Variational Bayes approach for model aggregation in unsupervised classification with Markovian dependency
We consider a binary unsupervised classification problem where each observation is associated with an unobserved label that we want to retrieve. More precisely, we assume that there are two groups of observation: normal and abnormal. The `normal' obs…
Authors: Stevenn Volant, Marie-Laure Martin Magniette, Stephane Robin
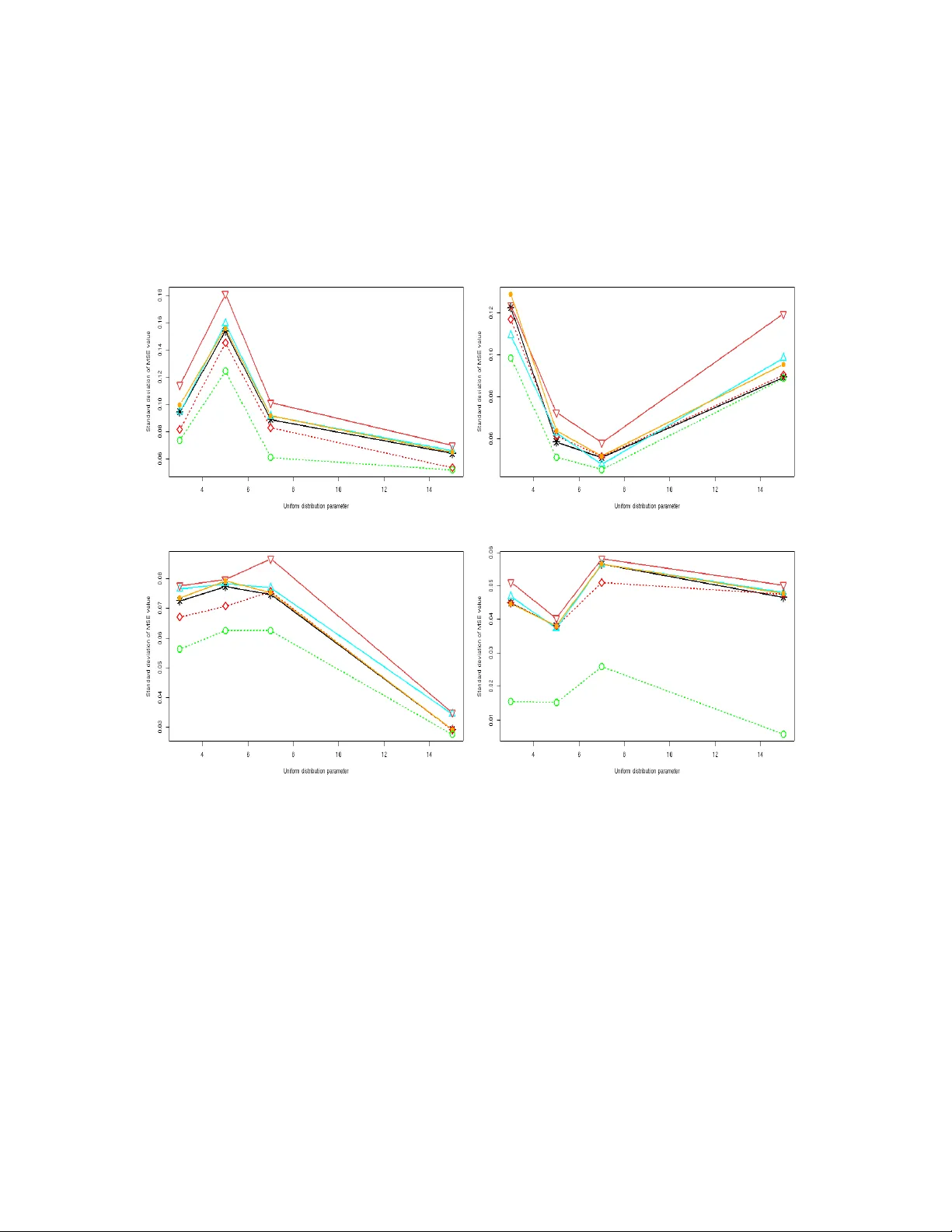
V ariational Ba y es approac h for mo del aggregation in unsup ervised classification with Mark o vian dep endency Stev enn V olan t 1 , 2 , Marie-Laure Martin Magniette 1 , 2 , 3 , 4 , 5 and St´ ephane Robin 1 , 2 Octob er 22, 2018 1 AgroP arisT ech, 16 rue Claude Bernard, 75231 P aris Cedex 05, F rance. 2 INRA UMR MIA 518, 16 rue Claude Bernard, 75231 P aris Cedex 05, F rance. 3 INRA UMR 1165, UR GV, 2 rue Gaston Cr ´ emieux, CP5708, 91057, Evry Cedex, F rance. 4 UEVE, UR GV, 2 rue Gaston Cr ´ emieux, CP5708, 91057, Evry Cedex, F rance. 5 CNRS ERL 8196, UR GV, 2 rue Gaston Cr ´ emieux, CP5708, 91057, Evry Cedex, F rance. Abstract W e consider a binary unsup ervised classification problem where each observ ation is asso ciated with an unobserv ed lab el that we wan t to retrieve. More precisely , w e assume that there are t wo groups of observ ation: normal and abnormal. The ‘normal’ observ ations are coming from a kno wn distribution whereas the distribution of the ‘abnormal’ observ ations is unknown. Sev eral mo dels ha ve b een developed to fit this unkno wn distribution. In this pap er, w e prop ose an alternativ e based on a mixture of Gaussian distributions. The inference is done within a v ariational Bay esian framew ork and our aim is to infer the posterior probabilit y of belonging to the class of in terest. T o this end, it makes no sense to estimate the mixture comp onen t n um b er since eac h mixture mo del pro vides more or less relev an t information to the posterior probabilit y estimation. By computing a w eighted av erage (named aggregated estimator) o ver the mo del collection, Bay esian Mo del Averaging (BMA) is one w ay of combining models in order to accoun t for information provided b y each model. The aim is then the es- timation of the weigh ts and the p osterior probability for one sp ecific model. In this w ork, w e derive optimal appro ximations of these quan tities from the v ariational theory and prop ose other approximations of the weigh ts. T o p erform our method, we con- sider that the data are dep enden t (Marko vian dep endency) and hence we consider a Hidden Mark ov Mo del. A simulation study is carried out to ev aluate the accuracy of the estimates in terms of classification. W e also present an application to the analysis of public health surv eillance systems. Keyw ords: Mo del av eraging, V ariational Ba yes inference, Marko v Chain, Unsu- p ervised classification. 1 1 In tro duction Binary unsup ervised classification W e consider an unsup ervised classification prob- lem where eac h observ ation is asso ciated with an unobserved lab el that w e w an t to retrieve. Suc h problems o ccur in a wide v ariet y of domains, suc h as climate, epidemiology (see Cai et al. [17]), or genomics (see McLachlan et al. [11]) where we w ant to distinguish ‘normal’ observ ations from abnormal ones or, equiv alen tly , to distinguish pure noise from signal. In suc h situations, some prior information about the distribution of ‘normal’ observ ations, or ab out the distribution of the noise is often av ailable and we w an t to take adv an tage of it. More precisely , based on observ ations X = { X t } , w e w ant to retrieve the unknown binary lab els S = { S t } asso ciated with each of them. W e assume that ‘normal’ observ ations (lab elled with 0) ha ve distribution φ , whereas ‘abnormal’ observ ations (labelled with 1) ha ve distribution f . W e further assume that the n ull distribution φ is known, whereas the alternativ e distribution f is not. In a classification p erspective, w e w ant to compute T t = Pr { S t = 0 | X } . (1) Ba y esian mo del av eraging (BMA) The probability T t dep ends on t he unkno wn distribution f . Many mo dels can b e considered to fit this distribution and we denote M = { f m ; m = 1 , . . . , M } a finite collection of suc h mo dels. As none of these mo dels is lik ely to b e the true one, it seems more natural to gather information provided by each of them, rather than to try to select the ‘b est’ one. The Ba yesian framew ork is natural for this purp ose, as w e hav e to deal with mo del uncertaint y . Ba yesian model av eraging (BMA) has b een mainly dev elop ed b y Ho eting et al. [4] and pro- vides the general framew ork of our w ork. It has been demonstrated that BMA can impro ve predictiv e p erformances and parameter estimation in Madigan and Raftery [8], Madigan et al. [7], Raftery et al. [13, 18] or Raftery and Zheng [14]. Jaakkola and Jordan [5] also demonstrated that model a veraging pro vides a gain in terms of classification and fitting. The determination of the w eigh t α m asso ciated with each model m when av eraging is a k ey ingredient of all these approaches. W eigh t determination As shown in Ho eting et al. [4] the standard Ba y esian reasoning leads to α m = Pr { M = m | X } , where M stands for the mo del. In a classical context, the calculation of α m requires one to integrate the joint conditional distribution P ( M , Θ | X ), where Θ is the v ector of model parameters, and sev eral approac hes can be used. The BIC criterion (Sc hw arz [16]) is based on a Laplace appro ximation of this integral, whic h is ques- tionable for small sample sizes. One other classical metho d is the MCMC (Monte Carlo Mark ov Chain) [1] whic h samples the distribution and can provide an accurate estimation of the join t conditional, but at the cost of huge (sometimes prohibitive) computational time. In the unsup ervised classification con text, the problem is ev en more difficult as w e need to 2 in tegrate the conditional P ( M , Θ , S | X ) since the lab els are unobserved. This distribution is generally not tractable but, for a giv en mo del, Beal and Ghahramani [2] dev elop ed a v ariational Bay es strategy to approximate P (Θ , S | X ). V ariational tec hniques aim at min- imising the Kullbac k-Leibler (KL) div ergence b et ween P (Θ , S | X ) and an appro ximated distribution Q Θ ,S (W ainwrigh t and Jordan [19], Cordunean u and Bishop [3]). Jaakk ola and Jordan [5] prov ed that the v ariational appro ximation can be improv ed by using a mixture of distributions rather than factorised distribution as the approximating distribu- tion. A mixture distribution Q mix is chosen to minimise the KL-divergence with respect to P (Θ , S | X ). Unfortunately , they need to av erage the log of Q mix o ver all the configura- tions whic h leads to un tractable computation and a costly algorithm inv olving a smo othing distribution m ust b e implemen ted. Our contribution In this article, we prop ose v ariational-based w eights for model av er- aging, in presence of a Mark ov dep endency betw een the unobserved lab els. W e pro ve that these weigh ts are optimal in terms of KL-divergence from the true conditional distribution P ( M | X ). T o this end, w e optimise the KL-div ergence betw een P (Θ , S, M | X ) and an ap- pro ximated distribution Q Θ ,S,M (Section 2). This optimisation problem differs from that of Jaakk ola and Jordan (see equation 14 in [5]). Based on the appro ximated distribution of P ( θ , S | M , X ), we derive other estimations of the w eights. W e then go back to the sp ecific case of unsup ervised classification and consider a collection M of mixtures of parametric exp onential family distributions (Section 3). W e prop ose a complete inference pro cedure that do es not require an y sp ecific developmen t in terms of inference algorithm. In order to assess our approac h, we prop ose a sim ulation study whic h highligh ts the gain of mo del a v eraging in terms of binary classification (Section 4). W e also presen t an application to the analysis of public health surv eillance systems (Section 5). 2 V ariational w eigh ts 2.1 A t wo-step optimisation problem In a Bay esian Mo del Averaging con text, w e fo cus on av eraged estimator to accoun t for mo del uncertain t y It implies ev aluating the conditional distribution: P ( M | X ) = Z P ( H , M | X ) dH , (2) where H stands for all hidden v ariables, that is H = ( S, Θ), and M denotes the model. In order to calculate this distribution, w e need to compute the join t posterior distri- bution of H and M . Due to the laten t structure of the problem this is not feasible but the mean field/v ariational theory allows one to derive an approximation of this distribu- tion. It has mainly b een developed by P arisi [12] and pro vides an alternative approac h to 3 MCMC for inference problem within a Bay esian framework. The v ariational approach is based on the minimisation of the KL-div ergence b et ween P ( H , M | X ) and an appro ximated distribution Q H,M . The optimisation problem can be decomp osed as follo ws: min Q H,M K L ( Q H,M || P ( H , M | X )) = min Q M [ K L ( Q M || P ( M | X )) + X m Q M ( m ) min Q H | m K L ( Q H | m || P ( H | X , m )) # . (3) This decomposition separates Q M and Q H | M , and so these optimisations can b e realised in- dep enden tly . W e are mostly in terested in Q M whic h pro vides an appro ximation of P ( M | X ) giv en in Equation 2. F urthermore, since the collection M is finite, w e do not need to put an y restriction on the form of Q M and may deal with the w eights α m = Q M ( m ) for each m ∈ M . In the follo wing, we will first minimise the KL-div ergence with regard to Q M lead- ing to w eights that depend on Q H | m . In a second step, w e will consider the appro ximation of P ( H | X , m ). 2.2 W eight function of an y approximation of P ( H | X, m ) W e no w consider the optimisation of Q M . Prop osition 2.1 pro vides the optimal w eights. Prop osition 2.1 The weights that minimise K L ( Q H,M || P ( H , M | X )) with r esp e ct to Q M , for given distributions { Q H | m , m ∈ M} , ar e α m ( Q H | m ) ∝ P ( m ) exp[ − K L ( Q H | m || P ( H | X , m )) + log P ( X | m )] , with P m α m ( Q H | m ) = 1 . Pro of 2.1 K L ( Q H,M || P ( H , M | X )) c an b e r ewritten as: X m Z Q H | m ( h ) Q M ( m ) log Q H | m ( h ) Q M ( m ) P ( h, m, X ) /P ( X ) dh = X m Z Q H | m ( h ) Q M ( m ) log Q H | m ( h ) + log Q M ( m ) + log P ( X ) − log P ( h, m, X ) dh = X m Z Q H | m ( h ) Q M ( m ) log Q H | m ( h ) P ( h, X | m ) + log Q M ( m ) − log P ( m ) dh + log P ( X ) = X m Q M ( m ) K L ( Q H | m || P ( H , X | m )) + log Q M ( m ) − log P ( m ) + log P ( X ) The miminisation with r esp e ct to Q M subje ct to P m Q M ( m ) = 1 gives the r esult. Note that if Q H | m = P ( H | X , m ) then KL-divergence in the exp onential is 0, so α m resumes to P ( m | X ). 4 2.3 W eights based on the optimal approximation of P ( H | X, m ) W e no w derive three differen t weigh ts from the v ariational Bay es approximation. F ull v ariational approximation T o solv e the optimisation problem 3 we still need to minimise the div ergence K L ( Q H | m || P ( H | X , m )) for eac h mo del m , where H = ( S, Θ). Due to the latent structure, the optimisation cannot b e done directly . When P ( X, S | Θ , M ) b elongs to the exp onen tial family and if P (Θ | M ) is the conjugate prior, the V ariational Ba yes EM (VBEM: Beal and Ghahramani [2]) algorithm allo ws us to minimise this KL- div ergence within the class of factorised distributions: Q m = { Q H | m : Q H | m = Q S | m Q Θ | m } . Due to the restriction, the optimal distribution Q V B H | m = arg min Q ∈Q m K L ( Q H | m || P ( H | X , m )) is only an appro ximation of P ( H | X , m ). This allows us to define the optimal v ariational w eights. Corollary 2.1 The weights b α V B m achieving the optimisation pr oblem 3 for factorise d c on- ditional distribution Q H | m ar e: b α V B m ∝ P ( m ) exp[ − min Q H | m ∈Q m K L ( Q H | m || P ( H | X , m )) + log P ( X | m )] . Plug-in w eights The weigh ts α m = Pr { M = m | X } can b e estimated by using a plug-in estimation based on a direct application of Ba y es’ theorem. The conditional probabil- it y P ( m | X ) is prop ortional to P ( X | m ) that equals to P ( X | m, Θ) P (Θ | m ) /P (Θ | X , m ) for an y v alue of Θ, whic h av oids in tegrating o v er S . The distribution Q V B Θ | m resulting from the VBEM algorithm is an appro ximation of P (Θ | X , m ). Setting Θ at its (approximate) p osterior mean θ ∗ = E Q V B Θ (Θ), w e define the following plug-in estimate b α P E m ∝ P ( m ) P ( X | m, θ ∗ ) P ( θ ∗ | m ) Q V B Θ | m ( θ ∗ ) . (4) Imp ortance sampling The weigh ts given in Corollary 2.1 are based on an approxima- tion of the conditional distribution P ( H | X ). But, the w eights defined in 2 can be estimated via imp ortance sampling (Marin and Rob ert [9]). F or any distribution R , w e ha ve P ( m | X ) ∝ Z P ( m ) P ( X | h, m ) P ( h | m ) R ( h ) R ( h ) dh. Imp ortance sampling pro vides an un biased estimator of P ( m | X ). The imp ortance function R can be c hosen to minimise the v ariance of the estimator. The minimal v ariance is reac hed 5 when R ( H ) equals P ( H | X ) [9]. Th us, in the v ariational framework, the approximated p osterior distribution Q V B H | m is a natural choice for the imp ortance function R , leading to the follo wing weigh ts: b α I S m ∝ P ( m ) 1 B B X b =1 P ( X | H ( b ) , m ) P ( H ( b ) ) Q V B H | m ( H ( b ) ) , { H ( b ) } b =1 ,...,B i.i.d. ∼ Q V B H | m . Although this estimate is unbiased, when the num b er of observ ations is large, it ma y re- quire a long computational time to get a reasonably small v ariance. 3 Unsup ervised classification 3.1 Binary hidden Marko v mo del W e now come back to the original binary classification problem with Mark ov dep endence b et w een the labels. T o this aim we consider a classical hidden Mark o v mo del (HMM). W e assume that { S t } 1 ≤ t ≤ n is a first order Marko v chain with transition matrix Π = { π ij ; i, j = 0 , 1 } . The observ ed data { X t } 1 ≤ t ≤ n are independent conditionally to the lab els. W e denote φ the emission distribution in state 0 (’normal’) and f the emission distribution in state 1 (‘abnormal’). W e recall that the function φ is known whereas f is unkno wn and we consider the collection M = { f m ; m = 1 , . . . , M } where f m is a mixture of m comp onen ts: f m ( x ) = m X k =1 p k φ k ( x ) , with m X k =1 p k = 1 . This collection is large as it allo ws us to fit the data from a t wo-component mixture (see McLac hlan et al. [11]) to a semi-parametric kernel-based density (see Robin et al. [15]). When f is appro ximated b y a mixture of m components, the initial binary HMM with laten t v ariable S can be rephrased as an ( m + 1)-state HMM with hidden Mark ov c hain { Z t } taking its v alues in { 0 , . . . , m } with transition matrix Ω = π 00 π 01 p 1 . . . π 01 p m π 10 π 11 p 1 . . . π 11 p m . . . . . . . . . . . . π 10 π 11 p 1 . . . π 11 p m . The observ ed data { X t } 1 ≤ t ≤ n are independent conditionally to the { Z t } with distribution X t | Z t ∼ φ Z t , where φ 0 = φ . Hence, we ha v e tw o latent v ariables Z and S which corresp ond to the group within the whole mixture and to the binary classification, resp ectively . 6 3.2 V ariational Ba yes inference The VBEM (Beal and Ghahramani [2]) aims at minimising the KL-div ergence in exp o- nen tial family/conjugate prior con text. The quality of the VBEM estimators has been studied in W ang and Titterington ( [22], [23], [21]) for mixture mo dels. W ang and Tit- terington [20] ha ve also studied the qualit y of v ariational appro ximation for state space mo dels. The VBEM algorithm has b een studied b y McGrory and Titterington [10] for the HMM with emission distributions b elonging to the exp onen tial family . In these articles, the authors hav e demonstrated the conv ergence of the v ariational Bay es estimator to the maxim um likelihoo d estimator, at rate O (1 /n ). They also sho w that the cov ariance matrix of the v ariational Bay es estimators is underestimated compared to the one obtained for the maxim um likelihoo d estimators. In our case, P ( X , S | Θ , M ) do es not b elong to the exp onential family whereas P ( X, Z | Θ , M ) do es. W e will therefore make the inference on the ( m + 1)-state hidden Mark o v mo del in- v olving Z rather than the binary hidden Mark o v mo del in volving S . Despite the spe- cific form of the transition matrix Ω, it do es not mo dify the framework of the exp o- nen tial family/conjugate prior. T o be sp ecific, log P ( X , Z | Θ , M ) can b e decomposed as log P ( Z | Θ , M ) + log P ( X | Z , Θ , M ) and only the first term in volv es Ω: log P ( Z | Θ , M ) = m X k =1 m X j =1 N kj log π 11 + N 00 log π 00 + m X k =1 N k 0 log π 10 + m X j =1 N 0 j log π 01 + m X k =1 Z 1 k log q 1 + Z 10 log q 0 + m X k =0 m X j =1 N kj log p j + m X k =1 Z 1 k log p k , (5) with N kj = P t ≥ 2 Z t − 1 ,k Z tj and q is the stationary distribution of Π. Since log P ( Z | Θ , M ) can b e written as a scalar pro duct Φ .u ( Z ) with Φ the vector of parameters and u ( Z ) the v ector con taining the { N kj } 1 ≤ k,j ≤ m and the sums o v er Z , it sho ws that Z | Θ , M b elongs to the exponential family and that this sp ecific form of Ω only affects the updating step of h yp er-parameters. 3.3 Mo del a v eraging F or each mo del m from the collection M , the VBEM algorithm provides the optimal distributions Q V B H | m , from which w e can derive the three weigh ts defined in Section 2: b α V B m , b α P E m and b α I S m . Based on these weigh ts, w e can get an av eraged estimate of the distribution f : e f A = X b α A m b f m , 7 where A corresp onds to one of the prop osed approaches (VB, PE or IS). Although the largest mo del only in volv es M comp onents, the a veraged distribution is a mixture with M ( M + 1) / 2 comp onen ts. As w e are mostly in terested in the estimation of the p osterior probabilit y T t defined in 1, w e similarly define its a veraged estimate: e T A t = 1 − X m b α A m E Q V B Z | m ( S t ) , where E Q V B Z | m ( S t ) corresponds to the exp ected v alue of S calculated with the optimal v ariational p osterior distribution of Z . This expectation do es not dep end on A . 4 Sim ulation study In this section, we study the efficiency of the estimators defined in the previous sections. First, we study the accuracy of α V B and α P E in terms of weigh t estimation. Then, w e fo cus on the accuracy from a classification p oin t of view. W e therefore liken the a veraged estimator of the p osterior probabilit y T t to the theoretical one. W e also compare the a veraging approach with a classical tw o-state HMM and with the HMM whic h has the highest weigh t calculated with the imp ortance sampling approac h, called throughout the pap er “selected HMM”. 4.1 Sim ulation design W e sim ulate a binary HMM as describ ed in Section 3, where f is non Gaussian and define as the probit transformation of a uniform-distribution on [0 , 1 c ], with c ∈ [5 , 7 , 10 , 15]. The difficult y of the problem decreases with the parameter c . W e also consider four differen t transition matrices whic h hav e the same form given by: Π u = 1 − lu lu l (1 − u ) 1 − l (1 − u ) (6) where l is the shifting rate whic h v aries from 0 to 1 and u corresp onds to the prop or- tion of the group of in terest and is c hosen within { 0 . 05 , 0 . 1 , 0 . 2 , 0 . 3 } . F or eac h of the 16 configurations w e generate P = 100 samples of size n = 100. The inference is done in a semi-homogeneous case: for eac h sim ulation condition, w e fit a 7-comp onen t Gaussian mixture with common v ariance σ 2 and mean µ k for the alternative. In a Ba yesian context, the parameters are random v ariables with prior distributions. These distributions are c ho- sen to be consisten t with the exp onential conjugate family . W e denote b y λ the precision parameter, λ = 1 σ 2 , w e hav e: • T ransition matrix: F or j = 1 , 2, π j. ∼ D (1 , 1). 8 • Mixture proportions: p ∼ D (1 , . . . , 1). • Precision: λ ∼ Γ(0 . 01 , 0 . 01). • Means: µ k | λ ∼ N 0 , 1 0 . 01 × λ 4.2 Results W e present the results for l = 0 . 6. W e considered other v alues for this parameter but the p erformances are almost similar. 4.2.1 Accuracy of the w eight W e consider the imp ortance sampling as a reference for weigh t estimation as it pro vides an unbiased estimate of the true weigh ts whatever the approximation. W e compared it to VB and PE weigh ts b y calculating the total v ariation distance, which quan tifies the dissimilarit y b et ween t wo distributions α 1 and α 2 : δ ( α 1 , α 2 ) = 1 2 X x | α 1 ( x ) − α 2 ( x ) | . (7) The closer to 0 this distance is, the better the estimation of the w eights. u u 0 . 05 0 . 1 0 . 2 0 . 3 c P E V B P E V B P E V B P E V B 5 0 . 419 0 . 069 0 . 370 0 . 101 0 . 453 0 . 120 0 . 456 0 . 069 7 0 . 438 0 . 096 0 . 403 0 . 101 0 . 287 0 . 101 0 . 257 0 . 072 10 0 . 386 0 . 092 0 . 271 0 . 180 0 . 232 0 . 115 0 . 107 0 . 092 15 0 . 372 0 . 093 0 . 303 0 . 158 0 . 258 0 . 129 0 . 102 0 . 101 T able 1: T otal v ariation distance betw een the estimated w eigh ts with respect to importance sampling for eac h v alue of u and c . T able 1 shows that VB w eights are the closest to IS w eigh ts. The total v ariation distance δ ( α V B , α I S ) is close to 0 whatever the sim ulation study . In con trast, the PE w eights seem not to b e correct for approximating the true w eights except when the t w o p opulations are w ell separated. These trends are also brought out when we fo cus on the weigh ts calculated for the P samples giv en a sim ulation condition. On av erage, compared to the PE approac h, the VB metho d tends to provide weigh t estimations close to those of the IS approach. F or instance, for c = 7 and u = 0 . 2, they mix three mo dels with a h uge w eight ( ≈ 0 . 70) for f 1 and w eigh ts around 0 . 15 for f 2 and f 3 . How ev er, the VB method has more stable estimated 9 w eights than IS. PE is the more stable approac h among the three but it tends to only select the t wo-component mo del with an a verage w eigh t around 0 . 95. Conclusion on the weigh t estimati on By directly analysing the w eight estimation, the similarities b et w een the IS and the VB methods ha ve clearly appeared. The VB method pro vides a go o d estimation of the true weigh ts which is not the case for PE. Hence, when the computational time of the IS metho d is becoming very high, we get a real adv antage b y using the VB metho d in terms of w eigh t estimation. 4.2.2 Accuracy of the p osterior probabilities Once the weigh ts hav e b een estimated, the av eraged estimates of the p osterior prob abilities T t are computed for each approac h. The aim of the VB method is to cluster the data in to tw o p opulations. In many cases, these p opulations are difficult to distinguish but some observ ations are easily classifiable without an y statistical approach. Hence, we put aside observ ations with a theoretical probability of b elonging to the cluster of in terest smaller than 0 . 2 or higher than 0 . 8. A classical indicator to measure the quality of a given classification is the MSE (Mean Square Error) whic h ev aluates the difference betw een the a veraged estimate e T A of one metho d of A and the theoretical v alues T ( th ) . M S E A = 1 P P X p =1 1 n n X t =1 ( e T A t,p − T ( th ) t,p ) 2 , (8) The M S E A estimation allo ws us to ev aluate the quality of the estimates pro vided b y Mo del m ov er all datasets p = { 1 , ..., P } and one approach of A . The smaller the MSE, the b etter the p erformances are. Since w e deal with synthetic data, we can look at the b est ac hiev able MSE. This aims at minimising the MSE within the av eraged estimator family to obtain an oracle weigh t W e denote this oracle b y α ∗ and w e hav e: α ∗ = argmin α || T ( th ) − M X m =1 α m b T ( m ) || 2 , (9) with P M m =1 α m = 1 and ∀ m ∈ { 1 , ..., M } , 0 ≤ α m ≤ 1. The v ariable b T ( m ) is the estimation of T supplied b y mo del m . This oracle can b e view ed as the weigh ts we w ould choose if the theoretical p osterior probabilit y of b elonging to the group of in terest were known. This oracle estimator is obtained by a functional regression under non-negativity constrain t and it can b e written as: α ∗ = ( b T 0 b T ) − 1 b T 0 T ( th ) × γ (10) 10 u = 0 . 05 c P E V B I S S electedH M M O racle 5 0 . 44(0 . 04) 0.36 (0.03) 0 . 38(0 . 04) 0 . 42(0 . 03) 0 . 31(0 . 02) 7 0 . 54(0 . 04) 0.42 (0.04) 0 . 43(0 . 04) 0 . 47(0 . 03) 0 . 34(0 . 02) 10 0 . 35(0 . 04) 0.30 (0.04) 0.30 (0.04) 0 . 34(0 . 04) 0 . 21(0 . 03) 15 0 . 38(0 . 04) 0 . 34(0 . 04) 0.33 (0.04) 0 . 36(0 . 03) 0 . 23(0 . 03) u = 0 . 1 c P E V B I S S electedH M M O racle 5 0 . 40(0 . 04) 0.37 (0.03) 0 . 39(0 . 03) 0 . 39(0 . 03) 0 . 29(0 . 03) 7 0 . 29(0 . 03) 0.23 (0.03) 0.23 (0.03) 0 . 25(0 . 03) 0 . 17(0 . 02) 10 0 . 28(0 . 03) 0 . 28(0 . 03) 0.23 (0.03) 0 . 28(0 . 03) 0 . 16(0 . 02) 15 0 . 25(0 . 04) 0 . 22(0 . 03) 0.20 (0.03) 0 . 22(0 . 03) 0 . 17(0 . 02) u = 0 . 2 c P E V B I S S electedH M M O racle 5 0 . 33(0 . 03) 0.29 (0.03) 0 . 30(0 . 03) 0 . 31(0 . 03) 0 . 19(0 . 02) 7 0 . 26(0 . 03) 0.23 (0.02) 0 . 24(0 . 02) 0 . 25(0 . 02) 0 . 18(0 . 02) 10 0 . 23(0 . 03) 0 . 20(0 . 02) 0.19 (0.02) 0 . 23(0 . 01) 0 . 17(0 . 02) 15 0 . 08(0 . 01) 0 . 09(0 . 01) 0.07 (0.01) 0 . 09(0 . 01) 0 . 06(0 . 02) u = 0 . 3 c P E V B I S S electedH M M O racle 5 0 . 23(0 . 02) 0.19 (0.01) 0 . 20(0 . 01) 0 . 22(0 . 01) 0 . 16(0 . 01) 7 0 . 13(0 . 01) 0.11 (0.01) 0 . 12(0 . 01) 0 . 13(0 . 01) 0 . 09(0 . 01) 10 0 . 17(0 . 02) 0 . 12(0 . 01) 0.11 (0.01) 0 . 18(0 . 01) 0 . 03(0 . 01) 15 0 . 12(0 . 01) 0 . 10(0 . 01) 0.09 (0.01) 0 . 12(0 . 01) 0 . 06(0 . 01) T able 2: Mean(sd) of the misclassification rate for the three a v eraging approaches. where γ is a normalising constant and b T is the matrix containing the estimates b T ( m ) for all model m . Several algorithms allow one to calculate this estimator n umerically by taking constrain ts into account. In this article, the optimisation has b een ac hieved by the Newton-Raphson algorithm. Figure 1 displa ys the MSE calculated for the different metho ds under the v arious sim- ulation conditions. First, we notice that the VB metho d based on the optimal v ariational w eights pro vides go o d results in most of the cases. Moreov er, we observ e that an av eraging approac h with either the IS or VB metho d provides b etter results than the selected HMM. W e observe that the PE metho d and the tw o-state-HMM pro vide the worse estimates for man y simulation conditions than do the VB and IS metho ds. Another commen t is that there is no method whic h is the b est whatev er the sim ulation condition. Moreov er, the estimations get closer to the oracle estimator when the problem is b ecoming easier. Figure 2 shows the standard deviation of the MSE ov er all the sim ulation conditions. W e notice that the VB method has one of the lo w est v ariabilities. Once more, the tw o-state HMM has the w orst p erformances. T able 2 includes information on the misclassification for the three a veraging approac hes. 11 Figure 1: Mean square error (MSE) betw een the true p osterior probabilities and the esti- mates as a function of the uniform parameters. Metho ds: ”∆”: PE, ” ∇ ”: tw o-state-HMM, ”*”: IS, ” • ”: Selected HMM, ” ♦ ”: VB, ”O” : Oracle. T op left: Π 0 . 05 , T op right: Π 0 . 1 , Bottom left: Π 0 . 2 , Bottom righ t: Π 0 . 3 . VB and Oracle are in dotted lines. 12 Figure 2: Standard deviation of the MSE. Metho ds: ”∆”: PE, ” ∇ ”: t wo-state-HMM, ”*”: IS, ” • ”: Selected HMM, ” ♦ ”: VB, ”O” : Oracle. T op left: Π 0 . 05 , T op right: Π 0 . 1 , Bottom left: Π 0 . 2 , Bottom righ t: Π 0 . 3 . VB and Oracle are in dotted lines. 13 The misclassification rate is calculated on the P samples whatev er the simulation condition. The v alues in b old corresp ond to the smallest misclassification rate among the PE, VB and IS approaches. First, we note that the VB and the IS metho ds hav e very similar misclassification rates whatev er the sim ulation condition. Moreov er, this rate corresp onds to the b est rate of the three a veraging metho ds. The a veraged estimator supplied b y the plug-in w eights estimation seems to misclassify more data than the other approaches. Once again, T able 2 sho ws us that the VB approac h provides goo d results when the simulation condition is complicated. In fact, when c equals either 5 or 7, the av eraging metho d based on optimal v ariational w eights pro vides the low est misclassified rate among the three a veraging approac hes. Since the misclassification rate of the oracle is close to the rates obtained by VB and IS estimation, the t wo approaches provide go o d results for each v alue of c and u . An other comment is that the selected HMM approach alw a ys pro dives w orse results than the IS and VB ones. This means that the av eraging approach brings a gain to the p osterior probabilit y estimation. Figure 3 sho ws the en tropy of the w eigh ts. W e note that the optimal v ariational w eigh ts ha ve one of the largest entropies among all the prop osed weigh ts. This means that the VB metho d tends to mix several mo dels. Contrary to the other three w eights, PE has a low en tropy . This metho d seems to select only one mo del to infer p osterior probabilit y and do es not tak e others in to accoun t. Conclusion on the accuracy of the estimates Studying the MSE indicator allows us to compare the metho ds in terms of classification. Except for the “tw o-state-HMM” approac h, w e highlight that all the prop osed metho ds hav e quite similar b eha viours. Ho w- ev er, the VB metho d provides b etter results in terms of MSE and its standard deviation than do es the PE approach. These results are very close to those of IS and even often bet- ter. The fo cus on the misclassification rate confirmed the closeness b et ween our approac h and that of IS. These metho ds hav e a quite similar misclassification rates whatever the sim ulation condition. F urthermore, this rate corresp onds to the b est rate among the three a veraging approaches. The computational time is also a key p oin t of these classification metho ds. Indeed, the VB metho d has a negligeable computational time compared with IS. This ma y further dramatically increase with the size of the data. 5 Real data analysis 5.1 Description The data In this section, w e fo cus on the analysis of a real dataset collected from public health surv eillance systems. These data ha ve also been studied in the recent paper of Cai et al. [17] using an FDR (F alse Discov ery Rate) approac h. The database is composed of 1216 time p oin ts. The data and log-transformation of them are sho wn in figure 4. The 14 Figure 3: Entrop y of the weigh ts. Methods: ”∆”: PE, ” ∇ ”: tw o-state-HMM, ”*”: IS, ” • ”: Selected HMM, ” ♦ ”: VB, ”O” : Oracle. T op left: Π 0 . 05 , T op right: Π 0 . 1 , Bottom left: Π 0 . 2 , Bottom righ t: Π 0 . 3 . VB and Oracle are in dotted lines. 15 m mean v ariance proportions α V B 1 4 . 9 1.1 1 < 10 − 4 2 4 . 5 , 5 0.9 0 . 67 , 0 . 33 < 10 − 4 3 4 , 4 . 2 , 6 0.3 0 . 32 , 0 . 32 , 0 . 34 0 . 34 4 3 . 9 , 4 . 1 , 5 , 6 . 3 0.2 0 . 22 , 0 . 27 , 0 . 26 , 0 . 25 0 . 66 5 3 . 8 , 4 , 4 . 1 , 5 . 2 , 6 . 4 0.18 0 . 17 , 0 . 19 , 0 . 22 , 0 . 22 , 0 . 20 < 10 − 4 6 3 . 8 , 4 , 4 . 1 , 4 . 8 , 5 . 6 , 6 . 5 0.15 0 . 14 , 0 . 16 , 0 . 16 , 0 . 20 , 0 . 16 , 0 . 18 < 10 − 4 T able 3: P arameter estimation of the Gaussian mixture within the alternative distribution f . ev ent describ ed b y the data can b e classified into 2 groups: usual or unusual. These tw o groups corresp ond to a regular low rate and an irregular high rate respectively . Hence, the first group represen ts our group of interest and the other one the alternativ e. Moreo ver, it is clear that an even t highly dep ends on the past and Strat and Carrat [6] demonstrated that this kind of data can b e describ ed b y using a t wo-state HMM. In this analysis, we th us aim at retrieving the t wo groups in the p opulation and w e wan t to estimate well the p osterior probabilit y of belonging to the group of interest. Initialisation of the algorithm T o a void any influence of the prior distributions, they ha ve b een c hosen as describ ed in Section 4.1. As considered in the sim ulation section, the alternativ e distribution has b een fitted by a Gaussian mixture with common v ariance. The n umber of components m within the alternative distribution v aries from 1 to 6 and the fixed distribution N (2 . 37 , 0 . 76 2 ) has b een c hosen according to results of Cai et al [17]. 5.2 Results F or eac h n umber of comp onent we infer the mo del parameters and estimate the weigh ts with the VB method. The results w e obtained are summarized in T able 3. Ev ery mo del presen ted in T able 3 has the same estimation of the transition matrix 0 . 96 0 . 04 0 . 04 0 . 96 . In their article, Cai et al. selected a mo del with tw o heterogeneous Gaussian distributions for the alternative. In our approac h, due to the homogeneous as- sumption, the n umber of comp onen ts increases and w e keep t w o mo dels with three and four comp onen ts resp ectively . The other mo dels hav e a low w eight, smaller than 10 − 4 , and ha ve no influence on the p osterior probabilit y estimation. W e now focus on the classifica- tion provided by the a v eraged distribution and the 3-comp onent mo del prop osed by Cai et al. [17] and w e notice that only 3 p oin ts differ b et ween our approach from that of Cai. Ho wev er if we fo cus on these three p oints, we observe that they correspond to p oints with a p osterior probabilit y close to 0.5. These p oints are on the b orderline b et ween the t wo classes. As our approach tends to increase the p osterior probabilities (see figure 5), the epidemical ranges are greater with our approach. In tw o cases, the epidemics are declared 16 earlier with the VB method than with that of Cai. Figure 5 displays the av eraged p osterior probabilities against the estimations obtained b y the mo del prop osed b y Cai. The first comment is that the t wo approaches pro vide close estimations. This is esp ecially the case for probabilities smaller than 0.3 or greater than 0.7. These ranges corresp ond to low entrop y areas. The main comment is that an a veraging approach tends to refine p osterior probabilities b et w een 0.3 and 0.7. This high en tropy area is considered as a difficult area for estimating the probabilities. In fact, it mainly corresp onds to data p oints which are on the borderline b et ween the tw o classes. 6 Conclusion W e prop osed a method for binary classification problems based on av eraged estimators within a v ariational Ba yesian framew ork. This approac h allows us to av oid mo del selection and tak e mo del uncertaint y into accoun t. It can theoretically be prov ed that using an a veraged estimator pro vides a gain in terms of MSE and increases the lo wer bound of the log-lik eliho o d. W e prop osed a metho d based on optimal v ariational w eights which derive from a mo dification of the classical low er bound of the log-likelihoo d. Our method do es not required more computational time than classical one. F or studying the performances, the metho d has been used on b oth syn thetic and real data. The results we obtained on syn thetic data show ed that our metho d enhances the es- timator in terms of MSE in many sim ulation conditions. W e also highlighted that the a veraging approac h improv es the p osterior probability estimation provided b y the classical selection approach. Moreo ver, w e sho w ed that optimal v ariational w eigh ts are closer to imp ortance sampling than the plug-in one. Since the imp ortance sampling cop ed with computational time problems for high dimensional datasets, our method is of significant in terest in this case. A real data analysis has b een carried out on a clinical dataset. In this con text, the ag- gregation mo del still refines the estimation of posterior probabilities. W e note in particular that the classification is different in cases where the probabilit y is close to 0.5, i.e. when the classification is difficult. It allo ws us to refine the start of the epidemic perio d. 17 Figure 4: top: weekly ILI rate, middle: log-transformed w eekly ILI rate, b ottom: Aggre- gated p osterior probabilit y of ILI epidemic ov er w eeks. The three red p oints corresp ond to the p oin ts whic h hav e a different classification from one metho d to another. 18 Figure 5: Aggregated p osterior probabilities according to the estimation of the p osterior probabilities with the 2 heterogeneous comp onen ts model. The three red points corresp ond to the p oin ts whic h hav e a different classification from one metho d to another. 19 References [1] Christophe Andrieu. An in tro duction to mcmc for mac hine learning, 2003. [2] M. J Beal and Z. Ghahramani. The v ariational bay esian EM algorithm for incomplete data: with application to scoring graphical model structures, 2003. [3] Adrian Corduneanu and Christopher M. Bishop. V ariational bay esian mo del selection for mixture distributions. Statistics in Medicine, 18(24):3463–3478, 2001. [4] Jennifer A Ho eting, David Madigan, Adrian E Raftery , and Chris T V olinsky . Bay esian mo del a v eraging: A tutorial. Statistical science, 14(4):382—417, 1999. [5] T ommi S. Jaakkola and Michael I. Jordan. Improving the mean field appro ximation via the use of mixture distributions. In Pro ceedings of the NA TO Adv anced Study Institute on Learning in graphical models, pages 163–173, Erice, Italy , 1998. Kluw er Academic Publishers. [6] Y ann Le Strat and F abrice Carrat. Monitoring epidemiologic surv eillance data using hidden mark ov mo dels. Statistics in Medicine, 1999. [7] Da vid Madigan and F red Hutchinson. Enhancing the predictive performance of ba yesian graphical models. Communications in statistics: Theory and metho ds, 24, 1995. [8] Da vid Madigan and Adrian E Raftery . Model selection and accoun ting for mo del uncertain ty in graphical mo dels using o ccam’s window. Journal of the American Statistical Asso ciation, 1993. [9] Jean-Mic hel Marin and Christian P Rob ert. Imp ortance sampling methods for ba yesian discrimination b etw een embedded mo dels. 0910.2325, Octob er 2009. [10] C. A McGrory and D. M Titterington. V ariational ba yesian analysis for hidden mark ov mo dels. Australian & New Zealand Journal of Statistics, 51:227–244, 2006. [11] G. J. McLac hlan, R. W. Bean, and D. Peel. A mixture mo del-based approach to the clustering of microarra y expression data. 2002. [12] G P arisi. Statistical field theory. Addison W esley , 1988. [13] Adrian E Raftery , Jennifer A Ho eting, and Da vid Madigan. Bay esian mo del a v eraging for linear regression models. Journal of the American Statistical Asso ciation, 92:179— 191, 1997. 20 [14] Adrian E. Raftery , Yingye Zheng, N-W e, Merlise Clyde, Jennifer Hoeting, and David Madigan. Long-run p erformance of ba yesian model av eraging. Journal of the American Statistical Asso ciation, 98:931–938, 2003. [15] Stephane Robin, Avner Bar-Hen, Jean-Jacques Daudin, and Lauren t Pierre. A semi- parametric approac h for mixture mo dels: Application to local false disco very rate estimation. Comput. Stat. Data Anal., 51(12):5483–5493, 2007. [16] Gideon Sc hw arz. Estimating the dimension of a mo del. The Annals of Statistics, 6(2):461–464, 1978. [17] W enguang Sun and T on y Cai. Large-scale m ultiple testing under dep endence. Journal of the Ro yal Statistical So ciety, 71:393–424, 2009. [18] Chris T V olinsky , David Madigan, Adrian E Raftery , and Richard A Kronmal. Ba yesian mo del a veraging in prop ortional hazard mo dels: Assessing the risk of a strok e. Applied statistics, pages 433—448, 1997. [19] Martin J W ain wright and Michael I Jordan. Graphical Models, Exp onen tial F amilies, and V ariational Inference. No w Publishers Inc., Hanov er, MA, USA, 2008. [20] Bo W ang and D. M Titterington. Lack of consistency of mean field and v ariational ba yes appro ximations for state space mo dels. Neural Processing Letters, 20:151–170, 2003. [21] Bo W ang and D. M. Titterington. Lo cal con v ergence of v ariational ba yes estimators for mixing co efficien ts. 2003. [22] Bo W ang and D. M. Titterington. Conv ergence and asymptotic normality of v ari- ational bay esian appro ximations for exp onen tial family models with missing v alues. In Pro ceedings of the 20th conference on Uncertain ty in artificial in telligence, pages 577–584, Banff, Canada, 2004. A UAI Press. [23] Bo W ang and D. M. Titterington. Inadequacy of in terv al estimates corresp onding to v ariational bay esian approximations, 2004. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment