Online Robust Subspace Tracking from Partial Information
This paper presents GRASTA (Grassmannian Robust Adaptive Subspace Tracking Algorithm), an efficient and robust online algorithm for tracking subspaces from highly incomplete information. The algorithm uses a robust $l^1$-norm cost function in order t…
Authors: Jun He, Laura Balzano, John C.S. Lui
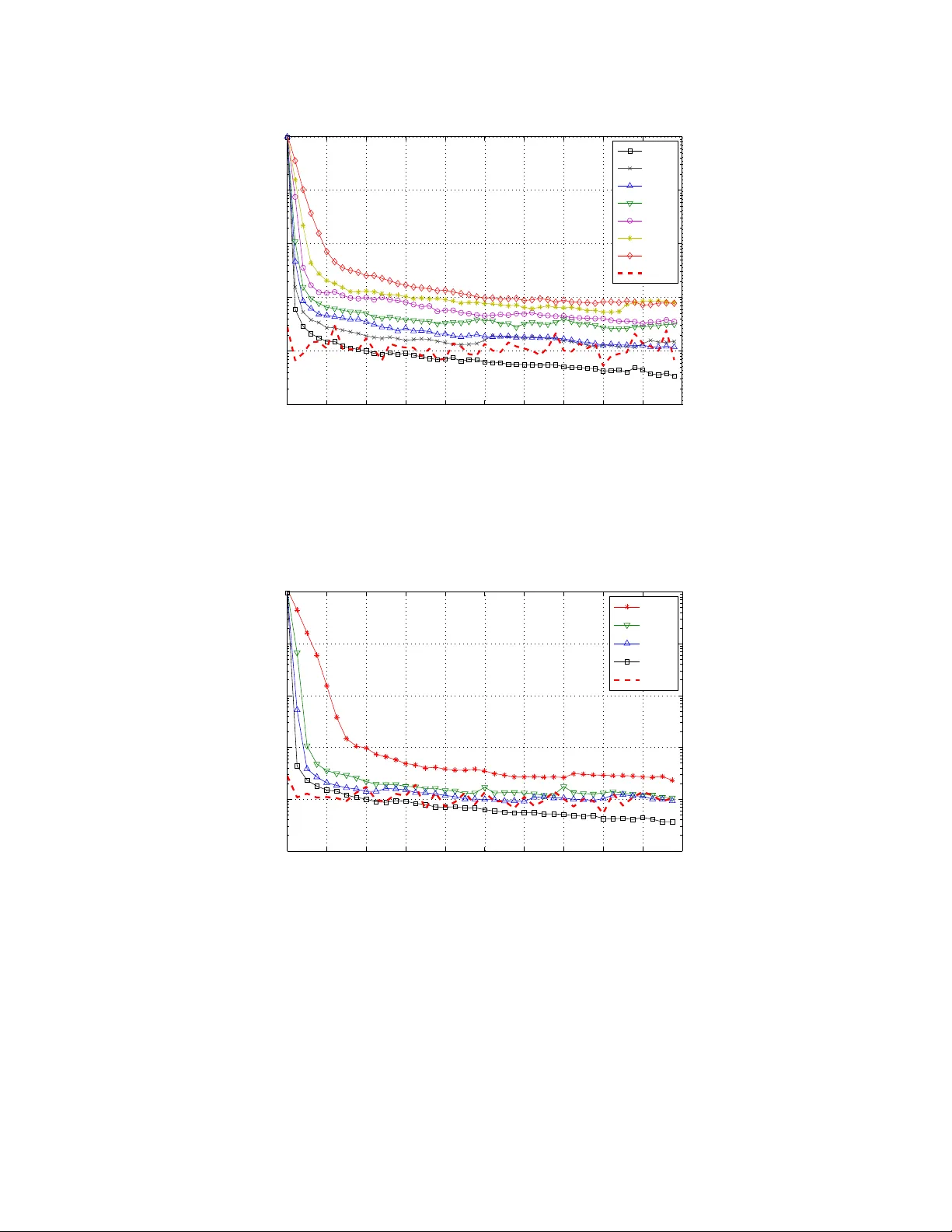
Online Robust Subspace T rac king from P artial Information Jun He ] , Laura Balzano † , and John C.S. Lui ‡ ] College of Electronic and Information Engineering, Nanjing Univ ersity of Information Science and T ec hnology , Nanjing, 210044, China hejun.zz@gmail.com † Departmen t of Electrical and Computer Engineering, Univ ersity of Wisconsin-Madison, Madison, WI, 53706, USA sun b eam@ece.wisc.edu ‡ Departmen t of Computer Science and Engineering, The Chinese Univ ersity of Hong Kong, N.T., Hong Kong cslui@cse.cuhk.edu.hk Septem b er 17, 2011 Abstract This pap er presen ts GRAST A (Grassmannian Robust Adaptive Subspace T rac king Algo- rithm), an efficien t and robust online algorithm for trac king subspaces from highly incomplete information. The algorithm uses a robust l 1 -norm cost function in order to estimate and track non-stationary subspaces when the streaming data v ectors are corrupted with outliers. W e apply GRAST A to the problems of robust matrix completion and real-time separation of bac kground from foreground in video. In this second application, w e show that GRAST A p erforms high- qualit y separation of mo ving ob jects from bac kground at exceptional speeds: In one p opular b enc hmark video example [28], GRAST A achiev es a rate of 57 frames p er second, even when run in MA TLAB on a p ersonal laptop. Keyw ords: Grassman manifold, Lagrangian alternating direction, subspace trac king, matrix separation, robust PCA, video surveillance. 1 In tro duction Lo w-rank subspaces hav e long b een a p o werful to ol in data mo deling and analysis. Applications in comm unications [35], source lo calization and target trac king in radar and sonar [24], and medical imaging [2] all lev erage subspace mo dels in order to recov er the signal of interest and reject noise. In these classical signal pro cessing problems, a handful of high-quality sensors are co-lo cated such that data can b e reliably collected. The c hallenges of mo dern data analysis breach this standard setup. A first difference, one that cannot b e ov erstated, is that data are b eing collected everywhere, on a more massive scale than ev er b efore, by cameras, sensors, and p eople. W e giv e just a few examples: There are an estimated minimum 10,000 surv eillance cameras in the cit y of Chicago and an estimated 500,000 1 in London [3, 33]. Netflix collects ratings from 25 million users on tens of thousands of movies [13]. On its p eak da y of the holida y season in 2008, Amazon.com collected data on 72 items purchased ev ery second [44]. The Large Synoptic Survey T elescop e, which will b e deploy ed in Chile and will photograph the whole sky visible to it every three nights, will pro duce 20 terabytes of data every nigh t [39]. A second and equally imp ortan t difference is that, in all these examples mentioned, the data collected ma y b e unreliable or an indirect indicator of what one really wan ts to kno w. The data are collected from many p ossibly distributed sensors or even from p eople whose resp onses may b e inconsisten t, and the data may b e missing or corrupted. In order to address these issues, algorithms for data analysis m ust b e computationally fast as w ell as robust to corruption and missing data. In this pap er we present the Grassmannian Robust Adaptiv e Subspace T racking Algorithm, or GRAST A, an online algorithm for robust subspace trac king that handles these three challenges at once. W e seek a lo w-rank mo del for data that may b e corrupted by outliers and hav e missing data v alues. GRAST A uses the natural l 1 -norm cost function for data corrupted by sparse outliers, and p erforms incremental gradient descent on the Grassmannian, the manifold of all d -dimensional subspaces for fixed d . F or each subspace up date, we use the gradient of the augmented Lagrangian function asso ciated to this cost. GRAST A op erates only one data v ector at a time, making it faster than other state-of-the-art algorithms and amenable to streaming and real-time applications. 1.1 Con tributions The con tributions of our work are threefold: 1.1.1 Efficien t Grassmannian Augmented Lagrangian Alternating Direction Algo- rithm W e propose an efficien t online robust subspace tracking algorithm – GRAST A, or Grassmannian Robust Adaptive Subspace T racking Algorithm – which com bines the augmented Lagrangian func- tion with the classic stochastic gradien t framew ork [25] and the structure of the Grassmannian [18], and solves via the augmen ted Lagrangian alternating direction metho d [7]. As we discuss in detail in Section 2 and 3, GRAST A alternates b et ween estimating a lo w-dimensional subspace S and a triple ( s, w , y ) which represen t the sparse corruptions in the signal, the weigh ts for the fit of the signal to the subspace, and the dual vector in the optimization problem. F or estimating the sub- space S , GRAST A uses gradient descent on the Grassmannian with ( s, w , y ) fixed; for estimating the triple ( s, w , y ), GRAST A uses ADMM [7]. When data vectors arise from an underlying subspace which is inheren tly low-dimensional, and are corrupted with noise and outliers, GRAST A is able estimate and trac k the subspace successfully , ev en when the vectors are highly incomplete. 1.1.2 F ast Robust Lo w-rank Matrix Completion W e sho w that GRAST A can successfully recov er a low-rank matrix from partial information, ev en if the partially observ ed en tries are corrupted b y gross outliers. GRAST A’s incremental up date results in a significant sp eed-up ov er other state-of-the-art robust matrix completion algorithms or RPCA (robust principal comp onen ts analysis) algorithms. 2 1.1.3 Realtime Separation of Bac kground and Mo ving Ob jects in Video Surv eillance Finally , we sho w that the online nature of GRAST A mak es it suitable for realtime high-dimensional sparse signal separation from a bac kground signal, suc h as the task of separating background and moving ob jects in video surv eillance. Compared to other RPCA metho ds, GRAST A can handle video frames at v ery high rates– up to 57 frames p er second in our examples– even when implemen ted in MA TLAB on a p ersonal laptop, which is a significant practical adv an tage ov er other state-of-the-art tec hniques. This pap er is organized as follo ws. W e motiv ate robust online subspace tracking and give bac kground on subspace tracking and matrix completion in Sections 1.2 and 1.3. The familiar reader can go directly to Section 2, where we formulate the robust subspace tracking problem and in tro duce the nov el subspace error function in Section 2. In Section 3, we presen t the Grassmannian Robust Adaptive Subspace T racking Algorithm (GRAST A) in detail and discuss critical parts of the implemen tation; we p oin t out the limitations and merits as compared with other RPCA algorithms. In Section 4, we compare GRAST A with GROUSE and RPCA algorithms via extensive numerical exp erimen ts and several real-world video surv eillance experiments. Section 5 concludes our w ork and giv es some discussion on future directions. 1.2 Motiv ations 1.2.1 Online Subspace T rac king within Outliers GRAST A is built on GR OUSE [4], an efficient online subspace tracking algorithm. GROUSE uses an l 2 -norm cost function, which is problematic when facing data corruption or noise distributed other than Gaussian. As an example, we consider using subspaces to detect anomalies in computer net works [26]. A non-robust subspace estimation algorithm like GR OUSE w ould need a sp ecial anomaly detection comp onen t in order to differentiate anomalies and outliers from the underlying subspace of the traffic data. Often these types of anomaly detection comp onen ts rely on a lot of parameter tuning and heuristic rules for detection. This motiv ates a more principled approach that is robust b y design: GRAST A. 1.2.2 Robust Principal Comp onen t Analysis Principal Comp onen ts Analysis [21] is a critical to ol for data analysis in many fields. Giv en a parameter d for the num b er of comp onen ts desired, PCA seeks to find the b est-fit (in an l 2 norm sense) d -dimensional subspace to data; in other words, it finds the b est d v ectors, the principal comp onen ts, suc h that the data can b e approximated by a linear combination of those d vectors. The residuals of an l 2 -norm error function will b e Gaussian distributed. Therefore, ev en with one outlier data p oin t, the principal comp onen ts can b e arbitrarily far from those without the outlier data p oin t [20]. Mo dern data applications– suc h as those in sensor net works, collab orativ e filtering, video surveillance or the netw ork monitoring example just given– will all exp erience data failures that result in outliers. Sometimes the outliers are ev en the signal of interest, as in the case of net work anomaly detection or iden tifying mo ving ob jects in the foreground of a surv eillance camera. 3 A goo d deal of research is therefore focused on Robust PCA, including [11, 14]. Recen t w ork fo cuses on a problem definition whic h seeks a lo w-rank and sparse matrix whose sum is the observ ed data. The ma jorit y of algorithms use SVD (singular v alue decomposition) computations to perform Robust PCA. The SVD is to o slow for man y real-time applications, and consequen tly many online SVD and subspace identification algorithms hav e b een developed, as w e discuss in Section 1.3.1. W e are therefore motiv ated to bridge the gap b etw een online algorithms and robust algorithms with GRAST A. Of course w e emphasize that b esides the abilit y to do matrix separation into lo w-rank and sparse parts, GRAST A can also effectively handle the scenario where the low-rank subspace is dynamic. 1.3 Bac kground 1.3.1 Subspace T racking First we briefly describ e the subspace tracking problem set-up and GROUSE [4] algorithm b efore reviewing previous literature on subspace tracking. Consider a sequence of d -dimensional subspaces S t ⊂ R n , d < n , and a sequence of vectors v t ∈ S t . The ob ject of a subspace tracking algorithm is to estimate S t , giv en only v t and the previous subspace estimate S t − 1 . Inc omplete Data V e ctors No w considering the issue of incomplete data vectors, the ob ject of an algorithm for subspace trac king with missing data is to estimate S t giv en v Ω t – an incomplete v ersion of v t , observed only on the indices Ω ⊂ { 1 , . . . , n } . The GROUSE [4] algorithm addresses exactly this problem. GR OUSE is an incremental gradient descent algorithm p erformed on the Grassmannian G ( d, n ), the space of all d -dimensional subspaces of R n . The algorithm minimizes an l 2 -norm cost b et ween observed incomplete vectors and their fit to the subspace v ariable. Each step of the algorithm is simple and requires v ery few op erations. How ev er, the use of the l 2 loss mak es GROUSE very susceptible to outliers. Complete Data V e ctors Comon and Golub [15] giv e an early survey of adaptive metho ds for trac king subspaces, b oth coming from the matrix computation literature, including Lanczos-based recursion algorithms, and gradient-based metho ds from the signal pro cessing literature. There is a v ast literature on the adaptation of QR and SVD factorizations to the adaptiv e, online con text. The w ork in [6, 34, 43] are all along these lines. The fastest algorithm for incremen tal SVD is given in [9]; this algorithm makes mo difications, one column at a time, to the thin SVD of a strictly rank- d n × n matrix in O ( n 2 d ) time. Initial work in signal pro cessing for subspace tracking was aimed at estimating from data the largest eigensubspace for a signal co v ariance matrix. This is useful, for example, in direction-of- arriv al (DO A) estimation: the w ell-known w ork in [38] in tro duces ESPRIT, a parameter estimation algorithm that estimates the DOA of plane wa v es emanating from a target and b eing receiv ed b y a sensor array . ESPRIT w as a follow up to the MUSIC algorithm [40], and ESPRIT gains computational efficiency o ver MUSIC for a slight tradeoff in generalit y of sensor arra y design. Around the same time, Y ang and Ka veh [47] in tro duced an approach for subspace tracking that, lik e GROUSE, uses incremental gradien t, thus making it more suitable for adaptive estimation of the signal subspace and cov ariance matrix. This w ork w as follow ed by [17, 32, 46] with v arious 4 impro vemen ts and con v ergence analyses. Unlike GR OUSE, these algorithms all conduct gradien t descen t in the am bient space as opposed to op erating along the geo desics of the Grassmannian. Also unlik e GROUSE, these algorithms all require fully observ ed vectors. Smith [18, 19, 42] thoroughly pursued conjugate gradient descen t metho ds on the Grassmannian for solving the subspace trac king problem using the Ra yleigh quotien t as a cost function as opposed to the F robenius norm of GR OUSE. In [19] the authors give a v ery careful definition of the problem, giving a nice surv ey comparing the applicability of v arious approac hes. In [18] is an extensive list of subspace trac king references. W e note here that none of the work in this subsection addressed issues of robustness to corrupted data or missing data. R obust Subsp ac e T r acking The work of [31] addresses the problem of robust online subspace trac king. They fo cus on the problem where outliers are found in a fraction of vectors (that is, some v ectors ha ve no outliers), though they do remark that this can be extended to handle the case where outliers are sparse in ev ery vector. They ha ve a very nice prop osition relating l 0 -(pseudo)norm minimization to the least trimmed squares estimator. W e note here that GRAST A differs from [31] in that it directly fo cuses on the case where ev ery v ector ma y hav e outliers, it op erates on the Grassmannian for greater efficiency , and it can handle missing data. A comparison to [31] is a sub ject of future inv estigation. 1.3.2 Matrix Completion The popular Netflix prize [1] stimulated research on the matrix completion problem: Given very few entries of a low-rank matrix, can one recov er (or complete) the en tire matrix? When Cand ` es and Rech t prov ed that, under some incoherence conditions, nuclear norm minimization reco vers a highly incomplete low rank matrix with high probability [12], an entire area w as op ened up for further analysis and algorithmic v ariations. Algorithms that hav e b een prop osed to solve matrix completion include ADMiRA [27], OptSpace [22], Singular V alue Thresholding [10], FPCA [30], SET [16], APGL [45], GROUSE [4], and many others. Of these, GR OUSE is the only online matrix completion algorithm in that it proceeds incrementally , one column at a time. This along with the fact that eac h up date of GR OUSE has lo w computational complexit y mak es GROUSE the fastest of the state-of-the-art matrix completion algorithms by nearly an order of magnitude [4]. 2 Problem Set-up W e denote the ev olving d -dimensional subspace of R n as S t at time t . In applications of in terest w e hav e d n . Let the columns of an n × d matrix U t b e orthonormal and span S t . T racking the ev olving subspace S t is equiv alent to estimating U t at eac h time step 1 . 2.1 Mo del A t each time step t , we assume that v t is generated b y the following mo del: v t = U t w t + s t + ζ t (2.1) 1 W e remind the reader here that U t is not unique for a giv en subspace, but the pro jection matrix U t U T t is unique. 5 where w t is the d × 1 w eight vector, s t is the n × 1 sparse outlier vector whose nonzero en tries may b e arbitrarily large, and ζ t is the n × 1 zero-mean Gaussian white noise vector with small v ariance. W e observe only a small subset of entries of v t , denoted b y Ω t ⊂ { 1 , . . . , n } . Conforming to the notation of GROUSE [4], we let U Ω t denote the submatrix of U t consisting of the rows indexed by Ω t ; also for a vector v t ∈ R n , let v Ω t denote a vector in R | Ω t | whose entries are those of v t indexed by Ω t . A critical problem raised when w e only partially observ e v t is how to quan tify the subspace error only from the incomplete and corrupted data. GROUSE [4] uses the natural Euclidean distance, the l 2 -norm, to measure the subspace error from the subspace spanned b y the columns of U t to the observ ed vector v Ω t : F g rouse ( S ; t ) = min w k U Ω t w − v Ω t k 2 2 . (2.2) It w as shown in [5] that this cost function gives an accurate estimate of the same cost function with full data (Ω = { 1 , . . . , n } ), as long as | Ω t | is large enough 2 . How ever, if the observed data vector is corrupted by outliers as in Equation (2.1), an l 2 -based b est-fit to the subspace can b e influenced arbitrarily with just one large outlier; this in turn will lead to an incorrect subspace up date in the GR OUSE algorithm, as we demonstrate in Section 4.1. 2.2 Subspace Error Quan tification by l 1 -Norm In order to quantify the subspace error robustly , we use the l 1 -norm as follo ws: F g rasta ( S ; t ) = min w k U Ω t w − v Ω t k 1 . (2.3) With U Ω t kno wn (or estimated, but fixed), this l 1 minimization problem is the classic least absolute deviations problem; Bo yd [7] has a nice surv ey of algorithms to s olv e this problem and describ es in detail a fast solv er based on the technique of ADMM (Alternating Direction Metho d of Multipliers) 3 . More references can b e found therein. According to [7], we can rewrite the right hand of Equation (2.3) as the equiv alen t constrained problem b y introducing a sparse outlier v ector s : min k s k 1 (2.4) s.t. U Ω t w + s − v Ω t = 0 The augmen ted Lagrangian of this constrained minimization problem is then L ( s, w , y ) = k s k 1 + y T ( U Ω t w + s − v Ω t ) + ρ 2 k U Ω t w + s − v Ω t k 2 2 (2.5) where y is the dual vector. Our unkno wns are s , y , U , and w . Note that since U is constrained to a non-con vex manifold ( U T U = I ), this function is not con vex (neither is Equation (2.2)). How ever, note that if U were estimated, we could solv e for the triple ( s, w , y ) using ADMM; also if ( s, w , y ) w ere estimated, we could refine our estimate of U . This is the alternating approac h we take with GRAST A. W e describ e the tw o parts in detail in Sections 3.1 and 3.2. 2 In [5] the authors show that | Ω t | must be larger than µ ( S ) d log(2 d/δ ), where µ ( S ) is a measure of incoherence on the subspace and δ controls the probability of the result. See the paper for details. 3 http://www.stanford.edu/ ~ boyd/papers/admm/ 6 2.3 Relation to Robust PCA and Robust Matrix Completion If the subspace S do es not ev olve ov er time, this problem reduces to subspace estimation, whic h can b e related to Robust PCA. F or a set of time samples t = 1 , . . . , T , we observ e a sequence of incomplete corrupted data v ectors v Ω 1 , . . . , v Ω T . Let the matrix V = [ v 1 , . . . , v T ]. Let P Ω ( · ) denote op erator which selects from each column the corresp onding indices in Ω 1 , . . . , Ω T ; th us P Ω ( V ) denotes our partial observ ation of the corrupted matrix V . Note that from our mo del in Equation (2.1), w e can write V as a sum of a sparse matrix S and a lo w-rank matrix L = U W , where the orthonormal columns of U ∈ R n × d span S (whic h is stationary), and W ∈ R d × T holds the w eight vectors w t as columns. The global v ersion of the l 1 cost function in Equation (2.3) follows: ¯ F ( S ) = T X t =1 min w k U Ω t w − v Ω t k 1 = min W ∈ R d × T X ( i,j ) ∈ Ω | ( U W − V ) ij | (2.6) = min W ∈ R d × T kP Ω ( U W − V ) k 1 . The righ t hand of Equation (2.6) can b e rewritten as the equiv alen t constrained problem: min kP Ω ( S ) k 1 (2.7) s.t. P Ω ( U W + S ) = P Ω ( V ) U ∈ G ( d, n ) whic h is the same problem studied in [41], and the authors prop ose an efficient ADMM solver for this problem. Unlike the set-up of [11, 14], this problem is not conv ex; ho wev er it offers m uch more computationally efficien t solutions. GRAST A differs from the algorithm of [41] in tw o ma jor w ays: it uses incremental gradient to minimize this cost function one column at a time for even greater efficiency , and it uses geo desics on the Grassmannian to compute the up date of U . 3 Grassmannian Robust Adaptiv e Subspace T rac king As w e hav e said, GRAST A alternates b etw een estimating the triple ( s, w , y ) and the subspace U . Here we discuss those t wo pieces of our algorithm. Section 3.1 describ es the up date of ( s, w , y ) based on an estimate b U t for the subspace v ariable. Section 3.2 describ es the update of our subspace v ariable to b U t +1 based on the estimate of ( s ∗ , w ∗ , y ∗ ) resulting from the first step. Finally , Section 3.4 describ es our algorithm for adaptively choosing the gradient step-size. 3.1 Up date of the sparse vector, w eigh t v ector, and dual vector Giv en the current estimated subspace b U t , the partial observ ation v Ω t , and the observed entries’ indices Ω t , the optimal ( s ∗ , w ∗ , y ∗ ) of Equation (2.4) can b e found with the follo wing minimization of the augmen ted Lagrangian. ( s ∗ , w ∗ , y ∗ ) = arg min s,w,y L ( b U Ω t , s, w , y ) (3.1) 7 Equation (3.1) can b e efficiently solv ed by ADMM [7]. That is, s , w , and the dual vector y are up dated in an alternating fashion: w k +1 = arg min w L ( b U Ω t , s k , w , y k ) s k +1 = arg min s L ( b U Ω t , s, w k +1 , y k ) y k +1 = y k + ρ ( b U Ω t w k +1 + s k +1 − v Ω t ) (3.2) Sp ecifically , these quan tities are computed as follo ws. In this pap er w e alwa ys assume that U T Ω t U Ω t is in vertible, which is guaranteed if | Ω t | is large enough [5]. W e hav e: w k +1 = 1 ρ ( b U T Ω t b U Ω t ) − 1 b U T Ω t ( ρ ( v Ω t − s k ) − y k ) (3.3) s k +1 = S 1 1+ ρ ( v Ω t − b U Ω t w k +1 − y k ) (3.4) y k +1 = y k + ρ ( b U Ω t w k +1 + s k +1 − v Ω t ) (3.5) where S 1 1+ ρ is the element wise soft thresholding op erator [8]. W e discuss this ADMM solver in detail as Algorithm 2 in Section 3.5. 3.2 Subspace Up date As we mentioned in Section 1.3, the set of all subspaces of R n of fixed dimension d is called Gr assmannian , which is a compact Riemannian manifold, and is denoted by G ( d, n ). Edelman, Arias and Smith (1998) hav e a comprehensiv e survey [18] that co vers ho w b oth the Grassmannian geo desics and the gradient of a function defined on the Grassmannian manifold can b e explicitly computed. GRAST A achiev es online robust subspace trac king by p erforming incremental gradient descent on the Grassmannian step by step. That is, we first compute a gradient of the loss function, and then follo w this gradien t along a short geo desic curv e on the Grassmannian. Figure 1 illustrates the basic idea of gradient descent along a geo desic. 3.2.1 Augmen ted Lagrangian as the Loss F unction It seems that it w ould b e natural to use Equation (2.3) as the robust loss function. Ho wev er, there is a critical limitation of this approach: when regarding U as the v ariable, this loss function is not differen tiable everywhere. Here we prop ose to use the augmen ted Lagrangian as the subspace loss function once we hav e estimated ( s ∗ , w ∗ , y ∗ ) from the previous b U Ω t and v Ω t b y Equation (3.2). The new loss function is stated as Equation (3.6): L ( U ) = k s ∗ k 1 + y ∗ T ( U Ω t w ∗ + s ∗ − v Ω t ) + ρ 2 k U Ω t w ∗ + s ∗ − v Ω t k 2 2 (3.6) This new subspace loss function is differen tiable. F urthermore, when the data vector is not cor- rupted b y outliers, Equation (3.6) reduces to the l 2 -norm loss function of GROUSE [4]. 8 Geodesic U 0 U t min s,w,y L ( U 0 , s, w , y ) min s,w,y L ( U t , s, w , y ) G ( d, n ) − ▽ L Figure 1: Illustration of the gradien t descent along geo desic on the Grassmannian manifold 3.2.2 Grassmannian Geodesic Gradien t Step In order to take a gradien t step along the geo desic of the Grassmannian, according to [18], w e first need to derive the gradient formula of the real-v alued loss function Equation (3.6) L : G ( d, n ) → R . F rom Equation (2.70) in [18], the gradient O L can b e determined from the deriv ative of L with resp ect to the comp onen ts of U . Let χ Ω t is defined to b e the | Ω t | columns of an n × n identit y matrix corresp onding to those indices in Ω t ; that is, this matrix zero-pads a vector in R | Ω t | to b e length n with zeros on the complement of Ω t . The deriv ativ e of the augmen ted Lagrangian loss function L with resp ect to the comp onents of U is as follo ws: d L dU = [ χ Ω t ( y ∗ + ρ ( U Ω t w ∗ + s ∗ − v Ω t ))] w ∗ T (3.7) Then the gradient O L is O L = ( I − U U T ) d L dU [18]. Here we in tro duce three v ariables Γ, Γ 1 , and Γ 2 to simplify the gradient expression: Γ 1 = y ∗ + ρ ( U Ω t w ∗ + s ∗ − v Ω t ) (3.8) Γ 2 = U T Ω t Γ 1 (3.9) Γ = χ Ω t Γ 1 − U Γ 2 (3.10) Th us the gradient O L can b e further simplified to: O L = Γ w ∗ T (3.11) F rom Equation (3.11), it is easy to v erify that O L is rank one since Γ is a n × 1 vector and w ∗ is the optimal d × 1 w eight vector. Then it is trivial to compute the singular v alue decomp osition of O L , whic h will be used for the follo wing gradient descent step along the geo desic according to Equation (2.65) in [18]. The sole non-zero singular v alue is σ = k Γ kk w ∗ k , and the corresp onding left and right singular vectors are Γ k Γ k and w ∗ k w ∗ k resp ectiv ely . Then w e can write the SVD of the 9 gradien t explicitly by adding the orthonormal set x 2 , . . . , x d orthogonal to Γ as left singular vectors and the orthonormal set y 2 , . . . , y d orthogonal to w ∗ as righ t singular vectors as follows: O L = Γ k Γ k x 2 . . . x d × diag ( σ , 0 , . . . , 0) × w ∗ k w ∗ k y 2 . . . y d T (3.12) Finally , follo wing Equation (2.65) in [18], a gradient step of length η in the direction − O L is giv en by U ( η ) = U + ( cos ( η σ ) − 1) U w ∗ t k w ∗ t k − sin ( η σ ) Γ k Γ k w ∗ t T k w ∗ t k . (3.13) 3.3 Remarks Here we p oin t out that at each subspace up date step, our approach do es not remo v e outliers explicitly . In fact, we use the gradient of the augmen ted Lagrangian L ( U ) Equation (3.6) which exploits the dual vector y ∗ to lev erage the outlier effect. That is the key to success. Even when the ADMM solver 3.2 can not identify the outliers due to our current estimated subspace b eing far a wa y from the true subspace, with the help of the dual v ector y ∗ the gradien t of the augmented Lagrangian giv es us the right direction at e ac h step which leads us to the righ t subspace. W e also must p oin t out that since w e estimate ( s ∗ , w ∗ , y ∗ ) at each step using the ADMM solver, w e can not recov er the exact subspace with sufficient accuracy if we do not allo cate enough iterations for the ADMM solver [7]. F ortunately , as it also emphasized in [7], only a few tens of iterations p er subspace up date step are sufficien t to achiev e a mo dest accuracy , whic h is often acceptable for practical use. Extensive exp erimen ts in Section 4 show that our algorithm is fast and alw a ys pro duces acceptable results, even when the vectors are noisy and hea vily corrupted by outliers. 3.4 Adaptiv e Step-size The question of ho w large a gradien t step to tak e along the geo desic is an imp ortan t issue, and it depends on a fundamen tal tradeoff b etw een tracking rate and steady-state error. Rather than the constan t step-size rule prop osed for subspace tracking in GR OUSE, here we prop ose to use the adaptiv e step-size rule to ac hieve b oth precise conv ergence for a stationary subspace and fast adaptation to a changing subspace. W e use the following formula to up date the step-size η t : η t = C 1 + µ t (3.14) where C is the predefined constan t step-size scale. If we use µ t = t to up date η t , it is obvious that the step-size satisfies the following prop erties: lim t →∞ η t = 0 and ∞ X t =1 η t = ∞ This is the classic diminishing step-size rule in sto c hastic gradien t descent literature, and has b een pro ven to guarantee conv ergence to a stationary p oin t [37] [25]. Ho wev er, our goal is not only to identify the stationary subspace precisely . W e hav e the more am bitious goal of k eeping trac k of the subspace when the subspace is slowly changing. Obviously , 10 with a changing subspace, if we use a diminishing step-size rule, when η t is shrinking to 0 our steps will b e to o small to track the dynamic subspace. T o contin ually adapt to the changing subspace, GR OUSE [4] prop oses a constan t step-size whic h needs careful selection to balance the tradeoff b et w een tracking rate and steady-state error. Here we prop ose to use an adaptiv e step-size rule to pro duce a prop er step-size η t that empiri- cally achiev es b oth precise conv ergence for a stationary subspace and fast adaptation to a c hanging subspace. The basic idea is inspired by Plakhov [36] and Klein [23]: if t w o consecutiv e gradien ts O L t − 1 and O L t are in the same direction, i.e. h O L t − 1 , O L t i > 0, it in tuitively means that the cur- ren t estimated b U t is relatively far aw a y from the true subspace S t . If this is the case, heuristically w e should take a sligh tly larger step along − O L t than the previous step-size η t − 1 . Otherwise, if O L t − 1 and O L t are not in the same direction, i.e. h O L t − 1 , O L t i < 0, again in tuitiv ely this means that the curren t estimated b U t is relativ ely close the true subspace S t , and again heuristically w e should take a sligh tly smaller step along − O L t than the previous step-size η t − 1 . Besides the sign of the tw o consecutive gradients giving us in tuition for the step-size adaptation, the inner pro duct h O L t − 1 , O L t i also giv es us the prop er adapted magnitude for our step-size [36] [23]. W e still use Equation (3.14) to pro duce η t at eac h time, but up date µ t according to the inner pro duct of tw o consecutiv e gradients h O L t − 1 , O L t i as follo ws: µ t = max { µ t − 1 + sig moid ( −h O L t − 1 , O L t i ) , 0 } (3.15) where the sig moid function is defined as: sig moid ( x ) = f M I N + f M AX − f M I N 1 − ( f M AX /f M I N ) e − x/ω with sigmoid (0) = 0, f M AX > 0, f M I N < 0, and ω > 0. f M AX and f M I N are c hosen to control ho w muc h the step-size grows or shrinks; and ω controls the shap e of the sig moid function. In this pap er we alwa ys set f M AX = 1, f M I N = − 1, and ω = 0 . 1. When the estimated subspace b U t is v ery close to the true subspace S t , the adaptiv e step-size η t → 0, or equiv alen tly µ t → + ∞ from Equation (3.14). Now we consider the following scenario: supp ose w e ha ve iden tified the subspace precisely– and therefore µ t > N for some large n umber N then suddenly the subspace c hanges dramatically . Ho w quic kly will this step-size rule adapt to the new subspace? In practical applications, taking too muc h time to adapt to the new subspace is undesirable. Sp ecifically , only shrinking µ t at most | f M I N | is too conserv ative in this scenario. It is easy to verify that, since at eac h up date step µ t shrinks at most | f M I N | , the increase of η t is limited and therefore this approac h w ouldn’t take v ery large steps ev en though the subspace has changed. When the subspace c hanges drastically , we should shrink µ t more to accelerate the adaptation pro cess. F or GRAST A, w e tak e this approach and call it a ”Multi-Lev el” adaptiv e step-size rule. Though w e do not pro vide the con vergence pro of here, empirically this multi-lev el adaptiv e approac h demon- strates muc h faster con vergence p erformance than the single-level strategy discussed ab o v e. W e lea ve further detailed comparison to future inv estigation. Our multi-lev el adaptation is as follows. W e only let µ t c hange in ( µ M I N , µ M AX ), where µ M I N and µ M AX are presc ribed constan ts. F or the exp erimen ts in this pap er we alwa ys set µ M I N = 1 and µ M AX = 15. Then in this case Equation (3.15) is adapted to Equation (3.16): µ t = max { µ t − 1 + sig moid ( −h O L t − 1 , O L t i ) , µ M I N } (3.16) 11 W e in tro duce a level v ariable l t that will get smaller when our subspace estimate is far from the data. Then the step-size η t is as follo ws: η t = C 2 − l t 1 + µ t (3.17) Once µ t calculated b y Equation (3.16) is larger than µ M AX , we increase the lev el v ariable l t b y 1 and set µ t = µ 0 , where µ 0 ∈ ( µ M I N , µ M AX ) and µ 0 is selected close to µ M I N (in our exp erimen ts w e let µ 0 = 3). If µ t ≤ µ M I N , we decrease l t b y 1 and also set µ t = µ 0 . Therefore, when our subspace estimate is off, we are increasing η t exp onen tially instead of linearly . On one hand this new multi-lev el adaptive rule follows the basic adaptiv e step-size rule discussed ab o ve; on the other hand exploiting this multi-lev el prop ert y , this new approac h adapts more quic kly to a c hanging subspace. Once w e ha v e iden tified the subspace changing and µ t ≤ µ M I N , if the subspace really c hanges dramatically , l t will k eep decreasing until µ t is again within the range ( µ M I N , µ M AX ). Com bining these ideas together, we state our no vel adaptive step-size rule as Algorithm 3. 3.5 Algorithms The discussion of Sections 3.1 to 3.4 can be summarized in to our algorithm as follows. F or eac h time step t , when we observe an incomplete and corrupted data v ector v Ω t , our algorithm will first estimate the optimal v alue ( s ∗ , w ∗ , y ∗ ) from our current estimated subspace U t via the l 1 minimiza- tion ADMM solver 3.2; then compute the gradient of the augmen ted Lagrangian loss function L b y Equation (3.11); then estimate a prop er step-size η t from the tw o consecutive gradien ts O L t − 1 and O L t b y Equation (3.15) and 3.17 ; and finally do the rank one subspace up date via Equation (3.13). W e state our main algorithm GRAST A (Grassmannian Robust Adaptive Subspace T racking Algorithm) in Algorithm 1. GRAST A consists of t wo imp ortan t sub-procedures: the ADMM solv er of the least absolute deriv ations problem, and the computation of the adaptive step-size. W e state the t wo sub-pro cedures as Algorithm 2 and Algorithm 3 separately . Unlik e GR OUSE, whic h has a closed form solution for computing the gradien t, GRAST A es- timates ( s ∗ t , w ∗ t , y ∗ t ) by the ADMM iterated Algorithm 2. Certainly we w ould ha ve a p oten tial p erformance b ottlenec k if Algorithm 2 takes to o muc h time at eac h subspace up date step. Ho w- ev er, we see empirically that only a few tens of iterations in Algorithm 2 at each step allows GRAST A to track the subspace to an acceptable accuracy . In our video exp erimen ts with Algo- rithm 2, w e alw a ys set the maxim um iteration K around 20 to balance the trade-off b et ween the subspace tracking accuracy and computational p erformance. W e mak e a slight mo dification to the original ADMM so vler presented in [7]: in addition to returning w ∗ w e also return the sparse vector s ∗ and the dual v ector y ∗ for the further computation of the gradient O L . It is eas y to verify that in the w orst case the ADMM solv er needs at most O ( | Ω | d 3 + K d | Ω | ) flops. In order to pro duce the prop er step-size η t from Algorithm 3, w e need to maintain the gradien t O L t − 1 from the previous time step throughout the subspace trac king pro cess. Keeping O L t − 1 only requires additional O ( n + d ) memory usage. The main computation of of Algorithm 3 is the inner pro duct h O L t − 1 , O L t i , whic h is the trace of the pro duct O L t − 1 and O L t , t wo n × d matrices, and will cost O ( nd 2 ) flops. 12 Algorithm 1 Grassmannian Robust Adaptive Subspace T racking Require : An n × d orthogonal matrix U 0 . A sequence of corrupted v ectors v t , each v ector observed in en tries Ω t ⊂ { 1 , . . . , n } . A structure OPTS1 that holds parameters for ADMM. A structure OPTS2 that holds parameters for the adaptive step size computation. Return : The estimated subspace U t at time t . 1: for t = 0 , . . . , T do 2: Extract U Ω t from U t : U Ω t = χ T Ω t U t 3: Estimate the sparse residual s ∗ t , w eight vector w ∗ t , and dual vector y ∗ t from the observed en tries Ω t via Algorithm 2 using OPTS1: ( s ∗ t , w ∗ t , y ∗ t ) = arg min w,s,y L ( U Ω t , w , s, y ) 4: Compute the gradien t of the augmented Lagrangian L , O L as follows: Γ 1 = y ∗ t + ρ ( U Ω t w ∗ t + s ∗ t − v Ω t ), Γ 2 = U T Ω t Γ 1 , Γ = χ Ω t Γ 1 − U Γ 2 O L = Γ w ∗ t T 5: Compute step-size η t via the adaptive step-size up date rule according to Algorithm 3 using OPTS2. 6: Up date subspace: U t +1 = U t + (( cos ( η t σ ) − 1) U t w ∗ t k w ∗ t k − sin ( η t σ ) Γ k Γ k ) w ∗ t T k w ∗ t k where σ = k Γ kk w ∗ t k 7: end for Algorithm 2 ADMM Solver for Least Absolute Deviations [7] Require : An | Ω t | × d orthogonal matrix U Ω t , a corrupted observ ed vector v Ω t ∈ R | Ω t | , and a structure OPTS whic h holds four parameters for ADMM: ADMM step-size constan t ρ , the absolute tolerance abs , the relativ e tolerance rel , and ADMM maximum iteration K . Return : sparse residual s ∗ ∈ R | Ω t | ; w eight vector w ∗ ∈ R d ; dual v ector y ∗ ∈ R | Ω t | . 1: Initialize s , w , y : s 1 = s 0 , w 1 = w 0 , y 1 = y 0 (either to zero or to the final v alue from the last subspace up date of the same data v ector for a w arm start.) 2: Cac he P = ( U T Ω t U Ω t ) − 1 U T Ω t 3: for k = 1 → K do 4: Up date weigh t vector: w k +1 = 1 ρ P ( ρ ( v Ω t − s k ) − y k ) 5: Up date sparse residual: s k +1 = S 1 ρ +1 ( v Ω t − U Ω t w k +1 − y k ) 6: Up date dual vector: y k +1 = y k + ρ ( U Ω t w k +1 + s k +1 − v Ω t ) 7: Calculate primal and dual residuals: r pri = k U Ω t w k +1 + s k +1 − v Ω t k , r dual = k ρU T Ω t ( s k +1 − s k ) k 8: Up date stopping criteria: pri = p | Ω t | abs + rel max {k U Ω t w k +1 k , k s k +1 k , k v Ω t k} , dual = √ d abs + rel k ρU T Ω t y k +1 k 9: if r pri ≤ pri and r dual ≤ dual then 10: Con verge and break the lo op. 11: end if 12: end for 13: s ∗ = s K +1 , w ∗ = w K +1 , y ∗ = y K +1 13 Algorithm 3 Multi-Level Adaptive Step-size Up date Require : Previous gradient O L t − 1 at time t − 1, curren t gradient O L t at time t . Previous step- size v ariable µ t − 1 . Previou s level v ariable l t − 1 . Constan t step-size scale C . Adaptiv e step-size parameters f M AX , f M I N , µ M AX , µ M I N . Return : Current step-size η t , step-size v ariable µ t , and lev el v ariable l t . 1: Update the step-size v ariable: µ t = max { µ t − 1 + sig moid ( −h O L t − 1 , O L t i ) , µ M I N } where sig moid function is defined as: sig moid ( x ) = f M I N + f M AX − f M I N 1 − ( f M AX /f M I N ) e − x/ω , with sig moid (0) = 0. 2: if µ t ≥ µ M AX then 3: Increase to a higher lev el: l t = l t − 1 + 1 and µ t = µ 0 4: else if µ t ≤ µ M I N then 5: Decrease to a lo wer level: l t = l t − 1 − 1 and µ t = µ 0 6: else 7: Keep at the curren t level: l t = l t − 1 8: end if 9: Update the step-size: η t = C 2 − l t / (1 + µ t ) 3.6 Computational Cost and Memory Usage Eac h subspace up date step in GRAST A needs only simple linear algebraic computations. The total computational cost of each step of Algorithm 1 is O ( | Ω | d 3 + K d | Ω | + nd 2 ), where again | Ω | is the n umber of samples p er vector used, d is the dimension of the subspace, n is the ambien t dimension, and K is the num b er of ADMM iterations. Sp ecifically , estimating ( s ∗ t , w ∗ t , y ∗ t ) from Algorithm 2 costs at most O ( | Ω | d 3 + K d | Ω | ) flops; computing the gradien t O L needs simple matrix-vector multiplication which costs O ( | Ω | d + nd ) flops; producing the adaptive step-size costs O ( nd 2 ) flops; and the final up date step also costs O ( nd 2 ) flops. Throughout the trac king pro cess, GRAST A only needs O ( nd ) memory elements to main tain the estimated low-rank orthonormal basis b U t , O ( n ) elements for s ∗ and y ∗ , O ( d ) elements for w ∗ , and O ( n + d ) for the previous step gradient O L t − 1 in memory . This analysis decidedly shows that GRAST A is b oth computation and memory efficient. 4 Numerical Exp erimen ts In the following exp erimen ts, we explore GRAST A’s p erformance in v arious scenarios: subspace trac king, robust matrix completion, and the video surv eillance application. W e use relativ e error to quantify the p erformance of GRAST A. If the recov ered data is a vector, the relative error is defined as follo ws: Rel E r r = k b v − v k 2 k v k 2 (4.1) If the reco vered data is a matrix, the relativ e error is defined as follows: Rel E r r = k c M − M k F k M k F (4.2) 14 W e also use ”Noise Relative P ow er” to quantify the additional Gaussian white noise p erturbation, whic h is defined as follows: N Rel = k ζ k 2 k v k 2 (4.3) Here v is the true data vector and ζ is the additional Gaussian noise as in Equation (2.1). In all the following exp erimen ts, w e use Matlab R2010b on a Macb o ok Pro laptop with 2.3GHz In tel Core i5 CPU and 4 GB RAM. T o improv e the p erformance, we implemen t Algorithm 2 in C++ and mak e it as a MEX-file to b e integrated into GRAST A Matlab scripts. 4.1 Comparison with GR OUSE Our first goal is to compare GRAST A with the non-robust algorithm GROUS E to sho w the need for a robust subspace estimation and tracking algorithm. 4.1.1 Subspace T racking with Sparse Outliers In many of the follo wing e xperiments, we use this generativ e model to generate a series of data v ectors: v t = U true w t + s t + ζ t . (4.4) U true is an n × d matrix whose d columns are realizations of an i.i.d. N (0 , I n ) random v ariable that are then orthornomalized. The weigh t v ector w t is a d × 1 vector whose entries are realizations of i.i.d. N (0 , 1) random v ariables, that is Gaussian distributed with mean zero and v ariance 1. The sparse vector s t is an n × 1 vector whose nonzero entries are Gaussian noise with the maximum of the data v ector U true w as the v ariance; the lo cations of the nonzero en tries are c hosen uniformly at random without replacement. The noise ζ t is an n × 1 v ector whose en tries are i.i.d N (0 , ω 2 ). This parameter ω 2 go verns the SNR with resp ect to the low-rank part of our data. F or the entire comparison against GROUSE, we used a maximum of K = 60 iterations of the ADMM algorithm p er subspace iteration. Figure 2 illustrates the failure of GR OUSE, and success of GRAST A, when these sparse outliers are added only at p eriodic time interv als. W e can see that GROUSE is significan tly thrown off, despite the outliers o ccurring in an isolated v ector. This illustrates clearly our motiv ation for adding robustness to the subspace tracking algorithm. 4.1.2 Robust Matrix Completion W e aim to complete 500 × 500 dimensional matrices of rank 5. The matrices are corrupted by dif- feren t fractions of outliers, dep ending on the exp erimen tal setting, and sampled uniformly without replacemen t with densit y 0 . 30. W e generate the low-rank matrix by first generating tw o 500 × 5 factors Y L and Y R with i.i.d. Gaussian en tries and then adding normally distributed noise with v ariance ω 2 . The lo cation of sparse outliers is distributed uniformly , and the outlier v alues are normally distributed with v ariance equal to the maximum of the matrix. F or each setting of the fraction of outliers, w e randomly generate 5 matrices, eac h of whic h is solv ed via GROUSE and GRAST A separately . Both GROUSE and GRAST A cycle through the matrix columns 10 times. T able 1 sho ws the av eraged results of a comparison b et ween GROUSE and GRAST A. As exp ected, GRAST A v astly outp erforms GR OUSE across the b oard ev en with the smallest n umber of outliers. 15 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 # of vectors seen Rel−err GRASTA GROUSE Figure 2: Subspace tracking comparison b et ween GROUSE and GRAST A from partial in- formation. A t time 500, 1000, . . . , and 4500, 10% observ ed en tries are corrupted by outliers, and all en tries are p erturbed by small Gaussian noise with the v ariance of ω 2 = 10 − 6 . F raction of Outliers 0 0.01 0.05 0.10 0.15 0.20 GR OUSE 3.17E-6 3.95E-1 5.04E-1 8.27E-1 8.79E-1 9.35E-1 GRAST A 7.25E-6 8.92E-5 1.13E-4 2.14E-4 2.91E-4 4.41E-4 T able 1: Robust matrix completion comparison b et w een GRAST A and GROUSE. W e only observ e 30% of the lo w-rank matrix which is corrupted b y sparse outliers. W e show the av eraged results of 5 trials with different fractions of outliers. Here the matrix is 500 × 500, the rank is 5, and all entries are p erturb ed by small Gaussian noise with the v ariance of ω 2 = 10 − 6 . 4.2 Stationary Subspace Iden tification No w w e wish to examine GRAST A’s performance on the stationary subspace iden tification problem under v arious conditions. In most experiments (and unless otherwise noted) the am bien t dimension is n = 500 and the inherent subspace dimension is d = 5. W e again generate the v ectors using Equation (4.4) ab o ve and the descriptive text that follows Equation (4.4). W e v ary the fraction of en tries that are corrupted, and we v ary the fraction of entries that are observed. W e start with Figure 3, whic h shows subspace estimation p erformance under a v arying fraction of added outliers. W e can see in this problem instance that with 10% corrupted en tries, the relativ e error reaches the relativ e noise flo or after a num b er of iterations that is a small multiple of the am bient dimension. F or more corruption, more vectors (gradient iterations) are needed, but even with 50% outliers and more, the relative error trends tow ard the relativ e noise p o wer. In Figure 4, we consider GRAST A’s error p erformance for v arying sub-sampling rates. Here the fraction of corrupted v alues is fixed at 10%. W e can see that again, even with a 30% sampling rate, the relativ e error quickly reaches the relative noise p ow er. No w we wish to take a closer lo ok at the case when we ha ve both dense outlier corruption 16 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 x 10 4 10 −4 10 −3 10 −2 10 −1 10 0 # of vectors seen Rel−err ρ s =0.1 ρ s =0.2 ρ s =0.3 ρ s =0.4 ρ s =0.5 ρ s =0.6 ρ s =0.7 N Rel Figure 3: The p erformance of stationary subspace identification using full information within differen t fractions of outliers. W e show the results from sparse outliers 10% to dense outliers 70%. The ambien t dimension is n = 500, and the subspace dimension is d = 5. All observed en tries are also p erturbed by small Gaussian noise with the v ariance of ω 2 = 10 − 5 . 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 x 10 4 10 −4 10 −3 10 −2 10 −1 10 0 # of vectors seen Rel−err ρ o =0.1 ρ o =0.3 ρ o =0.5 ρ o =1.0 N Rel Figure 4: The p erformance of stationary subspace identification within 10% outliers using partial information. W e show the results with different sub-sampling ratios, from using just 10% information to using full information. The ambien t dimension is n = 500 and subspace dimension d = 5, and all observed entries are also p erturbed b y small Gaussian noise with the v ariance of ω 2 = 10 − 5 . 17 and subsampling of the signal. This is an imp ortan t scenario for applications where the “outlier corruption” is a signal of in terest obscuring a lo w-rank bac kground signal, and we wish to subsample in order to improv e computational complexity . F or example this would apply to anomaly detection problems or to the problem of separation of background and moving ob jects in video as w e show in Section 4.5. Figure 5 illustrates that even when the vector is highly corrupted with 50% added outliers, GRAST A can identify the underlying low-rank subspace ev en with only 50% of the en tries. W e v ary the dimension (or rank) of the underlying subspace, and b ecause of this there is not one relativ e noise p o wer benchmark to compare against; how ever w e see that the trend is similar to those in previous figures. 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 x 10 4 10 −4 10 −3 10 −2 10 −1 10 0 # of vectors seen Rel−err rank=2 rank=4 rank=6 rank =8 rank=10 Figure 5: The performance of subspace identification under dense error corruption. Here ρ s = 0 . 5 which means 50% en tries of every data v ector are corrupted, and we only observ e 50% en tries of each v ector. The am bient dimension is n = 500, we v ary the inherent dimension d , and all observ ed entries are also p erturbed b y small Gaussian noise with the v ariance of 10 − 5 . W e generate 20000 vectors to show the p erformance ov er time. 4.3 Dynamic Subspace T racking The fact that GRAST A op erates one vector at a time allows it to track an ev olving subspace. In this section we show GRAST A’s performance under t wo mo dels of ev olving subspaces. In these exp eriments, w e use the same set-up as b efore: n = 500, d = 5, and v t is generated by Equation (4.4), except that U true = U [ t ], i.e. the subspace we wish to estimate v aries with time t : v t = U [ t ] w t + s t + ζ t . (4.5) 4.3.1 Rotating Subspace T rac king W e use the following ordinary differential equation to simulate a rotating subspace: ˙ U = B U, U [0] = U 0 (4.6) 18 where B is a skew-symmetric matrix. Consequently , the subspace U [ t ] is up dated via U [ t ] = e tδ B U 0 , where δ con trols the amoun t of rotation of with eac h time step t . As w e see in Figure 6, for the rotation parameter δ fixed at 10 − 5 , GRAST A successfully latches on and trac ks the rotating subspace. 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 10 −4 10 −3 10 −2 10 −1 10 0 # of vectors seen Rel−err ρ o =0.3 ρ o =0.5 ρ o =0.7 ρ o =1.0 Figure 6: The performance of tracking a rotating subspace within 10% outliers. At every time the subspace rotates δ = 10 − 5 . The noise v ariance is ω 2 = 10 − 5 . W e show the results with v arying sub-sampling. 4.3.2 Sudden Subspace Change T rac king F or this experiment, w e wan ted to see the behavior of GRAST A when the subspace expe rienced a sudden dramatic change. At interv als of 5000 vectors, we randomly changed the true subspace to a new random subspace. The results are in Figure 7. Again from these simulations w e see that GRAST A successfully identifies the subspace change and tracks the subspace again. 4.4 Comparison with Robust PCA Here w e compare GRAST A with RPCA on the recov ery of corrupted lo w-rank matrices. F or RPCA w e use [29], or the IALM (Inexact Augmen ted Lagrange Multiplier) metho d 4 . The corrupted matrices can b e written as M = L + S + N , where L are the low-rank matrices w e w ant to recov er, S are the sparse outlier matrices, and N are the Gaussian noise matrices with small v ariance relativ e to the sparse outliers. W e use d = 5 matrices of size 2000 × 2000 to do the comparison. The lo w-rank matrices L are generated by the same metho d of the previous robust matrix completion exp erimen ts: as the product of tw o 2000 × 5 factors Y L and Y R with i.i.d. 4 The co de we used is a v ailable here: http://perception.csl.uiuc.edu/matrix- rank/sample_code.html . W e do wnloaded it in April 2011. 19 0 0.25 0.5 0.75 1 1.25 1.5 1.75 2 x 10 4 10 −4 10 −3 10 −2 10 −1 10 0 10 1 # of vectors seen Rel−err ρ o =0.3 ρ o =0.5 ρ o =0.7 ρ o =1.0 N Rel Figure 7: The p erformance of subspace tracking within 10% outliers. A t time 5000, 10000, 15000, and 20000, the subspace undergo es a sudden change. Parameters are again n = 500, d = 5, ω 2 = 10 − 5 . W e show the results with different sub-sampling ratios. Gaussian en tries. The sparse outlier matrices S are generated by selecting a fraction of en tries uniformly at random without replacement, whose v alues are set according to Gaussian distribution with the maxim um of L as the v ariance 5 . W e v ary the fraction of corruptions from 10% (sparse outliers) to 50% (dense outliers), and w e also v ary the v ariance Gaussian noise matrices N from a mo derate p erturbation of ω 2 = 10 − 4 to a larger perturbation of ω 2 = 10 − 3 . F or GRAST A w e cycled through the matrix columns t wice and used a maxim um of K = 60 iterations of the ADMM algorithm; w e used a maximum of 20 iterations of IALM. T able 2 shows the results of the comparison. W e ran RPCA with full data, GRAST A with full data, and then GRAST A with v arious levels of subsampling. When there are v ery few outliers and little noise, RPCA ac hiev es a reasonable error rate at computational speeds similar to GRAST A. Ho wev er with an in crease in noise or fraction of outliers, GRAST A achiev es go o d error p erformance in muc h less time. As a particular example, when ω 2 = 10 − 3 and the fraction of outliers is 30%, in 69 s econds GRAST A with full data ac hieves b etter error p erformance than RPCA in 363 seconds, and GRAST A with 30% subsampling achiev es b etter error p erformance in only 23 seconds. 4.5 Realtime Video Bac kground T rac king and F oreground Detection In this subsection we discuss the application of GRAST A to the prominen t problem of realtime separation of foreground ob jects from the background in video surveillance. Imagine w e had a video with only the bac kground: When the columns of a single frame of this video are stac ked in to a single column, several frames together will lie in a lo w-dimensional subspace. In fact if the bac kground is completely static, the subspace would b e one-dimensional. That subspace can b e 5 W e note here that in [29], the authors use a uniform distribution for the outliers, as opp osed to Gaussian. The authors in [11] use ± 1 Bernoulli v ariables. Gaussian is the most c hallenging case, b ecause more outliers will b e near zero and confuse the estimation. 20 GRAST A ρ o = 1 . 0 GRAST A ρ o = 0 . 5 GRAST A ρ o = 0 . 3 IALM ρ s = 0 . 1 ω 2 = 1 × 10 − 4 1.38 E-4 / 56.62 sec 2.03 E-4 / 30.46 sec 2.73 E-4 / 20.51 sec 5.80 E-5 / 35.26 sec ω 2 = 5 × 10 − 4 3.64 E-4 / 58.31 sec 4.65 E-4 / 31.23 sec 6.07 E-4 / 20.79 sec 1.67 E-3 / 93.16 sec ω 2 = 1 × 10 − 3 7.64 E-4 / 59.55 sec 9.59 E-4 / 31.81 sec 1.23 E-3 / 20.66 sec 3.64 E-3 / 117.76 sec ρ s = 0 . 3 ω 2 = 1 × 10 − 4 4.65 E-4 / 67.90 sec 7.28 E-4 / 35.10 sec 1.06 E-3 / 22.96 sec 1.80 E-4 / 232.26 sec ω 2 = 5 × 10 − 4 6.13 E-4 / 67.19 sec 9.08 E-4 / 34.53 sec 1.26 E-3 / 22.63 sec 2.64 E-3 / 324.26 sec ω 2 = 1 × 10 − 3 9.87 E-4 / 69.06 sec 1.44 E-3 / 35.61 sec 1.93 E-3 / 22.85 sec 5.62 E-3 / 362.62 sec ρ s = 0 . 5 ω 2 = 1 × 10 − 4 1.26 E-3 / 83.11 sec 2.05 E-3 / 39.90 sec 3.58 E-3 / 25.33 sec 1.43 E-1 / 341.01 sec ω 2 = 5 × 10 − 4 1.33 E-3 / 81.51 sec 2.24 E-3 / 40.33 sec 3.93 E-3 / 25.38 sec 1.45 E-1 / 351.26 sec ω 2 = 1 × 10 − 3 1.64 E-3 / 82.23 sec 2.85 E-3 / 41.91 sec 5.08 E-3 / 25.67 sec 1.62 E-1 / 372.21 sec T able 2: Reco very of corrupted low-rank matrices; a comparison b et ween GRAST A and Robust PCA. W e use full information of the corrupted matrices to do robust PCA, and v ary the sub-sampling rate ρ o from 0 . 3 to 1 . 0 (30% of the data to full information), to p erform GRAST A. The matrix is 2000 × 2000, rank=5. W e v ary the fraction of corruptions from sparse outliers 10% to dense outliers 50%, and also v ary the Gaussian noise v ariance ω 2 from mo derate noise p erturbation ω 2 = 1 × 10 − 4 to relativ e strong noise corruption ω 2 = 1 × 10 − 3 . estimated in order to identify and separate the foreground ob jects; if the bac kground is dynamic, subspace trac king is necessary . GRAST A is uniquely suited for this burgeoning application. Here we consider three scenarios in the video tasks, with a sp ectrum of challenges for subspace trac king. In the first w e ha ve a video with a static background and ob jects mo ving in the foreground. In the second, w e hav e a video with a still bac kground but with c hanging lighting. In the third, we sim ulate a panning camera to examine GRAST A’s p erformance with a dynamic background. The results are summarized in T able 3. 4.5.1 Static Bac kground If the video background is kno wn to b e static or near static, w e can use GRAST A to track the bac kground and separate the moving foreground ob jects in real-time. Since the background is static, we use GRAST A first to identify the bac kground, and then we use only Algorithm 2 to separate the foreground from the background. More precisely w e do the following: 1. Randomly select a few frames of the video to train the static low-rank subspace U . In our exp erimen ts, w e select frames randomly from the en tire video; ho wev er for real-time pro cessing these frames ma y b e c hosen from initial piece of the video, as long as we can b e confiden t that ev ery pixel of the background is visible in one of the selected frames. The low-rank subspace U is then iden tified from these frames using partial information. W e use 30% of the pixels, select 50 frames for training, and set RANK = 5 in all the follo wing exp erimen ts. 2. Once the video bac kground B G has been iden tified as a subspace U , separating the foreground ob jects F G from eac h frame can be simply done using Equation (4.7), where the w eight vector w t can b e solved for via Algorithm 2, again from a small subsample of each frame’s pixels. B G = U w t F G = v ideo ( t ) − B G (4.7) 21 T able 3 sho ws the real-time 6 video separation results. F rom the first experiment, we use the “Hall” dataset from [28] whic h consists of 3584 frames each with resolution 144 × 176. W e let GRAST A cycle 5 times o v er the 50 training frames just from 30% random entries of eac h frame to get the stationary subspace U . T raining the subspace costs 6 . 9 seconds. Then we p erform bac kground and foreground separation for all frames in a streaming fashion, and when dealing with eac h frame we only randomly observ e 5% entries. The separation task is p erformed by Equation (4.7), and the separating time is 62 . 5 seconds, whic h means w e ac hiev e 57 . 3 FPS (frames per second) real-time p erformance. Figure 8 shows the separation quality at t = 1 , 230 , 1400. In order to sho w GRAST A can handle higher resolution video effectively , we use the “Shopping Mall” [28] video with resolution 320 × 256 as the second exp erimen t. W e also do the subspace training stage with the same parameter settings as “Hall”. W e do the bac kground and foreground separation only from 1% en tries of each frame. F or “Shopping Mall” the separating time is 39 . 1 seconds for total 1286 frames. Th us w e ac hieve 32 . 9 FPS real-time performance. Figure 9 shows the separation qualit y at t = 1 , 600 , 1200. In all of these video exp erimen ts w e used a maximum of K = 20 iterations of the ADMM algorithm p er subspace up date. The details of eac h trac king set-up are describ ed in T able 4. Dataset Resolution T otal F rames T raining Time T racking and FPS Separating Time Hall 144 × 176 3584 6.9 sec 62.5 sec 57.3 Shopping Mall 320 × 256 1286 23.2 sec 39.1 sec 32.9 Lobby 144 × 176 1546 3.9 sec 71.3 sec 21.7 Hall with Virtual Pan (1) 144 × 88 3584 3.8 sec 191.3 sec 18.7 Hall with Virtual Pan (2) 144 × 88 3584 3.7 sec 144.8 sec 24.8 T able 3: Real-time video background and foreground separation by GRAST A. Here we use three differen t resolution video datasets, the first t wo with static bac kground and the last three with dynamic bac kground. W e train from 50 frames; in the first tw o exp eriments they are chosen randomly , and in the last three they are the first 50 frames. In all exp erimen ts, the subspace RANK = 5. Dataset T raining T racking Separation T raining Algorithm T racking/Separation Algorithm Sub-Sampling Sub-Sampling Sub-Sampling Hall 30% - 5% F ull GRAST A Alg 1 Alg 2+Eqn 4.7 Shopping Mall 30% - 1% F ull GRAST A Alg 1 Alg 2+Eqn 4.7 Lobby 30% 30% 100% F ull GRAST A Alg 1 F ull GRAST A Alg 1 Hall with Virtual Pan (1) 100% 100% 100% F ull GRAST A Alg 1 F ull GRAST A Alg 1 Hall with Virtual Pan (2) 50% 50% 100% F ull GRAST A Alg 1 F ull GRAST A Alg 1 T able 4: Here we summarize the approac h for the v arious video exp erimen ts. When the bac kground is dynamic, we use the full GRAST A for trac king. W e used K = 20 iterations of the ADMM algorithm for all video exp erimen ts. 4.5.2 Dynamic Bac kground: Changing Ligh ting Here we wan t to consider a problem where the lighting in the video is c hanging throughout. W e use the “Lobby” dataset from [28], whic h has 1546 frames, each 144 × 176 pixels. In order to adjust 6 W e comment here that to call something “real-time” pro cessing of course will depend on one’s application requiremen ts and hardware (camera frame capture rate, in the example of video pro cessing). F or example, standard 35mm film video uses 24 unique frames per second. The maximum frame rate for most CCTVs is 30 frames p er second. 22 Figure 8: Real-time video background and foreground separation from partial information. W e sho w the separation qualit y at t = 1 , 230 , 1400. The resolution of the video is 144 × 176. The first ro w is the original video frame at eac h time; the middle ro w is the reco vered bac kground at eac h time only from 5% information; and b ottom ro w is the foreground calculated by Equation (4.7). Figure 9: Real-time video background and foreground separation from partial information. W e sho w the separation qualit y at t = 1 , 600 , 1200. The resolution of the video is 320 × 256. The first ro w is the original video frame at eac h time; the middle ro w is the reco vered bac kground at eac h time only from 1% information; and b ottom ro w is the foreground calculated by Equation (4.7). 23 to the lighting changes, GRAST A tracks the subspace throughout the video; that is, unlike the last tw o exp erimen ts, w e run the full GRAST A Algorithm 1 for ev ery frame. W e use 30% of the pixels of ev ery frame to do this up date and 100% of the pixels to do the separation. Again, see the n umerical results in T able 3. The results are illustrated in Figure 10. Figure 10: Real-time video bac kground and foreground separation from partial information. W e show the separation quality at t = 180 , 366 , 650 , 1000 , 1360. The resolution of the video is 144 × 176 and has a total of 1546 frames. The first row is the original video frame at eac h time; the middle row is the reco vered bac kground at each time only from 30% information; and b ottom ro w is the foreground calculated by Algorithm 2 using full information. The differing bac kground colors of the b ottom row is simply an artifact of colormap in Matlab. 4.5.3 Dynamic Bac kground: Virtual P an In the last exp eriment, we demonstrate that GRAST A can effectively track the righ t subspace in video with a dynamic bac kground. W e consider panning a ”virtual camera” from left to righ t and righ t to left through the video to simulate a dynamic background. P erio dically , the virtual camera pans 20 pixels. The idea of the virtual camera is illustrated cleanly with Figure 11. W e c ho ose “Hall” as the original dataset. The original resolution is 144 × 176, and we set the scop e of the virtual camera to hav e the same heigh t but half the width, so the resolution of the virtual camera is 144 × 88. W e set the subspace R AN K = 5. Figure 12 shows how GRAST A can quic kly adapt to the changed background in just 25 frames when the virtual camera pans 20 pixels to the right at t = 101. W e also let GRAST A track all the 3584 frames and do the separation task for all frames. When we use 100% of the pixels for the tracking and separation, the total computation time is 191 . 3 seconds, or 18 . 7 FPS, and adjusting to a new camera p osition after the camera pans takes 25 frames as can b e seen in Figure 12. When we use 50% of the pixels for trac king and 100% of the pixels for separation, the total computation time is 144 . 8 seconds or 24 . 8 FPS, and the adjustment to the new camera p osition tak es around 50 frames. 24 Virtual camera panning right 20 pixels Figure 11: Demonstration of panning the ”virtual camera” righ t 20 pixels. Figure 12: Real-time dynamic bac kground tracking and foreground separation. At time t = 101, the virtual camera slightly pans to right 20 pixels. W e sho w ho w GRAST A quickly adapts to the new subspace at t = 100 , 105 , . . . , 125. The first row is the original video frame at each time; the middle row is the track ed background at each time; the b ottom ro w is the separated foreground at each time. 5 Discussion and F uture W ork In this pap er we hav e presented a robust online subspace tracking algorithm, GRAST A. The algo- rithm estimates a low-rank mo del from noisy , corrupted, and incomplete data, even when the b est lo w-rank mo del ma y b e changing ov er time. Though this work presents some very successful algorithms, many questions remain. First and foremost, b ecause the cost function in Equation (2.3) has the subspace v ariable U which is constrained to a non-conv ex manifold, the resulting optimization is non-conv ex. A pro of of con vergence to the global minimum of this algorithm is of great in terest. 25 GRAST A uses alternating minimization, alternating first to estimate ( s, w , y ) and then fixing this triple of v ariables to estimate U . Observe that if ( s, w , y ) are correct estimates, w e could then estimate U without the robust cost function. This would b e quite useful in situations when sp eed is of utmost imp ortance, as the GR OUSE subspace up date is faster than the GRAST A subspace up date. Of course, kno wing when ( s, w , y ) are accurate is a very tricky business. Exploring this tradeoff is part of our future work. W e hav e shown that one of the v ery promising applications of GRAST A is that of separating bac kground and foreground in video surveillance. W e are v ery interested to apply GRAST A to more videos with dynamic backgrounds: for example, natural bac kground scenery whic h may blow in the wind. In doing this we will study the resulting trade-off b et ween the kinds of mo vemen t that would b e captured as part of the bac kground and the mov ement that would b e identified as foreground. Ac kno wledgmen ts The authors would lik e to thank IP AM, the Institute for Pure and Applied Mathematics, and the In ternet Multi-Resolution Analysis program, whic h brough t them together to w ork on this problem. W e also thank Rob Now ak and Ben Rec ht for their thoughtful suggestions. References [1] A CM SIGKDD and Netflix. Pr o c e e dings of KDD Cup and Workshop , 2007. Proceedings av ailable online at http://www.cs.uic.edu/ ~ liub/KDD- cup- 2007/proceedings.html . [2] Mic hel A. Audette, F rank P . F errie, and T erry M. P eters. An algorithmic o verview of surface registration tec hniques for medical imaging. Me dic al Image Analysis , 4(3):201 – 217, 2000. [3] Don Babwin. Cameras mak e c hicago most closely w atched U.S. city . Huffington Post , April 6 2010. Av ailable at http://www.huffingtonpost.com/2010/04/06/cameras- make- chicago- most_n_ 527013.html . [4] Laura Balzano, Rob ert Now ak, and Benjamin Rech t. Online identification and tracking of subspaces from highly incomplete information. In Pr o c e e dings of Al lerton , September 2010. Av ailable at http: //arxiv.org/abs/1006.4046 . [5] Laura Balzano, Benjamin Rech t, and Rob ert Now ak. High-dimensional matched subspace detection when data are missing. In Pr o c e e dings of ISIT , 2010. [6] Christian H. Bischof and Gautam M. Scroff. On up dating signal subspaces. IEEE T r ansactions on Signal Pr o c essing , 40(1), Jan uary 1992. [7] S. Bo yd, N. Parikh, E. Chu, B. Peleato, and J. Ec kstein. Distributed optimization and statistical learning via the alternating direction metho d of multipliers. F oundations and T r ends in Machine L e arning , 3(1):1–123, 2011. [8] S.P . Boyd and L. V andenberghe. Convex optimization . Cambridge Univ Pr, 2004. [9] M Brand. F ast low-rank mo difications of the thin singular v alue decomposition. Line ar Algebr a and its Applic ations , 415(1):20–30, 2006. [10] Jian-F eng Cai, Emmanuel J. Cand ` es, and Zuow ei Shen. A singular v alue thresholding algorithm for matrix completion. SIAM Journal on Optimization , 20(4):1956–1982, 2008. 26 [11] E. J. Cand ` es, X. Li, Y. Ma, and J. W right. Robust principal comp onent analysis? Journal of the ACM , 58(1):1–37, 2009. [12] Emman uel Cand ` es and Benjamin Rec ht. Exact matrix completion via conv ex optimization. F oundations of Computational Mathematics , 9(6):717–772, 2009. [13] Netflix Media Center. Accessed August 2011 at http://www.netflix.com/MediaCenter . [14] V. Chandrasek aran, S. Sanghavi, P .A. P arrilo, and A.S. Willsky . Rank-sparsity incoherence for matrix decomp osition. SIAM Journal on Optimization , 21:572, 2011. [15] Pierre Comon and Gene Golub. T racking a few extreme singular v alues and vectors in signal processing. Pr o c e e dings of the IEEE , 78(8), August 1990. [16] W ei Dai, Olgica Milenk ovic, and Ely Kerman. Subspace evolution and transfer (set) for low-rank matrix completion. IEEE T r ansactions on Signal Pr o c essing , 59(7):3120–3132, 2011. [17] J.-P . Delmas and J.-F. Cardoso. Performance analysis of an adaptive algorithm for tracking dominan t subspaces. Signal Pr o c essing, IEEE T r ansactions on , 46(11):3045 –3057, nov 1998. [18] Alan Edelman, T omas A. Arias, and Steven T. Smith. The geometry of algorithms with orthogonalit y constrain ts. SIAM Journal on Matrix Analysis and Applic ations , 20(2):303–353, 1998. [19] Alan Edelman and Steven T. Smith. On conjugate gradient-lik e metho ds for eigen-like problems. BIT Numeric al Mathematics , 36:494–508, 1996. 10.1007/BF01731929. [20] P eter J. Hub er and Elv ezio M. Ronchetti. R obust Statistics . Wiley , 2009. [21] I. Jolliffe. Princip al Comp onent Analysis . Springer-V erlag, 1986. [22] R.H. Kesha v an, A. Montanari, and S. Oh. Matrix completion from noisy entries. Journal of Machine L e arning R ese ar ch , 11:2057–2078, July 2010. [23] S. Klein, J.P .W. Pluim, M. Staring, and M.A. Viergev er. Adaptiv e sto c hastic gradient descent optimi- sation for image registration. International journal of c omputer vision , 81(3):227–239, 2009. [24] H. Krim and M. Vib erg. Tw o decades of array signal pro cessing research: the parametric approac h. Signal Pr o c essing Magazine, IEEE , 13(4):67–94, July 1996. [25] H.J. Kushner and G. Yin. Sto chastic appr oximation and r e cursive algorithms and applic ations , vol- ume 35. Springer V erlag, 2003. [26] An ukool Lakhina, Mark Crov ella, and Christophe Diot. Diagnosing netw ork-wide traffic anomalies. In Pr o c e e dings of SIGCOMM , 2004. [27] Kiryung Lee and Y oram Bresler. Efficient and guaranteed rank minimization by atomic decomp osition. In IEEE International Symp osium on Information The ory , 2009. [28] Liyuan Li, W eimin Huang, Ireme Y u-Hua Gu, and Qi Tian. Statistical modeling of complex background for foreground ob ject detection. IEEE T r ansactions on Image Pr o c essing , 13(11):1459–1472, Nov ember 2004. [29] Z. Lin, M. Chen, L. W u, and Y. Ma. The augmen ted lagrange multiplier method for exact reco very of corrupted lo w-rank matrices. Arxiv pr eprint arXiv:1009.5055 , 2010. [30] Shiqian Ma, Donald Goldfarb, and Lifeng Chen. Fixed p oin t and bregman iterative metho ds for matrix rank minimization. Mathematic al Pr o gr amming , 128:321–353, 2011. 10.1007/s10107-009-0306-5. [31] Gonzalo Mateos and Georgios B. Giannakis. Sparsity control for robust principal comp onen t analysis. In Pr o c e e dings of 44th Asilomar Confer enc e on Signals, Systems, and Computers , Pacific Grov e, CA, No vem b er 2010. 27 [32] G Mathew, V ellenki Reddy , and Soura Dasgupta. Adaptiv e estimation of eigensubspace. IEEE T r ans- actions on Signal Pr o c essing , 43(2), F ebruary 1995. [33] Mic hael McCahill and Clive Norris. Cctv in london. W orking P ap er 6, Cen tre for Criminology and Criminal Justice, Universit y of Hull, United Kingdom, June 2002. Av ailable at http://www.urbaneye. net/results/ue_wp6.pdfSimilar . [34] Marc Mo onen, Paul V an Do oren, and Joos V andew alle. An SVD up dating algorithm for subspace trac king. IEEE T r ansactions on Signal Pr o c essing , 40(6):1535–1541, June 1992. [35] E. Moulines, P . Duhamel, J.-F. Cardoso, and S. Mayrargue. Subspace metho ds for the blind iden tifica- tion of m ultichannel fir filters. Signal Pr o c essing, IEEE T r ansactions on , 43(2):516–525, feb 1995. [36] A. Plakhov and P . Cruz. A sto chastic appro ximation algorithm with step-size adaptation. Journal of Mathematic al Scienc es , 120(1):964–973, 2004. [37] H. Robbins and S. Monro. A sto chastic appro ximation metho d. The Annals of Mathematic al Statistics , pages 400–407, 1951. [38] R Roy and T Kailath. ESPRIT – estimation of signal parameters via rotational in v ariance tec hniques. IEEE T r ansactions on A c oustics, Sp e e ch, and Signal Pr o c essing , 37(7):984–995, July 1989. [39] Andrew Schec htman-Rook. Personal Comm unication, 2011. Details at http://www.lsst.org/lsst/ science/concept_data . [40] Ralph O. Schmidt. Multiple emitter lo cation and signal parameter estimation. IEEE T r ansactions on A ntennas and Pr op agation , AP-34(3):276–280, March 1986. [41] Y. Shen, Z. W en, and Y. Zhang. Augmented lagrangian alternating direction metho d for matrix sepa- ration based on low-rank factorization. TR11-02, R ic e University , 2011. [42] Stev en T. Smith. Ge ometric Optimization Metho ds for A daptive Filtering . PhD thesis, Harv ard Uni- v ersity , 1993. [43] G. W. Stew art. An up dating algorithm for subspace tracking. IEEE T r ansactions on Signal Pr o c essing , 1992. [44] T ess Stynes. Amazon lauds its holida y sales. Wal l Str e et Journal , January 15 2009. Av ailable at http://online.wsj.com/article/SB123029910235635355.html . [45] Kim-Ch uan T oh and Sangw o on Y un. An accelerated pro ximal gradient algorithm for nuclear norm regularized linear least squares problems. Pacific Journal of Optimization , 6(3):615–640, 2010. [46] Bin Y ang. Pro jection approximation subspace trac king. IEEE T r ansactions on Signal Pr o c essing , 43(1), Jan uary 1995. [47] Jar-F err Y ang and Mostafa Kav eh. Adaptiv e eigensubspace algorithms for direction or frequency esti- mation and tracking. IEEE T r ansactions on A c oustics, Sp e e ch, and Signal Pr o c essing , 36(2), F ebruary 1988. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment