Delay and Power-Optimal Control in Multi-Class Queueing Systems
We consider optimizing average queueing delay and average power consumption in a nonpreemptive multi-class M/G/1 queue with dynamic power control that affects instantaneous service rates. Four problems are studied: (1) satisfying per-class average de…
Authors: Chih-ping Li, Michael J. Neely
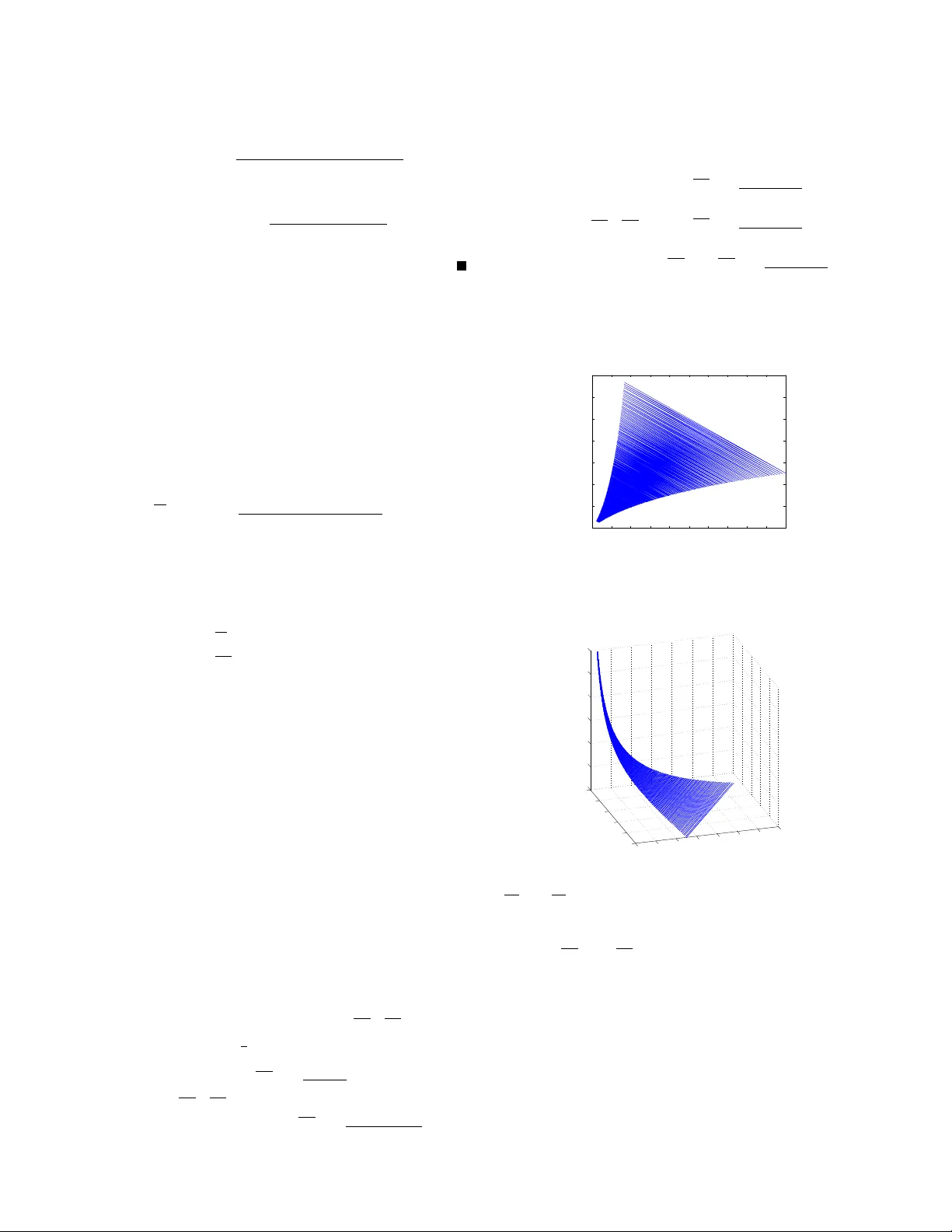
1 Delay and Po wer -Optimal Control in Multi-Class Queueing Systems Chih-ping Li, Student Member , IEEE and Michael J. Neely , Senior Member , IEEE Abstract —W e consider optimizing a verage queueing delay and av erage power consumption in a nonpr eemptive multi-class M /G/ 1 queue with dynamic power control that affects instan- taneous service rates. Four problems are studied: (1) satisfying per -class av erage delay constraints; (2) minimizing a separable con vex function of av erage delays subject to per -class delay constraints; (3) minimizing average power consumption subject to per -class delay constraints; (4) minimizing a separable con vex function of a verage delays subject to an av erage power constraint. Combining an achievable region approach in queueing systems and the L yapunov optimization theory suitable for optimizing dynamic systems with time av erage constraints, we propose a unified framework to solve the above pr oblems. The solutions are variants of dynamic cµ rules, and implement weighted priority policies in every busy period, where weights are determined by past queueing delays in all job classes. Our solutions require limited statistical knowledge of arrivals and service times, and no statistical knowledge is needed in the first pr oblem. Overall, we pro vide a new set of tools for stochastic optimization and control over multi-class queueing systems with time a verage constraints. I . I N T RO D U C T I O N Stochastic scheduling over multi-class queueing systems has important applications such as CPU scheduling, request processing in web servers, and QoS provisioning to different types of traf fic in a telecommunication network. In these sys- tems, po wer management is increasingly important due to their massiv e energy consumption. T o study this problem, in this paper we consider a single-server multi-class queueing system whose instantaneous service rate is controllable by dynamic power allocations. This is modeled as a nonpreemptive multi- class M /G/ 1 queue with N job classes { 1 , . . . , N } , and the goal is to optimize average queueing delays of all job classes and av erage power consumption in this queueing network. W e consider four delay and power control problems: 1) Designing a policy that yields a verage queueing delay W n of class n satisfying W n ≤ d n for all classes, where { d 1 , . . . , d N } are giv en feasible delay bounds. Here we assume a fixed power allocation and no power control. 2) Minimizing a separable conv ex function P N n =1 f n ( W n ) of a verage queueing delays ( W n ) N n =1 subject to delay constraints W n ≤ d n for all classes n ; assuming a fixed power allocation and no power control. Chih-ping Li (web: http://www-scf.usc.edu/ ∼ chihpinl) and Michael J. Neely (web: http://www-rcf.usc.edu/ ∼ mjneely) are with the Department of Electrical Engineering, University of Southern California, Los Angeles, CA 90089, USA. This material is supported in part by one or more of the following: the NSF Career grant CCF-0747525, the Network Science Collaborative T echnology Alliance sponsored by the U.S. Army Research Laboratory . 3) Under dynamic power allocation, minimizing a verage power consumption subject to delay constraints W n ≤ d n for all classes n . 4) Under dynamic po wer allocation, minimizing a separa- ble conv ex function P N n =1 f n ( W n ) of av erage queueing delays ( W n ) N n =1 subject to an average power constraint. These problems are presented with increasing complexity for the readers to gradually familiarize themselves with the methodology we use to attack these problems. Each of the abov e problems is highly nontri vial, thus nov el yet simple approaches are needed. This paper provides such a framew ork by connecting two po werful stochastic optimization theories: The achie vable re gion appr oach in queueing systems, and the Lyapuno v optimization theory in wireless networks. In queueing systems, the achiev able region approach that treats optimal control problems as mathematical programming ones has been fruitful; see [1]–[4] for a detailed surve y . In a nonpreemptiv e multi-class M /G/ 1 queue, it is known that the collection of all feasible av erage queueing delay vectors form a special polytope (a base of a polymatroid) with vertices being the performance vectors of strict priority policies ([5], see Section III for more details). As a result, every feasible a verage queueing delay vector is attainable by a randomization of strict priority policies. Such randomization can be implemented in a framed-based style, where a priority ordering is randomly deployed in ev ery b usy period using a probability distrib ution that is used in all busy periods (see Lemma 1 in Section III). This view of the delay performance region is useful in the first two delay control problems. In addition to queueing delay , when dynamic power control is part of the decision space, it is natural to consider dynamic policies that allocate a fixed power in ev ery busy period. The resulting joint power and delay performance region is then spanned by frame-based randomizations of power control and strict priority policies. W e treat the last two delay and power control problems as stochastic optimization over such a performance region (see Section VI-A for an example). W ith the above characterization of performance regions, we solve the four control problems using L yapunov optimization theory . This theory is originally dev eloped for stochastic optimal control over time-slotted wireless networks [6], [7], later extended by [8], [9] that allow optimizing v arious per- formance objectives such as average power [10] or throughput utility [11], and recently generalized to optimize dynamic systems that hav e a renewal structure [12]–[15]. The L yapunov optimization theory transforms time av erage constraints into virtual queues that need to be stabilized. Using a L yapunov drift argument, we construct frame-based policies to solv e 2 the four control problems. The resulting policy is a sequence of base policies implemented frame by frame, where the collection of all base policies span the performance region through time sharing or randomization. The base policy used in each frame is chosen by minimizing a ratio of an expected “drift plus penalty” sum ov er the expected frame size, where the ratio is a function of past queueing delays in all job classes. In this paper the base policies are nonpreemptive strict priority policies with deterministic power allocations. Our methodology is as follows. By characterizing the per- formance region using the collection of all randomizations of base policies, for each control problem, there exists an optimal random mixture of base policies that solves the problem. Although the probability distribution that defines the optimal random mixture is unknown, we construct a dynamic policy using L yapunov optimization theory . This policy makes greedy decisions in ev ery frame, stabilizes all virtual queues (thus satisfying all time av erage constraints), and yields near-optimal performance. The existence of the optimal randomized policy is essential to prov e these results. In our policies for the four control problems, requests of different classes are prioritized by a dynamic cµ rule [1] which, in every busy period, assigns priorities in the decreasing order of weights associated with each class. The weights of all classes are updated at the end of e very busy period by simple queue-like rules (so that different priorities may be assigned in dif ferent busy periods), which capture the running difference between the current and the desired performance. The dynamic cµ rule in the first problem does not require any statistical kno wledge of arri v als and service times. The policy for the second problem requires only the mean but not higher moments of arri vals and service times. In the last two problems with dynamic power control, beside the dynamic cµ rules, a power level is allocated in ev ery busy period by optimizing a weighted sum of power and power -dependent average delays. The policies for the third and the last problem require the mean and the first two moments of arriv als and service times, respectiv ely , because of dynamic power allocations. In each of the last three problems, our policies yield perfor- mance that is at most O (1 /V ) away from the optimal, where V > 0 is a control parameter that can be chosen sufficiently large to yield near -optimal performance. The tradeoff of choos- ing large V values is the amount of time required to meet the time average constraints. In this paper we also propose a pr oportional delay fairness criterion, in the same spirit as the well-known rate proportional fairness [16] or utility proportional fairness [17], and show that the corresponding delay objective functions are quadratic. Overall, since our policies use dynamic cµ rules with weights of simple updates, and require limited statistical knowledge, they scale gracefully with the number of job classes and are suitable for online implementation. In the literature, work [18] characterizes multi-class G/ M /c queues that have polymatroidal performance regions, and provides two numerical methods to minimize a separable con vex function of average delays as an unconstrained static optimization problem. But in [18] it is unclear how to control the queueing system to achieve the optimal performance. Minimizing a con ve x holding cost in a single-server multi- class queue is formulated as a restless bandit problem in [19], [20], and Whittle’ s index policies [21] are constructed as a heuristic solution. W ork [22] proposes a generalized cµ rule to maximize a con vex holding cost over a finite horizon in a multi-class queue, and shows it is asymptotically optimal under heavy traffic. This paper provides a dynamic control algorithm for the minimization of con ve x functions of average delays. Especially , we consider additional time average power and delay constraints, and our solutions require limited statis- tical kno wledge and ha ve provable near-optimal performance. This paper also applies to power -aware scheduling problems in computer systems. These problems are widely studied in different contexts, where two main analytical tools are com- petitiv e analysis [23]–[27] and M /G/ 1 -type queueing theory (see [28] and references therein), both used to optimize metrics such as a weighted sum of average power and delay . This paper presents a fundamentally different approach for more directed control over average power and delays, and considers a multi- class setup with time average constraints. In the rest of the paper , the detailed queueing model is given in Section II, followed by a summary of useful M /G/ 1 prop- erties in Section III. The four delay-po wer control problems are solved in Section IV-VII, followed by simulation results. I I . Q U E U E I N G M O D E L W e only consider queueing delay , not system delay (queue- ing plus service) in this paper . System delay can be eas- ily incorporated since, in a nonpreemptiv e system, average queueing and system delay dif fer only by a constant (the av erage service time). W e will use “delay” and “queueing delay” interchangeably in the rest of the paper . Consider a single-server queueing system processing jobs categorized into N classes. In each class n ∈ { 1 , 2 , . . . , N } , jobs arrive as a Poisson process with rate λ n . Each class n job has size S n . W e assume S n is i.i.d. in each class, independent across classes, and that the first four moments of S n are finite for all classes n . The system processes arriv als nonpreemp- tiv ely with instantaneous service rate µ ( P ( t )) , where µ ( · ) is a concav e, continuous, and nondecreasing function of the allocated power P ( t ) (the concavity of rate-power relationship is observed in computer systems [28]–[30]). W ithin each class, arriv als are served in a first-in-first-out fashion. W e consider a frame-based system, where each frame consists of an idle period and the following busy period. Let t k be the start of the k th frame for each k ∈ Z + ; the k th frame is [ t k , t k +1 ) . Define t 0 = 0 and assume the system is initially empty . Define T k , t k +1 − t k as the size of frame k . Let A n,k denote the set of class n arriv als in frame k . For each job i ∈ A n,k , let W ( i ) n,k denote its queueing delay . The control over this queueing system is power allocations and job scheduling across all classes. W e restrict to the following frame-based policies that are both causal and work- conserving : 1 1 Causality means that every control decision depends only on the current and past states of the system; work-conserving means that the server is never idle when there is still work to do. 3 In ev ery frame k ∈ Z + , use a fixed power level P k ∈ [ P min , P max ] and a nonpreemptiv e strict priority policy π ( k ) for the duration of the busy period in that frame. The decisions are possibly random. In these policies, P max denotes the maximum power allocation. W e assume P max is finite, but sufficiently large to ensure feasibility of the desired delay constraints. The minimum power P min is chosen to be large enough so that the queue is stable e ven if po wer P min is used for all time. In particular , for stability we need N X n =1 λ n E [ S n ] µ ( P min ) < 1 ⇒ µ ( P min ) > N X n =1 λ n E [ S n ] . The strict priority rule π ( k ) = ( π n ( k )) N n =1 is represented by a permutation of { 1 , . . . , N } , where class π n ( k ) gets the n th highest priority . The motiv ation of focusing on the above frame-based poli- cies is to simplify the control of the queueing system to achiev e complex performance objecti ves. Simulations in [31], howe ver , suggest that this method may incur higher variance in performance than policies that take control actions based on job occupancies in the queue. Y et, job-level scheduling seems difficult to attack problems considered in this paper . It may in volv e solving high-dimensional (partially observ able) Markov decision processes with time av erage power and delay constraints and con ve x holding costs. A. Definition of A verage Delay The a verage delay under policies we propose later may not hav e well-defined limits. Thus, inspired by [13], we define W n , lim sup K →∞ E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h P K − 1 k =0 | A n,k | i (1) as the av erage delay of class n ∈ { 1 , . . . , N } , where | A n,k | is the number of class n arriv als during frame k . W e only consider delay sampled at frame boundaries for simplicity . T o verify (1), note that the running average delay of class n jobs up to time t K is equal to P K − 1 k =0 P i ∈ A n,k W ( i ) n,k P K − 1 k =0 | A n,k | = 1 K P K − 1 k =0 P i ∈ A n,k W ( i ) n,k 1 K P K − 1 k =0 | A n,k | . Define w av n , lim K →∞ 1 K K − 1 X k =0 X i ∈ A n,k W ( i ) n,k , a av n , lim K →∞ 1 K K − 1 X k =0 | A n,k | . If both limits w av n and a av n exist, the ratio w av n /a av n is the limiting av erage delay for class n . In this case, we get W n = lim K →∞ E h 1 K P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i lim K →∞ E h 1 K P K − 1 k =0 | A n,k | i = E h lim K →∞ 1 K P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h lim K →∞ 1 K P K − 1 k =0 | A n,k | i = w av n a av n , (2) which shows W n is indeed the limiting av erage delay . 2 The definition in (1) replaces lim by lim sup to guarantee it is well-defined. I I I . P R E L I M I NA R I E S This section summarizes useful properties of a nonpreemp- tiv e multi-class M /G/ 1 queue. Here we assume a fixed power allocation P and a fixed service rate µ ( P ) (this is extended in Section VI). Let X n , S n /µ ( P ) be the service time of a class n job . Define ρ n , λ n E [ X n ] . Fix an arriv al rate vector ( λ n ) N n =1 satisfying P N n =1 ρ n < 1 ; the rate vector ( λ n ) N n =1 is supportable in the queueing network. For each k ∈ Z + , let I k and B k denote the k th idle and busy period, respectiv ely; the frame size T k = I k + B k . The distribution of B k (and T k ) is fixed under an y work-conserving policy , since the sample path of unfinished work in the system is independent of scheduling policies. Due to the memoryless property of Poisson arriv als, we have E [ I k ] = 1 / ( P N n =1 λ n ) for all k . For the same reason, the system renews itself at the start of each frame. Consequently , the frame size T k , busy period B k , and the per-frame job arriv als | A n,k | of class n , are all i.i.d. ov er k . Using rene wal re ward theory [32] with rene wal epochs defined at frame boundaries { t k } ∞ k =0 , we hav e: E [ T k ] = E [ I k ] 1 − P N n =1 ρ n = 1 (1 − P N n =1 ρ n ) P N n =1 λ n (3) E [ | A n,k | ] = λ n E [ T k ] , ∀ n ∈ { 1 , . . . , N } , ∀ k ∈ Z + . (4) It is useful to consider the randomized policy π rand that is defined by a given probability distribution over all possible N ! priority orderings. Specifically , policy π rand randomly selects priorities at the beginning of e very new frame according to this distribution, and implements the corresponding nonpreemptive priority rule for the duration of the frame. Again by renewal rew ard theory , the average queueing delays ( W n ) N n =1 rendered by a π rand policy satisfy in each frame k ∈ Z + : E X i ∈ A n,k W ( i ) n,k = E Z t k +1 t k Q n ( t ) d t = λ n W n E [ T k ] , (5) where we recall that W ( i ) n,k represents only the queueing delay (not including service time), and Q n ( t ) denotes the number of class n jobs waiting in the queue (not including that in the server) at time t . Next we summarize useful properties of the performance region of average queueing delay vectors ( W n ) N n =1 in a nonpreemptiv e multi-class M /G/ 1 queue. For these results we refer readers to [1], [5], [33] for a detailed introduction. Define the value x n , ρ n W n for each class n ∈ { 1 , . . . , N } , and denote by Ω the performance region of the vector ( x n ) N n =1 . The set Ω is a special polytope called (a base of) a polyma- tr oid [34]. An important property of the polymatroid Ω is: 2 The second equality in (2), where we pass the limit into the expectation, can be proved by a generalized Lebesgue’ s dominated con vergence theorem stated as follows. Let { X n } ∞ n =1 and { Y n } ∞ n =1 be two sequences of random variables such that: (1) 0 ≤ | X n | ≤ Y n with probability 1 for all n ; (2) For some random variables X and Y , X n → X and Y n → Y with probability 1 ; (3) lim n →∞ E [ Y n ] = E [ Y ] < ∞ . Then E [ X ] is finite and lim n →∞ E [ X n ] = E [ X ] . The details are omitted for brevity . 4 (1) Each vertex of Ω is the performance vector of a strict nonpreemptiv e priority rule; (2) Con versely , the performance vector of each strict nonpreemptiv e priority rule is a verte x of Ω . In other words, there is a one-to-one mapping between vertices of Ω and the set of strict nonpreemptive priority rules. As a result, every feasible performance vector ( x n ) N n =1 ∈ Ω , or equi valently e very feasible queueing delay vector ( W n ) N n =1 , is attained by a randomization of strict nonpreemptive priority policies. For completeness, we formalize the last known result in the next lemma. Lemma 1. In a nonpreemptive multi-class M /G/ 1 queue, define W , ( W n ) N n =1 | ( ρ n W n ) N n =1 ∈ Ω as the performance r egion [5] of average queueing delays. Then: 1) The performance vector ( W n ) N n =1 of each frame-based randomized policy π rand is in the delay re gion W . 2) Con versely , every vector ( W n ) N n =1 in the delay re gion W is the performance vector of a π rand policy . Pr oof of Lemma 1: Gi ven in Appendix A. Optimizing a linear function over the polymatroidal region Ω will be useful. The solution is the following cµ rule: Lemma 2 (The cµ rule [1], [33]) . In a nonpreemptive multi- class M /G/ 1 queue, define x n , ρ n W n and consider the linear pr ogram: minimize: N X n =1 c n x n (6) subject to: ( x n ) N n =1 ∈ Ω (7) wher e c n ar e nonnegative constants. W e assume P N n =1 ρ n < 1 for stability , and that second moments E X 2 n of service times ar e finite for all classes n . The optimal solution to (6) - (7) is a strict nonpr eemptive priority policy that assigns priorities in the decr easing or der of c n . That says, if c 1 ≥ c 2 ≥ . . . ≥ c N , then class 1 gets the highest priority , class 2 gets the second highest priority , and so on. In this case, the optimal average queueing delay W ∗ n of class n is W ∗ n = R (1 − P n − 1 k =0 ρ k )(1 − P n k =0 ρ k ) , wher e ρ 0 , 0 and R , 1 2 P N n =1 λ n E X 2 n . I V . A C H I E V I N G D E L A Y C O N S T R A I N T S The first problem we consider is to construct a frame-based policy that yields average delays satisfying W n ≤ d n for all classes n ∈ { 1 , . . . , N } , where d n > 0 are given constants. W e assume a fix ed power allocation and that the delay constraints are feasible. Our solution relies on tracking the running difference be- tween past queueing delays for each class n and the desired delay bound d n . For each class n ∈ { 1 , . . . , N } , we define a discrete-time virtual delay queue { Z n,k } ∞ k =0 where Z n,k +1 is updated at frame boundary t k +1 following the equation Z n,k +1 = max Z n,k + X i ∈ A n,k W ( i ) n,k − d n , 0 . (8) Assume Z n, 0 = 0 for all n . In (8), the delays W ( i ) n,k and constant d n can viewed as arriv als and service of the queue { Z n,k } ∞ k =0 , respectiv ely . If this queue is stabilized, we know that the a verage arriv al rate to the queue (being the per -frame av erage sum of class n delays P n ∈ A n,k W ( i ) n,k ) is less than or equal to the average service rate (being the v alue d n multiplied by the average number of class n arriv als per frame), from which we infer W n ≤ d n . This is formalized below . Definition 1. W e say queue { Z n,k } ∞ k =0 is mean rate stable if lim K →∞ E [ Z n,K ] /K = 0 . Lemma 3. If queue { Z n,k } ∞ k =0 is mean rate stable, then W n ≤ d n . Pr oof of Lemma 3: From (8) we get Z n,k +1 ≥ Z n,k − d n | A n,k | + X i ∈ A n,k W ( i ) n,k . Summing the above over k ∈ { 0 , . . . , K − 1 } , using Z n, 0 = 0 , and taking expectation yields E [ Z n,K ] ≥ − d n E " K − 1 X k =0 | A n,k | # + E K − 1 X k =0 X i ∈ A n,k W ( i ) n,k . Dividing the above by E h P K − 1 k =0 | A n,k | i yields E [ Z n,K ] E h P K − 1 k =0 | A n,k | i ≥ E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h P K − 1 k =0 | A n,k | i − d n . T aking a lim sup as K → ∞ and using (1) yields W n ≤ d n + lim sup K →∞ E [ Z n,K ] K K E h P K − 1 k =0 | A n,k | i . Using E [ | A n,k | ] = λ n E [ T k ] ≥ λ n E [ I k ] = λ n E [ I 0 ] , we get W n ≤ d n + 1 λ n E [ I 0 ] lim K →∞ E [ Z n,K ] K = d n by mean rate stability of Z n,k . A. Delay F easible P olicy The following policy stabilizes e very { Z n,k } ∞ k =0 queue in the mean rate stable sense and thus achiev es W n ≤ d n for all classes n . Delay F easible ( DelayF e as ) P olicy: • In e very frame k ∈ Z + , update Z n,k by (8) and serve jobs using nonpreemptiv e strict priorities assigned in the decreasing order of Z n,k ; ties are broken arbitrarily . W e note that the DelayF eas polic y does not require any statis- tical knowledge of job arriv als and service times. Intuitiv ely , each Z n,k queue tracks the amount of past queueing delays in class n exceeding the desired delay bound d n (see (8)), and the DelayF eas policy giv es priorities to classes that more sev erely violate their delay constraints. 5 B. Motivation of the DelayF eas P olicy The structure of the DelayF eas policy follows a L yapunov drift ar gument. Define v ector Z k , ( Z n,k ) N n =1 . For some finite constants θ n > 0 for all classes n , we define the quadratic L yapunov function L ( Z k ) , 1 2 N X n =1 θ n Z 2 n,k as a weighted scalar measure of queue sizes ( Z n,k ) N n =1 . Define the one-frame Lyapunov drift ∆( Z k ) , E [ L ( Z k +1 ) − L ( Z k ) | Z k ] as the conditional expected difference of L ( Z k ) over a frame. T aking square of (8) and using (max[ a, 0]) 2 ≤ a 2 yields Z 2 n,k +1 ≤ Z n,k + X i ∈ A n,k W ( i ) n,k − d n 2 . (9) Multiplying (9) by θ n / 2 , summing over n ∈ { 1 , . . . , N } , and taking conditional expectation on Z k , we get ∆( Z k ) ≤ 1 2 N X n =1 θ n E X i ∈ A n,k W ( i ) n,k − d n 2 | Z k + N X n =1 θ n Z n,k E X i ∈ A n,k W ( i ) n,k − d n | Z k . (10) Lemma 7 in Appendix B shows that the second term of (10) is bounded by a finite constant C > 0 . It leads to the following L yapunov drift inequality: ∆( Z k ) ≤ C + N X n =1 θ n Z n,k E X i ∈ A n,k W ( i ) n,k − d n | Z k . (11) Over all frame-based policies, we are interested in the one that, in each frame k after observing Z k , minimizes the right side of (11). Recall that our policy on frame k chooses which nonpreemptiv e priorities to use during the frame. T o show that this is exactly the DelayF eas policy , we simplify (11). Under a frame-based policy , we hav e by renew al reward theory E X i ∈ A n,k W ( i ) n,k | Z k = λ n W n,k E [ T k ] , where W n,k denotes the long-term average delay of class n if the control in frame k is repeated in ev ery frame. T ogether with E [ | A n,k | ] = λ n E [ T k ] , inequality (11) is re-written as ∆( Z k ) ≤ C − E [ T k ] N X n =1 θ n Z n,k λ n d n ! + E [ T k ] N X n =1 θ n Z n,k λ n W n,k . (12) Because in this section we do not hav e dynamic po wer allocation (so that power is fixed to the same value in e very busy period), the value E [ T k ] is the same for all job scheduling policies. Then our desired polic y , in ev ery frame k , chooses a job scheduling to minimize the metric P N n =1 θ n Z n,k λ n W n,k ov er all feasible delay vectors ( W n,k ) N n =1 . If we choose θ n = E [ X n ] for all classes n , 3 the desired policy minimizes P N n =1 Z n,k λ n E [ X n ] W n,k in ev ery frame k . From lemma 2, this is achiev ed by the priority service rule defined by the Dela yFeas policy . C. P erformance of the DelayF eas P olicy Theorem 1. F or every collection of feasible delay bounds { d 1 , . . . , d N } , the DelayF eas policy yields averag e delays satisfying W n ≤ d n for all classes n ∈ { 1 , . . . , N } . Pr oof of Theor em 1: It suffices to sho w that the Dela yFeas policy yields mean rate stability for all Z n,k queues by Lemma 3. By Lemma 1, there exists a randomized priority policy π ∗ rand (introduced in Section III) that yields average delays W ∗ n satisfying W ∗ n ≤ d n for all classes n . Since the Dela yFeas polic y minimizes the last term of (12) in each frame (under θ n = E [ X n ] for all n ), comparing the Dela yF eas policy with the π ∗ rand policy yields, in ev ery frame k , N X n =1 θ n Z n,k λ n W DelayF eas n,k ≤ N X n =1 θ n Z n,k λ n W ∗ n . It follows that (12) under the DelayF eas policy is further upper bounded by ∆( Z k ) ≤ C + E [ T k ] N X n =1 θ n Z n,k λ n ( W DelayF eas n,k − d n ) ≤ C + E [ T k ] N X n =1 θ n Z n,k λ n ( W ∗ n − d n ) ≤ C . T aking expectation, summing over k ∈ { 0 , . . . , K − 1 } , and noting L ( Z 0 ) = 0 , we get E [ L ( Z K )] = 1 2 N X n =1 θ n E Z 2 n,K ≤ K C . It follows that E Z 2 n,K ≤ 2 K C /θ n for all classes n . Since Z n,K ≥ 0 , we get 0 ≤ E [ Z n,K ] ≤ r E h Z 2 n,K i ≤ p 2 K C /θ n . Dividing the above by K and passing K → ∞ yields lim K →∞ E [ Z n,K ] K = 0 , ∀ n ∈ { 1 , . . . , N } , and all Z n,k queues are mean rate stable. 3 W e note that the mean service time E [ X n ] as a v alue of θ n is only needed in the arguments constructing the DelayF eas policy . The Dela yFeas policy itself does not need the knowledge of E [ X n ] . 6 V . M I N I M I Z I N G D E L AY P E NA LTY F U N C T I O N S Generalizing the first delay feasibility problem, next we optimize a separable penalty function of a verage delays. For each class n , let f n ( · ) be a nondecreasing, nonnegativ e, con- tinuous, and conv ex function of av erage delay W n . Consider the constrained penalty minimization problem minimize: N X n =1 f n ( W n ) (13) subject to: W n ≤ d n , ∀ n ∈ { 1 , . . . , N } . (14) W e assume that a constant po wer is allocated in all frames, and that constraints (14) are feasible. The goal is to construct a frame-based policy that solves (13)-(14). Let ( W ∗ n ) N n =1 be the optimal solution to (13)-(14), attained by a randomized priority policy π ∗ rand (by Lemma 1). A. Delay Pr oportional F airness One interesting penalty function is the one that attains pr oportional fairness . W e say a delay vector ( W ∗ n ) N n =1 is delay pr oportional fair if it is optimal under the quadratic penalty function f n ( W n ) = 1 2 c n W 2 n for each class n , where c n > 0 are giv en constants. The intuition is two-fold. First, under the quadratic penalty functions, an y feasible delay v ector ( W n ) N n =1 necessarily satisfies N X n =1 f 0 n ( W ∗ n )( W n − W ∗ n ) = X n =1 c n ( W n − W ∗ n ) W ∗ n ≥ 0 , (15) which is analogous to the rate pr oportional fair [16] criterion N X n =1 c n x n − x ∗ n x ∗ n ≤ 0 , (16) where ( x n ) N n =1 is any feasible rate vector and ( x ∗ n ) N n =1 is the optimal rate vector . Second, rate proportional fairness, when deviating from the optimal solution, yields the aggre- gate change of proportional rates less than or equal to zero (see (16)); it penalizes large rates to increase. When delay proportional fairness deviates from the optimal solution, the aggregate change of proportional delays is always nonnegati ve (see (15)); small delays are penalized for trying to improv e. B. Delay F airness P olicy In addition to having the { Z n,k } ∞ k =0 queues updated by (8) for all classes n , we setup new discrete-time virtual queues { Y n,k } ∞ k =0 for all classes n , where Y n,k +1 is updated at frame boundary t k +1 as: Y n,k +1 = max Y n,k + X i ∈ A n,k W ( i ) n,k − r n,k , 0 , (17) where r n,k ∈ [0 , d n ] are auxiliary variables chosen at time t k independent of frame size T k and the number | A n,k | of class n arri vals in frame k . Assume Y n, 0 = 0 for all n . Whereas the Z n,k queues are useful to enforce delay constraints W n ≤ d n (as seen in Section IV), the Y n,k queues are useful to achiev e the optimal delay vector ( W ∗ n ) N n =1 . Delay F airness ( DelayF air ) P olicy: 1) In the k th frame for each k ∈ Z + , after observing Z k and Y k , use nonpreempti ve strict priorities assigned in the decreasing order of ( Z n,k + Y n,k ) / E [ S n ] , where E [ S n ] is the mean size of a class n job . Ties are broken arbitrarily . 2) At the end of the k th frame, compute Z n,k +1 and Y n,k +1 for all classes n by (8) and (17), respectively , where r n,k is the solution to the con ve x program: minimize: V f n ( r n,k ) − Y n,k λ n r n,k subject to: 0 ≤ r n,k ≤ d n , where V > 0 is a predefined control parameter . While the DelayF eas policy in Section IV does not require any statistical knowledge of arriv als and service times, the Dela yFa ir policy needs the mean b ut not higher moments of arriv als and service times for all classes n . In the example of delay proportional fairness with quadratic penalty functions f n ( W n ) = 1 2 c n W 2 n for all classes n , the second step of the DelayF air policy solves: minimize: 1 2 V c n r 2 n,k − Y n,k λ n r n,k subject to: 0 ≤ r n,k ≤ d n . The solution is r ∗ n,k = min h d n , Y n,k λ n V c n i . C. Motivation of the DelayF air P olicy The Dela yF air policy follows a L yapunov drift argument similar to that in Section IV. Define Z k , ( Z n,k ) N n =1 and Y k , ( Y n,k ) N n =1 . Define the L yapunov function L ( Z k , Y k ) , 1 2 P N n =1 ( Z 2 n,k + Y 2 n,k ) and the one-frame L yapunov drift ∆( Z k , Y k ) , E [ L ( Z k +1 , Y k +1 ) − L ( Z k , Y k ) | Z k , Y k ] . T aking square of (17) yields Y 2 n,k +1 ≤ Y n,k + X i ∈ A n,k W ( i ) n,k − r n,k 2 . (18) Summing (9) and (18) over all classes n ∈ { 1 , . . . , N } , dividing the result by 2 , and taking conditional expectation on Z k and Y k , we get ∆( Z k , Y k ) ≤ C − N X n =1 Z n,k d n E [ | A n,k | | Z k , Y k ] − N X n =1 Y n,k E [ r n,k | A n,k | | Z k , Y k ] + N X n =1 ( Z n,k + Y n,k ) E X i ∈ A n,k W ( i ) n,k | Z k , Y k , (19) where C > 0 is a finite constant, different from that used in Section IV -B, upper bounding the sum of all ( Z k , Y k ) - independent terms. This constant exists using arguments sim- ilar to those in Lemma 7 of Appendix B. 7 Adding to both sides of (19) the weighted penalty term V P N n =1 E [ f n ( r n,k ) T k | Z k , Y k ] , where V > 0 is a pre- defined control parameter , and ev aluating the result under a frame-based policy (similar as the analysis in Section IV -C), we get the following L yapunov drift plus penalty inequality: ∆( Z k , Y k ) + V N X n =1 E [ f n ( r n,k ) T k | Z k , Y k ] ≤ C − E [ T k ] N X n =1 Z n,k λ n d n ! + E [ T k ] N X n =1 E [ V f n ( r n,k ) − Y n,k λ n r n,k | Z k , Y k ] + E [ T k ] N X n =1 ( Z n,k + Y n,k ) λ n W n,k . (20) W e are interested in minimizing the right side of (20) in ev ery frame k over all frame-based policies and (possibly random) choices of r n,k . Recall that in this section a constant po wer is allocated in all frames so that the value E [ T k ] is fixed under any work-conserving policy . The first and second step of the Dela yFair policy minimizes the last (by Lemma 2) and the second-to-last term of (20), respectively . D. P erformance of the DelayF air P olicy Theorem 2. Given any feasible delay bounds { d 1 , . . . , d N } , the Dela yFair policy yields aver age delays satisfying W n ≤ d n for all classes n ∈ { 1 , . . . , N } , and attains averag e delay penalty satisfying lim sup K →∞ N X n =1 f n E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h P K − 1 k =0 | A n,k | i ≤ C P N n =1 λ n V + N X n =1 f n ( W ∗ n ) , wher e V > 0 is a predefined contr ol parameter and C > 0 a finite constant. By choosing V suf ficiently lar ge, we attain arbitrarily close to the optimal delay penalty P N n =1 f n ( W ∗ n ) . W e remark that the tradeoff of choosing a large V value is the amount of time required for virtual queues { Z n,k } ∞ k =0 and { Y n,k } ∞ k =0 to approach mean rate stability (see (23) in the next proof), that is, the time required for the virtual queue backlogs to be negligible with respect to the time horizon. Pr oof of Theorem 2: Consider the optimal randomized policy π ∗ rand that yields optimal delays W ∗ n ≤ d n for all classes n . Since the DelayF air policy minimizes the right side of (20), comparing the DelayF air policy with the policy π ∗ rand and with the genie decision r ∗ n,k = W ∗ n for all classes n and frames k , inequality (20) under the DelayF air policy is further upper bounded by ∆( Z k , Y k ) + V N X n =1 E [ f n ( r n,k ) T k | Z k , Y k ] ≤ C − E [ T k ] N X n =1 Z n,k λ n d n + E [ T k ] N X n =1 ( Z n,k + Y n,k ) λ n W ∗ n + E [ T k ] N X n =1 V f n ( W ∗ n ) − Y n,k λ n W ∗ n ≤ C + V E [ T k ] N X n =1 f n ( W ∗ n ) . (21) Removing the second term of (21) yields ∆( Z k , Y k ) ≤ C + V E [ T k ] N X n =1 f n ( W ∗ n ) ≤ C + V D, (22) where D , E [ T k ] P N n =1 f n ( W ∗ n ) is a finite constant. T aking expectation of (22), summing ov er k ∈ { 0 , . . . , K − 1 } , and noting L ( Z 0 , Y 0 ) = 0 yields E [ L ( Z K , Y K )] ≤ K ( C + V D ) . It follows that, for each class n queue { Z n,k } ∞ k =0 , we hav e 0 ≤ E [ Z n,K ] K ≤ v u u t E h Z 2 n,K i K 2 ≤ r 2 E [ L ( Z k , Y K )] K 2 ≤ r 2 C K + 2 V D K . (23) Passing K → ∞ prov es that queue { Z n,k } ∞ k =0 is mean rate stable for all classes n . Thus constraints W n ≤ d n are satisfied by Lemma 3. Similarly , the { Y n,k } ∞ k =0 queues are mean rate stable for all classes n . Next, taking expectation of (21), summing over k ∈ { 0 , . . . , K − 1 } , dividing by V , and noting L ( Z 0 , Y 0 ) = 0 yields E [ L ( Z K , Y K )] V + N X n =1 E " K − 1 X k =0 f n ( r n,k ) T k # ≤ K C V + E " K − 1 X k =0 T k # N X n =1 f n ( W ∗ n ) . Removing the first term and di viding by E h P K − 1 k =0 T k i yields N X n =1 E h P K − 1 k =0 f n ( r n,k ) T k i E h P K − 1 k =0 T k i ≤ K C V E h P K − 1 k =0 T k i + N X n =1 f n ( W ∗ n ) ( a ) ≤ C P N n =1 λ n V + N X n =1 f n ( W ∗ n ) , (24) where (a) follows E [ T k ] ≥ E [ I k ] = 1 / ( P N n =1 λ n ) . By [14, Lemma 7 . 6 ] and con vexity of f n ( · ) , we get N X n =1 E h P K − 1 k =0 f n ( r n,k ) T k i E h P K − 1 k =0 T k i ≥ N X n =1 f n E h P K − 1 k =0 r n,k T k i E h P K − 1 k =0 T k i . (25) Combining (24)(25) and taking a lim sup as K → ∞ yields lim sup K →∞ N X n =1 f n E h P K − 1 k =0 r n,k T k i E h P K − 1 k =0 T k i ≤ C P N n =1 λ n V + N X n =1 f n ( W ∗ n ) . The ne xt lemma, proved in Appendix C, completes the proof. 8 Lemma 4. If queues { Y n,k } ∞ k =0 ar e mean rate stable for all classes n , then lim sup K →∞ N X n =1 f n E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h P K − 1 k =0 | A n,k | i ≤ lim sup K →∞ N X n =1 f n E h P K − 1 k =0 r n,k T k i E h P K − 1 k =0 T k i . V I . D E L A Y - C O N S T R A I N E D O P T I M A L P O W E R C O N T R O L In this section we incorporate dynamic power control into the queueing system. As mentioned in Section II, we fo- cus on frame-based policies that allocate a constant power P k ∈ [ P min , P max ] over the duration of the k th busy period (we assume zero power is allocated when the system is idle). Here, interesting quantities such as frame size T k , busy period B k , the set A n,k of per-frame class n arriv als, and queueing delay W ( i ) n,k are all functions of power P k . Similar to the delay definition (1), we define the average po wer consumption P , lim sup K →∞ E h P K − 1 k =0 P k B k ( P k ) i E h P K − 1 k =0 T k ( P k ) i , (26) where B k ( P k ) and T k ( P k ) emphasize the power dependence of B k and T k . It is easy to show that both B k ( P k ) and T k ( P k ) are decreasing in P k . The goal is to solve the delay-constrained power minimization problem: minimize: P (27) subject to: W n ≤ d n , ∀ n ∈ { 1 , . . . , N } (28) ov er frame-based power control and nonpreemptive priority policies. A. P ower-Delay P erformance Region Every frame-based power control and nonpreemptive prior- ity policy can be viewed as a timing sharing or randomiza- tion of stationary policies that make the same deterministic decision in ev ery frame. Using this point of vie w , next we giv e an example of the joint power -delay performance region resulting from frame-based policies. Consider a two-class nonpreemptiv e M /G/ 1 queue with parameters: • λ 1 = 1 , λ 2 = 2 , E [ S 1 ] = E [ S 2 ] = E S 2 2 = 1 , E S 2 1 = 2 . µ ( P ) = P . For each class n ∈ { 1 , 2 } , the service time X n has mean E [ X n ] = E [ S n ] /P and second moments E X 2 n = E S 2 n /P 2 . For stability , we must have λ 1 E [ X 1 ] + λ 2 E [ X 2 ] < 1 ⇒ P > 3 . In this example, let [4 , 10] be the feasible power region. Under a constant power allocation P , let W ( P ) denote the set of achiev able queueing delay vectors ( W 1 , W 2 ) . Define ρ n , λ n E [ X n ] and R , 1 2 P 2 n =1 λ n E X 2 n . Then we hav e W ( P ) = ( W 1 , W 2 ) W n ≥ R 1 − ρ n , n ∈ { 1 , 2 } 2 X n =1 ρ n W n = ( ρ 1 + ρ 2 ) R 1 − ρ 1 − ρ 2 . (29) The inequalities in W ( P ) show that the minimum delay for each class is attained when it has priority ov er the other . The equality in W ( P ) follows the M /G/ 1 conservation la w [35]. Using the above parameters, we get W ( P ) = ( W 1 , W 2 ) W 1 ≥ 2 P ( P − 1) W 2 ≥ 2 P ( P − 2) W 1 + 2 W 2 = 6 P ( P − 3) . Fig. 1 shows the collection of delay regions W ( P ) for dif ferent values of P ∈ [4 , 10] . This joint region contains all feasible delay vectors under constant power allocations. Fig. 2 sho ws 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 delay W 1 delay W 2 Fig. 1. The collection of a verage delay re gions W ( P ) for different power lev els P ∈ [4 , 10] . 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 4 5 6 7 8 9 10 delay W 2 (P) delay W 1 (P) power P Fig. 2. The augmented performance region of power -delay vectors ( P, W 1 ( P ) , W 2 ( P )) . the associated augmented performance region of power -delay vectors ( P , W 1 ( P ) , W 2 ( P )) ; its projection onto the delay plane is Fig. 1. After timing sharing or randomization, the performance region of all frame-based power control and nonpreemptiv e priority policies is the con ve x hull of Fig. 2. The problem (27)-(28) is vie wed a stochastic optimization o ver such a con ve xified power -delay performance region. B. Dynamic P ower Contr ol P olicy W e setup the same virtual delay queues Z n,k as in (8), and assume Z n, 0 = 0 for all classes n . W e represent a strict nonpreemptiv e priority policy by a permutation ( π n ) N n =1 of 9 { 1 , . . . , N } , where π n denotes the job class that gets the n th highest priority . Dynamic P ower Contr ol ( DynPo wer ) P olicy: 1) In the k th frame for each k ∈ Z + , use the nonpreempti ve strict priority rule ( π n ) N n =1 that assigns priorities in the decreasing order of Z n,k / E [ S n ] ; ties are broken arbitrarily . 2) Allocate a fixed power P k in frame k , where P k is the solution to the following minimization of a weighted sum of power and average delays: minimize: V N X n =1 λ n E [ S n ] ! P k µ ( P k ) (30) + N X n =1 Z π n ,k λ π n W π n ( P k ) subject to: P k ∈ [ P min , P max ] . (31) The value W π n ( P k ) , given later in (37), is the average delay of class π n under the priority rule ( π n ) N n =1 and power allocation P k . 3) Update queues Z n,k for all classes n ∈ { 1 , . . . , N } by (8) at ev ery frame boundary . The abov e DynPo wer policy requires the kno wledge of arriv al rates and the first two moments of job sizes for all classes n (see (37)). W e can remove its dependence on the second moments of job sizes, so that it only depends on the mean of arriv als and job sizes; see Appendix D for details. C. Motivation of the DynPo w er P olicy W e construct the L yapunov drift argument. Define the L yapunov function L ( Z k ) = 1 2 P N n =1 Z 2 n,k and the one-frame L yapunov drift ∆( Z k ) = E [ L ( Z k +1 ) − L ( Z k ) | Z k ] . Similar as the deriv ation in Section IV -B, we have the L yapunov drift inequality: ∆( Z k ) ≤ C + N X n =1 Z n,k E X i ∈ A n,k W ( i ) n,k − d n | Z k . (32) Adding the weighted energy V E [ P k B k ( P k ) | Z k ] to both sides of (32), where V > 0 is a control parameter, yields ∆( Z k ) + V E [ P k B k ( P k ) | Z k ] ≤ C + Φ( Z k ) , (33) where Φ( Z k ) , E " V P k B k ( P k ) + N X n =1 Z n,k X i ∈ A n,k ( W ( i ) n,k − d n ) | Z k # . W e are interested in the frame-based policy that, in each frame k , allocates po wer and assigns priorities to minimize the ratio Φ( Z k ) E [ T k ( P k ) | Z k ] . (34) Note that frame size T k ( P k ) depends on Z k because the po wer allocation that affects T k ( P k ) may be Z k -dependent. For any giv en power allocation P k , T k ( P k ) is independent of Z k . Lemma 5 next shows that the minimizer of (34) is a de- terministic power allocation and strict nonpreemptiv e priority policy . Specifically , we may consider each p ∈ P in Lemma 5 denotes a deterministic power allocation and strict priority policy , and random variable P denotes a randomized power control and priority policy . Lemma 5. Let P be a continuous r andom variable with state space P . Let G and H be two random variables that depend on P such that, for each p ∈ P , G ( p ) and H ( p ) are well- defined random variables. Define p ∗ , argmin p ∈P E [ G ( p )] E [ H ( p )] , U ∗ , E [ G ( p ∗ )] E [ H ( p ∗ )] . Then E [ G ] E [ H ] ≥ U ∗ r egar dless of the distribution of P . Pr oof: For each p ∈ P , we have E [ G ( p )] E [ H ( p )] ≥ U ∗ . Then E [ G ] E [ H ] = E P [ E [ G ( p )]] E P [ E [ H ( p )]] ≥ E P [ U ∗ E [ H ( p )]] E P [ E [ H ( p )]] = U ∗ , which is independent of the distribution of P . Under a fixed po wer allocation P k and a strict nonpreemp- tiv e priority rule, (34) is equal to V E [ P k B k ( P k )] + P N n =1 Z n,k λ n ( W n,k ( P k ) − d n ) E [ T k ( P k )] E [ T k ( P k )] = V P k P N n =1 λ n E [ S n ] µ ( P k ) + N X n =1 Z n,k λ n ( W n,k ( P k ) − d n ) , (35) where by renew al theory E [ B k ( P k )] E [ T k ( P k )] = N X n =1 ρ n ( P k ) = N X n =1 λ n E [ S n ] µ ( P k ) and power-dependent terms are written as functions of P k . It follows that our desired policy in every frame k minimizes V N X n =1 λ n E [ S n ] ! P k µ ( P k ) + N X n =1 Z n,k λ n W n,k ( P k ) (36) ov er constant power allocations P k ∈ [ P min , P max ] and nonpre- emptiv e strict priority rules. T o further simplify , for each fixed power lev el P k , by Lemma 2, the cµ rule that assigns priorities in the decreasing order of Z n,k / E [ S n ] minimizes the second term of (36) (note that minimizing a linear function over strict priority rules is equi valent to minimizing over all randomized priority rules, since a vertex of the performance polytope attains the minimum). This strict priority policy is optimal regardless of the value of P k , and thus is overall optimal; priority assignment and power control are decoupled. W e represent the optimal priority policy by ( π n ) N n =1 , recalling that π n denotes the job class that gets the n th highest priority . Under priorities ( π n ) N n =1 and a fixed power allocation P k , the av erage delay 10 W π n ( P k ) for class π n is equal to W π n ( P k ) = 1 2 P N n =1 λ n E X 2 n (1 − P n − 1 m =0 ρ π m )(1 − P n m =0 ρ π m ) = 1 2 P N n =1 λ n E S 2 n ( µ ( P k ) − P n − 1 m =0 ˆ ρ π m )( µ ( P k ) − P n m =0 ˆ ρ π m ) , (37) where ˆ ρ π m , λ π m E [ S π m ] if m ≥ 1 and 0 if m = 0 . The abov e discussions lead to the DynPo wer policy . D. P erformance of the DynPo wer P olicy Theorem 3. Let P ∗ be the optimal average power of the pr ob- lem (27) - (28) . The DynPo w er policy achie ves delay constr aints W n ≤ d n for all classes n ∈ { 1 , . . . , N } and attains average power P satisfying P ≤ C P N n =1 λ n V + P ∗ , wher e C > 0 is a finite constant and V > 0 a pr edefined contr ol parameter . Pr oof of Theor em 3: As discussed in Section VI-A, the power -delay performance region in this problem is spanned by stationary power control and nonpreemptive priority policies that use the same (possibly random) decision in every frame. Let π ∗ denote one such policy that yields the optimal av erage power P ∗ with feasible delays W ∗ n ≤ d n for all classes n . Let P ∗ k be its power allocation in frame k . Since policy π ∗ makes i.i.d. decisions over frames, by renewal re ward theory we have P ∗ = E [ P ∗ k B ( P ∗ k )] E [ T ( P ∗ k )] . Then the ratio Φ( Z k ) E [ T k ( P k ) | Z k ] under policy π ∗ (see the left side of (35)) is equal to V E [ P ∗ k B ( P ∗ k )] E [ T ( P ∗ k )] + N X n =1 Z n,k λ n W ∗ n − d n ≤ V P ∗ . Since the DynPo wer policy minimizes Φ( Z k ) E [ T k ( P k ) | Z k ] ov er frame-based policies, including the optimal policy π ∗ , the ratio Φ( Z k ) E [ T k ( P k ) | Z k ] under the DynPo wer policy satisfies Φ( Z k ) E [ T k ( P k ) | Z k ] ≤ V P ∗ ⇒ Φ( Z k ) ≤ V P ∗ E [ T k ( P k ) | Z k ] . Using this bound in (33) yields ∆( Z k ) + V E [ P k B k ( P k ) | Z k ] ≤ C + V P ∗ E [ T k ( P k ) | Z k ] . T aking expectation, summing over k ∈ { 0 , . . . , K − 1 } , and noting L ( Z 0 ) = 0 yields E [ L ( Z K )] + V K − 1 X k =0 E [ P k B k ( P k )] ≤ K C + V P ∗ E " K − 1 X k =0 T k ( P k ) # . (38) Since E [ T k ( P k )] is decreasing in P k and, under a fixed power allocation, is independent of scheduling policies, we get E [ T k ( P k )] ≤ E [ T 0 ( P min )] and E [ L ( Z K )] + V K − 1 X k =0 E [ P k B k ( P k )] ≤ K ( C + V P ∗ E [ T 0 ( P min )]) . Removing the second term and dividing by K 2 yields E [ L ( Z K )] K 2 ≤ C + V P ∗ E [ T 0 ( P min )] K . Combining it with 0 ≤ E [ Z n,K ] K ≤ v u u t E h Z 2 n,K i K 2 ≤ r 2 E [ L ( Z K )] K 2 and passing K → ∞ prov es that queue { Z n,k } ∞ k =0 is mean rate stable for all classes n . Thus W n ≤ d n for all n by Lemma 3. Further , removing the first term in (38) and dividing the result by V E h P K − 1 k =0 T k ( P k ) i yields E h P K − 1 k =0 P k B k ( P k ) i E h P K − 1 k =0 T k ( P k ) i ≤ C V K E h P K − 1 k =0 T k ( P k ) i + P ∗ ( a ) ≤ C P N n =1 λ n V + P ∗ , where (a) uses E [ T k ( P k )] ≥ E [ I k ] = 1 / ( P N n =1 λ n ) . Passing K → ∞ completes the proof. V I I . O P T I M I Z I N G D E L AY P E N A L T I E S W I T H A V E R A G E P O W E R C O N S T R A I N T The fourth problem we consider is to, over frame-based power control and nonpreemptive priority policies, minimize a separable con vex function of delay vectors ( W n ) N n =1 subject to an av erage power constraint: minimize: N X n =1 f n ( W n ) (39) subject to: P ≤ P const . (40) The value P is defined in (26) and P const > 0 is a given feasible bound. The penalty functions f n ( · ) are assumed nondecreasing, nonnegati ve, continuous, and con vex for all classes n . Power allocation in ev ery busy period takes values in [ P min , P max ] , and no power is allocated when the system is idle. In this problem, the region of feasible power -delay vec- tors ( P , W 1 , . . . , W N ) is complicated because feasible delays ( W n ) N n =1 are indirectly decided by the po wer constraint (40). Using the same methodology as in the previous three prob- lems, we construct a frame-based policy to solve (39)-(40). W e setup the virtual delay queue { Y n,k } ∞ k =0 for each class n ∈ { 1 , . . . , N } as in (17), in which the auxiliary variable r n,k takes values in [0 , R max n ] for some R max n > 0 sufficiently 11 large. 4 Define the discrete-time virtual power queue { X k } ∞ k =0 that ev olves at frame boundaries { t k } ∞ k =0 as X k +1 = max [ X k + P k B k ( P k ) − P const T k ( P k ) , 0] . (41) Assume X 0 = 0 . The { X k } ∞ k =0 queue helps to achiev e the power constraint P ≤ P const . Lemma 6. If the virtual power queue { X k } ∞ k =0 is mean rate stable, then P ≤ P const . Pr oof: Giv en in Appendix E. A. P ower-constr ained Delay F airness P olicy P ower-constr ained Delay F airness ( PwDelayF air ) P olicy: In the busy period of each frame k ∈ Z + , after observing X k and ( Y n,k ) N n =1 : 1) Use the nonpreemptive strict priority rule ( π n ) N n =1 that assigns priorities in the decreasing order of Y n,k / E [ S n ] ; ties are broken arbitrarily . 2) Allocate power P k for the duration of the busy period, where P k solves: minimize: X k " − P const + P k µ ( P k ) N X n =1 λ n E [ S n ] # + N X n =1 Y π n ,k λ π n W π n ( P k ) subject to: P k ∈ [ P min , P max ] , where W π n ( P k ) is defined in (37). 3) Update X k and Y n,k for all classes n at ev ery frame boundary by (41) and (17), respectiv ely . In (17), the auxiliary variable r n,k is the solution to minimize: V f n ( r n,k ) − Y n,k λ n r n,k subject to: 0 ≤ r n,k ≤ R max n . B. Motivation of the PwDelayF air P olicy The construction of the L yapunov drift argument follows closely with those in the previous problems; details are omitted for bre vity . Define v ector χ k = [ X k ; Y 1 ,k , . . . , Y N ,k ] , the L ya- punov function L ( χ k ) , 1 2 ( X 2 k + P N n =1 Y 2 n,k ) , and the one- frame L yapunov drift ∆( χ k ) , E [ L ( χ k +1 ) − L ( χ k ) | χ k ] . W e can show there exists a finite constant C > 0 such that ∆( χ k ) ≤ C + X k E [ P k B k ( P k ) − P const T k ( P k ) | χ k ] + N X n =1 Y n,k E X i ∈ A n,k W ( i ) n,k − r n,k | χ k . (42) Adding the term V P N n =1 E [ f n ( r n,k ) T k ( P k ) | χ k ] to both sides of (42), where V > 0 is a control parameter , and ev aluating the result under a frame-based policy yields ∆( χ k ) + V N X n =1 E [ f n ( r n,k ) T k ( P k ) | χ k ] ≤ C + Ψ( χ k ) , (43) 4 For each class n , we need R max n to be larger than the optimal delay W ∗ n in problem (39)-(40). One way is to let R max n be the maximum average delay over all classes under the minimum power allocation P min . where Ψ( χ k ) , E [ T k ( P k ) | χ k ] N X n =1 Y n,k λ n W n,k ( P k ) + X k E [ P k B k ( P k ) | χ k ] − X k P const E [ T k ( P k ) | χ k ] + E [ T k ( P k ) | χ k ] N X n =1 E [ V f n ( r n,k ) − Y n,k λ n r n,k | χ k ] , where W n,k ( P k ) is the av erage delay of class n if the control and power allocation in frame k is repeated in ev ery frame. W e are interested in the frame-based policy that minimizes the ratio Ψ( χ k ) E [ T k ( P k ) | χ k ] in each frame k ∈ Z + . Lemma 5 shows the minimizer is a deterministic policy , under which the ratio is equal to N X n =1 Y n,k λ n W n,k ( P k ) + X k ( P k ρ sum ( P k ) − P const ) + N X n =1 ( V f n ( r n,k ) − Y n,k λ n r n,k ) , where ρ sum ( P k ) , P N n =1 λ n E [ S n ] /µ ( P k ) . Under similar simplifications as the DynPo wer policy in Section VI-B, we can show that the PwDelayF air policy is the desired policy . C. P erformance of the PwDelayF air P olicy Theorem 4. F or any feasible average power constraint P ≤ P const , the PwDelayF air policy satisfies P ≤ P const and yields averag e delay penalty satisfying lim sup K →∞ N X n =1 f n E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h P K − 1 k =0 | A n,k | i ≤ C P N n =1 λ n V + N X n =1 f n ( W ∗ n ) , (44) wher e V > 0 is a predefined contr ol parameter . Pr oof of Theor em 4: Let π ∗ rand be the frame-based randomized policy that solves (39)-(40). Let ( W ∗ n ) N n =1 be the optimal av erage delay vector , and P ∗ , where P ∗ ≤ P const , be the associated power consumption. In frame k ∈ Z + , the ratio Ψ( χ k ) E [ T k ( P k ) | χ k ] ev aluated under policy π ∗ rand and genie decisions r ∗ n,k = W ∗ n for all classes n is equal to N X n =1 Y n,k λ n W ∗ n + X k P ∗ − X k P const + N X n =1 V f n ( W ∗ n ) − Y n,k λ n W ∗ n ≤ V N X n =1 f n ( W ∗ n ) . (45) Since the PwDelayF air policy minimizes Ψ( χ k ) E [ T k ( P k ) | χ k ] in ev ery frame k , the ratio under the PwDelayF air policy satisfies Ψ( χ k ) E [ T k ( P k ) | χ k ] ≤ V N X n =1 f n ( W ∗ n ) . 12 Then (43) under the PwDelayF air policy satisfies ∆( χ k ) + V E " N X n =1 f n ( r n,k ) T k ( P k ) | χ k # ≤ C + V E [ T k ( P k ) | χ k ] N X n =1 f n ( W ∗ n ) . (46) Removing the second term in (46) and taking expectation, we get E [ L ( χ k +1 )] − E [ L ( χ k )] ≤ C + V E [ T k ( P k )] N X n =1 f n ( W ∗ n ) . Summing over k ∈ { 0 , . . . , K − 1 } , and using L ( χ 0 ) = 0 yields E [ L ( χ K )] ≤ K C + V E " K − 1 X k =0 T k ( P k ) # N X n =1 f n ( W ∗ n ) ≤ K C 1 (47) where C 1 , C + V E [ T 0 ( P min )] P N n =1 f n ( W ∗ n ) , and we have used E [ T k ( P k )] ≤ E [ T 0 ( P min )] . Inequality (47) suffices to conclude that queues X k and Y n,k for all classes n are all mean rate stable. From Lemma 6 the constraint P ≤ P const is achiev ed. The proof of (44) follows that of Theorem 2. V I I I . S I M U L AT I O N S Here we simulate the DelayF eas and DelayF air policy in the first two delay control problems; simulations for the DynP o wer and PwDela yFair policy in the last two delay-power control problems are our future work. The setup is as follows. Consider a two-class M / M / 1 queue with Poisson arriv al rates ( λ 1 , λ 2 ) = (1 , 2) , loading factors ( ρ 1 , ρ 2 ) = (0 . 4 , 0 . 4) , and mean exponential service times E [ X 1 ] = ρ 1 /λ 1 = 0 . 4 and E [ X 2 ] = ρ 2 /λ 2 = 0 . 2 (we use service times directly since there is no power control). The average delay region W of this two-class M / M / 1 queue, giv en in (29), is W = ( ( W 1 , W 2 ) W 1 + W 2 = 2 . 4 W 1 ≥ 0 . 4 , W 2 ≥ 0 . 4 ) . (48) For the DelayF eas policy , we consider fi ve sets of delay constraints ( d 1 , d 2 ) = (0 . 45 , 2 . 05) , (0 . 85 , 1 . 65) , (1 . 25 , 1 . 25) , (1 . 65 , 0 . 85) , and (2 . 05 , 0 . 45) ; they are all (0 . 05 , 0 . 05) aw ay from a feasible point on W . For each constraint set ( d 1 , d 2 ) , we repeat the simulation for 10 times and take an av erage on the resulting av erage delay , where each simulation is run for 10 6 frames. The results are giv en in Fig. 3, which shows that the DelayF eas policy adaptiv ely yields feasible average delays in response to different constraints. Next, for the DelayF air policy , we consider the following delay proportional fairness problem: minimize: 1 2 W 2 1 + 2 W 2 2 (49) subject to: ( W 1 , W 2 ) ∈ W (50) W 1 ≤ 2 , W 2 ≤ 2 (51) where the delay region W is giv en in (48). The additional delay constraints (51) are chosen to be non-restrictiv e for 0.4 0.8 1.2 1.6 2 Class 1 average delay 0.4 0.8 1.2 1.6 2 Class 2 average delay Delay region W Delay bounds (d1, d2) Simulation results Fig. 3. The performance of the DelayF eas policy under different delay constraints ( d 1 , d 2 ) . the ease of demonstration. The optimal solution to (49)-(51) is ( W ∗ 1 , W ∗ 2 ) = (1 . 92 , 0 . 48) ; the optimal delay penalty is 1 2 ( W ∗ 1 ) 2 + 2( W ∗ 2 ) 2 = 2 . 304 . W e simulate the DelayF air policy for different values of control parameter V ∈ { 10 2 , 10 3 , 5 × 10 3 , 10 4 } . The results are in T able I. Every entry in T able I V W DelayF air 1 W DelayF air 2 Delay penalty 100 1 . 611 0 . 785 2 . 529 1000 1 . 809 0 . 591 2 . 335 5000 1 . 879 0 . 523 2 . 312 10000 1 . 894 0 . 503 2 . 301 Optimal value: 1 . 92 0 . 48 2 . 304 T ABLE I T H E A V E R AG E D E LAY S A ND D E L AY P E NA LT Y U N DE R T H E Dela yFair P O L IC Y F O R D I FF E RE N T V A L U E S O F C O NT R OL PA R A ME T E R V . is the av erage ov er 10 simulation runs, where each simulation is run for 10 6 frames. As V increases, the Dela yF air policy yields av erage delays approaching the optimal (1 . 92 , 0 . 48) and the optimal penalty 2 . 304 . I X . C O N C L U S I O N S This paper solves constrained delay-power stochastic op- timization problems in a nonpreemptive multi-class M /G/ 1 queue from a new mathematical programming perspectiv e. After characterizing the performance region by the collec- tion of all frame-based randomizations of base policies that comprise deterministic power control and nonpreemptive strict priority policies, we use the L yapunov optimization theory to construct dynamic control algorithms that yields near-optimal performance. These policies greedily select and run a base policy in every frame by minimizing a ratio of an expected “drift plus penalty” sum ov er the expected frame size, and require limited statistical knowledge of the system. Time av erage constraints are turned into virtual queues that need to be stabilized. While this paper studies delay and power control in a nonpreemptiv e multi-class M /G/ 1 queue, our framew ork shall have a much wider applicability to other stochastic op- timization problems ov er queueing networks, especially those that satisfy strong (possibly generalized [36]) conservation laws and have polymatroidal performance regions. Different 13 performance metrics such as throughput (together with ad- mission control), delay , power , and functions of them can be mixed together to serve as objecti ve functions or time average constraints. It is of interest to us to explore all these directions. Another connection is, in [15], we have used the frame- based L yapunov optimization theory to optimize a general functional objective over an inner bound on the performance region of a restless bandit problem with Markov ON/OFF bandits. This inner bound approach can be viewed as an ap- proximation to such comple x restless bandit problems. Multi- class queueing systems and restless bandit problems are two prominent examples of general stochastic control problems. Thus it would be interesting to dev elop the L yapunov opti- mization theory as a unified frame work to attack other open stochastic control problems. R E F E R E N C E S [1] D. D. Y ao, “Dynamic scheduling via polymatroid optimization, ” in P erformance Evaluation of Complex Systems: T echniques and T ools, P erformance 2002, T utorial Lectur es . London, UK: Springer -V erlag, 2002, pp. 89–113. [2] D. Bertsimas, I. C. Paschalidis, and J. N. Tsitsiklis, “Optimization of multiclass queueing networks: Polyhedral and nonlinear characteriza- tions of achievable performance, ” Ann. Appl. Pr obab . , vol. 4, no. 1, pp. 43–75, 1994. [3] D. Bertsimas, “The achiev able region method in the optimal control of queueing systems; formulations, bounds, and policies, ” Queueing Syst. , vol. 21, no. 3-4, pp. 337–389, Sep. 1995. [4] J. Nino-Mora, “Stochastic scheduling, ” in Encyclopedia of Optimization , 2nd ed., C. A. Floudas and P . M. Pardalos, Eds. Springer, 2009, pp. 3818–3824. [5] A. Federgruen and H. Groenev elt, “M/G/c queueing systems with multiple customer classes: Characterization and control of achiev able performance under nonpreemptiv e priority rules, ” Manage. Sci. , vol. 34, no. 9, pp. 1121–1138, Sep. 1988. [6] L. T assiulas and A. Ephremides, “Stability properties of constrained queueing systems and scheduling policies for maximum throughput in multihop radio networks, ” IEEE T rans. Autom. Contr ol , vol. 37, no. 12, pp. 1936–1948, Dec. 1992. [7] ——, “Dynamic server allocation to parallel queues with randomly varying connectivity , ” IEEE T rans. Inf. Theory , vol. 39, no. 2, pp. 466– 478, Mar . 1993. [8] L. Georgiadis, M. J. Neely , and L. T assiulas, “Resource allocation and cross-layer control in wireless networks, ” F oundations and T rends in Networking , vol. 1, no. 1, 2006. [9] M. J. Neely , “Dynamic power allocation and routing for satellite and wireless networks with time varying channels, ” Ph.D. dissertation, Massachusetts Institute of T echnology , November 2003. [10] ——, “Energy optimal control for time varying wireless networks, ” IEEE T rans. Inf. Theory , vol. 52, no. 7, pp. 2915–2934, Jul. 2006. [11] M. J. Neely , E. Modiano, and C.-P . Li, “Fairness and optimal stochastic control for heterogeneous networks, ” IEEE/ACM T rans. Netw . , vol. 16, no. 2, pp. 396–409, Apr . 2008. [12] M. J. Neely , “Stochastic optimization for markov modulated networks with application to delay constrained wireless scheduling, ” in IEEE Conf. Decision and Contr ol (CDC) , 2009. [13] ——, “Dynamic optimization and learning for renew al systems, ” in Asilomar Conf. Signals, Systems, and Computers , Nov . 2010, invited paper . [14] ——, Stochastic Network Optimization with Application to Communi- cation and Queueing Systems . Mor gan & Claypool, 2010. [15] C.-P . Li and M. J. Neely , “Network utility maximization over partially observable marko vian channels, ” arXiv report, Aug. 2010. [Online]. A vailable: http://arxiv .org/abs/1008.3421 [16] F . P . K elly , “Charging and rate control for elastic traffic, ” European T rans. T elecommunications , v ol. 8, pp. 33–37, 1997. [Online]. A vailable: http://www .statslab.cam.ac.uk/$ \ sim$frank/elastic.html [17] W .-H. W ang, M. Palaniswami, and S. H. Low , “ Application-oriented flow control: Fundamentals, algorithms, and f airness, ” IEEE/ACM T rans. Netw . , vol. 14, no. 6, pp. 1282–1291, Dec. 2006. [18] A. Federgruen and H. Groenevelt, “Characterization and optimization of achievable performance in general queueing systems, ” Oper . Res. , vol. 36, no. 5, pp. 733–741, 1988. [19] P . S. Ansell, K. D. Glazebrook, J. Nino-Mora, and M. O’Keeffe, “Whittle’ s index policy for a multi-class queueing system with conv ex holding costs, ” Math. Methods of Oper . Res. , vol. 57, pp. 21–39, 2003. [20] K. D. Glazebrook, R. R. Lumley , and P . S. Ansell, “Index heuristics for multiclass M/G/1 systems with nonpreemptiv e service and con ve x holding costs, ” Queueing Syst. , vol. 45, no. 2, pp. 81–111, Oct. 2003. [21] P . Whittle, “Restless bandits: Acti vity allocation in a changing world, ” J. Appl. Probab . , vol. 25, pp. 287–298, 1988. [22] J. A. van Mieghem, “Dynamic scheduling with conve x delay costs: The generalized cmu rule, ” Ann. Appl. Pr obab . , vol. 5, no. 3, pp. 809–833, 1995. [23] L. L. H. Andre w , M. Lin, and A. Wierman, “Optimality , fairness, and robustness in speed scaling designs, ” in ACM SIGMETRICS , 2010. [24] N. Bansal, H.-L. Chan, and K. Pruhs, “Speed scaling with an arbitrary power function, ” in A CM-SIAM Symp. Discrete Algorithms , New Y ork, NY , 2009, pp. 693–701. [25] L. L. H. Andrew , A. W ierman, and A. T ang, “Optimal speed scaling under arbitrary power functions, ” in ACM P erformance Evaluation Review , 2009. [26] S. Albers and H. Fujiwara, “Energy-efficient algorithms for flow time minimization, ” ACM T rans. Algorithms , vol. 3, no. 4, Nov . 2007. [27] N. Bansal, K. Pruhs, and C. Stein, “Speed scaling for weighted flow time, ” in Pr oc. ACM-SIAM Symp. Discrete algorithms (SODA) . Philadelphia, P A, USA: Society for Industrial and Applied Mathematics, 2007, pp. 805–813. [28] A. W ierman, L. L. H. Andrew , and A. T ang, “Po wer-a ware speed scaling in processor sharing systems, ” in IEEE Pr oc. INFOCOM , Rio de Janeiro, Brazil, Apr . 2009, pp. 2007–2015. [29] S. Kaxiras and M. Martonosi, Computer Arc hitectur e T echniques for P ower-Efficiency , ser . Synthesis Lectures on Computer Architecture. Morgan & Claypool, 2008. [30] A. Gandhi, M. Harchol-Balter, R. Das, and C. Lefurgy , “Optimal power allocation in server farms, ” in A CM SIGMETRICS , Seattle, W A, USA, 2009, pp. 157–168. [31] P . S. Ansell, K. D. Glazebrook, I. Mitrani, and J. Nino-Mora, “ A semidefinite programming approach to the optimal control of a single server queueing system with imposed second moment constraints, ” Journal of the Oper . Res. , vol. 50, no. 7, pp. 765–773, Jul. 1999. [32] S. M. Ross, Stochastic Processes , 2nd ed. John W iley & Sons, Inc., 1996. [33] D. P . Bertsekas and R. G. Gallager, Data Networks , 2nd ed. Prentice Hall, 1992. [34] D. J. A. W elsh, Matr oid Theory , P . M. Cohn and G. E. H. Reuter, Eds. London, UK: Academic Press, 1976. [35] L. Kleinrock, Communication Nets: Stochastic Message Flow and Delay . New Y ork, NY , USA: McGraw-Hill, 1964. [36] D. Bertsimas and J. Nino-Mora, “Conserv ation laws, extended poly- matroids, and multiarmed bandit problems; a polyhedral approach to indexable systems, ” Math. of Oper . Res. , vol. 21, no. 2, pp. 257–306, May 1996. A P P E N D I X A Pr oof of Lemma 1: W e index all N ! nonpreemptiv e strict priority policies by { π j } j ∈J , where J = { 1 , . . . , N ! } is an index set and π j denotes the j th priority ordering. Consider a randomized policy π rand defined by the probability distribution { α j } j ∈J , where π rand uses priority ordering π j for the duration of a frame with probability α j in ev ery frame. Let W sum n ( π j ) denote the sum of queueing delays in class n during a frame in which policy π j is used. Like wise, define W sum n ( π rand ) under policy π rand . By conditional expectation, we get E [ W sum n ( π rand )] = X j ∈J α j E [ W sum n ( π j )] . (52) Next, define W n ( π j ) as the average queueing delay for class n if policy π j is used in ev ery frame. Define W n ( π rand ) under 14 policy π rand similarly . From renew al reward theory , we hav e E [ W sum n ( π rand )] = λ n W n ( π rand ) E [ T ] (53) E [ W sum n ( π j )] = λ n W n ( π j ) E [ T ] , (54) where E [ T ] is the av erage frame size. Note that E [ T ] is independent of scheduling policies. From (52)-(54) we get W n ( π rand ) = X j ∈J α j W n ( π j ) . (55) Define x n ( π j ) , ρ n W n ( π j ) for all priority orderings π j . Define x n ( π rand ) similarly . Multiplying (55) by ρ n for all classes n and noting that vertices of the polytope Ω are performance vectors of strict priority policies, we hav e ( x n ( π rand )) N n =1 = X j ∈J α j ( x n ( π j )) N n =1 ∈ Ω , which proves the first part. In the conv erse, for any given vector ( W n ) N n =1 in the delay region W , there exists a probability distribution { β j } j ∈J such that ρ n W n = X j ∈J β j x n ( π j ) ⇒ W n = X j ∈J β j W n ( π j ) for all classes n . From (55), the randomized π rand policy defined by the probability distrib ution { β j } j ∈J achiev es the desired average delays ( W n ) N n =1 . A P P E N D I X B Lemma 7. In a multi-class M /G/ 1 queue with N classes and a constant service rate (assuming a constant power allocation and no power contr ol), if the first four moments of service times X n ar e finite for all classes n ∈ { 1 , . . . , N } , and that the system is stable with P N n =1 λ n E [ X n ] < 1 , then, in every frame k ∈ Z + , the expectation E X i ∈ A n,k W ( i ) n,k − d n 2 is finite for all classes n under any work-conserving policy . Pr oof of Lemma 7: For brevity , we only give a sketch of proof. Using E ( a − b ) 2 ≤ 2 E a 2 + b 2 , it suffices to show E X i ∈ A n,k W ( i ) n,k 2 , E h d 2 n | A n,k | 2 i are both finite. W e only show the first expectation is finite; the finiteness of the second expectation follows that of the first expectation. Define N k as the number of arriv als of all classes served in frame k ; we hav e | A n,k | ≤ N k for all k and classes n . In the k th frame, since the queueing delay W ( i ) n,k of each job i ∈ A n,k is bounded by the busy period B k , we have E X i ∈ A n,k W ( i ) n,k 2 ≤ E B 2 k N 2 k . Note that B k and N k are dependent because a large busy period serves more jobs. By Cauchy-Schwarz inequality we hav e E B 2 k N 2 k ≤ q E [ B 4 k ] E [ N 4 k ] . It suffices to show that both E B 4 k and E N 4 k are finite. First we argue E B 4 k < ∞ . In the following we drop the index k for notational con venience. Since the frame size B is the same under any work-conserving policy , we consider LIFO scheduling with preemptive priority . In this scheme, let a 0 denote the arriv al that starts the current busy period. Arriv al a 0 can be of any class, and the duration it stays in the system is equal to the busy period B . Next, let { a 1 , . . . , a M } denote the M jobs that arrive during the service of job a 0 . Let B (1) , . . . , B ( M ) denote the duration they stay in the system. Under LIFO with preemptive priority , we observe that B (1) , . . . , B ( M ) are independent and identically distributed with the starting busy period B (since any new arriv al never sees any previous arriv als, and starts a new busy period). Consequently , we hav e B = X + M X m =1 B ( m ) , (56) where X denote the service time of a 0 . Note also that each duration B ( m ) for all m ∈ { 1 , . . . , M } is independent of M . By taking square and expectation of (56), we can compute E B 2 in closed form and show that it is finite if the first two moments of X n for all n are finite. Likewise, by raising (56) to the third and fourth power and taking expectation, we can compute E B 3 and E B 4 and sho w they are finite if the first four moments of X n are finite (showing E B 4 < ∞ requires the finiteness of the first three moments of B ). Like wise, to show E N 4 is finite, under LIFO with pre- emptiv e priority we observe N = 1 + M X m =1 N ( m ) , (57) where N ( m ) denotes the number of arriv als, including a m , served during the course of arriv al a m staying in the system; N ( m ) are i.i.d. and independent of M . By raising (57) to the second, third, and fourth power and taking expectation, we can compute E N 4 in closed form and show it is finite. A P P E N D I X C Pr oof of Lemma 4: From (17) we get Y n,k +1 ≥ Y n,k − r n,k | A n,k | + X i ∈ A n,k W ( i ) n,k . Summing o ver k ∈ { 0 , . . . , K − 1 } and using Y n, 0 = 0 yields K − 1 X k =0 X i ∈ A n,k W ( i ) n,k − Y n,K ≤ K − 1 X k =0 r n,k | A n,k | . 15 T aking expectation and dividing by λ n E h P K − 1 k =0 T k i yields E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i λ n E h P K − 1 k =0 T k i − E [ Y n,K ] λ n K E [ T 0 ] ≤ E h P K − 1 k =0 r n,k | A n,k | i λ n E h P K − 1 k =0 T k i . (58) where in the second term we use E [ T k ] = E [ T 0 ] for all k . In the last term of (58), since the value r n,k is independent of | A n,k | and T k , we get E h P K − 1 k =0 r n,k | A n,k | i λ n E h P K − 1 k =0 T k i = E h P K − 1 k =0 r n,k T k i E h P K − 1 k =0 T k i . (59) Defining as θ ( n ) K the left side of (58) and using (58) (59) yields θ ( n ) K ≤ E h P K − 1 k =0 r n,k T k i E h P K − 1 k =0 T k i . (60) Since f n ( · ) is nondecreasing for all classes n , we get lim sup K →∞ N X n =1 f n θ ( n ) K ≤ lim sup K →∞ N X n =1 f n E h P K − 1 k =0 r n,k T k i E h P K − 1 k =0 T k i . (61) Define the value η ( n ) K , E h P K − 1 k =0 P i ∈ A n,k W ( i ) n,k i E h P K − 1 k =0 | A n,k | i = θ ( n ) K + E [ Y n,K ] λ n K E [ T 0 ] . (62) T o complete the proof, from (61) it suffices to show lim sup K →∞ N X n =1 f n ( η ( n ) K ) = lim sup K →∞ N X n =1 f n ( θ ( n ) K ) . (63) Let the left-side of (63) attains its lim sup in the subsequence { K m } ∞ m =1 . It follows lim sup K →∞ N X n =1 f n ( η ( n ) K ) = lim m →∞ N X n =1 f n ( η ( n ) K m ) ( a ) = N X n =1 f n lim m →∞ η ( n ) K m ( b ) = N X n =1 f n lim m →∞ θ ( n ) K m ≤ lim sup K →∞ N X n =1 f n ( θ ( n ) K ) , where (a) follows the continuity of f n ( · ) for all classes n , (b) follows (62) and mean rate stability of Y n,k . The other direction can be prov ed similarly . A P P E N D I X D W e show how to remove the dependence on the second mo- ments of job sizes S n in the DynPo wer policy in Section VI-B. Using (37), we rewrite (30) as ˆ R " V ˆ R N X n =1 λ n E [ S n ] ! P k µ ( P k ) + N X n =1 Z π n ,k λ π n ( µ ( P k ) − P n − 1 m =0 ˆ ρ π m )( µ ( P k ) − P n m =0 ˆ ρ π m ) # (64) where ˆ R , 1 2 N X n =1 λ n E S 2 n , ˆ ρ π m , ( λ π m E [ S π m ] , 1 ≤ m ≤ N 0 , otherwise. By ignoring constant ˆ R and redefining e V , V / ˆ R in (64), it is equiv alent in the k th frame of the DynPo wer policy to allocate power P k ∈ [ P min , P max ] that minimizes e V N X n =1 λ n E [ S n ] ! P k µ ( P k ) + N X n =1 Z π n ,k λ π n ( µ ( P k ) − P n − 1 m =0 ˆ ρ π m )( µ ( P k ) − P n m =0 ˆ ρ π m ) . (65) The sum (65) does not depend on second moments of job sizes. From Theorem 3 and using V = e V ˆ R , this alternati ve policy yields average power P satisfying P ≤ C P N n =1 λ n e V ˆ R + P ∗ , and we preserve the property that the resulting average P is O (1 / e V ) away from the optimal P ∗ . A P P E N D I X E Pr oof of Lemma 6: From (41) we hav e X k +1 ≥ X k + P k B k ( P k ) − P const T k ( P k ) . Summing ov er k ∈ { 0 , . . . , K − 1 } , taking expectation, and using X 0 = 0 yields E [ X K ] ≥ E " K − 1 X k =0 P k B k ( P k ) # − P const E " K − 1 X k =0 T k ( P k ) # . Dividing by E h P K − 1 k =0 T k ( P k ) i and passing K → ∞ yields P ≤ P const + lim sup K →∞ E [ X K ] K K E h P K − 1 k =0 T k ( P k ) i ( a ) ≤ P const + lim sup K →∞ E [ X K ] K N X n =1 λ n , where (a) uses E [ T k ( P k )] ≥ E [ I k ] = 1 / ( P N n =1 λ n ) . Then the result follows by mean rate stability of queue { X k } ∞ k =0 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment