Monte Carlo Methods in Statistics
Monte Carlo methods are now an essential part of the statistician's toolbox, to the point of being more familiar to graduate students than the measure theoretic notions upon which they are based! We recall in this note some of the advances made in th…
Authors: Christian P. Robert
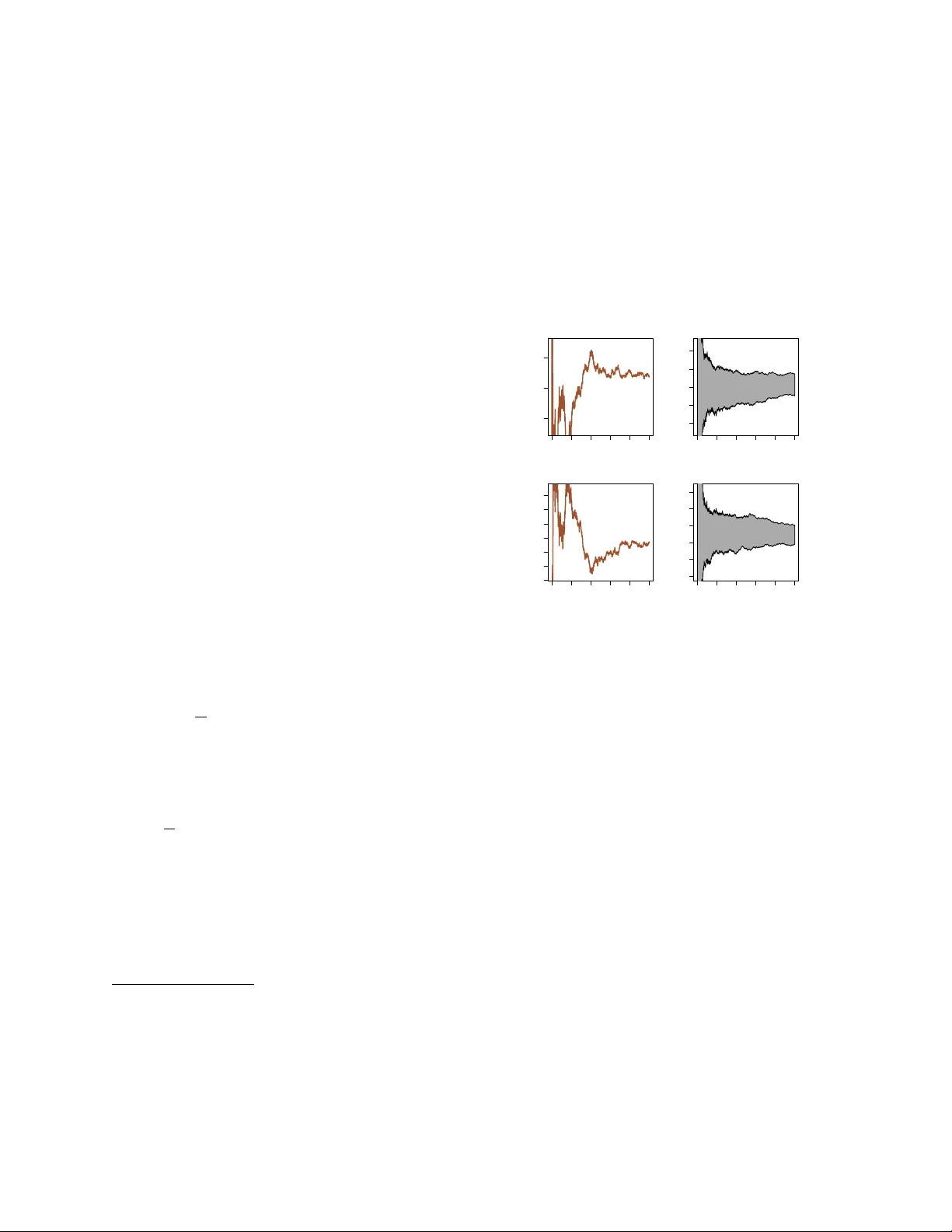
Mon te Carlo Metho ds in Statistics Christian R ober t ∗ Univ ersit´ e P aris Dauphine and CREST, INSEE No vem b er 26, 2024 Mon te Carlo metho ds are no w an essential part of the statistician’s to olbox, to the point of being more familiar to graduate studen ts than the measure theo- retic notions upon which they are based! W e recall in this note some of the adv ances made in the design of Mon te Carlo techniques to wards their use in Statis- tics, referring to Rob ert and Casella (2004, 2010) for an in-depth cov erage. The basic Mon te Carlo principle and its extensions The most app ealing feature of Monte Carlo metho ds [for a statistician] is that they rely on sampling and on probabilit y notions, which are the bread and butter of our profession. Indeed, the foundation of Monte Carlo approximations is identical to the v alidation of empirical moment estimators in that the av erage 1 T T X t =1 h ( x t ) , x t ∼ f ( x ) , (1) is conv erging to the exp ectation E f [ h ( X )] when T go es to infinit y . F urthermore, the precision of this ap- pro ximation is exactly of the same kind as the preci- sion of a statistical estimate, in that it usually ev olves as O( √ T ). Therefore, once a sample x 1 , . . . , x T is pro duced according to a distribution density f , all standard statistical to ols, including b ootstrap, apply to this sample (with the further appeal that more data points can b e pro duced if deemed necessary). As illustrated by Figure 1, the v ariability due to a single Mon te Carlo exp erimen t m ust be accoun ted for, when dra wing conclusions about its output and ev aluations ∗ Professor of Statistics, CEREMADE, Univ ersit´ e P aris Dauphine, 75785 Paris cedex 16, F rance. Supported by the Agence Nationale de la Recherc he (ANR, 212, rue de Bercy 75012 Paris) through the 2009-2012 pro ject ANR-08-BLAN- 0218 Big’MC . Email: xian@ceremade.dauphine.fr . The au- thor is grateful to Jean-Michel Marin for helpful comments. 0 2000 6000 10000 −0.005 0.000 0.005 Number of simulations Monte Carlo approximation 0 2000 6000 10000 −0.02 0.00 0.02 Number of simulations Monte Carlo approximation 0 2000 6000 10000 0.2415 0.2425 0.2435 0.2445 Number of simulations Monte Carlo approximation 0 2000 6000 10000 0.238 0.242 0.246 Number of simulations Monte Carlo approximation Figure 1: Monte Carlo ev aluation (1) of the exp ecta- tion E [ X 3 / (1 + X 2 + X 4 )] as a function of the n umber of simulation when X ∼ N ( µ, 1) using (left) one sim- ulation run and (right) 100 indep enden t runs for (top) µ = 0 and (b ottom) µ = 2 . 5. of the ov erall v ariability of the sequence of approxi- mations are provided in Kendall et al. (2007). But the ease with which suc h metho ds are analysed and the systematic resort to statistical intuition explain in part why Mon te Carlo metho ds are privileged ov er n umerical metho ds. The representation of in tegrals as exp ectations E f [ h ( X )] is far from unique and there exist there- fore many p ossible approaches to the ab o ve approx- imation. This range of choices corresp onds to the imp ortance sampling strategies (Rubinstein 1981) in Mon te Carlo, based on the obvious iden tity E f [ h ( X )] = E g [ h ( X ) f ( X ) /g ( X )] pro vided the supp ort of the densit y g includes the supp ort of f . Some choices of g ma y how ever lead to appallingly po or p erformances of the resulting Mon te 1 Carlo estimates, in that the v ariance of the result- ing empirical a verage ma y b e infinite, a danger w orth highligh ting since often neglected while ha ving a ma- jor impact on the qualit y of the approximations. F rom a statistical persp ectiv e, there exist some natural choices for the imp ortance function g , based on Fisher infor- mation and analytical approximations to the likeli- ho od function like the Laplace approximation (Rue et al. 2008), ev en though it is more robust to replace the normal distribution in the Laplace approxima- tion with a t distribution. The sp ecial case of Bay es factors (Rob ert and Casella 2004) B 01 ( x ) = Z Θ f ( x | θ ) π 0 ( θ )d θ Z Θ f ( x | θ ) π 1 ( θ )d θ , whic h driv e Ba yesian testing and mo del choice, and of their approximation has led to a sp ecific class of im- p ortance sampling techniques known as bridge sam- pling (Chen et al. 2000) where the optimal imp or- tance function is made of a mixture of the p osterior distributions corresp onding to both mo dels (assum- ing both parameter spaces can b e mapp ed in to the same Θ). W e wan t to stres s here that an alternative appro ximation of marginal likelihoo ds relying on the use of harmonic me ans (Gelfand and Dey 1994, New- ton and Raftery 1994) and of direct sim ulations from a p osterior density has rep eatedly b een used in the literature, despite often suffering from infinite v ari- ance (and thus numerical instability). Another p o- ten tially v ery efficien t appro ximation of Ba y es factors is pro vided by Chib’s (1995) represen tation, based on parametric estimates to the p osterior distribution. MCMC metho ds Mark ov chain Monte Carlo (MCMC) metho ds hav e b een prop osed man y y ears (Metrop olis et al. 1953) b efore their impact in Statistics w as truly felt. How- ev er, once Gelfand and Smith (1990) stressed the ul- timate feasibilit y of pro ducing a Marko v chain with a giv en stationary distribution f , either via a Gibbs sampler that simulates each conditional distribution of f in its turn, or via a Metrop olis–Hastings algo- rithm based on a proposal q ( y | x ) with acceptance probabilit y [for a mov e from x to y ] min 1 , f ( y ) q ( x | y ) f ( x ) q ( y | x ) , then the spectrum of manageable mo dels grew im- mensely and almost instantaneously . Due to parallel developmen ts at the time on graph- ical and hierarchical Ba yesian mo dels, lik e generalised −3 −1 0 1 2 3 0.0 0.2 0.4 0.6 0 4000 8000 −0.4 −0.2 0.0 0.2 0.4 iterations Gibbs approximation Figure 2: (left) Gibbs sampling appro ximation to the distribution f ( x ) ∝ exp( − x 2 / 2) / (1 + x 2 + x 4 ) against the true density; (right) range of conv ergence of the appro ximation to E f [ X 3 ] = 0 against the num b er of iterations using 100 indep endent runs of the Gibbs sampler, along with a single Gibbs run. linear mixed mo dels (Zeger and Karim 1991), the w ealth of multiv ariate mo dels with av ailable condi- tional distributions (and hence the p otential of im- plemen ting the Gibbs sampler) was far from negligi- ble, especially when the a v ailability of laten t v ariables b ecame quasi univ ersal due to the slice sampling rep- resen tations (Damien et al. 1999, Neal 2003). (Al- though the adoption of Gibbs samplers has primarily tak en place within Bay esian statistics, there is noth- ing that preven ts an artificial augmen tation of the data through such techniques.) F or instance, if the densit y f ( x ) ∝ exp( − x 2 / 2) / (1+ x 2 + x 4 ) is known up to a normalising constant, f is the marginal (in x ) of the joint distribution g ( x, u ) ∝ exp( − x 2 / 2) I ( u (1 + x 2 + x 4 ) ≤ 1), when u is restricted to (0 , 1). The corresp onding slice sampler then con- sists in simulating U | X = x ∼ U (0 , 1 / (1 + x 2 + x 4 )) and X | U = u ∼ N (0 , 1) I (1 + x 2 + x 4 ≤ 1 /u ) , the later b eing a truncated normal distribution. As sho wn b y Figure 2, the outcome of the resulting Gibbs sampler p erfectly fits the target density , while the con vergence of the exp ectation of X 3 under f has a b eha viour quite comparable with the iid setting. While the Gibbs sampler first app ears as the natu- ral solution to solve a simulation problem in complex mo dels if only b ecause it stems from the true target 2 −2 0 2 4 0.0 0.2 0.4 0.6 0 4000 8000 −0.4 −0.2 0.0 0.2 0.4 iterations Gibbs approximation Figure 3: (left) Random walk Metrop olis–Hastings sampling approximation to the distribution f ( x ) ∝ exp( − x 2 / 2) / (1 + x 2 + x 4 ) against the true density for a scale of 1 . 2 corresp onding to an acceptance rate of 0 . 5; (right) range of con v ergence of the approximation to E f [ X 3 ] = 0 against the n umber of iterations us- ing 100 indep enden t runs of the Metropolis–Hastings sampler, along with a single Metropolis–Hastings run. f , as exhibited by the widespread use of BUGS Lunn et al. (2000), whic h mos tly fo cus on this approac h, the infinite v ariations offered by th e Metrop olis–Hastings sc hemes offer m uch more efficien t solutions when the prop osal q ( y | x ) is appropriately chosen. The basic c hoice of a random walk proposal q ( y | x ) being then a normal density cen tred in x ) can b e improv ed by ex- ploiting some features of the target as in Langevin al- gorithms (see Rob ert and Casella 2004, section 7.8.5) and Hamiltonian or hybrid alternatives (Duane et al. 1987, Neal 1999) that build up on gradients. More recen t prop osals include particle learning ab out the target and sequential improv ement of the prop osal (Douc et al. 2007, Rosenthal 2007, Andrieu et al. 2010). Figure 3 repro duces Figure 2 for a random w alk Metrop olis–Hastings algorithm whose scale is calibrated tow ards an acceptance rate of 0 . 5. The range of the conv ergence paths is clearly wider than for the Gibbs sampler, but the fact that this is a generic algorithm applying to an y target (instead of a sp ecialised version as for the Gibbs sampler) must b e b orne in mind. Another ma jor improv ement generated by a sta- tistical imp erativ e is the developmen t of v ariable di- mension generators that stemmed from Ba yesian mo del c hoice requirements, the most important example be- ing the reversible jump algorithm in Green (1995) whic h had a significan t impact on the study of graph- ical mo dels (Bro oks et al. 2003). Some uses of Mon te Carlo in Statis- tics The impact of Monte Carlo metho ds on Statistics has not b een truly felt until the early 1980’s, with the publication of Rubinstein (1981) and Ripley (1987), but Monte Carlo metho ds hav e now b ecome inv alu- able in Statistics b ecause they allow to address opti- misation, in tegration and exploration problems that w ould otherwise b e unreac hable. F or instance, the calibration of many tests and the deriv ation of their acceptance regions can only b e achiev ed b y simula- tion techniques. While integration issues are often link ed with the Bay esian approach—since Bay es esti- mates are p osterior exp ectations like Z h ( θ ) π ( θ | x ) d θ and Ba yes tests also inv olv e in tegration, as men tioned earlier with the Bay es factors—, and optimisation difficulties with the lik eliho o d p ersp ectiv e, this clas- sification is by no wa y tight—as for instance when lik eliho o ds in volv e unmanageable in tegrals—and all fields of Statistics, from design to econometrics, from genomics to psychometry and environmics, hav e no w to rely on Mon te Carlo appro ximations. A whole new range of statistical metho dologies hav e entirely inte- grated the simulation asp ects. Examples include the b ootstrap metho dology (Efron 1982), where multi- lev el resampling is not conceiv able without a com- puter, indirect inference (Gouri ´ eroux et al. 1993), whic h construct a pseudo-lik eliho od from sim ulations, MCEM (Capp ´ e and Moulines 2009), where the E- step of the EM algorithm is replaced with a Mon te Carlo approximation, or the more recen t appro xi- mated Ba yesian computation (ABC) used in p opula- tion genetics (Beaumont et al. 2002), where the like- liho od is not manageable but the underlying mo del can b e simulated from. In the past fifteen y ears, the collection of real problems that Statistics can [afford to] handle has truly undergone a quantum leap. Mon te Carlo meth- o ds and in particular MCMC techniques ha ve forev er c hanged the emphasis from “closed form” solutions to algorithmic ones, expanded our impact to solv- ing “real” applied problems while con vincing scien- tists from other fields that statistical solutions were indeed a v ailable, and led us into a world where “ex- act” may mean “sim ulated”. The size of the data sets and of the models currently handled thanks to those to ols, for example in genomics or in climatol- 3 ogy , is something that could not ha ve b een conceived 60 years ago, when Ulam and von Neumann in ven ted the Monte Carlo metho d. References Andrieu, C. , Doucet, A. and Holenstein, R. (2010). P article Marko v chain Monte Carlo (with discussion). J. R oyal Statist. So ciety Series B , 72 . (to app ear). Beaumont, M. , Zhang, W. and Balding, D. (2002). Appro ximate Bay esian computation in p opulation ge- netics. Genetics , 162 2025–2035. Brooks, S. , Giudici, P. and Rober ts, G. (2003). Ef- ficien t construction of reversible jump Marko v chain Mon te Carlo prop osal distributions (with discussion). J. R oyal Statist. So ciety Series B , 65 3–55. Capp ´ e, O. and Moulines, E. (2009). On-line exp ectation-maximization algorithm for latent data mo dels. J. R oyal Statist. So ciety Series B , 71(3) 593– 613. Chen, M. , Shao, Q. and Ibrahim, J. (2000). Monte Carlo Metho ds in Bayesian Computation . Springer- V erlag, New Y ork. Chib, S. (1995). Marginal likelihoo d from the Gibbs out- put. J. Americ an Statist. Asso c. , 90 1313–1321. D amien, P. , W akefield, J. and W alker, S. (1999). Gibbs sampling for Bay esian non-conjugate and hier- arc hical mo dels by using auxiliary v ariables. J. R oyal Statist. So ciety Series B , 61 331–344. Douc, R. , Guillin, A. , Marin, J.-M. and Rober t, C. (2007). Con vergence of adaptive mixtures of imp or- tance sampling schemes. Ann. Statist. , 35(1) 420–448. Duane, S. , Kennedy, A. D. , Pendleton, B. J. , and R oweth, D. (1987). Hybrid Mon te Carlo. Phys. L ett. B , 195 216–222. Efron, B. (1982). The Jacknife, the Bo otstr ap and Other R esampling Plans , vol. 38. SIAM, Philadelphia. Gelf and, A. and Dey, D. (1994). Ba yesian mo del c hoice: asymptotics and exact calculations. J. R oyal Statist. So ciety Series B , 56 501–514. Gelf and, A. and Smith, A. (1990). Sampling based ap- proac hes to calculating marginal densities. J. A meric an Statist. Asso c. , 85 398–409. Gouri ´ eroux, C. , Monf or t, A. and Rena ul t, E. (1993). Indirect inference. J. Applie d Ec onom. , 8 85– 118. Green, P. (1995). Reversible jump MCMC computa- tion and Bay esian mo del determination. Biometrika , 82 711–732. Kendall, W. , Marin, J.-M. and Rober t, C. (2007). Confidence bands for Bro wnian motion and applica- tions to Monte Carlo simulations. Statistics and Com- puting , 17 1–10. Lunn, D. , Thomas, A. , Best, N. , and Spiegelhal ter, D. (2000). WinBUGS – a Bay esian mo delling frame- w ork: concepts, structure, and extensibility . Statistics and Computing , 10 325–337. Metropolis, N. , Rosenbluth, A. , R osenbluth, M. , Teller, A. and Teller, E. (1953). Equations of state calculations by fast computing mac hines. J. Chem. Phys. , 21 1087–1092. Neal, R. (1999). Bayesian L e arning for Neur al Networks , v ol. 118. Springer–V erlag, New Y ork. Lecture Notes. Neal, R. (2003). Slice sampling (with discussion). Ann. Statist. , 31 705–767. Newton, M. and Rafter y, A. (1994). Appro ximate Ba yesian inference by the w eighted lik eliho od b oostrap (with discussion). J. R oyal Statist. So ciety Series B , 56 1–48. Ripley, B. (1987). Sto chastic Simulation . John Wiley , New Y ork. R ober t, C. and Casella, G. (2004). Monte Carlo Sta- tistic al Metho ds . 2nd ed. Springer-V erlag, New Y ork. R ober t, C. and Casella, G. (2010). Intr o ducing Monte Carlo Metho ds with R . Springer-V erlag, New Y ork. R osenthal, J. (2007). AMCM: An R interface for adap- tiv e MCMC. Comput. Statist. Data Analysis , 51 5467– 5470. R ubinstein, R. (1981). Simulation and the Monte Carlo Metho d . John Wiley , New Y ork. R ue, H. , Mar tino, S. and Chopin, N. (2008). Approxi- mate Bay esian inference for latent Gaussian mo dels by using integrated nested Laplace approximations (with discussion). J. R oyal Statist. So ciety Series B , 71 (2) 319–392. Zeger, S. and Karim, R. (1991). Generalized linear mo dels with random effects; a Gibbs sampling ap- proac h. J. Americ an Statist. Asso c. , 86 79–86. 4
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment