Online Variational Bayes Inference for High-Dimensional Correlated Data
High-dimensional data with hundreds of thousands of observations are becoming commonplace in many disciplines. The analysis of such data poses many computational challenges, especially when the observations are correlated over time and/or across spac…
Authors: Sylvie Tchumtchoua, David B. Dunson, Jeffrey S. Morris
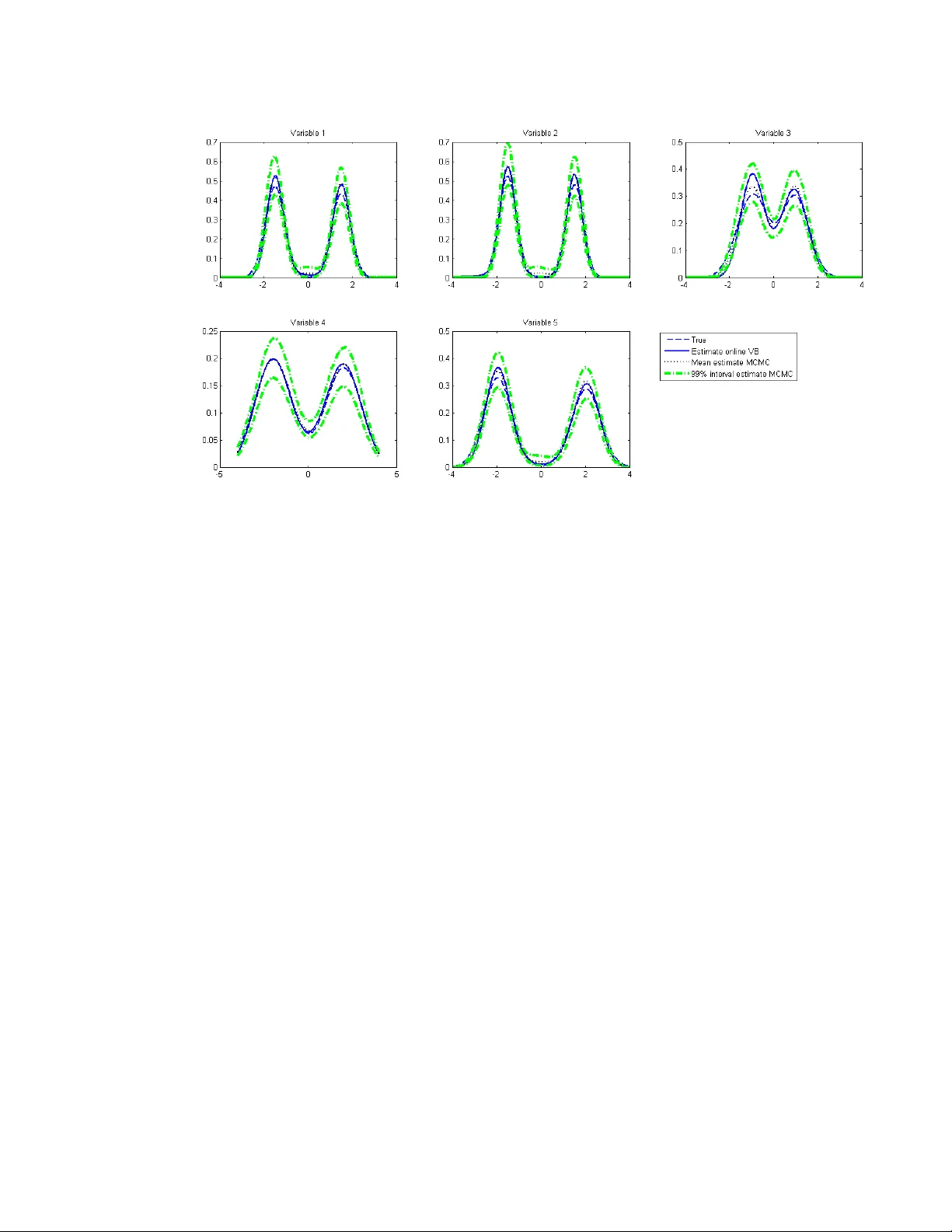
Online V ariational Ba y es Inference for High-Dimensional Correlated Data Sylvie Tc hum tc houa, Da vid B. Dunson, and Jeffrey S. Morris ABSTRA CT High-dimensional data with h undreds of thousands of observ ations are becoming common- place in man y disciplines. The analysis of such data poses man y computational challenges, esp ecially when the observ ations are correlated ov er time and/or across space. In this pap er w e prop ose flexible hierarc hical regression mo dels for analyzing suc h data that accommo date serial and/or spatial correlation. W e address the computational c hallenges inv olv ed in fit- ting these mo dels b y adopting an appro ximate inference framew ork. W e dev elop an online v ariational Bay es algorithm that w orks by incrementally reading the data in to memory one p ortion at a time. The p erformance of the metho d is assessed through simulation studies. W e applied the metho dology to analyze signal intensit y in MRI images of sub jects with knee osteoarthritis, using data from the Osteoarthritis Initiativ e. Keywor ds: Conditional autoregressive mo del; Correlated high-dimensional data; Hierar- c hical mo del; Image data; Nonparametric Bay es; Online v ariational Bay es. 1. INTRODUCTION High-dimensional data arise in a wide range of disciplines, including neuroscience, social and b eha vioral sciences, bioinformatics, and finance. In this paper we fo cus on settings where the num b er of observ ations p er sub ject is v ery large relativ e to the n umber of sub je cts and the observ ations are correlated ov er time and/or across space. Suc h data are v ery p opular in medical research, neuroscience and psyc hology where images consisting of h undreds of thousands of v oxels/pixels are collected at sev eral time points on m ultiple sub jects. Con- ducting statistical analysis on suc h data p oses t wo key issues. The first issue p ertains to the size of the data; statistical metho ds for analyzing the data all at once are computationally infeasible as they require storing the en tire data set in to memory , whic h is imp ossible with most statistical pack ages. The second issue is related to accoun ting for temp oral and spatial dep endence in the analysis. In image data for example, one exp ects neigh b oring and or distan t pixels/vo xels or regions to hav e similar neuronal activit y or texture information. In addition, sequences of images tak en o ver time are lik ely to exhibit some temporal correlation. Sev eral approac hes hav e b een prop osed in the literature to o vercome these issues. One approac h uses a tw o-step pro cedure where a linear mo del is first fitted to eac h sub ject’s time series at eac h v o xel lo cation separately . In a second stage another regression model is sp ecified with v oxel-lev el regression co efficien ts as resp onse v ariables and region of interest (R OI) random effects (Bowman et al., 2008) or intra R OI regression co efficien ts and regres- sion coefficients at other stim uli (Derado, Bo wman and Kilts, 2010) as explanatory v ariables. Although this tw o-step approach on the surface eliminates the sample size problem, it do es not adequately model spatial/temp oral dep endence. The model in Bo wman et al. (2008) 1 accoun ts for b et ween R OI spatial correlation but assumes homogeneous within-region corre- lation, do es not mo del temp oral correlation, and cannot handle very large data sets. On the other hand, the mo del in Derado, Bowman and Kilts (2010) is suitable for large data sets but do es not mo del b et ween-region correlation. Morris and Carroll (2006) prop osed a functional mixed model where the discrete wa velet transform is used to translate the data from the time domain to the frequency domain and all the mo deling assumptions and estimation are made in the frequency domain. This w ork w as extended to mo del image data and use basis functions other than w av elets b y Morris et al. (2011). While such an approac h makes the computations feasible in mo derate to large datasets, by assuming that basis co efficients are indep enden t it restricts the within-function co v ariance function in a wa y that is difficult to intuitiv ely grasp and to relate to commonly- used spatial co v ariance matrices. Both the t w o-step approac h and the functional mixed effect mo del are fitted in the Ba yesian framew ork using Marko v chain Mon te Carlo (MCMC) tec hniques that approxi- mate the p osterior distribution b y repeatedly sampling from the parameters’ conditional p osterior distributions. Standard MCMC for hierarchical models with longitudinal and/or spatial dep endence do not scale well computationally as sample size increases. In addi- tion, assessing conv ergence of the algorithm can b e difficult in complex models. This has motiv ated v arious alternativ e forms of p osterior approximation. Rue, Martino and Chopin (2009) prop osed approximate Ba yesian inference for latent Gaussian mo dels by using in- tegrated nested Laplace appro ximations whic h is computationally faster than MCMC but their approac h do es not extend to more flexible mo dels, such as mixtures. 2 W ang and Dunson (2011) proposed a fast sequen tial updating and greedy searc h algorithm for Diric hlet pro cess mixture mo dels that accommo dates very large datasets and do es not require reading the en tire data in to memory but their algorithm relies on the Dirichlet pro cess prediction rule and thus cannot b e applied to parametric Bay esian hierarc hical mo dels with v ery large datasets. Carv alho et al. (2010) prop osed a particle learning approach for mixture mo dels in the state-space framework that builds on the more general framework of Lop es et al. (2010). The algorithm appro ximates the increasing state vector with fixed-dimensional sufficien t statistics. Chopin et al. (2010) sho wed that the metho d’s p erformance is p o or for large sample sizes unless the n umber of particles increases exp onentially with the num b er of observ ations. This mak es the algorithm not appropriate for very large datasets. V ariational Bay es (VB) (Jordan et al., 1999) is another alternative to MCMC that is deterministic and that approximates the p osterior distribution with an analytically tractable distribution so that the Kullbac k-Leib er distance b et ween the complex p osterior and its appro ximation is minimized. The approach typically approximates the p osterior with a factorized form for which conjugate priors can be c hosen. VB has b een used in image analysis and signal pro cessing b y sev eral authors including P enny , Kieb el and F riston (2003), Oik onomou, T rip oliti and F otiadis (2010), Qi et al. (2008), and Cheng et al. (2005). The first t wo studies focus on fMRI time series. Although VB is faster than MCMC for mo derate to large datasets, its implemen tation with very large datasets is computationally exp ensiv e as the VB algorithm inv olves up dating observ ation-sp ecific parameters. Another limitation of VB for v ery large datasets is that the data is often too large to fit into memory . The k ey limiting factor for extremely large data is the memory management. P arallel pro cessing can sp eed up the computations by man y factors, but if data cannot b e read in, which is the 3 case for many mo dern applications, then even given h undreds of pro cessors the analysis is a non-starter. The ob jectiv e of this pap er is tw ofold. The first is to develop flexible hierarchical re- gression mo dels for analyzing v ery large multiple-sub jects data that accommodate spatial and/or temporal correlation. The second is to prop ose an online VB algorithm that w orks b y reading in to memory one p ortion of the data at a time (for example one image at a time for imaging data), approximating the posterior based on these data and then updating the ap- pro ximation as additional data are read in. Harrison and Green (2010) prop osed a Bay esian spatio-temp oral mo del for fMRI data where general linear mo dels with an autoregressiv e er- ror process are fitted to eac h v oxel’s time series individually , and a conditional autoregressiv e prior is sp ecified on the regression and autoregressiv e co efficien ts. T o o v ercome the computa- tional c hallenges, they used a VB algorithm where the prior distribution at a given iteration dep ends on the p osterior of neigh b oring co efficients at the previous iteration. Our approach differs from theirs in three resp ects. First, our approac h is a unified framew ork that mo dels all the v oxels at once and is flexible enough to b e used with very large data sets with either only spatial or temp oral or b oth spatial and temp oral correlation. Second, unlike theirs, our approac h is suitable for data collected on sev eral sub jects and offers a flexible wa y to accoun t for heterogeneity among the sub jects. Finally , the online asp ect of our algorithm refers to reading in to memory one part of the data at a time whereas their VB algorithm defines prior distribution sequentially but pro cesses all the co efficients at once. Our online VB algorithm is instead closely related to that of Hoffman, Blei and Bac h (2010) who prop osed an online VB algorithm for laten t Dirichlet allo cation, fo cusing on the particular class of bag-of-words mo dels for do cumen t topics. 4 The outline of the pap er is as follows. Spatial, temp oral, and spatio-temp oral semipara- metric hierarc hical mo dels are dev elop ed in the next Section. VB inference is describ ed in Section 3 and an online v ersion of it in Section 4. Sim ulation examples are given in Section 5, and application to MRI images in Section 6. Section 7 concludes. 2. SEMIP ARAMETRIC HIERARCHICAL MODELS 2.1. The mo dels Let i = 1 , ..., n index sub jects, t = 1 , ..., T index time, and k = 1 , ..., K index the spatial units. Let Y it denote the K × 1 v ector of resp onses for the i th sub ject at time t , and X it b e the K × g matrix of cov ariates including a column of ones. W e sp ecify the mo del Y it = η i µ it + X it β i + it , (1) where µ it is an m − dimensional( m < K ) vector of time-v arying common factors, η i is a K × m vector of loadings, and β i is a g × 1 v ector of co efficients for sub ject i . it is a vector of error terms assumed indep endently and iden tically normally distributed: it ∼ N ( 0 , σ − 2 I ). The first term in the right-hand side of Equation (1) sp ecifies a factor mo del with b oth laten t factors and loadings v arying across sub jects. In contrast to standard factor analysis where the loadings are t ypically constan t across sub jects, w e allow the loadings to v ary across sub jects in order to accoun t for additional heterogeneit y among sub jects. This sp ecification follo ws from Ansari, Jedidi and Dub e (2002). 5 T o mo del serial correlation, w e assume a first-order autoregressive structure for µ it : µ it ∼ N ( µ i,t − 1 , θ − 1 i I ) , µ i 0 ∼ N ( µ 0 , ϑ I ) . (2) T o mo del spatial dep endence, we follow the literature on spatial data analysis (see, e.g., White and Ghosh (2009), Hrafnkelsson and Cressie (2003) and Gelfand and V ounatsou (2003)) and sp ecify a conditional autoregressiv e mo del for each column of η i . Let η ij = ( η i 1 j , η i 2 j , ..., η iK ) 0 b e the loadings on the j th factor. W e hav e η ij ∼ N 0 , τ − 1 ( I − ρC ) − 1 Ω , or, stac king all the columns together, η i ∼ M N K × m 0 , I m , τ − 1 ( I − ρC ) − 1 Ω , (3) where M N K × m ( ., ., . ) denotes the matrix normal distribution, D = ( d rs ) denote the proximit y matrix, d r + = P s d rs , Ω = diag 1 d 1+ , ..., 1 d K + , and C is a K × K matrix with elemen ts c rs = d rs d r + . D = ( d rs ) is defined as in White and Ghosh (2009) and Hrafnk elsson and Cressie (2003): d rs = 0 if r = s , k r − s k − φ otherwise, where φ > 0 controls the rate at which the spatial correlation decreases with distance. The v alue of φ is c hosen so that the loading at a giv en lo cation only dep ends on the loadings in a small neigh b orho o d of that lo cation. This results in the matrix C being sparse. 6 Equations (1)-(3) define a mo del with both spatial and temporal correlation. It closely resem bles the spatial dynamic factor mo del of Lopes, Salazar and Gamerman (2008) and the semiparametric dynamic factor mo del of P ark et al. (2009), b oth of whic h are designed for m ultiv ariate time series on a single sub ject. How ever our mo del accommo dates m ultiple sub jects and offers a flexible w ay to accounts for heterogeneit y among them in addition to mo deling temp oral and spatial dep endences. Moreo ver, unlik e theirs, our mo del can b e estimated with v ery large data sets. Park et al. (2009) applied their mo del to fMRI data but they o vercome the computational challenges by reducing the size of the original images from 64 × 64 × 30 to 32 × 32 × 15. The mo del describ ed by (1)-(3) encompasses as sp ecial cases mo dels for multiv ariate time series data with no spatial correlation: Y it = µ it + X it β i + it , (4) and mo dels for spatial data observ ed at only few time p oints used as indicator v ariables in the design matrix X it : Y it = η i + X it β i + it . (5) Finally , a nice prop erty of the factor specification is that temporal and spatial effects are not separable if the n umber of factor is greater than one (Lop es, Salazar and Gamer- man, 2008). A model that uses an additive form µ it + η i do es not allo w spatio-temp oral in teraction and can b e restrictiv e (Cressie and Huang, 1999). An alternativ e approach to allo wing space-time in teraction is to sp ecify a spatial pro cess that evolv es ov er time (Kottas, Duan and Gelfand, 2008). Although there is a ric h recen t literature on Gaussian process 7 appro ximations that scale to reasonably large data sets (refer to T okdar (2007); Banerjee et al. (2008); Banerjee, Dunson and T okdar (2011) among others), suc h metho ds are not sufficien tly efficient to accommo date our motiv ating applications. 2.2. Prior distributions Let Θ i = β 0 i , θ 0 i 0 . W e flexibly mo del heterogeneity among sub jects b y assuming that Θ i are dra wn from an unknown distribution which has the Dirichlet pro cess prior: Θ i ∼ G, G = ∞ X r =1 π r δ Θ ∗ r , π r = v r Y lr z i ! Step 5. Sample the common factors µ it from µ i 0 ∼ N ϑ − 1 + θ i − 1 µ i 1 θ i + µ 0 ϑ − 1 , ϑ − 1 + θ i − 1 µ it ∼ N σ 2 η 0 i η i + θ i − 1 σ 2 η i ( Y it − X it β i ) + µ i,t − 1 θ i , σ 2 η 0 i η i + θ i − 1 27 Step 6. Sample the loadings η ij from η ij ∼ N Ψ ij σ 2 X t µ it,j ( Y it − X it β i ) ! , Ψ i = K σ 2 X t µ 2 it,j I + τ − 1 ( I − ρC ) − 1 Ω ! − 1 Step 7. Sample the parameter τ from τ ∼ Ga a τ + 0 . 5 mnK , b τ + 0 . 5 X i,j ( η 0 ij Ω − 1 ( I − ρC ) η ij ! Step 8. Sample the parameter ρ from Pr( ρ = ρ l ) ∝ exp ( − 0 . 5 X i,j η 0 ij Ω − 1 ( I − ρ l C ) η ij ) Step 9. Sample the inv erse v ariance σ 2 from σ 2 ∼ Ga a σ + nK T / 2 , b σ + 1 2 X t,i : z i = r n ( Y it − η i µ it − X it ˜ β i ) 0 ( Y it − η i µ it − X it ˜ β i ) o ! App endix B. V ARIA TIONAL OBJECTIVE FUNCTION Let W = ( V , Θ ∗ , Z , η , µ , ρ, τ , σ 2 , α ) denote the v ector of unknown parameters and A = ( a α , b α , a θ , b θ , a τ , b τ , µ 0 , ϑ ) the kno wn hyper-parameters. The p osterior distribution p ( W | Y , X , A ) is appro ximated with a more tractable distribu- tion q ( W ) whic h maximizes the low er b ound on the log marginal likelihoo d given by: ` ( Y | X , A ) = Z q ( W ) l og p ( Y | W , X , A ) p ( W | A ) q ( W ) d W = E q l og p ( σ 2 ) − l og q ( σ 2 ) + E q [ l og p ( α ) − l og q ( α )] + E q [ l og p ( ρ ) − l og q ( ρ )] + E q [ l og p ( τ ) − l og q ( τ )] 28 + E q [ l og p ( V | α ) − l og q ( V )] + E q [ l og p ( θ ∗ ) − l og q ( θ ∗ )] + E q [ l og p ( β ∗ ) − l og q ( β ∗ )] + E q [ l og p ( Z | V ) − l og q ( Z )] + E q [ l og p ( µ | Z ) − l og q ( µ )] + E q [ l og p ( η ) − l og q ( η )] + E q [ l og p ( Y | W , X , A )] . (7) The exp ectations in the ob jective function are ev aluated as E q l og p ( σ 2 ) − l og q ( σ 2 ) = ( ψ ( ˜ a σ ) − l og ( ˜ b σ ))( a σ − ˜ a σ ) − ˜ a σ ˜ b σ ( b σ − ˜ b σ ) + l og b a σ σ Γ(˜ a σ ) ˜ b ˜ a σ σ Γ( a σ ) . E q [ l og p ( α ) − l og q ( α )] = ( ψ (˜ a α ) − l og ( ˜ b α ))( a α − ˜ a α ) − ˜ a α ˜ b α ( b α − ˜ b α ) + l og b a α α Γ(˜ a α ) ˜ b ˜ a α α Γ( a α ) . E q [ l og p ( τ ) − l og q ( τ )] = ( ψ (˜ a τ ) − l og ( ˜ b τ ))( a τ − ˜ a τ ) − ˜ a τ ˜ b τ ( b τ − ˜ b τ ) + l og b a τ τ Γ(˜ a τ ) ˜ b ˜ a τ τ Γ( a τ ) . E q [ l og p ( V | α ) − l og q ( V )] = ˜ a α ˜ b α − 1 [ ψ ( γ r 2 ) − ψ ( γ r 2 + γ r 2 )] + ψ (˜ a α ) − l og ( ˜ b α ) − [ ψ ( γ r 2 ) − ψ ( γ r 1 + γ r 2 )] . E q [ l og p ( θ ∗ ) − l og q ( θ ∗ )] = R X r =1 ( ψ ( τ r 1 ) − l og ( τ r 2 ))( a τ − τ r 1 ) − τ r 1 τ r 2 ( b τ − τ r 2 ) + l og b a τ τ Γ( τ r 1 ) τ τ r 1 r 2 Γ( a τ ) . E q [ l og p ( Z | V ) − l og q ( Z )] = X i,t,r κ ir ( ψ ( γ r 1 ) − ψ ( γ r 1 + γ r 2 ) + r − 1 X l =1 [ ψ ( γ l 2 ) − ψ ( γ l 1 + γ l 2 )] − l og ( κ ir ) ) . E q [ l og p ( µ | Z ) − l og q ( µ )] = 1 2 n X i =1 T X t =1 R X r =1 κ ir { [ ψ ( τ r 1 ) − l og ( τ r 2 ) − l og (2 π )] − [( λ it, 1 − λ i,t − 1 , 1 ) 0 ( λ it, 1 − λ i,t − 1 , 1 ) + tr ( λ it, 2 + λ i,t − 1 , 2 )] } − nT 2 ( l og ( | λ it, 2 | ) + l og (2 π ) + 1) . 29 E q [ l og p ( η i ) − l og q ( η i )] = − 0 . 5 m l og ( | Ψ i | ) + 0 . 5 m K ( ψ (˜ a τ ) − l og ( ˜ b τ )) − M +1 X l =1 π l l og ( I − ρ l C ) − 1 Ω ! − ˜ a τ 2 ˜ b τ M +1 X l =1 ( m tr Ω − 1 ( I − ρ l C ) Ψ i + m X k =1 ξ 0 ik Ω − 1 ( I − ρ l C ) ξ ik ) . E q [ l og p ( Y | W , X , A )] = 1 2 ˜ a σ ˜ b σ X i,t,r κ ir ( Y it − ξ i λ it, 1 − X it ˜ β 0 r ) 0 ( Y it − ξ i λ it, 1 − X it ˜ β 0 r ) + ( tr ( Ψ i ) + ξ 0 i ξ i ) tr ( λ it, 2 ) + λ 0 it, 1 tr ( Ψ i ) λ it, 1 + tr X 0 it X it ˜ Σ 0 r + nT 2 ψ (˜ a σ ) − l og ( ˜ b σ ) − l og (2 π ) . App endix C. V ARIA TIONAL BA YES UPDA TE EQUA TIONS The v ariational Ba yes up date equations are derived as: • ˜ a σ = a σ + nK T / 2 ˜ b σ = b σ + 1 2 P i,t,r κ ir n ( Y it − ξ i λ it, 1 − X it ˜ β 0 r ) 0 ( Y it − ξ i λ it, 1 − X it ˜ β 0 r ) o + 1 2 P i,t,r κ ir n ( tr ( Ψ i ) + ξ 0 i ξ i ) tr ( λ it, 2 ) + λ 0 it, 1 tr ( Ψ i ) λ it, 1 + tr X 0 it X it ˜ Σ 0 r o . • ˜ a α = a α + R − 1 , ˜ b α = b α − P R − 1 r =1 ( ψ ( γ r 2 ) − ψ ( γ r 1 + γ r 2 )) . • ˜ a θ r = a θ + 0 . 5 T P i κ ir , ˜ b θ r = b θ + 0 . 5 P i,t κ ir { ( λ it, 1 − λ i,t − 1 , 1 ) 0 ( λ it, 1 − λ i,t − 1 , 1 ) + tr ( λ it, 2 + λ i,t − 1 , 2 ) } . • ˜ Σ 0 r = Σ − 1 0 + ˜ a σ ˜ b σ P i P t κ ir X 0 it X it − 1 , ˜ β 0 r = ˜ Σ 0 r β 0 0 Σ − 1 0 + ˜ a σ ˜ b σ P i P t κ ir ( Y it − ξ i λ it, 1 ) 0 X it . • λ i 0 , 2 = ϑ − 1 + P r κ ir ˜ a θ r ˜ b θ r − 1 , λ i 0 , 1 = λ i 0 , 2 λ i 1 , 1 P r κ ir ˜ a θ r ˜ b θ r + µ 0 ϑ − 1 , λ it, 2 = ( tr ( Ψ i ) + ξ 0 i ξ i ) ˜ a σ ˜ b σ + P r κ ir ˜ a θ r ˜ b θ r − 1 , λ it, 1 = λ it, 2 P r κ ir ξ 0 i ( Y it − X it β 0 r ) ˜ a σ ˜ b σ + λ i,t − 1 , 1 ˜ a θ r ˜ b θ r . • γ r 1 = 1 + P n i =1 κ ir , γ r 2 = ˜ a α ˜ b α + P n i =1 P R l = r +1 κ il . 30 • ψ ik = T ˜ a σ ˜ b σ + ˜ a τ ˜ b τ Ω − 1 kk − 1 , k = 1 , ..., K , ξ ij k = ψ ik ˜ a σ ˜ b σ P r κ ir P t λ ikt, 1 ( Y ikt − X ikt ˜ β 0 r ), j = 1 , ..., m , k = 1 , ..., K • ˜ a τ = a τ + 0 . 5 mnK , ˜ b τ = b τ + 0 . 5 P i P l π l { m tr (Ω − 1 Ψ i ) + P m l =1 ξ 0 il Ω − 1 ( I − ρ l C ) ξ il } . • κ ir ∝ exp ( w ir ), w ir = − ˜ a σ 2 ˜ b σ P t n ( Y it − ξ i λ it, 1 − X it ˜ β 0 r ) 0 ( Y it − ξ i λ it, 1 − X it ˜ β 0 r ) o − ˜ a σ 2 ˜ b σ P t n ( tr ( Ψ i ) + ξ 0 i ξ i ) tr ( λ it, 2 ) + λ 0 it, 1 tr ( Ψ i ) λ it, 1 + tr X 0 it X it ˜ Σ 0 r o − 0 . 5 ˜ a θ r ˜ b θ r P t { ( λ it, 1 − λ i,t − 1 , 1 ) 0 ( λ it, 1 − λ i,t − 1 , 1 ) + tr ( λ it, 2 + λ i,t − 1 , 2 ) } + ψ ( γ r 1 ) − ψ ( γ r 1 + γ r 2 ) + P r − 1 l =1 { ψ ( γ l 2 ) − ψ ( γ l 1 + γ l 2 ) } + K T 2 ( ψ (˜ a σ ) − l og ( ˜ b σ )) , where ψ ( . ) is the digamma function. • ˜ π l ∝ exp ( $ l ), $ l = 0 . 5 m n K ( ψ (˜ a τ ) − l og ( ˜ b τ )) − 0 . 5 m n ( l og ( | Ω | ) − l og ( | ( I − ρ l C ) | )) − a τ 2 b τ P i { m tr (Ω − 1 Ψ i ) + P m k =1 ξ 0 ik Ω − 1 ( I − ρ l C ) ξ ik } . REFERENCES Ansari, A., Jedidi, K., and Dub e, L. (2002), “Heterogeneous factor analysis models: a Ba yesian approach,” Psychometrika , 67(1), 49–78. Balamo o dy , S., Williams, T. G., W aterton, J. C., Bow es, M., Ho dgson, R., T aylor, C. J., and Hutc hinson, C. E. (2010), “Comparison of 3T MR scanners in regional cartilage-thic kness analysis in osteoarthritis: a cross-sectional multicen ter, multiv endor study ,” Arthritis R e- se ar ch & Ther apy , 12:R202. Banerjee, S., Gelfand, A. E., Finley , A. O., and Sang, H. (2008), “Gaussian predictive pro cess mo dels for large spatial data sets,” Journal of the R oyal Statistic al So ciety Serie B , 70, 31 825-848. Banerjee, A., Dunson, D. B., and T okdar, S. (2011), “Efficient Gaussian Pro cess Regression for Large Data Sets, T echnical rep ort, Duk e Universit y Department of Statistical Science. Barry , R. , and P ace, R. K. (1999), “A Mon te Carlo Estimator of the Log Determinan t of Large Sparse Matrices,” Line ar A lgebr a and its Applic ations , 289, 41-54. Blei, D. M., and Jordan, M. I. (2006), “V ariational Inference for Dirichlet Pro cess Mixtures,” Bayesian A nalysis , 1(1), 121–144. Bo wman, F. D., Caffo, B., Bassett, S. S., and Kilts, C. (2008), “A Ba y esian Hierarc hical F ramew ork for Spatial Mo deling of fMRI Data,” Neur oimage , 39, 146–156. Carballido-Gamio, J., Blumenkran tz, G., Lync h, J. A., Link, T. M., and Ma jumdar, S. (2010), “Longitudinal analysis of MRI T2 knee cartilage laminar organization in a subset of patients from the osteoarthritis initiativ e,” Magnetic R esonanc e in Me dicine , 63, 465– 472. Carv alho, C. M., Lop es, H. F., P olson, N. G., and T addy , M. A. (2010), “Particle Learning for General Mixtures,” Bayesian A nalysis , 5(4), 709–740. Cheng, L., Jiao, F., Sch uurmans, D., and W ang, S. (2005), “V ariational Bay esian image mo delling,” In International Confer enc e on Principles of Know le dge R epr esentation and R e asoning . Chopin, N., Iacobucci, A., Marin, J., Mengersen, K., Rob ert, C. P ., Ryder, R. and Sc hafer, C. (2010), “On particle learning,” ArXiv e-prin ts URL: Cressie, N., and Huang, H. (1999), “Classes of Nonseparable, Spatio-T emp oral Stationary Co v ariance F unctions,” J ournal of the A meric an Statistic al Asso ciation , 94(448), 1330– 1340. 32 Derado, G., Bo wman, F. B., and Kilts, C. D. (2010), “Mo deling the Spatial and T emp oral Dep endence in fMRI Data,” Biometrics , 66, 949-957. Ding, C., Cicuttini, F., and Jones, G. (2010), “Ho w important is MRI for detecting early osteoarthritis?,” Natur e Clinic al Pr actic e Rheumatolo gy , 4, 4–5. F earnhead, P . (2004), “Particle filters for mixture mo dels with an unkno wn num b er of com- p onen ts,” Journal of Statistics and Computing , 14, 11–21. Gelfand, A. E., and V ounatsou, P . (2003), “Prop er Multiv ariate Conditional Autoregressiv e Mo dels for Spatial Data Analysis,” Biostatistics , 4(1), 11–25. Gomes, R.,W elling, M., and P erona, P . (2008), “Incremental learning of nonparametric Ba yesian mixture mo dels,” In IEEE Confer enc e on Computer Vision and Pattern R e c o g- nition . Harrison, L. M., and Green, G.G.R. (2010), “A Ba yesian spatiotemp oral model for v ery large data sets,” Neur oImage , 50, 1126-1141. Hoffman, M. D., Blei, D. M., Bach, F. (2010), “Online Learning for Latent Dirichlet Allo ca- tion,” In Neur al Information Pr o c essing Systems . Honk ela, A. and V alp ola, H. (2003), “On-line v ariational Bay esian learning,” In Pr o c e e dings of the 4th International Symp osium on Indep endent Comp onent Analysis and Blind Signal Sep ar ation (ICA ’03) , 803–808. Hrafnk elsson, B., and Cressie, N. (2003), “Hierarc hical Mo deling of Count Data with Appli- cation to n uclear fall-out,” Envir onmental and e c olo gic al Statistics , 10, 179–200. Kottas A., Duan J. A., and Gelfand, A. E. (2008), “Mo deling disease incidence data with spatial and spatio temp oral Dirichlet pro cess mixtures,” Biometric al Journal , 50(1), 29–42. 33 Jordan, M., Ghahramani, Z., Jaakkola, T., and Saul, L. (1999), “An introduction to v aria- tional metho ds for graphical mo dels,” Machine L e arning , 37, 183-233. Lop es, H. F., Salazar, E., and Gamerman, D. (2008), “Spatial Dynamic F actor Analysis,” Bayesian A nalysis , 3(4), 759–792. Lop es, H., Carv alho, C. M., Johannes, M., and Polson, N. (2010), “P article Learning for Sequen tial Ba yesian Computation (with discussion),” In J. Bernardo, M. J. Ba y arri,J. Berger, A. Dawid, D. Hec k erman, A. F. M. Smith and M. W est (Eds.), Bayesian Statistics , V olume 9. Oxford. In Press. Morris, J. S. and Carroll, R. J. (2006), “W a velet-based functional mixed mo dels,” Journal of the R oyal Statistic al So ciety, Serie B , 68, 179–199. Morris, J. S., Baladanda yuthapani, V., Herric k, R. C., Sanna, P ., and Gutstein, H. G. (2011), Automated analysis of quan titative image data using isomorphic functional mixed models, with application to proteomics data. The A nnals of Applie d Statistics , 5(2A), 894–923. Oik onomou, V.P ., T rip oliti, E.E., and F otiadis, D.I. (2010), “Ba yesian Metho ds for fMRI Time-Series Analysis Using a Nonstationary Mo del for the Noise,” IEEE T r ansactions, Information T e chnolo gy in Biome dicine , 14(3), 664–674. P ark, B. U., Mammen, E., Hardle, W., and Borak, S. (2009), “Time Series Modelling With Semiparametric F actor Dynamics,” Journal of the Americ an Statistic al Asso ciation , 104, 284–298. P enny , W., Kieb el, S., and F riston, K. (2003), “V ariational Bay esian inference for fMRI time series,” Neur oImage , 19, 727-741. Qi, Y., Liu, D., Carin, L., and Dunson, D. (2008), “Multi-task compressive sensing with Diric hlet pro cess priors,” International Confer enc e on Machine L e arning . 34 Rue, H., Martino , S., and Chopin, N. (2009), “Approximate Ba y esian inference for latent Gaussian mo dels b y using integrated nested Laplace approximations,” Journal of the R oyal Statistic al So ciety: Series B , 71(2), 319–392. Sato, M. (2001), “Online mo del selection based on the v ariational bay es,” Neur al Computa- tion , 13(7), 1649–1681. T okdar, S. (2007), “T ow ards a faster implementation of density estimation with logistic Gaussian pro cess priors,” Journal of Computational and Gr aphic al Statistics , 16, 633-655. W ang, L., and Dunson, D. B. (2011), “F ast Bay esian Inference in Dirichlet Pro cess Mixture Mo dels,” Journal of Computational and Gr aphic al Statistics , 20(1), 196–216. White, G., and Ghosh, S. K. (2009), “A Sto chastic Neighborho o d Conditional Autoregressive Mo del for Spatial Data,” Computational Statistics and Data A nalysis , 53(8), 3033–3046. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment