Hybrid Decoding of Finite Geometry LDPC Codes
For finite geometry low-density parity-check codes, heavy row and column weights in their parity check matrix make the decoding with even Min-Sum (MS) variants computationally expensive. To alleviate it, we present a class of hybrid schemes by concat…
Authors: Guangwen Li, Dashe Li, Yuling Wang
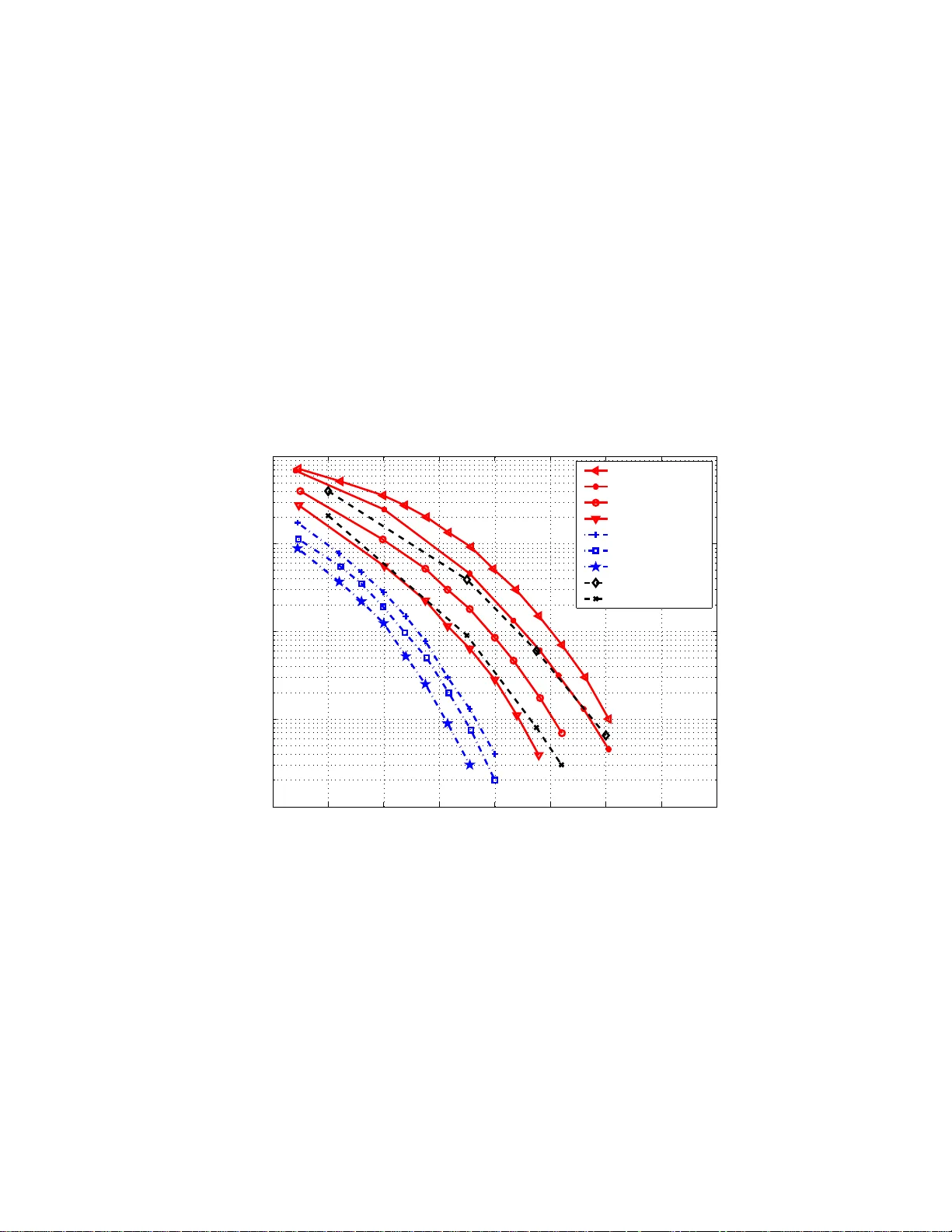
Hybrid Decoding of Finite Geometry LDPC Codes Guangwen Li, Dashe Li, Y uling W ang, W enyan Sun Abstract For finite g eometry low-density parity-chec k codes, heavy row and colum n weights in their par ity check matrix make the d ecoding with even Min-Sum (M S) variants co mputation ally expensi ve. T o alleviate it, we present a class of hybr id schemes by con catenating a p arallel bit flipping (BF) variant with an Min-Sum ( MS) variant. I n most SNR region of interest, with out com promising p erform ance or conv ergence rate, simulatio n results show that th e p ropo sed hybrid sch emes can sa ve substantial computatio nal comp lexity with respect to MS variant decoding alone . Specifically , the BF variant, with much less c omputatio nal com plexity , bears most decod ing load befo re resor ting to MS variant. Computation al and hardware complexity is also elaborated to justify the feasibility of the hyb rid schemes. 1 Hybrid Decoding of Finite Geometry LDPC Codes I . I N T RO D U C T I O N Low-density parity-check (LDPC) codes, given a sufficiently long block lengt h, can approach Shannon limit with beli ef propagation (BP) decodin g [1][2]. Hence, it remains a research focus among o thers in the coding field. Lately , a class of finit e geometry (FG) LDPC codes have attracted great interest, by virtue of the fact that they are encodable in lin ear time with feedback shift registers [3][4]. Howe ver , compared to other classical LDPC codes, it requi re much more complexity to decode with standard BP algorit hms for FG-LDPC codes, due to heavy row and column weights in their parity check matrix. There exist m any low complexity decoding schemes applicable for FG-LDPC codes. The hard decodings [5][6] hav e th e least complexity b ut suffe r seve re performance loss. T o all e viate the degradation, at the cost of moderate comp lexity , a class of bit flipping (BF) variants imp rove performance after t aking int o account the soft information of received sequences. In [7], a BF function was de vised wherein both the most and the least reliable bits inv olved in one check sum are considered. Further i mprovement was reported [8] by weighting each t erm in the BF function. A bootstrapping step [9][10] was proposed to update those unreliable bits prior to calculating their BF function values. Based on [3], the methods presented in [11][12] achieved better performance, as a result of considerin g the impact of its recei ved soft information on the BF functi on value of a specific bit. Howe ver , o ne com mon drawback of above BF variants is that only one bit is flipped p er iteration, which is adverse to fast con ver gence requirement. T o lower the decoding latency caused by such serial BF st rategy , [13], [14] and [15] presented three d ecoding methods in t he form o f multi-bi t flipping p er iteration. In [13], when the flipping signal counter for each bit has reached a predesig ned th reshold, the perti nent bi ts flip im mediately; in [14], the nu mber of bit s chosen to b e flipped approximates the q uotient of t he num ber of uns atisfied check sum s and the colu mn weight of parit y check matrix . In [15], it was suggested to flip th ose bits wit h positive flipping function va lues p er iteration. Further decodi ng gain is obtained by addi ng into these multi -bit flipping algorithms a delay-handling procedure [16], which delays flipping thos e 2 bits whose soft information presents higher magnitude amon g ot hers. W i th respect to the serial flipping, these parallel or multi-bi t flipping metho ds show a sig nificant con verge nce advantage at no cost of performance loss. On the ot her hand, substant ial complexity i s sav ed by estimating complex tanh function in standard BP with simple min function, which leads to M in-Sum (MS) or BP-based algorithm [17][18]. Then MS variants such as normali zed Min-Sum (NMS) and offset Min-Sum (OMS) [19] proves eff ectiv e to fill most performance gap between MS and standard BP , at the cost of minor complexity increase. Despite this, the hea vy row and column weights of FG-LDPC codes may anno y the MS v ariant s from perspective of complexity; while the BF variants present much less complexity b u t suffering some performance l oss. T o expect good performance and low comp lexity si multaneousl y , one natural way is to concatenate so me comp onent decoders to ful fill one decoding. This strategy was attempted in [15], wherein standard BP is called only when a m ulti-bit BF scheme failed. Howe ver , due to the serious performance m ismatch between standard BP and the multi -bit BF scheme p roposed in [15 ], such concatenation resul ts in frequent in vocations of standard BP i n most of waterfall SNR region, which subs equently weakens the efforts of reducing complexity . Diffe rent from i t, a gear shift decoding was presented in [20 ], it selects appropriate decoder among a vailable ones at each i teration, according to the opt imal trell is route obtained after extrinsic information transfer ( EXIT) chart analysis. Theoretically , the gear shift decoding reac hes the tar gets of reducin g decoding latency whi le keeping performance. But se veral obstacles h inder its application for finite FG-LDPC codes. For one thi ng, t he delicate optim al decoding route deriv ed from E XIT chart analys is m ay deviate seriously from the real situation, si nce EXIT chart analysis is accurate lar gely for codes of large girth but FG-LDPC codes are known for the existence of abundant s hort l oops. For another , th e EXIT chart of BF va riants remains unknown, but excluding s uch a class of decoding schemes may lead to an absence of a competit iv e decoder option for gear shi ft decoding . In the paper , we adopt a similar framework to that of [15] where two two component decoders form an hybrid scheme. The former component decoder m ay be substitu ted wi th a newly proposed BF variant; the latter is an MS variant instead of standard BP , considering near BP performance is achie ved with such an MS va riant. At modest and hi gh SNR regions, both decoding performance of the latter decoder and low c omputatio nal complexity close to the former 3 decoder are achieved, which are verified via simulations and complexity analysis. The remainder of the paper i s organized as follows. Section II dis cusses the m otiv ati on of designing such a class of hyb rid schemes. Section III describes i ts implem entation using BF and MS variants. Simulation resu lts, con vergence rate and comp lexity analysis are presented in Section IV . Finally Section V concludes the work. I I . M OT I V A T I O N O F H Y B R I D D E C O D I N G W ith the goal s of high performance and l ow complexity , a sati sfying concatenation of two component decoders meets four conditions. First, the two decoders present distinct characteristics. Specifically , t he former requires much less complexity than t he latter . Secondly , the performance gap between them is within som e lim it to ensure performance m atch. In oth er words, wh ile no gap wipes of f th e need of employing hy brid schemes, excessive ly large gap, manifested by no well overlapped waterfall regions for both decoders, results in frequent in vocations of the second component decoder . Thirdly , in order not t o worsen t he whol e decoding latency , it is beneficial that th e con ver gence rates of two decoders are comparable by and large. Lastly , th e hardware complexity of both decoders is sh ared t o the greatest extent to lower implem entation cost. In [15], a m ulti-bit flipping schem e and standard BP are jointed to serve the purpose of decoding. Howe ver , the mult i-bit flipping suffers s erious performance loss when compared to standard BP . Such a concatenation violates th e menti oned condition t wo and is less meaningful , since standard BP still takes a substantial load in most SNR re gion. Compared t o the serial ones, the m ulti-bit BF variants requires m uch less decoding it erations [16]. Accordin g to condition three, mul ti-bit BF variant is thus preferable over serial one when selectin g the first component decoder . Moreover , the multi -bit BF variant with the least complexity and the closest performance to its su ccessor has the hi ghest priority . On the o ther hand, for FG-LDPC codes, MS variants with proper correcting factors, present almos t t he same performance as standard BP , thus good candidates of the second component decoder . I I I . I M P L E M E N T A T I O N O F H Y B R I D D E C O D E R S Assume a bin ary ( N , K ) LDPC code with block length N and dim ension K . Its parity check matrix is of the form H M × N , where M is the num ber of check sum s. For high rate FG-LDPC codes, the relation M = N in dicates there exist many redun dant check sum s in H . The BPSK 4 modulation maps a codeword c = [ c 1 , c 2 , . . . , c N ] to a sym bol sequence x = [ x 1 , x 2 , . . . , x N ] with x i = 1 − 2 c i , where i = 1 , 2 , . . . , N . A fter t he symbols are transm itted throug h an addi tive white Gaussian n oise (A WGN) memoryless channel, we obtain at the recei ver a corrupted sequence y = [ y 1 , y 2 , . . . , y N ] , where y i = x i + z i , z i is an independent Gaussian random va riable with zero m ean and variance σ 2 . For con venience, the vectors below are treated as column or row vectors depending on the context. T o differentiate each BF variant, the initials of the first t wo authors’ surname hyph ened by th e letters ”WBF” m ake up a unique nam e, unless stated otherwise. A. BF varia nts In LP-WBF [7], the BF function of variable node i at the l -th it eration is defined as f ( l ) i = X k ∈M ( i ) f ( l ) i,k , i ∈ [1 , N ] (1) f ( l ) i,k = | y i | − 1 2 (min j ∈N ( k ) | y j | ) if s ( l ) k = 0 , | y i | − 1 2 (min j ∈N ( k ) | y j | ) − max j ∈N ( k ) | y j | if s ( l ) k = 1 . (2) where M ( i ) denot es the neig hboring check nodes of variable node i , N ( k ) is the neighboring var iable n odes of check no de k , s ( l ) k is t he k -th component of syndrome s at the l -t h iteration. W ith t he i ntuition th at the more reliable bi ts in volved in a check sum , the more reliable the check wi ll be, SZ-WBF [8] defines a BF functi on by weight ing each term of the s ummation (1). That is , f ( l ) i = X k ∈M ( i ) w i,k f ( l ) i,k , i ∈ [1 , N ] (3) w i,k = max(0 , α 1 − k{ j | | y j | ≤ β 1 , j ∈ N ( k ) \ i }k ) (4) where N ( k ) \ i denotes the neighboring var iable nodes of check node k except variable node i , α 1 is an integer constant, β 1 is a real constant, k · k is t o obt ain th e s et cardinality . For serial BF variants such as SZ-WBF , only one bit with the smallest f ( l ) i is flipped at the l -t h iteration. Hence, the maxim um number of it erations I m needs to be predesigned hi gh enough to allow d ecoding conv ergence. 5 Due to a positive correlation between the number of erroneous bits and that of un satisfied check sums, NT -WBF [14] suggests flipping λ ( l ) bits of the smallest f ( l ) i defined by (1) at the l -t h iteration, λ ( l ) = ⌊ w h ( s ( l ) ) d v ⌋ where w h ( · ) d enotes t he calculation of Hammin g weight, d v is t he column weight of matrix H , ⌊ x ⌋ is th e integral part of x . At each iteration, LZ-WBF [15] flips all the bits with flipping function values greater than zero, am ong wh ich, the flippi ng functi on i s defined as [11] f ( l ) i = X k ∈M ( i ) (2 s ( l ) k − 1)( min j ∈ N ( k ) | y j | ) − β 2 | y i | , i ∈ [1 , N ] (5) where β 2 is a real weighting factor . WZ-WBF [13] uses the same BF function as in [12], namely , f ( l ) i = X k ∈M ( i ) (2 s ( l ) k − 1)( min j ∈ N ( k ) \ i | y j | ) − β 3 | y i | , i ∈ [1 , N ] (6) where β 3 is a real weighting fac tor . Then at each i teration, for each unsat isfied check sum, a flipping signal is ass igned to som e in volved bit. And only t hose bits are flipped which have accumulated flippi ng s ignals more than a threshold . T o p re vent some reliable bits from flippi ng hastil y , improved parallel weighted bit flippin g (IPWBF) [16] added a delay-handling step into t he steps of WZ-WBF . Compared with IPWBF , the propos ed LF-WBF va ries b y utilizin g the BF function of SZ- WBF , whi le keeping oth er steps l ar gely unchanged. T o be self-contained, LF-WBF is described as follows: 1) Preprocess: Ass ume a threshold T be the va lue of the ⌊ β 4 N ⌋ -th s mallest element among array | y i | , i ∈ [1 , N ] , where β 4 is a real cons tant within [0 , 1] , then those bits wi th | y i | greater than T are marked reliable, otherwise unreliable. 2) Initi alize: l ← 0 ; calculat e initial v alues of f (0) i , i ∈ [1 , N ] according t o (2), (3). For the bits ∈ { i || y i | > T , i ∈ [1 , N ] } , the delay-handli ng counters a i ← 0 ; note hard-decision of y as ˆ c (0) . 3) Syndrome and reset: Calculate s ( l ) = H ˆ c ( l ) . If s ( l ) = 0 , s top to return ˆ c ( l ) as the decoding result. If not, b i ← 0 , i ∈ [1 , N ] , b i is a flipping counter which sums the flipping signals for bit i . 6 4) Collect flip ping si gnals: Update f ( l ) i , i ∈ [1 , N ] based on (2), (3). For each k ∈ { k | s ( l ) k 6 = 0 , k ∈ [1 , M ] } , i dentify the index i ∗ = arg min i ∈N ( k ) f ( l ) i , th en b i ∗ ← b i ∗ + 1 , that is, a flipping signal i s coll ected for bi t i ∗ . 5) Decide flipping bits: It is divided into two sub steps. a) For the bits ∈ { i | b i ≥ α 2 , i ∈ [1 , N ] } , where α 2 , as a pos itive integer , represents the flipping threshold, flip them if on ly the resulting syndrome s ( l +1) = 0 . Oth erwise turn t o the next substep. b) Delay-handling: For the unreliabl e bits ∈ { i | b i ≥ α 2 , | y i | ≤ T , i ∈ [1 , N ] } , put them in a to-be-flipped list; for t he reliable bit s ∈ { i | b i ≥ α 2 , | y i | > T , i ∈ [1 , N ] } , update by a i ← a i + 1 . Subsequently , put the b its ∈ { i | a i ≥ α 3 , i ∈ [1 , N ] } in the to-be- flipped li st, where α 3 is a s mall positive integer defining a d elay-handling th reshold. Obviously , it is meaningful o nly for α 3 ≥ 2 . Relax α 3 ← α 3 − 1 if only the to-be- flipped li st i s em pty , then flip the bit s ∈ { i | b i = α 3 , i ∈ [1 , N ] } . Declare failure if n o bit is qualified yet. Since delay-handling step may potentially in crease the a verage number of d ecoding i tera- tions, substep one reduces it s im pact effecti vely . 6) Flip and reset: Flip these bits in th e t o-be-flipped list. Reset all t he bit s ∈ { i | a i ≥ α 3 , i ∈ [1 , N ] } b y a i ← 0 . Noticeably , before the next resetti ng occurs, the duration of a i may last sev eral iterations while that o f b i is always o ne iteration. 7) l ← l + 1 . If l < I m , goto step 3 to continue one more iteration; otherwis e, declare failure. B. MS varia nts At the check nodes end, compared with st andard BP impl emented in Log-likelihood ratio (LLR) domain, NMS and OMS [19], approximate (7) wi th (8) and (9), respectively , t hus saving most complexity , L ( l ) j,i = 2 tanh − 1 Y k ∈N ( j ) \ i tanh Z ( l − 1) j,k 2 (7) L ( l ) j,i = 1 β 5 Y k ∈N ( j ) \ i sgn ( Z ( l − 1) j,k ) · min k ∈N ( j ) \ i | Z ( l − 1) j,k | (8) L ( l ) j,i = Y k ∈N ( j ) \ i sgn ( Z ( l − 1) j,k ) · max ( min k ∈N ( j ) \ i | Z ( l − 1) j,k | − β 6 , 0 ) (9) 7 where L ( l ) j,i denotes the message sent from check node j to variable no de i at the l -th i teration; Z ( l − 1) j,k denotes the message sent from variable node k to check no de j at the ( l − 1) -th iteratio n; β 5 or β 6 , being a real constant, functions as a s caling or offset factor , respectiv el y . T o furth er reduce complexity , at the variable node end, the calculating of (10) is approxim ated with (11) i n the norm alized APP-based (NAB) algorithm [19 ]. Z ( l ) j,i = F i + X k ∈M ( i ) \ j L ( l ) k ,i (10) Z ( l ) j,i = F i + X k ∈M ( i ) L ( l ) k ,i , ∀ j ∈ M ( i ) (11) Where F i is t he initial LLR o f bit i . For t he difference-set cyclic (DSC) codes, it was reported N AB yields almost as good performance as NMS [19]. As shown in the simulation later , similar observation also ho lds for FG-LDPC codes. C. Bl ock graph of a hybrid decodin g scheme LF-WBF Initialize Update flipping function values Select flipping bits Check sums satisfied? Max iterations reached? Y N N Y Successful decoding MS variant Check sums satsified? Max iterations reached? N N Initialize Update messages of variable and check nodes Successful decoding Y Decoding failure Y Input Fig. 1 Block graph of hybrid decodi ng schem e There are many BF variants and MS variants, thu s the combinatio ns of BF variant plus MS variant is abundant. For instance of ’LF-WBF+NMS’, as shown in Fig. 1, two comp onent decoders are independent comparatively . T he latter takes over decoding s o lon g as the former failed. D. Optimize parameters by differ ential evolution It i s hard to optim ize the group of parameters inv olved in LF-WBF theoretically . Hence, diffe rential evolution (DE), known as a heuristi c search m ethod, i s exploited t o approxim ate the opt imality . Simil ar to the genetic algori thm, DE is a si mple and reliable optimizatio n t ool 8 [21]. In DE, via various operations including mutation, combination and selection, a popul ation of solut ion vectors are u pdated generation by generation, wit h those ne w vectors wi th small objective values s urviv ed, until the population con ver ges to the global optimu m. T o aid LF-WBF to optimize its parameter vector ( α 1 , α 2 , α 3 , β 1 , β 4 ) , th e objective function of DE is designated to find t he minim um bit error rate (BER) given a block of received sequences. In order to save comput ation, each parameter of LF-WBF is roug hly ass igned an ev aluation interval b eforehand. For inst ance, α 1 , α 2 are in tegers in [1 , d v / 2] , α 3 is a small positive in [1 , 4] , β 1 , β 4 are real numbers in [0 , 1] . For (273 , 191 ) and (102 3 , 781) FG-LDPC codes [3], D E results are give n in T able-I with var ied channel variance σ 2 . I V . S I M U L A T I O N R E S U L T S A N D D I S C U S S I O N A. P arameters selection It is verified that decoding performance of LF-WBF is largely insensitive to the minor change of it s parameters, t hus in all SNR region, we assume th e settings as shown on the first row o f T able-II, after referring to T able-I. The additional advantage of s uch simpl ification is th at the overa ll hybrid decoding requires no m ore a priori i nformation about the channel, namely , ho lding as well the property of uniformly most p ower ful (UM P)[18] for MS variants. For LZ-WBF and WZ-WBF , the dat a presented in T able-II come from the existing lit erature, as mentioned in the last column of T able-II. After applying DE for MS va riants, we select the settings as the last three rows of T able-II for N A B, NM S and OMS. Noticeably , the opti mization results o f the scaling factor for N AB and NMS are different. T able-I : Parameters opt imization o f LF-WBF for (273,191) (left) and (1023,781) (rig ht) FG-LDPC codes using diffe rential evolution σ α 1 α 2 α 3 β 1 β 4 0.58 10 4 4 0.31 0.064 0.575 9 4 3 0.57 0.11 0.57 6 4 4 0.50 0.054 0.565 5 3 4 0.47 0.07 σ α 1 α 2 α 3 β 1 β 4 0.565 5 9 2 0.38 0.036 0.56 12 8 3 0.51 0.071 0.555 10 8 3 0.41 0.075 0.55 6 6 3 0.32 0.025 9 T able-II : P arameters settings of v arious decoding schemes for (273,19 1) and (1023,78 1) FG-LDPC codes Scheme Parameter(s)=those for (273,191); those for (1023,781 ) Source LF-WBF ( α 1 , α 2 , α 3 , β 1 , β 4 ) = (6 , 4 , 2 , 0 . 45 , 0 . 07 ); (8 , 7 , 2 , 0 . 4 , 0 . 04) DE LZ-WBF β 2 =1.5; 2.1 [15] WZ-WBF ( α 2 , β 3 ) = (4 , 1 . 3); (10 , 1 . 8) [22] SZ-WBF ( α 1 , β 1 ) =N/A; (9,0.5) [8] N AB β 5 =5.7; 7.1 DE NMS β 5 =2.9; 3.7 DE OMS β 6 =0.22; 0.20 DE B. Decoding p erformance The frame error rate (FER) curves of some BF variants and MS variants are plott ed in Fig. 2 for (273,191) code. 2 2.5 3 3.5 4 4.5 10 −4 10 −3 10 −2 10 −1 10 0 E b /N 0 (dB) FER LZ−WBF(20) NT−WBF(20) WZ−WBF(20) LF−WBF(20) NAB(20) OMS(20) NMS(20) Fig. 2 FER curves for (273,191 ) FG-LDPC code under various BF or MS variants In the l egend, th e numb er in th e brackets stand s for th e maxim um number of iteration I m . It is foun d that BF variants are in general inferior to MS v ariants from perspectiv e of performance. Specifically , at the point FER= 10 − 3 , LF-WBF leads WZ-WBF , NT -WBF and LZ-WBF about 0.25, 0 .58 and 0.6 dB, respectiv ely . But it lags behind N AB, OMS and NMS about 0.2, 0 .26, 10 0.32 dB, respectively . Further comparison between LF-WBF and IPWBF [16] shows that t hey present t he sim ilar decoding performance, thus exchangeable each other . Therefore, LF-WBF owns the most matched SNR region as that o f M S variants among the a vailable BF variants. Considering LDPC codes commonly h a ve l ar ge enough minimu m distance, the cases seldom occur wh ere BF variant results in an undetectable error but MS va riant decodes correctly . On the oth er hand, there exist a few cases where BF v ariant works but MS va riant fails. Thus in the form of a BF va riant plus an MS variant, the hy brid decoding will keep at least the same performance as the MS variant alone. Howe ver , for each combination , the matching degree between two component decoders impacts heavily the overall decoding complexity . For (10 23,781) code, the FER curves are pl otted in Fig. 3. It is o bserved that when the bl ock 2.8 3 3.2 3.4 3.6 3.8 4 4.2 4.4 10 −4 10 −3 10 −2 10 −1 10 0 E b /N 0 (dB) Frame Error Rate LZ−WBF(20) NT−WBF(20) WZ−WBF(20) LF−WBF(20) NAB(20) OMS(20) NMS(20) LP−WBF(200) SZ−WBF(200) Fig. 3 FER performance for (1023,78 1) FG-LDPC code under BF or MS variants length increases from 273 to 1023, the curves relation wit hin BF va riants and MS va riants sti ll holds, except that t he closeness among these curves slightly sh ifts. For ins tance, at the point FER= 10 − 3 , there exists about 0 . 3 dB b etween LF-WBF and NMS, whi le LF-WBF exceeds LZ- WBF more t han 0.3 dB. Also included are the curves of two serial approaches: LP-WBF and SZ-WBF . The p erformance of LP-WBF and SZ-WBF with I m = 200 approximates NT -WBF and LF-WBF with I m = 20 , respectiv ely . M eanwhile, the full loo p detectio n [8], which proves 11 ef fectiv e in av oiding decoding trappings for s erial BF variants, is util ized for both LP-WBF and SZ-WBF . C. Con ver gence rate Since some appl ications require I m to be s mall, it is thus meanin gful to in vestigate the con ver gence rate of various d ecoding s chemes. At a typical point SNR=3.42 dB (or σ =0.57) of (273,191) code, T able-III gives performance comparison am ong each schemes under va ried I m . It is seen that altho ugh I m = 3 is too rigorous for all d ecoding schemes, each BF variant reaches i ts individual decoding capabil ity at t he sp ecified point wit hin I m = 20 . Th at i s, m ore iterations after the 20-th iteration achiev es no further decoding improvement; wh ile MS variants require I m to be at least 50 to fu lly decode the recei ved sequences. A lso included in T able-III is the data of BP . Interestingly , at I m = 3 , BP yields the best decoding performance among o thers. But its con vergence rate is not sati sfying. It is shown that I m = 50 is not ev en sufficient for BP decoding, because t he performance im proves from FER=1.6e-3 to 7 .2e-4 when I m increases to 200. For this reason, give n a small I m = 20 , LF-WBF ev en excels BP a l ittle, as s hown in T able-III. Further simul ation shows that LF-WBF wi th I m = 20 performs better than BP in the region where SNR is greater than 3.42 dB. Another noticeable point shown in T able-III is t hat the performance of BP is generally inferior to MS variants, despite its high compl exity . Therefore, BP is less attractive to be selected as th e second com ponent decoder of a hybrid scheme. T aking into account the fact th at serial BF va riants require much more I m than above multi -bit BF T able-III : Decoding performance of various schemes under varied I m for (273,191) FG-LDPC code at SNR=3.42 dB Scheme I m = 3 I m = 10 I m = 20 I m = 50 I m = 200 LZ-WBF 9.2e-2 3.6e-2 3.6e-2 3.6e-2 3.6e-2 NT -WBF 5.9e-1 4.4e-2 3.8e-2 3.8e-2 3.8e-2 WZ-WBF 2.5e-2 9.6e-3 9.8e-3 9.8e-3 9.8e-3 LF-WBF 4.5e-2 4.2e-3 2.8e-3 2.4e-3 2.3e-3 N AB 1 .1e-1 2.1e-3 7.6e-4 4.4e-4 4.4e-4 OMS 1.6e-2 9.6e-4 6.6e-4 5.0e-4 4.6e-4 NMS 1.1e-2 5.2e-4 3.8e-4 3.6e-4 3.4e-4 BP 9.4e-3 3.9e-3 2.9e-3 1.6e-3 7.2e-4 12 var iants [14][16], and LF-WBF performs th e best among existi ng multi -bit BF variants, LF- WBF plu s so me M S variant intuit iv ely presents a competitive form of hybri d decoding schem e. The similar poin ts are supported as well after generalized t o oth er l onger FG-LDPC codes. Let A ni denote av erage number of iteratio ns for each decoding scheme, as seen in Fig. 4 for (1023,781) code, A ni of NT -WBF sticks out prominently wh ile that of LZ-WBF varies sl owly with E b / N 0 , both are due to the algorithms th emselves. In most SNR region of interest, all BF var iants except NT -WBF present comparable A ni as MS v ariants, thus meeting well the con dition three discussed i n Section II . 2.8 2.9 3 3.1 3.2 3.3 3.4 3.5 2 4 6 8 10 12 14 16 18 20 E b /N 0 (dB) A ni LZ−WBF(20) NT−WBF(20) WZ−WBF(20) LF−WBF(20) NAB(20) OMS(20) NMS(20) Fig. 4 A verage number of iteratio ns A ni of v arious decodings schemes for (1023,781) FG-LDPC code D. Computational complexity analysis Practically , any BF va riant followed by an MS v ariant will yi eld the s ame decoding per - formance as the latter alone. For instance, LF-WBF plus MS v ariant performs almost equally as LZ-WBF pl us M S variant, regardless of the fact t hat LF-WBF is far sup erior t o LZ-WBF . Howe ver , computati onal complexity differs enormously with respect to each hybrid scheme. Generally , i t is hard to accurately d escribe th e required complexity for each decoding scheme, so data obt ained in th e sim ulations i s presented to support our v iewpoints i f necessary . 13 Let d v , d c individually denot e the column and row weights of parity check matrix H , then for each BF variant, its complexity roughly consists of three parts: preprocessing, updati ng BF function a nd selecting flipping bits. T o the b est of our knowledge, the complexity of preprocessing and initialization is largely om itted in existing l iterature. Howe ver , the fol lowing analy sis and simulatio n wil l show i t contributes substant ially to the complexity at very high SNR region. Ignoring sim ple binary operations and a s mall number of real mult iplications in volved so me- times, i t suf fice to address the dominant real additions for each BF variant, assumin g one real comparison is treated as one real addition. At th e stage of preprocessing, for LP-WBF and NT -WBF , about N (2 d c − 3) com parisons are needed in computing min and max terms of (2). Similarly , for LZ-WBF and WZ-WBF , about N ( d c − 1) comparis ons is required individually in computing the min term of (5) and (6). Besides that for LP-WBF , both SZ-WBF and LF-WBF require extra N comparisons to obtain w i,k term of (4). W ith respect to SZ-WBF , LF-WBF requires about N log 2 ⌊ β 4 N ⌋ + N more comparisons to determ ine the bit with the ⌊ β 4 N ⌋ -th small est m agnitude and to mark the delay-flippi ng b its. Prior to updating the BF function of each b it, it is i nitialized with d v − 1 additions for each BF var iant. For multi-bit BF variants, th ere are two ways o f updating th e BF function of perti nent bits since th e second iteration. One i s to in voke d v d c additions per flipped bi t to update its BF function; another is to u pdate the BF funct ion of each bit after comparing its column of H with the syndromes before and after th e latest iteration. The latter is more economical, considering two flipping bi ts in the same check sum result in t wo extra additions for the former , but av oidable for the latter . For serial BF variants, t otally d v d c terms are used to update t he BF function of those affected bit s per iteration . T o decide which bits to flip, each BF variant has its own approach. For LP-WBF and SZ- WBF , it just requires N − 1 com parisons to find t he bit with t he smallest BF functi on value; for WZ-WBF and LF-WBF , d c − 1 comparisons are required per unsatisfied check to collect flipping signals for each bit; for NT -WBF , its complexity at this stage is equal to selecting the smallest say 5 el ements in an unordered array . Noticeably , no comput ation is requi red for LZ-WBF , since it s imply flips t hose bi ts wi th p ositive BF function values. T o sum up, T abl e-IV giv es the complexity compositi on for each BF v ariant. In the t able, A nb denotes th e average number o f selected bits per it eration for NT -WBF , A nc is th e average number of updated BF function terms per bit per it eration, A ns is the a verage number of unsatisfied checks 14 T able-IV : Approxim ated real additions per sequence for various decoding s chemes of FG-LDPC codes Schemes Preprocess Update BF function (include initialization) Select bit(s) t o flip LZ-WBF N ( d c − 1) N ( d v − 1) + ( A ni − 1) N A nc 0 NT -WBF N (2 d c − 3) N ( d v − 1) + ( A ni − 1) N A nc A ni N log 2 A nb WZ-WBF N ( d c − 1) N ( d v − 1) + ( A ni − 1) N A nc A ni A ns ( d c − 1) LF-WBF N (2 d c − 1 + log 2 ⌊ β 4 N ⌋ ) N ( d v − 1) + ( A ni − 1) N A nc A ni A ns ( d c − 1) SZ-WBF N (2 d c − 2) N ( d v − 1) + ( A ni − 1) d v d c A ni ( N − 1) LP-WBF N (2 d c − 3) N ( d v − 1) + ( A ni − 1) d v d c A ni ( N − 1) N AB A ni (2 N d v + M ( ⌈ log 2 d c ⌉ − 2)) OMS, NMS A ni ( N (4 d v − 3) + M ( ⌈ log 2 d c ⌉ − 2)) per iteration. Also included are th e complexity expressions of N AB, OMS and NMS as reported in [7], wherein ⌈·⌉ is the ceiling function. For (1023,781) code, N = 1023 , d v = d c = 32 [3]. Assume I m = 20 for multi -bit BF variants, I m = 200 for MS variants and serial BF v ariants t o ensure full decoding con ver gence, at a typical point of SNR=3.28 dB (or σ = 0 . 555 ), T able-V presents the figures observed i n simulation , among wh ich the last column is t he number of real additions according to the expressions of T able-IV. Noti ceably , the last two rows of T able-V giv es complexity of two ins tances of hy brid decoding s chemes as well. After s tudying T able-V, we find that t he class of BF var iants demonstrates a s ubstantial T able-V : Complexity comparison per sequ ence for var ious decod- ing s chemes of (1023,7 81) FG-LDPC code at SNR=3.28 dB Scheme A ni A ns A nb A nc number of real additions(e+5) LZ-WBF 4.70 N/A N/A 8.11 0 . 94 NT -WBF 9.61 N/A 9.73 7.72 1 . 94 WZ-WBF 4.48 348.01 N/A 10.41 1 . 49 LF-WBF 4.74 37 3.63 N/ A 10.10 1 . 95 SZ-WBF 49.08 1 . 95 LP-WBF 68.66 2 . 34 N AB 5.53 N/A 3 . 79 OMS 4.47 5 . 78 NMS 3.77 4 . 93 LZ-WBF+NMS (Data for LZ-WBF) + (NMS with A ni =1.88) 3 . 40 LF-WBF+NMS (Data for LF-W BF) + (NMS with A ni =0.88) 3 . 10 15 adva ntage over MS variants in terms of com plexity . Am ong the BF variants, LZ-WBF p resents the least complexity due to its f ast con ver gence, low-complexity preprocessing and no complexity demand of selecting bits; despit e its sim plicity , at low and modest SNR regions, t he comb ination of LZ-WBF and NMS requires more com plexity than th at of LF-WBF and NMS, as a result that the former combi nation demands one mo re iteration of NMS on average, as shown in T able-V. Und er the condition of o ff ering equiv alent performance, the last three rows of T able-V illustrates that both hybrid decoding schemes can sa ve mu ch complexity , wit h respect to its second component decoder alone. T o better illustrate complexity comparison in the whole SNR region, Fig. 5 present com plex- 2.6 2.8 3 3.2 3.4 3.6 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 E b /N 0 (dB) Complexity ratio (273,191): NMS(200) (273,191): Hybrid one (273,191): Hybrid two (1023,781): NMS(200) (1023,781): Hybrid one (1023,781): Hybrid two Fig. 5 Complexity ratio curves of Hy brid one: LZ-WBF(20)+NMS(200) and Hybrid two: LF-WBF(20)+NMS(200) for (273,19 1) and (1023,781) FG- LDPC codes ity rati o curves for (27 3,191) and (1023 ,781) codes. Ass uming the compl exity of NMS is a benchmark, t hen complexity ratio is defined as the ratio of the compl exity of a sp ecified h ybrid scheme and t hat of NMS. For NM S, since another A ni N d v divisions is actually required [7], we roughly treat as total compl exity the sum of this expression and the related formula in T able-IV. At very low SNR region, any of the hybri d schemes shows no much advantage, due to the fact 16 that m ost decodings are up to NMS. Howe ver , with increased SNR, both h ybrid schemes yield more and more complexity reduction, resulting from more in volvements o f LZ-WBF or LF- WBF in decoding. For short (273 ,191) code, the com bination of ’LZ -WBF+NMS’ exceeds t hat of ’LF-WBF+NMS’ at the poin t SNR=3.05 dB. While the occurrence extends to SNR=3.45 dB for (1023,781) code. Hence, it suggests that the intersection of t hese two schemes will move to a h igher SNR wit h lo nger block lengt h. Let C N M S , C LZ N , C LF N denote t he complexity of above three decoding s chemes. For suf- ficiently long FG-LDPC codes, to seek the asymptotic performance ratios in very h igh SNR region, the following approxi mations are deri ved based on T abl e-IV, C LZ N C N M S = d c + d v − 2+( A ni − 1) A nc A ni (5 d v + ⌈ log 2 d c ⌉− 5) ≈ 2 5 A ni , C LZ N C N M S = 2 d c + d v − 2+log 2 ⌊ β 4 N ⌋ )+( A ni − 1) A nc + A ni ( d c − 1) A ns / N A ni (5 d v + ⌈ log 2 d c ⌉− 5) ≈ 9+ A ni 15 A ni . wherein the following simulatio n results are exploited: d v = d c , both are large numb ers compared with oth er terms; A ni of various schem es ranges in [1, 2] and tends t o be near each other; A nc of LZ-WBF or LF-WBF is small compared to d v ; A ns / N is abou t on e third. Simi lar approach can be used to deriv e compl exity ratios of other hybrid combinations. E. Har dwar e complexity Seemingly , the propos ed hybrid schemes add much mo re hardware com plexity with respect to its second com ponent decoder alone. Howe ver , most hardware complexity can be shared instead bet ween t wo component decoders. For instance of ’LF-WBF+NMS’, assum ing NMS hardware is ava ilable, then min, max operations at the p reprocessing p hase of LF-WBF , and collecting flippin g sig nals at the selecting flipping b its phase of LF-WBF , can be accomplished via the check node logics o f NMS, while the initializati on step via the bit node logi cs of NMS. Thus compared with N MS, ’LF-WBF+NMS’ onl y includes a fe w more in teger count ers and interconnection lo gics. Therefore, th e extra hardware compl exity of hybrid decodi ng schemes is lar gely ignorable. V . C O N C L U S I O N S For fini te FG-LDPC codes, t he concatenation of BF variant and MS variant proves its eff ec- tiv eness in decoding at a wide rang of SNR re gion, by means of achieving per formance of the MS 17 var iant with substanti al reduced computatio nal comp lexity . Whil e LZ-WBF plus MS variant has its adva ntage at high SNR region of interest; the proposed LF-WBF plus MS variant dem onstrates better comp lexity saving at the rest of SNR region, due to the well overlapped waterf all regions between two component decoders. Evid ently , if we can gear among these hy brid s chemes based on varied SNRs, the decoding will be more powerful and robust. For BP decoding , it is known that flooding schedu le is not optimal. Sharon et al. [23][24][25] proved t hat serial mess age p assing schedule, imp lemented by fully utilizing a vailable updated messages, can halve t he aver age number of it erations of flooding schedule without performance penalty . But it ri sks resul ting i n higher decoding latency . Contrary to it , our h ybrid schem e y ields a g ood t radeof f among p erformance, com plexity and latency . R E F E R E N C E S [1] D . MacKay , “Good error-correcting codes based on very sparse matrices, ” IEE E Tr ansactions on Information T heory , vol. 45, no. 2, pp. 399–431, 1999. [2] S . Chung, G. Forne y Jr , T . Richardson, and R. Urbanke, “On the design of low-dens ity parity-check codes within 0.0045 dB of the Shannon l imit, ” IEEE Communications Letters , vol. 5, no. 2, pp. 58–60, 2001. [3] Y . K ou, S. Lin, and M. Fossorier , “Low-density parity-check codes based on finite geometries: arediscovery and new results, ” IEEE Tr ansactions on Information T heory , vol. 47, no. 7, pp. 2711–273 6, 2001. [4] H . T ang, J. Xu, S. L in, and K. Abdel-Ghaff ar , “Codes on fi nite geometries, ” IEEE T ransactions on Information T heory , vol. 51, no. 2, pp. 572–596, 2005. [5] R . Gal lager , “Low-density parity-check codes, ” IE EE T ransaction s on Information Theory , vol. 8, no. 1, pp. 21–28, 1962. [6] R . Lucas, M. Fossorier , K. Y u, and S . L in, “Iterativ e decoding of one-step majority logic deductible codesbased on belief propagation, ” IEEE Tr ansactions on Communications , vol. 48, no. 6, pp. 931–937, 2000. [7] Z . L iu and D. Pados, “ A decoding algorithm f or finite-geometry LD PC codes, ” IE EE T ransactions on Communications , vol. 53, no. 3, pp. 415–421, Mar . 2005. [8] M. Shan, C. Zhao, and M. Jiang, “Improv ed weighted bit-flipping algorithm for decoding LDP C Codes, ” IEE Pr oceedings- Communications , vol. 152, no. 6, pp. 919–922, 2005. [9] A . Nouh and A. Banihashemi, “Bootstrap decoding of low-density parity-check codes, ” IE EE Communications Letters , vol. 6, no. 9, pp. 391–3 93, 2002. [10] —— , “Reliability-based schedule for bit-flipping decoding of low-density Parity-check codes, ” IEE E T ransactions on Communications , vol. 52, no. 12, pp. 2038–204 0, 2004. [11] J. Z hang and M. Fossorier , “A modified weighted bit-flipping decoding of low-de nsity parity-check codes, ” IE EE Communications Lett ers , vol. 8, no. 3, pp. 165–167, 2004. [12] M. Jiang, C. Zhao, Z. S hi, and Y . Chen, “An improv ement on the modified weighted bit flipping decoding algorithm for LDPC codes, ” IE EE Communications Letters , vol. 9, no. 9, pp. 814–816, 2005. [13] X. W u, C. Zhao, and X. Y ou, “Parallel W eighted Bit-Flipping Decoding, ” IEE E Communications Letters , vol. 11, no. 8, pp. 671–673, 2007. 18 [14] T . Ngatched, F . T akawira, and M. Bossert, “An improved decoding algorithm for finite-geometry LDPC codes, ” IEEE T ransactions on Communications , vol. 57, no. 2, pp. 302–306, 2009. [15] J. L i and X. Zhang, “Hybrid Iterative Decoding for Lo w-Density Parity-Check Codes Based on Finite Geometries, ” IEE E Communications Lett ers , vol. 12, no. 1, pp. 29–31, 2008. [16] G. Li and G. Feng, “Improv ed parallel weighted bit-flipping decoding algorithm f or LDPC codes, ” IET Communications , vol. 3, no. 1, pp. 91–99 , 2009. [17] N. W iberg, Codes and decoding on general graphs . Department of Electrical Engineering, Link ¨ oping University , 1996. [18] M. Fossorier , M. Mihaljev ic, and H. Imai, “Reduced complexity iterative decoding of lo w-density parity checkcodes based on belief propaga tion, ” IEEE T ransaction s on Communications , vol. 47, no. 5, pp. 673–680, 1999. [19] J. Chen, A. Dholakia, E. Eleftheriou, M. Fossorier , and X. Hu, “Reduced-Comp lexity Decoding of LDPC Codes, ” IEEE T ransactions on Communications , vol. 53, no. 8, pp. 1288–1299, 2005. [20] M. Ardakani and F . Kschischang, “Gear-shift decoding, ” IEEE Tr ansactions on Communications , vol. 54, no. 7, pp. 1235– 1242, 2006. [21] R. St orn and K. Pr ice, “Dif ferential evo lution-a simple and ef ficient adaptiv e scheme for global optimization o ver continuous spaces, ” Jo urnal of Global Optimization , vol. 11, no. 4, pp. 341–35 9, 1997. [22] W . Xiaofu, L. Cong, J. Ming, X. Enyang, Z. Chunming, and Y . Xiaohu, “T oward s understanding weighted bit-flipping decoding, ” in IEE E Int. Symp. Inform. Theory , vol. 7, pp. 1561–1566. [23] D. Levin, E. Sharon, and S. Litsyn, “Lazy scheduling for LDPC decoding, ” IEEE Communications Letters , vol. 11, no. 1, pp. 70–72, 2007. [24] H. Kfir and I. Kanter , “Parallel versus seq uential updating for be lief propagation decodin g, ” Physica A: Statistical Mechanics and i ts Applications , vol. 330, no. 1-2, pp. 259–270 , 2003. [25] E. Sharon, S. Litsyn, and J. Goldberger , “Efficient Serial Message-Passing Schedules for LDP C Decoding, ” IEEE T ransactions on Information Theory , vol. 53, no. 11, pp. 4076–409 1, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment