Regularized Least-Mean-Square Algorithms
We consider adaptive system identification problems with convex constraints and propose a family of regularized Least-Mean-Square (LMS) algorithms. We show that with a properly selected regularization parameter the regularized LMS provably dominates …
Authors: Yilun Chen, Yuantao Gu, Alfred O. Hero
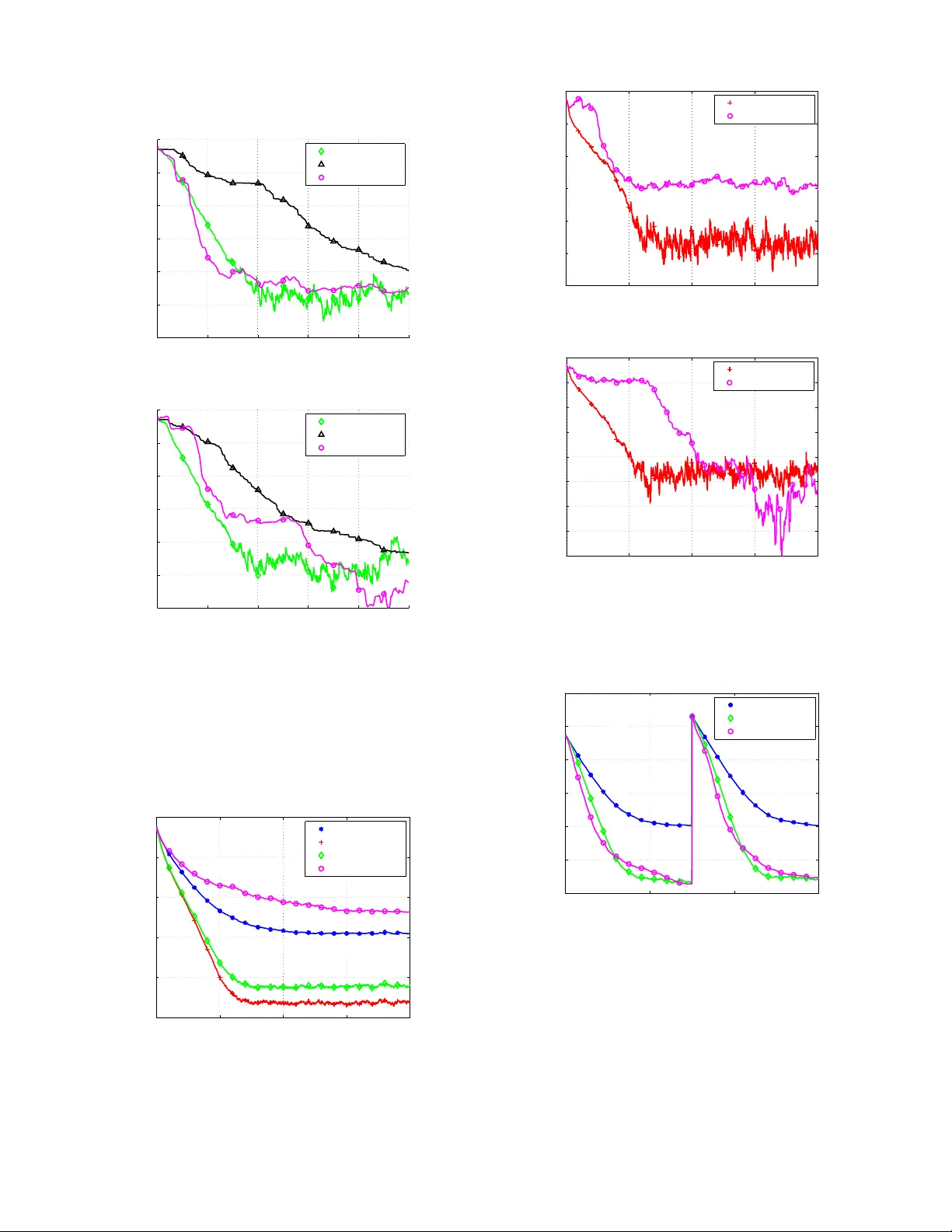
1 Re gularized Least-Mean-Square Algorithms Y ilun Chen, Student Member , IEEE, Y uantao Gu, Member , IEEE, and Alfred O. Hero, III, F ellow , IEEE Abstract —W e consider adaptive system identification problems with con vex constraints and propose a family of r egularized Least-Mean-Square (LMS) algorithms. W e show that with a properly selected regularization parameter the regularized LMS pro vably dominates its con ventional counterpart in terms of mean square deviations. W e establish simple and closed-form expres- sions for choosing this regularization parameter . For identifying an unknown sparse system we propose sparse and group-sparse LMS algorithms, which ar e special examples of the regularized LMS family . Simulation results demonstrate the adv antages of the proposed filters in both conv ergence rate and steady-state error under sparsity assumptions on the true coefficient vector . Index T erms —LMS, NLMS, con vex regularization, sparse system, group sparsity , l1 norm I . I N T RO D U C T I O N The Least Mean Square (LMS) algorithm, introduced by W idrow and Hoff [1], is a popular method for adaptive system identification. Its applications include echo cancelation, channel equalization, interference cancelation and so forth. Although there exist algorithms with faster conv ergence rates such as the Recursive Least Square (RLS) methods, LMS-type methods are popular because of its ease of implementation, low computational costs and robustness. In many scenarios often prior information about the un- known system is available. One important example is when the impulse response of the unkno wn system is kno wn to be sparse, containing only a few large coefficients interspersed among man y small ones. Exploiting such prior information can improv e the filtering performance and has been in vestigated for sev eral years. Early work includes heuristic online selection of acti ve taps [2]–[4] and sequential partial updating [5], [6]; other algorithms assign proportional step sizes of different taps according to their magnitudes, such as the Proportionate Normalized LMS (PNLMS) and its variations [7], [8]. Motiv ated by LASSO [9] and recent progress in compres- siv e sensing [10], [11], the authors in [12] introduced an ` 1 -type regularization to the LMS framew ork resulting in two sparse LMS methods called ZA-LMS and RZA-LMS. This methodology was also applied to other adapti ve filtering framew orks such as RLS [13], [14] and projection-based adap- tiv e algorithms [15]. Inheriting the advantages of con ventional LMS methods such as robustness and low computational costs, the sparse LMS filters were empirically demonstrated Y . Chen and A. O. Hero are with the Department of Electrical Engi- neering and Computer Science, University of Michigan, Ann Arbor, MI 48109, USA. T el: 1-734-763-0564. Fax: 1-734-763-8041. Emails: { yilun, hero } @umich.edu. Y . Gu is with the Department of Electronic Engineering, Tsinghua Univer - sity , Beijing 100084, China. T el:+86-10-62792782, Fax: +86-10-62770317. Email: gyt@tsinghua.edu.cn. This work was partially supported by AFOSR, grant number F A9550-06- 1-0324. to achieve superior performances in both con vergence rate and steady-state behavior , compared to the standard LMS when the system is sparse. Howe ver , while the regularization parameter needs to be tuned there is no systematical way to choose the parameter . Furthermore, the analysis of [12] is only based on the ` 1 penalty and not applicable to other regularization schemes. In this paper, we extend the methods presented in [12], [16] to a broad family of regularization penalties and consider LMS and Normalized LMS algorithms (NLMS) [1] under general con ve x constraints. In addition, we allo w the con ve x constraints to be time-varying. This results in a regularized LMS/NLMS 1 update equation with an additional sub-gradient term. W e show that the regularized LMS prov ably dominates its con ventional counterpart if a proper regularization parame- ter is selected. W e also establish a simple and closed-form formula to choose this parameter . For white input signals, the proposed parameter selection guarantees dominance of the regularized LMS over the con ventional LMS. Next, we show that the sparse LMS filters in [12], i.e., ZA-LMS and RZA-LMS, can be obtained as special cases of the regularized LMS family introduced here. Furthermore, we consider a group-sparse adapti ve FIR filter response that is useful for practical applications [8], [17]. T o enforce group sparsity we use ` 1 , 2 type regularization functions [18] in the regularized LMS framework. For sparse and group-sparse LMS methods, we propose alternativ e closed-form expressions for selecting the regularization parameters. This guarantees prov able domi- nance for both white and correlated input signals. Finally , we demonstrate performance advantages of our proposed sparse and group-sparse LMS filters using numerical simulation. In particular , we sho w that the regularized LMS method is robust to model mis-specification and outperforms the contemporary projection based methods [15] for equiv alent computational cost. The paper is or ganized as follows. Section II formulates the problem and introduces the regularized LMS algorithm. In Section III we de velop LMS filters for sparse and group- sparse system identification. Section IV pro vides numerical simulation results and Section V summarizes our principal conclusion. The proofs of theorems are provided in the Ap- pendix. Notations : In the follo wing parts of paper , matrices and vectors are denoted by boldface upper case letters and boldface lower case letters, respectively; ( · ) T denotes the transpose operator , and k · k 1 and k · k 2 denote the ` 1 and ` 2 norm of a vector , respectiv ely . 1 W e treat NLMS as a special case of the general LMS algorithm and will not distinguish the two unless required for clarity . 2 I I . R E G U L A R I Z E D L M S A. LMS framework W e begin by briefly revie wing the framework of the LMS filter , which forms the basis of our deriv ations to follow . Denote the coefficient vector and the input signal vector of the adaptive filter as ˆ w n = [ ˆ w n, 0 , ˆ w n, 1 , · · · , ˆ w n,N − 1 ] T (1) and x n = [ x n , x n − 1 , · · · , x n − N +1 ] T , (2) respectiv ely , where n is the time index, x n is the input signal, ˆ w n,i is the i -th coefficient at time n and N is the length of the filter . The goal of the LMS algorithm is to identify the true system impulse response w from the input signal x n and the desired output signal y n , where y n = w T x n + v n . (3) v n is the observation noise which is assumed to be independent with x n . Let e n denote the instantaneous error between the filter output ˆ w T n x n and the desired output y n : e n = y n − ˆ w T n x n . (4) In the standard LMS framew ork, the cost function L n is defined as the instantaneous square error L n ( ˆ w n ) = 1 2 e 2 n and the filter coef ficient vector is updated in a stochastic gradient descent manner: ˆ w n +1 = ˆ w n − µ n ∇ L n ( w n ) = ˆ w n + µ n e n x n , (5) where µ n is the step size controlling the conv ergence and the steady-state beha vior of the LMS algorithm. W e refer to (5) as the con ventional LMS algorithm and emphasize that µ n can be both time-varying and functions of x n . For example, µ n = α n k x n k 2 2 (6) yields the normalized LMS (NLMS) algorithm with variable step size α n . B. Re gularized LMS Con ventional LMS algorithms do not impose any model on the true system response w . Ho wever , in practical scenarios often prior kno wledge of w is available. For example, if the system is known to be sparse, the ` 1 norm of w can be upper bounded by some constant [9]. In this work, we study the adaptiv e system identification problem where the true system is constrained by f n ( w ) ≤ η n , (7) where f n ( · ) is a conv ex function and η n is a constant. W e note that the subscript n in f n ( · ) allows adaptiv e constraints that can vary in time. Based on (7) we propose a regularized instantaneous cost function L reg n ( ˆ w n ) = 1 2 e 2 n + γ n f n ( ˆ w n ) (8) and update the coefficient vector by ˆ w n +1 = ˆ w n − µ n ∇ L reg n ( ˆ w n ) = ˆ w n + µ n e n x n − ρ n ∂ f n ( ˆ w n ) , (9) where ∂ f n ( · ) is the sub-gradient of the con vex function f n ( · ) , γ n is the regularization parameter and ρ n = γ n µ n . Eq. (9) is the proposed regularized LMS. Compared to its con ventional counterpart, the regularization term, − ρ n ∂ f n ( ˆ w n ) , al ways promotes the coef ficient v ector to sat- isfy the constraint (7). The parameter ρ n is referred to as the regularization step size. Instead of tuning ρ n in an ad hoc manner , we establish a systematic approach to choosing ρ n . Theorem 1. Assume both { x n } and { v n } ar e Gaussian independent and identically distributed (i.i.d.) pr ocesses that ar e mutually independent. F or any n > 1 E k ˆ w n − w k 2 2 ≤ E k ˆ w 0 n − w k 2 2 (10) if ˆ w 0 = ˆ w 0 0 and ρ n ∈ [0 , 2 ρ ∗ n ] , where w is the true coefficient vector and ˆ w 0 n and ˆ w n ar e filter coefficients updated by (5) and (9) with the same step size µ n , r espectively . ρ ∗ n is calculated by ρ ∗ n = max (1 − µ n σ 2 x ) f n ( ˆ w n ) − η n k ∂ f n ( ˆ w n ) k 2 2 , 0 (11) if µ n ar e constant values (LMS), or ρ ∗ n = max (1 − α n / N ) f n ( ˆ w n ) − η n k ∂ f n ( ˆ w n ) k 2 2 , 0 (12) if µ n is chosen using (6) (NLMS), wher e N is the filter length, σ 2 x is the variance of { x n } and η n is an upper bound of f n ( w ) defined in (7). The proof of Theorem 1 is provided in the Appendix. Remark 1 . Theorem 1 shows that with the same initial condition and step size µ n , the regularized LMS algorithm prov ably dominates conv entional LMS when the input signal is white. The parameter ρ ∗ n in (11) or (12) can be used as the value for ρ n in (9) to guarantee that regularized LMS will hav e lower MSD than con ventional LMS. The v alue ρ ∗ n only requires specification of the noise variance and η n which upper bounds the true value f n ( w ) . Simulations in latter sections show that the performance of the regularized LMS is robust to misspecified values of η n . Remark 2 . Eq. (11) and (12) indicate that to ensure supe- riority the regularization is only “triggered” if f n ( ˆ w n ) > η n . When f n ( ˆ w n ) ≤ η n , ρ ∗ n = 0 and the regularized LMS reduces to the con ventional LMS. Remark 3 . The closed form expression for ρ ∗ n is derived based on the white input assumption. Simulation results in latter sections show that the (11) and (12) are also empirically good choices ev en for correlated input signals. Indeed, in the next section we will show that prov able dominance can be guaranteed for correlated inputs when the re gularization function is suitably selected. 3 0 100 200 300 400 500 −0.2 0 0.2 (b) 0 100 200 300 400 500 −2 0 2 (a) Fig. 1. Examples of (a) a general sparse system and (b) a group-sparse system. I I I . S PA R S E S Y S T E M I D E N T I FI C A T I O N A sparse system contains only a fe w large coef ficients interspersed among man y negligible ones. Such sparse systems are arise in many applications such as digital TV transmission channels [17] and acoustic echo channels [8]. Sparse systems can be further divided into general sparse systems and group- sparse systems, as shown in Fig. 1 (a) and Fig. 1 (b), respec- tiv ely . Here we apply our regularized LMS to both general and group sparse system identification. W e sho w that ZA-LMS and RZA-LMS in [12] are special examples of regularized LMS. W e then propose group-sparse LMS algorithms for identifying group-sparse systems. A. Spar se LMS For a general sparse system, the locations of active non-zero coefficients are unkno wn b ut one may kno w an upper bound on their number . Specifically , we will assume that the impulse response w satisfies k w k 0 ≤ k, (13) where k · k 0 is the ` 0 norm denoting the number of non-zero entries of a vector , and k is a known upper bound. As the ` 0 norm is non-conv ex it is not suited to the proposed frame work. Follo wing [9] and [10], we instead adopt the ` 1 norm as a surrogate approximation to the ` 0 norm: k w k 1 = N − 1 X i =0 | w i | . (14) Using the regularization penalty f n ( w ) = k w k 1 in regularized LMS (9), we obtain ˆ w n +1 = ˆ w n + µ n e n x n − ρ n sgn ˆ w n , (15) where the component-wise sgn( · ) function is defined as sgn( x ) = ( x/ | x | x 6 = 0 0 x = 0 . (16) Equation (15) yields the ZA-LMS introduced in [12]. The regularization parameter ρ n can be calculated by (11) for LMS and by (12) for NLMS, where f n ( ˆ w n ) = k ˆ w n k 1 and η n is an estimate of the true k w k 1 . An alternati ve approach to approximating the ` 0 norm is to consider the following function [12], [15], [19]: k w k 0 ' N − 1 X i =0 1 | w i | + δ · | w i | , (17) where δ is a sufficiently small positi ve real number . Inter- preting (17) as a weighted ` 1 approximation, we propose the regularization function f n ( w ) f n ( w ) = N − 1 X i =0 β n,i · | w i | , (18) and β n,i = 1 | ˆ w n,i | + δ , (19) where ˆ w n,i is the i -th coef ficient of ˆ w n defined in (1). Using (18) in (9) yields ˆ w n +1 ,i = ˆ w n,i + µ n e n x n − i − ρ n β n,i sgn ˆ w n,i , (20) which is a component-wise update of the RZA-LMS proposed in [12]. Again, ρ n can be computed using (11) for LMS or (12) for NLMS, where η n is an estimate of the true k w k 0 , i.e., the number of the non-zero coef ficients. B. Gr oup-sparse LMS In many practical applications, a sparse system often ex- hibits a grouping structure, i.e., coefficients in the same group are highly correlated and take on the values zero or non-zero as a group, as shown in Fig. 1 (b). The motiv ation for developing group-sparse LMS is to take advantage of such a structure. W e begin by employing the mixed ` 1 , 2 norm for promoting group-sparsity , which was originally proposed in [18] and has been widely adopted for v arious structured sparse regression problems [20], [21]. The ` 1 , 2 norm of a v ector w is defined as k w k 1 , 2 = J X j =1 k w I j k 2 , (21) where { I j } J j =1 is a group partition of the whole inde x set I = { 0 , 1 , . . . , N − 1 } : J [ j =1 I j = I , I j ∩ I j 0 = φ when j 6 = j 0 , (22) and w I j is a sub-vector of w index ed by I j . The ` 1 , 2 norm is a mixed norm: it encourages correlation among coefficients inside each group via the ` 2 norm and promotes sparsity across those groups using the ` 1 norm. k w k 1 , 2 is con vex in w and reduces to k w k 1 when each group contains only one coefficient, i.e., | I 1 | = | I 2 | = · · · = | I J | = 1 , (23) where | · | denotes the cardinality of a set. Employing f n ( w ) = k w k 1 , 2 , the ` 1 , 2 regularized LMS, which we refer to as GZA- LMS, is ˆ w n +1 ,I j = ˆ w n,I j + µ n e n x I j − ρ n ˆ w n,I j k ˆ w n,I j k 2 + δ , j = 1 , ..., J, (24) 4 w I 1 w I 2 w I 3 w I 4 Fig. 2. A toy example illustrating the ` 1 , 2 norm of a 16 × 1 coefficient vector w : k w k 1 , 2 = P 4 j =1 k w I j k 2 . and δ is a sufficiently small number ensuring a non-zero denominator . T o the best of our knowledge this is the first time that the ` 1 , 2 norm has been proposed for the LMS adaptiv e filters. T o further promote group selection we consider the follow- ing weighted ` 1 , 2 regularization as a group-wise generalization of (18): f n ( w ) = J X j =1 β n,j k w I j k 2 , (25) where β n,j is a re-weighting parameter defined by β n,j = 1 k ˆ w n,I j k 2 + δ , (26) and the corresponding regularized LMS update is then ˆ w n +1 ,I j = ˆ w n,I j + µ n e n x I j − ρ n β n,j ˆ w n,I j k ˆ w n,I j k 2 + δ , j = 1 , ..., J, (27) which is referred to as GRZA-LMS. As both the ` 1 , 2 norm and the weighted ` 1 , 2 norm are con vex, Theorem 1 applies under the assumption of white input signals and ρ n can be calculated by (11) or (12). The parameter η n can be chosen as an estimate of the true k w k 1 , 2 for GZA-LMS (24), or the number of non-zero groups of w for GRZA-LMS (27). Finally , we note that GZA-LMS and GRZA-LMS reduce to ZA-LMS and RZA-LMS, respectiv ely , if each group contains only one element. C. Choosing r e gularization parameter for corr elated input Theorem 1 giv es a closed form expression for ρ n and (11) or (12) is applicable for any con vex f n ( w ) . Howe ver , the dominance ov er conv entional LMS is only guaranteed when the input signal is white. Here we develop an alternativ e formula to determine ρ n that applies to correlated input signals for sparse and group-sparse LMS, i.e., (15), (20), (24) and (27). W e begin by considering the weighted ` 1 , 2 regularization (25) and the corresponding GRZA-LMS update (27). Indeed, the other three algorithms, i.e., (24), (20) and (15), can be treated as special cases of (27). For general wide-sense stationary (WSS) input signals, the regularization parameter ρ n of (27) can be selected according the follo wing theorem. Theorem 2. Assume { x n } and { v n } ar e WSS stochastic pr ocesses which ar e mutually independent. Let ˆ w n and ˆ w 0 n be filter coefficients updated by (27) and (5) with the same µ n , respectively . Then, E k ˆ w n +1 − w k 2 2 ≤ E ˆ w 0 n +1 − w 2 2 (28) if ˆ w n = ˆ w 0 n and ρ n ∈ [0 , 2 ρ ∗ n ] , w is the true coefficient vector and ρ ∗ n is ρ ∗ n = max f n ( ˆ w n ) − η n − µ n r n k ∂ f n ( ˆ w n ) k 2 2 , 0 , (29) wher e f n ( ˆ w n ) is determined by (25), η n is an upper bound of f n ( w ) and r n = ˆ w T n x n · x T n ∂ f n ( ˆ w n )+ η n · max j k x I j k 2 β n,j ·| x T n ∂ f n ( ˆ w n ) | . (30) The proof of Theorem 2 can be found in the Appendix. W e make the following remarks. Remark 4 . Theorem 2 is deri ved from the general form (27) and can be directly specialized to (24), (20) and (15). Specifically , • GZA-LMS (24) can be obtained by assigning β n,j = 1 ; • RZA-LMS (20) can be obtained when | I j | = 1 , j = 1 , ..., J ; • ZA-LMS (15) can be obtained when both | I j | = 1 , j = 1 , ..., J and β n,j = 1 . Remark 5. Theorem 2 is v alid for any WSS input signals. Howe ver , the dominance result in (28) is weaker than that in Theorem 1, as it requires ˆ w n = ˆ w 0 n at each iteration. Remark 6. Eq. (29) can be applied to both LMS and NLMS, depending on if µ n are deterministic functions of x n as specified in (6). This is different from Theorem 1 where we hav e separate expressions for LMS and NLMS. Remark 7. ρ ∗ n in (29) is non-zero only if f n ( ˆ w n ) is greater than η n + µ n r n (rather than η n as presented in Theorem 1). This may yield a more conservati ve performance. I V . N U M E R I C A L S I M U L AT I O N S In this section we demonstrate our proposed sparse LMS algorithms by numerical simulations. Multiple experiments are designed to ev aluate their performances over a wide range of conditions. A. Identifying a gener al sparse system Here we perform e valuation of the proposed filters for general sparse system identification, as illustrated in Fig. 1 (a). There are 100 coef ficients in the time varying system and only fiv e of them are non-zero. The fiv e non-zero coefficients are assigned to random locations and their v alues are also randomly drawn from a standard Gaussian distribution. The resultant true coefficient vector is plotted in Fig. 3. 1) White input signals: Initially we simulate white Gaus- sian input signal { x n } with zero mean and unit v ariance. The measurement noise { v n } is an independent Gaussian random process of zero mean and variance σ 2 v = 0 . 1 . For ease of parameter selection, we implement NLMS-type filters in our simulation. Three filters (NLMS, ZA-NLMS and RZA-NLMS) are implemented and their common step-size µ n is set via (6) 5 0 20 40 60 80 100 −1 −0.5 0 0.5 1 Fig. 3. The general sparse system used for simulations. 0 500 1000 1500 2000 −25 −20 −15 −10 −5 0 5 Iterations MSD (dB) NLMS ZA−NLMS RZA−NLMS APLW1, q=1 APLW1, q=10 Fig. 4. White input signals: performance comparison for dif ferent filters. with α n = 1 . The regularization parameter ρ n is computed using (12), where η n is set to η n = k w k 1 ( i.e., the true v alue) for ZA-NLMS and η n = 5 for RZA-NLMS. F or comparison we also implement a recently proposed sparse adaptive filter , referred to as APWL1 [15], which sequentially projects the coefficient vector onto weighted ` 1 balls. W e note that our simulation setting is identical to that used in [15] and thus we adopt the same tuning parameters for APWL1. In addition, the weights β n,i for RZA-NLMS is scheduled in the same manner as that in [15] for a fair comparison. The simulations are run 100 times and the a verage estimates of mean square deviation (MSD) are shown in Fig. 4. It can be observ ed that ZA-NLMS improv es upon NLMS in both con vergence rate and steady-state behavior and RZA- NLMS does ev en better . The parameter q of APL W1 is the number of samples used in each iteration. One can see that RZA-NLMS outperforms APL W1 when q = 1 , i.e., the case that APL W1 operates with the same memory storage as RZA-NLMS. W ith larger p APL W1 begins to perform better and exceeds RZA-NLMS when q ≥ 10 . Howe ver , there is a trade-off between the system complexity and filtering performance, as APWL1 requires O ( q N ) for memory storage and O ( N log 2 N + q N ) for computation, in contrast to LMS- type methods which require only O ( N ) for both memory and computation. Next, we in vestigate the sensiti vity to η n for ZA-NLMS and RZA-NLMS. The result shown in Fig. 5 indicates that ZA-NLMS is more sensiti ve to η n than RZA-NLMS, which is highly robust to misspecified η n . Further analysis re veals that the projection based methods such APWL1 may exhibit unstable con verging behaviors. Fig. −80 −60 −40 −20 0 20 40 60 80 100 −20 −15 −10 −5 0 5 %discrepancy MSD (dB) ZA−NLMS RZA−NLMS Fig. 5. Sensitivity of ZA-NLMS and RZA-NLMS to η n : MSD for ZA-NLMS and RZA-NLMS at the 750th iteration for white input signals. 6 shows two independent trials of the simulation implemented in Fig. 4. It can be seen that there exist several local minima in APWL1. For example, Fig. 6 (b) seems to indicate that APWL1 ( q = 10 ) con ver ges at the 400th iteration with MSD ' − 12 dB, yet its MSD actually reaches values as lo w as − 25 dB at the 900th iteration. This slow con vergence phenomenon is due to the fact that the weighted ` 1 ball is determined in an online fashion and the projection operator is sensitive to mis-specifications of the con vex set. In the contrast, our regularized LMS uses sub-gradient rather than projection to pursue sparsity , translating into improv ed conv ergence. 2) Corr elated input signals: Next, we e valuate the filtering performance using correlated input signals. W e generate the sequence { x n } as an AR(1) process x n = 0 . 8 x n − 1 + u n , (31) which is then normalized to unit variance, where { u n } is a Gaussian i.i.d. process. The measurement system is the same as before and the v ariance of the noise is also σ 2 v = 0 . 1 . W e compare our RZA-NLMS with APWL1 ( q = 10 ) and standard NLMS is also included as a benchmark. All the filter parameters are set to the same values as that in the previous simulation, except we employ both (12) and (29) to calculate ρ n in RZA-NLMS. The simulations are run 100 times and the av erage MSD curves are plotted in Fig. 7. While Theorem 1 is deriv ed based on white input assumptions, using (12) to determine ρ n achiev es an empirically better performance compared to using (29) – whose use guarantees dominance but yields a conservati ve result. This confirms our conjecture in Remark 7. W e also observe a severe perfor- mance de gradation of APWL1 for correlated input signals. Fig. 8 draws two independent trials in this simulation. The phenomenon described in Fig. 6 becomes more frequent when the input signal is correlated, which drags down the av erage performance of APWL1 significantly . Finally , we note that the filtering performance of a group sparse system ( e.g., Fig. 1 (b)) may be very different from that of a general sparse system. This will in vestigated in Section IV -B. 3) T racking performance: Finally , we study the tracking performance of the proposed filters. The time-varying system is initialized using the same parameters as used to generate 6 200 400 600 800 1000 −25 −20 −15 −10 −5 0 5 Iterations MSD (dB) RZA−NLMS APLW1, q=1 APLW1, q=10 (a) 200 400 600 800 1000 −25 −20 −15 −10 −5 0 5 Iterations MSD (dB) RZA−NLMS APLW1, q=1 APLW1, q=10 (b) Fig. 6. T wo dif ferent trials of RZA-NLMS and APWL1 for white input signals. APWL1 exhibits unstable conver gence. 0 1000 2000 3000 4000 −20 −15 −10 −5 0 5 Iterations MSD (dB) NLMS RZA−NLMS 1 RZA−NLMS 2 APLW1, q=10 Fig. 7. Correlated input signals: performance comparison for different filters, where RZA-NLMS 1 and RZA-NLMS 2 use (12) and (29) to determine ρ n , respectiv ely . 0 1000 2000 3000 4000 −25 −20 −15 −10 −5 0 5 Iterations MSD (dB) RZA−NLMS 1 APLW1, q=10 (a) 0 1000 2000 3000 4000 −35 −30 −25 −20 −15 −10 −5 0 5 Iterations MSD (dB) RZA−NLMS 1 APLW1, q=10 (b) Fig. 8. T wo different trials of RZA-NLMS and APWL1 for correlated input signals. 0 500 1000 1500 −20 −15 −10 −5 0 5 10 Iterations MSD (dB) NLMS RZA−NLMS APLW1, q=10 Fig. 9. Comparison of tracking performances when the input signal is white. Fig. 3. At the 750th iteration the system encounters a sudden change, where all the active coef ficients are left-shifted for 10 taps. W e use white input signals to excite the unknown system and all the filter parameters are set in an identical manner to Section IV -A1. The simulation is repeated 100 times and the av eraged result is shown in Fig. 9. It can be observed that both RZA-NLMS and APWL1 ( q = 10 ) achiev e better tracking performance than the con ventional NLMS. 7 50 100 150 200 −2 0 2 4 Fig. 10. The group-sparse system used for simulations. There are two activ e blocks; each of them contains 15 non-zero coef ficients. 0 500 1000 1500 2000 −20 −10 0 10 20 30 Iterations MSD (dB) NLMS RZA−NLMS GRZA−NLMS Fig. 11. MSD comparison for the group-sparse system for white input signals. B. Identifying a gr oup-sparse system Here we test performance of the group-sparse LMS filters dev eloped in Section III-B. The unknown system contains 200 coefficients that are distributed into two groups. The locations of the two groups are randomly selected, which start from the 36th tap and the 107th tap, respecti vely . Both of the two groups contain 15 coef ficients and their v alues are randomly drawn from a standard Gaussian distribution. Fig. 10 shows the response of the true system. The input signal { x n } is initially set to an i.i.d. Gaussian process and the variance of observation noise is σ 2 v = 0 . 1 . Three filters, GRZA-NLMS, RZA-NLMS and NLMS, are implemented, where the performance of NLMS is treated as a benchmark. In GRZA-NLMS, we divide the 200 coef ficients equally into 20 groups, where each of them contains 10 coefficients. The step size µ n of the three filters are all set according to (6) with α n = 1 . W e use (12) to calculate ρ n , where η n is set to 30 (the number of non-zero coef ficients) for RZA-NLMS and 2 (the number of non-zero blocks) for GRZA-NLMS, respecti vely . W e repeat the simulation 200 times and the av eraged MSD is shown in Fig. 11. It can be seen that GRZA-NLMS and RZA-NLMS outperform the standard NLMS for 10 dB in the steady-state MSD, while GRZA- NLMS only improv es upon RZA-NLMS, but only marginally . This is partially due to the fact that in the white input scenario each coefficient is updated in an independent manner . W e next consider the case of correlated input signals, where { x n } is generated by (31) and then normalized to have unit variance. The parameters for all the filters are set to the same values as in the white input e xample and the av eraged MSD 0 2000 4000 6000 8000 10000 −20 −15 −10 −5 0 5 10 15 20 25 Iterations MSD (dB) NLMS RZA−NLMS GRZA−NLMS Fig. 12. MSD comparison for the group-sparse system for correlated input signals. 0 1000 2000 3000 4000 5000 6000 −20 −15 −10 −5 0 5 10 15 20 25 Iterations MSD (dB) NLMS RZA−NLMS GRZA−NLMS Fig. 13. T racking performance comparison for the group-sparse system for white input signals. curves are plotted in Fig. 12. In the contrast to the white input example, here RZA-NLMS slightly outperforms NLMS but there is a significant impro vement of GRZA-NLMS ov er RZA- NLMS. This demonstrates the power of promoting group- sparsity especially when the input signal is correlated. Finally , we ev aluate the tracking performance of the adap- tiv e filters. W e use white signals as the system input and initialize the time-varying system using that in Fig. 10. At the 2000th iteration, the system response is right-shifted for 50 taps, while the v alues of coef ficients inside each block are unaltered. W e then keep the block locations and reset the values of non-zero coefficients randomly at the 4000th iteration. From Fig. 13 we observe that the tracking rate of RZA-NLMS and GRZA-NLSM are comparable to each other when the system changes across blocks, and GRZA-NLMS shows a better tracking performance than RZA-NLMS when the system response changes only inside its acti ve groups. V . C O N C L U S I O N In this paper we proposed a general class of LMS-type filters regularized by con vex sparsifying penalties. W e deri ved closed-form expressions for choosing the regularization pa- rameter that guarantees prov able dominance ov er conv entional 8 LMS filters. W e applied the proposed regularized LMS filters to sparse and group-sparse system identification and demon- strated their performances using numerical simulations. Our regularized LMS filter is deri ved from the LMS framew ork and inherits its simplicity , lo w computational cost and lo w memory requirements, and robustness to parameter mismatch. It is likely that the con vergence rate and steady-state performance can be improved by extension to second-order methods, such as RLS and Kalman filters. Efficient extensions of our results for sparse/group-sparse RLS filters are a worthy topic of future study . V I . A P P E N D I X A. Pr oof of Theorem 1 W e prove Theorem 1 for LMS, i.e., the case that µ n are constants. NLMS, where µ n is determined by (6), can be deriv ed in a similar manner . According to (9), ˆ w n +1 − w = ( I − µ n x n x T n )( ˆ w n − w ) − ρ n ∂ f n ( ˆ w n ) + µ n v n x n . (32) Noting that ˆ w n , x n and v n are mutually independent, we have E k ˆ w n +1 − w k 2 | ˆ w n = ( ˆ w n − w ) T E I − µ n x n x T n 2 ( ˆ w n − w ) + µ 2 n σ 2 v E k x n k 2 + 2 ρ n ( w − ˆ w n ) T E n I − µ n x n x T n o ∂ f n ( ˆ w n ) + ρ 2 n k ∂ f n ( ˆ w n ) k 2 . (33) As { x n } is a Gaussian i.i.d. process, x n is a Gaussian random vector with mean zero and cov ariance σ 2 x I . Thus, E n I − µ n x n x T n 2 o = (1 − 2 σ 2 x µ n + N σ 4 x µ 2 n ) I , (34) E I − µ n x n x T n = (1 − σ 2 x µ n ) I , (35) and E k x n k 2 = N σ 2 x . (36) Substituting (34), (35) and (36) into (33), we have E k ˆ w n +1 − w k 2 | ˆ w n = (1 − 2 σ 2 x µ n + N σ 4 x µ 2 n ) k ˆ w n − w k 2 + N µ 2 n σ 2 x σ 2 v + 2 ρ n (1 − σ 2 x µ n )( w − ˆ w n ) T ∂ f n ( ˆ w n ) + ρ 2 n k ∂ f n ( ˆ w n ) k 2 . (37) As f n ( · ) is a con ve x function, by the definition of sub-gradient, we have ( w − ˆ w n ) T ∂ f n ( ˆ w n ) ≤ f n ( w ) − f n ( ˆ w n ) ≤ η n − f n ( ˆ w n ) . (38) Therefore, E k ˆ w n +1 − w k 2 | ˆ w n ≤ (1 − 2 σ 2 x µ n + N σ 4 x µ 2 n ) k ˆ w n − w k 2 + N µ 2 n σ 2 x σ 2 v − 2 ρ n (1 − σ 2 x µ n )( f n ( ˆ w n ) − η n ) + ρ 2 n k ∂ f n ( ˆ w n ) k 2 . (39) Define C ( ρ n ) = − 2 ρ n (1 − σ 2 x µ n )( f n ( ˆ w n ) − η n ) + ρ 2 n k ∂ f n ( ˆ w n ) k 2 , (40) and take expectation on both sides of (39) with respect to ˆ w n to obtain E k ˆ w n +1 − w k 2 ≤ (1 − 2 σ 2 x µ n + N σ 4 x µ 2 n ) E k ˆ w n − w k 2 + N µ 2 n σ 2 x σ 2 v + E { C ( ρ n ) } . (41) It is easy to check that C ( ρ n ) ≤ 0 if ρ n ∈ [0 , 2 ρ ∗ n ] , where ρ ∗ n is defined in (11). Therefore, E k ˆ w n +1 − w k 2 ≤ (1 − 2 σ 2 x µ n + N σ 4 x µ 2 n ) E k ˆ w n − w k 2 + N µ 2 n σ 2 x σ 2 v (42) if ρ n ∈ [0 , 2 ρ ∗ n ] . For the standard LMS, there is E k ˆ w 0 n +1 − w k 2 = (1 − 2 σ 2 x µ n + N σ 4 x µ 2 n ) E k ˆ w 0 n − w k 2 + N µ 2 n σ 2 x σ 2 v . (43) Therefore, under the condition that E k ˆ w 0 − w k 2 = E k ˆ w 0 0 − w k 2 , (10) can be obtained from (42) and (43) using a simple induction ar gument. B. Pr oof of Theorem 2 W e start our proof from (32) and calculate the follo wing conditional MSD: E k ˆ w n +1 − w k 2 | ˆ w n , x n = ( ˆ w n − w ) T ( I − µ n x n x T n ) 2 ( ˆ w n − w ) + µ 2 n σ 2 v k x n k 2 + D ( ρ n ) , (44) where D ( ρ n ) = 2 ρ n ( w − ˆ w n ) T ( I − µ n x n x T n ) ∂ f n ( ˆ w n )+ ρ 2 n k ∂ f n ( ˆ w n ) k 2 . (45) For the cross term 2 ρ n ( w − ˆ w n ) T ( I − µ n x n x T n ) ∂ f n ( ˆ w n ) we hav e 2 ρ n ( w − ˆ w n ) T ( I − µ n x n x T n ) ∂ f n ( ˆ w n ) = 2 ρ n ( w − ˆ w n ) T ∂ f n ( ˆ w n ) + 2 ρ n µ n ˆ w T n x n · x T n ∂ f n ( ˆ w n ) − 2 ρ n µ n w T x n · x T n ∂ f n ( ˆ w n ) ≤ 2 ρ n ( η n − f n ( ˆ w n )) + 2 ρ n µ n ˆ w T n x n · x T n ∂ f n ( ˆ w n ) + 2 ρ n µ n w T x n · x T n ∂ f n ( ˆ w n ) . (46) W e now establish upper -bounds for | w T x n | . Indeed, w T x n = J X j =1 w T I j x n,I j ≤ J X j =1 β n,j w T I j 1 β n,j x n,I j ≤ J X j =1 β n,j k w I j k 2 k x n,I j k 2 β n,j ≤ J X j =1 β n,j k w I j k 2 max j k x n,I j k 2 β n,j = f n ( w n ) max j k x n,I j k 2 β n,j ≤ η n max j k x n,I j k 2 β n,j . (47) 9 Substituting (46) and (47) into (45) we obtain that D ( ρ n ) ≤ − 2 ρ n ( f n ( ˆ w n ) − η n − µ n r n )+ ρ 2 n k ∂ f n ( ˆ w n ) k 2 2 , (48) where r n is defined in (30). Note that D ( ρ n ) ≤ 0 if ρ n ∈ [0 , 2 ρ ∗ n ] ( ρ ∗ n is defined in (29)). There is E k ˆ w n +1 − w k 2 | ˆ w n , x n ≤ ( ˆ w n − w ) T ( I − µ n x n x T n ) 2 ( ˆ w n − w ) + µ 2 n σ 2 v k x n k 2 , (49) if ρ n ∈ [0 , 2 ρ ∗ n ] . Therefore, E k ˆ w n +1 − w k 2 | ≤ E ( ˆ w n − w ) T ( I − µ n x n x T n ) 2 ( ˆ w n − w ) + µ 2 n σ 2 v E k x n k 2 = E ( ˆ w 0 n − w ) T ( I − µ n x n x T n ) 2 ( ˆ w 0 n − w ) + µ 2 n σ 2 v E k x n k 2 = E k ˆ w 0 n +1 − w k 2 | , (50) which proves Theorem 2. R E F E R E N C E S [1] B. W idrow and S.D. Stearns, Adaptive Signal Pr ocessing , New Jersey: Prentice Hall, 1985. [2] S. Ka wamura and M. Hatori, “ A T AP selection algorithm for adapti ve filters, ” in Pr oceedings of ICASSP , 1986, vol. 11, pp. 2979–2982. [3] J. Homer , I. Mareels, R.R. Bitmead, B. W ahlberg, and A. Gustafsson, “LMS estimation via structural detection, ” IEEE T rans. on Signal Pr ocessing , v ol. 46, pp. 2651–2663, October 1998. [4] Y . Li, Y . Gu, and K. T ang, “Parallel NLMS filters with stochastic active taps and step-sizes for sparse system identification, ” in Acoustics, Speech and Signal Processing , 2006. ICASSP 2006 Proceedings. 2006 IEEE International Confer ence on . IEEE, 2006, vol. 3. [5] D.M. Etter, “Identification of sparse impulse response systems using an adaptiv e delay filter, ” in Proceedings of ICASSP , 1985, pp. 1169–1172. [6] M. Godav arti and A. O. Hero, “Partial update LMS algorithms, ” IEEE T rans. on Signal Processing , vol. 53, pp. 2382–2399, 2005. [7] S.L. Gay , “ An efficient, fast con ver ging adaptiv e filter for network echocancellation, ” in Proceedings of Asilomar , 1998, vol. 1, pp. 394– 398. [8] D.L. Duttweiler, “Proportionate normalized least-mean-squares adapta- tion in echo cancelers, ” IEEE T rans. on Speech and Audio Processing , vol. 8, pp. 508–518, 2000. [9] R. Tibshirani, “Regression shrinkage and selection via the lasso, ” J. Royal. Statist. Soc B. , v ol. 58, pp. 267–288, 1996. [10] E. Cand ` es, “Compressi ve sampling, ” Int. Congress of Mathematics , vol. 3, pp. 1433–1452, 2006. [11] R. Baraniuk, “Compressive sensing, ” IEEE Signal Pr ocessing Magazine , vol. 25, pp. 21–30, March 2007. [12] Y . Chen, Y . Gu, and A O Hero, “Sparse LMS for system identification, ” in Acoustics, Speech and Signal Pr ocessing, 2009. ICASSP 2009. IEEE International Confer ence on . IEEE, 2009, pp. 3125–3128. [13] B. Babadi, N. Kalouptsidis, and V . T arokh, “SP ARLS: The sparse RLS algorithm, ” Signal Pr ocessing, IEEE T ransactions on , vol. 58, no. 8, pp. 4013–4025, 2010. [14] D. Angelosante, J.A. Bazerque, and G.B. Giannakis, “Online Adapti ve Estimation of Sparse Signals: Where RLS Meets the ` 1 -Norm, ” Signal Pr ocessing, IEEE Tr ansactions on , vol. 58, no. 7, pp. 3436–3447, 2010. [15] Y . Kopsinis, K. Sla vakis, and S. Theodoridis, “Online Sparse Sys- tem Identification and Signal Reconstruction using Projections onto W eighted ` 1 Balls, ” Arxiv pr eprint arXiv:1004.3040 , 2010. [16] Y . Gu, J. Jin, and S. Mei, “ ` 0 Norm Constraint LMS Algorithm for Sparse System Identification, ” IEEE Signal Pr ocessing Letters , vol. 16, pp. 774–777, 2009. [17] W .F . Schreiber, “ Advanced television systems for terrestrial broadcast- ing: Some problems and some proposed solutions, ” Pr oceedings of the IEEE , v ol. 83, no. 6, pp. 958–981, 1995. [18] M. Y uan and Y . Lin, “Model selection and estimation in regression with grouped variables, ” Journal of the Royal Statistical Society: Series B (Statistical Methodology) , vol. 68, no. 1, pp. 49–67, 2006. [19] E.J. Candes, M.B. W akin, and S.P . Boyd, “Enhancing sparsity by reweighted l 1 minimization, ” Journal of F ourier Analysis and Ap- plications , v ol. 14, no. 5, pp. 877–905, 2008. [20] L. Meier , S. V an De Geer , and P . Buhlmann, “The group lasso for logistic regression, ” Journal of the Royal Statistical Society: Series B (Statistical Methodology) , vol. 70, no. 1, pp. 53–71, 2008. [21] F .R. Bach, “Consistency of the group Lasso and multiple kernel learning, ” The Journal of Machine Learning Researc h , vol. 9, pp. 1179– 1225, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment