Probabilistic Models over Ordered Partitions with Application in Learning to Rank
This paper addresses the general problem of modelling and learning rank data with ties. We propose a probabilistic generative model, that models the process as permutations over partitions. This results in super-exponential combinatorial state space …
Authors: Tran The Truyen, Dinh Q. Phung, Svetha Venkatesh
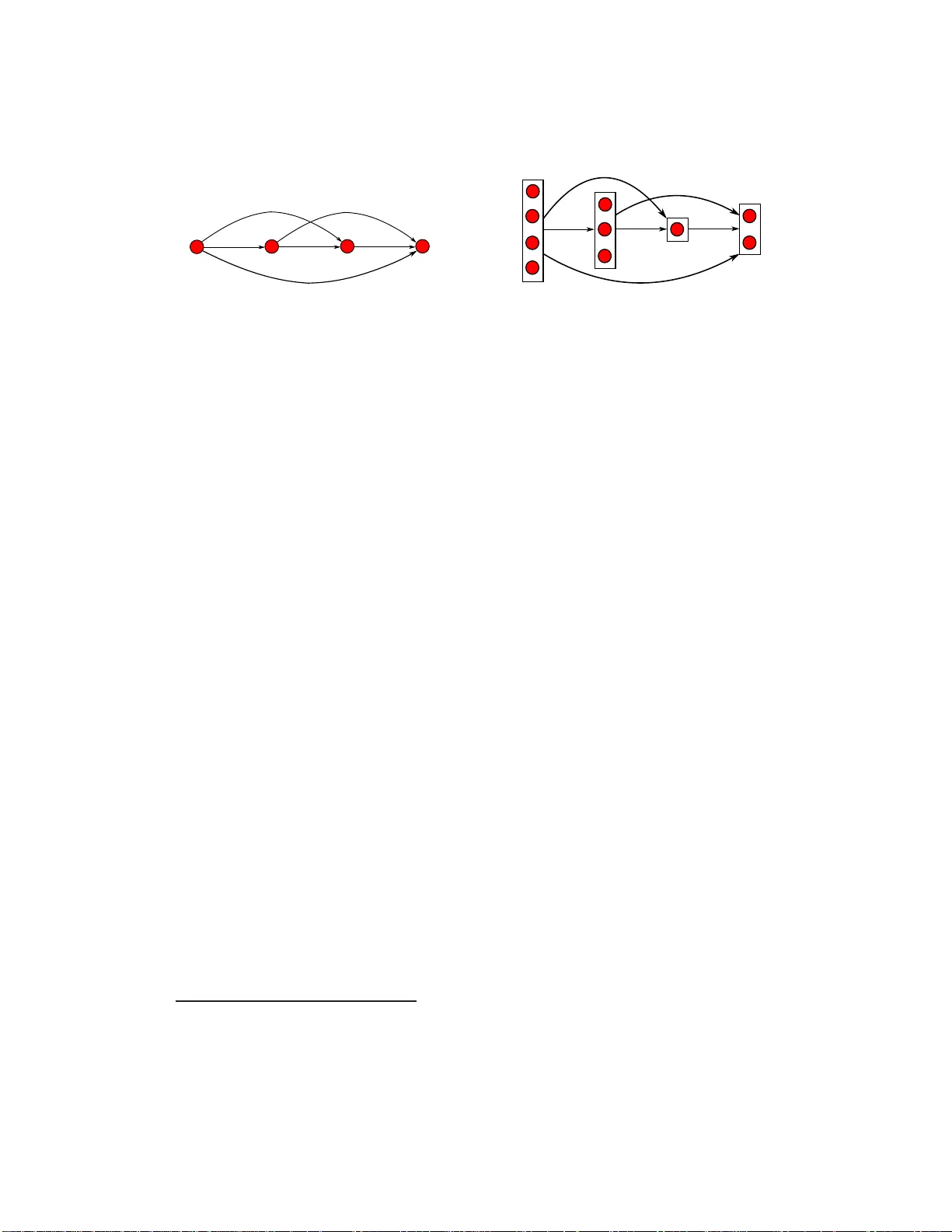
Probabilis tic Models ov er Ordered P artition s with Applicatio n in Learning to Rank T ran The Tr uyen, Dinh Q. Phung and Svetha V enkatesh Department of Computing, Curtin Univ ersity GPO Box U1987, Perth, W estern Australia 6845, Australia {t.tran2,d.phung ,s.venkatesh}@curtin.edu.au T echnical Report October 24, 2018 Abstract This paper addresses the general problem of modelling and learning rank data with ties. W e propose a probabilistic generativ e model, that models t he process as permutations ov er partitions. This results in super-e xponential combinatorial state space with unkno wn nu mbers of partitions and unkno wn ordering among them. W e approach the problem from the discrete choice theory , where subsets are chosen in a stagewise manner , reducing the state space per each stage significantly . Further , we show that with suitable parameterisation, we can still learn t he models in linear time. W e ev aluate the proposed models on the problem of learning to rank with the data from t he recently h eld Y ahoo! challenge, and demonstrate tha t th e mod els are competiti ve against well-known ri vals. 1 Introd uction Ranking app ears to be natu ral to humans as we of ten express pref erence over th ings. Conse- quently , ran k data has b een widely studied in statistical sciences (e.g. see [20] for a comp rehensive survey). Mo re recently , the in tersection between m achine learning and inform ation retrieval has resulted in a fruitful sub-area called lea rning to rank (e.g. see [17] for a recent re view), w here the goal is to learn rank functions that can accurately order objects fr om retrieval systems. Broadly speaking, a ran k is a type of permutatio n, wh ere the ordering of objects has some meaning ful interpretatio n - e.g. the rank of student perfor mance in a class. Althoug h we would like to obtain a complete ordering ov er a set of objects, often this is p ossible only in sma ll s ets. In larger sets , it is mor e natural to rate an object from a r ating scale, and the r esult is that many obje cts may ha ve the same ra ting. Such phenom ena is co mmon in large sets such as movies, boo ks o r web-pag es wherein many objects may ha ve tied ratings . This pa per focuses on the modellin g and learning rank data with ties. P revious work often in volves p aired compar isons (e.g. see [7][11][24]), ignorin g simultaneous interaction s among ob- jects. Suc h in teractions can be stro ng - in the case of lea rning to rank, objects ar e of ten returned from a qu ery , an d thus clearly r elated to the quer y a nd to each o ther . W e take an alternative ap- proach by modelling objects with the same tie as a partition, translating the problem into rankin g 1 or ord ering these partition s. This p roblem transform ation results in a comb inatorial problem - set partitioning with u nknown n umber s o f subsets with un known or der amo ngst them . For a given number of partitions, the order amongst them is a permutation of the partitions being considered, wherein each partition has objects of the same rank. A gen erative vie w of the pro blem can th en be as fo llows: Choose the fir st pa rtition with elements of rank 1, the n cho ose the next partitio n from the remaining o bjects with elements r anked 2 and s o on. The number of partitio ns then does not hav e to b e specified in advance, an d can be treated as a random variable. The jo int distribu- tion f or each ord ered partition can then b e co mposed using a variant of th e Plackett-Luce mo del [18][23], substituting obje ct poten tials b y the partition po tential. W e pro pose two cho ices for these po tential fu nctions: First, we conside r the potential of each p artition to be the nor malised sum of individual o bject potentials in that par tition, leadin g to a simple no rmalisation factor in the estimation of the joint distribution. Second, we pr opose a MCMC based par ameter estimation for the general choice of potential func tions. W e specify this mod el as the Pro babilistic Mo del over Ordered Partitions. Dem onstrating its application to the learning to ra nk pro blem, we use the dataset from the recently held Y ahoo ! ch allenge [28]. Besides the regular first-order features, we study seco nd-o rder features constructed as the Cartesian pr oduct over th e featu re set. W e show that ou r results bo th in terms of predictive perfo rmance and train ing time are comp etitiv e with other well-known meth ods s uch as RankNet [3], Ranking SVM [15 ] and ListMLE [27]. W ith the choice of our pr oposed simp le po tential function, we get th e added advantage of lower com pu- tational cost as it is linear in th e qu ery size com pared to qu adratic complexity for the p airwise methods. Our main co ntributions ar e the constru ction of a pro babilistic mode l over ordere d p artitions and associated in ference and learnin g techniques. The complexity of this p roblem is super- exponential with r espect to num ber of o bjects ( N ) becau se both the number of partitions an d their order ar e unknown - it grows expo nentially as N ! / ( 2 ( ln 2 ) N + 1 ) [2 1, pp . 396–3 97]. Our contribution is to overcome this comp utational comp lexity through the ch oice of suitable poten- tial fu nctions, y ielding learn ing alg orithms with linear com plexity , thus making th e alg orithm deployable in real settings. The novelty lies in the r igorou s examination o f prob abilistic mode ls over ordered partitions, extending earlier work in discrete cho ice theor y [9][18][23]. The signif- icance of the model is its pote ntial fo r u se in many app lications. One example is the learnin g to rank with ties pr oblem and is studies in this paper . Further, the mod el opens new potential appli- cations for example, novel typ es of clustering, in which the clusters are automatically ordered. 2 Backgrou nd In th is sectio n, we review some b ackgro und in ran k mo delling an d lea rning to rank which are related to our work. Rank models. Probabilistic mod els o f permu tation in gener al and of ran k in par ticular hav e been widely a nalysed in statistical sciences (e.g . [20] f or a co mpreh ensiv e survey). Since the number of all possible permutations over N objects is N ! , multinomial models are only computa- tionally feasible for s mall N (e.g. N ≤ 10). One approach to a void this s tate space explosion is to deal directly with the data space, i.e. b ased o n th e distance between two r anks. The assumption is that there exists a modal rankin g over all ob jects, an d wh at we observe ar e ranks rando mly distributed around the mode. The most well-k now model is perha ps the Mallo ws [19], wh ere the probab ility of a rank decreases exp onentially with the distance from the mode. Depend ing on 2 the distance measures, the model may differ; and the popular distance measures includ e those by Kendall and Sp earman. The pr oblem with this ap proach is that it is hard to h andle the cases of multiple modes, with ties and incomplete ranking. Another line of reasoning is largely associated with the discrete choice theory (e.g. see [18]), which ass u mes that each object has an intrinsic w orth which is the basis for th e ordering between them. For example, Brad ley an d T err y [1] assum ed that the prob ability of object pr eference is propo rtional to its worth, resulting in the logistic style distribution f or pairwise comparison . Su b- sequently , Luce [1 8] and Plackett [23] extended this m odel to mu ltiple objects. Mo re precisely , for a set of N ob jects den oted by { x 1 , x 2 , ..., x N } th e pr obability of ord ering x 1 ≻ x 2 ≻ ... ≻ x N is defined as P ( x 1 ≻ x 2 ≻ ... ≻ x N ) = N ∏ i = 1 φ ( x i ) ∑ N j = i φ ( x j ) where x i ≻ x j denotes the preference of object x i over x j , and φ ( x i ) ∈ R is the worth of the o bject x i . The idea is that, we p roceed in selecting objects in a s tagewise m anner: Cho ose the first ob ject among N objects with pro bability of φ ( x 1 ) / ∑ N j = 1 φ ( x j ) , the n choose the secon d o bject among the r emaining N − 1 objects with pro bability of φ ( x 2 ) / ∑ N j = 2 φ ( x j ) a nd so on un til all objects are chosen. It can be verified that the distribution is proper, that is P ( x 1 ≻ x 2 ≻ ... ≻ x N ) > 0 an d the probab ilities of all possible o rderin gs will sum to one. This paper w ill f ollow this appr oach as it is easily interpretable and flexible to incorporate ties and incomplete ranks. Finally , for com pleteness, we m ention in pa ssing the third appro ach, which treats a permu ta- tion as a symmetric group and applyin g spectral decomp osition techniques [8][1 3]. Learning t o r ank. Learning-to -rank is an ac ti ve topic in th e intersection between machine learning and informatio n retriev al (e.g. see [17] for a recent survey). The basic idea is that we can learn ran king fun ctions that can capture the r elev ance of an ob ject (e.g. d ocumen t or im- age) with respect to a qu ery . Althoug h it appear s to be an application o f r ank theory , the setting and goal are inh erently different from tradition al rank data in statistical sciences. Often, the poo l of all possible objects in a ty pical retriev al system is very large, and often c hanges over time. Thus, it is not possible to enum erate o bjects in the rank mod els. Instead, each object-q uery pair is associated with a feature vecto r , which often describes how relev ant th e o bject is with r espect to the query . As a result, the d istribution over ob jects is query- specific, an d t h ese distributions share the same parameter set. As d iscussed in [17], machine learning methods e xten ded to ranking can be divided into: P oin twise appr oach which includes metho ds such as ordinal regression [5][ 6]. Eac h qu ery- docume nt pair is assigned a ordin al la bel, e.g. from the set { 0 , 1 , 2 , ..., M } . This simplifies the problem as we do not need to w or ry abo ut the exponential num ber of per mutations. The complex- ity is there fore linea r in the numb er of q uery-d ocume nt pairs. Th e dr awback is th at the o rdering relation between docum ents is not explicitly modelled. P airwise appr oach which spans pref erence to binar y classification [3][10][1 5] m ethods, where the goal is to learn a classifier that can separate two documen ts (per query ). T his casts the r anking problem into a standard classification framework, where in many alg orithms are readily a vailable, for example, SVM [15], neural network and logistic r egression [3], and boo sting [10]. T he com- plexity is quadratic in number o f do cuments pe r qu ery an d line ar in num ber of que ries. Again, this appro ach ignores t he simultan eous interaction about objects within the same query . 3 Figure 1: Com plete o rdering (lef t) versus subset orderin g (right). For the subset orde ring, the bound ing boxes represen ts the subsets of elements of the same rank. Subset sizes are 4 , 3 , 1 , 2, respectively . Listwise app r o ach which mode ls the distribution of permu tations [ 4][26][27]. The ultimate goal is to model a fu ll distribution of all perm utations, and the p rediction phase o utputs the most probab le permuta tion. This approach appears to be most natural for the ranking problem . In fact, the methods suggested in [4][27] are application s of the Plackett-Luce model. 3 Modelling Sets with Order ed Partitions 3.1 Pr oblem Description Let X = { x 1 , x 2 , . . . , x N } be a collection of N objects. In a complete r anking setti ng , each o bject x i is furthe r assigned with a ranking index π i , resulting in the ranked list of { x π 1 , x π 2 , . . . , x π N } where π = ( π 1 , . . . , π N ) is a permutation over { 1 , 2 , . . . , N } . For example, X might be a set of do cumen ts returned by a sear ch engin e in response to a q uery , an d π 1 is the in dex to th e first d ocumen t, π 2 is the index to second d ocumen t and so on. Id eally π should contain o rdering infor mation for all returned docum ents; however , th is ta sk is no t always possible for any non-trivial size N due to the labor cost in volved 1 . Instead, in many situation s, during t rain ing a docum ent is rated 2 to indicate the its degree of relev an ce for th e q uery . This creates a scenar io where more than on e do cument will be assigned to the same rating – a situation known as ‘ ties ’ in learnin g-to-ra nk. When we enumera te over each object x i and putting those with the same rating together , the s et of N objects X can now be v iewed as being divided into K partitions with each partition is assign ed with a number to indicate the its unique ran k k ∈ { 1 , 2 , .., K } . The ranks are obtain ed by sortin g rating s associated with each partition in th e decreasing order . Ou r es sential contr ibution in this section is a prob abilistic model o ver this set of partition s, learning its parameter from data, and perfo rming inference . Consider a more ge neric setting i n which we kno w that objects will b e ra ted ag ainst an ordinal value fro m 1 to K but do not know individual ratings. This means that we hav e to con sider all possible ways to split th e set X into exactly K partition s, and then rank those p artitions f rom 1 to K wh erein the k th p artition c ontains all objects rated with the same value k . This is the first rough descriptio n of state space for our mode l. Formally , for a given K an d the o rder amon g the partitions σ , we write the set X = { x 1 , . . . , x N } as a union of K p artitions X = ∪ K j = 1 X σ j (1) 1 W e are aware that cli ckthrough data can help to obtain a complete ordering, but the dat a may be noisy . 2 W e caution the co nfusion between ‘rating’ and ‘ranki ng’ here. Ranking is th e process of sorting a set of objec ts in an increa sing or decreasing order , whereas in ‘rating’ each object is giv en with a va lue indicatin g its preference . 4 where σ = ( σ 1 , . . . , σ K ) is a permutatio n over { 1 , 2 , .., K } and each partition X k is a non-em pty subset o f objects with th e same rating k . Th ese partition s are p airwise d isjoint and having card i- nality ra nge f rom 1 to N . It is easy to see th at when K = N , each X k is a singleton , σ is now a complete pe rmutation over { 1 , . . . , N } and th e problem reduc es exactly to the co mplete ran king setting mentione d earlier . T o get an idea of the state space, it is not hard to see that there are N K K ! ways to partition a nd ord er X where N K is the numbe r of p ossible ways to divide a set o f N objects in to K partition s, otherwise known as Stirling n umbers of second kind [25, p . 105]. If we consider all the possible values of K , the size of our state space is N ∑ k = 1 N k k ! = Fubini ( N ) = ∞ ∑ j = 1 j N 2 j + 1 (2) which is also known i n com binatoric s as the Fubini’ s number [21, pp. 3 96–3 97]. This is a super- exponential growth num ber . For instanc e, Fub ini ( 1 ) = 1, Fub ini ( 3 ) = 13 , Fubini ( 5 ) = 5 41 and Fubini ( 10 ) = 102 , 24 7 , 56 3. Its asymptotic beh aviour can a lso be sh own [ 21, pp . 396–39 7] to approa ch N ! / ( 2 ( ln 2 ) N + 1 ) as N → ∞ where we no te that ln ( 2 ) < 1, and thus it gro ws much faster than N ! . Clearly , for unknown K this presen ts a very challengin g problem. In this paper , we sha ll present an efficient and a gene ric approach to tackle this state-space e xp losion. 3.2 Pr obabili stic Model over Orde red Partitions Return to our problem, our task no w to m odel a distrib ution over the ordered p artitioning of set X into K partitions and the ordering σ = ( σ 1 , . . . , σ K ) among K p artitions given in Eq (1): p ( X ) = p ( X σ 1 , . . . , X σ K ) (3) A two-stage view h as b een giv en thus far: first X is partitioned in any arbitrar y way so long a s it c reates K partitions and then these partition s are ranked , result in a ranking index vector σ . This descrip tion is gener ic and one can proceed in different ways to fu rther character ise Eq (3). W e pr esent here a gene rativ e, multistage view to this same pro blem so that it len ds n aturally to the spec ification of the distribution in Eq ( 17): First, we construct a sub set X 1 from X b y collecting all objects wh ich (supposed ly) hav e the largest rating s. If the re are more ele ments in the the remaind er set { X \ X 1 } to be selected, we construct a subset X 2 from { X \ X 1 } whose elements h ave the seco nd largest ra tings. This p rocess co ntinues until there is no more object to be selected. 3 An advantage of this view is th at the resulting to tal n umber of p artitions K σ is au tomatically g enerated, no need to b e specified in advance and can be tr eated a s a rand om variable. If o ur d ata truly contains K partitio ns then K σ should be equal to K . Using th e chain rule, we write the joint distribution ov er K σ ranked partitions as p ( X 1 , . . . , X K σ ) = p ( X 1 ) K σ ∏ k = 2 p ( X k | X 1 , . . . , X k − 1 ) = p 1 ( X 1 ) K σ ∏ k = 2 p k ( X k | X 1: k − 1 ) (4) where we have used X 1: k − 1 = { X 1 , . . . , X k − 1 } for brevity . 3 This process resembles the generati ve process of Plack ett-Luce discrete choic e model [18][23], exce pt we apply on partit ions rather than single element. It clear from here that Placke tt-Luce model is a special case of ours wherein each partit ion X k reduces to a singleto n. 5 3.3 Parameterisation, Lear ning and Inferenc e It remains to specify the lo cal distribution P ( X k | X 1: k − 1 ) . L et us first co nsider wh at choices d o w e have after the first ( k − 1 ) partitions have been selected. It is clear that we can select any o bjects from the remain der set { X \ X 1: k − 1 } for ou r next partition k th. If we de note this remain der set by R k = { X \ X 1: k − 1 } and N k = | R k | is the number of remaining objects, then our next partition X k is a subset of R k ; f urtherm ore, there is p recisely 2 N k − 1 such non -empty subsets. Using the notation 2 R k to denote the power set of the set R k , i.e, 2 R k contains all possible n on-emp ty subsets 4 of R , we are ready to specify each local conditio nal distribution in Eq (17) as: p k ( X k | X 1: k − 1 ) = Φ k ( X k ) Σ S ∈ 2 R k Φ k ( S ) (5) where Φ k ( S ) > 0 is an o rder-in variant 5 set function d efined over a set o r partition S , and th e summation in the denominator clearly makes the definition in Eq(5) a proper distribution. Th e set function Φ k ( · ) can also b e interpreted as the potential function in standard p robab ilistic grap hical models literature. Although the s tate space 2 R k for this local conditio nal distribution is significantly smaller than the space of all po ssible ordered partitions of N objects, it is still exp onential as we hav e shown earlier to be 2 N k − 1. In general, dir ectly co mputin g the normalising term is still not possible, let alone learning th e m odel parameters. In wh at fo llows, we will study a n efficient special case which has (su b)-qu adratic co mplexity in learning, and a general case with MCMC a pprox imation. W e further term our Pr obabilistic Model over Or der ed P artition as PMOP . 3.3.1 Full-Decomposition PMOP Under a full-d ecompo sition setting, we assum e the following lo cal additive deco mposition at each k th step: Φ k ( X k ) = 1 | X k | ∑ x ∈ X k φ k ( x ) (6) The n ormalising term | X k | is to en sure th at the probab ility is not m onoto nically increasing with number of o bjects in th e partition. Gi ven this f orm, the local norm alisation factor rep resented in the denom inator of Eq (5) can now efficiently represented as the sum of all weig hted sums of objects. Since each object x in the rem ainder set R k participates in the same add itiv e manner tow ard s the construction of the denominator in Eq (5), it must admit the follo wing form 6 : ∑ S ∈ 2 R k Φ k ( S ) = ∑ S ∈ 2 R k 1 | S | ∑ x ∈ S φ k ( x ) = C × ∑ x ∈ R k φ k ( x ) (7) where C is some constant and its e xact v alue is not ess en tial under a maximum l ikelihoo d param- eter learning treatment (reader s are referred to Appendix A for the computation of C ) . T o s ee this, substitute Eq (6) and (7) into Eq (5): 4 The usual understand ing would also conta in the empty set, but we exc lude it in this paper . 5 i.e., the function val ue does not depend on the order of elements within the partition . 6 T o illustrate this intuition, suppose the remainder set is R k = { a , b } , hence its po wer set, exclu ding / 0, contains 3 subsets { a } , { b } , { a , b } . U nder the full-deco mposition assumption, the denominator in Eq (5) becomes φ ( r a ) + φ ( r b ) + 1 2 { φ ( r a ) + φ ( r b ) } = ( 1 + 1 2 ) ∑ x ∈{ a , b } φ ( r x ) . The const ant term is C = 3 2 in this case. 6 log p ( X k | X 1: k − 1 ) = log Φ k ( X k ) Σ S ∈ 2 R k Φ k ( S ) = log 1 C | X k | ∑ x ∈ X k φ k ( x ) ∑ x ∈ R k φ k ( x ) = log ∑ x ∈ X k φ k ( x ) ∑ x ∈ R k φ k ( x ) − lo g C | X k | (8) Since log C | X k | is a constan t w . r .t the param eters used to parameterise th e p otential fu nctions φ k ( · ) , it d oes not affect the grad ient o f the log-likelihoo d. It is also clear that maximising the likelihood given in Eq (17) is equ iv alent to max imising each local log-likelihoo d function giv en in Eq (8) for each k . Discardin g the constant term in Eq (8), we re-write it in this simpler form: log p ( X k | X 1: k − 1 ) = log ∑ x ∈ X k g k ( x | X 1: k − 1 ) where g k ( x | X 1: k − 1 ) = φ k ( x ) ∑ x ∈ R k φ k ( x ) (9) Depend on the spec ific form chosen fo r φ k ( x ) , maximising log-likelihood in the form o f Eq (9) can be carried on in most cases. Gradient- based learning this type of model is genera lly takes N 2 time complexity . However , using dyn amic p r ogramming techniqu e, we show th at if th e function φ k ( x ) does not depend on its position k, then the gradient-b ased learning comple xity can be r educed to linear in N . T o see how , dro pping the explicit d epend ency of the subscrip t k in the definition o f φ k ( · ) , we ma intain an au xiliary array a k = ∑ x ∈ R k φ ( x ) wher e a K σ = ∑ x ∈ X K σ φ ( x ) and a k = a k + 1 + ∑ x ∈ X k φ ( x ) fo r k < K σ . Clearly a 1: K σ can b e comp uted in N time in a backward fashion. Thus, g k ( · ) in Eq (9) can also be computed linearly via the r elation g k ( x ) = φ ( x ) / a k . This als o implies that the total log-likelihoo d can also computed linearly in N . Furthermo re, the gr adient of log-likelihoo d function can also be computed linearly in N . Giv en th e likelihood fun ction in Eq (17), using Eq (9), the log-likelihoo d fu nction and its gra- dient, without explicit mention of the parameters, can be sho wn to be 7 L = log p ( X 1 , . . . , X K σ ) = K ∑ k = 1 log ∑ x ∈ X k g k ( x | X 1: k − 1 ) = K ∑ k = 1 log ∑ x ∈ X k φ ( x ) a k (10) ∂ L = ∑ k ∂ log ∑ x ∈ X k φ ( x ) − ∑ k ∂ log a k = ∑ k ∑ x ∈ X k ∂ φ ( x ) ∑ x ∈ X k φ ( x ) − ∑ k 1 a k ∑ x ∈ R k ∂ φ ( x ) (11) It is clear that the first sum mation over k in th e RHS of the last equation takes exactly N time since ∑ K k = 1 | X k | = N . For the second summation over k , it is m ore in volved because both k and R k can po ssibly ran ge from 1 to N , so d irect compu tation will cost at m ost N ( N − 1 ) / 2 time. Similar to th e case of a k , we now maintain an 2-D aux iliary arr ay 8 b k = ∑ x ∈ R k ∂ φ ( x ) , where b K σ = ∑ x ∈ X K σ ∂ φ ( x ) an d b k = b k + 1 + ∑ x ∈ X k ∂ φ ( x ) f or k < K σ . Thus, b 1: K σ , and therefo re the gradient ∂ L , can be co mputed in N F tim e in a b ackward fashio n, where F is th e number of parameters. 3.3.2 General State PMOP and MCMC Infer ence In the gener al case without any assump tion o n th e form of the potential function Φ k ( · ) using only Eq (5 ) and (17), the log- likelihood functio n and its g radient, again without e xplicit mention of the 7 T o be more precise, for k = 1 we define X 1:0 to be / 0. 8 This is 2-D because we also need to index the paramet ers as w ell as the subsets. 7 model parameter, are: L = log p ( X 1 ) + K σ ∑ k = 2 log p k ( X k | X 1: k − 1 ) (12) ∂ L = K σ ∑ k = 1 ∂ log Φ k ( X k ) − K σ ∑ k = 1 ( ∑ S ∈ 2 R k p k ( S | X 1: k − 1 ) ∂ log Φ k ( S ) ) (13) Clearly , both the distribution p k ( X k | X 1: k − 1 ) and the expectation ∑ S ∈ 2 R k p k ( S | X 1: k − 1 ) ∂ log Φ k ( S ) are gener ally intractab le to ev aluate. In this paper, we make use o f MCMC methods to appro xi- mate p k ( X k | X 1: k − 1 ) . Ther e ar e two n atural choices: the Gibbs samplin g and Metropo lis-Hastings sampling. For Gibbs sampling we no te tha t this pro blem can be v iewed as samp ling fro m a ran- dom field with bin ary variables. Each object is attached with binary variable whose states a re either ‘ selected ’ or ‘ not selected ’ a t k th stage. Thus, ther e will be 2 N k − 1 join t states in th e ran - dom field, where we recall that N k is the total numb er of remainin g objects after ( k − 1 ) -th stage. The pseudo code fo r Gibbs and Metropolis-Hasting s rou tines perfo rmed at k th stage is illustrated in Alg. (1). Algorithm 1 MCMC sampling approach es for PMOP in general case. Gibbs sampling 1. Randomly choose an initial subset X k 2. Repeat until stopping criteria met • For each remaining object x at stage k , random ly select the object with the probab ility Φ k ( X + x k ) Φ k ( X + x k ) + Φ k ( X − x k ) where Φ k ( X + x k ) is the potential of the currently selected subset X k if x is included and Φ k ( X − x k ) is when x is not. Metropolis-Hastings s ampling 1. Randomly choose an initial subset X k 2. Repeat until stopping criteria met • Randomly choose numbe r of objects m , subject to 1 ≤ m ≤ N k . • Randomly choose m distinct objects from remaining set R k = { X \ X 1: k − 1 } to construct a new partition denoted by S • Set X k ← S with the pro bability of min n 1 , Φ k ( S ) Φ k ( X k ) o Finally , we note that in practical implem entation o f learning , we follow the p ropo sal in [1 2] wherein fo r each local distribution at k th round we run the MCMC for o nly a few steps startin g from the observed subset X k . This tech nique is k nown to produce a biased estimate, b ut empirical evidences ha ve so far ind icated that the b ias is small and the estimate is effectiv e. Impo rtantly , it is very fas t co mpared to full sampling. 3.4 Learn ing-to-Rank wi th PMOP T o conclude the pre sentation of our proposed mode l fo r probab ilistic mo delling over ord ered partitions ( PMOP), we p resent a specific applica tion of PMOP for th e p roblem o f lea ning-to - rank. T he ultimate goal after training is that, for eac h query the system n eeds to return a list of 8 related objec ts and their ranking . 9 Slightly different from the standar d rank setting in statistics, the objects in learning -to-ran k problem are often not indexed (e. g. the identity of th e object is not captured in any parameter). Instead, we will assume that for each qu ery-o bject pair ( q , x ) we can extract a f eature vector x q . Mo del distribution specified in this way is th us qu ery-specific . As a result, we are not interested in finding the single mode for the rank distrib utio n over all queries 10 , but in finding the ran k mode for each query . At the ranking p hase, sup pose for a unseen query q a list of X q = n x q 1 , . . . , x q N q o objects r elated to q is returned . Th e ta sk is then to r ank th ese objects in dec reasing o rder of relev ance w .r .t q . Enumerating over all possible ran king take an o rder of N q ! time. Instead we would like to establish a scoring function f ( x q , w ) ∈ R for the qu ery q and each ob ject x re turned where w is now in troduce d as the parame ter . Sorting can then b e carried out much mo re efficiently in the complexity orde r of N q log N q instead o f N q !. The function specification can be a simple a linear combinatio n of f eatures f ( x q , w ) = w ⊤ x q or m ore co mplicated f orm, suc h as a mu ltilayer neu ral network, can be used. In th e pr actice o f lear ning-to -rank, the d imensionality of featur e vector x q is o ften rema ins the same ac ross all qu eries, and since it is observed, we u se PMOP d escribed bef ore to specify condition al model specific to q over the set of returned objects X q as follows. p ( X q | w ) = p ( X q 1 , X q 2 , ..., X q K σ | w ) = P ( X q 1 | w ) K σ ∏ k = 2 p ( X q k | X q 1: k − 1 , w ) (14) W e can see th at Eq ( 14) has exactly th e same form of Eq ( 17) specified fo r PMOP, but applied instead on the q uery-spe cific set o f o bjects X q and additional p arameter w . Durin g trainin g, each qu ery-ob ject pair is labelled by a relevance score, which is typically an integer fro m the set { 0 , .., M } wh ere 0 mea ns the obje ct is irrelev ant w . r .t th e query q , and M means the object is h ighly relev ant 11 . The value of M is ty pically much smaller than N q , thu s, the issue of ties, described at the beginning of this section, o ccur frequ ently . In a nu tshell, for each training quer y q and its rated associated list o f objects a PMOP is created. The imp ortant parameterisation to note here is that the p arameter w is shared acr oss all qu eries ; and thus, enabling ranking for un seen query in the future. Using the sco ring function f ( x , w ) we specify the in dividual potential fu nction φ ( · ) in th e exponential form: φ k ( x , w ) = exp { f ( x , w ) } The local p otential fu nction defined over for partitio n Φ k X q k can now be explicitly constru cted under full-d ecompo sition (Sub section 3 .3.1) and g eneral case (Subsection 3. 3.2) as respec tiv ely follows. Full-decom position: Φ k X q k = 1 | X q k | ∑ x ∈ X q k exp { f ( x , w ) } (15) 9 W e note a confusion that may arise here is that, although during training each training query q is supplied with a list of related objects and their ratings, during the ranking phase the system still needs to return a ranking over the list of relate d objects for an unseen query . 10 This would lead to something like the static rank ove r all possible objects in the datab ase - like those in Google’ s Page Rank [2]. 11 Note that general ly K 6 = M + 1 because there may be gaps in rating scales for a specific query . 9 General case: Φ k X q k = exp 1 | X q k | ∑ x ∈ X q k f ( x , w ) (16) The gradient of the log-likelihood f unction can also b e computed efficiently . For full-dec omposition , it can be shown to be: ∂ log p X q k | X q 1: k − 1 ∂ w = ∑ x ∈ X q k φ k ( x , w ) x ∑ x ∈ X q k φ k ( x , w ) − ∑ x ∈ R q k φ k ( x , w ) x ∑ x ∈ R q k φ k ( x , w ) For the general case, the gradient of the log-likelihood functio n can be sho wn to be: ∂ log p X q k | X q 1: k − 1 ∂ w = ¯ x q k − ∑ S k ∈ 2 R q k p S k | X q 1: k − 1 ¯ s k where ¯ x q k = 1 | X q k | ∑ x ∈ X k x q The quantity p X q k | X q 1: k − 1 can be interpreted as the probability that t he sub set X q k is chosen out of all possible subsets at stage k , and ¯ x k is the centre of the chosen subset. The expectation ∑ S k P ( S k | X q 1: k − 1 ) ¯ s k is expensiv e to e valuate, since there are 2 N k − 1 possible subsets. Thus, we resort to MCMC techniq ues. W e follow th e suggestion in [12] to start the Markov chain from the o bserved subset X k and ru n for a few iteration s. The parame ter update is stochastic w ← w + η ∑ k ¯ x q k − 1 n n ∑ l = 1 ¯ s ( l ) k ! where ¯ s ( l ) k is the centre of the subset sampled at iteration l , and η > 0 is the learning rate, and n is number of samples. T yp ically we choose n to be small, e.g. n = 1 , 2 , 3. 4 Discussion In ou r specific cho ice of the local distribution in Eq (5), we share the same idea with that of Plackett-Luce, in which the probab ility o f cho osing the subset is prop ortional to the subset’ s worth, which is realised by the sub set p otential. In fact, when we limit the subset size to 1, i.e. there are no ties, the prop osed model reduce s t o the well-known Plackett-Luce models. It is worth me ntioning that the factorisation in Eq (17) and the choice of lo cal distribution in Eq (5) are not unique. In fact, the chain- rule can be app lied to any sequence o f cho ices. For example, we can factorise in a backward manner p ( X 1 , . . . , X K σ ) = p 1 ( X K σ ) K σ − 1 ∏ k = 1 p k ( X k | X k + 1: K σ ) (17) where X k + 1: K σ is a shorthan d for { X k + 1 , X k + 2 , ..., X K σ } . In terestingly , we can interp ret this re verse process as sub set elimin ation : First we choose to eliminate the worst subset, then the second 10 worst, an d so on. This line o f re asoning ha s been discussed in [9] but it is lim ited to 1-element subsets. Howev er, if we are free to choose th e par ameterisation of p k ( X k | X k + 1: K σ ) as we h av e done for p k ( X k | X 1: k − 1 ) in Eq (5), there are not guarantee tha t the forward and backward f actor i- sations admit the same distribution. Our model can be plac ed in to the framew or k of prob abilistic graph ical mod els (e.g . see [16][22]). Recall that in standar d pro babilistic graphica l models, we have a set of variables, each of which receiv es v alu es fro m a fixed set of states. Gen erally , variables and states are orthog onal con cepts, and th e state space of a variable d o not explicitly d epends on the states of other variables 12 . In our setting, the objects play the role of the variables, and their member ships in the subsets are th eir states. Howev er, since th ere are expon entially many sub sets, enumer ating the state spaces as in standard graphical mod els is n ot p ossible. Instead, we can co nsider the ranks of th e subsets in the list as the states, since the ranks o nly ran ge fro m 1 to N . Dif fere nt from the standard graphica l m odels, the v aria bles and the states are not alw ays indepen dent, e.g. when the subset sizes are limited to 1, then the state assignments of variables are mutually e xclusive, since for each position, ther e is o nly one object. Probabilistic graphica l mod els are gene rally directed (such as Bayesian networks) or undire cted (such as Markov random fields), and o ur PMOP can be tho ught as a dir ected m odel. Th e un directed setting is also of g reat inter est, b ut it is beyo nd the scope of this paper . W ith respect to tie h andling , most previous work focuses on pairwise models. T he basic idea is to assi gn some prob ability mass for the e vent of ties [7][ 11][24]. For in stance, denote b y x i ≻ x j the pref erence of x i over x j , and by x i ≈ x j the tie between the two ob jects, Rao and Kupper [24] propo sed the following models P ( x i ≻ x j ) = φ ( x i ) φ ( x i ) + θ φ ( x j ) P ( x i ≈ x j ) = ( θ 2 − 1 ) φ ( x i ) φ ( x j ) [ φ ( x i ) + θ φ ( x j )] [ θ φ ( x i ) + φ ( x j )] (18) where θ ≥ 1 is the par ameter to con trol the contr ibution of ties. When θ = 1, the mode l reduces to the stan dard Brad ley-T erry model [1] . This method of ties han dling is fu rther stud ied in [29] in the co ntext of learnin g to rank . Another metho d is introdu ced in [7], where the probab ility masses are defined as P ( x i ≻ x j ) = φ ( x i ) φ ( x i ) + φ ( x j ) + ν p φ ( x i ) φ ( x j ) P ( x i ≈ x j ) = ν p φ ( x i ) φ ( x j ) φ ( x i ) + φ ( x j ) + ν p φ ( x i ) φ ( x j ) (19) where ν ≥ 0. The app lications o f these two tie-handlin g mod els to learning to ran k ar e detailed in Appendix C. For ties of mu ltiple objects, we can create a group of objects, an d work directly on grou ps. For exam ple, let X i and X j be two spo rt teams, the pa irwise team or dering can be defined u sing the Bradley-T erry model as P ( X i ≻ X j ) = ∑ x ∈ X i φ ( x ) ∑ x ∈ X i φ ( x ) + ∑ s ∈ X j φ ( s ) 12 Note that, this is dif ferent from saying the states of vari ables are independent . 11 The extension of the Plackett-Luce mo del to m ultiple group s has been discu ssed in [14]. Howe ver, we should emphasize that this s etting is not the same as ours, becau se th e partitionin g is known in advance, an d the gro ups b ehave just like standard super-objects. Our setting, on the other hand , assumes no fixed partitioning, and the membership of the objects in a group is arbitrary . 5 Evaluation 5.1 Setting The data is from Y ahoo ! learning to rank challenge [28]. This is cur rently the largest dataset av ailable for resear ch. At th e time of this wr iting, the d ata contains th e groun dtruth lab els of 473 , 134 do cuments returned f rom 19 , 944 queries. The label is th e relev ance judgmen t from 0 (irrelev ant) to 4 ( perfectly rele vant). Features for each document-qu ery pairs are also supplied by Y ahoo! , and there are 519 uniqu e features. W e split the data into two sets: the training set contains rou ghly 90% queries, and the test set is the remainin g 10 %. T wo perfor mance metr ics ar e repor ted: th e Normalised Discounted Cu- mulative Gain at position T (NDCG@ T ), and the Expec ted Reciprocal Rank (ERR). NDCG@ T metric is defined as NDCG@ T = 1 κ ( T ) T ∑ i = 1 2 r i − 1 log 2 ( 1 + i ) where r i is the rele vance judg ment of the document at position i , κ ( T ) is a normalisation constan t to make sure that the gain is 1 if the rank is correct. The ERR is d efined as ERR = ∑ i 1 i V ( r i ) i − 1 ∏ j = 1 ( 1 − V ( r j )) where V ( r ) = 2 r − 1 16 which puts ev en more emphasis on the top-ran ked docum ents. For co mparison, we imp lement several well-known meth ods, includin g Rank Net [3], Ran k- ing SVM [15] a nd ListMLE [ 27]. The RankNet and Rank ing SVM are pairwise method s, and they d iffer on the choice of loss functio ns, i.e. logistic lo ss for the RankNet and hing e loss fo r the Ranking SVM 13 . Similarly , choosing quadra tic loss gives us a rank regression method, which we will call Rank Regress. From rank modellin g point of v iew , the RankNet is essentially the Bradley-T erry mo del [ 1] a pplied to lear ning to ran k. Like wise, th e ListMLE is e ssentially the Plackett-Luce model. W e also imp lement two variants of the Bradley-T erry model with ties han - dling, o ne by Rao-Kupp er [24] (den oted by PairT ies-RK; th is also appears to be implem ented in [29] u nder the function al gradien t setting) and ano ther by Davidson [7] (denoted by PairT ies-D; and this is the first time t h e Da vid son method is applied to learning to rank). See Appendix C for implementatio n details. There are three method s resulted from our framework (see d escription in Section 3.4). T he first is the PM OP with full-deco mposition ( denoted by PMOP-FD), the secon d is with Gibbs sam- pling (denote d by PMOP-Gibbs), an d the third is with Me tropolis-Hasting s sampling (deno ted by PMOP-MH). 13 Strictl y speaking, RankNet makes use of neural networks as the s coring function, but the over all loss is still logistic, and for simplic ity , we use simple perceptron. 12 First-order features Second-o rder features ERR NG@1 NG@5 ERR NG@1 NG@5 Rank Regress 0.4882 0.683 0.667 2 0.497 1 0.702 1 0.6 752 RankNet 0.491 9 0.690 3 0.6 698 0.5 049 0.7 183 0.683 6 Ranking SVM 0.4868 0 .6797 0.66 62 0.49 70 0.70 09 0. 6733 ListMLE 0.495 5 0.699 3 0.6 705 0.5 030 0.7 172 0 .681 0 PairTies-D 0.4941 0.694 4 0.6 725 0.5 013 0.7 131 0.678 6 PairTies-RK 0.494 6 0.697 0 0.6 716 0.5 030 0.7 136 0 .6793 PMOP-FD 0.5038 0 .7137 0.67 62 0.50 86 0.72 72 0 .6858 PMOP-Gibbs 0 .5037 0 .7105 0.679 2 0.504 0 0.712 4 0.6 706 PMOP-MH 0.50 45 0.71 39 0. 6790 0. 5053 0. 7122 0.671 3 T ab le 1: Perfor mance m easured in ERR and NDCG@T . PairT ies-D and PairT ie s-RK are the Davidson method and Rao-Kupper method for ties handlin g, respectively . P MOP-FD is the PMOP with fu ll-decomp osition, and PMOP-Gib bs/MH is the PMOP with Gibbs/Metr opolis- Hasting sampling (see Section 3.4 for a description) . For those pairwise m ethods without ties hand ling, we simply igno re the tied docum ent pairs. For the ListMLE, we simply sort the d ocumen ts within a q uery by relev ance scores, and those with ties are order ed acco rding to the sorting algor ithm. All metho ds, except f or PMOP-Gibbs/MH, are trained using the L imited Memor y Newton Meth od kn own as L-BFGS. The L-BFGS is stopped if the relativ e im provement over t h e loss is less than 10 − 5 or a fter 100 iterations. As the PMOP- Gibbs/MH are stoc hastic, we run the MCMC for a f ew steps per query , then update the parameter using the Stochastic Gradient Ascent. The lear ning rate is fixed to 0 . 1, a nd the learnin g is stopped after 1 , 00 0 iterations. As f or featu re representation , we first norma lised th e fe atures across the whole tr aining set to roughly hav e mean 0 a nd stan dard deviation 1. W e then employ both the first-o rder fea tures and secon d-ord er features (by ta king the Cartesian p roduct of first-order features). The ration ale for the second- order feature s is that since the first-order f eatures ar e selected manua lly based on Y ah oo! experienc e, features are h ighly correlated . Thus secon d-ord er feature s ma y captur e aspects not previously th ought b y fea ture designe rs. Since th e nu mber of second-ord er featu res is large, we perfor m a correlation -based selection . Fir st, we comp ute the Pearson’ s correlation between each seco nd-o rder f eature with the label, th en cho ose those f eatures whose ab solute correlation is b eyond a threshold. F o r this par ticular data, we found the thresho ld of 0 . 15 is useful, althoug h we did not perfor m an extensive search. Th e nu mber of selected second -ord er features is 14 , 188. 5.2 Results The results ar e repo rted in T able 1. The following conclusion s can b e drawn. First, the use of second order f eatures impr oves the perfor mance for nearly all the baseline methods. In our algorithm s, the second ord er f eatures yield b etter p erfor mance for PMOP-FD (incor poratin g the full decompo sition). Second, using either first or second order features, all our algorithms outperfor m the baselin e methods. For example, the PMOP-MH wins over the best perfo rming baseline, ListMLE, b y 1 . 82%, using first-order featur es. In our view , this is a significant improvement given the s co pe o f 13 Pairwise models PMOP/ListMLE max { O ( N 2 ) , O ( N F ) } O ( N F ) T ab le 2: Lea rning complexity of models, where F is the number of unique features. For pairwise models, see Appendix B for the details. the d ataset. W e n ote th at the difference in the top 20 in the leaderboa rd of the Y a hoo! challenge is just 1 . 56%. As for trainin g time, the PMOP-FD is numerica lly the fastest metho d. Th eoretically , it has the linear co mplexity similar to ListMLE. All other pa irwise methods are quadratic in qu ery size, and thus numerically slower . The PMOP-Gibbs/MH is also line ar in the query s ize, by a constant factor that is determined by the number of iterations. See T ab le 2 for a summary . 6 Conclusions Addressing the g eneral problem of rank ing with ties, we have prop osed a genera ti ve probab ilistic model, with suitable parameterisation to address the p roblem com plexity . W e present efficient algorithm s for learnin g and inf erence.W e ev alu ate the p roposed m odels on the problem of learning to rank with the data from the cu rrently h eld Y ahoo! challeng e. demon strating that the m odels are comp etitiv e a gainst well-kn own riv als designed specifically for the pro blem, both in pr edictive perfor mance and training time. Refer ences [1] R.A. Bradley and M.E . T erry . Rank analysis of incomplete b lock d esigns. B iometrika , 39:324 –345 , 1952 . [2] S. Brin a nd L. Page. The anatomy of a large- scale hy pertextual W eb search engine. Com- puter networks and ISDN systems , 30(1-7 ):107– 117, 1998 . [3] C. Burges, T . Shaked, E. Renshaw , A. Lazier, M. Deeds, N. Hamilton , an d G. Hullen der . Learning to rank using gradient descent. In Pr oc. of ICML , pag e 96, 2005. [4] Z. Cao, T . Qin, T .Y . Liu, M.F . Tsai, and H. Li. Learnin g t o ran k: fr om pairwise approach to listwise appro ach. In P r o ceeding s of the 24 th internationa l conference on Machine le arning , page 136. A CM, 2007 . [5] W . Chu and Z. Ghahraman i. Gaussian processes for ordinal regression. Journal of Ma chine Learning Resear ch , 6(1):101 9, 2 006. [6] D. Cossock and T . Zhang. Statistical analysis of baye s o ptimal subset r anking . IEEE T rans- actions on Information Theory , 54(11) :5140– 5154, 2008 . [7] R.R. Davidson. On extending the Bradley-T erry model to accommod ate ties in paire d com- parison experiments. Journal of th e A merican Statistical Association , 65(3 29):3 17–32 8, 1970. 14 [8] P . Diaconis. A gen eralization of spectral ana lysis with applica tion to ranked d ata. The Annals of Statistics , pages 949–9 79, 1989 . [9] M.A. Fligner and J.S. V erdu cci. Mu ltistage ra nking models. Journal of the American Sta - tistical Association , 83(403) :892– 901, 198 8. [10] Y . Freu nd, R. Iye r , R.E. Schap ire, and Y . Singer . An efficient boo sting alg orithm f or com- bining preferen ces. Journal of Machine Learning Resear ch , 4(6):93 3–96 9, 200 4. [11] W A Glenn and HA David. T ies in paired-co mparison experiments using a mod ified Thurston e-Mosteller model. Bio metrics , 16(1):86 –109, 1960. [12] G.E. Hinto n. T rain ing p rodu cts o f experts by m inimizing contrastive divergence. Neural Computation , 14:17 71–18 00, 200 2. [13] J. Huang , C. Guestrin, and L. Guibas. Four ier theoretic probabilistic inference over permu - tations. The Journal of Machine Learning Researc h , 10:997 –107 0, 2009. [14] T .K. Huang, R.C. W eng, and C.J. Lin . Ge neralized Brad ley-T erry mode ls an d mu lti-class probab ility estimates. The Journal of Machine Learning Resear ch , 7:115, 2006. [15] T . Joach ims. Optimizing sear ch eng ines using click throug h d ata. In Pr oc. of SIGKDD , pages 133– 142. A CM New Y o rk, NY , USA, 200 2. [16] S.L. Lauritzen. Graph ical Models . Oxfor d Science Publication s, 1996. [17] T .Y . Liu. Le arning to ra nk for information retriev al. F oundation s and T rends in In formation Retrieval , 3(3):225–3 31, 20 09. [18] R.D. Luce. In dividua l choice behavior . W iley Ne w Y ork, 1959. [19] C.L. Mallows. No n-null ranking models. I. Bio metrika , 44(1):114 –130 , 1957. [20] J.I. Marden. An alyzing and modeling rank data . Chapman & Hall/CRC, 1995 . [21] M. Mure ¸ san. A concrete a ppr oach to classical analysis . Spring er V erlag, 2008. [22] J. Pearl. Pr ob abilistic Rea soning in Intelligent Systems: Networks of Plau sible In fer ence . Morgan Kaufmann , San Franc isco, CA, 1988. [23] R.L. Plackett. The analysis of permu tations. Applied Statistics , pages 193– 202, 1975. [24] P .V . Rao and L. L. Kupper . T ies in paired -comp arison experiments: A gen eralization of the Brad ley-T erry mod el. Journal o f the A merican Statistical Association , pag es 19 4–204 , 1967. [25] J.H. van Lint and R.M. W ilson. A course in combinatorics . Cambridg e Uni v Pr , 1992. [26] M.N. V olkovs and R.S. Zemel. BoltzRank: lear ning to maximize expected ranking gain. In Pr oceedings of the 26th Annu al In ternationa l Confer enc e on Mac hin e Learn ing . A CM Ne w Y ork, NY , USA, 2009 . [27] F . Xia, T .Y . Liu, J. W a ng, W . Zhang, and H. Li. L istwise approac h to learning to r ank: theory and algorithm. In Pr oc. of ICML , pag es 1192–1 199, 2 008. 15 [28] Y ahoo ! Y ahoo! learn ing to r ank ch allenge. h ttp://learning torank challenge. yahoo.com, 2010. [29] K. Zhou, G.R. Xue, H. Zha, and Y . Y u. Lear ning to rank with ties. In Pr oc. of SIGIR , pages 275–2 82, 2008 . A Computing C Let us calculate the constant C in Eq (7). Let use rewrite the equatio n for ease of compr ehension ∑ S ∈ 2 R k 1 | S | ∑ x ∈ S φ k ( x ) = C × ∑ x ∈ R k φ k ( x ) where 2 R k is the power set with respect to the set R k , or th e set of all no n-empty subsets of R k . Equiv alently C = ∑ S ∈ 2 R k 1 | S | ∑ x ∈ S φ k ( x ) ∑ x ∈ R k φ k ( x ) If all objects are the same, then this can be simplified to C = ∑ S ∈ 2 R k 1 | S | ∑ x ∈ S 1 N k = 1 N k ∑ S ∈ 2 R k 1 = 2 N k − 1 N k where N k = | R k | . In the last equ ation, we hav e ma de use o f the fact th at ∑ S ∈ 2 R k 1 is the numb er of all p ossible no n-emp ty sub sets, or equiv alently , the size of the power set, wh ich is kn own to be 2 N k − 1. One way to der iv e this result is th e imag ine a collection of N k variables, each has two states: ‘ selected ’ and ‘ not selected ’ , wher e ‘selected ’ means the object b elongs to a subset. Since there are 2 N k such configur ations over all states, the number of non -empty subsets must be 2 N k − 1 . For arbitrary objects, let us examine the the probability that the object x belong to a subset of size m , which is m N k . Recall from standard c ombinato rics that the number o f m -elem ent sub sets is the binomial coefficient N k m , where 1 ≤ m ≤ N k , and . Thu s the numb er o f times an object appears in any m -subset is N k m m N k . T aking into account that this number is weig hted do wn by m (i.e. | S | in Eq (7)) , the the contr ibution tow ard s C is then N k m 1 N k . Finally , we can c ompute the constant C , which is the weighted n umber of times an object belongs to any subset of any size, as follows C = N k ∑ m = 1 N k m 1 N k = 1 N k N k ∑ m = 1 N k m = 2 N k − 1 N k W e have made use of the known id entity ∑ N k m = 1 N k m = 2 N k − 1 . 16 B Pairwise Losses Let δ i j ( w ) = φ ( x i , w ) − φ ( x j , w ) , th e pairwise losses are loss ( x i ≻ x j ; w ) = log ( 1 + exp ( − δ i j ( w ))) for logistic loss in RankN et max { 0 , 1 − δ i j ( w ) } for h inge loss in Ranking SVM ( 1 − δ i j ( w )) 2 for q uadratic loss in Pair Regress The overall loss is then Loss = ∑ i < j loss ( x i ≻ x j ; w ) T ak ing deriv ativ e with respect to w yields ∂ Loss ∂ w = ∑ i ∑ j | j < i ∂ loss ( x i ≻ x j ; w ) ∂ δ i j ( w ) ∂ φ ( x i , w ) ∂ w − ∂ φ ( x j , w ) ∂ w = ∑ i ∑ j | j < i ∂ loss ( x i ≻ x j ; w ) ∂ δ i j ( w ) ! ∂ φ ( x i , w ) ∂ w − ∑ j ∑ i | i > j ∂ loss ( x i ≻ x j ; w ) ∂ δ i j ( w ) ! ∂ φ ( x j , w ) ∂ w As it takes N 2 time to co mpute all the partial derivati ves ∂ loss ( x i ≻ x j ; w ) ∂ δ i j ( w ) for all i , j where j < i , the overall grad ient requires N 2 + N F time . Thus the co mplexity o f the pairwise m ethods is O ( max { N 2 , N F } ) . C Learnin g the Paired T ies Models This section describes the details of learning the paired ties models discussed in Section 4. Rao-Kupper method. Recall that th e Rao -Kupper model d efines the following prob ability masses P ( x i ≻ x j | w ) = φ ( x i , w ) φ ( x i , w ) + θ φ ( x j , w ) P ( x i ≺ x j | w ) = φ ( x j , w ) θ φ ( x i , w ) + φ ( x j , w ) P ( x i ≈ x j | w ) = ( θ 2 − 1 ) φ ( x i , w ) φ ( x j , w ) [ φ ( x i , w ) + θ φ ( x j , w )] [ θ φ ( x i , w ) + φ ( x j , w )] 17 where θ ≥ 1 is the ties factor and w is the mod el parameter . For ease of u nconstra ined optimisa- tion, let θ = 1 + e α for α ∈ R . In learning, we want to esti ma te both α and w . Let P i = φ ( x i , w ) φ ( x i , w ) + ( 1 + e α ) φ ( x j , w ) P ∗ j = φ ( x j , w ) φ ( x i , w ) + ( 1 + e α ) φ ( x j , w ) P ∗ i = φ ( x i , w ) ( 1 + e α ) φ ( x i , w ) + φ ( x j , w ) P j = φ ( x j , w ) ( 1 + e α ) φ ( x i , w ) + φ ( x j , w ) T ak ing partial deriv atives of the log-likeliho od gi ves ∂ log P ( x i ≻ x j | w ) ∂ w = ( 1 − P i ) ∂ log φ ( x i , w ) ∂ w − ( 1 + e α ) P j ∂ log φ ( x j , w ) ∂ w ∂ log P ( x i ≻ x j | w ) ∂ α = − P j e α ∂ log P ( x i ≈ x j | w ) ∂ w = ( 1 − P i − ( 1 + e α ) P ∗ i ) ∂ log φ ( x i , w ) ∂ w + ( 1 − P j − ( 1 + e α ) P ∗ j ) ∂ log φ ( x j , w ) ∂ w ∂ log P ( x i ≈ x j | w ) ∂ α = 2 ( 1 + e α ) ( 1 + e α ) 2 − 1 − P ∗ i − P ∗ j e α Davidson m et hod. Recall that in the Da vidson method the prob ability masses are defined as P ( x i ≻ x j | w ) = φ ( x i , w ) φ ( x i , w ) + φ ( x j , w ) + ν p φ ( x i , w ) φ ( x j , w ) P ( x i ≺ x j | w ) = φ ( x j , w ) φ ( x i , w ) + φ ( x j , w ) + ν p φ ( x i , w ) φ ( x j , w ) P ( x i ≈ x j | w ) = ν p φ ( x i , w ) φ ( x j , w ) φ ( x i , w ) + φ ( x j , w ) + ν p φ ( x i , w ) φ ( x j , w ) where ν ≥ 0. Again, for simplicity of unconstraine d optimisation , let ν = e β for β ∈ R . Let P i = φ ( x i , w ) φ ( x i , w ) + φ ( x j , w ) + e β p φ ( x i , w ) φ ( x j , w ) P j = φ ( x j , w ) φ ( x i , w ) + φ ( x j , w ) + e β p φ ( x i , w ) φ ( x j , w ) P i j = e β p φ ( x i , w ) φ ( x j , w ) φ ( x i , w ) + φ ( x j , w ) + e β p φ ( x i , w ) φ ( x j , w ) 18 T ak ing deriv ativ es of the log-likelihood gi ves ∂ log P ( x i ≻ x j | w ) ∂ w = ( 1 − P i − 0 . 5 P i j ) ∂ log φ ( x i , w ) ∂ w − ( P i + 0 . 5 P i j ) ∂ log φ ( x j , w ) ∂ w ∂ log P ( x i ≻ x j | w ) ∂ β = − P i j ∂ log P ( x i ≈ x j | w ) ∂ w = ( 0 . 5 − P i − 0 . 5 P i j ) ∂ log φ ( x i , w ) ∂ w + ( 0 . 5 − P j − 0 . 5 P i j ) ∂ log φ ( x j , w ) ∂ w ∂ log P ( x i ≈ x j | w ) ∂ β = 1 − P i j 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment