Design and Analysis of SD_DWCA - A Mobility based clustering of Homogeneous MANETs
This paper deals with the design and analysis of the distributed weighted clustering algorithm SD_DWCA proposed for homogeneous mobile ad hoc networks. It is a connectivity, mobility and energy based clustering algorithm which is suitable for scalabl…
Authors: T.N. Janakiraman, A. Senthil Thilak
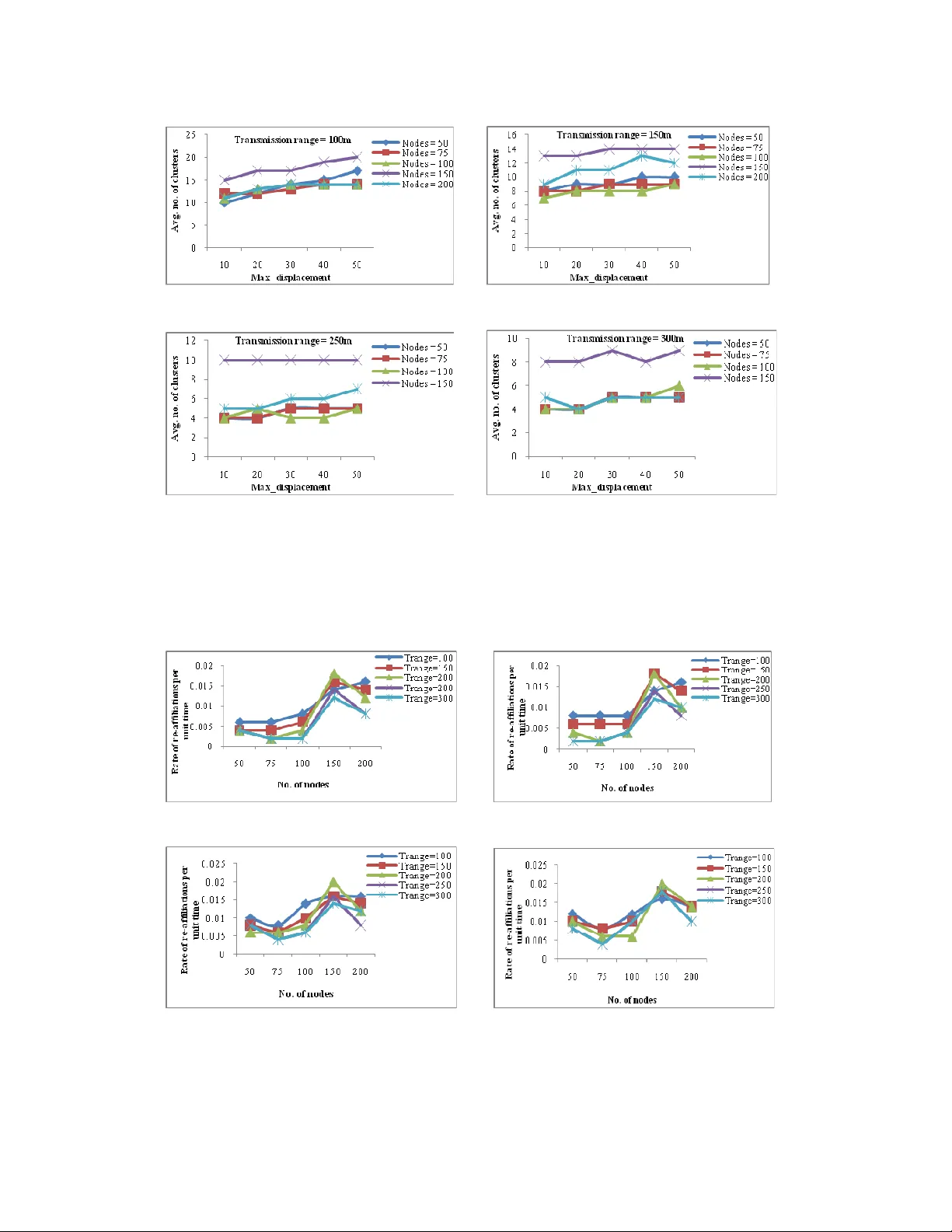
International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 DOI : 10.512 1/ijcnc.2011.330 7 94 D ESIG N A ND A NALYSIS OF SD_DWCA – A M OBILITY B ASED C LUSTERI NG OF H OMOGENEO US MANET S T.N. J anakiraman 1 and A. Senthil Thilak 2 1, 2 Department of Mathemat ics, National Institute of Technology, Tiruchirapa lli-620015, Tamil Nadu, Indi a 1 janaki@n itt.edu, tnj raman2000@ya hoo.com 2 asthilak 23@gmail.com A BSTRACT This paper deals with the design a nd analysis of the distribu ted weighted cl ustering a lgori thm SD_DWCA proposed for homogeneous mobile a d hoc networks. It is a connectivity, m obility and e nergy based clustering a lgorithm which is su itable for s calable ad hoc ne tworks. The algor ithm uses a new gra ph parameter called str ong degr ee define d based on the q uality of neighbours of a node. The parameter s are so ch osen to ens ure high connecti vity, cluster stability and energy ef ficient comm unication among nodes of high dy namic nat ure. T his paper also in cludes t he ex perimental result s of the algorithm impl emented using the network simulator NS2. The experime ntal re sults show that t he al gorithm i s suitable for high speed netw orks and generate s table clusters wit h less mainte nance overhead. K EYWORDS Mobile ad hoc networks, SD_DWCA, Connectivit y, Strong degree , Cluster Stability 1. I NTRODUC TION Mobile Ad hoc Network s [MANETs], which are ot herwise called a s multi-hop networks or peer-to-peer networks are t hose formed b y a series o f autonomous mobile hosts interlinked by means of bandwidth-constrained wir e less links wi th limited battery power. Ad ho c networks, as their name indicates, are unpredictable with frequently changing topology. Ea c h node has a circular transmission range and those nodes which lie wi thin this rang e alone can communicate with this node. The t rans mi ss ion range of all the nodes can either be unifor m or may vary and the nodes may either be of simil a r or of dissimilar nature. If t he tr ans mission range of all the nodes is uniform or the nodes are o f same nature, i.e., t he y are of same architecture th e n the network is termed as a Homogeneous n e twork. Otherwise, it is referred to as a heterogene ous network. The m anagement and control f unct ions of the network are distribute d among th e nodes in t he entire network. As the network is highly decentralized, all network activities includin g topology d iscovery , keeping track of topological changes due t o mobi lity, transmitting a nd maintaining routing i nforma tion and efficient usage of battery power must be executed and monitored by t he no des t hemselv es. Si nce these net works are hi ghly dynamic and ad h oc in nature, e xec uting these contr ol functions becomes a bottle-neck. In or der to perform this management and control o pera tion s and to communicate m essages amo ng n odes having no permanent bonding, it i s essential t o set u p a virtual backbone and this i s accomplished by the process of clustering. Clustering is the pro cess of grouping n odes based on c e rtain strategies and th e above mentioned functions can either b e distributed among the nodes in each cluster or performed by the l ead er nodes/Cluster-heads of each cluster rather than distributing t hrough out th e network. This International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 95 reduces, t o a grea t extent, t he informa tion exchange between the network nodes and the information to be maintained by each node thereb y r educ ing the o ve rheads incur red. Several algorithms are available for clustering of mobil e a d hoc networks [1], [12], [15], [18], [21], [24]. Particularly, classified as mobility-only- based algorithms [ 5], [13], [ 16], power-only-based [2], [18], [1 9] and combination- based algorit hms [7-9], [18 ], [21], [ 22]. The algorithm di s cussed i n this p a per is a combination-base d algorithm, pr opos ed in [23]. In our algorithm , a new graph parameter called stron g degr ee is defi ned a nd in a ddition, we consider tw o other para meters, namel y , mobilit y metric [introduced by Xing et al. in 2 0] and batter y po wer. The re st of this paper is organized as foll ows. The basic defin it ions and graph theoretic terminologies used in this algorithm are g iven in section 2 an d s ection 3 outli nes a review of the existing clustering algorithms. Section 4 includes the basic idea which led to the d e velopment of the algorit hm and the obj ec tives of the algorithm. Section 5 gives the d escription and section 6 the complexity analysi s of the algorit hm . Section 7 says how the clusters can be ranked based on their cluster members. Section 8 includes the simulation study and finally, Section 9 concludes the paper. 2. B ASIC D EFINITIONS A ND T ERMINOLOGIES In this paper, the mobile ad hoc network taken und e r consideration is assumed to be homogeneous, i.e., each node has uniform transm ission p ower. Hence, fro m now on, b y a network, we mean a Hom og eneous Mobile Ad Hoc Network unl e ss ot herwise specified. In a general wir e less network, t o identify the n eigh boring nodes, each node broadcasts a “Hello” message containin g information like i ts position in the terrain, node id etc. Those nod es which are within the transmission r a nge of t he transmitting node can r eceive t he m essage and t hey either send an acknowledgement to t he s e nder or simply s tore t he information r ec eived from the sender to ident ify a nd re cord details about their neighbors. These r ecorde d dat a, in turn can be utilized for clustering and/o r routing. As the nodes are mobile, each node p eriodica lly should send and receive the hello messages, to keep track of their neighbor info. Thus, the neighbor set is peri od ically updated fo r each node. This communication strategy can in general be modelled by using an undirected g raph as follows. 2.1. Gr ap h Theor y vs. MANE T A graph G is defi ne d to be an ordered pair (V, E), where V i s a non-empty set of nodes and E denotes the set of edge s /li n ks between d ifferent pairs of nodes in V . An y set of devices which are capable of i nterac ting wit h each other can be mo de led by using graphs. To represent any given network using a graph, say G , the set of all nodes in th e n e twork is taken as the n ode set V , where two nodes are made adj acent, if the corresponding t wo nodes are within the transmission range of eac h other, i.e., each is in the neighbour set of the other. The graph G thus obtained is referred to as the underlying graph or the network graph. If u and v are any two nodes in G , then d(u, v) denotes t he least number of hops to move from u to v and vice versa and i s referred to a s the Hop-di stanc e between u and v and ed(u, v) denotes the Euclidean dist a nce between u and v. Thus, in a homogeneous network, f or a given transmission range r, two nodes u and v can co m mun ica te with each ot he r if and only if they are at an Euclidean distance less than or equal to r, i. e., ed(u, v) ≤ r . For a given node u, N(u) denotes the set of neighbors of u , i.e, N(u) is the set of those nodes which are 1-hop away from u and its cardinality is defin e d as the d egree of u, whi c h is denoted by deg(u) . The hop-distance between u a nd i ts farthest node in G is called the eccentri c ity o f u in G and is denoted by e cc( u) , i.e., )} , ( { max ) ( ) ( v u d u ecc G V v ∈ = . The minimum and maximum e c centricities of G a re defined respectively as radius [ r(G ) ] and diameter [ d(G) ] of G. A subset S of the node set V(G) of a International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 96 graph G i s said t o be a dominating set of G , if ea ch of the nodes in the network is either in S or is adjacent to some node in S . 2.2. Ca tegorization of Neighbors of a Node For a given node u (transmitting node), t he nodes which are close r to u will receive stronger signals and those nodes whi c h are far apart from u will get weaker signals. Based on this notion, we classify the neighbors of a transmitting node as follows [23], [24]: i. Strong neighbor ii. Weak ne ighbor iii. Medium neig hbor Strong neighbor: A node v is said to be a st rong neighbor of a node u , if the Euclidean distance between u and v is less than or equal to r/2. i.e., 0 ≤ ed(u, v) ≤ r/2. Medium neighbor: A node v i s said to be a medium neighbor of a node u, i f r/2 < ed(u, v) ≤ 3r/4. Weak neighbor: A node v is s aid to be a weak neighbor of a node u, if 3r/4 < ed(u, v ) ≤ r. Strong neighbor Medium neighbor Weak neighbor u Figure 1. Three types of nei gh bors of node u 3. P RIOR W ORK As m entioned e arlier, because of the ad hoc and dynamic n ature of the net works under consideration, it is essential t o set up a virtual backbone so as to fac ilitate effective communication. Further, due to frequent chang es in t he topological inf o rmation, it is ve ry difficult to maintain the neighbor and r outing table for the entire set of nodes i n the n e twork. Therefore, to provide an optimal cost effective communica tion , the am ount of in formation maintained by each node (whi ch is essential for controlling and routing) i s reduce d to a certain extent by constructing a hierarchical o rganiza tion of t he network. The organization should be in such a way that it is r etaine d as long as possible and changes less frequently. This hierarchical organization can be provided by the proc ess of clustering. Several clustering procedures are available in the lit e rature f or clustering o f MANETs. They are categorized in different w ays . One such classifica tion is the Cluster-Head (CH) based and Non-Cluster-Head (NCH) b ased clustering al go rithms [10] , [21] depending o n whether a special mobile node named clu ster- head, is requir e d f or the formations of clusters or not . The algorith m d iscusse d in this paper comes under the category of CH based clustering algorithms. So, few of the r ela ted CH bas ed algorithms are discusse d be low. Lowest ID Heuristic (L ID). In the L ow e st I D (LID) heuristic pr oposed by Baker and Ephremides [3, 4], every node in the network is assigned a u nique identifier (ID) and the node IDs are broadcast to the respective n eighbors . Each node comp ares its ID with those of it s neighbors and it d ec lares itse lf as a C luste r- Head , if its ID is t he lowest am on g all its neighbors. The clusters are formed with such nodes as Cluster-Heads and their neighbors as respective cluster membe rs. If a node can hear two o r more cluster-heads it is designated as a cluster- gateway. The major drawback of the algorithm is that when a highly mobile node is cho se n as cluster-head, b eing the nod e with smallest id among its neighbors, i t causes inconvenient re- International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 97 clustering and undesired cl uste r-head changes. S ec ond ly , since t his algorith m i s i nc lin e d t o choose nodes ha ving s maller IDs as cluster-heads, the sm a ller ID nodes suf fer from battery drainage leading to short lifespan. Further, the id is not assigned based on any pra c tical constraint and hence , the election of cluster-heads is not meaningful. Highest Degree Heu r istic (HD). The highest degree (HD) h e uristic is based on the connectivity between a node and i ts neighbors and was prop ose d by Gerla et al. [11, 17 ]. Thi s connectivity value of a node i s broadcast to all its neighbors and if a node has higher connectivity value t han its n eig hbors, then it is elected as a cluster-head and a cluster is formed with the elected cluster-head and its nei g hbors. Any ti e in cluster-head election is broken b y node IDs. Cluster-gateways are formed with the nodes capable of hearing two or mor e cluster- heads. Since this a lgorithm doesn’t restrict the n umber of n ode s that ca n be h a ndled by a cluster-head, the heads run out o f power very quickly. Mobility-only-based Clust e ring Algorithms. In MOBIC given by Basu et al. [5], th e relative mobility metric is introduced, in order to for m stable clusters and is defined as the logarithm of the ratio of two success ive rece ived signal streng ths and an aggrega te relati v e mobi lity metric M is computed for each node by taking the va riance (with respect t o zero) of the enti re set of pair- wise relative mobility values of the no de and each of it s neig hbors. Then i t follows th e same procedure as in LI D h euristic t o form clusters with node ID i n L ID replaced by t he value M here. H e nce, i t has all t he d rawba cks of LID. The same problem i s met with the MobDHop clustering algorithm given by Er and Seah [13]. Power-only-based Clustering Algorithms. In genera l , for any cluster-head el ec tion procedure, a node wi th hi gher battery power is c onsidered to be a better c andidate to play the key role of a cluster head. In that way, the algorithms given in [18], [19] consider battery power as the only system parameter for electing cluster-heads. But, as t he mobility of nodes is not conside red in the election, th e possibility of re-clustering is still high when elected cluster-heads h ave high mobility. Combination-based Clustering Algorithms. C hatt erj ee et al. [7, 8] a nd C hoi and Woo[9] have given clustering algorithms using multiple-metrics . In each of the se algo rith ms , they considered mobility and battery power as two of the important metrics toge ther with other parameters. In all th e se algorithms, th e average speed is computed by consideri ng t he ( x , y) po s iti ons of the nodes at v arious instants (from i nitial time t = 1 t o t = T, where T is the t ime at whi ch the algorithm is executed or weig ht is computed) and is used as t he mobility metric. The (x, y) positions are obtained using GPS, th e accuracy of which i s not ideal for fine com puting and the operations of wh ich c ould drain the limited battery power of the n ode quickly. Further, regarding power metri c, Chatterjee et al. [ 7, 8] u se d t he cumul a tive time period for whi c h a node acts as a c luster-head f or computin g battery power. But, this cannot accurate ly reflect the current level of battery power because a busy node (i.e., a node which might have lost much of its energy in j ust transferring or forwarding the control packe ts) may alm ost run out of power without being a cluster-head [2 0]. Choi and Woo [9] used consumed battery po wer as a metric for computing batt e ry po wer. T hus, int e grating these two (mobi l ity and po wer) parameters together with the other parameters , node weig ht is defined for each node in those a lgorith ms and the clustering procedure is simil a r t o tha t of HD heuristic except that here node weight is used in the place of node deg ree. 4. M OTIVATI ON A ND O BJECTIVE O F T HE A LGORITHM In the algori thm analyz ed in this paper, we consider three important p a rameters, namely, battery power, mobility measure and strong degree . Though there are several algorithms available in the literature, st a rtin g from t he highest degree h euristic, almost all the above menti oned International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 98 algorithms use the d egree of a node a s an important p ara meter and pri orities were given t o nodes hav in g highest degre e. While choosing the nodes with highest degree for a cting as cluster-head, all the strong, medium and weak neighbours of a node contribute for t he highest degree of that node. But , there may be some no des, say, u and v such t hat the nu mbe r of strong neighbours of u is less than that of v and the nu m ber o f medium (and weak) neighbours of u is greater th a n that of v with d e g(u) > deg(v). Thus, as per t he st ra tegies u se d in t he existing algorithms, on comparing u and v, u becomes e ligibl e for CH election, even though it has l es ser number of strong neig hbours than v. But, at a lat e r instant, due to mobility, the node u may lose its eligibility of remaining as a CH. This mak e s the c luster structure less st a ble an d the cluster members attached to that clu s ter have to be r e -affiliated or sometimes re-clustering has t o be done. This is because , the nodes which are at the rim o f the circula r trans mission range , (weak neighbors) of the cluster-he ad and the nodes which ar e considerably far away from the cluster- head (medium neighbors) are more likely to move away from the clu ster- head, compared to strong neighbors. Thi s factor highly affects t he stability of t he clusters generated and th is leads to f re quent cl uster- head up dates , re-affiliati on , r e- clustering etc. and h ence cluster-maintenance cost i s also increased. This problem motivated us t o start defining this concept. Considering such a situation , we ’ve defined a n e w d egree called strong degree and this was in cluded as one of the main parameters in S D_DWCA [23]. Apart from this, we also include the mobility of the nodes and the bat tery power for CH election. For, if a CH is allowed to continue its status for a longer perio d, then it will l e ad to batt e ry dr ainage a nd hen ce we should continue with re- affiliation or r e -clustering. Hence, to avoid excessive usage of a CH, batt ery power is considered for selecting cluster heads. With these three parameters, the algorit h m is developed with the following objectives . 1. The network nodes are partitioned into different groups of various sizes, so as to form a hierarchical orga nization of the n etwork. 2. The clusters hav e t o be stable as long as possible, but, without excess ive batt e ry drainage. 3. The cluster formation and ma intenance overhead should be minimized. 4. The cluster-heads should not be ove rloaded. 5. During t he cluster set up and maintenance phase, the load sho uld be distribut e d among all the nodes in the network. 6. Re-affiliations should be minimized. 7. Re-clustering should be avoided a s much as possible. At times of necess ity, r e- affiliations are allowed instead of re-c lustering to reduc e the cost of cluster maintenance. 8. The algorithm should overcome the problem of scalability. 9. The generated c lusters shoul d facilitate hierarchical routing. 5. S TRONG D EGREE B ASED D ISTRIBUTED W EIGHTED C LUSTERING A LGORITHM (SD_DWCA) 5.1 Metric s 5.1.1. Strong Neighbour Set - Let G = (V, E) be t he underlying net work graph and u ∈ V(G) . The Strong neighbour s e t of u i s d e fined to be the set of all strong neighbours of u and is denoted by SN(u) . i.e., SN(u) = {v ∈ N(u): 0 ≤ ed(u, v) ≤ r/2} 5.1.2. St r ong Degree - The Strong degree of a nod e u ∈ V(G) is the cardinality of the set SN(u) and is denoted by d sn (u) . International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 99 In the sa me way, the medium neighbour s et (denoted by MN(u )) and we ak neighbour se t (denoted by WN(u)) are defined using t he respective definitio ns given in section 2.2. The medium degree of a node u ∈ V(G) is the c ardinality of the set MN(u) and is denoted by d mn (u) and the weak degree o f a node u ∈ V(G) is t he cardinality of th e set WN(u) and is denoted by d w n (u) . In general, t he de g ree of a node i s th e sum of the nu m ber of stron g neighbours, me dium neighbors and weak neighbours, i. e., deg(u) = | SN(u) | + | MN(u) | + | WN(u) | = d sn (u) + d mn (u) + d w n (u) . 5.1.3 Mobility metric: Here, w e adopt the mobility me asure defined by Xing et al. [21]. For each node u i n the network, after receiving two successive hello messages from its 1-hop neighbors, t he relative mobility metric with respect t o each of its 1-hop neighbors is computed using t he formul a (1). If node v i s a neighbor of node u, then the relative mobilit y metric of u with respect to v is denoted by R v (u), and is defined as follows: R v (u) = v v r r 2 1 -------------------------(1) Here, v r 1 and v r 2 denote the two s uccessive signal strengths received by u from v. This received signal strength can be read from RSS indicator. The signal strengths received v r 1 and v r 2 may be like either v r 1 < v r 2 or v r 1 = v r 2 or v r 1 > v r 2 . Thus, we have the foll owing cases. Case i: R v (u) < 1 If R v (u) < 1, then it indicates that the nodes u and v move close to each other. Case ii: R v (u) > 1 If R v (u) > 1, then it indicates that the nodes u and v move away from each other. Case iii: R v (u) = 1 If R v (u) = 1, then it indi c ates that either t he nodes u and v do not move at all or they move with the same speed in the same direction. In t his way, the relative mobility v alue of a node is computed with re spect to each of its neighbors and the root mean square deviation of these values taken from the value 1 (a s give n in equation (2)) is used as the mobility measure of u and is denoted by M (u). M(u) = deg(u) (u)) R (u) (R 2 N(u) v v − ∑ ∈ , ---------------------------(2) where (u) R = 1. In the cluster-head election p roce dure, to m aintain the stability of elected cluster-heads, the cluster-heads are expected not t o move away from their cluster memb e rs. Hence, the value R v (u) of each node u with respe ct to each of it s nei ghbours is preferred to be les s t ha n or equal to 1 and therefore (u) R = 1, instead of actual mean. Supp ose, some n eigh bour of node u has sent more than two periodical hello mess ages, but u didn’ t re ceive two of them success ivel y or u received only one of th em, then that neighbour is excluded in the weight calculation of node u. This is because, that p articu lar neighbour of u might have moved away from u, i .e., might be a weak neighbour of u or there might be signal attenuation. International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 100 5.1.4. Power Metric: To consider t he ba ttery level of each mobil e node, an d to ensure that the clu s ter -hea ds are not excessively uti liz ed, i .e., used until they get completely d ra ined out, we use a metric denoted by RE(u), which denotes the residual energy/remaining batt e ry power of node u. If IE(u) denotes the initial energy assigned to node u and CE(u) denotes t he c onsumed battery power of u , then, RE(u) = IE(u) – CE(u). To compute t his value, each node records its remaining battery power after sending and receiving every message. 5.2 Node Weight To elect CHs, each node is initially a ssigned a weight computed using formula (3). W(u) = RE(u) α M(u)] [1/ α (u) d α 3 2 sn 1 + + ------------------- -- -- (3) Here, the constants 1 α , 2 α and 3 α denote t he weighing f a ctors. In almost all types of applications, it i s natural to giv e equal weig htage to all th e three p arameters which we’ve considered. So, we choose t he values of t he three weighing facto rs as 1/3, so that t heir su m is unity. If in som e application, any of these parameters have to be given special importance then the weighing factors can be c hosen accordingly. Here, t he f irst parame ter, stro ng degree is cho s en to maintain stability o f clust e r-heads and thereby, t he stability of the generated clusters, the second parameter i s chosen to ma ke the algorithm to be adaptive to mobility and the t hird t o choose a node which can afford to play the key role of a cluster-head for a longe r period, compared to others. The algorithm includes two phases , namely, cluster formation and cluster maintenan ce as explained below. 5.3 Cluster Formation At any instant t, Le t G t denote the graph corresponding to the underlying topology of the nodes at that particular instant and V(G t ) denote the no de s et of G t . It is assumed th a t all nodes send and receive data with equal transmission range and the nodes are moving with veloc ity ranging in the interval [ 0, V max ] and they are free to move in any direction. The status o f eac h node is initially se t to “UNKNOW N”. 5.3.1. Initial Cluster Form ation. Step 1: Each node period ica lly sends and receives hello messages. The hel lo messages are s e nt with a predefined broadca st interval (BI). Step 2: While sending a hello message , a node sends its node id, (x , y) position (to categorize the neighbor). Mea nwhile, the sender should record its rema ining battery power. Step 3: A n ode, upon receiving a hello message, stores the neighbor info received. Also the received sig n a l strength and the time stamp are recorded. Step 4: As specified, if a node fails to rece ive two successive hello messages after a neighbor has sent atleas t t hree messages, then the neighbor is excluded in weigh t computation. Step 5: With the above i nformation, each n ode computes it s own we ight after a fix e d duration. This time gap is specified t o allow th e hello mess ages to be sent and received b y each node from all its neighbors . Step 6: After c omputing the weight v alue, eac h node bro a d c asts t his weight va lue to all its neighbors. Step 7: Then, each node compares its weight with that of its neighbors. If the weight of a node is maximum , then it declares itself as a cluster-head and sends a mess ag e “CLUSTER_INF O” together with its node id, to all its neighbors. International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 101 Here, each node has an active participation in the cluster formation process and hence the algorithm is referred to as distributed. Step 8: On receiving the message C L USTER_INFO, if the current status of the r e ceiving node is UNKNOWN, then it becomes a cluster member of t he sender and stores the sender’s id as its cluster-head id and in tu rn b roadc asts the message to all its neighbors. Oth e rwise, if it is already a member of another cluster and if the weig ht of it s cluster-head is less than that of the sender, th en it changes i ts affi liation, i.e., c hanges its cluster-head id as the id of the se nder. Step 9: Finally, the c lusters generated are obtained as output. Step 10: After making all comparisons, n odes still in the status of “ UNKNOW N” are collected separately and are termed as “Critical n odes” . T he critica l n odes ar e then subjected to an adjustment proce dure. 5.3.2. Formation of Adjusted Clus ters. Let C d e note the set of critical nodes obtained after i nitial cluster formation. If some (atleast two) of the critical no de s are adjacent, then they are allowed to form a cluster on their own. In this ca se, among all the neighbors, the one with higher weight is chosen as the Cluster-head and the rest are considered a s cluster members. If still t here ar e left out nodes, then they become cluster-heads on t heir own. This process di stinguishes ou r algori thm from the ot he r existing algorithms. In most of the existing algorithms, if th e re is any node l e ft uncovered, then either re- clustering t akes place [7], [8] or the nodes are th emse lves declared as cluster- heads [9]. But, in the proposed algorithm, the no des are grouped as far as possib le, thereby reducing the number of clusters generated. 5.4 Cluster M aintenance In general, while de a lin g w ith mobile networks, the p osition (position in t he terrain) and status (cluster-head/mem b er/c ritical node, in our case) of t he nodes at the time of cluster formation will chang e in d ue course, because of nodes’ mobility. Hence, in order to provide a v alid hierarchical stru c turi ng to facilitate an efficient routing, it is necessary to consider this topology change and discuss the behavior of the cl ustering procedure in su ch cases. This leads to the cluster maintenance ph a se. The change in the in itial topology may be caused due to node failure because of battery drainage, addition of a new node into n e twork, link fail ure, lin k establishment. Hence, we d isc uss the behavior of our algorithm in all these f our ca ses separately. Case i: Node failure As p er the clustering pr ocedure given in [23] , a node failure means either the drainage of the battery power of a node below a fixed threshold va lue or complete ex haustion of battery power of a n ode. Generally, the idea of clust e ring i s adopted to properly utilize the r esources of the nodes such as battery p ower, limit ed bandwidth etc, in data tr a nsmission. Hence, the cluster- heads are allowed t o pl a y a k ey role than the non-cluster heads. This leads to higher usage of battery power b y cluster-heads rather than the ot her no de s. So, we assume th a t only the cluster- heads h ave a greater chance of getting dr aine d out quickly and we deal with the fail ure of cluster-heads. To avoid cluster-heads being overloaded or to avoid excessive usa ge of battery by a subset of the nodes, w e f ix a threshold value f or energy/battery power. During the formation of clusters, each c luster-head periodically checks whether its re sidual energy is above the threshold value. When it goes below the threshold va lue, the cluster-head sends a resignation message and all t he nodes in the cluster should affiliate themselv e s to other existing clusters. Hence, each cluster member of such a cluster will s end a find_CH message to all its neighboring cluster h eads . Any clu ster-hea d which receives thi s message wi ll i n tur n send an acknowledgement message to the senders and in cludes that node in its list of cluster members. International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 102 If a sending node re ceive s a cluster-head acknowledgement message from more than one node, then it gets att a ched to t he one having m aximum wei ght. When a node gets completely drained out, it will be isolate d from communication. But, the periodical check up o f available battery power of the maximum ut i lized nodes will avoid such a situation as f a r as p oss ibl e . This also increases the network life tim e. Case ii: Node addition There is a chance f or a new node entering into the network. In such a case, t he newly entering node should att a ch it s elf to an existing cluster. Hence, after identifying it s neighbors by passing hello messages, it br oadc asts the fi nd_CH mes sage and f ixes its appropriate status as explained in the previous case. Case iii: Link failure There is also a possibility fo r th e nodes which are already grouped into some cl uster to move outside the b oundary of the cluster. Then, such a node also sends a find_CH message and gets attached to some ex ist ing c luster as in case i. Case iv: Link establishment When there is a po ss ibility for nod e s attached t o one cluster moving outside its existing cluster boundary, the same will move close r to some other cluster boundary. This will induce new lin k establishments and al so continuous mo vement of the nodes will als o in duce frequent link establishments and failures. To handle n ew link establishments, each cluster-head should periodically update its n eighbor table. If a cluster-head finds a new n ode in its n eig hbor table, it checks wh e ther it s weight is greater t han that of the new node. If it i s greater, it continues its status and adds the n e w neighbor as its cluster me mber. If not, it will chec k in its neighbor table whether t he re are m a ny (quantified a s atleast two) nodes which are common n e ighbors of bot h the ex isting cluster-head and th e newly added ne ighbor, then the current cl uster-head will interchange its r ole with th e n e wl y added n eighbor. The nodes i n the current cluster, which are non-neighbors of t he newly elected cluster-head will get attached to t he appropriate neighboring clusters by passing find_CH mes sage. If an execution o f the above clustering procedure yields no critical node s , then t he clustering is said to be a perfect clustering. On the other hand, if there are some critical nodes left out and the number of cri tical n odes can be reduced to zero by t he adjustment procedure, then the clustering is said to be a fairly perfect clus tering [23] . 6. C OMPLEXITY A NALYSIS To perform the analysis, it is a ssumed that the contin uous run time of t he algorithm is divided into discrete time steps. Here, one ti me step is defined as the time durati on for the sending of a message (control packe ts) by a s e nder and a complete p roce ssing of it by t he recipient [6]. The approach adopted in t his pa per is mot iv ated by t he theoretica l ana lysis of DMAC made in [6], [13]. It is also assumed that any message transmitted by a sender is suc c essful l y r eceived and processed by a ll its recipients in one time step. We compute the total overhead ( messa ge/time) incurred in thre e steps as f ollows: Overhea d due to hello p rotoc ols, cluster f ormation and cluster maintenance. Let M H , M CF , M CM denote the message complexities du e to hello protocol, cluster formation, cluster maintenance respectively and T H , T CF , T CM respe ctively d enote the time complexities due to h e llo protocol, cluster formation, cluster maintenance and M and T denote the overall message and time complexities res pe ctive ly. T he tot a l me ssage complexity of the algorithm i s the sum of M H , M CF and M CM . Similarly, T is the total of T H , T CF and T CM . International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 103 6.1 O verhead d ue to He llo P rotoc ol s Each node periodically broadcasts the hello messages to keep track of its knowledge about its neighbours, at a fi xed pr edefine d i nterva l BI. T hus, t he frequency of hello messages broadcast by a node is T /BI, where T is the tot al runni ng time of the algo rit hm, until which each node has to maintain its neighbour data. Hence, on the whole, N*(T/BI) h ello messages are t o be transmitted, for the entire set of n odes to maintain their neighbour data and so the message complexity due to h e llo protoc ols is M H = ), N ( Θ as (T/BI) is a fixed constant, pr e defined before execution. By our as sumption, it takes one t ime step for the t ransmis sion of hello messages by each node and successful reception of it by all it s neighbours. Hence , totall y N time steps are required for successful trans mission and reception. Thus, T H = ) N ( Θ . 6.2 O verhead d ue to Cl uster Formation Cluster formation i s done by invoking th e two procedures in se ction 5.3.1 and 5.3.2. Suppose that there are N c clusters and C r critical nodes before the execution of adjustment procedure. Then, the total number of CMs in the network will be N – N c – C r . In the pr oc ess of cluster formation, initially, each node computes its weight val ue in constant time and broadcasts this weight value to all its neighbours, so that M 1 = N* ) 1 ( Θ . The respective neighbours store thi s received weight info in their neigh bour table for further comparison in one time step, so that T 1 = N* ) 1 ( Θ . Upon receiving this weight i nfo, each nod e compares its weight with th a t of its neighbours and decides whether it is maximum. If maximum, it broadcasts a CLUSTER_INFO message to all its neighbours. But, this message broadcas t is done only by the CHs. Therefore, totally, if N c is the total number of cluste rs generated, then ) 1 ( * N c Θ CLUSTER_INFO messages are tr ans mitted, i.e., M 2 = ). 1 ( * N c Θ Each node upon receiv in g thi s CLUSTER_INFO decides i ts role as whether to become a CM of the sender (if its current status is UNKNOWN ) or change its a ffi l iatio n (if already a CM) or to retain/cha ng e its status ba sed on weight comparison (in ca se, it is alrea dy a CH). This takes one t ime step for each node, i .e., T 2 = ). 1 ( * N c Θ After this decision making process, eac h CM broadca sts its CH id to all its neighbours and th e neighbours store this info for further processing. Henc e, M 3 = ) 1 ( * ) C N N ( r c Θ − − =T 3 . Regarding the adjustment procedure, the critical nodes will look into their neighbor t a ble for nodes with UNKNOWN status. If such neighbours are available, then the adjusted clusters are formed based on weight comparison. The nodes which declare themselves as CHs will also send CLUSTER_INFO me ssages to their nei gh bors. I n the wor st case, all the c ritical nodes ca n become as CHs so that C r messages are transmitted and M 4 = C r * ) 1 ( Θ = T 4 . Therefore, the total message a nd time complexities due to cluster formation are given by, M CF = M 1 + M 2 + M 3 + M 4 = N* ) 1 ( Θ + * N c ) 1 ( Θ + * ) C N N ( r c − − ) 1 ( Θ + C r * ) 1 ( Θ = ) N ( Θ and T CF = T 1 + T 2 + T 3 + T 4 = ) N ( Θ . The above explained broadcasting of messages by different category of network nodes is summarized in Table 1. Now, suppose max ∆ is the maximum number of nei gh bors of the nodes in the network, i.e., the maximum degree of the u nderlying network graph/t o pology, then each cluster may contain at the most max ∆ CMs and hen ce in the worst case , we have totally ) 1 N/( max + ∆ clusters/CHs and International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 104 max max N*( / ( 1 )) ∆ ∆ + CMs. Here, max ∆ can be a constant or a function of N. If i t is constant, t hen M 2 =M 3 = ) N ( Θ . Table 1. Summa ry of messages broadcast by network nodes for c luster formation Message Broadcasting node Time of broadcasting Hello(my_id, my_pos) All nod e s Periodically @ BI WEIGHT _IN FO (id, wt) All nodes Few secon ds after start of simulation CLUST ER_ INF O(id, wt) CH Critical nodes After weight compa rison Cluster_id(id, my_cid) CM After joining to some cluster 6.3 O verhead d ue to Cl uster M aintenance The maintenance phase is invoked in any of the fo ur situations discus sed in section 5. 4. But, in all th es e cases, the nodes adjust themselves by sendi ng eith e r a find_CH message or a resignation me ssage. T he resignation message CH_RESIGN(id) is sent only by the CHs going beyond th e ir battery limi t and the message comp lexit y f or such transmission is ). ( max ∆ Θ On the whole, in the worst case, su c h a message can be t ransmitted by all the CHs to their respective neighbors. But, t his is eq uivalent to in voking the c lustering procedure again. The find_CH message is broadcast in all the four c ases. Case i will lead to m number of broadcasts, where m denotes the n umbe r of CMs attached to the resigned CH. Case i i wi ll lea d to n a broadcasts, where n a denotes the number of newly added nodes, (o ne message corres ponding to each newl y added node). Case iii will cause t wo broadcasts, because any link failure will lea d to change of status of two nodes joined by the link. Similarly, in Case iv, there will be two bro a dcasts f or each newly added link. Thus, t he total number of find _CH br oa dcasts is m + n a + (2*l f ) + (2*l a ), where l f , l a denote respec tively the number of link failures a nd l ink establishme nts. 7. R ANKING O F C LUSTERS In the cluster f ormation and a djustment p rocedures g iven in sections 5.3 .1. and 5.3.2., the cluster-head is primarily elected base d on th e node weight and then the clusters are formed with the cluster-head and it s nei ghbors. W hile generating clusters in t h is fashion, th e neighbors of the cluster-head which are considered to be cluster members m a y be either strong neighbors, medium neighbors or weak neighbors. Based on this criterion, it is possible to rank the clusters If all the cluster members in a particular cluster are strong neighbors of that cluster-he ad, then the conn e ctivity in this case will be strong enough and t he cluster-hea d can retain its status fo r a longer perio d. But, th is will not cause the problem of quick batt e ry drainage due to t he strategy followed in ass igning nod e weights . Thus, the clusters generated with the above features are ranked a s the topmost (in t e rms of stability) clusters and are t e rmed as Strong or B alanced Clusters . Similarly, the c lusters whose c luster m embers a re all medium neighbors a re referred to as Medium or Semi-balance d Clusters . The clusters whose cluster members are all weak International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 105 neighbors are ranked as Weak or Unbalance d Cluste r s . T here may be cases in which the cluster members are combinations of strong, medium and weak neighbors and such clusters are termed as Intermediate Clusters . In due course, because of the dy namic nature of our network, these Clusters can change int o any of the above mentioned three types of c lusters. 8. S IMULA TION S TUDY 8.1. Simulation P arameters The va lidity of the t he oretical ana lysis and the performance evaluation of SD_ DWCA a re obtained via simulation of the algorit hm using NS-2 with CMU wireless extension. We simulate a system o f N nodes whose positions are randomly genera t e d on a terrain of size XxY with a restri c ted diameter u sing the scenario generator available in NS-2 with the i npu t parameters as l isted in Table 2. Table 2. Simulation Parame ters for SD_DWCA Parameter Meaning Value(s) use d in Si m ulation N Number of nodes 50,75,100,150,200 XxY Terrain size/Network deploy ment area 750x750 Max Speed Maximum Speed with which the nodes move in r a ndom directions [0, V max ], where V max = 10, 20, 30, 40, 50m/s Tx Range Tr a nsmission range 100, 150, 200, 250, 300 (metres ) PT Pause Time 30s Mobility Model The mobility model base d on wh ich the nodes move in random directions Random Way Point mobility model IE Initial Energy 100 Joules Mac Type Type of MAC laye r 802.11 Traffic Type of application use d in data transmiss ion between sources & destinations CBR Packet size_ Size of packet transmitted 1000bytes Interval_ Time interval betwee n transmission of packets 0.005s T Simulation time 500s 8.2. Perfor m ance Me trics To measure the performance of our algorithm, the following me trics are considered. 1. Average number of Clusters – The number of clusters generated on an average d uring the simulation run time of our algorithm 2. Rate of re-affili a tions – The number of cluster members which change their affiliatio ns (Event o f link breakage with the current cluster-head and l ink establishment with a n ew cluster-head due to mobility) per unit time. International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 106 3. Average end-to-end throughput – The nu mbe r of by tes s u cce ssfully transmitted per u nit time. i.e., the ratio of the trans mitted packet size to the average end-to-end delay 4. Overhead due to cluster f ormation – The number of c ontrol pa ckets required to be transmitted for successful forma tio n o f clusters 5. Overhead due to cluster Maintenace – The number of control packets to be transmit ted to update the change in cluster structure due to mob ility of nodes and arrival of new nodes 8.2.1. Average number of clusters The foll owing graphs are plotted to analyze of impa c t of tr a nsmission range and mobility on the average number of cl usters for a varied number of nodes in the network. Figure 2 gives the impact of transmission range on the average n umber of clusters. The graphs are pl otted for Transmission r ange varying from 100-300 (i n steps o f 50) for v aried number of nodes ranging from 50 to 200, keeping max imum displacement fixed. Figure 2(a) (Max_dip =10m/s) Figure 2(b) (Max_dip =30m/s) Figure 2(c ) (Max_dip =50m/s) Fig ure 2. Impact of Tr a nsmission range on average no. of clusters It can be seen from the above graphs that the a ve rage number of clusters generated decreases as the transmission range increases, whi c h is a natural phenome n a . This is due to the well-known fact th at as the communication range of each node in c reases, more number of nodes can be grouped into a single c luster thereby reducing the number of clusters gene rated. Again, to analyze the impact of mobility, the graphs are plo tte d f or Max speed var ying f rom 10- 50m/s (in steps of 10) for varie d number of no de s ranging from 5 0 to 200, keeping transmission range fixed. This analysis is a lso performed t o see t he validity of the algorithm for high- speed networks. It can be witnessed f rom th e graphs shown in Figure 3(a), (b), (c) & (d ) t ha t t h ough the n umbe r of clusters g enerated in c reases with increase in velocity/maximum spe ed, the r ate of increase is negligibly small. In some cases (Figure 3(b), (c)), the number of clusters obt a ined remains almost constant w ith increase in velocity. This guarantees th a t the algorithm can be used to cluster high-speed netw orks. International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 107 Figure 3(a) (Tx range =100m) Figure 3(b) (Tx range =150m) Figure 3(c) (Tx range =250m) Figure 3(d) (Tx range =300m) Fig ure 3. Impact of Mobility on average no. of clusters 8.2.2. Rate of re-affiliations The f ollowing graphs are plotted to analyze t he stabi lity of the cluster structures de veloped . From the graphs sh own in Figure 4, it can be inferred that the rate of re- affili atio n increases as Figure 4(a) (Max_disp =10m /s) Figure 4(b) (M ax_disp =20m/s) Figure 4(c) (Max_dis p =40m/s) Figure 4(d) (M ax_disp =50m/s) Figure 4. No. of nodes vs . Rate of re-affiliations International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 108 the number of n odes increases and reaches a peak value (which is nearly 0.02 much lesser than unity) a nd aft e r th a t dec reases to almost 0.005. The sa me beh aviour is analyzed even with increase i n maximum speed with which t he n odes are allowed to move. This shows that the proposed algorithm generates highly stable clusters even fo r networks with high mobility. This is guaranteed by the choice of the weig ht parameters. 8.2.3. Average end-to-end througput Communication throughput influence the operation and performance of some appli c ations. Hence, it is ess e ntial t o i nves tigate the thr oug hput pe rformance for ad h oc wir eless n e tworks. The average thr oughpu t is computed b y dividing the packet size by t he average end-to-end delay and t he actual throughput is computed by dividing the t otal number of bytes received by the total end-to-end delay . [ 25] In thi s paper, we h ave the average throughput as a perfor m ance metric obt a ined by dividin g 1000 (Packet size u sed in the simulation) by the average end-to-end dela y . It is measured in terms of kilobytes pe r sec ond. Figure 5. Nodes vs. Throughput Figure 6. Tx Range vs. Throughput The graph in Figure 5 is p lotted by varying the number of nodes against throughput. As the number of nodes increases the t hroughput decreases and attains a saturation point and after that the t hroughpu t again increases, decreases and attains a saturation point. Hence, the throughput oscillates but varies b e tween 150 to 400 KB/se c. Si mila r behav ious is seen in t he case o f Figure 6, where the graph is plotted by va rying the transmission rang e against throughput for by giving different maximum m obility speed. 8.2.4. Overhead due to Cluster set-up As in t heoretica l analysis, the overhead incurred by the proposed algorithm is d isc ussed u nder two cases. One is for initial cluster formation and the other for c luster maintenance. The algorithm is developed with the objectiv e o f avoiding re-clustering and minimizing the number of re-affiliations thereby redu c ing the overall cluster maintenance cost. It c an be seen fro m Figure 7(a), t he overhead incurred is minimum in general a nd that is also maintained at a c onstant level eve n for increase in number of nodes and also increase in transmission range ke eping maximum speed fix e d. Simil arly , from Figure 7(b), the overhead increases as the transmiss io n rang e increases when the number of nodes is kept fixed. International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 109 Figure 7(a). Tx range vs. Overhead Figure 7(b). Tx Range vs. Overhead (keeping max s peed f ixe d) (keeping no. of nodes fixed) 8.2.5. Overhead due to Cluster M aintenance From t he graph given F ig ure 8(a) and (b), i t can b e seen t hat the ove rhead due to cluste r maintenance also has a similar behaviour, when plott e d against transmission range and number of nodes keeping maximum spee d at 10m/sand transmission range 200m fixed respectively. Figure 8(a). Tx range vs. Overhead Figure 8(b). No. of nodes vs. Overhea d (keeping max s peed= 10m/s ) (keeping Tx range=200m) As mentioned already, the avoidance of re-clus tering will be meaningful provided the overhead due t o cluster maintenance is considerably lesser th a n that of overhead of cluster formation. This i s validated b y the graphs shown in F igure 9(a) a nd (b). Here OH_set-up d enotes overhead due to cluster set-up a nd OH_CM denotes overhead due to cluster ma intenance. Figure 9(a) Tx Range vs. Ove rhead F igure 9(b) No. of nodes vs. Overhead Figure 9. Com p arison of ove rhead due to cluster set-up and clus ter maintenance International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 110 9. C ONCLUSION In the n e tworks c onsidered h e re, we allow mobility o f t he n odes in all p ossible directions . Hence, a node which is a w e ak n e ighbor at an instant ma y beco me a medium or strong neighbor at a later instant. Similarly, a medium neighbor may either become a strong or a weak neighbor and this leads to re-election of CHs. But, this si tuation can be avoided as much a s po ssib le b y the choice of our mobi lity metric. Thus, the algorithm is reli a ble even for hi gh s peed networks. It is evident from t he adjustment pr oc edures given in section 5.3.2 that to reduce t he number of critical nodes, we adopt re-a ffiliation rather th a n re-clustering and thi s greatly reduces the cost of cluster maintenance. Thus, the p roposed alg orithm is e ffi c ient in terms of both ex e cution and maintenance. The experimental results obtained supp ort the theoretical observa tion s . R EFERENCES [1] A.A. Abbasi, M.I. Buhari, M.A. Badhusha , “ Cluste ring Heuristics in Wireless Networks: A surve y ”, Pr oc. 20 th European C onference on Model ling and Simulation (2006). [2] R. Aoud jit, M. Lala m, A.M. Zoughi, M. Belkadi, M. Daoui, “ Load Balancin g: An Appr oach Based on Clusterin g in Ad Hoc Netw o r k s”, J. Computing and Information Tech nology, vol. 1 7 , No. 2, pp. 177-184 (2 0 09) [3] D.J. B a k er, A . Epremides, “A distributed algorithm f o r organizing mobile ra dio telecomm unication networks”, Proc. 2nd International conference on Distributed Computer sy ste ms, pp. 4 76-48 3. IEEE Press, France (1981) [4] D.J. Bak er, A . Epremides, “The architectu ral organizati on of a mobile radio netw o rks via a distributed alg o rithm”, IEEE Transacti o ns on C ommunications, vol. COM-29, N o . 11, pp. 1694- 1701 (1981) [5] P. Basu, N. Kha n, T.D .C. Little, “A mobilit y based metric for clustering in mobile ad hoc networks”, P roc. of IEEE ICD CS, pp. 413-418. P hoenix, Ariz on a, U SA (2001) [6] C. Bettstetter, Stefan Konig “On the message and time complexity of a distrib uted mo bilit y- adaptive cluste ring algorit hm in wire less ad h oc networks”, Proc. 4 th European w ireless, pp. 1 28- 134. Florence, Italy (2002) [7] M. Chatterjee, S.K. Das, D. Tur gut, “A Wei ght Based Distributed Clusteri ng Alg o ri thm for MANET, HiPC 2000”, LNCS , pp . 511-521. Springer- Verlag, Heidelber g (2000) [8] M. C hatterjee, S.K. Das, D. Turgut, “WCA: A Wei ghted Cl ustering Algorithm for Mobile Ad H oc Networks”, Cluster C omputing, v ol. 5, pp. 193- 204. Kluwer Ac ademic Pub lishers, The Netherlands (2002) [9] W. Ch oi, M. Wo o , “ A Distributed Weighted Cl ustering Al gorithm for Mobile A d hoc Ne tworks”, Proc. of AICT/ ICIW 2006. IE EE (2006) [10] S.J. Francis, E.B. Rajsingh, “P erformance A nalysis of Clusterin g P rotocols i n Mobile A d H oc Networks”, J. Computer Scienc e, vol. 4, No. 3, p p . 19 2-204 (2008) [11] M. Gerla, J.T.C. Tsai, “ Multi-cluster, mobile, multimedia ra dio netw ork”, Wireless Netw orks , vol. 1, No. 3, p p. 255-265 (1995) [12] R.C. Hincapié, B .A. Correa, L . Os pina, “Survey on cluste ring Techniq ues f or mobil e ad hoc networks”, IEEE (2006) [13] Inn Inn E R, K.G.S. W inston “Per formance Anal y sis of M obi li ty-based d-H op (M obDHop) Clusterin g Al gorithm f or Mobile Ad Hoc Net works”, Computer N etworks, vol. 50, p p. 3375-3339 (2006) [14] Inn Inn ER, K. G.S. Win ston “Clusteri ng overhead a nd conver gence time a nalysis of the m obility- based multi- hop c lustering al go rit hm for mobile a d hoc netw o r ks”, P roc. 11 th Int. c onference on parallel and dis tri buted s y stems (ICPADS’ 05), pp. 1144-1155 (2005) [15] T. J ohansson, L. Carr-Mat y č ková, “O n Cluste ring in Ad Hoc Ne tworks”, Proc. Vehicular Tec h. Conf. Fall, Swe dish National Computer Network ing Workshop (20 03) [16] A.B. McDonald, T. F . Znat h i, “A Mobilit y -ba sed framew ork for adapti ve clusteri ng in wireless ad hoc netw orks”, IE EE Jo u rnal on Selected Are as in Comm unications, vol. 17, No. 8, pp. 1 466-1487 (1999) [17] A.K. P arekh, “Sel ecting routers in ad-h o c w ireless netw orks”, P roc. SB/IE EE I nternational Telecommunica tions Symposi um (1994) [18] S. Gajurel “ Multi-Criteria Clu stering (2006) International J ournal of Comp uter Networks & Communicati o ns (IJCNC) Vol.3, No.3, May 2011 111 [19] P.R. Sheu, C.W. Wan g , “A Stable Cluster ing Algorith m based on Batter y P o wer f or Mobile Ad Hoc Netw o rks”, Tamkang Jour nal of Science and Engineering, vol . 9, No. 3, pp. 233-242 (2006) [20] Z. Xi ng, L. Gr uenwald, K.K. Pha ng, “A Robust C lustering Algorit hm f or Mobile Ad H oc Networks”, Handbook of Re search on N ext Gener ation Netw o rks and U biquitous Computing, December 2 008 [21] J.Y. Yu, P. H.J. Chong, “A Survey of Clusterin g Sc hemes for Mobile A d Hoc Netw orks”, IEEE Communica tions Surve y s and Tutorials, First Quarter , vol. 7, No. 1, pp. 32-47 (2005) [22] W. Yang, G. Zhan g , “A We ight-based c lustering a lgorithm for mobile A d hoc networks”, Proc. 3 rd Int. Conf. on w ireless and mo b ile c ommunications (200 7) [23] T.N. Jana k ira man and A.S. Thilak, “A Distribute d Mobilit y -Adapti ve a nd Energ y Dr iven Clusterin g Al gorithm f o r MANETs usin g str ong degree”, Adva nces i n Netw o rks and Communica tions, N. Meghanathan e t al. (eds.), CCIS, V ol. 1 32, Part – II, pp. 645-655, Proc. of CCSIT 2011 , Springer, Heidel berg, 2011. [24] T.N. Janakira man a nd A.S. Thilak, “A Wei ght ba sed double star embe dded clustering of homogeneous mobile a d hoc networks using g raph t heory”, Advances i n Networks a nd Communica tions, N. Meghanathan e t al. (eds.), CCIS, V ol. 1 32, Part – II, pp. 329-339, Proc. of CCSIT 2011 , Springer, Heidel berg, 2011. [25] C.K. Toh, “Ad Hoc Mobile Wireles s Netw orks P rotocols and Systems”, P earson Ed ucation, Inc. and Dorling K indersley Publis hing, Inc., India, 2 nd edition, 2009. Authors T.N. J anakiraman is c urrently A ssociate Profe ssor o f Department of Mathematics, Nat ional Institute of Technolog y , Tiruc hirapalli, India. He completed his undergrad uat e Studies at Madras Universit y, India i n 1980 and c ompleted his Post graduation at N ational Col le ge, Trich y , India i n 1983. He did his Ph. D. in Mathematics (Gr aph The o r y a nd its applicat ions) at Madras Un iversity wit h a UGC sp onsored re search fell o w sh ip and recei v ed his doctoral degree in the y ear 1991. He was a Postdoctora l Research associate f or 1 year (1993- 1994) i n Madra s U niversity under t he He has two spon sored res earch pr oj ec ts to his credit and published aroun d 70 paper s in re fereed Nati onal/International journals. His r esearch i n terest s include P ure Grap h Theor y , Applica tions of Graph Theor y t o Fault tolera nt networks, Ce ntral location pr obl ems, Cl ustering of wired & wir eless a d h oc networks, Clusteri ng of cellul ar a nd flexible manufact uring models, Image processin g , Gra ph coding a nd Graph Algorithms. A. S enthil Thilak is currentl y a research Sc holar of D epartment of Mathematics, Nat ional Institute of Technolog y , Tiruc hirapalli, India. She recei v ed her Master’s de gree in Mathematics and Maste r of Philosoph y in Mathematics fr om Seethala kshmi Ramasw ami College, Tiruchirapalli, India. She has com pleted Post Graduate Dipl oma in Computer Applications in Bharathi dasan Universit y , Tiruchira palli, India. She has p ublished three papers in refere ed Nati onal/International Jour nals. H er main rese arch interests inclu de P u re G raph The ory, Al gorithmic Graph The o r y an d applications of graph theor y t o wireless ad hoc netw orks.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment