Preference elicitation and inverse reinforcement learning
We state the problem of inverse reinforcement learning in terms of preference elicitation, resulting in a principled (Bayesian) statistical formulation. This generalises previous work on Bayesian inverse reinforcement learning and allows us to obtain…
Authors: Constantin Rothkopf, Christos Dimitrakakis
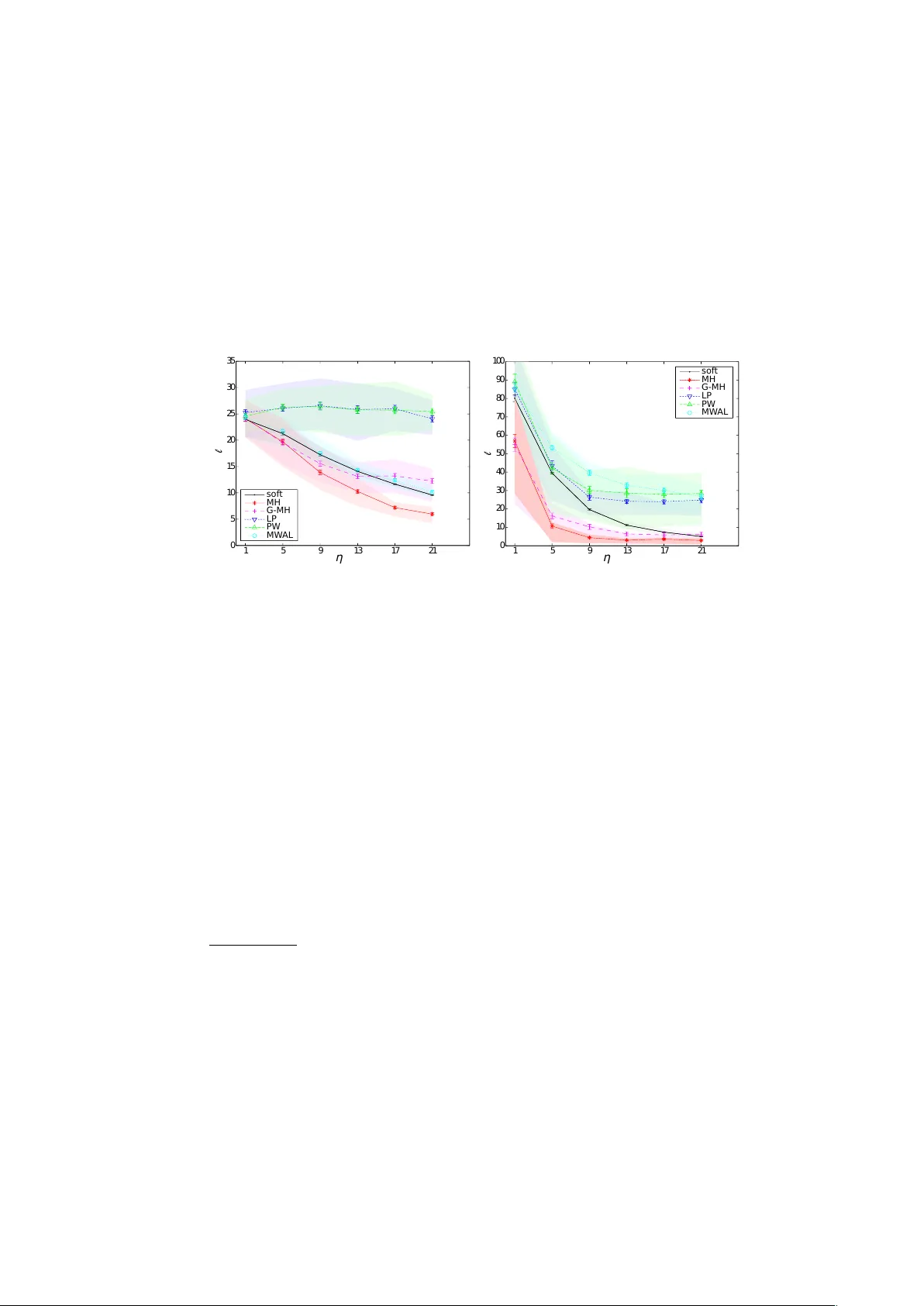
Preference elicitation and in v erse reinforcemen t learning Constan tin A. Rothk opf 1 and Christos Dimitrak akis 2 1 F rankfurt Institute for Adv anced Studies, F rankfurt, Germany rothkfopf@fias.uni-frankfurt.de 2 EPFL, Lausanne, Switzerland christos.dimitrakakis@epfl.ch Abstract. W e state the problem of in verse reinforcemen t learning in terms of preference elicitation, resulting in a principled (Bay esian) sta- tistical formulation. This generalises previous work on Bay esian inv erse reinforcemen t learning and allo ws us to obtain a posterior distribution on the agen t’s preferences, p olicy and optionally , the obtained reward sequence, from observ ations. W e examine the relation of the resulting approac h to other statistical metho ds for inv erse reinforcement learning via analysis and exp erimen tal results. W e show that preferences can b e determined accurately , ev en if the observed agen t’s policy is sub-optimal with resp ect to its o wn preferences. In that case, significantly improv ed p olicies with resp ect to the agent’s preferences are obtained, compared to b oth other metho ds and to the performance of the demonstrated p olicy . Key w ords: In v erse reinforcemen t learning, preference elicitation, de- cision theory , Bay esian inference 1 In tro duction Preference elicitation is a well-kno wn problem in statistical decision theory [10]. The goal is to determine, whether a given decision maker prefers some even ts to other ev ents, and if so, by how m uch. The first main assumption is that there exists a partial ordering among ev ents, indicating relativ e preferences. Then the corresp onding problem is to determine whic h even ts are preferred to which others. The second main assumption is the exp ected utilit y hypothesis. This p osits that if we can assign a numerical utility to each even t, suc h that even ts with larger utilities are preferred, then the decision maker’s preferred choice from a set of possible gambles will b e the gam ble with the highest exp e cte d utility . The corresp onding problem is to determine the n umerical utilities for a giv en decision mak er. Preference elicitation is also of relev ance to cognitiv e science and behavioural psyc hology , e.g. for determining rewards implicit in b eha viour [19] where a prop er elicitation pro cedure may allow one to reach more robust exp erimen tal conclu- sions. There are also direct practical applications, such as user mo delling for 2 Constan tin A. Rothkopf and Christos Dimitrak akis determining customer preferences [3]. Finally , by analysing the apparent prefer- ences of an expert while performing a particular task, w e may b e able to discov er b eha viours that match or even surpass the p erformance of the exp ert [1] in the v ery same task. This pap er uses the formal setting of preference elicitation to determine the preferences of an agen t acting within a discrete-time stochastic en vironmen t. W e assume that the agent obtains a sequence of (hidden to us) rewards from the en- vironmen t and that its preferences ha ve a functional form related to the rewards. W e also supp ose that the agent is acting nearly optimally (in a manner to b e made more rigorous later) with respect to its preferences. Armed with this infor- mation, and observ ations from the agent’s interaction with the environmen t, we can determine the agent’s preferences and p olicy in a Bay esian framew ork. This allo ws us to generalise previous Ba yesian approaches to inv erse reinforcement learning. In order to do so, we define a structured prior on reward functions and p olicies. W e then derive t wo different Marko v chain pro cedures for preference elicitation. The result of the inference is used to obtain p olicies that are signifi- can tly improv ed with resp ect to the true pr efer enc es of the observed agent. W e sho w that this can b e achiev ed even with fairly generic sampling approaches. Numerous other inv erse reinforcement learning approaches exist [1, 18, 20, 21]. Our main contribution is to provide a clear Bay esian formulation of inv erse reinforcemen t learning as preference elicitation, with a structured prior on the agen t’s utilities and p olicies. This generalises the approach of Ramac handran and Amir [18] and pav es the wa y to principled pro cedures for determining dis- tributions on reward functions, policies and reward sequences. Performance-wise, w e show that the p olicies obtained through our metho dology easily surpass the agen t’s actual p olicy with resp ect to its own utility . F urthermore, we obtain p olicies that are significantly better than those obtained with other inv erse re- inforcemen t learning metho ds that we compare against. Finally , the relation to exp erimental design for preference elicitation (see [3] for example) must b e p ointed out. Although this is a very interesting planning problem, in this pap er we do not deal with active preference elicitation. W e fo cus on the sub-problem of estimating preferences giv en a particular observed b eha viour in a giv en en vironmen t and use decision theoretic formalisms to derive efficien t pro cedures for inv erse reinforcemen t learning. This pap er is organised as follo ws. The next section formalises the prefer- ence elicitation setting and relates it to inv erse reinforcement learning. Section 3 presen ts the abstract statistical mo del used for estimating the agent’s prefer- ences. Section 4 describ es a mo del and inference procedure for joint estimation of the agen t’s preferences and its policy . Section 5 discusses related w ork in more detail. Section 6 presents comparativ e exp erimen ts, which quantitativ ely exam- ine the quality of the solutions in terms of b oth preference elicitation and the estimation of impro ved p olicies, concluding with a view to further extensions. Preference elicitation and in verse reinforcement learning 3 2 F ormalisation of the problem W e separate the agent’s preferences (which are unkno wn to us) from the environ- men t’s dynamics (whic h we consider known). More sp ecifically , the environmen t is a controlled Marko v pro cess ν = ( S , A , T ), with state space S , action space A , and transition kernel T = { τ ( · | s, a ) : s ∈ S , a ∈ A } , indexed in S × A suc h that τ ( · | s, a ) is a probability measure 3 on S . The dynamics of the environmen t are Mark ovian: If at time t the environmen t is in state s t ∈ S and the agen t p erforms action a t ∈ A , then the next state s t +1 is dra wn with a probability indep enden t of previous states and actions: P ν ( s t +1 ∈ S | s t , a t ) = τ ( S | s t , a t ) , S ⊂ S , (2.1) where w e use the con ven tion s t ≡ s 1 , . . . , s t and a t ≡ a 1 , . . . , a t to represen t sequences of v ariables. In our setting, we ha ve observed the agent acting in the environmen t and obtain a sequence of actions and a sequence of states: D , ( a T , s T ) , a T ≡ a 1 , . . . , a T , s T ≡ s 1 , . . . , s T . The agent has an unknown utility function , U t , according to which it selects actions, which w e wish to disco ver. Here, we assume that U t has a structure cor- resp onding to that of reinforcement learning infinite-horizon discounted rew ard problems and that the agen t tries to maximise the exp ected utilit y . Assumption 1 The agent’s utility at time t is the total γ -disc ounte d r eturn fr om time t : U t , ∞ X k = t γ k r k , (2.2) wher e γ ∈ [0 , 1] is a disc ount factor, and the r ewar d r t is given by the (sto chastic) r ewar d function ρ so that r t | s t = s, a t = a ∼ ρ ( · | s, a ) , ( s, a ) ∈ S × A . This c hoice establishes corresp ondence with the standard reinforcemen t learning setting. 4 The con trolled Marko v pro cess and the utilit y define a Marko v decision pro cess [16] (MDP), denoted by µ = ( S , A , T , ρ, γ ). The agent uses some p olicy π to select actions with distribution π ( a t | s t ), which together with the Marko v decision pro cess µ defines a Marko v chain on the sequence of states, such that: P µ,π ( s t +1 ∈ S | s t ) = Z A τ ( S | a, s t ) d π ( a | s t ) , (2.3) 3 W e assume the measurabilit y of all sets with respect to some appropriate σ -algebra. 4 In our framework, this is only one of the many p ossible assumptions regarding the form of the utilit y function. As an alternative example, consider an agent who collects gold coins in a maze with traps, and with a utilit y equal to the logarithm of the n umber of coins if it exists the maze, and zero otherwise. 4 Constan tin A. Rothkopf and Christos Dimitrak akis where we use a subscript to denote that the probability is tak en with resp ect to the pro cess defined jointly b y µ, π . W e shall use this notational con ven tion throughout this pap er. Similarly , the exp e cte d utility of a p olicy π is denoted by E µ,π U t . W e also introduce the family of Q -v alue functions Q π µ : µ ∈ M , π ∈ P , where M is a set of MDPs, with Q π µ : S × A → R suc h that: Q π µ ( s, a ) , E µ,π ( U t | s t = s, a t = a ) . (2.4) Finally , we use Q ∗ µ to denote the optimal Q -v alue function for an MDP µ , such that: Q ∗ µ ( s, a ) = sup π ∈P Q π µ ( s, a ) , ∀ s ∈ S , a ∈ A . (2.5) With a sligh t abuse of notation, we shall use Q ρ when w e only need to distinguish b et ween different reward functions ρ , as long as the remaining comp onen ts of µ remain fixed. Lo osely sp eaking, our problem is to estimate the reward function ρ and dis- coun t factor γ that the agent uses, giv en the observ ations s T , a T and some prior b eliefs. As shall b e seen in the sequel, this task is easier with additional assump- tions on the structural form of the p olicy π . W e derive t wo sampling algorithms. The first estimates a joint p osterior distribution on the policy and rew ard func- tion, while the second also estimates a distribution on the sequence of rewards that the agen t obtains. W e then show how to use those estimates in order to obtain a p olicy that can p erform significantly b etter than that of the agent’s original p olicy with resp ect to the agent’s true preferences. 3 The statistical mo del In the simplest version of the problem, w e assume that γ , ν are known and w e only estimate the reward function, given some prior o ver rew ard functions and p olicies. This assumption can b e easily relaxed, via an additional prior on the discoun t factor γ and CMP ν . Let R be a space of reward functions ρ and P to be a space of p olicies π . W e define a (prior) probability measure ξ ( · | ν ) on R such that for an y B ⊂ R , ξ ( B | ν ) corresp onds to our prior b elief that the rew ard function is in B . Finally , for any reward function ρ ∈ R , we define a conditional probability measure ψ ( · | ρ, ν ) on the space of p olicies P . Let ρ a , π a denote the agent’s true reward function and p olicy respectively . The joint prior on reward functions and p olicies is denoted by: φ ( P , R | ν ) , Z R ψ ( P | ρ, ν ) d ξ ( ρ | ν ) , P ⊂ P , R ⊂ R , (3.1) suc h that φ ( · | ν ) is a probabilit y measure on R × P . W e define tw o mo dels, depicted in Figure 1. The b asic mo del , sho wn in Figure 1(a), is defined as follo ws: ρ ∼ ξ ( · | ν ) , π | ρ a = ρ ∼ ψ ( · | ρ, ν ) , Preference elicitation and in verse reinforcement learning 5 ξ ψ ρ π D (a) Basic mo del ξ ψ ρ π r T D (b) Reward-augmen ted mo del Fig. 1. Graphical model, with reward priors ξ and p olicy priors ψ , while ρ and π are the reward and p olicy , where w e observ e the demonstration D . Dark colours denote observ ed v ariables and ligh t denote latent v ariables. The implicit dep en- dencies on ν are omitted for clarit y . W e also introduce a r ewar d-augmente d mo del , where we explicitly mo del the rew ards obtained by the agent, as sho wn in Figure 1(b): ρ ∼ ξ ( · | ν ) , π | ρ a = ρ ∼ ψ ( · | ρ, ν ) , r t | ρ a = ρ, s t = s, a t = a ∼ ρ ( · | s, a ) . F or the momen t w e shall leav e the exact functional form of the prior on the rew ard functions and the conditional prior on the p olicy unsp ecified. Nev erthe- less, the structure allows us to state the following: Lemma 1. F or a prior of the form sp e cifie d in (3.1) , and given a c ontr ol le d Markov pr o c ess ν and observe d state and action se quenc es s T , a T , wher e the actions ar e dr awn fr om a r e active p olicy π , the p osterior me asur e on r ewar d functions is: ξ ( B | s T , a T , ν ) = R B R P π ( a T | s T ) d ψ ( π | ρ, ν ) d ξ ( ρ | ν ) R R R P π ( a T | s T ) d ψ ( π | ρ, ν ) d ξ ( ρ | ν ) , (3.2) wher e π ( a T | s T ) = Q T t =1 π ( a t | s t ) . Pr o of. Conditioning on the observ ations s T , a T via Bay es’ theorem, we obtain the conditional measure: ξ ( B | s T , a T , ν ) = R B ψ ( s T , a T | ρ, ν ) d ξ ( ρ | ν ) R R ψ ( s T , a T | ρ, ν ) d ξ ( ρ | ν ) , (3.3) where ψ ( s T , a T | ρ, ν ) , R P P ν,π ( s T , a T ) d ψ ( π | ρ, ν ) is a marginal likelihoo d term. It is easy to see via induction that: P ν,π ( s T , a T ) = T Y t =1 π ( a t | s t ) τ ( s t | a t − 1 , s t − 1 ) , (3.4) where τ ( s 1 | a 0 , s 0 ) = τ ( s 1 ) is the initial state distribution. Thus, the reward function p osterior is prop ortional to: Z B Z P T Y t =1 π ( a t | s t ) τ ( s t | a t − 1 , s t − 1 ) d ψ ( π | ρ, ν ) d ξ ( ρ | ν ) . Note that the τ ( s t | a t − 1 , s t − 1 ) terms can b e tak en out of the integral. Since they also app ear in the denominator, the state transition terms cancel out. u t 6 Constan tin A. Rothkopf and Christos Dimitrak akis 4 Estimation While it is en tirely p ossible to assume that the agen t’s p olicy is optimal with resp ect to its utility (as is done for example in [1]), our analysis can b e made more interesting b y assuming otherwise. One simple idea is to restrict the p olicy space to stationary soft-max p olicies: π η ( a t | s t ) = exp( η Q ∗ µ ( s t , a t )) P a exp( η Q ∗ µ ( s t , a )) , (4.1) where w e assumed a finite action set for simplicit y . Then w e can define a prior on p olicies, given a rew ard function, b y sp ecifying a prior on the in v erse temp erature η , suc h that giv en the rew ard function and η , the policy is uniquely determined. 5 F or the c hosen prior (4.1), inference can b e p erformed using standard Mark ov c hain Monte Carlo (MCMC) methods [5]. If w e can estimate the rew ard function w ell enough, we may b e able to obtain p olicies that surpass the p erformance of the original p olicy π a with resp ect to the agent’s reward function ρ a . Algorithm 1 MH: Direct Metrop olis-Hastings sampling from the join t distri- bution φ ( π , ρ | a T , s T ). 1: for k = 1 , . . . do 2: ˜ ρ ∼ ξ ( ρ | ν ). 3: ˜ η ∼ Gamma ( ζ , θ ) 4: ˜ π = Softmax ( ˜ ρ, ˜ η , τ ) 5: ˜ p = P ν, ˜ π ( s T , a T ) / [ ξ ( ρ | ν ) f Gamma ( ˜ η ; ζ , θ )]. 6: w.p. min 1 , ˜ p/p ( k − 1) do 7: π ( k ) = ˜ π , η ( k ) = ˜ η , ρ ( k ) = ˜ ρ , p ( k ) = ˜ p . 8: else 9: π ( k ) = π ( k − 1) , η ( k ) = η ( k − 1) , ρ ( k ) = ρ ( k − 1) , p ( k ) = p ( k − 1) . 10: done 11: end for 4.1 The basic mo del: A Metrop olis-Hastings pro cedure Estimation in the basic mo del (Fig. 1(a)) can b e p erformed via a Metrop olis- Hastings (MH) pro cedure. Recall that p erforming MH to sample from some distribution with density f ( x ) using a prop osal distribution with conditional densit y g ( ˜ x | x ), has the form: x ( k +1) = ( ˜ x, w.p. min n 1 , f ( ˜ x ) /g ( ˜ x | x ( k ) ) f ( x ( k ) ) /g ( x ( k ) | ˜ x ) o x ( k ) , otherwise . 5 Our framework’s generality allows an y functional form relating the agent’s pref- erences and p olicies. As an example, we could define a prior distribution ov er the -optimalit y of the chosen p olicy , without limiting ourselves to soft-max forms. This w ould of course change the details of the estimation pro cedure. Preference elicitation and in verse reinforcement learning 7 In our case, x = ( ρ, π ) and f ( x ) = φ ( ρ, π | s T , a T , ν ). 6 W e use indep endent prop osals g ( x ) = φ ( ρ, π | ν ). As φ ( ρ, π | s T , a T , ν ) = φ ( s T , a T | ρ, π , ν ) φ ( ρ, π ) /φ ( s T , a T ), it follows that: φ ( ˜ ρ, ˜ π | s T , a T , ν ) φ ( ρ, π | s T , a T , ν ) = P ν, ˜ π ( s T , a T ) φ ( ˜ ρ, ˜ π | ν ) P ν,π ( k ) ( s T , a T ) φ ( ρ ( k ) , π ( k ) | ν ) . This gives rise to the sampling pro cedure describ ed in Alg. 1, which uses a gamma prior for the temp erature. 4.2 The augmen ted mo del: A h ybrid Gibbs pro cedure The augmented mo del (Fig. 1(b)) enables an alternative, a tw o-stage hybrid Gibbs sampler, describ ed in Alg. 2. This conditions alternatively on a reward sequence sample r T ( k ) and on a rew ard function sample ρ ( k ) at the k -th iteration of the c hain. Th us, w e also obtain a p osterior distribution on r ewar d se quenc es . This sampler is of particular utility when the reward function prior is conju- gate to the reward distribution, in which case: (i) The reward sequence sample can b e easily obtained and (ii) the reward function prior can b e conditioned on the reward sequence with a simple sufficien t statistic. While, sampling from the rew ard function p osterior contin ues to require MH, the resulting h ybrid Gibbs sampler remains a v alid procedure [5], which may give b etter results than sp ec- ifying arbitrary prop osals for pure MH sampling. As previously mentioned, the Gibbs pro cedure also results in a distribution o ver the rew ard sequences observ ed b y the agent. On the one hand, this could b e v aluable in applications where the reward sequence is the main quantit y of interest. On the other hand, this has the disadv an tage of making a strong assumption ab out the distribution from whic h rewards are dra wn. Algorithm 2 G-MH: Tw o stage Gibbs sampler with an MH step 1: for k = 1 , . . . do 2: ˜ ρ ∼ ξ ( ρ | r T ( k − 1) , ν ). 3: ˜ η ∼ Gamma ( ζ , θ ) 4: ˜ π = Softmax ( ˜ ρ, ˜ , τ ) 5: ˜ p = P ν, ˜ π ( s T , a T ) / [ ξ ( ρ | ν ) f Gamma ( ˜ η ; ζ , θ )]. 6: w.p. min 1 , ˜ p/p ( k − 1) do 7: π ( k ) = ˜ π , η ( k ) = ˜ η , ρ ( k ) = ˜ ρ , p ( k ) = ˜ p . 8: else 9: π ( k ) = π ( k − 1) , η ( k ) = η ( k − 1) , ρ ( k ) = ρ ( k − 1) , p ( k ) = p ( k − 1) . 10: done 11: r T ( k ) | s T , a T ∼ ρ T ( k ) ( s T , a T ) 12: end for 6 Here w e abuse notation, using φ ( ρ, π | · ) to denote the density or probabilit y function with respect to a Leb esgue or counting measure asso ciated with the probability measure φ ( B | · ) on subsets of R × P 8 Constan tin A. Rothkopf and Christos Dimitrak akis 5 Related w ork 5.1 Preference elicitation in user mo del ling Preference elicitation has attracted a lot of attention in the field of user mo d- elling and online advertising, where tw o main problems exist. The first is how to mo del the (uncertain) preferences of a large n umber of users. The second is the problem of optimal exp eriment design [see 7, c h. 14] to maximise the exp ected v alue of information through queries. Some recent mo dels include: Braziunas and Boutilier [4] who introduced mo delling of generalised additive utilities; Chu and Ghahramani [6], who proposed a Gaussian pro cess prior ov er preferences, given a set of instances and pairwise relations, with applications to multiclass classifica- tion; Bonilla et al. [2], who generalised it to multiple users; [13], whic h prop osed an additively decomp osable multi-attribute utility mo del. Exp erimental design is usually p erformed by approximating the intractable optimal solution [3, 7]. 5.2 In verse reinforcement learning As discussed in the introduction, the problems of inv erse reinforcement learning and appren ticeship learning inv olve an agent acting in a dynamic environmen t. This makes the mo delling problem different to that of user mo delling where preferences are betw een static choices. Secondly , the goal is not only to determine the preferences of the agen t, but also to find a p olicy that would b e at least as go od that of the agent with res pect to the agent’s own preferences. 7 Finally , the problem of exp erimen t design do es not necessarily arise, as w e do not assume to ha ve an influence ov er the agen t’s en vironment. Linear programming One interesting solution prop osed by [14] is to use a linear program in order to find a rew ard function that maximises the gap b etw een the b est and second best action. Although elegant, this approach suffers from some drawbac ks. (a) A go od estimate of the optimal p olicy must b e given. This ma y b e hard in cases where the demonstrating agent do es not visit all of the states frequen tly . (b) In some pathological MDPs, there is no such gap. F or example it could b e that for any action a , there exists some other action a 0 with equal v alue in every state. P olicy walk Our framework can b e seen as a generalisation of the Bay esian approac h considered in [18], which do es not employ a structured prior on the re- w ards and policies. In fact, they implicitly define the join t posterior o ver rew ards and p olicies as: φ ( π , ρ | s T , a T , ν ) = exp η P t Q ∗ µ ( s t , a t ) ξ ( ρ | ν ) φ ( s T , a T | ν ) , 7 In terestingly , this can also b e seen as the goal of preference elicitation when applied to multiclass classification [see 6, for example]. Preference elicitation and in verse reinforcement learning 9 whic h implies that the exp onen tial term corresp onds to ξ ( s T , a T , π | ρ ). This ad ho c c hoice is probably the weak est p oin t in this approach. 8 Rearranging, we write the denominator as: ξ ( s T , a T | ν ) = Z R×P ξ ( s T , a T | π, ρ, ν ) d ξ ( ρ, π | ν ) , (5.1) whic h is still not computable, but we can employ a Metrop olis-Hastings step using ξ ( ρ | ν ) as a prop osal distribution, and an acceptance probability of: ξ ( π , ρ | s T , a T ) /ξ ( ρ ) ξ ( π 0 , ρ 0 | s T , a T ) /ξ ( ρ 0 ) = exp[ η P t Q π ρ ( s t , a t )] exp[ η P t Q π 0 ρ 0 ( s t , a t )] . W e note that in [18], the authors employ a different sampling pro cedure than a straightforw ard MH, called a p olicy grid walk. In exploratory exp eriments, where we examined the p erformance of the authors’ original metho d [17], we ha ve determined that MH is sufficient and that the most crucial factor for this particular metho d was its initialisation: as will b e also b e seen in Sec. 6, we only obtained a small, but consistent, improv ement up on the initial reward function. The maximum entrop y approach. A maximum entrop y approach is re- p orted in [22]. Given a feature function Φ : S × A → R n , and a set of tra jecto- ries n s T k ( k ) , a T k ( k ) : k = 1 , . . . , n o , they obtain features Φ T k ( k ) = Φ ( s i, ( k ) , a i, ( k ) ) T k i =1 . They show that giv en empirical constrain ts E θ,ν Φ T k = ˆ E Φ T k , where ˆ E Φ T = 1 n P n k =1 Φ T k ( k ) is the empirical feature exp ectation, one can obtain a maxim um en tropy distribution for actions of the form P θ ( a t | s t ) ∝ e θ 0 Φ ( s t ,a t ) . If Φ is the iden tity , then θ can b e seen as a scaled state-action v alue function. In general, maxim um en tropy approac hes ha ve go od minimax guarantees [12]. Consequen tly , the estimated p olicy is guaranteed to b e close to the agent’s. Ho wev er, at b est, by b ounding the error in the p olicy , one obtains a tw o-sided high probability b ound on the relative loss. Thus, one is almost certain to p erform neither muc h b etter, nor muc h worse that the demonstrator. Game theoretic approach An in teresting game theoretic approach was sug- gested b y [20] for appren ticeship learning. This also only requires statistics of observ ed features, similarly to the maxim um entrop y approac h. The main idea is to find the solution to a game matrix with a num b er of ro ws equal to the num- b er of p ossible p olicies, which, although large, can b e solved efficiently by an exp onen tial w eighting algorithm. The metho d is particularly notable for b eing (as far as we are aw are of ) the only one with a high-probability upp er b ound on the loss relative to the demonstrating agent and no corresponding lo wer b ound. 8 Although, as mentioned in [18], suc h a choice could be justifiable through a max- im um entrop y argument, w e note that the maxim um-entrop y based approac h re- p orted in [22] do es not employ the v alue function in that wa y . 10 Constan tin A. Rothkopf and Christos Dimitrak akis Th us, this metho d may in principle lead to a significan t impro vemen t ov er the demonstrator. Unfortunately , as far as we are a ware of, sufficient conditions for this to o ccur are not kno wn at the momen t. In more recen t work [21], the au- thors ha ve also made an interesting link b et ween the error of a classifier trying to imitate the exp ert’s b eha viour and the p erformance of the imitating p olicy , when the demonstrator is nearly optimal. 1 5 9 1 3 1 7 2 1 0 5 1 0 1 5 2 0 2 5 3 0 3 5 η l sof t MH G- MH LP PW MW AL (a) Random MDP 1 5 9 1 3 1 7 2 1 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 1 0 0 sof t MH G- MH LP PW MW AL η l (b) Random Maze Fig. 2. T otal loss ` with respect to the optimal p olicy , as a function of the inv erse temp erature η of the softmax p olicy of the demonstrator for (a) the Random MDP and (b) the Random Maze tasks, av eraged o v er 100 runs. The shaded areas indicate the 80% p ercentile region, while the error bars the standard error. 6 Exp erimen ts 6.1 Domains W e compare the proposed algorithms on t wo different domains, namely on ran- dom MDPs and random maze tasks. The R andom MDP task is a discrete-state MDP , with four actions, suc h that eac h leads to a differen t, but possibly o verlap- ping, quarter of the state set. 9 The reward function is drawn from a Beta-pro duct h yp erprior with parameters α i and β i , where the index i is o ver all state-action 9 The transition matrix of the MDPs was c hosen so that the MDP was communicating (c.f. [16]) and so that each individual action from any state results in a transition to approximately a quarter of all av ailable states (with the destination states ar- riv al probabilities b eing uniformly selected and the non-destination states arriv al probabilities b eing set to zero). Preference elicitation and in verse reinforcement learning 11 pairs. This defines a distribution ov er the parameters p i of the Bernoulli dis- tribution determining the probabilit y of the agen t of obtaining a rew ard when carrying out an action a in a particular state s . F or the R andom Maze tasks we constructed planar grid mazes of differen t sizes, with four actions at eac h state, in which the agen t has a probability of 0 . 7 to succeed with the current action and is otherwise mov ed to one of the adjacent states randomly . These mazes are also randomly generated, with the rewards function b eing drawn from the same prior. The maze structure is sampled b y randomly filling a grid with walls through a pro duct-Bernoulli distribution with parameter 1 / 4, and then rejecting any mazes with a num b er of obstacles higher than |S | / 4. 6.2 Algorithms, priors and parameters W e compared our metho dology , using the basic ( MH ) and the augmen ted ( G- MH ) mo del, to three previous approaches. The linear programming ( LP ) based approac h [14], the game-theoretic approach ( MW AL ) [20] and finally , the Ba yesian in verse reinforcemen t learning metho d ( PW ) suggested in [18]. In all cases, eac h demonstration was a T -long tra jectory s T , a T , provided by a demonstrator em- plo ying a softmax p olicy with resp ect to the optimal v alue function. All algorithms hav e some parameters that must b e selected. Since our metho d- ology employs MCMC the sampling parameters must b e chosen so that conv er- gence is ensured. W e found that 10 4 samples from the chain were sufficient, for b oth the MH and hybrid Gibbs (G-MH) sampler, with 2000 steps used as burn- in, for b oth tasks. In b oth cases, we used a gamma prior Gamma (1 , 1) for the in verse temperature parameter η and a pro duct-b eta prior Beta | S | (1 , 1) for the rew ard function. Since the b eta is conjugate to the Bernoulli, this is what we used for the reward sequence sampling in the G-MH sampler. Accordingly , the conditioning p erformed in step 11 of G-MH is closed-form. F or PW , w e used a MH sampler seeded with the solution found b y [14], as suggested by [17] and b y our own preliminary experiments. Other initialisations, suc h as sampling from the prior, generally pro duced w orse results. In addition, w e did not find an y improv emen t by discretising the sampling space. W e also v erified that the same n umber of samples used in our case w as also sufficient for this metho d to conv erge. The linear-programming ( LP ) based in verse reinforcement learning algo- rithm by Ng and Russell [14] requires the actual agent p olicy as input. F or the r andom MDP domain, w e used the maximum lik eliho o d estimate. F or the maze domain, w e used a Laplace-smoothed estimate (a pro duct-Diric hlet prior with parameters equal to 1) instead, as this w as more stable. Finally , we examined the MW AL algorithm of Sy ed and Sc hapire [20]. This requires the cumulativ e discounted feature exp ectation as input, for appropri- ately defined features. Since we had discrete environmen ts, we used the state o c- cupancy as a feature. The feature exp ectations can b e calculated empirically , but w e obtained better performance b y first computeing the transition probabilities of the Marko v chain induced by the maximum likelihoo d (or Laplace-smo othed) 12 Constan tin A. Rothkopf and Christos Dimitrak akis p olicy and then calculating the exp ectation of these features giv en this chain. W e set all accuracy parameters of this algorithm to 10 − 3 , whic h w as sufficient for a robust b ehaviour. 6.3 P erformance measure In order to measure performance, we plot the L 1 loss 10 of the v alue function of eac h p olicy relative to the optimal p olicy with resp ect to the agen t’s utilit y: ` ( π ) , X s ∈S V ∗ µ ( s ) − V π µ ( s ) , (6.1) where V ∗ µ ( s ) , max a Q ∗ µ ( s, a ) and V π µ ( s ) , E π Q π µ ( s, a ). In all cases, w e av erage ov er 100 exp erimen ts on an equal num b er of ran- domly generated en vironments µ 1 , µ 2 , . . . . F or the i -th exp erimen t, we generate a T -step-long demonstration D i = ( s T , a T ) via an agent employing a softmax p olicy . The same demonstration is used across all metho ds to reduce v ariance. In addition to the empirical mean of the loss, w e use s haded regions to show 80% p ercentile across trials and error bars to display the standard error. 1 0 1 0 0 5 0 0 1 0 0 0 2 0 0 0 5 0 0 0 0 5 1 0 1 5 2 0 2 5 3 0 3 5 T l sof t MH G- MH LP PW MW AL (a) Effect of amount of data 1 0 2 0 5 0 1 0 0 2 0 0 0 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 | S| l sof t MH G- MH LP PW MW AL (b) Effect of environmen t size Fig. 3. T otal loss ` with resp ect to the optimal p olicy , in the Random MDP task. Figure 3(a) shows ho w p erformance impro ves as a function of the length T . of the demonstrated sequence. Figure 3(b) shows the effect of the n umber of states |S | of the underlying MDP . All quantities are av eraged o ver 100 runs. The shaded areas indicate the 80% p ercentile region, while the error bars the standard error. 10 This loss can b e seen as a scaled version of the exp ected loss under a uniform state distribution and is a b ound on the L ∞ loss. The other natural choice of the optimal p olicy stationary state distribution is problematic for non-ergo dic MDPs. Preference elicitation and in verse reinforcement learning 13 6.4 Results W e consider the loss of five differen t p olicies. The first, soft , is the policy of the demonstrating agent itself. The second, MH , is the Metrop olis-Hastings pro cedure defined in Alg. 1, while G-MH is the hybrid Gibbs pro cedure from Alg. 2. W e also consider the loss of our implemen tations of Linear Programming ( LP ), Policy W alk ( PW ), and MW AL , as summarised in Sec. 5. W e first examined the loss of greedy policies, 11 deriv ed from the estimated rew ard function, as the demonstrating agent b ecomes greedier. Figure 2 shows results for the t wo different domains. It is easy to see that the MH sampler sig- nifican tly outp erforms the demonstrator, even when the latter is near-optimal. While the hybrid Gibbs sampler’s p erformance lies b et ween that of the demon- strator and the MH sampler, it also estimates a distribution ov er reward se- quences as a side-effect. Thus, it could be of further v alue where estimation of rew ard sequences is important. W e observ ed that the performance of the baseline metho ds is generally inferior, though nev ertheless the MW AL algorithm tracks the demonstrator’s p erformance closely . This sub optimal p erformance of the baseline metho ds in the R andom MDP setting cannot b e attributed to p oor estimation of the demonstrated p olicy , as can clearly b e seen in Figure 3(a), which sho ws the loss of the greedy p olicy deriv ed from each metho d as the amoun t of data increases. While the prop osed samplers improv e significan tly as observ ations accum ulate, this effect is smaller in the baseline methods w e compared against. As a final test, we plot the relativ e loss in the R andom MDP as the n umber of states increases in Figure 3(b). W e can see that the relativ e p erformance of methods is in v ariant to the size of the state space for this problem. Ov erall, we observed the basic mo del ( MH ) consistently outp erforms 12 the agen t in all settings. The augmented mo del ( G-MH ), while sometimes outp er- forming the demonstrator, is not as consistent. Presumably , this is due to the join t estimation of the reward sequence. Finally , the other metho ds under con- sideration on av erage do not improv e upon the initial p olicy and can b e, in a large num b er of cases, significan tly w orse. F or the linear programming inv erse RL metho d, perhaps this can b e attributed to implicit assumptions ab out the MDP and the optimalit y of the given p olicy . F or the p olicy w alk inv erse RL metho d, our b elief is that its sub optimal p erformance is due to the very re- strictiv e prior it uses. Finally , the p erformance of the game theoretic approac h is slightly disappointing. Although it is muc h more robust than the other tw o baseline approac hes, it never outp erforms the demonstrator, even thought tech- nically this is p ossible. One p ossible explanation is that since this approach is w orst-case b y construction, it results in o verly conserv ativ e policies. 11 Exp erimen ts with non-greedy policies (not shown) produced generally worse results. 12 It w as pointed out b y the anon ymous review ers, that the loss we used may b e biased. Indeed, a metric defined ov er some other state distribution, could give differen t rankings. How ever, after lo oking at the results carefully we determined that the p olicies obtained via the MH sampler were strictly dominating. 14 Constan tin A. Rothkopf and Christos Dimitrak akis 7 Discussion W e in tro duced a unified framework of preference elicitation and inv erse reinforce- men t learning, presented tw o statistical inference mo dels, with t wo corresp onding sampling procedures for estimation. Our framework is flexible enough to allow using alternative priors on the form of the p olicy and of the agent’s preferences, although that w ould require adjusting the sampling pro cedures. In exp eriments, w e sho wed that for a particular choice of p olicy prior, closely corresponding to previous approaches, our samplers can outp erform not only other w ell-known in verse reinforcement learning algorithms, but the demonstrating agent as well. The simplest extension, whic h w e ha ve already alluded to, is the estimation of the discount factor, for which we ha ve obtained promising results in preliminary exp erimen ts. A slightly harder generalisation o ccurs when the environmen t is not known to us. This is not due to difficulties in inference, since in man y cases a p osterior distribution o ver M is not hard to maintain (see for example [9, 15]). Ho wev er, computing the optimal policy giv en a b elief ov er MDPs is harder [9], ev en if w e limit ourselves to stationary p olicies [11]. W e would also like to consider more types of preference and p olicy priors. Firstly , the use of spatial priors for the rew ard function, whic h w ould b e necessary for large or contin uous environmen ts. Secondly , the use of alternative priors on the demonstrator’s p olicy . The generality of the framew ork allows us to formulate different preference elicitation problems than those directly tied to reinforcement learning. F or ex- ample, it is p ossible to estimate utilities that are not additive functions of some laten t rew ards. This do es not app ear to b e easily achiev able through the exten- sion of other in verse reinforcemen t learning algorithms. It w ould b e interesting to examine this in future work. Another promising direction, which w e ha ve already inv estigated to some degree [8], is to extend the framework to a fully hierarchical mo del, with a h yp erprior on reward functions. This would b e particularly useful for modelling a p opulation of agents. Consequently , it w ould ha ve direct applications on the statistical analysis of b ehavioural exp eriments. Finally , although in this pap er we hav e not considered the problem of ex- p erimental design for preference elicitation (i.e. active preference elicitation), w e b eliev e is a v ery in teresting direction. In addition, it has man y applications, suc h as online advertising and the automated optimal design of behavioural exp er- imen ts. It is our opinion that a more effectiv e preference elicitation pro cedure suc h as the one presented in this pap er is essen tial for the complex planning task that exp erimen tal design is. Consequently , we hope that researchers in that area will find our metho ds useful. Ac knowledgemen ts Man y thanks to the anonymous review ers for their com- men ts and suggestions. This w ork w as partially supported by the BMBF Pro ject ”Bernstein F okus: Neurotechnologie F rankfurt, FKZ 01GQ0840”, the EU-Pro ject IM-CLeV eR, FP7-ICT-IP-231722, and the Marie Curie Pro ject ESDEMUU, Gran t Num b er 237816. Bibliograph y [1] P . Abb eel and A.Y. Ng. Apprenticeship learning via inv erse reinforcemen t learning. In Pr o c e e dings of the 21st international c onfer enc e on Machine le arning (ICML 2004) , 2004. [2] Edwin V. Bonilla, Shengb o Guo, and Scott Sanner. Gaussian pro cess pref- erence elicitation. In NIPS 2010 , 2010. [3] C. Boutilier. A POMDP formulation of preference elicitation problems. In AAAI 2002 , pages 239–246, 2002. [4] Darius Braziunas and Craig Boutilier. Preference elicitation and generalized additiv e utilit y . In AAAI 2006 , 2006. [5] George Casella, Stephen Fienberg, and Ingram Olkin, e ditors. Monte Carlo Statistic al Metho ds . Springer T exts in Statistics. Springer, 1999. [6] W. Chu and Z. Ghahramani. Preference learning with gaussian pro cesses. In Pr o c e e dings of the 22nd international c onfer enc e on Machine le arning , pages 137–144. A CM, 2005. [7] Morris H. DeGro ot. Optimal Statistic al De cisions . John Wiley & Sons, 1970. [8] Christos Dimitrak akis and Constantin A. Rothkopf. Ba yesian multitask in verse reinforcement learning, 2011. (under review). [9] Mic hael O’Gordon Duff. Optimal L e arning Computational Pr o c e dur es for Bayes-adaptive Markov De cision Pr o c esses . PhD thesis, Universit y of Mas- sac husetts at Amherst, 2002. [10] Milton F riedman and Leonard J. Sav age. The exp ected-utilit y hypothesis and the measurabilit y of utilit y . The Journal of Politic al Ec onomy , 60(6): 463, 1952. [11] Thomas F urmston and David Barb er. V ariational metho ds for reinforce- men t learning. In AIST A TS , pages 241–248, 2010. [12] P eter D. Gr ¨ unw ald and A. Philip Dawid. Game theory , maximum en- trop y , minim um discrepancy , and robust bay esian decision theory . A nnals of Statistics , 32(4):1367–1433, 2004. [13] Shengb o Guo and Scott Sanner. Real-time multiattribute ba yesian prefer- ence elicitation with pairwise comparison queries. In AIST A TS 2010 , 2010. [14] Andrew Y. Ng and Stuart Russell. Algorithms for inv erse reinforcement learning. In in Pr o c. 17th International Conf. on Machine L e arning , pages 663–670. Morgan Kaufmann, 2000. [15] P . Poupart, N. Vlassis, J. Ho ey , and K. Regan. An analytic solution to discrete Bay esian reinforcement learning. In ICML 2006 , pages 697–704. A CM Press New Y ork, NY, USA, 2006. [16] Marting L. Puterman. Markov De cision Pr o c esses : Discr ete Sto chastic Dynamic Pr o gr amming . John Wiley & Sons, New Jersey , US, 2005. [17] D Ramachandran, 2010. P ersonal communication. [18] D. Ramac handran and E. Amir. Bay esian in verse reinforcement learning. In in 20th Int. Joint Conf. Artificial Intel ligenc e , volume 51, pages 2856–2591, 2007. 16 Constan tin A. Rothkopf and Christos Dimitrak akis [19] Constan tin A. Rothk opf. Mo dular mo dels of task b ase d visual ly guide d b ehav- ior . PhD thesis, Department of Brain and Cognitiv e Sciences, Department of Computer Science, Universit y of Ro c hester, 20 08. [20] Umar Syed and Rob ert E. Schapire. A game-theoretic approach to appren- ticeship learning. In A dvanc es in Neur al Information Pr o c essing Systems , v olume 10, 2008. [21] Umnar Syed and Rob ert E. Schapire. A reduction from apprenticeship learning to classification. In NIPS 2010 , 2010. [22] Brian D. Ziebart, J. Andrew Bagnell, and Anind K. Dey . Mo delling inter- action via the principle of maximum causal entrop y . In Pr o c e e dings of the 27th International Confer enc e on Machine L e arning (ICML 2010) , Haifa, Israel, 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment