Pure Exploration for Multi-Armed Bandit Problems
We consider the framework of stochastic multi-armed bandit problems and study the possibilities and limitations of forecasters that perform an on-line exploration of the arms. These forecasters are assessed in terms of their simple regret, a regret n…
Authors: Sebastien Bubeck (INRIA Futurs), Remi Munos (INRIA Futurs), Gilles Stoltz (DMA
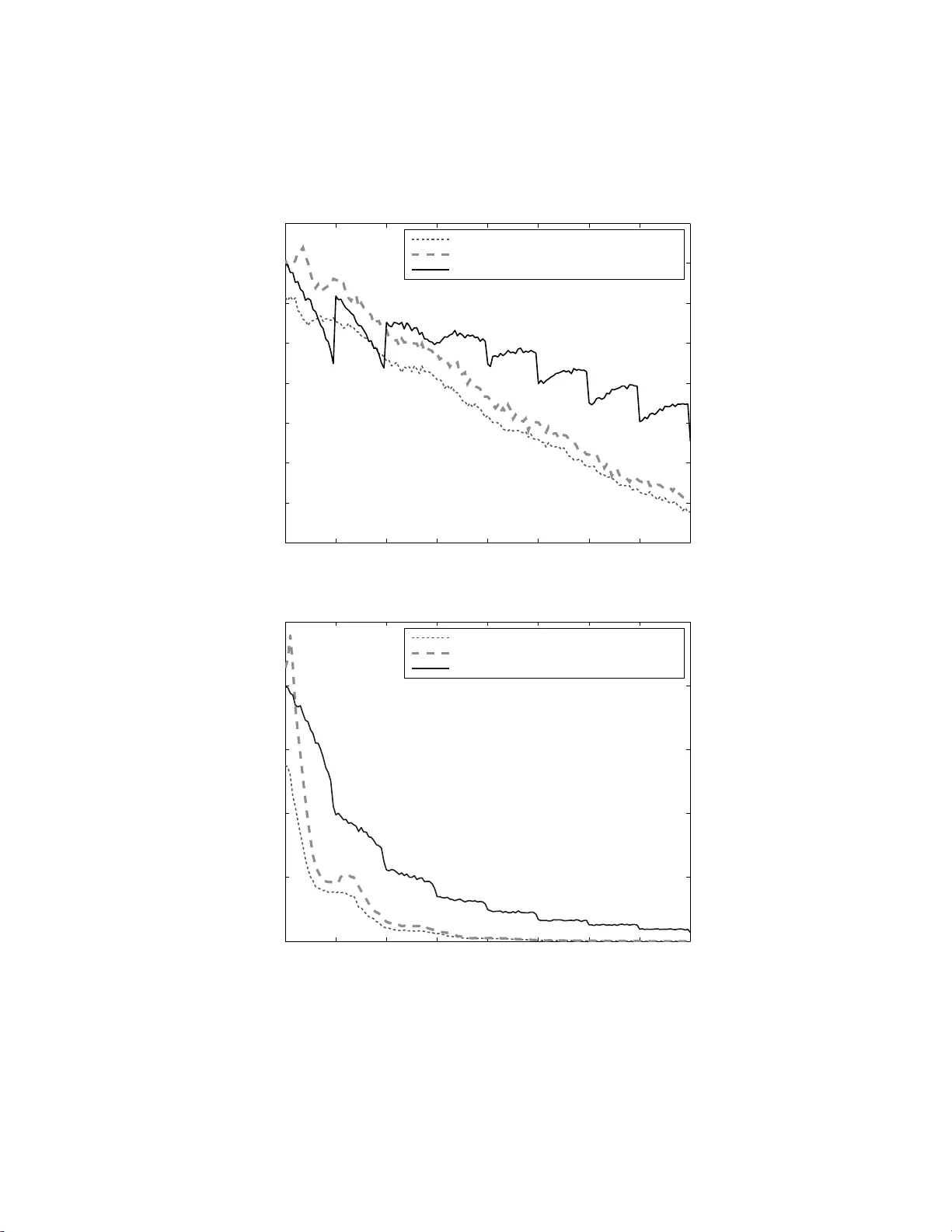
Pure Explor atio n in Finit ely–Arm ed and Contin uous–Arm ed Bandits S´ ebastien Bube c k ∗ INRIA Lil le – No r d Eur op e, Se queL pr oje ct, 40 avenue Hal ley, 59650 Vil leneuve d’Asc q, F r anc e R ´ emi Munos INRIA Lil le – Nor d Eur op e, Se queL pr oje ct, 40 avenue Hal ley, 59650 Vil leneuve d’Asc q, F r anc e Gilles Stoltz Ec ole Normale Sup ´ erieur e, CNRS 75005 Paris, F r a nc e & HEC Paris, CNRS, 78351 Jouy-en-Josas, F r a nc e Abstract W e consider the framework of sto chastic m ulti-ar med ba ndit pro blems and study the p os sibilities and limitations of forecas ters that perform an on- line explo- ration of the arms. These fo recasters a re as sessed in terms o f their simple regre t, a regre t notion that ca ptures the fact that explo ration is only constrained by the nu mber of a v ailable rounds (not necessarily known in adv ance), in contrast to the case when the cumulativ e regr et is co nsidered and when exploitation needs to b e p erfo r med at the same time. W e b elieve that this p erformance cr iterion is suited to situations when the cos t o f pulling an a rm is express ed in terms of re s ources r ather than rewards. W e discuss the links b etw een the simple and the cum ulative regret. One of the ma in results in the c a se o f a finite num b er of a r ms is a general lower bound o n the simple regr e t of a fore c a ster in terms of its c um ulative r egret: the smaller the latter, the larger the former. Keeping this result in mind, we then exhibit upp er b ounds on the s imple r egret of some forecaster s. The pap er ends with a study devoted to contin uous-armed bandit problems; we s how that the simple r egret can b e minimized with resp ect to a family of probability distributio ns if and only if the cum ulative regre t c a n b e minimized for it. Bas e d on this equiv alence, we ar e able to prove that the sep- arable metric space s are exactly the metric spaces on which these regrets can ∗ Corresp onding author. Email addr esses: sebastien. bubeck@inria.fr (S´ ebastien Bubeck), remi.mun os@inria.fr (R´ emi M unos), gilles.stolt z@ens.fr (Gilles Stoltz) Pr eprint submitte d to Elsevier Novemb er 26, 2024 be minimized with r esp ect to the family o f a ll proba bilit y distr ibutio ns with contin uous mea n-pay off functions . Keywor ds: Multi-armed bandits, Contin uous-armed bandits, Simple reg ret, Efficient explor a tion 1. Introduction Learning pr o cesses usua lly face an exploratio n versus exploitation dilemma, since they hav e to ge t infor mation o n the environment (exploration) to b e able to take go o d a ctions (exploitatio n). A key example is the m ulti-ar med bandit problem [19], a sequential decision pr oblem wher e, at e a ch s tage, the forecaster has to pull one o ut o f K giv en sto chastic ar ms and g e ts a re w ar d drawn at random ac c ording to the distribution of the chosen arm. The usual asses sment criterion o f a foreca ster is given by its cumulativ e reg ret, the s um of differences betw een the ex pected reward o f the b est arm a nd the obtained rew ar ds. Typical go o d foreca sters, like UCB [3], trade off b etw een exploration and explo itation. Our setting is as follows. The foreca ster may sample the arms a given num ber of times n (not necessa rily known in adv ance) and is then asked to output a recommended arm. He is ev aluated b y his simple reg ret, that is, the difference betw een the average pa yoff of the b est arm and the av erage payoff obtained by his r ecommendation. The distinguishing feature from the cla s sical multi- armed bandit problem is that the ex plo ration phas e and the ev aluation phase are sepa rated. W e now illustra te why this is a natural framework for numerous applications. Historically , the fir st occ ur rence of mu lti-a r med bandit problems w as g iven by medical trials. In the ca se o f a severe dise ase, ill patients only ar e included in the trial and the cost of pic king the wrong trea tmen t is high (the as so ciated reward would equal a la rge negative v a lue). It is imp o rtant to minimize the cum ulative regret, since the test and cure phases c o incide. Ho wev er, for cos metic pro ducts, there exists a test phase sepa rated from the commercializ ation phase, and one aims at minimizing the regr e t of the c o mmercialized pro duct r ather than the cumulativ e regret in the test phase, which is ir relev ant . (Here, several formulæ fo r a c r eam a r e cons ider ed and some quantit ative measurement, like skin moisturiza tion, is p erformed.) The pure explo ration pro blem addresses the desig n of strateg ies making the bes t po ssible use of av ailable n umerical res ources (e.g ., as cpu time) in orde r to optimize the p erfor ma nce of some decisio n-making task. That is, it o ccur s in situations with a preliminary explor ation phase in which costs a re not measured in ter ms of rewards but rather in terms o f re s ources, that c ome in limited budget. A motiv ating example co ncerns r ecent works on computer-go (e.g ., the MoGo progra m [10]). A g iven time, i.e., a given a mount of cpu times is given to the play er to explor e the p ossible outcome of sequences o f plays and output a fina l decision. An efficient explora tion of the search space is obtained by considering a hierarch y of forecasters minimizing some cumulative regret – see, for instance, 2 the uct strategy [14] and the bast stra teg y [7]. How ever, the cum ulative regr et do es not seem to be the right way to base the strategies on, since the simulation costs are the same for explo ring all options, ba d and g o o d o ne s . This o bserv ation was actually the starting p oint of the notion of s imple regr e t and of this work. A final related example is the ma x imization of some function f , obser ved with noise, se e , e.g., [12, 6 ]. Whenever ev aluating f a t a p oint is costly (e.g., in ter ms of numerical or financial costs), the issue is to choose as a dequately as p ossible where to query the v alue of this function in order to hav e a go o d approximation to the maxim um. The pure explora tio n pro blem co nsidered here addresses exactly the design of ada ptiv e explor ation strateg ies making the best use o f av aila ble resourc es in order to make the mo st precis e prediction once all resource s are co nsumed. As a remar k, it a lso turns out that in a ll examples considered a bove, we may imp ose the further restriction that the foreca ster ignores ahead of time the amount o f av ailable res o urces (time, budget, or the num ber of patients to b e included) – that is, we seek for anytime p erformance. The problem of pur e explor ation pres en ted a bove was refer red to as “bud- geted multi-armed bandit problem” in the op en problem [16] (where, how ever, another no tion of regret than simple re g ret is considered). The pure explor ation problem was s o lved in a minmax sense for the case of t wo a r ms only and re- wards given by probability dis tributions ov er [0 , 1] in [20]. A rela ted s etting is considered in [9] and [17], where forecas ters p erfo rm exploration during a ra n- dom num b er of rounds T and aim at identif ying an ε –b est ar m. These articles study the p oss ibilities and limitations of po licies achieving this goal with ov er- whelming 1 − δ probability and indicate in pa r ticular upp er and low er bo unds on (the exp ectation of ) T . Another r elated problem is the identification of the bes t ar m (with high pr obability). How ever, this binar y a ssessment criterio n (the forecaster is either right or wro ng in recommending a n ar m) do es no t capture the p ossible clo seness in p erfo r mance of the recommended a rm compared to the optimal one, w hich the simple regret do es. Mo reov er unlike the latter, this criterion is not suited for a distr ibutio n- free analys is . Contents and structure of t he p ap er W e present formally the model in Section 2 and indicate therein that our aim is to study the links b etw een the simple a nd the cumulative regret. In- tuitiv ely , an efficient allo cation strategy for the simple reg ret sho uld rely on some ex ploration–ex ploitation trade-off but the rest o f the pap er s hows that this tra de - off is not exactly the same as in the case of the cum ulative regret. Our fir st main contribution (Theorem 1, Section 3) is a lower b ound on the simple regr et in terms of the cumulativ e r egret suffere d in the explo ration phase, which shows that the minimal simple regret is larg er as the b ound on the cum ulative regre t is smalle r. This in particular implies tha t the uniform exploratio n of the a rms is a go o d b enchmark when the num ber o f explor a tion rounds n is larg e. 3 In Section 4 we then study the simple reg ret of some natur al forecas ters, including the o ne based on unifor m explo ration, whose simple regr et v anished exp onentially fast. ( Note : The upp er bo unds pres en ted in this paper can how- ever be improv ed by the recent results of [2].) In Section 5, we s how how one can somewha t circumven t the fundamental low er b ound indicated ab ov e: some strategies desig ned to have a small c umulative regret can o utper fo rm (for small or mo derate v alues of n ) str a tegies with exp onential rates of conv ergence for their simple regr et; this is shown b oth by means of a theoretical study and by simulations. Finally we inv estigate in Section 6 the contin uous-ar med bandit problem where the set of a r ms is a top olo gical space. In this s etting we us e the simple regret as a to ol to prove that the sepa r able metric spaces are exactly the metric spaces for which it is p ossible to have a sublinea r cum ulative regret with re - sp ect to the fa mily of a ll pro bability dis tr ibutions with co n tinuous mean-payoff functions. This would b e our se c o nd main co n tribution. 2. Problem se tup, notatio n , structure of the pap er W e consider a seq uen tial decisio n pro blem given by sto chastic m ulti-armed bandits. A finite num b er K > 2 of arms, deno ted by i = 1 , . . . , K , a re av ailable and the i –th o f them is pa r ameterized by a fixe d (unknown) probability distri- bution ν i ov er [0 , 1], with expecta tion deno ted b y µ i . At those rounds when it is pulled, its asso ciated reward is dra wn at random according to ν i , independently of a ll previous rewards. F or each arm i and all time rounds n > 1, w e denote by T i ( n ) the num b er of times a rm i was pulled fr o m rounds 1 to n , and by X i, 1 , X i, 2 , . . . , X i,T i ( n ) the sequence of asso ciated r ewards. The forecaster has to deal sim ultaneously with t wo tas ks, a pr imary o ne a nd a seconda ry one. The secondary tas k consists in explora tio n, i.e., the foreca ster should indicate at each ro und t the arm I t to b e pulled, based o n past r ewards (so that I t is a r a ndom v ariable). Then the foreca s ter gets to see the asso cia ted reward Y t , als o denoted by X I t ,T I t ( t ) with the notation ab ov e. The seq uence of random v ariable s ( I t ) is referr ed to a s a n allo cation s tr ategy . The pr imary task is to o utput at the end of each round t a recommendatio n J t to b e used in a one-shot instance if/when the environment sends so me stopping signal meaning that the exploratio n phase is ov er . The sequenc e of random v ariables ( J t ) is referred to as a recommendation strateg y . In total, a fo r ecaster is given by an allo cation and a recommendation stra tegy . Figure 1 summarizes the description of the seq ue ntial ga me and points out that the infor ma tion av aila ble to the forecaster for cho osing I t , resp ectively J t , is formed by the X i,s for i = 1 , . . . , K a nd s = 1 , . . . , T i ( t − 1), r esp ectively , s = 1 , . . . , T i ( t ). Note that we also allow the forecaster to use an exter nal randomizatio n in the definition of I t and J t . As we are only interested in the perfo r mances of the reco mmendation strat- egy ( J t ), we call this problem the pure explo ration proble m for multi-armed 4 P arameters: K probability distributions for the rewards of the arms, ν 1 , . . . , ν K . F or eac h rou n d t = 1 , 2 , . . . , (1) t he forecaster chooses I t ∈ { 1 , . . . , K } ; (2) t he environmen t draw s the rewar d Y t for that action (also denoted by X I t ,T I t ( t ) with the notation introduced in the t ex t); (3) t he forecaster outputs a recommendation J t ∈ { 1 , . . . , K } ; (4) if the environment sends a stopping signal, then the game takes an end ; otherwise, t he next roun d starts. Figure 1: The pure exploration problem for multi-armed bandits (with a finite num b er of arms). bandits and ev aluate the for ecaster through its simple regret, defined a s follows. First, we denote by µ ∗ = µ i ∗ = max i =1 ,...,K µ i the exp ectation of the re w ar ds of the b est arm i ∗ (a b est arm, if there a r e s everal of them with same maximal exp ectation). A useful notatio n in the sequel is the gap ∆ i = µ ∗ − µ i betw een the maximal expe cted rew ar d and the one of the i –th arm; as w ell a s the minimal gap ∆ = min i :∆ i > 0 ∆ i . Now, the simple reg ret at r ound n equals the reg ret on a one- shot instance of the ga me for the r ecommended arm J n , that is, put mor e formally , r n = µ ∗ − µ J n = ∆ J n . A qua n tity of related interest is the cumulativ e re gret a t r o und n , which is defined as R n = n X t =1 µ ∗ − µ I t . A p opular treatment of the multi-armed ba ndit problems is to cons truct for e - casters ensuring that E R n = o ( n ), see, e.g ., [15] o r [3], a nd even R n = o ( n ) a.s., as follows, e.g., from [4, Theorem 6.3] together with the Bor el–Cantelli lemma. The quantit y r ′ t = µ ∗ − µ I t is sometimes called instantaneous r egret. It differs from the simple reg r et r t and in particula r, R n = r ′ 1 + . . . + r ′ n is in g eneral not equal to r 1 + . . . + r n . Theorem 1, among others, will how ever indicate s ome connections b etw een r n and R n . Remark 1. The setting de s crib ed ab ove is conc e rned with a finite num b er o f arms. In Section 6 we will extend it to the c a se of arms indexe d b y a ge neral top ological space . 5 3. The sm aller the cumulativ e reg ret, the larger the si mple regret It is immediate that for well-c hosen reco mmendation strategies, the simple regret can b e upp er b ounded in terms of the cumulativ e regr et. F or instance, the stra tegy that at time n recommends ar m i with probability T i ( n ) /n (re call that we allow the foreca ster to use an e xternal ra ndomization) ensures that the simple re gret s atisfies E r n = E R n /n . Therefor e , upper b ounds on E R n lead to upper b ounds on E r n . W e show here that, conversely , upp er b ounds on E R n also lead to low er bo unds o n E r n : the sma ller the guara nt eed upp er b ound on E R n , the larg er the low er b o und on E r n , no ma tter what the recommendatio n stra tegy is. This is interpreted as a v ariation of the “classical” tra de-off b etw een explo - ration and exploitatio n. Here, while the recommendation strategy ( J n ) r elies only on the exploita tio n of the r esults of the preliminary ex plo ration phase, the design of the allo cation strategy ( I t ) cons is ts in an efficient exploration o f the arms. T o g uarantee this efficient explora tion, past pay offs of the arms have to b e co nsidered and thus, even in the explo ration phase, some explo itation is needed. Theor em 1 and its corolla ries aim a t quantifying the needed resp ective amount of explor ation and exploita tion. In particular, to hav e an as ymptotic optimal r a te of decrease for the simple regret, each ar m should be sampled a linear num ber of times, while for the cumulativ e regret, it is known that the forecaster should not do so mo re than a logar ithmic n umber o f times on the sub o ptimal arms. F ormally , our main r e s ult is r ep o rted b elow in Theorem 1. It is stro ng in the sense that it lo wer b ounds the simple r egret o f any for ecaster for all possible sets of Bernoulli distributions { ν 1 , . . . , ν K } ov er the rewards with par ameters that are all distinct (no tw o parameter s can be equal) and all different fr om 1. Note how ever that in particular these conditions entail that there is a unique bes t arm. Theorem 1 (Main resul t). F or any for e c aster (i.e., for any p air of al lo c ation and r e c ommenda tion st r ate gies) and any function ε : { 1 , 2 , . . . } → R such t hat for al l (Bernoul li) distributions ν 1 , . . . , ν K on the r ewar ds, ther e exists a c onstant C > 0 with E R n 6 C ε ( n ) , the fol lowing holds true: for al l sets of K > 3 Bernoul li distributions on the r ewar ds, with p ar am- eters that ar e al l distinct and al l differ ent fr om 1 , ther e exists a c onst ant D > 0 and an or dering ν 1 , . . . , ν K of the c onsider e d distributions such that E r n > ∆ 2 e − D ε ( n ) . W e insist o n the fa ct that only sets , that is, unordered collections, of dis- tributions a re considered in the second part of the statement of the theorem. Put differently , we merely show therein that for each or dered K –tuple of dis - tributions that are as indicated ab ov e, there exis ts a reordering that leads to 6 the stated lower bo und on the simple regr et. This is the b est res ult that can be ac hieved. Indeed, some fo recasters are sensitive to the o rdering o f the dis- tributions and might get a zero regr et for a significant fraction of the o r dered K –tuples s imply b ecause, e.g., their strateg y is to c o nstantly pull a g iven arm, which is so metimes the optimal strateg y just by ch ance . T o get low er b ounds in all ca s es we must therefore allow reor derings of K –tuples (or , equiv alently , orderings of sets). Corollary 1 (General di stribution-dep enden t low er b ound). F or any fo- r ec aster, and any set of K > 3 Bernoul li distributions on the r ewar ds, with p a- r ameters t hat ar e al l distinct and al l differ en t fr om 1 , ther e exist t wo c onstant s β > 0 and γ > 0 and an or dering of the c onsider e d distributions such that E r n > β e − γ n . Theorem 1 is prov ed b elow and Corolla ry 1 follows from the fact that the cum ulative regret is always b ounded b y n . T o get fur ther the p oint of the theorem, one sho uld keep in mind that the typical (distribution-dep endent) r ate of growth of the cumulativ e regr et of go o d algo r ithms, e.g., UCB1 [3], is ε ( n ) = ln n . This, as asser ted in [15], is the optimal r ate. Hence a recommendation strategy based on such allo cation stra tegy is b ound to suffer a simple r egret that decrea ses at b est p olyno mially fast. W e state this result for the s light mo dification UCB( α ) of UCB1 stated in Figure 2 a nd intro duced in [1]; its pro of relies on noting tha t it a c hieves a cumulative re gret b ounded by a la rge enough distribution- de p endent constant times ε ( n ) = α ln n . Corollary 2 (Distribution-dep e n de n t low er b ound for UCB ( α ) ). The al- lo c atio n str ate gy ( I t ) given by the for e c aster UCB ( α ) of Figur e 2 ensur es that for any r e c ommendatio n str ate gy ( J t ) and al l sets of K > 3 Bernoul li distributions on the r ewar ds, with p ar ameters that ar e al l distinct and al l differ ent fr om 1 , ther e exist two c onstants β > 0 and γ > 0 (indep endent of α ) and an or dering of the c onsider e d distributions such that E r n > β n − γ α . Proof. The in tuitive version of the pro o f of Theorem 1 is a s follows. The ba sic idea is to consider a tie case when the b e st and worst arms hav e zero empirica l means; it happens often enough (with a probability at least exp onential in the nu mber of times we pulled these ar ms) and results in the forecaster bas ically having to pick another arm a nd suffer ing some regret. Perm utations are used to control the case of unt ypical or naive forec asters that would despite all pull an arm with zero empirical mean, since they fo r ce a situation when those for ecasters choose the worst arm instea d of the bes t one. F ormally , we fix the for ecaster (a pa ir of a llo cation a nd recommenda tion strategies) and a cor resp onding function ε such that the a ssumption of the theorem is satisfied. W e denote b y p n = ( p 1 ,n , . . . , p K,n ) the probability distri- bution from which J n is drawn at r andom thanks to an a uxiliary distribution. 7 Note that p n is a rando m vector which dep e nds on I 1 , . . . , I n as well as on the obtained rewards Y 1 , . . . , Y n . W e cons ider below a set of K > 3 distinct Bernoulli distributions, sa tis fying the conditio ns o f the theorem; a c tually , we only use b elow that their pa rameters are (up to a first or dering) such that 1 > µ 1 > µ 2 > µ 3 > . . . > µ K > 0 a nd µ 2 > µ K (th us, µ 2 > 0). Step 0 introduce s a no ther lay er of no ta tion. The la tter dep ends on p ermu- tations σ of { 1 , . . . , K } . T o have a ge ntle start, we first describ e the notation when the p ermutation is the iden tity , σ = id. W e denote b y P and E the probability and exp ectatio n with resp ect to the origina l K -tuple ν 1 , . . . , ν K of distributions over the arms. F or i = 1 (re s pectively , i = K ), we denote b y P i, id and E i, id the probability a nd expecta tion with resp ect to the K - tuples formed by δ 0 , ν 2 , . . . , ν K (resp ectively , δ 0 , ν 2 , . . . , ν K − 1 , δ 0 ), where δ 0 denotes the Dirac measure on 0. F or a g iven per m utation σ , we consider a similar no tation up to a r eorder- ing, as follows. The sy m b ols P σ and E σ refer to the pro bability and exp ecta- tion with resp ect to the K -tuple of distributions ov er the ar ms formed b y the ν σ − 1 (1) , . . . , ν σ − 1 ( K ) . Note in particula r that the i –th b est arm is lo cated in the σ ( i )–th p osition. Now, we denote for i = 1 (resp e ctiv ely , i = K ) by P i,σ and E i,σ the pro babilit y and exp ectation with resp ect to the K -tup le formed by the ν σ − 1 ( i ) , exce pt that w e replaced the bes t of them, lo ca ted in the σ (1)–th p os i- tion, by a Dirac measure on 0 (resp ectively , the best and worst of them, lo c a ted in the σ (1)–th and σ ( K )– th p ositions , b y Dirac measure s on 0). W e provide now a pr o o f in six steps. Step 1 lower b o unds the quantit y of interest by a n av era ge of the simple regrets obtained b y re ordering, max σ E σ r n > 1 K ! X σ E σ r n > µ 1 − µ 2 K ! X σ E σ 1 − p σ (1) ,n , where we used that under P σ , the index of the b est arm is σ (1) and the minimal regret for playing any other ar m is at least µ 1 − µ 2 . Step 2 rewr ites each term of the sum ov er σ as the pro duct of three simple terms. W e use fir st that P 1 ,σ is the s ame as P σ , except that it ensures that arm σ (1) has zero reward thro ug hout. Denoting by C i,n = T i ( n ) X t =1 X i,t the cumulativ e r e w ar d of the i –th ar m till round n , one then gets E σ 1 − p σ (1) ,n > E σ h 1 − p σ (1) ,n 1 { C σ (1) ,n =0 } i = E σ h 1 − p σ (1) ,n C σ (1) ,n = 0 i × P σ C σ (1) ,n = 0 = E 1 ,σ 1 − p σ (1) ,n P σ C σ (1) ,n = 0 . 8 Second, rep eating the argument fr om P 1 ,σ to P K,σ , E 1 ,σ 1 − p σ (1) ,n > E 1 ,σ h 1 − p σ (1) ,n C σ ( K ) ,n = 0 i P 1 ,σ C σ ( K ) ,n = 0 = E K,σ 1 − p σ (1) ,n P 1 ,σ C σ ( K ) ,n = 0 and therefore, E σ 1 − p σ (1) ,n > E K,σ 1 − p σ (1) ,n P 1 ,σ C σ ( K ) ,n = 0 P σ C σ (1) ,n = 0 . (1) Step 3 deals with the second term in the right-hand s ide of (1), P 1 ,σ C σ ( K ) ,n = 0 = E 1 ,σ h (1 − µ K ) T σ ( K ) ( n ) i > (1 − µ K ) E 1 ,σ T σ ( K ) ( n ) , where the equality can b e s een by conditioning on I 1 , . . . , I n and then taking the exp ectation, wherea s the inequa lit y is a co nsequence o f Jensen’s inequality . Now, the exp ected num ber of times the sub optimal arm σ ( K ) is pulled under P 1 ,σ (for which σ (2 ) is the optimal arm) is b ounded by the regret, by the very definition of the latter: ( µ 2 − µ K ) E 1 ,σ T σ ( K ) ( n ) 6 E 1 ,σ R n . By hypothesis, there exists a constant C s uc h that for all σ , E 1 ,σ R n 6 C ε ( n ); the constant C in the hypothesis of the theorem dep ends o n the (order o f the) distributions but this can b e circumv en t by tak ing the maximum of K ! v a lues to get the previous statement. W e fina lly get P 1 ,σ C σ ( K ) ,n = 0 > (1 − µ K ) C ε ( n ) / ( µ 2 − µ K ) . Step 4 low er b ounds the third term in the right-hand side o f (1) as P σ C σ (1) ,n = 0 > (1 − µ 1 ) C ε ( n ) /µ 2 . W e denote by W n = ( I 1 , Y 1 , . . . , I n , Y n ) the histor y of pulled arms and o btained pay offs up to time n . What follows is reminiscent of the techniques used in [17]. W e ar e interested in certain rea lizations w n = ( i 1 , y 1 , . . . , i n , y n ) of the his to ry: we consider the subset H formed b y the ele ments w n such that whenever σ (1) was play ed, it got a null r e ward, that is, such that y t = 0 for a ll indexes t with i t = σ (1). F or all arms j , we then denote by t j ( w n ) the r ealization of T j ( n ) corres p onding to w n . Since the likelihoo d of an element w n ∈ H under P σ is (1 − µ 1 ) t σ (1) ( w n ) times the one under P 1 ,σ , we g et P σ C σ (1) ,n = 0 = X w n ∈H P σ { W n = w n } = X w n ∈H (1 − µ 1 ) t σ (1) ( w n ) P 1 ,σ { W n = w n } = E 1 ,σ h (1 − µ 1 ) T σ (1) ( n ) i . The argument is concluded as befor e , first by Je nsen’s inequa lit y and then, by us ing that µ 2 E 1 ,σ T σ (1) ( n ) 6 E 1 ,σ R n 6 C ε ( n ) b y definition of the regret a nd the hypothesis put on its control. 9 Step 5 resor ts to a symmetry argument to show that as far a s the first term of the r ight -ha nd side of (1) is conce r ned, X σ E K,σ h 1 − p σ (1) ,n i > K ! 2 . Since P K,σ only dep ends o n σ (2) , . . . , σ ( K − 1), we denote by P σ (2) ,. ..,σ ( K − 1) the common v alue of thes e pr obability dis tributions when σ (1) and σ ( K ) v ary (and a simila r notation for the a sso ciated exp ectation). W e can thus g roup the per m utations σ t wo by t wo according to these ( K − 2 )–tuples, one o f the t wo p ermutations b eing de fined by σ (1) equal to o ne of the tw o elements of { 1 , . . . , K } not pres en t in the ( K − 2)–tuple, and the other o ne b eing such that σ (1) equa ls the other such element. F orma lly , X σ E K,σ p σ (1) ,n = X j 2 ,...,j K − 1 E j 2 ,...,j K − 1 X j ∈{ 1 ,...,K }\{ j 2 ,...,j K − 1 } p j,n 6 X j 2 ,...,j K − 1 E j 2 ,...,j K − 1 1 = K ! 2 , where the summations over j 2 , . . . , j K − 1 are ov er all p ossible ( K − 2)–tuples o f distinct elements in { 1 , . . . , K } . Step 6 simply puts all pieces together and low er b ounds max σ E σ r n by µ 1 − µ 2 K ! X σ E K,σ 1 − p σ (1) ,n P σ C σ (1) ,n = 0 P 1 ,σ C σ ( K ) ,n = 0 > µ 1 − µ 2 2 (1 − µ K ) C / ( µ 2 − µ K ) (1 − µ 1 ) C /µ 2 ε ( n ) . 4. Upp er b ounds on the sim ple regret In this section, w e aim at qualifying the implications of Theore m 1 by p o int - ing out that is should b e in terpre ted as a result for larg e n only . F or mo derate v alues of n , strategies not pulling ea ch arm a linear num b er o f times in the ex- ploration phase ca n hav e a smaller simple reg r et. T o do so, we consider only tw o natural and well-used allo cation strategies since the aim of this pap er is mos tly to study the links betw een the cumulativ e a nd simple r egret and not really to prov e the b est p oss ible b o unds on the simple regret. Mo re sophistica ted alloc a - tion str a tegies were considered recently in [2 ] and they ca n b e used to improve on the upp er b ounds o n the simple regret presented b elow. The first a llo cation strateg y is the unifor m a llo cation, which we use a s a simple b enc hmar k; it pulls each arm a linear num b er of times (see Figur e 2 for its for mal description). The se c ond one is UCB( α ) (a v ariant of UCB1 int ro duced in [1] using an explo ration rate para meter α > 1 and describ ed also in Figure 2). It is designed for the c lassical exploration–explo ita tion dilemma (i.e., 10 Uniform allo cation (Unif ) — Plays all arms one after the oth er F or eac h rou n d t = 1 , 2 , . . . , pull I t = [ t mo d K ], where [ t mo d K ] denotes the v alue of t mo dulo K . UCB ( α ) — Plays at each round the arm with the h ighest upp er confidence b ound Par ameter: exploration factor α > 1 F or eac h rou n d t = 1 , 2 , . . . , (1) for each i ∈ { 1 , . . . , K } , if T i ( t − 1) = 0 let B i,t = + ∞ ; otherwise, let B i,t = b µ i,t − 1 + s α ln t T i ( t − 1) where b µ i,t − 1 = 1 T i ( t − 1) T i ( t − 1) X s =1 X i,s ; (2) Pu ll I t ∈ argmax i =1 ,...,K B i,t (ties b roken b y choosing, for instance, the arm with smallest ind ex ). Figure 2: Two all ocation strategies. it minimizes the cumulativ e re g ret) and pulls sub optimal arms a logar ithmic nu mber of times only . In addition to these allo cation strategies we consider three recommendatio n strategies, the ones that reco mmend r esp ectively the e mpir ical distribution of plays, the empirical b est arm, o r the most play ed arm. They are formally defined in Figure 3. T able 1 summarizes the distribution-depe ndent and distr ibutio n-free b ounds we c o uld prove in this pa per (the difference b et ween the tw o families of b ounds is whether the constants in the bo unds can dep end or not on the unknown distributions ν j ). It s hows that tw o interesting couples of strateg ies a re, on the one ha nd, the uniform a llo cation together with the choice of the empirica l bes t arm, and on the other hand, UCB( α ) to g ether with the choice of the most play ed arm. The first pair was p erha ps exp ected, the second one might b e consider ed more surpr ising. T able 1 also indicates that w hile for distr ibution-dep e nden t b ounds, the asymptotic o ptimal rate of decreas e for the simple r egret in the num ber n of rounds is exp onential, for distribution-free b ounds, this r ate worsens to 1 / √ n . A simila r situation a r ises for the cumulativ e r egret, see [15] (optimal ln n r ate for distribution-dep endent b ounds) v ers us [4 ] (optimal √ n rate for distribution-fre e bo unds). Remark 2. The dis tr ibution-free lower b ound in T able 1 follows from a stra ight- forward adaptation o f the pro of of the low er b ound o n the cumulativ e reg r et in 11 P arameters: the history I 1 , . . . , I n of play ed actions and of their associated rewa rds Y 1 , . . . , Y n , group ed according to the arms as X i, 1 , . . . , X i,T i ( n ) , for i = 1 , . . . , n Empirical distribution of plays (EDP) Recommends arm i with probability T i ( n ) /n , that is, dra ws J n at rand om accord- ing to p n = T 1 ( n ) n , . . . , T K ( n ) n . Empirical b est arm (EBA) Only considers arms i with T i ( n ) > 1, computes their asso ciated empirical means b µ i,n = 1 T i ( n ) T i ( n ) X s =1 X i,s , and forms the recommendation J n ∈ argmax i =1 ,...,K b µ i,n (ties broken in some wa y). Most play ed arm (MP A ) Recommends th e most play ed arm, J n ∈ argmax i =1 ,...,K T i ( n ) (ties broken in some wa y). Figure 3: Three recommendation strategies. [4]; one ca n prove that, for n > K > 2, inf sup E r n > 1 20 r K n , where the infim um is taken ov er all fo r ecasters while the s upremum consider s all sets of K distr ibutions ov er [0 , 1]. (The pro of uses exactly the same reduction to a s to chastic setting as in [4]. It is even simpler than in the indicated reference since her e , o nly what happens at round n based o n the informatio n provided by previo us rounds is to b e cons ide r ed; in the cumu lative case considered in [4], such an ana lysis had to be made a t each round t 6 n .) 4.1. A simple b enchmark: the uniform al lo c ation stra te gy As expla ined ab ov e, the combination of the uniform allo ca tion with the r ec- ommendation indicating the empirical best arm, forms a n imp orta n t theoretical 12 Distribution-dep endent EDP EBA MP A Uniform e − n (Pr.1) UCB( α ) ( α ln n ) /n (Rk.3) n − (Rk.4) n 2(1 − α ) (Th.2) Lo wer b ound e − n (Cor.1) Distribution-free EDP EBA MP A Uniform r K ln K n (Cor.3) UCB( α ) r αK ln n n (Rk.3) √ ln n (Rk.4) r αK ln n n (Th.3) Lo wer b ound r K n (Rk.2) T able 1: Distri bution-dependen t (top) and distribution-fr ee (b ottom) upper b ounds on the expected simple regret of the considered pairs of allo cation (rows) and recommendation (columns) strategies. Low er b ounds are also indicated. The symbols denote the unive rsal constan ts, whereas the are distribution-dependent constant s. In paren theses, we pr o vide the reference within this paper (index of the prop osi tion, theorem, remark, corollary) where the stated b ound is pr o ved. benchmark. This sectio n studies briefly its theoretical pr op e rties: the r a te of decrease of its simple reg ret is exp onential in a distributio n-depe ndent sens e a nd equals the optimal (up to a logarithmic term) 1 / √ n r ate in the distribution-free case. Below, we mean by the recommendatio n given by the empirica l b est ar m at round K ⌊ n/K ⌋ the recommendation J K ⌊ n/K ⌋ of EBA (see Figur e 3), where ⌊ x ⌋ denotes the low er in teger part of a r e al num b er x . The reason why at ro und n we prefer J K ⌊ n/K ⌋ to J n is only technical. The a nalysis is indeed simpler when all av era ges over the rewards obtained by each arm a re ov er the same num b er of terms. This happ ens at r ounds n m ultiple of K and this is why w e prefer taking the recommendation of r ound K ⌊ n/ K ⌋ instead of the one of r ound n . W e pro po se first t wo distribution-depe nden t b ounds, the fir st one is shar per in the ca se when ther e are few arms, while the sec o nd one is suited for large K . Prop ositio n 1 (Di s tribution-dep e nden t; Unif and EBA). The un iform al- lo c atio n s t r ate gy asso ciate d with t he r e c ommendation given by the empiric al b est arm (at r ound K ⌊ n/K ⌋ ) ensur es that E r n 6 X i :∆ i > 0 ∆ i e − ∆ 2 i ⌊ n/K ⌋ for al l n > K ; and also, for al l η ∈ (0 , 1) and al l n > max K, K ln K η 2 ∆ 2 , E r n 6 max i =1 ,...,K ∆ i exp − (1 − η ) 2 2 j n K k ∆ 2 . 13 Proof. T o prov e the first inequality , we rela te the simple regret to the proba- bilit y of choosing a non-optimal ar m, E r n = E ∆ J n = X i :∆ i > 0 ∆ i P { J n = i } 6 X i :∆ i > 0 ∆ i P b µ i,n > b µ i ∗ ,n where the upp e r b ound follows from the fact that to b e the e mpir ical b est a rm, an ar m i m ust hav e p erfor med, in particula r, better tha n a b est a rm i ∗ . W e now apply Ho effding’s inequa lity for independent b ounded r andom v ariables, see [11]. The quantities b µ i,n − b µ i ∗ ,n are given b y a (normalize d) sum of 2 ⌊ n/ K ⌋ random v ariable s tak ing v alues in [0 , 1] or in [ − 1 , 0] and hav e exp ectation − ∆ i . Thu s, the probability of interest is b ounded by P b µ i,n − b µ i ∗ ,n > 0 = P n b µ i,n − b µ i ∗ ,n − − ∆ i > ∆ i o 6 exp − 2 ⌊ n/K ⌋ ∆ i 2 2 ⌊ n/K ⌋ = exp − j n K k ∆ 2 i , which yields the first r e sult. The second ineq ua lit y is pr ov ed by reso rting to a sha rp er concentration ar- gument, namely , the metho d of b ounded difference s , see [18], see also [8, Cha p- ter 2]. The co mplete pro of c a n b e found in Section App endix A.1. The distribution-free b ound of Cor ollary 3 is obtained not dir ectly as a corolla r y of Pr op osition 1, but a s a conse q uence o f its proo f. (It is not eno ugh to optimize the b ound of Prop osition 1 over the ∆ i , for it would yie ld an additional m ultiplicative factor o f K .) Corollary 3 (Distribution-free; Unif and EBA). The uniform al lo c ation str ate gy asso ciate d with the r e c ommendation given by the empiric al b est arm (at r ound K ⌊ n/K ⌋ ) ens ur es that sup ν 1 ,...,ν K E r n 6 2 r K ln K n + K , wher e the supr emum is over al l K –t u ples ( ν 1 , . . . , ν K ) of distributions over [0 , 1] . Proof. W e extr act from the pro of o f P rop osition 1 that P { J n = i } 6 exp − j n K k ∆ 2 i ; we now distinguish whether a given ∆ i is more or less than a threshold ε , use that P P { J n = i } = 1 and ∆ i 6 1 fo r all i , to wr ite E r n = K X i =1 ∆ i P { J n = i } 6 ε + X i :∆ i >ε ∆ i P { J n = i } (2) 6 ε + X i :∆ i >ε ∆ i exp − j n K k ∆ 2 i . 14 A simple study shows that the function x ∈ [0 , 1] 7→ x exp( − C x 2 ) is decr easing on 1 / √ 2 C , 1 , fo r any C > 0. Therefore, taking C = ⌊ n/K ⌋ , we get that whenever ε > 1 p 2 ⌊ n/K ⌋ , E r n 6 ε + ( K − 1) ε exp − ε 2 j n K k . Substituting ε = p (ln K ) / ⌊ n/K ⌋ c o ncludes the pr o of. 4.2. Analysis of UCB ( α ) as an al lo c ation str ate gy W e start by studying the recommendation g iven by the most play ed arm. A (distr ibution-dep enden t) bo und is stated in Theorem 2; the b ound do es not inv olve any quantit y depending on the ∆ i , but it only holds for rounds n la rge enough, a statement that do es inv olve the ∆ i . Its int ere st is first that it is simple to rea d, and second, that the techniques used to prov e it imply easily a second (distribution-free) b ound, sta ted in Theorem 3 a nd which is compara ble to Coro lla ry 3. Theorem 2 (Distribution-dep e nden t; UCB ( α ) and MP A). F or α > 1 , the al lo c ation st r ate gy given by UCB ( α ) asso ciate d with the r e c ommendatio n given by the most playe d arm ensur es that E r n 6 K α − 1 n K − 1 2(1 − α ) for al l n sufficiently lar ge, e.g., such that n > K + 4 K α ln n ∆ 2 and n > K ( K + 2 ) . The p olynomia l rate in the upper b ound a bove is not a coincidence ac cord- ing to the lower bo und e x hibited in Co r ollary 2. Here, s ur prisingly enough, this po lynomial ra te of decr ease is distribution-fre e (but in co mpensa tion, the bo und is only v alid a fter a distribution-dep endent time). This ra te illustrates Theorem 1: the lar ger α , the large r the (theoretical b ound on the) cumulativ e regret of UCB( α ) but the smaller the simple reg ret of UCB( α ) asso ciated with the reco mmendation g iven by the most play ed arm. Theorem 3 (Distribution-free; UCB ( α ) and MP A). F or α > 1 , the al lo- c ation str ate gy given by UCB ( α ) asso ciate d with t he r e c ommendation given by the most playe d arm ens u r es t hat, for al l n > K ( K + 2) , sup ν 1 ,...,ν K E r n 6 r 4 K α ln n n − K + K α − 1 n K − 1 2(1 − α ) = O r K α ln n n ! , wher e the supr emum is over al l K –t u ples ( ν 1 , . . . , ν K ) of distributions over [0 , 1] . 15 4.2.1. Pr o ofs of The or ems 2 and 3 W e star t by a technical lemma from which the tw o theorems will follow easily . Lemma 1 . L et a 1 , . . . , a K b e r e al n umb ers such that a 1 + . . . + a K = 1 and a i > 0 for al l i , with the additio nal pr op erty that for al l sub optimal arms i and al l optimal arms i ∗ , one has a i 6 a i ∗ . Then for α > 1 , the al lo c ation stra te gy given by UCB ( α ) asso ciate d with the r e c ommendation given by the most playe d arm ensur es that E r n 6 1 α − 1 X i 6 = i ∗ ( a i n − 1) 2(1 − α ) for al l n sufficiently lar ge, e.g., such that, for al l sub optimal arms i , a i n > 1 + 4 α ln n ∆ 2 i and a i n > K + 2 . Proof. W e first prove that whenever the mos t play ed arm J n is different from an optimal a rm i ∗ , then at least one of the sub optimal arms i is s uc h that T i ( n ) > a i n . T o do so, we use a contrapositive metho d and as s ume that T i ( n ) < a i n for all sub optimal arms. Then, K X i =1 a i ! n = n = K X i =1 T i ( n ) < X i ∗ T i ∗ ( n ) + X i a i n where, in the inequality , the fir s t summatio n is over the optimal ar ms, the sec o nd one, ov er the subo ptimal ones. Therefor e, we get X i ∗ a i ∗ n < X i ∗ T i ∗ ( n ) and there exis ts at least one optimal arm i ∗ such that T i ∗ ( n ) > a i ∗ n . Since by definition of the vector ( a 1 , . . . , a K ), one has a i 6 a i ∗ for all sub optimal arms, it co mes that T i ( n ) < a i n 6 a i ∗ n < T i ∗ ( n ) for a ll sub optimal ar ms , and the most play ed ar m J n is thus a n optimal arm. Thu s, using that ∆ i 6 1 fo r a ll i , E r n = E ∆ J n 6 X i :∆ i > 0 P T i ( n ) > a i n . A side-r esult extr acted from [1, pro of of Theo rem 7], see also [3, pr o of of Theo- rem 1], sta tes that for all sub optimal a rms i a nd all r ounds t > K + 1, P n I t = i and T i ( t − 1) > ℓ o 6 2 t 1 − 2 α whenever ℓ > 4 α ln n ∆ 2 i . (3) W e denote b y ⌈ x ⌉ the upper integer par t o f a real n umber x . F or a sub optimal arm i and since by the assumptions on n and the a i , the choice ℓ = ⌈ a i n ⌉ − 1 16 satisfies ℓ > K + 1 a nd ℓ > (4 α ln n ) / ∆ 2 i , P T i ( n ) > a i n = P T i ( n ) > ⌈ a i n ⌉ 6 n X t = ⌈ a i n ⌉ P n T i ( t − 1) = ⌈ a i n ⌉ − 1 a nd I t = i o 6 n X t = ⌈ a i n ⌉ 2 t 1 − 2 α 6 2 Z ∞ ⌈ a i n ⌉− 1 v 1 − 2 α d v 6 1 α − 1 ( a i n − 1) 2(1 − α ) , (4) where we used a union bound for the second inequa lit y and (3) for the third inequality . A summation ov er a ll sub optimal ar ms i concludes the pro of. Proof (of Theorem 2). It consists in a pplying Lemma 1 with the uniform choice a i = 1 /K and reca lling that ∆ is the minimum of the ∆ i > 0. Proof (of Theorem 3). W e start the pr o of b y using that P P { J n = i } = 1 and ∆ i 6 1 for all i , and can thus write E r n = E ∆ J n = K X i =1 ∆ i P { J n = i } 6 ε + X i :∆ i >ε ∆ i P { J n = i } . Since J n = i only if T i ( n ) > n/K , we get E r n 6 ε + X i :∆ i >ε ∆ i P n T i ( n ) > n K o . Applying (4) with a i = 1 /K leads to E r n 6 ε + X i :∆ i >ε ∆ i α − 1 n K − 1 2(1 − α ) , where ε is chosen such that for all ∆ i > ε , the condition ℓ > n/K − 1 > (4 α ln n ) / ∆ 2 i is satisfied ( n/K − 1 > K + 1 b eing satisfied by the a ssumption on n and K ). The conclusion thus follows fro m taking, for instance, ε = p (4 αK ln n ) / ( n − K ) and upp er b ounding all rema ining ∆ i by 1. 4.2.2. Other r e c ommendation str ate gies W e discuss here the c o mb inatio n o f UCB( α ) with the tw o other r ecommen- dation strategies, na mely , the ch oic e of the empirica l b est ar m and the use o f the empirica l distribution of plays. 17 Remark 3 (UCB ( α ) and EDP). W e indicate in this remar k from whic h re- sults the cor resp onding bounds of T able 1 follow. As noticed in the b eginning of Section 3, in the ca se of a recommendation formed by the empirical distribu- tion of plays, the simple r egret is b ounded in terms of the cumulativ e regr et as E r n 6 E R n /n . Now, the results in [3, 1] indicate that the cumulative r egret of UCB( α ) is less than something of the form α ln n + 3 K 2 + K 2( α − 1) , where denotes a consta n t dep endent o n ν 1 , . . . , ν K . The distribution-fr ee bo und on E R n (and thus o n E r n ) follows fro m the control, yielded by (3) and a summation, E T i ( n ) 6 4 α ln n ∆ 2 i + 3 2 + 1 2( α − 1) , together with the concavity argument E R n = X i :∆ i > 0 ∆ i E T i ( n ) = X i :∆ i > 0 ∆ i p E T i ( n ) p E T i ( n ) 6 s 4 α ln n + 3 2 + 1 2( α − 1) X i :∆ i > 0 p E T i ( n ) 6 s 4 α ln n + 3 2 + 1 2( α − 1) K n , where Jensen’s inequality guar anteed that P p E T i ( n ) 6 √ K n . Remark 4 (UCB ( α ) and EBA). W e can rephra se the results of [14] as us- ing UCB1 as an a llo cation stra tegy and for ming a recommendation according to the empirical bes t a rm. In pa rticular, [14, Theorem 5] provides a distribution- depe ndent b ound on the probability o f not pic king the b est arm with this pr o- cedure and can b e used to derive the following bo und o n the simple reg ret o f UCB( α ) combined with E BA: fo r all n > 1, E r n 6 X i :∆ i > 0 4 ∆ i 1 n ρ α ∆ 2 i / 2 where ρ α is a p ositive constant dep ending on α only . T he leading constants 1 / ∆ i and the dis tr ibution-dep enden t exp onent make it not a s useful as the one presented in Theore m 2. The b est distribution-free bo und we could get from this bo und was of the order of 1 / √ ρ α ln n , to b e compared to the asympto tic optimal 1 / √ n ra te stated in Theorem 3. 5. Conclus ions for the case of finitel y m an y arms: Comparis o n of the b ounds, simulation study W e first explain why , in some cases, the b ound provided by o ur theoretical analysis in Lemma 1 (for UCB( α ) and MP A) is better than the b ound stated in 18 Prop osition 1 (for Unif and EBA). The central p o int in the ar gument is that the bo und of Lemma 1 is of the for m n 2(1 − α ) , fo r some distribution- dep endent constant , that is , it has a distribution-free conv erge nc e rate. In co mparison, the b ound of Prop ositio n 1 inv olves the g aps ∆ i in the ra te o f co n vergence. Some care is needed in the compariso n, since the b ound for UCB( α ) ho lds only for n large enough, but it is easy to find s itua tions where for mo derate v alues of n , the bo und exhibited for the sampling with UCB( α ) is b etter than the one for the uniform allo catio n. The s e situations typically inv olve a rather lar ge num ber K of ar ms; in the la tter ca se, the unifor m allo cation s tr ategy only sa mples ⌊ n/ K ⌋ times each ar m, wher eas the UCB strategy fo cuse s rapidly its exploration o n the bes t arms. A gener a l argument is prop ose d in Sectio n Appendix A.2 a s well as a nu meric al example, showing that for mo dera te v alue s o f n , the bo unds asso ciated with the sampling with UCB( α ) are b etter than the ones as s o ciated with the uniform sampling. This is further illustrated numerically , in the right part of Figur e 4). T o mak e s hort the longer story describ ed in this pape r, one can distinguis h three regimes, acco rding to the v alue of the n umber of rounds n . The state- men ts of these regimes (the ranges of their corres po nding n ) inv olve distribution- depe ndent quantifications, to determine which n are cons ide r ed small, mo dera te, or large. • F or la r ge v alues of n , uniform exploration is b etter (a s shown by a com- bination o f the low er b ound of Cor ollary 2 and of the upp er b ound o f Prop osition 1). • F or mo der ate v alues of n , sampling with UCB( α ) is preferable, as discussed just ab ov e (and in Section Appendix A.2). • F or sma ll v alues of n , little can b e s aid a nd the b est b ounds to consider are p erha ps the distr ibution-free b ounds, which are of the same order of magnitude for the tw o pair s o f strategies . W e pro p os e t wo simple exp eriments to illustrate our theore tical ana lysis; each o f them was r un on 10 4 instances of the pro blem a nd we plotted the av erage simple regret. This is a n instance of the Monte-Carlo metho d and provides accur ate estimato rs of the exp e cted simple regret E r n . The first exp eriment (upp er plo t of Figure 4) s hows that for sma ll v alues of n (here, n 6 80), the uniform alloca tion s trategy can hav e an interesting b ehavior. Of course the r ange of these “small” v alues of n can be made arbitr arily large by decr easing the g ap ∆. The seco nd one (low er plot of Figure 4 ) corresp onds to the numerical example to b e describ ed in Section Appendix A.2. In b oth cases, the unclear picture for small v alues of n b ecome clea rer for mo derate v alues and shows an a dv an tage in fav or o f UCB– based allo ca tio n stra tegies. It also a ppea rs (here and in other non rep orted exp eriments) that it is b etter in practice to use reco mmenda tions based on the empirical bes t ar m rather than 19 on the most play ed arm. In par ticula r, the theore tica l upp er b ounds indicated in this pa per for the combination of UCB as an a llo cation strateg y and the recommendation based o n the empirica l b est ar m (see Remark 4) are probably to b e improved. Remark 5. W e mo stly illus tr ated here the small a nd mo derate n regimes. This is b ecause for large n , the simple reg ret is usually very sma ll, even b elow com- puter precisio n. Therefor e, b ecause of the c hose n ra nges, we do not see yet the uniform allo c ation strategy getting b etter than UCB–ba sed strategies , a fact that is true how ever for la rge enough n . This has an imp ortant impact o n the int erpr etation of the lower b ound o f Theorem 1. While its s tatemen t is in finite time, it should b e interpreted a s providing an asy mptotic r esult only . 6. Pure explo ration for con tinuous–armed bandits This sectio n is of theo retical interest. W e co nsider the X – armed bandit problem alre ady studied, e.g., in [6, 1 2], and (re)define the notions of cumu- lative and simple regr et in this setting. W e show that the cumulativ e regr et can b e minimized if and only if the simple re gret can b e minimized, and use this equiv alence to characterize the metric spaces X in which the cumulativ e regret can b e minimized: the s eparable ones. Here, in addition to its natural int erpr etation, the simple reg r et thus app ears as a to ol for proving results on the cumulativ e r e gret. 6.1. Description of the mo del of X –arme d b andits W e consider a b ounded in terv al of R , say [0 , 1] again. W e denote b y P ([0 , 1]) the s et of proba bilit y distributions over [0 , 1]. Similarly , given a top ological space X , we denote b y P ( X ) the set of probability distributions ov er X . W e then call en viro nmen t on X any mapping E : X → P ([0 , 1]). W e say that E is contin uous if the mapping that a sso ciates to each x ∈ X the exp ectation µ ( x ) of E ( x ) is contin uous; we call the latter the mean-pay off function. The X –ar med bandit problem is describ ed in Figure s 5 and 6. There, a n environmen t E on X is fixed and we w ant v arious notions o f regret to b e sma ll, given this environment. W e consider now families of environment s and say that a family F of en- vironments is explor able–exploitable (resp ectively , explor able) if there e x ists a forecaster such that for any environment E ∈ F , the exp ected cum ulative reg ret E R n (exp e c tation taken with resp ect to E and all a uxiliary ra ndomizations) is o ( n ) (resp ectively , E r n = o (1)). Of course , explorability o f F is a milder re- quirement than explo rability–exploitability of F , as can b e seen by co nsidering the r e commendation given by the empirical distribution of plays of Fig ure 3 and applying the same arg umen t as the one used at the b eginning of Section 3. In fact, it can b e s een that the t wo notions are equiv alent, and this is why we will henceforth c o ncentrate o n explo rability only , for whic h c hara cterizations as the ones of Theor em 4 are simpler to exhibit and prove. 20 40 60 80 100 120 140 160 180 200 0.11 0.115 0.12 0.125 0.13 0.135 0.14 0.145 0.15 Allocation budget Expectation of the simple regret ν i =B(1/2),i=1..19; ν 20 =B(0.66) UCB(2) with empirical best arm UCB(2) with most played arm Uniform sampling with empirical best arm 40 60 80 100 120 140 160 180 200 0 0.05 0.1 0.15 0.2 0.25 Allocation budget Expectation of the simple regret ν i =B(0.1),i=1..18; ν 19 =B(0.5); ν 20 =B(0.9) UCB(2) with empirical best arm UCB(2) with most played arm Uniform sampling with empirical best arm Figure 4: K = 20 arms with Bernoulli di stributions of parameters indicated on top of eac h graph. x -axis: num ber of r ounds n ; y -axis: simple r egrets E r n (estimated by a Mont e-Carlo method). 21 Parameters: an environmen t E : X → P ([0 , 1]) F or ea ch round t = 1 , 2 , . . . , (1) the fo r ecaster choo s es a distr ibution ϕ t ∈ P ( X ) and pulls a n ar m I t at r a ndom accor ding to ϕ t ; (2) the environment draws the reward Y t for that action, a c cording to E ( I t ). Go al: Find an a llo cation strateg y ( ϕ t ) such that the cumulativ e r egret R n = n s up x ∈X µ ( x ) − n X t =1 µ ( I t ) is small (i.e., o ( n ), in exp ectation). Figure 5: T he classical X –armed bandit problem. Lemma 2 . A family of envir onments F is explor able if and only if it is explor able– exploitable. The pro o f ca n b e found in Section 6.3. It relie s essentially on des ig ning a strategy suited for cumulativ e r egret from a stra teg y minimizing the simple re- gret; to do so, explo ration a nd explo ita tion o ccur at fix ed rounds in tw o distinct phases and only the pay offs obtained during explor ation rounds are fed int o the base allo ca tion stra tegy . 6.2. A p ositive r esult for metric sp ac es W e denote by P ([0 , 1]) X the family of a ll po ssible environments E on X , and b y C P ([0 , 1 ]) X the subset of P ([0 , 1]) X formed by the contin uous environ- men ts. Example 1. Previo us sec tions were a bo ut the family P ([0 , 1]) X of all en viro n- men ts over X = { 1 , . . . , K } b eing ex plo rable. The main result concerning X –armed bandit problems is formed by the following equiv alences in metric spac es. It gene r alizes the r e sult of E x ample 1. Theorem 4 . L et X b e a m et ric sp ac e. Then the family C P ([0 , 1 ]) X is ex- plor abl e if and only if X is sep ar able. Corollary 4 . Le t X b e a set. The family P ([0 , 1 ]) X is ex plor abl e if and only if X is c ountable. 22 Parameters: an environmen t E : X → P ([0 , 1]) F or ea ch round t = 1 , 2 , . . . , (1) the fo r ecaster choo s es a distr ibution ϕ t ∈ P ( X ) and pulls a n ar m I t at r a ndom accor ding to ϕ t ; (2) the environment draws the reward Y t for that action, a c cording to E ( I t ); (3) the forecas ter o utputs a r e commendation ψ t ∈ P ( X ); (4) if the environment sends a stopping signal, then the game takes a n end; other wise, the next round star ts. Go al: Find a n allo cation stra tegy ( ϕ t ) and a reco mmendation strategy ( ψ t ) suc h that the simple reg ret r n = sup x ∈X µ ( x ) − Z X µ ( x ) d ψ n ( x ) is small (i.e., o (1), in exp ectation). Figure 6: T he pure exploration pr oblem for X –armed bandits. The pro ofs can b e found in Section 6.4. Their main technical ingr edient is that there exists a probability distribution ov er a metric space X giving a po sitive probability mass to all op en sets if and only if X is separ able. Then, whenever it exis ts, it allows some uniform e x ploration. Remark 6. W e discuss her e the links with results rep or ted r ecent ly in [13]. The latter restricts its a tten tion to a setting wher e the space X is a metric space (with metric denoted b y d ) and where the environmen ts m ust hav e mean-pay off functions that are 1– Lipschitz with res pect to d . Its main concern is ab out the bes t achiev able order of magnitude of the cumulativ e reg ret with res pect to T . In this r esp ect, its main r esult is that a distribution-dep endent b ound prop ortiona l to log( T ) can b e achieved if and only if the completion of X is a compact metric space with countably man y po in ts. Otherwis e, b ounds o n the regret a re pro p or tional to a t least √ T . In fact, the links b etw een o ur work and this ar ticle are not in the statements of the results proved but rather in the techn iques used in the pr o ofs. 6.3. Pr o of of L emma 2 Proof. In view of the co mmen ts befor e the statement of Lemma 2, we need only to prove that an explo rable fa mily F is also explora ble–exploitable. W e 23 consider a pa ir of allo c a tion ( ϕ t ) and r ecommendation ( ψ t ) stra tegies such that for all en vir onment s E ∈ F , the simple regre t sa tis fy E r n = o (1), and provide a new strategy ( ϕ ′ t ) such that its cumulativ e reg ret satisfies E R ′ n = o ( n ) for a ll environmen ts E ∈ F . It is defined informally a s follows. At round t = 1, it uses ϕ ′ 1 = ϕ 1 and g e ts a r eward Y 1 . B ased o n this r e w ar d, the recommendatio n ψ 1 ( Y 1 ) is formed a nd at r ound t = 2 , the new strategy plays ϕ ′ 2 ( Y 1 ) = ψ 1 ( Y 1 ). It gets a reward Y 2 but do es no t ta ke it into acco unt . It bas es its choice ϕ ′ 3 ( Y 1 , Y 2 ) = ϕ 2 ( Y 1 ) only o n Y 1 and gets a r eward Y 3 . Based on Y 1 and Y 3 , the recommendation ψ 2 ( Y 1 , Y 3 ) is formed and play ed at r ounds t = 4 a nd t = 5, i.e., ϕ ′ 4 ( Y 1 , Y 2 , Y 3 ) = ϕ ′ 5 ( Y 1 , Y 2 , Y 3 , Y 4 ) = ψ 2 ( Y 1 , Y 3 ) . And s o on: the sequence of distributions c hos en by the new strategy is formed using the applications ϕ 1 , ψ 1 , ϕ 2 , ψ 2 , ψ 2 , ϕ 3 , ψ 3 , ψ 3 , ψ 3 , ϕ 4 , ψ 4 , ψ 4 , ψ 4 , ψ 4 , ϕ 5 , ψ 5 , ψ 5 , ψ 5 , ψ 5 , ψ 5 , . . . F ormally , we consider r egimes indexed by integers t > 1 and of length 1 + t . The t –th r egime starts at round 1 + t − 1 X s =1 (1 + s ) = t + t ( t − 1) 2 = t ( t + 1) 2 . During this regime, the fo llowing distributions are used, ϕ ′ t ( t +1) / 2+ k = ϕ t Y s ( s +1) / 2 s =1 ,...,t − 1 if k = 0; ψ t Y s ( s +1) / 2 s =1 ,...,t − 1 if 1 6 k 6 t . Note that we only k eep tr ack of the pay offs o btained when k = 0 in a regime. The re g ret R ′ n at round n of this strategy is as follows. W e decomp ose n in a unique manner as n = t ( n ) t ( n ) + 1 2 + k ( n ) where k ( n ) ∈ 0 , . . . , t ( n ) . (5) Then (using a lso the to wer r ule ), E R ′ n 6 t ( n ) + E r 1 + 2 E r 2 + . . . + t ( n ) − 1 E r t ( n ) − 1 + k ( n ) E r t ( n ) 24 where the first ter m comes from the time ro unds when the new strateg y used the ba se allo ca tion strategy to explo re and wher e the other terms come from the ones when it exploited. This inequality can b e rewritten as E R ′ n n 6 t ( n ) n + k ( n ) E r t ( n ) + P t ( n ) − 1 s =1 s E r s n , which shows that E R ′ n = o ( n ) whenever E r s = o (1) as s → ∞ , since the first term in the right-hand side is of the or der of 1 / √ n and the s e cond one is a Ce saro av era g e. This concludes that the ex hibited strateg y has a small cum ulative regret for all environments of the family , which is th us ex plorable– exploitable. 6.4. Pr o of of The or em 4 and its c or ol lary The key ingredient is the following characterization of separ ability (which relies on an application of Zorn’s lemma); see, e.g., [5, Appe ndix I, pa ge 216 ]. Lemma 3 . A metric sp ac e X , with distanc e denote d by d , is sep ar able if and only if it c ontains no unc ountable subset A such that ρ = inf d ( x, y ) : x, y ∈ A > 0 . Separability can then b e characterized in ter ms of the existence o f a prob- ability distr ibution with full supp or t. Thoug h it seems natural, we did not see any reference to it in the literature and this is why we state it. (In the pro o f of Theorem 4, we will only use the str a ightforw ard direct part of the characteriza- tion.) Lemma 4 . L et X b e a m etric sp ac e. Ther e exists a pr ob ability distribution λ on X with λ ( V ) > 0 for al l op en sets V if and only if X is sep ar able. Proof. W e prov e the conv erse implication first. If X is separable, we denote by x 1 , x 2 , . . . a dense sequence. If it is finite w ith length N , w e let λ = 1 N N X i =1 δ x i and otherwise, λ = X i > 1 1 2 i δ x i . The result follows, since ea ch op en set V contains at least some x i . F or the direct implication, we use Lemma 3 (and its notations). If X is not sepa r able, then it co n tains uncountably many disjo int o pen balls, formed by the B ( a, ρ/ 2), for a ∈ A . If there existed a proba bilit y distribution λ with full supp ort o n X , it would in pa r ticular give a p ositive probability to all these balls; but this is imp os s ible, since ther e are unco un tably man y o f them. 25 6.4.1. Sep ar ability of X implies explor ability of the family C P ([0 , 1 ]) X The pro of of the conv er s e part of the characterization provided by Theor em 4 relies o n a somewha t uniform explor ation that hits each op e n set o f X after a random waiting time w ith distribution dep ending on the probability of the op en set. Proof. Since X is s e pa rable, there exists a probability distribution λ o n X with λ ( V ) > 0 for a ll op en sets V , as asser ted by Le mma 4. The pro p os ed stra tegy is then construc ted in a w ay simila r to the one ex- hibited in Section App endix A.2, in the sense that we also consider succes sives regimes, wher e the t –th of them has a lso length 1 + t . They use the following allo cations, ϕ t ( t +1) / 2+ k = λ if k = 0; δ I k ( k +1) / 2 if 1 6 k 6 t . Put in words, at the b eginning o f each reg ime, a new p oint I t ( t +1) / 2 is drawn at random in X acc ording to λ , and then, a ll previously dr awn po in ts I s ( s +1) / 2 , for 1 6 s 6 t − 1, and the new p oint I t ( t +1) / 2 are pulled again, one after the other. The re c o mmendations ψ n are deterministic and put a ll probability mass on the b est empirical a rm among the first play ed g ( n ) arms (where the function g will b e determined by the analysis). F o rmally , for all x ∈ X such that T n ( x ) = n X t =1 I { I t = x } > 1 , one defines b µ n ( x ) = 1 T n ( x ) n X t =1 Y t I { I t = x } . Then, ψ n = δ X ∗ n where X ∗ n ∈ arg max 1 6 s 6 g ( n ) b µ n I s ( s +1) / 2 (ties broken in some w ay , a s usua l; and g ( n ) to be chosen small enough so that all co nsidered arms hav e b een play ed at least once). Note that explo ration a nd exploitation appe a r in tw o distinct phases, as was the cas e a lr eady , for ins tance, in Section 4 .1. W e now denote µ ∗ = sup x ∈X µ ( x ) and µ ∗ g ( n ) = max 1 6 s 6 g ( n ) µ I s ( s +1) / 2 ; the simple r egret can then b e decomp osed as E r n = µ ∗ − E h µ X ∗ n i = µ ∗ − E h µ ∗ g ( n ) i + E h µ ∗ g ( n ) i − E h µ X ∗ n i , 26 where the first difference c a n b e thought of as an appr oximation erro r, and the second one, as resulting from an es timation err or. W e now show that b oth differences v anish in the limit. W e first deal with the appr oximation error . W e fix ε > 0. Since the mean- pay off function µ is contin uous on X , there ex ists an op en set V such that ∀ x ∈ V , µ ∗ − µ ( x ) 6 ε . It follows that P n µ ∗ − µ ∗ g ( n ) > ε o 6 P n ∀ s ∈ 1 , . . . , g ( n ) , I s ( s +1) / 2 6∈ V o 6 1 − λ ( V ) g ( n ) − → 0 provided that g ( n ) → ∞ (a condition that will be s atisfied, see below). Since in addition, µ ∗ g ( n ) 6 µ ∗ , we g et lim sup µ ∗ − E h µ ∗ g ( n ) i 6 ε . F or the difference r esulting from the estimation erro r, we denote I ∗ n ∈ arg max 1 6 s 6 g ( n ) µ I s ( s +1) / 2 (ties broken in some wa y). Fix an arbitrar y ε > 0. W e note that if for a ll 1 6 s 6 g ( n ), b µ n I s ( s +1) / 2 − µ I s ( s +1) / 2 6 ε , then (together with the definitio n of X ∗ n ) µ X ∗ n > b µ n X ∗ n − ε > b µ n I ∗ n − ε > µ I ∗ n − 2 ε . Thu s, w e have prov ed the inequalit y E h µ ∗ g ( n ) i − E h µ X ∗ n i 6 2 ε + P ∃ s 6 g ( n ) , b µ n I s ( s +1) / 2 − µ I s ( s +1) / 2 > ε . (6) W e use a union b ound and control each (conditional) probability P b µ n I s ( s +1) / 2 − µ I s ( s +1) / 2 > ε A n (7) for 1 6 s 6 g ( n ), where A n is the σ –algebr a g enerated by the r andomly drawn po in ts I k ( k +1) / 2 , for thos e k with k ( k + 1) / 2 6 n . Conditionally to them, b µ n I s ( s +1) / 2 is an average o f a deterministic num ber of summands, which only depe nds on s , and thus, cla s sical concentration-of-the-measure ar guments can be used. F or instance, the quantities (7) ar e b ounded, via a n applicatio n of Ho effding’s inequality [11], by 2 exp − 2 T n I s ( s +1) / 2 ε 2 . 27 W e lower bo und T n I s ( s +1) / 2 . The p oint I s ( s +1) / 2 was pulled t wice in r egime s , once in each regime s + 1 , . . . , t ( n ) − 1, and mayb e in t ( n ), wher e n is decomp osed again as in (5). That is , T n I s ( s +1) / 2 > t ( n ) − s + 1 > √ 2 n − 1 − g ( n ) , since we only consider s 6 g ( n ) a nd since (5 ) implies that n 6 t ( n ) t ( n ) + 3 2 6 t ( n ) + 2 2 2 , that is, t ( n ) > √ 2 n − 2 . Substituting this in the Ho effding’s b ound, integrating, and taking a union bo und lead fr o m (6) to E h µ ∗ g ( n ) i − E h µ X ∗ n i 6 2 ε + 2 g ( n ) ex p − 2 √ 2 n − 1 − g ( n ) ε 2 . Cho osing for instance g ( n ) = √ n/ 2 ensures tha t lim sup E h µ ∗ g ( n ) i − E h µ X ∗ n i 6 2 ε . Summing up the tw o sup erior limits, we fina lly get lim sup E r n 6 lim sup µ ∗ − E h µ ∗ g ( n ) i + lim sup E h µ ∗ g ( n ) i − E h µ X ∗ n i 6 3 ε ; since this is true for all arbitra ry ε > 0, the pro of is co ncluded. 6.4.2. Explor ability of the family C P ([0 , 1 ]) X implies sep ar abi lity of X W e now prove the direct par t of the c harac ter ization provided by Theore m 4. It basica lly follows from the imp ossibility of a uniform explor ation, as a sserted by Lemma 4. Proof. Let X be a non-s e pa rable metric space with metric denoted b y d . Let A b e an arbitrar y uncountable subset of X a nd let ρ > 0 be defined as in Lemma 3; in particular, the balls B ( a, ρ/ 2) ar e disjoint, for a ∈ A . W e now consider the subset of C P ([0 , 1 ]) X formed by the environment s E a defined as follows. They ar e index ed by a ∈ A and their c orresp onding mean-pay off functions a re g iven by µ a : x ∈ X 7− → 1 − d ( x, a ) ρ/ 2 + . The ass o ciated environments E a are deterministic, in the sense that they ar e defined as E a ( x ) = δ µ a ( x ) . Note that ea ch µ a is contin uous, that µ a ( x ) > 0 for all x ∈ B ( a, ρ/ 2) but µ a ( x ) = 0 for all x ∈ X \ B ( a, ρ/ 2); that the b est arm under E a is a and that its g ets a reward equal to µ ∗ a = µ a ( a ) = 1. 28 W e fix a forecaster and denote by E a the exp ectation under environmen t E a with resp ect with the auxiliary randomizations used by the for ecaster. Since µ a v anishes outside B ( a, ρ/ 2) and has a maximum equal to 1 , E a r n = 1 − E a Z X µ a ( x ) d ψ n ( x ) > 1 − E a h ψ n B ( a, ρ/ 2) i . W e now show the existence of a non-empty s et A ′ such that for all a ∈ A ′ and n > 1, E a h ψ n B ( a, ρ/ 2) i = 0 ; (8) this indica tes that E a r n = 1 for all n > 1 and a ∈ A ′ , thus preven ting in particular C P ([0 , 1 ]) X from b eing explorable by the fixed foreca ster. The set A ′ is constructed b y studying the b ehavior of the for ecaster under the environmen t E 0 yielding deterministic null r ewards througho ut the s pace, i.e., asso cia ted with the mean-payoff function x ∈ X 7→ µ 0 ( x ) = 0. In the first round, the forecaster c ho oses a deter ministic distribution ϕ 1 = ϕ 0 1 ov er X , picks I 1 at ra ndom according to ϕ 0 1 , g ets a deter ministic pay off Y 1 = 0 , a nd finally recommends ψ 0 1 ( I 1 ) = ψ 1 ( I 1 , Y 1 ) (which dep ends on I 1 only , since the obtained pay offs are all null in a deterministic wa y). In the second round, it chooses an allo catio n ψ 0 2 ( I 1 ) (that depends only on I 1 , for the same reasons as befor e), picks I 2 at ra ndom acco rding to ψ 0 2 ( I 1 ), gets a null reward, and recommends ψ 0 2 ( I 1 , I 2 ); and so on. W e denote by A the probability distribution giving the auxiliary randomiza - tions used to draw the I t at r andom, and for a ll int ege rs t and all mea surable applications ν : ( x 1 , . . . , x t ) ∈ X t 7− → ν ( x 1 , . . . , x t ) ∈ P ( X ) we in tro duce the distributions A · ν ∈ P ( X ) defined as the following mixture o f distributions. F or a ll measur able s ets V ⊆ X , A · ν ( V ) = E A Z X I V d ν ( I 1 , . . . , I t ) . A probability distribution can only put a p ositive mass on an at most countable nu mber of disjoint sets. Therefore, let B n and C n be defined as the at most countable s e ts of a such that, resp ectively , A · ϕ 0 n and A · ψ 0 n give a p ositive probability mass to B ( a, ρ/ 2). Then, let A ′ = A \ [ n > 1 B n ∪ [ n > 1 C n be the uncountable, thus non empty , set o f those elements of A which are in no B n or C n . By co ns truction, for all a ∈ A ′ , the foreca ster only ge ts null rewards; this is beca use a is in no B n and therefore, with pr obability 1, none of the ϕ 0 n hits 29 B ( a, ρ/ 2), which is exactly the set of those elemen ts of X for which µ a > 0. As a conseq ue nc e , the forecas ter behaves simila rly under the e nvironments E a and E 0 , which means that for all mea surable sets V ⊆ X and all n > 1, E a ϕ n ( V ) = A · ϕ 0 n ( V ) and E a ψ n ( V ) = A · ψ 0 n ( V ) . In particular, s ince a is in no C n , it hits in no recommendatio n ψ 0 n the ba ll B ( a, ρ/ 2), which is exactly what rema ined to b e prov ed, see (8). 6.4.3. The c ountable c ase of Cor ol lary 4 W e adopt an “` a la Bourbaki” approach and derive this sp ecial case fro m the general theory . Proof. W e endow X with the dis c rete top ology , i.e., cho o se the distance d ( x, y ) = I { x 6 = y } . Then, all applications defined on X ar e contin uous; in particular, C P ([0 , 1 ]) X = P ([0 , 1]) X . In addition, X is then separ able if and only if it is countable. T he result thus follows immediately from Theorem 4 . 6.5. An additional re mark ab out u n iform b ounds In this pap er, w e mostly consider non-uniform b ounds (bo unds that are individual as far as the en vir onments are conc e r ned). As for uniform b ounds, i.e., b ounds o n quantities o f the form sup E ∈F E R n or sup E ∈F E r n for some family F , tw o o bserv ations c an b e made. First, it is ea sy to see that no sublinea r uniform bound can b e obtained for the family of all co n tinuous environmen ts, as s o o n as there exis ts infinitely man y disjoint op en ba lls. How ever one ca n exhibit such sublinear uniform b ounds in so me sp ecific scenarios ; for instance, when X is totally b ounded and F is formed by contin uous functions with a common b ounded Lipschitz constant. Ac kno wledge m en ts The author s a ckno wledge supp ort b y the F rench National Research Agency (ANR) under gra n ts 08- COSI-004 “ Explora tion–exploitation for efficient re- source allo c a tion” (EXPLO/ RA) and JCJC 0 6-137 444 “F rom applications to theory in lear ning and adaptive sta tistics” (A TLAS), as well as by the P ASCAL Net work o f Exce lle nce under EC gr ant no. 5 06778 . An ex tended abstract of the present pa per app eared in the Pr o c e e dings of the 20th International Confer enc e on Algori thmic L e arning The ory (AL T’09 ). 30 App endix A. App endi x App endix A .1. Pr o of of the se c ond statement of Pr op osition 1 W e use b elow the no tations introduced in the pr o of of the first s tatemen t of Prop osition 1. Proof. Since some reg ret is suffered only when an a rm with sub optimal ex- pec tation has the bes t empirical perfo rmance, E r n 6 max i =1 ,...,K ∆ i P max i :∆ i > 0 b µ i,n > b µ i ∗ ,n . Now, the q ua n tity o f interest ca n be rewritten a s j n K k max i :∆ i > 0 b µ i,n − b µ i ∗ ,n = f ~ X 1 , . . . , ~ X ⌊ n/K ⌋ for some function f , where for all s = 1 , . . . , ⌊ n/K ⌋ , we denote by ~ X s the v ector ( X 1 ,s , . . . , X K,s ). (The function f is defined as a max imum of at mos t K − 1 sums of differences.) W e apply the metho d of b ounded differ ences, see [18], s e e also [8, Chapter 2 ]. It is straightforward that, s ince all random v ariables of int ere st take v alues in [0 , 1 ], the b ounded differe nc e s co ndition is satisfied with ranges all equal to 2. There fore, the indicated co ncentration inequality states that P max i :∆ i > 0 b µ i,n − b µ i ∗ ,n − E max i :∆ i > 0 b µ i,n − b µ i ∗ ,n > ε 6 exp − 2 ⌊ n/K ⌋ ε 2 4 for all ε > 0. W e c ho os e ε = − E max i :∆ i > 0 b µ i,n − b µ i ∗ ,n > min i :∆ i > 0 ∆ i − E max i :∆ i > 0 b µ i,n − b µ i ∗ ,n + ∆ i (where we used that the maximum of K first quantities plus the minim um of K other quantities is les s than the ma xim um o f the K sums). W e now argue that E max i :∆ i > 0 b µ i,n − b µ i ∗ ,n + ∆ i 6 s ln K ⌊ n/K ⌋ ; this is done by a classica l ar gument, using bounds o n the moment generating function of the random v ariables o f int er est. Consider Z i = ⌊ n/K ⌋ b µ i,n − b µ i ∗ ,n + ∆ i for all i = 1 , . . . , K ; they cor r esp ond to cen tered sums of 2 ⌊ n/K ⌋ indep endent random v ariables tak ing v alues in [0 , 1] o r [ − 1 , 0]. Ho effding’s lemma (see, e.g ., [8, Chapter 2 ]) thus imply that for all λ > 0, E e λZ i 6 exp 1 8 λ 2 2 ⌊ n/K ⌋ = exp 1 4 λ 2 ⌊ n/K ⌋ . 31 A well-known inequa lit y for maxima of subg aussian ra ndom v ariables (see [8, Chapter 2]) then yields E max i =1 ,...,K Z i 6 p ⌊ n/K ⌋ ln K , which leads to the claimed upp er b ound. Putting things together, we get that for the c hoice ε = − E max i :∆ i > 0 b µ i,n − b µ i ∗ ,n > min i :∆ i > 0 ∆ i − s ln K ⌊ n/K ⌋ > 0 (for n sufficien tly la rge, a s tatement made pr ecise b elow), we have P max i :∆ i > 0 b µ i,n > b µ i ∗ ,n 6 exp − 2 ⌊ n/K ⌋ ε 2 4 6 exp − 1 2 j n K k min i :∆ i > 0 ∆ i − s ln K ⌊ n/K ⌋ ! 2 . The result follows for n such that min i :∆ i > 0 ∆ i − s ln K ⌊ n/K ⌋ > (1 − η ) min i :∆ i > 0 ∆ i ; the seco nd part of the statement of P rop osition 1 indeed only conside r s such n . App endix A .2. Detaile d discussion of the heuristic ar guments pr esente d in Se c- tion 5 W e firs t state the following co r ollary to Lemma 1. Theorem 5 . The al lo c ation st ra te gy given by UCB ( α ) (wher e α > 1 ) asso ciate d with the r e c ommendatio n given by the most playe d arm ensu r es t hat E r n 6 1 α − 1 X i 6 = i ∗ β n ∆ 2 i − 1 2(1 − α ) for al l n sufficiently lar ge, e.g., such that n ln n > 4 α + 1 β and n > K + 2 β (∆ ′ ) 2 , wher e ∆ ′ = max i ∆ i and we denote by K ∗ the numb er of optimal arms and β = 1 K ∗ ∆ 2 + X i 6 = i ∗ 1 ∆ 2 i . 32 Proof. W e apply Lemma 1 with the c hoice a i = β / ∆ 2 i for all sub o ptimal arms i and a i ∗ = β / ∆ 2 for all optimal a rms i ∗ , where β de no tes the nor ma lization constant. F or illustration, consider the cas e when there is one optimal arm, one ∆– sub o ptimal arm a nd K − 2 arms that ar e 2∆–sub optimal. Then 1 β = 2 ∆ 2 + K − 2 (2∆) 2 = 6 + K 4∆ 2 , and the pr evious b ound of The o rem 5 implies that E r n 6 1 α − 1 4 n 6 + K − 1 2(1 − α ) + K − 2 α − 1 n 6 + K − 1 2(1 − α ) (A.1) for all n sufficiently lar ge, e.g ., n > max ( K + 2)(6 + K ) , (4 α + 1) 6 + K 4∆ 2 ln n . (A.2) Now, the upp er b ound on E r n given in Prop osition 1 for the uniform a llo cation asso ciated with the recommenda tion pr ovided b y the e mpir ical b est a rm is larger than ∆ e − ∆ 2 ⌊ n/K ⌋ , for all n > K. Thu s for n mo der ately la rge, e.g., suc h that n > K and ⌊ n/K ⌋ 6 (4 α + 1) 6 + K 4∆ 2 ln n K , (A.3) the b ound for the unifor m allo cation is a t least ∆ exp − ∆ 2 (4 α + 1) 6 + K 4∆ 2 ln n K = ∆ n − (4 α +1)(6+ K ) / 4 K , which may b e muc h worse than the upper b ound (A.1) for the UCB( α ) s tr ategy whenever K is la r ge, as ca n b e seen by compa ring the exp onents − 2( α − 1) versus − (4 α + 1 )(6 + K ) / 4 K . The reaso n is that the unifor m allo cation strategy only samples ⌊ n/ K ⌋ each arm, whe r eas the UCB strategy fo cuses r apidly its explor a tion on the b etter arms. References [1] J.-Y. Audiber t, R. Munos, and C. Szep esv´ ari. Exploration-e xploitation trade-off using v ariance estimates in multi-armed bandits. The or etic al Com- puter Scienc e , 41 0:1876 –1902 , 2009 . [2] J.-Y. Audibert, S. Bub eck, a nd R. Munos. Best ar m identification in mult i- armed bandits. In Pr o c e e dings of the 23r d Annual Confer enc e on L e arning The ory (COL T) , 2 010. 33 [3] P . Auer, N. Cesa-Bia nchi, and P . Fischer. Finite-time analysis o f the m ulti- armed bandit problem. Machine L e arning Journal , 47(2-3 ):2 35–25 6, 2002. [4] P . Auer, N. Cesa- Bianchi, Y. F reund, a nd R. Schapire. The non-s to chastic m ulti-ar med bandit pro ble m. SIAM J ournal on Computing , 32(1):4 8–77, 2002. [5] P . Billingsle y . Conver genc e of Pr ob ability Me asur es . Wiley and Sons, 1968 . [6] S. Bub eck, R. Munos, G. Stoltz, a nd C. Szep e s v´ ari. Online optimization in X –armed bandits. In Pr o c e e dings of t he 23r d A dvanc es on Neur al In for- mation Pr o c essing Systems (NIPS) , pages 201–2 0 8, 2009. [7] P .-A. Co quelin and R. Munos. Ba ndit algorithms for tree search. In Pr o- c e e dings of the 23r d Confer enc e on Unc ertainty in Artificial In tel ligenc e (UAI) , pag e s 67–7 4, 200 7 . [8] L. Devroye and G. Lugosi. Combinatorial Metho ds in Density Estimation . Springer, 2 001. [9] E. Even-Dar, S. Mannor , and Y. Mans o ur. P AC b ounds for multi-armed bandit and Marko v decision pro ce sses. In Pr o c e e dings of the 15th A nnu al Confer enc e on Computational L e arning The ory (COL T) , pages 255 – 270, 2002. [10] S. Gelly , Y. W ang, R. Muno s, and O . T eytaud. Mo dification of UCT with patterns in Mo nte-Carlo go . T echnical Rep ort RR-60 62, INRIA, 200 6. [11] W. Ho effding. Pro bability inequa lities for sums of bo unded random v ari- ables. Journal of the Americ an Statistic al Asso ciatio n , 58:13 –30, 1 9 63. [12] R. Kleinberg. Nea rly tight b ounds for the contin uum-armed bandit prob- lem. In Pr o c e e dings of the 18th A dvanc es on Neur al Information Pr o c essing Systems (NIPS) , pages 697–7 04, 20 04. [13] R. Kleinber g and A. Slivkins. Sharp dic hotomies for r egret minimization in metric s paces. In Pr o c e e dings of the ACM–SIAM S ymp osium on Discr ete Algo rithms (SODA) , pag e s 827– 846, 201 0 . [14] L. Ko csis and C. Szepesv ari. Bandit bas ed Monte-Carlo planning. In Pr o- c e e dings of the 15th Eu ro p e an Confer enc e on Machine L e arning (ECML) , pages 2 8 2–293 , 2006. [15] T.L . La i a nd H. Robbins. Asy mpto tica lly e fficien t adaptive allo catio n rules. A dvanc es in Applie d Mathematics , 6:4–22 , 1985 . [16] O . Madani, D. Lizotte, and R. Greiner . The budgeted multi-armed bandit problem. In Pr o c e e dings of the 17th Annual Confer enc e on Computational L e arning The ory (COL T) , pag es 643 –645, 20 0 4. Op en pr oblems sessio n. 34 [17] S. Mannor and J .N. Tsitsiklis. The s ample complexity of explo ration in the m ulti-ar med bandit problem. Journal of Machine L e arning R ese ar ch , 5:623– 648, 200 4. [18] C. McDiarmid. On the metho d of b ounded differences. In J . Siemo ns, editor, Surveys in Combinatorics , pages 1 48–18 8. London Mathematical So ciety Lectur e Note, Ser ies 1 4 1, 198 9. [19] H. Robbins. Some asp e c ts of the sequential design of experiments. Bul letin of the Americ an Mathematics So ciety , 58:52 7–535 , 1952. [20] K . Schlag. Eleven tests needed for a recommendation. T echnical Repo rt ECO200 6/2, Euro pea n Universit y Institute, 2006. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment