Training Logistic Regression and SVM on 200GB Data Using b-Bit Minwise Hashing and Comparisons with Vowpal Wabbit (VW)
We generated a dataset of 200 GB with 10^9 features, to test our recent b-bit minwise hashing algorithms for training very large-scale logistic regression and SVM. The results confirm our prior work that, compared with the VW hashing algorithm (which…
Authors: Ping Li, Anshumali Shrivastava, Christian Konig
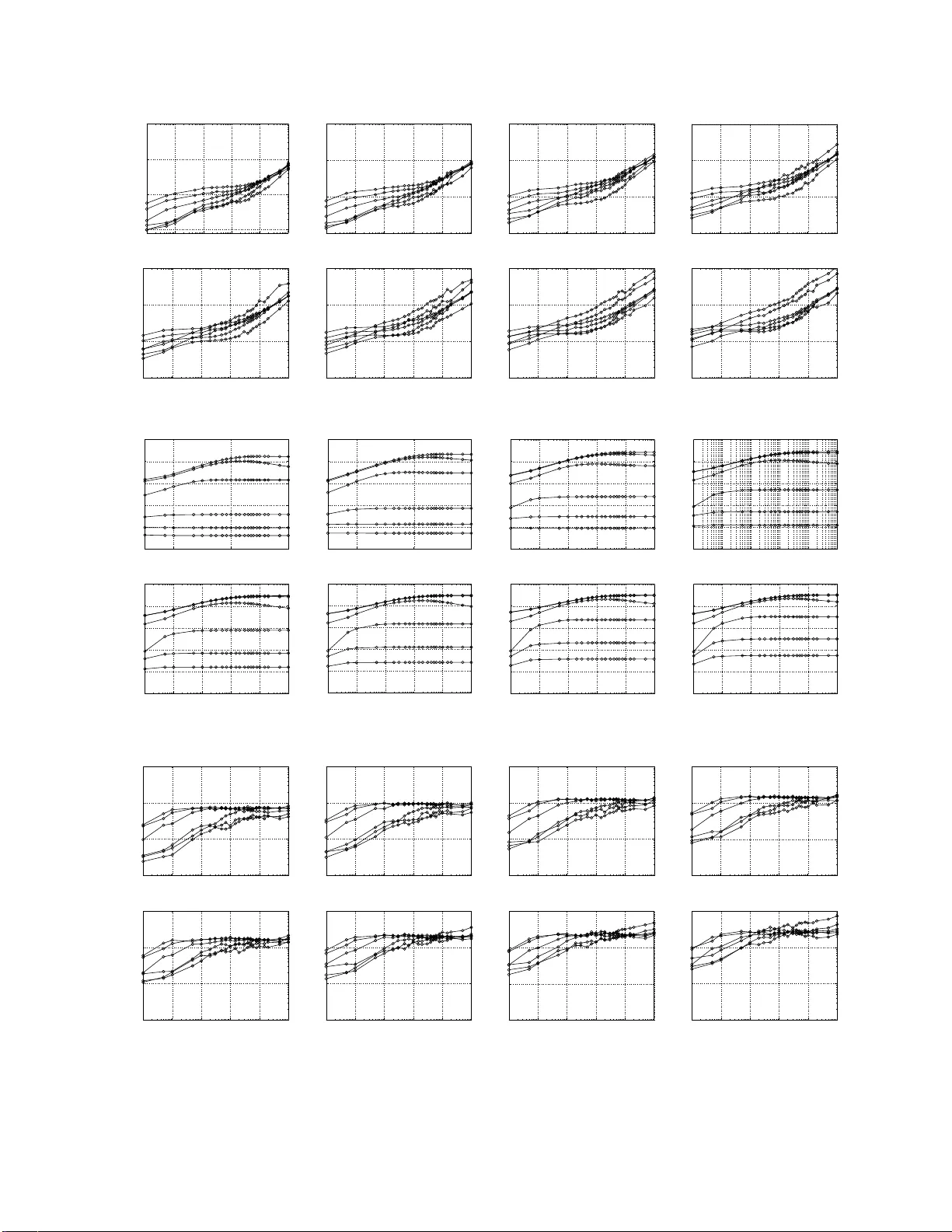
T raining Logistic Regression and SVM on 200GB Data Using b-Bit Minwise Hashing and Compariso ns with V o wpal W abbit (VW) Ping Li Dept. of Statistical Science Cornell Unive rsity Ithaca, NY 14853 pingli@cornell. edu Anshumali Shri vasta va Dept. of Computer Science Cornell Unive rsity Ithaca, NY 14853 anshu@cs.cornell.edu Arnd Christian K ¨ onig Microsoft Research Microsoft Corporation Redmond, W A 98052 chrisko@microsoft.com Abstract Our recent work on large-scale learning using b -bit minwise hashing [21, 22] was tested on the webspam dataset (about 24 GB in LibSVM format), which may be way too small co mpared to real datasets used in industry . Since we could not access the proprietary dataset used in [ 31] for testing the V owpal W abbit (VW) hashing algorithm, in this paper we present an expe rimental study based on the expand ed rcv1 dataset (about 20 0 GB in L ibSVM format). In our earlier report [22], t he exp eriments demonstrated that, with merely 200 hashed v alues per data point, b -bit minwise hashing can achiev e similar test accuracies as VW wit h 10 6 hashed valu es per data point, on the webspam dataset. In this paper , our new experiments on t he (expande d) r cv1 dataset clearly agree with our earlier observ at ion that b -bit minwise hashing algorithm i s substantially more accurate than VW hashing algorithm at the same storage. For e xample, with 2 14 (16384) hashed v alues per da ta point, VW achie ves similar test ac curacies as b -bit hashing with merely 30 hashed value s per data point. This is of course not surprising as the report [22] has already demonstrated that the variance of t he VW algorithm can be order of magnitude(s) larger than the variance of b -bit minwise hashing. It was sho wn in [22] that VW has the same variance as random projections. At least in the context of search, minwise hashing has been wi dely used in industry . It is well-understood that the preprocessing cost is not a major issue because the preprocessing is tr iv ially parallelizable and can be conducted of f-line or combined with the data-collection process. Ne vertheless, in this paper , we report that, ev en merely from the perspectiv e of academic machine learning practice, the preprocessing cost is not a major issue f or t he following reasons: • The preprocessing incurs only a one-time cost. The same processed data can be used for many training exper - iments, f or example, for many different “C” values in SVM cross-v ali dation, or for different combinations of data splitting (into training and testing sets). • For training truly large-scale datasets, the dominating cost is often the d ata loading time. In our 200 GB datase t (which may be sti ll very small according to t he industry standard), the preprocessing cost of b -bit minwise hashing is on the same order of magnitude as the data loading time. • Using a GP U, the preprocessing cost can be easily reduced to a small fraction (e.g., < 1 / 7 ) of the data loading time. The standard industry practice of minwise hashing is to use univ ersal hashing to replace permutations. In other words, there is no need to store an y permu tation ma ppings, on e o f the rea sons why mi nwise hashing is popular . In this paper , we also provide experiments to verify t his practice, based on the si mplest 2-univ ersal hashing, and i llustrate that the performanc e of b -bit minwise hashing does not degrad e. 1 Introd uction Many machine learning applications are f a ced with large and inherently high-dimension al datasets. For e xample, [29] discusses training datasets with (on a verag e) 10 11 items and 10 9 distinct features. [ 31] experimented with a dataset of potentially 16 trillion ( 1 . 6 × 10 13 ) unique features. Interestingly , while large- scale lea rning has become a very urgent, hot topic, it is usu ally very difficult fo r researchers from un i versities to obtain truly large, h igh-dime nsional datasets 1 from industry . For example, the experiments in o ur recent work [ 21, 22] on large-scale learning using b -bit minw ise hashing [23, 24, 20] were based on the webspam dataset (about 24 GB in LibSVM format), which may be too small. T o overcome th is difficulty , we have generated a d ataset o f about 200 GB (in L ibSVM format) f rom th e rcv1 dataset, using the original featur es + all pa irwise combinatio ns o f features + 1/30 of the 3-way combinatio ns of features. W e choose 200 GB (wh ich o f c ourse is still very small) because re lati vely inexpen si ve workstatio ns with 192 GB memory are in the mar ket, wh ich m ay make it p ossible for LIBLINE AR [11, 15], the popular solver f or logistic regression and linear SVM, to p erform the train ing of the entire dataset in m ain m emory . W e hop e in th e near f uture we will b e able to purchase suc h a workstation . Of cour se, in this “inform ation explosion” age, the growth of data is always much f aster than the growth of memory capacity . Note that the our hashing metho d is o rthogo nal to p articular solvers of logistic regression and SVM. W e have tested b -bit minwise hashing with o ther solvers [ 17, 2 7, 3] and observed substantial impr ovements. W e choo se L IB- LINEAR [11] as the w o rk horse beca use it is a popular t ool and may be f amiliar t o non-experts. Our experiments may be ea sily validated by simp ly g enerating the hashed d ata off-line and f eeding th em to LIBLINEAR ( or othe r solvers) without mod ification to th e code. Also, we notice th at the source co de o f LIBLINEAR, unlike many other excellent solvers, can be com piled in V isual Studio without modification . As m any practition ers are u sing WINDO WS 1 , we use LIBLINEAR through out th e paper, for the sake of maximizing the repeatab ility of our w o rk. Unsurprising ly , our expe rimental results agr ee with our prior studies [22] that b -bit minwise hashing is su bstan- tially more accurate tha n the V owpal W ab bit (VW) hashing alg orithm [31] at the s ame storage. Note that in our pa per , VW refers to the particu lar hash ing alg orithm in [31], not the online learning p latform that the authors o f [31, 28] have been dev eloping. For ev aluatio n purpo ses, we mu st separate out hashing algorithm s fr om l earning algorithms because they are orthogon al to each other . All rando mized algo rithms includin g minwise h ashing and r andom projectio ns rely o n pseud o-rand om numbers. A comm on practice of minwise hashing ( e.g., [4]) is to u se universal hashing fun ctions to rep lace perfect rando m permutatio ns. In this pap er , we also pr esent an em pirical stud y to verif y tha t th is c ommon practice d oes not d egrade the learning perfor mance. Minwise h ashing has been widely d eployed in ind ustry and b - bit m inwise hashing requir es on ly m inimal modi- fications. It is well-un derstood at least in the co ntext of search that the (on e time) preproc essing co st is not a major issue because the pr eprocessing step, which is tr i vially parallelizable, can be cond ucted off-line or combined in the data-collectio n process. I n the context o f pure machine learning research, one thing we notice is that for training truly large-scale datasets, the data loadin g time is often d ominating [ 32], fo r online algorithms as well as b atch algo rithms (if the data fit in memory). Thus, if we have to load the data many times, for example, for testing different “ C ” values in SVM or runnin g an onlin e algo rithms f or m ultiple epoch es, then th e benefits of d ata reduction algorithm s such as b -bit minwise hashing would be enormous. Even on our dataset of 2 00 GB on ly , we observe that the prepr ocessing cost is roug hly on the same ord er of mag- nitude as the da ta loading time. Furthermo re, using a GPU (which is inexpen si ve) f or fast hashing , we can reduce the prepro cessing cost of b -bit minwise h ashing to a small fraction of the d ata loading tim e. In oth er words, th e dom inating cost is the still the data loading time. W e are currently exper imenting b -bit m inwise h ashing f or mac hine learn ing with ≫ TB datasets and the results will be reported in subsequent technical reports. It is a very f un process to exper iment with b - bit minwise hashing an d we certainly would like to share our experience with the machine learning and data mining commun ity . 2 Re view Minwise Hashing and b-Bit Minwise Hashing Minwise hashing [4, 5] has been successfully applied to a very wide ran ge of real-world prob lems especially in the context of search [4, 5, 2, 13, 7, 6, 30, 16, 10, 8, 14, 18, 26], for ef ficiently co mputing set similarities. Minwise hashing mainly works well with binary data, which can be viewed either as 0/1 vectors or as sets. Gi ven 1 Note that t he cur rent ve rsion of Cygwin has a ve ry seriou s memory limita tion and he nce i s not suitable f or l arge -scale ex periments, e ven th ough all popular solvers ca n be compiled under Cygwin. 2 two sets, S 1 , S 2 ⊆ Ω = { 0 , 1 , 2 , ..., D − 1 } , a widely used (nor malized) measure of similarity is the r esemb lance R : R = | S 1 ∩ S 2 | | S 1 ∪ S 2 | = a f 1 + f 2 − a , where f 1 = | S 1 | , f 2 = | S 2 | , a = | S 1 ∩ S 2 | . In this method , one applies a random permu tation π : Ω → Ω on S 1 and S 2 . T he collision probab ility is simply Pr ( min ( π ( S 1 )) = m in ( π ( S 2 ))) = | S 1 ∩ S 2 | | S 1 ∪ S 2 | = R . One can repeat the permuta tion k times: π 1 , π 2 , ..., π k to estimate R without bias, as ˆ R M = 1 k k X j =1 1 { min( π j ( S 1 )) = min( π j ( S 2 )) } , (1) V ar ˆ R M = 1 k R (1 − R ) . (2) The common p ractice of minwise h ashing is to store each hashed value, e.g., min( π ( S 1 )) an d min( π ( S 2 )) , using 64 bits [12]. T he storage (and computa tional) co st will be prohib iti ve in truly large-scale (industry ) application s [25]. In ord er to apply min wise hashin g for efficiently training lin ear learnin g algorith ms such as logistic regression or linear SVM, we need to express the estimator (1) as an inner product. For simplicity , we introduce z 1 = min( π j ( S 1 )) , z 2 = min ( π j ( S 2 )) , and we hope that the term 1 { z 1 = z 2 } can be expressed as an inner product. Ind eed, because 1 { z 1 = z 2 } = D − 1 X t =0 1 { z 1 = t } × 1 { z 2 = t } we know im mediately th at the estimator (1) for minwise h ashing is an inner prod uct b etween two extremely h igh- dimensiona l ( D × k ) vectors. E ach vector, which has exactly k 1’ s, is a concatena tion o f k D -dimen sional vectors. Because D = 2 64 is possible i n industry applications, th e total ind exing spac e ( D × k ) may be too high to directly use this representa tion for training. The recent development of b-bit minwise hashing [2 3, 24, 20] provides a s trikingly si mple solution b y storing only the lowest b bits (instead of 64 bits) of each hashed value. For conv e nience, we d efine e 1 ,i = i th lowest bit of z 1 , e 2 ,i = i th lowest bit of z 2 . Theorem 1 [23] Assume D is larg e (i.e., D → ∞ ) . P b = Pr b Y i =1 1 { e 1 ,i = e 2 ,i } ! = C 1 ,b + (1 − C 2 ,b ) R, (3) r 1 = f 1 D , r 2 = f 2 D , f 1 = | S 1 | , f 2 = | S 2 | , C 1 ,b = A 1 ,b r 2 r 1 + r 2 + A 2 ,b r 1 r 1 + r 2 , C 2 ,b = A 1 ,b r 1 r 1 + r 2 + A 2 ,b r 2 r 1 + r 2 , A 1 ,b = r 1 [1 − r 1 ] 2 b − 1 1 − [1 − r 1 ] 2 b , A 2 ,b = r 2 [1 − r 2 ] 2 b − 1 1 − [1 − r 2 ] 2 b . As r 1 → 0 an d r 2 → 0 , the limits ar e A 1 ,b = A 2 ,b = C 1 ,b = C 2 ,b = 1 2 b (4) P b = 1 2 b + 1 − 1 2 b R (5) 3 The case r 1 , r 2 → 0 is very com mon in practice becau se the data are of ten r elativ ely h ighly sparse (i. e., r 1 , r 2 ≈ 0 ), although they c an be very large in the absolute scale. For example , if D = 2 64 , then a set S 1 with f 1 = | S 1 | = 2 54 (which rough ly corresp onds to the size of a small novel) is highly s parse ( r 1 ≈ 0 . 001 ) ev en tho ugh 2 54 is actually very large in the abso lute scale. One can also verify that the error b y using (5) to replac e (3) is bound ed b y O ( r 1 + r 2 ) , which is very small when r 1 , r 2 → 0 . In fact, [24] extensi vely used this argument f or studying 3-way set similarities. W e can then estimate P b (and R ) fro m k in depende nt per mutations: π 1 , π 2 , ..., π k , ˆ R b = ˆ P b − C 1 ,b 1 − C 2 ,b , ˆ P b = 1 k k X j =1 ( b Y i =1 1 { e 1 ,i,π j = e 2 ,i,π j } ) , (6) V ar ˆ R b = V ar ˆ P b [1 − C 2 ,b ] 2 = 1 k [ C 1 ,b + (1 − C 2 ,b ) R ] [1 − C 1 ,b − (1 − C 2 ,b ) R ] [1 − C 2 ,b ] 2 (7) Clearly , the similarity ( R ) info rmation is ad equately encod ed in P b . In oth er words, of ten there is no need to explicitly estimate R . Th e e stimator ˆ P b is an in ner p roduct betwee n two vecto rs in 2 b × k dimen sions with exactly k 1’ s. Theref ore, if b is not too large (e.g ., b ≤ 1 6 ), this intuitio n p rovides a simple practical strategy f or using b -b it minwise hashing for large-scale learning. 3 Integrating b -Bit Minwise Hashing with (Linear) Learnin g Algorithms Linear a lgorithms such as linear SVM an d log istic regression have become very powerful and extremely p opular . Representative software packages inc lude SVM perf [17], Pe g asos [27], B ottou’ s SGD SVM [3], and LIBLINEA R [11]. Giv en a d ataset { ( x i , y i ) } n i =1 , x i ∈ R D , y i ∈ { − 1 , 1 } , th e L 2 -regularized linear SVM solves the following optimization prob lem: min w 1 2 w T w + C n X i =1 max 1 − y i w T x i , 0 , (8) and the L 2 -regularized logistic regression solves a similar problem: min w 1 2 w T w + C n X i =1 log 1 + e − y i w T x i . (9) Here C > 0 is an imp ortant p enalty param eter . Since our purp ose is to demo nstrate the effectiv eness of o ur pro- posed sch eme using b - bit hashing , we simply provide results for a wid e r ange of C values an d assume that th e be st perfor mance is ac hiev ab le if we cond uct cross-vali dations. In our a pproach , we app ly k ind ependen t random p ermutation s on each feature vector x i and store the lowest b bits of each hashed value. This way , we obtain a new dataset which can be stored using merely nbk b its. At run-tim e, we expand each ne w data point into a 2 b × k -leng th v ector . For example, s uppose k = 3 a nd the hashed values are origin ally { 12013 , 2 5964 , 20191 } , wh ose binary digits are { 0101 11011 101101 , 1100101 0110 1100 , 100111011011111 } . Consider b = 2 . Then the binary digits a re stor ed as { 01 , 0 0 , 11 } (wh ich co rrespond s to { 1 , 0 , 3 } in decimals). At run-time, we need to expa nd them into a vector of length 2 b k = 12 , to be { 0 , 0 , 1 , 0 , 0 , 0 , 0 , 1 , 1 , 0 , 0 , 0 } , which will be the ne w feature vector fed to a solver: Original hashed v alues ( k = 3 ) : 12013 25964 20191 Original binary representation s : 01011 10111 01101 11001 01011 01100 10011 1011 0 11111 Lowest b = 2 bin ary digits : 01 00 11 Expand ed 2 b = 4 binary digits : 0010 0001 1000 New feature vector fed to a solver : { 0 , 0 , 1 , 0 , 0 , 0 , 0 , 1 , 1 , 0 , 0 , 0 } 4 4 Experimental Results of b -Bit M inwise Ha shing on Expanded RCV1 Datas et In our e arlier techn ical r eports [2 1, 22], o ur exper imental settings closely followed th e work in [32] by testing b -bit minwise hashing o n the webspam dataset ( n = 35000 0 , D = 166091 43 ). Follo win g [3 2], we rand omly selected 20% of sam ples f or testing an d used the re maining 80% samples fo r training. Since the webspa m d ataset (24 GB in LibSVM format) may be too small compared by datasets used in industry , in this paper we present an empirical study on th e expanded r cv1 dataset by u sing th e original fe atures + all pairwise co mbination s (prod ucts) of f eatures + 1/30 of 3-way combinations (products) of features. W e chose LIBLINE AR as the tool to demonstrate the effectiveness of our algor ithm. All experim ents were co n- ducted on workstations with Xeon(R) CPU (W5590@3.33 GHz) an d 48GB RAM, under W indows 7 System. T able 1: Data inform ation Dataset # Examples ( n ) # Dimensions ( D ) # Nonzero s Median (Mean) T rain / T est Split W ebspam (24 GB) 3500 00 16609 143 3889 (3728) 80% / 20% Rcv1 (200 GB) 67739 9 101001 7424 3051 (12062) 50% / 50% Note that we used the or iginal “test ing” data o f r cv1 to ge nerate our new exp anded da taset. Th e o riginal “training” data of rcv1 h ad only 20 242 examp les. Also, to ensure reliable test results, we r andomly split o ur expanded r cv1 dataset into two halves, for training and testing. 4.1 Experimental Results Using Linear SVM Since th ere is an im portant tunin g parame ter C in linear SVM and logistic regre ssion, we cond ucted our extensive experiments for a wide range of C values (from 1 0 − 3 to 10 2 ) with finer spacings in [0 . 1 , 10 ] . W e mainly exp erimented with k = 30 to k = 500 , and b = 1 , 2 , 4 , 8, 12 , and 16. Figur es 1 and 2 provide the test accuracies an d train times, re spectiv ely . W e ho pe in the near future we will add the baseline results b y tr aining LIBLINEAR on the en tire (200 GB) dataset, o nce we have the resources to do so. Note th at with merely k = 30 , we can achie ve > 9 0% test accuracies (using b = 12 ). The VW algorithm can also achieve 90 % accura cies with k = 2 14 . For this d ataset, th e b est per formanc es were usually ach iev ed when C ≥ 1 . Note th at we plot all the results f or different C values in one figure so that others can easily verify our work, to maximize the repeatability . 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy svm: k =30 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy svm: k =50 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy svm: k =100 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) svm: k =150 rcv1: Accuracy b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) svm: k =200 rcv1: Accuracy b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy svm: k =300 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy svm: k = 400 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 b = 1 b = 2 b = 4 b = 8 b = 12 b = 16 C Accuracy (%) svm: k =500 rcv1: Accuracy Figure 1: Linear SVM test accuracy on rcv1 . 4.2 Experimental Results Using Logistic Regr ession Figure 3 p resents the test accu racy and Figure 4 p resents the trainin g time using log istic regression. Again, just like our experiments with SVM, u sing me rely k = 30 and b = 1 2 , we can achieve > 90% test accuracies; and u sing k ≥ 300 , we can achiev e > 95% test accura cies. 5 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=30 b = 8 12 b = 16 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=50 12 16 b = 8 12 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=100 b = 16 12 b = 8 12 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=150 b = 16 12 b = 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=200 b = 16 12 b = 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=300 b = 16 12 b = 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time svm: k=400 12 b = 16 b = 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 svm: k=500 b = 8 12 b = 16 C Training time (sec) rcv1: Train Time Figure 2: Linear SVM training time on rcv1 . 10 −2 10 0 10 2 50 60 70 80 90 100 C Accuracy (%) logit: k =30 rcv1: Accuracy b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −2 10 0 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy logit: k =50 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy b = 1 b = 2 b = 4 b = 8 b = 12 b = 16 logit: k =100 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy logit: k =150 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) rcv1: Accuracy logit: k =200 b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 logit: k =300 rcv1: Accuracy 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 rcv1: Accuracy logit: k =400 10 −3 10 −2 10 −1 10 0 10 1 10 2 50 60 70 80 90 100 C Accuracy (%) b = 16 b = 12 b = 8 b = 4 b = 2 b = 1 rcv1: Accuracy logit: k =500 Figure 3: Logistic regression test acc uracy on r cv1 . 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=30 b = 1 b = 2 b = 4 b = 16 b = 12 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=50 b = 16 8 b = 1 b = 4 b = 2 b = 12 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=100 b = 8 b = 16 b = 12 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=150 b = 16 12 8 b = 4 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=200 b = 16 12 8 b = 1 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=300 b = 16 12 b = 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time logit: k=400 b = 16 12 b = 8 10 −3 10 −2 10 −1 10 0 10 1 10 2 10 0 10 1 10 2 10 3 C Training time (sec) rcv1: Train Time b = 16 12 b = 8 logit: k=500 Figure 4: Logistic regression tra ining time on r c v1 . 6 5 Comparisons with V owpal W ab bit (VW) The two m ethods, rando m projection s [1, 19] an d V owpal W ab bit ( VW) [31, 2 8] are n ot lim ited to b inary d ata ( although for ultr a high-d imensional used in the context o f search, th e data a re o ften binar y). The VW algorithm is also related to the Count-Min sketch [9]. I n this paper , we use “VW” particu larly for the hashing algorithm in [31]. Since VW has the same variance as rando m projection s (RP ), we first provide a re view for both RP and VW . 5.1 Random Pr ojections (RP) For conv enience, we d enote two D -dim data vectors by u 1 , u 2 ∈ R D . Aga in, the task is to estimate the inne r product a = P D i =1 u 1 ,i u 2 ,i . The gen eral idea is to multiply the d ata vectors, e. g., u 1 and u 2 , by a random matr ix { r ij } ∈ R D × k , where r ij is sampled i.i.d. from the following generic distribution with [19] E ( r ij ) = 0 , V ar ( r ij ) = 1 , E ( r 3 ij ) = 0 , E ( r 4 ij ) = s, s ≥ 1 . (10) W e must have s ≥ 1 bec ause V ar ( r 2 ij ) = E ( r 4 ij ) − E 2 ( r 2 ij ) = s − 1 ≥ 0 . This generates two k - dim vectors, v 1 and v 2 : v 1 ,j = D X i =1 u 1 ,i r ij , v 2 ,j = D X i =1 u 2 ,i r ij , j = 1 , 2 , ..., k The gen eral distributions wh ich satisfy (10) include th e standar d nor mal distribution (in this case, s = 3 ) and the “sparse projection ” d istribution s pecified as r ij = √ s × 1 with prob. 1 2 s 0 with prob. 1 − 1 s − 1 with prob. 1 2 s (11) [19] provided the following unbiased estimator ˆ a r p,s of a and the genera l v arian ce formula: ˆ a r p,s = 1 k k X j =1 v 1 ,j v 2 ,j , E ( ˆ a r p,s ) = a = D X i =1 u 1 ,i u 2 ,i , (12) V ar ( ˆ a r p,s ) = 1 k D X i =1 u 2 1 ,i D X i =1 u 2 2 ,i + D X i =1 u 1 ,i u 2 ,i ! 2 + ( s − 3) D X i =1 u 2 1 ,i u 2 2 ,i (13) which mean s s = 1 achieves the smallest variance. Th e only elemen tary distribution we know that satisfies (10) with s = 1 is th e two point distrib u tion in {− 1 , 1 } with equal probab ilities, i.e. , (11) with s = 1 . 5.2 V owpal W abbit (VW) Again, in this pap er , “V W” al ways refers to the particular algorithm in [ 31]. VW may be viewed as a “bias-co rrected” version o f the Count-Min ( CM) sketch a lgorithm [9]. In the or iginal CM algorithm , the key step is to indepe ndently and u niformly h ash e lements of the data vectors to buckets ∈ { 1 , 2 , 3 , ..., k } and the hashed value is the su m o f th e elements in the bucket. T hat is h ( i ) = j with probab ility 1 k , where j ∈ { 1 , 2 , ..., k } . For convenience, we introdu ce an indicator function : I ij = 1 if h ( i ) = j 0 otherwise which allow us to write the hashed data as w 1 ,j = D X i =1 u 1 ,i I ij , w 2 ,j = D X i =1 u 2 ,i I ij 7 The estimate ˆ a cm = P k j =1 w 1 ,j w 2 ,j is (severely) biased for th e task of estimating the inner produ cts. [31] pro - posed a c reativ e method for bias-corr ection, which consists o f pr e-multiplyin g (element-wise) the original data vectors with a rand om v ector whose entries are sampled i.i. d. from the two-point distribution in {− 1 , 1 } with equal prob abil- ities, which corresp onds to s = 1 in (1 1). [22] co nsidered a mor e gen eral situation, fo r any s ≥ 1 . After ap plying multip lication and hashin g on u 1 and u 2 as in [31], the resultant vectors g 1 and g 2 are g 1 ,j = D X i =1 u 1 ,i r i I ij , g 2 ,j = D X i =1 u 2 ,i r i I ij , j = 1 , 2 , ..., k (14) where r i is defined as in (10), i.e., E ( r i ) = 0 , E ( r 2 i ) = 1 , E ( r 3 i ) = 0 , E ( r 4 i ) = s . [2 2] proved that ˆ a vw ,s = k X j =1 g 1 ,j g 2 ,j , E ( ˆ a vw ,s ) = D X i =1 u 1 ,i u 2 ,i = a, (15) V ar ( ˆ a vw ,s ) = ( s − 1) D X i =1 u 2 1 ,i u 2 2 ,i + 1 k D X i =1 u 2 1 ,i D X i =1 u 2 2 ,i + D X i =1 u 1 ,i u 2 ,i ! 2 − 2 D X i =1 u 2 1 ,i u 2 2 ,i (16) The v arian ce (16) says we do need s = 1 , otherwise the addition al term ( s − 1) P D i =1 u 2 1 ,i u 2 2 ,i will not vanish e ven as th e sample size k → ∞ . In other words, the choice of rand om distribution in VW is essentially the o nly o ption if we want to r emove the bias by pre-mu ltiplying the data vectors (element-wise) with a vector of rando m variables. Of course, once we let s = 1 , the variance (16) becomes identical to the variance of random projections (13). 5.3 Comparing b -bit Minwise Hashing with RP and VW in T erms of V ariances Each sample of b - bit minwise hashin g re quires exactly b b its of storage. For VW , if we consider the number of bins k is sm aller tha n the nu mber of n onzeros in each data vecto r , then the r esultant hashed data vectors are d ense and we probab ly need 3 2 b its o r 16 b its p er h ashed data en try ( sample). [ 22] de monstrated that if each sample of VW n eeds 32 bits, then VW needs 10 ∼ 100 (or e ven 10000) times more space than b -bit minwise hashin g in order to achie ve the same variance. Of co urse, w hen k is mu ch larger than the nu mber of non zeros in each d ata vector, then the r esultant hashed data vector will be sparse and the st orage would be similar to the origin al data s ize. One reason why VW is not accura te is bec ause the variance (16) (fo r s = 1 ) is domina ted by the pr oduct o f two marginal s quared l 2 norms P D i =1 u 2 1 ,i P D i =1 u 2 2 ,i ev en when the inner product is zero. 5.4 Experiments W e experiment with VW using k = 2 5 , 2 6 , 2 7 , 2 8 , 2 9 , 2 10 , 2 11 , 2 12 , 2 13 , and 2 14 . Note that 2 14 = 16384 . It is difficult to train L IBLINEAR with k = 2 15 because the t raining size o f the ha shed data by VW is c lose to 48 GB wh en k = 2 15 . Figure 5 and Fig ure 6 plot the test accurac ies for SVM an d logistic regression, respec ti vely . I n eac h figure, every panel has the same set of solid cur ves for VW but a different set o f dashed curves for different b -bit minwise hashing . Since k ranges very lar ge, here we choose to present the test accuracies against k . Repre sentativ e C values (0.01, 0.1, 1, 10) are selected for the presentations. From Figures 5 and 6, we can see clearly that b -bit minwise ha shing is s ubstantially more accurate than VW at the same storage. In o ther words, in order to a chieve th e same accur acy , VW will require substantially mo re storage than b -bit minwise hashing. Figure 7 presents th e training times for comparing VW w ith 8 -bit m inwise hashing. In this case, we can see that ev en at the same k , 8-bit hashing may have some compu tational adv an tages compared to VW . Of course, as it is clear that VW will re quire a much larger k in order to ach iev e the sam e accuracies as 8-b it minwise hashin g, we know that the advantage of b -bit minwise hashing in terms of training time reductio n is also enorm ous. 8 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) svm: VW vs hashing rcv1: Accuracy C = 0.01 C = 0.1,1,10 C = 0.01,0.1,1,10 1−bit 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) rcv1: Accuracy svm: VW vs hashing 2−bit C = 0.01,0.1,1,10 C = 0.01 C = 0.1,1,10 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) rcv1: Accuracy svm: VW vs hashing 4−bit C = 0.01 C = 0.1,1,10 C = 0.01 C = 10 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) rcv1: Accuracy svm: VW vs hashing 8−bit C = 0.1,1,10 C = 0.01 C = 0.01 C = 10 10 1 10 2 10 3 10 4 50 60 70 80 90 100 C = 0.01 K Accuracy (%) C = 0.01 C = 0.1,1,10 rcv1: Accuracy svm: VW vs hashing 12−bit C = 10 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) C = 0.1,1,10 C = 0.01 rcv1: Accuracy svm: VW vs hashing 16−bit C = 10 C = 0.01 Figure 5 : SVM test a ccuracy o n rcv1 fo r comp aring VW (solid) with b -bit m inwise h ashing (dashed ). Ea ch pan el plots the same results for VW and results for b -bit minwise hashing for a different b . W e select C = 0 . 01 , 0 . 1 , 1 , 10 . 10 1 10 2 10 3 10 4 50 60 70 80 90 100 C = 0.01 C = 0.01,0.1,1,10 C = 0.1,1,10 K Accuracy (%) logit: VW vs hashing rcv1: Accuracy 1−bit 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) C = 1 logit: VW vs hashing 2−bit rcv1: Accuracy C = 0.1,1,10 C = 0.01 C = 0.01,0.1,1,10 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) C = 0.1,1,10 C = 0.01 C = 0.1,1,10 C = 0.01 rcv1: Accuracy logit: VW vs hashing 4−bit 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) rcv1: Accuracy logit: VW vs hashing 8−bit C = 0.01 C = 0.1,1,10 C = 0.01 C = 0.1,1,10 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) rcv1: Accuracy logit: VW vs hashing 12−bit C = 0.01 C = 0.1,1,10 C = 0.1,1,10 C = 0.01 10 1 10 2 10 3 10 4 50 60 70 80 90 100 K Accuracy (%) C = 0.01 C = 0.1,1,10 C = 0.01 C = 10 logit: VW vs hashing 16−bit Figure 6: Logistic Regression test accura cy on rcv1 for comparing VW with b -bit minwise hashing. 10 1 10 2 10 3 10 4 10 0 10 1 10 2 10 3 C = 0.01 C = 0.1 C = 10 8−bit K Training time (sec) C = 0.01 C = 0.1 C = 1 rcv1: Train Time svm: VW vs hashing C = 1 C = 10 10 1 10 2 10 3 10 4 10 0 10 1 10 2 10 3 K Training time (sec) rcv1: Train Time logit: VW vs hashing 8−bit C = 10 C = 1 C = 0.1 C = 0.01 C = 0.01 C = 0.1 C = 1 C = 10 Figure 7: T raining time for SVM (left) and log istic regression (r ight) on rcv1 for comp aring VW with 8 - bit minwise hashing. 9 Note th at, as suggested in [22], th e training time o f b -bit m inwise hashing can be furth er redu ced by ap plying a n additional VW s tep on top o f the data generated by b -bit m inwise hashing. This is because VW is an e xcellent tool f or achieving compact in dexing wh en th e data dimension is (extremely) much larger than the av erage nu mber of nonzeros. W e condu ct the experimen ts on r cv1 with b = 16 and notice that this strategy indeed can reduce the training time of 16 -bit minwise hashing by a factor 2 or 3. 6 Pr epr ocessing Cost Minwise h ashing has b een widely used in (searc h) indu stry and b -b it minwise hashin g requires on ly very minimal ( if any) m odifications. Th us, we expect b -bit minwise hashing will be adopted in practice. It is also well-un derstood in practice that we can use (good ) hashing function s to very ef ficiently simulate permutations. In many real-world scenarios, the prep rocessing step is no t c ritical becau se it requ ires only one scan of the d ata, which can b e cond ucted off-line (or o n the data-collectio n stage, or at the same time as n-grams are generated ), an d it is trivially parallelizable. In fact, becau se b -bit minwise hashing can substantially reduce the memory consumption , it may be n ow a ffordable to stor e considerab ly more examples in the mem ory (af ter b -bit hashing) than b efore, to av oid ( or minimize) disk IOs. Once the hashed data have b een g enerated, they ca n be used and r e-used for many tasks such a s superv ised learning, clusterin g, dup licate detections, near-neigh bor search, etc. For example, a learning task may need to re- use the same (hashe d) dataset to p erform many cro ss-validations and pa rameter tun ing ( e.g., for experimenting with many C values in logistic regression or SVM). For train ing tru ly large-scale datasets, of ten the data loa ding tim e can be dom inating [32]. T able 2 co mpares the d ata load ing times with the prep rocessing times. F or b oth webspam and rcv1 datasets, wh en using a G PU, the prepro cessing time fo r k = 5 00 per mutations is only a small fraction o f the data loading time. W ith out GPU, th e prepro cessing time is ab out 3 o r 4 times high er th an the data loading time, i.e., th ey are r oughly o n the same ord er of magnitu des. When the training datasets are mu ch larger than 200 GB, we expect that difference betwee n the data loading time an d the prep rocessing time will be m uch smaller, even witho ut GPU. W e would like to remind that the prepro cessing time is only a one-time cost. T able 2: The data loading and prepr ocessing ( for k = 5 00 p ermutation s) tim es (in seconds). Dataset Data Loadin g P reproc essing Preprocessing with GPU W ebspam (24 GB) 9 . 7 × 10 2 41 × 1 0 2 0 . 49 × 10 2 Rcv1 (200 GB) 1 . 0 × 10 4 3 . 0 × 1 0 4 0 . 14 × 10 4 7 Simulating Pe rmutations Using 2-Universal Has hing Conceptually , minwise hashing r equires k permu tation mappings π j : Ω − → Ω , j = 1 to k , where Ω = { 0 , 1 , ..., D − 1 } . If we are able to store these k p ermutation mapping s, th en the operation is straigh tforward. For pr actical indus- trial applications, howe ver , storing perm utations would be in feasible. Instead, permuta tions are usually simu lated b y universal hashing , which only requires storing very fe w numb ers. The s implest (and possibly the mo st popular) appro ach is to use 2-universal ha shing . That is, we define a series of hashing function s h j to replace π j : h j ( t ) = { c 1 ,j + c 2 ,j t mod p } mod D, j = 1 , 2 , ..., k , (17) where p > D is a prime number and c 1 ,j is chosen uniformly from { 0 , 1 , ..., p − 1 } and c 2 ,j is chosen uniformly from { 1 , 2 , ..., p − 1 } . This way , instead of storing π j , we only nee d to store 2 k num bers, c 1 ,j , c 2 ,j , j = 1 to k . There are sev- eral small “trick s” for speedin g up 2- universal hashing (e.g., av oiding mod ular arithmetic). An inter esting thread migh t be http://mybiasedc oin.blogspot. com/2009/12/text- book- algorithms- at- soda- guest- post.html Giv en a feature v ector (e.g., a d ocumen t parsed as a list of 1-g ram, 2 -gram, and 3- grams), for any non zero lo cation t in the or iginal feature vector, its new location becom es h j ( t ) ; and we walk th rough all nonz eros lo cations to find 10 the m inimum of the n ew lo cations, which will be the j th hashed value f or that feature vecto r . Since th e gen erated parameters, c 1 ,j and c 2 ,j , are fixed (and st ored), this pro cedure becomes determ inistic. Our experiments on webspa m can show that even with this simplest h ashing method , we can still ach iev e g ood perfor mance comp ared to using perfect rand om pe rmutations. W e can not realistically stor e k perm utations fo r the r cv1 dataset be cause its D = 10 9 . Thus, we on ly verif y the practice o f using 2 -universal h ashing on th e webspam dataset, as demonstra ted in Figure 8. 10 −3 10 −2 10 −1 10 0 10 1 10 2 88 90 92 94 96 98 100 C Accuracy (%) k = 50 100 k = 500 SVM: b = 8 Spam: Accuracy Perm 2 − U 10 −3 10 −2 10 −1 10 0 10 1 10 2 88 90 92 94 96 98 100 C Accuracy (%) logit: b = 8 Spam: Accuracy k = 50 k = 500 100 Perm 2 − U Figure 8: T est accura cies on webspam for co mparing permu tations (da shed) with 2 -universal h ashing (solid) ( av- eraged over 50 runs), for both linear SVM (lef t) and lo gistic r egression (righ t). W e c an see that the solid cu rves essentially overlap th e da shed cu rves, verifying that even the simple st 2 -universal hashing method c an b e very effec- ti ve. 8 Conclusion It has been a lot of fun to develop b -b it minwise hashing and apply it t o machin e learning for training very large-scale datasets. W e h ope engineers will find our metho d applicable to their work. W e also hop e this w ork can dr aw interests from research groups in statistics, theoretical CS, machine learning, or search technolo gy . Refer ences [1] Dimitris Achlioptas. Database-friendly random projections: Johnson-Lindenstrau ss w ith binary coins. J ournal of Computer and System Sciences , 66(4):671–68 7, 2003. [2] Michael Bendersky and W . Bruce Croft. Finding text reuse on the web . In WSDM , pages 262–271, B arcelona, Spain, 2009. [3] Leon Bottou. http://leon.bottou.org/projects/sgd. [4] Andrei Z. Broder . On the resemblance and containment of documents. In the Compress ion and Complexity of Sequences , pages 21–29, Positano, Italy , 1997. [5] Andrei Z . Broder , Stev en C . Glassman, Mark S. Manasse, and Geof frey Zweig. Syntactic clustering of t he web . I n WWW , pages 1157 – 1166, Santa Clara, CA, 1997. [6] Gregory Buehrer and Kumar Chellapilla. A scalable pattern mining approach to web graph compression with communities. In WSDM , pages 95–106, Stanford, CA, 2008. [7] Ludmila Cherk asov a, Kav e Eshghi, Charles B. Morrey III, Jo seph T ucek, and A listair C. V eitch. Applying syn tactic similarity algorithms for enterprise information management. In KDD , pages 1087–1096 , Paris, France, 2009. [8] Flavio Chierichetti, Ravi Kumar , Silvio Lattanzi, Michael Mitzenmacher , Alessandro Panconesi, and Prabhakar Raghav an. On compressing social network s. In KDD , pages 219–228 , Paris, France, 200 9. [9] Graham Cormode and S. Muthukrishnan. An improved data stream summary: the count-min sketch and its applications. J ournal of Algorithm , 55(1):58–7 5, 2005. [10] Y on Dourisboure, F ilippo Geraci, and Marco Pell egrini. Extraction and classification of dense implicit communities in the web graph. ACM T rans. W eb , 3(2):1–36, 2009. 11 [11] Rong-En Fan, Kai-W ei Chang, Cho-Jui Hsieh, Xiang-Rui W ang, and Chih-Jen L in. Liblinear: A library for large linear classification. Journa l of Machine Learning Resear ch , 9:1871–1874 , 2008. [12] Dennis Fetterly , Mark Manasse, Marc Naj ork, and Janet L. W iener . A large-scale study of the ev olution of web pages. In WWW , pages 669–678 , Budapest, Hungary , 2003. [13] George Forman, Kav e Eshghi, and Jaap S uermondt. Efficient detection of large-scale redundanc y in enterprise file systems. SIGOPS Oper . Syst. R ev . , 43(1):84–91, 2009. [14] Sreeniv as Gollapu di a nd Aneesh Sharma. An axiomatic approach fo r result di versification. In W WW , p ages 381–390 , Madrid, Spain, 2009. [15] Cho-Jui Hsieh, Kai-W ei Chang, Chih-Jen Lin, S. Sathiya Keerthi, and S . Sundararajan. A dual coordinate descent method for large-scale linear svm. In Proceed ings of t he 25th international confer ence on Machine learning , ICML, pages 408–415, 2008. [16] Nitin Jindal and Bing Liu. Opinion spam and analysis. In WSDM , pages 219–230, Palo Alto, California, USA, 2008. [17] Thorsten Joachims. Training line ar svms in linear time. In KDD , pages 217 –226, Pit tsbur gh, P A, 2006. [18] K onstantinos Kalpakis and Shilang T ang. Collaborativ e data gathering in wireless sensor networks using measurement co- occurrence. Computer Communications , 31(10):1979–199 2, 2008. [19] Ping Li, Tre vor J. Hastie, and Kenne th W . Church. V ery sparse random projections. In K DD , pages 287–29 6, Philadelphia, P A, 2006. [20] Ping Li and Arnd Christian K ¨ onig. Theory and applications b-bit minwise hashing. In Commun. ACM , 2011. [21] Ping Li, Joshua Moore, and Arnd Christian K ¨ onig. b-bit minwise hashing for large-scale linear SVM. T echnical report. [22] Ping L i, Anshumali Shriv astav a, Joshua Moore, and Arnd Christian K ¨ onig. Hashing algorithms for large-scale learning. T echnical report. [23] Ping Li and Arnd Christian K ¨ onig. b-bit minwise hashing. I n WWW , pages 671–68 0, Raleigh, NC, 2010. [24] Ping Li, Arnd Christian K ¨ o nig, and W enhao Gui. b-bit minwise hashing f or estimating three-way si milarities. In NIP S , V ancou ver , BC , 2010. [25] Gurmeet Singh Manku, Arvind Jain, and Anish Das S arma. Detecting Near-Duplicates for Web-Crawling. In WWW , Banff, Alberta, Canada, 2007. [26] Marc Najork, Sreeniv as Gollapudi, and Rina Panigrahy . Less is more: sampling the neighborhood graph makes salsa better and faster . In WSDM , pages 242–251, Barcelona, Spain, 2009. [27] Shai Shalev-Shw artz, Y oram S inger , and Nathan Srebro. Pegaso s: Primal estimated sub-gradient solver for svm. In ICML , pages 807–814 , Corv alis, Oregon , 2007. [28] Qinfeng Shi, James Petterson, Gideon Dror, John Langford, Alex Smola, and S.V .N. V i shwana than. Hash kerne ls for struc- tured data. Jou rnal of Machine Learning Resear ch , 10:2615–2637 , 2009. [29] Simon T ong. Lessons learned dev eloping a practical large scale machine learning system. http://googleresearch.blog spot.com/2010 /04/lessons-learned-de veloping-practi cal.html, 2008. [30] T anguy Urvo y , Emmanuel Chauv eau, Pascal Filoche, and Thomas Lav ergne. T racking web spam with html style similarities. ACM T rans. W eb , 2(1):1–28, 2008. [31] Kilian W einberger , Anirban Dasgupta, John Langford, Alex Smola, and Josh Attenberg. Feature hashing for large scale multitask learning. In ICML , pages 1113–1120, 2009. [32] Hsiang-Fu Y u, Cho-Jui Hsieh, Kai-W ei Chang , and Chih-Jen Lin. Large linear classification when data cannot fit in memory . In KDD , pages 833–842 , 2010. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment