Policy Iteration is well suited to optimize PageRank
The question of knowing whether the policy Iteration algorithm (PI) for solving Markov Decision Processes (MDPs) has exponential or (strongly) polynomial complexity has attracted much attention in the last 50 years. Recently, Fearnley proposed an exa…
Authors: Romain Holl, ers, Jean-Charles Delvenne
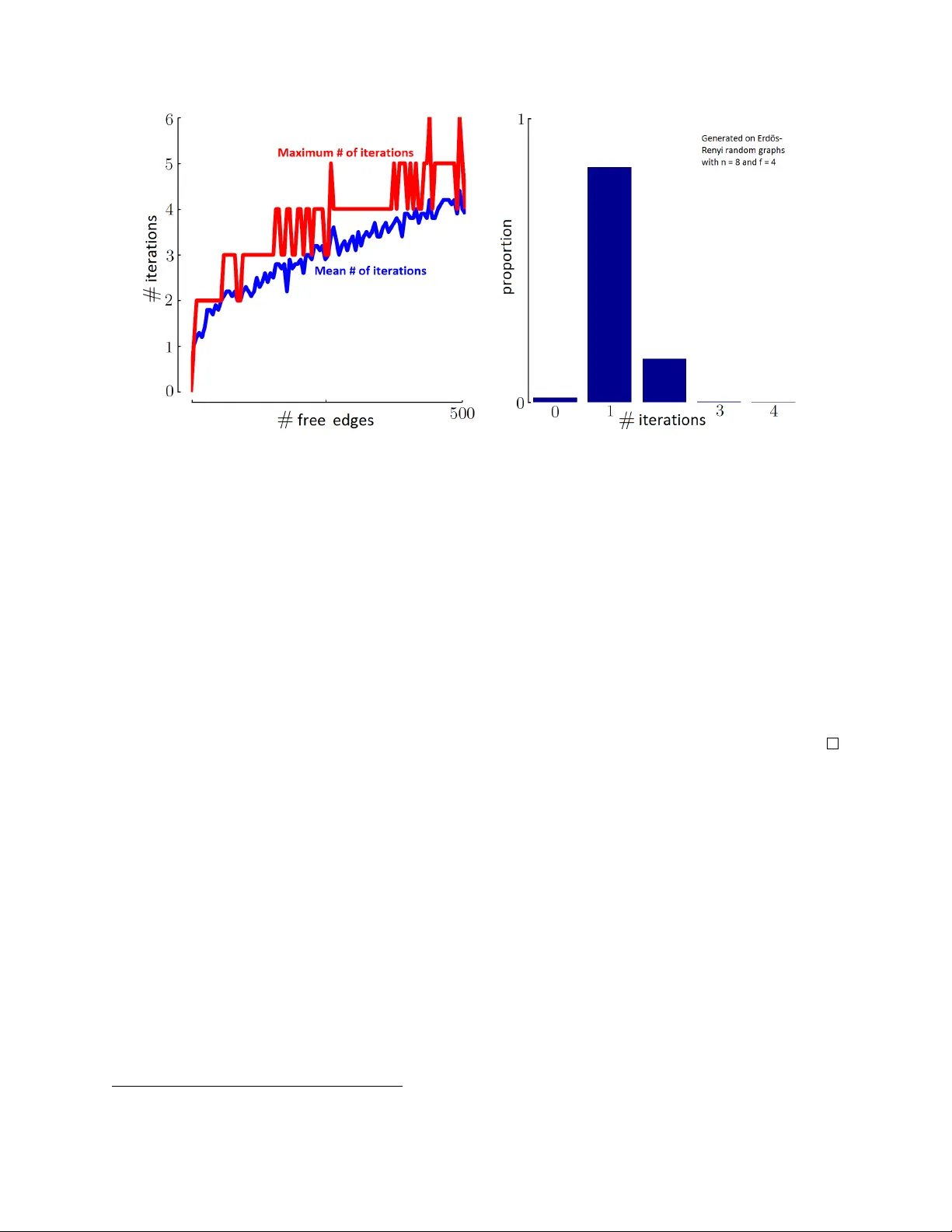
P olicy Iteration is w ell suited to optimize P ageRank Romain Hollanders ∗ † Jean-Charles Delv enne ∗ ‡ Raphaël Jungers ∗ § July 2011 Abstract The question of kno wing whether the p olicy Iteration algorithm (PI) for solving Mark ov Decision Pro cesses (MDPs) has exponential or (strongly) polynomial complexit y has attracted muc h atten tion in the last 50 years. Recen tly , F earnley prop osed an example on which PI needs an exp onen tial num b er of iterations to con verge. Though, it has been observed that F earnley’s example lea ves op en the p ossibilit y that PI b eha v es well in man y particular cases, such as in problems that in volv e a fixed discount factor, or that are restricted to deterministic actions. In this paper, we analyze a large class of MDPs and we argue that PI is efficient in that case. The problems in this class are obtained when optimizing the PageRank of a particular no de in the Mark ov c hain. They are motiv ated b y several practical applications. W e show that adding natural constrain ts to this PageRank Optimization problem (PRO) mak es it equiv alent to the problem of optimizing the length of a sto c hastic path, which is a widely studied family of MDPs. Finally , we c onjecture that PI runs in a p olynomial num b er of iterations when applied to PR O. W e give n umerical arguments as well as the pro of of our conjecture in a n umber of particular cases of practical imp ortance. In tro duction In search engines, it is critical to b e able to compare webpages according to their relative imp ortance, with as few as p ossible computational resources. This is done by computing the PageR ank of every w ebpage from the web [BP98] : pages with higher PageRank will then app ear higher in the list of results. T o compute this PageRank, the first step is to mo del the web as a digraph in which the w ebpages are represen ted by no des and the links b etw een them are represen ted by directed edges. Then, the P ageRank of a no de is defined as the av erage p ortion of time sp en t in that no de during an infinite and uniform random w alk on the graph. This random walk can b e seen as the infinite pro cess of a random surfer that, from its current page, picks up any av ailable outgoing link with uniform probabilit y and jumps to the page p ointed b y that link. The utility of PageRank is not limited to search engines and it has b een prop osed in several other applications suc h as financial mark et, spam detection, web-cra wling, seman tic netw orks, and many others. It can also b e used in an y application that requires ranking nodes in order of relativ e ∗ Departmen t of Mathematical Engineering, ICTEAM, UCLouv ain, 4, av enue Lemaitre, B-1348 Louv ain-la-Neuve, Belgium. This work was supp orted b y the AR C grant ’Large Graphs and Netw orks’ from the F renc h Communit y of Belgium and b y the IAP netw ork ’Dysco’ funded b y the office of the Prime Minister of Belgium. The scientific resp onsablit y rests with the authors. † Corresp onding author, romain.hollanders@uclouvain.be ‡ jean-charles.delvenne@uclouvain.be § raphael.jungers@uclouvain.be 1 imp ortance. See [Ber05] for a survey on PageRank and its applications. The introduction of the concept of PageRank has also generated a large n umber of questions and c hallenges. Among these, the problem of optimizing the PageRank of webpages raises increasing in terest, as evidenced b y the gro wing literature on the sub ject [AL04, MV06, dKND08, IT09, CJB09, F ABG10]. It is also of great practical interest and well-s tudied in the engineering communit y where go o d practice metho ds are dev elop ed to ensure a high P ageRank [CLF09]. P ageRank Optimization (PRO) is also the fo cus of this pap er. Here, we study how to maximize (or minimize) the PageRank of some target no de when con trol is granted on some subset of edges, meaning that some edges (called the fr e e e dges ) may b e c hosen to b e activ ated or deactiv ated. A t ypical example of PR O is the so-called webmaster pr oblem in which a w ebmaster tries to maximize the P ageRank of one of his w ebpage b y determining which links under his control (i.e. on his website, or on an allied w ebsite for instance) he should activ ate and which links he should not [AL04, dKND08]. F urthermore, the same to ols ma y b e used to find ho w muc h the P ageRank of some no des can v ary when the presence or absence of some links, called fr agile links , is uncertain (e.g. b ecause a link is broken, the serv er is down or because of traffic problems) [IT09]. The main difficult y to solve PRO is to deal with the exp onen tial num b er of p ossible free edges configurations : since each edge has tw o p ossible states - on or off - the num b er of p ossible con- figurations is 2 f , where f is the num b er of free edges. T o escap e this difficulty , Ishii and T emp o first prop osed an approximate algorithm that would find an interv al con taining the minimum and maxim um P ageRank of the target no de [IT09]. One y ear later, Csá ji et al. proposed a wa y of for- m ulating the problem as a Sto chastic Shortest Path problem (SSP) - which is a subclass of Markov De cision Pr o c esses (MDPs) - thereby showing that an exact solution of the problem could b e found in weakly polynomial time using linear programming [CJB09]. (F or some refinements to PRO, see also [F ABG10]. F or more on SSPs and MDPs see e.g. [Put94], [BT91] and [Ber07].) Y et in practice, MDPs (and thus also SSPs) are solved muc h more efficiently using algorithms adapted to their sp e- cial structure. Among these algorithms, Policy Iter ation (PI) [How60] p erforms amazingly w ell and is guaran teed to conv erge to the optimal solution in a finite num b er of iterations. How ev er, ev en though PI usually con verges in few iteration, theoretical upp er and lo wer b ounds on its complexit y are exp onential in many cases. The main goal of this pap er is to show that the existing exp onen tial lo wer b ounds, as they are, should not apply to PRO. Instead, w e b elieve that p olynomial upp er b ounds exist in that case. There is a significan t researc h effort for understanding the complexity of PI. Let us quic kly review existing complexity results. F or general MDPs, the best upper bound - O (2 m /m ) - is due to Mansour and Singh [MS99], where m designates the n umber of choices to b e made in the problem, while the largest lo wer b ound is also exp onen tial and has recently b een found b y F earnley through a carefully built example [F ea10]. This was a breakthrough after 50 years of research on the question of the complexit y of PI. The story is different for discounted MDPs (i.e. a class of MDPs in which the impact of future costs are progressiv ely reduced by some discount factor) for which a first strongly p olynomial upp er bound has recently b een found by Y e [Y e10] and then further impro ved by Hansen et al. [HMZ10], yet only for fixed discount factors. Though, even if upp er and lo wer b ounds seem to meet in b oth cases, the story do es not end here. Indeed, F earnley’s example is imp ossible to adapt to some other imp ortant particular cases of MD Ps. This is for example the case for Deterministic MDPs (DMDPs) for whic h the b est low er b ound currently known is quadratic and has b een found b y Hansen and Zwick [HZ10]. Besides, strongly polynomial time algorithms exist to solve that problem [MTZ10] (including PI when fixed discoun t is included to the problem [Y e10]), whic h hints that DMDPs migh t b e easier to solve than general MDPs. In this w ork, we argue that PR O might be another particular case for which a p olynomial reduction 2 of F earnley’s example is not p ossible. W e first show how a natural generalization of PRO makes it equiv alent to general SSPs and vice v ersa, giving a new p oint of view on SSPs (and MDPs). Then, we identify the exclusive nature of the choice of actions in an SSP as the main constraint that makes it differen t and most probably harder to solv e than PRO. Based on extensive n umerical computations, w e then conjecture that PI con v erges in a p olynomial num b er of iterations in the case of PRO. W e also give a n umber of particular cases in which we show that PI con v erges in p olynomial time. In this work, w e try to mak e a step to wards deep er insight on the existing link b et ween the properties of an MDP instance and the resulting efficiency of PI. The pap er is organized as follows. In Section 1, we giv e formal definitions for SSP and PRO and w e generalize PR O in a natural wa y . In Section 2, w e sho w ho w that generalization of PR O can b e transformed into an SSP and vice versa. In Section 3, w e conjecture that PI should p erform well when applied to PRO, arguing with numerical evidence. Then, in Section 4, we give a num b er a particular cases of PR O for which PI behav es w ell. 1 Definitions In this section, w e giv e a formal definition for Stochastic Shortest Path and for PageRank Opti- mization problems. W e also formulate a natural generalization of the latter. Sto c hastic Shortest Path. An instance of the Sto chastic Shortest Path problem (SSP) is a tuple ( S , U , P , C ) where S is the finite set of states , U is the finite set of all actions and U s ⊆ U is the set of actions av ailable in state s ∈ S (there is at least one action for each state), and P u s,s 0 and C u s,s 0 are resp ectively the tr ansition pr ob ability of going from state s ∈ S to state s 0 ∈ S when choosing action u ∈ U s and the (real-v alued) c ost incurred b y this displacemen t [BT91]. W e also ask for the transition probabilities to b e non-negative and to sum to one, namely P s 0 ∈S P u s,s 0 = 1 , for all starting state s ∈ S and action u ∈ U s . An action is said pr ob abilistic if it includes randomization b et ween sev eral arriv al states, whereas it is said deterministic otherwise. In SSP , w e consider the random pro cess of an agent that starts at some starting state s 0 and then jumps to a new av ailable state at eac h time step (according to the action taken in its current state and the asso ciated transiti on probabilities). The main feature of an SSP , compared to general MDPs, is that w e assume the existence of an absorbing cost-free state τ (also called tar get state) that is required to b e reachable with a non-zero probability path by ev ery other state, whichev er actions are c hosen. In this context, the goal of the c ontr ol ler of the pro cess is to choose the righ t action in eac h state in order to minimize the exp ected sum of costs incurred by the agent before reaching the target state, whatev er the starting state. The choice of a unique action to tak e in each state is called a p olicy (or strategy) µ : S → U . The c hosen p olicy is pr op er if the agen t ev entually reaches τ for any starting state. It is impr op er otherwise. A p olicy is optimal iff it is b etter at minimizing the controller’s goal than an y other p olicy , for an y starting state. One fundamental result ab out MDPs that can be adapted to SSPs guarantees that there alw ays exists an optimal (not necessarily unique) prop er p olicy , pro vided that there exists at least one prop er p olicy [Put94, Ber07]. Note that it is alwa ys p ossible to formulate an SSP problem as a linear program whose size is p olynomial in the n umber of states and the maximum n um b er of actions p er state of the SSP instance. P ageRank Optimization. T o define a PageR ank Optimization problem (PRO), we first define its supp ort gr aph G = ( V , E ) , where V = V 0 ∪ v is the set of no des, E ⊆ V × V is the set of directed edges of the graph and v is the target node for whic h we wan t to maximize (or minimize) the PageRank. F or that task, control is gran ted on some subset F ⊆ E of edges (called the set of fr e e e dges ) in whic h 3 w e may c ho ose to activ ate or deactiv ate any edge, whereas the edges in E \F are fixed and cannot b e remov ed. The goal in PR O is to choose the right subset of free edges that we activ ate so that the PageRank of node v is maximal (or minimal). Here w e fo cus on the maximization problem but a straigh tforward mo dification of the approac h can b e used to deal with the minimization problem as w ell. PR O can b e form ulated as an SSP in polynomial time [CJB09] as follo ws. First observ e that maximizing the P ageRank of v (i.e. its frequency of visit by the random surfer) is equiv alen t to minimizing the av erage time betw een tw o visits of v . Let us split v in to a starting no de v s and a target no de v t suc h that v s has all outgoing links of v and v t has all its ingoing links, plus a zero-cost self-lo op. Maximizing the PageRank of v is then equiv alent to minimizing the av erage distance from v s to v t . Observ e that v t is now an absorbing no de. In this setting, an action is the c hoice b etw een activ ation or deactiv ation for a giv en free edge and a p olicy is a subset of activ ated free edges. Therefore, PRO can b e seen as a particular case of SSP where V = V 0 ∪ { v s , v t } is the set of states and F is the set of 2 f actions 1 , where f is the n umber of free edges. This SSP instance has a polynomial num b er of states and actions. Uniform transition probabilities and unit costs are assumed here (except for the target no de v t whic h is cost-free). If we do not assume that the supp ort graph G is strongly connected, extra care must b e tak en. Indeed, in that case, there ma y b e nodes (or connected components) that do not hav e an y outgoing edge. T o deal with such dangling no des (or comp onents), many techniques exist [Ber05], such as connecting them to ev ery other no de. W e may choose an y of the existing solution and assume that w e hav e already dealt with dangling no des. Another case for whic h we m ust b e careful is when all outgoing edges from a no de are free. Indeed, suc h a no de would b ecome a dangling no de is every free edge w as deactiv ated. How ever, in that case, Csá ji et al. hav e shown that the optimal p olicy w ould alwa ys activ ate exactly one of these free edges, i.e. the one that p oin ts tow ards the no de that is closest to the target no de [CJB09]. F urthermore, an algorithm lik e PI w ould only consider policies in whic h exactly one of these free edges are activ e. Therefore, in this case, we may alwa ys consider that there are as many actions as free edges, where eac h action consists in activ ating exactly one of the free edges. As a consequence of the ab ov e, w e may alwa ys consider that all no des are able to reac h the target no de with p ositive probability , whatever the chosen p olicy (so that every p olicy is prop er). Generalized PageRank Optimization. A natural w ay of extending PR O is to allo w arbitrary transition probabilities and costs. W e call such a relaxation a Gener alize d PageR ank Optimization problem (GPR O), which w e now formally define. A con venien t w ay to deal with arbitrary transition probabilities in the context of GPRO, where the out-degree of the no des may v ary , is to assign a w eight to each p ossible transition and to compute the transition probabilities in prop ortion to these w eights. More precisely , we define the weigh t set W such that W i,j > 0 if ( i, j ) ∈ E and W i,j = 0 otherwise. Giv en a p olicy µ (i.e. a configuration of free edges), w e define the corresp onding w eight set W µ as W µ i,j = ( W i,j if ( i, j ) ∈ E µ , 0 otherwise , where E µ is the set of activ ated edges when p olicy µ is chosen. T ransition probabilities Q µ are then 1 F or precision, taking an action in a state in which k outgoing edges are free should be seen as c ho osing the subset of these k edges that should b e activ ated. See Section 2 for a construction to deal with the size of these subsets in p olynomial time. 4 defined according to the w eights b y : Q µ i,j = W µ i,j P k ∈V W µ i,k . In a no de i , weigh ts enable to distribute the probabilities among the activ ated edges that leav e i , and this in prop ortion to their m utual imp ortance. Note that for Q to b e w ell defined, there must alw ays exist at least one edge with p ositiv e w eight going out of any starting no de i , for any p olicy µ . F or any no des i, j , a cost matrix K is also defined suc h that K i,j is the cost of going from i to j . Finally , in the GPR O framework, w e also allow some exclusivit y constraints in the follo wing case : in a no de in whic h there are only t wo free edges and no fixed edges going out, we may assume that exactly one of these edges m ust b e activ ated while the other m ust b e deactiv ated. W e will see that these exclusivity constraints will enable us to make the link with SSP . W e b elieve that such constrain ts are the key difference with PR O that makes the latter problem easier to solve. Putting everything together, w e define a GPRO instance b y the tuple ( V , F , W , K ) . The original edge set E can b e obtained from W . Let us no w mak e some comm ents ab out the in tro duced concepts. Remarks. 1. A PRO problem can b e formulated as a GPR O problem in which W i,j = 1 if ( i, j ) ∈ E and W i,j = 0 otherwise, and in whic h K i,j = 1 for all ( i, j ) ∈ E (except when i = v t ). 2. Exclusivit y constraints can b e mo deled using small w eights. Indeed, in a no de where there is a free and a fixed edge, if the free edge has a weigh t significantly higher than the fixed edge, it means that this edge will b e chosen with high probabilit y if activ ated, while the fixed edge will alwa ys b e chosen with probability one if the free edge is deactiv ated : so dep ending on the activ ation state of the free edge, one edge or the other will b e c hosen, which imitates the exclusiv e b ehavior of SSP actions, as illustrated in figure 1. How ev er at that p oint, w e hav e not b een able to adapt such a model to any instance with the guaran tee that the optimal solution w ould not change, at least not with w eights that hav e p olynomial v alue. s s 0 s 00 A B ⇒ s s 0 s 00 1 ε Figure 1: Left : exclusive actions in the GPR O framew ork. The con troller is ask ed to choose either A or B . Right : the equiv alent action mo deled with w eights in the GPR O framework. The controller is asked to activ ate or deactiv ate the free (dashed) edge. Here, ε represents a “small enough” weigh t. 3. In SSP and GPR O, exclusivity constrain ts concern edges that lea ve the same no de. Csá ji et al. hav e shown in [CJB09] that if one adds exclusivit y constrain ts b etw een free edges that lea ve different no des, PRO b ecomes NP-hard to solve. This fact is another clue tow ards the fact that these constrain ts do make a difference in the efficien t solv ability of these problems. 4. Solving a GPRO problem can b e seen as the search of the b est subgraph of a given graph (the supp ort graph) such that some edges cannot b e remo ved, and suc h that it satisfies additional exclusivit y constraints. 5. Because of the con text of PR O, w e fo cused here on an SSP-lik e criterion in whic h an absorbing state has to b e reac hed as quickly as p ossible. Ho wev er, the GPRO formulation could ha ve b een adapted to match any MDPs’ classical optimization criteria, lik e the av erage-cost and the discoun ted-cost criteria for instance. 5 2 Comparison b et w een PR O and SSP In this section, we show that from an y instance of SSP , we can build a GPRO instance that has the same optimal solution, and vice v ersa. Theorem 1. Given any instanc e of an SSP pr oblem with n states and a total of m available actions, it c an b e r e duc e d in p olynomial time to a GPR O pr oblem with O ( m ) no des and O ( m ) fr e e e dges that has the same optimal solution. Similarly, given any instanc e of a GPR O pr oblem with n no des and f fr e e e dges, it c an b e tr ansforme d in p olynomial time into an SSP pr oblem with O ( n ) single-action states and f 2-actions states that has the same optimal solution. Pr o of. W e first sho w ho w to reduce an SSP to a GPRO and then a GRPO to an SSP . Going from SSP to GPR O. Let us create a GPR O instance with a set of no des V that corresp onds to the set of states S of the SSP . Then, we first claim that any SSP can b e expressed as another SSP problem in which there are at most t w o actions p er state, without changing the optimal solution. Then w e sho w ho w probabilistic 2-actions states can be split in to one deterministic 2-actions state and t wo single-action states. W e conclude by sho wing how single-action states and deterministic 2-actions states can b e reduced in the GPRO framework. Claim 1 : Given any state s of an SSP instance with k ≥ 2 av ailable actions, s can b e split in to ( k − 1) 2-actions states without changin g the optimal solution of the original SSP . W e sho w this b y induction on k . The base case for k = 2 is trivial. Then, if it is true for k − 1 , it is still true for k . Indeed, let us split s in to tw o states s 0 and s 00 and supp ose that s 00 has ( k − 1) actions that corresp ond to the last ( k − 1) actions of s while s 0 has tw o actions : one that corresp onds to the first action of s and one that go es to state s 00 deterministically with probability 1 and cost 0 . A ctions that were previously p ointing to wards s are now p ointing tow ards s 0 . Hence state s 0 corresp onds to state s but it has a restricted decision to take : either the first action of s or some of the other actions. The optimal action to take in s do es not change in this construction since if the first action of s w as optimal, it will also b e taken in s 0 and if not, it means that some of the other actions of s w ould b e preferable so the decision is p ostp oned b y choosing the second action of s 0 that go es to s 00 . Since s 00 has ( k − 1) av ailable actions, it can be split in to ( k − 2) 2-actions states without c hanging the optimal solution b y induction hypothesis, which mak es a total of ( k − 1) 2-actions states. Claim 2 : A probabilistic 2-actions state s of an SSP instance can b e split into one deterministic 2-actions state u and tw o (probabilistic) single-action states u 0 and u 00 . In u , the choice of one of the t wo av ailable actions is done, allowing the pro cess to mov e deterministically to either u 0 or u 00 with probabilit y 1 and cost 0 . Now the only av ailable action in u 0 (resp. u 00 ) p erforms the randomization relativ e to the first (resp. second) action of s . Using Claims 1 and 2, we transform the original SSP problem with n states and a total of m actions in to an equiv alen t SSP problem with O ( m ) states, all of them b eing either deterministic 2-actions states or probabilistic single-action states. Indeed, we first create an equiv alen t SSP with only 2-actions states using Claim 1 and then we transform every probabilistic 2-actions state into one deterministic 2-actions states and t wo probabilistic single-action states using Claim 2. These transformations can b e done in p olynomial time and the resulting SSP problem is equiv alent to the first SSP in the sense that it still has the same optimal solution. W e now giv e the to ols to transform this new SSP problem in to a GPRO. Claim 3 : In an SSP instance, a deterministic action in state s in which one must choose either action A or action B can b e repro duced using exclusivit y constrain t in the GPR O setting. W e saw 6 in Section 1 that this is done b y giving tw o free edges to the no de s that corresp onds to state s , and assuming that these edges are linked with an exclusivity constraint. So, 2-actions states in the SSP setting can b e mo deled using tw o free edges in the GPR O setting. Claim 4 : A single-action state s that randomizes b etw een a set of states S 0 can b e reduced to the GPR O framework by adding an edge from the no de s corresp onding to s to every no de s 0 that corresp ond to the states in S 0 . T o every such edge ( s, s 0 ) , w e giv e a w eight W s,s 0 = P s,s 0 and a cost K s,s 0 = C s,s 0 . It is not hard to see that the obtained randomization effect in GPR O is equiv alent to that of the SSP (same transition probabilities and same costs). Hence, single-action states can b e mo deled without any free edge. W e ma y no w reduce the new SSP problem obtained from Claims 1 and 2 into a GPRO, using Claims 3 and 4. Indeed, Claim 3 tells us how to reduce deterministic 2-actions states in a GPR O setting, whereas Claim 4 gives us the argument to reduce probabilistic single-action states, b oth in polynomial time. The resulting GPRO problem has O ( m ) no des (as man y as the n umber of states of the transformed SSP) and O ( m ) free edges ( 2 free edges for ev ery 2 -actions state). In the resulting GPR O, all the no des corresp ond to some state from the transfor med SSP and they all ha ve the same probability distribution and transition costs, so the optimal solution of b oth problems is iden tical. Going fr om GPR O to SSP. A GPRO is already an instance of SSP with how ever a small distinction concerning the wa y the action set is describ ed : in GPRO, actions are tak en in the free edges while in SSP , actions are taken in the states. Ho wev er, we may assume that the actions in GPR O are also tak en in the states but then, extra care m ust b e taken. Indeed, if sev eral free edges go out from one single no de (sa y k free edges), then ev ery possible configuration of these free edges (so 2 k configurations) must b e considered as an a v ailable action in that node and therefore, the n umber of actions p er no de can grow exp onentially (in the worst case, we may end up with one no de that has 2 f a v ailable actions, where f is the n umber of free edges). Before going further, we must consider the case of a no de in whic h all outgoing edges are free. It that case, w e saw in section 1 that w e may consider as many actions as there are free edges such that each action corresp onds to a situation in which exactly one free edge is activ ated. Therefore, suc h no des with k outgoing free edges ma y b e transformed in to a state with k actions. No w let us consider a no de i with k > 1 outgoing free edges in addition to some fixed edges. W e sho w that suc h no des can b e transformed in to a substructure in whic h ev ery no de has at most t wo outgoing free edges. The main idea of the construction, illustrated at figure 2, is to create a new artificial no de for ev ery outgoing free edge, whic h is designed to act exactly as the original free edge. In no de i the choice of an y edge is tak en with resp ect to their weigh t but indep endently from the activ ation state of the free edges. If a free edge is c hosen, the pro cess jumps to the corresp onding auxiliary no de with cost 0. If the edge was activ ated, the path that leav es the structure is taken with probability 1 and the cost that corresp onds to the original edge while if it is not, the pro cess returns to node i with probabilit y 1 and cost 0. This procedure is then rep eated un til an activ ated edge is c hosen. Th us, since there is alw ays at least one fixed outgoing edge, w e are alw ays able to lea ve the structure. Observe that the auxiliary no des exactly match the no des with exclusive constrain ts describ ed in the definition of GPRO and they can thus b e transformed into states with t wo deterministic actions in the SSP setting. The whole pro cess needs a p olynomial n umber of transformations (add one no de and tw o edges for some free edges). As a final remark for this section, observe that all the arguments we ha ve b een using are not 7 i W 0 W 1 W 2 ⇒ i W 1 W 2 W 0 Figure 2: In the right figure, there are maxim um tw o free edges (i.e. dashed edge) p er node, even though the tw o substructures hav e the same dynamics. All the costs of the blac k edges are zero, while the costs of the colored edges are the same as the costs of the edges of corresp onding color in the left figure. sp ecific to the SSP optimization criterion. Here, we fo cused on SSP b ecause the GPRO formulation originally comes from an SSP-like problem. How ever, it is easy to generalize GPRO to mak e it also equiv alen t to an y MDP , whatev er the c hosen optimization criterion. The same arguments that w e used here may b e used to make the requested link. As a consequence, an MDP can alwa ys b e form ulated as the search of the b est subgraph in a supp ort graph (with some constraints on the edges that are allow ed to b e remov ed). This may b e useful to enrich the wa y MDPs are usually view ed and enhance the asso ciated intuition. 3 Applying P olicy Iteration to PR O An adaptation of Policy Iteration (PI) to PRO has b een prop osed b y Csá ji et al. in [CJB09]. When writing the algorithm, we represent a configuration of free edges by the set of activ ated free edges that we denote by p olicy µ . W e also define the first hitting time ϕ µ i of no de i under p olicy µ as the a verage time needed to reac h the target no de v t when starting the pro cess at no de i and following p olicy µ afterw ards. Of course, ϕ µ v t = 0 . First hitting times can b e computed in p olynomial time b y solving a linear system. W e call the resulting adaptation of PI : PageR ank Iter ation (PRI). The differen t steps are formalized in Algorithm 1. Algorithm 1 P a geRank Itera tion Require: An arbitrary p olicy µ 0 , k = 0 . Ensure: The optimal p olicy µ ∗ . 1: while µ k 6 = µ k − 1 do 2: Ev aluation step : compute ϕ µ k . 3: Greedy Impro vemen t step : µ k +1 = { ( i, j ) ∈ F : ϕ µ k i ≥ ϕ µ k j + 1 } . 4: k ← k + 1 . 5: end while 6: return µ k . T o summarize the op erating mode of PRI, w e start with an arbitrary policy and then proceed iterativ ely . At each iteration w e determine the set of free edges that are suc h that, if they were indep enden tly switched (i.e. switched on if edge is off and vice versa), the resulting p olicy w ould impro ve on the preceding one. Then, PRI b eing a greedy version of PI, we mak e all the improving 8 switc hes sim ultaneously , assuming that this would b e ev en b etter than single switc hes. This pro ce- dure improv es the p olicy iteratively until no more improv ements are p ossible, meaning that it has con verged to the optimal p olicy . Observ e that one do es not hav e to transform the PRO problem in an SSP problem, as the mo difications of the p olicies are handled implicitly directly in the PR O problem. Since eac h iteration needs p olynomial time to compute, the only condition for PRI to run in p olyno- mial time is to run in a p olynomial num b er of iterations. Unfortunately , determining b ounds on the n umber of iterations of PRI is an op en question : the b est kno wn upper b ound O (2 f /f ) is adapted from Mansour and Singh [MS99] whereas F earnley’s exp onential low er bound seems unlikely to apply to PRI for the reasons exp osed in the previous sections. W e formulate the follo wing conjecture, based on extensive computations. Conjecture 1. The numb er of iter ations of PRI is p olynomial in the numb er of fr e e e dges. T o test Conjecture 1, w e hav e first generated random instances of increasing size of PRO and hav e recorded the n umber of iterations. Figure 3 (left) shows that the num b er of iterations of PRI seems to grow at most linearly with the n umber of free edges. On the figure, random instances ha ve b een generated using a p ower-law distribution [ACL01] but iden tical sim ulations ha v e also been p erformed on Er dös-R ényi random graphs [ER60] or on p ortions of the real web, with ab out the same tendency eac h time. In a second time, w e hav e tried to generate instances that would p erform more than f iterations. Therefore, we hav e generated more than 200 million Erdös-Rényi and P ow er-law random instances, with parameters ranging from 3 to 10 free edges, 5 to 15 no des and a highly v ariable num b er of edges, without ever b eing able to find such an example. Figure 3 (righ t) shows ho w the num b er of iterations of PRI are distributed when generating man y instances with n = 8 and f = 4 . Note that w e hav e also b een exploring bigger v alue for f and n but since PRI b ehav es so well in practice, we ha ve only been able to obtain a few iterations w.r.t. the problem size for these instances (alwa ys less than 8 iterations). By concentrating on small instances, w e were able to generate some examples that w ere close to cross that f -iterations b ound. Ev en if crossing this b ound was possible, our sim ulations give a go o d indication ab out the scarcity of suc h examples when considering random graphs. Sho wing that random instances for whic h PRI takes more than f iterations are unlik ely to b e observ ed is in our plans for further research. 4 P articular cases In this section, we formulate some particular cases of PR O on which it can be sho wn that PRI b eha ves w ell. In many applications, it is assumed that the random w alk used to compute PageRank can b e in terrupted at any time with some fixed probability c and start again from an arbitrary no de of the graph [Ber05]. This restarting probabilit y is called zapping . It can b e seen as if the random surfer could get b ored of p erforming its search with probability c and decide to start a new search from a new randomly chosen no de. W e show b elow that in such cases, PRI conv erges in weakly p olynomial time. Theorem 2. PRO with fixe d non-zer o zapping pr ob ability c c an b e solve d in we akly p olynomial time using PRI. 9 Figure 3: Left : the evo lution of the num b er of iterations when the num b er of free edges grows. F or each v alue of f , 5 tests ha ve b een p erformed (here on Po wer Law random graphs) and the av erage (in blue) and the maximum (in red) n umber of iterations hav e been recorded. Right : the distribution of the n umber of iterations of PRI after o ver 3 million tests on small Erdös-Renyi random graphs with 8 no des and 4 free edges each. Among all, 5 tests (so 1.5 E -4%) hav e pro duced 4 iterations - hitting the barrier of f iterations. Pr o of. Our pro of relies on results from T seng and Puterman [T se90, Put94]. Puterman shows that PI conv erges alwa ys in less iterations than the other w ell-kno wn algorithm V alue Iteration (VI). F urthermore, T seng sho ws that VI conv erges in at most O ( n log ( nδ ) η − r ) , where n is the n umber of states, δ is the binary input size, η is the minim um non-zero transition probabilit y and r is the minim um num b er of steps needed to join tw o arbitrary no des. In case of zapping, there is alwa ys a non-zero probability for any no de to reac h any other no de in only one step, i.e. when zapping happ ens. Hence r = 1 . Besides, because of the uniform random walk, η is alwa ys at least c/n . Regrouping all the arguments, we show that PI must con verge in at most O ( n 2 log( nδ ) /c ) steps, whic h is weakly 2 p olynomial in n for a fixed v alue of c . In the next case, we show that PRI conv erges in at most f iterations when all free edges come out of the same arbitrary no de w . Note that a particular case of this result was one of the main con tribution of [dKND08] : they were able to form ulate an explicit optimal strategy when all edges come out of the starting no de v s . Theorem 3. PRI takes less than f iter ations when al l the fr e e e dges go out of the same no de w and/or out of the starting no de v s . Pr o of. W e are goin g to show that in all considered cases, PRI alw a ys mak es at least one final decision in each step (final in the sense that it will nev er b e undone in a subsequent iteration). If this is true, then of course PRI takes at most f iterations since we ma y consider at least one less free edge at eac h iteration. F urthermore, observe that the no des may alw ays b e sorted w.r.t. their first hitting time at eac h iteration of PRI : this will b e the k ey to derive our result. The pro of go es in three steps : first we supp ose that all free edges lea ve no de v s , then that they all leav e some other no de w and w e finally unify these tw o results to prov e the claim. 2 The b ound is only we akly p olynomial b ecause it depends on the num b er of bits that are necessary to represent the num b ers in a problem instance. 10 • Case 1 : al l fr e e e dges le ave no de v s . Since no edge en ters v s , switching a free edge that lea ves v s do es not influence the first hitting times of the other no des (it do es not shorten or lengthen their path). Hence, their first hitting times is fixed from the b eginning and only ϕ v s decreases in the iterative pro cess. Suppose that every free edge is initially activ ated. Then, since ϕ v s can only decrease, ϕ v s − ( ϕ u + 1) can also only decrease for any no de u suc h that ( v s , u ) ∈ F , and therefore free edges can only b e deactiv ated by PRI (see line 3 of the algorithm). So PRI nev er undo es an y of its choices and it con verges in at most f iterations. If the initial p olicy w as different, the argument is the same except at the first step where free edges ( v s , u ) such that ϕ v s ≥ ( ϕ u + 1) are activ ated and the other free edges are deactiv ated. Then again, free edges can only b e deactiv ated since ϕ v s is the only one to decrease. • Case 2 : al l fr e e e dges le ave some no de w 6 = v s . Here, the key is to see that when switching a free edge, ϕ w decreases more than the other no des’ first hitting times. If this is true, then it means that for an y no de u 6 = w , ϕ w − ( ϕ u + 1) can only decrease and that free edges can only b e deactiv ated at each step, so the argument used in case 1 is still v alid. Hence PRI would again take at most f iterations. It only remains to prov e that ϕ w indeed decrease faster than an y other first hitting time, which w e do next. Let us consider an y no de u 6 = w . Among all the paths starting from u that lead to the target no de v t , only those that go through w will b e shortened when switc hing free edges, since all free edges leav e w . Let us th us partition the set of all paths from u to v t in to the ones that go through w that w e denote b y P uwv , and the ones that do not go through w that w e denote b y P uv . W e also denote the a verage w eighted length of the paths in P uv b y ϕ uv and the probabilit y to tak e such a path by p uv , all w.r.t the probability for the considered paths to be c hosen. If a path go es through w , it means that u reac hes w before reaching v t (since v t is absorbing). Therefore, the probability of hitting w b efore hitting v t is giv en by p uw = 1 − p uv , and we denote the av erage weigh ted length of paths b etw een u and the first visit of w by ϕ uw . Using these notations, w e can write the first hitting time of u as follows : ϕ µ k u = p uv ϕ uv + (1 − p uv )( ϕ uw + ϕ µ k w ) (1) where ( ϕ uw + ϕ µ k w ) is the a v erage weigh ted length of a path that go es through no de w b efore reac hing v t . In this equation, observe that only ϕ µ k w can c hange during the iterativ e pro cess of PRI since the c hanges to the probability distributions and to the av erage lengths of paths can only happ en when trav elling through w . Let us now supp ose that in some step k of PRI, ϕ µ k w decreases from ∆ ϕ k , so ϕ µ k +1 w = ϕ µ k w − ∆ ϕ k . Using equation (1), the influence of this decrease on ϕ µ k u is th us : ϕ µ k +1 u = ϕ µ k u − (1 − p uv )∆ ϕ k . Hence, ϕ µ k u decreases of at most ∆ ϕ k , but only if all its paths to v t pass through w . Therefore, the first hitting time of w decreases more than the first hitting time of any other no de. This concludes the pro of for this case. • Case 3 : al l fr e e e dges le ave either v s or w . Since no de w is not influenced by no de v s , we can consider the PRI pro cess in w indep endently from the pro cess in v s . Th us, in no de w , applying case 2, PRI makes at least one switch that is final in eac h step until every free edge lea ving w reaches its optimal activ ation state. At that p oint, the first hitting times of every no de is fixed for the rest of the pro cess except maybe in no de v s . If ϕ v s has not reached its optimal v alue y et, w e let PRI run as if we w ere in case 1. So, w e first focus on w and observ e that at least one final switc h is made there at eac h step un til the optimal configuration of the 11 free edges lea ving w is reached. And then we fo cus on no de v s where the same observ ation can b e made. Com bining b oth subpro cesses, we conclude that one final decision is made at eac h iteration and so, again, PRI takes at most f iterations to con v erge. References [A CL01] W. Aiello, F. Ch ung, and L. Lu. A random graph mo del for p ow er la w graphs. Exp eri- mental Mathematics , 10(1):53–66, 2001. [AL04] K. A vrac henk ov and N. Litv ak. Decomp osition of the go ogle pagerank and optimal linking strategy . T e chnic al r ep ort, INRIA , 2004. [Ber05] P . Berkhin. A survey on pagerank computing. Internet Mathematics , 2(1):73-120, 2005. [Ber07] D. P . Bertsek as. Dynamic Pr o gr amming and Optimal Contr ol . A thena Scientific, Bel- mon t, Massach usetts, 3rd edition, 2007. [BP98] S. Brin and L. Page. The anatomy of a large-scale h yp ertextual w eb searc h engine. Computer Networks and ISDN Systems , 30(1-7):107–117, 1998. [BT91] D. P . Bertsek as and J. N. T sitsiklis. An analysis of sto chastic shortest path problems. Mathematics of Op er ations R ese ar ch , 16(3):580-595, 1991. [CJB09] B. C. Csáji, R. M. Jungers, and V. D. Blondel. Pagerank optimization by edge selection. CoRR , abs/0911.2280, 2009. [CLF09] D. Chaffey , C. Lake, and A. F riedlein. Search engine optimization - b est practice guide. Ec onsultancy.c om Ltd , 2009. [dKND08] C. de Kerc ho ve, L. Nino ve, and P . V an Do oren. Maximizing pagerank via outlinks. Line ar Algebr a and its Applic ations , 429:1254-1276, 2008. [ER60] P . Erdős and A. Rén yi. On the evolution of r andom gr aphs . Citeseer, 1960. [F ABG10] O. F ercoq, M. Akian, M. Bouhtou, and S. Gaub ert. Ergo dic control and p olyhedral approac hes to pagerank optimization. Arxiv pr eprint arXiv:1011.2348 , 2010. [F ea10] J. F earnley . Exp onential low er b ounds for p olicy iteration. CoRR, abs/1003.3418 , 2010. [HMZ10] T. D. Hansen, P . B. Miltersen, and U. Zwick. Strategy iteration is strongly p olynomial for 2-pla yer turn-based sto c hastic games with a constant discoun t factor. 2010. [Ho w60] R.A. How ard. Dynamic Pr o gr amming and Markov Pr o c esses . MIT Press, Cambridge, MA, 1960. [HZ10] T. Hansen and U. Zwic k. Lo wer b ounds for ho w ard’s algorithm for finding minim um mean-cost cycles. A lgorithms and Computation , pages 415–426, 2010. [IT09] H. Ishii and R. T emp o. Computing the pagerank v ariation for fragile w eb data. SICE J. of Contr ol, Me asur ement, and System Inte gr ation , 2(1):1-9, 2009. [MS99] Y. Mansour and S. Singh. On the complexity of p olicy iteration. Fifte enth Confer enc e on Unc ertainty in Artificial Intel ligenc e , 1999. 12 [MTZ10] O. Madani, M. Thorup, and U. Zwick. Discoun ted deterministic mark o v decision pro cesses and discounted all-pairs shortest paths. A CM T r ansactions on A lgorithms (T ALG) , 6(2):33, 2010. [MV06] F. Mathieu and L. Viennot. Lo cal asp ects of the global ranking of web pages. In Pr o- c e e dings of the 6th International W orkshop on Innovative Internet Community Systems , v olume 44. Citeseer, 2006. [Put94] M. L. Puterman. Markov de cision pr o c esses . John Wiley & Sons, 1994. [T se90] P . T seng. Solving h-horizon, stationary marko v decision problems in time prop ortional to log(h). Op er ations R ese ar ch L etters , 9(4):287-297, 1990. [Y e10] Y. Y e. The simplex metho d is strongly p olynomial for the mark ov decision problem with a fixed discoun t rate. (Submitte d) , 2010. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment