City on the Sky: Flexible, Secure Data Sharing on the Cloud
Sharing data from various sources and of diverse kinds, and fusing them together for sophisticated analytics and mash-up applications are emerging trends, and are prerequisites for grand visions such as that of cyber-physical systems enabled smart ci…
Authors: Dinh Tien Tuan Anh, Wang Wenqiang, Anwitaman Datta
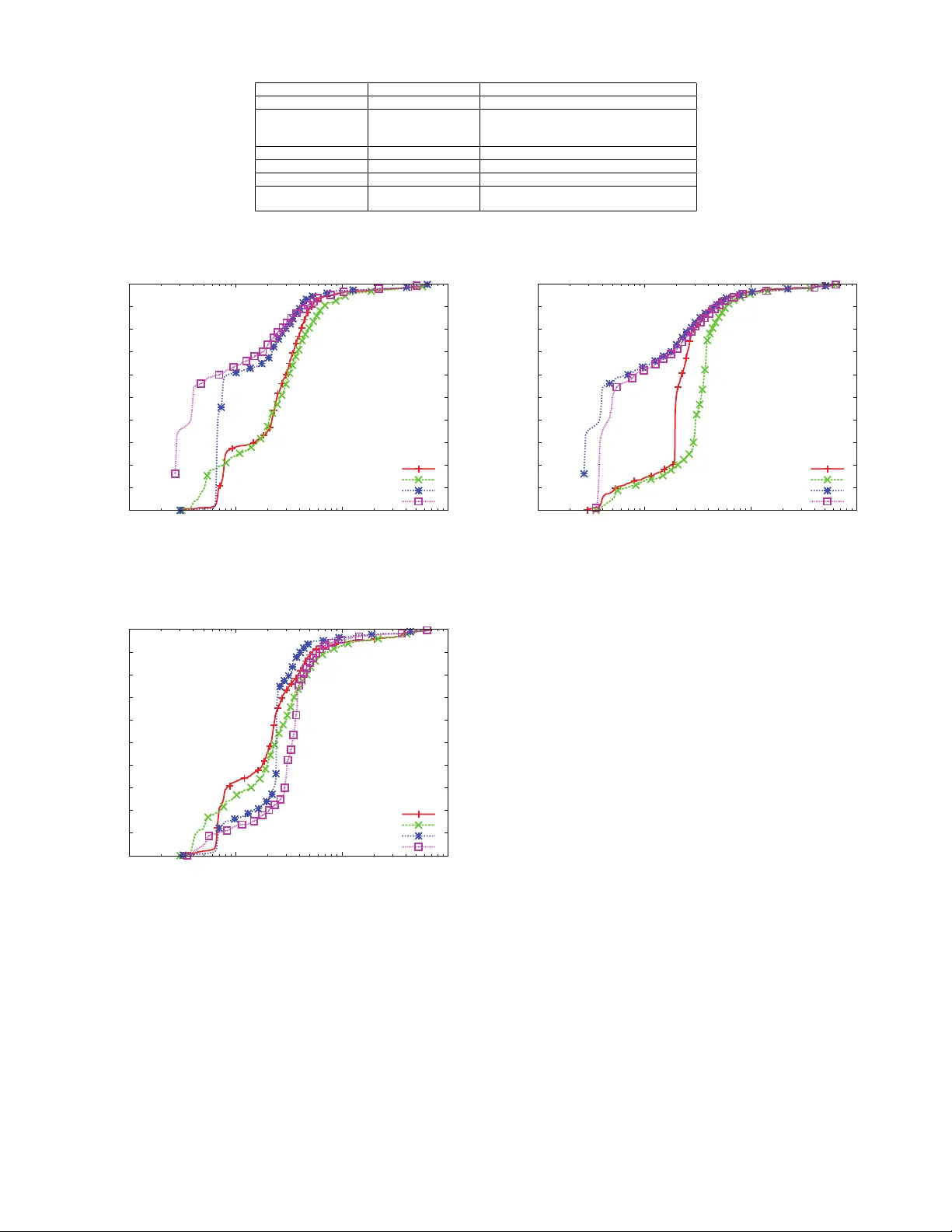
1 City on the Sk y: Fle xible, Secure Data Sharing on the Cloud Dinh T ien T uan Anh, W ang W enqiang, Anwitaman Datta { ttadinh,wqwang,anwitaman } @ntu.edu.sg Abstract —Sharing data from various sources and of diverse kinds, and fusing them together for sophisticated analytics and mash-up applications are emer ging trends, and are pr erequisites for grand visions such as that of cyber-ph ysical systems enabled smart cities. Cloud infrastructure can enable such data sharing both because it can scale easily to an arbitrary volume of data and computation needs on demand, as well as because of natural collocation of diverse such data sets within the infrastructure. Howev er , in order to convince data owners that their data are well protected while being shared among cloud users, the cloud platform needs to provide flexible mechanisms for the users to express the constraints (access rules) subject to which the data should be shared, and likewise, enfor ce them effectively . W e study a comprehensi ve set of practical scenarios where data sharing needs to be enfor ced by methods such as aggregation, windowed frame, value constrains, etc., and observ e that existing basic access control mechanisms do not provide adequate flexibility to enable effective data sharing in a secure and controlled manner . In this paper , we thus pr opose a framework f or cloud that extends popular XA CML model significantly by integrating flexible access control decisions and data access in a seamless fashion. W e hav e prototyped the framework and deployed it on commercial cloud envir onment for experimental runs to test the efficacy of our approach and evaluate the performance of the implemented prototype. K e ywor ds: cloud computing, access control, flexible shar - ing, fine-grained policies, XACML I . I N T RO D U C T I O N The emer gence of cloud computing in recent years is rapidly changing the way businesses and go vernment agencies, as well as individuals, are storing and managing their data as well as workflo ws. Instead of de veloping and maintaining indi vidual data management infrastructures and data sharing mechanisms, data owners now leverage on the cloud services to make their data a vailable to users. The fact that data from multiple sources now reside in one logical place, i.e., the cloud, makes it much easier than e ver before to de velop large scale applications that require data and knowledge from multiple domains and sources. These applications could include en vironmental study , city infrastructure planning, disaster monitoring, and many more. In an era when the cloud infrastructure was non-existent, to dev elop such applications, the de veloper would ha ve to first talk to individual data o wners to specifically provide the data to them, which is likely to in volv e tedious administration procedures such as signing documents reg arding the privileges and responsibilities of each parties, apart from the cumbersome process of actually shipping the data. Then the developer would ha ve to de velop software that work with the individ- ual data exchange interfaces/protocols provided by different owners to collect and reformat the data before they could be fed into the applications for analysis or real-time monitoring tasks. On the multitenant cloud, such data from div erse sources are naturally collocated, making it much easier and much more efficient for the application de velopers to obtain what they need for their work. More specifically , the storage and data ex- change can be handled efficiently by the cloud providers. This means data owners need not worry about how to share, b ut what and who to share. Putting one’ s proprietary data online on the cloud raises concerns regarding data security , pri vac y and o wnership. Even if the cloud service provider is trusted, and legally obliged (through service lev el agreements and law enforcement) to prevent ille gal access of data and information leakage, there needs to be meaningful, comprehensive and flexible ways for the data owners to express their sharing preferences, in a manner which can readily be interpreted and enforced by the cloud service provider . This paper discusses how this can be achieved. One can further argue ho w this can be realized if the cloud service provider is not even trusted, but that is an issue outside the scope of this work, and is part of our future work. The objectiv e of this work is to propose and showcase a framew ork for sharing data on the cloud. The frame work, called eXA CML , facilitates sharing in an easy-to-use , secur e , flexible and scalable manner . F or security , we make use of/e x- tend XA CML [21] — the XML-based and popular framework for access control. XACML has become a standard for specify- ing and enforcing access control policies. It ev aluates requests for resources against a set of policies and returns permit or deny decision, which does not in volv e accessing any data. In eXA CML, we extend XACML to support more fine-grained policies as well as to handle data processing. W e demonstrate eXA CML ’ s flexibility by using it in different access control scenarios with different lev els of granularity . For usability , eXA CML provides an intuitiv e, easy-to-use interface for data owners and data users to specify and enforce security policies and to access shared data. Finally , we carry out experiments to ev aluate the framework performance in a cloud-like environ- ment, the results of which suggests that eXACML is scalable. W e motiv ate our work with scenarios from ongoing works on better city planning, specifically related to weather and traffic information, and the ev aluations are also based on datasets, part of which are real, while the rest is synthetic. In summary , the main contributions of this work are as follows: 1) W e demonstrate the needs for secure and flexible data 2 sharing with practical examples in volving city planning and management based on data from weather and traf fic monitoring stations. W e discuss scenarios in which ac- cess control with dif ferent lev els of granularity of data access are needed. 2) W e extend the XA CML framew ork to support fine- grained policies. In particular , fine-grain access control policies (which require data filtering) are expressed within obligations that are passed from the Policy Deci- sion Point (PDP) to the Policy Enforcement Point (PEP), which connects to the database and processes the data queries embedded in the obligations. W e refer to this implementation as XA CML* . W e discuss why this approach could perform better than the traditional approach based on views. 3) W e implement a prototype of the framework ( eXA CML ), providing additionally , an easy-to-use user interface. The prototype allo ws data o wners to easily add and modify their policies. Data users can query meta data and details of access policies at remote servers. They can also specify aggregated data from multiple sources in single requests. Responses to data requests contain information of matching policies, enabling flex- ible conflict resolutions. 4) W e ev aluate the performance of our prototype in cloud- like settings. Our experiments illustrate that the frame- work incurs lo w o verhead. W e attribute this scalability to the framework’ s ability to cache responses and perform aggregation of responses from multiple sources prior to returning them to the data users. The rest of this paper is organized as follows: Section 2 describes practical scenarios that motiv ates our frame work. Section 3 details our extensions to XA CML, followed by the logical design of our framework in Section 4. The prototype and its ev aluation are presented in Section 5. W e discuss related and future works in Section 6 and Section 7 and conclude in Section 8. Before proceeding further , we’ll like to make a final note on the scope of the current work and implementation. Broadly speaking, there are two kinds of data - data already stored in the system (which we refer to as archived/archi v al data), and data stream, where live data is flowing into the system. Like wise, the queries could be ‘on demand’, typically on the stored data, or continuous queries, to be ev aluated on the incoming data streams. The current implementation deals with on demand queries on stored data. This is summarized in T able I. I I . M OT I V A T I N G E X A M P L E As increasing portion of the world population is rapidly moving to the cities, while the resources at our disposal are shrinking at an alarming rate, numerous research and industrial initiativ es (e.g., IBM’ s smart cities initiative 1 ) are focusing in realizing what are being termed as ‘smart(er) cities’ in order to manage resources efficiently at the city 1 http://www .ibm.com/smarterplanet/us/en/smarter cities/ov erview/index. html scale. Enabling such a move towards smarter cities are cyber- physical systems aggregating data and actuating the necessary resource management actions at the edge, while the necessary data storage and analytics is carried out on cloud based back- end. In this section, we use some scenarios of road congestion analysis to showcase the need among data owners for flexible data sharing. A. Settings. Noticing that one of the major expressways in the city suf- fers serious congestion during every monsoon season, Singa- pore’ s Land Transport Authority (L T A) has, after preliminary studies, hypothesized that such congestion is mainly caused by three factors, (1) large number of vehicles on the road, (2) slow speed of vehicles, (3) bad weather . T o v alidate such preliminary conclusions and build a traf- fic condition model during the monsoon season, researchers need more data. Fortunately , many organizations hav e been collecting related data: L T A itself has a number of sensors deployed along the road side to record traffic volume, i.e., the number of vehicles passing by at unit time; furthermore, another independent entity , a large local taxi compan y , collects the speed and location data from their taxis’ GPS devices. At almost any time, there are a number of such taxis running ov er the whole stretch of the express way . Likewise, the national en vironmental agency (NEA) has several weather stations deployed close to the congested areas, that record weather parameters such as temperature, humidity , rain rate, etc. If all these different data owners use a shared cloud infras- tructure 2 to store and process the above mentioned data-sets for their indi vidual needs, then when complex analytics in v olv- ing multiple such datasets become necessary , the data is readily av ailable on the infrastructure thanks to such collocation on the multi-tenant cloud. Suppose the data are stored in relational tables as shown in T able II for traffic volume information, T able III for cab’ s location and speed information and T able IV for weather information. B. Example 1 Suppose that NEA decides to share (possibly for a price) only the rain rate data with L T A researchers, since other weather parameters such as temperature and humidity are not expected to affect traffic condition as much as rainfall does in the context of Singapore, and hence L T A does not want pay for the temperature or humidity information. Furthermore, ev en if the original collected data a vailable with NEA is for one minute interv al, it may want to expose only the data corresponding to five minute averages to L T A. It may also expose the more detailed data to its o wn employees or to other customers. The first constraint corresponds to the projection operation in the relational database model and a sample SQL query will 2 Note that we are unaware of the current practice of the individual organizations mentioned abov e, and what follows is a hypothetical scenario. 3 Query/Database Archiv al (relational) databases Stream databases On demand query current implementation n/a Continuous query n/a Future work T ABLE I: Scope of eXA CML, regarding database and query type SamplingT ime T rafficV olume 2011-06-06 10:00:00 60 2011-06-06 10:05:00 67 2011-06-06 10:10:00 50 ... ... T ABLE II: T able T rafficInfo: T raffic volume data from road side sensors SamplingT ime Speed (km/hr) latitude longitude 2011-06-06 10:00:00 100 x1 y1 2011-06-06 10:05:00 80 x2 y2 2011-06-06 10:10:00 40 x3 y3 ... ... T ABLE III: T able V ehicleInfo: V ehicle speed and location data from GPS devices SamplingT ime T emperature(C) Humidity (%) RainRate (mm/hr) ... 2011-06-06 10:00:00 27.2 70 0.0 ... 2011-06-06 10:01:00 27.5 70 0.0 ... 2011-06-06 10:02:00 27.5 73 0.0 ... 2011-06-06 10:03:00 27.4 72 0.0 ... 2011-06-06 10:04:00 27.3 75 0.0 ... 2011-06-06 10:05:00 27.3 76 0.0 ... 2011-06-06 10:06:00 27.0 77 0.1 ... 2011-06-06 10:07:00 27.1 80 5.0 ... 2011-06-06 10:08:00 26.8 81 14.0 ... 2011-06-06 10:09:00 26.6 82 20.0 ... 2011-06-06 10:10:00 26.5 85 34.4 ... ... ... ... ... ... T ABLE IV: T able W eatherInfo: W eather data from weather stations be something like ” select RainRate fr om W eatherInfo ”. The second constraint can be considered as a sliding windo w query ov er a data stream, i.e., the time series rain rate data. Standard SQL does not support these kind of queries well, hence additional operations need to be implemented on top of the RDBMS query engine. T o specify a sliding window query on a time series data sequence in our scenario, fi ve parameters are needed, namely , the starting time , ending time , window size , window advance step and aggr e gation function . The starting time and ending time are the general temporal constraints that specify the segment of the data stream to be returned. The window size and window advance step decide the length of the query window and ho w fast the window is moving along the data stream. The aggr e gation function includes numerical functions such as averag e() , max() , min() , count() , etc., which are applied to the data records to summarize the portion of the data stream within the window . C. Example 2 Consider that the taxi company agrees to help the re- searchers by providing their taxis’ location and speed data, b ut the compan y only wants to share such information for taxis within some specific regions in the vicinity of the congested areas being studied, instead of exposing the information about its whole fleet, which it deems important business secret not to be exposed to third parties. T o enforce such a constraint, a selection operator is applied to the longitude and latitude columns to filter out those records that are not supposed to be shared with the researchers. F or the sake of simplicity , assume that this range is specified by a rectangle with the geographical coordinate of the upper left verte x as (a 1 ,b 1 ) and of the lower right verte x as (a 2 ,b 2 ), we can have the corresponding SQL query: select SamplingT ime, Speed fr om V ehicleInfo v wher e v .longitude = > a 1 and v .longitude < = a 2 and v .latitude > = b 2 and v .latitude < = b 1 . T o enable the abov e access contraints in XA CML, we make use of the obligation element in policy element to specify the constraints. Fig. 4 and Fig. 5 present two examples of XA CML obligations that embed these constraints. In Figure 4, line 2 indicates that the permission to perform the sliding windo w query if the decision returned from PDP is ‘permit’. Line 3 indicates that the aggre gation function to be used in the sliding window query is average calculation. Lines 5 to 8 specify that starting time is zero o’clock of June 6th, 2011, ending time is zero o’clock of June 7th, 2011, window size is 5 minutes and window advance step is also of 5 minutes. Line 9 indicates that the sliding window is applied on SamplingT ime column as well, besides on the actual rain rate data column, which is not shown here within the obligation part. Line 3 in Figure 5 shows the selection predicate to be included in the SQL query to be ev aluated on the data table, which only allows vehicle information to be returned if the vehicle’ s location is within a 4 giv en boundary . D. Fine-gr ained P olicies The examples above demonstrate real needs for an access control model that supports fine-grained policies inv olving fine-grained data processing. At a high lev el, the models need to be able to express and enforce the follo wing types of policies: 1) Aggregated data: Only results of aggregation functions ov er raw data such as aver age , sum , min , max are shared. 2) T rigger-based: a row of data is accessible only if the value of a column satisfies a certain predicate: exceeds a specific threshold, or is contained within a range. As an example, a taxi company is granted access to temperature reading only if the temperature is over 30 o C. 3) Sliding window: a sliding window is specified by its starting time, ending time, window size and advance step. Only aggregated data (average, for instance) over the windo ws are accessible. 4) Approximation: only data whose values approximate those gi ven in the requests are accessible. F or example, a request includes a value X , and the policies is specified such that a ro w of data is returned only if the column c ’ s value V satisfies | V − X | < for some distance function. W e next e xplore how such fine-grained policies can be flexibly supported. I I I . F L E X I B L E S H A R I N G T H RO U G H F I N E - G R A I N E D P O L I C I E S Existing frameworks, such as XACML, do not nativ ely support dif ferent lev els of granularity to support fine-grained access control. Nevertheless, XA CML has emerged in recent years as a mature and widely used model for expressing and enforcing access control policies. Therefore, we extend XA CML in order to support fine-grained policies, including those described in Section 2. For the rest of this paper , we assume relational databases (SQL types) are used for managing data in the back-end. W ithout loss of generality , but for the purpose of simplicity of exposition, we consider that each database consists of a single table inde xed by time v alues. When requesting for data, the user pro vides his credentials (for example, name and role) and specifies the location of data. The response contains either a deny decision (i.e. no access to the data), or permit decision together with the returned data as specified in the policies. A. XACML XA CML is an O ASIS frame work for specifying and enforc- ing access control [21]. It is XML based and the latest version is 3 . 0 . XA CML allows administrators to control their resources by writing policy files, which are then loaded into a Policy Decision Point (PDP) module. An user wishing to access a specific resource sends request to a Policy Enforcement Point (PEP) where the decision is made by consulting the PDP . XA CML specifies standards for writing policies, requests and interpreting the response. 1) Subjects , Resour ces and Actions . A subject in XACML has a set of credentials such as its name, role, etc. The subject wishes to perform certain actions (read, write, for example) on a set of system r esour ces . 2) Requests . Request for accessing system resources are written in XML. The subject credentials, system re- sources and actions are specified in one or more At- tribute elements included in the Subject, Resource and Action elements respectively . Fig. 1 sho ws an example of an XA CML request from a subject with role admin to perform r ead action the temperatur e column from weather data database. 3) P olicies . A policy contains a T arg et , a set of Rules each of which has at most one Condition , and a set of Obligations . Multiple policies can be grouped into a policy set , which has its own T arget element. The policy is index ed by its T arget element, which consists of a number of conditions needed to be satisfied by the request before the rest of the policy can be e valuated. Conditions are essentially boolean expressions over the values included in the request. The policy returns ac- cess control decision which is either P ermit , Deny , Not Applicable or Intermediate . The last two are used when there is no applicable policy or an error occurred during ev aluation. Fig. 2 illustrates an example of an XA CML policy that grants access to subjects with government role to the samplingtime and temperatur e columns of weather data . When more than one rules are applicable to a par- ticular request, they are e valuated according to rule combination algorithm specified in the policy . Similarly , multiple applicable policies in a policy set are ev aluated according to a specified policy combination algorithm . Examples of combining algorithms (for both policies and rules) are P ermit-overrides where a permit policy or rule is ev aluated, and F irst-applicable where the first applicable policy is ev aluated. 4) P olicy Enforcement P oint (PEP) . User requests first go through the PEP , which translates them into canonical forms before passing to the PDP . Additionally , PEP also interprets responses and obligations returned from the PDP . In summary , PEP deals with application logics and acts as the access control enforcement mechanism. Our framew ork extends PEP to provide support for more fine-grained policies. 5) P olicy Decision P oint (PDP) . Data owners’ policies are loaded into the PDP , which ev aluates requests receiv ed from the PEP against the acti ve policies. Its main task is to efficiently find applicable policies for a giv en request and to quickly ev aluate their rules and conditions to determine the access control decision. It sends back to PEP a well-formed response containing a decision and a set of obligations. 5 admin weather_data temperature read Fig. 1: Example of a well-formed XA CML request, in which the user with the role admin requests r ead access to the column temperatur e of the database weather data government weather_data samplingtime temperature Fig. 2: Example of a well-formed XA CML policy which grant access to column samplingtime or temperatur e of the database weather data to any subject with role goverment 6 3'3 3(3 'DWDEDVH 3ROLFLHV 5HTXHVW 5HTXHVW 'HFLVLRQ 2EOLJDWLRQV 4XHU\EDVHGRQ REOLJDWLRQV 'DWD 5HVSRQVH Fig. 3: Extensions to XACML that support more flexible access control policies. B. V ie w-Based vs Obligation-Based The traditional access control model in relational databases is based on view [24]. Basically , a view is the result of a SQL query on existing tables, to which read/write access are specified. The database management systems maintain the views and enforce access control rules on them. A simple approach based on view to support fine-grained policies with XA CML can be realized as follows. First, views are created with no access control restriction, and assigned with unique resource IDs. This can handle all types of policies discussed earlier . PEP maintains a mapping between the IDs and actual views. Next, the IDs are used to specify the resources in XA CML policies, as well as to construct data requests. Once PDP returns a permit decision, PEP retrie ves and returns the corresponding views. Howe v er , there are a number of weaknesses with this approach: • V iews need to be created prior to policies or requests. They must also be removed explicitly by the data o wner . • V iews are static and may be very large in number (potentially infinite number of views for trigger-based and sliding window policies). Maintaining these views are inef ficient at best and impossible at worst. • An user requesting for data must also maintain a mapping of all the view IDs they wish to access. Not only is such a requirement undesirable for data users, but also it is expensi ve to implement. Fig. 3 illustrates the obligation-based approach (extensions to XA CML is highlighted in bold). The basic idea is to embed queries for creating views into obligations. The PEP , upon receipt of the obligations, executes the embedded queries on the database and returns the results in a well-formed response. Unlike the view-based approach, the size of data (views) maintained by PEP is bounded. Furthermore, popular queries can be cached by the database management system or the PEP . In the experiment section, we demonstrate the benefit of caching in improving request time. C. Implementations 1) Obligations.: Using obligation-based approach, policy writers utilize different types of obligations to specify different database queries. Our current implementation supports four types of obligations (T able V): Description ObligationId Column aggre gation exacml:obligation:column-aggregation Simple selection exacml:obligation:simple-selection Sliding windo w exacml:obligation:column-sliding-window Approximation exacml:obligation:column-approximation T ABLE V: Obligation types 1) Column aggr egation : consists of a string attrib ute with ID exacml:obligation:aggregation-id . The string represents an aggregation function, such as a verage (Fig. 4, line 2-3), min, max, count or sum. 2) Simple selection : consists of a string attribute with ID exacml:obligation:selection-id . The string is a boolean expression that will be used as the WHERE clause when constructing the database query . An ex- ample of this obligation is shown in Fig. 5, in which the policy restricts access to data to within a certain geographical region. 3) Sliding window : we assume that the column from which the sliding windows are based is of type DateT ime (although sliding windows could be constructed from any other sortable types). The obligation consists of a number of attributes: • Sliding windo w column: string attribute with ID exacml:obligation:sliding-window-column-id specifies the column of type DateT ime from which sliding windo ws are constructed. • Start and End: time attributes with IDs exacml:obligation:sliding-window-start-id and exacml:obligation:sliding-window-end-id respectiv ely . • W indo w size: integer attribute with ID exacml:obligation:sliding-window-size-id specifies the window size (in hours). • Advance step: integer attribute with ID exacml:obligation:sliding-window-step-id specifies how the sliding window advances, i.e. the number hours between starting time of two consecutiv e windows. Fig. 4 (line 4-10) sho ws an example of a sliding window based on SamplingT ime column. The window’ s size is 5 hours, starting from 2011-06-06 00:00:00 , advancing in 5-hour steps until 2011-06-07 00:00:00 . 4) Appr oximation : this obligation specifies the acceptable distance between the column values with respect to the values included in the request. Attributes containing column IDs are specified in both the requests and the policies. Specifically: • In the request: string attribute with ID exacml:data-value-id is of the form : which represent the value of the specified column. • In the policy: string attribute with ID exacml:obligation:approximation-param-id 7 contains the column IDs. Columns specified in the requests must be a subset of what is specified in the policies. Also required is a double attribute with ID exacml:obligation:approximation-value-id which represents the distance between the vector of column values in the database and that included in the request. 2) Handling obligations.: PEP e xtracts attributes embedded in the obligations and constructs corresponding queries to be ex ecuted on the database. It is not uncommon for a policy to hav e more than one types of obligations, which allows for more expressiv e, fine-grained conditions for accessing data. Essentially , PEP creates queries of the following form: select f(column_1), f(column_2),..,f(column_n) from Table_name where Where_Condition (1) where column_i (1 ≤ i ≤ n ) and Table_name are extracted from the Resources element of the request. When no obligation is returned, f and Where_Condition are set to empty strings. In this case, the query becomes: select column_1, column_2,..,column_n from Table_name PEP obtains f from the string attribute in the column ag- gregation obligation. When a simple selection obligation is re- turned, Where_condition is taken directly from its string attribute. For approximation obligations, the PEP first retriev es a vector of values from the request, namely ( x 1 , x 2 , .., x k ) from columns c 1 , c 2 , .., c k . It then obtains the distance value δ in the obliga- tion, and sets Where_condition as: sqrt (( c 1 − x 1 ) . ( c 1 − x 1 ) + .. + ( c k − x k ) . ( c k − x k )) < δ Handling sliding-window obligations are more complex. First, the tuple ( star t, end, window siz e, adv ancing step ) are extracted from the obligation. The total number of windows are: nW = b end − star t − w indow siz e + 1 adv ancing step c + 1 For every window , PEP creates a dif ferent query . More specif- ically , let c be the column (of type DateT ime) from which the sliding windows are constructed, a query i (0 ≤ i < nW ) is of the form: select f(column_1), f(column_2),..,f(column_n) from Table_name where Where_Condition AND c ≥ start+step * i AND c < start+step * i+size where Where_Condition are constructed from simple selection and approximation obligations. I V . T H E L O G I C A L F R A M E W O R K This section presents our design of the framew ork that enables secure, easy-to-use, flexible and scalable data sharing. The security comes from the use of XA CML for specifying and enforcing access control. The flexibility property is the result of our enhancement to XA CML which supports a wider Policy management Data request eXACML Data owner Data user Proxy Client Data owner Data user Client interface XACML* XACML* Server Server XACML* XACML* Server Server Databases Databases Fig. 6: eXA CML frame work. XA CML* denotes the extended XA CML described in Section 3. range of access control policies. Usability and scalability are achiev ed through a simple client interface and the use of a proxy server , whose details are described below . A. Entities Fig. 6 illustrates the main entities and how they interact in our framework. Clients consist of data o wners who wish to share and enforce access control on their datasets, and of data users who are interested in accessing the data. A data owner can have more than one datasets and a data user can request access to multiple datasets. Databases are database servers which manage clients’ datasets. Access to the database is controlled by at least one instance of XA CML* (discussed below). These servers are likely to be remote and maintained by a third party (cloud) provider . Our framework — eXA CML — is positioned in between clients and databases (Fig. 6). Its roles are to mediate their interactions and to safeguard the databases. Essentially , eX- A CML is made up of a client interface, a proxy server , cloud servers and XA CML* instances. • Clients interact with the databases through a local client interface that parses inputs into request messages and forwards them to the proxy server . It waits and interprets response messages before returning them back to the clients. This interface abstracts out the complexity of exchanging well-formed messages with the proxy server . It allows clients to share and query data in an intuitive manner . • A cloud server (or server ), usually located in the same machine as the databases, accepts and processes client requests. W e will refer to this component as server . It manages and responses to meta queries concerning XA CML* instances. For data requests, it forwards them to the appropriate XA CML* instances and sends the results to the proxy in well-formed messages. 8 avg 2011-06-06 00:00:00 2011-06-07 00:00:00 5 5 samplingtime Fig. 4: Obligation portion of the XA CML policy for Example II-B longitude >= a1 and longitude <= a2 and latitude >= b2 and latitude <= b1 Fig. 5: Obligation portion of the XA CML policy for Example II-C • XA CML* is an implementation of the extended XACML model described in Section 3 (Fig. 3). It processes data requests (receiv ed from the cloud server) by first asking PDP for the access decision. If permitted, it ex ecutes the obligations, which inv olves querying the database. The result is forwarded back to the cloud server . • Communications between clients and servers go through a proxy server (or pr oxy ). It processes requests from clients before forwarding them to the servers, and com- bines the results into client response messages. As an example, suppose a request from a data user requires accessing data from multiple datasets, the proxy first creates multiple requests and sends to the corresponding servers. It waits for all the responses from servers, then combines the results into a single response message for the data user . The benefit of having the proxy server is two-fold: 1) Impr oved performance : Combining data before re- turning to the users reduces communication costs. Caching at the proxy can also improve response time and reduce both computation and communica- tion costs for the database servers. W e demonstrate this ef fect in the ev aluation section. 2) Additional level of abstraction : The proxy server acts like a DNS service mapping datasets into to global, easy-to-remember names, achie ving network data independence, which makes it easier for clients to manage and query data. B. T rust and Data Model W e assume cloud sev ers and the proxy server are honest . This means that they are trusted to run the correct, latest eXA CML framework. They are also trusted not to violate data priv acy . More specifically , the proxy is trusted not to tamper with the data recei ved from database servers, and not to violate data priv acy . The only adversaries are rouge clients who can collude in attempt to gain unauthorized access to the datasets belonging to honest data o wners. W e remark that these assumptions (particularly , that of trusted service pro viders) are reasonable since cloud service providers are stri ving to gain reputation to run their business, and furthermore hav e legal obligations based on Service Level Agreements [23]. W e assume that datasets are managed by relational database systems. For simplicity , each data owner has at most one dataset. This assumption can be relaxed by virtualizing the data o wner , so that it has multiple identities, each of which possesses a different dataset. C. Cloud Model W e now discuss different ways to connect the database, XA CML* and cloud server components. As seen in Fig. 6, the 9 Server XACML* Database Virtual machine Server XACML* Database Virtual machine Proxy Fig. 7: Interaction model of the cloud server , XA CML* and database number of servers, the number of databases and XA CML* in- stances do not hav e to match. In particular , multiple databases may share the same XA CML* instance, while a cloud server may handle multiple XACML* instances. A server represents a logical, addressable machine to which the proxy connects. One server can handle requests for mul- tiple datasets, but we assume each server is connected to one dataset. This assumption is reasonable since each data o wner has at most one dataset, and it is likely that data owners use independent virtual machines. Next, we consider the question of how XA CML* in- stances are shared among databases. At one extreme, a sin- gle XACML* instance is sufficient to deal with all access requests. In this case, the servers connect to the the same XA CML* instance, and policies are added to the same PDP . The PEP has access to multiple databases at different ma- chines. Howe ver , this approach introduces a single point of failure, and data owners may prefer to have their access control systems separated from each other . Moreover , extra layers of authorization is required to pre vent rouge clients from uploading policies associated with datasets of honest data owners. At the other extreme, the server maintain one XA CML* instance per dataset. Since data requests can be processed in parallel, this approach could lead to significant improv ement in performance. Howe ver , a potential drawback is the overhead in maintaining a lar ge number of XACML* instances, especially if many are idle. When multiple datasets share the same physical machine (but are in separate virtual machines), it makes more sense for them to share one XACML* instance. This approach benefits from the parallelism in processing requests, while having reduced o verhead in maintenance. Howe ver , sharing an XA CML* instance experience the same problem with single point of failure and e xtra layer of authorization as with a single XA CML* instance. Considering the abov e trade-of fs, in this paper, we finally adopted the simple, no-sharing approach, i.e. one server con- nects to one XA CML* that safeguards one database (illustrated in Fig. 7). This model does not require another layer of authorization and therefore is easy to implement. D. One or Multiple Pr oxies? Having multiple proxies addresses the trust problem as- sociated with a single proxy . It could also improv e client throughputs, since requests can be processed in parallel. Howe v er , joining data — one of the proxy’ s main features — across multiple proxies is more complex. Since proxies also maintain data caches, a mechanism for cache coherence among distributed servers is also required. Therefore, trade- offs between efficiency and maintenance ov erhead must be carefully considered. Our current frame work emplo ys only one proxy . W e defer the protocols with multiple proxies for future work. E. Initialization In the beginning, a data owner creates a database for its datasets and initializes an XA CML* instance at a remote data server . The XACML* instance starts with an initial policy specifying who can add and remov e data and policies. This process is done by inv oking {success,fail} <- initDatabase(host, port, dataID, databaseType, credentials) where host, port are the address of the server , dataID is the unique identifier of the dataset, databaseType is name of the database management system (MySQL, for exam- ple), and credentials consists of the data owner’ s name, role and other authentication information for accessing the server . The client interface wraps these parameters into a message forwarded to the proxy , then sends it to the specified server . After authenticating the data owner , the server creates the database, starts an XACML* instance and connects its PEP to the database. Finally , the server uploads a r oot policy to the newly created XA CML* instance. The root policy specifies that only users with credentials can add new data, upload new and remove existing policies. This policy prev ents other clients from adding their own policies to this XA CML* instance. If successful, the proxy creates a ne w mapping from dataID to the dataset, as explained next. F . Data and P olicy Management. Once a database is initialized successfully , it can be identi- fied uniquely by its dataID . The proxy maintains a mapping dataID_to_desc , which is a list of: dataID: All client requests contain dataIDs . The proxy resolves locations of the dataset using its mapping, before forming new requests and forwarding them to the appropriate database servers. a) Adding and r emoving data.: T o add or remove new data from a dataset, the data owner inv okes {succses, fail} <- addData(data file, dataID, credentials) {success, fail} <- removeData(remove query, dataID, credentials) 10 where data file contains data to be added to dataID using the gi ven credentials . remove query is the query to remove records from the database. The client interface sends a request to the proxy , which in turn constructs and forwards a well-formed XA CML request together with the file hash or query hash to the server . The server keeps the hash as the pending add or pending r emoval token. Only if the access control decision is ‘permit’ does the client interface sends data file or remove query to the server , which v erifies that the content hash matches with the pending add or pending r emove before performing the query . In this protocol, the hash value is used to prevent other data owners from adding rouge data or remove unauthorized data. b) Loading and remo ving policy . : Every loaded polic y is identified uniquely by its ID of the form dataID:policyID where policyID is the integer index of the policy . The XA CML* instance maintains an inde x counter which adv ances whenev er a new policy is added. T o add or remove a policy , a data owner in vokes {policyID, fail} <- loadPolicy(policy file, dataID, credentials) {success, fail} <- removePolicy(policyID, dataID, credentials) where policy file contains the XA CML file to be uploaded to dataID using the giv en credentials . The policy to be removed is identified by the tuple ( dataID, policyID ). The client interface forwards a request to the proxy , which creates a well-formed XA CML request (for loading or removing policy) using dataID and the credential . Once arri ved at the server , the request is ev aluated by the appropriate XA CML* instance. Only if the decision is permit is the policy file added or the policy dataID:policyID is remo ved from the corresponding PDP . In case of policy addition, the new policy ID — the current index counter’ s value — is forwarded back to the data owner . W e assume that policy is small, thus there is no need for the 2-step protocols as in adding and removing data. c) Querying policy . : Both data owner and the server keep track of the policy IDs associated with the dataset. One can query about the loaded policies for a dataset, using {{(policyID, description)}, fail} <- queryPolicy(dataID, credentials} which returns a set of tuples (policyID, description) where description is the Description element of the corresponding policy . G. Data Request. A data user issues a request for data through the client interface. The request may in volv e accessing multiple datasets. The data user knows dataIDs , but may not know of the detailed structure of the datasets. 1) Querying meta data.: A data user can issue a query for the dataset’ s meta data prior to requesting the raw data. T ypical meta data includes table names and schemas. Data o wners can restrict access to such information through a set of policies. T o query meta data, the data user inv okes: {{tableID}, fail} <- queryTables(dataID, credentials) {(columnID, type)}, fail} <- queryColumns(dataID, tableID, credentials) The proxy translates the client request into a well-formed, standard XACML request in which the Action attribute is set to show_table or show_column respectively . If the PDP returns a permit decision, the PEP retriev es and returns the database’ s metadata accordingly . The result for queryTables (if permitted) is a set of tableIDs , which can later be used in requesting raw data. The result for queryDataScheme is a set of tuples (columnID, type) representing the column name and type. 2) Querying data.: Clients can request data by in voking: {{data record}, {matching policies}, fail} <- queryData(requested resources, joining condition) where requested resources = {} represents the resources requested from dif ferent datasets. joining condition specifies how the results from those datasets are joined. These results are returned separately if joining condition is null . constraints contains conditions that are applied to the returned data. For example, column i > θ where col umn i ∈ { columns } indicates that the request is only for data whose col umn i values are greater than θ . The protocol proceeds as follows: 1) For every requested resource, the proxy creates a well- formed XA CML request using dataId , columns as Resour ces and actions as Actions attributes. The request is then forwarded to the server specified by dataId . 2) The XA CML* instance returns access control decision, the accompanied data (if decision permitted), and IDs of the matching policies. 3) The proxy , on receipt of non-empty data, applies con- ditions specified in contraints . Depending on the value of joining column , it performs data joining (discussed next) before sending the final response to the client. H. Data Joining. The joining condition parameter used in queryData specifies how the results are joined before returning to the client. In particular: joining condition ∈ { null , { c 1 , c 2 , .., c k }} where k is the number of requested resources and c i (1 ≤ i ≤ k ) are the joining columns of the returned data. When joining column = null , the proxy forwards what it receiv es from the server directly back to the client. Otherwise, it waits until getting data from all requested servers, then constructs a client response by joining the results using normal database join operations. 11 I. Conflict Resolution. It is possible for clients to receive empty data for their requests, especially when the requests in volv e more than one datasets. This arises because different policies associated with different datasets are enforced. W e refer to this as policy conflict , which happens in one of the two cases: 1) There is at least one policy that denies the client’ s access. 2) All policies permit access, b ut the joined data still results in an empty set. F or example, one policy allows access to data where column i > θ whereas another policy allo ws access to data where col umn i ≤ θ . Another example is when two policies specify different sliding windows, as a consequence the joining columns do not have v alues in common. W e provide a simple mechanism for dealing with policy conflict. Responses from queryData includes IDs of the matching policies. When conflict occurs, the client is aware of the cause and is able to contact the dataset o wner to resolv e the conflict. W e assume that such resolution is done out-of-band and is not within the scope of the framework. J. Caching. The proxy maintains a cache of data receiv ed from the servers. Since operations in the cloud server are slo w , espe- cially when in volving database access, caching can improv e the response time. It is also reasonable to expect a cache- friendly request pattern from clients, as popular data are frequently requested. W e consider a simple design, in which data cache is the map : where request is the XA CML request with the corresponding data . • Cache r eplacement : when full, an old entry is evicted in a random fashion. • Cache coher ence : stale entries can lead to security vio- lation. For instance, a new policy update denies a client access to a dataset, but the cache contains data of pre vious access which will be served by the proxy at the client’ s next request. W e address this problem by simply purging entire cache every time a policy is loaded or removed. V . P RO TO T Y P E A N D E V A L U A T I O N A. Prototype W e have implemented a prototype of eXA CML, which consists of ov er 3400 lines of Jav a code. Database accesses are provided by JDBC API, while communications between clients, proxy and servers are done through Socket inter- face. For XA CML*, we extended Sun’ s XA CML implemen- tation [28] — an open source, Java project that supports XA CML 2.0 standard. W e instrumented its PEP module to handle more obligations (Section 3). The prototype supports all the features discussed in the previous section: a client is able to load, remove, query data and policies. Our prototype provides an easy-to-use graphical interface for querying and managing data. A query form (Fig. 8b) takes in user credentials and requests. A response from the server includes the data server information, matching policies (a) Data view (b) Query form Fig. 8: User interface for querying data (a) Polic y vie w (b) Polic y upload Fig. 9: User interface for managing access control policies. 12 and the data (if applicable), which are displayed in the data view window (Fig. 8a). Policies are updated and queried using similar GUI, as shown in Fig. 9. B. Evaluation W e ev aluated our prototype’ s performance, and its ability to support dynamic, fine-grained access control policies. The system performance is measured by the time taken to ful- fill user requests. W e compare our prototype’ s performance against that of a system that ex ecutes the requests directly , i.e. without the access control layer . W e refer to the later as dir ect-query system . 1) Methodologies. : a) Setup. : W e emulate a cloud-like en vironment running our prototype, as shown in Fig. 6. More specifically , we make use of four machines, two running servers, on running the proxy and the other represents a client. The machines belong to the PDCC cluster 3 , each has one Xeon processor 3.0Ghz, running OCS5.1 (2.6.18-53El5smp) operating system with 4GB of RAM. The machines are connected via InfiniBand 20Gbps. The servers maintain two databases: a weather database and a traffic database. The former contains four tables with real data taken from four different weather stations collected in a 5-day duration and with one-minute sampling interval. W e synthesize the traffic database with two tables containing records of traf fic v olume and vehicle speed that match with the weather datasets. b) W orkloads. : W e generate synthetic workloads that include large numbers of policies and requests. Since our prototype is compared against a direct-query system, the work- loads also contain a large number of direct database queries, each corresponds to a request in our prototype. A dir ect query is forwarded to the server , which e xecutes and returns the same data as when executing the corresponding request in our sys- tem. The parameters used in generating workloads are sho wn in T able. VI. The workloads and source code for generating them can be found at http://sands.sce.ntu.edu.sg/trac/exacml/ First, we use nD irectQuer ies and dir ectQuery Dist to create a set D Quer y of direct queries of fi ve dif ferent types: selection, approximation, aggregation, sliding windo w and data joining. The first three types are ordinary database SELECT query , which is forwarded by the server directly to the database engine. Sliding windo w queries are first con v erted into multiple SELECT queries, one for every window , which are then sent to the database engine. Data joining queries contain two sub-queries (of the other four types) chosen at random and for different data servers. Each data server pro- cesses and returns the result independently . Next, nP olicies unique XA CML policies are generated, each with dif ferent exacml.subject:role-id . Every policy corresponds to a direct query whose type is either selection, approximation, aggregation or sliding window . Therefore, the set of policy obligations and DQuer y represent the same set of SELECT queries to be executed by the database engines. 3 http://pdcc.ntu.edu.sg/content/128- cores- linux- cluster- pdccsce Next, we generate a set of requests. For every policy , we construct one matching and one non-matching request. The matching request contains credentials, resources and actions as specified in the policy . For the non-matching request, we use a different exacml:rdbms-database-id from the weather and traf- fic database names. For each data joining direct query , we create corresponding (matching and non-matching) requests made up of two sub-requests. Each sub-requests from the matching request corresponds to a sub-query in the data joining direct query . In summary , a matching request executed in our prototype returns the same data as the corresponding query e valuated in the direct-query system. Finally , we create a workload of nR equests requests fol- lowing Zipf distribution with ske w parameter α . This workload models a realistic use of the prototype, in which a small number of popular data are requested frequently . Such request pattern is found in many other systems, such as P2P file- sharing and web caching [3], [16]. W e select maxRank unique queries from D Quer ies at random, then assign them with random ranks. A sequence of queries is generated from the selected set with Zipf distribution, using α = 0 . 223 (as in [16]). For ev ery direct query , this workload also contains the corresponding policy , matching and non-matching request. 2) Metrics.: In the following experiments, we inv estigate our prototype’ s effecti veness in granting data access to au- thorized requests and denying unauthorized ones. W e also measure its performance in terms of the time taken to fulfill authorized data requests. This is compared against the direct- query system, i.e. one without eXA CML. W e also provide quantitativ e analysis of the proxy , especially its caching and data joining features. 3) Experiments and Results.: W e first load nP olicies unique policies onto the data server . The measured time is reasonably small, with mean of 0 . 034 s and standard deviation of 0 . 016 per loading operation. W e then run two sets of experiments: 1) The workload consisting of nD irectQuer ies unique queries and the corresponding unique requests. W e en- able the data joining option at the proxy in the first run, and disable it in the second. T o disable cache, we simply change the proxy configuration file. T o run without the joining option, we re-generate the workload without data joining queries and requests. W e measure the time taken to fulfill direct queries and data requests. 2) The workload contains nReq uests queries and the cor- responding requests, which follow the Zipf distribution. In both experiments, non-matching requests are denied access. Fig. 10 and Fig. 11 compare the performance of our prototype against direct-query system, using measurements of matching requests. In both figures, there is a number of requests taking over 5 s to finish. They are sliding window requests, which translates into a large number of SELECT queries to be e xecuted by the database engines. That the serv er needs to wait and aggregate the results into a single client message, and that JDBC implementation incurs non-significant ov erhead for executing a SELECT query both contribute to the noticeable delay . 13 V ariable V alue Description nDir ectQueries 1000 number of direct queries directQuer yD ist 248:248:248:156:100 distribution of direct queries (selection:approximation:aggregation:sliding window:joining request) nP olicies 900 number of unique policies nReq uests 1500 number of matching requests α 0.223 ske w parameter for Zipf distribution maxRank 300 maximum rank of unique requests from which Zipf distribution is generated T ABLE VI: Summary of parameters used in setting up experiments 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.01 0.1 1 10 CDF Time (s) unique queries,direct unique queries, pCloudXACML zipf queries, direct zipf queries, pCloudXACML Fig. 10: Overall performance, with vs without exacmlXA CML. Caching and joining options are on 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.01 0.1 1 10 CDF Time (s) unique queries,direct unique queries, pCloudXACML zipf queries, direct zipf queries, pCloudXACML Fig. 11: Overall performance with exacmlXA CML when the joining and caching options are disabled Fig. 10 illustrates eXACML ’ s ov erhead when both caching and data joining options at the proxy are enabled. For unique queries and requests, there is no overhead from the 99 th percentile. 80% of the requests incurs less than 10% overhead. The largest o verhead is less than 0 . 4 s and is observed from between 87% to 90% percentile. An interesting pattern in which eXACML outperforms the direct-query system can be seen at lower percentiles. Besides network and computational variations, this can be attributed to the data joining feature at the proxy (discussed later). For requests and queries follo wing 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.01 0.1 1 10 CDF Time (s) with cache, no joining without cache, no joining with cache, with joining no cache, with joining Fig. 12: Benefit of caching on performance. Queries follow Zipf distribution Zipf distribution, eXACML performs better most of the time (up until the 89 th percentile). This is thanks to the caching mechanism at the proxy , whose benefit will be analyzed in more detail later . Fig. 11 shows ho w the overhead changes when the proxy performs neither caching nor data joining. The overhead is more discernible: for unique requests, the overhead starts from 20 th percentile, as compared to 45 th percentile in Fig. 10. Similarly , for queries following Zipf distribution, the o verhead is seen from 10 th percentile, as compared to 89 th percentile in Fig. 10. This implies that caching and data joining at the proxy are most effecti ve when the query distribution is heavy-tailed. W e proceed to analyze benefits of caching at the proxy . Request times for Zipf-distribution queries with and without cache are extracted from the e xperiments and plotted in Fig. 12. W e show the results with and without data joining queries. In both cases, caching results in better performance. By itself, i.e. without the joining data feature, caching leads to 50% improvement for more than 80% of the requests. For the workload including data joining queries, a similar pattern can be seen, although the improvement is not as noticeable. Finally , we analyze the benefit of the data joining feature at the proxy . W e run the same experiments as before, b ut with workloads consisting of only data joining queries and requests. The results shown in Fig. 13 are for both unique and Zipf- distribution requests. It can be seen that eXA CML outperforms the direct-query system up until 65 th percentile for unique queries and 70 th percentile for Zipf-distribution queries. This is because for most requests, eXA CML helps reducing the 14 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.01 0.1 1 10 CDF Time (s) unique queries, direct unique queries, pCloudXACML zipf-distribution, direct zipf-distribution, pCloudXACML with cache Fig. 13: Benefit of proxy performing data joins. All queries require data joining data size substantially (by joining the results from two serv ers) before transferring it back to the client. In contrast, without eXA CML, the client has to wait for all data to come back individually before performing joining by itself. Notice that some requests in eXA CML still experience longer delay (after 70 th percentile), because extra communication between client and proxy (as opposed to the direct communication between client and server) and computation overhead at the proxy are not fully discounted. V I . R E L A T E D W O R K There e xists cloud-based systems that enable data sharing from multiple sources. SenseW eb [26], SensorBase [10] are examples of cloud services that let users upload and share their sensor data. They support coarse-grained access control model in which an user either makes its dataset public, shares it with a list of collaborators or keeps it priv ate. Similarly , Google’ s Fusion T able [14] allows user to upload generic data and to perform simple analysis such as data visualization on the cloud. Recently , companies such as Okta [22] have started implementing cloud-brokerage models that provide centralized service for management of enterprises’ resources, including access control. Howe ver , these access control model is also coarse-grained, which means it cannot deal with the access scenarios we consider in this paper . In addition, data owners in these systems upload their datasets onto a centralized cloud, whereas our work does not make such assumption (we consider multi-cloud environment in which different data owner uses its own cloud provider). There are also numerous works focusing on access control and data priv acy on the cloud. Airav at [27], for example, assumes the cloud is trusted in enforcing access control. It uses a simple mandatory access control system av ailable in SELinux [1], and provides a trusted environment for ex e- cuting MapReduce [11] jobs while guaranteeing differential priv ac y [12]. Our work makes the same assumption about clouds’ trustworthiness, b ut aims at impro ving the access con- trol aspect of the system, which is complementary to Airavat. Other works [29], [15], [23] assume the cloud is untrusted and employ cryptographic approach for access control. In [29], data is encrypted with attrib ute-based encryption [13], [7] by a proxy using a proxy re-encryption technique. Embedded in the ciphertext are conditions that must be met when decrypting. Plustus and CloudProof [15], [23] use broadcast encryption [19] to protect the data, while key management [15] is done using key rolling and lazy rev ocation techniques. These cryptographic approaches provide strong guarantees for data security , but they cannot express fine-grained access control policies as described in our work. Thus the focus in these works is also complimentary to ours. In addition, key management and rev ocation protocols are complex and incur much ov erhead in such an untrusted en vironment. Multiple policies matching in XA CML is usually resolved by the top-lev el policy combining algorithms. XACML sup- ports only a limited number of combining algorithms. Ninghui et al. [20] and Rao et al. [25] propose a formal language for e x- pressing more fine-grained policy composition. The language can deal with ev aluation errors and combining of obligations. Mazolleni et al. [17] propose a method for combining policies based on their similarity and users’ preferences. T ime-series data — similar to those considered in our paper — could arri ve at the system in continuous streams, for which relational databases such as MySQL and Postgresql are not ideal. Aurora [2] is a popular data stream management system that addresses limitations of relational databases when it comes to stream data. Carminati et al. [9], [8] are among the first to propose a model and implementation of access control for data streams based on Aurora. The model supports four access scenarios: column-based, value-based, general windo w and sliding window . Our framework supports all of these scenarios for on-demand queries ov er archiv al databases. The extension to eXA CML that deals with continuous queries over stream databases is left for future work. V I I . F U T U R E W O R K W e have implemented a simple prototype and carried out preliminary e valuation of our frame work. The next step would be to improve the prototype and perform more comprehensiv e ev aluations. More specifically , the cloud-like en vironment set up in the experiment contains only two data servers. In addition, only one dataset comes from real monitoring stations, and the workloads are synthetic. Therefore, we plan to acquire more realistic datasets and workloads, and to ev aluate the prototype with larger numbers of data servers. W e also plan to export our prototype into real cloud en vironments such as Amazon EC2 and Microsoft’ s Azure [4], [18], and benchmark it with real data mining applications accessing real datasets. W e assumed that each dataset is guarded by an independent XA CML* instance. W e hav e acknowledged the trade-offs in having multiple datasets sharing one XA CML* instance, especially when datasets reside in the same physical machine. Another trade-of f is the number of proxy servers. It would be interesting to inv estigate these trade-of fs further by extending the frame work with XA CML* sharing and distributed proxies. As shown in T able I, eXACML only deals with archiv al databases and queries. The immediate extension will be to 15 support stream databases and continuous queries. Relational databases are not the best tool for handling stream data, for which other models have been proposed [2]. W e will examine the design and compare performance of the extended eXA CML to that of the existing works on access control for stream data [9], [8]. Regarding data sharing, access control only addresses the problem of authorization. W e have so far made an assumption that authentication is implicit, that is, clients are gi ven static credentials and the serv ers always accept the gi ven credentials. W e plan to incorporate an authentication model into our framew ork. It is an interesting challenge in decentralized settings, of which our multi-cloud scenario is an example, since authentication may depend not only on static credentials but also on previous interactions between parties and the states of the entire system. Authentication is also an important when the cloud provider has to log and notify data o wners of access to their data (for billing purposes, for example). W e plan to use other access control languages such as DynPal [6] or SecPal [5], because they are more suitable for handling dynamic authentication than XACML. Finally , we have always assumed the cloud is trusted in enforcing access control policies and not to violate user’ s data security and pri vac y . Howe ver , users with sensiti ve data or data that have been expensi ve to collect will demand highest lev el of security . As a consequence, they cannot assume the cloud is trusted in handling their data. Existing works have taken the cryptographic approach that encrypt data and attempts to outsource the key management to the cloud. Nev ertheless, the range of access control policies supported by the existing systems has been limited. For future work, we aim to find practical cryptographic protocols that can handle more fine- grained access control scenarios. Since eXACML contains two components belonging to third parties: the proxy server and the cloud servers, we will in vestigate relaxing the trust assumption for these components one by one. V I I I . C O N C L U S I O N In this paper, we hav e proposed a framework (eXACML) that allo ws users to share their data on the cloud in a secure, flexible, easy-to-use and scalable manner . W e considered a trusted cloud en vironment, in which data are maintained in relational databases. The cloud en vironment makes it easy for data owners to share and benefit from mining the aggregated data. The main challenge is how to let users control access to their data in most flexible ways. W e achieved security and flexibility by extending the XA CML frame work, allo wing users to specify fine-grained access control policies. Our framew ork contains a proxy server residing in between clients and the cloud servers. It processes requests from the clients, joins and caches responses from the servers before sending back to the client. W e hav e implemented a prototype and carried out preliminary experiments to ev aluate its perfor - mance. The results suggested that the framework is scalable, as the overhead incurred is small, thanks to the caching and data joining features at the proxy . In addition, the prototype provides a graphical user interface that lets users share and manage their data in an easy-to-use manner . W e believe that in order to take full advantage of cloud computing, having a framework such as ours is very important. Our paper has taken the first steps to wards realizing a practical and usable sharing-friendly cloud environment. W e have also identified many avenues for future work, such as improving scalability with more proxies, adding support for stream data and other policy languages, and relaxing assumptions on the trustworthiness of the cloud. a) Acknoledgments.: This work has been supported by A*Star TSRP grant number 1021580038 for ‘pCloud: Priv ac y in data value chains using peer-to-peer primitives’ project. The authors will like to thank Dr . Lim Hock Beng for providing access to the weather data sets used in some of the experiments. R E F E R E N C E S [1] “Security-enhanced linux, ” http://fedoraproject.org/wiki/SELinux. [2] D. J. Abadi, D. Carney , U. Cetintemel, M. Cherniack, C. Conv ey , S. Lee, M. Stonebraker , N. T atb ul, and S. Zdonik, “ Aurora: a new model and architecture for data stream management, ” in VLDB’03 , 2003. [3] L. A. Adamic and B. A. Huberman, “Zipf ’ s law and the internet, ” Glottometrics , 2002. [4] Amazon, “ Amazon elastic compute cloud, ” /url- http://aws.amazon.com/ec2/. [5] M. Y . Becker, “Secpal formalization and extensions, ” Microsoft Re- search, T ech. Rep. MSR-TR-2009-127, 2009. [6] ——, “Specification and analysis of dynamic authorisation policies, ” in IEEE Computer Security F oundations Symposium , 2009. [7] J. Bethencourt, A. Sahai, and B. waters, “Ciphertext-policy attribute- based encryption, ” in IEEE Symposium on Security and Privacy , 2007. [8] B. Carminati, E. Ferrari, and K. L. T an, “Enforcing access control o ver data streams, ” in SACMA T , 2007. [9] ——, “Specifying access control policies on data streams, ” in DASF AA , 2007. [10] U. Center for Embedded networked sensing, “Sensorbase, ” /url- http://sensorbase.org. [11] J. Dean and S. Ghemawat, “Mapreduce: simplified data processing on large clusters, ” in NSDI 2004 , 2004. [12] C. Dwork, “Differential priv acy , ” in 33rd international colloquium on automata, languag es and prigramming , 2006, pp. 1–12. [13] V . Go yal, O. Pandey , A. Sahai, and B. W aters, “ Attribute-based encryp- tion for fine-grained access control of encrypted data, ” in CCS , 2006. [14] G. Inc., “Google fusion tables (beta), ” /url- http://www .google.com/fusiontables/Home. [15] M. Kallahalla, E. Riedel, R. Swaminathan, Q. W ang, and K. Fu, “Plutus: scalable secure file sharing on untrusted storage, ” in F AST 2003 , 2003. [16] A. Klemm, C. Lindemann, M. K. V ernon, and O. P . W aldhorst, “Char- acterizing the query behavior in peer-to-peer file sharing systems, ” in SIGCOMM 2004 , 2004, pp. 55–67. [17] P . Mazzoleni, E. Bertino, B. Crispo, and S. Siv asubramanian, “Xacml policy integration algorithms: not to be confused with xacml policy combination algorithms!” in 11th A CM symposium on Access contr ol models and technologies , 2006, pp. 219–227. [18] Microsoft, “W indows azure platform, ” /url- http://www .microsoft.com/windo wsazure/. [19] D. Naor, M. Naor , and J. B. Lotspiech, “Revocation and tracing schemes for stateless receivers, ” in CRYPTO 2001 , 2001, pp. 41–62. [20] L. Ninghui, Q. W ang, W . Qardaji, E. Bertino, P . Rao, J. Lobo, and D. Lin, “ Access control policy combining: theory meets practice, ” in 14th ACM symposium on Access contr ol models and technologies , 2009, pp. 135–144. [21] OASIS, “OASIS eXtensible Access Control Markup Language (XA CML) TC, ” http://www .oasis- open.org/committees/xacml/, 2011. [22] Okta Inc., http://okta.com. [23] R. A. Popa, J. R. Lorch, D. Molnar, H. J. W ang, and L. Zhuang, “Enabling security in cloud storage SLAs with CloudProof, ” in USENIX Anual T echnical Confer ence 2011 , 2011. [24] R. Ramankrishnan and J. Gehrke, Database Management Systems , 3rd ed. McGraw-Hill higher Education, 2002. 16 [25] P . Rao, D. Lin, E. Bertino, N. Li, and L. Lobo, “ An algebra for fine- grained integration of xacml policies, ” in 14th ACM symposium on Access contr ol models and tec hnologies , 2009, pp. 63–72. [26] M. Research, “Senseweb, ” /urlhttp://research.microsoft.com/en- us/projects/senseweb/. [27] I. Roy , S. T . Setty , A. Kilzer, V . Shmatikov , and E. Witchel, “ Airav at: security and priv acy for mapreduce, ” in NSDI 2010 , 2010. [28] Sun Microsystem, Inc, “Sun’ s xacml implementation, ” http://sunxacml. sourceforge.net, 2004. [29] S. Y u, C. W ang, K. Ren, and W . Lou, “ Achie ving secure, scalable and fine-grained data access control in cloud computing, ” in INFOCOM 2010 , 2010, pp. 534–42.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment