Classification and categorical inputs with treed Gaussian process models
Recognizing the successes of treed Gaussian process (TGP) models as an interpretable and thrifty model for nonparametric regression, we seek to extend the model to classification. Both treed models and Gaussian processes (GPs) have, separately, enjoy…
Authors: Tamara Broderick, Robert B. Gramacy
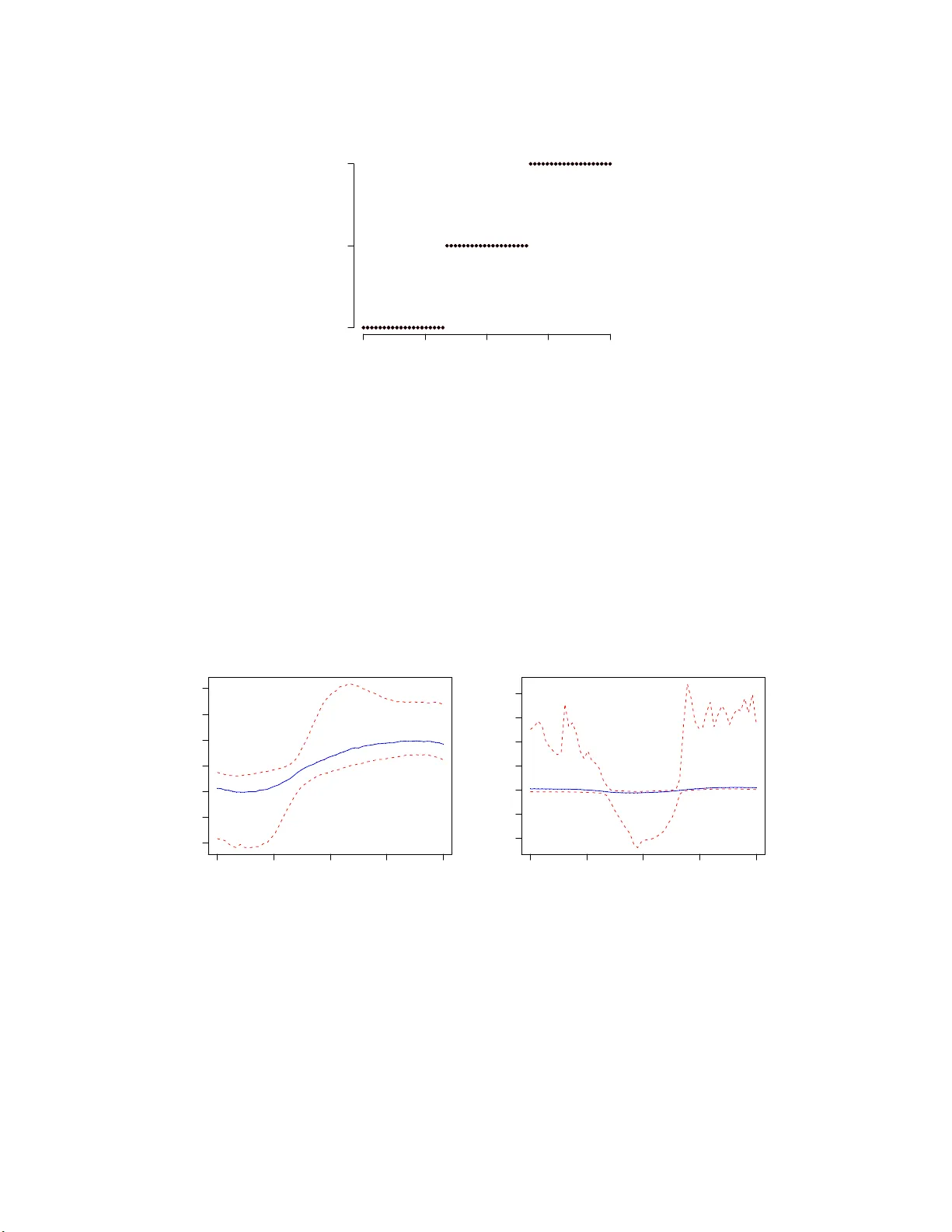
Classification and categorical inputs with treed Gaussian pro cess mo dels T amar a Bro derick tab@ stat.be rkeley.edu Department of Stati stics Universit y of Calif o rnia, Berkeley Rob ert B. Gramacy bobb y@stats lab.cam.ac.uk Stati stical Lab ora tory Universit y of C am bridge, UK Abstract Recognizing the su cce sses of treed Gaussian p r ocess (TGP) mo dels as an inter- pretable and thrift y mo del for nonparametric regression, w e seek to extend t he mo del to classification. Both treed mo dels and Gaussian pr ocesses (GPs) h a v e, separately , en- jo y ed great succe ss in applicatio n to classificatio n p roblems. An example of th e former is Ba y esian CAR T. In the latter, real-v alued GP output ma y b e utilized for classificatio n via laten t v a riables, which p ro vide classification ru les by means of a softmax fun cti on. W e form ulate a Ba y esian mod el a v eraging sc heme to com bine th ese t w o mod els and describ e a Mon te C arlo metho d for samp ling f rom the full p osterior distribution with join t prop osals for the tree top olo gy and the GP parameters corresp ondin g to laten t v a riables at the lea ves. W e co ncentrat e on effici ent sampling of the la ten t v ariables, whic h is imp ortan t to obtain goo d mixing in the expanded p aramete r space. T h e tree structure is particularly helpf u l for this task and also for dev eloping an efficien t scheme for h andling catego rical predictors, whic h c ommonly arise in classificatio n problems. Our pr oposed classification TGP (CTGP) metho dology is illustr ate d on a collectio n of syn thetic and r ea l data sets. W e assess p erformance r elativ e to existing metho ds and thereb y sho w ho w CT GP is highly flexible, offers tr ac table inference, p rod uces rules that are easy to in terpret, and p erforms wel l out of sample. k eyw ords: treed mo dels, Gaussian p rocess, Ba y esian m odel a ve raging, laten t v a riable 1 In tro ducti on A Gaussian pro cess (GP) (e.g., R a sm us sen and Williams, 2006) is a p opular nonparamet- ric model for regression and classification that specifies a prior o v er functions. F o r ease of computation, ty pical priors often confine the functions to statio na rit y . While stationarity is a reasonable assumption for man y data sets, still man y more ex hibit only lo cal station- arit y . In t he latter case, a stationary mo del is inadequate, but a f ully nonstationary mo del is undesirable as w ell. Inference can b e difficult due to a nonstationary mo del’s complex- it y , m uc h of whic h is unnecessary to obtain a go o d fit. A treed Gaussian pro cess (TGP) 1 (Gramacy and Lee, 2 0 08), in con trast, can tak e adv an tage of lo cal tr ends mor e efficien tly . It defines a treed partitioning pro cess on the predictor space and fits distinct, but hierar- c hically r elat ed, statio nary GPs to separate regions at the leav es . The treed form o f the partition make s the mo del particularly in terpretable. A t the same time, the partitio ning results in smaller matrices for in v ersion than would b e required under a standard GP mo del and thereb y pro vides a nonstationary mo del t ha t actually fa cilitates faster inference. Recognizing the successes o f TGP for regression, w e seek to extend the mo del to classifi- cation. Separately , b oth treed mo dels and GPs ha v e already b een b een successfully a pplied to classification. Bay e sian metho ds in the first case outline a tree prior and series of pro pos- als for tree manipulation in a Monte Carlo sampling f r a mew ork, leading to Ba y esian CAR T (Chipman et al., 1 998)—extending t he classical v ersion due to Breiman et al. (19 84). In the second case lies a metho d by whic h real-v alued GP output ma y b e utilized in a classification con text (Neal, 1998 ); for some n um b er of classes, the real outputs of a commensurate n um b er of G Ps ( M − 1 for M classes) a re take n as prior s fo r laten t v ariables that yield probabilities via a softmax function. This leads to tw o w a ys to com bine trees with GPs for classification. The data ma y b e partitioned once by the tree pro cess, and then w e ma y asso ciate M − 1 GPs to eac h region of t he partition, or instead, M − 1 separate f ull TGPs ma y b e instantiated. W e propo se taking the latter route in the in terests of faster mixing. W e describ e a Mon te Carlo sampling sc heme to summarize the posterior predictiv e distribution. The algorithm tra v erses the full space of classification TGPs using joint prop osals for tree-top ology mo difi- cations and the GP parameters at the lea v es o f the tree. W e explore sc hemes fo r efficien tly sampling the latent v ariables, whic h is imp ortan t to obtain go o d mixing in the (significan tly) expanded pa r a meter space compared t o the regr ession case. The r emainder of the pap er is outlined a s follows . W e shall first review the G P mo del for regression and classification in Section 2. Section 3 b egins with a r eview of t he extension of GPs to nonstationa ry regression mo dels by treed partitioning, cov e ring the basics of inference and prediction with particular fo cus o n the Monte Carlo metho ds used to in tegrate o v er the tree structure. W e then discuss how categorical inputs may b e dealt with efficien tly in this framew ork. This dis cussion represen ts a new con tribution to the regression litera t ure and, w e s hall argue, is particularly relev a nt to our classification extensions; it is the categorical inputs that can most clearly b enefit from the in terpretation and speed features offered b y treed partitioning. W e are then a ble to describ e the TGP mo del for classification in detail in Section 3.3. In Section 4 w e illustrate our prop osed metho dology on a collection of syn thetic and real data sets. W e assess p erformance relative to existing metho ds and thereb y demonstrate that this nonstationary classification mo del is highly flexible, offers tractable inference, pro duces rules t ha t are easy to in terpret, and (most imp ortantly) p erforms w ell out of sample. Finally , in Section 5 w e conclude with a short discussion. 2 Gaussian pr o cesses for regress ion and classificatio n Gaussian pro cess (GP) mo dels are highly flexible and nonlinear mo dels that hav e b een applied in regression a nd classification con texts for ov e r a decade (e.g., Neal, 1997, 1998; 2 Rasm ussen and Williams, 20 06). F or real-v alued P -dimensional inputs, a G P is f o rmally a prior o n the space of functions Z : R P → R suc h that the f unction v alues at an y finite set of input p oints x hav e a join t G aussian distribution (Stein, 1 999). A particular GP is defined b y its mean function and corr elat io n function. The mean function µ ( x ) = E ( Z ( x )) is often con- stan t or linear in the explanator y v ariable co ordinates: µ ( x ) = β T f ( x ), where f ( x ) = [1 , x ]. The correlation function is defined as K ( x, x ′ ) = σ − 2 E [ Z ( x ) − µ ( x )][ Z ( x ′ ) − µ ( x ′ )] T . W e further assume that the correlat io n function can b e decomp osed into tw o comp onen ts: an underlying strict correlation function K ∗ and a noise t erm of constant a nd strictly p ositiv e size g that is indep enden tly a nd iden tically distributed at the predictor p oin ts. K ( x ( i ) , x ( j ) ) = K ∗ ( x ( i ) , x ( j ) ) + g δ i,j Here, δ i,j is the K ronec k er delta, and w e call g the nugget . In t he mo del, the nugget term represen ts a source of measuremen t error. W riting the GP as Z ( x ) = µ ( x ) + w ( x ) + η ( x ), w e hav e µ ( x ) as the fixed mean function, w ( x ) as a zero-mean Gaussian random v ariable with correlation K ∗ ( x ), and η ( x ) as an i.i.d. Gaussian noise pro cess. Computationally , the n ugget term helps ensure that K remains nonsingular, allow ing the frequen t in v ersion of K without concern for n umerical instability that might otherwise plague efficien t sampling from the Bay e sian p osterior as necessary for the analysis that fo llows. Due to its simplicit y , a p opular choice for K ∗ ( x, x ′ ) is the squared exp onen tial correlation K ∗ ( x, x ′ ) = exp − || x − x ′ || 2 d , where the strictly p ositiv e parameter d describ es the r ange (or length-sc ale ) of the pro cess. I.e., d gov erns the rate of decay of cor r elation a s the distance || x − x ′ || b et w een lo cations x and x ′ increases. The underlying (G a uss ian) pro cess that results with this c hoice of K is b oth stationary and isotropic. It is easily extended to incorp orate a v ector-v alued parameter so tha t correlation ma y deca y at ra tes that differ dep ending o n direction: K ∗ ( x, x ′ ) = exp ( − P X p =1 ( x p − x ′ p ) 2 d p ) . The resulting pro cess is still stationary , but it is no longer isotropic. F urther discu ssion of correlation s tructures for G Ps can b e found in Abrahamsen (1997) or Stein (199 9). These structures include the p opular Mat ´ ern class (Mat´ ern, 19 8 6), whic h allo ws the smo othness of the pro cess to b e pa rameterize d. The ch oice of correlation function is en tirely up to the practitioner—the metho ds described herein apply generally fo r a n y K ( · , · ). The GP mo del, describ ed ab o v e for the problem of regression, can b e extended to classifi- cation b y introducing laten t v ariables (Neal, 199 7). In this case, t he data consist of predictors X a nd classes C . Supp ose there are N data p oints and M classes. W e in tro duce M sets of laten t v ariables { Z m } M m =1 , one for each class. F or a particular class m , the generative mo del is a GP as b efore: Z m ∼ N N ( µ m ( X ) , K m ( X , X )). The class probabilities ar e no w obtained 3 from the latent v ariables via a softmax f unction p ( C ( x ) = m ) = exp( − Z m ( x )) P M m ′ =1 exp( − Z m ′ ( x )) . (1) The g enerativ e mo del then specifies that t he class at a p oin t is dra wn from a single-trial m ultinomial distribution with these proba bilities. In practice, o nly M − 1 GPs are required since we may fix the latent v ariables of the final class to zero without loss of g eneralit y . In this mo del, it remains to place priors, p erhaps of a hierarc hical nature, o n the par a me- ters of eac h G P . The challenge of efficien tly sampling f r o m the p osterior of the la ten t v ariables also remains. Neal (1 997) suggests sampling the hyperparameters with a Gaussian random w alk or by t he h ybrid Monte Carlo metho d. Our choice o f hierarc hical model, in contrast, allo ws almost entirely Gibbs sampling mov es (Gra ma cy and Lee, 20 08). Neal suggests sam- pling the latent v ariables (individually) with ada ptiv e rejection sampling (Gilks and Wild , 1992). W e prefer to use Metrop olis–Hastings (MH) draws with a carefully c hosen prop osal distribution and consider blo ck -sampling the la t en t v ariables (see Section 3.3.3). The GP mo del, for b oth regression and classification, features some notable dra wbac ks. First, a s mentioned ab ov e, t he p opular correlation functions are typic ally stationary whereas w e may b e in terested in data whic h are at o dds with the stationarit y assumption. Second, the t ypical correlation functions are clumsy for binary or categorical inputs. F inally , the frequen t in v ersions of a correlation matrix, an O ( N 3 ) o p eration, are necessary for GP mo deling, whic h mak es these a nalyse s computationally exp ensiv e. 3 T reed Gaus s ian pro cess es P artitioning the predictor space addresses all three of the p otential dra wbac ks men tioned ab o v e a nd o ffers a natural blo ck ing strategy (suggested b y the da t a) for sampling the la ten t v a riables as required in the classification mo del. In particular, after par t itioning the predictor space, w e may fit differen t, indep enden t mo dels to t he data in eac h partit io n. Doing so can accoun t f or nonstatio narit y across the full predictor space. P artitions can o ccur on categorical inputs; separating these inputs from the GP predictors allow s them to b e treated in classical CAR T fa shion. Finally , partitions result in smaller lo cal co v ariance matrices, whic h are more quic kly in v erted. 3.1 TGP for regression CAR T (Breiman et al., 1984) and BCAR T (for Bay esian CAR T) (Chipman et al., 1998, 2002) for regression es sen tially use t he same partitio ning sc hem e as TGP but with simpler mo dels fit to each partitio n describ ed b y the tree. More precisely , each branch of the tree— in any of these mo dels—divides the predictor space in tw o. Consider predictors x ∈ R P ; for some split dimens ion p ∈ { 1 , . . . , P } and split v alue v , p oin ts with x p ≤ v are ass igned to the left branc h, and p oin ts with x p > v ar e assigned to the righ t branch. P artitioning is r ecursiv e a nd may o ccur on any input dimension p , so arbitrary axis-aligned regions 4 in the predictor space may b e defined. Conditional on a treed partition, mo dels are fit in eac h o f the leaf regio ns. In CAR T the underlying mo dels are “ constan t” in that only the mean a nd standard deviation o f the real-v alued outputs are inferred. The underlying CAR T tree is “gro wn” according to one of man y decision theoretic heuris tics a nd may be “pruned” using cross-v alidation metho ds. In BCAR T, these mo dels ma y b e either constan t (Chipman et al., 1998) or linear (Chipman et al., 2002) a nd, by con trast with CAR T, the partitioning structure is de termined by Mon te Carlo inference on the joint p osterior of the tree and the mo dels used at the leav es . In regression TGP (hereafter R TGP), the leaf mo dels are GPs, but otherwise the setup is iden tical to BCAR T. Note that the constant and linear mo dels are sp ecial cases of the GP mo del. Th us R TGPs encompass BCAR T for regression and ma y pro ceed according to a nearly identical Monte Carlo metho d, describ ed shortly . F o r implemen tation and inference in the R TGP mo del class, w e tak e adv an tage of the op en source tgp pack age (G ramacy and T a ddy , 20 0 8) f o r R a v ailable on CRAN ( R Dev elopmen t Core T eam , 2008). Details of the computing tec hniques, algorithms, default parameters, and illustrations are pro vided b y Gramacy (2007). 3.1.1 Hierarc hical model The hierarchical mo del for the R TGP b egins with the tree prior. W e define this prior recursiv ely fo llo wing Chipman et al. ( 1998). T o assem ble tree T , start with a single (r o ot ) no de. F o r m a queue with this ro ot no de. Recursiv ely , for each no de η in the queue, decide to split η with some probability p split ( T , η ). If η splits, first choose a splitting rule f o r η according to the distribution p rule ( T , η ), and t hen put the new c hildren of η in the queue. It remains to define the distributions p split ( T , η ) and p rule ( T , η ). The c hoice p split ( T , η ) = α (1 + D η ) − β , with α ∈ (0 , 1) and β > 0, includes a base probabilit y of splitting α and a p enalt y factor (1 + D η ) − β , whic h is exp onen tial in the no de depth D η in T . A simple distribution p rule o v er split-p oin ts is first uniform in the co ordinates of the explanatory v ariable space and then uniform o v er splitting v alue s that result in distinct data sets at the c hild no des. When non- informativ e priors are used at the lea v es of the tree it is sensible to ha v e the tree prior enforce a minim um data requiremen t for each region of the partition(s). W e ta k e the tgp defaults in this resp ect, whic h a utomatically determine an a ppropriate minimum as a function of the predictor dimension P . No w let r ∈ { 1 , . . . , R } index the R non-ov erlapping regio ns partitioned by the tree T formed from the ab o v e pr o cedure. In the regression pro blem, each region contains N ( r ) p oin ts of data: ( X r , Z r ). F r is defi ned to b e an extension to the predictor matrix with an in tercept term: F r = (1 , X r ); th us, F r has P + 1 columns. A “constan t mean” ma y b e obtained with F r = 1; in this case, P = 0 in Eq. (2 ) below. The generativ e mo del for the GP in region r incorp orates the multiv ariate no r mal ( N ), inv e rse-gamma (IG), and Wishart ( W ) distributions a s follows. Z r | β r , σ 2 r , K r ∼ N N ( r ) ( F r β r , σ 2 r K r ) β r | σ 2 r , τ 2 r , W , β 0 ∼ N P +1 ( β 0 , σ 2 r τ 2 r W ) σ 2 r ∼ IG( α σ / 2 , q σ / 2) β 0 ∼ N P +1 ( µ, B ) (2) τ 2 r ∼ IG( α τ / 2 , q τ / 2) W − 1 ∼ W (( ρV ) − 1 , ρ ) 5 The h yp erparameters µ, B , V , ρ, α σ , q σ , α τ , q τ are constan t in the mo del, for whic h w e tak e the tgp defaults. 3.1.2 Estimation Our aim in this section is to approximate t he join t distribution of the tree structure T , the R sets of GP parameters { θ r } r ∈{ 1 ,...,R } in eac h region depicted by T , and GP h yp erparameters θ 0 (those v aria bles in Eq. (2) that are not treated a s constan t but also not indexed b y r ). T o do so, w e sample from this distribution using Mark o v Chain Monte Carlo (MCMC). W e sequen tially dra w θ 0 | rest, θ r | rest for eac h r = 1 , . . . , R , and T | rest. All parameters ( θ r , r = 1 , . . . , R ) and h yp erparameters of the GPs can b e sampled with Gibbs steps, with the exception of the cov ariance function parameters { d r , g r } . Expres sions are pro vided b y Gramacy and Lee (2008), and full deriv atio ns are prov ided b y Gramacy (2005), whic h are b y now quite standard in the literature so they are not repro duced here. Mon te Carlo inte gratio n o v er tree space, conditional o n the G P parameters θ r , r = 1 , . . . , R is, b y contrast, more inv olv ed. D ifficulties arise when w e randomly dra w a new tree structure from the distribution T | rest b ecause it is p ossible that the new tree ma y hav e more leaf no des (or few er) than b efore. Changing the n um b er of leaf no des c hanges t he dimension of θ = ( θ 1 , . . . , θ R ), so simple MH draw s are not sufficien t for T . Instead, rev ersible jump Mark o v Chain Monte Carlo (RJ-MCMC) a llows a principled transition b et w een models of differen t sizes (Ric hardson and Green, 1 997). Ho w ev er, by c ho osing the GP parameters at the leaf no des of the prop osal tr ee carefully , the distinction betw ee n MH and RJ-MCMC can be effectiv ely ignored. In the case where the num ber of leaf no des does not c hange betw e en the curren t tree state and the prop osal tree, main taining the same collection o f { θ r } allo ws us t o igno re the RJ-MCMC Jacobian factor. In the case where the n um ber of leaf no des increases—and the increase will alw a ys b e by exactly o ne leaf no de—drawing the G P para meters fr o m their prio rs similarly sets the Jacobian facto r in the RJ-MCM C acceptance ratio to unity ; this lea v es just the usual MH acceptance ratio. Gramacy and Lee (2008) describ e prop osals that facilitate mo v es throughout the space of p ossible trees and ho w these mov es are made rev ersible. The mo v es are called gr ow , prune , change , and swap , where the fina l mo v e has a sp ecial sub-case r otate to increase the resulting MCMC acceptance ratio. This list of four mo v es is largely the same as in t he BCAR T mo del (Chipman et al., 1998), with the exception of r otate . D uring MCMC, the mov e s are ch osen uniformly at random in each iteration. 3.1.3 Prediction F ro m the hierarc hical mo del in Section 2 , we can solv e for the predictiv e distribution of the outputs Z . Conditional on the cov a riance structure, standard m ultiv ariate normal theory giv es that the predicted v alue of Z ( x ∈ region r ) is normally distributed with E ( Z ( x ) | data , x ∈ region r ) = f ⊤ ( x ) ˜ β r + k r ( x ) ⊤ K − 1 r ( Z r − F r ˜ β r ) , V ar( Z ( x ) | data , x ∈ region r ) = σ 2 r [ κ ( x, x ) − q ⊤ r ( x ) C − 1 r q r ( x )] , (3) 6 where C − 1 r = ( K r + τ 2 r F r W F ⊤ r ) − 1 q r ( x ) = k r ( x ) + τ 2 r F r W f ( x ) κ ( x, y ) = K r ( x, y ) + τ 2 r f ⊤ ( x ) W f ( y ) Here, w e ha v e f ⊤ ( x ) = (1 , x ⊤ ) under the mo del with a linear mean, or f ⊤ ( x ) = 1 under the constan t mean. F urther, k r ( x ) is an n r -long v ector with k r,j ( x ) = K r ( x, x j ) for all x j ∈ region r , and ˜ β r = E ( β | F r , Z r , rest) is giv en in closed form b y Gramacy and Lee (2008). Conditional on a particular tree T , the expressions in Eq. ( 3) b etra y tha t the predictiv e surface is discon tin uous acro ss the partit io n b oundaries of T . Ho w ev er, in the aggrega t e of samples collected from t he joint p osterior distribution of ( T , θ ), t he mean tends to smo oth out near lik ely partition b oundaries as t he tree o peratio ns gr ow, prune, c hange , and swap in tegrate o v er t r ees and GPs with larg e p osterior pro ba bility . Uncertain t y in the p osterior for T translates in to higher p osterior predictiv e uncertain ty near regio n b oundaries. When the data actually indicate a non- smo oth process, the treed G P retains the flexibilit y necessary to mo del discontin uities . When t he data are consisten t with a con tin uous pro cess, t he treed GP fits ar e almost indistinguishable from con tin uous (Gramacy a nd Lee, 2008). 3.2 Categorical inputs Classical treed metho ds, suc h as CAR T, can cop e q uite naturally with categorical, binary , and o rdinal inputs. F o r example, categorical inputs can b e enco ded in binary , and splits can b e prop osed with rules suc h as x p < 1. Once a split is made on a binary input, no further pro cess is needed, mar ginally , in that dimension. Ordinal inputs can also b e co ded in binary , and thus treated as categorical, or treated as real-v alued and handled in a defa ult w ay . GP regress ion, how ev e r, handles suc h non-real-v alued inputs less naturally , unless (p erhaps) a custom and non-standard f orm of the co v ar ia nce function is used (e.g., Qian et al., 2 0 08). When inputs are scaled to lie in [0 , 1], binary-v alued inputs x p are a lw a ys a constant distance apart— at the largest p ossible distance in the range. When using a separable correlation function, parameterized by length-scale parameter d p , the lik eliho o d will increase as d p gets larg e if the output do es not v ary with x p and will tend to zero if it do es (in or der to b est appro ximate a step function correlation). Moreo ver, the binary enco ding of even a few categorical v ariables (with sev era l leve ls) w ould cause a proliferation of binary inputs whic h w o uld eac h require a unique ra nge parameter. Mixing in the high dimensional parameter space defining the GP correlation structure w ould consequen tly b e p o or. Clearly , this f unctiona lity is more parsimoniously ac hiev ed by part it ioning, e.g., using a tree. Ho w ev er, t rees with f a ncy regression mo dels at the lea ve s p ose other problems, as discusse d b elo w. Rather than manipulate the GP correlation to handle categorical inputs, the tree presen ts a more natura l mec hanism for suc h binary indicators. That is, they can b e included a s candidates for treed partitioning but ignored when it comes to fitting the mo dels at the lea v es o f t he tree. They mus t b e excluded from the GP mo del at the lea v es since, if eve r a Bo olean indicator is partitioned up on, the design matrix (for the GP or LM) w ould contain a column of zeros o r o nes and therefore w ould not b e of full rank. The b enefits of r emo ving the Bo oleans from the GP mo del(s) go b ey ond pro ducing full- rank design matrices at the lea v es of the tree. Lo osely sp eaking, remo ving the Bo olean indicators fr o m the GP part of t he treed 7 GP giv es a more pa rsimonious mo del. The tree is able to capture all o f the dep endence in the resp onse as a function of the indicator input, and the GP is the appropriate non- linear mo del for accoun t ing fo r the remaining relationship b et w een the real-v alued inputs and outputs. F urther adv antages to this appro ac h include sp eed (a partitioned mo del giv es smaller co v ar ia nce matr ices to inv ert) and impro v ed mixing in the Mark ov c hain when a separable cov ariance function is used since the size of the parameter space defining the correlation structure w ould remain manageable. Note that using a non-separable co v ariance function in the presence of indicators would result in a p o or fit. Go o d range ( d ) settings for the indicators w ould not necess arily coincide with go o d range settings for the real- v alued inputs. Finally , the treed mo del allow s the pra ctitioner to immediately ascertain whether the resp onse is sensitiv e to a particular categorical input b y tallying the prop ortion of time the Mark o v c hain visited trees with splits on the corresp onding binary indicator. A m uc h more in v olv ed Mon te Carlo tec hnique (e.g., follow ing Saltelli et al., 2008) w ould otherwise b e required in the absence of the tree. If it is kno wn that, conditional on having a treed pro cess for the binary inputs (enco ding categories), the relationship b et w een the remaining real-v alued inputs and the resp onse is stationary , then w e can impro v e mixing in the Mark ov c hain further b y ignoring the real- v a lued inputs when prop osing tree op erations. In Section 4.1 w e shall illustrate the b enefit of the treed approach to categorical inputs in the regression context. There is a p ossible dra wback to allowin g (only) the tree pro cess to g o ve rn the relationship b et we en the binary predictors a nd the resp onse; an y non-trivial tr eed partition w ould for ce the GP part of the mo del to relate the real-v alued inputs and the resp onse separately in distinct regions. By con trast, o ne global GP—with some me c hanism for directly handling binary inputs—ag g regates information o v er the entire predictor space. W e can imagine a scenario where the corr elat io n structure for the real-v alued inputs is globally stat ionary , but the resp onse still dep ends (in part) up on the setting of a categorical input. Then par titioning up on that categorical input could w eak en the GP’s ability to learn t he underlying stationary pro cess g o v erning the real-v alued inputs. In this case, the approach describ ed by Qian et al. (2008), whic h explicitly accoun t s f o r correlation in the resp onse across differen t v alues of the categorical predictors, ma y b e preferred. Ho wev er, we shall arg ue in Section 3 .3 that in the classification con text this p ossibilit y is less of a worry b ecause the GP part o f t he mo del is only a prior f o r the laten t Z -v alues, and therefore its influence on the p osterior is rather we ak compared to the class lab els C . Suc h small influences tak e a bac k seat to the (b y comparison) enormous sp eed and in terpretabilit y b enefits that are o ffered b y treed partitioning on binary inputs as illustrated empirically in Sections 4.2 and 4.3 . These b enefits are not enjo y ed by the Qia n et al. (2 008) approac h. 3.3 TGP for classification Recall that in order to adapt the G P for classification (Section 2), w e in tro duced M − 1 sets of la t en t v ariables Z m so that each predictor X correspo nds to M − 1 la ten t v a riable v alues. The class C ( X ) then has a single-draw m ultinomial distribution with probabilities obta ined via t he softmax function (1) applied to these laten t v ariables. 8 3.3.1 P ossible model form ulations In the TGP case, how ev er, it is not immediately clear ho w these lat ent v a r ia bles fit into the tree structure. W e can imag ine at least tw o p ossibilities. First, recall that in t he R TGP mo del, the tree part it ions the predictor space in to regions. In each region, w e fit a GP . One laten t v ariable extension to this mo del w ould b e to fit a CGP at eac h leaf of the tree. Instead of a single GP , eac h leaf CGP consists of M − 1 GPs. The output of these G Ps w ould b e the M − 1 laten t v ariable sets in that particular region. T ogether, the output o ve r all regions w o uld form the en tir e set of la ten t v ariables. Since this mo del features just one tree, we call it an OTGP . Alternativ ely , w e migh t not c ho ose to generate a CGP at each leaf of a single tree. Rat her, w e could recall that the CGP amalgamates laten t v aria bles from M − 1 real-v alued mo dels. Instead of t he M − 1 GPs of the CGP , then, we could generate M − 1 indep ende n t, full TG P mo dels. The output of the m th TGP would b e the full set of lat en t v a r ia bles Z m for the m th class. Since this mo del features m ultiple, indep enden t trees, w e call it an MTGP . Note that in this latter case, the trees need not all hav e the same splits. W e can imagine M − 1 p erfect copies of X indexed by class. Then ( X m , Z m ) ma y b e partitioned differen tly for each m . In the OTGP case, on the o ther hand, ( X m , Z m ) is partitioned in to exactly the same regions across all m . W e c ho ose to fo cus on the MTGP in the following analysis as w e exp ect it to exhibit b etter mixing than the OTGP when the n um b er of classes is greater than t w o. F or a particular c ho ice of prior and hierarchical model, the OTGP ma y b e though t of as an MTGP where the trees are all constrained to split on the same v ariable–v alue pair s. The MTGP may th us more easily mo del natural splits in a set o f data since each tree can b e differen t. Imagine a data set where class 1 o ccurs predominantly in regio n 1, class 2 o ccurs predominan tly in region 2, and class 3 in regio n 3. As we will s ee in Section 4.2, a single split in eac h of the t w o MTGP trees may b e sufficien t to capture t hes e divisions. F or O TG Ps, ho wev er, the o v erarc hing tree in the same case would require tw o splits to represen t the partitio n. But a greater n um b er of splits is less lik ely under the giv en tree prior (Section 3.1.1). Moreo v er, the final splits in the MTGP are more in terpretable since w e immediately see whic h class lab el w as relev an t for a giv en split. In the OTGP , a split may b e primarily relev ant to a particular class lab el or set of class la bels, but it will still b e applied across all class lab els. Along similar lines, when a gr ow or chan g e mov e is pro posed in the tree, evidence from all of the GPs of the OTGP accumu lates for o r against the mov e. Thus it is less lik ely that the acceptance probability will b e high enough fo r suc h a mov e to tak e place in the OTGP . But f or the MTGP , o nly the laten t v ariables o f class m directly influence the prop osal probability of gr ow s or changes in the m th t r ee. So it is easier for the MTGP trees to gr ow and thereb y take adv antage o f the tr ee structure in the mo del. Finally , as a practical consideration, the MTGP is more directly implemen ted as an extension of the R TGP . The com binat ion of tree and laten t v ariable sets for each class can b e essen tially the same—dep ending on hierarc hical mo del choice in the classification case—as the existing R TGP formulation with the latent v aria bles a s the outputs. Th us, t he MTGP mo del ma y b e co ded b y making minor mo difications to the the tgp pac k age. Since w e 9 henceforth use only the MTGP , w e will refer to it as a CTGP (TGP for classification) in analogy to t he acron ym R TGP . 3.3.2 Hierarc hical model CGP τ 2 m,r ∼ I G ( α τ / 2 , q τ / 2) σ 2 m,r ∼ I G ( α σ / 2 , q σ / 2) β m, 0 ∼ N P +1 ( µ, B ) W − 1 m ∼ W (( ρV ) − 1 , ρ ) Z m,r | β m,r , σ 2 m,r , K m,r ∼ N N ( m,r ) ( F m,r β m,r , σ 2 m,r K m,r ) p ( n ) m ∝ exp( − Z m ( x ( n ) )) C ( x ( n ) ) ∼ Multi(1 , p ( n ) ) β m,r | σ 2 m,r , τ 2 m,r , W m , β m, 0 ∼ N P +1 β m, 0 , σ 2 m,r τ 2 m,r W m T m , Region m,r R m r =1 ∼ T ree-Prior( α T , β T ) CTGP GP 1:( M − 1) , 1: R m TGP 1:( M − 1) Figure 1: CTGP hierarc hical mo del with GP , CG P , and TGP elemen ts emphasized. The hierarc hical mo del for the CTGP mo del is straig h tforward. Giv en dat a ( X , C ), w e in tro duce latent v ar ia bles { Z m } M − 1 m =1 . T here is one set for eac h class or, equiv alen tly , one set for eac h tree. Eac h of the M − 1 trees divides the space in to an indep enden t region set of cardinalit y R m . And eac h tree has its ow n, indep enden t, R TGP prior where the h yp erparameters, parameters, and laten t v ariable v alues—for fixed class index m —are generated as in Eq. (2). While this full mo del is iden tical to the R TGP case, we prefer a constan t mean for the classification task as the linear mean incorp orates extra degrees of freedom with less of a clear b enefit in mo deling flexibilit y . Finally , t he generativ e mo del for the class lab els incorp orates the la ten t v a riables from all M − 1 t r ees. The softmax function app ears j ust as in the CGP case (1). F ig ure 1 summarizes the f ull mo del via a plate diagram. The devil is, of course in the details, whic h follow . 3.3.3 Estimation T o appro ximate the join t distribution of the M − 1 TGPs, w e sample with MCMC as in Section 3.1.2 to a lar g e exten t. Sampling is accomplished b y visiting eac h tree in t urn. F or the m th class, w e sequen tially dra w θ m, 0 | rest, θ m,r | rest f or eac h regio n r of R m , T m | rest, a nd finally the latent v ariables Z m,r | rest for eac h r . The first three draws are the same as for the R TGP , although they may b e mo dified a s desc rib ed b elo w. The laten t v ariable draw Z m,r | rest is the step unique to the CTGP . One p ossible extension to the tree mov es in tro duced in Se ction 3.1.2, and describ ed in full detail in Gr amacy and Lee (2008), is to prop ose new laten t v aria bles along with eac h 10 mo v e. In this formulation, w e would accept or reject the new partition alo ng with the newly prop osed set of laten t v ariables a nd, p ossibly , newly pro posed GP para meters (c.f. gr ow ). A difficult y with these tree mov es in classification problems is that the class data C do es not pla y a direc t role; indeed, it is used only in de fining the acceptance pro babilit y of the laten t v ariable dra ws (see b elo w). It is tempting to try to incorp orate C more directly into determining the tree structure b y adding latent v ariable mo v es to gr ow , p rune , ch ange , and swap (but not r otate ). W e could, for instance, prop ose Z from its prio r. The n the class data would app ear in t he p osterior probability factor of the MH acceptance ratio . The tree op erations themselv es are no differen t whether the laten t v ariables are prop osed or no t . Ho w ev er, some exp erimen tal trials with this mo dification suggested that the resultan t mixing in tree space is p o or. In tuition seems to corrob orate this finding. Inc orp orating man y new random v ariables in to a prop osal will, generally , decrease the acceptance ratio for that pro p osal. Certainly , whe n the Z are all prop osed sim ultaneously in eac h leaf from their GP prior, it is unlik ely tha t they will predominantly arr a nge t hemselv es to b e in close corresp ondence with t he class lab els. Eve n when a blocking mechanis m is used, all of the laten t v ariables must b e accepted or rejected together—along with the prop osed tree mov e. Instead o f handicapping the tree mov es in this w ay , we therefore separate out the laten t v a riable prop osals. Moreo v er, we susp ect that the t r ee will be most helpful for categorical inputs, whic h a re not dealt with in a parsimonious w ay by the existing CGP mo del. Indeed, the lat ent v ariables ha v e enough flexibilit y to capture the relat io nship b et we en the real-v alued inputs and the class lab els in most cases. 3.3.4 Class laten t v ariables giv en the class tree and parameters While w e cannot sample directly from Z m,r | rest to obtain a Gibbs sampling draw, a par- ticular factorization of the full conditio nal fo r some subset of Z m,r suggests a reasonable prop osal distribution for MH. More sp ecifi cally , the p osterior is prop ortional to a pro duct of tw o factors: (a) the proba bilit y of the class giv en the laten t v aria bles a t its predictor(s) p ( C ( x I ) |{ Z m,r ( x I ) } M − 1 m =1 ) a nd (b) the pro ba bilit y of the laten t v aria ble(s) giv en the cu rren t GP a nd other laten t v ariables in it s region p ( Z m,r ( x I ) | X r , θ , T , Z m,r ( x − I )). Here I is an index set o ver the predic tors x , and as usual r lab els the region within a particular class; − I is the index set of p oints in regio n r of class m that are not in I . The lat t er distribution is m ult iv a r ia te normal, with dimension equal to the size of the latent v ariable set being pro- p osed, | I | . T o condense nota t io n in Eq. (4) , let Z I = Z m,r ( x I ) (similarly for F and ˜ β ), and let K I , I ′ = K m,r ( x I , x I ′ ). Then we ha v e Z I ∼ N | I | ( ˆ z , ˆ σ 2 ) ˆ z = F I ˜ β − I + K I , − I K − 1 − I , − I ( Z − I − F − I ˜ β − I ) (4) ˆ σ 2 = σ 2 r ( κ I , I − κ I , − I κ − 1 − I , − I κ − I , I ) κ I , I ′ = k I , I ′ + τ 2 r F I W F ⊤ I ′ The ab o ve is essen tially a condensation a nd slight generalization of the predictive distribution for the real- v alued output of an R TGP (3 ). T o c omplete the description, w e again slightly 11 generalize t he previous definitions of V ˜ β and ˜ β (Gramacy and Lee, 2008). Here, ˜ β I and V I are defined b y their role in the distribution β | X I , Z I , θ , T ∼ N P +1 ( ˜ β I , V ˜ β ,I ). The explicit form ulas are as follo ws. V − 1 ˜ β ,I = F ⊤ I K − 1 I , I F I + W − 1 /τ 2 r ˜ β I = V ˜ β ,I ( F ⊤ I K − 1 I , I Z I + W − 1 β 0 /τ 2 r ) W e sample from t he laten t v ariable distribution with MH steps. Suc h a step b egins with a prop osal of new laten ts Z ′ from the prior for Z conditional on the GP parameters, i.e., follo wing Eq. (4). Since the prior cancels with the prop osal probabilit y in the acceptance ratio, the new latent v a riables Z ′ are accepted with probability equal to the lik eliho o d ratio, where t he unprimed Z represen ts the current latent v ariable v alues. This lea v es: A = exp( − Z ′ m,r ( x I )) P M m ′ =1 exp( − Z ′ m ′ ,r ( x I )) × P M m ′ =1 exp( − Z m ′ ,r ( x I )) exp( − Z m,r ( x I )) . It is not necess ary to prop ose all of the la ten t v ariables in a region at o nce. W e may emplo y a blo c king sche me whereb y we prop ose some subset of t he laten t v ariables in region r conditioned on the r est; w e k eep prop osing for differen t (m utually exclusiv e) blo c ks un t il w e hav e iterat ed o v er all of the region’s la t en t v ariables, in each step conditioning on the accepted/rejected latents f rom the previously pro cessed blo c ks and those y et to b e pr o posed (i.e., hav ing the v alues obtained in the previous itera t ion of MCMC). There is a natural trade-off in blo ck size. Pro p osing Z m,r all at once leads to a small acceptance ratio and p o or mixing. But prop osing eac h z individually ma y result in only small, incremen tal changes. An adv antage o f the treed partition is that it yields a natural blo c king sc heme for up dating the latent v ariables b y making latents in a part icular region indep enden t o f tho se in other regions. While it may b e sensible t o blo c k fur t her within a leaf, the aut o matic blo c king pro vided b y the treed partition is a step forward from t he CGP . 3.3.5 Prediction The most like ly class lab el at a particular predictor v a lue corresp onds to t he smallest—or most negative—of the M laten t v a riables obtained a t that predictor; this observ ation follows from the softmax generative mo del for the class lab els giv en in Eq. (1) . Recall that the M th laten t is fixed at zero. W e predict the class lab els by k eeping a record of t he predicted class lab els at eac h round of the Mon te Carlo run a nd then tak e a ma jority v ote up on completion. W e ma y furthermore summarize the p osterior multinomial distribution ov er t he lab els by recording the prop ortion of times each class la bel had the low est latent v alue ov er the en tire Mark ov chain, obtaining a f ull accoun ting of our predictiv e uncertain ty in a true and fully Ba y esian fashion. 12 4 Illustratio ns and empirical re sults Before illustrating the CTGP algo rithm and comparing it to CGP on real a nd syn thetic data, we shall illustrate the use o f categorical inputs in the regression con text. Tw o examples without categorical inputs the n fo llo w in order to illustrate and b enc hmark CTGP ag ainst CGP when the inputs ar e real-v alued. W e conclude the section with a real data set in v olving credit card applications and exhibiting b oth t yp es of inputs. One aim there will b e to f urt her highligh t ho w an appropriate handling of categorical inputs via trees facilitates f aster and more accurate Ba y esian inference. But w e also sho w ho w this approach aids in iden tificatio n of a particular categorical feature to whic h the res p onse (credit card approv al) is sensitiv e. This last type of output w ould ha v e b een difficult to elicit in the classical CGP setup. 4.1 Categorical inputs for regression TGP Consider the fo llo wing mo dification of t he F riedman da ta (F riedman, 1 991; see also Section 3.5 of Gramacy, 2007). Augmen t 10 real- v alued co v ariates in the data ( x = { x 1 , x 2 , . . . , x 10 } ) with one categorical indicator I ∈ { 1 , 2 , 3 , 4 } that can b e enco ded in binary as 1 ≡ (0 , 0 , 0 , 1) 2 ≡ (0 , 0 , 1 , 0) 3 ≡ (0 , 1 , 0 , 0) 4 ≡ (1 , 0 , 0 , 0) . No w let the function that describ es the resp onses ( Z ), observ ed with standard normal noise, ha v e a mean E ( Z | x, I ) = 10 sin( π x 1 x 2 ) if I = 1 20( x 3 − 0 . 5) 2 if I = 2 10 x 4 + 5 x 5 if I = 3 10 x 1 + 5 x 2 + 20( x 3 − 0 . 5) 2 + 10 sin( π x 4 x 5 ) if I = 4 (5) that dep ends on the indicator I . Notice that when I = 4 the original F riedman data is reco vered, but with the first fiv e inputs in rev erse order. Irrespectiv e of I , the resp onse dep ends only up on { x 1 , . . . , x 5 } , th us com bining nonlinear, linear, and irrelev ant effects. When I = 3 the respo nse is linear in x . In the exp erimen ts that follow w e observ e Z ( x ) with i.i.d. N (0 , 1) noise. Note t hat the enco ding a b ov e precludes splits of the indicator v ariable with exactly t w o v a lues on eac h side. As has b een noted prev iously in the con text of CAR T (Ha stie et al., 2001), a f ull en umeration of non-o rdinal, categorical predictor splits is exp onen tial in the range of categorical predictor v alues. The enco ding ab o ve—whic h generalizes to an arbitrary n um b er of predictor v a lues —is mor e limited; the grow th in the n um b er of splits is linear in the n umber o f predictor v alues. Observ e that the full and restricted enco dings differ only for predictor ranges of size at least four. Arbitrary groupings of predictor v alues are still ac hiev able—a lthough the remaining v alues will not necess arily fo rm a single, opp osing group. Figure 2 compares b o xplots a nd summaries o f the ro ot mean squared error (RMSE) obtained for v arious regression algo r ithms (in the TGP class) when trained on 500 p oin ts from (5) sampled uniformly at random in [0 , 1] 10 × { 1 , 2 , 3 , 4 } and tested on a similarly 13 bcar t btlm btlm2 btgp btgp2 btgp3 1 2 3 4 RMSE on Friedman data model RMSE metho d bcart btlm bt lm2 btgp btgp 2 btgp3 95% 3.24 2.86 1.82 1.33 1.16 1.00 mean 2.83 2.69 1.7 0 1.1 5 0.66 0.5 6 median 2.79 2.69 1.68 1.15 0.53 0.49 5% 2.52 2.54 1.54 0.9 3 0.41 0.4 0 Figure 2: Summarizing ro o t mean squared error (RMSE) obtained with v arious r egress ion mo dels on 10 0 rep eat ed exp erimen ts with the adjusted F riedman data (5), eac h with a random training set of size 500 and a rando m test set of size 1 0 00. obtained hold-out test set of size 1000 . The results a nd b ehav ior of the v arious metho ds a re discusse d b elo w. One na ¨ ıv e approa ch to fitting this data w ould b e to fit a treed G P mo del ignoring the categorical inputs. But this mo del can only accoun t for the noise , giving hig h RMSE on a hold-out test set, and so is not illustrated here. Clearly , the indicators m ust b e included. One simple wa y to do so w ould b e to p osit a Bay esian CAR T mo del ( bcart in the Figure). In this case the indicators are treated as indicators (as is a ppro priate) but in some sense so are the real-v alued inputs since only constan t mo dels are fit at the leav es of the tr ee. As exp ected, the tree do es indeed partition on the indicators and the o ther inputs. One migh t hop e fo r a m uc h b etter fit fro m a treed linear mo del ( btlm ) to the data since the response is linear in some of its inputs. Unfortunately , this is no t the case. When a linear mo del with an improp er prior (the tgp default) is used at the leav es of the tree, the Bo olean indicators could not b e partitioned up on b ecause suc h a prop osal w ould cause the design matrices at the t w o new lea v es to b ecome rank-deficien t (they w ould eac h, resp ectiv ely , ha v e a column of all ze ros or a ll ones). A treed GP w ould ha ve the same problem. While suc h mo dels offer a more parsimonious represen tation of a smo othly v arying resp onse (i.e., not piecewise constant) compared to CAR T, a p enalt y is paid by the inability to pa rtition; impro v emen ts in mo deling the real- v alued predictors (via, for instance, the linear mo del) balance against the cos t o f sacrificing the catego rical predictors. Ultimately , the net result of these t w o effects translates in to only marginal impro v emen ts in predictiv e p erformance o v er Bay esian CAR T. 14 One p ossible remedy is to employ a prop er prior at the lea v es. But that has its o wn dra wbac ks. Instead, cons ider inclu ding the Bo olean indicators as candidates fo r treed par- titioning, but ignoring them w hen it come s to fitting the mo dels at the leav es of the tree. This w ay , whenev er the Bo olean indicators are pa r titioned up on, the design matrix (for the GP or LM) will not con tain the corresp onding Bo olean column and therefore will b e of full rank. T o implemen t this sc heme, and similar ones to follow , w e use the basemax argumen t to the b* functions in tgp as describ ed b y Gramacy and T addy (2 009). Consider the treed linear model again ( btlm2 ) under this new treatmen t. In this case t he MAP tree do es in- deed pa r tition on the indicators in an appropriate w a y—as w ell a s on some other real-v alued inputs—and t he result is the low er RMSE w e desire. A more high-p o wered approac h w ould b e to treat all inputs as real-v a lued by fitting a GP at the leav es of the tree ( btgp ). Binary partit io ns are a llo w ed on all inputs, X and I . As in a dire ct application of the BCAR T linear mo del, treating the Bo olean indicators as real-v alued is implic it in a direct application of the T GP fo r regr ession. How ever, we hav e already seen that this represen tation is inappropriate since it is kno wn that t he pro cess do es not v ary smo othly ov er the 0 and 1 settings of the four Bo olean indicators represen ting the categorical input I . Since the design ma t r ices w ould b ecome rank-defic ien t if the Boolean indicators were partitioned up on, there is no partitioning on these predictors. As t here are large cov ariance matrices to inv ert, the MCMC inf erence is very slo w. Still, t he resulting fit (obtained with muc h pa t ience) is b etter than the Bay esian CAR T and treed LM ones, as indicated b y the RMSE. W e exp ect to g et the b est of b oth worlds if we allow partitioning on the indicators but guard aga inst rank deficien t design matrices b y ig noring these Bo olean indicators for the GP mo dels at the lea v es ( btgp2 ). Indeed this is the c ase, as the indicators then b ecome v a lid candidates for pa r t itioning. Finally it is kno wn that, after conditioning on the indicators, the data sampled from F riedman function are w ell-mo deled with a GP using a stationary co v ariance structure and linear mean. W e can use this prior kno wledge to build a more parsimonious mo del. Moreo ve r, the MC MC inference for this reduced mo del w ould hav e lo wer Mon te Carlo e rror, since it w o uld bypass a t tempts to partition on the real-v alued inputs. These features a re f acilitated b y the splitmin argumen t to the b* functions, as describ ed by Gra macy and T addy (200 9). The lo w er RMSE results for this mo del ( btgp3 ) corro bor a te the analysis ab ov e. 4.2 Classification TGP on synthet ic d ata 4.2.1 Simple step data in 1d W e b egin with a trivial classification pro blem to illustrate the difference b et w een the CTGP and CGP mo dels. W e consider a generativ e mo del that assigns p oin ts less than − 2 / 3 to class 0, p oin ts b et we en − 2 / 3 and 2 / 3 to class 1, and p oin ts greater than 2 / 3 to class 2. The data set predictors a r e 60 p oin ts distributed ev enly b et w een − 2 and 2, inclusiv e. This “step” data is depicted in Figure 3. Lab el the po ints in order from x 0 = − 2 to x 59 = 2. Clearly , w e would exp ect CAR T and BCAR T to form a t r ee with o ne partition b et w een x 19 and x 20 15 X C −2 −1 0 1 2 0 1 2 Step data classes Figure 3: Class lab els for the step data and another b et we en x 39 and x 40 , p erfectly dividing the classes and correctly predicting all p oin ts outside the data set that do not fall b et w een these dividing p oin ts. The CG P mo del like wise captures the pattern of the data but do es so without the par- tition mec hanism. In part icular, running the CGP on this data returns t w o sets o f latent v a riables, one set corresp onding to class 0 a nd the other corresp onding to class 1. Note that one class lab el—here class 2—will alw ays b e repres en ted by laten t v ar ia bles that are fixed to zero. Otherwise, the mo del is ov erdetermined (Section 2 ) . −2 −1 0 1 2 −15 −10 −5 0 5 10 15 X Z0 Step data latents: class 0 −2 −1 0 1 2 −100 0 50 100 150 200 X Z1 Step data latents: class 1 Figure 4: Laten t v ariables obtained fo r the step data by the CGP for all non- trivial classes (i.e. 0 and 1). Median ov er MCMC rounds sho wn a s solid blue line; 90% inte rv al sho wn as dashed, red lines. F o r the first tw o classes in the CGP mo del, the laten t v a r ia ble v alues are depicted in Figure 4. As exp ected, the latent v ariable v alues, whic h follo w a Gaussian pro cess pr io r, v a ry smo othly across the predictor space . Since these v alues en ter in to a softma x function 16 to determine class probabilities in t he lik eliho o d, smaller v alues roughly corresp o nd to a higher p osterior probability f o r a par t icular class. Th us, w e see that the laten t v ariables for class 0 mark out a negative -v alued region corresponding to the training p oin ts in class 0. There is no real distinction, how ev er, a mongst the r emaining laten t v ariable v alues for this class. Lik ewise, the laten t v ariable v alues for class 1 mark out a negativ e-v alued region corresp onding to the tra ining p oin ts in class 1, and the remaining laten t v a r iable v alues— represen ting data in other classes—are all p ositiv e and of similar mo dulus. −2 −1 0 1 2 −600 −400 −200 0 X Z0 Step data latents: class 0 −2 −1 0 1 2 −30 −20 −10 0 10 20 30 X Z1 Step data latents: class 1 Figure 5: Laten t v ariables obtained fo r the step data b y the CTGP fo r all non-t r ivial classes (i.e. 0 and 1). Median ov er MCMC rounds sho wn a s solid blue line; 90% inte rv al sho wn as dashed, red lines. The CTGP mo del also captures t he pattern of the dat a . But in this v ery simple example, it reduces almost exactly to BCAR T. Just as for CGP , there are tw o sets of laten t v a r iables— one set for class 0 and one set for class 1 (Figure 5). Unlik e the smo oth v ariation of the CGP laten t v ariables, the CTGP take s adv an tage of the treed structure and limiting constant mo del. Thus , the latent v ariables in class 0 exhibit a sharp divide b et wee n x 19 and x 20 . This divide sets out a negativ e region for 0-lab eled laten t v ariables a nd sets the remaining latent v a lues at a constan t p ositiv e v alue. Similarly , the class 1 laten t v ariables exhibit a sharp divide betw een x 39 and x 40 . In con trast to the CG P , the divide in class 1 laten t v ariables here separates the data in classes 0 and 1 fro m the class 2 data and allows the divide in class 0 lat en t v ariables to take care of separating t he class 0 data from classes 1 and 2. This difference like ly arises f r o m the prior p enalt y on larger trees. A partitio n that separates class 1 data from the other tw o classes w o uld require a tree of heigh t t w o; the existing tree of heigh t o ne accomplishes the same task with a more parsimonious represen tation. Indeed, we can plot t he maxim um a p osteriori trees of heigh t greater than one for b oth classes (Figure 6) to v erify that the divisions here a re (a) caused by treed partitioning and (b) in exactly the places w e w ould exp ect given the training data. The figure demonstrates that b oth of these h yp otheses are indeed true. This example illustrates t hat the CTGP is capable o f partitioning o n con tin uous-v alued 17 x1 <> −0.711864 2.4792 20 obs 1 1.2824 40 obs 2 height=2, log(p)=−89.9066 x1 <> 0.644068 0.4305 40 obs 1 1.7912 20 obs 2 height=2, log(p)=−93.6361 Figure 6: T r ees fr om the CTGP fo r the step data. L e f t: class 0; Right: class 1 data in practice as we ll as theory . Nonetheless, this data is rather con triv ed and simplistic; with noisier data, it is m uch less lik ely for r eal-v alued partitioning to o ccur giv en our curren t prior. And the partitioning does not fundamen tally change the predictiv e accuracy of the mo del. How ev er, it do es allow for a muc h clearer interpretation. The tr eed partitioning in this example has the same v a lue for in tuition as BCAR T t rees whereas the CGP la ten t v a riables, while p o w erful for mo deling, ar e opaque in meaning. Finally , w e see ev en in this small example the running-t ime b enefi ts of t he CTGP o v er the CGP . While the latter to ok 52 . 28 seconds to run, the former elapsed only 24 . 22 seconds, a sp eedup of roughly a f actor of tw o. 4.2.2 2d Exponential data While the CTGP easily partit ions categorical inputs, as illustrated with real data in Section 4.3, it can b e difficult to manufacture non-trivial syn thetic classification data sets that a re ob vious candidates for partitioning amongst the real-v alued inputs. In con t rast, it can b e quite easy to manufacture regr ession data whic h r eq uires a nonstationary GP mo del. Here w e demonstrate ho w a simple Hessian calculation can conv ert nonstationary syn thetic regression data into class lab els that are lik ely to b enefit from part it io ning. Consider the syn thetic 2d exp o nen tial dat a used to illustrate R TGP by Gramacy (2007). The input space is [ − 2 , 6] × [ − 2 , 6], and the tr ue resp onse is giv en b y z ( x ) = x 1 exp( − x 2 1 − x 2 2 ) . (6) In the regression example a small amoun t of Gaussian noise (with sd = 0 . 00 1 ) is added. T o con v ert the real-v alued outputs to classification lab els we calculate the Hessian: H ( x 1 , x 2 ) = 2 x 1 (2 x 2 1 − 3) exp( − x 2 1 − x 2 2 ) 2 x 2 (2 x 2 1 − 1) exp ( − x 2 1 − x 2 2 ) 2 x 2 (2 x 2 1 − 1) exp( − x 2 1 − x 2 2 ) 2 x 1 (2 x 2 2 − 1) exp ( − x 2 1 − x 2 2 ) . Then, for a part icular input ( x 1 , x 2 ) w e assign a class lab el based on the sign of t he sum of the eigenv alues of H ( x 1 , x 2 ), indicating the direction of conca vit y at that p oin t. A function 18 lik e the 2 d expo nen tial one (6 ) whose conca vit y c ha ng es more quic kly in one region of the input space than in anot her (and is therefore w ell fit by a n R TGP mo del) will similarly hav e class la b els that c hang e mo r e quic kly in one region than in another and will similarly require a treed pro cess f or the b est p ossible fit. Figure 7 sho ws the resulting class lab els. Extensions −2 0 2 4 6 −2 0 2 4 6 2d Exponential Classes x1 x2 −2 0 2 4 6 −2 0 2 4 6 2d Exponential Latents x1 x2 Figure 7: L eft: 2d exp onen tial classification data obtained b y the Hessian eigen-metho d; Right: Mean latent v ariables obtained b y CTGP to multiple class lab els (up to m ( m − 1) / 2 of them) can b e accommo dated by a more general treatmen t of (the signs of ) the comp onen ts of the Hessian. Ov erla id on the plot in Figure 7 ( left ) is the maxim um a p osteriori tree—a single split— encoun tered in the trans-dimensional Mark ov c hain sampling fro m the CTGP p osterior. Here the tree is clearly separating the interesting part of the space, where class lab els actually v a ry , from the relatively large area where the class is constan t. As in the regression case, by partitioning, the CTGP is able to improv e up on predictiv e p erformance as w ell as compu- tational speed relativ e to the full CGP mo del. W e trained the classifie r(s) on ( X, C ) data obtained b y a maximu m entrop y design of size N = 400 subsampled from a dens e grid of 10000 p oints and calculated the misclassification rate on the r emaining 9600 lo cations. The rate w a s 3.3% for CGP and 1.7% for CTGP , sho wing a r elat ive impro v emen t o f roug hly 5 0%. CTGP wins here because the relationship b et w een response (class lab els) and predictors is clearly nonstationary . That is, no single collec tion of range parameters { d 1 , d 2 } is ideal f or generating t he latent Z - v alues t ha t w ould b es t represe n t t he class lab els through the soft- max. Ho w ev er, it is clear that tw o sets of pa rameters, for either side o f x 1 = 2 as obtained b y t r eed partitioning, w ould suffice. The sp eed improv emen t s obta ined by partitioning we re ev en more dra matic. CGP to ok 21.5 hours t o execute 15 0 00 RJ-MCMC r o unds whereas CTGP to ok 2.0 hours, an ov er 10- fold improv emen t . 19 4.3 Classification TGP on real data The previous exp eriment illustrates, a mo ng ot her things, treed pa r t itions on real-v a lued predictors in the classification contex t. How ev er, a strength of the R TGP demonstrated in Section 4.1 is that it can offer a more natural handling of categorical predictors compared to a GP . With this observ ation in mind, w e shall compare the CTGP to the CGP (as w ell as neural net w orks and recursiv e partitioning) on real data while restricting the treed partitions in t he CTGP to the catego rical inputs. F o r t his ev aluation, w e considered the Credit Approv al data set f r om the UCI Mac hine Learning database (Asuncion a nd Newman, 2007). The set consists of 690 instances group ed in to t w o classes: credit card application a pprov al (‘+’) and application failure (‘–’). The names and v alues of the fifteen predictors fo r eac h instance are confiden tial. Ho w ev er, asp ects of these attributes relev an t to our classification task are a v a ila ble. E.g., w e know that six inputs are con tin uous, and nine a re categorical. Among t he categorical predictors, the n um b er of distinct categories ranges from t w o to fo urteen. After binarization, w e ha v e a data set of 6 contin uous and 41 binary predictors. The CGP treats these a ll as con tin uous attributes. The CTGP forms GPs only ov er the six con tin uous attr ibutes and partitions on (and only o n) the 41 binary attributes. W e also considered t w o o ther standard classification algorithms. First, w e used the neural net w orks (NN) algor ithm as implemen ted by the nnet function a v ailable in the nnet library (Ripley, 20 09) in R . F or eac h test, w e used the tune function in the R library e1071 (Dimitriadou et a l., 2010) to simultaneous ly tune the num b er o f hidden lay er units ( 2 , 5, or 10) and the weigh t decay parameter (base ten logarithm equal to -3.0, -1.5 , o r 0 ) ba sed o n the training data. The tune function ev aluates the classification error f or each parameter-set v a lue via a cross-v alidation on the training data and then selects t he o ptimal parameters. All o ther settings f o r nnet parameters were k ept at the default. Second, w e used recursiv e partitioning (RP) as impleme n ted b y the rpart function (Therneau and A tkinson, 2010) in R . Again, for each test, we used the tune function t o select the complexit y par a meter (0.01, 0.02, 0.05, 0.1, 0.2, or 0 .5 ) based on the training data. All ot her settings were k ept at the default. Metho d Avg Stddev NN 18.1 6.1 RP 15.2 3.8 CGP 14.6 4.0 CTGP 14.2 3.6 T able 1: Av erage and standard deviation of misclassifi cation rate on the 1 00 credit-data folds f or v arious metho ds, listed in order of p erformance fro m worst to b est mean. Our comparison consists o f ten separate 10-fo ld cross-v alida t ions fo r a tot a l of 100 fo lds. The results are summarized in T able 1. The CTGP offers a sligh t improv emen t o v er the CGP with an av erage misclassification rate of 14 .2 %, compared to 14.6%. Similarly , the standard deviation of CGP misclassification a cro ss folds w a s 4.0 % while the CTGP exhibited slightly 20 x38 <> 0 0.4411 280 obs 1 1.9686 307 obs 2 height=2, log(p)=−936.458 x38 <> 0 1.1622 280 obs 1 x45 <> 0 0.7287 289 obs 2 1.5603 18 obs 3 height=3, log(p)=−1049.65 Figure 8: T rees from CTGP for 2 d exp onen tial da t a; no heigh t one smaller v ariability with a standa r d deviation of 3.6%. More impressiv e is the sp eed-up offered b y CTGP . The av erage CPU t ime per fo ld used by the CGP metho d was 5.52 hours; with an av erage CPU time p er fo ld of 1.62 hours, the CTGP sho w ed a mor e than t hree-f o ld impro v emen t. Finally , the in terpretativ e aspect of the CTGP , with an appropria te (treed) handling of the categorical inputs, is worth highlighting. F or a particular run of the algo rithm on the Credit Analysis dat a, the MAP tr ees of differen t heigh ts are sho wn in Figure 8. These tr ees, and o t hers , feature principal sp lits on the 38 th binary predictor, wh ic h is a binarization of the 9 th t w o-v alued catego r ical predictor. Therefore, the CTGP indicates, without additional w o r k, the significance of t his v ariable in predicting the success of a credit card application. T o extract similar inf o rmation from the CGP , o ne would ha ve to devise and run some additional tests—no small feat giv en the running time of single CGP execution. The fig ure also shows that the Marko v c hain visited other trees, including one with a split on the 45 th binary predictor. Ho w ev er a comparison of log p osteriors (show n in the Figure) and a tra ce of the heigh t s of the trees encoun tered in the Mark o v c hain (no t shown ) indicate that this split, and an y o thers, had v ery lo w p osterior pro babilit y . 5 Discuss ion In this pap er w e hav e illustrated how many of the b enefits of t he regression TGP mo del extend to classification. The comp onen ts o f TGP , i.e., treed mo dels and G Ps , hav e separately enjo y ed a long ten ure of success in application to classification pro blems . In the case o f the GP , M − 1 pro cess es ar e eac h used as a prior f or laten t v ar iables, whic h enco de the classes via a softmax function. While the CGP is a p ow erful metho d that typic ally offers improv emen ts o v er simpler approache s (including treed mo dels), draw back s include an implicit assumption of stationarity , clumsy handling of catego rical inputs, and slow ev aluation due to rep eated large matrix decompositions. In con trast, the treed metho ds are thrift y , provide a divide- and-conquer appro a c h to classification, and can naturally handle categorical inputs. Tw o p ossible wa ys of comb ining the GP with a tree pro cess natura lly suggest themselv es for, 21 first, partitioning up t he input space and t hus taking adv antage o f the divide-and-conquer approac h to a no nstationary prior on the laten t v ariables used for classification a nd, second, handling categorical inputs. W e argued tha t it is b etter to work with M − 1 separate TGP mo dels rather than deal with one treed mo del with M − 1 GPs at eac h leaf . Ho wev er, a drawbac k of this (MTGP) approac h is tha t , when there are no (useful) real-v a lued predictors, then it will b ehav e like BCAR T. But what results will b e an inefficien t implemen tation due to all of the latent v a riables inv o lv ed—as the MCMC basically tries t o in tegrate them out. So in this case, a direct implemen tation via BCAR T is preferred. Ho w ev er, when mixed catego rical and real-v alued inputs are presen t, the com bined tr ee and GP approac h allo ws the appropriate comp onen t of the mo del (tree in the case of categorical inputs, and GP in the case of real ones) to handle the marginal pro cess in eac h input dimension. The result is a classification mo del tha t is sp eedy , in terpretable, and highly accurate, com bining the strengths of GP and treed mo dels for classification. Ac k n o wledgmen ts This w ork w as partially supp orted b y Engineering and Phy sical Science s Researc h Counc il Gran t EP/D0657 04/1. TB’s researc h w as supp orted by a Marshall Scholarship. W e would lik e to t ha nk three anon ymous referees, whose man y helpful commen ts impro v ed the pap er. References Abrahamsen, P . (1997). “A Review of Gaussian Random Fields and Correlation F unctions.” T ec h. Rep. 917, Norw egian Computing Cen ter, Box 114 Blindern, N-0314 Oslo, Norwa y . Asuncion, A. a nd Newman, D . (2007). “UCI Mac hine Learning Rep ository .” Breiman, L., F riedman, J. H., Olshen, R., and Stone, C. (198 4 ). Classific ation and R e gr ession T r e es . Belmon t, CA: W adsworth. Chipman, H., Georg e, E., and McCullo c h, R. (1 998). “Bay esian CAR T Mo del Search (with discussion).” Journal o f the Americ an Statistic al Asso ciation , 93, 9 3 5–960. — (20 02). “Ba y esian T r eed Mo dels.” Machin e L e arning , 48, 303–3 2 4. Dimitriadou, E., Hor nik, K., Leisc h, F., Mey er, D., and W eingessel, A. (2010). “e1071: Misc F unctions of the Departmen t of Statistics (e1071) , TU Wien.” V ersion 1.5- 24. CRAN rep ository . Main tained b y F riedric h Leisc h. Obtained from http://cran .r-project.org/ web/ packages/e1071/e1071.pdf . F riedman, J. H. ( 1 991). “ Multiv ariate Adaptiv e Regression Spline s.” Annals of Statistics , 19, No. 1, 1–67. 22 Gilks, W. R. a nd Wild, P . (1992). “Adaptiv e rejection sampling for Gibbs sampling.” Applie d Statistics , 41, 337– 3 48. Gramacy , R. B. (2 005). “Ba y esian T reed Gaussian Pro cess Mo dels .” Ph.D. thesis, Unive rsit y of California , Sa n ta Cruz. — (2007 ) . “ tgp : An R P ac k age f o r Ba yes ian Nonstatio na ry , Semiparametric Nonlinear Regression and Design b y T reed Gaussian Pro cess Mo dels.” Journal of Statistic al Softwar e , 19, 9. Gramacy , R. B. and Lee, H. K. H. (2008). “Bay esian treed Ga uss ian pro cess mo dels with an application to computer mo deling.” Journal of the Americ an Statistic al Asso ciation , 103, 1119– 1130. Gramacy , R. B. and T a ddy , M. A. (2008). tgp : Bayesian tr e e d Gaussian pr o c ess mo dels . R pac k a ge v ersion 2.1- 2 . — (2 009). “Categorical inputs, sensitivit y analysis, optimization and imp ortance temp ering with tgp v ersion 2, an R pac k age fo r treed Ga uss ian pro cess mo dels.” T ec h. rep., Univ ersit y of Cambridge. Submitted to JSS. Hastie, T., Tibshirani, R., and F riedman, J. (2001) . The Elements of S tatistic al L e arnin g . New Y ork, NY: Springer-V erlag . Mat ´ ern, B. (1986 ). Sp atial V ariation . 2nd ed. New Y ork: Springer-V erlag. Neal, R. M. (1997 ) . “Monte Carlo implemen tation of Ga uss ian pro cess mo dels for Bay esian regression and classification.” T ec h. Rep. 9702, Deptartmen t of Statistics, Univ ersity of T oronto. — (199 8). “Regression and classification using Gaussian pro cess priors (with discussion).” In Bayesian Statistics 6 , ed. e. a. J. M. Bernardo, 4 7 6–501. Oxford Univ ersit y Press. Qian, Z., W u, H., and W u, C. (2008). “Ga uss ian pro cess mo dels for computer exp erimen ts with qualitative and quan titativ e factors.” T e chnome trics , 50, 383–396. Rasm ussen, C. E. and Williams, C. K. I. (2 006). Gaussian Pr o c esses for Machine L e arning . The MIT Press. Ric hardson, S. and Green, P . J. (1997 ). “On Bay esian Analysis of Mixtures With An Unkno wn Num b er of Comp onen ts.” Journal of the R oyal Statistic a l So ciety, Series B, Metho dolo gic al , 5 9, 731– 758. Ripley , B. (200 9 ). “F eed-forw ard Neural Net w o rks and Multinomial Lo g-Linear Mo d- els.” V ersion 7.3- 1. CRAN rep ository . Main tained by Brian R ipley . Obtained f r om http://cran .r-project.org/ web/ packages/nnet/nnet.pdf . 23 Saltelli, A., Ratto, M., Andres, T., Campo longo, F., Carib oni, J., Gatelli, D ., Sa isana, M., and T aran tola, S. (200 8). Glob al Sen s itivity A nalysis: Th e Prim er . John Wiley & Sons. R Dev elopmen t Core T eam (2 0 08). R : A language and envir onment for statistic al c omputing . R F oundation for Statistical Computing, Vienna, Aus. ISBN 3- 900051-00- 3. Stein, M. L. (199 9). I nterp olation of Sp atial Data . New Y ork, NY: Springer. Therneau, T. M. and A tkinson, B. (2 010). “rpart: Recursiv e P artitioning.” V ersion 3 .1-46. CRAN rep ository . Maintained b y Brian Ripley . Obtained fr o m http://cran .r-project.org/ web/ packages/rpart/index.html . 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment