Efficient Reinforcement Learning Using Recursive Least-Squares Methods
The recursive least-squares (RLS) algorithm is one of the most well-known algorithms used in adaptive filtering, system identification and adaptive control. Its popularity is mainly due to its fast convergence speed, which is considered to be optimal…
Authors: H. He, D. Hu, X. Xu
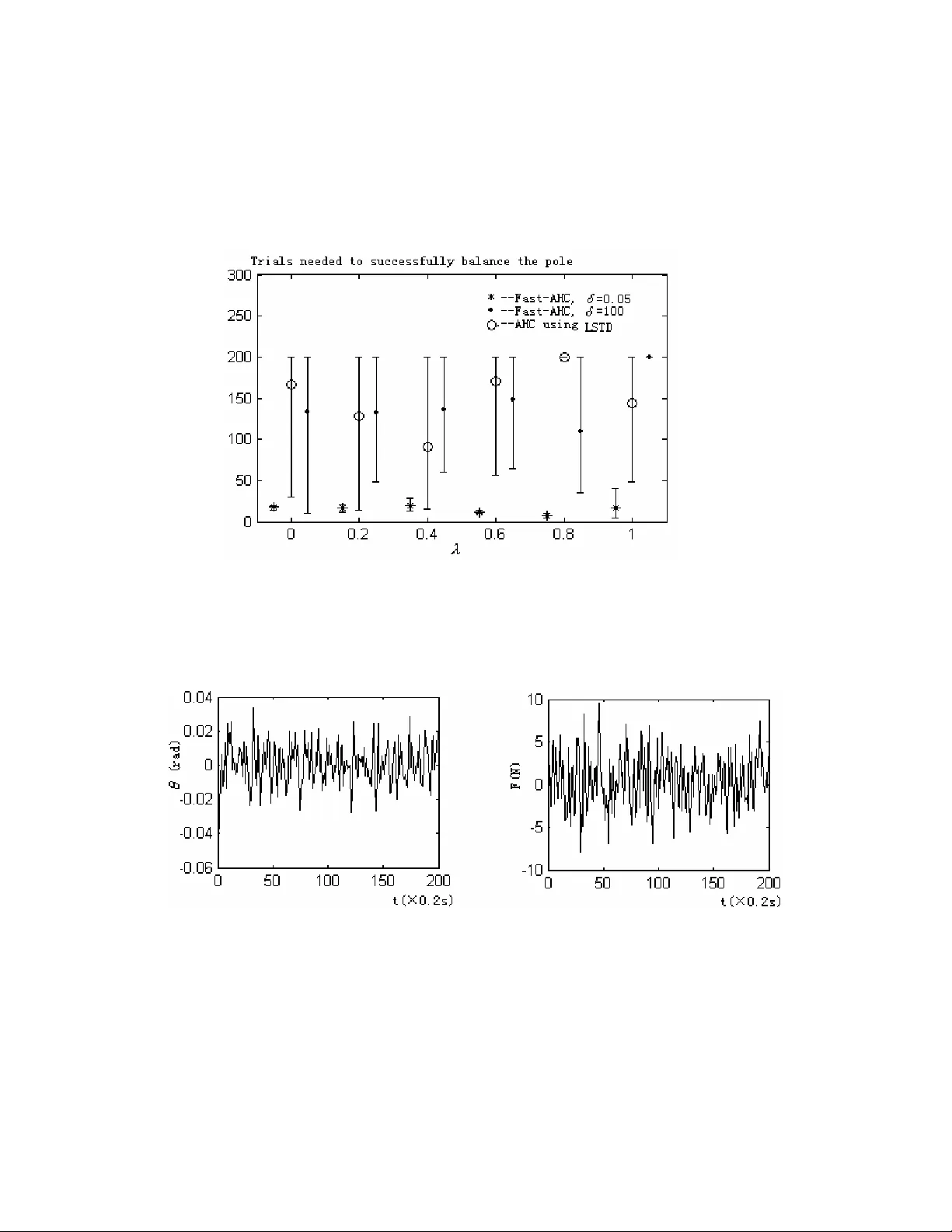
Journal of Artificial Intelligence Research 16 (2002) 259-292 Submitted 9/01; published 4/02 ©2002 AI Access Foundation and Mor gan Kaufmann Publishers. All rights reserved. Efficient Reinforcement Learning Using Recursive Least -Squares Methods Xin Xu XUXIN _ MAIL @263. NET Han-gen He HEHANGEN @ CS . HN . CN Dewen Hu DWHU @ NUDT . EDU . CN Department of Automatic Contr ol National University of Defense T echnology ChangSha , Hunan , 410073 , P .R.China Abstract The recursive least-s quares (RLS) algorithm is one of the most well-known algorithms used in adaptive filtering, system identification and adap tive control. Its popularity is mainly due to its fast convergence speed, which is considered to be optimal in practice. In this paper , RLS methods are used to solve reinforcement learning prob lems, where two new reinforcement learning algorithms using linear value function approximators are proposed and analyzed. The two algorithms are called RLS-TD( Ȝ ) and Fast-AHC (Fast Adaptive Heuristic Critic), respectively . RLS-TD( Ȝ ) can be viewed as the extension of RLS-TD(0) from Ȝ =0 to general 0 Ȝ 1, so it is a multi-step temporal-dif ference (TD) learning algorithm using RLS methods. The c onverge nce with probability one and the limit of convergence of RLS-TD( Ȝ ) are proved for ergodic Markov chains. Compared to the existing LS-TD( Ȝ ) algorithm, RLS-TD( Ȝ ) has advantages in computation and is more suitable for online learning. The effectiveness of RLS-TD( Ȝ ) is analyzed and verified by learning prediction experiments of Markov chains with a wide range of parameter settings. The Fast-AHC algorithm is derived by applying the proposed RLS-TD( Ȝ ) algorithm in the critic network of the adaptive heuristic critic method. Unlike conventional AHC algorithm, Fast-AHC ma kes use of RLS methods to improve the learning-prediction efficiency in the critic. Learning control exper iments of th e cart-pole balancing and the acrobot swing-up problems are conducted to compare the data ef ficiency of Fast-AHC with conventional AHC. From the experimental results, it is shown that the data efficiency of learning control can also be improved by using RLS methods in the learning-prediction process of the critic. The performance of Fast-AHC is also compared with that of the AHC method using LS-TD( Ȝ ). Furthermore, it is demonstrated in the experiments that different initial values of the variance matrix in RLS-TD( Ȝ ) are required to get better performance not only in learning prediction but also in learning control. The experimental results are analyzed based on the exi sting theoretical work on the transient phase of for getting factor RLS methods. 1. Introduction In recent years, reinforcement learning ( RL) has been an active res earch area not only in machine learning but also in control engineering, operations research and robotics (Kaelbling et al.,199 6; Bertsekas, et a l.,1996; Sutton and B arto,1998; Lin,1992). It is a co mputational approach to X U , H E , & H U 260 understand and automate goal-directed learning and decision-mak ing, witho ut relying on exemplary supervision or complete models of the e nvironment. In RL, an agent is placed in an initial unknown environment and only receives evaluative feedback from the environment. The feedback is called reward or reinforc ement signal. The ultimate goal of RL is to learn a strategy for selecting actions such that the expected sum of discounted rew ards is maximized. Since lots of problems in the real world are sequential decision processes with delayed evaluative feedback, the research in RL has been focused on theory and algorithms of learning to solve the optimal control problem of Markov decision processes (MDPs) which provide an elegant mathematical model for sequential decision-making. In operation s research, many result s have been presented to solve the optimal co ntrol problem o f MDPs with model information. However , in reinforcement learning, the model information is ass umed to be unknown, which is different from the methods studied in operations research such as dynamic programmin g. In dynamic programming, there ar e two elemental processes, which are the policy evaluation pro- cess and the policy improvement process, respective ly . In RL, there are two similar processes. One is called lear ning pr ediction and the other is called learning control. The g oal of learning control is to est imate the o ptimal polic y or o ptim al v alue funct ion of an MDP w ithout knowi ng its model. Learning prediction aims to solve the policy evaluation problem of a statio nary-policy MDP without any prior model and it can be regarded as a su b-problem of learning control. Furthermore, in RL, le arning predictio n is d ifferent from that in supervi sed learning . As pointed out by Sutton (1988), the prediction probl ems i n supervise d learnin g are single-step predict ion problems whil e those in reinforcement learning are multi-step prediction problems. T o solve multi-step prediction problems, a learning system must predict outcomes that depen d on a future sequence of decisions. Therefore, the theory and algorithms for m ulti-step learning prediction become an important top ic in RL and much research work has been done in the literature (S utton, 1988; T sitsiklis and R oy , 1997). Among the proposed multi-step learni ng prediction methods, temporal-difference (TD) learning (Sutton, 1988) is one of the most popular methods. It was st udied and applied in the earl y research of machine learning, including the celebrated checkers-playing program (Minsky , 1954; Samuel, 1959). In 1988, Sutton pr esented the f irst formal desc ription of temporal- difference methods and the TD( Ȝ ) algorithm (Sutton,1988). Convergence results are esta blished for tabular temporal-difference learning al gorithms where th e cardinality of tunable parame ters is the same as that of the state space (Sutton, 1988; W a tk ins,et al.,1992; Dayan,et al., 1994; Jaakkola, et al.,1994). Since many real-world applications hav e large or infinite state spa ce, value function approximation ( VF A) methods need to be used in those cases. When combined with nonlinear value function approximators, TD( Ȝ ) can not guarantee convergence and several results regarding divergence have been reported in the literature (T sitsiklis and Roy ,1997). For TD( Ȝ ) with linear function a pproximators, also called linear TD( Ȝ ) algorithms, severa l conver gence proofs have been presented. Dayan (1992) showed the conver gence in the mean for linear TD( Ȝ ) algorithms with arbitrary 1 Ȝ 0 d d . T sitsiklis and Roy (1994) pro ved the convergenc e for a special class of TD learning algorithms, known as TD(0), while in T sitsiklis and Roy (1997), they extended the early results to general linear TD( Ȝ ) case and proved the convergen ce with probability one. The above linear TD( Ȝ ) algorithms have rules for updating parameters sim ilar to those in gradient-descent methods. However , as in gradient-learning methods, a step-size schedule must be carefully designed not only to guarante e convergence but also to obtain good performance. In E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 261 addition, there is ineff icient use of data that slows the convergence of the algorithms. Based on the theory of linear least-squares estimation, Brartke and Barto (199 6) proposed two temporal-dif ference algorithms called the Least-Squares TD(0) algorithm (LS-TD(0)) and the Recursive Least- Squares TD(0) algorithm (RLS-TD(0)), respectively . LS-TD(0) and RLS-TD(0) are more ef ficient in a statistical sense than conventional linear TD( Ȝ ) algorithms and they eliminate the design of step-size schedules. Furthe rmore, the convergence of LS-TD(0) and RLS-TD(0) has been provided in theory . The above two algorithms can be viewed as the least-squares versions of conventional linear TD(0) methods. However , as has been shown in the literature, TD learning algorithms such as TD( Ȝ ) with 0< Ȝ <1 that update predictions based on the estimates of multiple steps are more efficient than Monte-Carlo methods as well as TD(0). By employing the m echanism of eligibility traces, which is determ ined by Ȝ , TD( Ȝ ) algorithms with 0< Ȝ <1 can extract more information from historical data. Recently , a class of linear temporal-dif ference learning algorithms called LS-TD( Ȝ ) has been proposed by Boyan (1999,2002), where least-squares methods are employed to compute the value-function estimation of TD( Ȝ ) with 0 Ȝ d 1. Althoug h LS-TD( Ȝ ) is more efficient than TD( Ȝ ), it requires too much computation per time-step when online updates are needed and the number of state features becomes lar ge. In s ystem identification, adaptive filtering and adaptive control, the recursive least-squares (RLS) (Y oung,1984; Ljung, 1983; Ljung,1977) method, comm only used to red uce the computational burden of least-squares methods, is more suitable fo r online estimation and control. Although RLS-TD(0) makes use of RLS me thods, it does not em ploy the m echanism of eligibility traces. Based on the work of T sitsiklis and Roy (1994, 1997), Boyan (1999,2002) and motivated by the above ideas, a new class of temporal-difference learning m ethods, called the RLS-TD( Ȝ ) algorithm, is proposed and analyzed formally in this paper . RLS-TD( Ȝ ) is superior to conventi onal linear TD( Ȝ ) algorithm s in that it ma kes use of RLS methods to imp rove the learning efficiency in a statistical point of view and eliminates the st ep-size schedules. RLS-TD( Ȝ ) has the mechanism of eligibility traces and can be vie wed as the extension of RLS-TD(0) from Ȝ =0 to general 0 Ȝ 1. The convergence with probability 1 of RLS-TD( Ȝ ) is proved for er godic Markov chains and the limit of convergence is also analyzed. In learning prediction experiments for Markov chains, the performance of RLS-TD( Ȝ ) and TD( Ȝ ) as well as LS-TD( Ȝ ) is compared, where a wide range of parameter settings is tested. In addition, the in- fluence of the initialization parameters in RLS-TD( Ȝ ) is also discussed. It is o bserved that the rate of conv ergence is influenced by the initialization of the variance matrix, which is a phenomenon investigated theoretically in adaptive filtering (Moustakides, 1997; Haykin, 1996). As will be analyzed in the following sections, there are two benefits of the extension from RLS-TD(0) to RLS-TD( Ȝ ). One is that the value of Ȝ (0 Ȝ 1) will still affect the perform ance of the RLS-based temporal-dif ference algorithms. Although for RLS-TD( Ȝ ), the rate of convergence is mainly influenced by the initialization of the variance matrix, the bound of approximation error is dominantly determined by the parameter Ȝ . The smallest error bound can be obtained for Ȝ =1 and the worst bound is obtained for Ȝ =0. These bounds suggest that the value of Ȝ should be selected appropriately to obtain the best approximation error . The second benefit is that RLS-TD( Ȝ ) is more suitable for online learning than LS-TD( Ȝ ) since the computation per time-step is reduced from O( K 3 ) to O( K 2 ), where K is the number of state features. The Adaptive-Heuristic-Critic (AHC) learning algorithm is a class of reinforcement learning X U , H E , & H U 262 methods that has an actor-c ritic architecture and can be used to solve full reinforcem ent learning or learning control problems. By applying the RLS-TD( Ȝ ) algorithm in the critic, the Fast-AHC algorithm is proposed in this paper . Using RLS methods in the critic, the performance of learning prediction in the critic is improved so that learning control problems can be solved more efficiently . Simulation experiments on the learning control of the cart-pole balancing problem and the swing-up of an acrobot are conducted to verify the effectiveness of the Fast-AHC method. By comparing with conventional AHC methods which use TD( Ȝ ) in the critic, it is demonstrated that Fast-AHC can obtain higher data efficiency than conventional AHC methods. Experiments on the performance comparisons between AHC methods using LS-TD( Ȝ ) and Fast-AHC are also conducted. In the learning control experiments, it is also illustrated that the initializing constant of the variance matrix in RLS-TD( Ȝ ) influences the performance of Fast-AHC and differen t values of the constant shoul d be selected to get better performance in different problem s. The above results are analyzed based on the theoretical work on the transient phase of RLS methods. This paper is organized as follows. In Section 2, an introduction on the previous linear temporal-dif ference algorithms is presented. In Section 3, the RLS-TD( Ȝ ) algorithm is proposed and its conver gence (with probability one) is proved. In Section 4, a simulation example of the value-function prediction for absorbing Markov chains is presented to illustrate the ef fectiveness of the RLS-TD( Ȝ ) algorithm, where different param eter settings for different algorithms including LS-TD( Ȝ ) are studied. In Section 5, the Fast-AHC method is proposed and the simulation experiments on the learning control of the cart-pole balancing and the acrobot are conducted to compare Fast-AHC with the conventional AHC method as well as the LS-TD( Ȝ )-based AHC method. Some simulation results are presented and analyzed in detail. The last section contains concluding rema rks and directions for future work. 2 . Previous W ork on Linear T emporal-Difference Algorithms In this section, a brief discussion on the conventional linear TD( Ȝ ) algorithm and RLS-TD(0) as well as the LS-TD( Ȝ ) alg orithm will be given. First of all, some mathematical notations are presented as follows. Consider a Markov chain whose states lie in a finite or countable infinite space S . The states of the Markov chain can be indexed a s {1,2,…, n }, where n is possibly infi nite. Although the algorithms and the results in this paper are applicable to Markov chains with general state space, the discussion in this paper will be restricted within the cases with a cou ntable state space to simplify the notation. The extension to Markov chains with a general state space only requires the translation of the matrix notation into operator notation. Let the trajectory generated by the Markov chain be denoted by { x t | t =0,1,2,…; x t ę S }.The dynamics of the Markov chain is described by a transition probability matrix P whose ( i , j )-th entry , denoted by p ij , is the transition probability for x t +1 = j given that x t = i . For each state tran sition from x t to x t +1 , a scalar reward r t is defined. The value function of each state is defined as follows: } { ) ( 0 0 ¦ f t t t i x r E i V J (1) where 0< 1 d J is a discount factor . In the TD( Ȝ ) algorithm, there are two basic mechanisms which are the temporal difference E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 263 and the eligibility trace, respectively . T emporal differences are defined as the differences between two successive estimations and have the following form. ) ( ~ ) ( ~ 1 t t t t t t x V x V r J G (2) where x t +1 is the successive state of x t , ) ( ~ x V denotes the estimate of the value function V ( x ) and r t is the reward received after the state trans ition from x t to x t +1 . The Eligibility trace can be viewed as an algebraic trick to i mprove learning ef ficiency without recording all the data of a multi-step prediction process. This trick is based on the idea of using the truncated return of a Markov chain. In temporal-difference learning with eligibility traces, an n -step truncated return is defin ed as ) ( ~ ... 1 1 1 n t t n n t n t t n t s V r r r R J J J (3) For an absorbing Markov chain whose length is T , the weighted average of truncated returns is T t T n t t T n n t R R R 1 1 1 1 Ȝ Ȝ Ȝ ) Ȝ 1 ( ¦ (4) where 1 Ȝ 0 d d is a decay ing factor and R T = T T t t r r r J J ... 1 is the Monte-Carlo return at the terminal state. In each step of the TD( Ȝ ) algorithm, the update rule of the value function estimation is determined by the weighted average of truncated returns defined above. The corresponding update equation is )) ( ~ ( ) ( ~ i t t t i t s V R s V ' O D (5) where Į t is a learning factor . The update equation (5) can be used only aft er the whole trajectory of the Markov chain is observed. T o realize incremental or online learning, eligibility traces are defined for each state as follows: ¯ ® z t i i t t i i t i t s s s z s s s z s z if ), ( if , 1 ) ( ) ( 1 JO JO (6) The online TD( Ȝ ) update rule with eligibility traces is ) ( ) ( ~ ) ( ~ 1 1 i t t t i t i t s z s V s V G D (7) where į t is the temporal difference at time step t , which is defined in (2) and z 0 ( s )=0 for all s . Since the state space of a Markov chain is usually lar ge or infinite in practice, function approximators such as neural networks are commonly used to approximate the value func tion. TD( Ȝ ) algorithms with linear function approximators are the most popular and well-studied ones. Consider a general linear function approximator with a fixed basis function vector T n x x x x )) ( ),..., ( ), ( ( ) ( I I I I 2 1 The estimated value function can be denoted as t T t W x x V ) ( ) ( ~ I (8) X U , H E , & H U 264 where W t =( w 1 , w 2 ,…, w n ) T is the weight vector . The corresponding incremental weight update rule is 1 1 1 ) ) ( ) ( ( t t t T t t T t t t t z W x W x r W W & I JI D (9) where the eligibility trace vector T nt t t t s z s z s z s z )) ( ),..., ( ), ( ( ) ( 2 1 & is defined as ) ( 1 t t t x z z I JO & & (10) In T sitsiklis and Roy (1997), the above linear TD( Ȝ ) algo rithm is proved to converge with probability 1 under certain assu mptions and the limit of convergence W * is also deriv ed, which satisfies the following equation. 0 )] ( [ )] ( [ 0 * 0 t t X b E W X A E (1 1) where X t =( x t , x t +1 , z t+ 1 ) ( t =1,2,…) for m a Markov process, E 0 [·] stands for the expectation with respect to the unique invariant distribution of { X t }, and A ( X t ) and b ( X t ) are defined as )) ( ) ( ( ) ( 1 t T t T t t x x z X A JI I & (12) t t t r z X b & ) ( (13) T o improve the efficiency of linear TD( Ȝ ) algorithms, least-squares methods are used with the linear TD(0) algorithm, and the LS-TD(0) and RLS-TD(0) algorithms are suggested (Brartke and Barto, 1996). In LS-TD(0) and RLS-TD(0), the foll owing quadratic objective function is defined. ¦ 1 1 2 1 ] ) ( [ T t T t T t t W r J JI I (14) Thus, the aim of LS-TD(0) and RLS-TD(0) is to obtain a least-squares estimation of the real value function which satisfies th e following Bellman equation. )] ( ) , ( [ ) ( 1 1 t t t t t x V x x r E x V J (15) By employing the instrumental variables approach (So derstrom and Stoica, 1983), the least-squares solution of (14) is given as ¦ ¦ T t t t T t T t t t TD LS r W 1 1 1 1 ) 0 ( ) ( ) ) ) ( ( ( I JI I I (16) where t I is the instrumental variable chosen to be uncorrelated with the input and output noises. In RLS-TD(0), recursive least-squares methods are used to decrease the computational bur - den of LS-TD(0). The update rules of RLS-TD(0) are as follows: ) ) ( 1 /( ) ) ( ( 1 1 1 t t T t t t T t t t t t t t P W r P W W I JI I JI I I (17) ) ) ( 1 /( ) ( 1 1 1 t t T t t t T t t t t t t P P P P P I JI I JI I I (18) The converge nce (with probability one) of LS-TD(0) and RLS- TD(0) is proved for periodic and absorbing Markov chains under certain assumptions (Brartke and Barto,1996). E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 265 In Boyan (19 99,2002), LS-TD( Ȝ ) is proposed by solving (1 1) directly and the model-based property of LS-TD( Ȝ ) is also analyzed. However , for LS-TD( Ȝ ), the computation per time-step is O( K 3 ), i.e., the cubic order of the state feature number . Therefore the computation required b y LS-TD( Ȝ ) increases very fast when K increases, which is undesirable for online learning. In the next section, we propose the RLS-TD( Ȝ ) algorithm by making use of recursive least-squares methods so that the computational burden of LS-TD( Ȝ ) can be reduced from O( K 3 ) to O( K 2 ). W e also give a rigorous mathematical analysis on the algorithm, where the convergence (with probability 1) of RLS-TD( Ȝ ) is proved. 3. The RLS-TD( Ȝ ) Algorithm For the Markov chain discussed above, when linear function approxim ators are used, th e least-squares estimation problem of (1 1) has the following objective function. 2 1 1 ) ( ) ( ¦ ¦ T t t T t t X b W X A J (19) where n t n n t R X b R X A u ) ( , ) ( are defined as (12) and (13), respectively , is a Euclid norm and n is the number of basis functions. In LS-TD( Ȝ ), the least-squares esti mate of the weight vector W is computed according to the following equation. ) ) ( ( ) ) ( ( 1 1 1 1 ) ( ¦ ¦ T t t T t t T T TD LS X b X A b A W O (20) where ¦ ¦ T t t T t T t T t t T x x z X A A 0 1 0 )) ( ) ( ( )) ( ( JI I & (21) ¦ ¦ T t t t T t t T r z X b b 0 0 ) ( & (22) As is well known in system identification, adaptive filtering and control, RLS methods are commonly used to solve the computational and memory problems of least-squares algorithms. In the sequel, we present the RLS-TD( Ȝ ) algorithm based on the above idea. First, the matrix in- verse lemma is given as follows: Lemma 1 (Ljung, et al.,1983). If n n R A u , 1 u n R B , n R C u 1 and A is invertible , then 1 1 1 1 1 1 ) ( ) ( CA B CA I B A A BC A (23) Let 1 t t A P (24) X U , H E , & H U 266 I P G 0 (25) t t t z P K & 1 1 (26) where į is a positive number and I is the identity m atrix. Then the weight update rules of RLS-TD( Ȝ ) are given by ) )) ( ) ( ( /( 1 1 t t t T t T t t t z P x x z P K & & JI I P (27) ) )) ( ) ( ( ( 1 1 1 t t T t T t t t t W x x r K W W JI I (28) ] )) ( ) ( ( )] )) ( ) ( ( [ [ 1 1 1 1 1 t t T t T t t t T t T t t t t P x x z P x x z P P P JI I JI I P P & & (29) where for the standard RLS-TD( Ȝ ) algorithm, µ =1; for the general for getting factor RLS-TD( Ȝ ) case, 0< µ 1. The forgett ing factor µ (0< µ 1) is usually used in adaptive filtering to improve the performance of RLS methods in non-st ationary environments. The forgetting factor RLS-TD( Ȝ ) algorithm with 0< µ 1 can be derived using similar techniques as in Haykin (1996). The detai led derivation of RLS-TD ( Ȝ ) is referred to Appendix A. In the follows, the descriptions of RLS-TD( Ȝ ) for two different kinds of Markov chains are given. First, a com plete description of RLS-TD( Ȝ ) for erg odic Markov chains is presented be low . Algorithm 1 RLS-TD( Ȝ ) for er godic Markov chains 1: Given: x A termination criterion for the algorithm . x A set of basis functions { ) ( i j I } ( j =1,2,…, n ) for each s tate i , where n is the number of basis funct ions. 2: Initialize: (2.1) Let t =0. (2.2) Initialize t he weight vector W t , the variance ma trix P t , the initial s tate x 0 . (2.3) Set the eligibi lity traces vector 0 z & =0. 3: Loop: (3.1) For the current state x t , observe the state transition from x t to x t +1 and the reward r ( x t , x t +1 ). (3.2) Apply equations (27)-(29) to update the weight vector . (3.3) t = t +1. until the termination criterion is satisfied . The RLS-TD( Ȝ ) algorithm for absorbing Markov chains is a little different from the above algorithm in coping with the state features of absorbing states. Fo llowing is a description of E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 267 RLS-TD( Ȝ ) for absorbing Ma rkov chains. Algorithm 2 RLS-TD( Ȝ ) for absorbing Ma rkov chains 1: Given: x A termination criterion for the algorithm . x A set of basis functions { ) ( i j I } ( j =1,2,…, n ) for each s tate i , where n is the number of basis funct ions. 2: Initialize: (2.1) Let t =0. (2.2) Initialize t he weight vector W t , the variance ma trix P t , the initial s tate x 0 . (2.3) Set the eligibi lity traces vector 0 z & =0. 3: Loop: (3.1) For the cur rent state x t , x If x t is an absorbing state, set I ( x t +1 )=0, r ( x t )= r T , where r T is the terminal reward. x Otherwise , observe the state transition from x t to x t +1 and the reward r ( x t , x t +1 ). (3.2) Apply equations (27)-(29) to update the weight vector . (3.3) If x t is an absorbing state, re-initialize the process by setting x t +1 to an initial state and set the eligibi lity traces t z & to a zero vector . (3.4) t = t +1. until the termination criterion is satisfied . In the above RLS-TD( Ȝ ) algorithm for absorbing Markov chains, the weight updates in the absorbing states are treated dif ferently and the process is re-initialized in absorbing states to transform the absorbing Markov chain into an equivalent ergodic Markov chain. So in the following conver gence analysis, we only focus on ergodic Marko v chains. Under similar assu mptions as in T sitsiklis and Roy (1997), we will prove that the proposed RLS-TD( Ȝ ) algorithm conver ges with probability one. Assumption 1. The Markov chain { x t }, whose transition pr obability matrix is P , is er godic , and ther e is a unique distributi on S that satisfies T T P S S (30) with S ( i )>0 for all i ę S and ± is a finite or infinite ve ctor , depending on the car dinality of S . Assumption 2. T ransition r ewar ds r ( x t , x t +1 ) satisfy f )] , ( [ 1 2 0 t t x x r E (31) wher e E 0 [ ] is the expectation wit h r espect to the distribution S . Assumption 3. The matrix ] ,..., , [ 2 1 n I I I ) n N R u has full column rank , that is , the basis X U , H E , & H U 268 functions i I ( i =1,2,…, n ) ar e linearly independent . Assumption 4. For every i ( i =1,2,…, n ), the basis function i I satisfies f )] ( [ 2 0 t i x E I (32) Assumption 5. The matrix ] ) ( 1 [ 1 1 0 ¦ T t t X A T P is non-singular for all T >0. Assumptions 1–4 are almost the same as those for the linear TD( Ȝ ) algorithm s discussed in T sitsiklis and Roy (1997) except that in Assumption 1, ergodic Markov chains are considere d. Assumption 5 is speci ally needed for the conver gence of the RLS-TD( Ȝ ) algorith m. Based on the above assumptions, the conver gence theorem for RLS-TD( Ȝ ) can be given as follows: Theore m 1. For a Markov chain which satisfies Assumptions 1 – 5 , the asymptotic estimate found by RLS-TD ( Ȝ ) conver ges, with pr obability 1, to W* determined by (1 1). For the proof of Theorem 1, please refer to Appendix B. The condition specified b y Assumption 5 can be sati sfied by setting P 0 = I G appropriately . According to Theorem 1, RLS-TD( Ȝ ) conver ges to the same solution as conventional linear TD( Ȝ ) algorithms do, which satisfies (1 1). So the limit of convergence can be characterized by the following theorem . Theorem 2 (T sitsiklis and Roy ,1997) Let W * be the weight vector determined by (1 1) and V * be the true value function of the Markov chain, then under Assumption 1–4, the following r elation holds . D D V V V W * * * * 1 Ȝ 1 3 d ) J J (33) wher e DX X X T D , D D T T ) ) ) ) 3 1 ) ( . For more explanations on t he notations in Theore m 2, please refer to Appendix B. As discussed by T sitsiklis and Roy (1997), the above theorem shows that the distance of the limiting function ) W * from the true value function V * is bounded and the smallest bound of approximation error can b e obtained when Ȝ =1. For every Ȝ <1, the bound actually deteriorates as Ȝ decreases. The worst bound is obtained when Ȝ =0. Although this is only a bound, it strongly suggests that higher values of Ȝ are likely to produce more accurate ap proximations of V *. Compared to LS-TD( Ȝ ), there is an additional parameter in RLS-TD( Ȝ ), which is the value į for the initial variance matrix P 0 . As was pointed out by Haykin (1996,pp.570), the exact value of the initializing constant į has an insignificant effect when the data length is lar ge enough. This means that in the limit, the final solutions obtained by LS and RLS are almost the same. For the influence of į on the transient phase, when the positive constant į becomes lar ge enough or goes to infinity , the transient behavior of RLS will be almost the same as that of LS methods (Ljung, 1983). But when į is initi alized with a relatively small value, the transient phases of RLS and LS will be dif ferent. In practice, it is observed that there is a variable performance of RLS as a function of the initialization of į (Moustakides, 1997). In some cases, RLS can exhibit a significantly faster convergen ce when initialized with a relatively small positive definite matrix than when initiali zed with a lar ge one (Haykin,1996; Moustakides, 1997; Hubi ng and Alexander , E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 269 1989). A first effort toward this direction is the statistical analysis of RLS for soft and exact initialization but limits to the case that the number of iterations is less than the size of the estimation vector (Hubing and A lexander , 1989). Moustakides (1997) provided a theoretical analysis on the relation between the algorithmic performance of RLS and the initialization of į . By using the settling time as the perform ance measure, Moustakid es proved that the well-known rule of initial ization with a relatively small ma trix is preferable for cases of hig h and medium signal-to-nois e ratio (SNR), whereas for low SNR, a relatively large matrix must be selected for achieving best results. In the following learning prediction experiments of RLS-TD( Ȝ ), as well as the learning control simulation of Fast-AHC, it is observed that the value of the initializing constant į also plays an important role in the convergence performance, and the above theoretical analyses provide a clue to exp lain our experimental results. 4. Learning Prediction Experiments on Markov Chains In this section, an illustrative example is given to show the effectiv eness of the proposed RLS-TD( Ȝ ) algorithm. Furtherm ore, the algorithmic performance under the influence of the initializing constant į is studied. The example is a finite-state absorbing Markov chain called the Hop-W orld problem (Boyan, 1999). As shown in Fig ure 1, the Hop-W orld proble m is a 13-state Markov chain with a n absorbing state. Fi gure 1: The Hop -W orld Problem In Figure 1, state 12 is the initial state for each trajectory and state 0 is the absorbing state. Each non-absorbing state has two possible state transitions with transition probability 0.5. Each state transition has reward –3 excep t the transition from state 1 to state 0 which has a reward of –2. Thus, the true value f unction for state i (0 İ i İ 12) is –2 i . T o apply linear temporal-differenc e algorithms to the value function prediction problem, a set of four-element state features or basis functions i s chos en, as shown in Figure 1. The state features of states 12,8,4 and 0 are, res pectively , [1,0,0,0], [0,1,0,0], [0,0,1,0], [0,0,0 ,1] and the state features of other stat es are obtained by linearly interpo lating between these. In our simulatio n, the RLS-TD( Ȝ ) alg orithm as well as LS-TD( Ȝ ) and conventional linear TD( Ȝ ) algorithms are used to solve the above value function prediction problem without knowing the model of the Markov chain. In the experiments, a trial is defined as the period from the initial state 12 to the term inal state 0. The performance of the algorithms is evaluated by the averaged root mean squared (RMS) error of value-func tion predictions over all the 13 states. For each parameter s etting, t he perform ance i s averaged over 20 independent M onte-Carlo runs. Figure 2 shows the learning curves of RLS-TD( Ȝ ) and conventional linear TD( Ȝ ) algorithms with three dif ferent parameter settings. The param eter Ȝ is set to 0.3 f or all the alg orithms and the X U , H E , & H U 270 step-size paramete r of TD( Ȝ ) has the following form. n N N n 0 0 0 1 D D (34) The above step-size schedule is also stud ied in Boyan (1999). In our experiments, three differ ent settings are used, which are (s1) 01 . 0 0 D , 6 0 10 N (s2) 01 . 0 0 D , 1000 0 N (35) (s3) 1 . 0 0 D , 1000 0 N . Diffe rent from those in Boyan (1999), the linear TD( Ȝ ) algorithms applied here are in their online forms, which update the weights after every state transitions. So the paramete r n in (34) is the number of state transitions. In each run, the weights are all initialize d to zeroes. In Figure 2, the learning curv es of conventional linear TD( Ȝ ) algorithm s with step-size schedules (s1), (s2) and (s3) are shown by curves 1,2 and 3, respectively . For each curve, the averaged RMS errors of value function predictions over all the states and 20 independent runs are plotted for each trial. Curve 4 shows the learning performance of RLS-TD( Ȝ ). One additional parameter for RLS-TD( Ȝ ) is the initial value į of the va riance matrix P 0 . In this experim ent, į is set to 500, which is a relatively large value. From Figure 2, it can be concluded that by making use of RLS methods, RLS-TD( Ȝ ) can obtain much better performance than conventional linear TD( Ȝ ) algorithms and eliminates the design problem of the step-size schedules. Other experim ents for linear TD( Ȝ ) and RLS-TD( Ȝ ) with different parameters Ȝ are also conducted and simil ar results are obtained when the initial values į of RLS-TD( Ȝ ) are large and the conclusion is confirmed. Figure 2: Perform ance comparison between RLS-TD( Ȝ ) and TD( Ȝ ) 1,2,3 ---TD(0.3) wit h step-size parameters specified by (s1), (s2) and (s3) 4—RLS-TD(0.3) with i nitial variance matrix P 0 =500 I W e have done demonstrative experiments to investigate the influence of į on the performance of the RLS-TD( Ȝ ) algorithm. Figure 3 shows the performance comparison between RLS-TD( Ȝ ) E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 271 algorithms using two different initial parameters of the variance matrix P 0 , which are P 0 =0.1 I and P 0 =1000 I , respecti vely . The forgetting factor is µ =0.995. The p erformance of the suggested algorithm is measured by the averaged RMS errors of the value function prediction in the first 200 trials over 20 independent runs and all the 13 states. In the experiments, 1 1 settings of the parameter Ȝ are tested , which are 0.1 n ( n =0,1,…,10). In Figure 3, it is clearly shown that the performance of RLS-TD( Ȝ ) with a large initial value of į is m uch better than RLS-TD( Ȝ ) with a small initial value of į . In other experiments with differe nt param eter settings of Ȝ and į , sim ilar results are also obtained. W e may ref er this phenomenon to the low SNR case of t he forgett ing factor RLS studied in Moustakides (1997). For the Hop-W orld problem, the stochastic state transitions could introduce high equation residuals ) ( ) ( t t X b W X A in (19), which correspond s to the additive noise with lar ge variance, i.e., the low SNR case. As has been discussed in Section 2, for the forgetting factor RLS in low SNR cases, a relatively lar ge initializing constant į must be selected for better results. A full understanding of this phenom enon is yet to be found. Figure 3: Perfor mance comparison of RLS-TD( Ȝ ) with dif ferent initial value of į ( µ =0.995) The per formance of RLS-TD( Ȝ ) with unit forget ting factor µ =1 is also tested in our experiments. Although the initial value effect in RLS with µ =1 has not been discussed intensively (Moustakides,1997) , the same effects of į are observed empirically in the case of µ =1 as that in µ <1, which is shown by Fi gure 4. In our other experiments, it is also found that when į is initializ ed with a small value, the performance is sensitive to the values of į and the parameter Ȝ . In this case , the conv ergence speed of RLS-TD( Ȝ ) increases as Ȝ increases from 0 to 1, which is shown in Figure 3. Furthermore, when Ȝ is fixed, the performance of RL S-TD( Ȝ ) deteriorates as į b ecomes smaller , as shown in Figure 5 . X U , H E , & H U 272 Figure 4: Perfor mance comparison of RLS-TD( Ȝ ) with dif ferent initial value of į ( µ =1) Figure 5: Learning curves of LS-TD( Ȝ ) and RLS-TD( Ȝ ) with d ifferent į ( µ =1 ) In Figure 5, the learning curves of RLS-TD( Ȝ ) with different initia lizing constants į are shown and compared with that of LS-TD( Ȝ ). In the experiment, Ȝ is set to 0.5. From Figure 5, it is shown that the performance of RLS-TD( Ȝ ) approaches that of LS-TD( Ȝ ) when į becomes l arge. As is well known, when į becomes large enough, the perform ance of RLS and LS methods will be almost the same. Figure 6 shows the performance comparison between LS-TD( Ȝ ) and RLS-TD( Ȝ ) with a large value of į . The initial variance matrix for RLS-TD( Ȝ ) is set to 500 I in every runs, where I is th e identity matrix. E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 273 Figure 6: Performance c omparison of LS-TD( Ȝ ) and RLS-TD( Ȝ ) with µ =1 and large initial value of į Based on the above experimental results, it can be concluded that the convergence speed of RLS-TD( Ȝ ) is mainly influenced by the initial value į of the variance matrix and the parameter Ȝ . Detailed discussions on the properties of RLS-TD( Ȝ ) are given as follows: (1) When į is relatively large, the effect of Ȝ becomes small. If į is lar ge enough or goes to infinity , the performance of RLS-TD( Ȝ ) and LS-TD( Ȝ ) will be almost the same, as was discussed above. In such cases, the ef fect of Ȝ on the speed of conver gence is insignificant, which coincides with the discussion in Boyan (1999). However , as described in Theorem 2, the value of Ȝ still af fects the ultimate error bound of value function approximation. (2) When į is relatively small, it is observed that the convergence performance of RLS-TD( Ȝ ) is dif ferent from that of LS-TD( Ȝ ) and is influenced by the values of both į and Ȝ . In the experiments of t he Hop-W orld pro blem, the results show that smaller values of į lead to slower conver gence. These results may be explained by the theoretical analysis on the transient phase of the forgetting factor RLS (Moustakides,1997). According to the theory in Moustakides (1997), larger values of į are needed for better performance in th e cases of low SNR while smaller į values are preferable for fast convergence in the cases of high and medium SNR. So diffe rent values of į must be selected for faster conver gence of RLS-TD( Ȝ ) in dif ferent cases. Especially , in some cases, such as the high SNR case disc ussed in Moustakid es (1997), RL S methods with sm all values of į can obtain a very fast speed o f convergence. (3) Compared to c onventional linear TD( Ȝ ) algorithm s, the RLS-TD( Ȝ ) algorithm can obtain m uch better perf ormance by m aking use of RLS met hods for value function predi ction problems. Furthermore, in TD( Ȝ ), a step-size schedule needs to be careful ly designed to achieve good performance, while in RLS-TD( Ȝ ), the initial value į of the variance matrix can be selected according to the c riterion of a “lar ge” or a “small” value. (4) For the comparison of LS-TD( Ȝ ) and RLS-TD( Ȝ ), which one is preferable depends on the objective. In online applications, RLS-TD ( Ȝ ) has advan tages in computational efficiency because the com putation per step for RLS-TD( Ȝ ) is O( K 2 ) and for LS-TD( Ȝ ), it is O( K 3 ), where X U , H E , & H U 274 K is the number of state features. Moreover , as will be seen later , RLS-TD( Ȝ ) can obtain better transient conver gence perfor mance than LS-TD( Ȝ ) in some cases. On the other hand, LS-TD( Ȝ ) may be preferable to RLS-TD( Ȝ ) in the long-term convergence performance, as can be seen in Figure 5. And from a system identification point of view , LS-TD( Ȝ ) can obtain unbiased parameter estimates in face of white additive noises while RLS-TD( Ȝ ) with finite į would possess lar ge parameter discrepancie s. 5. The Fast-AHC Algorithm and T wo Learning Control Experiments In this sectio n, the Fast-AHC algorithm is p roposed based on the above results on learnin g prediction to solve learning control pro blems. T wo learning control experiments are conducted to illustrate the ef ficiency of Fast-AHC . 5.1 The Fast-AH C Algorithm The ultimate goal of reinforcement learning is learnin g control , i.e., to estimate the optimal policies or the optimal val ue functions of Markov decision processes (MDPs). Until now , several reinforcement learning control algorithms including Q-learning (W atkins and Dayan,1992) , Sarsa-learning (Singh, et al.,2000) an d the Ada ptive Heuristic Critic (AHC) algorithm (Barto, Sutton and Anderson,1983 ) have been proposed. Among the above methods, the AHC met hod is differe nt from Q-learning and Sarsa-learning which are value-function-based m ethods. In the AHC method, value functions and po licies are separately represented while in value-functi on- based methods the policies are determined by the value functions directly . There are two components in the AHC method, which are called the critic and the actor, respectively . The actor is us ed to generate contr ol actions according t o the policies. T he critic is used to evaluate the policies represented by the actor and provide the actor with internal rewards wi thout waiting for delayed external rewards. Since the o bjective of the critic is policy evaluation or learning prediction, temporal-dif ference lea rning me thods are chosen as the critic’ s learning algorit hms. The learning algorithm of the actor is determine d by the estimation of the gradient of the policies. In the following discu ssion, a detailed introduction on the AHC method is given. Figure 7 shows the architecture of a learning system based on the AHC method. The learning system consists of a critic network and an actor network. The inputs of the critic network include the external rewards and the state feedback from the environme nt. The internal rewards provided by the critic network are ca lled the temporal-dif ference (TD) signals. As in most reinforcement learning methods, the whole system is modeled as an MDP denoted by a tuple { S , A , P , R }, where S is the state set, A is the acti on set, P is the state tr ansition probability and R is the reward function. The policy of the MDP is defined as a function S : S ė Pr( A ), where Pr( A ) is a proba bility distribut ion in the action sp ace. T he objective of the AHC method is to estimate the optima l policy ʌ * satisfying the following equatio n. ¦ f 0 * ] [ max max t t t r E J J J S S S S (36) where J is the discount factor and r t is the reward at time-step t ˈ E ʌ [ ] stands for the expectation with respect to the policy ʌ and the state transition probabilit ies and J ʌ is the expe cted total reward. E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 275 Fig ure 7: The AHC learning s ystem The value function for a stationary policy S and the optimal value function for the optimal policy are defined as foll ows: ] [ ) ( 0 0 ¦ f t t t s s r E s V J S S (37) ] [ ) ( 0 0 * * ¦ f t t t s s r E s V J S (38) According to the theory of dynamic programm ing, the optimal value function sat isfies the following Bellman equ ation. )] ' ( ) , ( [ max ) ( * * s EV a s R s V a J (39) where R ( s , a ) is the expected reward received after taking action a in state s . In AHC, the critic uses temporal-dif ference learning to approximate the value function of the current policy . When li near function approximators are used in the critic, the weig ht update equation is t t t t t t t z s V s V r W W )] ( ) ( [ 1 1 J D (40) where z t is the eligibility trace defined in (10). The action selection policy of the actor is determined by the current state and the value function estimation of the critic. Suppos e a neural network with weight vecto r u =[ u 1 , u 2 ,…, u m ] i s used in the actor , and the output of the actor network is ) , ( t t s u f y (41) The action ou tputs of the actor are determined by the following G aussian probabilistic dis- tribution. ) ) ( exp( ) ( 2 2 t t t t r y y y p V (42) where the mean value is given by (41) and the variance is given by )) ( exp( 1 /( 2 1 t t s V k k V (43) In the above equatio n, k 1 and k 2 are positive constants and V ( s t ) is the value function es- X U , H E , & H U 276 timation of the critic network. T o obtain the learning rule of the actor , an estimation of the policy gradient is given as follows: u y y y r u y y J u J t t t t t t t w w | w w w w w w V S S ˆ (44) where t r ˆ is the internal reward or the TD signal provided by the critic: ) ( ) ( ˆ 1 t t t t s V s V r r J (45) Since in the AHC method, the critic is used to estimate the value function of the actor ’ s policy and provide t he internal reinforcement using temporal-difference learning algorithms, the efficiency of temporal-different learning or learning prediction will gr eatly influence the whole learning sys tem’ s performan ce. Although the policy of the actor is changing, it may change relatively slowly especially when fast convergence of learning prediction in the critic can be realized. In the previous sections, RLS-TD( Ȝ ) is shown to have better data efficiency than conventional linear TD( Ȝ ) algorithms and a very fast convergence speed can be obtained when the initializing constant is chosen appropria tely . Thu s, apply ing RLS-TD( Ȝ ) to the policy evaluation i n the critic network will improve the learning prediction performance of the critic and is promising to enhance the whole sy stem’ s learning control p erformance. Based on the above idea, a new AHC method called the Fast-AHC algorithm is proposed in this paper . The efficiency of the Fast-AHC algorithm is verifi ed empirically and detailed analysis of the results is given. Following is a complete description of the Fast-AHC al gorithm. Algorithm 3: The Fast-AHC algorithm 1: Given: a c ritic neural network and an actor neural network, which are both linear in parameters, a stop criterion for the algorithm. 2: Initialize the state of the MDP and the learning parameters, set t =0. 3: While the stop criterion is not satisfied, (3.1) According to the current state t s , compute the output of the actor network t y , determine the actual action of the actor by the probability distribution given by (42). (3.2) T ake the action t y on the MDP , and observe the state transition from t s to 1 t s , set reward ) , ( 1 t t t s s r r . (3.3) Apply the RLS-TD( Ȝ ) algorithm des cribed in (27)-(29) to update the weights of the critic network. (3.4) Apply the following equation to update the weights of the actor network, t t t t a J a a w w S E 1 (46) where ȕ t is the learning factor of the actor . (3.5) Let t = t +1, return to 3. E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 277 5.2 Learning Control Exp eriments on The Cart-Pole Balancing Problem The balancing control of inverted pendulums is a typical nonlinear control problem and has been widely st udied not on ly in control the ory but also in artificial intelligenc e. In the research of artificial intelligence, the learning control of inverted pendulums is considered as a standard test problem for machine learning methods, especially for RL algorithms. It has been studied in the early wor k of Michie’ s BOXES system (Michie,et al.,1968) and later in Barto and Sutton (1983), where the learning controllers only have two output values: +10( N ) and –10( N ). In Berenji, et al.(1992) and L in, et al.(1994), AHC methods with continuous outputs are applied to the cart-pole balancing problem. In this paper , the cart-pole balancing problem with continuous control values is used to illustrate the effectiveness of the Fast-AHC method. Figure 8 shows a ty pical cart-pole bala ncing control system, which consists of a cart moving horizontally and a pole with one end fixed at t he cart. Let x de note the horizontal distance between the center of the cart and the center of the track, where x is negative when the cart is in the l eft part of the track. V ariable T denotes the angle of the pole from its upr ight position (in degrees) and F is the amount of f orce ( N ) applied to the cart to move it towards its left or right. So the control system has four state variables T T , , , x x , where T , x are the derivatives of x and T , respectively . In Figure 8, the mass of the cart is M =1.0kg, the mass of the pole is m =0.1kg, the half-pole length is l =0.5m, the coefficient of friction of the cart on the track is µ c =0.0005 and the coefficient of friction of the pole on the cart is µ p =0.000002. The boundary constraints on the state variables are given as follows. $ $ 12 12 d d T (47) m x m 4 . 2 4 . 2 d d (48) The dynamics of the control system can be described by the following equations. ° ° ° ¯ ° ° ° ® m M x ml F x ml l m M ml M m x ml F g M m c p c ) sgn( ) cos sin ( cos ) ( 3 4 ) ( )] sgn( sin [ cos sin ) ( 2 2 2 P T T T T T T P P T T T T T (49) where g is t he acceleration due to the gravity , which is –9.8 m / s 2 . The above parameters and dynamics equations are the same as those studied in Barto et al. (1983). Figure 8: T he cart-pole balancing control system X U , H E , & H U 278 In the learning control experiments of the pole-balancing probl em, the dynamics (49) is assumed to be unknown to the learning controller . In addition to the four state variables, the only available feedback is a fai lure sign al t hat notifie s t he con troller when a failure occurs, which means the values of the state variables exceed the boundar y constrain ts prescribed by inequalities (47) and (48). It is a typical reinforcement learning problem, where the failure signal serves as the reward. Since an external reward may only be available after a long sequence of actions, the critic in the AHC learning controller is used to provide the internal reinforcement signal to accomplish the learning task. Learning control experim ents on the pole-balancing problem are conducted using conventional AHC method which uses linear TD( Ȝ ) algorithms in the critic and the Fast-AHC method proposed in this paper . T o solve the continuous state space problem in reinforcement learning, a class of li near function approxima tors, which is called Cerebe llar Model Articulation Controller (CMAC) is used. As a neural network model based on the neuro-physiological theory about human cerebellar ˈ CMAC was first proposed by Albus (1975) and has been widely used in automatic control and function approximation. In CMAC neural networks , the dependen ce of adjustable parameters or weights with respect to outputs is linear . For detailed discussion on the structure of CMAC neural networks, one may refer to Albus (1975) and Sutton & Barto (1998). In the AHC and Fast-AHC learning controllers, two CMA C neural networks with four inputs and one output for each are u sed as the function ap proximators in the critic and the ac tor , respectively . Each CM AC has C tilings and M partitions for every input. So the total physical memory for each CMAC network is M 4 C . T o reduce the computation and memory requirements, a hashing technique described by the following equations is employed in our experiments. (For detailed discussion on the parameters of the CMAC networks , please refer to Appendix C). ¦ 4 1 1 ] ) ( [ ) ( i i M i a s A (50) F ( s )= A ( s ) mod K (51) In (50) and (51), s represents an input state vector , a ( i ) (0 a ( i ) M ) is the activated tile for the i- th element of s , K is the total number of the physical m emory and F ( s ) is the physical memory address corresponding to the state s , which is the rem ainder of A ( s ) divided by K . In order to compare the performance of different learning algorithms, the initial parameters o f each learning controller are selected as follows: The weights of the critic are all initialized to 0 and the weights of the actor are initialized to random numbers in interval [0,0.1]. The other parameters for the AHC and Fast-AHC algorithms are 95 . 0 J , 4 . 0 1 k and 5 . 0 2 k . In all the experiments, a trial is defined as the period from an initial state to a failure state and the initial state of each trial is set to a randomly generated state near the unstable equilibrium (0,0,0,0) with a maximum distance of 0.05. Equation (49) is employed to simulate the dynamics of the sy stem using the Euler method, which has a time step of 0.02s. When a trial lasts for more than 120,000 time steps, i t is said to be successful and the learning controller is assumed to be able to balance the pole. The reinforcement signal for t he problem is defined as ¯ ® otherwise 0, occurs failure if 1, t r (52) The performance of the Fast- AHC method is tested extensively , where different parameter settings including Ȝ and the initial variance matrix P 0 are chosen. In the experiments, the E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 279 forgetti ng factor of RLS-TD( Ȝ ) in the critic is set to a value that is equal to 1 or very close to 1. The learning control experiments using conventional AHC methods are also conducted for comparison. The performance comparisons between the two algorithms are shown in Figure 9, 10 and 1 1. In the above experiments, the initial variance matrixes of the Fast- AHC algorithm are all set to P 0 =0.1 I . The performance of Fast-AHC is compared with AHC for different Ȝ . The numbers of physical memories of the critic network and the actor network are chosen as 30 and 80, respectively . For each parameter setting of the two algorithms, 5 independent runs are tested. The performance is evaluated according to the trial number needed to successfully balance the pole. The learning factors for the actor networks are all set to 0.5, which is a manually optimized value for both algorithm s. In all the experiments, 1 1 settings of Ȝ are test ed. Figure 9: Performance comparison between Fast -AHC and AHC with Į = 0.01 Figure 10: Per formance comparison between Fast-AHC and AHC with Į =0.03 X U , H E , & H U 280 Figure 1 1: Perfor mance comparison between Fast-AHC and AHC with Į =0.05 In Figure 9, 10 and 11, the learning facto rs of the critic networks in AHC are chosen as Į =0.01, 0.03 and 0.05, respectively . It is found that when Į <0.01, the performance of AHC becomes worse. For the learnin g factors that are greater than 0.05, the AHC algorithm may become unstable, and even when Į =0.03 and Į =0.05, the AHC algorithm becomes unstable for Ȝ =1. For the time-varying learning factors specified in (s1)-(s3), the performance is worse t han the above constant learning factors. So the above three settings of the learning factor Į are typical and near optimal for the AHC algorithm. From the above experimental results, it can be concluded that by using RLS-TD( Ȝ ) in the critic network, the Fast-AHC algorithm can obtain better performance than convention al AHC algorithms. Although Fast-AHC requires more co mputation per step than AHC, it is more effici ent than AHC in that less tri als or data are needed to successfully balanc e the pole. As has been discussed in the previous sections, the convergen ce performance of RLS-TD( Ȝ ) is influenced by the initial value of the variance matrix. This is also the case in Fast-AHC. In the above learning control experiments, a small value į =0.1 is selected. In other experiments, when į is set to other small values, the performance of Fast-AHC is satisfac tory and is better than AHC. However , when į is equal to a relatively lar ge value, for example į =100 or 500 , the performance of Fast-AHC deteriorates significantl y . Since RLS-TD( Ȝ ) with a large initializing constant has similar performance as LS-TD( Ȝ ), it can be deduced that the AHC method using LS-TD( Ȝ ) in the critic will also have bad performance in t he cart-pole balancing problem. T o verify this, experiments are conducted using Fast-AHC wi th lar ge initializing constant į and AHC using LS-TD( Ȝ ). For each parameter setting, 5 independent runs are tested. In the experime nts, the maximum trials for each algorithm in one run is 200 so that if an algorithm fails to balance the pole within 200 trials, its performance is set to 200.When using LS-TD( Ȝ ) in the AHC method, there may be computational problems in the ma trix inversion during the first few steps of learning and two methods are tried to avoid this problem. One is the usage of TD( Ȝ ) in the first 60 steps of updates. The other is that the actor is not updated in the early stage of learning until LS-TD( Ȝ ) is E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 281 stable. However , similar results are found for the two methods. Figure 12 shows the experimental results which clearly verify that the performance of Fast-AHC with a lar ge initializin g constant į is similar to AHC using LS-TD( Ȝ ) and it is much worse than Fast-AHC with a small į . A detailed discussion of this phenomenon is provid ed in subsection 5.4. Figure 12: Perfo rmance comparison of Fast-AHC with dif ferent initial variance In the following Figure 13 and Figure 14, the variations of the pole angle ș and the control force F ar e plotted, where a successfully trained Fast-AHC learning controller is used to control the cart-pole system . Figure 13: V ariation of the pole angle Figure 14: V ariation of the con trol force 5.3 Learning Control Exp eriments of The Acrobot In this subsection, another learning control example, which is the swing-up control of the acrobot in minim um time, is presented. The learning control of the acrobot is a class of adaptive optimal control problem that is more difficult than the pole-balancing problem. It has been investigated in Sutton (1996), where CMAC-based Sarsa-learning algorithms were employed to solve it and only the case of discrete control a ctions was studied. In our experim ents, the case of continuous actions X U , H E , & H U 282 is considered. An acrobot moving in the vertical plane is shown in Figure 15, where OA and AB are the first link and the second link, respectively . The control torque is applied at point A. The goal of the swing-up control is to swing the tip B of the acrobot above the line CD which is higher than the joint O by an amount of the length of one link. Figure 15: The acrobo t The dynamics of the ac robot system is described by the following eq uations. 1 1 2 2 1 / ) ( d d I T T (53) ) / ( 2 1 1 2 2 I I W T d d (54) where 2 1 2 2 1 2 2 2 1 2 2 1 1 1 ) cos 2 ( I I l l l l m l m d c c c T (55) 2 2 2 1 2 2 2 2 ) cos ( I l l l m d c c T (56) 2 1 1 2 1 1 2 2 1 2 1 2 2 2 2 2 1 2 1 ) 2 / cos( ) ( sin 2 sin I S T T T T T T I g l m l m l l m l l m c c c (57) ) 2 / cos( 2 1 2 2 2 S T T I g l m c (58) In the above equations, the para meters i T , i T , i m , i l , i I , ci l are the angle, the angle velocity , the mass, the length, the moment of inertia and the length of the center of mass for link i ( i =1,2), respectively . Let s T denote the goal state of the swing-up control. Since the control aim is to swing up the acrobot in minimum time, the reward function r t is defined as ¯ ® else , 0 if , 1 T t s s r (59) In the simulation experiments, the control torque IJ is cont inuous and is bounded by [-3 N , 3 N ]. Similar to the cart-pole balan cing problem, CMAC neural networks are applied to solve the above E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 283 learning control problem with continuous states and actions. In the CMAC-based actor -critic controller , the actor network and the critic network both have C =4 tilings and M =7 partitions for each input. In the actor network, uniform coding is em ployed and non-uniform coding is used in the critic network. For details of the coding parameters, please refer to Appendix C. The sizes o f the physical memories for the actor network and the critic network are 100 and 80, respectively . In the CMAC networks, the following hashing techniques are used. (For the definition of A ( s ), a ( i ) and F ( s ), please refer to Subsection 5.2.) ¦ u 4 1 1 ] ) ( [ ) ( i i M i a s A (60) F ( s )= A ( s ) mod K (61) In the sim ulation, the parameters for the acr obot are chosen as m 1 = m 2 =1kg, I 1 = I 2 =1kgm 2 , l c1 = l c2 =0.5m, l 1 = l 2 =1m and g=9.8m/s 2 . The time step for simulation is 0.05s and the time interval for learning control is 0.2s. The learning parameters are Ȝ =0.6, Ȗ =0.90, ȕ =0.2, k 1 =0.4, k 2 =0.5. A trial is defined as the period that starts from the stable equilibrium and ends when the goal state is reached. After each trial, the state of the acrobot is re-initialized to its stable equilibrium. For each parameter setting, 5 independent runs are tested. Each run consists of 50 trials and after 50-th trial, the actor network is tested by controlling the acrobot alone, i.e., by setting the action variance defined in (43) to zero. The performance of the algorithms is evaluated according to the steps used by the actor networks to swing up the acrobot. The performance comparisons between Fast-AHC and AHC are shown in Figure 16,17 and 18. In the experiments, both algorithms are tested with different Ȝ and AHC is also tested with different learning fac tors of the critic networks. From the results, it is also shown that Fast-AHC c an achieve higher data efficiency than AHC. However , in this example, a relatively large G is used, which is different from the previous cart-pole balancing example. In other experim ents, good performance is obtained with large initializing constant and when G is very small, the performance deteriorates significantly . Thus this problem may be referred to the low SNR case in Moustakides (1997), where large values of G are preferable for best convergence rate of RLS methods. Figure 16: Performance comparison between Fast-AHC and AHC with Į =0.02 X U , H E , & H U 284 Figure 17: Performance comparison between Fast-AHC and AHC with Į =0.05 Figure 18: Performance comparison between Fast-AHC and AHC with Į =0.1 The following Figure 19 shows the performance comparison between Fast-AHC with a large (300) and a small (0.01) value of G , where 6 settings of the parameter Ȝ are tested for each algorithm. The performance of AHC using LS-TD( Ȝ ) is also shown. In Figure 20, a typical curve of the angle of the first link is plotted, where the acrobot is controlled by the actor network of the Fast-AHC method ( Ȝ =0.6) after 50 trials. E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 285 Figure 19: Performance comparison of Fast-AHC and AHC using LS-TD( Ȝ ) Figure 20: V ariation of the angle of link 1(Controlled by Fast-AHC after 50 trials) 5.4 Analysis of The Experimental Results Based on the above experim ental results, it can be concluded that by usi ng the RLS-TD( Ȝ ) algorithm in the critic n etwork, the Fast-AHC algorithm can obtain better performance than conventional AHC algorithms in that less trials or data are needed to converge to a near optimal policy . As is well known, one difficulty for the applications of RL methods is their slow convergenc e, especially in the cases where learning data are hard to be generated. For the Fast-AHC algorithm, although m ore com putation per step is required than conventional AHC methods, it will not be a serious problem when the nu mber of linear state features is small. In all of our learning control experiments, hashing techniques are used to reduce the state features in CMAC networks so that the computation of Fast-AHC can be reduced to an economical amount. Nevertheless, when the state feature number is large, conventional AHC methods may be preferable. In the ex periments, it is observed that the perf ormance of Fast-AHC is affected by the initializing constant į . These results are consistent with the property of RLS-TD( Ȝ ) and the RLS X U , H E , & H U 286 method in adaptive filtering, which has been discussed in Section 4. In the learning control experiments of the cart-pole balancing problem, better performance of Fast-AHC is obtained by using small values of į . While in the learning control of the acrobot, higher data efficiency is achieved using Fast-AHC with a relatively large į . These two different properties of Fast-AHC may be referred to the different SNR cases for RLS methods (Moustakides,1997). A thoro ugh theoretical analysis on this problem is an interesting topic for future research. In our experiments, the performance of the AHC method using LS-TD( Ȝ ) is also tested. As has been studied in Section 4, when the initializing constant į is large, the performance of RLS-TD( Ȝ ) and LS-TD( Ȝ ) does not dif fer much. So the performance of AHC using LS-TD( Ȝ ) is similar to that of Fast-AHC with lar ge values of į . As studied in Moustakides (19 97), the RLS m ethod can converge much faster than other adaptive filtering methods if the environment is stationary and the initializing constant is selected appropriately . In some cases, RLS may conver ge almost instantly . This is also verified in the learning prediction experiments of the RLS-TD( Ȝ ) algorithm. When applying RLS-TD( Ȝ ) in an actor-cr itic learning controller , although the policy of the actor will change over time, it can still be assumed that the changing speed of the policy is slow when co mpared with the fast convergence speed of RLS-TD( Ȝ ). Thus good performance of learning prediction can be obtained in the critic. Moreover , since the learning prediction performance of the critic is important to the policy learning of the actor , the improvement in learning prediction efficiency will contribute to the whole performance improvement of the controller . 6. Conclusions and Future W ork T wo new reinforcement learning algorithms using RLS methods, which are called RLS-TD( Ȝ ) and Fast-AHC, respectively , are proposed in this paper . RLS-TD( Ȝ ) can be used to solve learning prediction problems more effic iently than conventional linear TD( Ȝ ) algorithms. The convergence with probability 1 is proved for RLS-TD( Ȝ ) and the limit of convergence is also analyzed. Experimental results on learning prediction problems show that the RLS-TD( Ȝ ) algorithm is superior to conventional TD( Ȝ ) algorithms in data ef ficiency and it also eliminates the design problem of the step sizes in linear TD( Ȝ ) algorithms. RLS-TD( Ȝ ) can be viewed as the extension of RLS-TD(0) from Ȝ =0 to general 0< Ȝ 1. Although the ef fect of Ȝ on the convergence speed of RLS-TD( Ȝ ) may not be significant in some cases, the usage of Ȝ >0 will still affect the approximation error bound. Thus, when there are needs for value function estimation with high prec ision, large values of Ȝ are preferabl e to Ȝ =0. Furthermore, RLS- TD( Ȝ ) is superior to LS-TD ( Ȝ ) in computation when the weight vector must be updated after every observations. Since learning prediction can be viewed as a sub-problem of learning control, we extend the results in learning prediction to a learning control method called the AHC algorithm. Using RLS-TD( Ȝ ) in the critic network, Fast-AHC can achieve better performance than conventional AHC method in data efficiency . Simulation results on the learning control of the pole-balancing problem and the acrobot system confirm the above analy ses. In the experiments, it is found that the performance of RLS-TD( Ȝ ) as well as Fast-AHC is influenced by the initializing constant į of RLS methods. Different values of į are needed for best performance in dif ferent cas es. This is also a well-known phen omenon in RLS-based adaptive E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 287 filtering and the theoretical results in Moustakides (1997) provide some basis for the explanations of our results. A complete investigation of this problem is our ongoing work. The idea of using RLS-TD( Ȝ ) in the critic network may be applied to other reinforcement learning methods with actor-critic architectures. In Konda and T sitsiklis (1998), a new actor-critic algorithm using linear function approxi mators is proposed and the convergence under certain conditions is proved. One condition for the conver gence of this algorithm is that the convergence rate of the critic is much faster than that of the actor . Thus the application of RLS-TD( Ȝ ) in the critic may be preferable in order to ensure the convergence of the algorithm. The theoretical and empirical work on this problem deserves to be studied in the future. Acknowledgements This work is supported by the National Natural Science Foundation of China under Grants 60075020, 60171003 and China University Key T eacher ’ s Fellowship. W e would very much like to thank the anonymous reviewers and Associate Editor Michael L. Littman for their insights and constructive criticisms, which have helped improve the paper significantly . X U , H E , & H U 288 Appendix A. Derivation of the RLS-TD( Ȝ ) Al gorithm For the derivation of RLS-TD( Ȝ ), there are two diff erent cases, which are determined by the value of the forgetting factor . (1) RLS-TD( Ȝ ) wit h a unit forg etting fac tor . Since 1 t t A P (62) I P G 0 (63) t t t z P K & 1 1 (64) According to Lemma 1, t t T t T t t t T t T t t t t t P x x z P x x z P P A P )) ( ) ( ( )] )) ( ) ( ( 1 [ 1 1 1 1 1 1 JI I JI I & & (65) ) )) ( ) ( ( 1 /( 1 1 1 t t t T t T t t t t t z P x x z P z P K & & & JI I (66) ) ( ) ( t t t t t t i i i t t t t r z W P P r z P b A W & & ¦ 1 1 0 1 1 1 1 1 (67) Thus ] )) ( ) ( ( [ ) )) ( ) ( ( ( ] ))) ( ) ( ( [( t t T t T t t t t t T t T t t t t t t t t t T t T t t t t W x x r K W W x x z r z P W r z W x x z P P W 1 1 1 1 1 1 1 1 1 JI I JI I JI I & & & & (68) (2) RLS-TD( Ȝ ) with a forgetting factor µ<1 The derivation of RL S-TD( Ȝ ) wit h a forgetting factor µ<1 is similar to the exponentially weighted RLS algorithm in Haykins (1996, pp.566-569). Here we only present the results: ) )) ( ) ( ( /( 1 1 t t t T t T t t t z P x x z P K & & JI I P (69) ) )) ( ) ( ( ( 1 1 1 t t T t T t t t t W x x r K W W JI I (70) ] )) ( ) ( ( )] )) ( ) ( ( [ [ 1 1 1 1 1 t t T t T t t t T t T t t t t P x x z P x x z P P P JI I JI I P P & & (71) E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 289 Appendix B. Proof of Theor em 1 T o study the steady property of the Markov chain defined in Section 3, we construct a stationary process as follows. Let { x t } be a Markov chain that evolves according to the transition matrix P and is already in its steady state, which means that Pr{ x t = i }= S ( i ) for all i and t . Given any s ample path of the Markov chain, we define ¦ f t t t x z W W W I JO ) ( ) ( & (72) Then } , , { 1 t t t t z x x X & is a stationary process, which is the sa me as that discussed in ( T sitsiklis and Roy , 1997). Let D denote a N h N diagonal matrix with diagonal entries S (1), S (2),…, S ( N ), where N is the cardinality of state space X . Then Lemm a 2 can be deriv ed as follows. Lemma 2. (T sitsiklis and Roy , 1997) Under Assumption 1 - 4 , the following equations hold . 1) ) ) m T m t t DP x x E )] ( ) ( [ 0 I I , for m >0 (73) 2) ) ) ¦ f m T m m t T t DP x z E 0 0 ) ( )] ( [ JO I & , (74) 3) r DP x x r z E m T m m t t t t ) ¦ f 0 1 0 ) ( )] , ( [ JO & (75) wher e N R r , whose Nth component is equal to ] ) , ( [ 1 i x x x r E t t t . According to Lemma 2, E 0 [ A ( X t )] and E 0 [ b ( X t )] are well defined and finite. Furthermore, E 0 [ A ( X t )] is negative definite, so it is invertible. From equation (67), ] ) ( 1 1 [ ] ) ( 1 1 [ )] ( [ ] ) ( [ 1 0 1 0 1 1 1 0 1 0 1 0 1 1 1 0 ) ( ¦ ¦ ¦ ¦ T t t T t t T t t T t t TD RLS X b T W P T X A T P T X b W P X A P W O (76) Since ¦ f o T t t T t X A T X A E 1 0 ) ( 1 lim )] ( [ (77) ¦ f o T t t T t X b T X b E 1 0 ) ( 1 lim )] ( [ (78) and E 0 [ A ( X t )] is invertibl e, * 0 1 0 ) ( )] ( [ )] ( [ lim W X b E X A E W t t TD RLS T f o O (79) X U , H E , & H U 290 Thus ) ( O TD RLS W converges to W * with probability 1. Appendix C. Some details of the coding structures of C MAC net works In the following discussion, the coding structures of CMAC networks in the cart-pole balancing problem and the acrobot control problem are presented. (1) CMAC cod ing structures in the cart-pole balancing pr oblem In the CMAC networks, the state variables have the following boundaries. ] 12 , 12 [ $ $ T , ] deg/ 50 , deg/ 50 [ s s T ] 4 . 2 , 4 . 2 [ x , ] 1 , 1 [ x For the critic net work, C =4 and M =7. The hashing technique specified i n equations (50) and (51) is employed and the total memory size is 30. For the actor network, C =4 and M = 7. The hashing technique specified in equations (60) and (61) is employed and the total memory size is 100. (2) CMAC coding structures in the acrobot swing-up pr oblem In the simulation, the angles are bounded by ] , [ S S and the angular velocities are bounded by ] 4 , 4 [ 1 S S T , ] 9 , 9 [ 2 S S T . The tiling numbers of the actor and the critic both are equal to 4 ( C =4). The total memory sizes for the cr itic and the actor are 80 and 100 , respectively . In the actor network, each tiling partitions the range of each input into 7 equal intervals ( M =7). In the critic network, the partitions for each input are non-uniform, which are given by 1 T : { - ʌ , -1, -0.5, 0, 0.5, 1, ʌ }, 1 T : {-4 ʌ , -1.5 ʌ , -0.5 ʌ , 0, 0.5 ʌ , 1.5 ʌ , 4 ʌ } 2 T : { - ʌ , -1, -0.5, 0, 0.5, 1, ʌ }, 2 T : { -9 ʌ , -2 ʌ , -0.5 ʌ ,0, 0.5 ʌ ,2 ʌ , 9 ʌ } E FFICIENT R EI NFORCEMENT L EARNING U SI NG RLS M ETHODS 291 References Albus,J.S.(1975). A new approach to manipulat or control: the cerebellar model articulation controller (CMAC). Journal of Dynamic Systems, Measur ement, and Control , 9 7(3), 220-227. Barto,A.G ., Sutto n R.S., & A nderson C.W . (1983). Neuronlike adaptive elements that can solve difficult learning control problems. IEEE T ransactions on System, Man, and Cybernetics, 13, 834-846. Bertsekas D.P . & T sitsiklis J.N. (1996). Neur odynamic Pr ogramming . Belmont, Mass.: Athena Scientific. Berenji H.R. & Khedkar P . (1992). Learning and tuning fuzzy logic controllers through re- inforcements, IEEE T rans.On Neural Networks , 3(5), 724-740. Boyan. J.(1999). Least-squares temporal dif ference learning. In Bratko, I., and Dzeroski, S., eds., Machine Learning : Pr oceedings of the Sixteenth International Confer ence (ICML). Boyan, J.(2002). T echnical update: least-squares temporal difference learning. Machine Learning, Special Issue on Reinfor cement Learning , to appear . Brartke. S.J. & Barto A. (1996). Linear least-squares algorithms for temporal dif ference learning. Machine Learning, 22, 33-57. Dayan P .(1992). The convergence of TD( O ) for general O . Machine Learnin g , 8, 341-362. Dayan P .. & Sejnowski T .J. (1994). TD( O ) converges w ith probability 1. Machine Learning, 14, 295-301. Eleftheriou E. & Falconer,D.D. (1986). T racking properties and steady state performance of RLS adaptive filter algorithms. IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , 34, 1097-1 1 10. Eweda E. & Macchi, O. (1987). Convergence of the RLS and LMS adaptive filters. IEEE T rans. Cir cuits and Systems , 34, 799-803. Haykin S. (1996), Adaptive Filter Theory , 3 rd edition, Englewood Clif fs, NJ: Prentice-Hall. Hubing N.E. & Alexander S.T . (1989). Statistical analy sis of the soft constrained initialization of RLS algorithms. In Pr oc. of the IEEE Inter national Confer ence on Acoustics, Speech and Signal Pr ocessing . Jaakkola T ., Jordan M.I., & Singh S.P . (1994). On the convergence of stochastic iterative dynamic programming algorithms. Neural Computation . 6(6), 1 185-1201. Kaelbling L.P ., Littman M.L., & Moore A.W . (1996). Reinforcement learning: a survey . Journal of Artificial Intelligence Resear ch , 4, 2 37-285. Konda V .R, & T sitsiklis J.N. (2000). Actor-critic algorithms. In Neural Information Pr ocessing Systems , 2000, MIT Press. X U , H E , & H U 292 Lin L.J. (1992). Self-improving reactive agents based reinforcement learning, planning and teaching. Machine Learning , 8(3/4), 293-321. Lin C.T . & Lee C.S.G . (1994). Reinforcement structure/parameter learning for neural-network- based fuzzy Logic control system. IEEE T ransactions on Fuzzy System , 2(1), 46-63. Ljung L. & Soderstron T . (1983). Theory and Practice of Recursive Identification . MIT Press. Ljung L. (1977). Analysis of recursive stochastic algorithm. IEEE. T ransactions on A utomatic Contr ol , 22, 551. Michie D. & Chambers R.A. (1968). BOXES: An experiment in adaptive control . Machine Intelligence 2, Dale E. and Michie D., eds., Edinburgh: Oliver and Boyd, 137-152. Minsky M.L. (1954). Th eory of neural-analog reinforcement sy stems and its application to the brain-model problem. Ph.D. Thesis, Princeton University . Moustakides G .V . (1997). Study of the transient phase of the forgetting factor RLS. IEEE T rans. on Signal Pr ocessing , 45(10), 2468-2476. Samuel A.L. ( 1959). Some studies in machine learning using game of checkers. IBM Journal on Resear ch and Development , 3, 21 1-229. Singh, S.P ., Jaakkola T ., Li ttman M.L., & Szepe svari C. (200 0). Convergence results for single- step on-policy reinforcement-learning algorithms. Machine Learning , 38, 287-308. Sutton R. & Barto A. (1998). Reinfor cement Learning, an Intr oduction. Cambridge MA, MIT Press. Sutton R. (1988). Learning to predict by the method of temporal d ifferences. Machine Learning , 3(1), 9-44. T sitsiklis J.N. (1994). Asynchronous stochastic appr oximation and Q-learning. Machine Learning , 16, 185-202. T sitsiklis J.N. & Roy B.V . (1994). Feature-based methods for large scale dynamic programming. Neural Computation . 6(6), 1 185-1201. T sitsiklis J.N. & Roy B.V . (1997). An analysis of temporal difference learning with function approximation. IEEE T ransactions on Automatic Contr ol . 42(5), 674-690. W atkins C.J.C.H. & Dayan P . (1992). Q-Learning. Machine Learning . 8, 279-292. Y oung P . (1984). Recursive Estimation and T ime-Series Analysis . Springer -V erlag.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment