a + { ( b − a ) / ( N H − 2 ) } ( ℓ + 1)( ℓ = 0 , 1 , ..., N H − 3) and [ b, ∞ ). Let { q ( j ) ( h ) } be a histogr am upda ted a fter seeing the j th s core. The pr o cedures of up dating the histogram and DTO are g iven in Algorithm 1. 7 T able 1: Number of participants in each da ta set. data set ♯ of participants “Job hun ting” 200 “Y o utub e” 160 “NASA” 90 “BBC” 47 4 Exp erimen ts 4.1 Exp erimen tal setup W e collected four data sets from Twitter. Each data se t is asso ciated with a list of p osts in a ser vice called T ogetter 1 ; T ogetter is a c o llab orative ser vice where people can tag Twitter p osts that are related to each other and organize a list of posts that belo ng to a cer tain topic. O ur goal is to ev aluate whether the prop osed appro ach can detect the emerg ence o f the topics r ecognized and collected by p eople . W e hav e selected four data sets, “Job hun ting”, “Y outub e”, “NASA”, “BBC” eac h c o rresp onding to a us er organized list in T ogetter. F or each data set we collected p os ts from users that app ear e d in each list (par ticipants). The num b er o f participants in each da ta set is differen t; see T able 1. W e compa r ed our pro po sed appr oach with a keyword-based change-p oint detection metho d. In the keyw ord-bas e d metho d, we lo oked at a seq uenc e of o ccurr ence frequencies (obse r ved within one minut e) of a keyw ord rela ted to the topic; the keyw ord was manually selected to bes t captur e the topic. Then we applied DTO describ ed in Section 3.5 to the sequence of keyword frequency . In our experienc e , the sparsity of the k eyword frequency seems to b e a bad combination with the SDNML method; therefor e we did not use SDNML in the keyword-based method. W e use the smoo thing par ameter κ = 15, and the order o f the AR mo del 30 in the exp eriments; the parameter s in DTO was set as ρ = 0 . 05, N H = 20, λ H = 0 . 01, r H = 0 . 005 . F urther mo re, we hav e implemented a tw o-state version of Kleinberg ’s burst detection mo del [2] using link-anomaly score (8) a nd k eyword frequency (as in the keyw ord-ba sed c hang e-p oint analys is) to filter out relev a nt posts. F or the link-anoma ly scor e, we use d a threshold to filter out p o sts to include in the bur s t analysis. F or the keyword frequency , w e used all po sts that include the keyw ord for the burst a nalysis. W e used the firing ra te para meter of the Poisson p oint pro ces s 0 . 001 (1 / s) for the non-bur s t state a nd 0 . 01 (1/s) for the burst state, a nd the transition pro bability p = 0 . 3. W e consider the transitio n from the non-burst state to the burst sta te as an “alarm” . A drawback of the keyw ord-bas ed methods (dynamic thresholding a nd burst detection) is that the k ey- word related to the topic m ust be known in adv ance, although this is no t alwa ys the case in practice. The change-point detected by the k eyword-based methods can b e thoug h t o f as the time whe n the topic r e a lly emerges. Hence our goal is to detect emer ging topics as early as the keyword based methods. 4.2 “Job h un ting” data set This data set is r elated to a co nt roversial po st b y a famous per son in Japan that “the reason students having difficult y finding jobs is , beca use they are stupid” and v arious replies to that post. 1 h ttp://togette r.com/ 8 T able 2 : Detection time and the n umber of detections. The first detection time is defined as the time of the first aler t after the even t/p ost that initiated each to pic; see captions for Fig ur es 3 – 6 for the details. Method “Job hun ting” “Y outub e” “NASA” “BBC” Link-anomaly-based ♯ of d etections 4 4 14 3 change-point detection 1st detection time 22:55, Jan 08 08:44, No v 05 20:11, De c 02 19:52, Jan 21 Keywo rd- frequency-based ♯ of d etections 1 1 1 1 change-point detection 1st detection time 22:57, Jan 08 00:30, No v 05 04:10, Dec 03 22:41 , Jan 21 Link-anomaly-based ♯ of d etections 1 9 25 2 burst detection 1st detection time 23:07, Jan 08 00:07, Nov 05 00:44, Nov 30 20:51, Jan 21 Keywo rd- frequency-based ♯ of d etections 6 15 11 1 burst detection 1st detection time 22:50, Jan 08 23:59, No v 04 08:34, Dec 03 22:32 , Jan 21 The keyword used in the keyword-based metho ds was “Job hu nting.” Figur es 3(a) a nd 3(b) show the results of the prop os ed link-anoma ly-based change detection and burst detection, resp ectively . Fig ur es 3(c) and 3(d) sho w the results of the k eyword-frequency- ba sed change detection and burs t detectio n, resp ectively . The first alar m time of the propos ed link- a nomaly-bas e d change-po in t analysis was 22 :55, whereas tha t for the k eyword-frequency-ba sed counterpart was 22 :57; see also T able 2. The earliest detection was achieved by the k eyword-frequency- ba sed burst detection metho d. Nevertheless, from Figure 3, we can observe that the pr op osed link- anomaly-bas ed metho ds were able to detect the emer ging topic almost a s early as keyw ord- frequency-base d metho ds. 4.3 “Y outub e” data set This data set is r elated to the recent lea k ag e o f some confidential video b y the Japa n Coastal Guard officer. The k eyword used in the keyw ord-base d methods is “Senk aku.” Figures 4(a) and 4(b) show the results of link - anomaly-ba sed change detection and burst detection, resp ectively . Figures 4(c) and 4(d) show the results of k eyword-frequency based change detection and burst detection, respectively . The first alar m time of the propos ed link- a nomaly-bas e d change-po in t analysis was 08 :44, whereas tha t for the keyw or d- based coun terpar t was 00:30; see also T able 2. Although the agg regated anoma ly scor e (8) in Figur e 4(a) aro und midnigh t, No v 05 is elev ated, it seems that SDNML fails to detect this elev ation as a change p oint. In fact, the link- anomaly-ba sed bur st detection (Figure 4 (b)) raised an alar m a t 00:07 , which is ea rlier than the keyw ord-freq uency-based change-point analysis and closer to the the keyword-frequency- based burst detection at 23:59, Nov 04. 4.4 “NASA” data set This data se t is r elated to the discussio n a mong Twitter us e rs interested in a stronomy that preceded NASA’s press co nference ab out dis cov ery of an arsenic eating organism. The keyw ord used in the keyword-based mo dels is “a rsenic.” Figure s 5(a) a nd 5(b) show the re s ults of link-anomaly- based c hange detec tio n a nd burst detectio n, resp ectively . Fig ures 5(c) a nd 5(d) show the same results for the keyw ord-fr e quency-based methods. The fir st ala r m times of the tw o link-anomaly-ba s ed metho ds were 20:1 1, Dec 02 (change-point detection) and 00:44 , Nov 30 (burst detectio n), resp ectively . Both of these are earlier than NASA’s official press 9 conference (04:00, Dec 0 3) a nd are earlier than the keyword-frequency based metho ds (change-point detection at 04:1 0, Dec 03 and burst detection at 08 :34, Dec 0 3.); see T able 2. 4.5 ”BBC” data set This data set is related to ang ry reactions a mong Japanese Twitter user s aga inst a BBC comedy sho w that asked “who is the unluc kiest p erso n in the w or ld” (the answer is a Ja panese man who got hit by nuclear bo m bs in bo th Hiros hima and Nag asaki but surviv ed). The keyword used in the keyw or d- based mo dels is “British” (or “Br itain”). Fig ures 6(a) and 6 (b) show the results of link-anomaly - based change detection and bur st detectio n, r esp ectively . Figure s 6(c) a nd 6(d) show the same results for the k eyword-frequency-bas ed metho ds. The firs t ala rm time of the tw o link-anomaly -based metho ds was 19 :52 (change-po in t detection) a nd 20:51 (burs t detection), b oth o f which are earlier than the keyword-frequency-based coun terpa r ts at 22 :4 1 (ch ang e-p oint detectio n) and 22:32 (burst detectio n). See T able 2. 4.6 Discussion Within the four data sets w e have analyze d ab ove, the prop osed link - anomaly based metho ds co mpared fav orably ag ainst the keyw ord- frequency based methods o n “NASA” and “ BBC” da ta s e ts. O n the other hand, the keyword-frequency based metho ds w ere ea r lier to detect the topics on “Job hun ting” and “ Y outub e” data sets. The ab ov e o bserv a tion is natural, b ecause fo r “Job hun ting” and “Y outube ” data s ets, the keyw ords seemed to have b een unam biguously defined from the beg inning of the emergence of the topics, whereas for “NASA” and “BBC” data sets, the keyw ords a re more am biguo us . In particula r, in the case of “NASA” data set, p eople had been mentioning “a rsenic” eating orga nism e arlier than NASA’s official relea se but only ra rely (see Figur e 5(d)). Thus, the keyw ord-fr e quency-based methods could not detect the keyw ord as an emerging topic, altho ugh the keyword “arse nic ” app ear ed earlier than the official relea se. F o r “BBC” data set, the propo sed link-anomaly-bas ed burst mo del detects tw o burs t y areas (Figure 6 (b)). Interestingly , the link-anoma ly-based c hange-p oint analysis only finds the first area (Figure 6(a)), where as the keyw ord- frequency-base d metho ds only find the second a rea (Figures 6(c) and 6(d) ). This is probably because there was an initial stag e where p eople reac ted individually using different words and later there w as another stage in which the keywords are more unified. In o ur approach, the alar m was r a ised if the change-po int sco re exceeded a dyna mically optimized thresh- old ba sed o n the significance lev el parameter ρ . T able 3 shows results for a n umber of threshold para meter v alues. W e see that as ρ increased, the num b er o f false ala rms also increa sed. Me a nwhile, e ven whe n it was so small, o ur approach w as still able to detect the emerging topics as early as the keyword-based methods. W e s e t ρ = 0 . 0 5 as a default parameter v alue in o ur exp eriment. Although there are several alarms for “NASA” da ta set, most o f them are more or less related to the emerging topic. Notice again that in the keyword-based metho ds the keyword related to the topic must b e known in adv anc e , which is not alwa ys the case in practice. F urther note that our appr oach only uses links (ment ions), hence it can be applied to the case where topics a re concerned with information other than texts, such as images, vide o , sounds, etc. 10 T able 3: Number of a larms for the pro po sed change-p oint detectio n metho d based on the link-anoma ly score (8) for v ar ious significance lev el par a meter v alues ρ . ρ “J o b hun ting” “Y outube” “NASA” “BBC” 0.01 4 2 9 3 0.05 4 4 14 3 0.1 8 6 30 3 5 Conclusion In this pa p er , we hav e propo sed a new approa ch to detect the emergence of topics in a so cia l netw or k strea m. The bas ic idea of o ur appro ach is to fo cus on the so cial asp ect o f the p o sts reflected in the mentioning behaviour of users instea d of the textual conten ts. W e ha ve prop os ed a probability mo del that captures both the num b er o f men tions p er p ost and the freq uenc y o f mentionee. W e hav e combined the pro po sed men tion mo del with the SDNML change-p oint detectio n algor ithm [3] and Klein b erg’s burst detectio n model [2] to pin-p o int the emerge nc e o f a topic. W e ha ve applied the propos ed approa ch to four real da ta sets w e hav e collected from Twitter . The four data sets included a wide-spread discussion ab out a c ontro versial topic (“Jo b h unting” data s et), a quick propaga tion o f news about a video leaked on Y outube (“ Y outub e” data set), a r umo r a bo ut the upcoming press conference b y NASA (“NASA” data set), a nd an angry response to a foreign TV show (“BBC” data set). In all the data sets o ur pr op osed approa ch show ed promising p e rformance. In most data set, the detection b y the prop os e d approach w as as early as term- fr equency bas ed appro a ches in the hindsig h t of the keyw ord that best describes the topic that we ha ve manually c hose n afterwards. F ur thermore, for “NASA” and “BB C ” data sets, in which the keyw or d that defines the topic is more ambiguous than the fir st tw o data sets, the prop osed link-anomaly based a pproaches ha ve detected the emergence of the topics muc h earlier than the k eyword-based approaches. All the ana lysis presented in this pap er was co nducted o ff-line but the fr amework itself can b e applied o n- line. W e ar e planning to scale up the prop osed approach to ha ndle so c ial streams in real time. It w ould also be interesting to combine the pro po sed link-anomaly model with co nten t-bas e d topic detection appr oaches to further bo ost the per formance a nd reduce false alarms. Ac kno wledgmen ts This work w as par tia lly supported b y MEXT KAKENHI 23240 019, 227001 3 8, Aihara Pro ject, the FIRST progra m from JSPS, initiated by CSTP , Hakuho do Corp ora tion, NTT Corp or ation, and Microso ft Corp o - ration (CO RE Pro ject). References [1] J. Allan, J. Carbo nell, G. Do ddington, J. Y amron, Y. Y ang et al. , “T o pic detection and tracking pilot study: Final rep or t,” in Pr o c e e dings of the DARP A br o adc ast news tr anscription and un derstanding workshop , 199 8. 11 [2] J. Kleinberg, “Bursty and hierarchical structure in streams,” Data Min. Know l. Disc. , vol. 7, no. 4, pp. 373–3 97, 2 003. [3] Y. Urab e, K. Y amanishi, R. T omiok a, and H. Iwai, “ Rea l-time c hange- p oint detection using sequent ially discounting normalized maximum likelihoo d co ding ,” in Pr o c e e dings. of the 15th P AKD D , 2011. [4] S. Morinaga and K. Y amanishi, “T racking dynamics of topic trends using a finite mixture mode l,” in Pr o c e e dings of the 10th A CM SIGKDD , 200 4, pp. 8 11–81 6. [5] Q. Mei and C. Zhai, “Discovering ev olutionary theme patter ns from text: an explor ation of temp ora l text mining,” in Pr o c e e dings of the 11th A CM SIGKDD , 2 0 05, pp. 198–207. [6] A. Krause, J. Leskov ec, a nd C. Guestrin, “Data asso ciation for topic in tensity tracking,” in Pr o c e e dings of the 23 r d ICML , 2006, pp. 497 –504. [7] D. He and D. S. Parker, “T opic dynamics: an alternative mo del of burs ts in str eams of to pic s ,” in Pr o c e e dings of the 16th A CM SIGKDD , 201 0, pp. 4 43–45 2. [8] H. Small, “ Visualizing science by citation mapping,” Journal of the A meric an so ciety for Information Scienc e , v ol. 5 0, no. 9, pp. 799 –813, 1999. [9] D. Aldous, “Ex changeabilit y and r e lated topics,” in ´ Ec ole d’ ´ Et´ e de Pr ob abilit ´ es de Saint-Flour XIII— 1983 . Springer, 1 985, pp. 1–198. [10] K . Y amanis hi and J . T akeuc hi, “ A unifying framework for detecting outliers and change p oints fr o m non-stationar y time series data,” in Pr o c e e dings of the 8th AC M SIGKD D , 2002. [11] J . T akeuchi and K. Y a manishi, “A unifying framework for detecting outlier s a nd change p oints fro m time ser ies,” IEEE T. Know l. Data En. , v ol. 18, no. 44, pp. 482–492 , 200 6. [12] J . Rissanen, “Strong optimality of the normalized ML mo dels a s universal co des and info r mation in data,” IEEE T. Inform. The ory , v ol. 4 7 , no. 5 , pp. 1712–17 17, 200 2. [13] J . Riss anen, T. Ro os, a nd P . Myllym¨ aki, “Mo del selection by s e q uent ially norma liz e d lea s t squa res,” Journal of Multivaria te Analysis , vol. 101, no. 4, pp. 839–849, 2010. [14] K . Y amanishi and Y. Maruyama, “Dynamic syslog mining for net work fa ilure mo nitoring,” Pr o c e e ding of the 11 th ACM SIGKDD , p. 499, 2005. [15] T. M. Cover a nd J. A. Thomas, Elements of Information The ory . New Y ork: Wiley & Sons, 1991, 2nd edition, 200 6. [16] T. Ro o s and J. Rissa ne n, “On sequentially normalized maximum lik eliho o d mo dels,” in Workshop on information the or etic metho ds in scienc e and engine ering , 2 0 08. A Sequen tially discoun ting normalized maxim um lik eliho o d co d- ing This section describ es the sequentially discoun ting normalized maximum lik eliho o d (SDNML) co ding that we use for c hange-p oint detection in Section 3.4. The bas ic idea b ehind SDNML-based c hange detection is 12 as follows: when the data arrives in a sequen tial manner, w e can consider a change has o ccurred if a new piece of data cannot b e compressed using the statistical nature of the past. The or iginal paper [10, 1 1] used the pre dictive stochastic complexity as a measure of compressibility , wher e a s Urab e et al. [3] pr op osed to employ a tighter co ding scheme based on the SDNML. Suppo se that w e observe a discrete time serie s x t ( t = 1 , 2 , . . . , ); w e denote the data sequence b y x t := x 1 · · · x t . Consider the parametr ic class of co nditional probability densities F = { p ( x t | x t − 1 : θ ) : θ ∈ R p } , where θ is the p -dimens io nal par a meter vector and we a ssume x 0 to b e an empt y set. W e deno te the maximum likelihoo d (ML) estimator giv en the data s equence x t by ˆ θ ( x t ); i.e., ˆ θ ( x t ) := argma x θ ∈ R p Q t j =1 p ( x j | x j − 1 : θ ). The sequential normalized maximum lik eliho o d (SNML) mo del is a co ding distribution (see e.g., [15]) that is kno wn to be optimal in the sense of the conditional minimax [16] problem: min q ( ·| x t − 1 ) max x t − log q ( x t | x t − 1 ) + max θ ∈ R p log p ( x t : θ ) , (10) where p ( x t ) := Q t j =1 p ( x j | x j − 1 : θ ) is the join t densit y over x t induced by the co nditional densities from F . The minimization is taken o ver all conditiona l densit y functions and tries to minimize the regret (10) ov er any poss ible outcome o f the new sample x t . The SNML distribution is o btained as the o ptimal conditional density of the minimax problem (10) as follows [16]: p SNML ( x t | x t − 1 ) := p ( x t : ˆ θ ( x t )) K t ( x t − 1 ) , (11) where the nor malization co nstant K t ( x t − 1 ) := R p ( x t | ˆ θ ( x t ))d x t is ne c essary beca use the new sample x t is used in the estimation o f parameter vector ˆ θ ( x t ) a nd the n umerator in (11) is no t a prop er density function. W e call the quantit y − log p SNML ( x t | x t − 1 ) the SNML c o de-length . It is known from [16, 1 3] that the cum ulative SNML code- length, w hich is the sum of SNML co de-leng th over the seque nce , is optima l in the s e ns e that it asymptotically ac hieves the shortest co de-leng th. The sequentially disco unt ing normalize d maximum likelihoo d (SDNML) is obtained by applying the ab ov e SNML to the class of autor egressive (AR) mo del and replacing the ML es timation in (11) with a disc ounte d ML estimatio n, which mak es the SDNML-based change-p o int detection alg orithm more flexible than a n SNML-based o ne. Let x t ∈ R for eac h t . W e define the p th or der AR model as follo ws: p ( x t | x t − 1 t − k : θ ) = 1 √ 2 π σ 2 exp − 1 2 σ 2 x t − p X i =1 a ( i ) x t − i 2 ! , where θ ⊤ = ( a ⊤ , σ 2 ) = (( a (1) , . . . , a ( p ) ) , σ 2 ) is the parameter vector. In or der to compute the SDNML density function we need the discounted ML estimators of the para meters in θ . W e define the discoun ted ML estimator of the regress ion coefficient ˆ a t as follows: ˆ a t = argmin a ∈ R p t X j = t 0 +1 w t − j x j − a ⊤ ¯ x j 2 , (12) where w j ′ = r (1 − r ) j ′ is a sequence of sa mple weight s with the discounting co efficient r (0 < r < 1); t 0 is the s mallest num b er of samples such that the minimizer (12) is unique; ¯ x j := ( x j − 1 , x j − 2 , . . . , x j − k ) ⊤ . Note that the err or terms fro m older sa mples receive geometrica lly de c r easing weigh ts in (12). The larger 13 the discoun ting coefficient r is, the smaller the weight s of the older samples b ecome; thus we hav e stronger discounting effect. Moreover, we obtain the discounted ML estimator of the v a riance ˆ τ t as follows: ˆ τ t := a rgmax σ 2 t Y j = t 0 +1 p x j | x j − 1 j − k : ˆ a j , σ 2 = 1 t − t 0 t X j = t 0 +1 ˆ e 2 j = S t t − t 0 , where we define ˆ e 2 j = x j − ˆ a ⊤ j ¯ x j 2 and S t := P t j = t 0 +1 ˆ e 2 j . Clearly whe n the discounted estimator of the AR co efficient ˆ a j is av ailable, S t can be c o mputed in a sequen tial ma nner. In the sequel, we first describ e how to efficien tly compute the AR estimator ˆ a j . Finally we derive the SDNML density function using the discounted ML es timators ( ˆ a t , ˆ τ t ). The AR co efficie nt ˆ a j can simply be computed by solving the least-squar es pr oblem (12). It can, how ever, be o btained mo re efficien tly using the iterative formula describ ed in [16, 13]. Here we r epea t the for m ula for the discounted v ersio n presen ted in [3]. First define the sufficient statistics V t ∈ R p × p and χ t ∈ R p as follows: V t := t X j = t 0 +1 w j ¯ x j ¯ x ⊤ j , χ t := t X j = t 0 +1 w j ¯ x j x j . Using the sufficien t sta tistics, the discoun ted AR coe fficie n t ˆ a j from (12) can b e wr itten as follo ws: ˆ a t = V − 1 t χ t . Note that χ t can b e computed in a sequential ma nner . The inv erse matrix V − 1 t can a lso b e computed sequentially using the Sherman-Morrison- W o o dbury formu la as follows: V − 1 t = 1 1 − r V − 1 t − r 1 − r V − 1 t ¯ x t ¯ x ⊤ t V − 1 t 1 − r + c t , where c t = r ¯ x ⊤ t V − 1 t ¯ x t . Finally the SDNML densit y function is written as follows: p SDNML ( x t | x t − 1 ) = 1 K t ( x t − 1 ) s − ( t − t 0 ) / 2 t s − ( t − t 0 − 1) / 2 t − 1 , where the normalization factor K t ( x t − 1 ) is calculated as follows: K t ( x t − 1 ) = √ π 1 − d t r 1 − r r (1 − r ) − t − m 2 Γ(( t − t 0 − 1) / 2 ) Γ(( t − t 0 ) / 2) , with d t = c t / (1 − r + c t ). 14 Jan08 09:00 Jan08 15:00 Jan08 21:00 Jan09 03:00 Jan09 09:00 Jan09 15:00 Time Score (a) Link-anomaly-based chan ge-p oint analysis. Green: Aggre- gated anomaly score (8) at τ = 1 minute. Blue: Change-p oint score (9). Red: Alarm time. Jan08 09:00 Jan08 15:00 Jan08 21:00 Jan09 03:00 Jan09 09:00 Jan09 15:00 Time Score (b) Li nk-anomaly-based burst detection. Blue: Aggregat ed anomaly score (8) at τ = 1 second. Cy an: threshold for the filtering step in Kleinberg’s burst model. R ed: Burst state. Jan08 09:00 Jan08 15:00 Jan08 21:00 Jan09 03:00 Jan09 09:00 Jan09 15:00 Time Frequency (c) Keyword-frequency-base d c hange-p oin t analysis. Blue: F re- quency of k eyword “Job hun ting” p er one minute. Red: Alar m time. Jan08 09:00 Jan08 15:00 Jan08 21:00 Jan09 03:00 Jan09 09:00 Jan09 15:00 Time Frequency (d) Keyw ord-fr equency-base d burst detection. Bl ue: F requency of keyw ord “Job hun ting” p er one second. Red: Burst state (burst or not). Figure 3: Result of “ Job h unting” data set. The initial controv ersial p ost was po sted on 22:5 0, Jan 08 (gree n lines in (b) and (d)). 15 Nov04 11:00 Nov04 17:00 Nov04 23:00 Nov05 05:00 Nov05 11:00 Time Score (a) Link-anomaly-based chan ge-p oint analysis. Green: Aggre- gated anomaly score (8) at τ = 1 minute. Blue: Change-p oint score (9). Red: Alarm time. Nov04 11:00 Nov04 17:00 Nov04 23:00 Nov05 05:00 Nov05 11:00 Time Score (b) Li nk-anomaly-based burst detection. Blue: Aggregated anomaly score (8) at τ = 1 second. Cy an: threshold for the filtering step in Kleinberg’s burst model. R ed: Burst state. Nov04 11:00 Nov04 17:00 Nov04 23:00 Nov05 05:00 Nov05 11:00 Time Frequency (c) Keyword-frequency-base d c hange-p oin t analysis. Blue: F re- quency of k eyword “Senk aku” per one minute. Red: Alarm time. Nov04 11:00 Nov04 17:00 Nov04 23:00 Nov05 05:00 Nov05 11:00 Time Frequency (d) Keyw ord-fr equency-base d burst detection. Bl ue: F requency of k eyword “Senk aku” per one second. Red: Burs t state (burst or not). Figure 4: Res ult of “Y outub e” data s et. The first po st about the video leak a g e was p os ted on 23:48 , Nov 04 (green lines in (b) and (d)). 16 Nov28 08:00 Nov29 20:00 Dec01 08:00 Dec02 20:00 Dec04 08:00 Dec05 20:00 Time Score (a) Link-anomaly-based chan ge-p oint analysis. Green: Aggre- gated anomaly score (8) at τ = 1 minute. Blue: Change-p oint score (9). Red: Alarm time. Nov28 08:00 Nov29 20:00 Dec01 08:00 Dec02 20:00 Dec04 08:00 Dec05 20:00 Time Score (b) Li nk-anomaly-based burst detection. Blue: Aggregated anomaly score (8) at τ = 1 second. Cy an: threshold for the filtering step in Kleinberg’s burst model. R ed: Burst state. Nov28 08:00 Nov29 20:00 Dec01 08:00 Dec02 20:00 Dec04 08:00 Dec05 20:00 Time Frequency (c) Keyword-frequency-base d c hange-p oin t analysis. Blue: F re- quency of keyw ord “arsenic” p er one m i n ute. Red: Alarm time. Nov28 08:00 Nov29 20:00 Dec01 08:00 Dec02 20:00 Dec04 08:00 Dec05 20:00 Time Frequency (d) Keyw ord-fr equency-base d burst detection. Bl ue: F requency of keyw or d “arsenic” per one second . Red: Burst state (b urst or not). Figure 5: Result of “NASA” data set. The initial p ost predicting NASA’s finding ab out a rsenic-eating organis m w as p osted on 22:30, Nov 30 m uc h ea rlier than NASA ’s official press conference at 04 :00, Dec 03. 17 Jan21 12:00 Jan21 16:00 Jan21 20:00 Jan22 00:00 Jan22 04:00 Time Score (a) Link-anomaly-based chan ge-p oint analysis. Green: Aggre- gated anomaly score (8) at τ = 1 minute. Blue: Change-p oint score (9). Red: Alarm time. Jan21 12:00 Jan21 16:00 Jan21 20:00 Jan22 00:00 Jan22 04:00 Time Score (b) Li nk-anomaly-based burst detection. Blue: Aggregated anomaly score (8) at τ = 1 second. Cy an: threshold for the filtering step in Kleinberg’s burst model. R ed: Burst state. Jan21 12:00 Jan21 16:00 Jan21 20:00 Jan22 00:00 Jan22 04:00 Time Frequency (c) Keyword-frequency-base d c hange-p oin t analysis. Blue: F re- quency of keyw ord “British” p er one m i n ute. Red: Alarm time. Jan21 12:00 Jan21 16:00 Jan21 20:00 Jan22 00:00 Jan22 04:00 Time Frequency (d) Keyw ord-fr equency-base d burst detection. Bl ue: F requency of keyw or d “Britis h” per one secon d. Red: Burst state (burst or not). Figure 6: Result of “B BC” data set. The first p ost about BB C’s comedy show w as p osted on 17:08, Jan 21 (green lines in (b) and (d)). 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment