Active Learning for Node Classification in Assortative and Disassortative Networks
In many real-world networks, nodes have class labels, attributes, or variables that affect the network's topology. If the topology of the network is known but the labels of the nodes are hidden, we would like to select a small subset of nodes such th…
Authors: Cristopher Moore, Xiaoran Yan, Yaojia Zhu
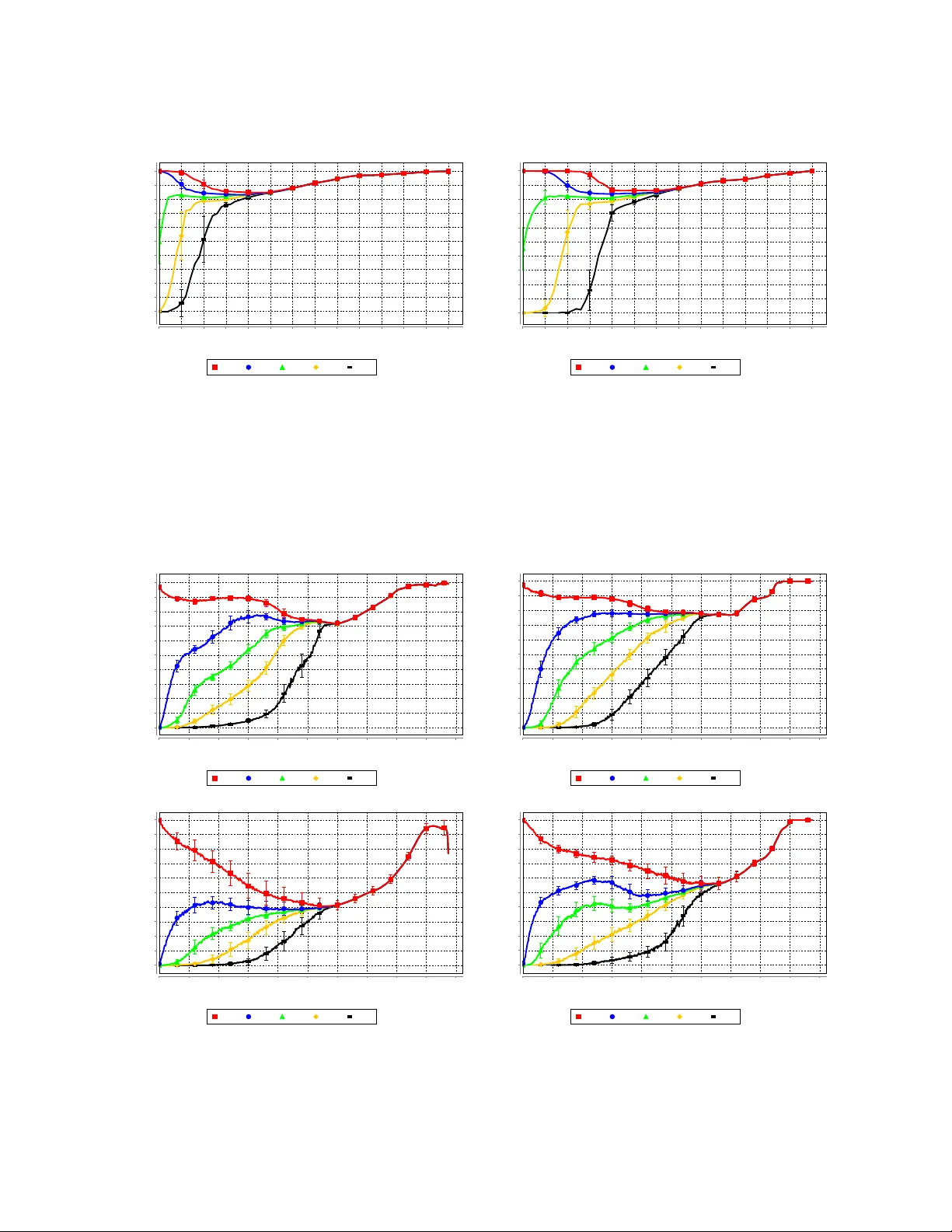
Active Learning f or Node Classification in Assor tative and Disassor tati ve Netw orks Cristopher Moore ∗ Computer Science Dept. Unive rsity of New Me xico Alb uquerque NM 87131 USA and Santa F e Institute moore@cs .unm.edu Xiaor an Y an Computer Science Dept. Unive rsity of Ne w Mexico Alb uquerque NM 87131 USA e v ery xt@gmail.com Y ao jia Zhu Computer Science Dept. Unive rsity of New Me xico Alb uquerque NM 87131 USA ya ojia.zhu@gmai l.com Jean-Bap tiste Rouquier Comple x Systems Institute Rhône-Alpes ENS Ly on, F rance jrouquie @gmail.com T erran Lane Computer Science Dept. Unive rsity of New Me xico Alb uquerque NM 87131 USA terran @cs.unm.edu ABSTRA CT In many real-w orld netw orks, nod es ha ve class lab els, at- tributes, or v ariables that affect th e n etw ork’s topology . If the top ology of the netw ork is known but the lab els of the nod es are hidden, we would like to select a small subset of nod es suc h that, if we knew their lab els, w e could accu- rately predict the l ab els of al l the other nodes. W e dev elop an activ e learning algori thm for this problem whic h uses information-theoretic techniques to choose whic h no d es to explore. W e test our algorithm on netw orks from three d if- feren t domains: a social netw ork, a net w ork of E nglish w ords that appear adjacently in a no vel , and a marine foo d web. Our algorithm makes no initial assumptions about how the groups connect, and p erforms well even when faced with quite general types of netw ork structure. In particular, we do not assume th at nod es of the same class are more lik ely to b e connected to eac h other—only that t hey connect to the rest of the n etw ork in similar wa ys. Categories and Sub je ct De scriptors: I.2.6 [ Artificial Intelligence ]: Learning G.2.2 [ Discrete Mathematics ]: Graph theory General T erms: Algorithms, Exp erimentatio n, Theory Keywords: complex net w orks, structure and fun ction, com- munit y detection, information theory , activ e learning, collec- tive classificatio n, transductive gr aph labeling 1. INTR ODUCTION In many social, b iological , and t ec hnological netw orks, nod es ha ve u nderlying attributes or v ariables that are cor- ∗ This work w as supp orted by the McDonnell F ound ation. Permission to make digit al or hard copi es of all or part of thi s work for personal or classroom use is grante d without fee provid ed that copies are not made or distribut ed for profit or commercial adv antage and that copies bear this notice and the full cita tion on the first pag e. T o copy othe rwise, to republi sh, to post on serv ers or to re distrib ute to list s, require s prior specific permission and/or a fee. KDD’11, August 21–24, 2011, San Diego , California, USA. Copyri ght 2011 A CM 978-1-4503-0813-7/1 1/08 . ..$10.00. related with the netw ork’s top ology . Blogs tend to link to other blogs with similar p olitical views [1]. In v ertebrate foo d w ebs, predators tend to eat prey whose mass is smaller, but not to o muc h smaller, than their own [11]. Netw orks of word adjacencies are correlated with those w ords’ parts of sp eech [30]. In the Internet, different types of service providers form different kinds of link s based on their capac- ities and business relationships [3, 13]—and so on. There has b een a great deal of w ork on efficien t algorithms for communit y detection in n etw orks (see [12 , 32] for re- views). Ho w ever, most of t his work defin es a “community” as a group of nod es with h igh density of connections within the group and a lo w density of connections to the rest of the netw ork. While this typ e of assortative comm unity struc- ture is common in social netw orks, we are in terested in a more general definition of functional community—a group of n od es th at conn ect to the rest of the netw ork in similar w a ys. A set of predators might form a functional group in a foo d web, not b ecause they eat each other, but because they eat similar p rey . In English, nouns often follo w adjectives, but seldom follo w other n ouns. Ev en some so cial n etw orks hav e di sassortat ive structure where pairs of n od es are more lik ely to b e connected if they are from d ifferent classes. F or example, some human so cieties are divid ed into moieties, and only allow marriages b et w een different moieties [21]. W e consider a setting where the top ology of th e netw ork is known, bu t the class lab els of the no des are not. This could b e the case, fo r instance, if we hav e a netw ork of blogs and hyperlinks b etw een them (like citations, track- backs, b logrolls, etc.) and we are tryin g to classif y the blogs according to their p olitical leanings. Another p ossible ap- plication is in online social n etw orks, where friendships are known and we are trying to infer h idden demographic v ari- ables. This problem is sometimes referred to as collectiv e classification [35]. How ever, in that w ork the focus is on classification of indiv id u al nodes. In contrast, our focu s is on the discov ery of functional communities in the netw ork, and our un derlying generativ e mo del is d esigned around the assumption of t h at these communities exist. W e mak e no initial assumptions ab out th e structure of the netw ork—for instance, whether its groups are assortativ e, disassortativ e, or some mixtu re of the t w o. W e assume that w e can learn t h e lab el of any given node, bu t at a cost, say in terms of work in the field or lab oratory . Our goal is to identif y a small sub set of nod es suc h that, once we explore them and learn their lab els, we can accurately predict the labels of all the others. W e p resent a general approac h to this problem. O ur algo- rithm uses information-theoretic measures to decide whic h nod e to explore next—that is, whic h one will give u s the most information ab out the rest of the netw ork. W e start with a probabilistic generative model of the netw ork, called a sto chastic blo ck mo del [20, 38], in which groups connect to each other according t o a matrix of probabilities. This mod el allow s an arbitrary mix t ure of assortativ e and disas- sortativ e structure, as wel l as d irected links from one group to another, and has b een used to mo del n etw orks in man y fields (e.g. [4, 19, 33]). W e stress, how ev er, that our app roac h could b e applied equally well t o many other probabilistic mo dels, suc h as those where no des belong to a mixture of classes [2], a h ier- arc hy of classes and subclasses [10 ], lo cations in a latent geo- graphical or social sp ace [17], or niches in a foo d web [39]. It could also be applied to degree-corrected b lock mo dels such as those in [23, 26, 31], which treat the no des’ degrees as parameters rather than data to b e predicted. At eac h stage of th e learning pro cess, some of the nod es’ labels are already kn ow n and we need to decide whic h no d e to explore next. W e do this by es timating, for each node, th e mutual information b etw een its lab el and the joint distribu- tion of all the others’ labels, conditioned on th e lab els of the nod es that are k nown so far. W e obtain th is estimate b y Gibbs sampling, giving each classification of nod es a prob- abilit y in tegrated ove r t he parameters of t he block mo del. W e then explore the no de for which this mutual information is largest. A key fact ab out th e mutual information, whic h we ar- gue is essential to our algorithm’s p erformance, is that it is not just a measure of uncertaint y : it is a combination of uncertaint y ab out a n od e’s lab el and the extent to whic h it is correlated with the lab els of oth er nod es. Thus the algo- rithm explores n o des which maximize the exp ected amount of information it will gain ab ou t the entire netw ork. It skips nod es whose labels seem obvious to it, or which are uncer- tain but ha ve little effect on other no des. In an assortativ e netw ork, for instance, it starts by exploring no des which are central to their communities, and th en explores no des along the b oundaries b etw een them, without b eing told in adv ance to pursu e this strategy . W e also p resent an alternate approach whic h maximizes a quantit y we call the aver age agr e ement . F or eac h no de v , this is the a vera ge number of no des at which tw o indep endent samples of t he Gibbs distribution agree, conditioned on the even t that they agree at v . L ike m utual information, a verag e agreemen t is high for no des that are highly correlated with the rest of th e netw ork. A similar idea (but not applied to netw orks) is present in [34]. W e test our algorithm on three real-worl d netw orks: the social netw ork of a kara te club, a netw ork of common adja- cent w ords in a Charles D ic kens no vel, and a marine fo o d w eb of sp ecies in the Antarctic. Each of these netw orks is curated in th e sense that we possess the correct nod e lab els, such as the faction of the so cial netw ork each individu al be- longs to, the part of sp eec h of eac h w ord, or the part of the habitat each sp ecies liv es in. W e judge our algorithm according to how accurately it predicts the lab els of t h e un- explored no des, as a function of the num ber of n od es it has explored so far. W e also compare our algorithm with several simple heuristics, such as exploring no des based on their de- gree or b etw eenness centrali ty , and fin d that it significan tly outp erforms them. 2. RELA TED WORK The idea of designing ex p eriments by maximizing th e mu- tual information b etw een the va riable we learn nex t an d the join t distribution of th e other v ariables, or equiv alen tly the exp ected amount of information we gain about the joint dis- tribution, has a long history in statistics, artificial intelli- gence, and machine learning, e.g. Mack ay [25] and Guo and Greiner [16]. Ind eed, it goes back to the work of Lindley [24] in the 1950s. How ever, to our kn owledge this is the first time it has b een coupled with a generative mo del to discov er hid- den v ariables in netw orks. In recent w ork, Zhu, Lafferty , and Ghahramani [41] stu dy active learning of no de lab els using Gaussian fields and har- monic functions defined using th e graph Laplacian. How - ever, this technique only app lies to n etw orks where neigh- b oring n od es are lik ely to b e in the same class—that is, netw orks with assortativ e communit y structure. In contrast, our tec hniques are ca pable of learning about muc h more gen- eral types of netw ork structu re, including disassortativ e and directed relationships betw een functional communities. Another approach to activ e learning of nod e lab els is found in the w ork of Bilgic and Geto or [6] and Bilgic, Mihalko v a, and Getoor [7], who use collective vector-based classifiers. By prop erly defining the collectiv e relationships b etw een nod es, b oth assortativ e or disassortative communities can b e learned in this framew ork. How ever, our technique dif- fers from theirs by using mutual information as the active learning criterion, which takes into accoun t not just u ncer- taint y , but correlations as well. Additional wor ks by Goldberg, Zhu, and W righ t [14] and T ong and Jin [36] also p erform semi-sup ervised learning on graphs, and han d le the disasso rtative case. But they wo rk in a setting where they k now , for eac h link , if th e end s should hav e the same or different labels, suc h as if one writer quotes another with pejorative w ords. I n con trast, we w ork in a set- ting where we hav e no suc h information: only the top ology is av ailable to us, and there are n o signs on the edges telling us whether w e should propagate similar or dissimilar labels. 3. MODEL AND METHODS W e represent our netw ork as a directed graph G = ( V , E ) with n nod es. W e assume that there are k classes of no des, so that eac h no de v h as a class lab el t ( v ) ∈ { 1 , . . . , k } . W e are given the graph G , and our goal is to learn the lab els t ( v ). T o do this, w e assume that G is generated by a probabilistic mod el, in which its top ology is correlated with t hese labels. The simplest such model, although by no means th e only one to which our metho ds could b e applied, is a stochastic block mo del [20, 38]. It assumes that for each pair of no des u, v , there is an edge from u to v with a probability p t ( u ) ,t ( v ) that dep ends only on t h eir lab els, and that these even ts are indep endent. Given a classification, i.e., a function t : V → { 1 , . . . , k } assigning a label to each no de, th e probabilit y of generating a given graph G in this model is P ( G | t, p ) = Y ( u,v ) ∈ E p t ( u ) ,t ( v ) Y ( u,v ) / ∈ E (1 − p t ( u ) ,t ( v ) ) = k Y i,j =1 p e ij ij (1 − p ij ) n i n j − e ij . (1) Here n i = |{ v ∈ V : t ( v ) = i }| is the num b er of no des of class i , and e ij = |{ ( u, v ) ∈ E : t ( u ) = i, t ( v ) = j }| is the num b er of edges from no des of class i to nod es of class j . If we wish to focus on un directed graphs, we can mo dify this expression by restricting the pro duct ov er pairs of classes with i ≤ j . W e can also forbid self-lo ops, if we wish, by replacing n 2 i in the term i = j with n i ( n i − 1) or n i 2 in the directed or undirected case resp ectively . This kind of sto chastic block mo del is we ll-known in the mac hine learning, statistics, and netw ork communities [5, 37, 15, 18, 19, 33] and h as also b een u sed in ecology to identif y groups of species in foo d webs [4]. Unlike e.g. [37, 18, 19], we do not assume t hat p ij takes one val ue when i = j and a smaller v alue when i 6 = j . In oth er w ords, w e do n ot assume an assortative community structure, where nod es are more likely to b e connected to other n od es of the same class. Nor do we require in general that p ij = p j i , since the directed nature of the edges may be important— for instance, in a fo o d web or word adjacency netw ork. If all classi fications t are equally likely a priori , then Ba yes’ rule implies th at the Gibb s distribution on the classifica- tions, i.e., th e p robabilit y of t given G , is p rop ortional to the probability of G giv en t : P ( t | G ) ∝ P ( G | t ) . (2) In order to defin e P ( G | t ), we need to in tegrate P ( G | t, p ) o ver some prior probability distribution on p . I f we assume that the p ij are indep end ent, then th is integral factors ov er the pro duct (1). In particular, if each p ij follo ws a b eta prior, we hav e the Bay esian estimate of edge probabilities P ( G | t ) = Z Z Z 1 0 d { p ij } P ( G | t, p ) = k Y i,j =1 Z 1 0 d p ij Beta( p ij | α, β ) p e ij ij (1 − p ij ) n i n j − e ij = k Y i,j =1 Γ( α + β ) Γ( α )Γ( β ) Z 1 0 d p ij p e ij + α − 1 ij (1 − p ij ) n i n j − e ij + β − 1 = k Y i,j =1 Γ( α + β ) Γ( α ) Γ( β ) Γ( e ij + α ) Γ( n i n j − e ij + β ) Γ( n i n j + α + β ) . (3) F or reasonable choices of th e hyperparameters α and β , the prior dominates only in small data cases, such as very small netw orks or sparsely p opulated classes . F or such small data cases, th e b eta prior allo ws t h e user to input some domain knowledge about, say , th e (dis)assortativit y of the target n etw ork’s community stru cture. In th e limit of large data, the prior will wa sh out and the data-driven community structure will d ominate. If the user wishes to remain agnostic, how ever, he or she can specify a uniform p rior ( α = β = 1) and allow the learning algorithm to estimate th e degree of assortativit y , disassortativit y , d irectedness, and so on entirely from the data. W e take this approach in this p ap er, in which case P ( G | t ) = k Y i,j =1 1 ( n i n j + 1) n i n j e ij . (4) An even simpler approac h is to assume that the p ij take their maximum likel ihoo d v alues ˆ p ij = argmax p P ( G | t, p ) = e ij /n i n j , (5) and set P ( G | t ) = P ( G | t, ˆ p ). This approac h was used, for instance, for a hierarchical blo ck m o del in [10]. When k is fixed and the n i are large, th is will give results similar to (4), since the in tegral o ver p is tightly peaked around ˆ p . Ho w- ever, for any p articular finite graph it makes more sense, at least to a Ba yesi an, to integrate o ver the p ij , since they ob ey a p osterior d istribution rather than taking a fixed v alue. Moreo v er, a ver aging o v er the p arameters as in (4) discour- ages o verfitting, since the av erage likelihood goes down when w e increase k and hence the volume of t h e parameter space. This giv es us a principled w a y to determine k au t omatically , although in this pap er w e set k by hand. Other metho ds to determine k include minimum description length (MDL) techniques [33] and the Ak aike information criterion [4] 4. A CTIVE LEARNING In the activ e learning setting, the algorithm can learn t h e class lab el of any given no de, but at a cost—sa y , by dev oting resources in the laboratory or the field. S ince these reso urces are limited, it h as to decide which no de to ex p lore. Its goal is to explore a small set of no des and use their labels to guess the lab els of the remaining n o des. One natural approach is to explore the n od e v with the largest mutual information (MI) b etw een its label t ( v ) and the lab els t ( G \ v ) of the other nodes according t o the Gibbs distribution (2). W e can write this as the difference betw een the entrop y of t ( G \ v ) and its conditional entropy gi ven t ( v ), MI( v ) = I ( v ; G \ v ) = H ( G \ v ) − H ( G \ v | v ) . (6) Here H ( G \ v | v ) is the entropy , av eraged ov er t ( v ) according to th e marginal of t ( v ) in the Gibbs distribut ion, of the joint distribution of t ( G \ v ) conditioned on t ( v ). In other words, MI( v ) is the exp ected amount of information we will gain abou t t ( G \ v ), or equ iv alently th e exp ected decrease in th e entrop y , that will result from learning t ( v ). Since the mutual information is symmetric, we also hav e MI( v ) = I ( v ; G \ v ) = H ( v ) − H ( v | G \ v ) , (7) where H ( v ) is the entrop y of the marginal distribu tion of t ( v ), and H ( v | G \ v ) is the entropy , on a verag e, of the dis- tribution of t ( v ) conditioned on the labels of the other no des. Thus MI( v ) is large if (i) we are uncertain about v , so that H ( v ) is large, and (ii) v is strongly correlated with the other nod es, so th at H ( v | G \ v ) is small. W e estimate these entropies by sampling from the space of classifications t according to the Gibbs d istribution. Sp ecif- ically , we use a single-site h eat-bath Mark o v chain. At eac h step, it chooses a n od e v uniformly from among the unex- plored no des, and chooses its label t ( v ) according t o the conditional distribution prop ortional t o P ( G | t ), assuming that the lab els of all oth er nod es sta y fixed. In add ition to exploring t h e space, this allows us to collect a sample of the conditional distribution of the chosen node v and its en trop y . Since H ( v | G \ v ) is the a verag e of the conditional entrop y , and since H ( v ) is th e entropy of the av erage conditional dis- tribution, we can write I ( v ; G \ v ) = − k X i =1 h P i i ln h P i i + * k X i =1 P i ln P i + , (8) where P i is the probability that t ( v ) = i and h·i d enotes the a verag e, according to the Gibbs d istribution, o ver the labels of th e other no des. W e offer no theoretical guaran tees abou t th e mix ing time of th is Mark o v c hain, and it is easy to see that there are families of graphs and val ues of k for which it it takes ex- p onential time. How ever, for the real-world netw orks we hav e tried so far, it app ears to conv erge to equilibrium in a reasonable amount of time. W e test for equilibrium by measuring wheth er the marginals change noticeably when the num b er of u p dates is increased by a factor of 2. W e im- prov e our estimates by ave raging ov er many run s, each one starting from an indep endently random initial state. W e say t h at the algori thm is in stage j if it has already explored j no des. In that stage, it estimates MI( v ) for eac h unexplored no de v , using t h e Marko v chain to sample from the Gibbs distribution conditioned on the lab els of the no des explored so far. It t h en explores the no de v with th e largest MI. W e provide it with th e correct val ue of t ( v ) from the curated netw ork , and it mov es on to the next stage. The mutual information is not the only q u antit y w e might use to iden tify whic h no de to explore. Anoth er is th e aver age agr e ement , which w e define as follo ws. Giv en t w o classifica- tions t 1 , t 2 , define their agr e ement as the num b er of no des on whose lab els they agree, | t 1 ∩ t 2 | = |{ v : t 1 ( v ) = t 2 ( v ) }| . (9) Since our goal is t o lab el as many no des correctly as p os- sible, we wish we could maximize th e agreement b etw een an classification t 1 , draw n from the Gibbs distribution, and the correct classification t 2 . How ever, the algorithm do esn’t know t 2 , so it assumes that it is drawn from t he Gibb s dis- tribution as w ell. Exploring v pro jects onto the part of th e join t distribution of ( t 1 , t 2 ) where t 1 ( v ) = t 2 ( v ). So, we define A A( v ) as the ex p ected agreement b etw een t w o clas- sifications t 1 , t 2 draw n indep endently from the Gibbs distri- bution, conditioned on the even t that th ey agree at v : AA( v ) = P t 1 ,t 2 : t 1 ( v )= t 2 ( v ) P ( t 1 ) P ( t 2 ) | t 1 ∩ t 2 | P t 1 ,t 2 : t 1 ( v )= t 2 ( v ) P ( t 1 ) P ( t 2 ) . (10) W e estimate the numera tor and denominator of AA( v ) u s- ing the same heat-b ath Gibb s sampler as for MI( v ), except that we sample indep end ent pairs of classi fications ( t 1 , t 2 ) by starting th e Mark o v chain at tw o indep endently random initial states. 5. RESUL TS AND DISCUSSION W e tested our algori thms on th ree different net w orks from three different fields. The first is Zac hary’s Karate Club [40]. As shown in Fig. 1, th is is a social netw ork consisting of 34 members of a k arate club, where und irected edges represent Figure 1: Zachar y’s Karate Cl ub. friendships. The club split into tw o factions, indicated by diamonds and circles resp ectively . One of them centered around the instructor ( no de 1) and the other around the club president (nod e 34), eac h of which formed their own club. Shaded no des are more p eripheral, and hav e weak er ties t o their communities. This net w ork is highly assortative, with a high densit y of edges within eac h faction and a low density of edges b etw een them. W e judge the p erformance of eac h algorithm by asking, at each stage and for each node, with what probabilit y the Gibbs distribution assigns it the correct lab el. I n each stage w e sampled the Gibbs distribu t ion using 100 indep end ently chos en initial conditions, doing 2 × 10 4 steps of the heat-bath Mark o v chai n for eac h one, and computing av erages using the last 10 4 steps. Increasing the num b er of Marko v chain steps to 10 5 p er stage prod uced only marginal improv ements in p erformance. Fig. 2 sho ws what fraction of the unex- plored no des are assigned the correct label with probability at least q , for var ious thresholds q = 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9, as a function of the stage j . After ex p loring just four or five n od es, b oth of our algo- rithms succeed in correctly predicting the lab els of most of the remaining no des—i.e., to which faction they b elong— with high accuracy . The A A algorithm p erforms slightl y b etter than MI, ac hieving an accuracy close to 100% after exploring nine n od es. Of course, the Karate Club netw ork is quite small, and t here are man y communit y-find in g algo- rithms th at classif y t h e tw o factions with p erfect or n ear- p erfect accuracy [32, 12]. P erhaps more interesting is t he or der in whic h ou r algo- rithms c ho ose to ex plore the nod es. I n Fig. 3, w e sort the nod es in order of the median stage at which they are ex - plored. Error bars show 90% confiden ce interv als o ve r 100 indep endent runs of eac h algorithm. Some no des sho w a large v ariance in the stage in which they are explored, while others are consisten tly explored at t h e b eginning or end of the process. Both algorithms start b y exploring no des 1 and 34, which are central to their resp ective communities. Note that these nodes are chosen, as w e argued abov e, not just b e- cause their labels are un certain, but because they are highly correlated with th e lab els of other no des. After learning that n od es 1 and 34 are in class 1 and 2 re- sp ectively , the algorithms “know” t hat th e netw ork consists of tw o assortativ e communities. They they ex plore no des K a r a t e c l u b w i t h M I 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 1 2 3 4 5 6 7 8 9 1 0 1 1 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s K a r a t e c l u b w i t h A A 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 1 2 3 4 5 6 7 8 9 1 0 1 1 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s Figure 2: Results of the active learning algorithms on Zac hary’s Karate Cl ub netw ork. Q u e r y o r d e r o f k a r a t e c l u b w i t h M I 1 3 4 3 9 2 5 1 2 1 7 2 9 1 0 6 1 3 3 0 5 3 3 2 8 2 0 2 7 1 8 2 3 7 2 1 2 2 1 1 1 5 1 6 1 9 2 6 1 4 3 2 3 1 8 2 2 4 4 V e r t e x I D 0 . 0 2 . 5 5 . 0 7 . 5 1 0 . 0 1 2 . 5 1 5 . 0 1 7 . 5 2 0 . 0 2 2 . 5 2 5 . 0 2 7 . 5 3 0 . 0 3 2 . 5 3 5 . 0 3 7 . 5 A v e r a g e o r d e r q u e r i e d w / S D Q u e r y o r d e r o f k a r a t e c l u b w i t h A A 1 3 4 1 0 1 2 9 1 7 3 1 2 0 2 9 3 2 2 1 3 1 8 1 5 2 8 1 6 2 3 2 7 1 9 2 1 1 1 5 1 4 2 6 2 5 6 7 3 0 8 3 3 3 2 2 4 4 2 V e r t e x I D 0 . 0 2 . 5 5 . 0 7 . 5 1 0 . 0 1 2 . 5 1 5 . 0 1 7 . 5 2 0 . 0 2 2 . 5 2 5 . 0 2 7 . 5 3 0 . 0 3 2 . 5 3 5 . 0 3 7 . 5 4 0 . 0 A v e r a g e o r d e r q u e r i e d w / S D Figure 3: The order in which the active learning algorithms explore node s i n Zac hary’s Karate Club. p e r f e c t b e s t o p e n e a r l y y o u n g l o w l o n g h a r d b e t t e r n o t h i n g Figure 4: The order in w hich the active learning al- gorithm MI explores no des in word adjacency net- wor k from the nov e l David Copp erfield . such as 3, 9, and 10 whic h lie at the b oundary b etw een these communities. Once th e b oundary is clear, they can easily p redict the lab els of the remaining nod es. The last nod es to be explored are t h ose such as 2, 4, and 24, which lie so deep inside their communities th at their labels are not in doub t. The second netw ork consists of the 60 most commonly o c- curring n ouns and the 60 most commonly occu rring adjec- tives in Charles Dic kens’ novel David Copp erfield . A directed edge connects any p air of wo rds that app ear adjacently in the tex t, p ointing from th e preceding word to the follo wing one. Excluding eight words whic h are disconnected from the rest leav es a netw ork with 112 n od es [29]. Unlike Zachary’s Karate Club, t his n etw ork is b oth directed and highly dis- assortativ e. O f th e 1494 edges, 1123 of them p oin t from adjectiv es to nouns. This lets u s classif y most no des early on, simply by labeling a no de as an adjectiv e or noun if its out-degree or in- degree is large. Accordingly , our algorithms focus their atten tion on words abou t whic h t hey are uncertain, lik e “early ,”“low ,” and “noth- ing,” whose out-degrees and in-degrees in the text are roughly equal, and w ords like “p erfect” that precede w ords of b oth classes (see Fig. 4, where green and yello w nod es represent nouns and adjectives resp ectively; rectangular no des are ex- plored first, and elliptical ones last). O nce these no des are resolv ed, both algo rithms achiev e high accuracy—80% ac- curacy after exploring 20 n o des and close to 100% after ex - ploring 65 no des (see Fig. 5 ). In each stage we sampled the Gibbs distribution using 100 indep endently chosen in itial conditions, doing 5 × 10 4 steps of t he heat-bath Marko v chain for each one, and comput- ing av erages using the last 2 . 5 × 10 4 steps. Increasing th e num ber of Marko v chain steps to 10 5 p er stage pro duced only m arginal improv emen ts in p erformance. As in Fig. 2, the y -axis shows the fraction of unexp lored no des which are labeled correctly by the conditional Gibbs distribution with probabilit y at least q , for q = 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9. The p er- formance of the tw o algorithms is similar in the later stages, but unlike th e Karate Club, here MI p erforms noticeably b etter than A A in the early stages. The third netw ork is a foo d web of 488 sp ecies in the W edd ell Sea in the Antarctic [11, 9, 22], with edges p ointing W o r d a d j a c e n c y n e t w o r k w i t h M I 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 4 5 5 0 5 5 6 0 6 5 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s W o r d a d j a c e n c y n e t w o r k w i t h A A 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 4 5 5 0 5 5 6 0 6 5 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s Figure 5: Results of the activ e learning algorithms on word adjacency ne t wor k in the nov e l David Copp e rfield b y Charles Dic kens. S e a f o o d w e b ( F e e d i n g t y p e ) w i t h M I 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s S e a f o o d w e b ( F e e d i n g t y p e ) w i t h A A 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s S e a f o o d w e b ( H a b i t a t ) w i t h M I 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s S e a f o o d w e b ( H a b i t a t ) w i t h A A 0 . 1 0 . 3 0 . 5 0 . 7 0 . 9 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s Figure 6: Results for the W e ddell Sea fo o d web. to each predator from its prey . This data set is very ric h, but we fo cus on tw o particular v ariables—the feeding t yp e and th e habitat in which the sp ecies liv es. The feeding typ e takes k = 6 val ues, n amely primary prod ucer, omnivorous, herbivorous/detriv orous, carnivo rous, detrivorous, and car- nivorous/ necrov orous. The h ab itat vari able takes k = 5 va l- ues, namely p elagic, b enthic, b enthopelagic, demersal, and land-based. W e show results of our algorithms for b oth va riables in Fig. 6. The results are av eraged ov er 100 runs of each algo- rithm. In eac h stage w e sampled the Gibbs d istribution us- ing 100 independently chosen initial conditions, doing 5 × 10 4 steps of the heat-b ath Marko v chain for each one, and com- puting a verag es using the last 2 . 5 × 10 4 steps. F or th e feed- ing typ e, after exploring half the n o des, b oth algorithms correctly lab el ab out 75% of the remaining no des. F or t he habitat v ariable, b oth algorithms are less accurate, although AA p erforms somewhat bet t er than MI. N ote that t he ac- curacy only includes t he unexp lored no des, not the n od es w e hav e already exp lored. Th u s it can d ecrease if we ex- plore easily-classified n od es early on, so that hard-to-classify nod es form a larger fraction of the remaining ones. Fig. 6 sho ws that b oth algorithms get to a state where they are confident, but wrong, ab out many of the unexplored nod es. F or the feeding t yp e v ariable, for instance, after the AA algorithm has exp lored 300 species, it lab els 75% of the remaining nodes correctly wi th probabilit y 90%, but it la b els the other 25% correctly with probabilit y less than 10%. In other w ords, it has a high degree of confiden ce about all the no des, but is wrong ab out many of them. Its accuracy impro ves as it explores more no d es, bu t it do esn’t achiev e high accuracy on all the unexp lored no des until there are only ab out 60 of t h em left. Why is this? W e argue that the fault lies, not with our learning algorithms and t he order in whic h th ey explore th e nod es, but with the sto chastic blo ck mo del and its ab il- it y to mo del the data. F or ex ample, for the habitat v ari- able, t h ese algorithms p erform well on p elagic, demersal, and land-b ased species. But the b enthic habitat, whic h is the largest and most diverse, includes sp ecies with many feeding types and trophic levels. These additional va riables hav e a large effect on the top ol- ogy , but th ey are not taken into accoun t by the blo ck mo d el. As a result, more th an h alf th e b enthic sp ecies are mislab eled by the blo ck mo del in the follo wing sense: ev en if we con- dition on the correct habitats of al l the oth er sp ecies, the sp ecies’ most likel y habitat is p elagic, b enthopelagic, dem- ersal, or land-b ased. Sp ecifically , 219 of the 488 sp ecies are mislabeled by the most lik ely block model, 94% of them with confidence ov er 0 . 9. Of course, w e can also regard our algorithms’ mistakes as evidence that these hab itat classifications are not cut and dried. Indeed, ecologists recognize that th ere are “connector sp ecies” that connect one habitat to another, and b elong to some ext ent to b oth. T o test our h yp othesis that it is the block model’s inability to model the data that causes some n od es to b e misclassi- fied, w e artificially mo dified the data set to make it consis- tent with the b lock model. Starting with the no des’ original class labels, we up dated the h abitat of each species to its most likely v alue according to the blo ck mo del, given the habitats of all th e other sp ecies. After iterating th is pro cess six times, we reac hed a fixed p oint where each sp ecies’ habi- tat is consistent with t he blo ck mo del’s predictions. On this synthetic data set b oth of our learning algorithms p erform p erfectly , predicting the habitat of every sp ecies with close to 100% accuracy after exploring just 18% of them. More generally , it is important to remem b er that the top ol- ogy of th e netw ork is only imp erfectly correlated with the nod es’ types. Zac hary [40] relates that one of members of the Karate Club joined the instructor’s faction even though the netw ork’s top ology suggests that he w as more strongly connected t o the president. The reason is that he w as only three weeks aw ay from a test for his black b elt when the split o ccurred. H e had already inv ested four years learning the instructor’s style of k arate, and if he had joined the pres- ident’s club he w ould hav e had to start ov er with a white b elt. In any real-world n etw ork, there is information of th is kind that is not reflected in the top ology and which is hid - den from our algorithm. If a nod e is of a given class for idiosyncratic reasons lik e these, we cannot exp ect any algo- rithm based solely on top ology and the other n od es’ class labels—no matter h ow sophisticated a p robabilistic mo del w e use—to correctly classify it. 6. COMP ARISON WITH SIMPLE HEURISTICS W e compared our active learning algorithms with seve ral simple heuristics. These include exploring the nod e with the highest d egree in the subgraph of u n explored no des, explor- ing the n od e with the highest b etw eenness centralit y (the fraction of shortest paths that go th rough it, see [8, 27, 28]) in the sub graph of un explored n od es, an d exploring a no de chos en u niformly at random from the unexplored ones. W e judge the p erformance of these heuristics using t he same Gibbs sampling process as for MI and AA. In Fig. 7, w e sho w the results of these heuristics at t h e 0 . 9 accuracy threshold on all three netw orks, including b oth the habitat and fee ding typ e v ariables in the foo d web. On Zac hary’s Karate Club (left) our algorithms outp erform these heuristics consisten tly . I n the David Copp erfield net- w ork (right), the highest-d egree and highest-b etw eenness heuristics enjo y an early lead, b ut quickly hit a ceiling and are surpassed by MI and AA. F or the W eddell Sea food web (b ottom), the highest-degree and highest-b etw eenness heuristics p erform p o orly th rough- out t he learning process. One reason for t his is that many nod es with high degree or high b etw eenness are easy to clas- sify from the labels of th eir neigh b ors. By ex ploring these nod es first, these heuristics lea ve themselv es mainly with hard-to-classify no des. The random-no d e heuristic p erforms surprisingly well early on, but all three h euristics are w orse than MI or AA once they hav e explored half t h e no des. 7. CONCLUSION Active learning, using m utual information or av erage agree- ment coupled with a generative mo del, offers a new app roach to analyzing netw orks where th e top ology is known, but knowl edge of class lab els is incomplete and costly to obtain. W e hav e sho wn for three netw orks, one so cial, one lexical, and one biological, that our algorithms do a goo d job of predicting t he labels of unexplored nodes after exploring a relativ ely small fraction of the netw ork, correctly recog nizing b oth assortative and d isassortative functional communities. Certainly not all netw orks are well-described by the simple C o m p a r i s o n o f l e a r n i n g m e t h o d s o n k a r a t e c l u b A A 0 . 9 M I 0 . 9 D e g r e e 0 . 9 B e t w e e n n e s s 0 . 9 R a n d o m 0 . 9 0 5 1 0 1 5 2 0 2 5 3 0 # o f n o d e s q u e r i e d 0 2 5 5 0 7 5 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s C o m p a r i s o n o f l e a r n i n g m e t h o d s o n w o r d a d j a c e n c y n e t w o r k A A 0 . 9 M I 0 . 9 D e g r e e 0 . 9 B e t w e e n n e s s 0 . 9 R a n d o m 0 . 9 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 1 1 0 # o f n o d e s q u e r i e d 0 2 5 5 0 7 5 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s C o m p a r i s o n o f l e a r n i n g m e t h o d s o n s e a f o o d w e b ( h a b i t a t ) A A 0 . 9 M I 0 . 9 D e g r e e 0 . 9 B e t w e e n n e s s 0 . 9 R a n d o m 0 . 9 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s C o m p a r i s o n o f l e a r n i n g m e t h o d s o n s e a f o o d w e b ( f e e d i n g t y p e ) A A 0 . 9 M I 0 . 9 D e g r e e 0 . 9 B e t w e e n n e s s 0 . 9 R a n d o m 0 . 9 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 3 5 0 4 0 0 4 5 0 5 0 0 # o f n o d e s q u e r i e d 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 % v e r t i c e s a b o v e t h r e s h o l d s Figure 7: A comparison of the MI and A A le arning algorithms with three si mple heuristics. block mod el we use here, but our approac h can b e general- ized to probabilistic netw ork mo dels which take information on the nod es’ locations or degrees in to account. Acknowledgments. W e are grateful to Joel Bader, Aaron Clauset, Jennifer Du nne, Nath an Eagle, Brian Karrer, Jon Kleinberg, Mark Newman, Cosma Shalizi, and Jerry Zhu for helpful conv ersations, and to Ute Jacob for the W eddell Sea fo od web data. J.-B. R. is also grateful to the Santa F e Institute for th eir hospitality . This w ork was supp orted by the McDonnell F oundation. 8. REFERENCES [1] L. Adamic and N. Glance. The p olitical blogosphere and the 2004 US election: Divided they blog. In Pr o c 3r d Intl Workshop on Link Disc overy. , 2005. [2] E. M. Airoldi, D. M. Blei, S. E. Fienberg, and E. P . Xing. Mixed memb ership sto chastic blo ckmodels. J. Machine L e arning R ese ar ch , 9:1981– 2014, 2008. [3] D. A lderson, L. Li, W. Willinger, and J. C. D oyle. Understanding internet topology: principles, mo dels, and v alidation. IEEE/ACM T r ans. Networks , 13(6):1205 –1218, 2005. [4] S. A llesina and M. Pa scual. F o o d w eb mo dels: a plea for groups. Ec olo gy L etters , 12:652–662, 2009. [5] P . J. Bick el and A . Chen. A nonparametric view of netw ork mo dels and newman-girv an and other mod u larities. Pr o c. Natl. A c ad. Sci. , 106:21068–21 073, 2009. [6] M. Bilgic and L. Getoor. Link- based activ e learning. In NIPS Workshop on Analyzing Networks and L e arning with Gr aphs , 2009. [7] M. Bilgic, L. Mihalko v a, and L. Geto or. Active learning for netw ork ed data. I n Pr o c. Intl. Conf. on Machine L e arning , 2010. [8] U. Brandes. A faster algorithm for b etw eenness central ity . Journal of Mathematic al So ciolo gy , 25(2):163– 177, 2001. [9] U. Brose, L. Cushing, E. L. Berlo w, T. Jonsson, C. Banasek-Rich ter, L. F. Bersier, J. L. Blanchard, T. Brey , S. R. Carp enter, M. F. Blandenier, et al. Body sizes of consum ers and their resources. Ec olo gy , 86(9):2545 –2545, 2005. [10] A . Clauset, C. Moore, and M. E. J. Newman. Hierarc hical structure and the prediction of missing links in n etw orks. Natur e , 453(7191):98–10 1, 2008 . [11] U . B. et al. Consumer-resource b o dy- size relationships in natural fo o d w ebs. Ec olo gy , 87(10):2411–2417 , 2006. [12] S . F ortun ato. Communit y d etection in graphs. Physics R ep orts , 2009. [13] L. Gao and J. Rexford. Stable internet routing without global co ordination. I EEE/ACM T r ans. Networks , 9(6):681–69 2, 2001. [14] A . B. Goldb erg, X. Zhu, and S. W righ t. Dissimilarit y in graph-based semi-sup ervised classificati on. J. Machine L e arning R ese ar ch W&P , 2:155–162, 2007. [15] R . Guimera and M. Sales-P ardo. Missing and spurious intera ctions and t he reconstruction of complex netw orks. Pr o c. Natl. A c ad. Sci . , 106:22073 –22078, 2009. [16] Y . Guo and R. Greiner. O ptimistic active learning using mutual information. In Pr o c. Intl. Joint Conf. on Art ificial Intel ligenc e , 2007. [17] M. S. H an d cock, A. E. R aftery , and J. M. T antrum. Model-b ased clustering for social netw orks. J. R oyal Statist. So c. A , 170(2):1–22 , 2007. [18] M. B. Hastings. Comm unity detection as an inference problem. Physic al Re view E , 74(3):035 102, 2006. [19] J. M. Hofman and C. H. Wiggins. Bay esian approac h to netw ork mod ularit y . Physic al Re view L etters , 100(25):25 8701, 2008. [20] P . W . Holland, K. B. Laskey , and S. Leinhardt. Sto chasti c blo ckmodels: first steps. So cial networks , 5:109–1 37, 1983. [21] M. Houseman and D. R. White. T aking Si des: Marriage Networks and Dr avidi an Kinship in L ow land South A meric a , pages 214–243. T ransformations of Kinship. Smithsonian In stitution Press, 1998. [22] U . Jacob. T r ophi c Dynamics of Ant ar ctic Shelf Ec osystems, F o o d Webs and Ener gy Flow Budgets . PhD thesis, Un iversi ty of Bremen, 2005. [23] B. Karrer and M. E. J. Newman. Sto chastic blockmod els and community structure in netw orks, 2010. Preprint, arXiv:1008.39 26 v1. [24] D . V. Lind ley . O n a measure of the information provided by an exp eriment. Ann. Math. Statist. , 27(4):986– 1005, 1956. [25] D . J. MacKay. Information-based ob jective functions for active data selection. Neur al Computation , 4(4):590–6 04, 1992. [26] M. Mørup and L. K. Hansen. Learning latent structure in complex netw orks. In NIPS Workshop on Ana lyzing Networks and L e arning with Gr aphs , 2009. [27] M. Newman. Scientific collaboration netw orks. I I. shortest paths, weigh t ed n etw orks, and centralit y . Physic al Re view E , 64(1), 2001. [28] M. E. J. Newman. A measure of b etw eenn ess central ity based on random w alks. So cial Networks , 27(1):39–5 4, 2005. [29] M. E. J. Newman. Finding community structure in netw orks using the eigenv ectors of matrices. Physic al R eview E , 74(3):36104, 2006. [30] M. E. J. Newman and E. A . Leich t. Mixture mo dels and exploratory analysis in netw orks. Pr o c. Natl. A c ad. Sci . , 104:9564– 9569, 2006. [31] A . S. Patterson, Y. Park, and J. S. Bader. Degree-corrected blo ck models. Manuscript. [32] M. A. Porter, J. P . Onnela, and P . J. Muc ha. Comm unities in netw orks. Notic es of the Americ an Mathematic al So ciety , 56(9):1082–10 97, 2009. [33] M. Rosv all and C. T. Bergstrom. An information-theoretic framew ork for resolving comm unity structu re in complex netw orks. Pr o c. Natl. A c ad. Sci . , 104(18):7327 , 2007. [34] N . Roy and A. McCallum. T ow ard optimal active learning through sampling estimation of error reduction. In Pr o c. 18th I ntl. Conf. on Machine L e arning , pages 441–448, 2001. [35] P . Sen, G. M. N amata, M. Bilgic, L. Getoor, B. Gallagher, and T. Eliassi-Rad. Collective classification in netw ork data. AI Magazine , 29(3):93–1 06, 2008. [36] W. T ong and R. Jin. Semi-sup ervised learning by mixed lab el propagation. I n Pr o c. 22nd Intl. Conf. on Ar tificial intel ligenc e , vo lume 1, pages 651–656, 2007. [37] J. ˇ Copi ˇ c, M. O. Jac kson, and A. Kirman. Identifying comm unity structu res from netw ork data. B.E. Pr ess Journal of The or etic al Ec onomics , 9(1):Article 30, 2009. [38] Y . J. W ang and G. Y. W ong. Sto chastic blo ckmo dels for directed graphs. J. A meric an Statistic al Assn. , 82(397):8– 19, 1987. [39] R . J. Williams, A. Anandanadesan, and D. Purves. The probabilistic n iche mod el reveals the niche structure and role of b o dy size in a complex foo d web. PL oS One , 5(8):e1209, 2010. [40] W. W. Zachary . An information flow mo del for conflict and fission in small groups. J. Ant hr op olo gic al R ese ar ch , 33(4):452–473, 1977. [41] X . Zhu, J. Lafferty , and Z. Gh ahramani. Combining active learning and semi-sup ervised learning using gaussian fields and harmonic functions. In Pr o c. ICML-2003 Workshop on the Continuum fr om L ab ele d to Unlab ele d Data , 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment