Solving puzzles described in English by automated translation to answer set programming and learning how to do that translation
We present a system capable of automatically solving combinatorial logic puzzles given in (simplified) English. It involves translating the English descriptions of the puzzles into answer set programming(ASP) and using ASP solvers to provide solution…
Authors: Chitta Baral, Juraj Dzifcak
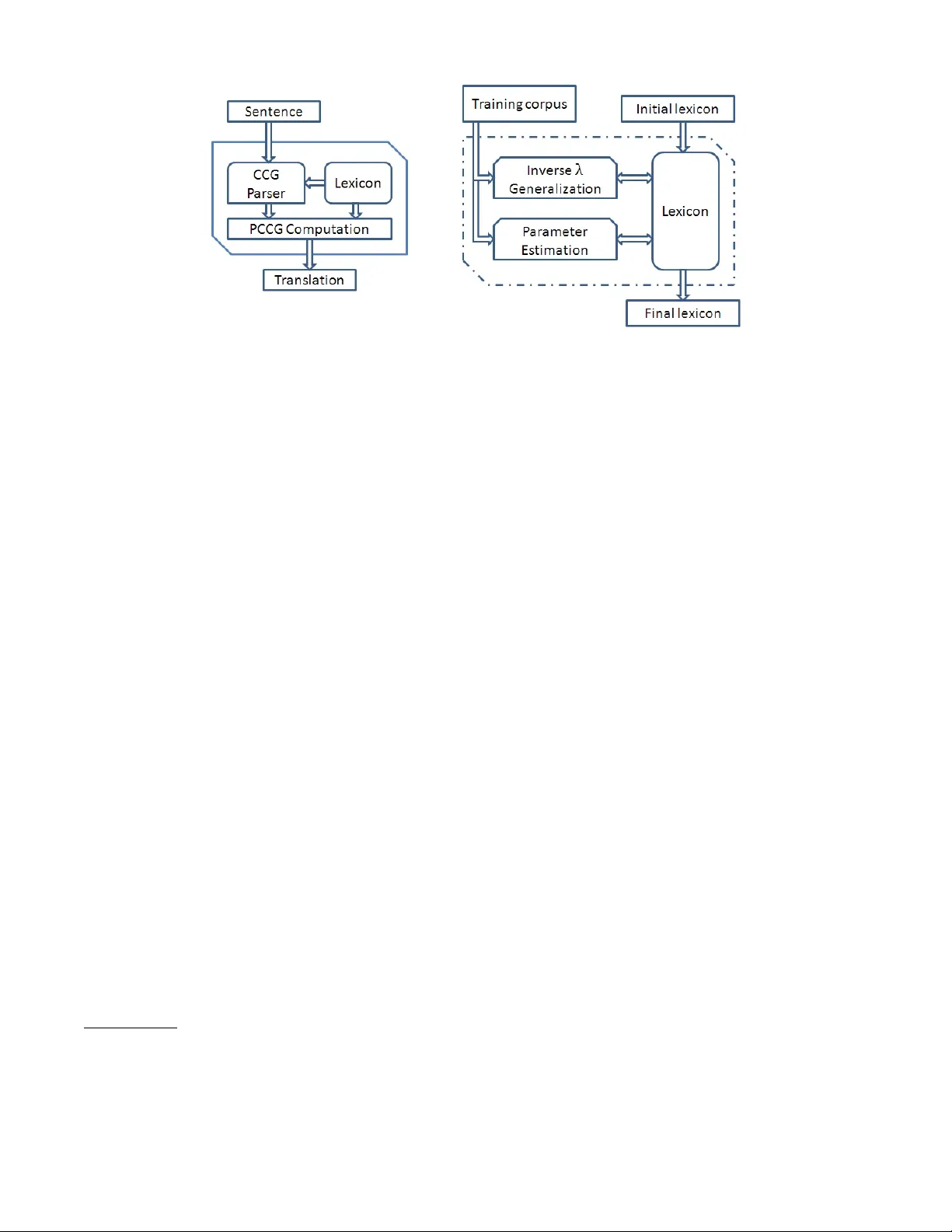
Solving puzzles described in English by automated translation to answer set pr ogramming and learning ho w to do that translation Chitta Baral School of Computing, Informatics and DSE Arizona State Univ ersity chitta@asu.edu Juraj Dzifcak School of Computing, Informatics and DSE Arizona State Univ ersity juraj.dzifcak@asu.edu Abstract W e present a system capable of automatically solving com- binatorial logic puzzles giv en in (simplified) English. It in- volv es translating the English descriptions of the puzzles into answer set programming(ASP) and using ASP solvers to pro- vide solutions of the puzzles. T o translate the descriptions, we use a λ -calculus based approach using Probabilistic Com- binatorial Cate gorial Grammars (PCCG) where the meanings of words are associated with parameters to be able to distin- guish between multiple meanings of the same word. Meaning of many words and the parameters are learned. The puzzles are represented in ASP using an ontology which is applicable to a large set of logic puzzles. Introduction and Moti vation Consider building a system that can tak e as input an En- glish description of combinatorial logic puzzles 1 (puz 2007) and solve those puzzles. Such a system would need and somewhat demonstrate the ability to (a) process language, (b) capture the knowledge in the text and (c) reason and do problem solving by searching ov er a space of possible so- lutions. No w if we were to build this system using a larger system that learns how to process ne w words and phrases then the latter system would need and somewhat demon- strate the ability of (structural) learning. The significance of the second larger system is with respect to being able to learn language (new words and phrases) and not expecting that humans will a-priori provide an exhausti ve vocabulary of all the words and their meanings. In this paper we describe our de velopment of such a sys- tem with some added assumptions. W e present e v aluation of our system in terms of ho w well it learns to understand clues (giv en in simplified 2 English) of puzzles and ho w well it can solve new puzzles. Our approach of solving puzzles gi ven in English inv olv es translating the English description of the puzzles to sentences in answer set programming (ASP) (Baral 2003) and then using ASP solvers, such as (Gebser et Copyright c 2022, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. 1 An example is the well-kno wn Zebra puzzle. http://en.wikipedia.org/wiki/Zebra Puzzle 2 Our simplified English is different from “controlled” English in that it does not have a pre-specified grammar . W e only do some preprocessing to eliminate anaphoras and some other aspects. al. 2007), to solve the puzzles. Thus a key step in this is to be able to translate English sentences to ASP rules. A sec- ond key step is to come up with an appropriate ontology of puzzle representation that makes it easy to do the translation. W ith respect to the first key step, we use a methodology (Baral et al. 2011) that assigns λ -ASP-Calculus 3 rules to each words. Since it seems to us that it is not humanly pos- sible to manually create λ -ASP-Calculus rules for English words, we hav e de veloped a method, which we call, In v erse λ to learn the meaning of English words in terms of their λ - ASP-Calculus rule. The ov erall architecture of our system is given in Figure 1. Our translation (from English to ASP) system, given in the left hand side of Figure 1, uses a Prob- abilistic Combinatorial Categorial Grammars (PCCG) (Ge and Mooney 2005) and a lexicon consisting of words, their corresponding λ -ASP-Calculus rules and associated (quan- titativ e) parameters to do the translation. Since a word may hav e multiple meaning implying that it may ha ve multiple associated λ -ASP-Calculus rules, the associated parameters help us in using the “right” meaning in that the translation that has the highest associated probability is the one that is picked. Gi ven a training set of sentences and their corre- sponding λ -ASP-Calculus rules, and an initial vocab ulary (consisting of some words and their meaning), In verse λ and generalization is used to guess the meaning of words which are encountered b ut are not in the initial le xicon. Because of this guess and because of inherent ambiguity of words hav- ing multiple meanings, one ends up with a lexicon where words are associated with multiple λ -ASP-Calculus rules. A parameter learning method is used to assign weights to each meaning of a word in such a way that the probability that each sentence in the training set would be translated to the gi ven corresponding λ -ASP-Calculus rule is maximized. The block diagram of this learning system is gi ven in the right hand side of Figure 1. W ith respect to the second key step, there are many ASP encodings, such as in (Baral 2003), of combinatorial logic puzzles. Ho we ver , most methods giv en in the literature, as- sume that a human is reading the English description of the puzzle and is coming up with the ASP code or code in some 3 λ -ASP-Calculus is inspired by λ -Calculus. The classical logic formulas in λ -Calculus are replaced by ASP rules in λ -ASP- Calculus. Figure 1: Overall system architecture high le vel language (Finkel, Marek, and T ruszczynski 2002) that gets translated to ASP . In our case the translation of En- glish description of the puzzles to ASP is to be done by an automated system and moreov er this systems learns aspects of the translation by going ov er a training set. This means we need an ontology of ho w the puzzles are to be represented in ASP that is applicable to most (if not all) combinatorial logic puzzles. The rest of the paper is organized as follo ws: W e start by discussing the assumptions we made for our system. W e then provide an overvie w of the ontology we used to rep- resent the puzzles. W e then giv e an overvie w of the natural language translation algorithm followed by a simple illustra- tion on a small set of clues. Finally , we provide an e v aluation of our approach with respect to translating clues as well as translating whole puzzles. W e then conclude. Assumptions and Background Kno wledge W ith our longer term goal to be able to solv e combinatorial logic puzzles specified in English, as mentioned earlier, we made some simplifying assumptions for this current work. Here we assumed that the domains of puzzles are gi ven (and one does not ha ve to extract it from the puzzle description) and focused on accurately translating the clues. Even then English throws up many challenges and we did a human preprocessing 4 of puzzles to eliminate anaphoras and fea- tures that may lead to a sentence being translated into mul- tiple clues. Besides translating the giv en English sentences we added some domain knowledge related to combinatorial logic puzzles. This is in line with the fact that often nat- ural language understanding in v olves going beyond literal understanding of a giv en text and taking into context some background knowledge. The follo wing example illustrates these points. A clue “Earl arrived immediately before the person with the Rooster . ” specifies sev eral things. Outside 4 The people doing the pre-processing were not told of any spe- cific subset of English or any “Controlled” English to use. They were only asked to simplify the sentences so that each sentence would translate to a single clue. of the fact that a man with the first name “Earl” came imme- diately before the man with the animal “Rooster”, a human would also immediately conclude that “Earl” does not hav e a “Rooster”. T o correctly process this information one needs the general kno wledge that if person A arrives before person B , A and B are different persons and giv en the assump- tion that all the objects are exclusiv e, an animal has a single owner . Also, to make sure that clue sentences correspond to single ASP rules, during preprocessing of this clue one may add “Earl is not the person with the Rooster . ” Puzzle repr esentation and Ontology For our experiments, we focus on logic puzzles from (puz 2007; puz 2004; puz 2005). These logic puzzles hav e a set of basic domain data and a set of clues. T o solve them, we adopt an approach where all the possible solutions are gener- ated, and then constraints are added to reduce the number of solutions. In most cases there is a unique solution. A sam- ple puzzle is giv en belo w , whose solution in v olv es finding the correct associations between persons, their ranks, their animals and their lucky elements. Puzzle Domain data: 1,2,3,4 and 5 are ranks earl, ivana, lucy, philip and tony are names earth, fire, metal, water and wood are elements cow, dragon, horse, ox and rooster are animals Puzzle clues: 1) Tony was the third person to have his fortune told. 2) The person with the Lucky Element Wood had their fortune told fifth. 3) Earl’s lucky element is Fire. 4) Earl arrived immediately before the person with the Rooster. 5) The person with the Dragon had their fortune told fourth. 6) The person with the Ox had their fortune told before the one who’s Lucky Element is Metal. 7) Ivana’s Lucky Animal is the Horse. 8) The person with the Lucky Element Water has the Cow. 9) The person with Lucky Element Water did not have their fortune told first. 10) The person with Lucky Element Earth had their fortune told exactly two days after Philip. The abov e puzzle can be encoded as follo ws. % DOMAIN DATA index(1..4). eindex(1..5). etype(1, name). element(1,earl). element(1,ivana). element(1,lucy). element(1,philip). element(1,tony). etype(2, element). element(2,earth). element(2,fire). element(2,metal). element(2,water). element(2,wood). etype(3, animal). element(3,cow). element(3,dragon). element(3,horse). element(3,ox). element(3,rooster). etype(4, rank). element(4,1). element(4,2). element(4,3). element(4,4). element(4,5). % CLUES and their translation %Tony was the third person to have %his fortune told. :- tuple(I, tony), tuple(J, 3), I!=J. %The person with the Lucky Element %Wood had their fortune told fifth. :- tuple(I, wood), tuple(J, 5), I!=J. %Earl’s lucky element is Fire. :- tuple(I, earl), tuple(J, fire), I!=J. %Earl arrived immediately before %the person with the Rooster. :- tuple(I, earl), tuple(J, rooster), tuple(I, X), tuple(J, Y), etype(A, rank), element(A, X), element(A, Y), X != Y-1. %The person with the Dragon had %their fortune told fourth. :- tuple(I, dragon), tuple(J, 4), I!=J. %The person with the Ox had their % fortune told before the %one who’s Lucky Element is Metal. :- tuple(I, ox), tuple(J, metal), tuple(I, X), tuple(J, Y), etype(A, rank), element(A, X), element(A, Y), X > Y. %Ivana’s Lucky Animal is the Horse. :- tuple(I, ivana), tuple(J, horse), I!=J. %The person with the Lucky Element %Water has the Cow. :- tuple(I, water), tuple(J, cow), I!=J. %The person with Lucky Element Water %did not have their fortune told first. :- tuple(I, water), tuple(I, 1). %The person with Lucky Element Earth %had their fortune %told exactly two days after Philip. :- tuple(I, earth), tuple(J, philip), tuple(I, X), tuple(J, Y), etype(A, rank), element(A, X), element(A, Y), X != Y+2. The puzzle domain data Each puzzle comes with a set of basic domain data which forms tuples. An example of this data is given above. Note that this is not the format in which they are provided in the actual puzzles. It is assumed that the associations are exclu- siv e, e.g. “earl” can o wn either a “dragon” or a “horse”, but not both. W e assume this data is provided as input. There are sev eral reasons for this assumption. The major reason is that not all the data is given in the actual natural language text de- scribing the puzzle. In addition, the text does not associate actual elements, such as “earth” with element types, such as “element”. If the text contains the number “6”, we might as- sume it is a rank, which, in f act, it is not. These domain data is encoded using the follo wing format, where ety pe ( A, t ) stores the element type t , while element ( A, X ) is the pred- icate storing all the elements X of the type ety pe ( A, ty pe ) . An example of an instance of this encoding is gi v en belo w . % size of a tuple index(1..n). % number of tuples eindex(1..m). % type and lists of elements of that type, % one element from % each index forms a tuple etype(1, type1). element(1, el11). element(1, el12). ... element(1, el1n). ... etype(m, typem). element(m, em11). element(1, elm2). ... element(1, elmn). W e now discuss this encoding in more detail. W e want to encode all the elements of a particular type, The type is needed in order to do direct comparisons between the elements of some type. For example, when we want to specify that “Earl arrived immedi- ately before the person with the Rooster . ”, as encoded in the sample puzzle, we want to encode something like ety pe ( A, r ank ) , el ement ( A, X ) , element ( A, Y ) , X ! = Y − 1 . , which compares the ranks of elements X and Y . The reason all the element types and elements have fixed numerical indices is to keep the encoding similar across the board and to not hav e to define additional grounding for the variables. For example, if we encoded elements as element ( name, ear l ) , then if we wanted to use the variable A in the encodings of the clue, it w ould ha ve to hav e defined domain which includes all the element types. These differ from puzzle to puzzle, and as such w ould ha v e to be specifi- cally added for each puzzle. By using the numerical indices across all puzzles, these are common across the board and we just need to specify that A is an index. In addition, to av oid permutation within the tuples, the follo wing facts are generated, where tuple ( I , X ) is the predicate storing the el- ements X within a tuple I : tuple(1,e11). ... tuple(1,e1n). which for the particular puzzle yields tuple(1, 1). tuple(2, 2). tuple(3, 3). tuple(4, 4).tuple(5,5). Generic modules and background kno wledge Giv en the puzzle domain data, we combine their encod- ings with additional modules responsible for generation and generic knowledge. In this work, we assume there are two type of generic modules av ailable. The first one is respon- sible for generating all the possible solutions to the puzzle. W e assume these are then pruned by the actual clues, which impose constraints on these. The follo wing rules are respon- sible for generation of all the possible tuples. Recall that we assume that all the elements are exclusi v e. 1{tuple(I,X):element(A,X)}1. :- tuple(I,X), tuple(J,X), element(K,X), I != J. In addition, a module with rules defining generic/background kno wledge is used so as to pro- vide higher level knowledge which the clues define. For example, a clue might discuss maximum, minimum, or genders such as woman. T o be able to match these with the puzzle data, a set of generic rules defining these concepts is used, rather than adding them into the actual puzzle data. Thus rules defining concepts and knowledge such as maximum, minimum, within range, sister is a woman and others are added. F or example, the concept “maximum” is encoded as: notmax(A, X) :- element(A, X), element(A, Y), X != Y, Y > X. maximum(A, X) :- not notmax(A,X), element(A,X). Extracting rele vant facts fr om the puzzle clues A sample of clues with their corresponding representations is given in the sample puzzle abov e. Let us take a closer look at the clue “T ony was the third person to have his fortune told. ”, encoded as : − tupl e ( I , tony ) , tupl e ( J, 3) , I 6 = J . This encoding specifies that if “T ony” is assigned to tuple I , while the rank “3” is assigned to a dif ferent tuple J , we obtain false. Thus this ASP rule limits all the models of it’ s program to have “T on y” assigned to the same tuple as “3”. One of the questions one might ask is where are the seman- tic data for “person” or “fortune told”. They are missing from the translation since with respect to the actual goal of solving the puzzle, they do not contribute anything mean- ingful. The fact that “T ony” is a “person” is inconsequen- tial with respect to the solutions of the puzzle. With this encoding, we attempt to encode only the relev ant informa- tion with regards to the solutions of the puzzle. This is to keep the structure of the encodings as simple and as gen- eral as possible. In addition, if the rule would be encoded as : − per son ( tony ) , tuple ( I , tony ) , tupl e ( J , 3) , I 6 = J. , the fact per son ( tony ) would hav e to be added to the program in order for the constraint to give it’ s desired meaning. How- ev er , this does not seem reasonable as there are no reasons to add it (outside for the clue to actually work), since “person” is not present in the actual data of the puzzle. T ranslating Natural language to ASP T o translate the english descriptions into ASP , we adopt our approach in (Baral et al. 2011). This approach uses inv erse -lambda computations, generalization on demand and tri vial semantic solutions together with learning. Ho w- ev er for this paper , we had to adapt the approach to the ASP language and dev elop an ASP- λ -Calculus. An example of a clue translation using combinatorial categorial grammar (Steedman 2000) and ASP- λ -calculus is giv en in table 1. The system uses the two inv erse λ operators, I nv erse L and I nv er se R as gi v en in (Baral et al. 2011) and (Gonzalez 2010). Giv en λ -calculus formulas H and G , these allow us to compute a λ -calculus formula F such that H = F @ G and H = G @ F . W e no w present one of the two In v erse λ operators, I nver se R as gi ven in (Baral et al. 2011). For more details, as well as the other operator , please see (Gon- zalez 2010).W e no w introduce the dif ferent symbols used in the algorithm and their meaning : • Let G , H represent typed λ -calculus formulas, J 1 , J 2 ,..., J n represent typed terms, v 1 to v n , v and w represent variables and σ 1 ,..., σ n represent typed atomic terms. • Let f () represent a typed atomic formula. Atomic formu- las may have a different arity than the one specified and still satisfy the conditions of the algorithm if the y contain the necessary typed atomic terms. • T yped terms that are sub terms of a typed term J are de- noted as J i . • If the formulas we are processing within the algorithm do not satisfy any of the if conditions then the algorithm returns null . Definition 1 (operator :) Consider two lists of typed λ - elements A and B, ( a i , ..., a n ) and ( b j , ..., b n ) r espectively and a formula H . The result of the operation H ( A : B ) is obtained by r eplacing a i by b i , for each appearance of A in H. Next, we present the definition of an in verse operators 5 I nver se R ( H , G ) : 5 This is the operator that was used in this implementation. In a companion work we de velop an enhancement of this operator which is prov en sound and complete. Definition 2 The function I nv er se R ( H , G ) is defined as: Given G and H : 1. If G is λv .v @ J , set F = I nver se L ( H , J ) 2. If J is a sub term of H and G is λv .H ( J : v ) • F = J 3. G is not λv .v @ J , J is a sub term of H and G is λw .H ( J ( J 1 , ..., J m ) : w @ J p , ..., @ J q ) with 1 ≤ p,q,s ≤ m. • F = λv 1 , ..., v s .J ( J 1 , ..., J m : v p , ..., v q ) . Lets assume that in the example giv en by table 1 the semantics of the word “immediately” is not known. W e can use the In v erse operators to obtain it as follo ws. Using the semantic representation of the whole sentence as giv en by table 1, and the word “Earl”, λx.tuple ( x, ear l ) , we can use the respectiv e operators to obtain the se- mantic of “arriv ed immediately before the man with the Rooster” as λz . : − z @ I , tupl e ( J , rooster ) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X 6 = Y − 1 . Repeating this process recursively we obtain λx.λy .x 6 = y − 1 as the representation of “arrived immediately” and λx.λy .λz .x @( y 6 = z − 1) as the desired semantic for “im- mediately”. The input to the ov erall learning algorithm is a set of pairs ( S i , L i ) , i = 1 , ..., n , where S i is a sentence and L i its cor- responding logical form. The output of the algorithm is a PCCG defined by the lexicon L T and a parameter vector Θ T . As gi ven by (Baral et al. 2011), the parameter vector Θ i is updated at each iteration of the algorithm. It stores a real number for each item in the dictionary . The overall learning algorithm is giv en as follo ws: • Input: A set of training sentences with their corresponding de- sired representations S = { ( S i , L i ) : i = 1 ...n } where S i are sentences and L i are desired expressions. W eights are giv en an initial value of 0 . 1 . An initial feature vector Θ 0 . An initial lexicon L 0 . • Output : An updated lexicon L T +1 . An updated feature vector Θ T +1 . • Algorithm: – Set L 0 – F or t = 1 . . . T – Step 1: (Lexical generation) – F or i = 1...n. ∗ F or j = 1...n. ∗ P arse sentence S j to obtain T j ∗ T ra v erse T j · apply I N V E RS E L , I N V E RS E R and GE N E RALI Z E D to find new λ -calculus expres- sions of words and phrases α . ∗ Set L t +1 = L t ∪ α – Step 2: (Parameter Estimation) – Set Θ t +1 = U P D AT E (Θ t , L t +1 ) 6 • return GE N E RALI Z E ( L T , L T ) , Θ( T ) 6 For details on Θ computation, please see (Zettlemoyer and Collins 2005) T o translate the clues, a trained model was used to trans- late these from natural language into ASP . This model in- cludes a dictionary with λ -calculus formulas corresponding to the semantic representations of words. These hav e their corresponding weights. T ables 1 and 2 give two sample translations of a sentence into answer set programming. In the second example, the parse for the “than the customer whose number is 3989. ” part is not sho wn to save space. Also note that in general, names and se v eral nouns were preprocessed and treated as a single noun due to parsing issues. The most noticeable fact is the abundance of expressions such as λx.x , which basi- cally directs to ignore the word. The main reason for this is the nature of the translation we are performing. In terms of puzzle clues, many of the words do not really contribute any- thing significant to the actual clue. The important parts are the actual objects, “Earl” and “Rooster” and their compari- son, “arri ved immediately before”. In a sense, the part “the man with the” does not pro vide much semantic contrib ution with regards to the actual puzzle solution. One of the rea- sons is the way the actual clue is encoded in ASP . A more complex encoding would mean that more words ha ve sig- nificant semantic contrib utions, ho wever it would also mean that much more background knowledge would be required to solve the puzzles. Illustration W e will now illustrate the learning algorithm on a subset of puzzle clues. W e will use the following puzzle sentences, as giv en in table 3 Lets assume the initial dictionary contains the following semantic entries for words, as gi ven in table 4. Please note that many of the nouns and noun phrases were preprocessed. The algorithm will than start processing sentences one by one and attempt to learn new semantic information. The algorithm will start with the first sentence, “Donna dale does not hav e green fleece. ” Using in v erse λ , the algo- rithm will find the semantics of “not” as λz . ( z @( λx.λy . : − x @ I , y @ I . )) . . In a similar manner it will continue through the sentences learning ne w semantics of words. An interest- ing set of learned semantics as well as weights for words with multiple semantics are giv en in table 5. Evaluation W e assume each puzzle is a pair P = ( D , C ) where D corre- sponds to puzzle domain data, and C correspond to the clues of the puzzle gi ven in simplified English. As discussed be- fore, we assume the domain data D is given for each of the puzzles. A set of training puzzles, { P 1 , ..., P n } is used to train the natural language model which can be used trans- late natural language sentences into their ASP representa- tions. This model is then used to translate clues for new puzzles. The initial dictionary contained nouns with most verbs. A set of testing puzzles, { P 0 1 , ..., P 0 m } , is v alidated by transforming the data into the proper format, adding generic modules and translating the clues of P 0 1 , ..., P 0 m using the trained model. Earl arrived immediately before the man with the Rooster . N P S \ N P ( S \ N P ) \ ( S \ N P ) (( S \ N P ) \ ( S \ N P )) / N P N P /N N ( N P \ N P ) / N P N P / N N N P S \ N P (( S \ N P ) \ ( S \ N P )) / N P N P ( N P \ N P ) /N P N P N P S \ N P (( S \ N P ) \ ( S \ N P )) / N P N P N P \ N P N P S \ N P (( S \ N P ) \ ( S \ N P )) / N P N P N P S \ N P ( S \ N P ) \ ( S \ N P ) N P ( S \ N P ) S earl arrived immediately λx.tuple ( x, earl ) λx.x λx.λy .λz.x @( y 6 = z − 1) λx.tuple ( x, earl ) λx.λy.x 6 = y − 1 λx.tuple ( x, earl ) λx.λy.x 6 = y − 1 λx.tuple ( x, earl ) λx.λy.x 6 = y − 1 λx.tuple ( x, earl ) λx.λy.x 6 = y − 1 λx.tuple ( x, earl ) before λx.λy.λz . : − z @ I , x @ J, tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , y @ X @ Y. λx.λy.λz . : − z @ I , x @ J, tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , y @ X @ Y. λx.λy.λz . : − z @ I , x @ J, tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , y @ X @ Y. λx.λy.λz . : − z @ I , x @ J, tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , y @ X @ Y. λy.λz . : − z @ I , tuple ( J, r ooster ) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , y @ X @ Y . λz. : − z @ I , tuple ( J, r ooster ) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, rank ) , element ( A, X ) , element ( A, Y ) , X 6 = Y − 1 . : − tuple ( I , ear l ) , tuple ( J, r ooster ) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X 6 = Y − 1 . the man with the Rooster . λx.x λx.x λx.λy.y @ x λx.x λx.tuple ( x, rooster ) λx.x λx.λy.y @ x λx.tuple ( x, rooster ) λx.x λx.λy.y @( λx.tuple ( x, r ooster )) λx.tuple ( x, rooster ) T able 1: CCG and λ -calculus deriv ation for “Earl arri v ed immediately before the person with the Rooster . ” Miss Hanson is withdrawing more than the customer whose number is 3989. N P ( S/ N P ) \ N P ( S \ ( S/ N P )) /N P N P / N P N P S/ N P ( S \ ( S/ N P )) / N P N P S/ N P ( S \ ( S/ N P )) S Miss Hanson is withdrawing λx.tuple ( x, hanson ) λx.λy. ( y @ x ) . λx.λz . ( x @ z ) λy. ( y @( λx.tuple ( x, hanson ))) . λx.λz. ( x @ z ) λy. ( y @( λx.tuple ( x, hanson ))) . more λx.λy. : − y @ I , x @ J, tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X > Y , I ! = J. λy. : − y @ I , tuple ( J, 3989) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X > Y , I ! = J. λz. : − z @ I , tuple ( J, 3989) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X > Y , I ! = J. : − tuple ( I , hanson ) , tuple ( J, 3989) , tuple ( I , X ) , tuple ( J, Y ) , ety pe ( A, rank ) , element ( A, X ) , element ( A, Y ) , X > Y , I ! = J. than the customer whose number is 3989. λx.tuple ( x, 3989) T able 2: CCG and λ -calculus deriv ation for “Miss Hanson is withdra wing more than the customer whose number is 3989. ” T o ev aluate our approach, we considered 50 different logic puzzles from various magazines, such as (puz 2007; puz 2004; puz 2005). W e focused on e v aluating the accu- racy with which the actual puzzle clues were translated. In addition, we also verified the number of puzzles we solved. Note that in order to completely solv e a puzzle, all the clues hav e to be translated accurately , as a missing clue means there will be se veral possible answer sets, which in turn will giv e an e xact solution to the puzzle. Thus if a system would correctly translate 90% of the puzzle clues, and assuming the puzzles ha v e on an a verage 10 clues, then one w ould e x- pect the ov erall accurac y of the system to be 0 . 9 10 = 0 . 349 , or around 34 . 9% . T o ev aluate the clue translation, 800 clues were selected. Standard 10 fold cross v alidation was used. P r ecision mea- sures the number of correctly translated clues, save for per - mutations in the body of the rules, or head of disjunctiv e rules. Recall measures the number of correct exact transla- tions. T o ev aluate the puzzles, we used the following approach. A number of puzzles were selected and all their clues formed the training data for the natural language module. The training data was used to learn the meaning of words and the associated parameters and these were then used to translate the English clues to ASP . These were then com- bined with the corresponding puzzle domain data, and the generic/background ASP module. The resulting program was solved using cl ing o , an extension of cl asp (Gebser et al. 2007). Accur acy measured the number of correctly solved puzzles. A puzzle was considered correctly solved if it provided a single correct solution. If a rule provided by the clue translation from English into ASP was not syntacti- cally correct, it was discarded. W e did several experiments. Using the 50 puzzles, we did a 10-fold cross validation to measure the accuracy . In addition, we did additional e xperi- ments with 10, 15 and 20 puzzle manually c hosen as training data. The manual choice was done with the intention to pick the training set that will entail the best training. In all cases, Donna dale does not have green fleece. : − tuple ( I , donna dale ) , tuple ( I , g reen ) . Hy Syles has a brown fleece. : − tuple ( I , hy syles ) , tuple ( J, br ow n ) , I ! = J. Flo Wingbrook’ s fleece is not red. : − tuple ( I , f lo w ingbr ook ) , tuple ( I , r ed ) . Barbie W yre is dining on hard-boiled e ggs. : − tuple ( I , eg g s ) , tuple ( J, bar bie wy r e ) , I ! = J . Dr . Miros altered the earrings. : − tuple ( I , dr miros ) , tuple ( J, ear r ing s ) , I ! = J. A garnet was set in Dr . Lukta’s piece. : − tuple ( I , g ar net ) , tuple ( J, dr lukta ))) , I ! = J. Michelle is not the one liked by 22 : − tuple ( I , michelle ) , tuple ( I , 22) . Miss Hanson is withdrawing more than the customer whose number is 3989. : − tuple ( I , hanson ) , tuple ( J, 3989) , tuple ( I , X ) , tuple ( J, Y ) , etype ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X > Y , I ! = J. Albert is the most popular . : − tuple ( I , alber t ) , tuple ( J, X ) , hig hest ( X ) , I ! = J. Pete talked about government. : − tuple ( I , pete ) , tuple ( J, g ov er nment ) , I ! = J. Jack has a shaved mustache : − tuple ( I , j ack ) , tuple ( J, mustache ) , I ! = J. Jack did not get a haircut at 1 : − tuple ( I , j ack ) , tuple ( I , 1) . The first open house was not listed for 100000. : − tuple ( I , X ) , f irst ( X ) , tuple ( I , 100000) . The candidate surnamed W aring is more popular than the PanGlobal : − tuple ( I , w aring ) , tuple ( J, panglobal ) , tuple ( I , X ) , tuple ( J, Y ) , etype ( A, time ) , element ( A, X ) , element ( A, Y ) , X < Y . Rosalyn is not the least popular . : − tuple ( I , r osaly n ) , tuple ( I , X ) , lowest ( X ) . T able 3: Illustration sentences for the ASP corpus verb v λx.λy. : − y @ I , x @ J, I ! = J. , λx.λy. ( x @ y ) , λx.λy . ( y @ x ) λx.x noun n λx.tuple ( x, n ) , λx.x noun n with general knowledge λx.n ( x ) Example:sister, maximum, female,... T able 4: Initial dictionary for the ASP corpus the C & C parser (Clark and Curran 2007) was used to obtain the syntactic parse tree. Results and Analysis The results are gi ven in tables 7 and 6. The “10-fold” corre- sponds to experiments with 10-fold validation, “10-s”, “15- s” and “20-s” to experiments where 10, 15 and 20 puzzles were manually chosen as training data respectiv ely . Precision Recall F-measure 87.64 86.12 86.87 T able 6: Clue translation performance. Accuracy 10-Fold 28/50 (56%) 10-s 22/40 (55%) 15-s 24/35 (68 . 57%) 20-s 25/30 (83 . 33%) T able 7: Performance on puzzle solving. The results for clue translation to ASP is comparable to translating natural language sentences to Geoquery and Robocup domains used by us in (Baral et al. 2011), and used in similar works such as (Zettlemoyer and Collins 2007) and (Ge and Mooney 2009). Our results are close to the values reported there, which range from 88 to 92 percent for the database domain and 75 to 82 percent for the Robocup do- main. As discussed before, a 90% accuracy is expected to lead to around 35% rate for the actual puzzles. Our result of 56% is significantly higher . It is interesting to note that as the number of puzzles used for training increases, so does the accuracy . Howe ver , there seems to be a ceiling of around 83 . 3% . In general, the reason for not being able to solv e a puz- zle lies in the inability to correctly translate the clue. In- correctly translated clues which are not syntactically correct are discarded, while for some clues the system is not capa- ble to produce any ASP representation at all. There are sev- eral major reasons why the system fails to translate a clue. First, ev en with large amount of training data, some puzzles simply hav e a relatively unique clue. For example, for the clue, “The person with Lucky Element Earth had their for- tune told exactly two days after Philip. ” the “exactly two days after” part is very rare and a similar clue, which dis- cusses the distance of elements on a time line is only present in two dif ferent puzzles. There were only 2 clues that con- tain “aired within n days of each other”, both in a single puzzle. If this puzzle is part of the training set, since we are not validating against it, it has no impact on the results. If it’ s one of the tested puzzles, this clue will essentially never be translated properly and as such the puzzle will nev er be correctly solved. In general, many of the clues required to solve the puzzles are very specific, and ev en with the addi- tion of generic kno wledge modules, the system is simply not capable to figure them out. A solution to this problem might be to use more background kno wledge and a larger training sample, or a specific training sample which focuses on vari- ous dif ferent types of clues. In addition, when looking at ta- bles 1 and 5, man y of the words are assigned very simple se- mantics that essentially do not contribute any meaning to the actual translation of the clue. Compared to database query language and robocup domains, there are several times as many simple representations. This leads to several prob- lems. One of the problems is that the remaining semantics might be ov er fit to the particular training sentences. For ex- ample, for “aired within n days of each other” the only words with non tri vial semantics might be “within” and some num- ber “n”, which in turn might not be generic for other sen- tences. The generalization approach adopted from (Baral et al. 2011) is unable to ov ercome this problem. The second problem is that a lot of words have these trivial semantics attached, e ven though they also have sev eral other non triv- word semantics weight not λz. ( z @( λx.λy . : − x @ I , y @ I . )) -0.28 not λy.λx. : − x @ I , y @ I . ) 0.3 has λx.λy. : − y @ I , x @ J, I ! = J. 0.22 has λx.λy. ( x @ y ) 0.05 has λx.λy. ( y @ x ) 0.05 has λx.x 0.05 popular λx.tuple ( x, popular ) 0.17 popular λx.x 0.03 a λx.x 0.1 not λx.λy . : − y @ I , x @ I . 0.1 on λx.x 0.1 the λx.x 0.1 in λx.λy. ( y @ x ) 0.1 by λx.x 0.1 most λy.λx.y @( tuple ( x, X ) , hig hest ( X )) 0.1 about λx.x 0.1 shaved λx.x 0.1 at λy .λx. ( x @ y ) 0.1 first λy.y @( λx.tuple ( x, X ) , f irst ( X )) 0.1 for λx.x . 0.1 least λx.tuple ( x, X ) , low est ( X ) 0.1 more λx.λy. : − y @ I , x @ J, tuple ( I , X ) , tuple ( J, Y ) , etype ( A, r ank ) , element ( A, X ) , element ( A, Y ) , X > Y , I ! = J. 0.1 T able 5: Learned semantics and final weights of selected words of the ASP corpus. ial representations. This causes problem with learning, and the tri vial semantics may be chosen over the n on-tri vial one. Finally , some of the C & C parses do not allow the proper use of inv erse λ operators, or their use leads to very com- plex expressions with se veral applications of @ . In table 1, this can be seen by looking the representation of the word “immediately”. While this particular case does not cause se- rious issues, it illustrates that when present se veral times in a sentence, the resulting λ expression can get very complex leading to third or fourth order λ -ASP-calculus formulas. Conclusion and Future w ork In this work we presented a learning approach to solve com- binatorial logic puzzles in English. Our system uses an ini- tial dictionary and general knowledge modules to obtain an ASP program whose unique answer set corresponded to the solution of the puzzle. Using a set of puzzles and their clues to train a model which can translate English sentences into logical form, we were able to solve man y additional puz- zles by automatically translating their clues, giv en in sim- plified English, into ASP . Our system used results and com- ponents from v arious AI sub-disciplines including natural language processing, knowledge representation and reason- ing, machine learning and ontologies as well as the func- tional programming concept of λ -calculus. There are many ways to extend our work. The simplified English limitation might be lifted by better natural language processing tools and additional sentence analysis. W e could also apply our approach to different types of puzzles. A modified encod- ings might yield a smaller v ariance in the results. Finally we would like to submit that solving puzzles giv en in a natu- ral language could be considered as a challenge problem for human le vel intelligence as it encompasses v arious f acets of intelligence that we listed earlier . In particular, one has to use a reasoning system and can not substitute it with sur - face level analysis often used in information retriev al based methods. References [Baral et al. 2011] Baral, C.; Gonzalez, M.; Dzifcak, J.; and Zhou, J. 2011. Using in v erse λ and generalization to trans- late english to formal languages. In Pr oceedings of the Inter- national Confer ence on Computational Semantics, Oxfor d, England, J anuary 2011 . [Baral 2003] Baral, C. 2003. Knowledge Repr esentation, Reasoning, and Declarative Pr oblem Solving . Cambridge Univ ersity Press. [Clark and Curran 2007] Clark, S., and Curran, J. R. 2007. W ide-co verage ef ficient statistical parsing with ccg and log- linear models. Computational Linguistics 33. [Finkel, Marek, and T ruszczynski 2002] Finkel, R. A.; Marek, V . W .; and Truszczynski, M. 2002. Constraint lingo: A program for solving logic puzzles and other tabular constraint problems. In JELIA , 513–516. [Ge and Mooney 2005] Ge, R., and Mooney , R. J. 2005. A statistical semantic parser that inte grates syntax and seman- tics. In Pr oceedings of CoNLL. , 9–16. [Ge and Mooney 2009] Ge, R., and Moone y , R. J. 2009. Learning a compositional semantic parser using an existing syntactic parser . In Pr oceedings of A CL-IJCNLP . , 611–619. [Gebser et al. 2007] Gebser , M.; Kaufmann, B.; Neumann, A.; and Schaub, T . 2007. Clasp : A conflict-dri ven answer set solver . In LPNMR , 260–265. [Gonzalez 2010] Gonzalez, M. A. 2010. An in v erse lambda calculus algorithm for natural language processing. Master’ s thesis, Arizona State Univ ersity . [puz 2004] 2004. Logic problems. Penny Press. [puz 2005] 2005. Logic puzzles. Dell. [puz 2007] 2007. England’ s best logic problems. Penny Press. [Steedman 2000] Steedman, M. 2000. The syntactic process . MIT Press. [Zettlemoyer and Collins 2005] Zettlemoyer , L., and Collins, M. 2005. Learning to map sentences to logical form: Structured classification with probabilistic categorial grammars. In AAAI , 658–666. [Zettlemoyer and Collins 2007] Zettlemoyer , L., and Collins, M. 2007. Online learning of relaxed ccg gram- mars for parsing to logical form. In Pr oceedings of EMNLP-CoNLL , 678–687.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment