Beta processes, stick-breaking, and power laws
The beta-Bernoulli process provides a Bayesian nonparametric prior for models involving collections of binary-valued features. A draw from the beta process yields an infinite collection of probabilities in the unit interval, and a draw from the Berno…
Authors: Tamara Broderick, Michael I. Jordan, Jim Pitman
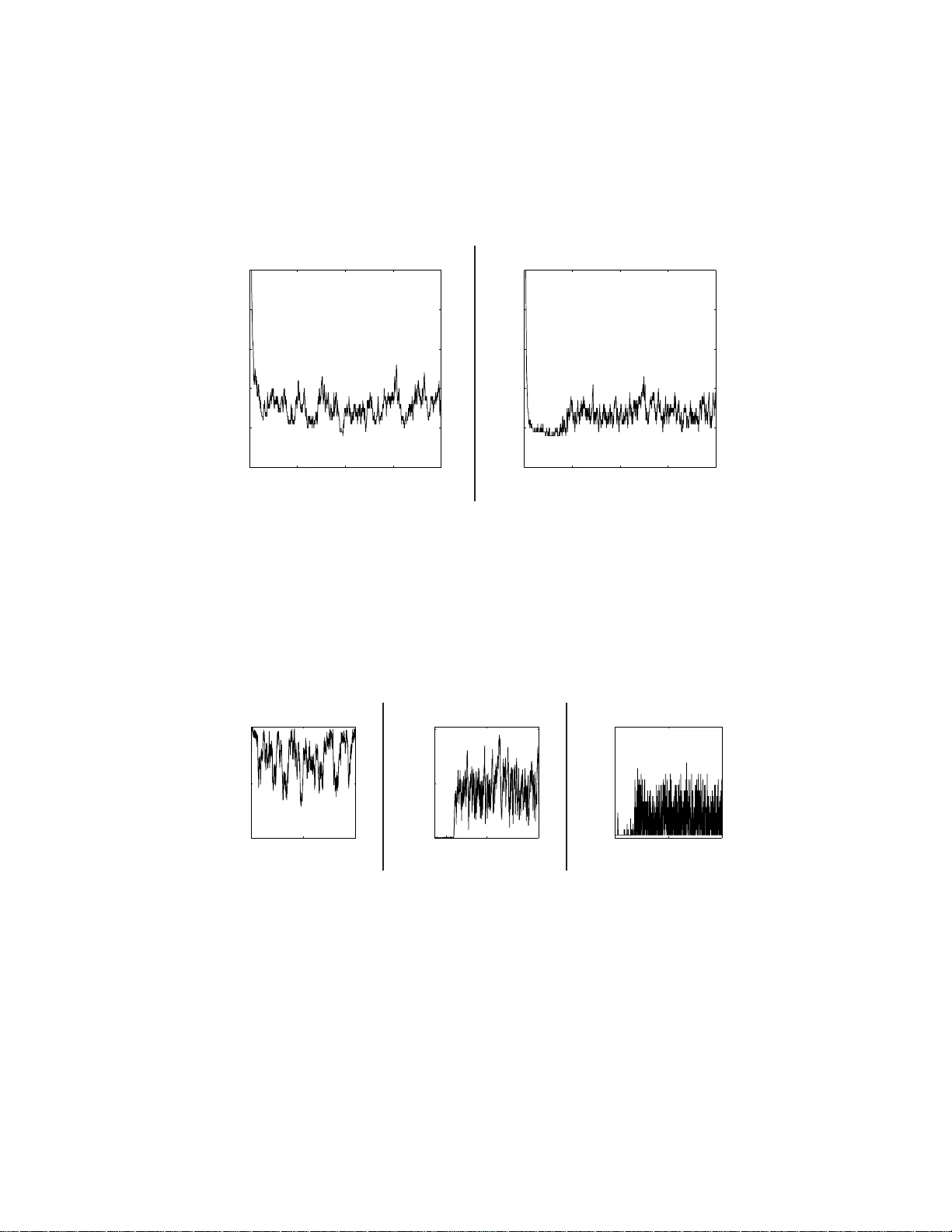
Beta pro cesses, stic k-breaking, and p o w er la ws T amara Bro deric k ∗ , Mic hael I. Jordan, Jim Pitman Abstract The b eta-Ber noulli pro cess pro vid es a Bay esian nonparametric prior for models inv olving collectio ns of binary-v alued features. A dra w from the b eta process yields an infin ite collec tion of probabilities in the unit interv al , and a draw fro m the Bernoulli pro cess turns th ese in to binary - v alued features. Recent w ork has provided stic k- breaking representations for the b eta pro cess analogous to th e w ell-known stick-breaking repre- senta tion for the Dirichlet pro cess. W e derive one such stick-breaking representa tion directly from th e characterization of the b eta pro cess as a completely rand om measure. This approach motiv ates a three-p arameter generalization of the b eta pro cess, and we study the p ow er law s that can b e obtained from this generalized b eta process. W e p resent a p osterior inference algorithm for the b eta-Bernoulli process that exploits the stic k- breaking representa tion, a nd we presen t exp erimental results for a discrete factor-analysis model. 1 In tro duc tion Large da ta sets ar e often heterog eneous, arising as ama lgams from underlying sub-p opulations. The a nalysis of larg e data se ts thus often inv olves some form of str a tification in which groupings a re identifi ed that a re mor e homo geneous than the orig inal da ta. While this can s ometimes b e done on the bas is of explicit cov ariates, it is also commonly the case that t he groupings are captured via discrete latent v ariables that are to be inferred as part of the analysis. Within a Bayesian fra mework, there are tw o widely employed mode ling motifs for problems o f this kind. The first is the Dirichlet-multinomial motif , which is based on the a ssumption tha t ther e are K “clus ters” that are ass umed to b e m utually exclusive and exhaustive, such that a llo cations of data to c lus ters ca n be mo deled via a m ultinomial r andom v aria ble w ho se parameter vector is drawn from a Dirichlet distribution. A second motif is the b eta-Bernoul li m otif , wher e a collec tion of K binary “ features” ar e used to descr ib e the data, and where each feature is mo dele d as a Be r noulli random v aria ble w ho se par ameter is o bta ined from a b eta dis tibution. The latter mo tif ca n be co nv erted to the former in principle—we can vie w particular pa tterns o f o nes a nd zer o s a s defining a cluster, th us obtaining M = 2 K clusters in total. But in practice mo dels based on ∗ Corresp onding author: tab@stat.berk eley.edu 1 the Dirichlet-m ultinomial mo tif typically require O ( M ) additional par ameters in the likelihoo d, whereas thos e ba sed on the b eta-B ernoulli motif typically require o nly O ( K ) additional parameters . Thus, if the combinatorial s tr ucture enco ded by the binary features captures real structure in the data, then the beta -Bernoulli motif can ma ke more efficient usag e o f its parameter s. The Dirichlet-mult inomia l motif can b e e xtended to a sto chastic pro cess known as the Dirichlet pr o c ess . A draw fr om a Dirichlet pro cess is a ran- dom probability measur e that ca n b e repr esented as follows [McCloskey, 196 5, Patil a nd T aillie , 1977, F erguso n, 1973, Sethuraman, 1994]: G = ∞ X i =1 π i δ ψ i , (1) where δ ψ i represents an a tomic measure at lo c a tion ψ i , wher e b oth the { π i } and the { ψ i } are ra ndom, and where the { π i } ar e nonneg a tive and sum to one (with probability one). Conditioning o n G and drawing N v alues indep endently from G yields a co lle c tion of K distinct v alues, where K ≤ N is random a nd gr ows (in exp ectation) a t rate O (log N ). T reating these dis tinct v alues as indices o f clusters, we obtain a model in which the num be r of clusters is random and sub ject to p osterior infere nc e . A great deal is known ab out the Dir ichlet pro ces s —there ar e direct connec- tions b etw een pro p e rties of G as a r a ndom measure (e.g., it can b e obtained from a Poisson po int pro ces s), prop erties of the sequence of v alues { π i } (they can b e obtained from a “s tick-breaking pr o cess”), and prop er ties o f the collec- tion of distinct v alues obta ined by s a mpling from G (they are characterized b y a sto chastic pr o cess known as the Chinese r estaura nt pr o c ess ). T he s e connectio ns hav e help ed to place the Dirichlet pro cess a t the center of Bay esian nonparamet- rics, driving the dev elo pment of a wide v ariety of inference algorithms for models based on Dirichlet pro cess priors and suggesting a ra nge of gener alizations [e.g . MacEachern, 1999, Ishw ara n and James, 20 01, W alker, 2 007, K alli et al., 20 09]. It is a lso p ossible to e x tend the beta -Bernoulli motif to a Bay esia n nonpar a- metric fra mework, and there is a gr owing litera ture on this topic. The underlying sto chastic pr o cess is the b eta pr o c ess , which is an instance o f a family o f rando m measures k nown a s c ompletely r andom me asur es [K ingman, 1967]. The b eta pro - cess was fir s t studied in the co ntext of surviv al analysis by Hjor t [1990], where the fo cus is o n mo deling haza rd functions via the r andom cumulativ e distri- bution function obtained by int egr ating the b eta pro ces s. Thibaux and Jor dan [2007] fo cused instead on the beta pro cess r ealization itse lf, which can b e rep- resented a s G = ∞ X i =1 q i δ ψ i , where b oth the q i and the ψ i are r andom a nd where the q i are contained in the int erv al (0 , 1). This ra ndom measure ca n be viewed as furnishing an infinite col- lection of coins, which, when tossed rep ea tedly , yield a binary featural des crip- tion of a set of entities in which the num b er of fea tur es with non-zer o v alues is 2 random. Thus, the res ulting b eta-Bernoul li pr o c ess ca n be viewed a s an infinite- dimensional version of the b eta-Ber no ulli motif. Indeed, Thiba ux and Jorda n [2007] show ed tha t b y integrating o ut the random q i and ψ i one obtains—by analogy to the deriv a tion of the Chines e restaurant pro ces s fro m the Dirichlet pro cess—a combinatorial s to chastic pro cess k nown as the Indian buffet pr o c ess , previously studied by Griffiths and Ghahra mani [20 0 6], who der ived it via a limiting pro c e s s inv olving random bina ry matrices obtained by sampling finite collections of be ta -Bernoulli v aria bles. Stic k- br eaking represe ntations o f the Dirichlet pro cess have b een par ticu- larly impor tant b oth for a lgorithmic developmen t and for exploring g eneral- izations of the Dirichlet pro ce s s. These representations yield explicit recursive formulas for obtaining the weigh ts { π i } in Eq. (1). In the case of the b eta pro cess, explicit non-recur sive represe ntations can be obtained for the weigh ts { q i } , based o n size- biased sampling [Thibaux and Jor dan, 20 0 7] and in verse L´ evy mea sure [W olp ert a nd Ickstadt, 2004, T eh e t al., 20 07]. Recent work has also yielded rec ur sive constr uctions that are mo re closely related to the stick- breaking re presentation of the Dirichlet pro cess [T eh et al., 20 07, Paisley et al., 2010]. Stic k- br eaking represe ntations of the Dirichlet pro cess per mit r eady gener a l- izations to stochastic pro cesses that yield p ow er- law b ehavior (whic h the Dirich- let pro cess do es no t), notably the P itman-Y o r pro cess [Ishw aran and J ames, 2001, Pitman, 2006]. Po wer-law g eneralizatio ns o f the b eta pro cess hav e als o bee n studied [T eh a nd G¨ or¨ ur, 2009] and stick-breaking- like representations de- rived. These latter r e presentations are, howev er, based on the non-recur sive sized-biased s ampling and inv erse-L´ ev y metho ds rather than the recurs ive rep- resentations of T eh et a l. [2007] a nd Paisley et al. [2010]. T eh et a l. [2007] and Paisley et al. [20 10] der ived their stick-breaking repre- sentations of the beta pro cess as limiting pro cesses, making use of the deriv a- tion of the Indian buffet pro cess by Griffiths and Ghahra mani [2 006] as a limit of finite-dimensional r andom ma trices. In the curr ent paper we show how to derive stick-breaking for the b eta pr o cess dir e ctly fro m the underlying r a ndom measure. This appr oach no t only has the a dv antage o f conceptual clarity (our deriv a tion is elementary), but it als o p ermits a unified p ersp ective on v arious generaliza tions of the b e ta pro cess that yield p ow er-law be havior. 1 W e show in particular that it yields a p ower-la w genera lization of the stick-breaking repre- sentation o f Paisley et al. [20 10]. T o illustra te o ur results in the context of a concrete a pplication, we study a discrete factor analy sis mo del previo usly consider ed by Griffiths and Ghahramani [2006] and Paisley et al. [20 1 0]. The mo del is of the for m X = Z Φ + E , (2) where X ∈ R N × P is the data and E ∈ R N × P is an error matrix. The matrix Φ ∈ R K × P is a matrix of factors, and Z ∈ R N × K is a binar y matrix of factor 1 A similar measure-theoretic deriv ation has b een pr esented recen tly by Paisley et al. [2011] , who fo cus on applications to truncations of the b eta pro cess. 3 loadings. The dimens ion K is infinite, and thu s the rows of Φ co mpr ise an infinite collectio n of factors . The matrix Z is obtained v ia a draw from a b eta- Bernoulli pro ces s; its n th row is an infinite binary vector of featur es (i.e., fa ctor loadings) enco ding which of the infinite c o llection of factors are used in mo deling the n th data p oint. The rema inder o f the paper is orga niz e d as fo llows. W e in tro duce the be ta pro cess, and its conjugate measure the Bernoulli pro cess, in Sectio n 2. In order to consider stick-breaking a nd p ow er law b ehavior in the b eta-Be r noulli frame- work, w e fir st review stick-breaking for the Dirichlet pro cess in Section 3 and power laws in clustering mo dels in Sec tio n 4 .1. W e consider p otential power laws that might exist in featural mo dels in Section 4 .2. Our main theoretical res ults come in the following tw o sections . First, in Section 5 , we provide a pro of that the stick-breaking repres e nt atio n of Paisley et al. [20 10], ex panded to include a third para meter, holds for a thr ee-parameter extensio n of the b eta pro cess . Our pro of takes a measure- theoretic a pproach based o n a Poisson pr o cess. W e then make use of the Poisson pro cess fra mework to establish asymptotic power laws, with ex act co nstants, for the thre e-parameter b eta pro ces s in Section 6.1. W e also show, in Section 6.2, that there a re asp ects of the b e ta-Bernoulli framework that cannot exhibit a p ow er law. W e illustrate the a symptotic p ow er laws o n a simulated da ta set in Section 7. W e pre s ent exp er imental results in Section 8, and we pr esent an MCMC algo rithm for p o s terior inference in App endix A. 2 The b eta pro cess and the Bernoulli pro cess The b eta pro cess and the Bernoulli pr o cess are instances o f the gener al family of random mea sures known as c ompletely r andom me asur es [K ingman, 196 7]. A completely random measure H on a probability space (Ψ , S ) is a ra ndom measure such that, for a ny disjoin t measura ble sets A 1 , . . . , A n ∈ S , the ra ndom v ar iables H ( A 1 ) , . . . , H ( A n ) ar e indep endent. Completely rando m measur es ca n b e obtained from an underlying Poisson po int pro ce s s. Let ν ( dψ , du ) denote a σ - finite measur e 2 on the pr o duct space Ψ × R . Draw a rea lization fr om a Poisson p o int pro cess with rate measure ν ( dψ , du ). This yields a s et of p oints Π = { ( ψ i , U i ) } i , where the index i may range ov er a co untable infinit y . Finally , co ns truct a rando m mea sure as follows: B = ∞ X i =1 U i δ ψ i , (3) where δ ψ i denotes an a tom at ψ i . This discrete r andom measure is such that for any measurable set T ∈ S , B ( T ) = X i : ψ i ∈ T U i . 2 The measure ν need not necessarily b e σ -finite to generate a completely random measure though we consider only σ - finite measures in this work. 4 Figure 1: The gr ay surface illustra tes the rate density in Eq. (4) co rresp onding to the beta pro ce s s. The base measure B 0 is tak en to b e uniform on Ψ. The non- zero endp oints o f the line s egments plotted be low the surfac e ar e a particular realization o f the Poisson pr o cess, a nd the line s egments themselves represent a realization of the b eta pro cess. That B is co mpletely ra ndom follows from the Poisso n p oint pro cess construc- tion. In addition to the repr esentation obtained from a Poisson pro cess, completely random meas ures may include a deterministic measure and a set of atoms at fixed lo cations. The comp onent of the co mpletely random measure genera ted from a Poisson p oint pro ces s as describ ed a bove is called the or dinary c omp o- nent . As shown by King man [1967], completely random measures are essentially characterized by this repr esentation. An example is s hown in Figure 1 . The b eta pr o c ess , deno ted B ∼ BP( θ , B 0 ), is an example of a completely random measure. As long as the b ase me asur e B 0 is contin uo us, which is our assumption here , B has o nly an or dinary comp onent with r a te measure ν BP ( dψ , du ) = θ ( ψ ) u − 1 (1 − u ) θ ( ψ ) − 1 du B 0 ( dψ ) , ψ ∈ Ψ , u ∈ [0 , 1] , (4) where θ is a p os itive function on Ψ. The function θ is called the c onc entr ation function [Hjort, 1 990]. In the rema inder we follow Thibaux and Jor dan [2 0 07] in taking θ to b e a real-v alued consta nt a nd refer to it as the c onc entr ation p ar ameter . W e assume B 0 is nonnega tive and fixe d. The total mas s of B 0 , γ := B 0 (Ψ), is called the mass p ar ameter . W e as sume γ is strictly p ositive and finite. The density in Eq. (4), with the choice of B 0 uniform ov er [0 , 1], is illustrated in Figure 1. The b eta pro ces s ca n b e viewed as providing a n infinite collection of coin- tossing pro babilities. T os sing these coins corr esp onds to a draw from the Bernoul li pr o c ess , yielding an infinite binary vector tha t we will treat a s a latent feature vector. More formally , a Bernoul li pr o c ess Y ∼ B eP ( B ) is a completely r andom measure with p otentially bo th fixed a tomic and or dinary comp onents. In defin- 5 0 0.5 1 Ψ 0 10 20 30 40 50 Ψ Figure 2: Upp er left : A draw B fro m the b eta pr o cess. L ower left : 50 dr aws from the B ernoulli pr o cess B eP ( B ). The vertical axis indexes the draw num b er among the 5 0 exchangeable draws. A p oint indicates a one at the corr e s p o nding lo cation on the ho rizontal axis, ψ ∈ Ψ. Right : W e can form a matrix fro m the low er left plot by including only thos e ψ v a lues with a non- zero num b er of Bernoulli successes among the 50 dr aws from the Bernoulli pro ce s s. The n, the nu mber of co lumns K is the num ber of such ψ , a nd the num b er o f rows N is the num be r of draws made. A black square indicates a one at the co rresp onding matrix p osition; a white square indicates a ze r o. 6 ing the Berno ulli pr o cess we conside r only the case in which B is discrete, i.e., o f the form in E q. (3), though not nec e ssarily a b eta pr o cess draw or even random for the moment. Then Y has o nly a fixed atomic co mpo nent and has the form Y = ∞ X i =1 b i δ ψ i , (5) where b i ∼ Bern( u i ) for u i the cor resp onding atomic ma ss in the meas ure B . W e can see that E ( Y | B ) = B (Ψ) from the mean of the Be rnoulli dis tribution, so the num b er of no n-zero p oints in an y realizatio n of the Bernoulli pro c e s s is finite when B is a finite measur e. W e can link the b eta pro ces s and N Bernoulli pro cess draws to gener ate a rando m feature matrix Z . T o that end, first draw B ∼ BP( θ , B 0 ) for fixed hyperpara meters θ and B 0 and then draw Y n iid ∼ BeP( B ) for n ∈ { 1 , . . . , N } . Note that since B is discrete, ea ch Y n will b e discr ete as in E q. (5), with po int masses only a t the atoms { ψ i } of the b eta pr o cess B . Note also that E B (Ψ) = γ < ∞ , so B is a finite measure, and it follows that the num b er of no n-zero po int masses in any draw Y n from the Bernoulli pro c e s s will b e finite. Therefor e, the to tal num b er of non-zero point mas ses K acr oss N such Bernoulli pro cess draws is finite. Now reor der the { ψ i } so that the first K are exactly those lo ca tions where some Berno ulli pro ce s s in { Y n } N n =1 has a non-zero p oint mass. W e can form a matrix Z ∈ { 0 , 1 } N × K as a function of the { Y n } N n =1 by letting the ( n, k ) en try equal o ne when Y n has a non- zero p oint mass at ψ k and zero otherwis e. If we wish to think of Z as having an infinite num ber of columns, the remaining columns re pr esent the po int ma sses of the { Y n } N n =1 at { ψ k } k>K , which we know to b e zer o by constructio n. W e r efer to the overall pro c edure of drawing Z a c- cording to, first, a beta pro cess and then rep eated Ber noulli pro cess draws in this wa y as a b eta-Bernoul li pr o c ess , and we write Z ∼ BP- BeP( N , γ , θ ). Note that we hav e implicitly int eg r ated out the { ψ k } , and the distribution of the matrix Z depe nds on B 0 only thro ugh its to tal mass , γ . As shown by Thibaux and Jorda n [2007], this pro cess yields the sa me distribution on row-exch ang eable, infinite- column matrices as the India n buffet pr o cess [Griffiths a nd Ghahr amani, 2006], which des crib es a sto chastic pro ce ss directly o n (equiv alence cla s ses of ) binary matrices. That is, the Indian buffet pr o cess is obtained as an exchangeable distribution o n binar y matrices when the underlying b eta pro cess measure is int egr ated out. This r e s ult is analo g ous to the deriv ation of the Chinese restau- rant pro ce s s a s the exchangeable distribution on partitions obtained when the underlying Dirichlet pro cess is integrated o ut. T he b eta-Berno ulli pro cess is illustrated in Figure 2. 3 Stic k- breaking for the Diric hlet pro cess The stick-breaking r epresentation of the Dirichlet pro ce ss [McCloskey, 19 65, Patil a nd T aillie , 197 7, Sethuraman, 1994] provides a simple r ecursive pr o cedure 7 1 − V 1 0 1 V 1 V 2 (1 − V 1 ) Figure 3 : A stick-breaking pro ces s starts with the unit interv al ( far left ). First, a r andom fraction V 1 of the unit int er v al is broken off; the r emaining stick has length 1 − V 1 ( midd le left ). Next, a random fra ction V 2 of the remaining stick is br o ken off, i.e., a fragment of size V 2 (1 − V 1 ); the remaining stick has length (1 − V 1 )(1 − V 2 ). This pro ce ss pro ceeds recursively and generates stick fragments V 1 , V 2 (1 − V 1 ) , . . . , V i Q j 0) . (8) That is, K N ,j is the num b er of clusters that are drawn exa c tly j times, and K N is the to tal num b er o f clusters. There are tw o types of p ow er- law b ehavior that a clustering mo del might exhibit. First, there is the type of p ower law b ehavior r eminiscent of Heaps’ law [Heaps, 1978, Gnedin et a l., 2007]: K N a.s. ∼ cN a , N → ∞ (9) for some constants c > 0 , a ∈ (0 , 1 ). Her e, ∼ means that the limit of the ratio of the left-hand a nd rig ht -ha nd s ide, when they a re b oth real-v alued and non- random, is one as the num b er of data p oints N g rows large. W e denote a p ow er 9 law in the form of Eq . (9) as T yp e I . Seco nd, ther e is the type of p ow er law behavior reminisce nt of Zipf ’s law [Zipf, 1 949, Gnedin et al., 2007]: K N ,j a.s. ∼ a Γ( j − a ) j !Γ(1 − a ) cN a N → ∞ (10) again for so me constants c > 0 , a ∈ (0 , 1). W e r efer to the power law in Eq. (1 0 ) as T yp e II . Sometimes in the case of Eq. (10), we a re interested in the b ehavior in j ; therefore we recall j ! = Γ( j + 1) and note the following fact ab out the Γ-function ratio in E q. (10) [c f. T ricomi and Erd´ elyi, 19 51]: Γ( j − a ) Γ( j + 1) ∼ j − 1 − a j → ∞ (11) Again, we s ee b ehavior in the form o f a p ow er law at work. Po wer-law behavior of Types I a nd I I [and equiv alent formulations; see Gnedin et al., 2007] has be e n observed in a v a r iety of real-world clustering prob- lems including, but no t limited to: the n umber of sp ecies p er plant genus, the in-degree or out-degre e of a graph constructed fro m hyper links o n the Inter- net, the num be r of p eople in cities, the num b er of words in do cuments, the nu mber of pa pe rs published by scientists, a nd the amount each p erson ear ns in income [Mitzenmacher, 2004, Goldwater et al., 2 006]. Bay esia ns mo deling these situations will prefer a prior that reflects this distributiona l attribute. While the Dirichlet pro ce s s e x hibits neither type of p ow er- law b ehavior, the Pitman-Y or pr o c ess yields b oth kinds o f p ower law [Pitman a nd Y or, 1997, Goldwater et al., 200 6] though we note that in this cas e c is a ra ndom v a riable (still with no dep endence on N or j ). The Pitman-Y or pro cess, denoted G ∼ PY( θ , α, G 0 ), is defined via the following stick-breaking r epresentation: G = ∞ X i =1 V i i − 1 Y j =1 (1 − V j ) δ ψ i V i indep ∼ Beta(1 − α, θ + iα ) ψ i iid ∼ G 0 , (12) where α is known as a disc oun t p ar ameter . The case α = 0 returns the Dirichlet pro cess (cf. E q. (6)). Note tha t in b oth the Dirichlet pro cess and Pitman-Y or pro ces s, the weigh ts { V i Q i − 1 j =1 (1 − V j ) } ar e the w eig hts of the pro cess in siz e -biased or der [Pitman, 2006]. In the Pitman-Y or case , the { V i } are no longer identically distributed. 4.2 P ow er la ws in featural mo dels The b eta-Ber noulli pro c e ss provides a sp ecific kind of feature-ba sed representa- tion of ent ities. In this section we study gener al fea tural mo de ls and consider the p ow er laws that mig ht arise for such mo dels. 10 In the cluster ing fra mework, we cons ide r ed N dr aws fr o m a pro cess that put exactly one mass of size o ne on some v a lue in Ψ and mass zer o elsewhere. In the featura l framework we consider N draws from a pro ces s that places some non-negative integer num ber of masses , each of size one, on an almost sur ely finite set of v alues in Ψ and mass zero elsewher e. As N i was the sum of masses at a po int lab eled ψ i ∈ Ψ in the cluster ing framework, so do we now let N i be the s um of masses a t a po int lab eled ψ i ∈ Ψ. W e use the same nota tion as in Section 4.1, but now we note that the co un ts N i no long e r sum to N in gener al. In the case of fea tur al mo dels, w e can still talk ab out Type I and I I power laws, b oth of which have the sa me interpretation as in the c a se of clustering mo dels. In the fea tural ca se, how ever, it is also p oss ible to consider a third type of p ow er law. If we let k n denote the num b er of features pres ent in the n th draw, we say that k n shows p ow er law b ehavior if P ( k n > M ) ∼ cM − a for p ositive constants c and a . W e call this las t type o f power law T yp e III . 5 Stic k- breaking for the b eta pro c ess The weights { q i } for the be ta pro cess can b e derived by a v ariety of pro cedure s , including size-biased sampling [Thibaux and Jordan, 200 7] and in verse L ´ evy measure [W olp ert a nd Ickstadt, 2004, T eh et al., 20 07]. The pro cedures that are closest in spirit to the stick-breaking representation for the Dirichlet pro cess ar e those due to Paisley et a l. [2 010] a nd T eh et al. [2007]. Our p oint of departure is the fo r mer, which has the following for m: B = ∞ X i =1 C i X j =1 V ( i ) i,j i − 1 Y l =1 (1 − V ( l ) i,j ) δ ψ i,j C i iid ∼ Pois( γ ) V ( l ) i,j iid ∼ Beta(1 , θ ) ψ i,j iid ∼ 1 γ B 0 . (13) This repr esentation is analog ous to the stick-breaking repres entation of the Dirichlet pro cess in that it represents a draw from the be ta pr o cess as a sum ov er indep endently drawn atoms, with the weigh ts obtained by a re c ursive pro- cedure. Howev er, it is worth noting that for every ( i, j ) tuple s ubscript for V ( l ) i,j , a different stick exis ts and is bro ken across the sup erscr ipt l . Th us, there ar e no sp ecial additive prop er ties a c ross weigh ts in the s um in Eq. (13); by contrast, the weigh ts in Eq. (12) sum to one a lmost surely . The generaliza tion of the one-par ameter Dirichlet pro ces s to the tw o-pa rameter Pitman-Y or pro cess s ug gests that we might co nsider g eneralizing the stick- 11 breaking repr esentation of the b eta pr o cess in E q. (1 3) as fo llows: B = ∞ X i =1 C i X j =1 V ( i ) i,j i − 1 Y l =1 (1 − V ( l ) i,j ) δ ψ i,j C i iid ∼ Pois ( γ ) V ( l ) i,j indep ∼ Beta(1 − α, θ + i α ) ψ i,j iid ∼ 1 γ B 0 . (14) In Section 6 we w ill show that introducing the additional parameter α indeed yields Type I and I I p ower law b ehavior (but not Type I I I). In the remainder of this se c tio n we pr esent a pr o of that these stick-breaking representations arise fro m the b eta pr o cess. In co nt ra distinction to the pro of of Eq. (1 3) by Paisley et al. [2010], which used a limiting pro cess defined o n sequences of finite binary ma trices, our approach makes a dire c t c o nnection to the Poisson pr o cess characterization of the b eta pro cess. O ur pro o f has several virtues: (1) it r elies on no asymptotic arg ument s and instead comes entirely fro m the Poisson pro cess representation; (2) it is, as a r esult, simpler and sho rter; and (3 ) it demo nstrates clearly the ease of inco rp orating a third para meter analogo us to the discount parameter of the Pitma n- Y or pro cess and thereby provides a strong motiv ation for the e x tended stic k-br eaking represe n tatio n in Eq. (14). Aiming tow ard the g eneral stick-breaking re presentation in Eq. (1 4), we beg in by de fining a three-pa rameter ge ne r alization of the b e ta pro cess. 3 W e say that B ∼ BP( θ, α, B 0 ), where we call α a disc ount p ar ameter , if, for ψ ∈ Ψ , u ∈ [0 , 1]), we hav e ν BP ( dψ , du ) = Γ(1 + θ ) Γ(1 − α )Γ( θ + α ) u − 1 − α (1 − u ) θ + α − 1 du B 0 ( dψ ) . (15) It is straightforward to show that this three - parameter density has s imila r prop erties to that of the tw o-par ameter b eta pro cess . F or instance, choosing α ∈ (0 , 1) and θ > − α is nec e ssary for the b eta pro cess to have finite total mass almost sure ly; in this case, Z Ψ × R + u ν BP ( dψ , du ) = Γ(1 − α )Γ( θ + α ) Γ(1 + θ ) < ∞ . (16) W e now turn to the main result of this s ection. Prop ositi on 1. B c an b e r epr esente d ac c or ding to the pr o c ess describ e d in Eq. (14) if and only if B ∼ BP ( θ , α, B 0 ) . 3 See also T eh and G¨ or ¨ ur [2009] or Kim and Lee [ 2001] , wi th θ ( t ) ≡ 1 − α, β ( t ) ≡ θ + α , where the left-hand s ides are in the notation of Kim and Lee [2001]. 12 Pr o of. Firs t note tha t the po ints in the set P 1 := n ( ψ 1 , 1 , V (1) 1 , 1 ) , ( ψ 1 , 2 , V (1) 1 , 2 ) , . . . , ( ψ 1 ,C 1 , V (1) 1 ,C 1 ) o are by construction indep endent and identically distributed conditioned o n C 1 . Since C 1 is Poisson-distr ibuted, P 1 is a Poisson p oint pr o cess. The same logic gives that in gene r al, for P i := ( ψ i, 1 , V ( i ) i, 1 i − 1 Y l =1 (1 − V ( l ) i, 1 ) ! , . . . , ψ i,C i , V ( i ) i,C i i − 1 Y l =1 (1 − V ( l ) i,C i ) !) , P i is a Poisson po int pro cess. Next, define P := ∞ [ i =1 P i As the co unt able unio n of Poisson pro cesses with finite rate mea sures, P is itself a Poisson p oint pro ces s. Notice that we can write B as the completely r andom measur e B = P ( ψ ,U ) ∈ P U δ ψ . Also, for any B ′ ∼ BP( θ , d, B 0 ), we ca n wr ite B ′ = P ( ψ ′ ,U ′ ) ∈ Π U ′ δ ψ ′ , where Π is Poisson p o int pro cess with r ate measure ν BP = B 0 × µ BP , and µ BP is a σ -finite measure with dens it y Γ(1 + θ ) Γ(1 − α )Γ( θ + α ) u − 1 − α (1 − u ) θ + α − 1 du. (17) Therefore, to show that B has the same distribution as B ′ , it is enough to show that P and Π hav e the same rate measur es. T o that end, let ν denote the r ate measur e of P : ν ( A × ˜ A ) = E # { ( ψ i , U i ) ∈ A × ˜ A ) } = 1 γ B 0 ( A ) · E ∞ X i =1 C i X j =1 1 { V ( i ) ij i − 1 Y l =1 (1 − V ( l ) ij ) ∈ ˜ A } = 1 γ B 0 ( A ) · ∞ X i =1 E C i X j =1 1 { V ( i ) ij i − 1 Y l =1 (1 − V ( l ) ij ) ∈ ˜ A } , (18) where the last line follows b y mo notone convergence. Ea ch term in the outer sum can be further decomp osed as E C i X j =1 1 { V ( i ) ij i − 1 Y l =1 (1 − V ( l ) ij ) ∈ ˜ A } = E E C i X j =1 1 { V ( i ) ij i − 1 Y l =1 (1 − V ( l ) ij ) ∈ ˜ A } C i = E [ C i ] E " 1 { V ( i ) i 1 i − 1 Y l =1 (1 − V ( l ) i 1 ) ∈ ˜ A } # 13 since the V ( l ) ij are iid acro ss j and indep endent of C i = γ E 1 { V i i − 1 Y l =1 (1 − V l ) ∈ ˜ A } (19) for V i indep ∼ Beta(1 − α, θ + iα ) , where the last equality follows s ince the choice of { V i } gives V i Q i − 1 l =1 (1 − V l ) d = V ( i ) i 1 Q i − 1 l =1 (1 − V ( l ) i 1 ). Substituting E q. (19) back into Eq . (18), canceling γ factor s , and a pplying monotone co nvergence again yields ν ( A × ˜ A ) = B 0 ( A ) · E ∞ X i =1 1 { V i i − 1 Y l =1 (1 − V l ) ∈ ˜ A } . W e note that b oth of the measures ν and ν BP factorize: ν ( A × ˜ A ) = B 0 ( A ) · E ∞ X i =1 1 { V ′ i i − 1 Y l =1 (1 − V ′ l ) ∈ ˜ A } ν B P ( A × ˜ A ) = B 0 ( A ) µ BP ( ˜ A ) , so it is enough to show tha t µ = µ BP for the measure µ defined by µ ( ˜ A ) := E ∞ X i =1 1 { V i i − 1 Y l =1 (1 − V l ) ∈ ˜ A } . (20) A t this po int a nd later in proving Prop os ition 3, we will make use of pa rt of Campb ell’s theorem, which we copy here from Kingman [1 993] for completeness . Theorem 2 (Part of Campb e ll’s Theorem) . L et Π b e a Poisson pr o c ess on S with r ate me asu re µ , and let f : S → R b e me asur able. If R S min( | f ( x ) | , 1) µ ( dx ) < ∞ , then E " X X ∈ Π f ( X ) # = Z S f ( x ) µ ( dx ) . (21) Now let ˜ U b e a size-biased pick fr om { V i Q i − 1 l =1 (1 − V l ) } ∞ i =1 . By construction, for any bo unded, meas urable function g , we hav e E h g ( ˜ U ) |{ V i } i = ∞ X i =1 V i i − 1 Y l =1 (1 − V l ) · g ( V i i − 1 Y l =1 (1 − V l )) . T ak ing exp e ctations yields E g ( ˜ U ) = E " ∞ X i =1 V i i − 1 Y l =1 (1 − V l ) g ( V i i − 1 Y l =1 (1 − V l )) # = Z ug ( u ) µ ( du ) , 14 where the final equa lity follows by Campb ell’s theorem with the choice f ( u ) = ug ( u ). Since this result holds for all b ounded, measurable g , we have that P ( ˜ U ∈ du ) = u µ ( du ) . (22) Finally , we note that, by Eq. (20), ˜ U is a size-bias e d sample from prob- abilities generated by stick-breaking with pr op ortions { Beta(1 − α, θ + i α ) } . Such a sample is then distributed Beta(1 − α, θ + α ) since, as mentioned ab ov e, the Pitman-Y or stick-breaking constr uc tio n gives the size-bia sed frequencies in order. So, rearr anging Eq. (22), we can wr ite µ ( du ) = u − 1 P ( ˜ U ∈ du ) = u − 1 Γ(1 + θ ) Γ(1 − α )Γ( θ + α ) u (1 − α ) − 1 (1 − u ) ( θ + α ) − 1 using the Beta(1 − α, θ + α ) density = µ BP ( du ) , as was to b e shown. 6 P o w er la w deriv ations By linking the three-parameter stick-breaking repr esentation to the p ow er- law beta pro c e ss in Eq. (15), we can use the results of the fo llowing sec tio n to conclude that the fea ture as signments in the thr ee-para meter mo del follow bo th Type I and Type II p ow er laws a nd that they do not follow a T yp e I I I power law (Sectio n 4 .2). W e note that T eh a nd G¨ or ¨ ur [2 0 09] found big- O b ehavior for Types I and I I in the three-par ameter Beta and a Poisson distribution fo r the Type I I I distribution. W e can strengthen these results to obtain e x act asymptotic b ehavior with constants in the first tw o cases a nd also conclude that Type I I I p ower laws can never hold in the featura l fra mework whenever the sum of the feature pro babilities is almost s urely finite, a n a s sumption that would app ear to b e a necess a ry comp onent o f any physically rea listic mo del. 6.1 T yp e I and I I p ow er la ws Our subsequent de r iv atio n expands up on the work of Gnedin et al. [200 7]. In that pap er , the main thr ust of the arg ument applies to the ca se in which the feature proba bilities are fixed rather than random. In what fo llows, we obtain power laws of Typ e I and I I in the case in which the featur e probabilities are ran- dom, in particular whe n the pr obabilities ar e g enerated from a Poisson pro cess. W e will see that this last assumption bec o mes conv enient in the cour se o f the pro of. Finally , we apply our r esults to the sp ecific example of the b eta- Bernoulli pro cess. Recall that we defined K N , the num b er o f repr esented clusters in the firs t N da ta p oints, and K N ,j , the num b er of clusters repre s ented j times in the fir st 15 N data p oints, in Eqs . (8) and (7), resp ectively . In Se c tion 4.2, w e no ted that same definitions in Eqs . (8) and (7) hold for featural mo dels if we now let N i denote the n umber of data points at time N in which feature i is repr esented. In ter ms o f the B ernoulli pr o cess, N i would b e the num b er of Bernoulli pro cess draws, out of N , where the i th atom has unit (i.e., nonzer o) weight. It nee d no t be the case that the N i sum to N . W or king directly to find power laws in K N and K N ,j as N increases is challenging in pa rt due to N b eing an integer. A standar d technique to surmount this difficulty is called Poissonization . In Poissonizing K N and K N ,j , we consider new functions K ( t ) and K j ( t ) wher e the argument t is contin uous, in co nt ra st to the integer argument N . W e will define K ( t ) and K j ( t ) such that K ( N ) and K j ( N ) hav e the same as ymptotic b ehavior a s K N and K N ,j , res p e c tively . In particular, our deriv ation of the asymptotic behavior o f K N and K N ,j will consist of three pa rts and will inv olve w or k ing extens ively with the mean feature counts Φ N := E [ K N ] and Φ N ,j := E [ K N ,j ] ( j > 1 ) with N ∈ { 1 , 2 , . . . } and the Poissonized mean fea tur e counts Φ( t ) := E [ K ( t )] and Φ j ( t ) := E [ K j ( t )] ( j > 1) . with t > 0 . First, we will take adv antage of Poissonization to find p ow er laws in Φ( t ) and Φ j ( t ) as t → ∞ (Prop o sition 3). Then, in order to r elate these results back to the o riginal pr o cess, we will show tha t Φ N and Φ( N ) have the same asymptotic b ehavior and also that Φ N ,j and Φ j ( N ) hav e the same asymptotic behavior (Lemma 5). Finally , to obtain r esults for the ra ndo m pro cess v alues K N and K N ,j , we will conclude by showing that K N almost surely has the same asymptotic b ehavior as Φ N and that P k 0 } . And we de fine K j ( t ) to b e the num be r of Poisson pr o cesses Π i with exactly j po ints in [0 , t ]: K j ( t ) := X i 1 {| Π i ∩ [0 , t ] | = j } . These definitions ar e very similar to the definitions of K N and K N ,j in Eqs. (8) and (7), resp ectively . The principal differe nce is that the K N are incremented only at in teger N whereas the K ( t ) can have jumps at a ny t ∈ R + . The same observ ation holds for the K N ,j and K j ( t ). In addition to Poissonizing K N and K N ,j to define K ( t ) and K j ( t ), we will also find it co nv enient to assume that the { q i } themselves are derived from a Poisson pro cess with r ate meas ure ν . W e note that Poissonizing fr om a discr ete index N to a contin uous time index t is an approximation and se parate from our a ssumption that the { q i } ar e gener ated fro m a Poisso n pr o cess though b oth are fundamentally tied to the eas e of working with Poisson pro ces s es. W e are now a ble to write out the mean feature counts in both the Poissonized 17 and origina l cases . First, the Poissonized definitions of Φ and K allow us to wr ite Φ( t ) := E [ K ( t )] = E [ E [ K ( t ) | q ]] = E [ E [ X i 1 {| Π i ∩ [0 , t ] | > 0 } | q ]] . With a simila r appro ach for Φ j ( t ), we find Φ( t ) = E [ X i (1 − e − tq i )] , Φ j ( t ) = E [ X i ( tq i ) j j ! e − tq i ] . With the assumption that the { q i } are drawn fro m a Poisson pro ces s with measure measure ν , we ca n a pply Campb ell’s theore m (Theo r em 2) to bo th the original and Poissoniz e d versions of the pro ces s to derive the final equality in each of the following lines Φ( t ) = E [ X i (1 − e − tq i )] = Z 1 0 (1 − e − tx ) ν ( dx ) (23) Φ N = E [ X i (1 − (1 − q i ) N )] = Z 1 0 (1 − (1 − x ) N ) ν ( dx ) (24) Φ j ( t ) = E [ X i ( tq i ) j j ! e − tq i ] = t j j ! Z 1 0 x j e − tx ν ( dx ) (25) Φ N ,j = N j E [ X i q j i (1 − q i ) N − j ] = N j Z 1 0 x j (1 − x ) N − j ν ( dx ) . (26) Now we establish our fir st result, which g ives a p ow er law in Φ( t ) and Φ j ( t ) when the Poisson pro ces s rate measure ν has co rresp onding p ower law prop er - ties. Prop ositi on 3. As ymptotic b ehavior of the inte gr al of ν of the fol lowing form ν 1 [0 , x ] := Z x 0 u ν ( du ) ∼ α 1 − α x 1 − α l (1 /x ) , x → 0 (27) wher e l is a r e gularly varying function and α ∈ (0 , 1) implies Φ( t ) ∼ Γ(1 − α ) t α l ( t ) , t → ∞ Φ j ( t ) ∼ α Γ( j − α ) j ! t α l ( t ) , t → ∞ ( j > 1 ) . Pr o of. The key to this res ult is in the re pea ted use of Ab elian or T aub er ian theorems. Let A b e a map A : F → G from o ne function space to ano ther: e.g., a n integral o r a Laplace trans form. F or f ∈ F , an Ab elian theorem gives us the as ymptotic behavior of A ( f ) from the a s ymptotic behavior of f , and a T aub er ian theorem gives us the as ymptotic b ehavior o f f fro m that o f A ( f ). First, integrating by pa rts yields ν 1 [0 , x ] = − x ¯ ν ( x ) + Z x 0 ¯ ν ( u ) du, ¯ ν ( x ) := Z ∞ x ν ( u ) du, 18 so the stated asymptotic be havior in ν 1 yields ¯ ν ( x ) ∼ l (1 / x ) x − α ( x → 0) by a T aub er ian theorem [F eller, 19 66, Gnedin et al., 2007] where the ma p A is an int egr al. Second, a nother integration by par ts yields Φ( t ) = t Z ∞ 0 e − tx ¯ ν ( x ) dx. The desired asymptotic b ehavior in Φ follows from the a symptotic b ehavior in ¯ ν and a n Abelian theorem [F eller, 1 966, Gnedin et al., 20 07] where the map A is a Lapla ce tra ns form. The r esult for Φ j ( t ) follows from a s imilar a rgument when we note that rep eated integration by par ts of Eq. (2 5) also yields a Laplace transform. The imp or tance of assuming that the q i are dis tributed a ccording to a Pois- son pro ces s is tha t this assumption allow ed us to write Φ as an integral and thereby make use o f c lassic Ab elian and T aub eria n theorems. The impor tance of Poissonizing the pro cesses K j and K N ,j is that we can write their means a s in Eqs. (23) and (25 ), which are—up to integration by parts—in the for m of Laplace transfor ms. Prop ositio n 3 is the mo st significant link in the chain of r esults needed to show asymptotic b ehavior of the feature counts K N and K N ,j in that it relates power laws in the known feature pr obability rate measure ν to p ow er laws in the mean b ehavior of the Poissonized version o f these pro cesses. It remains to show this mean b ehavior translates back to K N and K N ,j , firs t by r elating the means of the orig inal and Poissonized pro ce s ses and then b y relating the means to the almost s ure b ehavior of the counts. The next tw o lemmas a ddress the former concern. T oge ther they es tablish tha t the mea n feature counts Φ N and Φ N ,j hav e the s ame asymptotic behavior as the corresp onding Poissonized mean feature counts Φ( N ) and Φ j ( N ). Lemma 4. L et ν b e σ -finite with R ∞ 0 ν ( du ) = ∞ and R ∞ 0 u ν ( du ) < ∞ . Then the numb er of r epr esente d fe atu r es has unb ounde d gr owth almost sur ely. The exp e cte d numb er of r epr esente d fe ature s has u n b oun de d gr owth, and the exp e cte d numb er of fe atur es has su bline ar gr owth. That is, K ( t ) ↑ ∞ a.s ., Φ( t ) ↑ ∞ , Φ( t ) ≪ t. Pr o of. As in Gnedin et al. [2007], the first sta temen t follows fro m the fact that q is countably infinite a nd each q i is str ic tly p ositive. The s e cond statement follows from monotone c o nv ergence. The final s tatement is a conseq uence of P i q i < ∞ a .s. Lemma 5. Supp ose the { q i } ar e gener ate d ac c or ding to a Poisson pr o c ess with r ate m e asur e as in L emma 4. Then, for N → ∞ , | Φ N − Φ( N ) | < 2 N Φ 2 ( N ) → 0 19 | Φ N ,j − Φ j ( N ) | < c j N max { Φ j ( N ) , Φ j +2 ( N ) } → 0 . for some c onstants c j . Pr o of. The pro of is the same as that of Lemma 1 o f Gnedin et al. [2007]. E stab- lishing the ineq ualities results from algebra ic manipulations. The conv er g ence to zero is a co nsequence of Lemma 4. Finally , b efore consider ing the s pe cific case of the three- parameter b eta pro- cess, we wish to show that p ow er laws in the means Φ N and Φ N ,j extend to almost sure p ow er laws in the nu mber of repres ent ed fea tures. Prop ositi on 6. S upp ose t he { q i } ar e gener ate d fr om a Poisson pr o c ess with r ate m e asur e as in L emma 4. F or N → ∞ , K N a.s. ∼ Φ N , X k 0, X N P K N Φ N − 1 > ǫ < ∞ . T o that end, note P ( | K N − Φ N | > ǫ Φ N ) ≤ P (Φ N > ǫ Φ N + K N ) + P ( K N > ǫ Φ N + Φ N ) . The note after Theor e m 4 in F re edman [197 3] gives that P (Φ N > ǫ Φ N + K N ) ≤ exp − ǫ 2 Φ N P ( K N > ǫ Φ N + Φ N ) ≤ exp − ǫ 2 1 + ǫ Φ N . So P K N Φ N − 1 > ǫ ≤ 2 exp − 2 ǫ 2 Φ N ≤ c exp − 2 ǫ 2 N for so me co nstant c and sufficiently large N by Le mma s 4 and 5. The la st expression is s ummable in N , a nd Bo rel-Cantelli holds. The pro o f that P k 1) . Lemma 5 further yields Φ N a.s. ∼ Γ(1 − α ) C N α , N → ∞ Φ N ,j a.s. ∼ α Γ( j − α ) j ! C N α , N → ∞ ( j > 1) , and finally Prop o sition 6 implies K N a.s. ∼ Γ(1 − α ) C N α , N → ∞ (29) K N ,j a.s. ∼ d Γ( j − α ) j ! C N α , N → ∞ ( j > 1) . (30) These a re exa ctly the desired Typ e I and II pow er laws (E qs. (9) and (10)) for appropria te choices of the constants. 6.2 Exp onen tial deca y in the n um b er of features Next we cons ider a single data p oint and the num b er o f features which ar e expressed fo r that data p o int in the featural mo del. W e prov e results for the general case where the i th fea tur e has pro bability q i ≥ 0 such that P i q i < ∞ . Let Z i be a Berno ulli r andom v ar iable with succ e ss probability q i and such that all the Z i are independent. Then E [ P i Z i ] = P i q i =: Q . In this case, a Chernoff b o und [Chernoff, 1 952, Hager up and Rub , 19 9 0] tells us that, for any δ > 0, w e hav e P [ X i Z i ≥ (1 + δ ) Q ] ≤ e δQ (1 + δ ) − (1+ δ ) Q . 21 When M is lar ge enough suc h that M > Q , we c a n choo s e δ such that (1 + δ ) Q = M . Then this inequality b ecomes P [ X i Z i ≥ M ] ≤ e M − Q Q M M − M for M > Q. (31) W e see from Eq. (31) that the num b er of features P i Z i that ar e express ed for a data p oint exhibits sup er-exp onential tail decay and therefor e canno t hav e a p ow er law probability distribution when the sum of feature pr obabilities P i q i is finite. F or comparis o n, let Z ∼ Pois( Q ). Then [F ranceschetti et al., 2007] P [ Z ≥ M ] ≤ e M − Q Q M M − M for M > Q, the same tail b ound as in Eq. (31). T o apply the tail-b ehavior r e sult of Eq. (31) to the b eta pro cess (with tw o or three parameters ), we note that the total featur e pro bability mass is finite by Eq. (16). Since the same set of featur e pr obabilities is used in all subsequent Bernoulli pr o cess draws for the b eta-B ernoulli pro cess, the r e sult holds. 7 Sim u lation T o illustrate the three types of p ow er laws discuss ed ab ov e, we simulated b eta pro cess a tom weigh ts under three differ ent choices of the disco unt par a meter α , namely α = 0 (the class ic, t wo-parameter b eta pro cess), α = 0 . 3, and α = 0 . 6. In all three sim ulations , the remaining b eta pro c e s s pa rameters were kept constant at total mas s pa rameter v alue γ = 3 and concentration parameter v alue θ = 1 . The simulations were car ried out using our ex tension o f the Paisley et al. [2010] stick-breaking construction in Eq. (14). W e generated 2,00 0 ro unds of fea - ture probabilities; that is, we g enerated 2,000 rando m v aria bles C i and P 2 , 000 i =1 C i feature pr obabilities. With these pro babilities, we g e nerated N = 1 ,000 da ta po ints, i.e., 1,000 vectors of (2,000 ) indep endent Berno ulli r andom v ar iables with these pr obabilities. With these simulated data, we were able to pe r form an empirical ev alua tion of our theoretical results. Figure 5 illustrates p ower laws in the num b er o f represented features K N on the left (Type I p ow er law) a nd the n umber of fea tures r epresented by exa ctly one data p oint K N , 1 on the rig ht (Type I I p ow er law). Both o f these quantities are plotted as functions of the increa sing n umber of data p oints N . The blue po ints show the s imulated v a lue s for the c la ssic, tw o-para meter b eta pro cess case with α = 0. The center set of black p oints in each ca se cor r esp onds to α = 0 . 3, and the upp er set of black po ints in ea ch case corre s po nds to α = 0 . 6. W e also plot curves obtained from our theor e tical results in order to compare them to the simulation. Recall that in our theor etical developmen t, we no ted that there are tw o steps to es ta blishing the asymptotic b ehavior of K N and K N ,j as N increa ses. First, we compare the random q uantit ies K N and K N ,j to their resp ective means, Φ N and Φ N ,j . These means, a s computed via numerical 22 10 0 10 1 10 2 10 3 10 0 10 1 10 2 10 3 N u m b e r d a t a p o i n t s N Fe a t u r e c o u n t K N Fe a t u r e c o u n t g r o w t h w i t h N A s y m p t o t i c M e a n R e a l i z a t i o n 10 0 10 1 10 2 10 3 10 0 10 1 10 2 10 3 N u m b e r d a t a p o i n t s N Fe a t u r e c o u n t K N , j = 1 Fe a t u r e c o u n t g r ow t h w i t h N A s y m p t o t i c M e a n R e a l i z a t i o n Figure 5: Gr owth in the num b er of r e presented features K N ( left ) and the nu mber of features r epresented b y exactly o ne data p oint K N , 1 ( right ) as the total n umber of data p oints N grows. The p oints in the scatterplot are derived by simulation; blue for α = 0, center black is α = 0 . 3, and upp er black for α = 0 . 6. The red lines in the left plo t show the theo retical mean Φ N (Eq. (24)); in the right plot, they show the theo retical mean Φ N , 1 (Eq. (2 6)). The green lines show the theoretical asymptotic b ehavior, Eq. (29) on the left (T yp e I power law) a nd E q . (30) on the right (Type I I p ow er law). quadrature from Eq. (24) a nd directly from Eq. (26 ), ar e shown by red cur ves in the plots. Second, we compare the means to their own as ymptotic b ehavior. This a symptotic behavior, whic h we ultimately proved was shar e d with the resp ective K N or K N ,j in Eqs. (29) and (30), is shown b y green curves in the plots. W e can s ee in b oth plots that the α = 0 b ehavior is dis tinctly different from the straig ht -line b ehavior of the α > 0 exa mples. In bo th cases , we c a n see that any g rowth in α is slower than can b e describ ed by stra ig ht-line g rowth. In particular, when α = 0, the exp ected num b er of feature s is φ N = E [ K N ] = E " N X n =1 Pois γ θ n + θ # = N X n =1 γ θ n + θ ∼ γ θ log( N ) . (32) Similarly , when α = 0, the exp ected num ber o f features repr esented by exactly one data p o int , K N , 1 , is (by Eq. (26 )) Φ N , 1 = E [ K N , 1 ] = N 1 Z 1 0 x 1 (1 − x ) N − 1 · θx − 1 (1 − x ) θ − 1 dx = N θ · Γ(1)Γ( N − 1 + θ ) Γ( N + θ ) = θ N N − 1 + θ ∼ θ , where the seco nd line fo llows from using the norma lization constant of the (prop er) b eta distr ibution. Interestingly , while K N , 1 grows a s a p ow er law when 23 10 0 10 1 10 0 10 1 10 2 10 3 D a t a p o i n t c o u n t j Fe a t u r e c o u n t K N , j Fe a t u r e c o u n t g r o w t h i n j A s y m p t o t i c R e a l i z a t i o n 10 0 10 1 10 0 10 1 10 2 10 3 M D a t a c o u n t N u mb e r o f n w i t h k n ≥ M α = 0 . 3 α = 0 . 6 α = 0 . 0 Figure 6: L eft : Chang e in the num b er of feature s with exactly j representativ es among N da ta p oints for fixed N as a function of j . The blue p oints, with connecting lines, a re for α = 0; middle black ar e for α = 0 . 3, upp er bla ck for α = 0 . 6 . The green lines show the theoretical asymptotic behavior in j (Eqs. (10) a nd (11)) for the tw o α > 0 cases. Right : Change in the num b er of data po ints, indexed by n , with num b er of feature ass ig nments k n greater than some p ositive, rea l-v alued M as M increa ses. Neither the α = 0 case (blue) no r the α > 0 cases (black) exhibit Typ e I I I p ower laws. α > 0, its exp ectatio n is c o nstant when α = 0. While man y new featur es are instantiated as N increa s es in the α = 0 ca se, it seems that they are quickly represented by more data po ints tha n just the firs t one. Type I and I I p ow er laws are so mewhat easy to visualize since we have one p oint in our plo ts for each data po int simulated. The b ehavior of K N ,j as a function of j for fixed N and type I I I p ow er laws (or lack thereo f ) a re somewhat more difficult to visua lize. In the ca se of K N ,j as a function of j , we might exp ect that a larg e num b er of data p oints N is necessar y to see many groups of size j for j m uch grea ter tha n one. In the Type I II ca se, we hav e seen that in fact p ow er laws do not hold fo r any v alue of α in the b eta pr o cess. Rather, the num b er o f data p o ints exhibiting mo re tha n M fea tures dec reases more quic kly in M than a power law would predict; therefore, we ca nnot plot many v alues of M b efore this num b er effectively go e s to zer o. Nonetheless, Figur e 6 co mpares our simulated data to the approximation of Eq. (10 ) with Eq. (11) ( left ) a nd Type I I I p ow er laws ( right ). On the left, blue p oints as us ual deno te simulated data under α = 0; middle black points show α = 0 . 3, and upp er black p oints s how α = 0 . 6 . Here , we use co nnec ting lines b etw een plotted p oints to clar ify α v alues. The gr een lines fo r the α > 0 case illustra te the approximation of E q. (11). Aro und j = 10, we see that the nu mber of feaures ex hibited by j data po int s, K N ,j , degenera tes to mainly zero and one v a lues. Ho wev er, for smaller v alues of j we ca n still distinguish the power law trend. 24 10 0 10 1 10 2 10 3 10 −6 10 −4 10 −2 10 0 I n d e x Fr e q u e n c y O r d e r e d f e a t u r e f r e q u e n c i e s A s y m p t o t i c R e a l i z a t i o n Figure 7: F e a ture proba bilities from the b eta pro cess plotted in decreasing size order. Blue po int s r e pr esent proba bilities fro m the α = 0 case; center black po ints show α = 0 . 3, and upp er black po int s s how α = 0 . 6. The gre en lines show theoretical asymptotic b ehavior of the ranked pr obabilities (E q . (33)). On the right-hand side of Figure 6, w e display the num b er of data p oints exhibiting more than M featur es for v ario us v alues o f M acro ss the three v alue s of α . Unlike the previous plo ts in Fig ur e 5 a nd Figure 6 , there is no p ow er- law behavior for the ca ses α > 0, as predicted in Sec tio n 6.2. W e also no te that here the α = 0 . 3 curve do es not lie b etw een the α = 0 and α = 0 . 6 curves. Such an o ccurrence is not unusual in this ca se s inc e , as we saw in E q. (31), the ra te of decr ease is mo dulated by the total ma ss o f the feature pro babilities drawn from the b eta pro cess, whic h is r andom and not ne c e ssarily smaller when α is smaller. Finally , s ince our exp eriment inv olves ge ne r ating the underlying feature probabilities from the b eta pro cess as well as the a ctual feature assig nment s from rep eated draws from the Bernoulli pro cess, we may examine the feature probabilities themselves; see Figure 7. As us ual, the blue points repre sent the classic, tw o -parameter ( α = 0) b eta pro cess. Black p oints repres ent α = 0 . 3 (cent er ) and α = 0 . 6 (upp er). Perhaps due to the fact that there is o nly the beta pro cess noise to contend with in this asp ect of the simulation (and not the combined randomness due to the b eta pro cess and Berno ulli pro cess), we see the most striking demonstra tio n o f b o th p ow er law behavior in the α > 0 ca s es and faster decay in the α = 0 case in this figure. The tw o α > 0 cases clea rly adhere to a p ower law that may be predicted fro m our results a bove and the Gnedin et al. [20 0 7] results with C as in Eq. (2 8): # { i : q i ≥ x } a.s. ∼ C x − α x ↓ 0 . (33) Note that r anking the pro babilities mer ely inv er ts the plot that w ould b e cre- ated with x on the hor izontal axis and { i : q i ≥ x } on the vertical axis. The simulation demonstrates little noise ab out these power laws b e yond the 100th ranked pr obability . The decay for α = 0 is ma rkedly fas ter than the other ca ses. 25 8 Exp erimen tal results W e hav e s e en that the Poisson pro ces s for mulation a llows for a n easy extension of the b eta pro cess to a three - parameter mo del. In this s ection we study this mo del empirically in the setting of the modeling of handwritten digits. Paisley et al. [2010] present results for this pr oblem using a tw o-para meter b eta pro ce s s cou- pled with a discrete facto r a nalysis mo del; we r ep eat those exp er iment s with the thre e -parameter b eta pro ces s. The data c o nsists of 3,00 0 examples of hand- written digits, in pa rticular 1,0 00 handwriting samples o f ea ch o f the digits 3 , 5 , and 8 from the MNIST Handwritten Digits database [LeCun and Cortes, 1998, Row eis, 2007]. Each handwritten digit is repr esented by a matr ix of 2 8 × 28 pix- els; we pro ject these matr ices into 50 dimensio ns using pr incipal comp onents analysis. Thus, o ur data takes the form X ∈ R 50 × 3000 , and we may apply the beta pr o cess factor mo del from Eq. (2) with P = 5 0 a nd N = 3,00 0 to discover latent structure in this data. The g enerative mo del for X that we use is as follows [see P ais ley et al., 2010]: X = ( W ◦ Z )Φ + E Z ∼ BP-B eP( N , γ , θ , α ) Φ k,p iid ∼ N (0 , ρ p ) W n,k iid ∼ N (0 , ζ ) E n,p iid ∼ N (0 , η ) , (34) with h yp er parameters θ , α, γ , B 0 , { ρ p } P p =1 , ζ , η . Reca ll from Eq . (2) that X ∈ R N × P is the data, Φ ∈ R K × P is a matrix of factors, and E ∈ R N × P is an erro r matrix. Here, we int ro duce the weight matrix W ∈ R N × K , which mo dulates the binar y factor loadings Z ∈ R N × K . In Eq. (34), ◦ denotes element wise m ultiplication, and the indice s hav e r a nges n ∈ { 1 , . . . , N } , k ∈ { 1 , . . . , K } , p ∈ { 1 , . . . , P } . Since w e dr aw Z from a b eta-Berno ulli pro cess, the dimensio n K is theoretically infinite in the gener ative mo del notation o f Eq. (34). How ever, we hav e seen that the num b er of columns of Z with nonzer o ent rie s is finite a.s. W e use K to denote this num b er . W e initialized bo th the tw o-pa r ameter and the thr ee-para meter mo dels with the same num b er of latent fea tures, K = 200, and the same v alues for all shared parameters (i.e., every v ar iable except the ne w discount para meter α ). W e ran the exp er iment for 2,0 00 MCMC iterations , no ting that the MCMC runs in b oth mo dels seem to have reached equilibrium by 5 0 0 iteratio ns (see Fig ures 8 and 9). Figures 8 and 9 show the sampled v alues of v ar ious para meter s as a function of MCMC itera tion. In particular , we see how the num b er of features K (Fig- ure 8), the concentration parameter θ , and the discount par ameter α (Figure 9) change ov er time. All thr e e gr aphs illustrate that the thre e - parameter mo del takes a longer time to reach equilibrium tha n the tw o-para meter mo del (ap- proximately 500 iterations vs. approximatively 100 iteratio ns ). How e ver, once 26 0 500 1000 1500 2000 0 10 20 30 40 50 Iteration number K Two−parameter model 0 500 1000 1500 2000 0 10 20 30 40 50 Iteration number K Three−parameter model Figure 8 : The n umber of laten t features K a s a function of the MCMC iteration. Results for the original, tw o -parameter mo de l ar e represented on the left , and results for the new, three-par ameter model ar e illus trated o n the right . 0 1000 2000 0 50 100 Iteration number θ Two−parameter model 0 1000 2000 0 50 100 Iteration number θ Three−parameter model 0 1000 2000 0 0.5 1 Iteration number Three−parameter model α Figure 9: T he r andom v alues drawn for the hyperpa rameters as a function of the MCMC itera tion. Draws for the concentration pa rameter θ under the t wo-parameter mo del ar e shown on the left , and dr aws for θ under the three- parameter mo del ar e shown in the midd le . On the right a re dr aws of the new discount par ameter α under the three-par a meter mo del. 27 0 50 100 −1 −0.5 0 0.5 1 Lag Autocorrelation Two−parameter model K θ 0 50 100 −1 −0.5 0 0.5 1 Lag Autocorrelation Three−parameter model K θ α Figure 1 0: Auto co rrelation o f the num b er o f facto rs K , concentration para meter θ , and discount para meter α for the MCMC s amples after bur n-in (where burn- in is taken to end at 500 iteratio ns) under the t wo-parameter mo del ( left ) and three-para meter mo del ( right ). at equilibrium, the sampling time s eries asso ciated with the three-par ameter iterations exhibit low er auto co rrelatio n than the samples asso c ia ted with the t wo-parameter iterations (Figure 1 0). In the implementation of both the orig- inal tw o -parameter mo del and the three- pa rameter mo del, the range for θ is considered to b e b ounded ab ove by a pproximately 100 for co mputational r ea- sons (in accorda nce with the or iginal metho dolo gy of Paisley et al. [201 0]). As shown in Figure 9, this b ound affects sa mpling in the t wo-parameter ex pe r iment whereas, after burn-in, the e ffect is not notice a ble in the three-par ameter exp er- imen t. While the discount parameter α also comes close to the lower b ounda r y of its discretiza tion (Figure 9)—which cannot be exactly zero due to computa- tional concer ns—the samples no netheless seem to explo re the spa c e well. W e can see from Figur e 10 that the estimated v a lue of the concentraton parameter θ is mu ch low er when the discount par ameter α is also estimated. This b ehavior may b e seen to r e sult from the fact that the p ow er law growth of the exp ected n umber of represented features Φ N in the α > 0 case yields a generally higher exp ected num b er of features than in the α = 0 case for a fixed concentration parameter θ . F urther , we see fr om E q . (32) tha t the ex p ected nu mber of features when α = 0 is linear in θ . Ther e fore, if we instead fix the nu mber of featur es, the α = 0 model can c o mp e nsate by increa sing θ over the α > 0 mo del. Indeed, we s ee in Fig ure 8 that the num b er of features discov ered by both mo dels is roughly e q ual; in o r der to achiev e this num b er of features, the α = 0 mo del seems to b e comp ensating by ov e restimating the concentration parameter θ . T o get a sense o f the actual output of the mo del, we can lo ok at some of 28 Two-parameter mo del Three-par a meter mo del Figure 11 : U pp er : The top nine features by sa mpled representation acros s the data set on the final MCMC iteration for the o riginal, tw o-para meter mo del. L ower : The top nine features determined in the same w ay for the new, three- parameter mo del. the learned featur e s. In particular, we co llected the set of features from the la st MCMC itera tion in each mo del. The k th feature is expres s ed or not for the n th data p oint according to whether Z nk is o ne or zero. Therefore, we can find the mos t-expressed features a cross the da ta set using the set of fea tur es on this iteration as well as the sa mpled Z matrix on this itera tion. W e plot the nine most-express ed features under each mo del in Figure 11. In b oth mo dels, we can see how the features have captured distinguis hing featur es of the 3, 5, and 8 digits. Finally , we note that the three-par ameter version of the algorithm is com- petitive with the t wo-parameter version in running time once equilibrium is reached. After the bur n-in regime of 5 00 iterations, the average running time per iteratio n under the three-para meter mo del is 1 4.5 seco nds, compa red with 11.7 seconds average running time per iteratio n under the tw o- parameter mo del. 9 Conclusions W e hav e shown that the stick-breaking repres entation of the beta pro cess due to Paisley et al. [2010] ca n b e obtained directly from the representation o f the beta pr o cess a s a completely ra ndom measur e. With this r esult in hand the set of connectio ns b etw een the b eta pro cess, stick-breaking , and the Indian buffet pro cess are essentially as complete as those linking the Dirichlet pr o cess, stick- breaking, and the Chinese restaur ant pr o cess. W e hav e also shown that this a pproach motiv a tes a three-par ameter g eneral- ization of the stick-breaking representation of Paisley et al. [2010], which is the analog o f the Pitman- Y or gener alization of the stick-breaking representation for the Dirichlet pro cess. W e have shown that Type I and T yp e I I p ower laws follow from this three-para meter model. W e hav e also s hown that Type I II p ower laws cannot b e obtained within this framework. It is an op en problem to discov er useful clas ses of sto chastic pro cess e s tha t provide such p ower laws. 29 10 Ac kno wledgmen ts W e wish to thank Alexander Gnedin fo r useful discuss io ns and La ncelot James for helpful sug gestions. W e also thank John Paisley for useful discussio ns and for kindly providing access to his co de, which we used in o ur exper imental work. T ama ra B r o derick was funded by a Nationa l Scie nce F o undation Gradua te Re- search F ellowship. Michael Jor dan was supp orted in part b y IARP A-BAA-09-10 , “Knowledge Disc overy and Dissemination.” Jim Pitman was supp or ted in part by the National Science F oundation Award 0 80611 8 “ Combinatorial Sto chastic Pro cess es.” A A M ark o v chai n Mon te Carlo algorithm Posterior inference under the thre e - parameter model can be p erformed with a Marko v chain Monte Ca rlo (MCMC) a lg orithm. Many conditionals hav e simple forms that allow Gibbs sampling although others requir e further a ppr oximation. Most o f our sa mpling steps ar e as in Paisley et al. [2010] with the notable ex- ceptions of a new sampling s tep for the discount parameter α and integration of the discount par ameter α in to the existing framework. W e describ e the full algorithm here. A.1 Notation and auxiliary v ariables Call the index i in Eq. (14) the r oun d . Then int ro duce the ro und-indicator v ar iables r k such that r k = i exactly when the k th atom, wher e k indexes the sequence ( ψ 1 , 1 , . . . , ψ 1 ,C 1 , ψ 2 , 1 , . . . , ψ 2 ,C 2 , . . . ), o ccur s in r ound i . W e may write r k := 1 + ∞ X i =1 1 i X j =1 C j < k . T o recov er the r ound lengths C from r = ( r 1 , r 2 , . . . ), note tha t C i = ∞ X k =1 1 ( r k = i ) . (35) With the definition o f the ro und indicator s r in hand, we can rewrite the beta pro cess B as B = ∞ X k =1 V k,r k r k Y j =1 (1 − V k,j ) δ ψ k , where V k,j iid ∼ Beta(1 − α, θ + iα ) a nd ψ k iid ∼ γ − 1 B 0 as usual althoug h the indexing is not the same as in E q. (14). It follows that the expre s sion of the k th featur e for the n th data p o int is given by Z n,k ∼ Ber n ( π k ) , π k := V k,r k r k − 1 Y j =1 (1 − V k,j ) . 30 W e also int ro duce notation for the n umber of da ta p oints in whic h the k th feature is, resp ectively , express ed and not express ed: m 1 ,k := N X n =1 1 ( Z n,k = 1) , m 0 ,k := N X n =1 1 ( Z n,k = 0) Finally , let K b e the num b er of repres ent ed features; i.e., K := # { k : m 1 ,k > 0 } . Without loss of g enerality , we a s sume the r epresented features are the first K features in the index k . The ne w quantities { r k } , { m 1 ,k } , { m 0 ,k } , and K will be used in describing the sa mpler steps b elow. A.2 Laten t indicators First, we descr ib e the s ampling of the ro und indicators { r k } and the latent feature indicators { Z n,k } . In these and other steps in the MCMC alg orithm, we int egr ate out the stick-breaking prop ortions { V i } . A.2.1 Round indicator v ariables W e wish to sample the round indica to r r k for each feature k with 1 ≤ k ≤ K . W e can write the conditiona l for r k as p ( r k = i |{ r l } k − 1 l =1 , { Z n,k } N n =1 , θ, α, γ ) ∝ p ( { Z n,k } N n =1 | r k = i, θ , α ) p ( r k = i |{ r l } k − 1 l =1 ) . (36) It rema ins to calc ulate the tw o factors in the pro duct. F or the first factor in Eq. (36), we wr ite out the integration over stick- breaking pro p o rtions and approximate with a Monte Carlo integral: p ( { Z n,k } N n =1 | r k = i, θ , α ) = Z [0 , 1] i π m 1 ,k k (1 − π k ) m 0 ,k dV ≈ 1 S S X s =1 ( π ( s ) k ) m 1 ,k (1 − π ( s ) k ) m 0 ,k . (37) Here, π ( s ) k := V ( s ) k,r k Q r k − 1 j =1 (1 − V ( s ) k,j ), and V ( s ) k,j indep ∼ Beta(1 − α, θ + j α ). Also, S is the num ber of s amples in the s um approximation. Note that the computational trick employ ed in Paisley et al. [20 10] for sampling the { V i } relies on the first parameter o f the b eta distr ibution being equal to one; there fore, the sampling describ ed ab ov e, without further tr icks, is exactly the sampling that must b e used in this more general par ameterization. F or the second facto r in Eq. (36), there is no dep e ndence o n the α parameter, so the draws a re the same as in Paisley et a l. [2010]. F or R k := P k j =1 1 ( r j = r k ), we hav e p ( r k = r | γ , { r l } k − 1 l =1 ) 31 = 0 r < r k − 1 1 − P R k − 1 i =1 Pois( i | γ ) 1 − P R k − 1 − 1 i =1 Pois( i | γ ) r = r k − 1 1 − 1 − P R k − 1 i =1 Pois( i | γ ) 1 − P R k − 1 − 1 i =1 Pois( i | γ ) (1 − Pois(0 | γ )) Pois (0 | γ ) h − 1 r = r k − 1 + h for each h ≥ 1 . Note that these dr aws make the approximation that the first K featur es cor resp ond to the first K tuples ( i, j ) in the double sum o f E q. (14); these order ings do not in g e neral agre e . T o co mplete the ca lculation o f the p oster ior for r k , we need to s um ov er all v a lues of i to norma liz e p ( r k = i |{ r l } k − 1 l =1 , { Z n,k } N n =1 , θ, α, γ ). Since this is not computationally feas ible, an alterna tive metho d is to calculate Eq. (36) for increasing v alues of i until the r esult falls b elow a pre-determined thr e shold. A.2.2 F actor indicators In finding the p osterio r for the k th feature indicator in the n th latent factor, Z n,k , we can integrate o ut b o th { V i } and the weigh t v ariables { W n,k } . The conditional for Z n,k is p ( Z n,k | X n, · , Φ , Z n, − k , r , θ , α, η , ζ ) = p ( X n, · | Z n, · , Φ , η , ζ ) p ( Z n,k | r , θ , α, Z n, − k ) . (38) First, we consider the likeliho o d. F o r this factor , we integrate out W explic- itly: p ( X n, · | Z n, · , Φ , η , ζ ) = Z W p ( X n, · | Z n, · , Φ , W , η ) p ( W | ζ ) = Z W n,I N ( X n, · | W n,I Φ I , · , η I P ) N ( W n,I | 0 | I | , ζ I | I | ) dW n,I where I = { i : Z n,i = 1 } = N X n, · | 0 P , h η − 1 I P − η − 2 Φ I , · η − 1 Φ ⊤ I , · Φ I , · + ζ − 1 I | I | − 1 Φ ⊤ I , · i − 1 = N X n, · | 0 P , η I P + ζ Φ I , · Φ ⊤ I , · , where the final step follows fr om the Sher man-Morr ison-W o o dbury lemma. F or the se c ond factor in Eq . (38), we can wr ite p ( Z n,k | r , θ , α, Z n, − k ) = p ( Z n | r , θ , α ) p ( Z n, − k | r , θ , α ) , and the n umera tor a nd denominator can b oth b e es timated a s in tegr als over V using the same Monte Carlo integration trick as in Eq. (37). 32 A.3 Hyp erparameters Next, we describ e sa mpling for the three par ameters o f the b e ta pro cess. The mass and concentration para meters ar e shared by the tw o- pa rameter pro cess; the discount parameter is unique to the thr ee-para meter b eta pro cess. A.3.1 Mass parameter With the round indicators { r k } in hand as from Appendix A.2.1 ab ove, we can recov er the ro und le ng ths { C i } with E q. (35). Assuming an improp er gamma prior on γ —with b oth sha p e and inv erse scale parameters equal to zero —and recalling the iid Poisson genera tion of the { C i } , the po sterior for γ is p ( γ | r, Z , θ , α ) = Ga( γ | r K X i =1 C i , r K ) . Note tha t it is necessa ry to sa mple γ sinc e it o c c urs in, e.g., the co nditional for the ro und indicator v aria bles (Appendix A.2.1). A.3.2 Concen tration parameter The conditional fo r θ is p ( θ | Z, r, α ) ∝ p ( θ ) K Y k =1 p ( Z | r, θ, α ) . Again, we ca lc ulate the likelihoo d factors p ( Z | r , θ , α ) with a Mont e Carlo ap- proximation as in E q. (37). In order to find the co nditio na l ov er θ fr o m the like- liho o d and prior, we further approximate the s pa ce of θ > 0 by a discr etization around the pr e vious v alue of θ in the Mo nte Ca rlo sa mpler: { θ prev + t ∆ θ } t = T t = S , where S a nd T are chosen so tha t all p otential new θ v a lues a re nonneg a tive and so that the tails of the distribution fall b elow a pre-determined threshold. T o complete the description, we choo se the improp er prior p ( θ ) ∝ 1. A.3.3 Discoun t parameter W e sample the discount par ameter α in a similar manner to θ . The co nditio na l for α is p ( α | Z, r, θ ) ∝ p ( α ) K Y k =1 p ( Z | r, θ, α ) . As usual, we calculate the likeliho o d factors p ( Z | r , θ , α ) with a Monte Carlo approximation a s in E q. (3 7). While we discretize the sampling of α as we did for θ , note that sa mpling α is more stra ightforw ard since α must lie in [0 , 1]. Therefore, the choice of ∆ α completely characterizes the disc r etization of the int erv al. In particular , to av oid endpoint b ehavior, we c onsider new v alues of α among { ∆ α/ 2 + t ∆ α } (∆ α ) − 1 − 1 t =0 . Moreover, the c hoice o f p ( α ) ∝ 1 is, in this case, a prop er prior for α . 33 A.4 F actor analysis c omp onen ts In order to use the b eta pro c ess as a pr io r in the factor ana ly sis model describ ed in Eq. (2), we must also desc r ib e samplers for the featur e matrix Φ and weight matrix W . A.4.1 F eature matrix The conditional fo r the feature ma trix Φ is p (Φ · ,p | X , W , Z , η , ρ p ) ∝ p ( X · ,p | Φ · ,p , W , Z , η I N ) p (Φ · ,p | ρ p ) = N ( X · ,p | ( W ◦ Z )Φ · ,p , η I N ) N (Φ · ,p | 0 K , ρ p I K ) ∝ N (Φ · ,p | µ, Σ) , where, in the final line, the v ar iance is defined as follows: Σ := η − 1 ( W ◦ Z ) ⊤ ( W ◦ Z ) + ρ − 1 p I K − 1 , and similarly for the mean: µ := Σ η − 1 ( W ◦ Z ) ⊤ X · ,p . A.4.2 W eight matrix Let I = { i : Z n,i = 1 } . Then the co nditional for the weigh t matr ix W is p ( W n,I | X , Z, Φ , η ) ∝ p ( X n, · | Φ I , · , W n,I , η ) p ( W n,I | ζ ) = N ( X n, · | W n,I Φ I , · , η I p ) N ( W n,I | 0 | I | , ζ I | I | ) ∝ N ( W n,I | ˜ µ, ˜ Σ) , where, in the final line, the v ariance is defined a s ˜ Σ := η − 1 Φ I , · Φ ⊤ I , · + ζ − 1 I | I | − 1 , and the mea n is defined as ˜ µ := ˜ Σ η − 1 X n, · Φ ⊤ I , · . References D. M. Blei and M. I. Jorda n. V ariatio nal infere nc e fo r Dirichlet pr o cess mixtures. Bayesian Analysis , 1(1):12 1 –144 , 2 006. H. Chernoff. A measure of asymptotic efficiency for tests of a hypothesis ba sed on the sum of o bserv ations. The Annals of Mathematic al Statistics , pa ges 493–5 07, 195 2. W. F eller. An Intr o duction to Pr ob ability The ory and Its Applic ations, V ol. II. John Wiley , New Y o rk, 19 66. T. S. F er guson. A Bay esian analysis of s o me nonpar ametric problems . The Annals of Statistics , 1(2):209 –230 , 1 973. ISSN 00 90-53 64. 34 M. F ranceschetti, O. Dousse, D. N. C. Tse, and P . Thira n. Closing the gap in the ca pacity of wir eless netw or ks via p erco lation theory . Information The ory, IEEE T r ansactions on , 5 3(3):100 9–101 8, 200 7. D. F ree dma n. Another note on the Bor e l–Cantelli lemma and the strong law, with the Po isson appr oximation as a by-pro duct. The Annals of Pr ob ability , 1(6):910– 925, 19 73. A. Gnedin, B . Hansen, a nd J. Pitman. No tes on the o ccupancy problem with infinitely many b oxes: General asymptotics and p ow er laws. Pr ob ability Sur- veys , 4:14 6–17 1 , 2007. S. Go ldwater, T. Griffiths, and M. J ohnson. Interpolating be tw een types and to- kens by estimating p ow er-law gener ators. In A dvanc es in Neur al Information Pr o c essing Systems, 18 , Cambridge, MA, 20 06. MIT Pr e s s. T. Griffiths a nd Z. Ghahrama ni. Infinite latent feature models and the I ndia n buffet pr o cess. In A dvanc es in Neur al Information Pr o c essing Systems, 18 , volume 18 , Ca mbridge, MA, 200 6. MIT Press . T. Hagerup and C. Rub. A guided tour of Cher noff bo unds. Information Pr o c essing L etters , 3 3(6):305 –308, 1 990. H. S. Heaps. Information Re trieval: Computational and The or etic al Asp e cts . Academic Pres s, Orlando, FL, 1978 . ISBN 01233 5750 0 . N. L. Hjort. No nparametric Bay es estimators based on b eta pro ces ses in mo dels for life history data. The Annals of St atistics , 1 8(3):125 9–129 4, 19 9 0. ISSN 0090- 5364. H. Ishw ar an and L. F. James. Gibbs s ampling methods for stick-breaking prior s. Journal of t he Americ an Statistic al Asso ciation , 96(453 ):161–1 73, 200 1. ISSN 0162- 1459. M. Kalli, J. E . Griffin, and S. G. W a lker. Slice sa mpling mixture mo dels. St atis- tics and Computing , 21:93 –105 , 2 009. Y. K im and J. Lee. O n po sterior consistency o f s urviv a l mo dels. Annals of Statistics , pages 666– 686, 20 01. J. F. C. Kingman. Completely r andom mea sures. Pacific Journal of Mathemat- ics , 21(1 ):59–78 , 196 7. J. F. C. K ingman. Poisson Pr o c esses . Oxfor d University Press, 1993 . ISBN 01985 3693 3. Y. LeCun a nd C. Cortes. The MNIST databas e o f handwritten digits, 19 98. S. N. MacEachern. Depe ndent nonpa rametric pro cesses. In ASA Pr o c e e dings of the Se ction on Bayesian Statistic al Scienc e , pag es 50–5 5 , 1999. 35 J. W. McCloskey . A mo del for the distribution of individuals by sp e cies in an envir onment . PhD thesis, Michigan State Universit y , 196 5. M. Mitzenmacher. A brie f history of genera tive mo dels for p ow er law and lognorma l distributions. Internet Mathematics , 1(2):226 –251 , 2004. ISSN 1542- 7951. J. Paisley , A. Zaa s, C . W. W o o ds , G. S. Ginsburg , and L. Ca rin. A stick- breaking construction of the b eta pro cess. In International Confer enc e on Machine L e arning , Haifa, Israel, 201 0. J. Paisley , D. Blei, and M. I. Jordan. The stick-breaking construction o f the beta pro ce ss a s a po isson pro cess. Pre-print arXiv:110 9.0343 v1 [math.ST], 2011. G. P . Patil and C. T a illie. Diversit y as a concept a nd its implica tio ns for r andom communities. In Pr o c e e dings of the 41st Session of the International S tatistic al Institute , page s 497– 515, New Delhi, 1 977. J. P itman. Combinatorial sto chastic pr o c esses , v olume 1875 of L e c- tur e Notes in Mathematics . Spring er-V erlag, Berlin, 20 06. URL http:/ /bibs erver.berkeley.edu/csp/april05/bookcsp.pdf . J. P itman and M. Y or. The tw o-para meter Poisson-Dirichlet distribution derived from a stable sub ordinator . The Annals of Pr ob ability , 25(2 ):855–9 00, 19 97. ISSN 009 1-17 9 8. S. Row eis. MNIST handwritten digits, 2007. URL http:/ /www. cs.nyu.edu/ ~ roweis /data .html . J. Sethuraman. A constructive definition of Dir ichlet priors. Statistic a Sinic a , 4(2):639– 650, 19 94. Y. W. T eh and D. G¨ or ¨ ur. Indian buffet pro cesses with p ower-law b ehavior. In A dvanc es in Neur al Information Pr o c essing Systems , Cambridge, MA, 2009. MIT Press . Y. W. T eh, D. G¨ or ¨ ur, a nd Z. Ghahr a mani. Stick-breaking constructio n for the Indian buffet pro cess. I n Pr o c e e dings of t he In t ernational Confer enc e on Artificia l Intel ligenc e and Statistics, 11 , San J ua n, Puerto Rico, 200 7. R. Thiba ux a nd M. I. Jordan. Hierarchical b eta pro cesses and the Indian buffet pro cess. In International Confer enc e on A rtificial In t el ligenc e and Statistics , San Juan, P uerto Rico, 2007 . F. G. T r icomi and A. Erd´ elyi. The asymptotic expansio n of a ratio o f gamma functions. Pacific J ournal of Mathematics , 1(1):133 –142 , 1 951. S. G. W alker. Sampling the Dirichlet mixtur e mo del with s lices. Communic a- tions in St atist ics—Simulation and Computation , 36(1 ):45–54 , 200 7. 36 R. L. W olp er t and K. Ickstadt. Reflecting uncertaint y in inv erse problems: A Bay esian solution using L´ evy pro cesses . In verse Pr oblems , 20:175 9–17 71, 2004. G. K. Zipf. Hum an Behaviour and the Principle of L e ast-Effort . Addison-W esley , 1949. 37
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment