A Probabilistic Framework for Discriminative Dictionary Learning
In this paper, we address the problem of discriminative dictionary learning (DDL), where sparse linear representation and classification are combined in a probabilistic framework. As such, a single discriminative dictionary and linear binary classifi…
Authors: Bernard Ghanem, Narendra Ahuja
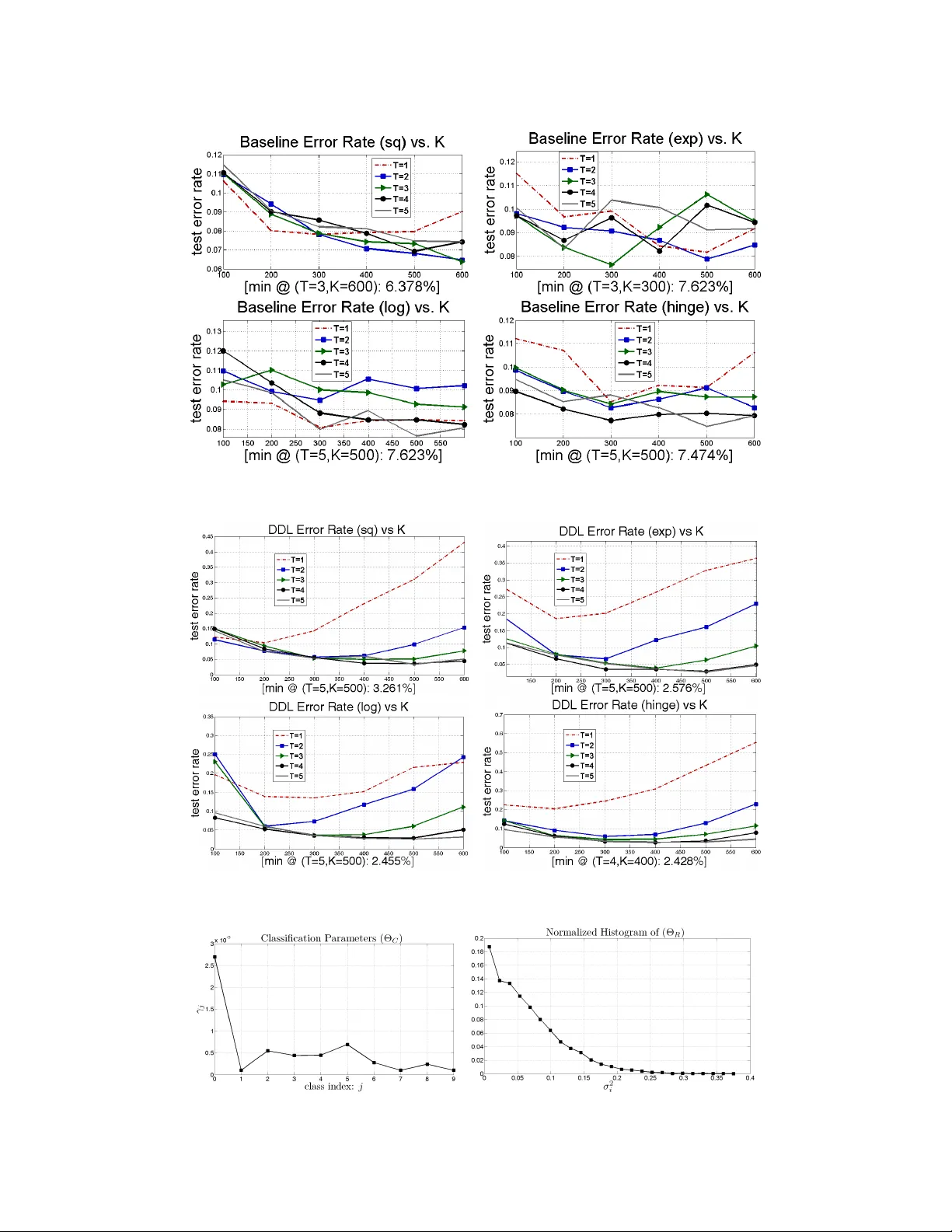
A Pr obabilistic Framework f or Discriminativ e Dictionary Lear ning Bernard Ghanem and Nar endra Ahuja Abstract In this paper , we address the problem of discriminati ve dictionary learning (DDL), where sparse linear representation and classification are combined in a probabilis- tic framework. As such, a single discriminati ve dictionary and linear binary clas- sifiers are learned jointly . By encoding sparse representation and discriminativ e classification models in a MAP setting, we propose a general optimization frame- work that allows for a data-driv en tradeoff between faithful representation and accurate classification. As opposed to pre vious work, our learning methodology is capable of incorporating a div erse family of classification cost functions (includ- ing those used in popular boosting methods), while av oiding the need for in volv ed optimization techniques. W e show that DDL can be solved by a sequence of up- dates that make use of well-known and well-studied sparse coding and dictionary learning algorithms from the literature. T o validate our DDL framework, we apply it to digit classification and face recognition and test it on standard benchmarks. 1 Introduction Representation of signals as sparse linear combinations of a basis set is popular in the signal/image processing and machine learning communities. In this representation, a sample ~ y is described by a linear combination ~ x of a sparse number of columns in a dictionary D , such that ~ y = D ~ x . Significant theoretical progress has been made to determine the necessary and suf ficient conditions, under which reco very of the sparsest representation using a predefined D is guaranteed [3, 27, 4]. Recent sparse coding methods achiev e state-of-the-art results for various visual tasks, such as face recognition [29]. Instead of minimizing the ` 0 norm of ~ x , these methods solve relaxed versions of the originally NP-hard problem, which we will refer to as traditional sparse coding (TSC). Howe ver , it has been empirically sho wn that adapting D to underlying data can improve upon state-of-the-art techniques in v arious restoration and denoising tasks [6, 23]. This adaptation is made possible by solving a sparse matrix factorization problem, which we refer to as dictionary learning . Learning D is done by alternating between TSC and dictionary updates [1, 8, 20, 15]. For an overvie w of TSC, dictionary learning, and some of their applications, we refer the reader to [28, 7]. In this paper , we address the problem of discriminati ve dictionary learning (DDL), where D is viewed as a linear mapping between the original data space and the space of sparse representations, whose dimensionality is usually higher . In DDL, we seek an optimal mapping that yields faithful sparse representation and allows for maximal discriminability between labeled data. These two objectiv es are seldom complimentary and they tend to introduce conflicting goals in many cases, thus, classification can be viewed as a r e gularizer for reliable representation and vice versa. From both viewpoints, this re gularization is important to pre vent o verfitting to the labeled data. Therefore, instead of optimizing both objectiv es simultaneously , we seek joint optimization. In the case of sparse linear representation, the problem of DDL was recently introduced and de veloped in [19, 21, 22], under the name supervised dictionary learning (SDL). In this paper , we denote the problem as DDL instead of SDL, since DDL inherently includes the semi-supervised case. SDL is also addressed in a recent work on task-driv en dictionary learning [18]. The form of the optimization 1 problem in SDL is shown in Eq. (1). The objecti ve is a linear combination of a representation cost e R and a classification cost e C using data labels L and classifier parameters W . min X , D , W e R ( Y , X , D ) + λe C ( X , W , L ) (1) Although [22, 21] use multiple dictionaries, it is clear that learning a single dictionary allows for sharing of features among labeled classes, less computational cost, and less risk of ov erfitting. As a result, our proposed method learns a single dictionary D . Here, we note that [13] addresses a similar problem, where D is predefined and e C is the Fisher criterion. Despite their merits, SDL methods hav e the following drawbacks. (i) Most methods use limited forms for e C (e.g. softmax applied to reconstruction error). Consequently , they cannot generalize to incorporate popular classi- fication costs, such as the exponential loss used in Adaboost or the hinge loss in SVMs. (ii) Pre vious SDL methods weight the training samples and the classifiers uniformly by setting the fixed mix- ing coefficient λ according to cross-validation. This biases their cost functions to samples that are badly represented or misclassified. As such, they are more sensitiv e to outlier , noisy , and mislabeled training data. (iii) From an optimization viewpoint, the SDL objectiv e functions are quite in volv ed especially due to the use of the softmax function for multi-class discrimination. Contributions: Our proposed DDL framework addresses the previous issues by learning a linear map D that allows for maximal class discrimination in the labeled data when using linear classifi- cation. (i) W e sho w that this framew ork is applicable to a general family of classification cost func- tions, including those used in popular boosting methods. (ii) Since we pose DDL in a probabilistic setting, the representation-classification tradeoff and the weighting of training samples correspond to MAP parameters that are estimated in a data-driv en fashion that av oids parameter tuning. (iii) Since we decouple e R and e C , the representations X act as the only liaisons between classification and representation. In fact, this is why well-studied methods in dictionary learning and TSC can be easily incorporated in solving the DDL problem. This a voids inv olved optimization techniques. Our framew ork is efficient, general, and modular , so that any improvement or theoretical guarantee on individual modules (i.e. TSC or dictionary learning) can be seamlessly incorporated. The paper is organized as follows. In Section 2, we describe the probabilistic representation and classification models in our DDL frame work and ho w they are combined in a MAP setting. Section 3 presents the learning methodology that estimates the MAP parameters and shows how inference is done. In Section 4, we validate our frame work by applying it to digit classification and face recognition and showing that it achie ves state-of-the-art performance on benchmark datasets. 2 Overview of DDL Framew ork In this section, we giv e a detailed description of the probabilistic models used for representation and classification. Our optimization framework, formulated in a standard MAP setup, seeks to maximize the likelihood of the gi ven labeled data coupled with priors on the model parameters. 2.1 Representation and Classification Models W e assume that each M -dimensional data sample can be represented as a sparse linear combination of K dictionary atoms with additive Gaussian noise of diagonal cov ariance: ~ y = D ~ x + ~ n ; ~ n ∼ N ( ~ 0 , σ 2 I ) . Here, we view the sparse representation ~ x as a latent variable of the representation model. In training, we assume that the training samples are represented by this model. Ho we ver , test samples can be contaminated by various types of noise that need not be zero-mean Gaussian in nature. In testing, we hav e: ~ y = D ~ x + ~ e + ~ n , where we constrain any auxiliary noise ~ e (e.g. occlusion) to be sparse in nature without modeling its explicit distribution. This constraint is used in the error correction method for sparse representation in [27]. It is clear that the representation in testing is identical to the one in training with the dictionary in the latter being augmented by identity . In both cases, the likelihood of observing a specific ~ y is modeled as a Gaussian: ( ~ y | ~ x , D ) ∼ N D ~ x , σ 2 I . Since a single dictionary is used to represent samples belonging to dif ferent classes, sharing of features is allowed among classes, which simplifies the learning process. 2 T o model the classification process, we assume that each data sample corresponds to a label vector ~ l ∈ {− 1 , +1 } C , which encodes the class membership of this sample, where C is the total number of classes. In our experiments, only one value in ~ l is +1 . W e apply a linear classifier (or equiv alently a set of additi vely boosted linear classifiers) to the sparse representations in a one-vs-all classification setup. The probabi listic classification model is shown in Eq. (2), where Ω( . ) is the classification cost function. Note that appending 1 to ~ x intrinsically adds a bias term to each classifier ~ w . Due to the linearity of the classifier , discrimination of the j th class is completely determined by the scalar cost function Ω ( ~ x ) = Ω ( z j ) , where z j = l j ~ w T j ~ x . This function quantifies the cost of assigning label l j to representation ~ x using the j th classifier ~ w j . For now , we do not specify the functional form of Ω( . ) . In Section 3, we show that most forms of Ω( . ) used in practice are easily incorporated into our DDL framework. Since we seek ef fecti ve class discrimination, we expect lo w classification cost for the gi ven representations. Therefore, by arranging all C linear classifiers in matrix W , the e vent ( ~ l | ~ x , W ) can be modeled as a product of C independent exponential distrib utions parameterized by γ j for j = 1 , . . . , C . By denoting ~ w j as the classifier of the j th class, we hav e: p ~ l | ~ x , W ∝ 1 Q C j =1 γ j e − P C j =1 1 γ j Ω ( l j ~ w T j ~ x ) (2) 2.2 Overall Probabilistic Model T o formalize notation, we consider a training set of N data samples in R d that are columns of the data matrix Y ∈ R M × N . The i th column of the label matrix L ∈ { +1 , − 1 } C × N is the label vector ~ l i corresponding to the i th data sample. Here, we assume that there are K atoms in the dictionary D ∈ R d × K , where K is a fixed integer that is application-dependent. T ypically , K d . Note that there hav e been recent attempts to determine an optimal K for a giv en dataset [24]. F or our experiments, K is kept fixed and its optimization is left for future work. The representation matrix X ∈ R K × N is a sparse matrix, whose columns represent the sparse codes of the data samples Y using dictionary D . The linear classifiers are columns in matrix W ∈ R K × C . W e denote Θ R = { σ 2 i } N i =1 and Θ C = { γ j } C j =1 as the representation and classification parameters respecti vely . In what follows, we combine the representation and classification models from the previous sec- tion in a unified frame work that will allo w for the joint MAP estimation of the unkno wns: D , X , W , Θ R , and Θ C . By making the standard assumption that the posterior probability con- sists of a dominant peak, we determine the required MAP estimates by maximizing the product: p ( Y | D , X , Θ R ) p ( L | X , W , Θ C ) p (Θ R ) p (Θ C ) . Here, we make a simplifying assumption that the prior of the dictionary and representations are uniform. T o model the priors of Θ R and Θ C and to avoid using hyper-parameters, we choose the objectiv e non-parametric Jeffere ys prior , which has been shown to perform well for classification and regression tasks [9]. Therefore, we obtain p (Θ R ) ∝ Q N i =1 1 σ 2 i and p (Θ C ) ∝ Q C j =1 1 γ j . The motiv ations behind the selection of these priors are that (i) the representation prior encourages a low variance representation (i.e. the training data should properly fit the proposed representation model) and that (ii) the classification prior encourages a low mean (and v ariance) 1 classification cost (i.e. the training data should be properly classified using the proposed classification model). By minimizing the sum of the negati ve log likelihood of the data and labels as well as the log priors, MAP estimation requires solving the optimization problem in Eq. (3), where L j i represents the label of the i th training sample with respect to the j th class. T o encode the sparse representation model, we explicitly enforce sparsity on X by requiring that each representation ~ x i ∈ S T = { ~ a : k ~ a k 0 ≤ T } . An alternati ve for obtaining sparse representations is to assume that ~ x i follows a Laplacian prior, which leads to an ` 1 regularizer in the objecti ve. While this sparsifying regularizer alle viates some of the complexity of Eq. (3), it leads to the problem of selecting proper parameters for these Laplacian priors. Note that recent efforts hav e been made to find optimal estimates of these Laplacian parameters in the context of sparse coding [11, 30, 2]. Howe ver , to av oid additional parameters, we choose the form in Eq. (3), where the first two terms of the objectiv e correspond to the representation cost and the last two to the classification cost. 1 The mean and variance of an e xponential distribution with parameter λ = 1 γ are γ and γ 2 respectiv ely . 3 min { D , W , X , Θ R , Θ C } N X i =1 k ~ y i − D ~ x i k 2 2 2 σ 2 i + N X i =1 ln σ M +2 i + C X j =1 N X i =1 Ω L j i ~ w T j ~ x i γ j + C X j =1 ln γ N +1 j (3) In the follo wing section, we show that Eq. (3) can be solved for a general family of cost functions Ω( . ) using well-kno wn and well-studied techniques in TSC and dictionary learning. In other words, dev eloping specialized optimization methods and performing parameter tuning are not required. 3 Learning Methodology Since the objecti ve function and sparsity constraints in Eq. (3) are non-con vex, we decouple the de- pendent v ariables by resorting to a blockwise coordinate descent method (alternating optimization). At each iteration, only a subset of variables is updated at a time. Clearly , learning D is decoupled from learning W , if X and (Θ R , Θ C ) are fix ed. Next, we identify the four basic update procedures in our DDL framework. In what follo ws, we denote the estimate of variable A at iteration k as A ( k ) . 3.1 Classifier Update (a) classification cost (b) classifier weights Figure 1: Four classification cost functions: square, exponential, logistic, and hinge loss in 1(a). 1(b) plots their impacts on classifier weights (second deriv ativ es) in our DDL framew ork. Since the classification terms in Eq. (3) are de- coupled from the representation terms and in- dependent of each other, each classifier can be learned separately . In this paper, we focus on four popular forms of Ω( . ) , as shown in Fig- ure 1(a): (i) the square loss: Ω( z ) = (1 − z ) 2 optimized by the boosted square leverage method [5], (ii) the exponential loss: Ω( z ) = e − z optimized by the AdaBoost method [10], (iii) the logistic loss: Ω( z ) = ln(1 + e − z ) opti- mized by the LogitBoost method [10], and (iv) the hinge loss: Ω( z ) = max(0 , 1 − z ) optimized by the SVM method. Since additiv e boost- ing of linear classifiers yields a linear classifier , we allo w for seamless incorporation of additiv e boosting, which is a nov el contribution. 3.2 Discriminative Sparse Coding In this section, we describe how well-known and well-studied TSC algorithms (e.g. Orthogonal Matching Pursuit (OMP)) are used to update X ( k +1) from X ( k ) . This is done by solving the problem in Eq. (4), which we refer to as discriminative sparse coding (DSC). DSC requires the sparse code to not only reliably represent the data sample but also to be discriminable by the one-vs-all classifiers. Here, we denote ~ l as the label vector of the i th data element (i.e. the i th column of L ). The ( k ) superscripts are omitted from variables not being updated to facilitate readability . Here, we note that DSC, as defined here, is a generalization of the functional form used in [13]. ~ x ( k +1) i = arg min ~ x ∈S T ~ b − A ~ x 2 2 + 2 C X j =1 Ω ~ g T j ~ x γ j where ~ b = ~ y i σ i ; A = D σ i ; ~ g j = l j ~ w j (4) Solving Eq. (4): The complexity of this solution depends on the nature of Ω( . ) . Ho wev er , it is easy to show that, by applying a projected Ne wton gradient descent method to Eq. (4), DSC can be formulated as a sequence of TSC problems, if Ω( z ) is strictly con vex. At each Newton iteration, a quadratic local approximation of the cost function is minimized. If we denote Ω 1 ( z ) and Ω 2 ( z ) as the first and second deriv atives of Ω( z ) respectiv ely and Ω 12 ( z ) = Ω 1 ( z ) Ω 2 ( z ) , the quadratic approximation of Ω( z ) around z p is Ω( z ) ≈ Ω( z p ) + Ω 1 ( z p )( z − z p ) + 1 2 Ω 2 ( z p )( z − z p ) 2 . Since Ω 2 ( z ) is a strictly 4 positiv e function, we can complete the square to get Ω( z ) ≈ 1 2 Ω 2 ( z p )[ z − ( z p − Ω 12 ( z p ))] 2 + cte . By replacing this approximation in Eq. (4), the objective function at the ( p + 1) th Newton iteration is: k ~ b − A ~ x k 2 2 + k H ( p ) ( ~ δ ( p ) − G T ~ x ) k 2 2 . In fact, this objectiv e takes the form of a TSC problem and, thus, can be solv ed by any TSC algorithm. Here, G is formed by the columnwise concatenation of ~ g j and we define δ ( p ) ( j ) = ~ g T j ~ x ( p ) − Ω 12 ( ~ g T j ~ x ( p ) ) for j = 1 , . . . , C . Also, we define the diagonal weight matrix H ( p ) , where H ( p ) ( j, j ) = ( Ω 2 ( ~ g T j ~ x ( p ) ) 2 γ j ) 1 2 weights the j th classifier . Based on this deri v ation, the same TSC algorithm (e.g. OMP) can be used to solve the DSC problem iterati vely , as illustrated in Algorithm 1. The con ver gence of this algorithm is dependent on whether the TSC algorithm is capable of recov ering the sparsest solution at each iteration. Although this is not guaranteed in general, the con vergence of TSC algorithms to the sparsest solution has been sho wn to hold, when the solution is sparse enough ev en if the dictionary atoms are highly correlated [3, 27, 12, 4]. In our experiments, we see that the DSC objecti ve is reduced sequentially and con ver gence is obtained in almost all cases. Furthermore, we provide a Stop Criterion (threshold on the relative change in solution) for the premature termination of Algorithm 1 to av oid needless computation. Algorithm 1 Discriminativ e Sparse Coding (DSC) INPUT : A , ~ b , G , ~ α , Ω , ~ x (0) , T , p max , Stop Criterion while (Stop Criterion) AND p ≤ p max do compute and form: ~ δ ( p ) and H ( p ) ; ~ x ( p +1) = TSC ~ b H ( p ) ~ δ ( p ) , A H ( p ) G T , T ; p = p + 1; end while OUTPUT : ~ x ( p ) Popular Forms of Ω( z ) : Here, we focus on particular forms of Ω( z ) , namely the four functions in Section 3.1. Before proceeding, we need to replace the traditional hinge cost with a strictly conv ex approximation. W e use the smooth hinge approximation introduced by [17], which can arbitrarily approximate the traditional hinge. As seen before, Ω 2 ( z ) and Ω 12 ( z ) are the only functions that play a role in the DSC solution. Obviously , only one iteration of Algorithm 1 is needed when the square cost is used, since it is already quadratic. For all other Ω( z ) , at the p th iteration of DSC, the impact of the j th classifier on the overall cost (or equiv alently on updating the sparse code) is determined by H ( p ) ( j, j ) . This weight is influenced by two terms. (i) It is in versely proportional to γ j . So, a classifier with a smaller mean training cost (i.e. higher training set discriminability ) yields more impact on the solution. (ii) It is proportional to Ω 2 ( l j ~ w T j ~ x ( p ) ) , the second deri vati ve at the pre vious solution. In this case, the impact of the j th classifier is determined by the type of classification cost used. In Figure 1(b), we plot the relationship between Ω( z ) and Ω 2 ( z ) for all four Ω( z ) types. For the square and hinge functions, Ω( z ) and Ω 2 ( z ) are independent, thus, a classifier yielding high sample discriminability (low Ω( z ) ) is weighted the same as one yielding low discriminability . For the exponential case, the relationship is linear and positi vely correlated, thus, the lower a classifier’ s sample discriminability is the higher its weight. This implies that the sparse code will be updated to correct for classifiers that misclassified the training sample in the pre vious iteration. Clearly , this makes representation sensitive to samples that are “hard” to classify as well as outliers. This sensitivity is ov ercome when the logistic cost is used. Here, the relationship is positiv ely correlated for moderate costs but negati vely correlated for high costs. This is consistent with the theoretical argument that LogitBoost should outperform AdaBoost when training data is noisy or mislabeled. 3.3 Unsupervised Dictionary Learning When X ( k ) , Θ ( k ) R , and Θ ( k ) C are fixed, D ( k ) can be updated by any unsupervised dictionary learning method. In our experiments, we use the KSVD algorithm, since it av oids expensi ve matrix in version operations required by other methods. Also, efficient versions of KSVD hav e recently been dev el- oped [25]. By alternating between TSC and dictionary updates (SVD operations), KSVD iterati vely reduces the ov erall representation cost and generates a dictionary with normalized atoms and the corresponding sparse representations. In our case, the representations are known apriori, so only a single iteration of the KSVD algorithm is required. For more details, we refer the readers to [1]. 5 3.4 Parameter Estimation and Initialization The use of the Jeffereys prior for Θ R and Θ C yields simple update equations: σ ( k ) i = ( 1 M +2 k ~ y i − D ( k ) ~ x ( k ) i k 2 2 ) 1 2 and γ ( k ) j = 1 N +1 P N i =1 Ω( L j i ( ~ w ( k ) j ) T ~ x ( k ) i ) . These variables estimate the sample representation v ariance and the mean/variance of the classification cost respecti vely . Since the o ver - all update scheme is iterativ e, proper initialization is needed. In our experiments, we initialize D (0) to a randomly selected subset of training samples (uniformly chosen from the different classes) or to random zero-mean Gaussian vectors, followed by columnwise normalization. Interestingly , both schemes produce similar dictionaries, although the randomized scheme requires more iterations for con vergence. The representations X (0) are computed by TSC using D (0) . Initializing the remaining variables uses the update schemes abo ve. Algorithm 2 summarizes the ov erall DDL framew ork. Algorithm 2 Discriminativ e Dictionary Learning (DDL) INPUT : Y , L , T , Ω , q max , p max , Stop Criterion Initialize D (0) , X (0) , Θ (0) R , Θ (0) C , and q = 0 while (Stop Criterion) AND q ≤ q max do for i = 1 to N do ~ x ( q +1) = DSC ( D ( q ) σ ( q ) i , ~ y i σ ( q ) i , W ( q ) diag ( ~ l i ) , 1 Θ ( q ) C , Ω , ~ x ( q ) , T , p max , Stop Criterion ) ; end for Learn classifiers W ( q +1) using L and X ( q +1) ; D ( q +1) = KSVD ( D ( q ) , X ( q +1) , T ) ; Update ~ σ ( q +1) and ~ γ ( q +1) ; q = q + 1 ; end while OUTPUT : D ( q ) , W ( q ) , X ( q ) , ~ σ ( q ) , and ~ γ ( q ) 3.5 Inference After learning D and W , we describe how the label of a test sample ~ y t is inferred. W e seek the class j t that maximizes p ( ~ y t | ~ l t ( j )) , where ~ l t ( j ) is the label vector of ~ y t assuming it belongs to class j . By marginalizing with respect to ~ x and assuming a single dominant representation ~ x t exists, j t is the class that maximizes p ( ~ y t | ~ x t , D ) p ( ~ x t | ~ l t ( j ) , W ) , as in Eq. (5). The inner maximization problem is exactly a DSC problem where ~ l t ( j ) is the hypothesized label vector . Here, we use the testing representation model to account for dense errors (e.g. occlusion), thus, augmenting D by identity . Computing j t in volves C independent DSC problems. T o reduce computational cost, we solve a single TSC problem instead: ~ x t = argmax ~ x ∈ S T p ( ~ y t | ~ x , D ) . In this case, j t = argmax j ∈ 1 ,...,C p ( ~ l t ( j ) | ~ x t , W ) . j t = argmax j ∈ 1 ,...,C max ~ x ∈ S T p ( ~ y t | ~ x , D ) p ( ~ l t ( j ) | ~ x , W ) (5) Implementation Details: There are sev eral ways to speedup computation and allow for quicker con vergence. (i) The DSC update step is the most computationally expensiv e operation in Algo- rithm 2. This is mitigated by using a greedy TSC method (Batch-OMP instead of ` 1 minimization methods) and exploiting the inherent parallelism of DDL (e.g. doing DSC updates in parallel). (ii) Selecting suitable initializations for D and the DSC solutions can dramatically speedup con- ver gence. F or example, choosing D (0) from the training set leads to a smaller number of DDL iterations than randomly choosing D (0) . Also, we initialize DSC solutions at a given DDL iteration with those from the pre vious iteration. Moreover , the DDL framew ork is easily extended to the semi-supervised case, where only a subset of training samples are labeled. The only modification to be made here is to use TSC (instead of DSC) to update the representations of unlabeled samples. 6 4 Experimental Results In this section, we provide empirical analysis of our DDL framew ork when applied to handwrit- ten digit classification ( C = 10 ) and face recognition ( C = 38 ). Digit classification is a standard machine learning task with two popular benchmarks, the USPS and MNIST datasets. The digit sam- ples in these two datasets ha ve been acquired under different conditions or written using significantly different handwriting styles. T o alleviate this problem, we use the alignment and error correction technique for TSC that was introduced in [26]. This corrects for gross errors that might occur (e.g. due to thickening of handwritten strokes or reasonable rotation/translation). Consequently , we do not need to augment the training set with shifted versions of the training images, as done in [18]. Furthermore, we apply DDL to face recognition, which is a machine vision problem where sparse representation has made a big impact. W e use the Extended Y ale B (E-Y ALE-B) benchmark for ev aluation. T o show that learning D in a discriminativ e fashion improv es upon traditional dictio- nary learning, we compare our method against a baseline that treats representation and classification independently . In the baseline, X and D are estimated using KSVD, W is learned using X and L directly , and a a winner-take-all classification strategy is used. Clearly , our framework is general, so we do not expect to outperform methods that use domain-specific features and machinery . How- ev er, we do achie ve results comparable to state-of-the-art. Also, we show that our DDL framework significantly outperforms the baseline. In all our experiments, we set q max = 20 and p max = 100 and initialize D to elements in the training set. Digit Classification: The USPS dataset comprises N = 7291 training and 2007 test images, each of 16 × 16 pixels ( M = 256 ). W e plot the test error rates of the baseline for the four classifier types and for a range of T and K v alues in Figure 2. Beneath each plot, we indicate the values of K and T that yield minimum error . This is a common way of reporting SDL results [18, 19, 21, 22]. Interestingly , the square loss classifier leads to the lowest error and the best generalization. For comparison, we plot the results of our DDL method in Figure 3. Clearly , our method achieves a significant impro vement of 4 . 5% over the baseline, and 1% and 0 . 5% ov er the SDL methods in [19] and [18] respectiv ely . Our results are comparable to the state-of-the-art performance ( 2 . 2% ) [16]). This result shows that adapting D to the underlying data and class labels yields a dictionary that is better suited for classification. Increasing T leads to an overall improvement of performance because representation becomes more reliable. Howe ver , we observe that beyond T = 3 , this improv ement is insignificant. The square loss classifier achiev es the lo west performance and the logistic classifier achiev es the highest. The variations of error with K are similar for all the classifiers. Error steadily decreases till an “optimal” K value is reached. Beyond this K value, performance deteriorates due to overfitting. Future work will study how to automatically predict this optimal value from training data, without resorting to cross-validation. In Figure 4, we plot the learned parameters Θ R (in histogram form) and Θ C for a typical DDL setup. W e observe that the form of these plots does not significantly change when the training setting is changed. W e notice that the Θ R histogram fits the form of the Jeffere ys prior , p ( x ) ∝ 1 x . Most of the σ values are close to zero, which indicates reliable reconstruction of the data. On the other hand, Θ C take on similar v alues for most classes, except the “0” digit class that contains a significant amount of variation and thus the highest classification cost. Note that these values tend to be inv ersely proportional to the classification performance of their corresponding linear classifiers. W e provide a visualization of the learned D in the supplementary material . Interestingly , we observe that the dictionary atoms resemble digits in the training set and that the number of atoms that resemble a particular class is in versely proportional to the accuracy of that class’ s binary classifier . This occurs because a “hard” class contains more intra-class v ariations requiring more atoms for representation. The MNIST dataset comprises N = 60000 training and 10000 test images, each of 28 × 28 pixels ( M = 784 ). W e show the baseline and DDL test error rates in T able 1. W e train each classifier type using the K and T v alues that achiev ed minimum error for that classifier on the USPS dataset. Compared to the baseline, we observe a similar improvement in performance as in the USPS case. Also, our results are comparable to state-of-the-art performance ( 0 . 53% ) for this dataset [14]. Face Recognition: The E-Y ALE-B dataset comprises 2 , 414 images of C = 38 individuals, each of 192 × 168 pixels, which we downsample by an order of 8 ( M = 504 ). Using a classification setup similar to [29] with K = 600 and T = 5 , we record the classification results in T able 1, 7 Figure 2: Baseline classification performance on the USPS dataset Figure 3: DDL classification performance on the USPS dataset Figure 4: Parameters Θ R and Θ C learned from the USPS dataset 8 which lead to implications similar to those in our pre vious e xperiments. Interestingly , DDL achieves similar results to the robust sparse representation method of [29], which uses all training samples ( K ≈ 1200 ) as atoms in D . This shows that learning a discriminativ e D can reduce the dictionary size by as much as 50% , without significant loss in performance. T able 1: Baseline and DDL test error on MNIST and E-Y ALE-B datasets MNIST (digit classification) E-Y ALE-B (face recognition) SQ EXP LOG HINGE SQ EXP LOG HINGE B ASELINE 8 . 35% 6 . 91% 5 . 77% 4 . 92% 10 . 23% 9 . 65% 9 . 23% 9 . 17% DDL 1.41 % 1.28 % 1.01 % 0.72 % 8.89 % 7.82 % 7.57 % 7.30 % 5 Conclusions This paper addresses the problem of discriminative dictionary learning by jointly learning a sparse linear representation model and a linear classification model in a MAP setting. W e dev elop an optimization framework that is capable of incorporating a diverse family of popular classification cost functions and solvable by a sequence of update operations that build on well-known and well- studied methods in sparse representation and dictionary learning. Experiments on standard datasets show that this frame work outperforms the baseline and achiev es state-of-the-art performance. References [1] M. Aharon, M. Elad, and A. M. Bruckstein. The K-SVD:an algorithm for designing of ov er- complete dictionaries for sparse representations. In IEEE T ransactions on Signal Processing , volume 54, 2006. [2] P . Bickel, Y . Ritov , and A. Tsybakov . Simultaneous analysis of Lasso and Dantzig selector. ArXiv e-prints , 2008. [3] M. Dav enport and M. W akin. Analysis of Orthogonal Matching Pursuit using the restricted isometry property. IEEE T ransactions on Information Theory , 56(9):4395–4401, 2010. [4] D. Donoho and M. Elad. Optimally sparse representation in general (nonorthogonal) dictio- naries via l minimization. Proc. of the National Academy of Sciences , 100(5):2197–202, 2003. [5] N. Duffy and D. Helmbold. Boosting methods for regression. Journal of Machine Learning Resear ch , 47(2):153–200, 2002. [6] M. Elad and M. Aharon. Image denoising via sparse and redundant representations o ver learned dictionaries. IEEE T ransactions on Ima ge Pr ocessing , 15(12):3736–45, 2006. [7] M. Elad, M. Figueiredo, and Y . Ma. On the Role of Sparse and Redundant Representations in Image Processing. Proceedings of the IEEE , 98(6):972–982, 2010. [8] K. Engan, S. Aase, and J. Husoy . Frame based signal compression using method of optimal directions (mod). In IEEE Intern. Symp. Circ. Syst. , 1999. [9] M. Figueiredo. Adaptiv e Sparseness using Jef freys’ Prior. NIPS , 1:697–704, 2002. [10] J. Friedman, R. Tibshirani, and T . Hastie. Additive logistic regression: a statistical view of boosting. The Annals of Statistics , 28(2):337–407, 2000. [11] R. Giryes, M. Elad, and Y . Eldar . Automatic parameter setting for iterati ve shrinkage methods. In IEEE Convention of Electrical and Electr onics Engineers in Isr ael , pages 820–824, 2009. [12] R. Gribon v al and M. Nielsen. Sparse representations in unions of bases. IEEE T ransactions on Information Theory , 49(12):3320–3325, 2004. [13] K. Huang and S. A viyente. Sparse representation for signal classification. In NIPS , pages 609–616, 2006. [14] K. Jarrett, K. Ka vukcuoglu, M. Ranzato, and Y . LeCun. What is the best multi-stage architec- ture for object recognition? ICCV , pages 2146–2153, 2009. [15] R. Jenatton, J. Mairal, G. Obozinski, and F . Bach. Proximal methods for sparse hierarchical dictionary learning. In ICML , 2010. [16] D. Keysers, J. Dahmen, T . Theiner, and H. Ney . Experiments with an extended tangent dis- tance. ICPR , 1(2):38–42, 2000. 9 [17] N. Loeff and A. Farhadi. Scene discov ery by matrix factorization. ECCV , pages 451–464, 2008. [18] J. Mairal, F . Bach, and J. Ponce. T ask-Dri ven Dictionary Learning. ArXiv e-prints , Sept. 2010. [19] J. Mairal, F . Bach, J. Ponce, G. Sapiro, , and A. Zisserman. Supervised dictionary learning. In NIPS , 2008. [20] J. Mairal, F . Bach, J. Ponce, and G. Sapiro. Online dictionary learning for sparse coding. ICML , pages 1–8, 2009. [21] J. Mairal, F . Bach, J. Ponce, G. Sapiro, and A. Zisserman. Discriminativ e learned dictionaries for local image analysis. In CVPR , 2008. [22] J. Mairal, M. Leordeanu, F . Bach, M. Hebert, and J. Ponce. Discriminativ e sparse image models for class-specific edge detection and image interpretation. ECCV , pages 43–56, 2008. [23] J. Mairal, G. Sapiro, and M. Elad. Learning multiscale sparse representations for image and video restoration. SIAM Multiscale Modeling and Simulation , 7(1):214–241, 2008. [24] R. Mazhar and P . Gader . EK-SVD: Optimized dictionary design for sparse representations. In ICPR , pages 1–4, 2008. [25] R. Rubinstein, M. Zibule vsky , and M. Elad. Efficient implementation of the k-svd algorithm using batch orthogonal matching pursuit. CS T echnion T echnical Report , pages 1–15, 2008. [26] A. W agner , J. Wright, A. Ganesh, Z. Zhou, and Y . Ma. T o wards a practical face recognition system: Robust registration and illumination by sparse representation. In CVPR , pages 597 –604, 2009. [27] J. Wright and Y . Ma. Dense error correction via l1-minimization. In IEEE T ransactions on Information Theory , number 2, pages 3033–3036, 2010. [28] J. Wright, Y . Ma, J. Mairal, G. Sapiro, T . Huang, and S. Y an. Sparse Representation for Computer V ision and Pattern Recognition. Pr oceedings of the IEEE , 98(6):1031–1044, 2010. [29] J. Wright, A. Y ang, A. Ganesh, S. Sastry , and Y . Ma. Rob ust face recognition via sparse representation. TP AMI , 31(2):210–27, 2009. [30] H. Zou. The Adaptiv e Lasso and its Oracle Properties. J ournal of the American Statistical Association , 101:1418–1429, 2006. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment