Comment: The Essential Role of Pair Matching
Comment on "The Essential Role of Pair Matching in Cluster-Randomized Experiments, with Application to the Mexican Universal Health Insurance Evaluation" [arXiv:0910.3752]
Authors: Jennifer Hill, Marc Scott
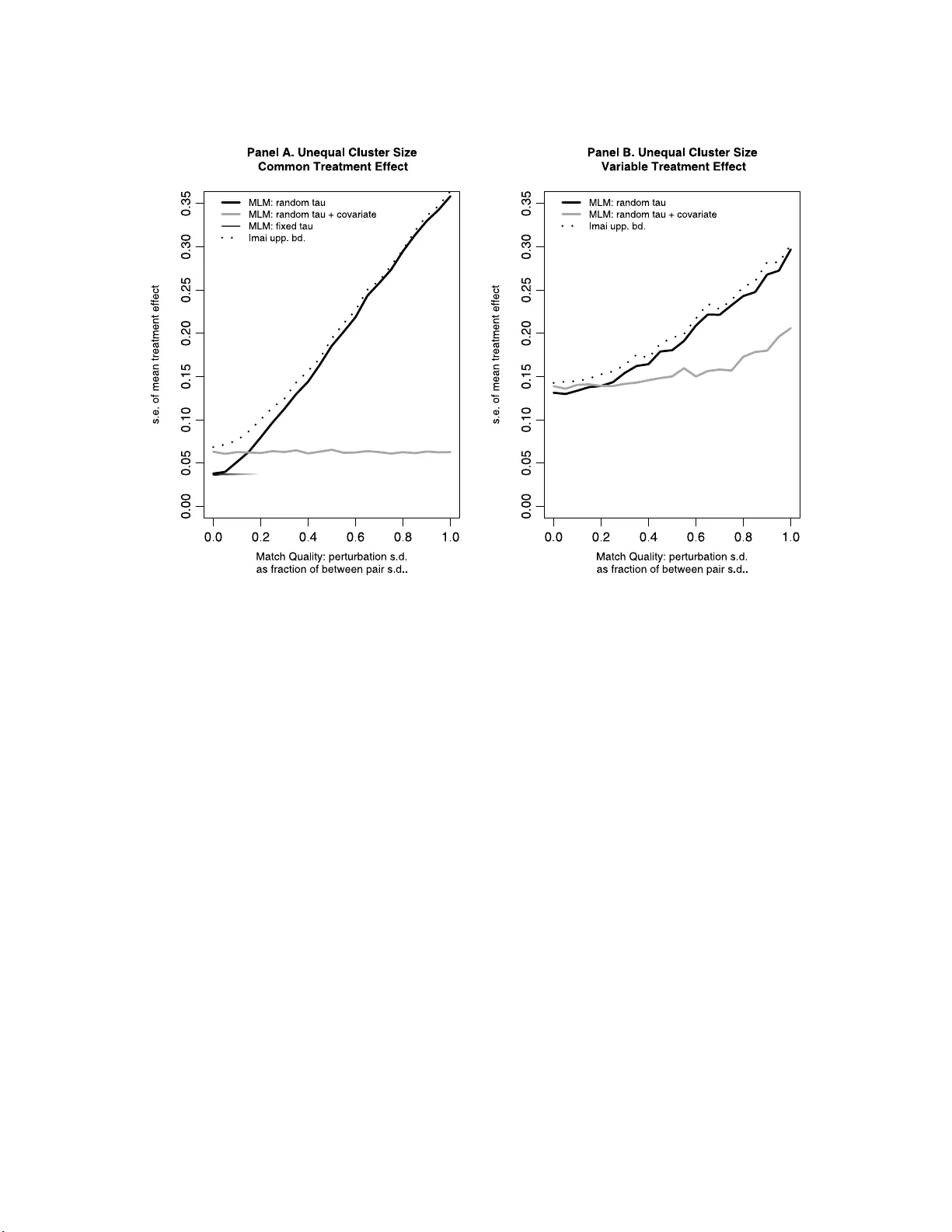
Statistic al Scienc e 2009, V ol. 24, No. 1, 54–5 8 DOI: 10.1214 /09-STS274A Main article DO I: 10.1214/09-STS274 c Institute of Mathematical Statisti cs , 2009 Comment: The Essential Role o f P air Matching Jennifer Hill and Ma rc Scott 1. INTRODUCTION W e a pp reciate ha ving the opp ortun it y to com- men t on the w ell-motiv ated, h ighly informativ e and carefully co nstru cted a rticle b y Imai, King and Nall (IKN). T here has b een a great deal of confusion o ver the y ears ab out the issue of pair-matc h ing, often due to a conflation of the implications of d esign ve rsu s analysis choice . Th is article sheds light on the de- bate and offers a set of h elpful alternativ e analysis c h oices. Our discussion d o es not tak e issue with IKN’s pro v o cativ e assertion that one should pair-matc h in cluster randomized trials “whenever feasible.” In- stead w e will exp lore the trade-offs b et wee n usin g the inf er ential fr amew ork ad vocated b y IKN versus fitting fairly standard multilev el mo dels (see, for in- stance, Gelman and Hill, 2007 ). The I K N design-based treatment effect estimators ha v e the adv antag e of b eing sim p le to calculate and ha ving b etter statistical prop erties in general than the harmonic mean estimator that IKN view to b e the most standard estimator in this setting. V ari- ance estimators for S A TE and CA TE are not iden- tified, bu t that is a fun ction of not m aking the as- sumption of constant treatmen t effects, which w e find realistic. IKN d o pro vide up p er b ound v ariance estimators for these quan tities of inte rest. Perhaps the biggest dr awbac k to these m etho ds is that they are not flexible if it is n ecessary or h elpful to extend the framew ork to accommo date add itional compli- cations or information. Jennifer Hil l and Mar c S c ott ar e Asso ciate Pr ofessors of Applie d S tatistics, Dep artmen t of Humanities and So cial S cienc es, Steinhar dt Scho ol of Cultur e, Educ ation and Human Development, New Y ork University, 246 Gr e ene St., R o om 300, New Y ork, New Y ork 10003, USA e-mail: jennifer.hil l@nyu.e du ; mar c.sc ott@n yu.e du . This is a n electronic r eprint of the or iginal article published by the Institute of Mathematical Statistics in Statistic al S cienc e , 2 009, V o l. 24 , No . 1, 5 4–58 . This reprint differs from the original in pagination and t yp ogr aphic detail. The strength of m ultilev el mo d els in this estima- tion setting is the fl exibilit y to build in complex- it y th at could pro vide us with additional inf orma- tion, incr ease our p recision, or sometimes even re- duce bias (for instance, when correcting for “b r o- k en” randomization). As an example, w hile the IKN v ariance estimato rs accommo date v arying treatmen t effects, the m ultilev el mo del pro vides a framew ork to actually examine these p air-to-pair differences. The mo del can also b e extended to allo w treatmen t ef- fects to v ary o ver co v ariate-defined subgroups which has the p otent ial to substanti ally increase our un - derstanding of effect transmission. Cond itioning on pre-treatmen t co v ariates can also help to increase precision (and ev en redu ce bias in situations where the rand omization has b een less pristine). Moreo ver, not only can m ultilev el mo dels in clud e co v ariates and random treatmen t effects quite r eadily , but the need for su c h terms can b e ev aluated statistically . A further example is th e abilit y of m o dels to ac- commo date m issing d ata at the individual lev el (rather than en tire clusters b eing missing due to group-leve l noncompliance or attrition whic h IKN addr ess). This can b e naturally in corp orated in to a mo del-based framew ork as we ll; it’s unclear ho w the IKN f rame- w ork would handle this complication. Of cours e, these adv an tages come at the cost of making some mo deling assu mptions. IKN go so f ar as to claim that these approac hes “violate th e v ery purp ose of exp erimen tal work wh ic h go es to great lengths and exp ense to a v oid these t yp es of assump - tions.” Ho w ev er, the primary purp ose of exp erimen- tal work is to av oid the u ntestable assumption of ignorabilit y (or strong ignorabilit y) that is so dif- ficult to a void in observ ational w ork. While it is true th at we do not n eed to build mo dels p ost- randomization in order to estimate treatmen t ef- fects, this can hardly b e view ed as th e goal of ran- domized exp erimen ts. In fact, r an d omization actu- ally incr eases robustness to mo d el-missp ecification, creating a safer climate within w hic h to build mo dels than wo uld otherwise exist. Moreo ve r, the paramet- ric assumptions w e make with a multile ve l mo del 1 2 J. HILL AND M. SCOTT are testable, for ins tance, using graphical regression diagnostics. It could b e argued that multile ve l mo dels hav e the d isadv ant age of b eing more complicated to fit. Ho wev er with the capabilities of cu rrent standard statistica l soft wa re the lev el of tec hnical exp ertise required to fit su c h m o dels is w ell within the reac h of most app lied researc hers to da y . 2. SIMPLE MUL TIL EVEL MODELS FOR ESTIMA TING TREA TMENT EFF ECTS First w e la y out a few simp le multile ve l mo dels for estimating treatmen t effects in th e setting of a pair- matc h ed cluster-randomized exp eriment. C learly w e ha v e not exhausted all p ossibilities, b ut the mo dels w e discuss ha v e the adv anta ge of b eing relativ ely simple, easily fit with standard soft ware, and readily expandable to m ore complex settings. A ve ry simple mo del for observ ation i in cluster j and pair k is Y ij k = τ T j k + α k + ε ij k , (1) with a common treatmen t effect, τ , as w ell as v ary- ing intercepts α k , wh ere α k ∼ N ( α 0 , σ 2 α ). T j k is a treatmen t indicator, an d j ∈ { 1 , 2 } while k ∈ { 1 , 2 , . . . , K } . As is common in m ultilev el mo dels of this sort, th e random terms are assumed indep enden t of the pr edictors, an assum ption which is particularly defensible in the con text of a rand omized exp eri- men t, and ε ij k ∼ N (0 , σ 2 ε ). A simple adj ustment , allo wing τ to v ary by pair, yields a m o del for h eterogeneous treatmen t effects: Y ij k = τ k T j k + α k + ε ij k , (2) with τ k ∼ N ( τ 0 , σ 2 τ ). W e t y p ically do n ot wan t to assume that α k and τ k are indep enden t, therefore there is a co v ariance term in the mo del, σ ατ , and the pair ( α k , τ k ) are assumed b iv ariate normal. A word of caution is wa rranted with regard to the τ k . These parameters cannot b e interpreted causally except in the sp ecial case in wh ic h we know that clusters h a v e b een p erfectly matc h ed on their p o- ten tial outcomes (w h ic h is imp laus ib le in practice). Otherwise, we cannot separately ident ify v ariation caused b y within-pair cluster mismatc h f rom v ari- ation that is d ue to treatmen t effects that actually v ary across p airs. Nonetheless, allo wing τ to v ary is imp ortant b ecause it allo ws us to test for this extra source of heterogeneit y (whatev er th e true s ource of the heterogeneit y). T o the extent that w e can sat- isfy ourselv es that w e ha ve indeed obtained close matc h es (mostly lik ely after ha ving also conditioned on some highly pr edictiv e pre-treatmen t v ariables), w e can mo v e to wa rd a causal in terpretation of these quan tities. Ho w ev er, if our goal is to explore treat- men t effect mo deration, w e’re probably b etter off doing so by (additionally) allo wing the treatment effects to v ary by co v ariate level s. W e can augment either of these mo dels by includ- ing cluster-lev el co v ariates, X j . Th is is particularly helpful wh en w e are un able to p erfectly matc h clus- ters. Here we fo cus on inclusion of co v ariates p urely for increasing precision (not to explore treatment effect mo d eration). In this case we add a cluster- sp ecific leve l to th e mo d el, as in Y ij k = τ k T j k + φ j k + ε ij k , (3) φ j k = X j k β + α k , where φ j k captures cluster-sp ecific v ariation that de- p end s on b oth X j k and our v aryin g pair interce pts, α k . 3. EXAMINING T HE IMPLICA TIONS OF IMPERFECT MA TCHING AND TR EA TMENT EFFECT HETEROGENEITY W e explore the implications of imp erf ect matc hing and th e presence of treatmen t effect heterogeneit y through a small set of simulat ions. Our pr imary sim- ulations v ary the f ollo wing comp onents: (i) cluster size p erfectly or imp erfectly m atc hed , (ii) cluster- sp ecific SA T E p erfectly or imp erfectly matc hed and (iii) treatment effect fixed or v aryin g. Simulations are rep eated 100 times f or eac h s cenario. The d ata generated in eac h sim ulation are fit u sing the tw o multilev el m o dels laid out in equations ( 1 ) and ( 2 ) ab o ve (w e’ll refer to them as MLM1 and MLM2, for the constant and v aryin g treatment ef- fect mo dels, resp ectiv ely). T o represent an analy- sis option that w ould b e easy to us e b y an applied researc h er we fi t the m ultilev el mo dels using the lmer command (pac k age is lme4 ) in R (R Dev elop- men t Core T eam, 2008 ; v ery similar pack ages exist in S tata, S AS and SPSS , among others) and used th e standard estimates. In theory , ho we ve r, one could fit these mo dels using a more flexible pac k age suc h as BUGS or JAG S in whic h case it would b e triv- ial to r ew eigh t the τ k in order to mak e in ferences ab out any of a w ide range of d ifferen t quantit ies of in terest. F or comparison purp oses we fi t the IKN SA TE estimator (to mir ror the multilev el mo d el’s COMMENT 3 implicit we igh ting sc heme by pair sample size) u s- ing the upp er b ound v ariance estimate to d emon- strate the relationship b etw een this b oun d and the uncertain t y estimate in MLM2. S ince we can com- pare nested multi lev el mo dels usin g likeli ho o d ratio tests (LR Ts ), w e also ev aluate whether the m o del detects evidence of v ariation in treatmen t effects. W e then extend the sim u lations to in corp orate a cluster-lev el co v ariate as describ ed in more detail b e- lo w , and fit the multilev el mo del describ ed in equa- tion ( 3 ) ab ov e. W e simulate matc hed-p air clus ter randomized ex- p eriments in a m an n er similar to the IKN simu- lations with the notable d ifferen ce that w e do not force cluster-sp ecific SA T E to b e p erfectly matc hed within pair (as d escrib ed b elo w ). The num b er of pairs in eac h simulatio n is 30. Thr oughout our sim- ulations, the a ve rage (or fixed) cluster size is 50. When cluster size is imp erfectly matc hed across clus- ters, we allo w it to v ary based on multi nomial dra ws from cluster lab els, eac h equally lik ely , dra wing a sufficien t sample so that the exp ected size of any cluster is 50. Using th is strategy , the a v erage differ- ence in cluster size is ab out 8 and the a v erage s tan- dard deviation of these differences across rep eated sim ulations is appr o ximately 6. P oten tial outcomes were simulated su c h that for a giv en p air k , with cluster j = 1 as the control, and cluster j = 2 as the treated, 1 Y · 1 k (0) ∼ N ( µ 0 , σ 2 0 ) , (4) Y · 2 k (0) = Y · 1 k (0) + δ k with δ k ∼ N (0 , π 2 σ 2 0 ) . (5) 1 After sub mitting a draft of this commen t, IKN asked for our co de and up on reviewing confirmed an error in our original simulati on setup; randomization had not b een im- p osed. Given th e necessary restrictions on iterative revisions in t his discussion setting w e will not up date our commen t to incorp orate the corrected results; h o wev er w e were per- mitted to change the description of the simulatio ns to refl ect what w as actually run (that is, with the error included). W e hav e, how ever, verified that after correcting our simulations (by imp osing rand omization such that b oth p otential out- comes and our cov ariate are indep endent of the treatment, the situation described in the rest of the discussion), our orig- inal conclusions remain; t h e results are ex tremely similar to those presen ted here. More details and t he co de app ear in our online app endix at https://files.nyu.edu/jlh17/public/ stat.sci.appendice s/ . The error did spark an interesting additional discussion abou t the p otential p roblems with adjusting for cov ariates when randomization has failed which I KN ex plore in t h eir rejoinder. Therefore δ k serv es the role of creating im balance in SA TE across clus ters (IKN do n ot allo w for th is in their simulatio ns). As π grows we mo v e from a situation w ith p erfect b alance to a situation in w h ic h w e may as well ha v e rand omly c hosen p air matc h es. T reatmen t effects were either k ept constant across pairs at τ j k = 3 . 2 for all j and k or were allo w ed to v ary . Heterogeneous treatment effects w ere gen- erated using a n onlinear d eterministic function of the cluster p oten tial ou tcome un der treatmen t such that τ j k = 30 / Y · j k (0). This creates a p artial ceiling effect in w hic h larger baseline v alues are asso ciated with smaller treatmen t effects an d as suc h the dis- tribution for b oth Y (1) and τ j k are quite ske wed (again mimic king the IKN example). 2 The mean of τ j k across j and k is ab out 3.2 on a ve rage un der this form ulation. Individu al-lev el obs erv ations are generated f rom these cluster p oten tial outcomes by addin g rand om errors, Y ij k ( · ) = Y · j k ( · ) + ǫ ij k , (6) with ǫ ij k ∼ N (0 , σ 2 ǫ ). W e c h ose µ 0 = 10, σ 2 ǫ = 1 and σ 2 0 = 4 for all sim ulations. 4. SIMULA TION RESUL TS In Figure 1 , we plot the standard error asso ciated with our three estimates of the common treatmen t effect when cluster size is not p erfectly matc hed (the scenario in w hic h cluster sizes are equal is nearly iden tical, with minor differen ces noted b elo w). Panel A d isp la ys the results in th e scenario when treat- men t effects are constant (ignore the thic k grey line at this p oint in the discussion). When π = 0, matc h qualit y is p erfect, and m ultilev el mo del estimators ha v e the s ame precision. Ho w ev er, as the matc h qual- it y degrades (as repr esented b y incr easing lev els of π ) the lines div erge rapidly with MLM2 refl ecting increasingly higher lev els of un certain t y . W e migh t think that MLM1 is the “correct” mo del in this sim ulation scenario—after all, the treatmen t is constant . Ho wev er, in terms of heterogeneit y , there is n o ident ifiable difference b et w een p o or matc hes 2 W e were able to obtain data from IKN on the distributon of pair sp ecific differences in means in the data they used as a starting p oint for their simulatio n. W e satisfied ourselves that the distribution in our simulati ons of the same qu antity is even more sk ewed, thus clearly violates the assumption of normalit y of the treatment effects built in to our multilevel mod el. 4 J. HILL AND M. SCOTT Fig. 1. Plots that display how the standar d err or f or e ach metho d varies with incr e asing disp arity in the m atches, as me asur e d by π . The left p anel displays r esults fr om the sc enario with c onstant tr e atment effe cts; the right p anel displays r esults fr om the sc enario with tr e atment effe ct heter o geneity. and v ariable treatmen t effects. So in the likely realm of imp erfect matc hes, which mo del do w e prefer, and why? Mo del selection tec h niques su c h as LR T s will guide us to wa rd mo d els that captur e v ariation, when it is pr esen t, and w e find that when π > 0 . 13, the null that σ 2 τ = 0 is rejected at the 0.05 level. W e represent this shift a wa y from MLM1 b y slo w ly grey- ing out its standard error in panel A. Thus mo d els can provide evidence of either im p erfect matc hin g or v ariable treatmen t effects, bu t with this design, cannot adjudicate b etw een the t w o. Of cours e, to the exten t that we can use cov ariates to sufficiently im- pro v e across-cluster equiv alence within pairs (that is, to make up for imbalance remaining after matc h - ing), we migh t ha v e more confi dence in using such tests to in fer that the treatmen t effect is constant . What’s interesting to note is that the IKN upp er b ound v ariance estimator for SA T E closely m imic ks the uncertain t y estimate fr om MLM2. Wh en clus- ter size is equal, the IKN estimator’s precision is nearly coinciden t with that of MLM2 (not shown). Of course, neither the IKN estimator n or MLM2 can distinguish b et wee n tru e treatment effects and p air mismatc h es. In Figure 1 , P anel B, we p lot the standard error asso ciated with t wo of our three estimates of the common treatment effect when cluster size is not p erfectly m atched and treatment effects v ary n on- linearly as sp ecified ab ov e. Again, ignore the thic k grey line at this p oin t in the discussion. When π = 0, there is already a difference in precision b et we en MLM1 and MLM2. MLM1 completely ignores an y heterogeneit y , so with this incorr ect assu mption, it underestimates the u ncertain t y . Giv en that LR Ts w ould correctly su ggest that MLM1 is insufficient , in other w ords, σ 2 τ > 0 , we do not includ e MLM1’s precision in the plot. W e now concentrat e on MLM2 and the I K N esti- mator, and again we see that the precision follo w s a comparable trend as π is increased and matc hes degrade. Imp erf ect matc h es and the v arying treat- men t effects are increasingly confounded, and the uncertain t y concomitan tly in cr eases. It is somewhat surpr ising that the precision curv es degrade at a slo wer r ate than those in P anel A, yielding sup e- rior pr ecision wh en π > 0 . 5. T his can b e attributed, ho w ev er, to the additional information con tained in the correlation b etw een treatment and pair effects, COMMENT 5 created by the n onlinear transf orm ation th at gener- ates τ j k . W e confir med this using a different sim u- lation setup for which v ariable treatmen t and pair effects w er e generated indep endently (not sho wn); in these simulat ions, the p recision degrades a b it more quic kly than in the case of common treatmen t effect, as exp ected. Th at MLM2 and the IKN estimator’s s.e. are at higher levels in Panel B wh en π < 0 . 5 is simply th e effect of increased baseline v ariation in treatmen t effects introdu ced in the simulatio ns with v ariable τ j k . An equ ally imp ortan t p oint here is that ev en though w e in essence in correctly mo del the s k ew ed treat- men t effects by pretending they are normally dis- tributed, this “mo del f ailure” did n ot introdu ce bias or reduce p recision (sk ew ma y h av e induced slight o verestimati on of the v ariance in the treatment ). 4.1 Cova riates W e op erationali ze co v ariates as ha ving partial in- formation on Y · j k (0), but not dir ectly on τ j k . T he simplest wa y to d o this, in our sim ulations, is to set X j k = Y · j k (0) + ζ j , where ζ j ∼ N (0 , σ 2 ζ ) is a n oise pro cess that limits our abilit y to r eco ver the lev el of the p otent ial outcome. When σ 2 ζ is small, we sh ould eliminate, or n early eliminate the v ariation b et ween pairs, σ 2 α . T h is shou ld result in increased precision for the treatment effect, particularly when treat- men t and with in pair d ifferences are greatly con- founded. In th e simulat ion r esu lts shown in Figure 1 , we c hose σ 2 ζ = 0 . 2 2 , wh ich is large enough to ob- scure s ome information in the cov ariate, but not so large as to render it nonsignifican t, and fit the mo del giv en in ( 3 ) ab o v e. The stand ard errors for treat- men t effects (our primary assessment ) are pr esen ted as a grey line whic h is remark ably constant across v arious lev els of m atc h qualit y . P anels A and B are quite s imilar, so our remarks app ly to either. When matc h qualit y is very go o d, conditioning on cov ari- ates actually adds a sm all amount of uncertain t y to the treatmen t estimate. Ho wev er, the pa yo ffs asso- ciated with co v ariates includ e: dr amatic reduction of b et ween pair v ariance σ 2 α , which pro vides the op- p ortun it y to iden tify a simpler (common treatmen t) mo del, when th is actually is the case, and impro ve d precision when matc h qu ality is p o or. T o summarize, the impact of a (significant) co v ariate or s et of co- v ariates s hould b e to decrease th e v ariance σ 2 α , and this has the p otent ial to yield remark able p r ecision gains. 5. CONCLUSION In some w a ys, the IKN framework is actually quite similar to the multile ve l f ramew ork that allo ws for v ariation in treatmen t effects across pairs. The ad- v an tage of the m ultilev el framew ork how ev er is in mo ving b ey ond the simplest scenario to incorp o- rate additional complexit y for greater pr ecision or greater u nderstandin g. W e h av e illustrated only a small n umb er of the p otenti al s et of su c h mo del ex- pansions. REFERENCES Gelman, A. and Hill, J. (2007). Data Analysis Using R e- gr ession and Multilevel/Hier ar chic al Mo dels . Cambridge Univ. Press, Cam bridge. R Deve lopment Co re Team (2008). R: A L anguage and Envir onment for Statistic al Computing . R F oundation for Statistical Computing, Vienn a, Austria. ISBN 3-900051- 07-0. Av ailable at http://www.R- project.org .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment