Toward a Classification of Finite Partial-Monitoring Games
Partial-monitoring games constitute a mathematical framework for sequential decision making problems with imperfect feedback: The learner repeatedly chooses an action, opponent responds with an outcome, and then the learner suffers a loss and receive…
Authors: Andras Antos, Gabor Bartok, David Pal
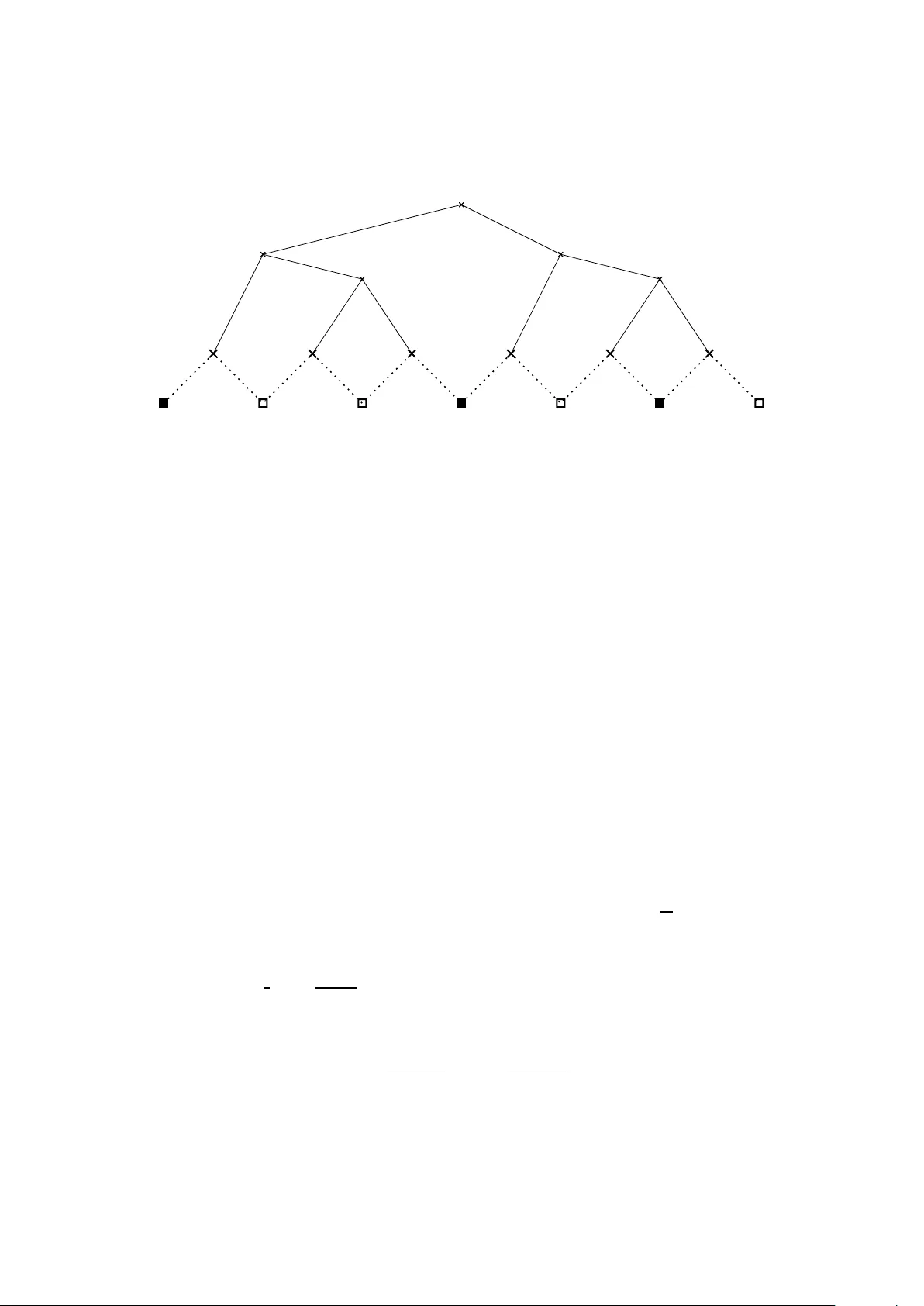
T o ward a Classification of Finite P artial-Monitoring Games I Andr ´ as Antos Machine Learning Gr oup, Computer and A utomation Resear ch Institute of the Hungarian Academy of Sciences, 13-17 K ende utca, H-1111 Budapest, Hungary G ´ abor Bart ´ ok ∗ , D ´ avid P ´ al , Csaba Szepesv ´ ari Department of Computing Science, University of Alberta, Edmonton, Alberta, T6G 2E8, Canada Abstract Partial-monitoring games constitute a mathematical framew ork for sequential decision making problems with imperfect feedback: The learner repeatedly chooses an action, the opponent responds with an outcome, and then the learner su ff ers a loss and recei ves a feedback signal, both of which are fixed functions of the action and the outcome. The goal of the learner is to minimize his total cumulativ e loss. W e make progress tow ards the classification of these games based on their minimax expected regret. Namely , we classify almost all games with tw o outcomes and a finite number of actions: W e show that their minimax expected re gret is either zero, e Θ ( √ T ), Θ ( T 2 / 3 ), or Θ ( T ), and we gi ve a simple and e ffi ciently computable classification of these four classes of games. Our hope is that the result can serv e as a stepping stone to ward classifying all finite partial-monitoring games. K e ywor ds: Online algorithms, Online learning, Imperfect feedback, Regret analysis 1. Introduction Partial-monitoring games constitute a mathematical framew ork for sequential decision making prob- lems with imperfect feedback. They arise as a natural generalization of man y sequential decision making problems with full or partial feedback such as learning with expert advice [2, 3, 4], the multi-armed bandit problem [5, 6, 7], label e ffi cient prediction [8, 9], dynamic pricing [10, 11], the dark pool problem [12], the apple tasting problem [13], online con v ex optimization [14, 15], online linear [16] and con vex optimization with bandit feedback [17]. A partial-monitoring game is a repeated game between tw o players: the learner and the opponent . In each round, the learner chooses an action and simultaneously the opponent chooses an outcome. Next, the learner recei ves a feedback signal and su ff ers a loss; ho we ver neither the loss nor the outcome are rev ealed to I Preliminary v ersion of this paper appeared at AL T 2010, September 6–8, 2010, Canberra, Australia [1]. This work was supported in part by AICML, AITF (formerly iCore and AIF), NSERC and the P ASCAL2 Network of Excellence under EC grant no. 216886. ∗ Corresponding authors Email addr esses: antos@cs.bme.hu (Andr ´ as Antos), bartok@cs.ualberta.ca (G ´ abor Bart ´ ok), dpal@cs.ualberta.ca (D ´ avid P ´ al), szepesva@cs.ualberta.ca (Csaba Szepesv ´ ari) URL: http://www.cs.bme.hu/~antos (Andr ´ as Antos), http://www.ualberta.ca/~bartok (G ´ abor Bart ´ ok), http://www.ualberta.ca/~dpal (D ´ avid P ´ al), http://www.ualberta.ca/~szepesva (Csaba Szepesv ´ ari) Pr eprint submitted to Theor etical Computer Science Thursday 25 th October , 2018 Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 2 the learner . The feedback and the loss are fix ed functions of the action and the outcome, and these functions are known by both players. The main feature of this model is that it captures that the learner has imperfect or partial information about the outcome sequence. In this work, we make the natural assumption that the opponent is oblivious , that is, the opponent does not hav e access to the learner’ s actions. The goal of the learner is to keep his cumulative loss small. Ho we ver , since the opponent could choose the outcome sequence so that the learner su ff ers as high loss as possible, it is too much to ask for an absolute guarantee for the cumulative loss. Instead, a competitiv e vie wpoint is taken and the cumulative loss of the learner is compared with the cumulativ e loss of the best among all the constant strategies, i.e., strategies that choose the same action in ev ery round. The di ff erence between the cumulati ve loss of the learner and the cumulati ve loss of the best constant strategy is called the r e gr et . Generally , the regret grows with the number of rounds of the game. If the growth is sublinear then the learner is said to be Hannan consistent 1 , and in the long run the learner’ s a verage loss per round approaches the av erage loss per round of the best action. Designing learning algorithms with low regret is the main focus of study of partial-monitoring games. For a gi ven game, the ultimate goal is to find out its optimal w orst-case (minimax) re gret, and design an algorithm that achie ves it. The minimax regret can be vie wed as an inherent measure of ho w hard the game is for the learner . The moti v ation behind this paper was the desire to determine the minimax regret and design an algorithm achie ving it for each game in a large class. In this paper we restrict our attention to games with a finite number of actions and two outcomes . This class is a subset of the class of finite partial-monitoring games , introduced by Piccolboni and Schindel- hauer [19], in which both the set of actions and the set of outcomes are finite. 1.1. Pr evious Results For full-information games (i.e., when the feedback determines the outcome) with N actions and losses lying in the interval [0 , 1], there exists a randomized algorithm with e xpected re gret at most √ T ln( N ) / 2 where T is the time horizon (see e.g., Lugosi and Cesa-Bianchi [20, Chapter 4] and references therein). Furthermore, it is kno wn that this upper bound is tight: There exist full-information games with losses lying in the interv al [0 , 1] for which the worst-case expected regret of any algorithm is at least Ω ( √ T ln N ) [20, Chapter 3]. Another special case of partial-monitoring g ames is the multi-armed bandit game, where the learner’ s feedback is the loss of the action he chooses. For a multi-armed bandit g ame with N actions and losses lying in the interval [0 , 1], the INF algorithm [21] has expected regret at most O ( √ T N ). (The well-known Exp3 algorithm [5] achie ves the bound O ( p T N log N ).) It is also kno wn that the bound O ( √ T N ) is optimal [5]. Piccolboni and Schindelhauer [19] introduced finite partial-monitoring games. They showed that, for any finite game, either there is a strategy for the learner that achieves regret of at most O ( T 3 / 4 (ln T ) 1 / 2 ) or the worst-case expected regret of any learner is Ω ( T ). Cesa-Bianchi et al. [22] improved this result and sho wed that Piccolboni and Schindelhauer’ s algorithm achiev es O ( T 2 / 3 ) regret. They also g av e an example of a game with worst-case expected regret at least Ω ( T 2 / 3 ). More recently , Lugosi et al. [23] designed algorithms and proved upper bounds in a slightly di ff erent setting, where the feedback signal is a possibly noisy function of the outcome or both the action and the outcome. Ho wev er , from these results it is unclear what determines which games ha ve minimax regret Θ ( √ T ), which games hav e minimax re gret Θ ( T 2 / 3 ) and whether there e xist finite games with minimax regret not 1 Hannan consistency is named after James Hannan who was the first to design a learning algorithm with sublinear regret for finite games with full feedback [18]. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 3 belonging to either of these categories. Cesa-Bianchi et al. [22] note that: “ It remains a challenging pr oblem to char acterize the class of pr oblems that admit r ates of con ver gence faster than O ( n − 1 / 3 ) . ” 2 1.2. Our Results W e classify the minimax expected regret of finite partial-monitoring games with two outcomes . From our classification we exclude certain “de generate games”; their precise definition is gi ven later in the paper . W e show that the minimax regret of any non-degenerate game falls into one of the four cate gories: 0, e Θ ( √ T ), Θ ( T 2 / 3 ), Θ ( T ) and no other option is possible 3 . W e call the four classes of games trivial , easy , har d , and hopeless , respecti vely . W e gi ve a simple and e ffi ciently computable geometric characterization of these four classes. Additionally , we show that each of the four classes admits a computationally e ffi cient learning algorithm achie ving the minimax expected regret, up to logarithmic factors. In particular , we design an e ffi cient learning algorithm for easy games with expected regret at most e O ( √ T ). F or hard games, the algorithm of Cesa-Bianchi et al. [22] has O ( T 2 / 3 ) regret. For tri vial games, a simple algorithm that chooses the same action in e very round has zero regret. For hopeless games, an y algorithm has Θ ( T ) regret. 2. Basic Definitions and Notations A finite partial-monitoring game is specified by a pair of N × M matrices ( L , H ) where N is the number of actions, M is the number of outcomes, L is the loss matrix , and H is the feedback matrix . W e use the notation n = { 1 , . . . , n } for any integer and denote the actions and outcomes by integers starting from 1, so the action set is N and the outcome set is M . W e denote by i , j and h i , j ( i ∈ N , j ∈ M ) the entries of L and H , respecti v ely . W e denote by i the i -th row ( i ∈ N ) of L , and we call it the loss vector of action i . The elements of L are arbitrary real numbers. The elements of H belong to some alphabet Σ , we only assume that the learner is able to distinguish two di ff erent elements of the alphabet. W e often use the set of natural or real numbers as the alphabet. The matrices L , H are kno wn by both the learner and the opponent. The game proceeds in T rounds. In each round t = 1 , 2 , . . . , T , the learner chooses an action I t ∈ N and simultaneously the opponent chooses an outcome J t ∈ M , then the learner receives the feedback h I t , J t . Nothing else is revealed to the learner; in particular J t and the loss I t , J t remain hidden. In principle, both I t and J t can be chosen randomly . Howe ver , to simplify our treatment, we assume that the opponent is deterministic and obli vious to the actions of the learner . Equiv alently , we can assume that the sequence of outcomes J 1 , J 2 , . . . , J T is a fixed deterministic sequence chosen before the first round of the game. On the other hand, it is important to allo w the learner to choose his actions I t randomly . A randomized strategy (algorithm) A of the learner is a sequence of random functions I 1 , I 2 , . . . , I T where each of the functions maps the feedback from the past outcomes (and learner’ s internal random “bits”) to an action; formally I t : Σ t − 1 × Ω → N . The learner is scored according to the loss matrix. In each round t , the learner incurs instantaneous loss I t , J t . The goal of the learner is to keep his cumulative loss P T t = 1 I t , J t small. The (cumulative) r e gr et of an algorithm A is defined as b R T = b R T ( A , G ) = T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t . 2 They used n instead of T and by rate they mean the a verage regret per time step. 3 The notation e Θ and e O hides poly-logarithmic factors in T . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 4 In other words, the regret is the excess loss of the learner compared to the loss of the best constant action. W e denote by R T = R T ( A , G ) = E [ b R T ( A , G )] the (cumulative) e xpected r e gr et . Let the worst-case expected r e gr et of A when used in G = ( L , H ) be ¯ R T ( A , G ) = sup J 1: T ∈ M T R T ( A , G ) , where the supremum is taken over all outcome sequences J 1: T = ( J 1 , J 2 , . . . , J T ) ∈ M T . The minimax expected r egr et of G (or minimax r e gr et , for short) is: R T ( G ) = inf A ¯ R T ( A , G ) = inf A sup J 1: T ∈ M T R T ( A , G ) , where the infimum is taken o ver all randomized strategies A . Note that, since R T ( A , G ) ≥ 0 for constant outcome sequences, R T ( G ) ≥ 0 also holds. W e identify the set of all probability distributions over the set of outcomes M with the probability simplex ∆ M = { p ∈ R M : P M j = 1 p ( j ) = 1 , ∀ j ∈ M , p ( j ) ≥ 0 } . W e use h· , ·i to denote the standard dot product. 3. Characterization of Games with T wo Outcomes In this section, we formally phrase our main characterization result. W e need a preliminary definition that is useful for any finite game: Definition 1 (Properties of Actions). Let G = ( L , H ) be a finite partial-monitoring game with N actions and M outcomes. Let i ∈ N be one of its actions. • Action i is called dominated if for an y p ∈ ∆ M there exists an action i 0 such that i 0 , i and h i 0 , p i ≤ h i , p i . • Action i is called non-dominated if it is not dominated. • Action i is called de gener ate if it is dominated and there e xists a distribution p ∈ ∆ M such that for all i 0 ∈ N , h i , p i ≤ h i 0 , p i . • Action i is called all-r evealing if an y pair of outcomes j , j 0 , j , j 0 satisfies h i , j , h i , j 0 . • Action i is called none-r evealing if an y pair of outcomes j , j 0 satisfies h i , j = h i , j 0 . • Action i is called partially-r evealing if it is neither all-re v ealing nor none-rev ealing. • All-re vealing and partially-re vealing actions together are called r e vealing actions. • T wo or more actions with the same loss v ector are called duplicate actions. The property of being dominated has an equiv alent dual definition. Namely , action i is dominated if there exists a set of actions with loss vectors not equal to i such that some con ve x combination of their loss vectors is componentwise upper bounded by i . In games with M = 2 outcomes, each action is either all-re vealing or none-re vealing. This dichotomy is one of the key properties that lead to the classification theorem for two-outcome games. T o emphasize the Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 5 ` · , 2 ` · , 1 i 3 i 2 i 1 i 4 Rev ealing non-dominated action Non-rev ealing non-dominated action Dominated action (rev ealing or non-revealing) Figure 1: The figure shows each action i as a point in R 2 with coordinates ( i , 1 , i , 2 ). The solid line connects the chain of non- dominated actions, which, by con vention are ordered according to their loss for the first outcome. dichotomy , from now on we will refer to them as rev ealing and non-r evealing whene ver it is clear from the context that M = 2. The abov e property also allows us to assume without of loss generality that there are no duplicate actions. Clearly , if multiple actions with the same loss vector exist, all b ut one can be remo ved (together with the corresponding rows of L and H ) without changing the minimax regret: If all of them are non- re vealing, we keep one of the actions and remov e all the others. Otherwise, we keep a revealing action and remov e the others. Then replacing an y algorithm by one that, instead of a remov ed action, chooses always the corresponding kept action, its loss cannot increase and equals to the loss of this algorithm for the original game. So the two games hav e the same minimax regret. The concepts of dominated and non-dominated actions can be visualized for two-outcome games by drawing the loss vector of each action as a point in R 2 . The points corresponding to the non-dominated actions lie on the bottom-left boundary of the con v ex hull of the set of all the actions, as sho wn in Figure 1. Enumerating the non-dominated actions ordered according to their loss for the first outcome gi ves rise to a sequence ( i 1 , i 2 , . . . , i K ), which we call the chain of non-dominated actions . T o state the classification theorem, we introduce the follo wing conditions. Separation Condition. A two-outcome game G satisfies the separation condition if, after r emoving dupli- cate actions, its c hain of non-dominated actions does not have a pair of consecutive actions i k , i k + 1 such that both of them ar e non-r e vealing. The set of games satisfying this condition will be denoted by S . Non-degeneracy Condition. A two-outcome game G is degenerate if it has a deg enerate r e vealing action. If G is not de gener ate, we call it non-degenerate and we say that it satisfies the non-degenerac y condition . As we will soon see, the separation condition is the ke y to distinguish between har d and easy games. On the other hand, the non-degenerac y condition is merely a technical condition that we need in our proofs. The set of degenerate games is excluded from the characterization, as we do not kno w the minimax regret of these games. W e are now ready to state our main result. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 6 Theorem 2 (Classification of T wo-Outcome Partial-Monitoring Games) . Let S be the set of all finite partial- monitoring games with two outcomes that satisfy the separation condition. Let G = ( L , H ) be a game with two outcomes that satisfies the non-degeneracy condition. Let K be the number of non-dominated actions in G , counting duplicate actions only once. The minimax expected r egr et R T ( G ) satisfies R T ( G ) = 0 ( ∀ T ) , K = 1 ; (1a) e Θ √ T , K ≥ 2 , G ∈ S ; (1b) Θ T 2 / 3 , K ≥ 2 , G < S , G has a r evealing action; (1c) Θ ( T ) , otherwise. (1d) W e call the games in cases (1a)–(1d) trivial , easy , har d , and hopeless , respectiv ely . Case (1a) is prov en by the follo wing lemma which shows that a trivial game is also characterized by ha ving 0 minimax regret in a single round or by having an action “dominating” alone all the others: Lemma 3. F or any finite partial-monitoring game , the following four statements ar e equivalent: a) The minimax r e gr et is zer o for each T . b) The minimax r e gr et is zer o for some T . c) Ther e exists a (non-dominated) action i ∈ N whose loss is not lar ger than the loss of any other action irr espectively of the choice of Natur e’s action. d) The game is trivial, i.e., K = 1 (using the definition in Theor em 2). The proof of this lemma can be found in the Appendix. Case (1d) of Theorem 2 is prov en in the Appendix as well. The upper bound of case (1c) can be deri v ed from a result of Cesa-Bianchi et al. [22]: Recall that the entries of H can be changed without changing the information rev ealed to the learner as long as one does not change the pattern of which elements in a ro w are equal and di ff erent. Cesa-Bianchi et al. [22] show that if the entries of H can be chosen such that rank( H ) = rank H L ! then O ( T 2 / 3 ) expected regret is achie v able. This condition holds tri vially for two-outcome games with at least one re vealing action and N ≥ 2. It remains to pro ve the upper bound for case (1b), the lower bound for (1b), and the lower bound for (1c); we prov e these in Sections 5, 6, and 7, respectiv ely . 4. Examples Before we di ve into the proof of Theorem 2, we gi ve a fe w e xamples of finite partial-monitoring games with two outcomes and show how the theorem can be applied. F or each example we present the matrices L , H and depict the loss v ectors of actions as points in R 2 . Example 4 (One-Armed Bandit). W e start with an example of a multi-armed bandit game. Multi-armed bandit games are those where the feedback equals the instantaneous loss, that is, when L = H . 4 4 “Classically”, non-stochastic multi-armed bandit problems are defined by the restriction that in no round Learner can g ain any information about the losses of actions other than the chosen one, that is, L is not kno wn in adv ance to Learner . (Also, the domain set of losses is often infinite there ( M = ∞ ).) When H = L in our setting, depending on L , this might or might not be the case; the “classical bandit” problem with losses constrained to a finite set is a special case of games with H = L , howe ver , the latter condition allows also other types of games where the Learner can recover the losses of actions not chosen, and so which could be “easier” than classical bandits due to the knowledge of L . Nev ertheless, it is easy to see that these games are at most as hard as classical bandit games. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 7 L = 0 0 − 1 1 ! , H = 0 0 − 1 1 ! , ` · , 2 ` · , 1 Rev ealing non-dominated action Non-rev ealing non-dominated action Because the loss of the first action is 0 regardless of the outcome, and the loss varies only for the second action, we call this game a one-armed bandit game. Both actions are non-dominated and the second one is re vealing, therefore it is an easy game and according to Theorem 2 its minimax regret is e Θ ( √ T ). (For this specific game, it can be sho wn that it is in fact Θ ( √ T ).) Example 5 (A pple T asting). Consider an orchard that wants to hand out its crop of apples for sale. Ho w- e ver , some of the apples might be rotten. The orchard can do a sequential test. Each apple can be either tasted (which rev eals whether the apple is healthy or rotten) or the apple can be giv en out for sale. If a rotten apple is gi ven out for sale, the orchard su ff ers a unit loss. On the other hand, if a healthy apple is tasted, it cannot be sold and, again, the orchard su ff ers a unit loss. This can be formalized by the following partial-monitoring game [13]: L = 1 0 0 1 ! , H = a a b c ! , ` · , 2 ` · , 1 Rev ealing non-dominated action Non-rev ealing non-dominated action The first action corresponds to gi ving out the apple for sale, the second corresponds to tasting the apple; the first outcome corresponds to a rotten apple, the second outcome corresponds to a healthy apple. Both actions are non-dominated and the second one is re v ealing, therefore it is an easy game and according to Theorem 2 the minimax re gret is e Θ ( √ T ). This is apparently a new result for this game. Also notice that the picture is a just a translation of the picture for the one-armed bandit. Example 6 (Label E ffi cient Prediction). Consider a situation when we would like to sequentially classify emails as spam or as le gitimate. For each email we hav e to output a prediction, and additionally we can request, as feedback, the correct label from the user . If we classify an email incorrectly or we request its label, we su ff er a unit loss. (If the email is classified correctly and we do not request the feedback, no loss is su ff ered.) This can be formalized by the following partial-monitoring game [22]: L = 1 1 0 1 1 0 , H = a b c c d d , ` · , 2 ` · , 1 Non-rev ealing non-dominated action Rev ealing dominated action Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 8 where the first action corresponds to a label request, and the second and the third action correspond to a prediction (spam and legitimate, respecti vely) without a request. The outcomes correspond to spam and legitimate emails. W e see that the chain of non-dominated actions contains two neighboring non-rev ealing actions and there is a dominated re v ealing action. Therefore, it is a hard game and, by Theorem 2, the minimax re gret is Θ ( T 2 / 3 ). This specific example was the only game kno wn so far with minimax re gret at least Ω ( T 2 / 3 ) [22, Theorem 5.1]. Example 7 (A Hopeless Game). The follo wing game is an example where the feedback does not rev eal any information about the outcome: L = 1 0 0 1 ! , H = a a b b ! , ` · , 2 ` · , 1 Non-rev ealing non-dominated action Because both actions are non-rev ealing and non-dominated, it is a hopeless game and thus its minimax regret is Θ ( T ). Example 8 (A T rivial Game). In the follo wing game, the best action, regardless of the outcome sequence, is action 2. A learner that chooses this action in every round is guaranteed to ha ve zero re gret. L = 2 1 1 0 1 1 , H = a b c d e f ` · , 2 ` · , 1 Rev ealing non-dominated action Rev ealing dominated action Because this game has only one non-dominated action (action 2), it is a tri vial game and thus its minimax regret is 0. Example 9 (A Degenerate Game). The next game does not satisfy the non-degeneracy condition and there- fore Theorem 2 does not apply . L = 2 0 1 1 0 2 , H = a a b c d d ` · , 2 ` · , 1 Non-rev ealing non-dominated action Rev ealing dominated (degenerate) action Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 9 Its minimax regret is between Ω ( √ T ) and O ( T 2 / 3 ). It remains an open problem to close this gap and determine the exact rate of gro wth. 5. Upper bound f or easy games In this section we present our algorithm for games satisfying the separation condition and the non-de- generacy condition, and prov e that it achie ves e O ( √ T ) regret with high probability . W e call the algorithm A pple T ree since it builds a binary tree, lea ves of which are apple tasting games. 5.1. The algorithm In the first step of the algorithm we can purify the game by first removing the dominated actions and then the duplicates as mentioned beforehand. The idea of the algorithm is to recursiv ely split the game until we arriv e at games with tw o actions only . No w , if one has only two actions in a partial-information game, the game must be either a full-information game (if both actions are rev ealing) or an instance of a one-armed bandit (with one rev ealing and one non-re vealing action). T o see why this latter case corresponds to one-armed bandits, assume without loss of generality that the first action is the rev ealing action. Now , it is easy to see that the regret of a sequence of actions in a game does not change if the loss matrix is changed by subtracting the same number from a column. 5 By subtracting 2 , 1 from the first and 2 , 2 from the second column we thus get the equi valent game where the second ro w of the loss matrix is zero, arriving at a one-armed bandit game (see Example 4). Since a one- armed bandit is a special form of a two-armed bandit, one can use Exp3.P due to Auer et al. [5] to achieve the O ( √ T ) regret. No w , if there are more than two actions in the game, then the game is split, putting the first half of the actions into the first and the second half into the second subgame, with a single common shar ed action . Recall that, in the chain of non-dominated actions, the actions are ordered according to their losses corre- sponding to the first outcome. This is continued until the split results in games with two actions only . The recursi ve splitting of the game results in a binary tree (see Figure 2). The idea of the strategy played at an internal node of the tree is as follo ws: An outcome sequence of length T determines the frequency ρ T of outcome 2. If this frequency is small, the optimal action is one of the actions of G 1 , the first subgame (simply because then the frequency of outcome 1 is high and G 1 contains the actions with the smallest loss for the first outcome). Con versely , if this frequency is large, the optimal action is one of the actions of G 2 . In some intermediate range, the optimal action is the action shared between the subgames. Let the boundaries of this range be ρ ∗ 1 < ρ ∗ 2 ( ρ ∗ 1 is thus the solution to (1 − ρ ) s − 1 , 1 + ρ s − 1 , 2 = (1 − ρ ) s , 1 + ρ s , 2 and ρ ∗ 2 is the solution to (1 − ρ ) s + 1 , 1 + ρ s + 1 , 2 = (1 − ρ ) s , 1 + ρ s , 2 , where s = d K / 2 e is the index of the action shared between the two subgames.) If we kne w ρ T , a good solution would be to play a strategy where the actions are restricted to that of either game G 1 or G 2 , depending on whether ρ T ≤ ρ ∗ 1 or ρ T ≥ ρ ∗ 2 . (When ρ ∗ 1 ≤ ρ T ≤ ρ ∗ 2 then it does not matter which action-set we restrict the play to, since the optimal action in this case is included in both sets.) There are two di ffi culties. First, since the outcome sequence is not kno wn in advance, the best we can hope for is to know the running frequencies ρ t = 1 t P t s = 1 I ( J s = 2 ) . Ho wev er , since the game is a partial-information game, the outcomes are not re vealed in all time steps, hence, even ρ t is inaccessible. 5 As a result, for any algorithm, if R T is its regret at time T when measured in the game with the modified loss matrix, the algorithm’ s “true” re gret will also be R T (i.e., the algorithm’ s re gret when measured in the original, unmodified game). Piccolboni and Schindelhauer [19] exploit this idea, too. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 10 v Child ( v , 1) Child ( v , 2) Figure 2: The binary tree built by the algorithm. The leaf nodes represent neighboring action pairs. Ne vertheless, for now let us assume that ρ t was av ailable. Then one idea would be to play a strategy restricted to the actions of either game G 1 or G 2 as long as ρ t stays below ρ ∗ 1 or above ρ ∗ 2 . Further , when ρ t becomes larger than ρ ∗ 2 while previously the strategy played the action of G 1 then we ha ve to switch to the game G 2 . In this case, we start a fresh copy (a r eset ) of a strate gy playing in G 2 . The same happens when a switch from G 2 to game G 1 is necessary . These resets are necessary because at the leaves we play according to strategies that use weights that depend on the cumulated losses of the actions exponentially . T o see an example when without resets the algorithm fails to achie ve a small regret consider the case when there are 3 actions, the middle one being re vealing. Assume that during the first T / 2 time steps the frequency of outcome 2 oscillates between the two boundaries so that the algorithm switches constantly back and forth between the games G 1 and G 2 . Assume further that in the second half of the game, the outcome is alw ays 2. This way the optimal action will be 3. Nev ertheless, up to time step T / 2, the player of G 2 will only see outcome 1 and thus will think that action 2 is the optimal action. In the second half of the game, he will not hav e enough time to recov er and will play action 2 for too long. Resetting the algorithms of the subgames av oids this beha vior . If the number of switches was large, the repeated resetting of the strategies could be equally problem- atic. Luckily this cannot happen, hence the resetting does minimal harm. W e will in fact sho w that this generalizes to the case e ven when ρ t is estimated based on partial feedback (see Lemma 11). Let us no w turn to how ρ t is estimated. As mentioned in Section 3, mapping a row of H bijectively leads to an equiv alent game, thus for M = 2 we can assume without loss of generality that in any round, the algorithm receiv es (possibly random) feedback H t ∈ { 1 , 2 , ∗} : if a rev ealing action is played in the round, H t = J t ∈ { 1 , 2 } , otherwise H t = ∗ . Let H 1: t − 1 = ( I 1 , H 1 , . . . , I t − 1 , H t − 1 ) ∈ ( N × Σ ) t − 1 , the (random) history of actions and observ ations up to time step t − 1. If the algorithm choosing the actions decides with probability p t ∈ (0 , 1] to play a re vealing action ( p t can depend on H 1: t − 1 ) then I ( H t = 2 ) / p t is a simple unbiased estimate of I ( J t = 2 ) (in fact, E I ( H t = 2 ) / p t |H 1: t − 1 = I ( J t = 2 ) ). As long as p t does not drop to a too lo w v alue, ˆ ρ t = 1 t P t s = 1 I ( H s = 2 ) p s will be a relati v ely reliable estimate of ρ t (see Lemma 12). Howe v er reliable this estimate is, it can still di ff er from ρ t . For this reason, we push the boundaries determining game switches to wards each other: ρ 0 1 = 2 ρ ∗ 1 + ρ ∗ 2 3 , ρ 0 2 = ρ ∗ 1 + 2 ρ ∗ 2 3 . (2) W e call the resulting algorithm A pple T ree , because the elementary partial-information 2-action games in the bottom essentially correspond to instances of the apple tasting problem (see Example 5). The algo- Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 11 function M ain ( G , T , δ ) Input: G = ( L , H ) is a game, T is a horizon, 0 < δ < 1 is a confidence parameter 1: G ← P urify ( G ) 2: B uild T ree ( r oot , G , δ ) 3: f or t ← 1 to T do 4: P la y ( root ) 5: end f or Figure 3: The main entry point of the A pple T ree algo- rithm function I nit E t a ( G , T ) Input: G is a game, T is a horizon 1: if I s R evealing ( G , 2) then 2: η ( v ) ← √ 8 ln 2 / T 3: else 4: η ( v ) ← γ ( v ) / 4 5: end if Figure 4: The initialization routine I nit E t a . function B uild T ree ( v , G , δ ) Input: G = ( L , H ) is a game, v is a tree node 1: if N um O f A ctions ( G ) = 2 then 2: if not I s R evealing ( G , 1) then 3: G ← S w ap A ctions ( G ) 4: end if 5: w i ( v ) ← 1 / 2, i = 1 , 2 6: β ( v ) ← √ ln(2 /δ ) / (2 T ) 7: γ ( v ) ← 8 β ( v ) / (3 + β ( v )) 8: I nit E t a ( G , T ) 9: else 10: ( G 1 , G 2 ) ← S plit G ame ( G ) 11: B uild T ree (C hild ( v , 1), G 1 , δ/ (4 T ) ) 12: B uild T ree (C hild ( v , 2), G 2 , δ/ (4 T ) ) 13: g ( v ) ← 1, ˆ ρ ( v ) ← 0, t ( v ) ← 1 14: ( ρ 0 1 ( v ) , ρ 0 2 ( v )) ← B ound aries ( G ) 15: end if 16: G ( v ) ← G Figure 5: The tree b uilding procedure rithm’ s main entry point is sho wn on Figure 3. Its inputs are the game G = ( L , H ), the time horizon and a confidence parameter 0 < δ < 1. The algorithm first eliminates the dominated and duplicate actions. This is follo wed by b uilding a tree, which is used to store v ariables necessary to play in the subgames (Figure 5): If the number of actions is 2, the procedure initializes various parameters that are used either by a bandit algorithm (based on Exp3.P [5]), or by the exponentially weighted average algorithm (EW A) [4]. In the other case, it calls itself recursiv ely on the split subgames and with an appropriately decreased confidence parameter . The main work er routine is called P la y . This is again a recursi ve function (see Figure 6). The special case when the number of actions is two is handled in routine P la y A t L eaf , which will be discussed later . When the number of actions is larger , the algorithm recurses to play in the subgame that was remembered as the game to be preferred from the last round and then updates its estimate of the frequency of outcome 2 based on the information recei ved. When this estimate changes so that a switch of the current preferred game is necessary , the algorithm resets the algorithms in the subtree corresponding to the game switched to, and changes the v ariable storing the inde x of the preferred g ame. The R eset function used for this purpose, sho wn on Figure 7, is also recursiv e. At the leaves, when there are only two actions, either EW A or Exp3.P is used. These algorithms are used with their standard optimized parameters (see Corollary 4.2 for the tuning of EW A, and Theorem 6.10 for the tuning of Exp3.P , both from the book of Lugosi and Cesa-Bianchi [20]). For completeness, their pseudocodes are sho wn in Figures 8 – 9. Note that with Exp3.P (lines 6 – 14) we use the loss matrix trans- formation described earlier , hence the loss matrix has zero entries for the second (non-rev ealing) action, while the entry for action 1 and outcome j is 1 , j ( v ) − 2 , j ( v ). Here i , j ( v ) stands for the loss of action i and outcome j in the game G ( v ) that is stored at node v . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 12 function P la y ( v ) Input: v is a tree node 1: if N um O f A ctions ( G ( v )) = 2 then 2: ( p , h ) ← P la y A t L eaf ( v ) 3: else 4: ( p , h ) ← P la y (C hild ( v , g ( v ))) 5: ˆ ρ ( v ) ← (1 − 1 t ( v ) ) ˆ ρ ( v ) + 1 t ( v ) I ( h = 2 ) p 6: if g ( v ) = 2 and ˆ ρ ( v ) < ρ 0 1 ( v ) then 7: R eset (C hild ( v , 1)); g ( v ) ← 1 8: else if g ( v ) = 1 and ˆ ρ ( v ) > ρ 0 2 ( v ) then 9: R eset (C hild ( v , 2)); g ( v ) ← 2 10: end if 11: t ( v ) ← t ( v ) + 1 12: end if 13: retur n ( p , h ) Figure 6: The recursi ve function P la y function R eset ( v ) Input: v is a tree node 1: if N um O f A ctions ( G ( v )) = 2 then 2: w i ( v ) ← 1 / 2, i ← 1 , 2 3: else 4: g ( v ) ← 1, ˆ ρ ( v ) ← 0, t ( v ) ← 1 5: R eset (C hild ( v , 1)) 6: end if Figure 7: Function R eset 5.2. Pr oof of the upper bound Theorem 10. Assume G = ( L , H ) satisfies the separation condition and the non-degeneracy condition and i , j ≤ 1 . Denote by b R T the r e gr et of Algorithm A pple T ree up to time step T . Ther e exist constants c, p such that for any 0 < δ < 1 and T ∈ N , for any outcome sequence J 1 , . . . , J T , the algorithm with input G , T , δ achie ves Pr h b R T ≤ c √ T ln p (2 T /δ ) i ≥ 1 − δ . Throughout the proof we will analyze the algorithm’ s behavior at the root node. W e will use time indices as follo ws. Let us define the filtration {F t = σ ( I 1 , . . . , I t ) } t , where I t is the action the algorithm plays at time step t . T o any variable x ( v ) used by the algorithm, we denote by x t ( v ) the v alue of x ( v ) that is measurable with respect to F t , but not measurable with respect to F t − 1 . From now on we abbre viate x t (root) by x t . W e start with two lemmas. The first lemma shows that the number of switches the algorithm mak es is small. Lemma 11. Let S be the number of times A pple T ree calls R eset at the r oot node. Then there exists a universal constant c ∗ such that S ≤ c ∗ ln T ∆ , wher e ∆ = ρ 0 2 − ρ 0 1 with ρ 0 1 and ρ 0 2 given by (2) . Note that here we use the non-degeneracy condition to ensure that ∆ > 0. Pr oof. Let s be the number of times the algorithm switches from G 2 to G 1 . Let t 1 < · · · < t s be the time steps when ˆ ρ t becomes smaller than ρ 0 1 . Similarly , let t 0 1 < · · · < t 0 s + ξ , ( ξ ∈ { 0 , 1 } ) be the time steps when ˆ ρ t becomes greater than ρ 0 2 . Note that for all 1 ≤ j < s , t 0 j < t j < t 0 j + 1 . Finally , for every 1 ≤ j < s , we define t 00 j = min { t | t 0 j ≤ t ≤ t j , ( ∀ t ≤ τ ≤ t j : ˆ ρ τ ≤ 1) } . In other words, t 00 j is the time step when ˆ ρ t drops belo w 1 and stays there until the next reset. First we observe that if t 00 j ≥ 2 / ∆ then ˆ ρ t 00 j ≥ ( ρ 0 1 + ρ 0 2 ) / 2. Indeed, if t 00 j = t 0 j then ˆ ρ t 00 j ≥ ρ 0 2 , on the other hand, if t 00 j , t 0 j then ˆ ρ t 00 j − 1 > 1 and, from the update rule we have ˆ ρ t 00 j = 1 − 1 t 00 j ˆ ρ t 00 j − 1 + 1 t 00 j · I J t 00 j = 2 p t 00 j ≥ 1 − ∆ 2 ≥ ρ 0 1 + ρ 0 2 2 . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 13 function P la y A t L eaf ( v ) Input: v is a tree node 1: if R evealing A ction N umber ( G ( v )) = 2 then Full-information case 2: ( p , h ) ← E w a ( v ) 3: else Partial-information case 4: p ← (1 − γ ( v )) w 1 ( v ) w 1 ( v ) + w 2 ( v ) + γ ( v ) / 2 5: U ∼ U [0 , 1) U is uniform in [0 , 1) 6: if U < p then Play rev ealing action 7: h ← CHOOSE(1) h ∈ { 1 , 2 } 8: L 1 ← ( 1 , h ( v ) − 2 , h ( v ) + β ( v )) / p 9: L 2 ← β ( v ) / (1 − p ) 10: w 1 ( v ) ← w 1 ( v ) e xp( − η ( v ) L 1 ) 11: w 2 ( v ) ← w 2 ( v ) e xp( − η ( v ) L 2 ) 12: else 13: h ← CHOOSE(2) here h = ∗ 14: end if 15: end if 16: retur n ( p , h ) Figure 8: Function P la y A t L eaf function E w a ( v ) Input: v is a tree node 1: p ← w 1 ( v ) w 1 ( v ) + w 2 ( v ) 2: U ∼ U [0 , 1) U is uniform in [0 , 1) 3: if U < p then 4: I ← 1 5: else 6: I ← 2 7: end if 8: h ← CHOOSE( I ) h ∈ { 1 , 2 } 9: w 1 ( v ) ← w 1 ( v ) e xp( − η ( v ) 1 , h ( v )) 10: w 2 ( v ) ← w 2 ( v ) e xp( − η ( v ) 2 , h ( v )) 11: retur n ( p , h ) Figure 9: Function E w a The number of times the algorithm resets is at most 2 s + 1. Let j ∗ be the first inde x such that t 00 j ∗ ≥ 2 / ∆ . For any j ∗ ≤ j ≤ s , ˆ ρ t 00 j ≥ ( ρ 0 1 + ρ 0 2 ) / 2 and ˆ ρ t j ≤ ρ 0 1 . According to the update rule we hav e for any t 00 j < t ≤ t j that ˆ ρ t = 1 − 1 t ! ˆ ρ t − 1 + 1 t · I ( J t = 2 ) p t ≥ ˆ ρ t − 1 − 1 t ˆ ρ t − 1 ≥ ˆ ρ t − 1 − 1 t and hence ˆ ρ t − 1 − ˆ ρ t ≤ 1 t . Summing this inequality for all t 00 j + 1 ≤ t ≤ t j such that j ≥ j ∗ we get ∆ 2 = ρ 0 1 + ρ 0 2 2 − ρ 0 1 ≤ ˆ ρ t 00 j − ˆ ρ t j ≤ t j X t = t 00 j + 1 1 t = O ln t j t 00 j . Thus, there exists c > 0 such that for all j ∗ ≤ j ≤ s 1 c ∆ ≤ ln t j t 00 j ≤ ln t j t j − 1 . (3) Adding (3) for j ∗ < j ≤ s we get ( s − j ∗ ) 1 c ∆ ≤ ln t s 2 / ∆ ≤ ln T . W e conclude the proof with observing that j ∗ ≤ 2 / ∆ . The next lemma shows that the estimate of the relative frequenc y of outcome 2 is not far away from its true v alue. Lemma 12. F or any 0 < δ < 1 , with pr obability at least 1 − δ , for all t ≥ 8 √ T ln(2 T /δ ) / (3 ∆ 2 ) , | ˆ ρ t − ρ t | ≤ ∆ . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 14 The proof of the lemma employs Bernstein’ s inequality for martingales. Bernstein’ s inequality f or martingales. [20, Lemma A.8] Let X 1 , X 2 , . . . , X n be a bounded martingale di ff er ence sequence with r espect to a filtr ation {F } n i = 0 and with | X i | ≤ K . Let S i = i X j = 1 X j be the associated martingale. Denote the sum of conditional variances by Σ 2 n = n X i = 1 E [ X 2 i | F i − 1 ] . Then, for all constants , v > 0 , Pr " max i ∈ n S i > and Σ 2 n ≤ v # ≤ exp − 2 2( v + K / 3) ! . Pr oof of Lemma 12. For 1 ≤ t ≤ T , let p t be the conditional probability of playing a re vealing action at time step t , given the history H 1: t − 1 . Recall that, due to the construction of the algorithm, p t ≥ 1 / √ T . If we write ˆ ρ t in its explicit form ˆ ρ t = 1 t P t s = 1 I ( H s = 2 ) p s we can observe that E [ ˆ ρ t |H 1: t − 1 ] = ρ t , that is, ˆ ρ t is an unbiased estimate of the relativ e frequency . Let us define random variables X s : = I ( H s = 2 ) p s − I ( J s = 2 ) . Since p s is determined by the history , { X s } s is a martingale di ff erence sequence. Also, from p s ≥ 1 / √ T we kno w that V ar ( X s |H 1: t − 1 ) ≤ √ T . Hence, we can use Bernstein’ s inequality for martingales with = ∆ t , ν = t √ T , K = √ T : Pr | ˆ ρ t − ρ t | > ∆ = Pr t X s = 1 X s > t ∆ ≤ 2 exp − ∆ 2 t 2 / 2 t √ T + ∆ t √ T / 3 ! ≤ 2 exp − 3 ∆ 2 t 8 √ T ! . W e ha ve that if t ≥ 8 √ T ln(2 T /δ ) / (3 ∆ 2 ) then Pr | ˆ ρ t − ρ t | > ∆ ≤ δ/ T . W e get the bound for all t ∈ [8 √ T ln(2 T /δ ) / (3 ∆ 2 ) , T ] using the union bound. Pr oof of Theor em 10. T o prove that the algorithm achiev es the desired regret bound we use induction on the depth of the tree, d . If d = 1, A pple T ree plays either EW A or Exp3.P . EW A is known to satisfy Theorem 10, and, as we discussed earlier , Exp3.P achiev es O ( √ T ln T /δ ) regret as well. As the induction hypothesis we assume that Theorem 10 is true for any T and any game such that the tree built by the algorithm has depth d 0 < d . Let Q 1 = { 1 , . . . , d K / 2 e} , Q 2 = {d K / 2 e , . . . , K } be the sets of actions associated with the subgames in the root. (Recall that the actions are ordered with respect to · , 1 .) Furthermore, let us define the follo wing Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 15 v alues: Let T 0 0 = 1, let T 0 i be the first time step t after T 0 i − 1 such that g t , g t − 1 . In other words, T 0 i are the time steps when the algorithm switches between the subgames. Finally , let T i = min( T 0 i , T + 1). From Lemma 11 we kno w that T S max + 1 = T + 1, where S max = c ∗ ln T ∆ . It is easy to see that T i are stopping times for any i ≥ 1. W ithout loss of generality , from now on we will assume that the optimal action i ∗ ∈ Q 1 . If i ∗ = d K / 2 e then, since it is contained in both subgames, the bound tri vially follo ws from the induction hypothesis and Lemma 11. In the rest of the proof we assume i ∗ < K / 2. Let S = max { i ≥ 1 | T 0 i ≤ T } be the number of switches, c = 8 3 ∆ 2 , and B be the ev ent that for all t ≥ c √ T ln(4 T /δ ), | ˆ ρ t − ρ t | ≤ ∆ . W e know from Lemma 12 that Pr[ B ] ≥ 1 − δ/ 2. On B we hav e that | ˆ ρ T − ρ T | ≤ ∆ , and thus, using that i ∗ < K / 2, ρ T ≤ ρ ∗ 1 . This implies that in the last phase the algorithm plays on G 1 . It is also easy to see that before the last switch, at time step T S − 1, ˆ ρ is between ρ ∗ 1 and ρ ∗ 2 , if T S is large enough. Thus, up to time step T S − 1, the optimal action is d K / 2 e , the one that is shared by the two subgames. This implies that P T S − 1 t = 1 i ∗ , J t − d K / 2 e , J t ≥ 0 . On the other hand, if T S ≤ c √ T ln(4 T /δ ) then T S − 1 X t = 1 i ∗ , J t − d K / 2 e , J t ≥ − c √ T ln(4 T /δ ) . Thus, we hav e b R T = T X t = 1 I t , J t − i ∗ , J t = T S − 1 X t = 1 I t , J t − i ∗ , J t + T X t = T S I t , J t − i ∗ , J t ≤ I ( B ) T S − 1 X t = 1 I t , J t − d K / 2 e , J t + T X t = T S I t , J t − i ∗ , J t + c √ T ln(4 T /δ ) + I B c T | {z } D ≤ D + I ( B ) S max X r = 1 max i ∈ Q π ( r ) T r − 1 X t = T r − 1 I t , J t − i , J t = D + I ( B ) S max X r = 1 max i ∈ Q π ( r ) T X m = 1 I ( T r − T r − 1 = m ) T r − 1 + m − 1 X t = T r − 1 I t , J t − i , J t , where π ( r ) is 1 if r is odd and 2 if r is even. Note that for the last line of the above inequality chain to be well defined, we need outcome sequences of length at most 2 T . It does us no harm to assume that for all T < t ≤ 2 T , say , J t = 1. Recall that the strategies that play in the subgames are reset after the switches. Hence, the sum b R ( r ) m = P T r − 1 + m − 1 t = T r − 1 I t , J t − i , J t is the re gret of the algorithm if it is used in the subgame G π ( r ) for m ≤ T steps. Then, exploiting that T r are stopping times, we can use the induction hypothesis to bound b R ( r ) m . In particular , let C be the ev ent that for all m ≤ T the sum is less than c √ T ln p (2 T 2 /δ ). Since the root node calls its children Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 16 with confidence parameter δ/ (2 T ), we hav e that Pr[ C c ] ≤ δ/ 2. In summary , b R T ≤ D + I C c T + I ( B ) I ( C ) S max c √ T ln p 2 T 2 /δ ≤ I B c ∪ C c T + c √ T ln(4 T /δ ) + I ( B ) I ( C ) c ∗ ln T ∆ c √ T ln p 2 T 2 /δ . Thus, on B ∩ C , b R T ≤ 2 p cc ∗ ∆ √ T ln p + 1 ( 2 T /δ ) , which, together with Pr[ B c ∪ C c ] ≤ δ concludes the proof. Remark The above theorem pro ves a high probability bound on the regret. W e can get a bound on the expected regret if we set δ to 1 / √ T . Also note that the bound gi ven by the induction gro ws in the number of non-dominated actions as O ( K log 2 K ). 6. Lower Bound f or Non-T rivial Games In the following sections, k · k 1 and k · k denote the L 1 - and L 2 -norm of a vector in a Euclidean space, respecti vely . In this section, we show that non-tri vial games ha ve minimax regret at least Ω ( √ T ). W e state and prov e this result for all finite games, in contrast to earlier related lo wer bounds which apply to specific losses (see Cesa-Bianchi and Lugosi [20, Theorems 3.7, 6.3, 6.4, 6.11] for full-information, label e ffi cient, and bandit games). Theorem 13 (Lower bound for non-trivial games) . If G = ( L , H ) is a finite non-trivial (K ≥ 2 ) partial- monitoring game then ther e exists a constant c > 0 such that for any T ≥ 1 the minimax e xpected r e gr et R T ( G ) ≥ c √ T . The proof presented below works for stochastic nature, as well. There is a far simpler proof in the Appendix, ho wev er , that one applies only for adversarial nature. Recall that ∆ M ⊂ R M is the ( M − 1)-dimensional probability simplex. For the proof, we start with a geometrical lemma, which ensures the e xistence of a pair i 1 , i 2 of non- dominated actions that are “neighbors” in the sense that for any small enough > 0, there exists a pair of “ -close” outcome distributions p + v and p − v such that i 1 is uniquely optimal under the first distribution, and i 2 is uniquely optimal under the second distribution ov ertaking each non-optimal action by at least Ω ( ) in both cases. Lemma 14 ( -close distributions) . Let G = ( L , H ) be any finite non-trivial game with N non-duplicate actions and M ≥ 2 outcomes. Then there e xist two non-dominated actions i 1 ,i 2 ∈ N , p ∈ ∆ M , v ∈ R M \ { 0 } , and c, α > 0 satisfying the following pr operties: (a) i 1 , i 2 . (b) h i 1 , p i = h i 2 , p i ≤ h i , p i for all i ∈ N and the coor dinates of p ar e positive. (c) Coor dinates of v satisfy P M j = 1 v ( j ) = 0 . F or any ∈ (0 , α ) , (d) p 1 = p + v ∈ ∆ M and p 2 = p − v ∈ ∆ M , (e) for any i ∈ N , i , i 1 , we have h i − i 1 , p 1 i ≥ c , Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 17 (f) for any i ∈ N , i , i 2 , we have h i − i 2 , p 2 i ≥ c . Pr oof of Lemma 14. For any action i ∈ N , consider the cell C i = { p ∈ ∆ M : ∀ i 0 ∈ N , h i , p i ≤ h i 0 , p i} in the probability simplex ∆ M . The cell C i corresponds to the set of outcome distributions under which action i is optimal. Each cell is the intersection of some closed half-spaces and ∆ M , and thus it is a compact con ve x polytope of dimension at most M − 1. Note that N [ i = 1 C i = ∆ M . (4) For C ⊆ ∆ M , denote int C its interior in the topology induced by the hyperplane { x ∈ R M : h (1 , . . . , 1) , x i = 1 } and rint C its relativ e interior 6 . Let λ be the ( M − 1)-dimensional Lebesgue-measure. It is easy to see that for any pair of cells C i , C i 0 , C i 0 ∩ int C i = ∅ , that is, λ ( C i ∩ C i 0 ) = 0, and so int C i ⊆ C i \ [ i 0 , i C i 0 . (5) Hence the cells form a cell-decomposition of the simple x. Any two cells C i and C i 0 are separated by the hyperplane f i , i 0 = { x ∈ R M : h i , x i = h i 0 , x i} . Note that C i ∩ C i 0 ⊂ f i , i 0 . The cells are characterized by the follo wing lemma (which itself holds also with duplicate actions): Lemma 15. Action i is dominated ⇔ C i ⊆ S i 0 : i 0 , i C i 0 ⇔ int C i = ∅ ⇔ λ ( C i ) = 0 , that is, C i is ( M − 1) - dimensional (has positive λ -measur e) if and only if ther e is p ∈ C i \ S i 0 : i 0 , i C i 0 . Hence there is thr ee kind of “cells”: 1. C i = ∅ (action i is never optimal), 2. C i , ∅ has dimension less than M − 1 , int C i = ∅ , λ ( C i ) = 0 , C i ⊆ S i 0 : i 0 , i C i 0 (action i is de gener ate), 3. action i is non-dominated, C i is ( M − 1) -dimensional, rint C i = int C i , ∅ , λ ( C i ) > 0 , ther e is p ∈ C i \ S i 0 : i 0 , i C i 0 . Mor eover S i < D C i = ∆ M for the set D of dominated actions. The proof is in the Appendix. The non-triviality of the game ( K ≥ 2) means that there are at least two non-dominated actions of type 3 abov e. In the cell decomposition, due to Lemma 15, there must exist two such ( M − 1)-dimensional cells C i 1 and C i 2 corresponding to two non-dominated actions i 1 , i 2 , such that their intersection C i 1 ∩ C i 2 is an ( M − 2)-dimensional polytope. Clearly , i 1 , i 2 , since otherwise the cells would coincide; thus part (a) is satisfied. Moreov er , rint( C i 1 ∩ C i 2 ) ⊆ rint ∆ M since otherwise λ ( C i 1 ) or λ ( C i 2 ) would be zero. W e can choose any p ∈ rint( C i 1 ∩ C i 2 ). This choice of p guarantees that p ∈ f i 1 , i 2 , h i 1 , p i = h i 2 , p i , p ∈ rint ∆ M , and part (b) is satisfied. Since C i 1 ∩ C i 2 is ( M − 2)-dimensional, it also implies that there exists δ > 0 such that the δ -neighborhood { q ∈ R M : k p − q k < δ } of p is contained in rint( C i 1 ∪ C i 2 ). Since p ∈ f i 1 , i 2 therefore the hyperplane of vectors satisfying (c) does not coincide with f i 1 , i 2 implying that we can choose v ∈ R M \ { 0 } satisfying part (c), k v k < δ , and v < f i 1 , i 2 . W e can assume h i 2 − i 1 , v i > 0 (6) 6 Relative interior of C ⊆ R M is its interior in the topology induced by the smallest a ffi ne space containing it. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 18 (otherwise we choose − v ). Since p ± v lie in the δ -neighborhood of p , the y lie in rint( C i 1 ∪ C i 2 ). In particular , since h i 1 , p + v i < h i 2 , p + v i and h i 2 , p − v i < h i 1 , p − v i , p + v ∈ rint C i 1 and p − v ∈ rint C i 2 . Let p 1 = p + v and p 2 = p − v . (7) The conv exity of C i 1 and C i 2 implies that for any ∈ (0 , 1], p 1 ∈ rint C i 1 and p 2 ∈ rint C i 2 . This, in particular , ensures that p 1 , p 2 ∈ ∆ M and part (d) holds. T o pro ve (e) define I = { i ∈ N : i is collinear with i 1 and i 2 } . W e consider two cases: As the first case fix action i ∈ I \ { i 1 } , that is, i is an a ffi ne combination i = a i i 1 + b i i 2 for some a i + b i = 1. Since i 1 and i 2 are non-dominated, this must be a conv ex combination with a i , b i ≥ 0. There is no duplicate action, thus i , i 1 implying b i , 0. Hence b i > 0, and from (7) for any ≥ 0 h i − i 1 , p 1 i = h b i i 2 − b i i 1 , p + v i = b i h i 2 − i 1 , v i ≥ c provided that 0 < c ≤ min i ∈I\{ i 1 } b i h i 2 − i 1 , v i = c 0 . From (6) we kno w that b i h i 2 − i 1 , v i and so c 0 are positi ve. As the second case suppose i < I . Then, the hyperplane f i 1 , i does not coincide with f i 1 , i 2 . Since p ∈ rint( C i 1 ∩ C i 2 ), p ∈ f i 1 , i would contradict to f i 1 , i ∩ rint C i 1 = ∅ implied by (5). Thus p ∈ C i 1 \ f i 1 , i and therefore h i 1 , p i < h i , p i . This means that if we choose 0 < c ≤ min( c 0 , 1 2 min i < I h i − i 1 , p i ) (that is positi ve and depends only on L and not on T ) then for < α = min(1 , c / max i < I |h i − i 1 , v i| ), from (7) we hav e again h i − i 1 , p 1 i ≥ 2 c + h i − i 1 , v i > c > c . Part (f) is pro ved analogously to part (e), and by adjusting α and c if necessary . W e now continue with a technical lemma, which quantifies an upper bound on the Kullback-Leibler (KL) div ergence (or relative entropy) between the two distributions from the previous lemma. Recall that the KL di ver gence between two probability distributions p , q ∈ ∆ M is defined as D ( p k q ) = M X j = 1 p j ln p j q j ! . Lemma 16 (KL di ver gence of -close distributions) . Let p ∈ ∆ M be a pr obability vector . F or any vector ε ∈ R M such that both p − ε and p + ε lie in ∆ M and | ε ( j ) | ≤ p ( j ) / 2 for all j ∈ M , the KL diverg ence of p − ε and p + ε satisfies D ( p − ε k p + ε ) ≤ c k ε k 2 for some constant c depending only on p. Pr oof of Lemma 16. Since p , p + ε , and p − ε are all probability vectors, notice that the coordinates of ε hav e to sum up to zero. Also if a coordinate of p is zero then the corresponding coordinate of ε has to be zero as well. As zero coordinates do not modify the KL di ver gence, we can assume without loss of generality that all coordinates of p are positi ve. By definition, D ( p − ε k p + ε ) = M X j = 1 ( p ( j ) − ε ( j )) ln p ( j ) − ε ( j ) p ( j ) + ε ( j ) ! . W e write the logarithmic factor as ln p ( j ) − ε ( j ) p ( j ) + ε ( j ) ! = ln 1 − ε ( j ) p ( j ) ! − ln 1 + ε ( j ) p ( j ) ! . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 19 W e use the second order T aylor expansion ln(1 ± x ) = ± x − x 2 / 2 + O ( | x | 3 ) around 0 to get that ln(1 − x ) − ln(1 + x ) = − 2 x + r ( x ), where r ( x ) is a remainder upper bounded for all | x | ≤ 1 / 2 as | r ( x ) | ≤ c 0 | x | 3 with some uni versal constant c 0 > 0. 7 Substituting D ( p − ε k p + ε ) = M X j = 1 ( p ( j ) − ε ( j )) " − 2 ε ( j ) p ( j ) + r ε ( j ) p ( j ) !# = − 2 M X j = 1 ε ( j ) + 2 M X j = 1 ε 2 ( j ) p ( j ) + M X j = 1 ( p ( j ) − ε ( j )) · r ε ( j ) p ( j ) ! . Here the first term is 0. Letting p = min j ∈ M p ( j ), the second term is bounded by 2 P M j = 1 ε 2 ( j ) / p = (2 / p ) k ε k 2 , and the third term is bounded by M X j = 1 ( p ( j ) − ε ( j )) r ε ( j ) p ( j ) ! ≤ c 0 M X j = 1 ( p ( j ) − ε ( j )) | ε ( j ) | 3 p 3 ( j ) = c 0 M X j = 1 | ε ( j ) | p ( j ) − ε ( j ) | ε ( j ) | p 2 ( j ) ! ε 2 ( j ) p ( j ) ≤ c 0 M X j = 1 | ε ( j ) | p ( j ) + | ε ( j ) | 2 p 2 ( j ) ! ε 2 ( j ) p ( j ) ≤ c 0 M X j = 1 1 2 + 1 4 ! ε 2 ( j ) p = 3 c 0 4 p k ε k 2 . Hence, D ( p − ε k p + ε ) ≤ 8 + 3 c 0 4 p k ε k 2 = c k ε k 2 for c = 8 + 3 c 0 4 p . Pr oof of Theor em 13. The proof is similar as in Auer et al. [5]. When M = 1, G is alw ays tri vial, thus we assume that M ≥ 2. W ithout loss of generality we may assume that all the actions are all-revealing. Then, as in Section 3 for M = 2, we can also assume that there are no duplicate actions, thus for any two actions i and i 0 , i , i 0 . Lemma 14 implies that there exist tw o actions i 1 , i 2 , p ∈ ∆ M , v ∈ R M , and c 1 , α > 0 satisfying conditions (a)–(f). T o avoid cumbersome inde xing, by renaming the actions we can achie ve that i 1 = 1 and i 2 = 2. Let p 1 = p + v and p 2 = p − v for some ∈ (0 , α ). W e determine the precise value of later . By Lemma 14 (d), p 1 , p 2 ∈ ∆ M . Fix any randomized learning algorithm A and time horizon T . W e use randomization replacing the out- comes by a sequence J 1 , J 2 , . . . , J T of random variables i.i.d. according to p k , k ∈ { 1 , 2 } , and independently of the internal randomization of A . Let N ( k ) i = N ( k ) i ( A , T ) = T X t = 1 Pr k [ I t = i ] ∈ [0 , T ] (8) be the expected number of times action i is chosen by A under p k up to time step T . With subindex k , Pr k and E k denote probability and expectation gi ven outcome model k ∈ { 1 , 2 } , respecti vely . Lemma 17. F or any partial-monitoring game with N actions and M outcomes, algorithm A and outcome distribution p k ∈ ∆ M such that action k is optimal under p k , we have ¯ R T ( A , G ) ≥ X i ∈ N i , k N ( k ) i h i − k , p k i , k = 1 , 2 . (9) 7 In fact, one can take c 0 = 8 ln(3 / e ) ≈ 0 . 79. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 20 The proof is in the Appendix. Parts (e) and (f) of Lemma 14 imply that h k , p k i ≤ h i , p k i for k ∈ { 1 , 2 } and any i ∈ N , hence ¯ R T ( A , G ) can be bounded in terms of N ( k ) i using Lemma 17. They also imply that for any i ∈ N if i , k then h i − k , p k i ≥ c 1 . Therefore, we can continue lo wer bounding (9) as X i ∈ N i , k N ( k ) i h i − k , p k i ≥ X i ∈ N i , k N ( k ) i c 1 = c 1 T − N ( k ) k . (10) Collecting (9) and (10), we see that the worst-case re gret of A is lo wer bounded by ¯ R T ( A , G ) ≥ c 1 T − N ( k ) k (11) for k ∈ { 1 , 2 } . A veraging (11) o ver k ∈ { 1 , 2 } we get ¯ R T ( A , G ) ≥ c 1 2 T − N (1) 1 − N (2) 2 / 2 . (12) W e no w focus on lower bounding 2 T − N (1) 1 − N (2) 2 . W e start by sho wing that N (2) 2 is close to N (1) 2 . The follo wing lemma, which is the key lemma of both lower bound proofs, carries that out formally and states that the expected number of times an action is played by A does not change too much when we change the model, if the outcome distributions p 1 and p 2 are “close” in KL-di ver gence: Lemma 18. F or any partial-monitoring game with N actions and M outcomes, algorithm A, pair of out- come distributions p 1 , p 2 ∈ ∆ M and action i, we have N (2) i − N (1) i ≤ T q D ( p 2 k p 1 ) N (2) rev / 2 and N (1) i − N (2) i ≤ T q D ( p 1 k p 2 ) N (1) rev / 2 , wher e N ( k ) rev = P T t = 1 Pr k [ I t ∈ R ] = P i ∈R N ( k ) i under model p k , k = 1 , 2 with R being the set of re vealing actions. 8 The proof is in the Appendix. W e use Lemma 18 for i = 2 and that N (2) rev ≤ T to bound the di ff erence N (2) 2 − N (1) 2 as N (2) 2 − N (1) 2 ≤ T p D ( p 2 k p 1 ) T / 2 = T 3 / 2 p D ( p 2 k p 1 ) / 2 . (13) W e upper bound D ( p 2 k p 1 ) using Lemma 16 with ε = v . The lemma implies that D ( p 2 k p 1 ) ≤ c 2 2 for < 0 with some 0 , c 2 > 0 which depend only on v and p . Putting this together with (13) we get N (2) 2 < N (1) 2 + c 3 T 3 / 2 where c 3 = √ c 2 / 2. T ogether with N (1) 1 + N (1) 2 ≤ T we get 2 T − N (1) 1 − N (2) 2 > 2 T − N (1) 1 − N (1) 2 − c 3 T 3 / 2 ≥ T − c 3 T 3 / 2 . Substituting into (12) and choosing = 1 / (2 c 3 T 1 / 2 ) gi ves the desired lo wer bound ¯ R T ( A , G ) > c 1 8 c 3 √ T 8 It seems from the proof that N ( k ) rev could be slightly sharpened to N ( k , T − 1) rev = P T − 1 t = 1 Pr k [ I t ∈ R ]. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 21 provided that our choice of ensures that < min( α, 0 ) = : 1 that depends only on L . This condition is satisfied for all T > T 0 = 1 / (2 c 3 1 ) 2 . Since c 1 , c 3 , and 1 depend only on L , for such T , R T ( G ) ≥ c 1 8 c 3 √ T . The non-triviality of the game implies that Lemma 3 d) does not hold, so neither does b), that is, R T ( G ) > 0 for T ≥ 1. Thus choosing c = min min 1 ≤ T ≤ T 0 R T ( G ) √ T , c 1 8 c 3 ! , c > 0 and for any T , R T ( G ) ≥ c √ T . Remark Theorem 13 also holds if M = ∞ . Namely , since the proof of c) ⇒ d) of Lemma 3 remains obviously v alid, the non-triviality of the game ( K ≥ 2) excludes that c) holds, and thus for each i ∈ N there is j i ∈ { 1 , 2 , . . . } such that i , j i is not minimal in the j th i column of L . Then take the minor of L consisting of its (at most N ) columns corresponding to O = { j 1 , . . . , j N } . For the corresponding finite game G O (that does not depend on A ), Lemma 3 c) still does not hold, thus nor d) does, and G O is also non-trivial. Hence Theorem 13 implies that 9 R T ( G ) = inf A sup j 1: T ∈{ 1 , 2 ,... } T R T ( A , G ) ≥ inf A sup j 1: T ∈O T R T ( A , G ) = R T ( G O ) = Ω √ T . 7. Lower Bound f or Hard Games In this section, we present an Ω ( T 2 / 3 ) lo wer bound for the e xpected regret of an y two-outcome g ame in the case when the separation condition does not hold. Theorem 19 (Lo wer bound for hard games) . If M = 2 and G = ( L , H ) satisfies the non-degeneracy condition and the separation condition does not hold then there exists a constant C > 0 such that for any T ≥ 1 the minimax e xpected r e gr et R T ( G ) ≥ C T 2 / 3 . Pr oof of Theor em 19. W e follo w the lo wer bound proof for the label e ffi cient prediction from Cesa-Bianchi et al. [22] with a fe w changes. The most important change, as we will see, is the choice of the models we randomize ov er . As the first step, the following lemma shows that non-re vealing de generate actions do not influence the minimax regret of a game. Lemma 20. Let G be a non-de gener ate game with two outcomes. Let G 0 be the game we get by remo ving the de gener ate non-r evealing actions fr om G. Then R T ( G ) = R T ( G 0 ) . The proof of this lemma can be found in the Appendix. By the non-de generacy condition and Lemma 20, we can assume without loss of generality that G does not hav e degenerate actions. W e can also assume without loss of generality that actions 1 and 2 are the two consecuti ve non-dominated non-rev ealing actions. It follows by scaling and a reduction similar to the one we used in Section 5.1 that we can further assume ( 1 , 1 , 1 , 2 ) = (0 , α ), ( 2 , 1 , 2 , 2 ) = (1 − α, 0) with some α ∈ (0 , 1). Using the non-degenerac y condition and that actions 1 and 2 are consecutive non-dominated actions, we get that for all i ≥ 3, there exists some λ i ∈ R depending only on L such that i , 1 > λ i 1 , 1 + (1 − λ i ) 2 , 1 = (1 − λ i )(1 − α ) , i , 2 > λ i 1 , 2 + (1 − λ i ) 2 , 2 = λ i α . (14) 9 The same reasoning can be used to show that we could assume without loss of generality M ≤ N in the proof of Theorem 13. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 22 Let λ min = min i ≥ 3 λ i , λ max = max i ≥ 3 λ i , and λ ∗ = λ max − λ min . W e define two models for generating outcomes from { 1 , 2 } . In model 1, the outcome distribution is p 1 (1) = α + , p 1 (2) = 1 − p 1 (1), whereas in model 2, p 2 (1) = α − , p 2 (2) = 1 − p 2 (1) with 0 < ≤ min( α, 1 − α ) / 2 to be chosen later . W e use randomization replacing the outcomes by a sequence J 1 , J 2 , . . . , J T of random v ariables i.i.d. according to p k , k ∈ { 1 , 2 } , and independently of the internal randomization of A . Let N ( k ) i be the e xpected number of times action i is chosen by A under p k up to time step T , as in (8). W ith subindex k , Pr k and E k denote probability and e xpectation gi ven outcome model k ∈ { 1 , 2 } , respectiv ely . Finally , let N ( k ) ≥ 3 = P i ≥ 3 N ( k ) i . Note that, if < 0 with some 0 depending only on L then only actions 1 and 2 can be optimal for these models. Namely , action k is optimal under p k , hence ¯ R T ( A , G ) can be bounded in terms of N ( k ) i using Lemma 17: ¯ R T ( A , G ) ≥ X i ∈ N i , k N ( k ) i h i − k , p k i = N X i = 3 N ( k ) i h i − k , p k i + N ( k ) 3 − k h 3 − k − k , p k i (15) for k = 1,2. Now , by (14), there exists τ > 0 depending only on L such that for all i ≥ 3, i , 1 ≥ (1 − λ i )(1 − α ) + τ and i , 2 ≥ αλ i + τ . These bounds and simple algebra gi ve that h i − 1 , p 1 i = ( i , 1 − 1 , 1 )( α + ) + ( i , 2 − 1 , 2 )(1 − α − ) ≥ ((1 − λ i )(1 − α ) + τ )( α + ) + ( αλ i + τ − α )(1 − α − ) = (1 − λ i ) + τ ≥ (1 − λ max ) + τ = : f 1 and h 2 − 1 , p 1 i = (1 − α )( α + ) − α (1 − α − ) = . Analogously , we get h i − 2 , p 2 i ≥ λ min + τ = : f 2 and h 1 − 2 , p 2 i = . Note that if < τ/ max( | 1 − λ max | , | λ min | ) then both f 1 and f 2 are positi ve. Substituting these into (15) giv es ¯ R T ( A , G ) ≥ f k N ( k ) ≥ 3 + N ( k ) 3 − k . (16) The follo wing lemma is an application of Lemma 18 and 16: Lemma 21. Ther e e xists a constant c > 0 (depending on α only) such that N (1) 2 ≥ N (2) 2 − cT q N (2) ≥ 3 and N (2) 1 ≥ N (1) 1 − cT q N (1) ≥ 3 . Pr oof. W e only prove the first inequality , the other one is symmetric. Using Lemma 18 with M = 2, i = 2 and the fact that actions 1 and 2 are non-re vealing, we ha ve N (2) 2 − N (1) 2 ≤ T q D ( p 2 k p 1 ) N (2) ≥ 3 / 2 . Lemma 16 with M = 2, p = ( α, 1 − α ) > , and ε = ( , − ) > gi ves D ( p 2 k p 1 ) ≤ ˆ c 2 , where ˆ c depends only on α . Rearranging and substituting c = √ ˆ c / 2 yields the first statement of the lemma. Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 23 Let l = arg min k ∈{ 1 , 2 } N ( k ) ≥ 3 . Now , for k , l we can lo wer bound the regret using Lemma 21 for (16): ¯ R T ( A , G ) ≥ f k N ( k ) ≥ 3 + N ( l ) 3 − k − cT q N ( l ) ≥ 3 ! ≥ f k N ( l ) ≥ 3 + N ( l ) 3 − k − cT q N ( l ) ≥ 3 ! , (17) as f k > 0. For k = l we do this subtracting cT 2 q N ( l ) ≥ 3 ≥ 0 from the right-hand side of (16) leading to the same lo wer bound, hence (17) holds for k = 1,2. Finally , av eraging (17) ov er k ∈ { 1 , 2 } we hav e the bound f 1 + f 2 2 N ( l ) ≥ 3 + N ( l ) 2 + N ( l ) 1 2 − cT q N ( l ) ≥ 3 = (1 − λ max + λ min ) 2 + τ ! N ( l ) ≥ 3 + T − N ( l ) ≥ 3 2 − cT 2 q N ( l ) ≥ 3 = τ − λ ∗ 2 ! N ( l ) ≥ 3 + T 2 − cT 2 q N ( l ) ≥ 3 . Choosing = c 2 T − 1 / 3 ( ≤ c 2 ) with c 2 > 0 gives ¯ R T ( A , G ) ≥ τ − λ ∗ c 2 T − 1 / 3 2 ! N ( l ) ≥ 3 + c 2 T 2 / 3 2 − cc 2 2 T 1 / 3 q N ( l ) ≥ 3 ≥ τ − λ ∗ c 2 2 ! N ( l ) ≥ 3 + c 2 T 2 / 3 2 − cc 2 2 T 1 / 3 q N ( l ) ≥ 3 = τ − λ ∗ c 2 2 ! x 2 + c 2 2 − cc 2 2 x ! T 2 / 3 = q ( x ) T 2 / 3 , where x = T − 1 / 3 q N ( l ) ≥ 3 and q ( x ) can be written and lower bounded as q ( x ) = τ − λ ∗ c 2 2 ! x − cc 2 2 2 τ − λ ∗ c 2 2 + c 2 2 − c 2 c 4 2 4 τ − 2 λ ∗ c 2 ≥ c 2 2 1 − c 2 c 2 2 τ − λ ∗ c 2 ! independently of x whenev er λ ∗ c 2 < 2 τ and c 2 ≤ 1. No w it is easy to see that if c 2 = min( τ/ ( c 2 + λ ∗ ) , 1) then these hold, moreov er , q ( x ) ≥ c 2 / 4 > 0 giving the desired lo wer bound ¯ R T ( A , G ) ≥ c 2 4 T 2 / 3 provided that our choice of ensures that < min( α/ 2 , (1 − α ) / 2 , 0 , τ/ | 1 − λ max | , τ/ | λ min | ) = : 1 that depends only on L . This condition is satisfied for all T > T 0 = ( c 2 / 1 ) 3 . Since c 2 and 1 depend only on L , for such T , R T ( G ) ≥ c 2 4 T 2 / 3 . If the separation condition does not hold then the game is clearly non-trivial which, using Lemma 3 b) and d) as in the proof of Theorem 13, implies that R T ( G ) > 0 for T ≥ 1. Thus choosing C = min min 1 ≤ T ≤ T 0 R T ( G ) T 2 / 3 , c 2 4 ! , C > 0 and for any T , R T ( G ) ≥ C T 2 / 3 . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 24 8. Discussion In this paper we classified non-degenerate partial-monitoring games with two outcomes based on their minimax re gret. An immediate question is how the classification e xtends to de generate games. Unfortu- nately , the degenerac y condition is needed in both the upper and lo wer bound proofs. W e do not ev en kno w if all de generate games fall into one of the four categories or there are some games with minimax re gret of e Θ ( T α ) for some α ∈ (1 / 2 , 2 / 3). Nonetheless, we conjecture that, if the rev ealing degenerate actions are included in the chain of non-dominated actions, the classification theorem holds without any change. The most important open question is whether our results generalize to games with more outcomes. A simple observation is that, given a finite partial-monitoring game, if we restrict the opponent’ s choices to any two outcomes, the resulting game’ s hardness serves as a lower bound on the minimax regret of the original game. This gi ves us a su ffi cient condition that a game has Ω ( T 2 / 3 ) minimax re gret. W e belie ve that the Ω ( T 2 / 3 ) lower bound can also be generalized to situations where two “ -close” outcome distrib utions are not distinguishable by playing only their respectiv e optimal actions. Generalizing the upper bound result seems more challenging. The algorithm A pple T ree heavily exploits the two-dimensional structure of the losses and, as of yet, in general we do not know how to construct an algorithm that achieves e O ( √ T ) regret on partial-monitoring games with more than two outcomes. It is also important to note that our upper bound result hea vily exploits the assumption that the opponent is obli vious. Our results do not extend to games with non-oblivious opponents, to the best of our knowledge. A ppendix A. Pr oof of Lemma 3. a) ⇒ b) is obvious. b) ⇒ c) For an y A , ¯ R T ( A , G ) ≥ sup j ∈ M , J 1 = ··· = J T = j E T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t = sup j ∈ M E T X t = 1 I t , j − T min i ∈ N i , j ≥ sup j ∈ M E h I 1 , j i − min i ∈ N i , j ! = f ( A ) . b) leads to 0 = R T ( G ) = inf A ¯ R T ( A , G ) ≥ inf A f ( A ) . Observe that f ( A ) depends on A through only the distribution of I 1 on N denoted by q = q ( A ) now , that is, f ( A ) = f 0 ( q ) for proper f 0 . This dependence is continuous on the compact domain of q , hence the infimum can be replaced by minimum. Thus min q f 0 ( q ) ≤ 0, that is, there exists a q such that for all j ∈ M , E h I 1 , j i = min i ∈ N i , j . This implies that the support of q contains only actions whose loss is not larger than the loss of any other action irrespecti vely of the choice of Nature’ s action. (Such an action is obviously non-dominated as sho wn by any p ∈ ∆ M supported on all outcomes.) c) ⇒ d) Action i in c) is non-dominated, and any other action with loss vector distinct from i is dominated (by i and any action with loss v ector i ). d) ⇒ a) For any action i ∈ N , as in the proof of Lemma 14, consider the compact con ve x cell C i in ∆ M . By Lemma 15 S i < D C i = ∆ M . This and d) imply that there is an i with C i = ∆ M , that is, i is optimal for any outcome. So the algorithm that always plays i has zero regret for all outcome sequences and T . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 25 Pr oof of Theor em 2 Case (1d) . W e know that K ≥ 2 and G has no re vealing action. Then for any A , ¯ R T ( A , G ) ≥ sup j ∈ M , J 1 = ··· = J T = j E T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t ≥ 1 M M X j = 1 E T X t = 1 I t , j − T min i ∈ N i , j = 1 M T X t = 1 E M X j = 1 I t , j − T M M X j = 1 min i ∈ N i , j . Here I t is a random variable usually depending on J 1: T − 1 , that is, on j through the outcomes. Howe ver , since G has no rev ealing action, no w the distrib ution of I t is independent of j , thus E [ P M j = 1 I t , j ] ≥ min i ∈ N P M j = 1 i , j for each t , and we have ¯ R T ( A , G ) ≥ T 1 M min i ∈ N M X j = 1 i , j − M X j = 1 min i ∈ N i , j | {z } c = cT , where c > 0 if K ≥ 2 (because c ≥ 0, and c = 0 would imply Lemma 3 c), thus also d)). Since c depends only on L , R T ( G ) ≥ cT = Θ ( T ). Pr oof of Lemma 15. By Definition 1, action i is dominated if and only if C i ⊆ S i 0 : i 0 , i C i 0 . C i ⊆ S i 0 : i 0 , i C i 0 ⇒ int C i = ∅ : Since i 0 , i ⇒ i , i , follo ws from (5). int C i = ∅ ⇒ λ ( C i ) = 0: Follo ws from con v exity of C i . λ ( C i ) = 0 ⇒ C i ⊆ S i 0 : i 0 , i C i 0 : indirect: if p ∈ C i is in the complementer of S i 0 : i 0 , i C i 0 , that is open in ∆ M , then there is a neighborhood S of p in ∆ M disjoint from S i 0 : i 0 , i C i 0 . Thus S ⊆ S i 0 : i 0 = i C i 0 = C i due to (4), and λ ( C i ) ≥ λ ( S ) > 0, contradiction. Since λ ( S i ∈D C i ) ≤ P i ∈D λ ( C i ) = 0, thus from (4) λ ( S i < D C i ) ≥ λ ( ∆ M ), and λ ( ∆ M \ S i < D C i ) = 0. The latest set is open in ∆ M , so it must be empty , that is, S i < D C i = ∆ M . Pr oof of Lemma 17. Clearly , the w orst-case expected regret of A is at least its av erage regret: ¯ R T ( A , G ) = sup j 1: T ∈ M T R T ( A , G ) ≥ E k [R T ( A , G )] = E k T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t , where the expectation on the right-hand side is taken with respect to both the random choices of the out- comes and the internal randomization of A . W e lower bound the right-hand side switching e xpectation and minimum to get E k T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t ≥ T X t = 1 E k I t , J t − min i ∈ N T X t = 1 E k i , J t = T X t = 1 N X i = 1 E k I ( I t = i ) i , J t − min i ∈ N T X t = 1 h i , p k i = T X t = 1 N X i = 1 E k I ( I t = i ) E k i , J t − T min i ∈ N h i , p k i Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 26 (by the independence of I t and J t ) = N X i = 1 h i , p k i T X t = 1 Pr k [ I t = i ] − T min i ∈ N h i , p k i = N X i = 1 N ( k ) i h i , p k i − T h k , p k i (A.1) = X i ∈ N i , k N ( k ) i h i − k , p k i . (A.1) follows from the fact that action k is optimal under p k . Clearly the term i = k can be omitted in the last equality . Pr oof of Lemma 18. W e only prov e the first inequality , the other one is symmetric. Assume first that A is deterministic, that is, I t : Σ t − 1 → N , and so I t ( h 1: t − 1 ) denotes the choice of the algorithm at time step t , giv en that the (random) history of observ ations of length t − 1, H 1: t − 1 = ( H 1 , . . . , H t − 1 ) takes h 1: t − 1 = ( h 1 , . . . , h t − 1 ) ∈ Σ t − 1 . (Note that this is a slightly di ff erent history definition than H 1: t − 1 defined in Section 5.1, as H 1: t − 1 does not include the actions since their choices are determined by the feedback any- way . In general, H 1: t − 1 is equi v alent to H 1: t − 1 ∪ ( I 1 , ..., I t − 1 ). Nev ertheless, if it is assumed that the feedback symbol sets of actions are disjoint then H 1: t − 1 and H 1: t − 1 are equiv alent.) W e denote by p ∗ k the joint distribu- tion of H 1: T − 1 ov er Σ T − 1 associated with p k . (For games with only all-revealing actions, assuming h i , j = j in H , p ∗ k is the product distribution ov er the outcome sequences, that is, formally , p ∗ k ( j 1: T − 1 ) = Q T − 1 t = 1 p k ( j t ).) W e can bound the di ff erence N (2) 2 − N (1) 2 as N (2) i − N (1) i = T X t = 1 ( Pr 2 [ I t = i ] − Pr 1 [ I t = i ] ) = X h 1: T − 1 ∈ Σ T − 1 T X t = 1 I ( I t ( h 1: t − 1 ) = i ) p ∗ 2 ( h 1: T − 1 ) − I ( I t ( h 1: t − 1 ) = i ) p ∗ 1 ( h 1: T − 1 ) = X h 1: T − 1 ∈ Σ T − 1 p ∗ 2 ( h 1: T − 1 ) − p ∗ 1 ( h 1: T − 1 ) · T X t = 1 I ( I t ( h 1: t − 1 ) = i ) ≤ T X h 1: T − 1 ∈ Σ T − 1 p ∗ 2 ( h 1: T − 1 ) ≥ p ∗ 1 ( h 1: T − 1 ) p ∗ 2 ( h 1: T − 1 ) − p ∗ 1 ( h 1: T − 1 ) (A.2) = T 2 p ∗ 2 − p ∗ 1 1 ≤ T q D ( p ∗ 2 k p ∗ 1 ) / 2 , where the last step is an application of Pinsker’ s inequality [24, Lemma 12.6.1] to distributions p ∗ 1 and p ∗ 2 . Using the chain rule for KL di ver gence [24, Theorem 2.5.3] we can write (with somewhat slopp y notation) D ( p ∗ 2 k p ∗ 1 ) = T − 1 X t = 1 D p ∗ 2 ( h t | h 1: t − 1 ) k p ∗ 1 ( h t | h 1: t − 1 ) , Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 27 where the t th conditional KL di ver gence term is X h 1: t − 1 ∈ Σ t − 1 Pr 2 ( H 1: t − 1 = h 1: t − 1 ) X h t ∈ Σ Pr 2 ( H t = h t | H 1: t − 1 = h 1: t − 1 ) ln Pr 2 ( H t = h t | H 1: t − 1 = h 1: t − 1 ) Pr 1 ( H t = h t | H 1: t − 1 = h 1: t − 1 ) . (A.3) Decompose this sum for the case I t ( h 1: t − 1 ) < R and I t ( h 1: t − 1 ) ∈ R . In the first case, we play a none-re v ealing action, thus our observation H t = h I t ( h 1: t − 1 ) , J t = h I t ( h 1: t − 1 ) , 1 is a deterministic constant in both models 1 and 2, thus both Pr 1 ( · | H 1: t − 1 = h 1: t − 1 ) and Pr 2 ( · | H 1: t − 1 = h 1: t − 1 ) are degenerate and the KL diver gence factor is 0. Otherwise, playing a rev ealing action, H t = h I t ( h 1: t − 1 ) , J t is the same deterministic function of J t (which is independent of H 1: t − 1 ) in both models 1 and 2, and so the inner sum in (A.3) is X h t ∈ Σ Pr 2 [ h I t ( h 1: t − 1 ) , J t = h t ] ln Pr 2 [ h I t ( h 1: t − 1 ) , J t = h t ] Pr 1 [ h I t ( h 1: t − 1 ) , J t = h t ] . (A.4) Since Pr k [ h I t ( h 1: t − 1 ) , J t = h t ] = P j t ∈ M : h I t ( h 1: t − 1 ) , j t = h t p k ( j t ) ( k = 1,2), using the log sum inequality [24, Theorem 2.7.1]), (A.4) is upper bounded by X h t ∈ Σ X j t ∈ M : h I t ( h 1: t − 1 ) , j t = h t p 2 ( j t ) ln p 2 ( j t ) p 1 ( j t ) = X j t ∈ M p 2 ( j t ) ln p 2 ( j t ) p 1 ( j t ) = D ( p 2 k p 1 ) . Hence, D ( p ∗ 2 k p ∗ 1 ) is upper bounded by T − 1 X t = 1 X h 1: t − 1 ∈ Σ t − 1 I t ( h 1: t − 1 ) ∈R Pr 2 ( H 1: t − 1 = h 1: t − 1 ) D ( p 2 k p 1 ) = D ( p 2 k p 1 ) T − 1 X t = 1 X i ∈R Pr 2 [ I t = i ] = D ( p 2 k p 1 ) N (2 , T − 1) rev , where N ( k , T − 1) rev = P T − 1 t = 1 Pr k [ I t ∈ R ]. This together with (A.2) gi v es N (2) i − N (1) i ≤ T q D ( p 2 k p 1 ) N (2 , T − 1) rev / 2. If A is random and its internal random “bits” are represented by a random value Z (which is independent of J 1 , J 2 ,. . . ), then N ( k ) i = E h ˜ N ( k ) i ( Z ) i for ˜ N ( k ) i ( Z ) = P T t = 1 Pr k [ I t = i | Z ]. Also let ˜ N ( k , T − 1) rev ( Z ) = P T − 1 t = 1 Pr k [ I t ∈ R| Z ]. The proof abo ve implies that for an y fixed z ∈ Range( Z ), ˜ N (2) i ( z ) − ˜ N (1) i ( z ) ≤ T q D ( p 2 k p 1 ) ˜ N (2 , T − 1) rev ( z ) / 2 , and thus, using also Jensen’ s inequality , N (2) i − N (1) i = E h ˜ N (2) i ( Z ) − ˜ N (1) i ( Z ) i ≤ E " T q D ( p 2 k p 1 ) ˜ N (2 , T − 1) rev ( Z ) / 2 # ≤ T q D ( p 2 k p 1 ) E h ˜ N (2 , T − 1) rev ( Z ) i / 2 = T q D ( p 2 k p 1 ) N (2 , T − 1) rev / 2 , that is clearly upper bounded by T q D ( p 2 k p 1 ) N (2) rev / 2 yielding the statement of the lemma. Pr oof of Lemma 20. W e prove the lemma by showing that for e v ery algorithm A on game G there exists an algorithm A 0 on G 0 such that for any outcome sequence, R T ( A 0 , G 0 ) ≤ R T ( A , G ) and vice v ersa. Recall that the minimax regret of a game is R T ( G ) = inf A sup J 1: T ∈ M T R T ( A , G ) , Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 28 ` · , 2 ` · , 1 Rev ealing non-dominated action Non-rev ealing degenerate action 1 2 3 4 Figure A.10: Degenerate non-rev ealing actions on the chain. The loss vector of action 2 is a conv ex combination of that of action 1 and 3. On the other hand, the loss vector of action 4 is component-wise lower bounded by that of action 3. where R T ( A , G ) = E T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t , First we observ e that the term E [min i ∈ N P T t = 1 i , J t ] does not change by removing de generate actions. Indeed, by the definition of degenerate action, if the minimum is giv en by a de generate action then there exists a non-degenerate action with the same cumulati ve loss. It follows that we only ha ve to deal with the term E [ P T t = 1 I t , J t ]. 1. Let A 0 be an algorithm on G 0 . W e define the algorithm A on G by choosing the same actions as A 0 at e very time step. Since the action set of G is a superset of that of G 0 , this construction results in a well defined algorithm on G , and trivially has the same e xpected loss as A 0 . 2. Let A be an algorithm on G . From the definition of degenerate actions, we know that for ev ery degenerate action i , there are tw o possibilities: (a) There exists a non-de generate action i 1 such that i is component-wise lo wer bounded by i 1 . (b) There are two non-degenerate actions i 1 and i 2 such that i is a con ve x combination of i 1 and i 2 , that is, i = α i i 1 + (1 − α i ) i 2 for some α i ∈ (0 , 1). An illustration of these cases can be found in Figure A.10. W e construct A 0 the following way . At e very time step t , if I A t (the action that algorithm A would take) is non-degenerate then let I A 0 t = I A t . If I A t = i is a degenerate action of the first kind, let I A 0 t be i 1 . If I A t = i is a degenerate action of the second kind then let I A 0 t be i 1 with probability α i and i 2 with probability 1 − α i . Recall that G is non-degenerate, so i has to be a non-revealing action. Ho we ver , i 1 and / or i 2 might be rev ealing ones. T o handle this, A 0 is defined to map the observ ation sequence, before using it as the argument of I t , replacing the feedbacks corresponding to degenerate action i by h i , 1 = h i , 2 . That is, intuitiv ely , A 0 “pretends” that the feedbacks at such time steps are irrele vant. It is clear that the expected loss of A 0 in e very time step is less than or equal to the expected loss of A , concluding the proof. Pr oof of Theor em 13 for adver sarial natur e For the proof, we start with a lemma, which ensures the existence of a pair i 1 , i 2 of actions and an outcome distribution p with M atoms such that both i 1 and i 2 are optimal under p . Lemma 22. Let G = ( L , H ) be any finite non-trivial game with N actions and M ≥ 2 outcomes. Then ther e exists p ∈ ∆ M satisfying both of the following pr operties: Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 29 (a) All coor dinates of p ar e positive . (b) Ther e e xist actions i 1 ,i 2 ∈ N such that i 1 , i 2 and for all i ∈ N , h i 1 , p i = h i 2 , p i ≤ h i , p i . Pr oof of Lemma 22. Note that distributions p with positiv e coordinates form the interior of ∆ M (int ∆ M ). For any action i ∈ N , as in the proof of Lemma 14, consider the compact conv ex cell C i in ∆ M , whose union is ∆ M (see (4)). Let p 1 be any point in the interior of ∆ M . By (4), there is a cell C i 1 containing p 1 . If C i 1 = ∆ M held then action i 1 would satisfy Lemma 3 c), thus also d), and the game would be trivial. So there must be a point, say p 2 , in ∆ M \ C i 1 . The intersection of the closed segment p 1 p 2 and C i 1 is closed and con v ex, thus it is a closed subse gment p 1 p for some p ∈ C i 1 ( p , p 2 ). p 1 ∈ int ∆ M and the con vexity of ∆ M imply p ∈ int ∆ M . Since the open segment p p 2 has to be covered by S i 0 : C i 0 , C i 1 C i 0 , that is a closed set, p ∈ S i : C i 0 , C i 1 C i 0 must also hold, that is, p ∈ C i 2 for some C i 2 , C i 1 (requiring i 1 , i 2 ). Hence p satisfies both (a) and (b). Pr oof of Theor em 13. When M = 1, G is always trivial, thus we assume that M ≥ 2. W ithout loss of generality we may assume that all the actions are all-re vealing. Let p ∈ ∆ M be a distrib ution of the outcomes that satisfies conditions (a) and (b) of Lemma 22. By renaming actions we can assume without loss of generality that 1 , 2 and actions 1 and 2 are optimal under p , that is, h 1 , p i = h 2 , p i ≤ h i , p i (A.5) for any i ∈ N . Fix any learning algorithm A . W e use randomization replacing the outcomes by a sequence J 1 , J 2 , . . . , J T of random v ariables i.i.d. according to p , and independent of the internal randomization of A . Clearly , as in the proof of Lemma 17, the worst-case e xpected regret of A is at least its average re gret: ¯ R T ( A , G ) ≥ E [R T ( A , G )] = E T X t = 1 I t , J t − min i ∈ N T X t = 1 i , J t = E T X t = 1 E [ I t , J t | I t ] − min i ∈ N T X t = 1 i , J t . (A.6) Here, in the last two expressions, the expectation is with respect to both the internal randomization of A and the random choice of J 1 , J 2 , . . . , J T . Now , since J t is independent of I t , we see that E [ I t , J t | I t ] = h I t , p i . By (A.5), we hav e h I t , p i ≥ h 1 , p i = h 2 , p i . Therefore (upper bounding also the minimum), T X t = 1 E I t , J t | I t − min i ∈ N T X t = 1 i , J t = T X t = 1 h I t , p i − min i ∈ N T X t = 1 i , J t ≥ T X t = 1 h 1 , p i − min i = 1 , 2 T X t = 1 i , J t (A.7) = max i = 1 , 2 T X t = 1 h 1 , p i − i , J t . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 30 Using the identity max { a , b } = 1 2 ( a + b + | a − b | ), the latest expression is 1 2 T X t = 1 h 1 , p i − 1 , J t + T X t = 1 h 1 , p i − 2 , J t + T X t = 1 h 1 , p i − 1 , J t − T X t = 1 h 1 , p i − 2 , J t = 1 2 T X t = 1 h 1 , p i − 1 , J t + h 2 , p i − 2 , J t + 1 2 T X t = 1 2 , J t − 1 , J t , where (A.5) was used in the first term. The e xpectation of the first term vanishes since E [ i , J t ] = h i , p i . Let X t = 2 , J t − 1 , J t . W e see that X 1 , X 2 , . . . , X T are i.i.d. random v ariables with mean E [ X t ] = 0. Therefore, E max i = 1 , 2 T X t = 1 h 1 , p i − i , J t = 1 2 E T X t = 1 X t ≥ c √ T , (A.8) where the last inequality follo ws from Theorem 23 stated below and the constant c depends only on 1 , 2 , and p . F or the theorem to yield c > 0, it is important to note that the distrib ution of X t has finite support and with positiv e probability X t , 0 since 1 , 2 and all coordinates of p are positi ve. Hence, both E [ X 2 t ] and E [ X 4 t ] are finite and positi ve. No w , putting together (A.6), (A.7), and (A.8) gi ves the desired lo wer bound ¯ R T ( A , G ) ≥ c √ T . Since c depends only on L , also R T ( G ) ≥ c √ T . The following theorem is a variant of Khinchine’ s inequality (see e.g. [20, Lemma A.9]) for asymmetric random v ariables. The idea of the proof is the same as there and originally comes from Little wood [25]. Theorem 23 (Khinchine’ s inequality for asymmetric random variables) . Let X 1 , X 2 , . . . , X T be i.i.d. random variables with mean E [ X t ] = 0 , finite variance E [ X 2 t ] = V ar ( X t ) = σ 2 , and finite fourth moment E [ X 4 t ] = µ 4 . Then, E T X t = 1 X t ≥ σ 3 p 3 µ 4 √ T . Pr oof. [26, Lemma A.4] implies that for any random variable Z with finite fourth moment E | Z | ≥ E [ Z 2 ] 3 / 2 E [ Z 4 ] 1 / 2 . Applying this inequality to Z = P T t = 1 X t we get E T X t = 1 X t ≥ T 3 / 2 σ 3 T p 3 µ 4 = σ 3 p 3 µ 4 √ T , that follo ws from E [ Z 2 ] = E T X t = 1 X t 2 = T X t = 1 E [ X 2 t ] = T σ 2 and E [ Z 4 ] = E T X t = 1 X t 4 = T X t = 1 E [ X 4 t ] + 6 X 1 ≤ s < t ≤ T E [ X 2 s ] E [ X 2 t ] = T µ 4 + 3 T ( T − 1) σ 4 ≤ 3 T 2 µ 4 , where we have used the independence of X t ’ s and E [ X t ] = 0 which ensure that mixed terms E [ X t X s ], E [ X t X 3 s ], etc. vanish. W e also used that σ 4 = E [ X 2 t ] 2 ≤ E [ X 4 t ] = µ 4 . Classification of finite partial-mon. games (Thursday 25 th October , 2018 @ 22:29) 31 References [1] G ´ abor Bart ´ ok, D ´ avid P ´ al, and Csaba Szepesv ´ ari. T oward a classification of finite partial-monitoring games. In Proceedings of Algorithmic Learning Theory (ALT 2010), Canberr a, Austr alia, September 6–8, 2010 , 2003. [2] Nick Littlestone and Manfred K. W armuth. The weighted majority algorithm. Information and Computation , 108:212–261, 1994. [3] Y oav Freund and Robert E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences , 1(55):119–139, 1997. [4] Nicol ` o Cesa-Bianchi, Y oav Freund, Da vid Haussler , Da vid P . Helmbold, Robert E. Schapire, and Manfred K. W armuth. How to use expert advice. J ournal of the ACM , 44(3):427–485, 1997. [5] Peter Auer , Nicol ` o Cesa-Bianchi, Y oav Freund, and Robert E. Schapire. The nonstochastic multiarmed bandit problem. SIAM Journal on Computing , 32(1):48–77, 2002. [6] S ´ ebastian Bubeck, R ´ emi Munos, Gilles Stoltz, and Csaba Szepesv ´ ari. Online optimization in X-armed bandits. In Advances in Neural Information Pr ocessing Systems 21 (NIPS) , pages 201–208, 2009. [7] Robert Kleinberg, Aleksandrs Slivkins, and Eli Upfal. Multi-armed bandits in metric spaces. In Pr oceedings of the 40th annual A CM Symposium on Theory of Computing (STOC 2008) , pages 681–690. A CM, 2008. [8] David Helmbold and Sandra P anizza. Some label e ffi cient learning results. In Pr oceedings of the 10th Annual Confer ence on Computational Learning Theory (COLT 1997) , pages 218–230. A CM, 1997. [9] Nicol ` o Cesa-Bianchi, G ´ abor Lugosi, and Gilles Stoltz. Minimizing regret with label e ffi cient prediction. IEEE T ransactions on Information Theory , 51(6):2152–2162, June 2005. [10] Robert Kleinberg and T om Leighton. The value of knowing a demand curve: Bounds on regret for online posted-price auctions. In Proceedings of 44th Annual IEEE Symposium on F oundations of Computer Science 2003 (FOCS 2003) , pages 594–605. IEEE, 2003. [11] A vrim Blum and Jason D. Hartline. Near-optimal online auctions. In Pr oceedings of the 16th Annual A CM-SIAM symposium on Discr ete Algorithms (SOD A 2005) , pages 1156–1163. Society for Industrial and Applied Mathematics, 2005. [12] Alekh Ag arwal, Peter Bartlett, and Max Dama. Optimal allocation strategies for the dark pool problem. In 13th International Confer ence on Artificial Intelligence and Statistics (AIST A TS 2010), May 12-15, 2010, Chia Laguna Resort, Sardinia, Italy , 2010. [13] David P . Helmbold, Nicholas Littlestone, and Philip M. Long. Apple tasting. Information and Computation , 161(2):85–139, 2000. [14] Martin Zinkevich. Online conv ex programming and generalized infinitesimal gradient ascent. In Pr oceedings of T wentieth International Confer ence on Machine Learning (ICML 2003) , 2003. [15] Martin Zinkevich. Online conv ex programming and generalized infinitesimal gradient ascent. T echnical Report: CMU-CS- 03-110, 2003. A vailable at: http://reports- archive.adm.cs.cmu.edu/anon/anon/usr0/ftp/2003/CMU- CS- 03- 110.pdf . [16] Jacob Abernethy , Elad Hazan, and Alexander Rakhlin. Competing in the dark: An e ffi cient algorithm for bandit linear optimization. In Proceedings of the 21st Annual Confer ence on Learning Theory (COL T 2008) , pages 263–273. Citeseer, 2008. [17] Abraham D. Flaxman, Adam T auman Kalai, and H. Brendan McMahan. Online con vex optimization in the bandit setting: gradient descent without a gradient. In Pr oceedings of the 16th annual A CM-SIAM Symposium on Discrete Algorithms (SOD A 2005) , page 394. Society for Industrial and Applied Mathematics, 2005. [18] James Hannan. Approximation to Bayes risk in repeated play . Contrib utions to the Theory of Games , 3:97–139, 1957. [19] Antonio Piccolboni and Christian Schindelhauer . Discrete prediction games with arbitrary feedback and loss. In Pr oceedings of the 14th Annual Confer ence on Computational Learning Theory (COLT 2001) , pages 208–223. Springer -V erlag, 2001. [20] G ´ abor Lugosi and Nicol ` o Cesa-Bianchi. Pr ediction, Learning, and Games . Cambridge Univ ersity Press, 2006. [21] Jean-Yves Audibert and S ´ ebastien Bubeck. Minimax policies for adversarial and stochastic bandits. In Pr oceedings of the 22nd Annual Confer ence on Learning Theory , 2009. [22] Nicol ´ o Cesa-Bianchi, G ´ abor Lugosi, and Gilles Stoltz. Regret minimization under partial monitoring. Mathematics of Operations Resear ch , 31(3):562–580, 2006. [23] G ´ abor Lugosi, Shie Mannor , and Gilles Stoltz. Strategies for prediction under imperfect monitoring. Mathematics of Oper a- tions Resear ch , 33(3):513–528, 2008. [24] Thomas M. Cov er and Joy A. Thomas. Elements of Information Theory . Wile y , New Y ork, second edition, 2006. [25] John E. Little wood. On bounded bilinear forms in an infinite number of v ariables. The Quarterly Journal of Mathematics , 1: 164–174, 1930. [26] Luc De vroye, L ´ aszl ´ o Gy ¨ orfi, and G ´ abor Lugosi. A Pr obabilistic Theory of P attern Recognition . Applications of Mathematics: Stochastic Modelling and Applied Probability . Springer-V erlag New Y ork, 1996.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment