Reliability-based design optimization using kriging surrogates and subset simulation
The aim of the present paper is to develop a strategy for solving reliability-based design optimization (RBDO) problems that remains applicable when the performance models are expensive to evaluate. Starting with the premise that simulation-based app…
Authors: V. Dubourg, B. Sudret, J.-M. Bourinet
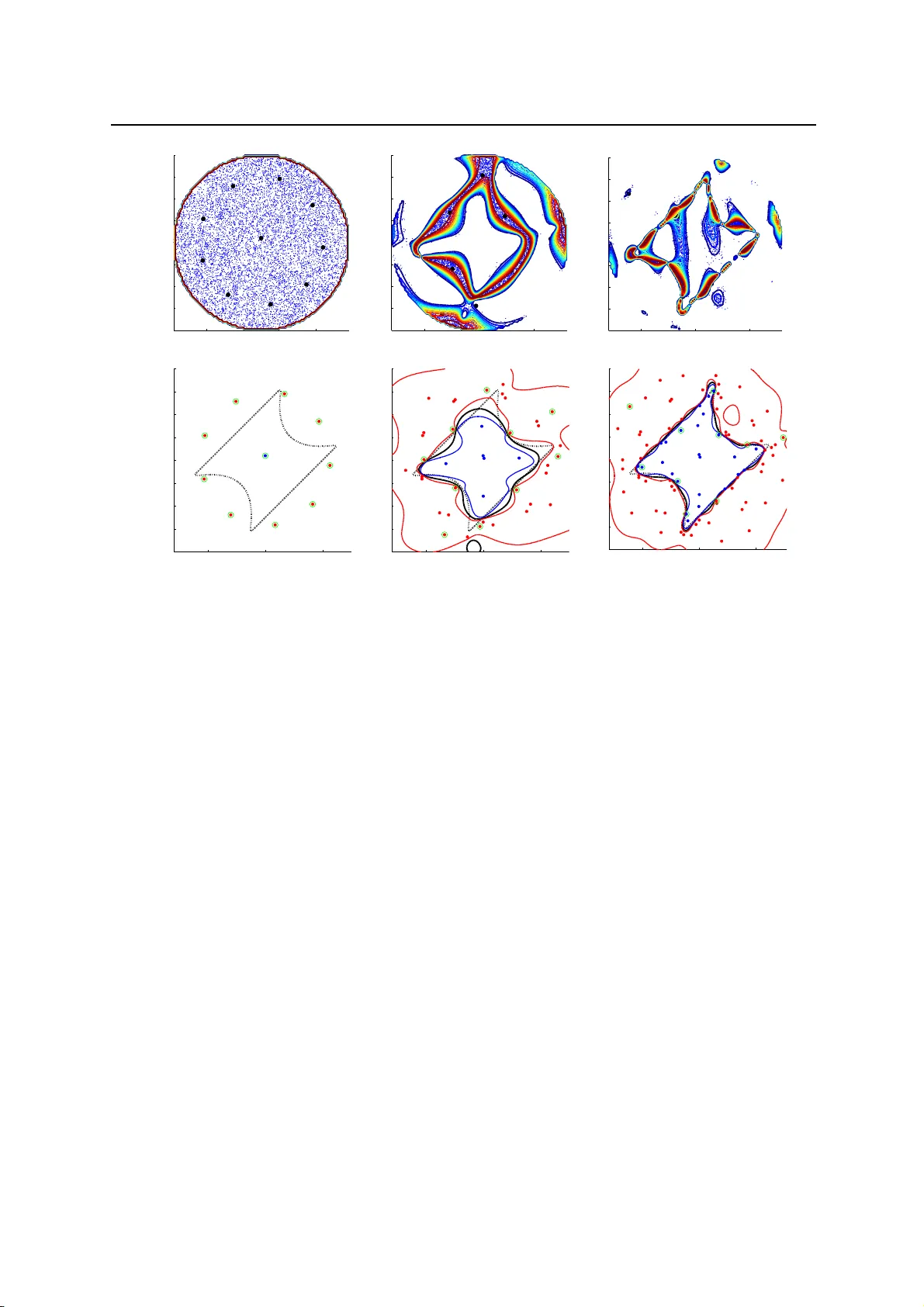
Struct Multidisc Optim manuscript No. DOI 10.1007 / s00158-011- 0653-8 R el iability-based design optimization using kriging surrogates and subset simulation V . Dubourg · B. Sudret · J.-M. Bourinet R eceived: 1 Septembe r 2010 / Revised: 18 F ebruary 2011 / Accepted: 30 Marc h 2011. Preprint submitted to Springer- V erlag. Abstract The aim of t he present paper is t o develop a s trategy for solv ing reliability -based design optimization (RBDO) pr o blems that remains applicable when the performance models are expensive to evaluate. St arting w ith the premise that simulation-base d app roaches are not affordable for such problems, and that the most-probable- failure-point-bas ed approaches do not permit to quantify the erro r on the estimation of the failure probability , an approach based on both m etamodels and advanced simulation techniques is explored. The kriging metamodeling technique is c hosen in o rder to surrogate the performance functions because it allows one to genuinely quantify the surrogate error . Th e surrogate error onto the limit-state surfaces is prop agated to the fail ure probabilities estimates in order to pro vide an empirical error measure. This error is then sequentially reduced by means o f a pop ulation- based adaptive refinement technique until the kriging surrogates are accurate enoug h for reliability analysis. This original refinement strate gy makes it possible to add several observations in the design of experiments at the same time. R eliabilit y and reliability sensitivity analyses are performed by m eans of the subset simulation technique for the sake of numerical efficiency . The adaptive surrogate-based strategy for reliability estimation is finally involved into a classical gradient-based o p timization algorithm in order to solve the RBDO problem. Th e kriging surrogates are built in a so-called augmented reliability space thus making them reusable from one nested RBDO iteration to the other . The strategy is comp ared to other approaches available in the literature on three academic examples in the field of structural mech anics. K e ywords reliability -based design optimization (RBDO) · kriging · surrogate modeling · subset simulati on · adaptive refinement 1 In troduction In structural mechanics, design optimization is the decision-making pro c ess that aims at finding the best set of design variables which minimizes some cost model while sat isfying some performance requirements. Due to the inconsistency between these two objective s, the optimal solutions often lie on the b oundaries of the admissibl e space. Thus, these solut ions are rather sensitive to uncertainty either in the parameters ( a l eatory ) or in the models themselves ( epistemi c ). Reliabili ty -based design optimi zation (RBDO) is a conc ept that accounts for uncertainty all along the optimizati on proc ess. B asically , the determinis tic performance model is wrapped into a more reali stic probabilistic constraint which is referred to as the fai l ure probability . Despite its attractive formulation, the appli- cation field of RBDO is stil l limited to academic examples. This is mostly due to the fact that it is either based on simplifying assumptions that might not hold in practice; or in contrast, it requires computationally intens ive stochastic simulations that are no t affordable for real industrial pro b lems. The present work attempts to propose an efficient strategy that would in fine bring the RBDO application field to mo re sophisticated examples, closer to real engineering cases. In other words, the challenge is (i) to provide an optimal safe design within a few h undred V . Dubourg · B.Sudret Phimeca Engineering, Centre d’Affair es du Zenith, 34 rue de Sarliev e, F -63800 Cournon d’Auvergne Clermont Universite, IFMA, EA 3867 , Laboratoire de Mecanique et Ingenieries, BP 10448, F -630 00 Clermont-F errand E-mail: dubourg @phimeca.com, sudret @phimeca.com J.-M. Bourinet Clermont Universite, IFMA, EA 3867 , Laboratoire de Mecanique et Ingenieries, BP 10448, F -630 00 Clermont-F errand E-mail: bourinet @ifma.fr 2 V . Dubourg et al. evaluati ons of the performance models and (ii ) to be able to quantify and minimize the errors induced b y the various assumptions that are made along the development of the r esolution strategy . The remaining part of this introduction is devote d to the formulation of the RBDO problem the authors attempt to solve. A short literature review is also p rovided as an argument for the presently proposed surrogate-based resolution strategy . Section 2 introduces the kriging surrog ate model. A specific emph asis is put on the epistemic nature of the prediction error that is then used in Section 3 in order to quantify and minim i ze the surrogate error . Section 4 involves the adaptive refinement strategy of the kriging surrogate into a nested reliability-based design optimization loop. The convergence of the approach is finally h euristically demonstrated in Section 5 through a few academic examples from the RB DO literature. 1.1 Problem formulation Given a parametric model for the random vector X describing the environment o f the system to be designed, the most basic formulati on for the RBDO problem reads as follows: θ ∗ = arg min θ ∈D θ c ( θ ) : ¨ f i ( θ ) ≤ 0, i = 1, . . . , n c P g l ( X ( θ )) ≤ 0 ≤ P 0 f l , l = 1, . . . , n p . (1) In this formulat ion, c is the objective function to be minimized with respect to the design variables θ ∈ D θ , while satisfying to n c deterministic soft co nstraints { f i , i = 1, . . . , n c } bounding the so-called admissible design space defined by the analyst. Note that in most applications these soft co nstraints consist in simple analy tical functions that p revent the optimization algorithm from exploring regions of the design space that have no physical meaning ( e.g. negative or infinite dimensions), so that these constraints are inexpensive to eva luate. A deterministic design optimization ( DDO) problem would simply require additional performance functions { g l , l = 1, . . . , n p } describing system failure with respect to the specific code of p r actice. As opposed to the p r evious soft constraints, these functions often involve the output of an expensive-to-evaluate black-box function M – e.g. a finite element model. RB DO differs from DD O in the sense that these constraints are wrapped into n p probabilistic constraints { P g l ( X ( θ )) ≤ 0 ≤ P 0 f l , l = 1, . . . , n p } . P 0 f l is the minimum safety requirement expressed h ere in the form of an acceptable probability of failure which may be different for each performance function g l . Such probabilities o f failure are convenientl y defined in terms of the following multidimensional integrals: P f l ( θ ) = P g l ( X ( θ )) ≤ 0 = Z g l ( x ) ≤ 0 f X ( x , θ ) d x , l = 1, . . . , n p . (2) One should notice that, in the present formulation, the design vector θ is a set of hyperparameters defining the random vector X . I n other words, in this work, design variables are exclusively considered as hyperparameters in the joint probability density function f X of the random vector X because it will later simplify the computation of relia bil i ty sensitivity – i.e. the g radients of the failure p robability . There is however no loss of g enerality since deterministic design variables might possibly be considered as artificially random (either normal o r uniform) with small varia nce – i.e. sufficiently close to ze ro. One could p o ssibly argue that this formulation lacks full probabilistic consideration because the cost function is defined in a deterministic manner as it only depends on the hyperparameters θ of the random vector X . A more realistic formulat ion should eventually account for the randomness of the cost function possibly induced by the one in X . However , the present formulation is extensi vely used in the RBDO literature for simplicity . Note however that thanks to the rather low complexity of usual cost mo dels (analytical functions), an accurate simulation-based estimation of a mean co st, say c ( θ ) = E [ c ( X ( θ ))] would not require a large c o mputational effort. 1.2 Short literature review The most straightforward approach to solve the RBDO problem in Eq. (1) consists in nesting a reliability analysis within a nonlinear c onstrained optimizati on loop. Such methods are referred to as double-loop or nested approaches. Despite their conceptual simplicity these approaches are often argued to lack efficiency since they require too m any evaluati ons of the performance functions g i that might involve the output of a time-consuming computer code. However for a bro ad range of applications where the performance functions are linear or weakly nonlinear – i .e. when the first order reliability method (FORM) is applicable, the nested approach is able to give results within a reasonable number of evaluations of the performance functions ( e.g. Enevoldsen and Sorensen (1994) achieve convergence within a few thousands evaluations). RBDO using kriging surrogat es and s ubset simulation 3 The formulation in Eq. (1) is known as the reliability index approac h (RIA). Note that RIA often refers to nested R B DO algorithm based on FORM despite the fact that the concept can easil y be extended to simulation- based reliability methods. Some authors, sta rting with T u et al. (1999), proposed an alterna tive formulation to the RBDO p roblem known as the performance mea sure approach (PMA). The p r obabilistic constraints are transformed into quantile co nstraints that are approximated using the first-order reliability theory . According to Y oun and Choi (2004), PMA would be mor e stable and efficient than RI A bec ause the inner reliability algorithms use d to solve the first-order quantile approximation (the so-called Mean V alue algorithms) are argued to be much more efficient than their probability approximation counterparts ( e.g. the Hasofer-Lind-Rackwitz-Fiessl er algorithm) . The nested approach becomes intractable in the case of more complex performance functions for which the nested reliabilit y analysis should resort to simulation-based methods. F or such cases however , R oyset and P olak (2004a,b) p roposed the so-called sample average a pproximation method which consists in gradually refining the simulation-bas ed reliability analysis as the optimization algorithm converges towards an optimal design. T o do so, they pro pose an empirical stepwise refinement criteria to define whether the number o f simulations sho uld be raised or not. Note also that the use of variance reduction techniques can significantly reduce the overall number of simulation runs such as d emonstrated in Jensen et al. (2009) where the authors used subset simulation. How- ever , simulation-based approaches still require too many performance functions evaluati ons to make the approach applicable to real engineering cases even though their application field is growing with the increasing availability of high performance c omputational (HPC) resources ( e.g. interconnected cluste rs of PCs). An alt ernative to double-l oop approach consists in decoupling the optimiza tion loop from the reliability analys es so that both can be sequential ly performed in an independent manner . Such approaches are referred to as sequential approaches or decoupled a pproaches (Roy set et al., 2001; Du and Ch en, 2004; Aoues and Chateauneuf, 2010). An advantage of these approaches is that they do not requi re any reliability sensitivity analysis since the optimiza tion is performed directly onto the performance function. H o wever , the decoupling often relies on the most probable failure point ( MPFP) assumptions and thus suffers from the possible non-unicity of this point and the st rong nonlinearit ies in the performance functions . Single-loop approaches ( Kuschel and Rackwitz, 1997; Kirjner-Neto et al., 1998; Kharmanda et al., 2002; Shan and W ang, 2008) attempt to full y reformulat e the original RBDO pro b lem into an equivalent DDO problem that allows a simple and effi cient resolution by means of classical optimization algorithms. The approach is mainl y based on concepts that are closely related to the notion of partial safety factors. It is certainly the mo st co mputationally efficient appro ach as soon as the assumptions under which the probabilistic-det erministic equival ence is built hold. Once again, most of them are based upon the assu mption that the MPFP exists and that it is unique. Stochastic subset optimization ( SSO) is a simulation-based approach recently proposed by T aflanidis and B eck (2009a) that consists in finding the region of the admissible design space where the failure prob ability density function is m inimal. It is based on cond itional simula tions in a so-called augmented reliability space where the design variables are arti ficially co nsidered as random with uniform d istribution. The range of unc ertainty in the design variables is r educ ed along with the identification of low failure prob ability density regions. The overall concept is closely related with the subset simulation relia bility method p roposed by Au and Beck (2001), and further explored by Au (2005) for reliability-ba sed design sensitiv ity analysis . In the end, the al gorithm provides a set of parameters that is likely to c ontain the op timal solution which can po ssibly be found b y means of a more refined stochastic search algorithm. However , the p roblem that SSO attempts to solve is not a full RBDO problem in the sense that it is designed to minimize the failure probability whereas the p urp ose of RBDO is to minimize a cost function under some maximal fa ilure probability constraint. Finally , the app r o ach that is investigated here is the surrogate-based (or response-surface-based ) approach. Start- ing with the premise that the performance function evaluat ion mig ht involve a time-consuming comp utational task, the approach consists in replacing this function by a surrog ate that is much faster to evaluate. This surrogate is usu- ally built and possibly refined from a few eval uations of the real performance function. V arious surrogates have been used in the structural reliability literature out of which: polynomial response surfa ces ( F aravelli, 1989; Bucher and Bourg und, 1990; Kim and Na, 1997; Das and Zheng, 2000), po lynomial chaos expansi ons (Sudret and Der Kiureghian, 2002; Berveill er et al., 2006; Blatman and Sudret, 2008, 2010), supp ort vector machines (Hurtado, 2004; Deheeger, 2008; Bourinet et al., 2010), neural networks (P apadrakakis and Lagaros, 2002) and krig ing (Bi- chon et al., 2008). Such surrog ates are argued h ere to be more flexible than the classical T aylor-expansion-based methods ( i.e. appro aches using the first- or second-order r eliability theory) that are commonly used in the RBDO literature. An additional interesting fact about this approach is that some of these surrogates, namely kriging and support vect or machines, allow one to quant ify an empirical surrogate error measure that can be propagated to the final quantit y of interest: the failure probability . 4 V . Dubourg et al. 2 T he kriging surrogate In computer experiments, surrogate mod eling addresses the problem of replacing a time-consuming mathematical model M called a simulator by an emulator that is much fa ster to evaluate. The emulat or has the same input space D x ⊆ R n and output space D y ⊆ R than the simulator . F or the sake of simplicity only scalar-output simulators are considered h ere. It is important to note here that both x and y are deterministic in this co ntext. I n the present RBDO application, the time- consuming models are the performance functions { g l , l = 1, . . . , n p } in Eq. ( 1). Kriging (Santner et al., 2003) is one particular emulator that is able to give a pr o babilistic response b Y ( x ) whose variance (spread) depends o n the quantity of available knowledge. In other words, the uncertainty in this prediction is purely epistemic and due to a lack of knowledge at specific input x . F or a more detailed discussion on the distinction that should be made between a leatory and epistemic sources of uncertainty , the reader is referred to Der Kiureghian and Ditlevsen ( 2009). This interesting property of the kriging surrogate will be used in the next sections to make the surrogate-based RBDO approach adaptive. In essence, kriging starts with the assumption that the output y ≡ M ( x ) is a sample path of a Gaussian stochas- tic process Y whose mean and autocovariance functions are unknown and to be determined from the values of the model response Y = { y i = M x i , i = 1, . . . , m } evaluated onto an experimental design X = { x 1 , . . . , x m } . More specifical ly , the so-called universal kriging (UK) model ass umes the Gaussia n process has a stationary autoco- variance function and is centered with respect to a non-stati onary trend in the form of a linear regression model so that it reads: Y ( x ) = p X i = 1 β i f i ( x ) + Z ( x ) = f ( x ) T β + Z ( x ) . (3) The first term is the regression part that requires the choice of a functiona l set f ∈ L 2 D x , R . The second term is a stationary G aussian proc ess with zero mean, constant variance σ 2 Y and stationary autocorrelation function R so that its autocovaria nce function reads as foll ows: C x , x ′ = σ 2 Y R x − x ′ , ℓ . (4) The parameters ℓ , β and σ 2 Y shall be determined according to a given class of symmetric positive definite autocor- relation functions and a given set of regression functions. The most widely used class of autocorrelation functions is the anisotropic g eneralized exponential model: R x − x ′ , ℓ = exp n X k = 1 − x k − x ′ k ℓ k s ! , 1 ≤ s ≤ 2. (5) Generally speaking, the choice of the autocorrelation model should be made consistently with the known proper- ties of M such as derivability o r periodicity ( see e.g. Rasmussen and Williams, 2006, ch. 4). C o mmon reg ression models involve zero, first and second-ord er polynomials of { x k , k = 1, . . . , n } . Note however that as for or d inary least-sq uares regression, the size p of the functional basis tog ether with the d imension of the input vector n dra- matically incr eases the num b er m of required observat ions. When attempting to model the output of a high-fidelity computer model, a good choice for the regression model may be an equivalent low-fidelity analytical model built on simplifying ass umptions. The construction of a kriging model consists in a two-stage framework that is further detailed in Subsections 2.1 and 2.3. 2.1 The conditional distribution of the prediction The first stage aims at looking for the distribution of some prediction b Y ( x ) = Y ( x ) | Y of the Gaussi an process (GP) at any location x ∈ D x conditional on the vector of observations Y = 〈 Y x 1 , . . . , Y x m 〉 T . Since Y is assumed to be a Gaussi an process, the vector of observations Y is distributed as follows: Y ∼ N F β , σ 2 Y R (6) where we have introduced the matrices F and R that are defined with respect to the assumed statistics of the Gaussian process. Their terms read as follows: F i j = f j x i , i = 1, . . . , m , j = 1, . . . , p (7) R i j = R x i − x j , ℓ , i = 1, . . . , m , j = 1, . . . , m . (8) RBDO using kriging surrogat es and s ubset simulation 5 It is also known that the augmented random vector ¬ Y T , Y ( x ) ¶ T is jointly Gaussia n by definition: Y Y ( x ) ∼ N ¨ F f ( x ) T « β , σ 2 Y R r ( x ) r ( x ) T 1 (9) where we have introduced the vector of cross-correlations r ( x ) between the observations and the prediction: r i ( x ) = R x − x i , ℓ , i = 1, . . . , m . (10) It is well known (see e.g. Sev erini, 2005, Chap. 8) that the conditional distribution of b Y ( x ) = Y ( x ) | Y is also Gaussian with mean: µ b Y ( x ) = f ( x ) T b β + r ( x ) T R − 1 Y − F b β (11) and varia nce: σ 2 b Y ( x ) = σ 2 Y 1 − r ( x ) T R − 1 r ( x ) + u ( x ) T ( F T R − 1 F ) − 1 u ( x ) (12) where we have introduced: b β = ( F T R − 1 F ) − 1 F T R − 1 Y (13) u ( x ) = F T R − 1 r ( x ) − f ( x ) . (14) 2.2 Properties of the kriging surrogate The kriging surrogate is an exact interpolator . Indeed, noting that the i -th column of the matrix R is equal to the vector r x i = e i , the following relat ion holds: R e i = r x i (15) where e i is the i -th b asis vector of R m which has all-zero co mponents except its i -th component equal to one. Using the symmetry property of R and plugging the latter relation in the predictor’s mean in Eq. (11) and in its variance in Eq. (12) fina lly allows to prove the following statement: µ b Y x i = y i σ b Y x i = 0 i = 1, . . . , m , ∀ ℓ , β , σ 2 Y (16) which m eans that the kriging surrogate interpolates the ob servations with varia nce equal to zero (deterministic prediction). This property holds for any regression and regular autocorrelation models, whatever the values of the parameters ℓ , β and σ 2 Y . 2.3 J oint maximum likelihood estimation of the Gaussian process parameters In the first stage it was assumed that the autocovariance function σ 2 Y R ( • , ℓ ) and the regression model f ( • ) T β are known . In computer experiments or in geostatistics it is never the case so that the models need to be chosen and their parameters must be determined using common statistical inference tech niques such as the variographi c analysis (V A) , maxim um lik el i hood estimation (MLE) or Bayesian estimation (BE). Historically , the kriging methodo logy was introduced by geostatisticia ns in order to p redict a map of soil proper- ties from in si tu observations for mining prospection. In this field, the autocovariance structure is usually est imated from the data using variographic a nalysis (Cressie, 1993). Then, provided the empirical variogram features some required pro perties it can b e turned into an autocovariance model. However , this method ology is not well-suited to our purpose because of its user-interactivity . In computer experiments, the m ost widely used methodology is the M LE technique. Provided a functional set f ∈ L 2 D x , R and a stationary autocorrelation model R ( • , ℓ ) are chosen, one can express the likelihood of the data with respect to the model and maximize it with respect to the sought parameters ( ℓ , β and σ 2 Y ). One can show that β and σ 2 Y can be derived analy tically ( using the first-order optimality c onditions) and solely depends on the autocovariance parameters ℓ that are solution of a numerically tractable global op timization problem – see e.g. W elch et al. (1992); Lophaven et al. ( 2002) for m o re d etails. This technique, imp lemented within the D ACE toolbox by Lophaven et al. (2002), was used for the applications p resented in this paper . Note that the BE technique consists in weighting the likelihood b y a prior over the autocovariance parameters and final ly allows to derive a full probabilistic posterior on them. Despites it has an attractive formulation as it allows one to quantify an additional epistemic uncertainty in the autocovariance parameters themselves, it is still 6 V . Dubourg et al. difficult to involve it in a nested general-purpose procedure such as the one proposed in this paper due to the required prior informat ion which might not be available. In the case of MLE, the variance σ 2 b Y underestimates the real variance as it does not account for (i) the empirical choice of the autocovariance structure of the GP , and (ii) the uncertainty induced by the statis tical inference of b ℓ . Note that BE d o es acco unt for this uncertainty but it is r ather difficult to propagate this additional uncertainty through the predictor – this is sometimes referred to as Bayesian kriging . Even though, the probabilistic response of the kriging model is c o nvenient as it allows one to: – provide probabilistic confidence interval s in addition to the prediction; – define refinement criteria to build the kriging surrogate in an adaptive refinement procedure depending on the region of interes t as introduced in Secti on 3. 3 Desig n of experiments for the kriging surrogate V arious refinement techniques have been proposed in the kriging-related literature, e.g. for global optimization (Jones et al., 1998) or for p robability / quant ile estimation (Oakley, 2004; Bichon et al., 2008; Lee and Jung , 2008; Ranjan et al., 2008; V azquez and Bect, 2009; Picheny et al., 2010). They are all based on the genuine prob abilistic nature of the kriging prediction. An adaptive refinement technique consists in finding the set of points that should be added to the design of experiments (DOE) in order to improve the prediction and reduce its associat ed epistemic uncertainty in some specific region of interest (Picheny et al., 2010). In global optimization, the region of interest is the vicinity of the optimum that can be sequentia lly achieved by means of the so-call ed efficient global optim i zation technique ( Jones et al., 1998). I n reliability and reliability -based design optimization, the region o f interest in the space of random variables X is the vicinity of the limit-sta te surfa ce g ( x ) = 0 (we drop the subscript l in this section for the sa ke of clarity). 3.1 Premise Provided an initial kriging prediction of the performance function g denoted by b G ∼ N µ b G , σ b G , the probable vicinity of the limit-sta te surface g = 0 can be defined in terms of the following margin of uncertainty (epistemic uncertainty): M = ¦ x : − k σ b G ( x ) ≤ µ b G ( x ) ≤ + k σ b G ( x ) © (17) where k migh t be chosen as k = Φ − 1 ( 97.5% ) = 1.96 meaning that a 95% confidence interval onto the prediction of the limit-s tate surface is ch osen. Any po int that belongs to this margin correspond to an uncertain sign of the prediction. The spread o f this margin should be reduced in order to make the reliability estimation accurate, and this can be achiev ed by adding new points in the DOE that are located in this margin. The probability that a point x ∈ D x falls into the margin M (with respect to the ep istemic uncertainty in the prediction) can be express ed in closed-form as follows: P ( x ∈ M ) = Φ k σ b G ( x ) − µ b G ( x ) σ b G ( x ) − Φ − k σ b G ( x ) − µ b G ( x ) σ b G ( x ) . (18) Note that the same criterion is used in Picheny et al. (2010) where it has been named the weighted integrated mean squared error (W -IM SE). Then, finding the point that maximizes this quantity on the support o f the PDF of X will finally bring the best improvement point in the DOE. Starting with this statement, many authors in the kriging literatu re decide to use global optimization algorithms in order to find the best improvement point. F or instance, Bichon et al. (2008) use a different criterion named the expected feasibil i ty function , and Lee and Jung (2008) use the constraint boundary sampling criterion, but both use a global o p timization algorithm to find the best improvement point. 3.2 Principle of the proposed refinement procedure In this paper , we propose a different strategy that allows one to add a set of improvement points. Indeed, all the proposed refinement criteria (including the one in Eq. (18)) are highly m ultimodal, thus meaning that: – the global optimization problem is not easy to solve; – there does not really exist one best point (especially for the contour approximation prob lem of interest), since each mode is associated with a potentially interesting point to add to the DOE. RBDO using kriging surrogat es and s ubset simulation 7 It may also be faster if one has the ability to perform several simulation runs of g at the same time ( e.g. on some distributed computational platform). Note that the idea is inspired from H urtado ( 2004); Deheeger and Lemaire (2007); Deheeger (2008); Bourinet et al. (2010) where the aut hors use the same idea applied to support vector classifiers . T o do so, the probability to fall in the margin o f epistemic uncertainty is multiplied by a weighting PDF w so that the follow ing criterion: C ( x ) = P ( x ∈ M ) w ( x ) (19) can itself be c onsidered as a PDF up to an unknown but finite normalizing constant. The weighting d ensity w can either be the original PDF of X , o r , as it is proposed here, the uniform PDF on a sufficiently large confidence region of the original PDF . Such a confidence region might be difficult to d efine for any given PDF , but as it is usually done in structural reliability (Ditlevsen and Madsen, 1996), the original random vector X can b e transformed into a probabilistically equivalent standard Gaussian random vector U for which the c o nfidence region is simply an h ypersphere with radius β 0 . The reader is referred to Lebrun and Dutfoy (2009) for a rec ent discussion on such mappings u = T ( x ) . In that given space, β 0 can be easily selected as e.g. β 0 = 8 which corresponds to the maximal reliability index that can be justified numerically , and the sought uniform PDF is simply defined in terms of the following indicator function: w ( u ) ∝ 1 p u T u ≤ β 0 ( u ) . (20) The normalizing constant of this PDF is the volume of the hypersphere and it could thus b e easily derived though it is not required to generate samples from C as explained hereafter . Note that another weighting PDF will be introduced later on ( in Section 4.1) for the RBDO problem of interest. Given that pseudo-PDF , one can g enerate N (say N = 10 4 ) samples by means of any well suited Markov chain Monte Carlo (MCMC) simul ation technique (R obert and Casella, 2004), such as the slice sampling technique ( Neal, 2003). The N g enerated candidates are expected to be highly conc entrated at the modes of C – and thus in M . This po p ulation of candidates is then reduced to a smaller one that has essentially the same statistical properties ( i.e. it uniformal ly covers M ) by means of the K -means clustering technique ( MacQueen, 1967). W e make a final remark c onsidering the three approximate failure subsets b F − 1 , b F 0 , b F + 1 defined as foll ows: b F i = ¦ x : µ b G ( x ) + i k σ b G ( x ) ≤ 0 © , i = − 1, 0, + 1. (21) Note that the extreme failure subsets are related with the margin of uncertainty through the foll owing set relation- ship: M = b F − 1 \ b F + 1 . Due to the positiveness of sta ndard deviation, the following statement holds: b F + 1 ⊆ b F 0 ⊆ b F − 1 ⇒ P X ∈ b F + 1 ≤ P X ∈ b F 0 ≤ P X ∈ b F − 1 . (22) Unfortunately , there is no proof that the real failure subset F satisfies the following relat ionship b F + 1 ⊆ F ⊆ b F − 1 due to the empirical assumptions that were made in Section 2. However , the sprea d of the interval [ P ( X ∈ b F + 1 ) , P ( X ∈ b F − 1 )] is a useful measure to check if the kriging surrogate is accurat e enoug h for reliabilit y anal ysis or not, and it is used in this paper as a stopping criterion for the proposed refinement procedure. Note that due to the inconvenient order of magnitude o f low probabilities, it is more meaningful to work with the generalized reliability indices that are defined as foll ows: b β i = − Φ − 1 P ( X ∈ b F i ) , i = − 1, 0, + 1. (23) Then, in the proposed applications, the accuracy criterion is usually set to ǫ β = 10 − 1 − 10 − 2 and the refinement stops when: max b β + 1 − b β 0 , b β 0 − b β − 1 ≤ ǫ β . (24) When b β i are estimated by means o f simulation techniques ( Monte-Carlo or subset simulation), the proposed accuracy criterion should account for the additional uncertainty induced by the lack of simulations . T o d o so, in the present paper , b β − 1 and b β + 1 estimates are r ep laced with their respective lower and upper 95% confidence bounds based on their associated variance of estimation . Thus, ǫ β should be selected in accordance with the given number of simulat ions used for reliability estimat ion. 8 V . Dubourg et al. 3.3 Im plementation In order to summarize the prop osed refinement procedure, we provide the pseudo-code in Algorithm 1. First, we initializ e the empty DOE ( X = ; , G = ; ) , the uniform refinement pseudo-PDF C for the first space-filling DOE and we select the level of confidence k in the metamodel. Then, we generate the candidate p opulation P from the density function C by means of any well-suited M CMC simulation technique (using e.g. slice sampling). This population is reduced to its K clusters’ center using K -means clustering – K being given. The performance function G is eval uated onto these K newly selected points X new and a new kriging model is built from the updated DOE ( X , G ) . Note that the kriging model construction step involv es the maximum likelihood estimation of the autocorrelation parameters ℓ ∈ [ ℓ L , ℓ U ] . The refinement pseudo-PDF C is also updated. Finally , a reliabil ity analysi s (using e.g. subset simulation) is performed onto the three approximate failure subse ts b F + 1 , b F 0 , and b F − 1 in order to compute the proposed erro r measure. The DOE is enriched if and while this error measure exceeds a given tolerance ǫ β = 10 − 1 − 10 − 2 . Algorithm 1 P opulation-based adaptive refinement stra tegy 1: X = ; , G = ; 2: w : = x 7→ w ( x ) 3: k : = Φ − 1 ( 97.5% ) , ǫ β : = 10 − 1 4: Refine : = true 5: P ( x ∈ M ) : = x 7→ 1 6: while Refine do 7: P : = MCMCAlgorithm ( C ) 8: X new : = KMeansAlgorithm ( P , K ) 9: G new : = g X new 10: X : = {X , X new } , G : = {G , G new } 11: b G : = MaximumLikelihoodKrigingMo del ( X , G , f ( • ) , R ( • , ℓ ) , ℓ L , ℓ U ) 12: P ( x ∈ M ) : = x 7→ Φ k σ b G ( x ) − µ b G ( x ) σ b G ( x ) − Φ − k σ b G ( x ) − µ b G ( x ) σ b G ( x ) 13: C : = x 7→ P ( x ∈ M ) w ( x ) 14: for i : = − 1, 0, + 1 do 15: b F i : = ¦ x : µ b G ( x ) + i k σ b G ( x ) ≤ 0 © 16: b β i : = Relia bilityAnalysis ( b F i ) 17: end for 18: Ref ine : = max b β + 1 − b β 0 , b β 0 − b β − 1 > ǫ β 19: end while Figure 1 illustrates the pro p osed adaptive refinement strategy applied to a nonlinear limit-s tate surface from W aarts ( 2000). The upper subfigures show the contours of the refinement pseudo-PDF C at each refinement step together with the candidate population generate d by slice sampling and its K clust ers’ center obtained by K -means clustering – K = 10 being g iven. F or this application, the weighting PDF w was selected as the uniform densit y in the β 0 -radius hypersphere – β 0 = 8. I t can be observed that th e refinement criterion features several modes as argued earlier in this Section. In the lower subfigures one can see the real limit-stat e surface represented as the dashed black curve, its kriging prediction represented as the black line and its associated margin of uncertainty M which is bounded below by the red line and above by the blue line. Another interpretation o f these figures is that any point within the blue b o unded shape is positive with a 95% confidence and any p o int inside the red bounded shape is negativ e with the same confidence level. 4 T he proposed adaptive surrogate-based RBDO strategy The proposed strategy to solve the RBDO problem in Eq. (1) c onsists in nesting the previously introduced kriging surrogate together with the proposed refinement strategy within a classical (but efficient) nested RBDO algorithm. 4.1 The augmented reliability space In this section, we describe the space where the kriging surrogates are built. Indeed, observing that building the kriging surrogates from an empty DOE for each nested r eliability analysis ( e.g. in the space of the standard normal random variables) would be particularly inefficient, it is proposed to build and refine one unique global kriging surrogate for all the nested reliability analyses. RBDO using kriging surrogat es and s ubset simulation 9 −5 0 5 −8 −6 −4 −2 0 2 4 6 8 u 1 u 2 −5 0 5 −8 −6 −4 −2 0 2 4 6 8 u 1 u 2 (a) Init.: 10-point DOE −5 0 5 −8 −6 −4 −2 0 2 4 6 8 u 1 u 2 −5 0 5 −8 −6 −4 −2 0 2 4 6 8 u 1 u 2 (b) Step 3: 40-point DOE −5 0 5 −8 −6 −4 −2 0 2 4 6 8 u 1 u 2 −5 0 5 −8 −6 −4 −2 0 2 4 6 8 u 1 u 2 (c) Step 9: 100-point DOE Fig. 1 An illustration of the proposed limit-state surface refinement technique Such a globality can be achieved b y working in the so-called augmented reliabili ty space such as defined in T aflanidis and Beck (2009b). In Kharmanda et al. ( 2002), the augmented reliability space is defined as the tensor product between the space of the standardized normal r ando m variables and the design space: D U × D θ , but the dimension of this space ( n + n θ ) suffers from bo th the number of random variables n and the number of design variables n θ . It is also argued here that this space m ay cause some loss of information as the performance functions are not in bijection with that augmented space. In contrast, in T aflanidis and B eck (2009b) and in the present approach, the dimension of the augmented reliability space is kept equa l to n by considering that the design vector θ simply augments the uncertainty in the random vector X . I ndeed, the augmented random vector V ≡ X ( Θ ) has a PDF h which accounts for both an instrumental uncertainty in the design choices Θ and the aleatory unc ertainty in the random vector X . Under such considerations, h reads as follows: h ( v ) = Z D θ f X ( x | θ ) π ( θ ) d θ ( 25) where f X is the PDF of X g iven the paramete rs θ and π is the PDF of Θ that can be assumed uniform on the d esign space D θ . An illustration of this augmented PDF is provided in Figure 2 in the univaria te case. The augmented reliability space is spanned by the axis V on the left in this simple case. The DOE should cover uniformally a sufficiently large c onfidence region of this augmented PDF in order to make the surrogate limit -state surfaces accurate wherever they can potentiall y be evaluated along the optimization process. More p recisely , they should be accurate for extreme design choices θ ( i.e. located o nto the boundaries of the optimization space D θ ) and extreme va lues of the marginal random vector X (to be able to compute reliabil ity indices as large as e.g. β 0 = 8). A confidence region is essentially the multivariate extension of the univariat e concept of confidence interval . Und er the previous general assumptions, it is hard to give a mathematical form to the contour of this region. However , one may easily build an h yperrectangular region that bounds the c onfidence region of interes t. Indeed, such an hyperrectangular region is defined as the tensor product of the confidence interval s on the augmented margins { V i , i = 1, . . . , n } . In order to compute the quantiles bounding these confidence intervals, one should additionall y assume that the design parameters are exclusiv ely involved in the definition of the margins – i.e. no p arameters in the d ependence structure (the copula ) as it will never be the case in most RB DO applica- tions. F or each margin, the lower quantiles { q − V i , i = 1, . . . , n } (at the probability level 1 − Φ β 0 = Φ − β 0 ) and 10 V . Dubourg et al. D D D Fig. 2 The augmented probability density function of a Gaussian random variate with unifor m mean . upper quantiles { q + V i , i = 1, . . . , n } ( at the probability level Φ + β 0 ) are respectively soluti ons of the following optimization problems: q − V i = min θ ∈D θ F − 1 X i Φ ( − β 0 ) | θ , i = 1, . . . , n (26) q + V i = max θ ∈D θ F − 1 X i Φ (+ β 0 ) | θ , i = 1, . . . , n (27) where { F − 1 X i , i = 1, . . . , n } are the quantile functions of the margins. If the domain D θ is rectangular and if one is able to derive an analytical expression for the qua ntile functions of the margins and their derivatives with respect to the parameters, then these optimization problems might be solved analyti cally . However assuming a mo re general setup where one has only numerical definition of these quantitie s, these problems can be efficiently solved by means of a simple gradient-based algorithm due to the convenient pro perties of the quantile functions – namely , the monotony with respect to the location and shape parameters. Finally , the sough t hyperrectangle can be easily defined by means of the following indicator function: 1 D V , β 0 ( v ) = ¨ 1 if q − V i ≤ v i ≤ q + V i , i = 1, . . . , n 0 otherwise (28) Again, the normalizing constant of this PDF could be easily derived (hyperrectangle volume) though it is no t required by the refinement procedure propo sed in Section 3. 4.2 The adaptive surrogate-based nested RBDO al gorithm 4.2.1 Optimi zation The kriging surrogate together with its adaptive refinement pr o cedure is finally plugged into a double-loop RBDO algorithm. The outer o ptimization loop is performed by means of the P olak-He optimization algorithm (P olak, 1997). Provided an initial design, this algorithm proceeds iterativel y in two steps: (i) the direction of optimization is determined solving a qua si-SQP sub-optimization problem and (ii) the step si ze is approximated by the Goldstein- Armijo approximate line-s earch rule. 4.2.2 Surrogate-based reliability and reliability sensitivity analyses The nested reliabili ty and reliability sensitivity analyses are performed with the subset simulation variance reduction technique (Au and Beck, 2001) onto the kriging surrogates. The subset simulation technique for reliability sensi- tivity analy sis is detailed in Song et al. (2009). Briefly , it takes advant age of the definit ion of the failure probability given in Eq. (2). Indeed, pointing out that the limit-state equation does not explicitly depend on the design vari- ables θ , the different iation of the fai lure probability only requires the differentiation of the joint PDF which can be derived analytically when the probabilistic mod el is defined in terms of margin distributions and copulas (Lebrun RBDO using kriging surrogat es and s ubset simulation 11 and Dutfoy , 2009). The trick is inspired from imp ortance sampling and p roceeds as follows: ∂ P f ∂ θ ≡ ∂ ∂ θ Z g ( x ) ≤ 0 f X ( x , θ ) d x (29) = Z g ( x ) ≤ 0 ∂ f X ( x , θ ) ∂ θ d x (30) = Z g ( x ) ≤ 0 ∂ f X ( x , θ ) ∂ θ f X ( x , θ ) f X ( x , θ ) d x (31) ≡ E f X 1 g ≤ 0 ( X ) ∂ f X ( X , θ ) ∂ θ f X ( X , θ ) . (32) The latte r quantity is known to have an unbiased consistent estimator which reads as follows: Õ ∂ P f ∂ θ = 1 N N X k = 1 1 g ≤ 0 x ( k ) ∂ f X ( x ( k ) , θ ) ∂ θ f X x ( k ) , θ (33) where the sample { x ( 1 ) , . . . , x ( N ) } is the same as the one used for the estimation of the failure prob ability P f . I n other words, the estimation of d ∂ P f ∂ θ does not require any additional simulation runs: it simply c onsists in a post- processing o f the samples generated for reliabil ity estimation. The concept can be easily extended to the subset simulation technique – see Song et al. (2009) for the d etails. 4.2.3 Impl em entation The overall methodology was implemented within the FERUM v4.0 toolbox ( B ourinet et al., 2009). It makes use of the Matlab toolboxes functions quadprog (for the SQP sub-optimization problem) and slicesample (to gen- erate samples from the refinement P DF C ). W e provide a summarize d p seudo-code of the proposed strategy in Algorithm 2. Algorithm 2 Adaptive surrogate- based nested RBDO strategy 1: θ ( 0 ) , θ L , θ U , j : = 0 2: for i = 1 to n do 3: q − V i : = min θ L ≤ θ ≤ θ U F − 1 X i x i , θ 4: q + V i : = max θ L ≤ θ ≤ θ U F − 1 X i x i , θ 5: end for 6: w : = v 7→ 1 D V , β 0 ( v ) 7: k : = Φ − 1 ( 97.5% ) , ǫ β : = 10 − 1 8: Refine : = true , Optimize : = true 9: while Refine a nd Optimize do 10: while R efine do 11: b G : = Refine KrigingModel ( w , k , ǫ β ) , → Use Algorithm 1 12: end while 13: b F 0 : = ¦ x : µ b G ( x ) ≤ 0 © 14: b β ( j ) , ∇ θ b β ( j ) : = Relia bilityAnalysis ( b F 0 , θ ( j ) ) 15: c ( j ) : = c ( θ ( j ) ) , ∇ θ c ( j ) : = ∇ θ c ( θ ( j ) ) 16: f ( j ) : = f ( θ ( j ) ) , ∇ θ f ( j ) : = ∇ θ f ( θ ( j ) ) 17: d ( j ) : = SolveQuasiSQP ( c ( j ) , f ( j ) , b β ( j ) , ∇ θ c ( j ) , ∇ θ f ( j ) , ∇ θ b β ( j ) ) 18: s ( j ) : = GoldsteinArmijoStepSizeR ule ( c , f , b β , d ( j ) ) 19: θ ( j + 1 ) : = θ ( j ) + s ( j ) d ( j ) 20: for i : = − 1, 0, + 1 do 21: b F i : = ¦ x : µ b G ( x ) + i k σ b G ( x ) ≤ 0 © 22: b β i : = Relia bilityAnalysis ( b F i , θ ( j + 1 ) ) 23: end for 24: Ref ine : = max b β + 1 − b β 0 , b β 0 − b β − 1 > ǫ β 25: Optimize : = θ ( j + 1 ) − θ ( j ) > ǫ θ or c ( j + 1 ) − c ( j ) > ǫ c or ∃ i f i > 0 or b β < β 0 26: end while 12 V . Dubourg et al. The first step of the algorithm consists in finding the hyperrectangular region that bounds the confidence region of the augmented probability density function accord ing to Section 4.1. Once this is done, o ne may define the uniform weighting density w ≡ 1 D V , β 0 in Eq. (28) and use it within the adaptive population-based refinement procedure detail ed in Section 3 and Algorithm 1. Kriging models are built for each performance function, and they are refined until they meet the selected accuracy regarding reliability estimation. It is worth noting that the kriging surrogates are built in the augmented reliability space spanned by V , but used in the current space of random variables spanned by X | Θ = θ ( j ) . As soon as they are accurate enough we perform surrogate-based reliabilit y and reliability sensitivity analysis in order to propose an improved design. A quasi-SQP algorithm is then used in order to determine the best improvement direction; and the G oldstein-Armijo approximate line-search rule is used to find the best step size along that direction. The current design is improved and the krig ing model accuracy for reliability estimation is being checked at the improved design. The co nvergence is obtained if the optimization has converged (using the regular criteria in gradient-based deterministi c optimization) and if the kriging models allow a sufficiently accurate reli ability estimation according to the pr o posed error m easure. 5 Applications In this section, the proposed adaptive nested surrogate-based RBDO strategy is applied to some examples from the literature for performance comparison purpo ses. All the kriging surrogates are sequentiall y refined in order to achieve an empirical erro r measure ǫ β ≤ 10 − 1 on the esti mation of the reliabil ity indices. 5.1 Elastic buckling of a straight column – An analytical reference In essence, the purpose of this first basic example is to validate the pr o posed algorithm with respect to a reference analyti cal solution. Let us consider a long simply-supported rectangular column with section b × h subjected to a constant service axial load F ser . Provided h ≤ b and its constitutive material is characterized by a linear elastic behavior through its Y oung’s modulus E , its critical b uckling load is g iven by the Euler formula: F cr = π 2 E b h 3 12 L 2 . (34) This allows one to form ulate the p erformance function which wil l be involve d in the probabilistic constraint as: g ( E , b , h , L ) = π 2 E b h 3 12 L 2 − F ser . (35) The probabilistic model c onsists in the 3 independent random variables given in T able 1. Applying the performance function as a d esign rule in a fully deterministic fashion ( i.e. using the means of the random variate s) allows to determine the service load F ser so that the initial deterministic design µ ( 0 ) b = µ ( 0 ) h = 200 mm sat isfies the limit-stat e equation g ( x ) = 0: F ser = π 2 µ E I 0 L 2 = π 2 µ E µ ( 0 ) b µ ( 0 ) 3 h 12 L 2 . (36) The reliability-base d design problem consists in finding the optimal means µ b and µ h of the random width b and height h . The op timal design is the one that minimizes the average cro ss section area which is approximated as follows: c ( θ ) = µ b µ h . (37) It should als o satisfy the following deterministic constraint : f ( θ ) = µ h − µ b ≤ 0 (38) V ariable Distribution Mean C.o.V . E (MP a) Lognormal 10 000 15% b (mm) Lognormal µ b 5% h ( m m) Logno rmal µ h 5% L (mm) Deterministic 3 000 – T able 1 Elastic buckling of a straight column – Probabilistic model RBDO using kriging surrogat es and s ubset simulation 13 in order to ensure that the Euler formula is applicable, as well as the following safety probabilisti c constraint: − Φ − 1 P g ( X ) ≤ 0 ≥ β 0 (39) where β 0 = 3 is the generaliz ed target reliability index. 5.1.1 Analytica l solution Due to the use of lognormal random variates in the probabilistic model together with the simple performance func- tion ( multiplications and divisions), the problem can be handled anal ytically . Indeed, the isoprobabilistic transf orm of the limit-state surface equation in terms of standard normal random variates is straightforward and leads to a linear equation. And it finally turns out after basic algebra that the Hasofer-Lind reliability index (associated with the exact fail ure probability) reads: β HL = log π 2 12 F ser + λ E + λ b + 3 λ h − 2 λ L p ζ 2 E + ζ 2 b + 9 ζ 2 h + 4 ζ 2 L (40) where λ • and ζ • denote the parameters of the lognormal random variates. The o ptimal solut ion of the RBDO problem is then simply derived b y saturating the two constraints in log-scale ( i.e. with respect to λ b and λ h ) and this lea ds to the square cross se ction with parameters: λ ∗ b = λ ∗ h = 1 4 β 0 Æ ζ 2 E + ζ 2 b + 9 ζ 2 h + 4 ζ 2 L − log π 2 12 F ser − λ E + 2 λ L . (41) 5.1.2 Num eric al solution The p roposed numerical strategy is applied in order to solve the RBDO p roblem numerically . The refi nement proce- dure of the limit-state surface is initializ ed with an initi al DO E of K 0 = 10 points and K = 10 points are sequentially added to the DOE if it is not accurate enough for reliability estimation. 0 2 4 6 8 200 220 240 260 280 300 Iterations Design variables µ b µ h 0 2 4 6 8 2 4 6 8 10 x 10 4 Iterations Cross section area 0 2 4 6 8 0 2 4 6 8 Iterations Reliability index (a) Run #1 – Star ting from the optimal deterministic design 0 2 4 6 200 220 240 260 280 300 Iterations Design variables µ b µ h 0 2 4 6 5 6 7 8 9 x 10 4 Iterations Cross section area 0 2 4 6 0 2 4 6 8 Iterations Reliability index (b) Run #2 – Star ting from a conservativ e design Fig. 3 Elastic buckling of a straight column – Converge nce 14 V . Dubourg et al. The convergence of the algorithm is depic ted in Fig ure 3 for two runs starting from different initia l designs. Run #1 is initiated with the optimal deterministic design µ b = µ h = b ∗ = h ∗ = 200 mm whereas Run #2 is initiated with an oversi zed design µ b = µ h = 300 mm. Convergence is achiev ed as all the constraints ( d eterministic and reliability- based) are satisfied and both the cost and design variables have reached a stable value. The algorithm converges to the exact solution derived in the previous subsection which is the square section with width µ ∗ b = µ ∗ h ≈ 231 mm – the approximation of the exact solu tion is only due to the numerical error . Note that the reliability -based op timal design is 15% higher than the optimal deterministic design for the chosen reliability level ( β 0 = 3). This optimum is reached using only 20 evalua tions of the performance function thanks to the kriging surrogate. The DOE used for this purpose is enriched only once and it is then accurate enough for all the design configurations including the optimal design. Ru nning the same RBDO algorithm without using the kriging surrogates ( i.e. using subset simulation onto the real perform ance function for the nested reliability and reliability sensitivit y analyses) requires about 4 × 10 6 evaluati ons of the performance function for the same number of iterations of the optimizer and converges to the same optimal design. 5.2 Short column case This simple mechanical example is extensi vely used in the RBDO litera ture as a benchmark for numerical methods in RBDO . In this p aper , we use the result s from the article by R oyset et al. (2001) as reference. It consists in a short column with rectangular cross section b × h . I t is subjected to an axial load F and two bending m o ments M 1 and M 2 whose axes are defined with respect to the two axes of inertia of the c ross section. Such a load combination is referred to as oblique bending due to the rotation of the neutral axis. Und er the additional assumption that the material is elastic perfectly plastic, the performance function describing the ultimate serviceability of the column with respect to its yield stress f y reads as foll ows: G M 1 , M 2 , P , f y , b , h = 1 − 4 M 1 b h 2 f y − 4 M 2 b 2 h f y − F b h f y 2 . (42) The stochastic mod el originally involves three independent random variables whose distributions are given in T able 2. Note that in the original paper , the design variables µ b and µ h are considered as deterministic. Since the present approach only deals with design variables that defines the joint PDF of the random vector X , they are considered here as Gaussian with a small coefficient of variation and the optimiza tion is performed with respect to their mean µ b and µ h . The o b jective function is formulated as follows: c ( µ b , µ h ) = c 0 ( µ b , µ h ) + P f ( µ b , µ h ) c f ( µ b , µ h ) = µ b µ h ( 1 + 100 P f ) (43) where the product P f × c f is the expected failure cost which is ch osen as proportional to the construction co st c 0 . The search for the op timal design is limited to the designs that satisfy the following geometrical constraint s: 1 / 2 ≤ µ b /µ h ≤ 2 with 100 ≤ µ b , µ h ≤ 1000, and the minimum rel iability is chosen as β 0 = 3. V ariable Distribution Mean C.o.V . M 1 (N.mm) Lognor mal 250 × 10 6 30% M 2 (N.mm) Lognor mal 125 × 10 6 30% P (N) Lognormal 2.5 × 10 6 20% f y (MP a) Lognormal 40 10% b (mm) Ga ussian µ b 1% ∗ h (mm) Ga ussian µ h 1% ∗ ∗ Additional uncer tainty introduced to m atch the RBDO problem formulation in Eq. (1) T able 2 Short column case from R oyset et al. (2001) – Probabilistic model The results are given in T able 3. In this table, β HL denotes the Hasofer-Lind reliability index (FORM -based), and β sim denotes the generaliz ed reliability index estimated by subset simula tion with a co efficient of varia tion less than 5%. The deterministic design optimization (DDO) was performed using the mean values of all the variables in T able 2 without considering uncertai nty and thus leads to a 50% fa ilure probability . Note that the corresponding optimal cost does not account for the expected failure c ost. The other lines of T able 3 shows the results of the RBDO problem. The first row g ives the reference results from Royset et al. ( 2001). The number of performance function calls was not given in the original paper . However it may be estimated to 4 × 10 6 given the methodology the authors used and assuming they targeted a 5% coefficient of variat ion on the failure probability in their M o nte- Carlo simulation. The second row provides the r esults from a FORM-based neste d RBDO algorithm (RI A). This RBDO using kriging surrogat es and s ubset simulation 15 Method Opt. design (mm) Cost (mm 2 ) # of func. calls R eliabil ity DDO b = 258 h = 500 1.29 × 10 5 50 β sim ≈ 0.01 RBDO ( β ≥ 3 ) R eferenc e (DSA) b = 372 h = 559 2.15 × 10 5 – β sim ≈ 3.38 FORM-based (RIA) b = 399 h = 513 2.12 × 10 5 9 472 β HL = 3.38 Present w / o kriging b = 369 h = 560 2.16 × 10 5 19 × 10 6 β sim ≈ 3.35 Present w / kriging b = 379 h = 547 2.17 × 10 5 140 β sim ≈ 3.32 T able 3 Short column case from R oyset et al. (2001) – Comparativ e results latter appro ach seems to lead to a slightly better design tho ugh it is due to the first-order reliability assumptions that are not conservative in this case. Ind eed, subset simulation leads to a little lower generalized reliability index β sim ≈ 3.19 (with a 5% C.o.V .) which in turns slightly increases the failure-dependent objective function to c ≈ 2.20 × 10 5 mm 2 . This example shows that F ORM-based approaches can mista kenly lead to non conservative optimal designs – without any self-quantifi cation of the possible degree of non conservatism. The third row gives the results obtained by the same nested RBDO algorithm, using however the subset simulation technique as the reliability (and reliability sensitivity ) estimator . Finally , th e last row gives the results o b tained when using krig ing as a surrogate for the limit-s tate surface. The kriging model used for this application used a constant regressi on model and a squared exponential autocovariance model. It wa s initia lized with a 50-point DOE and sequentiall y refined with K = 10 points per refine ment iteration. 0 5 10 300 400 500 600 Iterations Design variables µ b µ h 0 5 10 2 2.5 3 3.5 4 x 10 5 Iterations Cost 0 5 10 0 2 4 6 8 Iterations Reliability index Fig. 4 Short column case – Convergenc e Another interesting fact about this example is that the reliability constrai nt is not saturated at the op timum: the algorithm converges at a higher reliability level as illustrate d in Figure 4. This is due to the specific formulation of the cost functi on in Eq. (43) that accounts for a fai lure cost that is indexed onto the failure probability . Indeed, the cost function behaves itself as a constraint and the o ptimal reliability level is formulated in terms of an acceptable risk (probability of occurrence times consequence) instead of an acceptable r eliability index β 0 . 5.3 Bracket structure case This mechanical example is originally taken from Chateauneuf and Aoues (2008). It consists in the study of the failure m o des of the bracket structure pictured in Figure 5. The bracket structure is loaded by its own weight due to gravity and by an additional load at the right tip. The two failure modes under considerati ons are: – the maximum bending in the horizontal beam (CD, at point B) should not exceed the yield strength o f the constitutive mate rial, so that the first performance function reads as follows: g 1 w CD , t , L , P , ρ , f y = f y − σ B (44) where the maximum b ending stre ss reads: σ B = 6 M B w CD t 2 with: M B = P L 3 + ρ g w CD t L 2 18 , (45) 16 V . Dubourg et al. Fig. 5 Bracket structure case – Mechanical model – the m aximum axial load in the inclined member (AB) should not exceed the Euler critical buc kling load (ne- glecting its own weight), so that the second performance function reads as follows: g 2 w AB , w CD , t , L , P , ρ , f y = F buckling − F AB (46) where the c r itical Euler buckling load F buckling is defined as: F buckling = π 2 E I L 2 AB = π 2 E t w 3 AB 9 sin 2 θ 48 L 2 , (47) and the resu ltant of axial forces in member AB reads (neglecting its own weight): F AB = 1 cos θ 3 P 2 + 3 ρ g w CD t L 4 . (48) The probabilistic model for this example is the collection of independent random variables g iven in T able 4. No te that the co efficient of variation of the random design varia bles is kept constant along the optimization as in the original paper . V ariable Distribution Mean C.o.V . P (kN) Gumbel 100 15% E (GP a) G umbel 200 8% f y (MP a) Lognormal 225 8% ρ (kg / m 3 ) W eibull 7 860 10% L (m) Gaussian 5 5% w AB (mm) Gaussian µ w AB 5% w CD (mm) Gaussian µ w CD 5% t ( mm) Gaussian µ t 5% T able 4 Bracket structure case – Probabilistic model The RBDO problem consists in finding the rectangular cross sections of the two structural members that mini- mize the expected overall structural weight which is approximated as follow s: c µ w AB , µ w CD , t = µ ρ µ t µ L 4 p 3 9 µ w AB + µ w CD (49) while satisfying a minimum reliability requirement equal to β 0 = 2 with respect to the two limit-states in Eq. (44) and E q. ( 46) considered independently . The search for the optimal design is bounded to the followi ng hyperrectan- gle: 50 ≤ µ w AB , µ w CD , µ t ≤ 300 (in m m). The c omparative results are provided in T able 5 considering the results from Chateauneuf and Aoues (2008) as reference. RBDO using kriging surrogat es and s ubset simulation 17 Method Opt. design (mm) Cost (kg) # o f func. calls Re liability DDO w / PSF ∗ w AB = 61 w CD = 202 t = 269 2 632 40 β sim 1 ≈ 4.84 β sim 2 ≈ 2.82 RBDO ( β i ≥ 2, i = 1, 2 ) SORA ∗ w AB = 61 w CD = 157 t = 209 1 675 1 340 β sim 1 ≈ 1.96 β sim 2 ≈ 2.01 RIA ∗ w AB = 61 w CD = 157 t = 209 1 675 2 340 β sim 1 ≈ 1.96 β sim 2 ≈ 2.01 Present w / o kriging w AB = 58 w CD = 119 t = 241 1 550 5 × 10 6 5 × 10 6 β sim 1 ≈ 2.00 β sim 2 ≈ 2.01 Present w / kriging w AB = 59 w CD = 135 t = 226 1 610 100 150 β sim 1 ≈ 2.01 β sim 2 ≈ 2.03 ∗ As computed by Chateau neuf and Aoues (2008). T able 5 Bracket structure case – Comparative results The first row gives the deterministic optimal d esign that was obtained by Chateauneuf and Aoues (2008) using partial safety factors (PSF). It can be seen from the reliability indices that these PSF provide a significant safety level. However , one may rather want to find an even lighter design allowing for a lower safety level β 0 = 2. T o do so, the RBDO formulation of the problem is solved. Ch ateauneuf and Aoues (2008) used the SORA technique which is a decoupled FORM-based approach. The reliability indices at the optimal design were checked using the subset simulation technique (targeting a c oefficient of variation less than 5%) and revealed that the F ORM - based approach slightly underestimates the first optimal reli ability index in this case. The RIA technique which is a standard double-loop FORM-based app roach provides the same solution but it is less efficie nt. Implementing the proposed approach without plugg ing the kriging surrogates converges to similar results but clearly confirms that direct simula tion-based appro ach es are not tractable for RBDO . R eplacing the performance function by their kriging counterparts allows to save a significant num b er of simulati ons (10 2 opposed to 10 6 ) and in addition, to provide an error measure on the reliability estimation as op p osed to the FORM-based app r o aches. However , one may note the disparities between the prop osed designs. First, the disparit y between FORM-based methods and the presently pro posed strategies is explained by the conservatism o f the FORM assumptions in this case. Then, the disparity between the two present approaches is certainly due to the flatness of the sub-optimiza tion problem and the stochastic nature of the simulat ion-based reliability estimation. The convergence of the algorithm is depicted in Figure 6. 0 5 10 50 100 150 200 250 300 Iterations Design variables µ w AB µ w CD µ t 0 5 10 1500 2000 2500 3000 Iterations Cost 0 5 10 0 2 4 6 8 Iterations Reliability index β 1 β 2 Fig. 6 Bracket structure case – Converg ence 18 V . Dubourg et al. 6 Conclusion The aim of the present paper was to develop a strategy for solving reliability-based design optimization (RB DO) problems that is applicable to engineering prob lems involving time-consuming performance models. Starting with the premise that simulation-based approaches are not affordable when the p erformance function involves the out- put o f an expensive-to-e valuate computer mo del, and that the MPFP -based approach es do not allow to quantify the error on the estimation o f the failure probability , an approach based on kriging and subset simulation is explored. The strate gy has been tested on a set of examples from the RBDO literature and proved to be competitive with respect to its FORM-based counterparts. Indeed, convergence is achieved wit h only a few dozen evaluat ions of the real performance functions. In contrast with the F ORM-based approaches, the prop o sed error measure allows one to quantify and sequentially minimize the surrogate error onto the fina l quant ity of interest: the optimal fail ure probability . It is important to note that the numerical efficiency of the proposed strategy mainly relies upon the properties of the space where the kriging surrogates are built: the so-called augmented reliability space . This space is ob tained by considering that the design variables in the RBDO p roblem simply augments the uncertainty in the random vector involved in the reliability prob lem. B uilding the surrogates in such a space allows one to reuse them from one RBDO iteration to the other and thus saves a large number of performance functions evaluations. It is also worth noting that the original refinement strategy prop osed in Section 3 makes it possible to add several observations in the design of experiments at the same time, and thus to benefit from the availability of a distributed computing platform to speed up convergence. However , as alrea dy mentioned in the literature, it was observed that the number of experiment s increases with the numb er of variables involved in the performance functions and that the kriging strategy loses numerical effi- ciency when the DOE contains more than a few thousands experiments – although such an amount of information is not even availa ble in real-world engineering cases. This lat ter point requires further investigati on. A problem involving a nonlinear-fi nite-element- based performance function and 10 varia bles is currently inv estigated and will be published in a forthcoming paper . Acknowledgements The first autho r was funded by a CIFRE grant fro m Phimeca Engineering S.A. subsidi z ed by the ANRT (convention number 706 / 2 008). The financ ial support from DCNS is also grate fully acknowledged. RBDO using kriging surrogat es and s ubset simulation 19 R eferences Aoues Y , Chateauneuf A (2010) Benchmark study o f num erical methods for reliability-based design optimization. Struct Multidisc Optim 41(2):277–294 Au S, Beck J (2001) Estimation of small failure probabilitie s in h ig h dimensions by subset simul ation. Prob Eng Mech 16(4):263–277 Au SK (2005) R eliability-based design sensitivity by efficient simulation. Computers & Structures 83(14):1048– 1061 Berveiller M, Sudret B, Lemaire M (2006) Stochastic finite element s: a non intrusive approach by reg ression. Eur J Comput Mech 15(1-3):81–92 Bichon B, Eldred M, Swiler L, Mahadevan S, McF arland J (2008) Efficient global reliability analysis for nonlinear implicit performance functions. AIAA Journal 46(10):2459–2468 Blatman G, Sudret B ( 2008) Sparse polynomial chaos expansions and adaptive stochastic finite elements using a regression approach. Comptes Rendus Mécanique 336(6):518–523 Blatman G, Sudret B (2010) An adaptive algorithm to build up sparse polynomial chaos expansions for stochastic finite element ana lysis. Prob Eng Mech 25(2):183–197 Bourinet J M, M attrand C, Dubourg V (2009) A review of recent features and improvements add ed to FERU M software. In: Proc. I C OSSAR ’09, Int Conf . on Structural Safet y And R eliabil ity , Osaka, Japan Bourinet JM , Deheeger F , Lemaire M (2010) Assessing small failure probabilities by combined subset simulation and support vector machines. Submitted to Structural Safety Bucher C, Bourgund U (1990) A fast and efficient response surface approach for structural reliability problems. Structural Safet y 7(1):57–66 Chateauneuf A, Aoues Y (2008) Structural design optimizati on considering uncertainties, T aylor & Francis, chap 9, pp 217–246 Cressie N (1993) Sta tistics for spatial data, revi sed edition. John Wi ley & Sons Inc. Das PK, Zheng Y (2000) Cumulative formation of response surf ace and its use in reliability ana lysis. Prob Eng Mech 15(4):309–315 Deheeger F (2008) Couplage mécano-fiabiliste, 2 SMAR T méthodologie d’apprentissage stochastique en fiabilité. PhD thesis, U niversité Blaise P ascal - Clermont II Deheeger F , Lemaire M ( 2007) Support vector machine for efficient subset simulations: 2SMAR T method. In: Proc. 10th Int. Conf . on Applications of Stat. and Prob. in Civil Engineering (ICASP10), T okyo, Japan Der Kiureghian A, Di tlevsen O (2009) Aleat ory or epistemic? does it matter? Structura l Safety 31(2):105–112 Ditlevs en O , Madsen H (1996) Structural relia bility methods, Internet (v2.3.7, June-Sept 2007) edn. John Wiley & Sons Ltd, Chichester Du X, Chen W (2004) Sequential optimization and reliability assessment method for efficient probabilistic design. J Mech Des 126:225–233 Enevoldsen I, Sorensen JD (1994) R eliabili ty-based optimization in structural engineering. Structural Safety 15(3):169–196 F aravelli L (1989) R esponse surface approach for reliability analy sis. J Eng Mech 115(12):2763–2781 Hurtado J (2004) An examination of methods for approximating implicit limit state functions from the viewpoint of stati stical learning theory . Structural Saf ety 26:271–293 Jensen H, V aldebenito M, Schuëller G, Kusanovic D ( 2009) R eliability -based optimization of stochastic systems using line search. Com p ut Methods Appl M ec h Engrg 198(49-52):3915–3924 Jones D, Schonlau M, W elch W (1998) Efficient global optimization of expensive black-box functions. J Global Optim 13(4):455–492 Kharmanda G, Moh amed A, Lemaire M (2002) E fficient reliability-based design optimization using a hybrid space with applicati on to finite element analy sis. Struct Multidisc Optim 24(3):233–245 Kim SH, Na SW (1997) R esponse surf ace method using vector pro jected sampling points. Structural Safety 19(1):3– 19 Kirjner-Neto C, P o lak E , Der Kiureghian A (1998) An outer approximation approach to reliability-base d optimal design of struct ures. J Optim Theory Appl 98:1–16 Kuschel N, Rackwitz R (1997) T wo basic problems in reliabi lity-based structural optimization. Math Meth Oper R esearch 46( 3) :309–333 Lebrun R, Dutfoy A (2009) An innovating analysis of the Nataf transformation from the copula viewpoint. Prob Eng Mech 24(3):312–320 Lee T , Jung J (2008) A sampling technique enhancing accuracy and efficiency of metamodel-bas ed RBDO: Con- straint boundary sampling. Com puters & Structures 86( 13-14):1463–1476 Lophaven S, Nielse n H, Søndergaard J (2002) D ACE, A Matlab Kriging T oolbox. T echnical University of Denmark 20 V . Dubourg et al. MacQueen J (1967) Some methods for classificati on and analysis of multi variate o bservations. In: Le Cam J LM & Neyman (ed) Proc. 5 t h Berkeley Symp. on M ath. Stat. & Prob., University of California Press , Berkeley , CA, vol 1, pp 281–297 Neal R (2003) Slice sampling. Annals Stat 31:705–767 Oakley J (2004) E stimating percentiles of uncertain computer code outputs. J R oy Statist Soc Ser C 53(1):83–93 P apadrakakis M, Lagaros N (2002) R eliability-based structural optimization using neural networks and Monte Carlo simulation. Comput Methods Appl Mech Eng rg 191(32):3491–3507 Picheny V , Ginsbourg er D, R oustant, Haftka R (2010) Adaptive designs of experiments for accurate approximation of a target region. J Mech Des 132(7) P olak E (1997) Optimization algorithms and consistent appr o ximations. Sp r ing er Ranjan P , B ingham D, Mich ailidis G (2008) Sequential experiment design for contour estimation from complex computer codes. T ech nometrics 50( 4) :527–541 Rasmussen C, Williams C (2006) Gaussian processes for machine learning, Internet edn. Adaptive computation and machine learning, MIT Press, Cambridge, Massachusetts R obert C, Casella G (2004) Monte Carlo statis tical methods (2 nd Ed.). Springer Series in Statistics, Springer V erlag R oyset J, P olak E (2004a) Rel iability-ba sed optimal d esign using sample average approximations. Prob Eng Mech 19:331–343 R oyset JO , P olak E (2004b) Imp lementable algorithm for stochastic optimiza tion using sample average approxima- tions. J Opti m Theory Appl 122(1):157–184 R oyset J O , Der Kiureghian A, P olak E (2001) Relia bility-base d optimal structural design by the decoupling approach. R eliab Eng Sys Safety 73(3):213–221 Santner T , Wil liams B, Notz W (2003) The design and analysis of c o mputer experiments. Springer series in Statistics, Springer Severini T (2005) Elements of distribution theory . Cambridge serie s in statistical and pr o babilistic mathematics, Cambridge Universit y Press Shan S, W ang G (2008) Rel iable design space and complete single-loop reliabil ity-based design op timization. R eliab Eng Sys Saf ety 93(8):1218–1230 Song S, Lu Z, Qiao H (2009) Subset simulation for structural reliability sensitivity analysis. R eliab Eng Sys Safety 94(2):658–665 Sudret B, Der Ki ureghian A (2002) Comparison of finite element reliability methods. Prob Eng M ech 17:337–348 T aflanidis A, Beck J (2009a) Life-cycle cost optimal design of passive dissipative devices. Structural Safety 31(6):508–522 T aflanidis A, Beck J (2009b) Stoc h astic subset optimization for reliability optimization and sensitivity analysis in system design. C o mputers & Structures 87(5-6):318–331 T u J, Choi K, P ark Y (1999) A new study on reliability-ba sed d esign optimizati on. J Mech Des 121:557–564 V azquez E, Bect J (2009) A sequential Bayesian algorithm to estimate a probability of failure. In: 15th IF AC Sym- posium on Syst em Identification, IF AC, Saint- Malo W aarts PH (2000) Structural r eliability using finite element methods: an appraisal of DARS: Directional Adaptive Response Surface Sampling. PhD thesis, T echnical University of Delf t, The Netherlands W elch W , Buck R, Sacks J, W ynn H, Mitchell T , M orris M ( 1992) Screening, predicting, and computer experiment s. T echnometrics 34(1):15–25 Y oun B, Choi K (2004) Selecting p robabilistic app roaches for reliabil ity-based design o ptimization. AIAA J o urnal 42:124–131
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment