The Banff Challenge: Statistical Detection of a Noisy Signal
Particle physics experiments such as those run in the Large Hadron Collider result in huge quantities of data, which are boiled down to a few numbers from which it is hoped that a signal will be detected. We discuss a simple probability model for thi…
Authors: A. C. Davison, N. Sartori
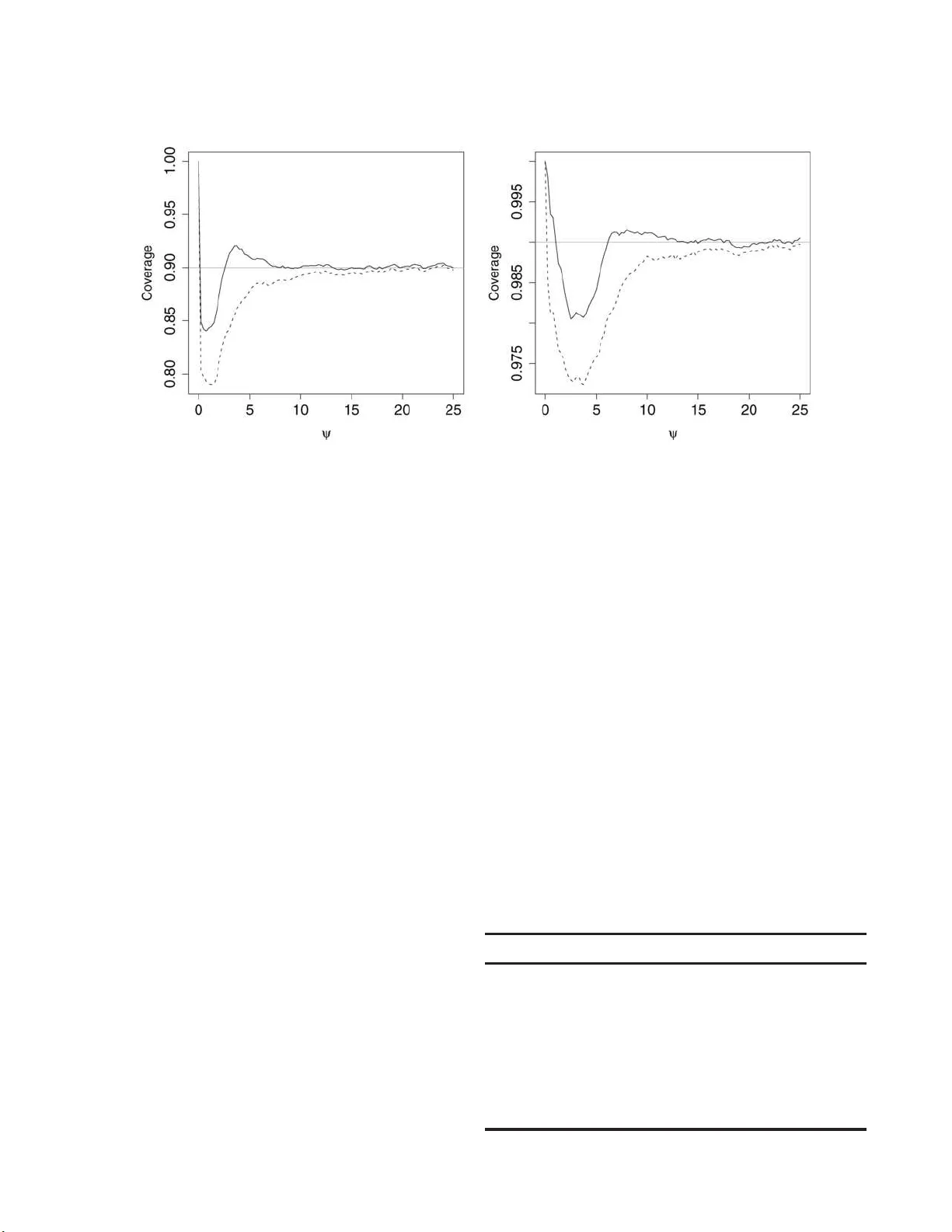
Statistic al Scienc e 2008, V ol. 23, No. 3, 354– 364 DOI: 10.1214 /08-STS260 c Institute of Mathematical Statisti cs , 2008 The Banff Challenge : Statistical Detection of a Noisy Sign al A. C. Davison and N. Sa rto ri Abstr act. P article physic s exp erimen ts suc h as those run in the Large Hadron Collider result in huge quan tities of data, whic h are b oiled do wn to a few n u m b ers from whic h it is hop ed that a signal will b e detected. W e discuss a simple probabilit y mo del for this and deriv e frequenti st and noninformativ e Ba y esian p ro cedures for inference ab out the sig- nal. Both are h ighly accurate in r ealistic cases, with the frequentist pro cedur e h a ving the edge for in terv al estimation, and the Ba y esian pro cedur e yielding sligh tly b etter p oin t estimate s. W e also argue th at the significance, or p -v alue, fu nction based on the mod ified lik eliho o d ro ot p ro vides a comprehensive presen tation of th e inf ormation in the data and should b e used for infer en ce. Key wor ds and phr ases: Ba yesia n inference, higher-ord er asymp totics, Large Hadron Collider, lik eliho o d, noninformativ e pr ior, orthogonal pa- rameter, particle physics, Po isson d istribution, signal detection. 1. INTRODUCTION P article physic s exp eriments such as th ose con- ducted in the Large Hadron Collider enta il the de- tection of a signal in the presence of bac kground noise. This essen tially statistical topic has b een d is- cussed in tensively in the recent lit erature (Mandelk- ern ( 2002 ), F raser, Reid and W ong ( 2004 ), and the references therein) an d at a series of meetings inv olv- ing statisticians and physicists; see Lyo ns ( 2008 ) for more details and further r eferences. One ke y issue is th e setting of confidence limits on the und erlying signal, based on d ata from ind ep endent observ ation c h annels. Anthony Davison is Pr ofessor of St atistics, Inst itute of Mathematics, Ec ole Polyte chnique F´ ed ´ er ale de L ausanne (EPFL), L ausanne, Switzerland (e-mail: Anthony. Davison@epfl.ch ). Nic ola Sart ori is Assistant Pr ofessor of Statistics, Dip artimento di Statistic a, Universit` a “Ca’ F osc ari” V enezia, V enezia, It aly and SSA V (e-m ail: sartori@unive.it ). This is a n electro nic r eprint of the o riginal a rticle published by the Institute of Mathematica l Statistics in Statistic al Scienc e , 2 008, V ol. 23, No. 3 , 35 4–36 4 . This reprint differs fr o m the original in pa gination a nd t yp ogr aphic detail. In t he simplest ve rsion of th e pr oblem there is j ust one c hann el, the observ ation from whic h is the n um- b er of times a p articular even t in a p article acceler- ator h as b een observe d. Th is is su pp osed to hav e a Poisson distr ib ution w ith mean γ ψ + β , where the p ositiv e kno wn constan ts β and γ repr esent re- sp ectiv ely a b ac kgroun d rate at wh ic h the ev ent o c- curs and the efficiency of the measurement device. There is a substan tial ph ysical literature ab out in fer- ence for the fo cu s of in terest, the unknown param- eter ψ . T ypically fr equen tist inf erence is preferred to Ba yesia n approac hes, bu t th is is the sub ject of a liv ely debate among the s cientists in v olv ed. In or- der to compare prop erties of v arious p r o cedures for inference ab out ψ , it was decided at the workshop on Stat istic al Infer enc e P r oblems in High Ener gy Physics and Astr onomy h eld at the Banff Interna- tional Researc h Station in 2006 that o ne participant w ould create artificial data that s h ould mimic those that might arise w hen the Large Hadron Collider is runnin g, and that other participant s w ould at- tempt to set confidence limits for the k n o wn un d er- lying signal. Thus was the Banff Challenge ( http:// newton.hep.upenn.edu/ ~ heinrich / birs/ ) b orn . F or a single c hann el the c hallenge ma y b e stat ed as follo ws: the a v ailable data y 1 , y 2 , y 3 are assumed to b e realizations of in dep end en t P oisson random 1 2 A. C. DA VISON AND N. SAR TORI v ariables w ith means γ ψ + β , β t, γ u , w here t, u are kno wn and the parameters ψ , β , γ are unknown. This expands the form ulation ab o v e to allo w for un cer- tain ty ab out th e v alues of the bac kground β and the efficiency γ , which are supp osed to b e estimable from subsidiary exp erim ents of kno wn lengths t and u . The goal is to summarize the evidence concerning ψ , large estimates of wh ic h will suggest presence of the signal. The p arameters β and γ are n ecessary for realism, b u t their v alues are only of concern to the extent that they impinge on inference for ψ . This is a highly idealized v ersion of one of many statistica l pr oblems that will arise in dealing with data from the Large Hadron Collider. The mo del is v ery simp le, b ut imp ortan t inferent ial issues arise nonetheless: ho w is evidence ab out the v alue of ψ b est summarized? Ho w should one deal with the n uisance parameters β , γ ? Th is second issue is ev en more critical in the case of multiple c h annels, where the n umber of nuisance parameters is m uc h larger. Belo w we follo w F raser, Reid and W ong ( 2004 ) in arguing that the evidence concerning ψ is b est sum- marized th r ough a so-called significance fun ction, and in Section 2 describ e the general construction of significance fun ctions that yield highly accurate frequent ist inferences ev en with man y n u isance pa- rameters; su c h a significance function is equiv alen t to a set of confidence in terv als at v arious lev els. In Section 3 w e give results for the P oisson mo d el for the t wo cases laid ou t in the Banff Challenge, with one c hannel and with ten channels. Statisticians are in b road agreemen t th at the lik e- liho o d fun ction is cen tral to p arametric inference. Ba yesia n in ference uses the lik eliho o d to u p d ate prior information to giv e a p osterior pr ob ab ility density that summ arises what it is r easonable to b eliev e ab out the parameters in ligh t of the data (Jeffreys ( 1961 ), O’Hagan and F orster ( 2004 )). This approac h is attractiv e and widely used in applications, bu t sci- en tists w ith differen t priors may arriv e at differen t conclusions b ased on the same d ata. One might ar- gue that this is inevitable giv en the v aried p oin ts of view held w ith in an y scien tific comm u nit y , but this lac k of u niqueness is a wk ward when an ob jectiv e statemen t is sought. One w ay to unite this multi- plicit y of p ossible p osterior b eliefs is to b ase inf er - ence on a n oninformativ e pr ior, which we discuss in Section 4 for the Po isson mo del d escrib ed ab o ve . One asp ect we discuss only p eripherally is the c h oice of the Po isson distr ibution to represent the v ariation of the observ ed ev ents. Statisticians typ- ically regard a mo del as one of man y p ossibilities, whereas ph ysicists tend to argue fr om first p rinci- ples and the kn own pr op erties of the systems that they study to w ard a strong b elief that certain mo d- els, suc h as the Poi sson la w us ed here, are correct. Under the Banff Challenge the P oissonness of the observ ations is tak en as giv en. 2. LIKELIHOOD AND SIGNIFICANCE There are many pu blished accounts of mo dern lik eliho o d theory . The outline b elo w is based on Braz- zale, Da vison and Reid ( 2007 ), wh erein f urther ref- erences ma y b e found . W e consider a probabilit y density function f ( y ; ψ , λ ) that dep ends on t w o parameters. The in terest parameter ψ is the fo cus of the in ve stigation; one ma y wish to test whether it has a sp ecific v alue ψ 0 , or to pro d uce a confidence interv al for the true but unkn o w n v alue of ψ . Often ψ is scalar, as h er e: ψ repr esen ts the signal cen tral to our enqu iry . The n uisance parameter λ is not of d irect in terest, but m ust be in cluded for th e mod el to b e realistic. I n the single-c hann el case the vecto r λ = ( β , γ ) rep r esen ts the b ac kgroun d signal and measur emen t efficiency . Let θ = ( ψ , λ ) denote the entire p arameter v ector. The log lik eliho o d fun ction is defi ned as ℓ ( θ ) = log f ( y ; θ ). The maxim um lik eliho o d estimator b θ sat- isfies ℓ ( b θ ) ≥ ℓ ( θ ) for all θ lying in the paramete r space Ω θ , whic h w e take to b e an op en sub s et of R d . W e supp ose that ψ ma y take v alues in the int erv al ( ψ − , ψ + ), where one or b oth of the limits ψ − , ψ + ma y b e infinite. A natur al summary of the supp ort for ψ pro vided by th e com bination of mo del and data is th e profile log lik eliho o d ℓ p ( ψ ) = ℓ ( b θ ψ ) = ℓ ( ψ , b λ ψ ) = max λ ℓ ( ψ , λ ) , where b λ ψ is th e v alue of λ that m aximizes the log lik eliho o d for fi xed ψ . Under regularity conditions on f und er which a ran- dom samp le of size n is generated from f ( y ; θ 0 ), the estimator b θ has an appr o ximate normal distribu tion with mean θ 0 and v ariance m atrix j ( b θ ) − 1 , w h ere j ( θ ) = − ∂ 2 ℓ ( θ ) /∂ θ ∂ θ T is the observe d in formation matrix. This result can b e used as the basis of con- fidence interv als for ψ 0 , based on the limiting stan- dard normal, N (0 , 1), distribution of the W ald piv ot t ( ψ 0 ) = j p ( b ψ ) 1 / 2 ( b ψ − ψ 0 ), wh er e j p ( ψ ) = − ∂ 2 ℓ p ( ψ ) ∂ ψ 2 = | j ( ψ , b λ ψ ) | | j λλ ( ψ , b λ ψ ) | , ST A TISTICAL DETEC TION O F A NOISY SIGNAL 3 | · | ind icates determinan t, and j λλ ( θ ) denotes the ( λ, λ ) corner of the observ ed in formation matrix. In man y wa ys a preferable b asis for confidence inte rv als is th e lik eliho o d root r ( ψ ) = sign( b ψ − ψ )[2 { ℓ p ( b θ ) − ℓ p ( b θ ψ ) } ] 1 / 2 , whic h ma y also b e treated as an N (0 , 1) v ariable. If it is required to test the hyp othesis that ψ = ψ 0 against the one-sided h yp othesis that ψ > ψ 0 , then the quantitie s 1 − Φ { r ( ψ 0 ) } and 1 − Φ { t ( ψ 0 ) } are treated as significance p robabilities, also kno wn as p -v alues, small v alues of wh ic h w ill cast doubt on the b elief th at ψ = ψ 0 . Thr oughout the pap er Φ rep- resen ts the cu m ulativ e probabilit y f u nction of the standard n ormal distribu tion. The monotonic decreasing fu nction Φ { r ( ψ ) } is an example of a significance f u nction, from whic h we ma y draw in ferences ab out ψ . An appr o ximate lo w er confidence b ound ψ α for ψ 0 is the solution to the equation Φ { r ( ψ ) } = 1 − α ; the confidence interv al ( ψ α , ψ + ) should conta in ψ 0 with probabilit y 1 − α . An appr o ximate upp er b ound ψ 1 − α is obtained b y solution of Φ { r ( ψ ) } = α , giving confidence interv al ( ψ − , ψ 1 − α ), and the t wo -sided interv al ( ψ α , ψ 1 − α ) will con tain ψ 0 with p robabilit y appro ximately (1 − 2 α ). Using these so-called first-order app ro ximations, these one-sided interv als in f act con tain ψ 0 with probabilit y 1 − α + O ( n − 1 / 2 ), w hile the t wo-sided in- terv al con tains ψ 0 with p robabilit y (1 − 2 α ) + O ( n − 1 ). Significance functions m ay b e based on the W ald piv ot t ( ψ ) or on related quant ities in v olving the log lik eliho o d der iv ativ e ∂ ℓ/∂ ψ , whic h also hav e app ro x- imate N (0 , 1) distribu tions for large n , b ut the in- terv als based on r ( ψ ) are preferable b ecause they al- w a ys yield confidence sets that are subsets of ( ψ − , ψ + ). F urther, they are in v arian t to in v ertible in terest- preserving r eparametrization, of the f orm ( ψ , λ ) 7→ ( g ( ψ ) , h ( λ, ψ )): if I is a co nfi d ence int erv al for ψ in the original parametrization, th en g ( I ) is the corre- sp ond ing interv al in the new parametrization; this prop erty is not p ossessed by interv als b ased on the W ald pivo t, f or example. A large b o dy of literature on higher-order para- metric asymptoti cs, b oth Ba yesia n and frequ entist, has con ve rged on a f ew key formulae that are use- ful for in f erence. There are n umerous d eriv ations of these form ulae in differen t cases, for example by Laplace app ro ximation to p osterior densities or by saddlep oint appro ximation to conditional d ensities; see Reid ( 2003 ) or Da vison ( 2003 , Sections 11.3.1, 12.3.3 ). F uller accoun ts are giv en by B razzale, Da vi- son and Reid ( 2007 ), Seve rini ( 2000 ), P ace and Sal- v an ( 1997 ) and Barndorff-Nielsen and Co x ( 1994 ). P erhaps the most practicable route to these imp ro v ed inferences is through significance functions base d on the m o dified lik eliho o d root r ∗ ( ψ ) = r ( ψ ) + 1 r ( ψ ) log q ( ψ ) r ( ψ ) , (1) where q ( ψ ) = | ϕ ( b θ ) − ϕ ( b θ ψ ) ϕ λ ( b θ ψ ) | | ϕ θ ( b θ ) | | j ( b θ ) | | j λλ ( b θ ψ ) | 1 / 2 (2) is determined b y a lo cal exp onenti al family app ro xi- mation w hose c anonical parameter ϕ ( θ ) is describ ed b elo w, and ϕ θ denotes the d × d matrix ∂ ϕ/∂ θ T of partial deriv ativ es. The numerator of the first term of ( 2 ) is th e determinan t of a d × d matrix whose first column is ϕ ( b θ ) − ϕ ( b θ ψ ) and whose r emaining columns are ϕ λ ( b θ ψ ). F or cont inuous v ariables, one- sided confidence in terv als based on the significance function Φ { ( r ∗ ( ψ ) } ha ve co ve rage error O ( n − 3 / 2 ) rather than O ( n − 1 / 2 ). F or a sample o f indep enden t co ntin uous obs er v a- tions y 1 , . . . , y n , w e defi n e ϕ ( θ ) T = n X k =1 ∂ ℓ ( θ ; y ) ∂ y k y = y 0 V k , where y 0 denotes the observ ed d ata, and V 1 , . . . , V n is a set of 1 × d v ectors that dep end on th e observ ed data alone. If th e observ ations are discrete, then the th eoretical ac curacy of the approximat ions is reduced to O ( n − 1 ), and the inte rpr etation of significance functions suc h as Φ { r ∗ ( θ ) } c hanges sligh tly . In the discrete setting of this pap er we tak e ( Da vison, F raser and Reid , 2006 ) V k = ∂ E( Y k ; θ ) ∂ θ T θ = b θ , (3) where E denotes exp ectation. An imp ortant sp ecial case is that of a log lik eliho o d with indep enden t con- tributions of curv ed exp onential family form, ℓ ( θ ) = n X k =1 { α k ( θ ) y k − c k ( θ ) } , (4) where α k ( θ ) y k denotes scalar pro duct. In th is case ϕ ( θ ) T = n X k =1 α k ( θ ) V k . (5) 4 A. C. DA VISON AND N. SAR TORI Inference u sing ( 1 ) is easily p erformed. If f unc- tions are a v ailable to compute ℓ ( θ ) and ϕ ( θ ), then the maximizations needed to obtain b θ and b θ ψ and the differen tiation needed to compute ( 2 ) m ay b e p erformed numerically . Inferences b ased on ( 1 ) are in v ariant to ad d ition to the log lik eliho o d of quantiti es dep endent only on the data, w h ic h lead to affine trans formations of ϕ ( θ ) by quan tities that are p arameter ind ep endent and whic h therefore lea ve ( 2 ) unchanged. As with other u s es of approxima tions in applied mathematics, asym p totic results lik e those sk etc h ed ab o v e in whic h n → ∞ are in tended for us e with samples whose size is fi xed and finite. The k ey is that some measure of information, whic h ma y de- p end on the p arameter v alues as wel l as on sam- ple size, b ecomes large; in the pr esen t case informa- tion also ac cumulate s as the Poisson means in cr ease. Both general th eory and the sim ulations describ ed b elo w suggest that the higher-order appro ximations outlined ab o v e are highly accurate ev en when little information is a v ailable. 3. LIKELIHOOD INFERENCE 3.1 Mo del F o rmulation Under the prop osed mo del, the observ ation for th e k th c hannel is assumed to b e a realizat ion of Y k = ( Y 1 k , Y 2 k , Y 3 k ), where the three comp onen ts are in- dep end en t P oisson v ariables w ith resp ectiv e means ( γ k ψ + β k , β k t k , γ k u k ), for k = 1 , . . . , n . Here Y 1 k rep- resen ts the m ain measur emen t, Y 2 k and Y 3 k are re- sp ectiv ely subsidiary b ac kgroun d and efficiency mea- surements, and t k and u k are known p ositiv e con- stan ts. The signal parameter ψ is of in terest, and ( β 1 , γ 1 , . . . , β n , γ n ) is tr eated as a n uisance parameter. In principle the nuisance p arameters are p ositiv e and ψ ≥ 0, but it is mathematically reasonable to en ter- tain negativ e v alues for ψ , pr o v id ed ψ > max k {− β k / γ k } . Belo w we use this extended parameter space for numerical pu rp oses, b ut restrict inte rpr etation of the results to the p h ysically meaningful v alues ψ ≥ 0, as suggested by F raser, Rei d and W ong ( 2004 ). F or computational purp oses w e tak e λ = ( λ 11 , λ 21 , . . . , λ 1 n , λ 2 n ), with ( λ 1 k , λ 2 k ) = (log β k − log γ k , log β k ), so that exp( λ 1 k ) > − ψ and λ 2 k ∈ R , k = 1 , . . . , n . The inv ariance pr op erties ou tlined in the previous section imply that inferen ces on ψ are un - affected by this reparametrization. The log lik eliho o d fun ction for θ = ( ψ , λ ) h as curve d exp onentia l family form ( 4 ) with α k ( θ ) T = { log ( ψ e λ 2 k − λ 1 k + e λ 2 k ) , λ 2 k , ( λ 2 k − λ 1 k ) } , (6) y T k = ( y 1 k , y 2 k , y 3 k ) , c k ( θ ) = ( ψ + u k ) e λ 2 k − λ 1 k + (1 + t k ) e λ 2 k . In general, b θ and b θ ψ m ust b e computed n umerically . It is conv enient t o compute b θ ψ first, and th en obtai n b θ b y maximizing the profile log like liho o d ℓ ( b θ ψ ). The dimension of the nuisance parameter m a y b e reduced by a conditioning argument that applies to P oisson resp onses, but for simplicit y of exp osition w e use th e P oisson formulatio n here. The trinomial mo del that emerges from the conditioning is used b elo w in Section 4.2 . Prop erties of the P oisson mo del imply that n u merical results from th e t wo formula- tions are iden tical. 3.2 One Channel When d ata fr om only one c h annel are a v ailable, that is, n = 1 , the log lik eliho o d has full exp onent ial form. The canonical p arameter ϕ ( θ ) giv en b y ( 6 ) is then equ iv alen t to ( 5 ) in the sen s e that an y affin e transformation of the canonical parameter giv es the same q ( ψ ) in ( 2 ) and the same inference for ψ . A stand ard w a y to summarize the evidence con- cerning ψ is to p resen t the profile log like liho o d ℓ p ( ψ ) and the significance function Φ { r ( ψ ) } (F raser, Reid and W ong ( 2004 )), b ut, as men tioned ab o v e, more accurate inf er en ces are obtained from the mo d- ified lik eliho o d ro ot, r ∗ ( ψ ). As the profile log lik eli- ho o d equals − r ( ψ ) 2 / 2, the quan tit y − r ∗ ( ψ ) 2 / 2 can b e regarded as the adju sted profile log like liho o d corresp ondin g to the significance fun ction Φ { r ∗ ( ψ ) } . F or illustration w e consider data with y 1 = 1, y 2 = 8, y 3 = 14 and t = 27 , u = 80, for which Figure 1 sho ws the profile and the adju sted profile log likeli - ho o ds an d the corresp ondin g significance functions, and a Ba yesia n solution whose construction is ex- plained in Secti on 4 . The maxim um lik eliho o d esti- mate, b ψ = 4 . 021, ma y b e determined from the sig- nificance function as the solution to the equation Φ { r ( b ψ ) } = 0 . 5. The analogous e stimate obtained us- ing the mod ified lik eliho o d ro ot, the median u n- biased estimate b ψ ∗ = 4 . 966, satisfies Φ { r ∗ ( b ψ ∗ ) } = 0 . 5. The corresp ond in g estimator has equal prob- abilities of falling to the left or to the right of th e ST A TISTICAL DETEC TION O F A NOISY SIGNAL 5 Fig. 1. Infer ential summ aries f or the il lustr ative single-channel data. L eft p anel: pr ofile r elative lo g likeliho o d ℓ p ( ψ ) − ℓ p ( b ψ ) (dashes), − r ∗ ( ψ ) 2 / 2 (solid) and − r ∗ B ( ψ ) 2 / 2 (dots). Right p anel: Φ { r ( ψ ) } (dashes) , Φ { r ∗ ( ψ ) } (solid) and Φ { r ∗ B ( ψ ) } (dots). Horizontal l ines ar e at values 0 . 99 , 0 . 0 1 and 0 . 5 , and give r esp e ctively the lower and upp er b ounds of a c onfidenc e interval of l evel 0.98, and a me dian unbiase d estimate of ψ . The interse ction of a signific anc e function with the vertic al li ne at ψ = 0 gives the c orr esp onding p -value for testing the hyp othesis ψ = 0 against ψ > 0 . true parameter v alue, a p rop erty p referable to clas- sical unbiasedness b ecause it does not d ep end on the parametrization. One min us the v alue of th e significance function at ψ = 0 give s the significance probabilit y for test- ing the presence of a signal, namely the p -v alue for testing the h yp othesis ψ = 0 against th e one-sided h yp othesis ψ > 0. In the pr esen t example, Φ { r (0) } = 0 . 837 and Φ { r ∗ (0) } = 0 . 873, thus giving p -v alues re- sp ectiv ely equ al to 0 . 16 3 and 0 . 127, b oth w eak evi- dence of a p ositiv e signal. This is hardly surpr ising, as y 1 = 1: j u st one even t has b een obser ved. As explained in Section 2 , th e significance function pro vides low er and upp er b ounds f or any desired confidence lev el. Figure 1 in dicates the c hoice of lo wer and upp er b ounds for lev el 0 . 99. In particular, for the mo dified lik eliho o d root, w e get Φ { r ∗ ( ψ ∗ 0 . 01 ) } = 0 . 99 and Φ { r ∗ ( ψ ∗ 0 . 99 ) } = 0 . 01, with ψ ∗ 0 . 99 = − 2 . 603 and ψ ∗ 0 . 01 = 36 . 519. It is p ossible f or these limits to b e negativ e, as happ ens in the presen t case for the lo wer b ou n d. In suc h instances, we tak e as a limit the maximum max( ψ ∗ α , 0) of the actual limit, ψ ∗ α , and the lo we r physically adm iss ible v alue of zero. The fact that the low er b ou n d is zero in this case is coheren t with the p -v alue for testing a p ositiv e sig- nal. In fact, a right -tail confidence int erv al of lev el 0 . 99 in this case con tains all p ossible parameter v al- ues, also including 0; th us it is [0 , + ∞ ) . A left-tail confidence in terv al is [0 , 36 . 510), although its usual in terpretation mak es it ill-suited to claim the pres- ence of signal. The analogous limits obtained u s- ing the lik eliho o d r o ot r ( ψ ) are ψ 0 . 99 = − 2 . 644 and ψ 0 . 01 = 33 . 83 5. In extreme situations confidence limits at an y stan- dard c hoice of α ma y b e negativ e, thus gi ving con- fidence in terv als including only the v alue ψ = 0. W e see th is feature of the metho d as a p er f ectly sen- sible frequentist answ er (see also Co x ( 2006 ), Ex- ample 3.7). In such instances the p -v alue for testing ψ = 0 against the alternativ e ψ > 0 w ould b e ve ry close to 1, th us str on gly sugge sting that there is n o p ositiv e signal. Ho wev er, doubt is cast on th e mo del when no physically realistic p arameter v alue is sup- p orted b y the observed d ata. In the Banff Challenge only co ve rage of left-tail confidence interv als (up p er b ound s) was tested, though w e regard p -v alues and lo w er b ound s as more ap- propriate for inference on ψ . Figure 2 shows the co verag e of 0 . 90 and 0 . 99 co nfi d ence limits as func- tions o f ψ for a set of 39,700 sim ulated data sets with large v ariability in the v alues of t he n u isan ce param- eters. The cov erage is ve ry go o d, with only minor underco ve rage in the 0 . 99 upp er b ounds when th e parameter ψ is small. Similar resu lts w ere obtained for another set of simulated d atasets, with smaller v ariabilit y in the nuisance parameters. W e also p er- formed some simulat ion studies w ith a v ariet y of parameter v alues, and found that our pro cedure is t ypically h ighly accurate. T able 1 displays results in 6 A. C. DA VISON AND N. SAR TORI Fig. 2. Cover ages of 0 . 90 (left p anel) and 0 . 99 (right p anel) upp er b ounds fr om 39,700 simulate d datasets fr om a single channel, with lar ge unc ertainty in the nuisanc e p ar ameters, f r om the Banff Chal lenge. The solid and dashe d lines c orr esp ond r esp e ctively to r ∗ ( ψ ) and r ∗ B ( ψ ) . The ide al c over age is shown by the horizontal lines. the wo rst scenario that we f ound. Apart fr om some minor issues in the righ t tail, r ∗ p erforms extremely w ell. In some b oun dary cases with y 1 = 0 it is imp os- sible to compu te the quant ities needed for ( 2 ). In these rare cases w e replaced r ∗ ( ψ ) w ith r ( ψ ). 3.3 Several Channels Our approac h extends easily to m ultiple c hannels. When ther e are n > 1 c han n els, t he n uisance param- eters ( λ 1 k , λ 2 k ) are c hann el-sp ecific, so the profile log lik eliho o d is simply the sum of profile log lik eliho o d con tributions for the individual c h annels, whic h is then maximiz ed n umerically to get th e o ve rall esti- mate b θ = ( b ψ , b λ ). The remaining ingredien t needed to compute the mo dified like liho o d ro ot r ∗ ( ψ ) is the 2 n + 1-dimen- sional canonical parameter ϕ ( θ ), wh ic h can b e ob- tained using ( 5 ) and ( 3 ). The fir st elemen t of ϕ ( θ ) is n X k =1 e b λ 2 k − b λ 1 k log( ψ e λ 2 k − λ 1 k + e λ 2 k ) , and the 2 n other el ement s are b ψ e b λ 2 k − b λ 1 k log( ψ e λ 2 k − λ 1 k + e λ 2 k ) + u j ( λ 2 k − λ 1 k ) e b λ 2 k − b λ 1 k , e b λ 2 k log( ψ e λ 2 k − λ 1 k + e λ 2 k ) + t j λ 2 k e b λ 2 k , k = 1 , . . . , n. An y affine transformation of ϕ ( θ ) would giv e the same mo dified lik eliho o d root. Figure 3 giv es the p rofile and adjusted profi le log lik eliho o ds for ψ and the corresp ondin g s ignificance functions for an illustrativ e dataset with n = 10 c han- nels sho wn in T able 2 . The int erpr etation of these plots is the same as f or Figure 1 . The mo difi ed lik e- liho o d root giv es a p -v alue of 7 . 70 9 × 10 − 7 for test- ing the presence of a signal, whereas that based on the like liho o d ro ot is 3 . 124 × 10 − 7 . Th e estimates are b ψ ∗ = 11 . 68 2 and b ψ = 11 . 487 and the low er and upp er b ound s are ψ ∗ 0 . 99 = 4 . 572, ψ ∗ 0 . 01 = 23 . 19 1 and ψ 0 . 99 = 4 . 496, ψ ∗ 0 . 01 = 22 . 907. T here is strong evi- dence of a p ositiv e signal from these data, though T able 1 Empiric al c over age pr ob abil ities in a single-channel simulation wi th 10,000 r eplic ations, ψ = 1 , log β = 1 . 1 , log γ = 0 , t = 33 and u = 100 Probability r r ∗ r ∗ B 0.0100 0.0080 0.0092 0.0104 0.0250 0.0225 0.0253 0.0263 0.0500 0.0437 0.0500 0.0514 0.1000 0.0887 0.0995 0.1019 0.5000 0.4669 0.5054 0.5045 0.9000 0.8947 0.9051 0.9036 0.9500 0.9186 0.9461 0.9320 0.9750 0.9736 0.9809 0.9785 0.9900 0.9816 0.9816 0.981 6 Figures in b old differ from the nominal lev el by more than sim ulation error. ST A TISTICAL DETEC TION O F A NOISY SIGNAL 7 Fig. 3. Inf er ential summaries for the si mulate d multiple-channel data in T able 2 . F or details, se e c aption to Figur e 1 . the mo dified lik eliho o d ro ot r ∗ ( ψ ) giv es we ak er sup- p ort than do es the ordinary likel iho o d ro ot r ( ψ ) . In fact the evidence her e corresp onds to significance near to th e “5 σ ” lev el u sed by p article physicists when deciding whether or not to announce a disco v- ery (Ly ons ( 2008 )). Boundary samples also arise in the multiple-c hannel case, though less f requent ly than with a single c han- nel. In such cases w e again used the lik eliho o d ro ot r ( ψ ) for inference on ψ . Figure 4 s h o ws co verage s of the 0 . 90 and 0 . 99 left- tail confidence inte rv als (up p er b ounds) computed with the mo dified likelihoo d ro ot from 70,000 simu- lated datasets with n = 10 from the Banff Ch allenge. Our approac h seems to p erform satisfactorily ev en with as man y as 20 nuisance parameters, though there is again some underco verag e fo r sm all v alues of ψ . T able 3 rep orts co verag e probabilities for limits at v arious confidence lev els for a s imulation p er f ormed T able 2 Simulate d multi pl e-channel data Channel y 1 y 2 y 3 t u 1 1 7 5 15 50 2 1 5 12 17 55 3 2 4 2 19 60 4 2 7 9 21 65 5 1 9 6 23 70 6 1 3 5 25 75 7 2 10 10 27 80 8 3 6 12 29 85 9 2 9 7 31 90 10 1 13 13 33 95 with ψ = 2. Th e results for the mo dified lik eliho o d ro ot are alw a ys within simulat ion error of th e nomi- nal lev els, th us giving v ery accurate inference for ψ . 4. BA YESIAN INFERENCE 4.1 Noninfo rmative Prio rs There is a close link b et we en th e mo difi ed lik eli- ho o d ro ot and analytical appro ximations useful for Ba yesia n in ference. Supp ose that p osterior inference is required for ψ and that the c hosen prior density is π ( ψ , λ ). Th en it turn s out that replacing ( 2 ) with q B ( ψ ) = ℓ ′ p ( ψ ) j p ( b ψ ) − 1 / 2 | j λλ ( b θ ψ ) | | j λλ ( b θ ) | 1 / 2 π ( b θ ) π ( b θ ψ ) in formula ( 1 ), where ℓ ′ p is the deriv ativ e of ℓ p ( ψ ) with resp ect to ψ , lea ds to a Laplace -t yp e appro xi- mation to th e marginal p osterior distrib ution for ψ , that we will den ote b y r ∗ B ( ψ ). This may b e u sed to include prior information, but, as men tioned ab o v e, the c hoice of p rior densit y can be v exing. In this sec- tion we discu s s n on in formativ e Ba yesian inference for ψ . F or mo dels with scalar ψ and a n uisance param- eter ξ that is orthogonal to ψ in the sense of Co x and R eid ( 1987 ), Tibshirani ( 1989 ) sho w s that up to a certain degree of appro ximation, a p rior den- sit y that is noninformativ e about ψ is prop ortional to | i ψψ ( ψ , ξ ) | 1 / 2 g ( ξ ) dψ dξ , (7) where i ψψ ( ψ , ξ ) denotes the ( ψ , ψ ) element of the Fisher information matrix, and g ( ξ ) is an arbitrary 8 A. C. DA VISON AND N. SAR TORI Fig. 4. Empiric al c over ages of 0 . 90 (left p anel) and 0 . 99 (right p anel) upp er b ounds fr om 70,000 simul ate d mul tipl e-channel datasets f r om the Banff Chal lenge. The solid and dashe d li nes c orr esp ond r esp e ctively to r ∗ ( ψ ) and r ∗ B ( ψ ) . p ositiv e function that satisfies m ild regularit y con- ditions. Under fu rther mild conditions ( 7 ) is a Jef- freys prior for ψ , an d it is also a m atching prior: fol- lo w in g W elc h and Pee rs ( 1963 ), R eid, Mukerjee an d F raser ( 2002 ) sh o w ho w ( 7 ) yields (1 − α ) one-sided Ba yesia n p osterior confi dence in terv als that contai n ψ w ith probabilit y (1 − α ) + O ( n − 1 ) in a frequenti st sense. Unfortunately ( 7 ) requires one to exp ress the mo del in terms of an orthogonal parametrization, and this may b e imp ossible. Belo w w e rewrite it in terms of an arbitrary parametrization. Supp ose therefore that the mo del is parametrized in terms of a scal ar int erest parameter ψ and a column v ector nuisance parameter ζ = ζ ( ψ, ξ ), with the log lik eliho o d w r itten as ℓ ∗ { ψ , ζ ( ψ , ξ ) } = ℓ ( ψ , ξ ) . Then th e elements of the Fisher information matri- ces in the tw o parametrizations are related by the equations i ψψ = i ∗ ψψ + 2 ζ T ψ i ∗ ζ ψ + ζ T ψ i ∗ ζ ζ ζ ψ , i ξ ψ = ζ T ξ i ∗ ζ ψ + ζ T ξ i ∗ ζ ζ ζ ψ , (8) i ξ ξ = ζ T ξ i ∗ ζ ζ ζ ξ , where i ξ ψ = E( − ∂ 2 ℓ/∂ ξ ∂ ψ T ), i ∗ ζ ζ = E( − ∂ 2 ℓ ∗ / ∂ ζ ∂ ζ T ), ζ ψ = ∂ ζ /∂ ψ , and so forth, with E again de- noting exp ectatio n. P arameter orthogonalit y implies that i ξ ψ ≡ 0, s o provided ζ ξ is not identica lly zero, ξ = ξ ( ψ , ζ ) is determined b y the partial differen tial equation ζ ψ = − i ∗− 1 ζ ζ i ∗ ζ ψ , (9) whic h alw ays h as a set of solutions f or scalar ψ . O n substituting ( 9 ) in to the first expression in ( 8 ), we find that in terms of the original parametrization the required elemen t of the Fisher information matrix ma y b e wr itten as i ψψ = i ∗ ψψ − i ∗ ψζ i ∗− 1 ζ ζ i ∗ ζ ψ , whence the n oninformativ e prior ( 7 ) ma y b e writte n as | i ∗ ψψ − i ∗ ψζ i ∗− 1 ζ ζ i ∗ ζ ψ | 1 / 2 (10) · g { ξ ( ψ , ζ ) }| ∂ ξ /∂ ζ | dψ dζ , whic h requires that the orthogonal parameter ξ b e expressed in terms of the original paramete rs; cf. ex- T able 3 Empiric al c over age pr ob abil ities in a mul tiple-channel simulation wi th 10,000 r eplic ations, ψ = 2 , β = (0 . 20 , 0 . 30 , 0 . 40 , . . . , 1 . 10) , γ = (0 . 20 , 0 . 25 , 0 . 30 , . . . , 0 . 65) , t = (15 , 17 , 19 , . . . , 33) and u = (50 , 55 , 60 , . . . , 95) Probability r r ∗ r ∗ B 0.0100 0.0099 0.0101 0.0109 0.0250 0.0244 0.0255 0.0273 0.0500 0.0493 0.0519 0.0542 0.1000 0.0967 0.1012 0.1035 0.5000 0.4869 0.5043 0.5027 0.9000 0.8900 0.9013 0.8942 0.9500 0.9421 0.9499 0.9427 0.9750 0.9687 0.9759 0.9689 0.9900 0.9875 0.9913 0.9864 Figures in b old differ from the nominal lev el by more than sim ulation error. ST A TISTICAL DETEC TION O F A NOISY SIGNAL 9 pression (5 ) of T ibshirani ( 1989 ). In the next section w e deriv e ( 10 ) for th e sin gle- and multiple- c hannel mo dels of Section 3 . 4.2 Application to Poisson Mo del The single-c h an n el mo del m ay b e reparametrized in terms of ψ , γ and ζ = β /γ , in whic h ca se Y 1 , Y 2 , Y 3 are indep endent Po isson v ariables with means γ ( ψ + ζ ) , ζ γ t, γ u . This implies that the trinomial densit y of ( Y 1 , Y 2 , Y 3 ) conditional on the total S = Y 1 + Y 2 + Y 3 do es not dep end on γ , and ther e is no loss of in - formation on ψ and ζ if we base inference on the trinomial or more generally th e m ultinomial mo del (Barndorff-Nielsen ( 1978 ), Chapter 10). In particu- lar, frequen tist inferences on ψ based on t he original mo del or on the conditional trinomial mo del lead to exactly th e same results. Here ζ is scalar. Apart fr om additiv e constants, the corresp onding log like liho o d is ℓ ∗ ( ψ , ζ ) = y 1 log( ψ + ζ ) + y 2 log ζ − s log ( ψ + ζ + u + ζ t ) , ψ + ζ , ζ > 0 , and E( Y 1 | S = s ) = s ( ψ + ζ ) /π , E( Y 2 | S = s ) = stζ /π , where π = ψ + ζ + u + ζ t . Thus in this p arametriza- tion the Fisher information m atrix for the trinomial mo del has form i ∗ ( ψ , ζ ) = s π 2 ( ζ + ψ ) · u + ζ t u − ψ t u − ψ t { ψt ( ψ + u ) + ζ u (1 + t ) } /ζ , and the orthogonal parameter is a solution of the equation ζ ψ = ζ ( ψt − u ) / { ψ t ( ψ + u ) + ζ u (1 + t ) } , suc h as ξ ( ψ , ζ ) = t log ζ + log ( ζ + ψ ) − (1 + t ) log( ψ + ζ + u + ζ t ) . It is imp ossible to expr ess ζ explicitly as a fun ction of ψ and ξ , and hence to use the noninformative prior in the form ( 7 ), b ut ( 10 ) is readily obtained, and after a little alge bra tu r ns out to b e p rop ortional to ψ t ( ψ + u ) + ζ u (1 + t ) ζ 2 ( ζ + ψ ) 2 ( ψ + ζ + u + ζ t ) 3 1 / 2 · g ( ζ + ψ ) ζ t ( ψ + ζ + u + ζ t ) 1+ t dψ dζ , (11) ζ , ψ + ζ > 0 , for an arbitrary but smooth and p ositiv e fu nction g . If data ( y 1 k , y 2 k , y 3 k , t k , u k ) are a v ailable for n in- dep end en t c hannels, then the cond itioning argum en t ab o v e y ields n ind ep endent trinomial distribu tions for ( y 1 k , y 2 k , y 3 k ) cond itional on the s k = y 1 k + y 2 k + y 3 k , whose probabilities dep end on th e parameters ψ , ζ k . Apart from an additiv e constan t the log lik e- liho o d is ℓ ∗ ( ψ , ζ 1 , . . . , ζ n ) = n X k =1 { y 1 k log( ψ + ζ k ) + y 2 k log ζ k − s k log( ψ + ζ k + u k + ζ k t k ) } , where ψ > − min( ζ 1 , . . . , ζ n ) and ζ 1 , . . . , ζ n > 0. Cal- culations lik e those leading to ( 11 ) rev eal th at the noninformativ e pr ior f or ψ is p rop ortional to n X k =1 s k t k u k / ( ζ k + ψ + u k + ζ t k ) · { ψ ( ψ + u k ) t k + ζ k u k (1 + t k ) } 1 / 2 (12) · n Y k =1 ψ ( ψ + u k ) t k + ζ k u k (1 + t k ) ζ k ( ζ k + ψ )( ζ k + ψ + u k + ζ k t k ) , times an arbitrary function of the quantit ies ξ k ( ψ , ζ k ) = t k log ζ k + log( ζ k + ψ ) − (1 + t k ) log( ψ + ζ k + u k + ζ k t k ) , k = 1 , . . . , n . Although ( 12 ) dep ends on the d ata thr ough s 1 , . . . , s n , these are constan ts un der the trinomial mo d el, as are the t k and u k under b oth Po isson and trinomial mo dels. The presence of s k t k u k in the first term of ( 12 ) has the h euristic explanation that a c hannel for whic h this pro duct is large w ill con tain more infor- mation ab out its nuisance parameters. 4.3 Numerical Results W e first consider the singl e-c hannel data analyz ed in Section 3.2 , with y 1 = 1, y 2 = 8, y 3 = 14, and t = 27, u = 80. The d otted lines in Figure 1 s h o w the appro ximate p osterior function, − r ∗ B ( ψ ) 2 / 2, and the corresp ondin g s ignificance fu nction obtained u sing the noninform ative prior ( 11 ), with g tak en to b e a constan t function. 10 A. C. DA VISON AND N. SAR TORI T ypically the prior d ensit y yields larger lo w er b ound s and smaller u pp er b oun ds than th ose ob- tained from the frequentist solution, b ecause the ef- fect of the p rior is to inject inform ation ab out the parameter of in terest. In the presen t case, the esti- mate b ψ ∗ B = 4 . 9182, wh ic h satisfies Φ { r ∗ B ( b ψ ∗ B ) } = 0 . 5, is smaller than the corresp onding estimate obtained using r ∗ ( ψ ), and the 0 . 99 lo w er and up p er b oun ds are r esp ectiv ely given by Φ { r ∗ B ( ψ ∗ B ;0 . 01 ) } = 0 . 99 and Φ { r ∗ B ( ψ ∗ B ;0 . 99 ) } = 0 . 01, with ψ ∗ B ;0 . 99 = − 1 . 820 and ψ ∗ B ;0 . 01 = 35 . 09 4. The p -v alue for testing the h yp othesis ψ = 0 against the one-sided h yp othesis ψ > 0 is equ al to 1 − Φ { r ∗ B (0) } = 0 . 1 063, which is again a w eak evi- dence of a p ositiv e signal . The co v erage prop erties of the non in formativ e Ba yesia n s olution are similar to b ut not quite so go o d as those of the frequ en tist solution, as s h o wn in Figure 2 and by the simulatio n r esults rep orted in the last column of T able 1 . Similar b ehavio r is seen in the m ultic hannel case. Figure 3 shows the app ro ximate p osterior function, − r ∗ B ( ψ ) 2 / 2, and the corresp onding significance func- tion obtained using the n oninformativ e prior ( 12 ) times a constan t function of ξ k ( ψ , ζ k ), k = 1 , . . . , n , for th e data in T able 2 . The app r o ximate Ba y esian solution giv es a p -v alue of 4 . 86 5 × 10 − 8 for test- ing the presence of a signal, smaller than that ob- tained fr om the frequentist solutions in Section 3.3 . The estimate is b ψ ∗ B = 11 . 632 and th e lo wer and u p- p er b ound s are ψ ∗ B ;0 . 99 = 4 . 699 and ψ ∗ B ;0 . 01 = 23 . 030. There is s tr onger evidence of a p ositiv e signal from this approac h than fr om the mo difi ed likel iho o d r o ot r ∗ ( ψ ) and th e ordinary lik eliho o d ro ot r ( ψ ). Ho w- ev er, sim u lation results rep orted in Figure 4 and T a- ble 3 show th at th e co v erage of confiden ce sets based on the approximat e Ba y esian solution is not qu ite so go o d as f or sets b ased on th e mo difi ed lik eliho o d ro ot. 5. DISCUSSION In this pap er we prop ose p ro cedures based on mo d- ern lik eliho o d theory for d etecting a signal in the presence of b ac k grou n d n oise, usin g a simple statis- tical mo del. W e suggest the us e of the significance function based on the mo dified likel iho o d ro ot as a comprehensiv e summary of the information for the parameter giv en the mo del and the observed data, from whic h p -v alues and one- or tw o-sided confi- dence limits ca n be obtained d irectly . Ev en wh en there are 20 nuisance parameters, our frequent ist pro cedure app ears to give essenti ally ex- act inferences for the signal parameter ψ . Its non - informativ e Bay esian count erpart p erforms slightly w orse in terms of co ve rage of confidence interv als and lev els for tests, but pro vides sligh tly b etter p oin t estimates as solutions to the equation Φ { r ∗ B ( ψ ) } = 0 . 5, analogous to m ed ian unbiased estimates. T he most serious departur es from the correct cov erage are for small v alues of ψ , corresp ond in g to w eak s ig- nals, a nd arise b ecause i n suc h cases very lo w coun ts y 1 corresp ondin g to the observed signal are quite lik ely to arise. The case of a w eak signal seems to b e of litt le practical in terest, b ecause in suc h cases no strong significance can b e obtained. Although the Banff Challenge concerned significance at the 90% and 99% lev els, b oth general theory and th e accu- racy of o ur results suggest that similar precision can b e exp ected for muc h more extreme significance lev- els. If y 1 = 0 our higher-order approac h es break do wn , though a closely relat ed first-order inference is a v ail- able. Suc h cases are scien tifically u ninte resting, bu t to a void difficulties it is tempting to replace y 1 b y y 1 + c , where c is a small p ositive quan tit y . Firth ( 1993 ) in v estigates under what circumstances this mo dification y ields an imp ro v ed estimat e of th e in- terest p arameter in exp onential family mo dels, take n on the ca nonical scale o f the exp onential family . Our mo del i s not a linear exp onen tial family , but ideas of Kosmidis ( 2007 ) migh t b e u sed to c ho ose c to yield an impro ved estimate of ψ . Our main interest is in confidence in terv als and tests, ho we ve r, and since Firth’s correction corresp onds to use of a d efault Jeffreys prior and we h a v e foun d th at use of a non- informativ e prior do es not improv e co verag e prop- erties of our m etho d, one sh ould n ot b e optimistic ab out the effect of this correction in our conte xt. In some instances the metho d may lead to empty confidence int erv als or interv als including only the v alue ψ = 0. Though galling to the exp eriment ers, this is not a critical pr oblem from a frequ en tist p er- sp ectiv e. On the one h an d , eve n in suc h extreme samples the confidence function wo uld yield a p - v alue to test for the p r esence of a signal, and on the other hand, the concen tration of the lik eliho o d and significance functions in a region of physic ally meaningless v alues of the parameter migh t suggest that the mo del is inappr opriate. ST A TISTICAL DETEC TION O F A NOISY SIGNAL 11 A CKNO WLEDGMENTS The work was sup p orted by the Swiss National Science F oundation, the Italian Ministry of Educa- tion (PRIN 2006) and the EPFL. W e thank the or- ganizers of the Banff w orkshop for in viting us to tak e part, the participants for s tim ulating discus- sions, and Da vid C o x, Rex Galbraith, t wo referees and the editor for comments on this pap er. W e thank particularly Jo el Heinrich for the computations un- derlying Figures 2 and 4 . REFERENCES Barndorff-Nielsen, O. E. (1978). Inf ormation and Exp o- nential F amilies in Statistic al The ory . Wiley , New Y ork. MR0489333 Barndorff-Nielsen, O. E. and Co x, D. R. (1994). In- fer enc e and Asymptotics . Chapman and Hall, London. MR1317097 Brazzale, A. R., D a vi son, A. C. and Reid , N. (2007). Ap- plie d Asymptotics: Case Studies in Smal l Sample Statist ics . Cam bridge Univ. Press, Cambridge. MR2342742 Co x, D. R. (2006). Principles of Statistic al Infer enc e . Cam- bridge Univ. Press, Cam bridge. MR2278763 Co x, D. R. and Reid, N. (1987). P arameter orthogonali ty and approximate conditional inference (with discussion). J. R oy. Statist. So c. Ser. B 49 1–39. MR0893334 Da vison, A. C. (2003). Statistic al Mo dels . Cambridge Un iv . Press, Cam bridge. MR1998913 Da vison, A. C., Fraser, D. A. S. a nd Re id, N. (2006). Improv ed lik eliho od inference for d iscrete data. J. R oy. Statist. So c. Ser. B 68 495 –508. MR2278337 Fir th, D. ( 1993). Bias redu ction of maximum likelihoo d es- timates. Biometrika 80 27–38. MR1225212 Fraser, D. A. S., Reid, N. and Wong, A. C. M. (2004). Inference for b ounded parameters. Phys. R ev. D 69 033002 . O’Hagan, A. and Forster, J. J. (2004). Kendal l’ s A dvanc e d The ory of Statistics. Volume 2B: Bayesian Infer enc e , 2nd ed. Hodd er Arnold, London. Jeffreys, H. (1961). The ory of Pr ob ability , 3rd ed. Claren- don Press, Oxford. MR0187257 Ko smidi s, I. (2007). Bias redu ction in ex p onential family nonlinear mod els. Ph.D. thesis, Dept. S t atistics, Univ. W arwic k . L yons, L. (2008). Op en statistical issues in particle physics. Ann . Appl. Statist. 2 887–915. Mandelkern, M. (2002). S etting confidence interv als for b ounded parameters (with discussion). Statist. Sci. 17 149– 172. MR1939335 P ace, L. and Sal v an, A. (1997). Principles of St atistic al In- fer enc e fr om a Ne o-Fisherian Persp e ctive . W orld Scienti fic, Singap ore. MR1476674 Reid, N. (20 03). Asymptotics and the theory of inference. Ann . Statist. 31 1695–173 1. MR2036388 Reid, N., Mukerj ee, R. and Frase r, D. A . S. (2002). Some asp ects of matching priors. In Mathematic al Statis- tics and Appli c ations: F estschrift for Constanc e van Ee- den ( M. Moore, S . F ro d a and C. L´ eger, eds.). L e ctur e Notes—Mono gr aph Series 42 31–44. IMS, Hayw ard, CA. MR2138284 Severini , T. A. (2000). Likeliho o d Metho ds in Statistics . Clarendon Press, Oxford. MR1854870 Tibshirani, R. J. ( 1989). Noninformative priors for one pa- rameter of man y . Biometrika 76 604–608. MR1040654 Welch, B. L. and Peers, H. W. (1963). On form ulae for confidence p oin ts based on integrals of weigh t ed likeli- hoo ds. J. R oy. Statist. So c. Ser. B 25 318–329. MR0173309
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment