HybridNN: Supporting Network Location Service on Generalized Delay Metrics
Distributed Nearest Neighbor Search (DNNS) locates service nodes that have shortest interactive delay towards requesting hosts. DNNS provides an important service for large-scale latency sensitive networked applications, such as VoIP, online network …
Authors: Yongquan Fu, Yijie Wang, Ernst Biersack
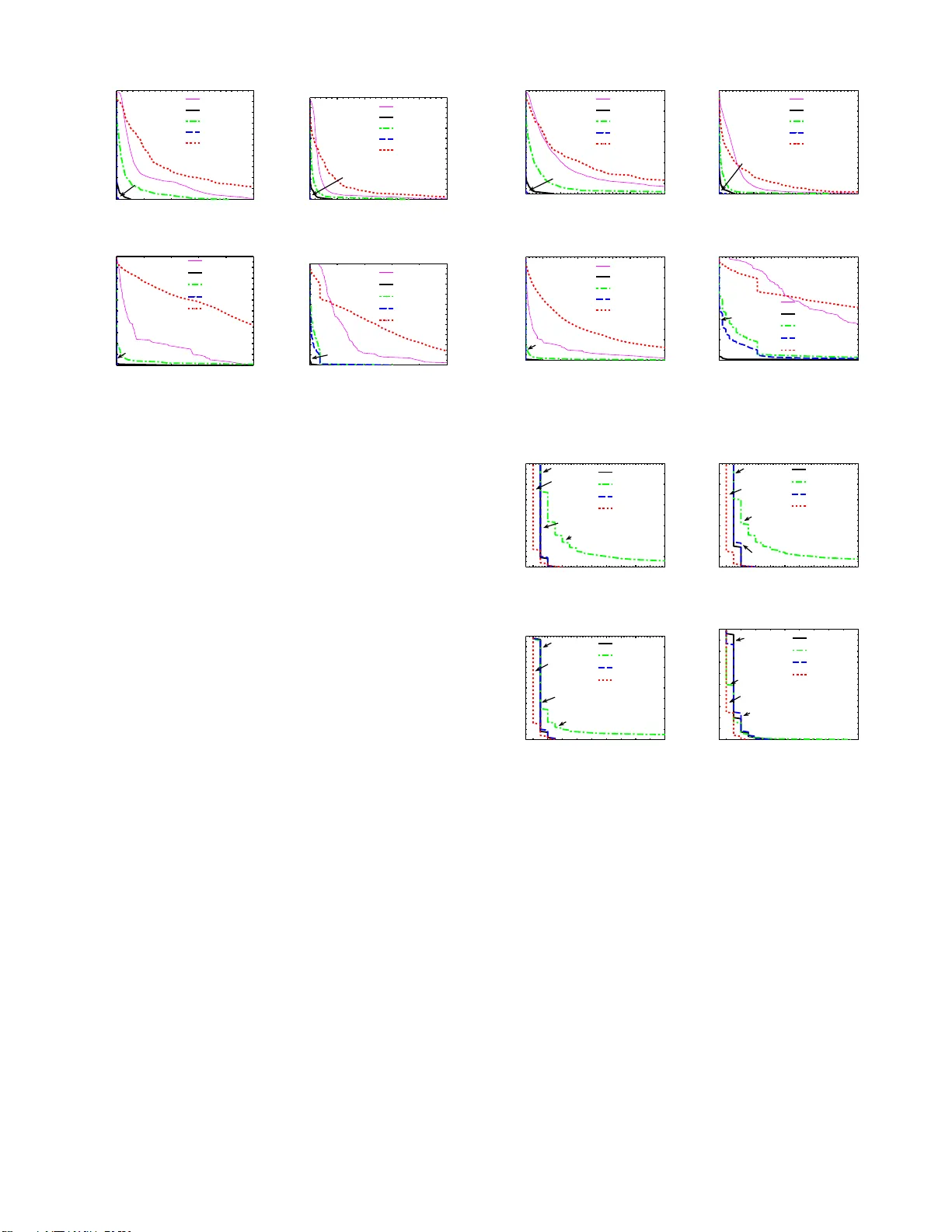
JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 1 HybridNN: Supporting Netw o rk Location Servic e on General ized Delay Metrics Y ongqua n Fu, Y ijie W ang, an d Ernst Biersack, Abstract —Distributed Nearest Neighbor Search (DNNS) lo- cates serv ice nodes th at ha v e shortest int eractiv e delay towards requesting hosts. DNNS prov ides an important service for l arg e- scale latency sensitive networked applications, su ch as V oIP , online network games, or interactive network ser vices on the cloud. Existing work assumes the delay to be symmetric, which does not generalize to appl ications that are sensit iv e to one-way delays, su ch as the multi media video delivery from th e server s to the hosts. W e propose a relaxed in frametric model f or t he network d elay space that does not assume the triangle inequality and delay symmetry to hold. W e prove that the DNNS r equests can be completed effi ciently if th e delay space exhib its modest inframetric dimensions, whi ch we can observe empirically . Fi- nally , we propose a DNNS method named HybridNN ( Hybrid N earest N eighbor sear ch) based on the inframetric model for fast and accurate DNNS. F or DNNS requests, HybridNN ch ooses closest neigh bors accurately via th e in frametric modelling, and scalably by combining d elay predictions with direct probes to a pruned set of n eighbors. Si mulation results sh ow th at Hybrid NN locates nearly optimally the nearest n eighbor . Experiments on PlanetLab show th at HybridNN can pro vide accurate near est neighbors that are close to optimal with modest query ov erhead and maintenance traffic. I . I N T RO D U C T I O N Latency-sensitive applications, suc h as P2P based V oIP and IPTV [ 1], in teractiv e network services on the cloud (e.g., Office Live W orkspace [2], Go ogle Maps [ 3]), online network games, need to transmit data fr om geo-d istributed servers (called a service node) in real-time to many hosts quickly . High transmission d elays redu ce th e Qu ality of Experience (Qo E) of users [4 ], which lead to significant business losses [5]. For instance, Google reports that its re venue d ecreases b y 20% when the latency of showing search results in creases by 500 ms; similarly , Amazon claims that its sales amou nt decre ases by 1% if the page-resp onse latency increases by 100 ms [5]. Since th ere are hundr eds or tho usands of service nod es that provide identical services to hosts, th ere is an increasing push for service providers to route real-time data to a host from geo- distributed servers that are n earest to tha t host. For example, Google routes users’ search q ueries to g eograph ical-nearby servers [6]; Akamai redirects hosts’ con tent reque sts to replica servers ma inly based on proximity conditions [7]; CoralCDN [8] uses OASIS [9] and DONAR [1 0] to select proxy servers near to end hosts based on geog raphic distances. Ho wev er, selecting ne arest servers to hosts are still far from standard due to se vera l challenge s. Y ongq uan Fu and Y ijie W ang are with National Key Laboratory for Paralle l and Distrib uted Processing, Colle ge of Computer Science, Univ ersity of Defense T echnology . Ernst Biersac k is with Networking and Securi ty Departme nt, Eurecom. Fig. 1. Illustrating the R T T and OWDs. Suppose B and C are two servers that are able to supply short videos to host A . If we use the R TT metric to minimize the delay of video deli very , we may arbitrari ly choose any of them to send videos to host A based on the R TT m etric , since the R TT between A , B and that betwee n A , C are all 300 ms. Howe ver , since the video files are transmitt ed from servers to hosts, the O WDs from servers to host s become more impor tant [16]. W e can see that the OWD from server C to host A is four times less than that from serv er B to host A . Therefore , choosing serve r C to serve host A significan tly minimizes the content transmission delay for host A , w hich is feasible only when we use the O WD metric for delay optimi zations. First, selecting nearest servers mu st pr ove to be r eliable, since service pr oviders need to ensure th e QoE fairly for all hosts . Selecting nearest servers usin g proximity coordinates [11], [12] or geograp hic distances [9 ] suf fer from the mismatch between the estimated dela ys and real- world delays [6], which makes the selection a ccuracy hard to be pr edicted. On th e other hand, selecting neare st servers using distributed search such a s Mer idian [13] or O ASIS [9] avoid such mismatch problem s using direct probes, but may terminate at ser vice nodes that are much worse tha n the n earest one s, since the search is easily trap ped into local min ima due to the clustering [14] and Triangle Inequality V iolations (TIV) [15] p roperties of the delay space. Second, selectin g near est servers must be awar e o f uni- dir ectional delays whenever possible . Sinc e routing o n the Internet is asymm etric [16], the delays fr om servers to h osts may de viate th ose in the reverse direction in se veral times. Furthermo re, One-W ay Delay (OWD) measuremen ts become increasingly practical due to the advance of measureme nt technique s such as OW AMP [ 17] or Re verse T ra ceroute [18]. Howe ver , delay optimiza tions using Roun d Trip T ime ( R TT) ignores such delay asymm etry . For mu ltimedia streamin g, application- lev el m ulticast, o r m ore ge neralized a pplications where d ata flows in on e direction s, such agnostics of u nidi- rectional delays d egrades the effectiv eness of selected servers, as sho wn in Fig 1. Third, selectin g n ear est servers must find goo d tradeoff between the r esp onse time and timeliness . The response time lasts se veral seconds for server selections using on-dem and JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 2 probin g suc h as Merid ian [13] or OASIS [9]. However , the response time d egrades the QoE o f users in latency-sensitive applications, such as online workspace, o nline mu sic. OASIS caches near est servers for e ach IP prefix using in-advance probes o nce a week, wh ich ha s better response time. Howe ver , the c ached server selec tions ten d be suboptim al, since the delays vary d ue to routing dyn amics or server workload s [19], and service n odes may be added o r removed dyn amically . Therefo re, it is difficult to find goo d tradeoff between respo nse time and the timeliness of server selections. The goal of this paper is to provide n e w algorith ms to ad- dress the first t wo challenges. T o this end, we develop a general enoug h delay mo del that c aptures the major statistics of the delay space, including: TIV , delay dynamics and asym metry of delays. Th is papers m akes three contributions. First, we analytically dem onstrate that we can find approx- imately n earest servers q uickly by iter ati vely searching clo ser nodes to the h ost using sampled nodes f rom proximity r egions of e ach nod e. Howe ver , the analytica l metho d requires a large number of sam ples, wh ich does no t scale well. Second, we introduce a novel d istributed algo rithm, nam ed HybridNN, th at finds nea rest service n odes for a ny ma chine on the Internet ( called a target). This algo rithm derives f rom our analytical method, which p reserves the accuracy and speediness of the analytical metho d. However , HybridNN has better dynamic ad aptation and red uced m easurement costs. (i) Dynamic ada ptation . A prac tical DNNS algo rithm n eeds to proactively maintain moder ate service nodes as samp les for DNNS q ueries, irrespective of the system dynam ics. Hy- bridNN d ynamically m aintains such neighbors using a con- centric r ing used in Meridian [13] or OASIS [9]. Howe ver, HybridNN has two improvements: • The maximum n umber o f n odes stored per ring is de- riv ed fro m the lower boun ds of requir ed samples in th e analytical method, wh ich implies that HybridNN requires the lowest possible nu mber of sam ples that has the same accuracy g uarantee as the analytical method. • Hybr idNN proposes a biased sampling ba sed concentr ic ring main tenance scheme, in ord er to sample en ough nodes for e ach ring . Specifically , different from previous neighbo r discoveries based on a gossip protoco l, we also periodically discover a small numb er of nearest no des and farthest nodes to each n ode as neigh bors in the concentr ic rin g. This is because gi ven a concentric ring, the in nermost and ou termost ring s contain on ly a f ew neighbo rs com pared to other r ings, which are hardly to be sampled using a g ossip ba sed neigh bor d iscovery protoco l. (ii) Reducing measurement costs . Hybr idNN ad opts scalable delay predictions to red uce the measuremen t costs. • Hybr idNN maintain s the con centric rin gs using estimated pairwise d elays with the revision [2 0] of the V iv aldi network co ordinate [21], which sign ificantly reduces th e maintenan ce overhead of HybridNN co mpared to Merid- ian. • Hybr idNN selects candidate n eighbor s that are close to the target using delay prediction s. Since delay pred ictions are o nly a pproxim ations of r eal-world d elays, Hy bridNN also uses a small n umber of d elay pr obes to a void bein g misled by inaccurate delay prediction s. Interestingly , al- though the network coo rdinate distances are sym metric, we empirically find that our h ybrid delay measurement approa ch provides the accurate nearest next-h op neighbor for both symmetric and asymmetric delay data sets. Th is is b ecause we replace inaccurate co ordinate d istances with direct p robes using the error indicator of V ivaldi coordin ate, which relie ves the mismatch between sym- metric coordinate distance s and asymm etric delay s. Third, we validate our algorithm using real-world delay data sets and PlanetLab deploymen ts. Th rough simulation study , we show that Hy bridNN finds servers close to o ptimal for symmetric and asymm etric d elay data sets. In fact, in mor e than 95% of cases, HybridNN locates the ground -truth nearest servers fo r th e targets. Further more, most quer ies term inate within four search hops, which implies that HybridNN can return the search results fast. Using PlanetLab deployments, we confirm that Hybrid NN can locate accu rate nearest servers with low qu ery loads an d contro l overhead, with mod erate query time that imp roves Meridian in m ore than 15% of cases. I I . S Y S T E M M O D E L A. Pr ob lem Defi nition In this section, we formally define the nearest server location problem . Let V d enote a set of service nodes and ho sts. Let a distance fun ction d denote the pairwise de lays between no de pairs in V . Let N be the num ber o f serv ice n odes. Our o bjectiv e is to minimize the serving delay s of latency- sensiti ve applications by finding a service node for a requesting host with the minimum delay . As d iscussed in the pre vious section, w e expect a gen eralized delay o ptimization scen ario where the delay may be symmetric o r asymm etric accordin g to the pr oblem con text and measuremen t tools. Fu rthermor e, the service nodes m ay b e added o r removed, which causes system churn s. As a result, we need to lo cate the service node that is clo sest to the target f rom d ynamic ser vice nodes. W e stu dy a distrib uted approac h to realize our objecti ve, since the centralized appr oach h as se veral well-known weak - nesses, inclu ding: it require s global delay measurem ents that is hard to ob tain for dynamic service nodes; it in curs the single point of failures. On th e other hand, the distrib uted appro ach av oids such weaknesses thro ugh collabor ations of service nodes. Specifically , we formu late the Distributed Nea rest Neighbor Search (DNNS) as: Definition II.1 . (Distrib uted Near est Neighbor Sear ch): F or a set of dynamic service n odes, given any ta r get T on the Internet, the objective of the Distributed Near est Neighbor Sear ch is to find one service nod e th at ha s the smallest delay to T , based on th e distributed c ollaboration o f service nod es. The definition of DNNS is not novel, since existing research on closest server discovery [22], [2 3], [12], [13], [9], [10] h as formu lated the similar pr oblem. In tuitiv ely , DNNS consists of multiple steps. At each step , a curre nt service node P tries to JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 3 Fig. 2. A DNNS query service substrate for network services. locate a new service node that is closer to the target T th an node P . The flowchart of a sample DNNS que ry is shown in Fig 2. When a host T accesses a networked service, the local service c lient modu le creates a DNNS query to locate the nearest service mach ine to the c lient T . Th e query message is firstly forwarded to the bootstrap machine of the DNNS service (Step 1). Th en our DNNS query system will for ward the query message recursiv ely until locating a nearest service machine (Step 2 → 3 ). Fina lly , our system return s the contact addresses of the fou nd serv ice n odes to host T ( Step 4 ). B. K e y DNNS R equir ements T o be useful for latency-sensitiv e applications, we identify key goals for the DNNS: • Accurat e , we nee d to find a service node with the lowest in teractiv e time in order to in crease the Qua lity of Experience of users. • Fast , we need to obtain the nearest service no de with low quer y per iods. Oth erwise, lo ng query time makes th e DNNS less attractiv e for server r edirections in latency- sensiti ve ap plications. • Scalable , the DNNS pr ocess should incur low ban dwidth costs with increasing system size. • Resilient to chur ns , the DNNS pro cess shou ld fin d accurate results wh en the serv ice node s cra sh or new service nodes a re ad ded. C. Discussion Since the DNNS pro cess may last several seconds due to on-dem and p robing , perf orming DNNS for e ach que ry fro m hosts may ev en hurt the Quality of Exper ience of users, which is sig nificant f or small W eb o bjects. For exam ple, Goog le typically returns respon ses in less th an 0.4 seconds; h owe ver , such low re sponse per iods are dif ficult to be realized when applying the DNNS proc ess befo re retu rning the respon ses. Therefo re, in o rder to realize a p ractical ne arest server redirection service, we nee d to proactively run DNNS for each host and red irect hosts’ req uests using cached DNNS results, in order to achieve millisecon d-level respo nse time . For example, O ASIS [9] shows th at it is feasible to cache DNNS queries of IP prefixes fo r server redirection s witho ut reducing the DNNS accur acy . W e do n ot study h ow to organize cache results in this paper; instead, we assum e that a DNNS cach ing service exists to m ap hosts’ requests to nearest servers u sing cached DNNS queries. Our focus is to realize a n accu rate, scalable and resilient DNNS system with lo w DNNS query periods. Since if the DNNS query last long p eriods, then crawling DNNS for every IP prefix will be less ef ficient. I I I . R E L AT E D W O R K First, for the theoretical co mputer science field, resear ch on the n earest n eighbor searc h m ainly focuses o n d esigning efficient alg orithms in the m etric space [24], [25], [26], [27]. Howe ver , applying algorithms in the metric spa ce into DNNS is in approp riate, sin ce the d elay spac e violates th e triang le inequality that is requ ired by the metric space mod el [20]. On the other hand, f or the network system field, research on ne arest neighb or sear ch can be classified into centralized and distributed approache s accordin g to the communicatio n patterns of th e search proce ss. A. Centralized App r oa ches The centralized sch eme uses a centralized sorting p rocess to select n earest neighb ors f or target nodes. Howe ver , the centralized app roach d oes not scale well with incre asing system size, since collecting and transmitting the d istance measuremen ts easily cause perfo rmance bottlen ecks, which degrades th e serv ice availability . Guyton et al. [11] pioneer the research on findin g the closest server replica in a centralized mann er . T hey use the Hotz’ s metric [2 8] to rep resent pairwise hop distan ces using O ( N ) measuremen ts to landm ark nodes, where N d enotes th e num - ber o f server replicas. However , smaller hop d istances d o n ot mean the shorter delays, because one hop m ay pass continents or a d ata cen ter . Later Carter and Crovella [29], [30] combin e the R TT and av ailable band width measurements to dynami- cally select optimal server replica with minim al response time. Howe ver , the dynamic server selection approach does not scale well due to the qu adric measurement costs. Netvig ator [31] collects R TT v alues fro m h osts to lan dmarks and m ilestone nodes b ased o n th e Traceroute me asurements, and estimates nearest servers based on local cluster ing. Howe ver , Netvigator does not guarantee th e estimation accu racy , and may get obsolete results sin ce Netvigator do es not perf orm active mea- surements. Different from Netv igator, CRP [32] leverage the dynamic association o f nodes with replica servers from CDNs to determin e the proxim ity between end hosts. CRP incurs low maintenan ce costs similar as Netviga tor . Howe ver , CRP does not gu arantee the accur acy . iPlane [33], [34] co nstructs a synthetic topolog y structure for the Internet. iPlane estimates the nearest servers usin g th e app roximated delay s on the synthetic topolog y . Ho we ver , in order to provide services for hosts spanning geo -distributed places, iPlane consum es heavy bandwidth costs to perfo rm active measur ements. B. Distrib uted Appr o aches The DNNS ap proach iteratively selects closer nodes using distributed nearest neighb or search by lo cal measurements JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 4 tow ards a small set of neig hbors, which reduces the n etwork measuremen t overhead a nd is m ore scalable than the ce ntral- ized appr oach. Existing DNNS methods fall into fou r families based on their search rules: (i) Bin based DNNS; (ii) T opology based DNNS; (iii) G reedy search based DNNS; ( i v) Ring search based DNNS. Bin based DNNS . Ratnasamy et al. [22] a ssign nod es into ”bins” b ased on the or dered sequence of R T T measur ements to lan dmarks, an d declare nodes are clo se to each o ther in the same bin . Howe ver , the bin a pproach do es not gu arantee the accuracy , an d fails when the landmarks cr ashes. T opo logy based DNNS . Tiers [35] locates the nearest nodes by a top-down approach with a hierarchical clustering tre e, but may cause load im balance for nod es n ear th e root of the tree. Besides, Tiers do not gu arantee the search accu racy sin ce th e tree does not strictly preserve th e p airwise p roximity . Greedy search based DNNS . Mitho s [23] iterati vely lo- cates p roximate neig hbors with O ( N ) hops by a gradie nt de- scent based protocol in the overlay construction, b ut terminates earlier bef ore locating the rea l nearest n odes d ue to the limited div ersity in th e neighbo r set. PIC [12] iteratively lo cates nearest neighbors at each search step in terms of the coordinate distance. Howe ver , PIC is pron e to be trapp ed into the local minima since the coord inate distance only appro ximates the delays. DON AR [10] redirec ts ho st r equests to o ptimal server relicas by conside ring the network proxim ity , the r outing o pti- mization an d server loads. DONAR uses ge ograph ic distances as the prox imity metric in order to reduce measur ement costs. Howe ver , DON AR may find su boptimal server r eplicas fo r delay minimizations since the d elay v alues are not con sistent with the g eograph ic distances. Ring search based DNNS . Our work is closely related to Meridian [13], which seeks app roximately n earest nodes in lo g ( N ) step s. Meridian [ 13] ma intains a loosely con - nected overlay using a go ssip based peer finding scheme. The neighbo rs are organized in concentric rings with expon entially increasing rad ii. For a DNNS request, Me ridian iteratively locates one next-hop node that is β ( β < 1 ) times closer to the target T tha n the current Meridian node. Compared to other families of DNNS, Meridian is m ore accurate by using rings o f neigh bors that p romote the d i versity of neighbor sets [13]. Howev er, se veral studies ha ve identified that Meridian may fail to find the closest service node du e to the last-hop clustering of servers [ 14], and TIV of the network d elay space [20]. Similar as Meridian, OASIS [9] organ ize n eighbor s as concentr ic rings for each serv ice node, a nd iteratively sear ch nearest service node for the request host in terms of the geogra phic distanc es. O ASIS redu ces the delay measurement costs in Meridian thro ugh th e static geogra phic coo rdinates, and has low response time usin g in-advance prob es. H owe ver, O ASIS does no t g uarantee the accuracy of the search re sults, since selecting the geo graphica lly closest servers may incur high delays [ 6]. T o add ress these pro blems, two adju stments are pro posed: (i) explicitly findin g the clustering subsets based on the struc- ture o f IP a ddresses [1 4] o r , (ii) adding additional neighb ors for DNNS th at may not be chosen d ue to th e TIVs [ 20]. Howe ver , find ing the clusters of n odes shar ing iden tical last hops bec omes insufficient when the service no des spread over nearby sub nets, which may still mislead the DNNS quer ies due to no fo rwarding nod es closer enou gh to the target. Furthermo re, finding all neighb ors th at ar e affected by the TIVs is challen ging sinc e calculating the TIVs fo r decentral- ized service nod es is very difficult; besid es, a dding addition al neighbo rs for DNNS also incre ases the q uery overhead . Du e to the limitations of modifications f or Meridian , significant challenges remain in DNNS. W e focu s on tackling these challenges in th is p aper . I V . D AT A S E T S Our empir ical data sets includ e four pub licly av ailable real-world R TT data sets, covering the delay measurem ents between wide-area DNS servers and tho se between end hosts [36]. (i) DNS3997 . A R TT matrix collected between 3997 DNS servers by Zh ang et al. [37] using the King method [38]. The ma trix is symmetric in that d ij = d j i , f or any pair of items i a nd j , wher e d den otes the delay matr ix. (ii) Ho st479 . A R TT delay matrix based on R T T measurements that last 15- day per iods between the V uze BitT orrent clients [3 9]. Host47 9 is asymmetric, where in over 40% of the cases delay pairs d AB and d B A in Ho st479 differ m ore than 4 tim es. This is because R TT measure ments between nod e pairs are not synch ronized and delay r esults are affected by varying queuein g delays at end hosts [39]. ( iii) DNS1143 . A R T T matrix between 1143 DNS servers collected by the MIT P2PSim project [40] using the King method [38 ]. The matrix is symmetric in th at d ij = d j i , for any pair of items i a nd j , where d deno tes the d elay matrix. (iv) DNS2500 . A R TT m atrix b etween 25 00 DNS servers b y the Mer idian pro ject [13] using the K ing method. The m atrix is also symmetric. Since obtaining the o ne-way d elays betwe en large-scale nodes is extremely difficult, we u se Ho st479 as an asymmetric delay data set. Howev er, we do no t claim that our experiments on Host479 are the same as those on the one-way delay metric. V . A G E N E R A L I Z E D D E L AY M O D E L F O R T H E D E L A Y S PAC E In this section, we p resent a simple and ge neral enou gh delay model fo r th e delay spa ce. Ou r model cap tures the im- portant ch aracteristics o f the delays, inclu ding TIV , dynamics and asymm etry of R TTs and OWDs . In the next section, we will analyze th e DNNS pro blem on our model. Assuming that we select a node P in V as the cen ter o f a ball, a nd choose a positive real nu mber r as the radius of the ball, then we call a c losed ball B P ( r ) as the set of no des whose delays to node P are not larger than r , i.e., B P ( r ) = { v | d ( P, v ) ≤ r , P , v ∈ V } . Fur thermore, the volume of a ball is th e nu mber of nodes covered by the ball. Besides, we d efine the cov er re lation of different set of nodes as fo llows: Definition V .1 (Cover) . Let S an d Ω be two sets of n odes, if Ω ⊆ S , then the set S is said to cover the set Ω . A. Definition W e first state the r equiremen ts for a delay m odel suitable for R TTs and OWDs used f or delay minimizations. (i) Th e JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 5 delay m odel should relax the symmetry require ments, since the OWDs are asymm etric due to routin g asymmetry [41]. Besides, altho ugh R TT is sym metric by only ac counting for the delays o n the ro uting path s, real-world R TT measurem ents may be a symmetric due to v ariations of queueing delays at end ho sts o r un -synchro nized m easurements [42]. ( ii) The delay mo del d should allow TI V to exist, sinc e the R TT metric exhibits TIV [15]. (iii) The delay m odel d shou ld allow dynamic delays, since the delay varies from time to time [19]. Therefo re, inspired by the inframetric model [43] that allo ws the TIVs, we extend the inf rametric model to a relaxed infra- metric mo del that relaxes the symmetry requirem ent, wher e the distance function d satisfies: Definition V .2 ( Relaxed Inf rametric Model) . Let a distance function d : V × V → ℜ + be a r elaxed ρ -in frametric ( ρ > 1 ), if d satisfies the following c onditions for an y pair of nodes u and v : (1) if d ( u, v ) =0, then u = v ; (2) d ( u, v ) ≤ ρ max { d ( u, w ) , d ( v , w ) } , for any arbitrary node w satisfying w / ∈ { u, v } . Pros of the Rela xed Inframet ric Model : Th e con dition (2) in Def V .2 states a gen eralized relation of any directed triple from V , which has tw o beneficial p roperties: • TIV -adaptive . Intuitively , smaller ρ implies that three edges are closer to each other ; while larger ρ implies that one edge is significantly larger than any of the other two edges, which may introduce a TIV . Therefo re, similar as the inframetric mo del, the relaxed inf rametric mod el naturally allo ws the occu rrence of TIVs. • Dynamics-a daptive . T he infram etric model allows the delay variations by varying the in frametric param eter ρ to describe the relations o f u pdated triples. T herefore , both inframetric model and the r elaxed infra metric model ar e able to mode l variations of triples due to delay variations. • Asymmetry -aware . The relaxed inframetr ic mod el a l- lows the asymmetry in the d elay space, which generalizes to R TTs and OWDs. As a result, we are able to analyze DNNS on symmetric and asym metric d elays throug h the relaxed inf rametric m odel. Having shown the advantages of th e relaxed infram etric model, next w e discu ss the statistical pr operty of th e in fra- metric parameter ρ . First, the seminal work states that if the d elay space obeys the tria ngle in equality , then ρ must be smaller or equal than 2 [43]. Howe ver , when ρ is smaller th an 2, there may exist TIVs. For example, g i ven a triple with pairwise R TTs 3 , 1 , 1 . 8 , we can see that the inframeter param eter ρ is ap proxima tely 1.67 but there also exists a TIV in the triple. Ther efore, we can see that ρ ≤ 2 is only a necessary but not a sufficient con dition for no T IVs. Second, we find that the inframetric parameter ρ is q uite low for mo st triples. First, th e 95th percen tiles o f all d ata sets of ρ are below 2 . 5 . Low infram etric param eter ρ means the largest edges in triples are not too much larger than the other edges o f the trip les. Second, amo ng the tr iples whose ρ are b igger than 2, their ρ values are arou nd 3 on average. Theref ore, selecting ρ =3 is reasonable to model most of the triples. B. Dimensions on the Relaxed Inframetric Mod el Having intro duced the definition of the relaxed infra metric model, now we analy ze the growth d imension of the relaxed inframetric model, which is the r atio o f the number o f nodes covered by two closed balls with th e identical center and varying radii [43], [44]. The growth d imension is imp ortant for efficient DNNS. As shown b y Karger an d Ruhl [44], assuming that the growth dimension is low , each nod e P can unifo rmly sample a mode st number of nod es to lo cate a nod e that is clo ser to any oth er node in V . T herefore, we can r ecursiv ely find n odes c loser to the target based on the above sam pling pr ocedure, which h elps the design of the DNNS alg orithms. Howe ver , since Karger and Ruhl assumes the triangle inequality to hold [ 44], we cannot immed iately apply their DNNS results into the relaxed inframetric model. Accordingly , we need ne w proof techniqu es for DNNS a nalysis. The growth dim ension fo r the infr ametric space [ 43] is defined as follows: Definition V .3 ( Gr owth [43 ] ) . F or a ρ -inframetric mo del, for any r ∈ ℜ + and P ∈ V , if | B P ( ρr ) | ≤ γ g | B P ( r ) | , where γ g ∈ ℜ + , the ρ -inframetric model is said to have a g r owth γ g ≥ 1 . The growth dimension γ g on the in frametric m odel general- izes the growth definitio n in the metric space which assumes the triang le inequality to hold [44], [37]. Th erefore, the growth γ g inherits the intuitive meanings of the g rowth definition in the metric space. Specifically , low growth γ g means that the nu mber of nodes covered by the closed ball B P ( ρr ) is compara ble to the number of nod es covered by the closed ball B P ( r ) . Therefore , when we exp and a b all aroun d a node P ∈ V , we can see that new nod es in V ”come into vie w” at a constant rate [44]. Finally , based on Def V .3, the infimum of the g rowth dimension γ g equals the ratio of the volume between B P ( ρr ) and B P ( r ) for any node P an d r adius r . Since we are interested in th e infimum, when we refe r to the growth of the inframetric space, we mean the in fimum acc ordingly . Next, we empirically e valuate th e g rowth dimension of the delay spa ce with respect to th e radius r and th e inf rametric parameter ρ . Ou r ev a luation complemen ts the seminal work on the gro wth in the infram etric mo del [ 43] u sing symmetric and asym metric data sets. Reca ll th at comp uting the growth is tr i vial b y compar ing the volumes of the balls with ide ntical centers and varying radii. Fig 3 shows the median and 90th percentile growth values for varying radii. The median growth of mo st da ta sets is relativ ely small, and declines quickly with increasing rad ii for m ost data sets except for Host479. For Host4 79, the median growth may increase as th e radii increase. On the other hand, the 90th pe rcentile growth s hows di vergent dynamics for different d ata sets, r e vealing ” M ”-shape dy namics, indicating that a small fraction of gr owth values may increase or decrease with increasing r adii. Furthermo re, by selecting different perc entages o f node s for the statistics, Fig 3 sh ows that the m edian growth is less sensiti ve to th e sample size compared to the magnitudes of JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 6 0 40 80 120 160 200 0 2 4 6 8 10 12 Radius (ms) Growth (a) DNS1143. 0 40 80 120 160 200 0 2 4 6 8 10 12 Radius (ms) Growth (b) DNS2500. 0 40 80 120 160 200 0 2 4 6 8 10 12 Radius (ms) Growth (c) DNS3997. 0 40 80 120 160 200 0 2 4 6 8 10 12 Radius (ms) Growth (d) Host479. Fig. 3. The statistics of the median and 90-th percent ile growth γ g for ρ = 3 ; - ♦ - deno tes median v alues computed from s ampled 20% nodes; -x- denotes median va lues computed from sampled 50% nodes; -o- denotes median v alues computed from sampled 75% nodes; - represents median val ues computed from all nodes; · · ·♦· · · denotes 90-perce ntile valu es computed from sampled 20% nodes; · · · x · · · denotes 90-percenti le val ues computed from sampled 50% nodes; -. o -. denotes 90-percenti le values computed from sampled 75% nodes; -.- represent s 90-percentil e values compute d from all nodes. radii; wh ile the 90 th pe rcentile growth beco mes relatively more sensiti ve to the sample size. In summa ry , the growth metric γ g of the d elay space is quite low . Fu rthermor e, with increasing radius, the growth γ g decreases to 2 q uickly on average. Howe ver , some times the growth v alues increa se for incre asing radius, which means that there are many nodes that have similar distances to ea ch oth er . This usually correspo nds to cases wh ere th e c enter o f the b all is a node on the edge of a cluster, where n odes in the same cluster have smaller distances c ompared to th ose to other nod es not in th e sam e cluster . V I . E FFI C I E N T D N N S O N T H E R E L A X E D I N F R A M E T R I C M O D E L In th is section, using th e relaxed inframetr ic model pr e- sented in Sec V, we analyze how to design an efficient DNNS using localized op erations suitable for d istributed systems. Proofs are o mitted d ue to sp ace limits, which can be fou nd in the full r eport [ 36]. Our major result is that it is feasible to design an accurate and fast DNNS algo rithm for the re laxed inf rametric mode, at the expen se of sam pling eno ugh candid ate servers fr om the proxim ity region of e ach no de. W e con struct a simple DNNS process satisfyin g our major result. However , the simple DNNS proce ss incurs relatively high me asurement costs d ue to the sampling con ditions, which will be improved in the n ext section. Fig. 4. Sampling close r nodes to a t arget T from B P ( ρr ) in the ρ -infra metric model with growth γ g . A. Sampling Co nditions to Locate Closer Nodes T o T ar gets In this section, W e analy ze sam ples required to locate a node closer to a target than the curre nt no de based on the gr owth dimension in Sec V -B . The sampling co nditions serves as th e basis for th e efficient DNNS algo rithmic d esign. Our results show that we can samp le a server closer to the target using bound ed samples at each n ode. In or der to obtain a no de that is β ( β ∈ (0 , 1] ) tim es closer to th e target than th e current nod e, we need to uniformly sample en ough n eighbor s from the p roximity region of each c urrent node. W ithout loss of generality , assume that a no de P needs to locate a node Q that is β ( β ≤ 1 ) times closer to a target T , which implies th at d QT ≤ β × d P T . L et d P T = r . W e can see th at n ode Q must be covered by the ball B P ( ρr ) , sin ce d P Q ≤ ρ ma x { d P T , d QT } = ρr . Fig 4 shows an example of samp ling a n ode closer to the target T in the closed ball B P ( ρr ) in th e g rowth dimen sion. W e first quantify the volume differences of balls with identical centers but dif ferent radii. Lemma VI.1. Given a ρ -inframetric with gr owth γ g ≥ 1 , for any x ≥ ρ , r > 0 and any node P , the volume of a b all B P ( r ) is at mo st x α smaller than that of the ball B P ( xr ) , wher e log ρ γ g ≤ α ≤ 2 log ρ γ g . Lemma VI.1 states that the v olume differences of the balls with iden tical centers and different radii are bound ed by x α , where x is the multiplicative ratio between different r adii, and the parameter α lies in a bounded inter val. W e calculate α by v arying the radius r and the multiplicati ve ratio x as sho wn in Fig 5. W e c an see th at α is mostly b elow 1, and d ecreases close to 0 quickly with increasing radiu s r or multiplicative ratio x . Therefo re, the volume difference x α scales sub-linearly in most cases. On the other hand, for small radius r or low m ultiplicativ e r atio x , the volume difference x α may scale ultra -linearly . Furthermo re, we also ch aracterize the inclusio n relation of balls with dif ferent centers, which generalizes the inclusions of balls around a node pair in the metric sp ace [44]. Lem ma VI.2 lays th e foundation for unifo rm sampling nodes to per form DNNS on th e inf rametric m odel. Lemma VI.2 . (Sand wich lemma) F or any p air of node p and q , and d pq ≤ r , the n B q ( r ) ⊆ B p ( ρr ) ⊆ B q ρ 2 r JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 7 0 20 40 60 80 100 10 40 70 100 130 160 200 0 0.5 1 1.5 2 x r (ms) Median α (a) DNS1143. 0 20 40 60 80 100 10 40 70 100 130 160 200 0 0.5 1 1.5 2 x r (ms) Median α (b) DNS2500. 0 20 40 60 80 100 10 40 70 100 130 160 200 0 0.5 1 1.5 2 x r (ms) Median α (c) DNS3997. 0 20 40 60 80 100 10 40 70 100 130 160 200 0 0.5 1 1.5 2 x r (ms) Median α (d) Host479. Fig. 5. Medi an α as functi on of the radius r and the multiplica ti ve ratio x . Using Lemma VI.1 and VI. 2, we can quantify the size o f sampled neighbo rs, to assure that at least one neighb or lies in the closed ball B T ( β r ) . Theorem VI.3. (Sampling efficiency in th e g r owth dimension) F or a ρ -inframetric model with gr o wth γ g ≥ 1 , fo r a service node P , and a DNNS targ et T sa tisfying d P T ≤ r , when selecting 3 ρ 2 β α nodes uniformly at rando m fr om B P ( ρr ) with r ep lacement, with pr obability of a t lea st 9 5%, on e of these n odes will lie in B T ( β r ) , where log ρ γ g ≤ α ≤ 2 log ρ γ g and β < 1 . Since α a nd ρ are determin ed by the d elay space, we can see that the number of samples d ecreases with increasing delay reduction th reshold β . As β appro aches 1, the numb er of required samples becomes approx imately 3 ρ 2 β α ≈ 3 ρ 2 α ∈ 3 γ 2 g , 3 γ 4 g based on Le mma VI.1. B. DNNS on the Inframetric Model In this section , we present the an alysis of DNNS on the Infram etric m odel. W e will show the search accuracy , search periods and search costs related to a DNN S p rocess. W e prove that, by recursively following such samp ling conditio ns, we can locate a server that is 1 /β -appro ximation to the optimal: the delay from th e found server to the target is n ot bigger tha n 1 /β times that from the near est server to the target. First, we r e view the g oal o f each DNNS step using the sampling cond itions in Sec VI-A. Assume that a n ode P wants to locate a node that is β times closer to a target T . The goal of the curr ent DNNS step is to lo cate a node β times closer to the target than the cu rrent node P . T o that end, Theo rem VI.3 shows that we need to samp le u p to 3 ρ 2 β α nodes unifor mly at random from B P ( ρr ) with r eplacement. Based on the sampling con dition in Theorem VI. 3, perform - ing DNNS in the growth dime nsion can be formulate d into a simple DNNS pr ocedure in Definition VI.4. Definition VI.4 (A simple DNNS metho d in the in frametric model) . samp ling 3 ρ 2 β α neighbo rs fr om the closed ball B P ( ρd PT ) at each intermediate no de P , forwarding the DNNS r equest to a next-hop n ode β times closer to the target than the no de P , and sto pping at a loca l minima when we can not fi nd such a ne xt-hop node. Furthermo re, we can qu antify the efficiency of fou nd neig h- bors b ased on th e above DNNS p rocedur e by Cor ollary VI.6. As a r esult, we can lo cate an a pproxim ately optimal nea rest neighbo r for a target T when β ap proache s o ne. Fu rthermor e, the num ber of r equired search steps is a lo garithm func tion of the ratio ∆ of the max imum delay to the minimum delay in the delay space, indic ating tha t the DNNS queries can co mplete quickly . Definition VI.5 ( ω -app roximation ) . F or a DNNS request with tar get T , a foun d ne ar est neig hbor A is a ω -app r oximatio n, if the delay between A to T is smaller than ω d ∗ , wh er e d ∗ is the delay be tween the real nea r est neigh bor to T . Corollary VI.6. F or a relaxed inframetric mode l with g r owth γ g , accor ding to the DNNS pr o cess in Definition VI.4, the found neares t neighbo r is a 1 β -appr oximation , and the number of searc h step s is smaller than log 1 β ∆ , wher e ∆ is the ratio of the maximu m d elay to the minimu m d elay of all pairwise delays. C. Limita tions of Theo r etical Resu lts T o find a better next-hop neigh bor without missing any closer nod es, based on the DNNS analysis in th e inframetric model in Sec VI-B, we sh ould sample app roximately 3 ρ 2 β α nodes who se delay s to current node P are not larger tha n ρd P T . Howe ver , the n umber of the can didate neighbo rs may be quite high , as sh own in Fig 6. W e can see th at th e number of r equired samples exceeds 1 00 accor dingly , f or β below 0. 4 or α ab ove 1 . Such h igh number of samples implies that we need extrem ely large number of samples for continuing the DNNS query . On the other han d, the n umber of samples decreases with decreasing α or with increasing β . When α is below 1, the number of samples is below 33 if the delay redu ction threshold β is above 0.8 . As a result, we can see that we need to cho ose a large β in or der to reduce the number of samples, since the median v alues o f α a re m ostly no more than 1 from Fig 5. D. Comparison with P r eviou s Inframetric Study Our rela xed inframetric model is inspired by the semin al study on the inframetric model [43] that as sumes the symmetry of the distance function . W e extend the inf rametric mode l study for th e I nternet d elays in fo ur aspects: • W e extend the infram etric model to allow both symmetric and asymmetric distance functio ns, which generalizes the R TTs and OWDs that are importan t f or latency-sen siti ve applications. JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 8 0.1 0.2 0.4 0.6 0.8 1 0.5 1 1.5 2 10 0 10 1 10 2 10 3 10 4 10 5 β α Number of Samples (log scale) Fig. 6. The number of sampled neighbors 3 ρ 2 β α by vary ing the volume dif ference paramete r α from the interv al [0 , 2] based on the analysis in Sec VI-A and the delay reduction threshold β . W e set the inframet ric parameter ρ to be 3 to represent most triple s. • W e clearly show the relatio n b etween infram etric param - eter ρ and th e TIV . The in frametric parame ter ρ ≤ 2 is a necessary b ut not sufficient condition fo r no TIVs. • W e fo rmulate the DNNS prob lem on the re laxed infra- metric model an d propose a simple DNNS m ethod that finds appr oximately n earest neighbor for any target using at most lo garithmic sear ch hops. Interestingly , our simple DNNS method works o n bo th sym metric and asymmetric delay metrics. V I I . R E A L I Z I N G A P R A C T I C A L D N N S A. Over coming Limitations o f the Simple DNNS Method Recall that the measurem ent costs limits the usefuln ess of the simp le DNNS method defined in Def VI.4 from Sec VII-A. Besides, in the distributed system context, since each service node does n ot hav e the global view of the delay space, sampling enough neig hbors from the closed ball centered at each serv ice nod e is difficult. W e discuss design pr inciples to tackle these two difficulties in this section. 1) Reduce Measur ement Costs: W e re duce the measure- ment c osts in two complem entary approach es: (i) Given that the number of required samp les of the simple DNNS method depend on varying p arameters, we seek to modif y the pa- rameters to obtain the lower b ound of the r equired number of samples. (ii) Giv en that network coo rdinates can be used for d elay estimation s, we a void comp lete measure ments from selected samples to the target usin g d elay estimations. First, recall that the nu mber o f sample s fo r the simp le DNNS method increases qu ickly with decreasing delay reduc- tion th reshold β . T herefore , to r educe the nu mber o f sample s, we should set the delay reductio n thresho ld β to be close to 1. On the other hand, since th e approxima tion ratio of the simple DNNS m ethod is 1 /β , we can see that large β also leads to better approxima tions of nearest neighbo rs. As a resu lt, w e set β to 1 in o rder to reduce the nu mber of sam ples an d obtain the best ap proximatio n accuracy . Second, althoug h we red uce the numbe r of samp les using modified β , we still need d elay measuremen ts b etween se- lected sample s to the targets, w hich con sume the band width costs and CPU loa ds of serv ice nodes. Th erefore, we h ope to reduc e the required delay measurements while obtainin g the sample tha t is closest to the target. T o that end, we use delay estimation s based on network coordinates to reduce the delay measur ement costs. Howe ver , since the delay es- timations incu r error s d ue to the emb edding distortion s of network coord inates, simply u sing delay estimations to find the near est n eighbor s becom es less reliable. In stead, we issue delay measurements whe n the delay estimatio ns a re inaccurate, so as to av oid the in accurate d elay estimations. 2) S ample Enough Neighbors F or Continuing DNNS Query: Based on th e simple DNNS method , each DNNS service has to maintain enough neighbo rs covering different delay r anges in the delay space, in order to find the neare st neighbo r to any target. T herefor e, each node has to ma ximize its di versity in the neighbor set. Gossip based n eighbor man agement is freq uently used f or existing DNNS metho ds. For example, M eridian [1 3] an d O ASIS [ 9] use an anti-entro py gossip p rotocol to d iscover neighbo rs, and store n eighbor s using ring s o f neighb ors called concentr ic ring s. However , during ou r experimen ts, the inn er- most and outerm ost rings in the concentric ring often find no or only few n eighbor s compa red to th e cap acity of the ring, while the rest of rings with radii ly ing in the middle p ortion of the delay distributions are filled with too many n eighbor s, leading to f requent ring managemen t events, incurring heavy computatio n and communicatio n overhead . W e explain the insufficiency of the gossip process in details. Assuming that we know the comp lete delay matrix, fo r each node, we compute the percen t of map ped nodes fo r each rin g, which serves as an up per bou nd of sampled neighb ors for that ring. The n we can analy ze whether the distributions of mapped nod es in concentric rings affect the gossip pr ocess. As shown in Fig 7, we can see that most nodes are map ped into a few number of rin gs, whose de lay ranges lie in the middle p ortion of the delay distributions. Howe ver , only q uite a few nodes are mapped into th e inne rmost and outer most rings, which r esult in a skewed distribution of m apped nodes for the concentric rin gs. As a result, since the gossip process adopts the un iform samp ling ap proach, the gossip process will inevitably sample insuf ficient neighbors fro m those rings that have too fe w m apped nodes. According ly , to improve the co ncentric ring m aintenance, we need to sample enou gh neighbo rs that lie in different d elay ranges. T o tha t end, we pr opose to find n earest neighbo rs and farthest ne ighbors for each serv ice node, in order to fill the innermo st and outermost r ings in the concentr ic ring. B. Our Design Based on the design principles in Sec VII-A, we design a novel DNNS method n amed Hybrid NN (Hy brid Near est Neighbor Search). W e present an overview of Hy bridNN. T o sample eno ugh can didate neig hbors fro m the pr oximity region of the current nod e, each node mu st first m aintain a neighbor set th at co ntains en ough neighbor s within each proxim ity region. Then using th e neigh bor set, we select can- didate neighbors using the sam pling condition s of the simple DNNS metho d, in order to cover the n eighbors closer to the target with high probab ility . Next, we determine the candid ate JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 9 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 2 3 4 5 6 7 8 9 10 11 12 13 Ring Number Pct of Mapped Nodes (a) DNS1143. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 2 3 4 5 6 7 8 9 10 11 12 13 Ring Number Pct of Mapped Nodes (b) DNS2500. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 2 3 4 5 6 7 8 9 10 11 12 13 Ring Number Pct of Mapped Nodes (c) DNS3997. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 2 3 4 5 6 7 8 9 10 11 12 13 Ring Number Pct of Mapped Nodes (d) Host479. Fig. 7. The pe rcent of mapped nodes into diffe rent rings, assuming that we obtain the complete delay matrix. The i -th ring contain s neighbors whose delays to a node P li e in the interva l αs i − 1 , αs i , with i > 0 , α a constant, s a multiplicat i ve increa se facto r ( α = 1 , s = 2 ms as configured by W ong et al. [13]). Besides, since our objecti ve is to determine the distrib ution of nodes mapped into the concent ric ring, we do not limit the maximum capacit y of each ring. neighbo r closest to the target, using delay estimations and direct pr obes, in ord er to o btain a b etter tradeo ff between sampling b andwidth and accu racy . Finally , u sing the cur rently nearest cand idate neighbo r to the target, we determine whether to terminate the DNNS quer y . As sho wn in Fig 8, HybridNN is composed o f five c ompone nts: Neighbor Maintenance : This component maintains the neigh- bor set fo r DNNS qu eries. Since nodes are m apped into the rings at the mid dle po rtion of th e concen tric ring, which implies that n eighbor s mapped into the head portion and tail portion of the con centric ring ar e difficult to be sampled using the u niform sampling b ased appro ach. As a result, we need to increase the sampling proba bility o f such neighbors, in order to fulfill the sampling co nditions for DNNS qu eries. T o th at end, we over-sampling neighbo rs in th e head portion s and tail portion s o f the concen tric rin gs, besid es we unifo rmly sampling neig hbors located in the m iddle portion s o f delays and. Selecting Candidate Neighbor : This co mponen t selects can- didate neig hbors to satisfy the sam pling conditio ns of the simple DNNS meth od. When a node P receives a DN NS query , node P determines its delay towards the target T , then selects neigh bors from its diversity-optimized neigh bor sets (Sec VII-C) by covering possible closer neighbors towards the target T (Sec VII -D). Further more, we pru ne those n eighbor s that could m islead th e DNNS qu ery in to p oor local min ima. Coordinate Maintena nce : T his comp onent update s the co or- dinate of the target in o rder to estimate delay s to targets from candidate neighbor s, since the target mach ine m ay not h a ve the coo rdinate for delay estimation (Sec VII- E). Addition ally , each service mach ine m aintains a network coordinate used for delay estimations. Determining Closest Neighbor : This compo nent d etermines Fig. 8. The flow chart of four search steps at a service node for a DNNS query . the n eighbor nearest to the target (Sec VII-F). Each n ode com- putes the c andidate neighbor c losest to th e target using delay estimations and direct p robes, in order to balance b etween the measuremen t costs and measurement accura cy . T erminat ion T est : This c ompon ent determines to c ontinue or stop a DNNS qu ery (Sec VII-G). Recall that in pr evious section we set the delay reduction th reshold β to be 1 on order to red uce th e number of samples and o btain better approx imation ratios to th e optimal r esults. T herefor e, Hy- bridNN conservati vely term inate the DNNS query only when all c andidate neig hbors having larger delays than the current node. Finally , HybridNN uses an extensible d elay measu rement interface. For instance, by d efault H ybridNN simply use the sy stem-built-in Pin g co mmand to obtain pairwise R TT measuremen ts. When there exist an o n-deman d OWD prob e service such as Reverse T r aceroute [18], H ybridNN config ures a RPC in terface to request the p airwise O WD results. C. Neig hbor Maintenance In or der to facilitate th e ne ighbor sampling for DNNS forwarding , each serv ice node maintain s neighbo rs that are sampled fro m different regions in the delay sp ace. W e intro- duce the ne ighbor d iscovery and update in this section. 1) Organize Neigh bors Into Rings fo r Pr oximity Selection: Since the proximity region for neighbor sampling in the simple DNNS method is a closed ball, we choose th e con centric ring to organ ize neighbo rs fo r each no de. For instance, if we need to locate all neig hbors th at ar e at most d 2 ms away , we select all neig hbors from those rin gs whose ring num bers are at most ⌈ log 2 d 2 ⌉ . An impo rtant parameter for th e concen tric ring is its r ing size ∆ , whic h determines the ma ximum numbe r of n eighbor s per ring. Since we need to sam ple en ough neighbors using the concen tric ring to gu arantee to loc ate a neighb or closer to the target with a high probability , we analytically determine the ch oice o f ∆ as fo llows. First, the total n umber of samples 3 ρ 2 β α is within th e interval 3 γ 2 g , 3 γ 4 g , since we set the delay reduc tion th reshold β to 1. Th erefore, if we set the number of ne ighbors ∆ at each ring to be at least O ( γ 2 g ) , we can ensure that with a high proba bility , we can find a neighbo r that is closer to the target than the cu rrent nod e P . Fur thermore , since γ g is low on average from previous sections, we can set the nu mber of neighb ors ∆ to be a mo dest integer (8 by default). Furthermo re, to adap t to th e dynamics of delays, we use a moving med ian as a laten cy filter for extracting stable d elay measuremen ts to each ne ighbor [45], which allows to have up- to-date delay estimates resilient to the me asurement noises. JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 10 2) Biased Sa mpling based Neigh bor Discovery: Based on the distribution of neigh bors for each ring in the previous section, we h av e seen that we need to over-sample neighb ors mapped into the head portion and the tail portion of the concentr ic rings. T o that en d, w e a dopt bo th un iform samp ling and over -sampling approa ches. Uniform sampling . W e reuse the go ssip process in Merid- ian. Briefly , each node P p eriodically starts th e gossip pro cess by un iformly selecting a neigh bor Q from P ’ s c oncentric ring as co mmunicatio n p artner, and sends a g ossip req uest message to n ode Q co ntaining r andomly sampled neigh bors, one neighbor per n on-empty rin g. Whe n Q recei ves the gossip request, Q will send a gossip ACK to P immediately; b esides, Q iteratively sends gossip requ ests tow ards the samp led neigh- bors in the gossip request message of P . Finally , if we u se the R TT me tric, then node P inser ts Q into the corr esponding ring accord ing to the ro und trip d elays measured as the period between the gossip request an d the gossip A CK. Alternatively , if node P is able to measur e the one-way delay f rom P to Q , then no de Q is inserted into the correspo nding ring according to th e on e-way delay from P to Q . Over -sampling . Our goal is to sample en ough n eighbors from those map ped n eighbors lying in the head and tail portion s of the co ncentric rin gs. For this p urpose, we use K closest n eighbor search an d K farthest neighbo r search. Th e returned nodes are directly stored into the concentr ic ring , as the delay values b etween the current service nod e to th e returned node s are obtained du ring the K closest ne ighbor search and K farth est neig hbor search processes. • K closest neig hbor sea r ch . Each node P p eriodically finds nearby no des by issuing K c losest neighb or search with itself as target. Her e K is a system parameter . Firstly , node P randomly selects a neighbor Q fro m its concentric ring, and sends to Q a K nearby neighbo r search mes- sage. Then nod e Q starts a K c losest neig hbor search process. After the K closest neighbo r search p rocess is completed , found nearby nodes and the correspon ding delays to P are retu rned to node P , an d P saves these returned nearby no des in to its con centric r ing. • K farthest neig hbor sear ch . Similar as the K closest neighbo r searc h process, ea ch node P periodically issues K farthe st neighbo r search . Later , the K farthest neighbor search results in clude f ound distant neig hbors and the correspo nding d elay values to n ode P . P store s th e returned distant neigh bors into its co ncentric ring by the correspo nding delay values. Due to space lim its, the de tails for K closest n eighbor search and K farthest neighb or searc h are omitted here, which can be found in the full technical rep ort [36]. 3) Replacin g Su boptimal Neighbors W ithout Pr ob es: In order to boun d the memor y overhead of the co ncentric ring, we nee d to manage the size o f th e con centric rings when some rings reach their maximum cap acity ∆ . T o reduce CPU costs due to frequen t ring ma nagements, we lower the fr equency of ring mana gements: we fir st set up ano ther tolerance threshold ∆ t for each ring; then we begin th e r ing manage ment when some rin gs having a t least ∆ + ∆ t neighbo rs; du ring the ring managem ent, we remove ∆ t neighbo rs from those rin gs that have at least ∆ + ∆ t neighbo rs. When we need to r emove ∆ t neighbo rs from some rin gs, we fo llow the removing p hilosophy of Mer idian: preser ve those th at maximize the diversity of neigh bors in a ring using the max imal hyp ervolume polyto pe algo rithm ( [13]). This is because the high er diversity in th e n eighbor set translates to better chances of locating a n earby nodes for any target. How- ev er , the maximal hypervolume polytope alg orithm r equires all-pair delay measur ements of nodes in a ring , which needs O ∆ 2 probes. In ord er to av oid such measur ements, w e turn to adopt n etwork coor dinates fo r d elay predictions. For d elay predictio ns, we use the revised V iv aldi algorith m [21] that is robust to TIVs [20]. W e den ote the revised V ivaldi [20] as TIV -V iva ldi( x i , e i , d ij , x j , e j ) , where the input x i , x j denote the coo rdinate of node i and j , respectively; the input e i , e j denote the averaged err or of node i ’ s and j ’ s coordin ates, re spectiv ely . The o utput of TIV -V ivaldi are th e updated coordinate x i and coordinate error e i of node i . Each service node passi vely m aintains a coo rdinate, an d estimates de lays usin g co ordinate distanc es. Besides, for es- timating delays with neighbors in the concentric ring, each service node also stores its neighbors’ c oordinate s. Since delay varies, each n ode u pdates its own an d cach ed coordin ates pe riodically . Rather than introdu ce ad ditional de- lay prob es, we u pdate coordin ates b y reusing the delay mea- surements to oth er service nod es durin g the b iased samplin g proced ure. Therefo re, we significantly reduce the maintenance costs compar ed to Meridian. First, each nod e r eceiving the gossip me ssage piggy backs its co ordinate to the send er along with the ack nowledged gossip message. After r eceiving the coordin ate from th e gossip receiver node, the go ssip sender node stores the new co ordinate of th e gossip receiver node, and up dates its own coord inate by trigg ering TIV -V iva ldi using the delays ob tained du ring th e gossiping pr ocess. D. Select Candidate Neighb ors Assume that node P r eceiv es a DNNS quer y to th e target T . Based on the sampling co nditions of the simple DNNS method, node P n eeds to select 3 ρ 2 β α neighbo rs who se delays to node P are in the d elay r ange [0 , ρd P T ] . Since eac h ring contains O ( γ 2 g ) neigh bors, we simply select all n eighbors of ring s number ed in the rang e [1 , ⌈ log 2 ( ρd P T ) ⌉ ] as candidate neighbo rs. Furthermo re, we also p rune se veral neighbors that mislead the DN NS p rocess. First, candidate neighb ors that contain too few non- empty rings are more likely to provide no h ints on con tinuing th e DNNS queries, thus the DNNS q ueries can be trapped into local minim a, d ue to the neighb ors’ sparse d i versity of the delay space. Th erefore, we remove all ne ighbors with fe wer tha n τ n on-emp ty ring s ( τ = 4 b y default). Second, all neigh bors th at have received the iden tical DNNS query sho uld be rem oved in order to avoid the search loops. Th erefore, let the forwar ding p ath of a DNNS qu ery be the sequ ence of n odes forwardin g the q uery . we r emove any nod e o n th e forwarding path. JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 11 E. Coor dinate Maintenance fo r T ar gets In order to red uce th e delay measurem ent costs, we predict delays from s ervice nodes to th e tar get, since eac h service node has co mputed its network co ordinate during the neighbo rhood managem ent process (Sec VII- C3). As a result, r eusing the coordin ates for predicting delays can re duce the mea surement costs. Unfortu nately , we ma y not kn ow th e coord inate of the target, as th e target can b e any machine on the Intern et. Therefo re, we propose to com pute the coor dinate for the target on-the- fly based on the TIV -V iva ldi . First, wh en node P receives the DNNS qu ery for a target T , nod e P will initialize the network c oordinate x T for target T if T ’ s coord inate is not stored in the DNNS quer y messag e. T o th at end, node P asks a fixed numbe r o f neighb ors ( at most 10) to directly pro be the target T . Then, nod e P updates target T ’ s coo rdinate by TIV -V ivaldi u sing the coord inates and delay measur ements from these neig hbors to target T , which upd ates T ’ s coord inate x T and coo rdinate error e T as the output of TIV -V ivaldi . Finally , node P stores target T ’ s coordin ate into the DNNS query and forwards to the next- hop node for recursive search. This completes the coord inate initialization for the target T . Second, after initializing T ’ s coordinate, each node Q that forwards the DNNS q uery will update target T ’ s coor dinate f or better conver gence of target T ’ s coor dinate. T o that en d, each node Q applies TIV -V ivaldi to u pdate target T ’ s co ordinate x T and coo rdinate error x T , usin g node Q ’ s c oordinate and delay d QT the target T . F . Determine Closest Neighbor After we assign a network coo rdinate to the target in Sec VII-E, we can use the network co ordinate distan ces to approx imate the real-world d elay and reduce the m easurement costs. Nevertheless, since the coord inate distances are only approx imations, clo sest neigh bors selected acco rding to the network co ordinates may be incon sistent with the real o nes. Therefo re, we locate closest neigh bors to the target T fr om the can didate neig hbors foun d in Sec VII-D, by co mbining the delay predictions with a small number o f d irect p robes. First, based on th e c oordinate distances from cand idate neighbo rs to target T , we find top- m nearest neighbo rs S c to the target T fro m the candid ate neigh bors. Second, since co ordinate distances may be er roneou s, we also choose those can didate n eighbor s S e whose co ordinates are no t re liable. Since each TI V -V i valdi coordinate x i is ac- compan ied by a coo rdinate error metr ic e i [20], we choose un- reliable neighbor s whose coordina te errors exceed a threshold. W e fo und that setting the threshold to be 0 .7 c an significantly reduce the negativ e im pact due to the c oordina te inaccu racies. Third, to ad apt to coordinate errors caused by TIV , since high coord inate distance errors indicate violatio ns of triang le inequality [2 0], we simply in clude all candidate neighb ors S t whose coordin ate distance and real delay to wards the cu rrent node P differs b y more than 50 ms, which has goo d tradeoff between accuracy and bandwidth costs. Finally , u sing th e un ion of selected cand idate neighbo rs S ∗ = S c ∪ S e ∪ S t , the curren t n ode P asks neigh bors in S ∗ to probe the delays to target T , from which nod e P d etermines the clo sest neigh bor . Ties are broken by cho osing the neighbo r with most accu rate coordinate. G. T ermina tion T est Recall fro m Sec VII- A, HybridNN set the delay r eduction threshold β to be 1, in order to re duce the numb er of selected neighbo rs and obtain better ap proximatio n ratios for th e f ound nearest ne ighbors. Th erefore, when the closest neighb or se- lected from Sec VII-F has a larger delay to the target than that of the cu rrent node P , node P termin ates the DNNS qu ery . Then node P sends the curr ently closest n ode to the ho st tha t issues the DNN S query . V I I I . E X T E N S I O N S T O H Y B R I D N N HybridNN can be r eadily extended to search mo re than just one nearest node . Here we will just give tw o examples namely , K closest neigh bor sear ch and K farth est n eighbor search, which are both utilized to oversample neig hbors in the network delay space in order to increase the d i versity for neighbo rhood managem ent. A. K D istrib uted Near est Neighbor S ear ch The K Distrib uted N earest Neighbor Sear ch ( KDN 2 S) aims to loca te th e K nearest neighbo rs to a target T , wher e K is a system parameter . T o store th e fou nd nearest neighbor s, we append a new field M . Ω that caches n earest neighbors to the DNNS query m essage M . A naiv e KDN 2 S solu tion is based on the fi nding and r emoving approach : first we find o ne closest n eighbor towards the target based on the Hyb ridNN alg orithm, the n we d elete the fou nd nearest neighb or from the system , and we restart the Hybrid NN algorithm from th e same qu ery node un til we locate K nearest ser vers to the target. Nev ertheless, deletin g the closest neigh bors fr om th e system is not p ractical f or a large- scale system due to the broa dcasting c ommunica tion overhead, and rep eated DNNS processes increase the query overhead for the service nod es on the DNNS forwarding paths. On the other hand , if we assume th at the concentric ring of each nod e does not appen d n ew neigh bors, the network coordin ate o f each no de keeps unchang ed and the network delays keep stable during the period of a KDN 2 S query , we find that there exists temporal corr elation in the f orwarding paths of con secutiv e DNNS queries starting fro m the identical node in th e naive KDN 2 S solution : if we issue a new DNNS query fr om th e same starting nod e immediately after the pr eceding DNNS qu ery , then the forwar ding p ath truncated the la st-hop node of th e new DNNS pr oc ess is a su bpath of the forwar ding path of the preceding DNNS query , since we can see that the intermedia te nodes on these two forwar ding pa ths ar e id entical in Hy bridNN. Our assump tion ge nerally h olds after the n etwork coo rdinates co n verge and the concentric rin gs contain eno ugh neig hbors. Furth ermore, the constancy of en d to en d ne twork delays has been confirmed to b e on the orders JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 12 Fig. 9. KDN 2 S. of hours by Zh ang and Du ffield [46] as well as the iPlane project [33], [34 ]. Using the te mporal correlation o f co nsecutive f orwarding paths fro m the same starting node, we propo se a backtr acking based KDN 2 S algorithm, as sho wn in Algorithm 1. A fter we find on e nearest n eighbor and ter minate at a service node P 1 by Hybrid NN, we r esume the KDN 2 S query from P 1 , by backtr acking fro m P 1 to its predece ssor no de P 2 on the DNNS forwarding path, and by re cursiv ely finding the nearest neighbo r a t P 2 , until we lo cate K n earest neighb ors. Wit h backtrack ing, the KD N 2 S resu mes th e query at servic e node s that are close to the target, th erefore we can quickly locate ne w nearest neighbors with reduced forwarding overhead co mpared to the n ai ve KDN 2 S solution. Fig 9 gives an examp le of KDN 2 S using Algorithm 1. Suppose an end h ost A needs two nea rest neig hbors to the target T . Node A sends a K DN 2 S requ est to a service node B . Then B starts the KDN 2 S by fo rwarding a KDN 2 S query M to a neighbo r P 2 closer to T . Similarly , P 2 forwards the q uery M to P 1 . Now no de P 1 finds that it cannot find a neighb or closer to th e target T tha n itself, theref ore, P 1 is th e fir st nearest neighbor to the target. Then P 1 append s its address into M . Ω as a foun d nearest neighb or . Ne xt P 1 triggers the KDN 2 S backtrack ing step by forwardin g M to P 1 ’ s pred ecessor P 2 on the KDN 2 S fo rwarding path. On receiving M , P 2 excludes P 1 from the cho ice of candidate ne ighbors, an d finds a n ew neighbo r P 3 closer to the target T than P 2 . Then P 2 forwards M to P 3 . P 3 decides th at it is the closest n ode to T am ong its ne ighbors. Therefo re, P 3 append s itself to M . Ω as a new nearest neighbor . Fin ally , P 3 sends the found nearest neighbors in M . Ω , i.e., P 1 and P 3 , to the end host A , which completes the KDN 2 S. B. K D istrib uted F arthest Neig hbor Sear ch Similar as the KDN 2 S, K Distributed Farthest Neig hbor Search (KDFNS) is also based on the backtr acking ide a. First, we locate one farthest neighbor and terminate at a service node P , then we backtra ck from node P to its pred ecessor nod e on the forwardin g path to recu rsi vely locate the rest K − 1 farthe st neighbo rs. T o locate one farthest neighb or , we r ecursively f or- ward the KDN 2 S query to a service node P 1 that is at least (1 + β farthest ) ( β farthest is 1.2 b y default) times farther to the target T than the current servic e node P . In other w ords, we need to locate a nod e that is not covered by the b all B T ((1 + β f ar thest ) d P T ) . Since B T ((1 + β f ar thest ) d P T ) ⊆ B P ( ρ (1 + β f ar thest ) d P T ) by Algorithm 1: The pseudo-c ode o f KDN 2 S. 1: KDN 2 S( H , T , K , M ) 2: { Input: current node H , t he target T , required number of closest neighbors K , query messag e M } 3: { Output: nearest neighbors to T } 4: if | M . Ω | == K then 5: Return M . Ω ; { enough closest neighbors } 6: end if 7: S ← chooseCandidates( P , T , M ); 8: S ← S − M . Ω { remov e found nearest neighbors to avoid search loops } 9: x T ← InitT argetCoord( P , T ) ; 10: [ u 1 , S c , D T ] ← NearestDetector( P , S , x T , M ); 11: [ φ 1 , d φ 1 T , P 1 ] ← T erminateT est( P , u 1 , S c , D T , M ); { find one closest neighbor , and t erminate at node P 1 } 12: M . Ω ← M . Ω ∪ { φ 1 } ; { cache φ 1 into the query message } 13: Select the predecessor node P 2 of node P 1 on the forwarding path M .Path; { find the predecessor for backtracking } 14: KDN 2 S( P 2 , T , K , M ) ; { recursi ve search } the sandwich lemma in Lemma VI.2, P 1 needs to be at least ρ (1 + β f ar thest ) d P T from node P . According ly , in e ach search step, we try to find such node P 1 from the co ncentric ring of the cu rrent service node P , whose delay value to P is larger or equa l the ρ (1 + β f ar thest ) d P T . If there exists a such node P 1 , then node P 1 recursively r uns the KDFNS as no de P . Oth erwise, if we c an no t lo cate such no de P 1 , the search is terminated, and th e currently farthest node to the target is cached as a farthest neighbor to the target. Afterwards, we select the rest K − 1 distant neighb ors by the backtrack ing process similar as that in K closest neighbo r search. Algorithm 2 shows th e comple te KDFNS process. First, we choose cand idate n eighbor s satisfying the delay constrain t to the cu rrent service n ode P . Then we find the farthest neighbo r to th e target ( F arthestDetecto r () ) combinin g th e delay predictio ns with direct pro bes in orde r to reduce the measuremen t overhead. Spe cifically , we choose m farthest neighbo rs from the candidate neighbo rs; besides, we also add neighbo rs with uncer tain coordinate s and erro neous predic- tions similar as Sec VII-F. Next, we determine one farthest neighbo r recursively (FarthestT ermin ateT e st). Finally , from the terminating no de P 1 , we bac ktrack to the pr edecessor node of P 1 on the forwarding pa th, a nd recursiv ely r un the KDFNS until we lo cate en ough farthest node s to the target. I X . S I M U L A T I O N In this section, we report the results of simulatio n experi- ments based on the real-world d ata sets in Sec IV. A. Experimental Setup W e com pare Hyb irdNN with several DNNS algorith ms. (1) Vi valdi . W e compu te the coordin ate of each node based on the V ivaldi algorith m [45], an d find the near est service nodes for each requ esting node u sing sho rtest coor dinate distances. The coordinate dimension fo r V i valdi is 5. (2) CoordNN . T o quantify th e usefu lness of dir ect pr obes of HybirdNN , we present a DNNS alg orithm CoordNN, which is identical with JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 13 Algorithm 2: The pseudo-cod e o f K DFNS. 1: KDFNS( H , T , K , M ) 2: { Input: current node H , the target T , required number of farthest neighbo rs K , que ry message M } 3: { Output: farthest neighbors to T } 4: if | M . Ω | == K then 5: Return M . Ω ; { complete the KDFNS } 6: end if 7: S ← chooseF arthestCandidates( P , T , M ); { choose neighbors whose delay v alues to P is larger than or eq ual to ρ (1 + β f ar thest ) d P T } 8: S ← S − M . Ω { remov e found farthest neighbors to avoid search loops } 9: x T ← InitT argetCoord( P , T ); 10: [ u 1 , S c , D T ] ← FarthestDetector( P , S , x T , M ); { select the farthest neighbo r to T from S } 11: [ φ 1 , d φ 1 T , P 1 ] ← FarthestT erminateT est( P , u 1 , S c , D T , M ); { find one farthest neighbor , and terminate at node P 1 } 12: M . Ω ← M . Ω ∪ { φ 1 } ; { cache φ 1 into t he query message } 13: Select the predecessor node P 2 of node P 1 on the forwarding path M .Path; { fi nd the predecessor for backtracking } 14: KDFNS( P 2 , T , K , M ) ; { recursiv e search } T ABLE I P A R A M E T E R V A L U E S O F H Y B R I D N N F O R S I M U L AT I O N . Parame ter Meaning V alue ∆ maximal size of the ring 8 ∆ + ∆ t threshold of the ring size for ring updat es 10 β nearest searc h threshold 1 ρ inframetr ic parameter 3 | x | coordina te dimension 5 K size of sampled neighbors for neighbor disco very 10 m number of neig hbors for direct probes 4 τ number of non-empt y rings 4 HybridNN except that it uses on ly and no direct pr obes wh en determinin g the be st next-hop neigh bors. (3) DirectDN2 S . T o ev aluate Hybrid NN, we pr esent a DNNS algorithm Di- rectDN2S, which is id entical with Hy bridNN excep t that it only utilizes dir ect pro bes for finding next-hop best neig hbors without pru ning neighbo rs ba sed on coordinate distances as HybridNN. (4) Meridian [13]. Meridian r ecursively forwards the DNNS que ries to a node th at is β tim es clo ser to the target than th e cu rrent nod e, and returns the found n earest neigh bor when no such node is selected. W e configu re the para meters of Meridian algor ithm identical with th e orig inal configu ration by W on g et al. [13], with the delay r eduction thresho ld β as 0.5, the uppe r bound on the size of each r ing as 10 , and the number of r ings in the concentr ic ring is 20. For HybridNN, th e default con figuration is summar ized in T able I . CoordNN and DirectDN2S share identical par ameters with Hybr idNN. W e also e valuated the sensitivity of param- eters for Hyb ridNN, wh ich is reasona bly robust aga inst the parameter choices. Th e de tailed sensitivity results of system parameters f or Hybr idNN can b e fou nd in th e techn ique report published online [36 ]. W e have d ev eloped a discre te-time simulator for DNNS. The sim ulator randomly chooses a set o f no des as serv ice nodes ( by d efault 500) th at can receive DNNS queries. Other nodes in the system are clients that can issue DNNS q ueries to these service nodes. For Host479, 200 nodes are the service nodes. Th e DNNS quer ies are rep eated 10 ,000 times. For each DNNS query , we unifor mly select o ne client as the target machine, and a random serv ice node receiving the query . Besides, the simu lation is r epeated 5 times by shuffling the set of service nodes to av oid biases in choosing servic e nodes. For HybridNN, CoordNN, Dir ectDN2S a nd Meridian, the inter- gossip events for neighb orhood discovery are g enerated b y an exponential d istribution with expected value of 1 second. T he inter-ring managemen t events are generated b y an exponential distribution with expected value of 2 second s. For Hybr idNN, DirectDN2S and CoordNN , the time interval be tween two oversampling events of K closest neighbo r search an d K farthest n eighbor search ar e g enerated by an exponential distribution with expected value of 60 seconds. The inter- DNNS e vent gener ation follows an exponential d istribution with expected value of 60 seconds. For V ivaldi, the coordinate of each nod e is up dated for 100 0 round s, by u niformly selecting a service node as th e cou nterpart dur ing each round. The performan ce metrics for each DNNS q uery in clude: ( 1) Absolute Error : defined as th e absolute difference be tween the estimated nearest neig hbor j and the rea l nearest n eighbor i to the target T , i.e., d j T − d iT . (2) Relative Error : d efined as th e ratio of the absolute erro r fo r the estimated nearest neighbo r j to the delay between the real nearest neighbor i and the target T , i. e., d jT − d iT d iT . The ab solute err or quan tifies the increased de lay values of the e stimated nearest neigh bors, while the relati ve error measures the m ultiplicative ratios to the optimal delay values for the estimated n eighbor s. There fore, large relative er rors d o not necessarily cor respond to high absolute errors. ( 3) Search Hop : defined as the number o f service no des o n the forwarding p ath minu s one . Theref ore, if node A fo rwards a DNNS query to node B an d node B returns the nearest neighb or to the q uery host, the search hop for the DNNS query is one. B. Comparison Absolute Error . Fig 10 shows th e absolute error s of the different algorithms. DirectDN2S achieves lowest absolu te errors excep t for the Host479 data sets. HybridNN is close to DirectDN2S in te rms of reducin g absolute er rors, h owe ver , HybridNN is th e mo st accur ate on Host47 9 data sets. Next, CoordNN is worse than both Direc tDN2S and Hybrid NN. The accuracy of DirectDN2S and Hyb ridNN co mpared to Co- ordNN indicates that utilizing direct probes greatly reduces the inaccuracy of th e estimation , while u sing coor dinate distances alone can lead to a bad lo cal min ima. The inaccuracy of DirectDN2S comp ared to Hyb ridNN on the Host479 d ata set is r ather counter-intuitive. The inaccuracy of D irectDN2S m ay b e c aused b y the asy mmetry in th e delay data sets tha t misleads the greedy search into a lo cal minima, since Direc tDN2S is mor e accurate th an Hybrid NN on the other thr ee data sets that ar e all symmetric for pairwise delays. On the other han d, HybridNN d oes not alw ays c hoose the neighbo r closest to the target as the f orwarding n ode, since HybridNN also incorporates the ap proximated delay p redic- tions wh en ch oosing neig hbors, which can help Hy bridNN bypass the bad local m inimum c aused by the asymmetry in the delay values. JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 14 0 30 60 90 120 150 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Absolute Error (ms) Pr(X>x) Vivaldi HybridNN CoordNN DirectDN2S Meridian DirectDN2S (a) DNS1143. 0 30 60 90 120 150 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Absolute Error (ms) Pr(X>x) Vivaldi HybridNN CoordNN DirectDN2S Meridian DirectDN2S (b) DNS2500. 0 30 60 90 120 150 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Absolute Error (ms) Pr(X > x) Vivaldi HybridNN CoordNN DirectDN2S Meridian DirectDN2S,HybridNN (c) DNS3997. 0 30 60 90 120 150 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Absolute Error (ms) Pr(X > x) Vivaldi HybridNN CoordNN DirectDN2S Meridian HybridNN (d) Host479. Fig. 10. The CCDFs of absolute errors. Furthermo re, Meridian shows g reater absolu te error s com- pared to other alg orithms includin g V i valdi, which im plies that the coordinate distances are at least effecti ve if used it in the centralized ap proach. W e are aware that the super iority of V iv aldi over Meridian in most cases ar e consistent with the experimen ts ind ependen tly perform ed by Choffnes and Bustamante [4 2]. The main re asons for the less accur acy of Merid ian are the lo cal minim a caused b y the TIV an d clustering in the delay space. On the other hand, V iv aldi can adapt to TIV using adaptive coordina te m ovements. Relative Err or . Fig 11 sho ws th e r elati ve erro rs of DNNS algorithm s. The r esults are consistent with tho se of the ab- solute errors. DirectDN2S achie ves nea r-zero relative erro rs for most DNNS qu eries on a ll data sets except Host479. HybridNN and DirectDN2S have similar acc uracy , while HybridNN is more accurate than DirectDN2S on Host479. Furthermo re, Coord NN is less accurate than Hybr idNN, wh ile Meridian and V iv aldi are less accurate than DirectDN2S, HybridNN and Coo rdNN. Search hops . Next, we quantify the distributions of the number of search h ops for DNNS algorithm s, as shown in Fig 12. Recall th at the search hops are eq ual to th e len gths o f DNNS forwarding paths minus one. W e can see that the search ho ps o f most DNNS queries are rather mo dest for all D NNS algor ithms. Mer idian in ab out 80% of the cases h as 2 search ho ps. While Hybrid NN and DirectDN2S in o ver 80 % of the cases ha ve no more than 3. Moreover , almost all searc hes for Merid ian, Hy bridNN, DirectDN2S are below 6 searc h hop s. On th e other hand, CoordNN has longer search ho ps than Meridian, HybridNN and the DirectDN2S; a nd a fraction of search hops e ven exceed 10 on all data sets. C. Sensitivity of P a rameter s In this section, we evaluate the robustness of HybirdNN to the system size as well as th e ch oices of sy stem p arameters. 0 5 10 15 20 25 30 35 40 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Relative Error Pr(X>x) Vivaldi HybridNN CoordNN DirectDN2S Meridian DirectDN2S (a) DNS1143. 0 5 10 15 20 25 30 35 40 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Relative Error Pr(X>x) Vivaldi HybridNN CoordNN DirectDN2S Meridian DirectDN2S (b) DNS2500. 0 5 10 15 20 25 30 35 40 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Relative Error Pr(X > x) Vivaldi HybridNN CoordNN DirectDN2S Meridian DirectDN2S,HybridNN (c) DNS3997. 0 5 10 15 20 25 30 35 40 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Relative Error Pr(X > x) Vivaldi HybridNN CoordNN DirectDN2S Meridian HybridNN (d) Host479. Fig. 11. The CCDFs of relati ve errors. 1 2 4 6 8 10 12 14 16 18 20 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Search Hops Pr(X>x) HybridNN CoordNN DirectDN2S Meridian HybridNN Meridian CoordNN DirectDN2S (a) DNS1143. 1 2 4 6 8 10 12 14 16 18 20 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Search Hops Pr(X>x) HybridNN CoordNN DirectDN2S Meridian HybridNN Meridian CoordNN DirectDN2S (b) DNS2500. 1 2 4 6 8 10 12 14 16 18 20 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Search Hops Pr(X>x) HybridNN CoordNN DirectDN2S Meridian HybridNN Meridian CoordNN DirectDN2S (c) DNS3997. 1 2 4 6 8 10 12 14 16 18 20 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Search Hops Pr(X>x) HybridNN CoordNN DirectDN2S Meridian HybridNN CoordNN DirectDN2S Meridian (d) Host479. Fig. 12. The CCDFs of search hops. 1) S ystem Size N : T o evaluate the size of service mach ines on the perf ormance o f H ybridNN, we ev aluate the perf ormance of HybridNN by increasing the size of service machines. W e select target ma chines r andomly from all no des, in cluding the clients and the service mac hines, as the size of clients shrinks when incr easing th e p ercentage of service machines. Fig. 13 shows the perfor mance o f HybridNN with increasing the percentage of serv ice n odes. Hyb ridNN ach ie ves similar accuracy when th e size of service n odes increase compared to clients. T herefor e, Hyb ridNN is quite robust to the different scales of sy stems. On the other hand, the q uery loads of HybridNN incre ase slowly , f or example, HybridNN near ly double the loads w hen the percentage of service n odes reache s 1. 2) I nframetric ρ : Fig. 14 shows the a ccuracy and loads as the incre ment of Infram etric parameter ρ . The accuracy o f HybridNN is insensitive to choices o f ρ . This is because for JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 15 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 2 4 6 8 10 Percentage of Service Nodes Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS1143. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 2 4 6 8 10 Percentage of Service Nodes Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS2500. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 2 4 6 8 10 Percentage of Service Nodes Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 2 4 6 8 10 Percentage of Service Nodes Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 13. Size of Service Nodes. most delays, its ρ -ed ge me trics are quite lower . The refore, with lower ρ we can cover po ssible b est next-h op neigh bors for DNNS qu eries. Fu rthermor e, altho ugh larger ρ incr eases the size of possible next-hop candidate neighbor s, the loads of DNNS q ueries o f Hyb ridNN keep stab le fo r different ρ , due to that we use nearly constant-sized next-hop nod es. Besides, we can see the stand ard deviations o f erro rs ar e quite low for most data sets. 2 2.5 3 3.5 4 0 2 4 6 8 10 Inframetric rho Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS1143. 2 2.5 3 3.5 4 0 2 4 6 8 10 Inframetric rho Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS2500. 2 2.5 3 3.5 4 0 2 4 6 8 10 Inframetric rho Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 2 2.5 3 3.5 4 0 2 4 6 8 10 Inframetric rho Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 14. Inframetric ρ . 3) Non-Empty Thr e shold τ : Fig. 15 shows the accuracy and loads as the increm ent of Non -empty threshold s fo r pru ning candidate neigh bors for next-hop nodes. As the in crement of non-em pty threshold s for pr uning cand idate n eighbor s that have too few rings con taining nodes, the stand ard deviation of Hybr idNN is reduced befor e th e threshold reaches 4, then increases after the thre shold is over 4, and the m edian errors are increased when the non-empty thr eshold excee d 8 . Besides, the loads are redu ced when the n on-emp ty thresholds increase. Therefo re, selectin g m odest-sized non -empty thresho lds (e.g., 4) can keep accuracy and reduc e loads. 2 4 6 8 10 0 2 4 6 8 10 Non−Empty Threshold Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS2500. 2 4 6 8 10 0 2 4 6 8 10 Non−Empty Threshold Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS1143. 2 4 6 8 10 0 2 4 6 8 10 Non−Empty Threshold Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 2 4 6 8 10 0 2 4 6 8 10 Non−Empty Threshold Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 15. Non-Empty Threshold. 4) Co or dinate Dimension | x | : Fig. 16 illustrates the ac- curacy and loads w hen the coor dinate dim ension changes. HybridNN achieves similar accuracy and loads as the accuracy of coordinates keeps stably accurate as the dimension is over 3. Th erefore, Hyb ridNN can adapt to inaccuracy of d ifferent dimensions of coord inates witho ut increasing DNNS query loads ef ficiently . 2 4 6 8 10 12 0 2 4 6 8 10 Dimension Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS1143. 2 4 6 8 10 12 0 2 4 6 8 10 Dimension Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS2500. 2 4 6 8 10 12 0 2 4 6 8 10 Dimension Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 2 4 6 8 10 0 2 4 6 8 10 Dimension Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 16. Coordinate Dimension. 5) No des P er Ring ∆ : Fig. 1 7 describe s the pe rforman ce of Hyb ridNN with incr easing upp er bounds of nodes per ring. HybridNN achieves high accuracy event the size of on e ring is as small as 5 . T his is because HybridNN selects neighbo rs from br oader rang e [0 , ρd ] , where d is the delay fr om cur rent node to targets. Besides, the loads of HybridN N g row slowly as the size of ring inc reases. As HybridNN utilizes coordin ate distances to select limited number of can didate ne ighbor . 6) Ov erSampled nea r e st and farth est nod es K : Fig. 18 illustrates the perfor mance of Hybrid NN as the variation JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 16 3 5 7 9 10 12 14 16 0 2 4 6 8 10 Nodes Per Ring Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS1143. 3 5 7 9 10 12 14 16 0 2 4 6 8 10 Nodes Per Ring Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS2500. 3 5 7 9 10 12 14 16 0 2 4 6 8 10 Nodes Per Ring Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 3 5 7 9 11 0 2 4 6 8 10 Nodes Per Ring Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 17. Nodes Per Ring. of oversampled num ber of n earest and farthest nodes K . HybridNN achiev es similar accuracy and loads wh en the over - sampled size K of nearest neigh bors and farthest neig hbors. This is be cause we perio dically star t the oversampled process, which can find many n earby or far -away n odes accumulativ ely . 2 6 10 14 30 34 38 42 0 2 4 6 8 10 Oversampled K Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS1143. 2 6 10 14 30 34 38 42 0 2 4 6 8 10 Oversampled K Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS2500. 2 6 10 14 30 34 38 42 0 2 4 6 8 10 Oversampled K Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 2 6 10 14 18 0 2 4 6 8 10 Oversampled K Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 18. Over-sample d number of neighbors. 7) Returned Nodes F o r Next-Hop Pr o be m : Fig. 19 plots the m edian error s and load s of Hyb ridNN with in creasing returned n odes for next-hop probe s for Hyb ridNN. For all data sets, Hy bridNN is accu rate when the size of estimated nearest candidate neighbo rs f or direct probes exceeds 2. Moreover , the load s of Hybrid NN increase slowly as the increment of relaxed pr obes. This is because we also add neighb ors with higher un certain coor dinates, weakening the increased over- head of relaxed probes. Besides, the search pr ocess typically terminates at 3 to 5 hops as we found during experiments, therefor e the measur ement overhead is mo stly bou nded below 3 KB. 2 4 6 8 10 0 2 4 6 8 10 Returned Nodes For Probe Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (a) DNS1143. 2 4 6 8 10 0 2 4 6 8 10 Returned Nodes For Probe Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (b) DNS2500. 2 4 6 8 10 0 2 4 6 8 10 Returned Nodes For Probe Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (c) DNS3997. 2 4 6 8 10 0 2 4 6 8 10 Returned Nodes For Probe Median Error (ms) 0 2 4 6 Load (KB) Accuracy Loads (d) Host479. Fig. 19. Returned Nodes For Next-Hop Probes. X . P L A N E T L A B E X P E R I M E N T S W e h av e implemen ted a pr ototype D NNS quer y system in Jav a u sing th e asynch ronou s com munication library . W e implemented both Hybr idNN a nd Meridian . T he core DNNS logic consists of around 5,00 0 lines of cod es comprising three main mo dules: (1) pro ber m odule, which uses the kern el-lev el ping f or delay measurem ents, to allievate application level perturb ations caused b y h igh loads of PlanetLab nodes; ( 2) neighbo rhood management module, which finds and maintains neighbo rs o n the co ncentric rings; (3) DNNS module, which utilizes the Hyb ridNN o r Meridian algo rithm. Our objectiv e is to com pare the accur acy and effi ciency of DNNS queries with re lated n earest ser ver locatio n m ethods using real- world deployments. T o th at end, we choose 173 servers distributed globally on the PlanetLab as the service nodes. Then we select another 412 servers o n the PlanetL ab as the target mac hines. Ou r experiments last on e wee k from 05-05 -2011 to 12-05-2 011. W e com pare Hyb ridNN with M eridian and iPlane [33]. W e choose the same paramete r co nfiguration s for Hybrid NN an d Meridian as in the Simula tion section (Sec IX-A). For iPlane, we q uery iPlane to obtain the delays between service no des and target machines, then we com pute the nearest service nod e for each target machine. Besides, in o rder to compare the fo und near est servers to the g round -truth nea rest servers, we co mpute the groun d-truth nearest servers using dir ect prob es (denoted as Dir ect ). Specif- ically , since pairwise delays between PlanetLab machin es keep varying due to routing dyn amics, we first use the me dian delay of any node pairs to summarize the long -term delay trend. Then we select the service node that has the lowest med ian delay v alue to the target. A. Accuracy First we compare the accuracy of dif ferent me thods with the absolute error m etric and the relati ve error metric d efined in Sec IX-A. The results ar e shown in Fig 20(a) and (b). JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 17 HybridNN h as significantly lower absolu te errors and re lati ve errors than Meridian. iPlane is similar with Hy bridNN, but incurs h igher erro rs. The inaccuracy of iPlane is caused by the mismatch of the e stimated routin g paths and th e real-world ones. The inaccuracy of Meridian shows that M eridian is easily trapped at local minimum far away from the optimal so lutions. On the other hand, Hybrid NN and iPlane are much accurate, which implies that hyb ridNN can av oid bad local minima in mo st cases. Nev ertheless, Hyb ridNN and iPlane also have around 3% of DNNS q ueries with relative errors above 10. we fin d th at Hyb ridNN incurs such hig h erro rs occur at the early stage, where nodes do not hav e enough neighbo rs in their concentr ic rings. B. Completion T ime Next, we ev aluate the comp letion time of in dividual DNNS queries for HybridNN and M eridian. Empirically , we h a ve found tha t both HybridNN and Meridian com plete D NNS queries within thr ee search ho ps, which is consistent with the simulation results in Fig 12. Howe ver , th e overall q uery time for DNNS searches d epends on not only the number of search hops, but also the co mpletion time of message exchanges an d delay probes. Fig 20(d) plots the distributions of query time of HybridNN and Meridian. Around 85% of the DNNS queries in HybridNN are similar with those of Meridian. Th erefore, query time for HybridNN and Merid ian a re similar in most cases. Howev er, around 20 % o f the queries take much large time to answer in Meridian, an d 10% have query time larger than 15 secon ds, while th e hy brid measurement app roach of HybridNN can av oid la rge qu ery laten cies. C. Query Overhead Next, to quan tify the b andwidth overhead of the DNNS queries of Hy bridNN and Meridian , we define the load o f a DNNS query as th e total size of th e transmitted p ackets during the DNNS process. W e plot the CDFs of the loads for HybridNN and Meridian in Fig 2 0(d). The load of Hy bridNN is significantly lower than that of Meridian . In more than 95% of the cases th e load of Hybrid NN is less than 2KBytes, while in more than 5 0% o f the cases the load of Meridian is more tha n 10 KBytes, which is du e to the large size of the candid ate n eighbor set f or DNNS queries. Therefo re, the delay estimatio n o f Hy bridNN su bstantially reduces th e measuremen t overhead. D. Contr ol Overhea d T o measure the efficiency of Hy bridNN an d Meridian. W e c ollected the bandwid th overhead of the n eighborh ood managem ent in HybridNN and Meridian for each service no de ev ery two minutes, as shown in Fig 20(e). The ma intenance overhead of M eridian includes b oth the gossip process and the ring main tenance costs, while the ma intenance of HybridNN includes the g ossip messages, K nearest neig hbor search messages and the K farthest neighb or search messages. The av erage maintenance overhead of Hybrid NN is 2 KBytes per minute, and for Mer idian is over 20 KBytes per minute. Since the time interval of ring maintenan ce fo r both Hy bridNN and Meridian is id entical, the all-pair prob es between nodes in the same ring is the main cause of the contro l overhead in Meridian. On the o ther hand, as Hybr idNN uses the coordin ate distances to up date the rings, it does not need to d o all-pair probes between n odes in a ring. X I . C O N C L U S I O N A N D F U T U R E W O R K W e have addressed the proble m of designing an accurate and efficient DNNS algorithm in a compreh ensiv e way . W e first formu late the DNNS prob lem to accou nt for both symmetr ic and asym metric delay metrics f or latency optimizatio ns. Gi ven the generalize d dela y metr ics, we proposed to use th e relaxed inframetric for m odelling the de lay spac e as a f oundatio n for designing new DNN S a lgorithms with strong theo retical guaran tees concern ing search overhead a nd accuracy of the search results. Next we apply all the insights gained to d esign a ne w DNNS algorithm called Hybrird NN. HybridNN locates nearest n eigh- bors for any target using low bandwidth costs. For locating closer server to any target, HybridNN maxim izes the diversity in the neig hbor set, by discovering neigh bors within each delay ran ge throu gh a ligh t-weight ne ighbor sampling p rocess. Next, in order to red uce the measuremen t costs o f locating closer ser vers, HybridNN c ombines ne twork coo rdinate based delay estimation an d direct pro bes for fast and efficient nearest neighbo r d etermination . Althou gh the symmetric coo rdinate distances may deviate fr om the asymmetric delays, Hybr idNN is able to locate the nearest neighb or to the target at each search step, since we use dir ect prob es to replace erroneo us delay estimations. Fina lly , Hy bridNN terminates the search process con servati vely in ord er to obtain better appr oxima- tions of nearest neig hbors. W e co nfirmed the efficiency and effecti veness of H ybridNN with extensiv e simulation and a prototy pe de ployment on the PlanetLab. Hybrid NN can locate approx imately clo sest neighbor s quick ly with lo w measure- ment costs. As future work, we plan to con tinue two lines o f research. First, currently we use the revised V i valdi to estimate de lays, which mismatches the asym metric d elay m etric du e to the symmetry of the c oordina te distances. W e plan to extend V iv aldi to asymmetric de lay metrics. Second , we plan to study in-advance DNNS prob ing in o rder to hide the waiting time of o n-deman d DNNS queries for more p ractical latency- optimization s. R E F E R E N C E S [1] R. Rodrigues and P . Druschel, “Peer -to-Pee r Systems, ” Commun. ACM , vol. 53, no. 10, pp. 72–82, 2010. [2] Microsoft, “Offic e Liv e W orkspac e, ” http:/ /workspac e.of ficeli ve.com/zh- hk/ , January 2011. [3] Google, “Googl e Maps, ” http: //maps.google .com/ , January 2011. [4] F . Agboma and A. Liotta, “QoE-awar e QoS Management, ” in Pr oc. of MoMM ’08 , 2008, pp. 111–116. [5] A. G. Greenberg, J. R. Hamilton, D. A. Maltz, and P . Pat el, “The Cost of a Cloud: Research Problems in Data Center Netw orks, ” Computer Communicat ion Revie w , vol . 39, no. 1, pp. 68–73, 2009. [6] R. Krish nan, H. V . Madhya stha, S. Srini v asan, S. Jain, A. Krishnamurthy , T . E . Anderson, and J. Gao, “Moving Beyond End-to-End Path Informa- tion to Optimize CDN performance, ” in Proc. of IMC’09 , pp. 190–201 . JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 18 0 20 40 60 80 100 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Absolute Error (ms) Pr(X>x) HybridNN Meridian iPlane (a) Absolute Error . 0 1 2 3 4 5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Relative Error Pr(X>x) HybridNN Meridian iPlane (b) Relati ve Error . 0 5 10 15 20 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Query Time (Sec) CDF Meridian HybridNN (c) Query time. 0 5 10 15 20 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Load (KB) CDF Meridian HybridNN (d) Query load. 0 120 240 360 480 600 0 20 40 60 Time (Min) Costs (KB) Meridian HybridNN (e) Control ov erhead. Fig. 20. Performance comparison on the Planet Lab . [7] A.-J. Su, D. R. Choffne s, A. Kuzmano vic, and F . E. Bustamante, “Drafti ng behind Akamai (trave locity-ba sed detourin g), ” in P r oc. of SIGCOMM’06 . [8] M. J. Freedman, E. Freudentha l, and D. Mazi ` eres, “Democrati zing content public ation with coral, ” in Proc. of NSDI’04 , pp. 18–18. [9] M. J . Freedman, K. Lakshminarayana n, and D. Mazi ` eres, “O ASIS: Anyca st for Any S ervic e, ” in Pr oc. of NSDI’06 . [10] P . W endell, J. W . Jiang, M. J. Freedman, and J. Rexford, “DON AR: Decent ralized Server Select ion for Cloud Service s, ” in Proc. of SIG- COMM’10 , pp. 231–242. [11] J. D. Guyton, J. D. Guyton, and M. F . S chwa rtz, “Locating Nearby Copies of Replicate d Internet Serve rs, ” in Pr oc. of SIGCOMM ’95 , pp. 288–298. [12] M. Costa, M. Castro , A. I. T . Ro wstron, and P . B. K ey , “PIC: Practical Interne t Coordinates for Dista nce Estimation, ” in Pr oc. of ICDCS’04 , pp. 178–187 . [13] B. W ong, A. Slivkin s, and E. G. Sirer , “Meridian: a Lightweight Networ k Location Service Witho ut V irtual Coordinates, ” in Pro c. of SIGCOMM’05 , pp. 85–96. [14] V . V ishnumurthy and P . Francis, “On the Dif ficulty of Finding the Nearest Peer in P2P Systems, ” in Proc. of IMC’08 , pp. 9–14. [15] C. L umezanu, R. Baden, N. Spring, and B. Bhattacha rjee, “Trian gle Inequal ity V ariati ons in the Internet, ” in Proc . of IMC ’09 , pp. 177–183. [16] A. Pat hak, H. Pucha, Y . Zhang, Y . C. Hu, and Z. M. Mao, “ A measurement study of internet delay asymm etry , ” in P r oc. of P A M’08 , pp. 182–191 . [17] S. Shaluno v , B . T eitelbaum, A . Karp, J. Boote, and M. Zekauskas, “A One-way Acti ve Measurement Protocol (OW AMP), ” RFC 4656 (Proposed Standard), 2006. [Onlin e]. A v ailabl e: http:/ /www . ietf.or g/rfc/rf c4656.txt [18] E. Katz-Bassett, H. V . Madhya stha, V . K. Adhika ri, C. S cott, J. Sherry , P . va n W esep, T . E. Anderson, and A. Krishnamurthy , “Re ver se tracer - oute, ” in Pr oc. of NSDI’10 , pp. 219–234. [19] V . Paxson, “End-to-en d internet pack et dynamics, ” in Pr oc. of SIG- COMM ’97 , 1997, pp. 139–152. [20] G. W ang, B. Z hang, and T . S. E. Ng, “T owards Netwo rk Triangle Inequal ity V iola tion A ware Distributed Systems, ” in Proc. of IMC’07 , pp. 175–188 . [21] F . Dabek, R. Cox, M. F . Kaashoek, and R. Morris, “V i va ldi: a Decen- traliz ed Network Coord inate System, ” in Proc. of SIGCOMM’04 , pp. 15–26. [22] S. Ratnasamy , M. Handley , R. Karp, and S. Shenker , “T opologic ally- aw are Overlay Constr uction and Server Selectio n, ” in Pr oc. of INFO- COM’02 , pp. 1190 – 1199 vol.3. [23] M. W aldvogel and R. Rinaldi, “Effic ient T opology-A ware Overlay Networ k, ” in Pr oc. of Hotnets-I , 2002. [24] G. R. Hjaltason and H. Samet, “Index- dri ven Similarity S earch in Metric Spaces (Surve y A rticl e), ” AC M T rans. Database Syst. , vol. 28, pp. 517– 580, 2003. [25] K. L. Clarkson, “Nearest-Neig hbor Searchi ng and Metric Space Dimen- sions, ” in Neare st-Neighbo r Method s for Learning and V ision: Theory and Practic e , G. Sha khnarovi ch, T . Darrell, and P . Indyk, Eds. MIT Press, 2006, pp. 15–59. [26] E. Ch ´ avez, G. Nav arro, R. Baeza-Y ates, and J. L . Marroqu ´ ın, “Searchi ng in Metric Spaces, ” ACM Comput. Surv . , vol . 33, pp. 273–321, 2001. [27] P . Indyk. (2004) Nearest Neighbors In High-Dimensio nal Spaces. [Online]. A vai lable: http:/ /citese erx.ist.psu.edu/viewdoc /summary?doi=10.1.1.10.3826 [28] S. M. Hotz, “Routing information organiza tion to support scalabl e interdo main routing with heteroge neous path requirements, ” PhD Thesis, Computer Science Department, Uni versit y of Southern Californi a, Los Angeles, Califor nia, 1994. [29] R. L. Cart er and M. E. Crovell a, “Serv er selection using dynamic path charac terizat ion in wide-area networks, ” in Proc. of INFOCOM ’97 , pp. 1014–. [30] ——, “On the netw ork impact of dynamic server selec tion, ” Computer Network s , vol. 31, no. 23-24, pp. 2529 – 2558, 1999. [31] P . Sharma, Z . Xu, S. Banerjee , and S.-J. Lee, “Estimating network proximity and latenc y , ” Computer Communicat ion Revie w , vol. 36, no. 3, pp. 39–50, 2006. [32] A.-J. Su, D. Chof fnes, F . E. Bustamante, and A. Kuzmanov ic, “Re lati ve netw ork positi oning via cd n redirecti ons, ” in P r oc. of ICDCS ’08 , pp. 377–386. [33] H. V . Madhyastha, E. Katz-Ba ssett, T . E. Anderson, A. Krishnamurthy , and A. V enkatarama ni, “iPla ne Nano: Path Predicti on for Peer-to-Pe er Applica tions, ” in Pr oc. of NSDI’09 , pp. 137–152. [34] H. V . Madhyastha, T . Isdal, M. Piatek, C. Dixon, T . E. Anderson, A. Krishna murthy , and A. V enkatarama ni, “iPlane: An Informa tion Plane for Distrib uted Service s, ” in Pro c. of OSDI’06 , pp. 367–380. [35] S. Banerj ee, C. Kommareddy , and B. Bhat tacharj ee, “Scalable Pee r Finding on the Internet, ” in Proc. of Global Internet Symposium 2002 . [36] Y . Fu, Y . W ang, and E. Biersack, “HybridNN: Supporting Network Location Service on Generalized Delay Metrics for Latency Sensi ti ve Applica tions, ” Eurecom, T echnical Report 1, Januar y 2011. [37] B. Zhang, T . S. E. Ng, A. Nandi, R. H. Riedi, P . Druschel, and G. W ang, “Measure ment-based analysis, modeling , and synthe sis of the internet delay space, ” IEEE/ACM T rans. Netw . , vol . 18, no. 1, pp. 229–242, 2010. [38] K. P . Gummadi, S. Saroiu, and S. D. Gribble, “King: E stimatin g Latency Betwee n Arbitrary Internet End Hosts, ” in Pr oc. of IMW ’02 , pp. 5–18. [39] D. R. Chof fnes, M. Sanchez, and F . E . Bustamante , “Netw ork Positi on- ing from the Edge - An Empirical Study of the Effecti veness of Network Positioni ng in P2P Systems, ” in P r oc. of INFOCOM’10 , pp. 291–295. [40] P2PSim, “The P2PSim Proj ect, ” http:/pdo s.csail.mit.edu/p2 psim/kingdata/. , October 2010. [41] Y . He, M. Fa loutsos, S. Krishnamurthy , and B. Huffa ker , “On routing asymmetry in the internet, ” in Proc . of GLOBECOM ’05 . [42] D. R. Choffne s an d F . E. Bustamante, “Pitf alls for te stbed ev aluations of internet syste ms, ” SIGCOMM Comput. Commun. Rev . , vol . 40, pp. 43–50, April 2010. [43] P . Fraigniaud, E. L ebhar , and L. V ienno t, “The Inframetric Model for the Inte rnet, ” in Pr oc. of INFOCOM’08 , pp. 1085–1093. [44] D. R. Karger and M. Ruhl, “Finding Nearest Neighbors in Growt h- restrict ed Metrics, ” in Pr oc. of STOC ’02 , 2002, pp. 741–750. [45] J. Ledl ie, P . Gardne r , and M. I. Selt zer , “Netw ork Coordinate s in the W ild, ” in Pr oc. of NSDI’07 . [46] Y . Zhang and N. G. Duffiel d, “On the Const ancy of Interne t Path Propertie s, ” in Pr oc. of IMW’01 , pp. 197–211. A P P E N D I X Lemma VI. 1: Given a ρ -inframetric with gr owth γ g ≥ 1 , for an y x ≥ ρ , r > 0 and an y node P , the volume of a b all B P ( r ) is at mo st x α smaller than that of the ball B P ( xr ) , wher e log ρ γ g ≤ α ≤ 2 log ρ γ g . Pr oo f: First, accordin g to the definition of th e g rowth, it follows: | B P ( xr ) | ≤ γ g B P x ρ r JOURNAL OF L A T E X CL ASS FILES, VOL. 6, NO. 1, J ANUAR Y 2007 19 Then, by recursively calling log ρ x times th e growth defini- tion, until x ρ ⌈ log ρ x ⌉ < 1 , then | B P ( xr ) | ≤ γ g ⌈ log ρ x ⌉ | B P ( r ) | = x log x γ g ⌈ log ρ x ⌉ | B P ( r ) | = x α | B P ( r ) | , α = log x γ g × log ρ x Therefo re, b y the definition of the ceiling func tion, we can calculate the lo wer b ound o f α as: α ≥ lo g x γ g × log ρ x = lo g ρ γ g On the o ther hand, du e to x ≥ ρ , γ g > 1 , we get log ρ γ g = log γ g log ρ ≥ log γ g log x = log x γ g thus we can com pute the upper bound of α as: α ≤ lo g x γ g × log ρ x + 1 = lo g ρ γ g + log x γ g ≤ lo g ρ γ g + log ρ γ g = 2 log ρ γ g this concludes th e proof. Lemma VI.2: ( Sandwich lemma) F or any pair of n ode p a nd q , and d pq ≤ r , then B q ( r ) ⊆ B p ( ρr ) ⊆ B q ρ 2 r Pr oo f: ( 1)For a ny no de i satisfy ing d qi ≤ r , i.e., i ∈ B q ( r ) , by the defin ition of the in frametric model, d pi ≤ ρ max { d pq , d qi } ≤ ρr ,thus i ∈ B p ( ρr ) , that is, B q ( r ) ⊆ B p ( ρr ) (2) For any node j satisfying j ∈ B p ( ρr ) , by the definition of the inframetric mo del, it follows d qj ≤ ρ { d pq , d pj } ≤ ρ 2 r Summing up ( 1) and (2 ) co nclude the pro of. Theor em VI.3: (Sampling efficiency in th e gr owth dimen- sion) F or a ρ -in frametric model with gr owth γ g ≥ 1 , fo r a ser - vice node P , a nd a DNNS tar get T satisfying d P T ≤ r , when selecting 3 ρ 2 β α nodes uniformly at rando m fr om B P ( ρr ) with r ep lacement, with pr obability of a t lea st 9 5%, on e of these n odes will lie in B T ( β r ) , where log ρ γ g ≤ α ≤ 2 log ρ γ g and β < 1 . Pr oo f: sinc e B T ( β r ) ⊂ B T ( r ) ⊆ B P ( ρr ) by the sandwich lemma VI. 2, all nodes covered by B T ( β r ) are also covered by B P ( ρr ) . Therefore, we o nly need to sample enoug h no des in B P ( ρr ) in or der to sample a n ode lo cated in B T ( β r ) . Furthermo re, for the pair o f n odes P and T satisfying d P T ≤ r , it follows | B P ( ρr ) | ≤ B T ρ 2 r = B T ρ 2 β β r Since we kn ow ρ > 1 , then ρ 2 β > ρ 2 > ρ , therefo re the precon ditions of lem ma VI.1 hold, by lemma VI.1, we ca n show th e re lation between the ball B P ( ρr ) and the ball B T ( β r ) wher e β < 1 , | B P ( ρr ) | ≤ B T ρ 2 β β r ≤ ρ 2 β α | B T ( β r ) | where lo g ρ γ g ≤ α ≤ 2log ρ γ g . T herefore, th e pr obability of unifor mly sam pling a node from B P ( ρr ) which lies in the ball B T ( β r ) is: | B T ( β r ) | | B P ( ρr ) | ≥ | B T ( β r ) | ρ 2 β α | B T ( β r ) | = 1 ρ 2 β α Consequently , the pro bability that 3 ρ 2 β α samples are not in the ball B T ( β r ) is at most 1 − 1 ρ 2 β α 3 ρ 2 β α ≤ 1 e 3 ≤ 0 . 05 Thus, with probab ility more th an 9 5% we succeed in loca ting a node lyin g in the ball B T ( β r ) with 3 ρ 2 β α samples. Corollary A.1. F o r a r elaxe d in frametric mo del with g r owth γ g , accor ding to the DNNS pr o cess in Definition VI.4, the found neares t neighbo r is a 1 β -appr oximation , and the number of searc h step s is smaller than log 1 β ∆ , wher e ∆ is the ratio of the maximu m d elay to the minimu m d elay of all pairwise delays. Pr oo f: If a DNNS request is fo rwarded from node P to node Q , the p r ogr ess is said to b e d P T d QT . Acco rding to the DNNS searc h pro cess, by T heorem VI.3, the progr ess is at least 1 β at every node P , th erefore in at most log 1 β ∆ steps, we reach som e nod e v satisfying d vT < 1 β d ∗ , wh ich termin ates the DNNS query pr ocess as we can not find suitable next- hop n eighbor s, where d ∗ is the minimum d elay to target T . Therefo re, the f ound n earest neighbo r v is 1 β -appro ximation.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment