Distributed Delayed Stochastic Optimization
We analyze the convergence of gradient-based optimization algorithms that base their updates on delayed stochastic gradient information. The main application of our results is to the development of gradient-based distributed optimization algorithms w…
Authors: Alekh Agarwal, John C. Duchi
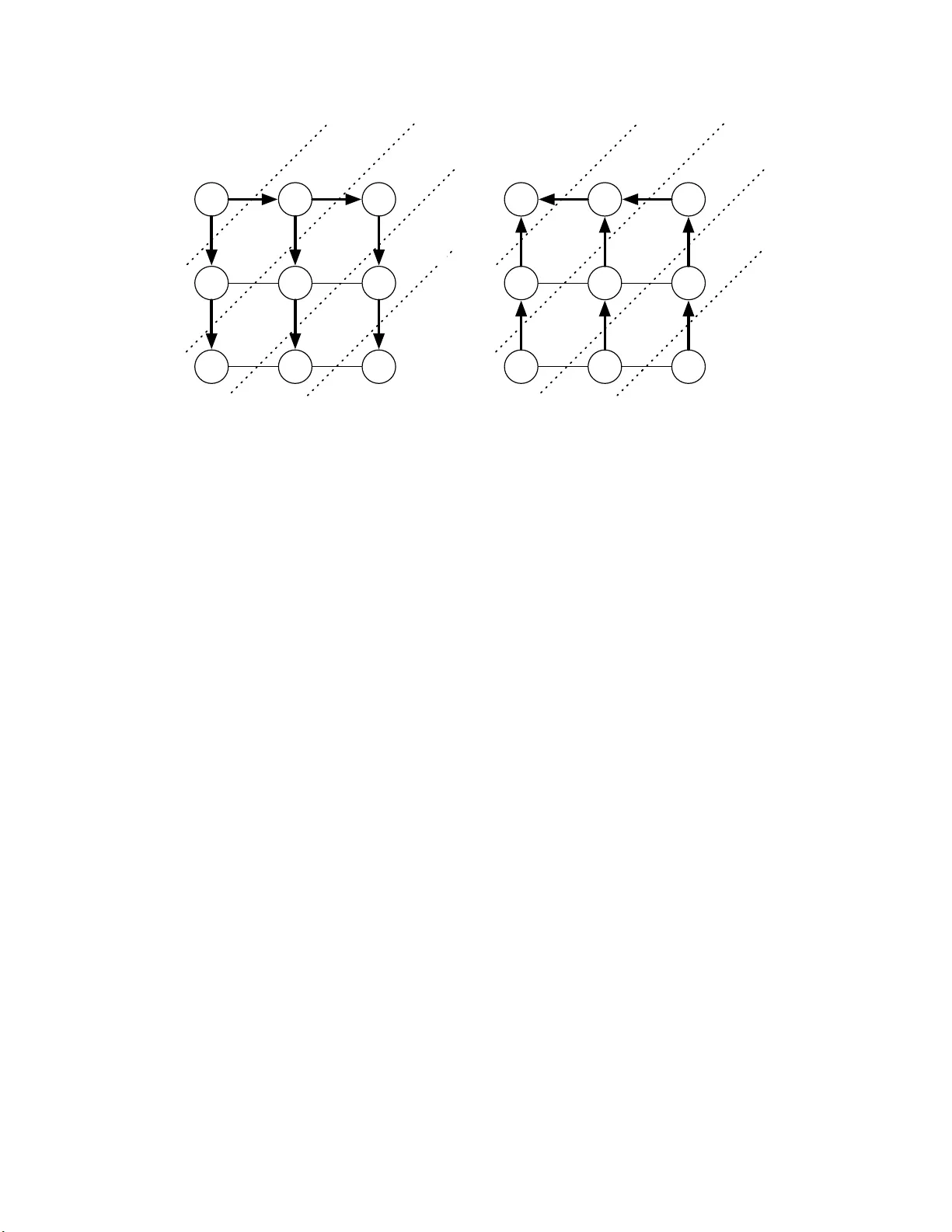
Distributed Dela y ed Sto c hastic Optimization Alekh Agarw al John C. Duc hi { alekh,jduc hi } @eecs.berkeley.ed u Departmen t of Elect rical En gineering and Computer Sciences Univ ersit y of California, Berk eley Abstract W e ana ly ze the conv er gence of gradient-based optimization algo rithms t hat base their up- dates on dela y ed stochastic gradient information. The main applica tion o f our results is to the development of gra dien t-bas ed distributed optimization a lgorithms where a master no de per forms parameter up dates while worker no des compute sto chastic g radien ts ba sed o n lo cal information in par allel, whic h ma y give rise t o delays due to asynchrony . W e tak e motiv a tion from statistical problems where the size of the data is so large that it cannot fit on one computer; with the adven t of huge datasets in bio logy , as tronom y , and the int ernet, such problems are now common. Our main co ntribution is to show that fo r smo oth sto chastic pro blems, the delays a re asymptotically negligible a nd we can ac hiev e order -optimal co n vergence results. In a pplication to distributed optimization, we dev elop pro cedures that ov er come comm unicatio n bottlenecks and synchronization requirements. W e sho w n -node a rc hitectures whose optimization error in sto c ha stic problems—in spite of asynchronous delays—scales asymptotically as O (1 / √ nT ) after T itera tions. This rate is known to b e optimal for a distributed s y stem with n no des even in the absence of delays. W e additiona lly c o mplemen t our theoretical results with numerical exp erimen ts on a sta tistical machine lea r ning task. 1 In tro duction W e fo cus on s to c hastic con vex optimizati on pr ob lems of the form minimize x ∈X f ( x ) for f ( x ) := E P [ F ( x ; ξ )] = Z Ξ F ( x ; ξ ) dP ( ξ ) , (1) where X ⊆ R d is a closed con ve x set, P is a p r obabilit y distrib ution o v er Ξ, and F ( · ; ξ ) is con v ex for all ξ ∈ Ξ, so that f is conv ex. The goal is to fi nd a parameter x that appr o ximately minimizes f o ver x ∈ X . C lassical s to c h astic gradient algorithms [RM51, Pol8 7] iterativ ely up d a te a parameter x ( t ) ∈ X by sampling ξ ∼ P , computing g ( t ) = ∇ F ( x ( t ); ξ ), and p erform in g the u p d at e x ( t + 1) = Π X ( x ( t ) − α ( t ) g ( t )), where Π X denotes p ro jection onto the set X . In this pap er, we analyze async h ronous gradien t metho ds, wh ere instead of receiving curr en t inform at ion g ( t ), the pro cedure receiv es out of date gradient s g ( t − τ ( t )) = ∇ F ( x ( t − τ ( t )) , ξ ), where τ ( t ) is the (p oten tially r a ndom) dela y at time t . The cen tral cont ribution of this pap er is to develo p algorithms that—und er natural assumptions ab out the fun ct ions F in the ob jectiv e (1)—ac hiev e asymptotical ly optimal rates for sto c hastic con v ex optimizatio n in sp ite of d el a ys. Our mo del of dela y ed gradient in f ormati on is particularly relev ant in distributed optimization scenarios, where a master main tains the parameters x while work ers compute sto c hastic gradien ts of the ob jectiv e (1). T he arc hitectural assumption of a master w ith sev eral work er no des is natural for distributed computation, and other researc h ers ha v e considered mo dels s imila r to th ose in this p a- p er [NBB01, LSZ09]. By allo w ing dela y ed and async h ronous u pd ate s, we can a void synchronizati on issues th at commonly hand ica p distr ibuted s ystems. 1 Master 1 2 3 n x ( t + n − 1) x ( t ) g 2 ( t − n + 1) g 1 ( t − n ) x ( t + 1) g n ( t − 1) Figure 1. Cyclic delayed update architecture. W or k er s compute gra dien ts cyclically and in pa r allel, passing out-of-date information to master. Mas ter resp onds with current para meter s. Diagr am shows parameters a nd gradients communicated b et w een r ounds t and t + n − 1. Certainly distrib uted optimizati on has b een stu died for sev eral d ec ades, tracing bac k at least to seminal work of Tsitsiklis and colleagues ([Tsi84, BT89]) on m inimiza tion of sm ooth functions where the p aramet er v ector is distrib u ted. More recen t work has studied problems in wh ic h eac h pro cessor or no de i in a net work has a lo cal function f i , and the goal is to minimize the sum f ( x ) = 1 n P n i =1 f i ( x ) [NO09, RNV10, JRJ09, D A W1 0]. Most prior w ork assu mes as a c onstr aint that data lies on several differen t no des throu gh ou t a net work. How ev er, as Dek el et al. [DGBSX10a ] first noted, in d istr ibuted sto c h ast ic settings indep end ent realizations of a stochastic gradient can b e computed concurrent ly , and it is th us p ossible to obtain an aggrega ted grad ient estimate with lo wer v ariance. Using mo dern sto c h a stic optimization algorithms (e.g. [JNT08, Lan10]), Dek el et al. give a series of reductions to sho w that in an n -no de n et w ork it is p ossible to ac hieve a sp eedup of O ( n ) o ver a single-pro cessor so long as the ob jectiv e f is s m ooth. Our w ork is closest to Nedi´ c et al.’s async hronous subgradien t m et ho d [NBB01], which is an incremen tal gradient pro cedure in w hic h gradient pro jection steps are tak en u sing out-of-date gradi- en ts. See Figure 1 for an illustration. T h e async hronous su bgradien t metho d p erforms non-smo oth minimization and suffers an asymptotic p enalt y in con vergence r a te du e to the dela ys: if the gradi- en ts are computed with a d ela y of τ , then the conv ergence rate of the pro cedure is O ( p τ /T ). The setting of distributed op timization p ro vides an elegan t illus tr at ion of the role p la yed by the d ela y in con vergence r at es. As in Fig. 1, the dela y τ can essentiall y b e of order n in Nedi´ c et al.’s s et ting, whic h giv es a con verge nce r ate of O ( p n/T ). A s im p le centrali zed sto c h asti c gradien t algorithm at- tains a rate of O (1 / √ T ), whic h suggests something is amiss in the distributed algorithm. Langford et al. [LSZ09] redisco v ered Nedi´ c et al.’s results and attempted to remo ve the asymptotic p enalty b y considering smo oth ob jectiv e fun ctions, though their appr oa c h has a tec h nical error (see Ap- p endix C), and ev en so they do n ot d emo nstrate an y pr o v able b enefits of distributed computation. W e analyze s imila r asyn c hronous algorithms, b ut w e show that for smo oth sto c hastic problems the dela y is asymptotically negligible—the time τ does n ot matter—and in fact, with parallelization, dela yed up dates can giv e p ro v able p erformance b enefits. W e build on results of Dek el et al. [DGBSX10a], who show that wh en the ob jectiv e f has Lipsc hitz-con tin uous gradien ts, then wh en n pro cessors compu te sto c h asti c gradien ts in parallel using a common parameter x it is p ossible to ac hiev e con v ergence rate O (1 / √ T n ) so long as the pro cessors are synchronized (under appropriate sync hron y conditions, this holds nearly indep en- 2 den tly of n et w ork top ology). A v arian t of th ei r app roac h is asymptotically robust to async hron y so long as most pro cessors remain syn c hronized for most of the time [DGBSX10b]. W e sho w re- sults similar to their initial disco v ery , b ut we analyze the effects of asynchronous gradien t u p d ate s where all the no des in the net w ork can suffer dela ys. Application of ou r main resu lts to the dis- tributed setting pr o vides con vergence rates in terms of the n um b er of no des n in the net w ork and the sto c hastic p rocess go v ern ing th e dela ys. C oncrete ly , we sho w that und er different assumptions on the net w ork and d ela y pro cess, w e ac hieve con v ergence rates ran ging from O ( n 3 /T + 1 / √ T n ) to O ( n/T + 1 / √ T n ), whic h is O (1 / √ nT ) asymptotically in T . F or problems with large n , we demon- strate faster rates ranging from O (( n/T ) 2 / 3 + 1 / √ T n ) to O (1 /T 2 / 3 + 1 / √ T n ). In either case, the time necessary to ac hieve ǫ -optimal solution to the problem (1) is asymptotically O (1 /nǫ 2 ), a factor of n —the size of the net work—b ette r than a centrali zed pro cedure in sp ite of d el a y . The r emaind er of the pap er is organized as follo ws. W e b egin by reviewing kno wn algorithms for solving the s toc hastic optimization problem (1) and stating our main assum ptions. Then in Section 3 we giv e abs trac t descriptions of our algorithms and state our main theoretical r esults, whic h w e mak e concrete in Section 4 by formally placing the analysis in the setting of d istributed sto c hastic optimization. W e complemen t the theory in Section 5 w ith exp erimen ts on a real-w orld dataset, an d p roofs follo w in the r emai ning sections. Notation F or the reader’s con v enience, we collect our (mostly standard) notation here. W e denote general n orms by k·k , and the dual n orm k ·k ∗ to the norm k·k is defined as k z k ∗ := sup x : k x k≤ 1 h z , x i . The sub differentia l set of a fu n ctio n f is ∂ f ( x ) := n g ∈ R d | f ( y ) ≥ f ( x ) + h g , y − x i for all y ∈ d om f o W e use the shorth and k ∂ f ( x ) k ∗ := sup g ∈ ∂ f ( x ) k g k ∗ . A function f is G -Lipsc h itz with resp ect to the n orm k·k on X if for all x, y ∈ X , | f ( x ) − f ( y ) | ≤ G k x − y k . F or con vex f , this is equiv alen t to k ∂ f ( x ) k ∗ ≤ G for all x ∈ X (e.g. [HUL96a]). A fu nction f is L -smo oth on X if ∇ f is L ip sc hitz con tinuous w ith resp ect to the n orm k·k , d efined as k∇ f ( x ) − ∇ f ( y ) k ∗ ≤ L k x − y k , equiv alen tly , f ( y ) ≤ f ( x ) + h∇ f ( x ) , y − x i + L 2 k x − y k 2 . F or conv ex differentia ble h , the Bregman divergence [Bre67] b et ween x and y is defined as D h ( x, y ) := h ( x ) − h ( y ) − h∇ h ( y ) , x − y i . (2) A con v ex function h is c -strongly conv ex with resp ect to a n orm k·k ov er X if h ( y ) ≥ h ( x ) + h g , y − x i + c 2 k x − y k 2 for all x, y ∈ X and g ∈ ∂ h ( x ) . (3) W e u se [ n ] to denote the set of inte gers { 1 , . . . , n } . 2 Setup and A lgori thms In th is section w e set u p and recall the dela y-free algorithms und erlying our approac h. W e then giv e the appropr ia te delay ed versions of these algorithms, wh ic h we analyze in the sequ el. 3 2.1 Setup and Dela y-free Algorithms T o build intuition for the algorithms w e analyze, we fi rst describ e tw o closely related first-order algorithms: the d ual a v eraging algorithm of Nestero v [Nes09 ] and th e mirror d esce n t algorithm of Nemiro vski and Y ud in [NY83], wh ic h is analyzed further b y Bec k and T eb oulle [BT03]. W e b egin by collecting n ot ation and giving u seful definitions. Both algorithms are based on a proxi mal function ψ ( x ), where it is n o loss of generalit y to assume that ψ ( x ) ≥ 0 f or all x ∈ X . W e assu m e ψ is 1-strongly con v ex (by scaling, th is is no loss of generalit y). By d efinitions (2 ) and (3), th e div ergence D ψ satisfies D ψ ( x, y ) ≥ 1 2 k x − y k 2 . In the oracle mo del of sto chastic op timization that we assume, at time t b oth algorithms query an oracle at the p oin t x ( t ), and the oracle then s amp les ξ ( t ) i.i.d. f r om the distrib ution P and returns g ( t ) ∈ ∂ F ( x ( t ); ξ ( t )). Th e du al av eraging algorithm [Nes09 ] up dates a d ual v ector z ( t ) and primal vect or x ( t ) ∈ X via z ( t + 1) = z ( t ) + g ( t ) and x ( t + 1) = argmin x ∈X n h z ( t + 1) , x i + 1 α ( t + 1) ψ ( x ) o , (4) while mirr or descen t [NY83, BT03] p erforms the up date x ( t + 1) = argmin x ∈X n h g ( t ) , x i + 1 α ( t ) D ψ ( x, x ( t )) o . (5) Both mak e a linear app ro ximation to th e fun ctio n b eing minim ized—a global approxi mation in the case of the dual a verag ing u p d at e (4) and a more lo cal appr o ximation for mir ror descent (5)—wh ile using th e p ro ximal function ψ to regularize the p oints x ( t ). W e n o w state the tw o essent ially standard assumptions [JNT08, Lan10, Xia10] w e m o st often mak e ab out the sto c hastic optimization problem (1), after wh ic h we recall the conv ergence rates of the algorithms (4) and (5). Assumption A (Lipsc hitz F unctions) . F or P -a.e. ξ , the function F ( · ; ξ ) is c onvex. Mor e over, for any x ∈ X , E [ k ∂ F ( x ; ξ ) k 2 ∗ ] ≤ G 2 . In particular, Assumption A implies that f is G -Lipsc h itz contin uous with resp ect to the norm k·k and that f is con v ex. Our second assu m ption h as b een u sed to s h o w rates of con v ergence b ase d on the v ariance of a gradien t estimator for sto c hastic optimizatio n pr oblems (e.g. [JNT08, Lan10]). Assumption B (Smooth F unctions) . The function f define d in (1 ) has L - Li ps chitz c ontinuous gr adient, and for al l x ∈ X the v arianc e b ound E [ k∇ f ( x ) − ∇ F ( x ; ξ ) k 2 ∗ ] ≤ σ 2 holds. 1 Sev eral commonly used fun ct ions satisfy the ab o ve assump tio ns, for example: (i) The lo gistic loss : F ( x ; ξ ) = log [1 + exp( h x, ξ i )], the ob jectiv e for logistic r egression in statistics (e.g. [HTF01]). The ob jectiv e F satisfies Assu m ptions A and B so long as k ξ k is b ounded. (ii) L e ast squar es or line ar r e gr ession : F ( x ; ξ ) = ( a − h x, b i ) 2 where ξ = ( a, b ) for a ∈ R d and b ∈ R , s a tisfies Assumptions A and B as long as ξ is b ounded and X is compact. W e also mak e a stand ard compactness assump tio n on the op timization set X . 1 If f is differentiable, then F ( · ; ξ ) is differentiable for P -a.e. ξ , and conv ersely , bu t F need not b e smoothly differentiable [Ber73]. Since ∇ F ( x ; ξ ) exists for P -a.e. ξ , we will write ∇ F ( x ; ξ ) with no loss of generalit y . 4 Assumption C (Compactness) . F or x ∗ ∈ argmin x ∈X f ( x ) and x ∈ X , the b ounds ψ ( x ∗ ) ≤ R 2 / 2 and D ψ ( x ∗ , x ) ≤ R 2 b oth hold . Under Assumptions A or B in addition to Assumption C, the up dates (4) and (5) hav e kno wn con vergence rates. Define the time a verage d v ector b x ( T ) as b x ( T ) := 1 T T X t =1 x ( t + 1) . (6) Then un der Assumption A, b oth algorithms satisfy E [ f ( b x ( T ))] − f ( x ∗ ) = O RG √ T (7) for the stepsize choic e α ( t ) = R/ ( G √ t ) (e.g. [Nes09, Xia10, NJLS09 ]). The result (7) is sharp to constan t factors in general [NY83, ABR W10], bu t can b e further impro v ed u nder Assump tio n B. Building on work of Ju ditsky et al. [JNT08] and Lan [Lan10], Dek el et al. [DGBSX10a , App endix A] show that und er Assu mptions B and C th e stepsize c hoice α ( t ) − 1 = L + η ( t ), where η ( t ) is a damping factor set to η ( t ) = σ R √ t , yields for either of the u pd ate s (4) or (5) the con v ergence rate E [ f ( b x ( T ))] − f ( x ∗ ) = O LR 2 T + σ R √ T . (8) 2.2 Dela yed Optimization Algor ithms W e n o w tur n to extending the dual a veraging (4) and mirr or descen t (5) up dates to the setting in whic h instead descen t (5) up dates to the setting in w hic h instead of r ec eiving a curren t gradient g ( t ) at time t , th e pro cedure r ec eiv es a gradien t g ( t − τ ( t )), th at is, a sto c hastic gradient of the ob jectiv e (1) computed at the p oin t x ( t − τ ( t )). In the simplest case, the dela ys are uniform and τ ( t ) ≡ τ for all t , b ut in general the dela ys m a y b e a non-i.i.d. sto c hastic p rocess. Our analysis admits an y sequence τ ( t ) of dela ys as long as the mapp ing t 7→ τ ( t ) satisfies E [ τ ( t )] ≤ B < ∞ . W e also require that eac h up d a te happ ens once, i.e., t 7→ t − τ ( t ) is one-to-one, though this second assumption is easily satisfied. Recall that the problems w e consider are sto chastic optimization problems of the form (1) . Under the assumptions ab o ve, we extend the mirror descent and du al a veragi ng algorithms in the simplest w a y: w e rep lace g ( t ) with g ( t − τ ( t )). F or d ual a verag ing (c.f. the up date (4)) this yields z ( t + 1) = z ( t ) + g ( t − τ ( t )) and x ( t + 1) = argmin x ∈X n h z ( t + 1) , x i + 1 α ( t + 1) ψ ( x ) o , (9) while for m ir ror d esce n t (c.f. the up date (5)) we ha ve x ( t + 1) = argmin x ∈X n h g ( t − τ ( t )) , x i + 1 α ( t ) D ψ ( x, x ( t )) o . (10) A generalization of Nedi´ c et al.’s r esults [NBB01] b y combining their tec hn iques with the con ver- gence pro ofs of dual a v eraging [Nes09 ] and m irror descen t [BT03] is as follo ws . Under Assum p- tions A and C, so long as E [ τ ( t )] ≤ B < ∞ for all t , c ho osing α ( t ) = R G √ B t giv es rate E [ f ( b x ( T ))] − f ( x ∗ ) = O RG √ B √ T . (11) 5 3 Con v ergence r at es for dela y ed optimization of smo oth functions In this section, w e state and discus s sev eral resu lts for asyn chronous sto c hastic gradient m et ho ds. W e give tw o sets of theorems. Th e first are for th e asynchronous metho d wh en w e mak e up dates to the p arame ter v ecto r x using one sto c h asti c sub grad ient, according to the up d ate r ules (9) or (10). The second metho d in volv es us in g several sto c hastic subgradients f or eve ry u p d ate , eac h w ith a p oten tially different dela y , w h ic h gives sh arper results th at w e pr esen t in Section 3.2. 3.1 Simple dela y ed optimization In tuitiv ely , the √ B -p enalt y due to dela ys for non-smo oth optimization arises from the fact that subgradients can c han ge dr asti cally when measured at s lightly different lo cations, so a small dela y can introdu ce significan t inaccuracy . T o ov ercome the dela y p enalt y , we no w turn to the smo othness assumption B as wel l as th e L ip sc hitz condition A (we assu me b oth of these conditions along with Assumption C h ol d for all the theorems). In the sm ooth case, dela ys mean th at stale gradien ts are only sligh tly p erturb ed, since our sto c hastic algorithms constrain the v ariabilit y of the p oin ts x ( t ). As we sh o w in the pro ofs of the remaining results, the error from d el a y essen tially b ecomes a second order term: the p enalt y is asymptotically negligible. W e stud y b oth up date rules (9) and (10), and w e set α ( t ) = 1 L + η ( t ) . Here η ( t ) will b e c hosen to b oth con trol the effects of d ela ys and for err ors from sto c h astic gradient information. W e prov e the follo wing theorem in Sec. 6.1. Theorem 1. L et the se quenc e x ( t ) b e define d by the up date (9). Define the stepsize η ( t ) ∝ √ t + τ or let η ( t ) ≡ η for al l t . Then E T X t =1 f ( x ( t + 1)) − T f ( x ∗ ) ≤ 1 α ( T + 1) R 2 + σ 2 2 T X t =1 1 η ( t ) + 2 LG 2 ( τ + 1) 2 T X t =1 1 η ( t − τ ) 2 + 2 τ GR. The m irror d escent up date (10) exhibits similar con v ergence prop erties, and w e p ro v e the next theorem in S ec. 6.2. Theorem 2. Use the c onditions of The or em 1 but gener ate x ( t ) by the up date (10). Then E T X t =1 f ( x ( t +1)) − T f ( x ∗ ) ≤ 2 LR 2 + R 2 [ η (1) + η ( T )]+ σ 2 2 T X t =1 1 η ( t ) +2 LG 2 ( τ +1) 2 T X t =1 1 η ( t − τ ) 2 +2 τ GR In eac h of th e ab o v e theorems, we can set η ( t ) = σ √ t + τ /R . As imm ediat e corollaries, w e recall the defin itio n (6) of the a verage d sequ en ce of x ( t ) and us e conv exit y to see that E [ f ( b x ( T ))] − f ( x ∗ ) = O LR 2 + τ GR T + σ R √ T + LG 2 τ 2 R 2 log T σ 2 T for either up d at e rule. In addition, w e can allo w the d ela y τ ( t ) to b e random: Corollary 1. L et the c onditions of The or em 1 or 2 hold, but al low τ ( t ) to b e a r andom mapping such that E [ τ ( t ) 2 ] ≤ B 2 for al l t . With the choic e η ( t ) = σ √ T /R the up dates (9) and (10) satisfy E [ f ( b x ( T ))] − f ( x ∗ ) = O LR 2 + B 2 GR T + σ R √ T + LG 2 B 2 R 2 σ 2 T . 6 W e provide the pr oof of the corollary in Sec. 6.3. The tak e-home message from the ab o v e corollaries, as we ll as Theorems 1 and 2, is that th e p enalt y in conv ergence rate d u e to th e dela y τ ( t ) is asymptotically negligible. As w e discuss in greater depth in the next section, this has fa v orable implications for r obust d istributed sto c hastic optimization algorithms. 3.2 Com binations of dela ys In s ome scenarios—including d istributed settings similar to those w e d iscuss in the next section— the pr ocedure h as access n ot to only a s in gle dela yed gradient but to several with d ifferen t dela ys. T o abstract a wa y the essential parts of this situation, we assum e th at the pr ocedure receiv es n gradien ts g 1 , . . . , g n , where eac h has a p oten tially d iffe ren t dela y τ ( i ). No w let λ = ( λ i ) n i =1 b elong to the pr ob ab ility simplex, though we lea v e λ ’s v alues u n sp eci fied for no w. Th en th e pro cedure p erforms the f ol lo wing up dates at time t : for dual a veragi ng, z ( t + 1) = z ( t ) + n X i =1 λ i g i ( t − τ ( i )) and x ( t + 1) = argmin x ∈X n h z ( t + 1) , x i + 1 α ( t + 1) ψ ( x ) o (12) while for m ir ror d esce n t, the up date is g λ ( t ) = n X i =1 λ i g i ( t − τ ( i )) and x ( t + 1) = argmin x ∈X n h g λ ( t ) , x i + 1 α ( t ) D ψ ( x, x ( t )) o . (13) The next t wo theorems bu ild on the pro ofs of Theorems 1 and 2, combining s ev eral tec hniques. W e pro vide the pro of of Theorem 3 in Sec. 7, omitting the pro of of Theorem 4 as it follo ws in a similar w a y from Theorem 2. Theorem 3. L et the se qu enc e x ( t ) b e define d b y the up date (12). Under assumptions A, B and C, let 1 α ( t ) = L + η ( t ) and η ( t ) ∝ √ t + τ or η ( t ) ≡ η for al l t . Then E " T X t =1 f ( x ( t + 1)) − T f ( x ∗ ) # ≤ LR 2 + η ( T ) R 2 + 2 n X i =1 λ i τ ( i ) GR + 2 n X i =1 λ i LG 2 ( τ ( i ) + 1) 2 T X t =1 1 η ( t − τ ) 2 + T X t =1 1 2 η ( t ) E n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] 2 ∗ . Theorem 4. Use the same c onditions as The or em 3, but assume that x ( t ) is define d by the u p- date (13 ) and D ψ ( x ∗ , x ) ≤ R 2 for al l x ∈ X . Then E " T X t =1 f ( x ( t + 1)) − T f ( x ∗ ) # ≤ 2 R 2 ( L + η ( T )) + 2 n X i =1 λ i τ ( i ) GR + 2 n X i =1 λ i LG 2 ( τ ( i ) + 1) 2 T X t =1 1 η ( t − τ ) 2 + T X t =1 1 2 η ( t ) E n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] 2 ∗ . The consequen ce s of Theorems 3 and 4 are p o werful, as we illustrate in the next section. 7 4 Distributed Optimizatio n W e no w turn to what w e see as the main p u rp ose and application of the ab o ve results: d ev eloping robust and efficien t algorithms for distrib u ted sto c h ast ic optimization. Our main motiv ations here are mac hine learning and statistica l applications wh ere the data is so large that it cannot fit on a single computer. Examp le s of th e form (1) include logistic r eg ression (for b ac kground, see [HTF01]), where the task is to learn a linear classifier that assigns lab els in {− 1 , +1 } to a series of examples, in which case we ha ve the ob jectiv e F ( x ; ξ ) = log [1 + exp( h ξ , x i )] as d esc rib ed in Sec. 2.1(i); or linear regression, wh er e ξ = ( a, b ) ∈ R d × R and F ( x ; ξ ) = 1 2 [ b − h a, x i ] 2 as d escrib ed in Sec. 2.1(ii). Both ob jectiv es s atisfy assu mptions A and B as discussed earlier. W e consider b oth s toc hastic and online/streaming scenarios for such problems. In the simplest setting, th e distrib ution P in the ob jectiv e (1) is the emp ir ic al d istribution o ver an observed dataset, that is, f ( x ) = 1 N N X i =1 F ( x ; ξ i ) . W e divide the N samples among n work ers so that eac h work er has an N /n -sized subset of d at a. In streaming app lic ations, the d istribution P is the unknown distr ib ution generating the d a ta, and eac h w ork er receiv es a stream of indep enden t d at a p oin ts ξ ∼ P . W orker i uses its subset of the data, or its stream, to compute g i , an estimate of the gradient ∇ f of the global f . W e make the simplifying assu mption that g i is an unbia sed estimate of ∇ f ( x ), whic h is satisfied, f or example, when eac h wo rk er receiv es an in depen den t stream of samples or computes the gradient g i based on samples pick ed at rand om without rep lacement from its su bset of the data. The arc hitectural assum p tio ns we mak e are n a tural and based off of master/w ork er top ologies, but the conv ergence results in Section 3 allo w us to giv e p r ocedures robu s t to dela y and asyn c hrony . W e consider t w o proto co ls: in the first, work ers compute and comm unicate async hronously and indep endent ly with the master, and in the second, work ers are at d ifferen t distances from the master an d comm u n ica te with time lags prop ortional to their d istance s. W e sh o w in th e latter part of this section that th e con vergence rates of eac h proto col, wh en applied in an n -no de net w ork, are O (1 / √ nT ) for n -node net w orks (though lo w er order terms are different for eac h). Before d escribing our arc hitectures, we note that p erhaps the simplest master-w ork er sc h eme is to ha v e eac h wo rk er sim ultaneously compute a sto c hastic gradient and s end it to th e master, wh ic h tak es a gradien t step on the a v eraged gradien t. While the n gradien ts are computed in parallel, accum u lating and a verag ing n gradien ts at th e master tak es Ω ( n ) time, offsetting th e gains of parallelizat ion. Thus we consider alternate archite ctures that are robust to dela y . Cyclic Dela y ed Arc hit ec ture This protocol is the d ela yed u p date alg orithm ment ioned in the in tro duction, and it parallelizes computation of (estimates of ) the gradien t ∇ f ( x ). F ormally , w ork er i has parameter x ( t ) and computes g i ( t ) = F ( x ( t ); ξ i ( t )), where ξ i ( t ) is a random v ariable sampled at wo rk er i from the distribu ti on P . The master main tains a parameter vec tor x ∈ X . The algorithm pr oceeds in roun ds, cyclically pip elining up dates. The algorithm b egins by initiating gradien t computations at different work ers at sligh tly offset times. At time t , the m ast er receiv es gradien t information at a τ -step d ela y from some work er, p erforms a p aramet er up date, and p asses the up dated central parameter x ( t + 1) b ac k to the work er. Other work ers do n ot see this up date and contin ue their gradien t computations on stale parameter v ectors. In th e simplest case, eac h 8 M x ( t − 1) x ( t − 2) x ( t − 3) x ( t − 4) x ( t ) M g ( t − 4) g ( t − 2) g ( t − 1) g ( t − 3) (a) (b) Figure 2. Ma ster-w orker averaging net work. (a): para meters stored at different distances from master no de at time t . A no de a t distance d from master has the parameter x ( t − d ). (b): gr adien ts computed a t different no des. A no de at dista nce d from ma ster co mputes gr adien t g ( t − d ). no de suffers a d ela y of τ = n , though our earlier analysis applies to rand om dela ys thr oughout the net work as well. Recall Fig. 1 for a graphic description of the p r ocess. Lo cally Averaged Delay ed Arc hit ecture A t a high lev el, the p rotocol we n o w describ e com- bines the dela y ed up dates of the cyclic dela y ed arc hitecture with av eraging tec hniques of p r evio us w ork [NO09, D A W10]. W e assume a netw ork G = ( V , E ), wh er e V is a set of n no des (w ork ers ) an d E are the edges b et ween the no des. W e select one of the n odes as the master, w h ic h maint ains the parameter v ector x ( t ) ∈ X o ve r time. The algorithm w orks via a series of m u lticasting and aggregati on steps on a spanning tree ro oted at the master no de. In the first phase, the algorithm broadcasts from the ro ot to wa rds the lea ve s. At s tep t the master sends its curr en t parameter vecto r x ( t ) to its immediate neigh b ors. Sim ultaneously , ev ery other no de br oa dcasts its current parameter vecto r (whic h, for a d epth d no de, is x ( t − d )) to its children in the sp anning tree. See Fig. 2(a). E very wo rk er receiv es its new parameter and computes its lo cal gradient at this parameter. The second part of the comm unication in a giv en iteratio n pro ceeds from lea v es tow ard the ro ot. The leaf no des communicate their gradien ts to their parent s. T he parent tak es the gradien ts of the leaf no des from the previous round (r eceiv ed at iteration t − 1) and a verage s them with its own gradient, passing this a verage d gradien t b ac k up the tree. Agai n sim ultaneously , eac h no de take s the a verag ed gradient v ectors of its c h ildren from the previous round s, a verages them with its cur ren t gradien t v ector, and p asses the result u p the sp anning tr ee . S ee Fig. 2(b) an d Fig. 3 for a visu a l description. Sligh tly more form ally , asso cia ted with eac h n ode i ∈ V is a dela y τ ( i ), whic h is (generally) t wice its d istance f rom the master. Fix an iteration t . Eac h no de i ∈ V has an out of date parameter v ector x ( t − τ ( i ) / 2), whic h it sends fu rther do w n the tree to its children. So, for example, the master n ode sends the ve ctor x ( t ) to its children, which send the parameter vec tor x ( t − 1) to th ei r 9 1 3 2 1 3 g 1 ( t − d ) + 1 3 g 2 ( t − d − 2) + 1 3 g 3 ( t − d − 2) { x ( t − d ) , g 2 ( t − d − 2) , g 3 ( t − d − 2) } g 2 ( t − d − 1) g 3 ( t − d − 1) { x ( t − d − 1) } { x ( t − d − 1) } Depth d Depth d + 1 Figure 3. Communication o f gra dien t information tow ard mas ter no de a t time t fro m no de 1 a t distance d fro m mas ter. Informa tio n sto red at time t by no de i in br ac k ets to right of no de. c h ild ren, whic h in tu rn send x ( t − 2) to their children, and so on. Eac h no de compu te s g i ( t − τ ( i ) / 2) = ∇ F ( x ( t − τ ( i ) / 2); ξ i ( t )) , where ξ i ( t ) is a r andom v ariable sampled at no de i fr om the distribu tio n P . Th e comm u nicat ion bac k up the hierarc h y p roceeds as f ollo ws: the leaf no des in the tree (sa y at d ep th d ) sen d th e gradien t v ecto rs g i ( t − d ) to their immediate parents in the tree. At the previous iteration t − 1, the paren t no des receiv ed g i ( t − d − 1) from their children, wh ich they a ve rage w ith their own gradients g i ( t − d + 1) and p ass to their p aren ts, and so on. The master no de at the ro ot of th e tree receiv es an a verag e of dela yed gradients from the entire tree, with eac h gradien t ha ving a p oten tially different dela y , giving rise to up dates of the form (12) or (13). 4.1 Con vergence rates for dela yed distributed minimization Ha ving describ ed our arc hitectures, we can no w giv e corolla ries to the th eoretical r esults from the previous sections that show it is p ossible to ac hieve asymptotically faster rates (o ver cen tralize d pro cedures) usin g distributed algorithms ev en without imp osing sync hronization requirements. W e allo w w ork ers to p ip eline up dates by computing asynchronously and in parallel, so eac h wo rk er can compute lo w v ariance estimate of the gradient ∇ f ( x ). W e b egin with a simple corollary to the results in Sec. 3.1. W e ignore th e constant s L , G , R , and σ , whic h are not dep end ent on the c haracteristics of the net work. W e also assum e that eac h w ork er u ses m ind ep endent samp les of ξ ∼ P to compute the sto c hastic gradient as g i ( t ) = 1 m m X j =1 ∇ F ( x ( t ); ξ i ( j )) . Using the cyclic proto col as in Fig. 1, Theorems 1 and 2 giv e th e f o llo wing result. Corollary 2. L et ψ ( x ) = 1 2 k x k 2 2 , assume the c onditions in Cor ol lary 1, and assume that e ach worker uses m samples ξ ∼ P to c ompute the gr adient it c ommunic ates to the master. Then with the choic e η ( t ) = √ T / √ m either of the up dates (9) or (10) satisfy E [ f ( b x ( T ))] − f ( x ∗ ) = O B 2 T + 1 √ T m + B 2 m T . 10 Pro of The corollary follo ws s traig h tforwardly f r om the r ea lizatio n that the v ariance σ 2 = E [ k∇ f ( x ) − g i ( t ) k 2 2 ] = E [ k∇ f ( x ) − ∇ F ( x ; ξ ) k 2 2 ] /m = O (1 /m ) when w orkers use m indep endent sto c hastic gradien t samples. In th e ab o v e corollary , so long as the b ound on the dela y B satisfies, sa y , B = o ( T 1 / 4 ), then th e last term in the b ound is asymptotically negligible, and w e ac hiev e a con vergence rate of O (1 / √ T m ). The cyclic dela y ed arc h itec ture h as the dra w b ac k that information from a w ork er can tak e O ( n ) time to reac h the master. Wh ile the algorithm is robust to dela y and do es not n ee d lo c k-step co o rdination of w ork ers, the d o wnside of th e arc hitecture is that the essent ially n 2 m/T term in the b ound s ab o ve can b e quite large. Indeed, if eac h work er computes its gradien t o v er m s a mples with m ≈ n —say to av oid idling of w ork ers — th en the cyclic arc hitecture has con v ergence rate O ( n 3 /T + 1 / √ nT ). F or mo derate T or large n , th e dela y p enalt y n 3 /T ma y dominate 1 / √ nT , offsetting th e gains of parallelization. T o add ress the large n dra wbac k, we tu r n our atten tion to the lo cally a v eraged arc hitecture describ ed by Figs. 2 and 3, where dela ys can b e smaller s in ce they dep end only on the heigh t of a spanning tree in the net work. Th e algorithm requ ir es more synchronizatio n than the cyclic arc h itecture but still p erforms limited lo cal comm unication. Eac h w orker computes g i ( t − τ ( i )) = ∇ F ( x ( t − τ ( i )); ξ i ( t )) where τ ( i ) is the dela y of work er i fr om the master and ξ i ∼ P . As a resu lt of the comm unication pro cedure, the master receiv es a conv ex com bination of the sto c hastic gradien ts ev aluated at eac h w ork er i , for which w e ga v e results in S ec tion 3.2. In th is arc hitecture, the master receiv es gradients of the form g λ ( t ) = P n i =1 λ i g i ( t − τ ( i )) for some λ in the simplex, whic h puts us in the setting of Th eo rems 3 and 4. W e no w mak e the reasonable assumption that the gradien t errors ∇ f ( x ( t )) − g i ( t ) are u ncorrelat ed across the no des in the net work. 2 In s tatistical applications, f or example, eac h w ork er ma y o w n indep endent data or receiv e streaming data from in dep en den t sources; more generally , eac h w ork er can simply receiv e indep endent samples ξ i ∼ P . W e also set ψ ( x ) = 1 2 k x k 2 2 , and obs er ve E n X i =1 λ i ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i )) 2 2 = n X i =1 λ 2 i E k∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i )) k 2 2 . This giv es the follo wing corollary to Theorems 3 and 4. Corollary 3. Set λ i = 1 n for al l i , ψ ( x ) = 1 2 k x k 2 2 , and η ( t ) = σ √ t + τ /R √ n . L et ¯ τ and τ 2 denote the aver age of the delays τ ( i ) and τ ( i ) 2 , r esp e ctively. Under the c onditions of The or e m 3 or 4, E " T X t =1 f ( x ( t + 1)) − T f ( x ∗ ) # = O LR 2 + ¯ τ GR + LG 2 R 2 n τ 2 σ 2 log T + Rσ √ n √ T ! . The log T multiplie r can b e reduced to a constan t if we set η ( t ) ≡ σ √ T /R √ n . By using the a verage d sequence b x ( T ) (6 ), Jensen’s inequ ality giv es that asymptotically E [ f ( b x ( T ))] − f ( x ∗ ) = O (1 / √ T n ), whic h is an optimal dep endence on the n um b er of samples ξ calculated by the method . W e also observ e in this architec ture, the dela y τ is b ounded by the graph diameter D , giving us the b ound: E " T X t =1 f ( x ( t + 1)) − T f ( x ∗ ) # = O LR 2 + DGR + LG 2 R 2 nD 2 σ 2 log T + Rσ √ n √ T . (14) 2 Similar results continue to hold un der w eak correlation. 11 The ab o v e corollaries are general and h old irresp ectiv e of the r ela tiv e costs of comm u nicat ion and compu ta tion. How ev er, w ith knowle dge of the costs, we can adapt the stepsizes sligh tly to giv e b etter rates of con verge nce when n is large or comm unication to the master no de is exp ensiv e. F or no w , we fo cus on the cyclic architec ture (the setting of Corollary 2), though th e same p rinciples apply to the lo cal a v eraging sc h eme. Let C denote the cost of comm unicating b et wee n the master and w ork ers in terms of the time to compute a single gradient sample, and assume that we set m = C n , so th at n o wo rk er n ode has idle time. F or simplicit y , we let the d ela y b e n o n-random, so B = τ = n . Consider the choic e η ( t ) = η p T / ( C n ) for the damping stepsizes, w here η ≥ 1. This setting in T heorem 1 giv es E [ f ( b x ( T ))] − f ( x ∗ ) = O η 2 C n 3 T + η √ T C n + 1 η √ T C n = O η 2 C n 3 T + η √ T C n , where th e last equalit y follo ws since η ≥ 1. Optimizing f o r η on the right yields η = m ax ( n 7 / 6 T 1 / 6 C 1 / 2 , 1 ) and E [ f ( b x ( T ))] − f ( x ∗ ) = O min ( n 2 / 3 T 2 / 3 , n 3 T ) + 1 √ T C n ! . (15 ) The conv ergence rates th us follo w t wo regimes. When T ≤ n 7 /C 3 , we ha v e con verge nce rate O ( n 2 / 3 /T 2 / 3 ), wh ile once T > n 7 /C 3 , we attain O (1 / √ T C n ) conv ergence. Roughly , in time prop ortional to T C , we ac hiev e optimizati on error 1 / √ T C n , whic h is order-optimal giv en that w e can compute a total of T C n sto c hastic gradien ts [ABR W10]. The scaling of this b ound is nicer than that p reviously: the dep endence on net w ork size is at worst n 2 / 3 , w hic h w e obtain by in crea sing the damping factor η ( t )—and hence decreasing the stepsize α ( t ) = 1 / ( L + η ( t ))—relativ e to the s et ting of Corollary 2. W e remark that applying the same tec hn ique to Corollary 3 give s con vergence rate scaling as the sm a ller of O (( D/T ) 2 / 3 + 1 / √ T C n ) and O (( nC D /T + 1 / √ T C n ). S ince the diameter D ≤ n , this is f a ster than the cyclic arc h itec ture’s b ound (15). 4.2 Running-time comparisons Ha ving deriv ed the rates of con vergence of the differen t distribu te d pro cedures ab o ve, w e no w explicitly study the ru n ning times of th e cen tralized sto c hastic gradient algorithms (4) and (5), the cyclic delay ed p rotocol with the up dates (9) and (10), an d the lo cal ly a verage d arc hitecture with the up dates (12) and (13). T o mak e comparisons more cleanly , we av oid constants, assuming without loss that th e v ariance b ound σ 2 on E k∇ f ( x ) − ∇ F ( x ; ξ ) k 2 is 1, and that sampling ξ ∼ P and ev aluating ∇ F ( x ; ξ ) requir es one u n it of time. Noting that E [ ∇ F ( x ; ξ )] = ∇ f ( x ), it is clear that if w e receiv e m u ncorrelate d samp les of ξ , the v ariance E k∇ f ( x ) − 1 m P m j =1 ∇ F ( x ; ξ j ) k 2 2 ≤ 1 m . No w we state our assump tions on the relativ e times u sed by eac h algorithm. Let T b e the n um b er of un it s of time allo ca ted to eac h algo rithm, and let th e cen tralized, cyclic delay ed and lo ca lly av eraged dela y ed algorithms complete T cen t , T cycle and T dist iterations, resp ectiv ely , in time T . It is clear that T cen t = T . W e assume that the distributed metho ds us e m cycle and m dist samples of ξ ∼ P to compu te sto c hastic gradients and that the d ela y τ of the cyclic algorithm is n . F or concreteness, we assume that comm unication is of the same ord er as computing the gradient of one sample ∇ F ( x ; ξ ) so that C = 1. In the cyclic setup of S ec. 3.1, it is reasonable to assume that m cycle = Ω( n ) to av oid idling of wo rk ers (Theorems 1 and 2, as well as th e b ound (15), show it is asymptotically b eneficial to ha ve m cycle larger, sin ce σ 2 cycle = 1 /m cycle ). F or m cycle = Ω( n ), the master requires m cycle n units of time to receiv e one gradien t up d ate, so m cycle n T cycle = T . In 12 Cen tralized (4, 5) E f ( b x ) − f ( x ∗ ) = O r 1 T Cyclic (9, 10) O min n 2 / 3 T 2 / 3 , n 3 T ! + 1 √ T n ! Lo cal (12, 13) E f ( b x ) − f ( x ∗ ) = O min D 2 / 3 T 2 / 3 , n τ 2 T ! + 1 √ nT ! T able 1 . Upp er b ounds on E f ( b x ) − f ( x ∗ ) for three computational architectures, where b x is the output o f each algo rithm after T units of time. Each alg orithm runs for the amount o f time it ta k es a centralized sto c hastic algorithm to p erform T iter ations as in (16). Here D is the diameter of the net work, n is the n um ber o f no des, and τ 2 = 1 n P n i =1 τ ( i ) 2 is the av er a ge sq uared communication delay fo r the lo cal averaging ar c hitectur e . Bounds for the cyclic architecture assume delay τ = n . the lo cally delay ed framew ork, if eac h no de uses m dist samples to compute a gradien t, the master receiv es a gradient ev ery m dist units of time, and h ence m dist T dist = T . F urther , σ 2 dist = 1 /m dist . W e summ arize our assu mptions b y saying that in T units of time, eac h algorithm p erforms the follo wing n u m b er of iterations: T cen t = T , T cycle = T n m cycle , and T dist = T m dist . (16) Plugging the ab o v e iteration count s into the earlier b ound (8) and Corollaries 2 and 3 via the sharp er result (15), w e can provide u pp er b ound s (to constan t f actors) on the exp ected optimization accuracy after T units of time for eac h of the distr ibuted arc hitectures as in T able 1. Asymptotically in the num b er of un its of time T , b oth the cyclic and lo cally comm unicating sto c hastic optimization sc h emes hav e the same con vergence rate. How ev er, top olo gical considerations sh o w that th e lo cal ly comm u nicat ing metho d (Figs. 2 and 3) has b etter p erformance than the cyclic arc hitecture, though it r equires more wo rk er co ordination. Since the low er order terms m atter only for large n or small T , we compare the terms n 2 / 3 /T 2 / 3 and D 2 / 3 /T 2 / 3 for the cyclic and lo cally av eraged algorithms, resp ectiv ely . Since D ≤ n for any net work, the lo call y av eraged algorithm alwa ys guaran tees b etter p erformance than the cyclic algorithm. F or sp ecific graph top ologies, ho wev er, we can quantify the time imp ro v emen ts: • n -no de cycle or path: D = n so that b oth m etho ds h a v e the same con v ergence rate. • √ n -b y- √ n grid: D = √ n , so the distrib uted metho d has a factor of n 2 / 3 /n 1 / 3 = n 1 / 3 im- pro v ement ov er the cyclic arc h ite cture. • Balanced trees and expander graph s: D = O (log n ), so the d istributed m etho d has a factor— ignoring logarithmic terms —of n 2 / 3 impro v ement ov er cyclic. Naturally , it is p ossible to mod ify our assumptions. In a net wo rk in whic h comm un ic ation is c heap, or con v ersely , in a problem for whic h the computation of ∇ F ( x ; ξ ) is more exp ensiv e than comm un ica tion, then the n um b er of samples ξ ∼ P for wh ic h whic h eac h w ork er computes gradien ts is small. Suc h p roblems are frequent in statistical mac hine learning, such as wh en learning conditional random field mo dels, whic h are useful in natural language pro cessing, computational biology , and other application areas [LMP01]. In this case, it is reasonable to ha v e m cycle = 13 1 2 3 4 5 6 8 10 12 15 18 22 26 0 200 400 600 800 Nu m b er of workers Time to ǫ accu racy Figure 4. Optimization per formance of the delay ed cyclic metho d (9) for the Reuters RCV1 datase t when we assume that the co st of communication to the mas ter is the same a s computing the gradient of one ter m in the ob jective (17). The nu m ber of samples m computed is equa l to n for e ac h worker. Plotted is the estimated time to ǫ -accur acy as a function of num ber o f workers n . O (1) , in whic h case T cycle = T n and the cyclic d ela yed arc hitecture has stronger con v ergence guaran tees of O (min { n 2 /T , 1 /T 2 / 3 } + 1 / √ T n ). In an y case, b oth non-cen tralized proto cols enjo y significan t asymptotically faster con v ergence rates for sto c hastic optimizatio n p roblems in spite of async h ronous dela ys. 5 Numerical Results Though this p aper fo cuses mostly on the theoretical analysis of the metho ds w e ha v e p resen ted, it is imp ortan t to u nderstand the practical asp ects of the ab o v e metho ds in solving real-w orld tasks and problems with real data. T o that end, we use the cyclic d el a yed metho d (12) to s ol v e a common statistica l mac hine learning problem. Sp ecifically , we fo cus on solving the logistic regression problem min x f ( x ) = 1 N N X i =1 log(1 + exp( − b i h a i , x i )) sub ject to k x k 2 ≤ R . (17) W e use th e Reuters RCV1 dataset [L YRL04], wh ic h consists of N ≈ 800000 news articles, eac h lab eled w ith some com bination of the four lab els economics, go v ernmen t, commerce, and medicine. In th e ab o v e example, th e vecto rs a i ∈ { 0 , 1 } d , d ≈ 10 5 , are feature v ectors representi ng the w ords in eac h article, and the lab els b i are 1 if the article is ab out go ve rnment, − 1 otherwise. W e sim ulate the cyclic dela y ed optimization algo rithm (9) for the problem (17) for sev eral c h oices of the num b er of work ers n and the n um b er of samp les m computed at eac h work er. W e summarize the results of our exp erimen ts in Figure 4 . T o generate the figur e, w e fix an ǫ (in this case, ǫ = . 05), then measure the time it tak es the sto chastic algorithm (9) to output an b x suc h that f ( b x ) ≤ inf x ∈X f ( x ) + ǫ . W e p erform eac h exp erimen t ten times. After compu ting the num b er of iterations required to ac hieve ǫ -accuracy , we con vert the results to runnin g time b y assuming it tak es one unit of time to compute the gradient of one term in the sum 14 defining the ob j ec tiv e (17). W e also assum e that it tak es 1 unit of time, i.e. C = 1, to comm un ica te from one of the w ork ers to th e master, for the m a ster to p erform an up date, and comm unicate bac k to one of the w ork er s . In an n no de system where eac h w ork er computes m samples of the gradient , the master receiv es an up d at e ev ery max { m n , 1 } time units. A cen tralized algorithm compu ting m samples of its gradient p erforms an u pd at e ev ery m time un its. By m u lti plying the num b er of iterations to ǫ -optimalit y by max { m n , 1 } for the distr ibuted metho d and by m for the cen tralized, w e can estimate the amount of time it tak es eac h algorithm to ac hieve an ǫ -accurate solution. W e no w tur n to discus sing Figure 4. The dela yed up date (9) enjoys sp eedup (the ratio of time to ǫ -accuracy f or an n -no de system versus the cent ralized p rocedu r e) nearly linear in the num b er n of w ork er machines unt il n ≥ 15 or so. Since we use the stepsize choic e η ( t ) ∝ p t/n , whic h yields the p redicted conv ergence rate giv en by Corollary 2, the n 2 m/T ≈ n 3 /T term in the con vergence rate p resumably b ecomes non-negligible for larger n . This expands on earlier exp erimenta l work with a similar metho d [LS Z 09 ], wh ic h exp erimen tally demonstrated linear sp eedup f or small v alues of n , but did n ot inv estigate larger net w ork sizes. Rou gh ly , as p redicte d by our theory , for n on- asymptotic regimes the cost of comm unication and dela ys due to using n no des mitigate some of the b enefits of parallelizatio n. Nev ertheless, as our analysis sho ws, allo wing d ela yed and async hronous up dates still giv es s ignifi ca n t p erformance impro v ements. 6 Dela y ed Up dates for Smo oth Optimization In this section, w e pro ve T h eo rems 1 and 2. W e collect in App endix A a few tec hn ica l r esults relev ant to our pro of; we will refer to r esults therein without comment. Before pro vin g either theorem, we state the lemma that is the k ey to our argumen t. Lemm a 4 sho ws that certain gradien t-differen cing terms are essentiall y of second order. As a consequence, when we com bin e the results of the lemma with Lemma 7, which b ounds E [ k x ( t ) − x ( t + τ ) k 2 ], th e gradient d ifferencing terms b ecome O (log T ) for step s iz e choice η ( t ) ∝ √ t , or O (1) for η ( t ) ≡ η √ T . Lemma 4. L et assumptions A and B on the function f and the c omp actness assumption C hold. Then for any se q uenc e x ( t ) T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i ≤ L 2 T X t =1 k x ( t − τ ) − x ( t + 1) k 2 + 2 τ GR . Conse qu ently, if E [ k x ( t ) − x ( t + 1) k 2 ] ≤ κ ( t ) 2 G 2 for a non-incr e asing se quenc e κ ( t ) , E T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i ≤ LG 2 ( τ + 1) 2 2 T X t =1 κ ( t − τ ) 2 + 2 τ GR. Pro of Th e pr oof follo ws b y usin g a few Bregman divergence identit ies to rewrite the left han d side of the ab o ve equations, th en recognizing that the result is close to a telescoping sum. Recalling the defin itio n of a Bregman div ergence (2), w e note th e f o llo wing well- kno wn four term equality , a consequence of str ai gh tforward algebra: for an y a, b, c, d , h∇ f ( a ) − ∇ f ( b ) , c − d i = D f ( d, a ) − D f ( d, b ) − D f ( c, a ) + D f ( c, b ) . (18) 15 Using the equalit y (18), w e see that h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i = D f ( x ∗ , x ( t )) − D f ( x ∗ , x ( t − τ )) − D f ( x ( t + 1) , x ( t )) + D f ( x ( t + 1) , x ( t − τ )) . (19) T o make (19) useful, we note that the Lip sc hitz con tin u it y of ∇ f implies f ( x ( t + 1)) ≤ f ( x ( t − τ )) + h∇ f ( x ( t − τ )) , x ( t + 1) − x ( t − τ ) i + L 2 k x ( t − τ ) − x ( t + 1) k 2 so th at recalling the defin itio n of D f (2) we ha v e D f ( x ( t + 1) , x ( t − τ )) ≤ L 2 k x ( t − τ ) − x ( t + 1) k 2 . In p articula r, using the non-n egativit y of D f ( x, y ), we can replace (19) with the b ound h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i ≤ D f ( x ∗ , x ( t )) − D f ( x ∗ , x ( t − τ ))+ L 2 k x ( t − τ ) − x ( t + 1) k 2 . Summing th e in equ al it y , we see that T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i ≤ T X t = T − τ +1 D f ( x ∗ , x ( t ))+ L 2 T X t =1 k x ( t − τ ) − x ( t + 1) k 2 . (20) T o b ound the first Br egman d iv ergence term, we recall that b y Assumption C and the strong con vexit y of ψ , k x ∗ − x ( t ) k 2 ≤ 2 D ψ ( x ∗ , x ( t )) ≤ 2 R 2 , and h ence th e optimalit y of x ∗ implies D f ( x ∗ , x ( t )) = f ( x ∗ ) − f ( x ( t )) − h∇ f ( x ( t )) , x ∗ − x ( t ) i ≤ k∇ f ( x ( t )) k ∗ k x ∗ − x ( t ) k ≤ 2 GR. This giv es the fir st b ound of the lemma. F or the second b ound, usin g con v exit y , we see that k x ( t − τ ) − x ( t + 1) k 2 ≤ ( τ + 1) 2 τ X s =0 1 τ + 1 k x ( t − s ) − x ( t − s + 1) k 2 , so b y taking exp ecta tions we h a v e E [ k x ( t ) − x ( t + τ + 1) k 2 ] ≤ ( τ + 1) 2 κ ( t − τ ) 2 G 2 . Since κ is non- increasing (by the defin iti on of the u pd ate sc heme) w e see that the sum (20) is further b ounded by 2 τ GR + L 2 P T t =1 G 2 ( τ + 1) 2 κ ( t − τ ) 2 as d esired. 6.1 Pro of of Theorem 1 The essent ial idea in this pr oof is to use conv exit y and smo othness to b ound f ( x ( t )) − f ( x ∗ ), then use the sequence { η ( t ) } , whic h decreases the stepsize α ( t ), to cancel v ariance terms. T o b egin, w e define the error e ( t ) e ( t ) := ∇ f ( x ( t )) − g ( t − τ ) where g ( t − τ ) = ∇ F ( x ( t − τ ); ξ ( t ) for some ξ ( t ) ∼ P . Note that e ( t ) do es not hav e zero exp ectation, as th ere is a time d ela y . 16 By using the con v exity of f and then the L -Lipsc hitz con tinuit y of ∇ f , for an y x ∗ ∈ X , w e ha v e f ( x ( t )) − f ( x ∗ ) ≤ h∇ f ( x ( t )) , x ( t ) − x ∗ i = h∇ f ( x ( t )) , x ( t + 1) − x ∗ i + h∇ f ( x ( t )) , x ( t ) − x ( t + 1) i ≤ h∇ f ( x ( t )) , x ( t + 1) − x ∗ i + f ( x ( t )) − f ( x ( t + 1)) + L 2 k x ( t ) − x ( t + 1) k 2 , so th at f ( x ( t + 1)) − f ( x ∗ ) ≤ h∇ f ( x ( t )) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 = h g ( t − τ ) , x ( t + 1) − x ∗ i + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 = h z ( t + 1) , x ( t + 1) − x ∗ i − h z ( t ) , x ( t + 1) − x ∗ i + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 . No w, by app lying L emma 5 in App endix A and the definition of the u p d at e (9), we see that − h z ( t ) , x ( t + 1) − x ∗ i ≤ − h z ( t ) , x ( t ) − x ∗ i + 1 α ( t ) [ ψ ( x ( t + 1)) − ψ ( x ( t ))] − 1 α ( t ) D ψ ( x ( t + 1) , x ( t )) , whic h implies f ( x ( t + 1)) − f ( x ∗ ) ≤ h z ( t + 1) , x ( t + 1) − x ∗ i − h z ( t ) , x ( t ) − x ∗ i + 1 α ( t ) [ ψ ( x ( t + 1)) − ψ ( x ( t ))] − LD ψ ( x ( t + 1) , x ( t )) − η ( t ) D ψ ( x ( t + 1) , x ( t )) + L 2 k x ( t ) − x ( t + 1) k 2 + h e ( t ) , x ( t + 1) − x ∗ i ≤ h z ( t + 1) , x ( t + 1) − x ∗ i − h z ( t ) , x ( t ) − x ∗ i + 1 α ( t ) [ ψ ( x ( t + 1)) − ψ ( x ( t ))] − η ( t ) D ψ ( x ( t + 1) , x ( t )) + h e ( t ) , x ( t + 1) − x ∗ i . (21) T o get the b ound (21), w e subs tituted α ( t ) − 1 = L + η ( t ) and then u sed th e f act that ψ is strongly con vex, so D ψ ( x ( t + 1) , x ( t )) ≥ 1 2 k x ( t ) − x ( t + 1) k 2 . By summ in g the b ound (21 ), w e h a v e the follo wing non-probabilistic inequalit y: T X t =1 f ( x ( t + 1)) − f ( x ∗ ) ≤ h z ( T + 1) , x ( T + 1) − x ∗ i + 1 α ( T ) ψ ( x ( T + 1)) + T X t =1 ψ ( x ( t )) 1 α ( t − 1) − 1 α ( t ) − T X t =1 η ( t ) D ψ ( x ( t + 1) , x ( t )) + T X t =1 h e ( t ) , x ( t + 1) − x ∗ i ≤ 1 α ( T + 1) ψ ( x ∗ ) + T X t =1 ψ ( x ( t )) 1 α ( t − 1) − 1 α ( t ) − T X t =1 η ( t ) D ψ ( x ( t + 1) , x ( t )) + T X t =1 h e ( t ) , x ( t + 1) − x ∗ i (22) 17 since ψ ( x ) ≥ 0 and x ( T + 1) minimizes h z ( T + 1) , x i + 1 α ( T +1) ψ ( x ). What remains is to con trol the summed e ( t ) terms in the b ound (22 ). W e can do this simp ly using th e second part of Lemm a 4. Indeed, w e hav e T X t =1 h e ( t ) , x ( t + 1) − x ∗ i (23) = T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i + T X t =1 h∇ f ( x ( t − τ )) − g ( t − τ ) , x ( t + 1) − x ∗ i . W e can apply Lemma 4 to th e first term in (23) by b ounding k x ( t ) − x ( t + 1) k with Lemma 7 . Since η ( t ) ∝ √ t + τ , Lemma 7 w ith t 0 = τ implies E [ k x ( t ) − x ( t + 1) k 2 ] ≤ 4 G 2 η ( t ) 2 . As a consequen ce , E T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ )) , x ( t + 1) − x ∗ i ≤ 2 τ GR + 2 L ( τ + 1) 2 G 2 T X t =1 1 η ( t − τ ) 2 . What r ema ins, then, is to b ound the sto c hastic (second) term in (23). This is straightfo rw ard, though: h∇ f ( x ( t − τ )) − g ( t − τ ) , x ( t + 1) − x ∗ i = h ∇ f ( x ( t − τ )) − g ( t − τ ) , x ( t ) − x ∗ i + h∇ f ( x ( t − τ )) − g ( t − τ ) , x ( t + 1) − x ( t ) i ≤ h ∇ f ( x ( t − τ )) − g ( t − τ ) , x ( t ) − x ∗ i + 1 2 η ( t ) k∇ f ( x ( t − τ )) − g ( t − τ ) k 2 ∗ + η ( t ) 2 k x ( t + 1) − x ( t ) k 2 b y the F enc h el- Y oung inequalit y applied to the conju ga te p air 1 2 k·k 2 ∗ and 1 2 k·k 2 . In add iti on, ∇ f ( x ( t − τ )) − g ( t − τ ) is in dep en den t of x ( t ) giv en the sigma-field con taining g (1) , . . . , g ( t − τ − 1), since x ( t ) is a fu nctio n of gradients to time t − τ − 1, so the first term has zero exp ectation. Also recall that E [ k∇ f ( x ( t − τ )) − g ( t − τ ) k ∗ ] 2 is b ounded by σ 2 b y assu mption. Com binin g the ab o ve t wo b oun ds into (23), we see that T X t =1 E [ h e ( t ) , x ( t + 1) − x ∗ i ] ≤ σ 2 2 T X t =1 1 η ( t ) + 1 2 T X t =1 η ( t ) k x ( t + 1) − x ( t ) k 2 + 2 LG 2 ( τ + 1) 2 T X t =1 1 η ( t − τ ) 2 + 2 τ GR. (24) Since D ψ ( x ( t + 1) , x ( t )) ≥ 1 2 k x ( t ) − x ( t + 1) k 2 , com bining (24) with (22) and n oti ng that 1 α ( t − 1) − 1 α ( t ) ≤ 0 giv es T X t =1 E f ( x ( t + 1)) − f ( x ∗ ) ≤ 1 α ( T + 1) ψ ( x ∗ ) + σ 2 2 T X t =1 1 η ( t ) + 2 LG 2 ( τ + 1) 2 T X t =1 1 η ( t − τ ) 2 + 2 τ GR. 6.2 Pro of of Theorem 2 The pro of of Th eo rem 2 is similar to that of Theorem 1, so w e will b e s o mewhat terse. W e define the error e ( t ) = ∇ f ( x ( t )) − g ( t − τ ), identi cally as in the earlier pro of, and b egin as w e d id in th e 18 pro of of T heorem 1. Recall that f ( x ( t + 1)) − f ( x ∗ ) ≤ h g ( t − τ ) , x ( t + 1) − x ∗ i + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 . (25) Applying th e first-order op timalit y condition to the definition of x ( t + 1) (5 ), w e get h α ( t ) g ( t − τ ) + ∇ ψ ( x ( t + 1)) − ∇ ψ ( x ( t )) , x − x ( t + 1) i ≥ 0 for all x ∈ X . In particular, we ha v e α ( t ) h g ( t − τ ) , x ( t + 1) − x ∗ i ≤ h∇ ψ ( x ( t + 1)) − ∇ ψ ( x ( t )) , x ∗ − x ( t + 1) i = D ψ ( x ∗ , x ( t )) − D ψ ( x ∗ , x ( t + 1)) − D ψ ( x ( t + 1) , x ( t )) . Applying th e ab o ve to the in equ al it y (25 ), w e see that f ( x ( t + 1)) − f ( x ∗ ) ≤ 1 α ( t ) [ D ψ ( x ∗ , x ( t )) − D ψ ( x ∗ , x ( t + 1)) − D ψ ( x ( t + 1) , x ( t ))] + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 ≤ 1 α ( t ) [ D ψ ( x ∗ , x ( t )) − D ψ ( x ∗ , x ( t + 1))] + h e ( t ) , x ( t + 1) − x ∗ i − η ( t ) D ψ ( x ( t + 1) , x ( t )) (26) where for the last inequalit y , we use the fact that D ψ ( x ( t + 1) , x ( t )) ≥ 1 2 k x ( t ) − x ( t + 1) k 2 , by the strong con vexit y of ψ , and that α ( t ) − 1 = L + η ( t ). By sum ming the inequalit y (26), we hav e T X t =1 f ( x ( t + 1)) − f ( x ∗ ) ≤ 1 α (1) D ψ ( x ∗ , x (1)) + T X t =2 D ψ ( x ∗ , x ( t )) 1 α ( t ) − 1 α ( t − 1) − T X t =1 η ( t ) D ψ ( x ( t + 1) , x ( t )) + T X t =1 h e ( t ) , x ( t + 1) − x ∗ i . (27) Comparing the b ound (27) with the earlier b ound f or the d ual a veraging algorithms (22), we see that the on ly essen tial difference is the α ( t ) − 1 − α ( t − 1) − 1 terms. Th e compactness assumption guaran tees that D ψ ( x ∗ , x ( t )) ≤ R 2 , ho wev er, s o T X t =2 D ψ ( x ∗ , x ( t )) 1 α ( t ) − 1 α ( t − 1) ≤ R 2 α ( T ) . The remaind er of the pro of uses Lemmas 7 and 4 completely identic ally to the pr oof of Th eo rem 1. 6.3 Pro of of Corollary 1 W e p r o v e this resu lt only for the mirror descen t algorithm (10), as the pro of for the dual-a v eraging- based algorithm (9) is similar. W e defin e the error at time t to b e e ( t ) = ∇ f ( x ( t )) − g ( t − τ ( t )), and observ e that w e only need to con trol the second term inv olving e ( t ) in the b ound (26) d ifferen tly . 19 Expanding th e error term s ab o v e and using F enc hel’s in equalit y as in th e pro ofs of Theorems 1 and 2, we ha v e h e ( t ) , x ( t + 1) − x ∗ i ≤ h∇ f ( x ( t )) − ∇ f ( x ( t − τ ( t ))) , x ( t + 1) − x ∗ i + h∇ f ( x ( t − τ ( t ))) − g ( t − τ ( t )) , x ( t ) − x ∗ i + 1 2 η ( t ) k∇ f ( x ( t − τ ( t ))) − g ( t − τ ( t )) k 2 ∗ + η ( t ) 2 k x ( t + 1) − x ( t ) k 2 , No w we note that conditioned on the d el a y τ ( t ), we hav e E [ k x ( t − τ ( t )) − x ( t + 1) k 2 | τ ( t )] ≤ G 2 ( τ ( t ) + 1) 2 α ( t − τ ( t )) 2 . Consequent ly w e apply Lemma 4 (sp ecifically , follo wing th e b ounds (19) and (20)) an d fi nd T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ ( t ))) , x ( t + 1) − x ∗ i ≤ T X t =1 [ D f ( x ∗ , x ( t )) − D f ( x ∗ , x ( t − τ ( t )))] + G 2 T X t =1 ( τ ( t ) + 1) 2 α ( t − τ ( t )) 2 . The sum of D f terms telescop es, lea ving only terms not receiv ed by the gradien t pro cedure within T iterations, and w e can use α ( t ) ≤ 1 η √ T for all t to derive the further b oun d X t : t + τ ( t ) >T D f ( x ∗ , x ( t )) + G 2 η 2 T T X t =1 ( τ ( t ) + 1) 2 . (28) T o con trol the quantit y (28), all w e need is to b ound the exp ected cardinalit y of the set { t ∈ [ T ] : t + τ ( t ) > T } . Using Chebyshev’s inequalit y and standard exp ectation b oun d s, we ha ve E [card( { t ∈ [ T ] : t + τ ( t ) > T } )] = T X t =1 P ( t + τ ( t ) > T ) ≤ 1 + T − 1 X t =1 E [ τ ( t ) 2 ] ( T − t ) 2 ≤ 1 + 2 B 2 , where the last in equ al it y comes from our assu mption that E [ τ ( t ) 2 ] ≤ B 2 . As in Lemma 4, we h a v e D f ( x ∗ , x ( t )) ≤ 2 GR , wh ic h yields E T X t =1 h∇ f ( x ( t )) − ∇ f ( x ( t − τ ( t ))) , x ( t + 1) − x ∗ i ≤ 6 GRB 2 + G 2 ( B + 1) 2 η 2 W e can con trol the remaining terms as in the pro ofs of Theorems 1 and 2. 7 Pro of of Theorem 3 The pro of of Th eo rem 3 is not to o d ifficult giv en our pr evio us work—all we n eed to do is red efi ne the error e ( t ) and use η ( t ) to con trol the v ariance terms that arise. T o that end, we define the gradien t err or terms that w e m ust con trol. In this pro of, we set e ( t ) := ∇ f ( x ( t )) − n X i =1 λ i g i ( t − τ ( i )) (29 ) 20 where g i ( t ) = ∇ f ( x ( t ); ξ i ( t )) is the gradien t of n ode i computed at the parameter x ( t ) and τ ( i ) is the dela y asso ciated with n ode i . Using Assumption B as in the p roofs of p revio us th eo rems, then app lying Lemma 5, we hav e f ( x ( t + 1)) − f ( x ∗ ) ≤ h∇ f ( x ( t )) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 = * n X i =1 λ i g i ( t − τ ( i )) , x ( t + 1) − x ∗ + + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 = h z ( t + 1) , x ( t + 1) − x ∗ i − h z ( t ) , x ( t + 1) − x ∗ i + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 ≤ h z ( t + 1) , x ( t + 1) − x ∗ i − h z ( t ) , x ( t ) − x ∗ i + 1 α ( t ) ψ ( x ( t + 1)) − 1 α ( t ) ψ ( x ( t )) − 1 α ( t ) D ψ ( x ( t + 1) , x ( t )) + h e ( t ) , x ( t + 1) − x ∗ i + L 2 k x ( t ) − x ( t + 1) k 2 . W e telescope as in the pro ofs of Theorems 1 an d 2, canceling L 2 k x ( t ) − x ( t + 1) k 2 with the L D ψ div ergence terms to see that T X t =1 f ( x ( t + 1)) − f ( x ∗ ) ≤ h z ( T + 1) , x ( T + 1) − x ∗ i + 1 α ( T ) ψ ( x ( T )) − T X t =1 η ( t ) D ψ ( x ( t + 1) , x ( t )) + T X t =1 h e ( t ) , x ( t + 1) − x ∗ i ≤ 1 α ( T + 1) ψ ( x ∗ ) − T X t =1 η ( t ) D ψ ( x ( t + 1) , x ( t )) + T X t =1 h e ( t ) , x ( t + 1) − x ∗ i . (30) This is exactly as in the non-probabilistic b ound (22) from the pro of of Theorem 1, but the d efini- tion (29) of the error e ( t ) h ere is differen t. What r ema ins is to cont rol the err or term in (30). W riting the terms out, we hav e T X t =1 h e ( t ) , x ( t + 1) − x ∗ i = T X t =1 * ∇ f ( x ( t )) − n X i =1 λ i ∇ f ( x ( t − τ ( i ))) , x ( t + 1) − x ∗ + + T X t =1 * n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] , x ( t + 1) − x ∗ + (31) Bounding th e first term ab o v e is simple via L emma 4: as in the p roof of Theorem 1 earlier, we ha ve E T X t =1 * ∇ f ( x ( t )) − n X i =1 λ i ∇ f ( x ( t − τ ( i ))) , x ( t + 1) − x ∗ + = n X i =1 λ i T X t =1 E [ h∇ f ( x ( t )) − ∇ f ( x ( t − τ ( i ))) , x ( t + 1) − x ∗ i ] ≤ 2 n X i =1 λ i LG 2 ( τ ( i ) + 1) 2 T X t =1 1 η ( t − τ ) 2 + n X i =1 λ i 2 τ ( i ) GR. 21 W e use th e same tec hn ique as the pro of of Theorem 1 to b ound the second term from (31). Indeed, the F enc h el- Y oung inequalit y giv es * n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] , x ( t + 1) − x ∗ + = * n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] , x ( t ) − x ∗ + + * n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] , x ( t + 1) − x ( t ) + ≤ * n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] , x ( t ) − x ∗ + + 1 2 η ( t ) n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] 2 ∗ + η ( t ) 2 k x ( t + 1) − x ( t ) k 2 . By assu mption, giv en the in formatio n at work er i at time t − τ ( i ), g i ( t − τ ( i ))) is indep endent of x ( t ), so the fir s t term h as zero exp ectatio n. More formally , this h appen s b ecause x ( t ) is a function of grad ients g i (1) , . . . , g i ( t − τ ( i ) − 1) from eac h of the no des i and hence the exp ectation of th e fir st term conditioned on { g i (1) , . . . , g i ( t − τ ( i ) − 1) } n i =1 is 0. The last term is canceled b y th e Br egman div ergence terms in (30), so com bin ing the b oun d (31) with the ab o v e t w o paragraph s yields T X t =1 E f ( x ( t + 1)) − f ( x ∗ ) ≤ 1 α ( t ) ψ ( x ∗ ) + 2 n X i =1 λ i LG 2 ( τ ( i ) + 1) 2 T X t =1 1 η ( t − τ ) 2 + n X i =1 λ i 2 τ ( i ) GR + T X t =1 1 2 η ( t ) E n X i =1 λ i [ ∇ f ( x ( t − τ ( i ))) − g i ( t − τ ( i ))] 2 ∗ . 8 Conclusion and Discussion In th is pap er, we hav e studied dual av eraging and mirr or descent algorithms for s m ooth and non- smo oth sto c hastic optimization in dela ye d settings, sho wing applications of our results to d istributed optimization. W e sho wed that for smo oth prob lems, we can preserv e the p erformance b enefits of parallelizat ion o ver cen tralized sto c h ast ic optimizatio n even w hen we r ela x sync h roniza tion re- quirement s. S pecifically , w e pr esen ted metho ds that tak e adv ant age of distributed computational resources and are robust to no de failures, comm unication latency , and n ode slowdo wns. In ad- dition, by distribu ting computation for sto c hastic optimization p r oblems, we were able to exploit async h ronous p rocessing without incurring any asymptotic p enalt y du e to the dela ys incur red. In addition, though we omit these results for brevit y , it is p ossible to extend all of our exp ected con vergence results to guarante es with high-probabilit y . Ac kno wledgmen ts In p erformin g this researc h , AA w as supp orted b y a Microsoft Researc h F ello wship , and JCD w as supp orted by the National Defense Science and Engineering Graduate F ello w ship (NDSEG) 22 Program. W e are v ery grateful to Ofer Deke l, Ran Gilad-Bac hr ach, Ohad Shamir, and Lin Xiao for illuminating conv ersations on distrib uted sto c h astic optimization and comm unication of their pr o of of the b ound (8). W e would also lik e to thank Y oram Singer for reading a d r aft of this manuscript and giving us efu l feedbac k. A T ec hn ical Results ab out Pro ximal F unctions In this section, we collect several u seful results ab out pr o ximal functions and con tin u it y prop erties of the solutions of p ro ximal op erato rs. W e giv e pr oofs of all uncited results in App endix B. W e b egin with results u seful for th e d ual-a veraging up dates (4) and (9). W e d efine the p ro ximal dual fu nction ψ ∗ α ( z ) := sup x ∈X h− z , x i − 1 α ψ ( x ) . (32) Since ∇ ψ ∗ α ( z ) = argmax x ∈X {h− z , x i − α − 1 ψ ( x ) } , it is clear that x ( t ) = ∇ ψ ∗ α ( t ) ( z ( t )). F urther b y strong con ve xit y of ψ , w e hav e that ∇ ψ ∗ α ( z ) is α -Lipschitz con tin u ous [Nes09, HUL96b, C hapter X], that is, for the norm k·k with resp ect to wh ic h ψ is strongly con v ex and its asso ciated dual norm k·k ∗ , k∇ ψ ∗ α ( y ) − ∇ ψ ∗ α ( z ) k ≤ α k y − z k ∗ . (33) W e will fi nd one more result ab out solutions to the du al av eraging up date useful. This resu lt has essen tially b een pro v en in many con texts [Nes09, Tse08, DGBSX10a]. Lemma 5. L et x + minimize h z , x i + Aψ ( x ) for al l x ∈ X . Then for any x ∈ X , h z , x i + Aψ ( x ) ≥ z , x + + Aψ ( x + ) + AD ψ ( x, x + ) No w we turn to describing pr op erties of the mirror-descent step (5), wh ic h we will also use frequent ly . Th e lemma allo ws us to b ound differences b et we en x ( t ) and x ( t + 1) for the mirror- descen t family of algorithms. Lemma 6. L et x + minimize h g, x i + 1 α D ψ ( x, y ) over x ∈ X . Then k x + − y k ≤ α k g k ∗ . The last tec hnical lemma we giv e explicitly b ounds the differences b et wee n x ( t ) and x ( t + τ ), for some τ ≥ 1, by using th e ab o ve con tinuit y lemmas. Lemma 7. L et Assumption A hold. Define x ( t ) via the dual-aver aging up dates (4 ), (9), or (12) or the mirr or-desc ent up dates (5), (10), or (13). L et α ( t ) − 1 = L + η ( t + t 0 ) c for some c ∈ [0 , 1] , η > 0 , t 0 ≥ 0 , and L ≥ 0 . Then for any fixe d τ , E [ k x ( t ) − x ( t + τ ) k 2 ] ≤ 4 G 2 τ 2 η 2 ( t + t 0 ) 2 c and E [ k x ( t ) − x ( t + τ ) k ] ≤ 2 Gτ η ( t + t 0 ) c . B Pro ofs of P ro ximal Op erator Prop erties Pro of of Lemma 6 The inequalit y is clear w h en x + = y , so assum e that x + 6 = y . S ince x + minimizes h g , x i + 1 α D ψ ( x, y ), the first ord er conditions for optimalit y imp ly αg + ∇ ψ ( x + ) − ∇ ψ ( y ) , x − x + ≥ 0 23 for any x ∈ X . T hus we can choose y = x and see that α h g , y − x i ≥ ∇ ψ ( x + ) − ∇ ψ ( y ) , x + − y ≥ x + − y 2 , where th e last inequalit y f ol lo ws from the strong conv exit y of ψ . Using H¨ older’s inequalit y giv es that α k g k ∗ k y − x k ≥ k x + − y k 2 , and dividing by k y − x k completes th e pro of. Pro of of Lemma 7 W e first sh o w th e lemma for the dual-a verag ing up dates. Recall that x ( t ) = ∇ ψ ∗ α ( t ) ( z ( t )) and ∇ ψ ∗ α is α -Lipschitz cont in uous. Using the triangle inequalit y , k x ( t ) − x ( t + τ ) k = ∇ ψ ∗ α ( t ) ( z ( t )) − ∇ ψ ∗ α ( t + τ ) ( z ( t + τ )) = ∇ ψ ∗ α ( t ) ( z ( t )) − ∇ ψ ∗ α ( t + τ ) ( z ( t )) + ∇ ψ ∗ α ( t + τ ) ( z ( t )) − ∇ ψ ∗ α ( t + τ ) ( z ( t + τ )) ≤ ∇ ψ ∗ α ( t ) ( z ( t )) − ∇ ψ ∗ α ( t + τ ) ( z ( t )) + ∇ ψ ∗ α ( t + τ ) ( z ( t )) − ∇ ψ ∗ α ( t + τ ) ( z ( t + τ )) ≤ ( α ( t ) − α ( t + τ )) k z ( t ) k ∗ + α ( t + τ ) k z ( t ) − z ( t + τ ) k ∗ . (34) It is easy to c h ec k that for c ∈ [0 , 1], α ( t ) − α ( t + τ ) ≤ cη τ ( L + η t c ) 2 t 1 − c ≤ cτ η t 1+ c . By conv exit y of k·k 2 ∗ , w e can b ound E [ k z ( t ) − z ( t + τ ) k 2 ∗ ]: E [ k z ( t ) − z ( t + τ ) k 2 ∗ ] = τ 2 E 1 τ τ X s =1 z ( t + s ) − z ( t + s − 1) 2 ∗ = τ 2 E 1 τ τ − 1 X s =0 g ( s ) 2 ∗ ≤ τ 2 G 2 , since E [ k ∂ F ( x ; ξ ) k 2 ∗ ] ≤ G 2 b y assump tio n. Thus, b ound (34 ) giv es E [ k x ( t ) − x ( t + τ ) k 2 ] ≤ 2( α ( t ) − α ( t + τ )) 2 E [ k z ( t ) k 2 ∗ ] + 2 α ( t + τ ) 2 E [ k z ( t ) − z ( t + τ ) k 2 ∗ ] ≤ 2 c 2 t 2 τ 2 G 2 η 2 t 2+2 c + 2 G 2 τ 2 α ( t + τ ) 2 = 2 c 2 τ 2 G 2 η 2 t 2 c + 2 G 2 τ 2 ( L + η ( t + τ ) c ) 2 , where w e u s e Cauc h y-Sc hw arz inequalit y in the fir st step. Since c ≤ 1, the last term is clearly b ounded by 4 G 2 τ 2 /η 2 t 2 c . T o get th e sligh tly tight er b ound on the first moment in the statemen t of the lemma, simp ly use the triangle inequalit y from the b ound (34) and that √ E X 2 ≥ E | X | . The pro of f o r th e m irror-descen t family of up dates is similar. W e fo cus on non-dela y ed up- date (5), as th e other u p date s simply mo dify the indexing of g ( t + s ) b elo w. W e kno w from Lemma 6 and the triangle in equalit y that k x ( t ) − x ( t + τ ) k ≤ τ X s =1 k x ( t + s ) − x ( t + s − 1) k ≤ τ X s =1 α ( t + s − 1) k g ( t + s ) k ∗ Squaring the ab o v e b oun d, taking exp ectations, an d recalling that α ( t ) is non-increasing, w e see E [ k x ( t ) − x ( t + τ ) k 2 ] ≤ τ X s =1 τ X r =1 α ( t + s ) α ( t + r ) E [ k g ( t + s ) k ∗ k g ( t + r ) k ∗ ] ≤ τ 2 α ( t ) 2 max r,s q E [ k g ( t + s ) k 2 ∗ ] q E [ k g ( t + r ) k 2 ∗ ] ≤ τ 2 α ( t ) 2 G 2 24 b y H¨ older’s inequalit y . S ubstituting the app ropriate v alue for α ( t ) completes the pro of. C Error in [LSZ09] Langford et al. [LSZ09], in Lemma 1 of their pap er, state an upp er b ound on h g ( t − τ ) , x ( t − τ ) − x ∗ i that is essent ial to the p roofs of all of their results. Ho wev er, th e lemma only holds as an equalit y for unconstrained optimization (i.e. when the set X = R d ); in the p resence of constrain ts, it fails to hold (ev en as an up p er b ound). T o see why , w e consider a simple one-dimensional examp le with X = [ − 1 , 1], f ( x ) = | x | , η ≡ 2 and w e ev aluate b oth sides of their lemma with τ = 1 and t = 2. The left hand sid e of their b ound ev aluates to 1, while the right hand side is − 1, an d the inequalit y claimed in the lemma fails. The pr oofs of their m ain theorems rely on the ap p lica tion of their Lemma 1 with equalit y , restricting those resu lts on ly to unconstrained optimization. Ho we v er , the results also require b oundedness of the gradients g ( t ) o ver all of X as w ell as b oundedness of the distance b etw een the iterates x ( t ). F ew con v ex f unctions hav e b ounded gradient s o ver all of R d ; and w ithout constrain ts the iterates x ( t ) are seldom b oun d ed for all iterations t . References [ABR W10 ] A. Agarw al, P . Bartlett, P . Ra viku mar, and M. W ainwrigh t, Information-the or e tic lower b ounds on the or acle c omplexity of c onvex optimizat ion , Submitted to IEEE T r ansactions on Information The ory , URL ht tp://arxiv.org/a bs/1009.0 571, 2010. [Ber73] D. P . Bertsek as, Sto c ha stic optimizat ion pr oblems with nondiffer entiable c ost func- tionals , Journal of Optimization Theory and Applications 12 (1973), n o. 2, 218–231. [Bre67] L. M. Bregman, The r elaxation metho d of finding the c ommon p oint of c onvex sets and its applic ation to the solution of pr oblems in c onvex pr o gr amming , USSR Com- putational Mathematics and Mathematical Physics 7 (1967) , 200–217. [BT89] D. P . Bertsek as and J. N. Tsitsiklis, Par al lel and distribute d c omputation: numeric al metho ds , Pren tice-Ha ll, Inc., 1989. [BT03] A. Bec k and M. T eb oulle, Mirr or desc e nt and nonline ar pr oje cte d sub gr adient metho ds for c onvex optimization , Op erations Researc h L etters 31 (2003), 167–17 5. [D A W10] J. Duc hi, A. Aga rw al, and M. W ain wright, Dual aver aging for dis- tribute d optimization : c onver g e nc e analysis and ne twork sc aling , URL h ttp://arxiv.o rg/abs/1005 .2012, 2010. [DGBSX10a ] O. Deke l, R. Gilad-Ba c hr ac h , O. Shamir, and L. Xiao, Optimal distribute d online pr e diction using mini-b atches , URL http:// arxiv.org/abs/1 012.13 67, 2010. [DGBSX10b] , R obust distribute d online pr e diction , URL h ttp://arxiv.org/ abs/1012 .1370, 2010. [HTF01] T. Hastie, R. Tib shirani, and J. F riedman, The elements of statistic al le arning , Springer, 2001. 25 [HUL96a] J. Hiriart-Urru t y and C . Lemar ´ echal , Convex Analysis and Minimization Algorithms I , Springer, 1996. [HUL96b] , Convex A na lysis and Minimization Algorithms II , S pringer, 1996 . [JNT08] A. J u ditsky , A. Nemiro vski, and C. T auv el, Solving variational ine qualities with the sto chastic mirr or-pr ox algorithm , URL http:/ /arxiv.org/abs/0 809.0 815, 2008. [JRJ09] B. J ohansson, M. Rabi, and M. Johansson, A r andomize d incr emental sub g r adient metho d for distribute d optimization in networke d systems , SIAM Journal on Opti- mization 20 (2009), no. 3, 1157–1170 . [Lan10] G. Lan, An optimal meth o d for st o chastic c omp osite optimization , Math- ematical Programming Series A (20 10), Online fi rst, to app ear. URL h ttp://www.ise.ufl.edu/glan/pap ers/OPT S A4 .p df. [LMP01] J. Laffert y , A. McCallum, and F. Pereira, Conditional r andom fields: Pr ob abilistic mo dels f or se gmenting and lab eling se que nc e da ta , Pro ceedings of the Eightneen th In ternational C onference on Mac hine Learnin g , 2001, pp . 282– 289. [LSZ09] J. Langford, A. Smola, and M. Zin k evic h , Slow le arners ar e fast , Adv ances in Neural Information Pr ocessing Systems 22, 2009, p p. 2331–2339 . [L YRL04] D. Lewis, Y. Y ang, T. Rose, and F. Li, R CV1: A new b enchmark c ol le ction for text c ate g orization r ese ar ch , Jour nal of Mac hine Learning Researc h 5 (2004), 361–397. [NBB01] A. Nedi´ c, D.P . Bertsek as, and V.S. Bork ar, Distribute d asynchr onous incr emental sub gr adient metho ds , Inherently Pa rallel Algorithms in F easibilit y an d Op timiza tion and their Applications (D. Butnariu, Y. Censor, and S . Reic h, eds .), Studies in Computational Mathematics, v ol. 8, Elsevier, 2001, pp. 381–4 07. [Nes09] Y. Nestero v, Primal-dual sub gr adient metho ds for c onvex pr oblems , Mathematical Programming A 120 (2009), no. 1, 261–283. [NJLS09] A. Nemiro vski, A. Jud itsky , G. Lan, and A. Shapiro, R obust sto chastic appr oximation appr o ach to sto chastic pr o gr amming , S IAM Journal on Optimization 19 (2009), n o . 4, 1574– 1609. [NO09] A. Nedi´ c and A. Ozdaglar, Distribute d sub gr adient metho ds for multi-agent optimiza- tion , IEE E T ransactions on Automatic Cont rol 54 (2009), 48–61. [NY83] A. Nemirovski and D. Y u d in, Pr oblem c omplexity and metho d efficiency in optimiza- tion , Wiley , New Y ork, 1983 . [P ol87] B. T . Po ly ak, Intr o duction to optimization , Optimization Softw are, Inc., 1987. [RM51] H. Robbins and S. Monro, A sto chastic appr oximation metho d , Annals of Mathemat- ical Statistics 22 (1951), 400–407. [RNV10] S. S. Ram, A. Nedi´ c, and V. V. V eera v alli, Distribute d sto chastic sub gr adient pr oje c- tion algorithms for c onvex optimizatio n , Journ al of Optimization Th eo ry and Appli- cations 147 (2010), no. 3, 516–54 5. 26 [Tse08] P . Tseng, On ac c eler ate d pr oximal gr adient metho ds for c onvex-c onc ave optimization , T ech. r eport, Departmen t of Mathematics, Univ ersit y of W ashington, 2008. [Tsi84] J. Tsitsiklis, Pr oblems in de c entr alize d de cision making and c omputation , Ph.D. the- sis, Massac husetts In stitute of T ec hnology , 1984 . [Xia10] L. Xiao, Dual aver aging metho ds for r e gu la rize d sto chastic le arning and online opti- mization , J ournal of Mac hine Learnin g Researc h 11 (2010), 2543–25 96. 27
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment