Low-Complexity Structured Precoding for Spatially Correlated MIMO Channels
The focus of this paper is on spatial precoding in correlated multi-antenna channels, where the number of independent data-streams is adapted to trade-off the data-rate with the transmitter complexity. Towards the goal of a low-complexity implementat…
Authors: Vasanthan Raghavan, Akbar Sayeed, Venu Veeravalli
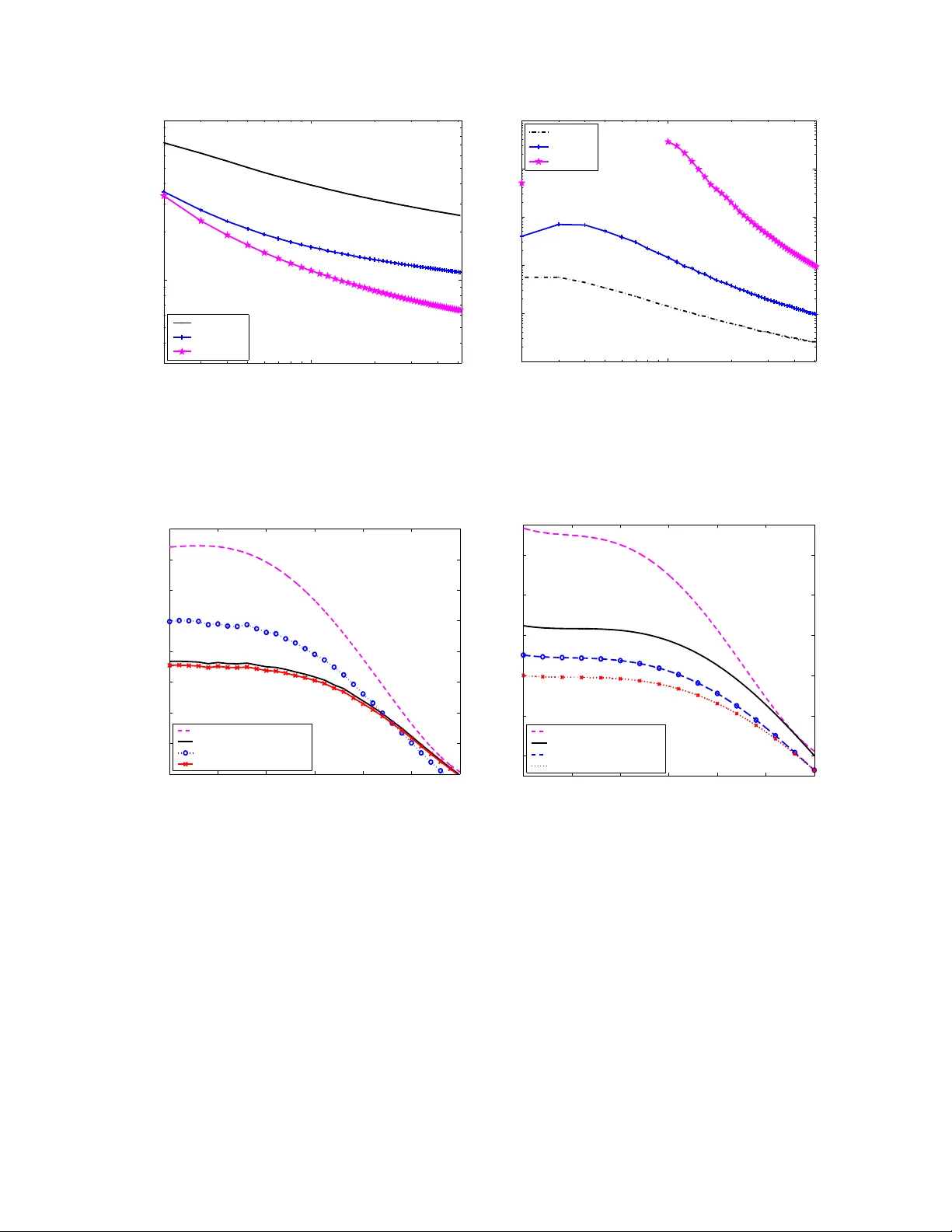
SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 1 Lo w-Comp le x ity Structured Precoding for Spatially Correlated MIMO Channels V asanthan Raghav a n, Akbar M. Sayeed, V enugopal V . V eerav alli ∗ Abstract The focus of this pape r is on spatial precod ing in correlated multi-antenna channels, where the number of indepen dent data-streams is adapted to trade-o ff the data- rate with the tra nsmitter co mplexity . T owards the goal of a low-comp lexity imp lementation , a structur ed pr ecoder is propo sed, where the precod er matrix ev olves fairly slowly at a rate c omparab le with the statistical evolution o f the channel. Here, the eigenv ectors of the preco der matrix correspond to the do minant eigen vectors o f the transm it covariance matrix, whereas the power alloc ation across the mode s is fixed, known at both the ends, and is of low-complexity . A particular c ase of the pr oposed scheme (semiu nitary precod ing), w here the sp atial modes are excited with equal power , is shown to be nea r-optimal in ma tched channels . A m atched channel is one wh ere the dominant eig env alues of the transmit cov ariance m atrix are well- condition ed and their nu mber equals the nu mber of indep endent d ata-streams, and the re ceiv e covariance matrix is also well-co nditioned . In mismatched chann els , whe re the above con ditions are n ot met, it is shown that the loss in p erform ance with semiunitary pre coding w hen compare d with a p erfect chann el in formatio n benchm ark is substantial. This loss needs to be mitigated v ia limited feed back technique s that p rovide partial channel informa tion to the transmitter . More impor tantly , we develop matching metrics that capture the d egree of matching of a channel to the preco der structure continu ously , and allow order ing two matrix chan nels in terms o f their mutual inf ormation or error prob ability p erform ance. Index T erms Structured preco ding, spatial precod ing, adaptive codin g, lo w-com plexity signaling , M IMO systems, correlated chann els, multimode sig naling, po int-to-po int links V . Raghav an and V . V . V eerav alli are with t he C oordinated S cience L aboratory and the Department of Electrical and Computer Engineering, University of Illinois at Ur bana-Champaig n, Urbana, IL 61801 USA. A. M. Sayeed is wi th the Department of Electrical and Computer Engineering, U ni versity of W isconsin-Madison, Madison, WI 53706 USA. Email: vasanthan raghavan@i eee.org, vvv@ui uc.edu. ∗ Corresponding author . This work was partly supported by the NSF under grant #CCF-004908 9 through the Univ ersity of Illinois, and grant #CCF- 043108 8 through the University of W isconsin. T his paper was presented in pa rt at the 42nd A nnual Allerton Conference on Communications, Control and Computing, Allerton, IL, 2006 and will be presented at the IEEE International Symposium on Information Theory , T oronto, Canada, 2008. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 2 I . I N T RO D U C T I O N Multiple antenna communications has recei ved sig nificant attention ov er t he l ast decade as a mechanism t o increase t he rate of information transfer , or the reliability of signal reception, or a combination of the two. The focus o f this w ork is on point-to-poin t spatial prec oding systems, where the number of in dependent data-streams is const rained to be a subset 1 , M , of the transmit dimensi on s o as to minim ize th e complexity and the cost ass ociated with transmissio n. Initial works on precoding study optimal signalin g strategies when perfect channel state i nformation (CSI) is av ailable at the transmi tter and the receiv er . These studies s how that a channel diagonalizing input that corresponds to exciting the dom inant M -dimensional eigen- space of the channel, with a power allocation th at can be computed via waterfilling, is robust under different design metrics [1]–[9]. Although perfect CSI pro vides a benchm ark on the performance, it is difficult t o obtain in practice. More importantl y , t he system performance is not robust un der CSI uncertainty . Even a small error in t he CSI at the t ransmitter can lead to a dramatic degradation in performance with a scheme that i s desi gned for the mism atched CSI [10]–[14]. Furthermore, e ven if perfect CSI is av ailable, tig ht constraint s on com plexity as well as energy consumption [15]–[19] at the RF lev el in the mobile ends may disallow the implementation of optimal solutions in practice. This is because Third Generation wireless systems and beyond are e xpected to be multi-carrier in nature and the burden of computi ng the opti mal in put is m agnified by the number of sub-carriers and the rate of ev olution o f t he channel realization s. Besides t his, t he s tructure of th e i nput coul d change, often dramatically , at the rate of ev olution of the channel realizati ons, which also m akes it diffi cult to implement. These reasons suggest that a slower rate of adapt ation of the i nput signals, that is of l ow complexity and is more robust to CSI uncertainty , is preferred in practice. In realist ic wi reless s ystems, where the channels are spatio-temporally correlated, the slow rate of statist ical ev olutio n i mplies t hat it is reasonabl e to assume perfect statistical knowledge of the channel at the transm itter . Since the s patial statistics experienced by the individual sub- carriers are identical [20]–[22], the b urden of computing the optimal input with only the statistical information at the transmitter is equi valent to that of a narrowband s ystem. Even in t his setting, optimal precoding has been stud ied for differ ent spatial correlation mod els [10], [11], [21], [23]–[32]. These works show that the eigen-di rections of the optim al input cova riance matrix correspond to a set of the M -dominant eigen vectors of the transmit cov ariance matrix and are hence, easily adaptable to changes in statistics. Howe ver , comp uting th e power allocation across 1 The number of data-streams, M , i s such that 1 ≤ M ≤ N t with N t denoting the transmit antenna dimension. Note that M is the rank of the input cov ariance matrix and the number of radio-frequency (RF) link chains as well. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 3 the M mo des requi res Monte Carlo aver aging or gradient descent-type app roaches [10], [11], [21], [28], [29]. While the computati onal compl exity of the p ower allocation algorith m may be af fordable at the base station end, whether it is p ossible or not at t he mobile end is qu estionable. Moreover , there has been no systematic study of statistics-based precoding approaches and hence, it is not clear as to h ow fa r th e p erformance of the stati stical scheme i s wit h respect to the perfect CSI benchmark. It should be noted that all the above works study precoder design with an emphasis on ob taining information-theoretic li mits on performance. In contrast, our focus here is on low-complexity schemes t hat can b e easily implement ed and easily adapted to changes in channel statis tics. In this work, we consider a narrowband setu p where spatial correlation is mod eled by a g eneral decompositio n [28], [33], [34 ] that: 1) Is based on physi cal princi ples, 2) Has b een verified by many recent measurement campaigns, and 3) Includes as special cases t he well-studied i.i.d. 2 model , the separable corre lation mod el [35], and the vir tual r epr esent ation [20], [21], [36]. W e propose the notion of structur ed pr ecodin g , where the po wer allocation across the M spatial modes is fix ed and known at both the ends. T wo s pecific cases are studied in depth in th is work: 1) A statistical semiunitar y 3 precoder , where the eigen-directions of the input correspon d to t he dominant eigen vectors of the transmit cov ariance matrix and the power al location is uniform, is studied th eoretically . 2) A precoder , where the eigen-directions are as before, and the power is allocated prop ortionate to the t ransmit covariance matrix eigen v alues below a threshold sig nal- to-noise ratio ( SNR ) and uniformly above this SNR , is studi ed vi a simulations. Follo wing th e philosophy propounded here, more complicated schemes, where the power allo cation across the modes can be computed with low-complexity , possibly as a function of the SNR and the statistics, can also be considered. Our focus is on two questions: 1) Wh en is t he first scheme near -optimal with respect to a perfect CSI benchmark?, and 2) What is the “gap” 4 in performance and ho w does it depend on the system and the channel parameters? The performance m etric used in this work is relativ e avera ge mutual information loss. W e also study relative uncoded error probability enhancement and relativ e mean-squared error ( MSE ) enhancement, whene ver they can be character ized analytically . The answers to the above questio ns lie i n th e noti on of mat ched and mismat ched channels , which are introdu ced in this work. A matched channel is one where t he channel is ef fective ly matched to the precoding scheme with t he fol lowing two conditionin g properties being true: 1) 2 I.I.D. stands for independen t and identically distributed. 3 An N t × M matrix X with M ≤ N t is said to be semiunitary if it satisfies X H X = I M . 4 This gap can possibly be bridged with a li mited feedback scheme [12]–[14], [37] that provides partial channel information to the transmitter . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 4 The M -dom inant eigen values of the transmit covariance m atrix are well-conditioned 5 , whereas the remaining ( N t − M ) eigen values are ill -conditioned away from the dominant ones, and 2) The receiv e covariance matrix i s also well-conditioned . A m ismatched channel is one where b oth the transmi t and the recei ve covariance matrices are ill-condit ioned, w ith t he addi tional condit ion that rank ( H ) ≥ M with p robability 1 . W e show that matched and m ismatched channels correspond to the cases where the relative performance of t he semiuni tary precoder are closest and farthest to t he perfect CSI precoder , respectiv ely . The degree of channel-to-precoder scheme m atching can be abstractly measured with ma tching metrics , t hat are also introduced in this w ork. As a by -product of our study , we also show that th e semiunit ary precoder is near -optim al in th e r elative antenna asymptot ic setting 6 for any channel. T his paper generalizes previous work [14] on the beamformin g case ( M = 1 ), where we studied the performance of t he st atistical beamform ing scheme. Organization: After elucidating the system model in Section II, we benchmark the structure of the opti mal s tructur ed pr ecoder in the perfect CSI case in Section I II. Using tools from majorization theory , we show that the optimal input naturally extends the channel-diagonalizing input from t he uncon strained case [1]–[9]. In Section IV, we elaborate on the problem setup o f structured prec oding. In Sections V-VII, using tools from random matrix theory and eigen vector perturbation theory , we study t he asymp totic (in antenna dimens ions) performance of a st atistical semiunitary pr ecoder t hat excites the M -dominant eigen vectors of the transmit cov ariance matrix. W e provide numerical stu dies to illustrate the benefits of t he proposed precoding scheme under realistic system assum ptions in Section VIII with a d iscussion of our resul ts and conclusio ns in Section IX. Proofs of most of t he claims have been relegated to the appendices. Notation: The M -dimens ional identity mat rix i s denot ed by I M . The i, j -th and i -th diagonal entries of a matrix X are denoted by X ( i, j ) and X ( i ) , respectiv ely . In more com plicated settings (for example, when the matrix X i s represented as a product or sum of m any matrices), the above entries are denoted by X ij and X i , respectiv ely . The complex conjugate, conju gate transpose, regular transp ose and in verse operations are deno ted by ( · ) ⋆ , ( · ) H , ( · ) T and ( · ) − 1 while the expectation, the trace and the determinant operators are given by E [ · ] , T r( · ) and det( · ) , respectiv ely . The t -dimensi onal complex vector space i s denoted by C t . Th e stand ard big-Oh ( O ) and small-oh ( o ) notation s are used alo ng with th e sta ndar d or d ering for eigen values of an n × n -dimens ional Hermitian matrix X : λ 1 ( X ) ≥ · · · ≥ λ n ( X ) . The lar gest and th e smallest eigen v alues are often denot ed also by λ max ( X ) and λ min ( X ) , respectively . The notation x + stands 5 If Λ t (1) ≥ · · · ≥ Λ t ( M ) denote the first M eigen v alues of the transmit co variance matrix and Λ t (1) Λ t ( M ) is (or is not) significantly larger than 1 , we loosely say that these eigen v alues are ill-(or well -)conditioned. 6 That is, when M N r → 0 or ∞ as { M , N t , N r } → ∞ . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 5 for max( x, 0) . I I . S Y S T E M S E T U P W e consider a comm unication model wit h N t transmit and N r recei ve antennas, where M ( 1 ≤ M ≤ N t ) independent data-streams ar e used in si gnaling. That is, the M -dim ensional input vector s is precoded into an N t -dimensional ve ctor vi a the N t × M precoding matrix F and transmitted over the channel. The discrete-time baseband si gnal model used is y = H F s + n , (1) where y is the N r -dimensional recei ved v ector , H is t he N r × N t -dimensional channel matrix, and n is the N r -dimensional (zero mean, u nit v ariance) additiv e white Gaussian noise. In practice, the choice of M is decided based on a trade-off between complexity , cost and performance g ain. A. Channel Mod el The main emphasis of this w ork is on the impact of spatial correlation. W e isolate the spatial aspect by assuming a block fading, narrowband model for the time-frequency correlation of H . It is well -known that Rayleig h fading (zero mean complex Gaussi an) is an accurate model for H in a non lin e-of-sight setting and hence, the complete spatial stati stics are described by the second-order moments of { H ( i, j ) } . The m ost general, m athematically t ractable spatial correlation m odel is a canonical decom- position 7 of th e channel along the t ransmit and the recei ve cov ariance bases [28], [33], [34]. In this model, we assume that the auto- and the cross-cov ariance m atrices of all ro ws of H ha ve the s ame eigen-basis (denoted by U t ), and the auto- and the cross-covariance matrices o f all the columns of H have the same eigen-basis (denoted by U r ). Thus, we can decompos e H as H = U r H ind U H t , (2) where H ind has in dependent, but not necessarily identi cally distributed entries, and U t and U r are unitary matrices. The transm it and the receiv e cova riance matrices are defined as Σ t , E [ H H H ] = U t E [ H H ind H ind ] U H t = U t Λ t U H t , (3) Σ r , E [ HH H ] = U r E [ H ind H H ind ] U H r = U r Λ r U H r , (4) where Λ t = E [ H H ind H ind ] and Λ r = E [ H ind H H ind ] are diagonal . 7 This model is referred to as the “eigen-beam or beamspace model” in [33] and is used in capacity analysis in [28]. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 6 Under certain special cases, the model in (2) reduces to s ome w ell-known spatial correlation models such as th e i .i.d. m odel, the separable correlation [35] and the virtual representation [20 ], [21], [36] framew orks. The readers are referred to [13] for details . The i.i.d. model, while being analyticall y tractable, is unrealistic for applications wh ere large antenna spacings or a ri ch scattering en vironment are not p ossible. Even though th e separable m odel may be an accurate fit under certain channel conditi ons [38], deficiencies acquired by the separabili ty property result in misleading estimates of s ystem performance [34], [39], [40]. The readers are refer red to [33], [39], [41] for m ore details on how the canonical, and more specifically th e virtual model fit measured data better . Gi ven a correlated channel, in this work, w e will ass ume without an y loss in generality that M ≤ rank ( Λ t ) ≤ N t . B. Channel St ate Information Initial works in the precoding literature hav e assumed perfect CSI at bo th the transmitter and the receiv er . Perfect CSI at the rece iver (the coherent case) is usually reasonable for systems that adopt a ‘training follo wed b y signaling’ model. On the oth er hand, both t he perfect and the no CSI assum ptions at the transmitt er are unrealistic, being too op timisti c and too pessimis tic, respectiv ely . This is so because the perfect CSI condition imp oses a huge burden on the training or the feedback apparatus on the reverse l ink whil e on the other hand, the spatial statistics of the channel entries ev olve over much slower timescales and can be l earned at both the ends. In this work, we st udy the coherent case with perfect st atistical knowledge at the transmi tter . C. T ransceiver Ar chitectur e The transm itted vector Fs (see (1)) has a power constraint ρ . The transmi t power constraint can be rewritten as ρ = E s H F H F s = T r E F s s H F H = T r F Q s F H , Q s , E s s H . (5) By decomposing F and Q s using si ngular v alue decompositio n (SVD) and renormalizing, it can be seen that the sys tem equation can be written as: y = H F s + n , F = r ρ M V F Λ 1 / 2 F , (6) where V F is an N t × M semiunitary matrix, Λ F is an M × M non-ne gative definite powe r shaping (allocation) matrix with T r( Λ F ) ≤ M , and s is an M × 1 vec tor with i.i.d. compon ents that have zero mean and variance one. That is, the general precoder can be thoug ht of as a power loading by Λ F , followed by a rotation wit h V F . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 7 The optim al reception st rategy of the inpu t symbols corresponds to no n-linear maxim um likelihood (ML) decoding. Howe ver , the exponential complexity of ML decodin g in bot h antenna dimensions and coherence length impli es that sim pler recei ver architectures are preferred. In t his work, we assume a linear minim um mean-squared error ( MMSE ) receiv er . W ith this receiv er , the symbo l corresponding to t he k -th data-stream is recover ed by projecting the received signal y on to the N r × 1 vector g k = r ρ M ρ M HFF H H H + I N r − 1 Hf k , (7) where f k is the k -th column of F . That is, the recovered symbol is b s ( k ) = g H k y , and the signal-to-interference-noise ratio ( SINR ) at the ou tput of the linear filter g k is SINR k = 1 h I M + ρ M F H H H HF − 1 i k − 1 . (8) Also, note th at the MSE of the k -th d ata-stream, MSE k , is g iv en by h I M + ρ M F H H H HF − 1 i k . D. A Case for Structur ed Pr ecoding Almost al l of the current works on precoder design do not assume any specific structure on the precoder matrix F . This is because the m ain focus of these works is on characterizing t he fundamental performance l imits of precoding. That is, to st udy optimal signaling s chemes from a mutual informati on or an error prob ability v iewpoint. The structure 8 of t he optim al precoder , F opt , critically depends on the knowledge of the eigenspace of H (see Sec. III). Even a small inaccuracy in the knowledge of the eigenspace of H could l ead t o a precoder with a sign ificantly degraded performance [10 ]–[14]. While this issu e does not arise i n the perfect CSI case, i t is critical in systems with imperfect CSI. In particular , imperfect channel knowledge arises in practice due to constraints on the quali ty and frequency of channel or statisti cal feedback and channel est imation at t he receiv er . Moreover , ev en if perfect C SI is av ailable at the transmitter , the effi cient utilization of this in - formation i s const rained b y fundament al lim its on energy per bit constraints at the computatio nal or p rocessing level [15]–[19]. These limi ts in tu rn i mply that a large num ber of computati ons are diffic ult t o realize in low-po wer devices, s uch as t hose found at the mob ile ends. For example, the m ove t ow ards mult i-carrier signaling and the fast rate at whi ch channel realizations e volve leads to com putational limits on how many SVD operations can be af forded. Another key aspect to note i s that the eigenspace of t he opt imal in put could change dramatically from one channel 8 By structure, we mean a set of eigen vectors and eigen values of F opt , that are captured by V F opt and Λ F opt , in (6). SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 8 realization to the next, and thi s poses constraint s on th e adaptivity of t he s olutions proposed in the literature. In fact, RF desi gn constraint s imposed by t he above limits are often the principal stumblin g blocks in rea lizing multi -antenna systems in practice. The readers are re ferred to [18] for a broad array of RF d esign chall enges, imposed by computational and com plexity constraints. All of the abov e reasons suggest t hat it may not be possible for F to be designed at an arbitrarily fast rate. They also s uggest that F canno t ha ve arbi trary structure and one cannot learn it with ar bitrarily fine precision. The case of statistical precoding, where t he optimal input is adapted in response t o the statist ical informati on has thus receiv ed significant attentio n. In t his case, computing the optim al power allocation across the excited m odes requires either Monte Carlo av eraging or gradient descent-type approaches (see Sec. IV). The affordability of the complexity of t hese approaches at the mobile end is again questionable. These reasons mot iv ate us to s tudy structure d pr ecoding, where the eigen-modes as well as the power allocati on across them are determined via lo w-complexity operations on the channel statistics. T he add itional structure impo sed on F serves the following purposes: 1) Isolating the im pact of inaccuracy in the singu lar vectors and singular values of F on performance with respect to a genie-aided design, 2) G iv en that there are resource constraint s o n the re verse link quantization, identi fying those features of the channel H th at requi re an approp riate resource allocation so as to opt imize system performance, and 3) Obtaining more realistic ‘intermediate’ benchmarks for systems in practice. W e first focus on a specific class of semi unitary prec oder , where Λ F = I M . W e then consider the m ore general structured precoder case, where Λ F is fixed, b ut is chosen different from th e identity matrix. I I I . P E R F E C T C SI B E N C H M A R K F O R S T RU C T U R E D P R E C O D I N G T owa rds the eve ntual goal of study ing a structured st atistical precoding scheme, we first characterize the optim al perfect CSI benchmark in thi s s ection. A. Unconstrained Pr ecoders If only on e data-stream is excited ( M = 1 ), the recei ved SNR i s g iv en b y ρ | z H Hf | 2 z H z , where f is the beamforming vector and z is the combini ng vector . It is straightforward to n ote t hat the jointly optimal desi gn of z and f can be reduced to a beamformer design by usi ng the combining vector Hf √ f H H H Hf , and that th e opti mal choices f opt and z opt are the dominant right singular vector of H and Hf opt √ λ max ( H H H ) , respectively [42]. In thi s case, the received SNR coincides with ρ λ max ( H H H ) . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 9 In contrast to beamform ing, t he precoding case wi th M > 1 requires a recourse to the st udy of eigen v alues of prod ucts of Hermitian m atrices. For t he (general) uncons trained p recoding case, the joint precoder-e qualizer design t urns out to have a channel diagonalizi ng structure. T o s tate this result , we need some addit ional notation. Let an SVD of H be give n by H = U H Λ H V H H , where V H = [ v 1 · · · v N t ] . W ithout an y loss in generality , we assume that the non-tri vial sin gular values of H are arranged in the standard order . Lemma 1: The optimal choi ce of V F opt and Λ F opt in (6) are as follows: V F opt corresponds to [ v 1 · · · v M ] , and the diagonal entries o f Λ F opt are obtained via waterfilling. Pr oof: The opt imality of the channel diagonalizing structure has been proved in [1]–[4], with the design metric being the a verage M SE of the data-streams. Other design metrics where the channel diagonali zing st ructure is optim al inclu de w eighted MSE of the data-streams [5], [6], determinant of the MSE matrix [7], and a peak-po wer const raint metric [8]. A unified con vex programming frame work for precoder opt imization is proposed in [9] by studying two broad classes of functio ns: Schur-conca ve 9 and Schur-con vex functions. In [9], the aut hors s how that most of the above design criteria can be formulated as eith er a Schur -concav e or Schur-con vex function of the MSE and t he channel diagonalizing structure is optim al i n ei ther case. B. Semiunitary P r ecoders When th e precoders are cons trained t o be structured, it is intuitive (but not obvious) t o expect a channel diagonalizing structure to be opt imal. The following series of propositi ons elucidate the o ptimality of this structure in th e semi unitary case wit h certain restrictions on the ob jectiv e function. T he m ore general st ructured case will be consi dered t hereafter . The readers are referred to App. A for m any rele vant definitio ns and results from majorization theory . Following t he introduction from App. A, we are prepared for the following. 1) Pr ecoders that Optimize Schur-concave Objective Functions: Pr oposition 1: Let f : R M 7→ R be a Schur -concav e function ov er i ts domain. Also, let f ( · ) be m onotonically increasing in its ar guments. That i s, let the univ ariate function f ( · · · , x k , · · · ) : R 7→ R be monot onically increasing for all k . If MSE = [ MSE 1 · · · MSE M ] , then the opti mal choice of semiuni tary precoder F opt that minimi zes f ( M SE ) is give n by F opt = [ v 1 · · · v M ] . (9) Pr oof: See Ap pendix B. The uti lity of the above propositi on can be gauged from the fact t hat a large class of us eful functions satisfy the Schur -concavity property . For example, from Remark 2 in App. A, we see 9 The definitions of Schur-con cave and Schur-con vex functions are pro vided in Appendix A. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 10 that any weig hted arithmeti c o r geometri c mean of { MSE k } (wit h weights chosen appropriately) is Schur -conca ve. The sam e remark il lustrates th e limitations of this partitioning because the mutual information function cannot (in general) be expressed as a Schur-conca ve (or a Schur- con vex) functi on of MSE . In th e special case of Gaussi an in puts, t he objective function f ( · ) t o be maximized is f ( · ) = log det I M + ρ M F H H H HF = − log det ( E ) , (10) where E is the m ean-squared error matrix d efined as E [( s − b s )( s − b s ) H ] , I M + ρ M F H H H HF − 1 . (11) It can be s hown that maximizin g the mutual information with the Gaussi an input (or alter- nately , minimizing the determinant of E ) can be easily accommodated in th e frame work of Prop. 1; see [9] for details. Alternately , an easy consequence of Lemma 10 (see App. A) is the fact that a channel diagonalizi ng structure maxim izes mutual information and this has been established i n [43]. Also note that if M = N t , any choice of F unit ary leads to the same value of f ( · ) . Extendin g the proof of [43] to the case of a non-Gaussian input requi res closed-form expressions for the m utual information, which are (in general) difficult to obtain. 2) Pr ecoders that Mini mize the A vera ge Err or Pr obability: Besides mutual informati on, un- coded error probability is another important metric that describes the performance of a commu- nication sy stem. W e now show ho w the machinery of m ajorization theory can b e used to study the error probabilit y . W e state the most general form of this st udy in the following propositi on, with its particularization to the error probabi lity case illustrated thereafter . Pr oposition 2: Let h : R 7→ R be a continu ous, in creasing, and con ve x function of it s ar gument. The op timal choi ce of F that m inimizes P M k =1 h ( MSE k ) is given by F opt = [ v 1 · · · v M ] Γ , (12) where Γ is an appropri ately cho sen un itary matrix (see App. B for detail s o n construction). Pr oof: See Ap pendix B. If h ( · ) is as in Prop. 2 , and g : R M 7→ R i s d efined as g ( MSE ) , M X k =1 h ( MSE k ) , (13) then i t is important to note from Lemma 7 in App. A that g ( · ) is a Schur-c on vex function of MSE . Thus, in general, Prop. 2 is neit her a consequence of nor impl ies Prop. 1. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 11 W e now show ho w Prop. 2 is us eful in the error probability setting. Let P err denote the probability that at least one of th e M d ata-streams i s i n error . Then, P err = 1 − M Y k =1 (1 − P k ) , (14) where P k is the probability that the k -th data-stream is in error . If some fixed constell ation is used for signaling across all the data-streams, we can w rite P k as P k = α Q β SINR k 1 / 2 , (15) where SINR k is the received SINR of the k -th d ata-stream after li near processing [44], α and β are constants dependent only on the type of t he constellation, and Q ( · ) i s the Q -function associated with a standard Gaussian random variable. Assuming that the error probability of the weakest data-stream is sufficiently small (which is reasonable for most desi gn problem s), we hav e P err ≈ P M k =1 P k . Alt ernately , one could consider a met ric that measures the a verage error probability of the in dividual data-streams: 1 M P M k =1 P k . Thu s, in eit her case, we are interested in studying the optim al choice of precoder F that minimizes P M k =1 P k . It is straightforward to note that P k ( · ) is a continuous and increasing function of M SE . Besides, it is shown in [9] t hat P k ( · ) is a con vex fun ction 10 of M SE as long as the argument i s suffi ciently small. W e are t hus just ified i n ass uming that P k ( · ) is conv ex, contin uous and increa sing in M SE . Then, Prop. 2 shows that P err is mini mized by F opt as in (12). 3) Pr ecoders that Optimize S chur -con ve x Objective Functions: It is natural to probe the optimalit y of F opt in (12) i f ins tead of the a verage error probability , we consi dered the error probability corresponding t o t he weakest data-stream. For this, we now need t he count erpart of Prop. 1 which is as follows. Pr oposition 3: Let f : R M 7→ R be a Schur-con vex functio n over its domain. Also, let f ( · ) be monoton ically increasing in its arguments. The optimal choice of semi unitary precoder F opt that minimi zes f ( M SE ) is give n by F opt = [ v 1 · · · v M ] Γ , (16) where Γ is the same uni tary m atrix as defined in Prop. 2. Pr oof: The proo f follows along the same li nes as Prop. 2. No details are p rovided. 10 In pa rticular, i t is shown in [9, App. H] that if the corresponding bit error rate values satisfy BER < 0 . 02 , this is true independe nt of the input constellation. Moreov er , in the case of BPSK and QPSK constellations, P k ( · ) is con vex over the entire domain of MSE . Note that, as stated i n [9], the assumption of BER < 0 . 02 is mil d in a practical scenario since the uncoded BER is usually much smaller than 0 . 02 . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 12 T o answer the question that led towards t he above prop osition, not e from Lemm a 8 in App. A that max k P k is a Schur-c on vex function of MSE . Thus from Prop. 3, th e opti mal precoder is as in (16 ). Further , note that the matrix Γ in t he description of F opt in (12) and (16) can be ignored since s is i.i.d . and therefore, so is Γs . C. General Structure d Pr ecoders W e now generalize our result s to t he general structured case. Pr oposition 4: Let the structure of the precoder be F = V F Λ 1 / 2 fixed , where Λ fixed is some fixed matrix of rank M with T r( Λ fixed ) ≤ M , albeit chosen arb itrarily . That is, in the ensuing optimizatio n Λ fixed is fixed and we onl y optimi ze ove r V F . As before, the structu re of th e optim al V F depends on the nature of the objective function. • Schur-conca ve objecti ve function s (and in particul ar , the mutual information with Gaussian input) are optimized by F of the form: F opt = [ v 1 · · · v M ] Λ 1 / 2 fixed . (17) • Schur-con vex objective functions (and in particular , the aver age uncoded error p robability) are o ptimized by F of the form : F opt = [ v 1 · · · v M ] Λ 1 / 2 fixed Γ (18) for an appropriately chosen unitary matrix Γ . Pr oof: W e follow the same proof techniques of Prop. 1-3. See Appendix B for details. Thus, e ven i n the m ore general structured precoding case, the channel diagonalizing structure is optimal. I V . S T A T I S T I C A L P R E C O D I N G : P RE L I M I N A R I E S W e now assume that instantaneous channel information is not a v ailable at the transmitter , but channel statist ics are known. A. Notations While much of the notations required in the rest of the paper have been established in Sec. II-A, we find it con venient to restate some of them that are often used in the ensu ing sections. W e assume that H is described by either the separable model or the more general non-separable model of (2). Let t he variance of H ind ( i, j ) be denoted by σ 2 ij . The ei gen values of the transmit cov ariance matrix are denoted by { Λ t ( k ) } in th e separable case while in the non -separable case, they are denoted by γ t,k , P N r i =1 σ 2 ik . In either case, we assume that the columns of H ind are SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 13 arranged such that the transmit eigen values are in decreasing o rder . The channel power of H , ρ c , is given by ρ c = P N r i =1 Λ r ( i ) = P N t i =1 Λ t ( i ) . The normali zed channel p ower is γ r , ρ c N r . In the separable case, let e Λ t denote t he princip al M × M sub-matrix of Λ t and e H iid denote the N r × M principal su b-matrix of H iid . That is, H iid = " e H iid |{z} N r × M × |{z} N r × ( N t − M ) # . (19) W i thout any e xplicit reference to k , we will often denote by b Λ t , the ( M − 1) × ( M − 1) matrix obtained from e Λ t by removing the k -th ro w and k -th column and by b H iid , the matrix obtained from e H iid by removing th e k -th colu mn alone. In the non-separable case, let e H ind denote the N r × M -dimensional principal sub-matri x of H ind . B. Unconstrained Pr ecoders Lemma 2: The optimal precoder F stat , opt is of t he form V stat Λ 1 / 2 stat , where V stat is a set of M dominant eigen vectors of the transmit cov ariance matrix Σ t and Λ stat is the unique solut ion to the following constrained opti mization: Λ stat = arg max Λ ∈L E H h log det I N r + ρ M e H ind Λ e H H ind i (20) with L = { Λ } denoting the conv ex set of all diagonal M × M non-negative definite matrices such t hat T r( Λ ) ≤ M . The optimali ty of the dominant eigen vectors of Σ t is not surprisi ng (see [10], [11], [21], [23]– [26], [28] and references t herein for problems of a simil ar nature). The optim ization in (20) i s standard: Maximizing a con ca ve fun ction over a con vex set. A gradient descent-type approach for this is provided in [30] and a Mon te Carlo approach is provided in [21], [28], [29]. C. St ructur ed Sta tistical Pr ecoders As e xplained in Sec. II-D, the complexity o f solving for Λ stat in (20) may be unaf fordable in many practical scenarios. W e therefore pursue t wo statistics-based precoders: F semi and F fixed , with F semi = V stat and F fixed = V stat Λ 1 / 2 fixed . The choice of Λ fixed that is of interest here is : Λ fixed ( k ) = M · Λ t ( k ) P M j =1 Λ t ( j ) if ρ < SNR T , 1 if ρ ≥ SNR T . (21) The threshold SNR ( SNR T ) is such that SNR T = α M Λ t ( M ) (22) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 14 for an appropriat e choice of α, α > 1 . This choice i s motiv ated by our rece nt work [45] on transient- SNR (the SNR at which exciting M modes is informati on theoreticall y opti mal) design . For a given channel realization, let I stat , semi ( ρ ) and P err , stat , semi ( ρ ) denote the mu tual informa- tion and error probabil ity achiev able with F semi , while I stat , fixed ( ρ ) and P err , stat , fi x ed ( ρ ) denote the corresponding quantities with F fixed , all at an SNR of ρ . Similarly , denote the corresponding quan- tities with th e t hree perfect CSI precoders described in Lem ma 1, (9) and (17) by: I perf , unconst ( ρ ) , I perf , semi ( ρ ) , I perf , fixed ( ρ ) , and P err , perf , unconst ( ρ ) , P err , perf , semi ( ρ ) , P err , perf , fixed ( ρ ) , respective ly . It is im portant t o note the distincti on between these quantities. Whil e I stat , • ( ρ ) and P err , stat , • ( ρ ) are functions of the channel realization H , the precoder st ructure i tself is independent of H , but only dependent on the channel statistics. On the other hand, I perf , • ( ρ ) and P err , perf , • ( ρ ) in addition to being dependent on the channel realization also correspond t o precoders whose structure is dependent on H and chosen o ptimally . D. A verage Relative Differ ence Metr ics T owa rds the goal of stu dying the propos ed scheme(s), we d e velop universal metrics that capture the performance g ap between the p roposed precoder(s) and an i deal benchmark. W e first motiv ate the choice of our metric in an abst ract context. Let ‘scheme 1 ’ and ‘scheme 2 ’ denote t wo sig naling schemes wit h I scheme , 1 ( ρ ) and I scheme , 2 ( ρ ) denoting the mutual in formation of t he two schemes at an SNR , ρ . Our goal is to quantify 11 whether schem e 1 is better than scheme 2 or not, and if so, by how m uch. For any signaling scheme, th e aver age mutual i nformation is a function of ρ as well as the statis tical description of the channel. Irrespectiv e of the spatial correlation, the av erage mutual information of any scheme tend s to zero as ρ → 0 and t ends to infinity as ρ → ∞ . F or this reason, the difference in av erage mutual information between the t wo s chemes can con ver ge t o zero as ρ → 0 at a rate dif ferent from that of eit her scheme, and could blow up to infinity as ρ → ∞ . Thus, th e diffe rence in a verage m utual in formation is not a good measure for comparing the two schemes. An ef ficient comparison of the two schemes is possible by using either of the following set of averag e r elative differ ence metrics : ∆ I sc heme 1 , s c heme 2 , E H [ I scheme , 1 ( ρ ) − I scheme , 2 ( ρ )] E H [ I scheme , 2 ( ρ )] , (23) f ∆ I sc heme 1 , s c heme 2 , E H I scheme , 1 ( ρ ) − I scheme , 2 ( ρ ) I scheme , 2 ( ρ ) . (24) Note that the choice of s cheme 2 in the d enominator of (23) and (24) is the scheme that performs relativ ely poorly . Thus , ∆ I • and f ∆ I • correspond to a worst-case m easure of relati ve 11 In our setting, ‘scheme 1 ’ correspond s to a perfect CS I precod er and ‘scheme 2 ’ to a structured statistical precoder . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 15 performance. The m etrics are more m eaningful (than the difference metric) in stu dying the relativ e gap (or closeness) between t he schemes 12 , in dependent of the SNR . While we hav e used the case of a verage mutual information t o motiv ate t he need for a relative di ff erence metric, the same argument is applicable in the error probabilit y case. In fact, the need for such a metric is more criti cal in the error probability case since t he error probabilities o f the schemes that are being compared (and hence, the d iffe rence between them) are small. E. Pr o blem Setup The main goal of this paper is to quantify , as a function of the statistics and antenna dimensions, ∆ I semi , E H [ I perf , unconst ( ρ ) − I stat , semi ( ρ )] E H [ I stat , semi ( ρ )] (25) in the case of mut ual i nformation, and ∆ P semi , E H P err , stat , semi ( ρ ) − P err , perf , unconst ( ρ ) P err , perf , unconst ( ρ ) (26) in the case of error probability . In addit ion, we are also interested i n t he corresponding qu antities for F fixed in (21): ∆ I fixed and ∆ P fixed . While closed-form expressions for the above metrics seem difficult to obtain across all SNR regimes, the following sim plifying assum ptions render these metrics theoretically tractable. • Asymp totics of Anten na Dimension(s): Any performance metric computati on in the spa- tially correlated, finite antenna sett ing suff ers from fundamental difficulties associated with a lack of knowledge of th e joint probabil ity dens ity function of sin gular va lues of th e channel matrix. Howe ver , under many set tings, in the asymptotics of antenna dimension(s), the density function of eig en values con ver ges (in an appropriate s ense) t o a certain determinist ic density functi on. M any recent works o n m ulti-antenna channels (see [10], [11], [21], [28] and references t herein) exploit thi s fundamental property in the characterization of various information theoretic quantities of int erest. In this work, we find it useful to separate our study i nto two cases: 1) An easily tractable case o f r elative r eceive antenna asymptotics , wh ere M N r → 0 , and 2) A more diffic ult case of pr o portional gr owth o f an tenna dimensions , where both { M , N r } → ∞ wit h M N r → γ and γ ∈ (0 , ∞ ) is a constant. The first case includes the following sub-cases in a unified 12 Empirical studies indicate that the correlation coefficient between I scheme , 1 ( ρ ) I scheme , 2 ( ρ ) and I scheme , 2 ( ρ ) i s negativ e. While this claim seems plausible given the reciprocal role of I scheme , 2 ( ρ ) in the two terms, we do not have a concrete mathematical proof of this claim. If this claim were to be true, we would have ∆ I • ≤ f ∆ I • . In an y case, it should be clear that ∆ I • and f ∆ I • are related to each other by an O (1) factor . In Sec. V and VI, we will characterize either coefficient depen ding on its tractability . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 16 way: a) N t and M ar e finite and N r → ∞ , b) M , N r → ∞ with M N r → 0 , and c) via a relabeling of indices the case where M N r → ∞ wi th either N r finite or N r → ∞ . • Signal ing Constellation: In the error probability case, it wi ll be shown in Sec. VI that the relativ e difference m etric can be written in terms of the SINR of the individual d ata-streams. Since exact closed-form expressions are known for the SINR s (see (8)) of a li near MMSE recei ver , independent of the signaling constellation, t here is no need to constrain th e inputs to be of any particular type. On the other hand, in the case of mutual i nformation, when Gaussian inputs are used for signalin g, the ave rage mutu al information is giv en by th e well - known log det( · ) formula. Howe ver , in the non-Gaussian case, closed-form expressions are diffic ult to obtain for m utual informatio n. Thus, we w ill restrict our attention t o av erage relativ e mutual information l oss in the Gaussian case. In the non-Gaussian case, the relative MSE enhancement i s a good indicator 13 of the mu tual informati on l oss. Besides this , the MSE enhancement serve s as a soft decision metric when the processed rec eive d data is fed through m ore complex, non-lin ear recei ver architectures such as a turbo- or LDPC -decoder . • H igh- SNR Regime: Comp uting universal upp er bo unds for th e metrics in (25) and (26), and the corresponding quanti ties for F fixed , that are tight across th e entire SNR range seems to be a difficult proposition. Ho wev er , when th e SNR is reasonably high (mo re precisely , ρ ≥ α M Λ t ( M ) for som e suitable α > 1 ), we will see t hat considerable simplifications and h ence, closed-form characterizations are possible. In this SNR re gime, the semi unitary precoder coincides with the precoder in (21 ) as does the performance of another com monly-used low-complexity rece iver , th e zeroforcing receiv er . V . M U T U A L I N F O R M A T I O N L O S S W I T H S E M I U N I T A RY P R E C O D I N G In this sec tion, we focus on the (a verage) relati ve loss in mutual i nformation with F semi , assuming Gaussian inputs. The difference ∆ I semi (see (25)) can be wri tten as ∆ I semi = E H [ I perf , un const ( ρ ) − I perf , semi ( ρ )] E H [ I stat , se mi ( ρ )] | {z } ∆ I 1 + E H [ I perf , semi ( ρ ) − I stat , se mi ( ρ )] E H [ I stat , semi ( ρ )] | {z } ∆ I 2 . (27) Since the argument withi n the expectation of the numerator of ∆ I 1 is n ot explicitly d ependent on t he spatial correlation m odel, it is st raightforward to obtain a bou nd for ∆ I 1 . 13 The mutual information is related to the MS E of the optimal MMSE recei ver through t he relationship established in [ 46], and not the MS E of the linear MMSE receiv er . Despite this difficulty , the MSE enhancement with a linear MMSE receiv er is a good indicator of mutual information loss in the non-Gaussian case [46]. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 17 Pr oposition 5: If ρ is such t hat ρ ≥ α E H h M Λ H ( M ) i for some α > 1 , ∆ I 1 is bounded as ∆ I 1 ≤ 2 M α 2 E H [ I stat , se mi ( ρ )] · E H 1 Λ H ( M ) 2 E H h 1 Λ H ( M ) i 2 . (28) Pr oof: See Ap pendix C. Intuitively , as α and hence t he SNR increases, th e waterfilling po wer allocation o f the optimal precoding scheme con ver ges to uniform power allocation across t he M modes (see [10], [11], [21] etc.) and thu s, ∆ I 1 decreases. The bound provided in (28) is not tight since we hav e not characterized the exact probability Pr( n H < M ) (in App. C) t hat determines ∆ I 1 . But the above bound is sufficient to capture the performance loss wi th uniform power allocation. Characterization of ∆ I 2 , which is explicitly dependent on th e spatial correlatio n mod el, is non- trivial. In the following series of t heorems, we provide b ounds for diff erent correlation models and regimes. W e first consi der the relative antenna asym ptotic case. A. Separable Model Theor em 1: Let the channel H be described by the s eparable m odel. From t he remark in Footnote 12, ∆ I 2 is well-approximated by its more tractable version, f ∆ I 2 : f ∆ I 2 , E H I perf , semi ( ρ ) − I stat , semi ( ρ ) I stat , se mi ( ρ ) . (29) For any fixed value of ρ , f ∆ I 2 is bounded as f ∆ I 2 ≤ 2 κ 1 γ r · q P N r i =1 ( Λ r ( i )) 2 N r · 1 M M X k =1 1 log 1 + ρ M Λ t ( k ) , (30) where κ 1 is a constant determined from an app lication of Lemma 13 (in App. A). Pr oof: See Ap pendix D. B. Canonical Model Theor em 2: Consider the canonical case with N t N r → 0 . Using the generalized asymptotic eigen v alue characterization in Lemma 13 (in App . A) and follo wing the approach of Theorem 1, we hav e ∆ I 2 ≤ 2 κ 2 · r N t N r · N r M M X k =1 " 1 γ t,k log 1 + ρ M γ t,k # (31) for some constant κ 2 determined from Lemma 13. T he proof is not provided. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 18 C. Special Case: Beamforming W e now pay attention t o the beamforming case ( M = 1 ), the low-complexity of which makes it an att ractiv e s ignaling choice in many wireless standards. While the SNR re gime where beamforming is capacity-optimal has been established i n prior work [10], [11], [21 ], [45], the performance gap between st atistical and perfect CSI b eamforming is less clear . Using tools from eigen vector perturbation theory , introduced in [14], we establ ish the fol lowing results. First, no te that the term ∆ I 1 is redun dant i n th e beamforming case. Let I perf ( ρ ) and I stat ( ρ ) denote t he mutual i nformation achiev able by beamfo rming wit h perfect CSI and stati stical information alone, respective ly . Define t he loss term ∆ I bf , E H [ I perf ( ρ ) − I stat ( ρ )] E H [ I stat ( ρ )] . (32) The following discussi on complements recent work on th e performance gap with the separable model [47], that ha ve been established by exploitin g so me recent advances in random matrix theory . Unl ike [47] which is based on exact random matrix th eory r esults and is applicable only for E [ I perf ( ρ ) − I stat ( ρ )] in the separable case, we generalize the results t o the canonical modeling framew ork, but do no t consider fine refinement of constants in t he following results for the sake of bre vity . Pr oposition 6: There exists a cons tant κ 3 such that ∆ I bf is given by ∆ I bf ≤ log 1 + ρ κ 3 · q N t log( N r ) N r E H [ I stat ( ρ )] . (33) The constant κ 3 is model- (separable or canonical) and regime- (proportional gro wth or relative asymptotics) d ependent. Simple bounds for κ 3 are as follo ws: 1) Λ t (1) 1 + κ 3 , 1 √ N t N r ρ c for the separable and relative asymptot ics case, 2) γ t, 1 + κ 3 , 2 √ N t N r for the canonical and relati ve asymptotics case, 3) κ 3 , 3 N r ρ c · Λ t (1) in the proporti onal gro wth sett ing for t he separable case, and 4) κ 3 , 4 N r for the canoni cal case. The constants κ 3 , i , i = 1 , · · · , 4 are independent of N t , N r , Σ t and Σ r . Pr oof: See Ap pendix E. D. Pr o portional Gr owth of Antenna Dimensi ons: Separable Case Theor em 3: Let H b e characterized b y the separable model. Let { M , N r } → ∞ with M N r → γ and γ ∈ (0 , ∞ ) . Let the follo wing conditions hold: 1) Λ t (1) Λ t ( M ) = O (1) , 2) Λ r (1) Λ t ( M ) = O (1) , 3) Λ r ( M ) Λ t ( M ) = O (1) , 4) P M k =1 Λ t ( k ) ρ c = b 1 = O (1) , and 5) P M k =1 Λ r ( k ) ρ c = b 2 = O (1) . If ρ ≥ α M Λ t ( M ) for SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 19 some α > 1 , ∆ I 2 is bounded as ∆ I 2 ≤ log( e/ M ) + κ 4 log( ρ/e ) + 1 M P M k =1 log Λ t ( k ) Λ r ( k ) ρ c (34) κ 4 = κ ′ 4 + min E H log λ max ( H H iid Λ r H iid ) G M , Λ r , E H log λ max ( H iid Λ t H H iid ) G M , Λ t (35) where κ ′ 4 depends only on the constant s in the statement of t he theorem, and G M , Λ • are the geometric means of eigen values, defined as G M , Λ r , M Y k =1 Λ r ( k ) ! 1 / M , G M , Λ t , M Y k =1 Λ t ( k ) ! 1 / M . (36) Pr oof: See Ap pendix F. E. Discussion It is of interest to understand th e structure of the scheme that is opt imal from a mutual information viewpoint for a gi ven channel. While many advances hav e been made along thi s direction (in particular , regarding the eigen vectors of the optim al input) [10], [11], [21], [23]– [32], a complete understanding is rendered difficult by the lac k of a comprehensive random matrix theory for correlated channels. Theorems 1-2 provide an alternative app roach, where we characterize the structure of H that is ‘best’ o r ‘worst’ for a given precoding scheme. Let us n ow freez e Λ r to be a fixed matrix s o as to develop an understanding of the structure of Λ t that minimi zes performance lo ss. Giv en that a constraint P N t i =1 Λ t ( i ) = ρ c has t o be met, it can be checked that performance loss in (30), (31) and (34) is minimized by the following choice: Λ t (1) = · · · = Λ t ( M ) = ρ c M and Λ t ( M + 1) = · · · = Λ t ( N t ) = 0 . On t he other extreme, the worst choice of Λ t that maxim izes the performance loss is of the form: Λ t (1) ≈ ρ c and Λ t ( i ) ≈ 0 , i ≥ 2 , b ut wit h the added constraint that rank ( Λ t ) ≥ M . It i s i mportant to not e that the lar gest gap 14 is not achieve d when ra nk ( Λ t ) = 1 . Motiva ted by Theorem 3, we define a matching metric fo r t he t ransmitter sid e : M t , M Y i =1 Λ t ( i ) , (37) that captu res the closeness of a gi ven channel from the best and worst channels (characterized above). As M t increases, the channel becomes more matched on the transmitt er side and t he performance loss decreases and vice versa . 14 In fact, i f rank ( Λ t ) = 1 , the statistical precoder achie ves the same throughput as the optimal precoder . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 20 Capturing the i mpact of Λ r on performance loss is difficult since Λ r is hidden in t he first-order analysis of Theorems 2 and 3. Nev ertheless, (30) shows that a matching metric for the r eceiver side can be defined as M r , N r X i =1 ( Λ r ( i )) 2 . (38) Again, wi th a constraint P N r i =1 Λ r ( i ) = ρ c to be met, it can be s een t hat M r is m inimized by Λ r = ρ c N r I N r and maxim ized by Λ r (1) ≈ ρ c and Λ r ( i ) ≈ 0 , i ≥ 2 , b ut wit h the added constraint th at rank ( Λ r ) ≥ M . It can be seen th at t he performance l oss is not maximized when rank ( Λ r ) < M . A channel that is m atched on both th e transmitter and the receiver s ides is referred to as a matched channel and is optimal for the given precoder structure (fixe d choice of M ). Th e structure of the matched channel can be summarized as: 1) The rank of Λ t is M with the dominant transmit eigen values being well-conditioned, and 2) Λ r is also well-conditi oned. A channel that is ill-cond itioned on both the transmi t and t he recei ve sides such that rank ( H ) ≥ M (with probability 1 ) is said t o be a mi smatched channel . An interesting cons equence of the study in Theorems 1 and 2 is that channel har dening, that occurs as N r increases, results i n t he vanishing of ∆ I semi . That is , st atistical inf ormation is as g ood as perfect CSI in the re ceive antenna as ymptotics. This beha vior is peculiar of this asymptotic regime and wil l also be observed in the error prob ability case. The high- SNR characterization for si gnaling with M spatial modes ( ρ ≥ α M Λ t ( M ) for som e α > 1 ) has also been identified in prior work [45]. V I . E R RO R P RO B A B I L I T Y E N H A N C E M E N T W I T H S E M I U N I TA RY P R E C O D I N G In this section, we study the (ave rage) relativ e error p robability enh ancement, ∆ P semi , with semiunitary precodin g in t he high- SNR regime. T o wards this goal, we first note th at ∆ P semi in (26) can be written 15 as ∆ P semi = E H " P M k =1 P k , stat , semi ( ρ ) − P k , p erf , uncon st ( ρ ) P M k =1 P k , p erf , uncon st ( ρ ) # (39) ( a ) ≤ E H " 1 M · M X k =1 P k , stat , semi ( ρ ) − P k , p erf , uncon st ( ρ ) P k , p erf , uncon st ( ρ ) # , (40) where (a) follows from Lemm a 9. 15 Note t hat ∆ P semi is independent of how error probability is defined: A veraged across data-streams or at least one data-stream in error . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 21 Pr oposition 7: The loss term, ∆ P semi , can be bounded as ∆ P semi ≤ E H 1 M · M X k =1 exp β 2 ∆ SINR k 2 q 1 + ∆ SINR k SINR k, stat , semi 1 − 1 β 2 SINR k, perf , unconst − 1 , (41) where ∆ SINR k , SINR k , p erf , uncon st − SINR k , stat , semi = 1 + Λ wf ( k ) λ k ( Λ t H H iid Λ r H iid ) ρ c − det I M + ρ M ρ c · e Λ 1 / 2 t e H H iid Λ r e H iid e Λ 1 / 2 t det I M − 1 + ρ M ρ c · b Λ 1 / 2 t b H H iid Λ r b H iid b Λ 1 / 2 t . See notations established in Sec. IV -A. Pr oof: See Ap pendix G. As i n Sec. V , we consider t he separable and canonical m odels for the relative antenna asymptotic case separately . A. Separable Model Theor em 4: In t he separable case, if ρ ≥ α M Λ t ( M ) for som e α > 1 , ∆ P semi can be b ounded as ∆ P semi ≤ 1 β 2 M M X k =1 1 ρ Λ t ( k ) M − 1 + β 2 1 + M α + β 2 ρ P M k =1 Λ t ( k ) M 1 α + 1 α 2 · E 1 Λ H ( M ) 2 E h 1 Λ H ( M ) i 2 + 1 γ r O √ N t + √ M √ N r ! . (42) Thus the dominant term of ∆ P semi in the relativ e antenna asympt otics and large α is o f the form: 1 β 2 ρ · P M k =1 1 Λ t ( k ) + β 2 P M k =1 Λ t ( k ) Λ t ( M ) . Pr oof: See Ap pendix H. B. Canonical Model W e characterize ∆ P 2 , the performance gap b etween the stati stical and perfect CSI s emiu- nitary precoders, alone for the sake of simplicity . Along the dev elopment of Theorem 4, it is straightforward to extend this result to ∆ P semi . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 22 Theor em 5: Let ρ ≥ α M γ t,M = α M P i σ 2 iM . The domi nant term of ∆ P 2 is bounded as ∆ P 2 ≤ β 2 ρ 2 α · P M k =1 γ t,k M + 1 β 2 ρ M X k =1 1 γ t,k + β 2 ρ 2 γ r · P M k =1 γ t,k M · O √ M + √ N t √ N r ! (43) = β 2 2 · P N r i =1 P M k =1 σ 2 ik P N r i =1 σ 2 iM + 1 β 2 αM · X i σ 2 iM · M X k =1 1 P i σ 2 ik . (44) Pr oof: The proof follows along the s ame li nes as Theorem 4 by app lying t he second part of Lemma 13 (see App. A). No explicit proof is provided. C. Special Case: Beamforming In the beamforming setting, our earlier w ork [14], [48] leverages adv ances in eigen vector perturbation theory to provide bounds on ∆ P bf , the gap in performance between statisti cal and perfect CSI beamforming. These result s are su mmarized in the following lemmas . Lemma 3: Let H be described by the separable mo del. Assume that Λ t (1) > Λ t (2) 1 + 2 γ r N η r for some η > 0 . T here exists a constant K 1 such t hat ∆ P bf ≤ K 1 · √ µ r, 2 Gap t γ r · s N t log( N r ) N r , (45) where µ r, 2 corresponds to the second mo ment of the recei ve eigen-mod es and Gap t corresponds to the separation between the t ransmit eigen-m odes, and are defined as µ r, 2 , P N r k =1 ( Λ r ( k )) 2 N r , Gap t , 1 − Λ t (2) Λ t (1) . (46) Lemma 4: Let H be described by the canonical model. If γ t, 1 N r > γ t, 2 N r + 2 N η r for some η > 0 , there exists a constant K 2 such t hat ∆ P bf ≤ K 2 · Gap c t · µ c r, 2 1 / 2 s N t log( N r ) N r , (47) where Gap c t and µ c r, 2 are d efined as Gap c t , 1 N t − 1 N t X k =2 N 2 r ( γ t, 1 − γ t,k ) 2 , µ c r, 2 , max j > 1 P i σ 2 ij σ 2 i 1 N r . (48) Thus in the asymptotics o f N r relativ e to N t , e ven channel statistical inform ation is suf ficient for near-perfec t CSI performance. Further , giv en a fixe d N t and N r , il l-conditionin g of Σ t and well-conditioni ng of Σ r reduces ∆ P bf . W e also p rovided evidence in [14], [48] that, of these two factors, the cond itioning of Σ t is more critical than t hat of Σ r . Theorems 4 -5 provide a multi-mo de generalization of these resul ts. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 23 D. Discussion As i n the mutual information case, we are int erested in channels that m inimize and maxim ize the perf ormance loss ∆ P semi . F rom (42) and (44), it is o bserved that the c hoice of Λ t that minimizes performance l oss is such that: 1) It minimizes Λ t ( k ) Λ t ( M ) , 1 ≤ k ≤ M , and 2) It also minimizes P M k =1 1 Λ t ( k ) . Both of these constraints are met by a channel that maxi mizes M t (as defined in (37) for the mu tual in formation c ase). That is, a channel that is matched on the transmitter s ide from a m utual in formation vi ewpoint is also mat ched on the t ransmitter s ide from an error probability vie wpoint . Howe ver , i t is di ffi cult to make similar conclusions about matching on the receiv er side. On the other hand, no te that as the constellation size increases, β decreases. Th us, for an y fixed ρ , the first dominant term of ∆ P semi in (42) and (44) increases as the const ellation si ze increases, wher eas the second term decreases. The tension between the two do minant terms determines the optimal choi ce of constellati on to use at a fixed SNR ov er a given channel . In the extreme case of asymptotically high SNR , th e first term vanishes and ∆ P semi is minimi zed with the lar gest constellation a vailable in the signaling set. T he optimality of a larger cons tellation at high- SNR from an error probabil ity vie wpoint is t o be intuitively expected. Further , as in the mutual information case, channel hardening result s i n vanishing ∆ P semi as N r increases. In the more realistic case of proportional growth of ant enna dim ensions, it is difficult to establish that ∆ SINR k → 0 as ρ → ∞ . W e pos tpone the s tudy of this case to future work. V I I . M S E E N H A N C E M E N T W I T H S TA T I S T I C A L P R E C O D I N G W e finally consider th e (ave rage) relative MSE enhancement. Define ∆ MSE as ∆ MSE , 1 M E H " M X k =1 MSE k , stat , semi − M SE k , perf , unconst MSE k , p erf , uncon st # . (49) The following proposit ion establishes the t rend of ∆ MSE un der certain settings . Pr oposition 8: In the recei ve antenna asymptoti cs case, if ρ ≥ α M Λ t ( M ) , ∆ MSE is bounded as ∆ MSE 1 + M α ≤ M α + M γ r · O √ M + √ N t √ N r ! + 1 M M X k =1 Λ t ( k ) Λ wf ( k ) − ρ M 1 + ρ Λ t ( k ) M . (50) As SNR increases, the dominant term of ∆ MSE is ∆ MSE ≤ M γ r · O √ M + √ N t √ N r ! . (51) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 24 Pr oof: Note t hat MSE k , • is defined as MSE k , • = 1 1+ SINR k, • and hence, we have ∆ MSE = M X k =1 E H ∆ SINR k 1 + SINR k , stat , semi . (52) Follo wing (130) and (131) in App endix H, (50) f ollows immediately in the recei ve antenna asymptotics case. While we expect ∆ MSE → 0 i n th e proport ional growth case also, we do not have a mathematical proof of this fact. This will be addressed in future work. V I I I . N U M E R I C A L S T U D I E S In this s ection, we illustrate the resul ts establis hed in th is paper via some n umerical studi es. W e consider 4 × 4 channels for our study where M = 2 data-streams are excited with: 1) Gaussian inputs for the mutual information case, and 2) QPSK inputs for the error probability case. In all the cases, the channel power is no rmalized t o N t N r = 16 . −25 −20 −15 −10 −5 0 5 10 15 20 25 0 2 4 6 8 10 12 14 16 18 20 SNR (dB) Average Mutual Information (nats/s/Hz) Perfect CSI, Matched Statistics, Matched Perfect CSI, Mismatched Statistics, Mismatched Fig. 1. Mutual information of the perfect CSI and the statistical semiunitary precoders ov er matched and mi smatched channels. • M atched vs. Mismatched Channels: The first study illustrates t he p erformance of s tatistical semiunitary precoding over matched and m ismatched channels. W e consider a 4 × 4 matched channel with normalized separable model, where diag ( Λ t ) = [8 8 0 0] . The mismatched SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 25 channel is characterized by diag ( Λ t ) = [4 4 4 4] . In both the cases, Λ r = 4 I 4 . Fig. 1 sho ws the av erage mutu al information with perfect CSI and st atistical semiuni tary precoding in the t wo chann els. As explained before, the m utual in formation in the four cases are given by: I matched , perf ( ρ ) = I matched , stat ( ρ ) = E " M X i =1 log 1 + ρ M N t M λ i ( e H H iid e H iid ) # (53) I mismatched , perf ( ρ ) = E " M X i =1 log 1 + ρ M λ i ( H H iid H iid ) # (54) I mismatched , stat ( ρ ) = E " M X i =1 log 1 + ρ M λ i ( e H H iid e H iid ) # , (55) where e H iid and H iid are N r × M and N r × N t i.i.d. m atrices. As can be seen from (53), (55) and Fig. 1, the performance o f the mismatched s tatistical precoder i s 10 log 10 N t M ≈ 3 dB away from bo th the matched precoders. It is also s urprising that the matched precoders hav e nearly the same performance as the mismatched (i.i.d. channel) optimal prec oder . This seems to be related to the choice of N t , N r , M and eigen-properties of i.i.d. rando m matrices. 15 20 25 30 35 40 45 50 55 60 0 0.05 0.1 0.15 0.2 0.25 Less Matched ← M t → More Matched ∆ I semi ρ = 10 dB ρ = 15 dB ρ = 20 dB 20 25 30 35 40 45 50 55 60 0 5 10 15 20 25 30 Less Matched ← M t → More Matched ∆ P semi ρ = 8 dB ρ = 10 dB (a) (b) Fig. 2. Gap in performance between statistical and perfect CSI semiunitary precoding as a fun ction of the matching metric, M t : (a) Mutual information and (b) Error probability . • P erformance Gap as a Fun ction of Matching Metric: The second study focuses on the gap in performance between the perfect CSI and t he stati stical precoders, as a function of SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 26 the degree of mat ching of th e channel to th e precoder st ructure. W e consider 4 × 4 channels with M = 2 , and freeze U t , U r to some arbitrary choice in our study . W e also freeze Λ r to 4 I 4 so as t o focus on the impact of matching on t he transmitter side. Note that the matching metric (defined in Sec. V -E), M t = Q M k =1 Λ t ( k ) , takes values i n the range (0 , 64] in our setting. A family of ∼ 1700 channels (each characterized uni quely by Λ t ( k ) , k = 1 , · · · , N t ) is generated such that P N t k =1 Λ t ( k ) = ρ c = 16 and M t takes values over its range. The channels become more matched (on the transmi tter side) to the precoder structure as M t increases. While much o f our s tudy in the preceding sections is based on asym ptotic random m atrix theory , Fig. 2 illust rates that th e no tion of matched channels developed in t his work is useful in chara cterizing performance, even in practically r elev ant regimes like 4 × 4 channels. Fig 2(a ) illustrates that ∆ I semi decreases as the channel becomes more matched on th e transmitter side for th ree choices of ρ , whereas Fig 2(b) il lustrates the same trend for ∆ P semi . Note that for a gi ven channel as ρ increases, ∆ I semi decreases wherea s ∆ P semi increases. This is because of the contrastin g beha viors of I stat , semi ( ρ ) and P err , perf , unconst ( ρ ) as ρ increases. It is important to note the following. In general, th ere exists no ordering relati onship between any two matrix channels [49]. Ne vertheless, Fig. 2 s hows that the relative (mutual information or error probabilit y) performance of two channels can be compared by u sing M t and M r . A channel th at is more matched leads to a smaller v alue of ∆ I • , as wel l as ∆ P • for any fixed SNR . • Asymp totic Optimali ty: The third s tudy illustrates the asympto tic o ptimality of stat istical precoding. Fig 3 plots ∆ I semi and ∆ P semi as a fun ction of N r with N t and M fixed at N t = 4 and M = 2 . The channels have separa ble correlation wit h Λ t = I 4 whereas Λ r = 4 N r I N r and hence, ρ c = 4 for all the channels. As can be seen from the st udy in the previous sections as well as the figures, channel hardening, where the eigen vectors of H H H con verge to the eigen vectors of Σ t = E [ H H H ] as N t N r → 0 ensures that even channel statist ical information is as good as perfect CSI wit h respect to performance. • L ow - and Medium- SNR Regimes: The last s tudy of this section studies the mut ual infor- mation performance of a statistical precoder in (21) when comp ared with a semiunit ary precoder in t he low- and the medium - SNR regimes. In the h igh- SNR regime, the optimal perfect CSI precoder excites t he M modes uniformly wit h equal po wer . Howe ver , in th e low- SNR regime, th e p erfect CSI precoder allocates power to the t ransmit eigen-mo des non- uniformly . The precoder structure in (21) excites th e M = 2 modes with power proportional to the t ransmit eigen values a nd hence, p erforms better th an the semi unitary precoder . Fig 4(a) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 27 10 1 10 −1 10 0 N r ∆ I semi ρ = 8 dB ρ = 14 dB ρ = 20 dB 10 1 10 −1 10 0 10 1 10 2 10 3 10 4 N r ∆ P semi ρ = 8 dB ρ = 14 dB ρ = 20 dB (a) (b) Fig. 3. Asymptotic optimality of t he statistical semiunitary precoder for fixed N t = 4 , M = 2 as N r increases: (a) Mutual information and (b) Error probability . −30 −25 −20 −15 −10 −5 0 4 6 8 10 12 14 16 18 20 SNR (dB) E[I • ] / SNR Perfect CSI, unconstrained Perfect CSI, semiunitary Statistical, prop. power Statistical, semiunitary −30 −25 −20 −15 −10 −5 0 4 6 8 10 12 14 SNR (dB) E[I • ] / SNR Perfect CSI, unconstrained Perfect CSI, semiunitary Statistical, prop. power Statistical, semiunitary x o (a) (b) Fig. 4. Low- and medium- SNR mutual information performance of the statist ical precoder in (21) when compared with the semiunitary precoder for a) separable and b) non-separable (canonical) models. shows the performance of t he statist ical precoder in a channel with separable correlation, while Fig. 4(b) corresponds t o a channel with non-separable correlation. In the s eparable case, th e t ransmit and the receive eigen va lues are given by diag ( Λ t ) = [9 . 80 5 . 66 0 . 45 0 . 09] and diag ( Λ r ) = [8 . 58 4 . 20 1 . 98 1 . 24] whereas in the canonical case the v ariance m atrix, SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 28 M = ( σ 2 ij ) , is given by M = 1 . 66 0 . 31 1 . 71 0 . 31 2 . 24 0 . 18 0 . 15 0 . 54 1 . 97 1 . 46 0 . 70 0 . 28 1 . 65 1 . 65 0 . 49 0 . 71 . (56) It is i nteresting to n ote that t he perfect CSI semi unitary precoder may either perform better or worse than that of the precoder in (21). Future work will l ook at this aspect m ore carefully . I X . C O N C L U D I N G R E M A R K S The main focus of this work is on precoding for spatially correlated m ulti-antenna channels that are often encountered in p ractice. Motiv ated and insp ired by man y recent wireless s tan- dardization ef forts, we proposed low-complexity structur ed pr ecoding techniques in this paper . Here, th e eigen-m odes of th e precoder are chosen to be t he d ominant eigen vectors of the transm it cov ariance matrix, whereas the power all ocation across the excited modes are obtained via certain simple, low-complexity methods. A special case of st ructured precoder is a semiunit ary precoder , where the spatial modes are excited with uniform power . In this work, we first establis hed the st ructure of the optimal perfect CSI st ructured precoder and sh owed th at it naturally extends the channel diagonali zing architecture of the perfect CSI unconstrained precoder . W e m otiv ated the need for a relative differe nce metric that captures the impact of lack of perfect CSI o n the precoder performance, ind ependent o f the operating SNR . W e then analytically characterized the a verage relative mut ual i nformation lo ss (as well as t he a verage relative uncoded error probability enhancement) of t he statistical semiunitary precoder using tools from random matrix and ei gen vector perturbation theories. Our results sho w that giv en a p recoder architecture (that is, fix ed antenna dimens ions and precoder rank), the relative difference metrics are mini mized b y a channel that is m atched to it. A matched channel is one t hat has: 1) The same number of dominant transm it eigen-modes as the precoder rank, and 2) The dominant transmit as well as the recei ve eigen-modes that are well-conditioned. Our theoretical study also characterizes matching metr ics that enable the comparison of two channels with respect to performance l oss captured by the relative diff erence metrics. In particular , as the channel becomes more matched to the precoder structure and the matching metrics chang e accordingly continuously , the performance loss decreases monotonically and vice versa . Numerical studies are provided to illustrate our results. Our w ork is a first attempt to analytically st udy the performance of lo w-complexity st atistical precoding with respect to a perfect CSI b enchmark. Much of this st udy has been rendered SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 29 possible du e to subs tantial advances i n capturi ng th e eigen-properties of random matrices with independent entries. Ne vertheless, there exist many directions a long wh ich thi s work can be dev eloped. W e no w list a few of t hese di rections. This work is l imited to t he high- SNR , large antenna asym ptotic regime where a com prehensive random matrix t heory is ava ilable to capture precoder performance [50]. Even in th is regime, it may be possible as in [47] to refine the constants in the bounds for the relative loss t erms and obtain further insi ghts on the impact of spatial correlation on performance lo ss. Besides that, in the case of proporti onal growth of ant enna dimensio ns with a non -separable correlation model, both mutual informati on as well as error probabi lity have not been characterized completely in this work. Lack of av ailabili ty of closed-form mutual information expressions for non-Gaussian inputs l imits the de velopment of t his work. The notion o f precoder-channel mat ching introd uced in this work can be de veloped further to aid in the design of low-complexity , structured and adaptiv e signalin g schemes. In the case o f mism atched channels, the construction of limited feedback s chemes t o bri dge th e gap in performance has been undertaken in [13], [51], [52]. The question of trade-offs between spatial versus spatio-temporal precoding [53] and extensions to more general Ricean fading [54], multi-us er [55], wi deband [56 ] systems are also of int erest. A P P E N D I X A. K e y Mat hematical Resu lts W e now introdu ce som e key mathem atical resul ts that will be needed in the ens uing proofs. Majoriza tion Theory: W e st art with a few results from majo rization theory [49]. Definition 1: Let a and b be two vectors in R m in non-increasing order 16 , i. e., a (1) ≥ · · · ≥ a ( m ) and b (1) ≥ · · · ≥ b ( m ) . Th en a is majo rized by b (deno ted b y a ≺ b ) if k X i =1 a ( i ) ≤ k X i =1 b ( i ) , 1 ≤ k ≤ m (57) with equality if k = m . Remark 1: For example, if m = 3 , any positiv e vector a such t hat P 3 i =1 a ( i ) = 1 satisfies the following majorization relationship: a low ≺ a ≺ a high (58) where a low = 1 3 1 3 1 3 and a high = [1 0 0] . Anot her example of a majorization relationshi p is provided by an m × m Hermiti an m atrix X , with m -dimensi onal vectors e and d denoting the 16 The non-increasing order for vectors results in ambiguity in a majorization relationship. T o resolv e this, in this section, we will assume that any two comparable vectors are always in the non-increasing order . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 30 eigen v alues and diagonal entries of X , respectively . W e hav e d ≺ e . From the definitio n, it can also be easily checked that if a ≺ b , then − a ≺ − b . Lemma 5: A matrix Q is sai d to be uni tary-stochastic if there exists a unit ary matrix Γ such that Q ( i, j ) = | Γ ( i, j ) | 2 [49, S ec. 2B.5, p. 23]. B y definition, a unitary-stochastic matrix i s doubly stochastic. If u ≺ v , there exists a uni tary-stochastic mat rix Q such that u = vQ . Definition 2: Let a and b be two vectors in R m in n on-increasing order . Th en a is weakly submajoriz ed by b (denoted by a ≺ w b ) if k X i =1 a ( i ) ≤ k X i =1 b ( i ) , 1 ≤ k ≤ m. (59) If the inequalit y i s in th e oppo site direction in (59), t hen a is weakly su permajorized by b and is denoted by a ≺ w b . Note that if a ≺ w b , then b ≺ w a and vice versa . Lemma 6: A vector a is submajorized by b if and onl y i f P g ( a ( i )) ≤ P g ( b ( i )) for all continuous, increasing con ve x functions g : R 7→ R . For su permajorization, replace g ( · ) by all continuous, decreasing con ve x functions. If g ( · ) is decreasing, con vex and a ≺ w b , we hav e [ g ( a (1)) · · · g ( a ( m ))] ≺ w [ g ( b (1)) · · · g ( b ( m ))] . (60) Pr oof: See [49, p. 10] for the first stat ement. For the second, see [49, p . 116 ]. Definition 3: A f unction f : A 7→ R wi th A ⊂ R m is said to be Schur -concave on A if { a , b } ∈ A and a ≺ b i mplies that f ( a ) ≥ f ( b ) . If howe ver , f ( a ) ≤ f ( b ) for all such a and b , f ( · ) is said to be Schur -con ve x on A . If a function is Schur-conca ve (or -con ve x) over R m , we just say t hat it is Schur-conca ve (or -con vex). Note that f ( · ) is Schur-conca ve if and only if − f ( · ) i s Schur-con vex. Remark 2: An example of Schur-con vex and Schur-conca ve functio ns is as follows. Let x = [ x 1 · · · x m ] with x i ≥ x i +1 . Consider the weighted arithmet ic mean of { x i } given b y f ( x ) = P m i =1 w i x i . The function f ( · ) is Schur -con vex if w i ≥ 0 and w 1 ≤ · · · ≤ w m . If w i ≥ 0 , but are i n t he reverse o rder , then f ( · ) is Schur -conca ve. See [9, Lemma 4] for proof of this claim . It is imp ortant to note that the sets of Schur-conca ve and Schur-c on vex functions neither partitio n nor cover the s pace of all function s, nor are they disjoi nt. Lemma 7: Let f : R 7→ R be a continuous con vex function. Then, P m i =1 f ( x i ) is Schur -con vex. That is, if u and v are two m × 1 vectors such that u ≺ v , then, P m i =1 f ( u ( i )) ≤ P m i =1 f ( v ( i )) . Let φ : R m 7→ R be Sc hur-con vex and the univ ariate function φ ( · · · , x i , · · · ) : R 7→ R be monotonicall y decreasing for all i . If a ≺ w b , we hav e φ ( a ) ≤ φ ( b ) . Pr oof: See [49, p. 11] for the first stat ement and [49, p. 59] for th e second. Lemma 8: Let f : R 7→ R be a continuous conv ex function. Then, max i =1 , ··· , m f ( x i ) is continuous and Schur-con vex. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 31 Pr oof: A composition of an increa sing, Schur -con ve x function with a con vex function results in a Schur -con ve x function [49, p. 63]. The p roof follows by noting that max i x i is a function that is increasing in its arguments and is Schur-c on vex. Lemma 9: Let { x i , i = 1 , · · · , K } and { y i , i = 1 , · · · , K } be two K -tuples such that { x i , y i } ≥ 0 for all i . Then, K X i =1 x i ≤ 1 K K X i =1 x i y i ! K X i =1 y i ! . (61) Pr oof: W e pro ve the lemma by induction. Consider the case K = 2 . W itho ut lo ss of generality , let x 1 ≤ x 2 and y 1 ≥ y 2 . W e therefore ha ve x 1 y 1 ≤ x 2 y 2 which impl ies that x 1 + x 2 ≤ x 1 y 1 y 2 + x 2 y 2 y 1 . (62) Adding x 1 + x 2 on bot h sides and rearranging, we see t hat the st atement is true for K = 2 . Let the statement be true for K = n − 1 for any ordering where x 1 ≤ · · · ≤ x n − 1 and y 1 ≥ · · · ≥ y n − 1 . W e will s how that the statement is true for the K = n case, where we augment t he ( n − 1) -t uples with x n and y n . Without los s of generality , we can assume that x 1 ≤ · · · ≤ x n and y 1 ≥ · · · ≥ y n after possible rearrangement and relabeling of i ndices. W e have n − 1 X i =1 x i + x n ( a ) ≤ 1 n − 1 n − 1 X i =1 x i y i ! n − 1 X i =1 y i ! + x n y n y n (63) ( b ) = 1 n n − 1 X i =1 x i y i ! n − 1 X i =1 y i ! + 1 n x n y n y n + 1 n ( n − 1) n − 1 X i =1 x i y i ! n − 1 X i =1 y i ! + n − 1 n · x n y n y n | {z } A (64) nA = n − 1 X i =1 x i y i − ( n − 1) x n y n ! · P n − 1 i =1 y i n − 1 − y n ! + y n n − 1 X i =1 x i y i ! + x n y n n − 1 X i =1 y i ! , where (a) fol lows from the induction hypothesis and (b) by breaking the sum into two p ieces. The st atement holds for K = n upon rearrangement after using the increasing and d ecreasing ordering assumption of x i and y i , respectiv ely . Matrix The ory: The P oincar e separation theor em connects the eigen values o f semiunit ary t rans- formations with those of th e transform ed mat rix [57 , Cor . 4.3. 16, p. 19 0]. Lemma 10: Let A be an n × n Hermiti an matrix. Let r be such that 1 ≤ r ≤ n and let w 1 , · · · , w r be a set of orthonormal v ectors in C n . Define B = W H A W where W = [ w 1 · · · w r ] . Let th e eigen va lues of A and B be arranged i n non-increasing order . Then, we hav e λ k ( B ) ≤ λ k ( A ) for all k = 1 , · · · , r . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 32 The following lemma p rovides boun ds for eigen values of sums and products of Hermitian matrices [57]. Lemma 11: If A and B are n × n Hermiti an mat rices, th en λ k ( A ) λ min ( B ) ≤ λ k ( AB ) ≤ λ k ( A ) λ max ( B ) , k = 1 , · · · , n, (65) λ k ( A ) + λ min ( B ) ≤ λ k ( A + B ) ≤ λ k ( A ) + λ max ( B ) , k = 1 , · · · , n. (66) W e also have n X k =1 λ k ( AB ) ≤ n X k =1 λ k ( A ) λ k ( B ) . (67) The foll owing lemma [58] helps in com puting t he determi nant of partitioned matrices. Lemma 12: If X , Y , Z and W are n × n matrices and W is in vertible, we have det X Y Z W = det( X − YW − 1 Z ) · det( W ) . (68) Random Matrix Theory: W e now characterize the eigen values o f certain families of random matrices. Lemma 13: Let X be a p × n com plex random matrix with i.i.d. entries of mean zero, comm on var iance 1 and a finite fourth m oment. Consider two cases: 1) p is finite and n → ∞ , and 2) { p, n } → ∞ with p/n → 0 . In either case, in the asymptot ics of n , the empirical eigen value distribution of XX H − n I p 2 √ np con verges pointwi se with prob ability 1 to the s emi-circular law F ( x ) where, F ( x ) = 0 if x < − 1 , R x y = − 1 2 π p 1 − y 2 d y if − 1 ≤ x ≤ 1 , 1 if x > 1 . (69) In particular , wit h p robability one, we have 1 − 2 r p n ≤ lim inf n λ min ( XX H ) n ≤ lim sup n λ max ( XX H ) n ≤ 1 + 2 r p n . (70) Let Λ be an n × n positiv e definite diagonal mat rix. Under the same assum ptions on X , p, n as above, there exists a finite constant γ 1 > 0 (dependent on p and n only through Λ ) such t hat, with probability 1 P i Λ ( i ) n − γ 1 r p n ≤ lim inf n λ min ( XΛX H ) n ≤ lim sup n λ max ( XΛX H ) n ≤ P i Λ ( i ) n + γ 1 r p n . SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 33 On the other hand, let X be a p × n com plex random matrix wit h independent entries from a fixed probabil ity sp ace s uch t hat X ( i, j ) is zero m ean, has v ariance σ 2 ij and sup n,p max ij E [ | X ( i, j ) | 4 ] ≤ γ 2 < ∞ . (71) Also, without lo ss of generality , assume that P n j =1 σ 2 ij are arranged i n decreasing order . Th en there exists a finite cons tant γ 3 > 0 (in dependent of p, n ) such that, for all i P n j =1 σ 2 ij n − γ 3 r p n ≤ lim inf n λ i ( XX H ) n ≤ lim sup n λ i ( XX H ) n ≤ P n j =1 σ 2 ij n + γ 3 r p n (72) with probability 1 . Pr oof: W e provide an elementary p roof of the claim when p i s finite, n → ∞ and X ( i, j ) are standard, complex Gaussian. Define the set A n , n ω : λ max ( X ( ω ) ΛX ( ω ) H ) n > 1 + ǫ 1 + ǫ 2 o . If we can show that P n Pr ( A n ) < ∞ , it fol lows from the Bore l-Cantelli lemma [59] that Pr (lim sup A n ) = 0 . By choosi ng ǫ 1 and ǫ 2 appropriately (as a functio n of n ), we can establish strict bounds on the eigen values. Breaking XΛX H into a diagonal component and an of f-diagonal component and using L emma 11, it follows via a union bound th at Pr ( A n ) ≤ p Pr P n i =1 ( | X (1 , i ) | 2 − 1) Λ ( i ) n > ǫ 1 + p 2 Pr | P n i =1 X (1 , i ) Λ ( i ) X (2 , i ) ⋆ | n > ǫ 2 . Using a Chernoff- type bo und [59], we ha ve t he following: Pr( A n ) ≤ p exp − ǫ 2 1 n 2 2 P n i =1 ( Λ ( i )) 2 + 2 p 2 exp − ǫ 2 2 n 2 c P n i =1 ( Λ ( i )) 2 (73) for some c > 0 . The smallest value o f ǫ 1 and ǫ 2 that can sti ll result in Pr (lim sup A n ) = 0 is such t hat ǫ 1 = O ( ǫ 2 ) = r P n i =1 ( Λ ( i )) 2 n · 1 n 1 / 2 − η , η > 0 . (74) Letting η ↓ 0 , we have lim sup λ max ( XΛX H ) n ≤ P n i =1 Λ ( i ) n + γ 4 r P n i =1 Λ ( i ) 2 n · 1 √ n , (75) where γ 4 > 0 is a constant independent o f p and n . Th e expression for λ min ( · ) is symmet ric with that of λ max ( · ) and can be obtained simil arly . The extension to the case where X has only independent entries (not necessarily complex Gaussian) also proceeds via the same l ogic. Since p → ∞ in Case 2), the abov e technique is not useful in establishi ng th e claim of the lemma. Here, the result follows from [60], [61, Theorem 2.9, p. 623]. The generalizations with Λ and independent entries fol low via the same proof technique as in [60] and hence no proofs are p rovided. The readers are referred t o [61] for a brief summ ary of t he general t echnique. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 34 B. Pr o ofs of Pr op. 1-4 Proof of Prop. 1: Let F be a fixed N t × M semiunit ary precoder and d efine B , I M + ρ M F H H H HF − 1 . (76) From (8), note that the vector MSE is the vector o f diagonal ent ries of B . Following Lemma 10, we hav e λ k F H H H HF ≤ λ k H H H for k = 1 , · · · , M . That is, the eigen values of B satisfy λ k ( B ) ≥ 1 1 + ρ M λ M − k +1 ( H H H ) , k = 1 , · · · , M . (77) Denote b y λ B the vector of eigen values of B . T he Schur-conca vity of f ( · ) and the f act that the di agonal ent ries of a Hermit ian m atrix are majorized by its eigen v alues when used wi th B results in f ( MSE ) ≥ f ( λ B ) . The mon otonicity of f ( · ) when combined with (77) impl ies t hat f ( M SE ) ≥ f · · · , 1 1 + ρ M λ M − k +1 ( H H H ) , · · · . (78) Note t hat the lower bound in (78 ) is independent of the choice of F , and hence, also serves as a univ ersal lowe r bound. Furthermore, the choice of F in (9) meets the lower bo und and is hence optimal. Proof of Prop. 2: Let F be a fixed semiunit ary matrix. Define the M × 1 v ectors d and e with d ( k ) , B ( k ) , where B = I M + ρ M F H H H HF − 1 and e ( k ) , 1 M P M i =1 1 1+ ρ M λ i ( F H H H HF ) , respectiv ely . Note that e ( k ) is equal for all k and hence, from Remark 1 we have d ≻ e . From Lemma 7, we have that P M k =1 h ( · ) is Schur-con vex. Hence, M X k =1 h ( d ( k )) ≥ M X k =1 h ( e ( k )) = M h ( e (1)) . (79) Using Lemma 10 and the in creasing prop erty of h ( · ) , we have M X k =1 h ( d ( k )) ≥ M h 1 M M X k =1 1 1 + ρ M λ k ( H H H ) ! . (80) Since the right-hand side of (80 ) is independent of the choice of F , i t serves as a lo wer bound on t he error probabi lity . Our go al is to show t hat the lowe r bound can be achiev ed and the choice of F that leads to the lower bound i s F opt . For this, let A be defined as A , 1 M P M i =1 1 1+ ρ M λ i ( H H H ) . Further , define t he two M × 1 vectors u and v such that u ( k ) = A for all k and v ( k ) = 1 1+ ρ M λ k ( H H H ) . Since u ≺ v , from Lemm a 5, there exists a unitary-stochastic matrix Q such that u = vQ with SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 35 Q ( i, j ) = | Γ ( i, j ) | 2 for som e Γ unitary . Consider the p recoder F as given in (12). The M SE across the data-streams with thi s p recoder i s giv en by MSE k = B − 1 k = I M + ρ M F H H H H F − 1 k (81) = I M + ρ M Γ H b Λ Γ − 1 k = Γ H I M + ρ M b Λ − 1 Γ k (82) with b Λ ( k ) = λ k ( H H H ) . From the definiti ons of Γ , v and the relationship u = vQ , i t is easy to check that MSE k = A for all k . Thus, with the choice of F as i n (12), we can achiev e the lower bound in (80). Proof of Prop. 4: For the Schur -concav e case, from Lemma 10 and (67), i t can be check ed that a ≺ w b , where a ( k ) = λ k ( Λ fixed V H F H H H V F ) and b ( k ) = Λ fixed ( k ) λ k ( H H H ) . Define g ( y ) = 1 1+ κy for some fix ed κ > 0 and note that g ( · ) is conv ex and decreasing. Thus, from Lemma 6 we ha ve g ( b ) ≺ w g ( a ) . Noting th at − f ( · ) is Schur-con vex and de creasing, from Lemma 7 we h a ve f ( g ( a )) ≥ f ( g ( b )) . This universal lower bound is achiev able by F opt as in (17). When f ( · ) is Schur-con vex, we proceed similar to the semiunitary case. Us ing g ( y ) = 1 1+ κy , from Lemma 6, we have M X k =1 g ( b ( k )) ≤ M X k =1 g ( a ( k )) . (83) Define u ( k ) = 1 M P M i =1 1 1+ ρ M Λ fixed ( i ) λ i ( H H H ) for all k and w ( k ) = 1 1+ ρ M Λ fixed ( k ) λ k ( H H H ) , and note that u ≺ w . That is, there exists a unitary-stochastic Q such that u = vQ . The result foll ows as before. C. Proof of Pr oposition 5 T o characterize th e behavior of ∆ I 1 , recall th e structure of the opti mal semiunitary precoder from Prop. 1 and note from Lemma 2 th at the perfect CSI unconst rained scheme corresponds to waterfilling along the first M dom inant transm it singular vectors. Thu s, we ha ve ∆ I 1 · E H [ I stat , semi ( ρ )] = E H " n H X i =1 log ( 1 + Λ H ( i ) Λ wf ( i )) − M X i =1 log 1 + ρ M Λ H ( i ) # , (84) where for each re alization H , n H modes are excited ( 1 ≤ n H ≤ M ) with po wer Λ wf ( i ) , µ H − 1 Λ H ( i ) + and the water leve l µ H is chosen s uch that P n H i =1 Λ wf ( i ) = ρ . It can be easily checked that Λ wf ( i ) can be written as Λ wf ( i ) = ρ n H + 1 n H n H X j =1 1 Λ H ( j ) − 1 Λ H ( i ) , (85) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 36 and n H is the largest value of k that satisfies: k X i =1 Λ H ( i ) − Λ H ( k ) Λ H ( i ) Λ H ( k ) ≤ ρ. (86) Hence, we hav e ∆ I 1 · E H [ I stat , semi ( ρ )] ≤ E H " n H X i =1 log 1 + ρ Λ H ( i )( M − n H ) n H M − 1 + Λ H ( i ) n H P n H j =1 1 Λ H ( j ) 1 + ρ Λ H ( i ) M !# . (87) Using the fact t hat log (1 + x ) ≤ x for all x > − 1 , after so me si mplifications we can further upper bound ∆ I 1 as ∆ I 1 · E H [ I stat , se mi ( ρ )] ≤ E H [ M − n H ] + M 2 ρ 2 · E H " M X i =1 1 Λ H ( i ) 2 # . (88) From (86), it is ea sily recognized that if ρ ≥ k Λ H ( k ) − P k i =1 1 Λ H ( i ) , and in p articular , if ρ ≥ k Λ H ( k ) , then n H ≥ k . T hus, if ρ > α E H h M Λ H ( M ) i for some α > 1 as in the statement of the theorem, both the terms in (88) can be bound ed by constants that depend only on the channel stat istics. For this no te th at, E H [ M − n H ] ≤ M · Pr( n H < M ) ≤ M · Pr M Λ H ( M ) > ρ (89) ≤ M · Pr 1 Λ H ( M ) > α E 1 Λ H ( M ) ( a ) ≤ M α 2 · E 1 Λ H ( M ) 2 E h 1 Λ H ( M ) i 2 , (90) where (a) fol lows from Chebyshev’ s inequality . A trivial upper bound for th e other term gives the desired result. D. Pr o of of Theor em 1 It can be checked th at f ∆ I 2 can be writt en as f ∆ I 2 = E H " P M k =1 log 1 + ρ M λ k ( H H H ) P M k =1 log 1 + ρ M λ k ( F H semi H H HF semi ) − 1 # (91) ( a ) ≤ E H " 1 M M X k =1 log 1 + ρ M λ k ( H H H ) log 1 + ρ M λ k ( F H semi H H HF semi ) − 1 # (92) ( b ) = 1 M M X k =1 E H log 1 + ρ M ρ c λ k ( Λ t H H iid Λ r H iid ) log 1 + ρ M ρ c λ k ( e Λ t e H H iid Λ r e H iid ) − 1 , (93) where (a) follows from Lemm a 9, and (b) from the n otations established in Sec. IV -A. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 37 Using Lemmas 1 1 and 13, we have the following in the li mit of N r , N t , M : f ∆ I 2 ≤ 1 M M X k =1 E H log 1 + ρ M ρ c Λ t ( k ) λ max ( H H iid Λ r H iid ) log 1 + ρ M ρ c Λ t ( k ) λ min ( e H H iid Λ r e H iid ) − 1 (94) ≤ 1 M M X k =1 E H log 1 + ρ M Λ t ( k ) 1 + κ 1 √ P i ( Λ r ( i )) 2 ρ c log 1 + ρ M Λ t ( k ) 1 − κ 1 √ P i ( Λ r ( i )) 2 ρ c − 1 (95) ≤ 2 κ 1 p P i ( Λ r ( i )) 2 ρ c · 1 M M X k =1 " 1 log 1 + ρ M Λ t ( k ) # , (96) where κ 1 is t he constant from an appl ication of Lem ma 13 in this sett ing. The l ast inequalit y follows by using the log-inequal ity and s ome trivial manipulations. The proof is complete. E. Pr o of of Pr opositi on 6 W e have the following well-known facts [42]: I perf ( ρ ) = log 1 + ρ λ max ( H H H ) , I stat ( ρ ) = log 1 + ρ N t X k =1 λ k | v H k u stat | 2 , (97) where u stat is an eigen vector correspond ing to the dominant eigen v alue of Σ t = E [ H H H ] , and an eigen-decomposition of H H H is of the form: H H H = P N t k =1 λ k v k v H k . The follo wing simplifications can then be made: E H [ I stat ( ρ )] · ∆ I bf = E H log 1 + ρ λ 1 − P k λ k | v H k u stat | 2 1 + ρ P k λ k | v H k u stat | 2 (98) ( a ) ≤ E H log 1 + ρ λ 1 (1 − | v H 1 u stat | 2 ) (99) ( b ) ≤ log 1 + ρ E H λ max ( H H H )(1 − | v H 1 u stat | 2 ) (100) ( c ) ≤ log 1 + ρ · q E H [(1 − | v H 1 u stat | 2 ) 2 ] · p E H [ λ 2 max ( H H H )] , (101) where (a) follows trivially by ignoring the contribution of k = 2 , · · · , N t in the summati on, (b) follows from Jensen’ s i nequality , and (c) from Cauchy-Schw arz i nequality . W e us e the eigen vector perturbation theory developed in [14] and in particular , the bound i n [14, Eqn. (16)] to establish that E H (1 − | v H 1 u stat | 2 ) 2 ≤ κ ′ 3 N t log( N r ) N r (102) for som e appropriate constant κ ′ 3 that is independent of the channel stati stics and d imensions. Using Lemma 11 and Lemm a 13, the conclu sion in (33) foll ows for the relative asymptotics case. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 38 For the proportional g rowth case, an upper bou nd needs to be establi shed for E H λ 2 max ( H H H ) . See [62] for an upper bound technique that builds o n the work by [63], which results in the statement of the theorem. F . Pr oof o f Theor em 3 As i n App. D, we can writ e ∆ I 2 as ∆ I 2 = E H [ I perf , semi ( ρ )] E H [ I stat , semi ( ρ )] − 1 (103) = E H h P M k =1 log 1 + ρ M λ k ( H H H ) i E H h P M k =1 log 1 + ρ M ρ c λ k ( e Λ t e H H iid Λ r e H iid ) i − 1 . (10 4) The denominato r of (104) can be computed following the m ethod in [50, Theorem 1] and equals E H [ I stat , semi ( ρ )] = M X k =1 log 1 + ρ ρ c µ 1 Λ t ( k ) + M X k =1 log 1 + ρ ρ c e µ 1 Λ r ( k ) − ρM ρ c µ 1 e µ 1 , (105) where µ 1 and e µ 1 satisfy the recursive equations µ 1 = 1 M M X k =1 Λ r ( k ) 1 + ρ ρ c e µ 1 Λ r ( k ) , e µ 1 = 1 M M X k =1 Λ t ( k ) 1 + ρ ρ c µ 1 Λ t ( k ) . (106) A s imple lower bound for E H [ I stat , semi ( ρ )] is obtained by using log (1 + x ) ≥ log( x ) for x > 0 : E H [ I stat , semi ( ρ )] ≥ M X k =1 log ρ 2 ρ 2 c e µ 1 e µ 1 Λ t ( k ) Λ r ( k ) . (10 7) W e now establish that the abov e bound is order-optimal as α increases (with ρ = α M Λ t ( M ) ), by lower bounding µ 1 e µ 1 . W e can easily show t hat µ 1 ≥ ρ c M · b 2 1 + α b 1 Λ r (1) Λ t ( M ) , e µ 1 ≥ ρ c M · b 1 1 + α b 2 Λ t (1) Λ t ( M ) , (108) and hence, 1 ≥ ρ ρ c µ 1 e µ 1 ≥ αC 1 1 + α ( C 1 + C 2 ) , (109) where C 1 = b 1 Λ r ( M ) Λ t ( M ) and C 2 = b 2 Λ t (1) Λ t ( M ) . T ightness o f the bound i n (107) foll ows from using the fact that log(1 + x ) ≤ log ( x ) + 1 x , x > 0 . Combining the above relationships, w e hav e E H [ I stat , semi ( ρ )] ≥ M log ραC 1 e (1 + α ( C 1 + C 2 )) + M X k =1 log Λ t ( k ) Λ r ( k ) ρ c . (110) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 39 Proceeding in the same way , one ca n obt ain an upper bound for E H [ I perf , semi ( ρ )] . Since t he main goal here i s to obtain t he trends of ∆ I 2 , we find it con venient and less cumbersome to replace the u pper bou nd with an app roximation ( log (1 + x ) ≈ log( x ) ) b y ignoring the term that decays as 1 x . Thu s, we hav e E H [ I perf , semi ( ρ )] ≈ M log ρ M + E H " M X k =1 log λ k ( Λ t H H iid Λ r H iid ) ρ c # (111) ( a ) ≤ M lo g ρ M + min( A, B ) (112) A = M E H log λ max ( H H iid Λ r H iid ) ρ c + M X k =1 log ( Λ t ( k )) (113) B = M E H log λ max ( H iid Λ t H H iid ) ρ c + M X k =1 log ( Λ r ( k )) , (114) where in (a) we ha ve used Lemma 10. Combi ning (110) and (112), we hav e the st atement of the theorem. G. Pr o of of Pr opositi on 7 First, we write ∆ P semi in terms of SINR of the individual data-streams by using P k , • = α Q β ( SINR k , • ) 1 / 2 and the expression for SI NR k , • in (8). Then, we use the following bound for Q ( x ) : exp( − x 2 / 2) x √ 2 π 1 − 1 x 2 ≤ Q ( x ) ≤ exp( − x 2 / 2) x √ 2 π (115) to establish the expression i n (41 ). It is straight forward to check that SINR k , p erf , uncon st = Λ wf ( k ) λ k ( H H H ) , (116) where the waterfilling p ower allocation { Λ wf ( k ) } i s as in (85) (see Ap p. C) and normalized t o M X k =1 Λ wf ( k ) = ρ. (117) Similarly , we h a ve SINR k , stat , semi = 1 [ G − 1 ] k − 1 = det( G ) [adj( G )] k − 1 , (118) G = I M + ρ M F H semi H H HF semi = I M + ρ M ρ c · e Λ 1 / 2 t e H H iid Λ r e H iid e Λ 1 / 2 t . (119) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 40 The matrix adj( G ) refers t o the adjoint of G , and [ G − 1 ] k and [adj( G )] k refer to the k -th diagonal entries o f G − 1 and a dj ( G ) , respecti vely . Using the definition of adjoint of a m atrix, we hav e [adj( G )] k = det I M − 1 + ρ M ρ c · b Λ 1 / 2 t b H H iid Λ r b H iid b Λ 1 / 2 t , (120) where b Λ t and b H iid are as per the no tations establish ed in Sec. IV -A. The expression for ∆ SINR k in the statement of th e propos ition follows immediately . H. Pr o of of Theor em 4 W e have the following upper bound for SINR k , p erf , uncon st : SINR k , p erf , uncon st = Λ wf ( k ) · λ k Λ t H H iid Λ r H iid ρ c (121) ( a ) ≤ Λ wf ( k ) Λ t ( k ) · λ max ( H H iid Λ r H iid ) ρ c , (122) where (a) follo ws from Lemma 11. T o compute SINR k , stat , semi , note t hat det( G ) , where G is as in (119) can be written as det( G ) = M Y j =1 1 + ρ M ρ c · λ j ( e Λ t e H H iid Λ r e H iid ) (123) ( a ) ≥ M Y j =1 1 + ρ M ρ c · Λ t ( j ) λ min ( e H H iid Λ r e H iid ) , (124) with (a) following from Lemma 11. Simil arly , we ha ve [adj( G )] k = M − 1 Y j =1 1 + ρ M ρ c · λ j ( b Λ t b H H iid Λ r b H iid ) (125) ≤ M Y j =1 , j 6 = k 1 + ρ M ρ c · Λ t ( j ) λ max ( b H H iid Λ r b H iid ) . (126) Using Lemma 13 from App. A in (118) and (12 2), th e following bounds h old with probabi lity 1 (in the lim it of N r , N t , M ) for SINR k , p erf , uncon st and SINR k , stat , semi : SINR k , p erf , uncon st ≤ Λ wf ( k ) Λ t ( k ) · 1 + C 1 γ r r N t N r ! , (127) 1 + SINR k , stat , semi ≥ Q M j =1 1 + ρ M · Λ t ( j ) 1 − C 1 γ r q M N r Q M j =1 , j 6 = k 1 + ρ M · Λ t ( j ) 1 + C 1 γ r q M − 1 N r (128) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 41 for some un iv ersal constant C 1 obtained from Lemm a 13. If ρ is such that ρ ≥ α M Λ t ( M ) , we can trivially lower bound SINR k , stat , semi as 1 + SINR k , stat , semi ≥ 1 + ρ M Λ t ( k ) 1 − C 1 γ r r M N r !! 1 + 1 α − C 1 γ r q M N r 1 + 1 α + C 1 γ r q M − 1 N r M − 1 (129) ( a ) ≥ 1 + ρ M Λ t ( k ) 1 − C 1 γ r r M N r !! · 1 + ( M − 1) 1 α − C 1 γ r q M N r 1 + 2( M − 1) 1 α + C 1 γ r q M − 1 N r , (130) where (a) follows from the fac t that 1 + ax ≤ (1 + x ) a ≤ 1 + 2 ax for x sufficiently small and a > 0 . After som e rout ine m anipulation s, ∆ SINR k can be bounded as ∆ SINR k ≤ M 1 α + 3 C 1 γ r r M N r ! + Λ t ( k ) Λ wf ( k ) − ρ M 1 + C 1 γ r r N t N r ! + ρ M Λ t ( k ) M α 1 + C 1 γ r √ N r (2 p N t + √ M ) + C 1 γ r √ N r (3 M √ M + p N t ) = M α 1 + ρ Λ t ( k ) M + Λ t ( k ) · Λ wf ( k ) − ρ M + ρ Λ t ( k ) γ r · O √ M + √ N t √ N r ! . (131) W e now use th e facts th at √ 1 + x ≤ 1 + x 2 for any x positive , and 1 1 − x is upper bounded by 1 + 2 x as long as x < 1 2 for the terms q 1 + ∆ SINR k SINR k, stat , semi and 1 1 − 1 β 2 SINR k, perf , unconst , respecti vely . The term exp β 2 ∆ SINR k 2 is b ounded by u sing the fa ct that e x can be bounded by 1 + ax for som e a > 1 in the s mall x regime. The com bination of the above facts yi elds ∆ P semi ≤ 1 M β 2 E H " M X k =1 1 Λ t ( k ) Λ wf ( k ) # + β 2 M α + β 2 M E H " M X k =1 Λ t ( k ) Λ wf ( k ) − ρ M # + ρβ 2 P M k =1 Λ t ( k ) M 1 α + 1 γ r O √ N t + √ M √ N r !! (132) up t o a constant scalin g mult iplicative cons tant on the ri ght side. For the first term, w e lo wer bound Λ wf ( k ) from (85) by Λ wf ( k ) ≥ ρ n H − 1 Λ H ( k ) ( a ) ≥ ρ M − 1 Λ t ( k ) 1 − C 1 γ r q N t N r , (133) where (a) follows from Lemm a 13. For the thi rd term, we h a ve E H " M X k =1 Λ t ( k ) Λ wf ( k ) − ρ M # ≤ M + ρ M X k =1 Λ t ( k ) · E H 1 n H − 1 M . (134) SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 42 Finally , we hav e E H 1 n H − 1 M ≤ 1 − 1 M Pr( n H < M ) ≤ 1 α 2 · E 1 Λ H ( M ) 2 E h 1 Λ H ( M ) i 2 , (135) where the second inequality foll ows from the bo und in (90). Combining th ese facts, we have ∆ P semi ≤ 1 β 2 M M X k =1 1 ρ Λ t ( k ) M − 1 + β 2 (1 + M α ) + β 2 ρ P M k =1 Λ t ( k ) M 1 α + 1 α 2 · E 1 Λ H ( M ) 2 E h 1 Λ H ( M ) i 2 + 1 γ r O √ N t + √ M √ N r ! (136) Thus the proof is comp lete. R E F E R E N C E S [1] K. H. Lee and D. P . P etersen, “Optimal Linear Coding for V ector Channels, ” IEEE T ran s. Commun. , vol. 24, no. 12, pp. 1283–1 290, Dec. 1976. [2] J. Salz, “Digital T ransmission over Cross-Coupled Linear Channe ls, ” A T&T T ech . J ournal , vol. 64, no. 6, pp. 1147–1159, July-Aug. 1985. [3] J. Y ang and S. Roy , “ On Joint T ransmitter and R ecei ver Optimization f or Multiple-Input-Multiple-Output ( MIMO) T ransmission Systems, ” IE EE T ra ns. Commun. , vol. 42, no. 12, pp. 3221–32 31, Dec. 1994. [4] A. Scaglione, G. B. Giannakis, and S. Barbarossa, “Redundant Fi lterbank Precoders and Equalizers Part I: Unifi cation and Optimal Designs, ” IEEE T rans. Sig. Pro c. , vol. 47, no. 7, pp. 1988– 2006, July 1999. [5] H. Sampath, P . Stoica, and A. Paulraj, “Generalized Linear Precoder and Decoder Design for MIMO Channels Using the W eighted MMSE Criterion, ” IEEE T rans. Commun. , vol. 49, no. 12, pp. 2198–2206 , Dec. 2001. [6] H. Sampath and A. Paulraj, “Linear Precoding for Space-T ime Coded Systems with Kno wn Fading Correlations, ” IEEE Commun. Letters , vol. 6, no. 6, pp. 239–241, June 2002. [7] J. Y ang and S. Roy , “Joint T ransmitter-Receiv er Optimization for Multi-input Multi-output Systems with Decision Feedback, ” IEEE T rans. Inform. Theory , vol. 40, no. 5, pp. 1334–1347, Sept. 1994. [8] A. Scaglione, P . Stoica, S. Barbarossa, G. B. Giannakis, and H. Sampath, “Optimal Designs for Space-T ime Linear Precoders and Decoders, ” IEEE T rans. Sig. Pro c. , vol. 50, no. 5, pp. 1051–106 4, May 2002. [9] D. P . Palomar , J. M. Cioffi, and M. A. Lagunas, “Joint T x-Rx Beamforming Design for Multicarrier MIMO Channe ls: A Unified Framewo rk for Con vex Optimi zation, ” IEEE T rans. Sig. Pro c. , vol. 51, no. 9, pp. 2381–24 01, Sept. 2003. [10] A. J. Goldsmith, S. A. Jafar , N. Jindal, and S. V ishwanath, “Capacity Limits of MIMO C hannels, ” IEE E Journ. Selected Ar eas in Commun. , vol. 21, no. 5, pp. 684–70 2, June 2003. [11] D. Gesbe rt, H. Bolcskei, D. A. Gore, and A. J. Pa ulraj, “Outdoor MIMO W i reless Channels: Mo dels and Performance Prediction, ” IEEE T rans. Commun. , vol. 50, no. 12, pp. 1926–1934, D ec. 2002. [12] D. J. Love and R. W . Heath, Jr ., “ Limited F eedback Dive rsity T echniques for Correlated Channels, ” IEEE Tr ans. V eh. T ech . , vol. 55, no. 2, pp. 718–722, Mar . 2006. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 43 [13] V . Raghav an, V . V . V eerav alli, and A. M. S ayeed, “Quantized Multimode Precoding in Spatially C orrelated Multi-Antenna Channels, ” Submitted to IEEE T rans. Sig . Proc . , Dec. 2007, A v ailable: [Onli ne]. http://www.ifp. uiuc.edu/ ∼ vasant h . [14] V . Raghav an, R. W . Heath, Jr . , and A. M. Sayeed, “Systematic Codebook Designs for Quantized Beamforming in Correlated MIMO Channels, ” IEEE Jou rn. Selected Ar eas in Commun. , vol. 25, no. 7, pp. 1298–13 10, Sept. 2007. [15] R. W . Ke yes, “Physical Limits in Digital Electronics, ” Proc . IEEE , vol. 63, no. 5, pp. 740–767, May 1975. [16] J. D. Meindl and J. A. Dav is, “ The F undamental Li mit on B inary Switching Energy for T erascale Integration (TS I), ” IE EE J ourn. Solid State Ci r cuits , vol. 35, no. 10, pp. 1515–1 516, Oct. 2000. [17] J. Rabaey , A . Chandrakasan, and B. Nikolic, Digitial Inte gra ted Circ uits: A Design P erspective , Prentice Hall, 2nd edition, 2003. [18] B. R azavi, RF Micr oelectr onics , Pr entice Hall, Upper Saddle Riv er , NJ, 1998. [19] P . G. Y -Massaad, M. Medard , and L. Zheng, “Impact of Processing Energy on the Capacity of Wireless Channels, ” Pr oc. IEEE Intern. Symp. on Inform. Theory and its Appl. (ISIT A) , 2004. [20] A. M. S ayeed and V . V . V eerav alli, “Essential Degrees of Freedom i n Space-T ime Fading Channels, ” Proc. IEEE Intern. Symp. P ersonal Indoor and Mobile Radio Commun. , vol. 4, pp. 1512–1516, S ept. 2002. [21] V . V . V eerav alli, Y . Liang, and A. M. Sayeed, “Correlated MIMO Rayleigh Fading C hannels: Capacity , Optimal Signaling and Asymptotics, ” IEEE T rans. Inform. T heory , vol. 51, no. 6, pp. 2058–20 72, June 2005. [22] A. S. Y . P oon, R. W . Brodersen, and D. N. C. Tse, “Degrees of F reedom i n Multiple-Antenna Channels: A Signal Space Approach, ” IEEE T rans. I nform. Theory , vol. 51, no. 2, pp. 523–5 36, Feb . 2005. [23] E. V isotsky and U. Madhow , “Space-Time Trans mit Precoding with Imperfect Feedback, ” IEEE T rans. Inform. T heory , vol. 47, no. 6, pp. 2632–26 39, Sept. 2001. [24] S. A. Jafar and A. J. Goldsmith, “Tran smitter Optimization and Optimality of Beamforming for Multiple Antenna Systems with Imperfect Feedback, ” IEEE T rans. W ire less Commun. , vol. 3, no. 4, pp. 1165–11 75, July 2004. [25] E. Jorswieck and H. Boche, “Channel Capacity and Capacity-Range of Beamforming in MIMO W ireless Systems under Correlated Fading with Cov ariance Feedback, ” IEEE Tr ans. W ire less Commun. , vol. 52, no. 10, pp. 1654–1657, Oct. 2004. [26] A. L. Moustakas, S . H. Si mon, and A. M. Sengupta, “MIMO C apacity through Correlated Channels i n the P resence of Correlated Interferers and Noise, ” IEEE T rans. Inform. Theory , vol. 49, no. 10, pp. 2545– 2561, Oct. 2003. [27] S. Zhou and G. B. G iannakis, “Optimal T ransmitter E igen-Beamforming and Space-T ime Bl ock Coding Based on Channel Mean Feedback, ” IEEE T rans. Sig . Pro c. , vol. 50, no. 10, pp. 1599–16 13, Oct. 2002. [28] A. M. T ulino, A. Lozano , and S. V erd ´ u, “Impact of Antenna Correlation on the Capacity of Multiantenna Chan nels, ” IEEE T ran s. Inform. T heory , vo l. 51, no. 7, pp. 2491–2509, July 2005. [29] H. V enkatachari and M. V aranasi, “Maximizing Mutual Information in General MIMO Fading Channels under Rank Constraint, ” Proc . IEEE Asilomar Conf. Signals, Systems and Computers , Nov . 2007. [30] X. Zhang , D. P . Palomar , and B. Ottersten, “Robust Design o f Li near MIMO T ranscei vers, ” T o appear in IEEE T rans. Sig. P r oc. , 2008. [31] M. Skog lund and G. Jongren, “On t he Capacity of a Multiple-Antenna Communication Li nk with Channel Side Information, ” IEEE Jou rn. Selected Ar eas in Commun. , vol. 21, no. 3, pp. 395–405 , Apr . 2003. [32] J. Akhtar and D. Gesbert, “Spatial Multiplexing over Correlated MIMO Channels with a Cl osed Form P recoder, ” IE EE T ran s. W ir eless Commun. , vol. 4, no. 5, pp. 2400–24 09, Sept. 2005. [33] W . W eichselber ger , M. Herdin, H. Ozcelik, and E. Bonek, “A Stochastic MIMO Channel Model with Joint Correlation of Both Link Ends, ” IEE E T rans. W i r eless Commun. , vo l. 5, no. 1, pp. 90–100 , Jan. 2006. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 44 [34] V . Raghav an, J. H. K otecha, and A. M. S ayeed, “Canonical Statisti cal Models for Correlated MIMO Fading Channels and Capacity Analysis, ” Submitted to IEEE T rans. Info rm. Theory , Nov . 2007, A vailable: [Online]. http://www .ifp.uiuc.edu / ∼ vasanth . [35] C.- N. Chuah, J. M. Kahn, and D. N. C. Tse, “Cap acity Scaling in MIMO Wireless Systems under C orrelated Fading, ” IEEE T ran s. Inform. T heory , vo l. 48, no. 3, pp. 637–650, Mar . 2002. [36] A. M. Sayeed, “Deconstructing Multi-Antenna Fading Channels, ” IEEE T rans. Sig. Pr oc. , vol. 50, no. 10, pp. 2563 –2579, Oct. 2002. [37] D. J. L ov e, R. W . Heath, Jr ., W . Santipach, and M. L. Honig, “What is the V alue of Limited Feedback for MIMO Channels?, ” IEEE Commun. Magaz. , vol. 42, no. 10, pp. 54–59, Oct. 2004. [38] K. Y u, M. Bengtsson, B. Ot tersten, D. McNamara, P . Karlsson, and M. Beach, “S econd Order St atistics of NLOS indoor MIMO Channels based on 5.2 GHz Measure ments, ” Pr oc. IEE E Global T elecommun. Conf. , vol. 1, pp. 25–29, Nov . 2001 . [39] H. Ozcelik, M. Herdin, W . W eichselberger , J. W allace, and E. Bonek, “Deficienc ies of ’Kronecker’ MIMO Radio Channel Model, ” Electr onics Letters , vol. 39, no. 16, pp. 1209– 1210, Aug. 2003. [40] J. W allace, H. Ozcelik, M. Herdin, E. Bonek, and M. Jensen, “Po wer and Complex Env elope Correlation for Modeling Measured Indoor MIMO Channels: A Beamforming Ev aluation, ” Pr oc. IE EE F all V ehicular T echnolo gy Conf. , vol. 1, pp. 363–36 7, Oct. 2003. [41] Y . Zhou, M. Herdin, A. M. Sayeed, and E. Bonek, “Experimental Study of MIMO C hannel Statistics and Capacity via the V irtual Represen tation, ” T ech. Rep ., Uni ve rsity of Wiscon sin-Madison, Ma y 20 06, A v ailable: [Online]. http://dun e.ece.wisc.ed u . [42] A. Paulraj, R. Nabar , and D. Gore, Introd uction to Space-T im e W ir eless Communications , C ambridge Univ . Press, 2003. [43] D. J. Love and R. W . Heath, Jr ., “Multimode Precoding for MIMO Wireless Systems, ” IEEE Tr ans. Sig. Proc. , vol. 53, no. 10, pp. 3674–368 7, Oct. 2005. [44] J. G. P roakis, Digit al Communications , McGraw-Hill, 4th edition, 2000. [45] V . Raghav an, V . V . V eerav alli, and R. W . Heath, Jr ., “Reduced Rank Signaling in Spatially Correlated MIMO Channels, ” Pr oc. IEEE Intern. Symp. Inform. Theory , 2007. [46] D. Guo, S. S hamai, and S. V erd ´ u, “Mutual Information and Minimum Mean-Square Error in Gaussian Channels, ” IEEE T ran s. Inform. T heory , vo l. 51, no. 4, pp. 1261–1282, Apr 2005. [47] A. Forenz a, M. Mckay , A. Pandharipande, R. W . Heath, Jr ., and I. B. Collings, “Adapti ve MIMO Transmission for Exploiting the Capacity of S patially Correlated MIMO Channels, ” IEE E Tr ans. V eh. T ech. , vol. 56, no. 2, pp. 619–630, Mar . 2007. [48] V . Ragha van , A. M. Sayeed, and N. Boston, “Near -Optimal Codeboo k Constructions for Limited Feedback Beamforming in Correlated MIMO Channels with Few Antennas, ” Pro c. IEEE Intern. Symp. Inform. Theory , pp. 2622–2626, July 2006 . [49] A. W . Marshall and I. Olkin, Inequalities: Theory of Majorization and it s Applications , Academic Press, NY , 1979. [50] W . Hachem, O. Khorunzhiy , Ph. Loubaton, J. Najim, and L . Pastur , “A Ne w Approach for Capacity Analysis for Large Dimensional Multi-Antenna Channels, ” T o appear in IEEE T rans. Inform. Theory , 2008. [51] J. C. Roh and B. D. R ao, “Multiple Antenna Channels with Partial Channel State Information at the T ransmitter, ” I EEE T ran s. W ir eless Commun , vol. 3, no. 2, pp. 677–68 8, Mar . 2004. [52] V . K. N. Lau, Y . Liu, and T . A. Chen, “On the Design of MIMO Bl ock Fading Channels with Feedback Link Capacity Constraint, ” IEEE T rans. Commun. , v ol. 52, no. 1, pp. 62–70, Jan. 2004. SUBMITTED TO THE IEEE TRANSA CTIONS ON INFORMA TION THEOR Y 45 [53] C. Lin, V . Raghav an, and V . V . V eerav alli , “T o Code or N ot to Code Across T ime: Space-Time Coding with Feedback, ” T o appear in IEEE Journ . Selected A r eas in Commun. , 2008. [54] G. T aricco, “On the Capacity of Separately-Correlated MIMO Rician Fading Channels, ” Pr oc. IEEE Gl obal T elecommun. Conf. , 2006 . [55] N. Jindal, “MIMO Broadcast Chan nels with Finite Rate Feedback, ” IEEE T ran s. Inform. Theor y , vol. 5 2, no. 11, pp. 5045–5 059, Nov . 2006. [56] N. Khaled, B . Mondal, R. W . Heath, Jr ., G. Leus, and F . P etre, “Interpolation Based Multi-Mode Precoding for MIMO- OFDM Systems with Limited Feedback, ” IEE E T rans. W i r eless Commun. , vol. 6, no. 3, pp. 1003–1 013, Mar . 2007. [57] R. A. Horn and C. R. Johnson, Matrix Analysis , Cambridge Univ ersity Press, 1985. [58] J. R. Silvester , “Determinants of Block Matrices, ” T he Mathematical Gazette , vo l. 84, no. 501, pp. 460–46 7, Nov . 2000. [59] R. A. Durrett, Pr obability: Theory and Examples , Duxbury Press, 2nd edition, 1995. [60] Z. D. Bai and Y . Q. Y in, “Conv ergen ce to the Semi-Circle Law, ” Annals Pr ob . , vol. 16, no. 2, pp. 863–87 5, 1988. [61] Z. D. Bai, “Methodologies in Spectral Analysis of Lar ge Dimensional Random Matrices, A Revie w, ” Statistica Sinica , vol. 9, pp. 611–67 7, 1999. [62] V . Ragha van and A. M. Sayeed, “Role of Channel Power in the Sub-Linear Capacity S caling of MIMO Channels, ” Proc . Allerton Conf. on Commu n., Contr ol, and Computing , 2004, A vailable: [Online]. http://ww w.ifp.uiuc.ed u/ ∼ vasanth . [63] Y . Q. Y in, Z . D. Bai, and P . R . Krishnaiah, “On Limit of the Largest Eigen va lue of the Large Dimensional Sample Cov ariance Matrix, ” Pro bability Theory and Related Fields , vol. 78, pp. 509–52 1, 1988.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment