Bandits with an Edge
We consider a bandit problem over a graph where the rewards are not directly observed. Instead, the decision maker can compare two nodes and receive (stochastic) information pertaining to the difference in their value. The graph structure describes t…
Authors: Dotan Di Castro, Claudio Gentile, Shie Mannor
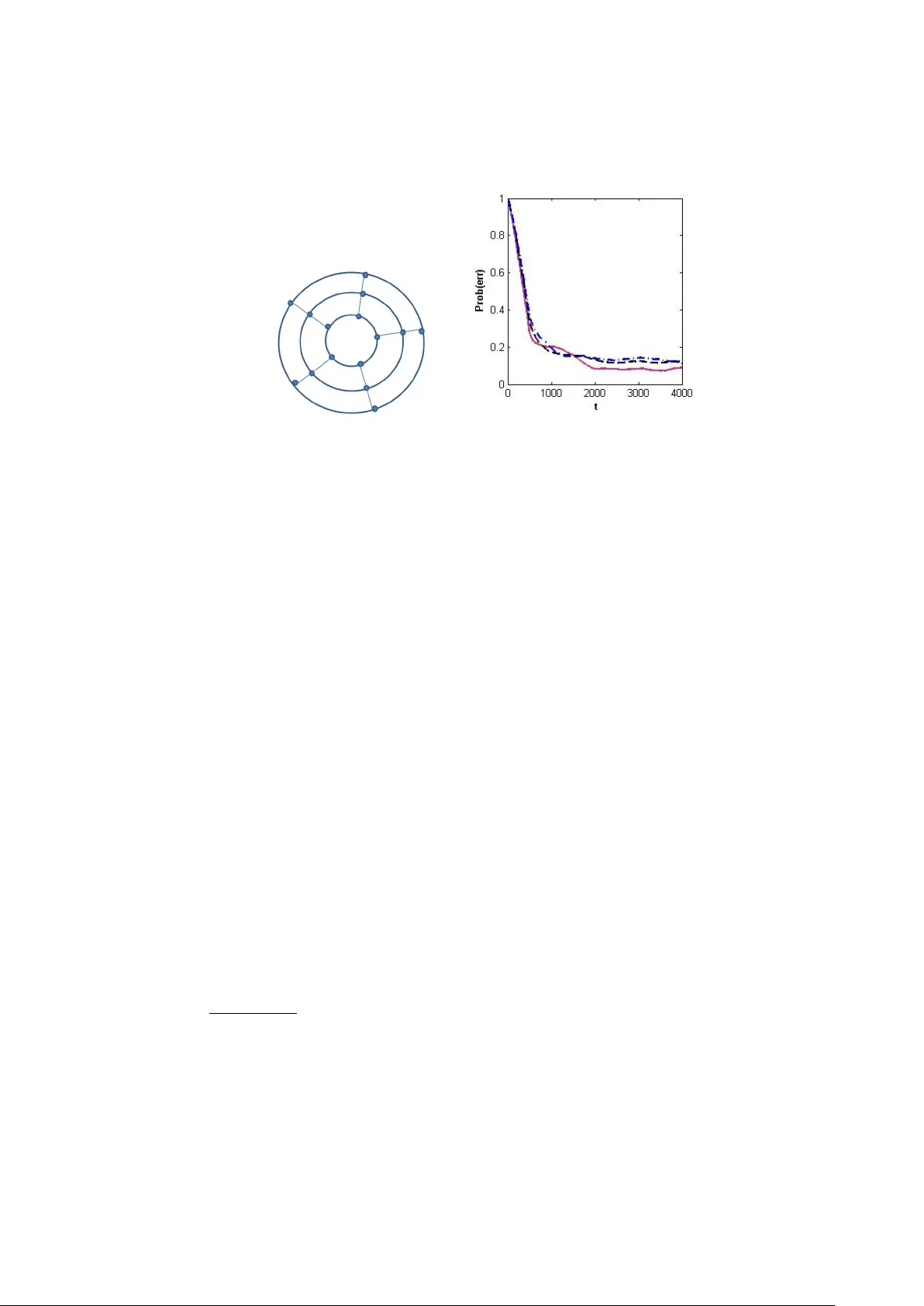
Bandits with an Edge Dotan Di Castro 1 , Claudio Gen tile 2 , and Shie Mannor 1 1 T ec hnion, Israel Institute of T ec hnology , Haifa, Israel 2 Univ ersita’ dell’Insubria, V arese, Italy dot@tx.technion.ac.il , claudio.gentile@uninsubria.it , shie@ee.technion.ac.il Abstract. W e consider a bandit problem o v er a graph where the re- w ards are not directly observ ed. Instead, the decision maker can com- pare tw o no des and receive (stochastic) information p ertaining to the difference in their v alue. The graph structure describ es the set of possi- ble comparisons. Consequently , comparing b et w een tw o no des that are relativ ely far requires estimating the difference betw een ev ery pair of no des on the path b et w een them. W e analyze this problem from the p erspective of sample complexity: How many queries are needed to find an approximately optimal node with probability more than 1 − δ in the P A C setup? W e sho w that the topology of the graph plays a crucial in defining the sample complexit y: graphs with a lo w diameter ha v e a muc h b etter sample complexit y . 1 In tro duction W e consider a graph where every edge can be sampled. When sampling an edge, the decision maker obtains a signal that is related to the v alue of the no des defining the edge. The ob jectiv e of the decision maker is to locate the node with the highest v alue. Since there is no p ossibilit y to sample the v alue of the no des directly , the decision maker has to infer which is the b est node b y considering the differences b et w een the nodes. As a motiv ation, consider the setup where a user interacts with a webpage. In the w ebpage, sev eral links or ads can b e presen ted, and the response of the user is to click one or none of them. Essen tially , in this setup we query the user to compare b etw een the different alternatives. The resp onse of the user is comparativ e: a preference of one alternative to the other will b e reflected in a higher probability of choosing the alternative. It is muc h less lik ely to obtain direct feedback from a user, asking her to provide an e v aluation of the w orth of the selected alternativ e. In suc h a setup, not all pairs of alternatives can b e directly compared or, even if so, there might b e constrain ts on the num ber of times a pair of ads can b e presented to a user. F or example, in the context of ads it is reasonable to require that ads for similar items will not appear in the same page (e.g., tw o comp eting brands of luxury cars will not app ear on the same page). In these con texts, a click on a particular link cannot b e seen as an absolute relev ance judgement (e.g., [13]), but rather as a relative preference. Moreov er, 2 Di Castro, Gen tile, Mannor feedbac k can b e noisy and/or inconsisten t, hence aggregating the choices into a coherent picture ma y b e a non-trivial task. Finally , in such con texts pairwise comparisons o ccur more frequently than m ultiple comparisons, and are also more natural from a cognitiv e p oin t of view (e.g.,[22]). W e mo del this learning scenario as bandits on graphs where the information that is obtained is differen tial. W e assume that there is an inherent and unknown v alue p er no de, and that the graph describes the allo w ed (pairwise) comparisons. That is, no des i and j are connected b y an edge if they can b e compared by a single query . In this case, the query returns a random v ariable whose distribution dep ends, in general, on the v alues of i and j . F or the sak e of simplicity , we assume that the observ ation of the edge b et w een nodes i and j is a random v ariable that dep ends only on the differ enc e betw een the v alues of i and j . Since this assumption is restrictiv e in terms of applicability of the algorithms, we also consider the more general setup where contextual information is observ ed b efore sampling the edges. This is intended to mo del a more practical setting where, sa y , a web system has preliminary access to a set of user profile features. In this pap er, our goal is to identify the no de with the highest v alue, a problem that has b een studied extensively in the machine learning literature (e.g., [10,1]). More formally , our ob jective is to find an approximately optimal no de (i.e., a node whose v alue is at most smaller than the highest v alue) with a giv en failure probability δ as quic kly as possible. When con textual information is added, the goal becomes to progressiv ely fasten the time needed for identifying a go od no de for the given user at hand, as more and more users interact with the system. Related w ork. There are tw o common ob jectives in sto c hastic bandit prob- lems: minimizing the regret and identifying the “b est” arm. While b oth ob- jectiv es are of interest, regret minimization seems particularly difficult in our setup. In fact, a recent line of researc h related to our pap er is the Dueling Ban- dits Pr oblem of Y ue et al. [24,25] (see also [11]). In the dualing bandit setting, the learner has at its disp osal a c omplete graph of comparisons betw een pairs of no des, and eac h edge ( i, j ) hosts an unknw on preference probability p i,j to b e in terpreted as the probability that no de i will b e preferred ov er no de j . F urther consistency assumptions (stochastic transitivit y and sto c hastic triangle inequalit y) are added. The complete graph assumption allows the authors to define a well-founded notion of regret, and analyze a regret minimization algo- rithm whic h is further enhanced in [25] where the consistency assumptions are relaxed. Although at first look our pap er seems to deal with the same setup, we highligh t here the main differences. First, the setups are differen t with resp ect to the top ology handled. In [24,25] the top ology is alwa ys a complete graph whic h results in the p ossibilit y to directly compare b et w een every tw o no des. In our work (as in real life) the top ology is not a complete graph, resulting in a framework where a comparison of tw o nodes requires sampling all the edges b et w een the no des. In the extreme case of a straight line we need to sample all the given edges in the graph in order to compare the t w o nodes that are farthest apart. Second, the ob jectiv e of minimizing the regret is natural for a complete Bandits with an edge 3 graph where it amounts to comparing a c hoice of the b est bandit repeatedly with the actual pairs c hosen. In a top ology other than the complete graph this notion is less clear since one has to restrict choices to edges that are a v ailable. Finally , the algorithms in [24,25] are geared to w ards the elimination of arms that are not optimal with high probability . In our setup one c annot eliminate suc h no des and edges b ecause it is crucial in comparing candidates for optimal no des. Therefore, the resulting algorithms and analyses are quite different. On the other hand, constraining to a given set of allow ed comparisons leads us to mak e less general statistical assumptions than [24,25], in that our algorithms are based on the abilit y to reconstruct the rew ard difference on adjacen t nodes by observing their connecting edge. F rom a different persp ective, the setup we consider is reminiscen t of online learning with partial monitoring [19]. In the partial monitoring setup, one usu- ally do es not observe the reward directly , but rather a signal that is related (probabilistically) to the unobserved rew ard. How ev er, as far we know, the al- ternativ es (called arms usually) in the partial monitoring setup are separate and there is no additional structure: when sampling an arm a rew ard that is related to this arm alone is obtained but not observed. Our work differs in imposing an additional structure, where the signal is derived from the structure of the problem where the signal is alwa ys relativ e to adjacent nodes. This means that comparing tw o no des that are not adjacent requires sampling all the edges on a path b et w een the t w o nodes. So that deciding which of t w o remote nodes has higher v alue requires a high degree of certaint y regarding all the comparisons on the path b et w een them. Another research area whic h is somewhat related to this paper is learning to rank via comparisons (a very partial list of references includes [7,13,8,4,14,5,12,23,18]). Roughly sp eaking, in this problem we ha v e a collection of training instances to b e associated with a finite set of possible alternatives or classes (the graph nodes in our setting). Ev ery training example is assigned a set of (p ossibly noisy or inconsisten t) pairwise (or groupwise) preferences betw een the classes. The goal is to learn a function that maps a new training example to a total order (or rank- ing) of the classes. W e emphasize that the goal in this paper is different in that w e work in the bandit setup with a given structure for the comparisons and, in addition, w e are just aiming at iden tifying the (appro ximately) best class, rather than ranking them all. Con ten t of the pap er. The rest of the paper is organized as follo ws. W e start from the formal mo del in Section 2. W e analyze the basic linear setup, where eac h no de is comparable to at most t w o nodes in Section 3. W e then mov e to the tree s etup and analyze it in Section 4. The general setup of a net w ork is treated in Section 5. Some exp eriments are then presented in Section 6 to elucidate the theoretical findings in previous sections. In Section 7 we discuss the more general setting with contextual information. W e close with some directions for future researc h. 4 Di Castro, Gen tile, Mannor 2 Mo del and Preliminaries In this section w e describ e the classical Multi-Armed Bandit (MAB) setup, de- scrib e the Graphical Bandit (GB) setup, state/recall t w o concen tration bounds for sequences of random v ariables, and review a few terms from graph theory . 2.1 The Multi-Armed Bandit Problem The MAB mo del [16] is comprised of a set of arms A , { 1 , . . . , n } . When sampling arm i ∈ A , a r ewar d whic h is a random v ariable R i , is pro vided. Let r i = E [ R i ]. The goal in the MAB setup is to find the arm with the highest exp ected rew ard, denoted b y r ∗ , where we term this arm’s reward the optimal r ewar d . An arm whose expected rew ard is strictly less than r ∗ is called a non-b est arm . An arm i is called an -optimal arm if its expected reward is at most from the optimal reward, i.e., E [ R i ] ≥ r ∗ − . In some cases, the goal in the MAB setup is to find an -optimal arm. A t ypical algorithm for the MAB problem do es the following. At each time step t it samples an arm i t and receiv es a rew ard R i t . When making its selection, the algorithm ma y dep end on the history (i.e., the actions and rew ards) up to time t − 1. Ev en tually the algorithm must commit to a single arm and select it. Next w e define the desired prop erties of suc h an algorithm. Definition 1. (P AC-MAB) An algorithm is an ( , δ ) -pr ob ably appr oximately c orr e ct (or ( , δ ) -P AC) algorithm for the MAB pr oblem with sample c omplex- ity T , if it terminates and outputs an -optimal arm with pr ob ability at le ast 1 − δ , and the numb er of times it samples arms b efor e termination is b ounde d by T . In the case of standard MAB problems there is no structure defined ov er the arms. In the next section we describe the setup of our work where suc h a structure exists. 2.2 The Graphical Bandit Problem Supp ose that we hav e an undirected and connected graph G = ( V , E ) with no des V = { 1 , . . . , n } and edges E . The no des are associated with rew ard v alues r 1 , . . . , r n , resp ectiv ely , that are unknown to us. W e denote the no de with highest v alue by i ∗ and, as before, r ∗ = r i ∗ . Define u , min j 6 = i ∗ r i ∗ − r j to b e the difference betw een the node with the highest v alue and the no de with the second highest v alue. W e call u the reward gap , and in terpret it as a measure for how easy is to discriminate betw een the t w o b est no des in the netw ork. As expected, the gap u has a significant influence on the sample complexit y bounds (provided the accuracy parameter is not large). W e sa y that nodes i and j are neighb ors if there is an edge in E connecting them (and denote the edge random v ariable by E ij ). This edge v alue is a random v ariable whose distribution is determined b y the no des it is connecting, i.e., ( i, j )’s statistics are determined by r i and r j . In Bandits with an edge 5 this w ork, we assume that 1 E E ij = r j − r i . Also, for the sak e of concreteness, w e assume the edge v alues are b ounded in [ − 1 , 1]. In this mo del, we can only sample the graph edges E ij that provide in- dep enden t realizations of the no de differences. F or instance, w e ma y interpret E ij = +1 if the feedbac k we receive says that item j is preferred ov er item i , E ij = − 1 if i is preferred o v er j , and E ij = 0 if no feedbac k is receiv ed. Then the rew ard difference r j − r i b ecomes equal to the difference b et w een the probability of preferring j ov er i and the probability of preferring i ov er j . Let us denote the realizations of E ij b y E ij t where the subscript t denotes time. Our goal is to find an -optimal no de, i.e., a node i whose reward satisfies r i ≥ r ∗ − . Whereas neighboring no des can b e directly compared by sampling its con- necting edge, if the nodes are far apart, a comparison b et w een the tw o can only b e done indirectly , b y following a path connecting them. W e denote a p ath b e- t w een node i and no de j by π ij . Observ e that there can be several paths in G connecting i to j . F or a giv en path π from i to j , we define the c omp ose d e dge v alue E ij π b y E ij π = P ( k,l ) ∈ π ij E kl , with E ii π = 0. By telescoping, the av erage v alue of a comp osed edge E ij only dep ends on its endpoints, i.e., E E ij π = X ( k,l ) ∈ π ij E E kl = X ( k,l ) ∈ π ij ( r l − r k ) = r j − r i , (1) indep enden t of π . Similarly , define E ij t to be the time- t realization of the com- p osed edge random v ariable E ij π when w e pull once all the edges along the path π joining i to j . A schematic illustration of the the GB setup is presen ted in Figure 1. Fig. 1. Sc hematic illustration of the the GB setup for 6 nodes The algorithms we presen t in the next sections hinge on constructing reliable estimates of edge reward differences, and then combining them into a suitable no de selection procedure. This pro cedure hea vily dep ends on the graph top ology . In a tree-lik e (i.e., acyclic) structure no inconsistencies can arise due to the noise in the edge estimators. Hence the no de selection pro cedure just aims at iden tifying the no de with the largest rew ard gap to a giv en reference node. On 1 Notice that, although the graph is undirected, we view edge ( i, j ) as a directed edge from i to j . It is understo o d that E j i = − E ij . 6 Di Castro, Gen tile, Mannor the other hand, if the graph has cycles, we hav e to rely on a more robust node elimination pro cedure, akin to the one inv estigated in [10] (see also the more recen t [1]). 2.3 Large Deviations Inequalities In this w ork w e use Ho effding’s maximal inequalit y (e.g., [6]). Lemma 1. L et X 1 , . . . , X N b e indep endent r andom variables with zer o me an satisfying a i ≤ X i ≤ b i w.p. 1. L et S i = P i j =1 X j . Then, P max 1 ≤ i ≤ N S i > ≤ exp − 2 P N i =1 ( b i − a i ) 2 ! . 3 Linear top ology and sample complexit y As a w arm-up, we start b y considering the GB setup in the case of a linear graph, i.e., E = { ( i, i + 1) : 1 ≤ i ≤ n − 1 } . W e call it the line ar setup . The algorithm for finding the highest node in the linear setup is presented in Algorithm 1. The algorithm samples all the edges, computes for each edge its empirical mean, and based on these statistics finds the highest edge. Algorithm 1 will also serve as a subroutine for the tree-top ology discussed in Section 4. The following prop osition Algorithm 1 The algorithm for the linear setup Input: > 0, δ > 0, line graph with edge set E = { ( i, i + 1) : 1 ≤ i ≤ n − 1 } 1: for i = 1 , . . . , n − 1 do 2: Pull edge ( i, i + 1) for T i times 3: Let ˆ E i,i +1 = 1 T i P T i t =1 E i,i +1 t b e the empirical av erage of edge ( i, i + 1) 4: Let ˆ E 1 i π 1 i = P i − 1 k =1 ˆ E k − 1 ,k b e the empirical a v erage of the comp osed edge E 1 i π 1 i , where π 1 i is the (unique) path from 1 to i . 5: end for Output: No de k = argmax i =1 ,...,n ˆ E 1 i π 1 i . giv es the sample complexity of Algorithm 1 in the case when the edges are b ounded. Prop osition 1. If − 1 ≤ E i,i +1 ≤ 1 holds, then Algorithm 1 op er ating on a line ar gr aph with r ewar d gap u is an ( , δ ) -P AC algorithm when the T i satisfy n − 1 X i =1 4 T i ! − 1 ≥ 1 max { , u } 2 log 2 δ . If T i = T then the sample c omplexity of e ach e dge is T ≥ 4 n max { ,u } 2 log 2 δ . Henc e the sample c omplexity of the algorithm is O n 2 max { ,u } 2 log 1 δ . Bandits with an edge 7 Pr o of. Let ˜ E i,i +1 t , ( r i +1 − r i ) − E i,i +1 t T i , t = 1 , ...T i . Eac h ˜ E i,i +1 t has zero mean with − 2 /T i ≤ ˜ E i,i +1 t ≤ 2 /T i . Hence ˜ E 1 , 2 1 , . . . , ˜ E 1 , 2 T 1 , ˜ E 2 , 3 1 , . . . , ˜ E 2 , 3 T 2 , . . . , ˜ E n − 1 ,n 1 , . . . , ˜ E n − 1 ,n T n − 1 (2) is a sequence of P n − 1 i =1 T i zero-mean and indep enden t random v ariables. Set for brevit y ˜ = max { , u } , and supp ose, without lost of generalit y , that some no de j has the highest v alue. The probability that Algorithm 1 fails, i.e., returns a no de whose v alue is b elo w the optimal v alue is b ounded b y Pr ∃ i = 1 , . . . , n : ˆ E 1 i π 1 i − ˆ E 1 j π 1 j > 0 and r i < r j − ˜ . (3) W e can write (3) ≤ Pr ∃ i = 1 , . . . , n : ˆ E 1 i π 1 i − ˆ E 1 j π 1 j − ( r i − r j ) > ˜ = Pr ∃ i = 1 , . . . , n : i − 1 X k =1 T i X t =1 ˜ E k,k +1 t > ˜ ≤ Pr ( ∃ partial sum in (2) with magnitude > ˜ ) ≤ 2 exp − ˜ 2 P n − 1 k =1 P T k t =1 (2 /T k ) 2 ! , where in the last inequality w e used Lemma 1. Requiring this probability to be b ounded b y δ yields the claimed inequality . u t The sample sizes T i in Prop osition 1 enco de constraints on the num ber of times the edges ( i, i + 1) can b e sampled. Notice that the statemen t therein implies T i ≥ 4 max { ,u } 2 log 2 δ for all i , i.e., we cannot afford in a line graph to undersample any edge. This is b ecause every edge in a line graph is a bridge , hence a po or estimation of any such edge w ould affect the differen tial reward estimation throughout the graph. In this resp ect, this proposition only allows for a partial tradeoff among these n um b ers. 4 T ree top ology and its sample complexit y In this section we in v estigate P AC algorithms for finding the b est no de in a tree. Let then G = ( V , E ) b e an n -no de tree with diameter D and a set of lea v es L ⊆ V . Without loss of generality we can as sume that the tree is ro oted at node 1 and that all edges are directed down w ards to the leav es. Algorithm 2 considers all possible paths from the ro ot to the leav es and treats eac h one of them as a line graph to be processed as in Algorithm 1. W e ha v e the follo wing prop osition where, for simplicit y of presentation, we do no longer differen tiate among the sample sizes T i,j asso ciated with edges ( i, j ). 8 Di Castro, Gen tile, Mannor Algorithm 2 The algorithm for the tree setup Input: > 0, δ > 0, tree graph with set of lea v es L ⊆ V 1: for all leav es k ∈ L do 2: Pull each edge ( i, j ) ∈ E for T times 3: Let ˆ E ij = 1 T P T t =1 E ij t b e the empirical av erage of edge ( i, j ), and m k = argmax (1 ,i ) ∈ π 1 ,k ˆ E 1 i π 1 i b e the maxim um empirical av erage along path π 1 k (as in Algorithm 1) 4: end for Output: No de m = argmax k ∈ L m k . Prop osition 2. If − 1 ≤ E ij ≤ 1 holds, then Algorithm 2 op er ating on a tr e e gr aph with r ewar d gap u is an ( , δ ) -P AC algorithm when the sample c omplexity T of e ach e dge satisfies T ≥ 4 D max { ,u } 2 log 2 | L | δ . Henc e the sample c omplexity of the algorithm is O nD max { ,u } 2 log | L | δ . Pr o of. The probabilit y that Algorithm 2 returns a no de whose a v erage rew ard is b elo w the optimal one coincides with the probabilit y that there exists a leaf k ∈ L such that Algorithm 1 op erating on the linear graph π 1 ,k singles out a no de m k whose a v erage rew ard is more than from the optimal one within π 1 ,k . Setting T = 4 | π 1 ,k | ˜ 2 log 2 | L | δ , with ˜ = max { , u } , ensures that the ab o v e happ ens with probabilit y at most δ / | L | . Hence each edge is sampled at most 4 D ˜ 2 log 2 | L | δ times and the claim follo ws b y a standard union b ound o v er L . u t 5 Net w ork Sample Complexit y In this section w e deal with the problem of finding the optimal reward in a general connected and undirected graph G = ( V , E ), being | V | = n . W e describ e a no de elimination algorithm that w orks in phases, sketc h an efficient implemen tation and provide a sample complexity . The following ancillary definitions will b e useful. W e sa y that a no de is a lo c al maximum in a graph if all its neighboring no des do not hav e higher exp ected reward than the no de itself. The distance b et w een node i and no de j is the length of the shortest path b et w een the t w o no des. Finally , the diameter D ( G ) of a graph G is the largest distance betw een an y pair of no des. Our suggested Algorithm op erates in log n phases. F or notational simplicit y , it will b e conv enien t to use subscripts to denote the phase num ber. W e b egin with Phase 1, where the graph G 1 = ( V 1 , E 1 ) is the original graph, i.e., at the b eginning all no des are participating, and n 1 = | V 1 | = n. W e then find a subgraph of G 1 , which we call sample d gr aph denoted by G S 1 , that includes all the edges inv olv ed in shortest paths b et w een all nodes in V 1 . W e sample eac h edge Bandits with an edge 9 in subgraph G S 1 for T 1 -times, and compute the corresp onding sample av erages. Based on these a v erages, w e find the lo cal maxima 2 of G S 1 . The k ey observ ation is that there can be at most n 1 / 2 maxima. Denote this set of maxima by V 2 . No w, define a subgraph, denoted by G 2 , whose no des are V 2 . W e rep eat the pro cess of getting a sampled graph, denoted b y G S 2 . W e sample the edges of the sampled graph G S 2 for T 2 -times and define, based on its maxima, a new subgraph. Denote the set of maxima by V 3 , and the pro- cess con tin ues un til only one no de is left. W e call this algorithm NNE ( Network No de Elimination ), whic h is similar to the action elimination procedure of [10] (see also [1]). The algorithm is summarized in Algorithm 3. Tw o p oin ts should Algorithm 3 The Netw ork Node Elimination Algorithm Input: > 0, δ > 0, graph G = ( V , E ), i = 1 1: Initialize G 1 = G , V 1 = V 2: Compute the shortest path b et w een all pairs of no des of G 1 , and denote each path b y π ij . 3: Initialize the shortest path set b y S P 1 = { π ij | i, j ∈ V 1 } 4: while | V i | > 1 do 5: n i = | V i | 6: Using the shortest paths in S P i , find a sampled graph G S i of G i 7: D i = D ( G S i ) 8: Pull each edge in G S i for T i times 9: Find the lo cal maxima set, V i +1 , on G S i , and get a subgraph G i +1 that contains V i +1 10: S P i +1 = { π ij ∈ S P i | i, j ∈ V i +1 } 11: i ← i + 1 12: end while Output: The remaining no de b e made regarding the NNE algorithm. First, as will b e observ ed b elo w, the sequence D ( G S i ) log n i =1 of diameters is nonincreasing. Second, from the imple- men tation viewp oint, a data-structure maintaining all shortest paths b et w een no des is crucial, in order to efficiently eliminate no des while trac king the short- est paths b et w een the surviving nodes of the graph. In fact, this data structure migh t just b e a collection of n breadth-first spanning trees ro oted at each no de, that encode the shortest path betw een the root and an y other node in the graph. When no de i gets eliminated, we first eliminate the spanning tree ro oted at i , but also prune all the other spanning trees where node i occurs as a leaf. If i is a (non-ro ot) internal no de of another tree, then i should not be eliminated from this tree since i certainly b elongs to the shortest path betw een another pair of surviving no des. Note that connectivit y is main tained through the process. The following result gives a P AC b ound for Algorithm 3 in the case when the E i,j are b ounded. 2 Ties can be brok en arbitrarily . 10 Di Castro, Gen tile, Mannor Prop osition 3. Supp ose that − 1 ≤ E i,j ≤ 1 for every ( i, j ) ∈ E . Then Algo- rithm 3 op er ating on a gener al gr aph G with diameter D and r ewar d gap u is an ( , δ ) -P AC algorithm with e dge sample c omplexity T ≤ P log n i =1 n i D i (max { , u } / log n ) 2 log n δ / log n ≤ n D (max { , u } / log n ) 2 log n δ / log n . Pr o of. In eac h phase w e hav e at most half the no des of the previous phase, i.e., n i +1 ≤ n i / 2. Therefore, the algorithm stops after at most log n phases. Also, b ecause we retain shortest path betw een the surviving nodes, we also hav e D i +1 ≤ D i ≤ D . A t each phase, similar to the previous sections, we mak e sure that it is at most δ / log n the probabilit y of identifying an / log n -optimal no de. Therefore, it suffices to pull the edges in eac h sampled graph G S i for T i ≤ n i D i (max { ,u } / log( n )) 2 log n i δ / log n times. Hence the o v erall sample complexity for an ( , δ )-P AC b ound is at most P log n j =1 T j , as claimed. The last inequalit y just follo ws from n i +1 ≤ n i / 2 and D i ≤ D for all i . u t Being more general, the bound con tained in Prop osition 3 is w eak er than the ones in previous sections when sp ecialized to line graphs or trees. In fact, one is left w ondering whether it is alwa ys conv enient to reduce the identification problem on a general graph G to the iden tification problem on trees by , say , extracting a suitable spanning tree of G and then inv oking Algorithm 2 on it. The answ er is actually negative, as the set of simulations rep orted in the next section sho w. 6 Sim ulations In this section we briefly in vestigate the role of the graph top ology in the sample complexit y . In our simple exp erimen t we compare Algorithm 2 (with tw o types of span- ning trees) to Algorithm 3 ov er the “spider web graph” illustrated in Figure 2 (a). This graph is made up of 15 nodes arranged in 3 concen tric circles (5 nodes eac h), where the circles are connected so as to resem ble a spider web. No de re- w ards are indep enden tly generated from the uniform distribution on [0,1], edge rew ards are just uniform in [-1,+1]. The tw o men tioned spanning trees are the longest diameter spanning tree (diameter 14) and the shortest diameter spanning tree (diameter 5). As w e see from Figure 2 (b), the latter tends to outp erform the former. How ever, b oth spanning tree-based algorithms are ev entually out- p erformed b y NNE on this graph. This is because in later stages NNE tends to handle smaller subgraphs, hence it needs only compare subsets of ”go od no des”. 7 Extensions W e no w sk etc h an extension of our framew ork to the case when the algorithm receiv es contextual information in the form of feature vectors b efore sampling Bandits with an edge 11 (a) (b) Fig. 2. ( a ) The spider-w eb topology . ( b ) Empirical error vs. time for the graph setup in (a) and spanning trees thereof. Three algorithms are compared: NNE (red solid line), the tree-based algorithm op erating on a smallest diameter spanning tree (blac k dashed line), and the tree-based algorithm op erating on a largest diameter spanning tree (blue dash-dot line). The parameters are n = 15 and = 0. Average of 200 runs. the edges. This is in tended to model a more practical setting where, sa y , a w eb system has preliminary access to a set of user profile features. This extension is reminiscent of the so-called c ontextual b andit learning set- ting (e.g., [17]), also called b andits with c ovariates (e.g., [21]). In suc h a setting, it is reasonable to assume that differen t users x s ha ve different preferences (i.e., differen t b est no des asso ciated with), but also that similar users tend to hav e similar preferences. A simple learning mo del that accommo dates the ab ov e (and is also amenable to theoretical analysis) is to assume each no de i of G to host a linear function u i : x → u > i x where, for simplicity , || u i || = || x || = 1 for all i and x . The optimal no de i ∗ ( x ) corresp onding to v ector x is i ∗ ( x ) = arg max i ∈ V u > i x . Our goal is to identify , for the given x at hand, an -optimal no de j such that u > j x ≥ u > i ∗ x − . Again, we do not directly observe no de rew ards, but only the differen tial rewards pro vided by edges. 3 When w e op erate on input x and pull edge ( i, j ), w e receiv e an indep enden t observ ation of random v ariable E ij ( x ) suc h that E [ E ij ( x )] = u > j x − u > i x . Learning pro ceeds in a sequence of stages s = 1 , . . . , S , each stage b eing in turn a sequence of time steps corresp onding to the edge pulls taking place in that stage. In Stage 1 the algorithm gets input x 1 , is allow ed to pull (sev eral times) the graph edges E ij ( x 1 ), and is required to output an -optimal node for x 1 . Let T ( x 1 ) b e the sample complexit y of this stage. In Stage 2, we retain the information gathered in Stage 1, receive a new v ector x 2 (p ossibly close to x 1 ) and rep eat the same kind of inference, with sample complexit y T ( x 2 ). The game con tinues un til S stages hav e b een completed. 3 F or simplicity of presen tation, w e disregard the rew ard gap here. 12 Di Castro, Gen tile, Mannor F or any giv en sequence x 1 , x 2 , . . . , x S , one exp ects the cum ulative sample size P S s =1 T ( x s ) to grow less than line arly in S . In other w ords, the additional effort the algorithm makes in the identification problem diminishes with time, as more and more users are in teracting with the system, esp ecially when these users are similar to eac h other, or even occur more than once in the sequence x 1 , x 2 , . . . , x S . In fact, w e can pro ve stronger results of the follo wing kind. Notice that the b ound do es not dep end on the num b er S of stages, but only on the dimension of the input space. 4 Prop osition 4. Under the ab ove assumptions, if G = ( V , E ) is a c onne cte d and undir e cte d gr aph, with n no des and diameter D , and x 1 , x 2 , . . . , x S ∈ R d is any se quenc e of unit-norm fe atur e ve ctors, then with pr ob ability at le ast 1 − δ a version of the NNE algorithm exists which outputs at e ach stage s an -optimal no de for x s , and achieves the fol lowing cumulative sample size S X s =1 T ( x s ) = O B log 2 B , wher e B = n D ( / log n ) 2 log n δ / log n d 2 . Pr o of (Sketch). The algorithm achieving this b ound combines linear-regression- lik e estimators with NNE. In particular, every edge of G main tains a linear estimator ˆ u ij in tended to approximate the difference u j − u i o ver both stages and sampling times within each stage. At stage s and sampling time t within stage s , the v ector ˆ u ij s,t suitably stores all past feature vectors x 1 , . . . , x s observ ed so far, along with the corresp onding edge rew ard observ ations. By using to ols from ridge regression in adv ersarial settings (see, e.g., [9]), one can show high- probabilit y approximation results of the form ( ˆ u ij s,t > x − ( u j − u i ) > x ) 2 ≤ x > A − 1 s,t x d log Σ s,t + log 1 δ , (4) b eing Σ s,t = P k ≤ s − 1 T ( x k ) + t , and A s,t the matrix A s,t = I + X k ≤ s − 1 T ( x k ) x k x > k + t x s x > s . In stage s , NNE is able to output an -optimal node for input x s as soon as the RHS of (4) is as small as c 2 , for a suitable constant c depending on the current graph top ology NNE is op erating on. Then the k ey observ ation is that in stage s the num b er of times we sample an edge ( i, j ) suc h that the ab o ve is false cannot b e larger than 1 c 2 log | A s,T ( x s ) | | A s, 0 | d log Σ s,T ( x s ) + log 1 δ , 4 A slightly differen t statement holds in the case when the input dimension is infinite. This statement quan tifies the cumulativ e sample size w.r.t. the amount to which the v ectors x 1 , x 2 , . . . , x S are close to eac h other. Details are omitted due to lac k of space. Bandits with an edge 13 where | · | is the determinan t of the matrix at argumen t. This follows from standard inequalities of the form P T ( x s ) t =1 x > s A − 1 s,t x s ≤ log | A s,T ( x s ) | | A s, 0 | . u t 8 Discussion This pap er falls in the research thread of analyzing online decision problems where the information that is obtained is comparative betw een arms. W e ana- lyzed a simple setup where the structure of comparisons is provided b y a giv en graph whic h, unlike previous w orks on this sub ject [24,25], lead us fo cus on the notion of finding an -optimal arm with high probabilit y . W e then describ ed an extension to the imp ortan t contextual setup. There are sev eral issues that call for further researc h that w e outline b elo w. First, we only addressed the exploratory bandit problem. It would be in ter- esting to consider the regret minimization version of the problem. While naively one can think of it as a problem with an arm p er edge of the graph, this may not be a very effectiv e model b ecause the n um b er of arms ma y go as n 2 but the n umber of parameters grows lik e n . On top of this, definining a meaningful no- tion of regret may not b e trivial (see the discussion in the in tro ductory section). Second, w e only considered graphs as opposed to h yp ergraphs. Considering com- parisons of more than tw o no des raises in teresting mo deling issues and w ell as computational issues. Third, we assumed that all samples are equiv alent in the sense that all the pairs w e can compare ha ve the same cost. This is not a realistic assumption in many applications. An approach akin to budgeted learning [20] w ould be interesting here. F ourth, we fo cused on upp er b ounds and construc- tiv e algorithms. Obtaining low er b ounds that depend on the netw ork top ology w ould b e interesting. The upper b ounds we ha v e provided are certainly lo ose for the case of a general net work. F urthermore, more refined upper b ounds are lik ely to exist which take in to accoun t the distance on the graph b et w een the go od no des (e.g., b et ween the b est and the second b est ones). In any even t, the algorithms w e developed for the net work case are certainly not optimal. There is ro om for improv ement b y reusing information b etter and b y adaptively se- lecting which p ortions of the net work to focus on. This is esp ecially in teresting under smo othness assumptions on the exp ected rewards. Relev ant references in the MAB setting to start off with include [2,15,3]. References 1. J.Y. Audib ert, S. Bub ec k, R. Munos (2010). Best Arm Identification in Multi- Armed Bandits. Confer enc e on L e arning The ory (COL T 2010). pp. 41–53 2. P . Auer, R. Ortner, C. Szep esvri (2007). Impro ved Rates for the Stochastic Con tinuum-Armed Bandit Problem. Confer enc e on L e arning The ory (COL T). pp. 454–468 3. S. Bubeck, R. Munos, G. Stoltz, C. Szepesv ari (2008). Online Optimization in X- Armed Bandits. Advanc es in Neur al Information Pr oc essing Systems (NIPS). pp. 201–208 14 Di Castro, Gen tile, Mannor 4. C. Burges, T. Shak ed, E. Rensha w, A. Lazier, M. Deeds, N. Hamilton, G. Hullender (2005). Learning to Rank Using Gradient Descent. International Confer enc e on Machine L e arning (ICML), 89–96 5. Z. Cao, T. Qin, T.Y. Liu, M.F. Tsai, H. Li (2007). Learning to Rank: F rom Pairwise to List wise Approach. International Confer enc e on Machine L e arning (ICML). pp. 129–136 6. N. Cesa-Bianc hi, G. Lugosi (2006). Pr e diction, L e arning, and Games . Cam bridge Univ ersity Press. 7. W. Cohen, R. Schapire, Y. Singer (1999). Learning to order things. Journal of Artificial Inteligenc e R ese ar ch (JAIR). 10 , pp. 243–270 8. O. Dekel C. Manning, Y. Singer (2003). Log-Linear Mo dels for Lab el Ranking, A dvanc es in Neur al Information Pr o c essing Systems (NIPS). 9. O. Dekel, C. Gen tile, K. Sridharan (2010). Robust Selective Sampling F rom Single and Multiple T eachers. Confer enc e on L e arning The ory (COL T 2010) pp. 346–358 10. E. Ev en-Dar, S. Mannor, Y. Mansour (2006). Action Elimination and Stopping Conditions for the Multi-Armed Bandit and Reinforcemen t Learning Problems. Journal of Machine L earning R ese ar ch (JMLR), 7 : 1079–1105, MIT Press 11. U. F eige, P . Raghav an, D. Peleg, and E. Upfal (1994). Computing with Noisy Information. SIAM J. Comput. , pp.1001–1018 12. E. Hullermeier, J. F urnkranz, W. Cheng, K. Brinker (2008). Label Ranking by Learning Pairwise Preferences. A rtificial Intel ligence , 172 , pp. 897–1916 13. T. Joac hims (2002). Optimizing Search Engines Using Clic kthrough Data. Eighth ACM International Confer enc e on Know le dge Disc overy and Data Mining (SIGKDD), pp. 133–142 14. T. Joac hims, F. Radlinski (2005). Query Chains: Learning to Rank from Implicit F eedbac k. Pr o c e e dings of the Eleventh ACM SIGKDD International Confer enc e on Know le dge Disc overy in Data Mining (ACM KDD), pp. 239–248 15. R. Klein b erg, A. Slivkins, and E. Upfal. Multi-armed bandit problems in metric spaces. In Pr o c. 40th ACM Symposium on The ory of Computing (STOC 2008), pp. 681–690. 16. T.L. Lai, H. Robbins (1985). Asymptotically Efficien t Adaptiv e Allo cation Rules. A dvanc es in Applie d Mathematics Elsevier , 6:1 , 4–22 17. J. Langford, T. Zhang (2007). The Epo ch-Greedy Algorithm for Con textual Multi- Armed Bandits. A dvanc es in Neur al Information Pr o c essing Systems 18. T.Y. Liu (2009). Learning to Rank for Information Retriev al. F oundations and tr ends in Information R etrieval , 3 , pp. 225–331 19. G. Lugosi, S. Mannor, G. Stoltz (2008). Strategies for Prediction Under Imp erfect Monitoring. Mathematics of Op erations R ese ar ch , 33:3 , pp. 513–528 20. O. Madani, D.L.J Lizotte, R. Greiner (2004). The Budgeted Multi-Armed Bandit Problem. Conferenc e on L e arning The ory (COL T), pp. 643–645. 21. P . Rigollet, A. Zeevi (2010). Nonparametric Bandits with Cov ariates. Confer enc e on L e arning The ory (COL T 2010) pp. 54–66 22. L. L. Th urstone (1927). A La w of Comparative Judgemen t. Psycholo gic al R eview , 34 , 278–286 23. F. Xia, T.Y. Liu, J. W ang, W. Zhang, H. Li (2008). List wise Approac h to Learning to Rank - Theory and Algorithm. International Confer enc e on Machine L e arning (ICML), pp. 1192–1199 24. Y. Y ue, J. Bro der, R. Kleinberg, T. Joachims (2011). The K-armed Dueling Ban- dits Problem. Journal of Computer and System Scienc es (JCSS), Sp ecial Issue on Learning Theory , to app ear Bandits with an edge 15 25. Y. Y ue, T. Joac hims (2011). Beat the Mean Bandit. International Confer enc e on Machine L e arning (ICML), to app ear
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment