Navigability of Complex Networks
Routing information through networks is a universal phenomenon in both natural and manmade complex systems. When each node has full knowledge of the global network connectivity, finding short communication paths is merely a matter of distributed comp…
Authors: ** M. Boguñá, D. Krioukov, K. Claffy **
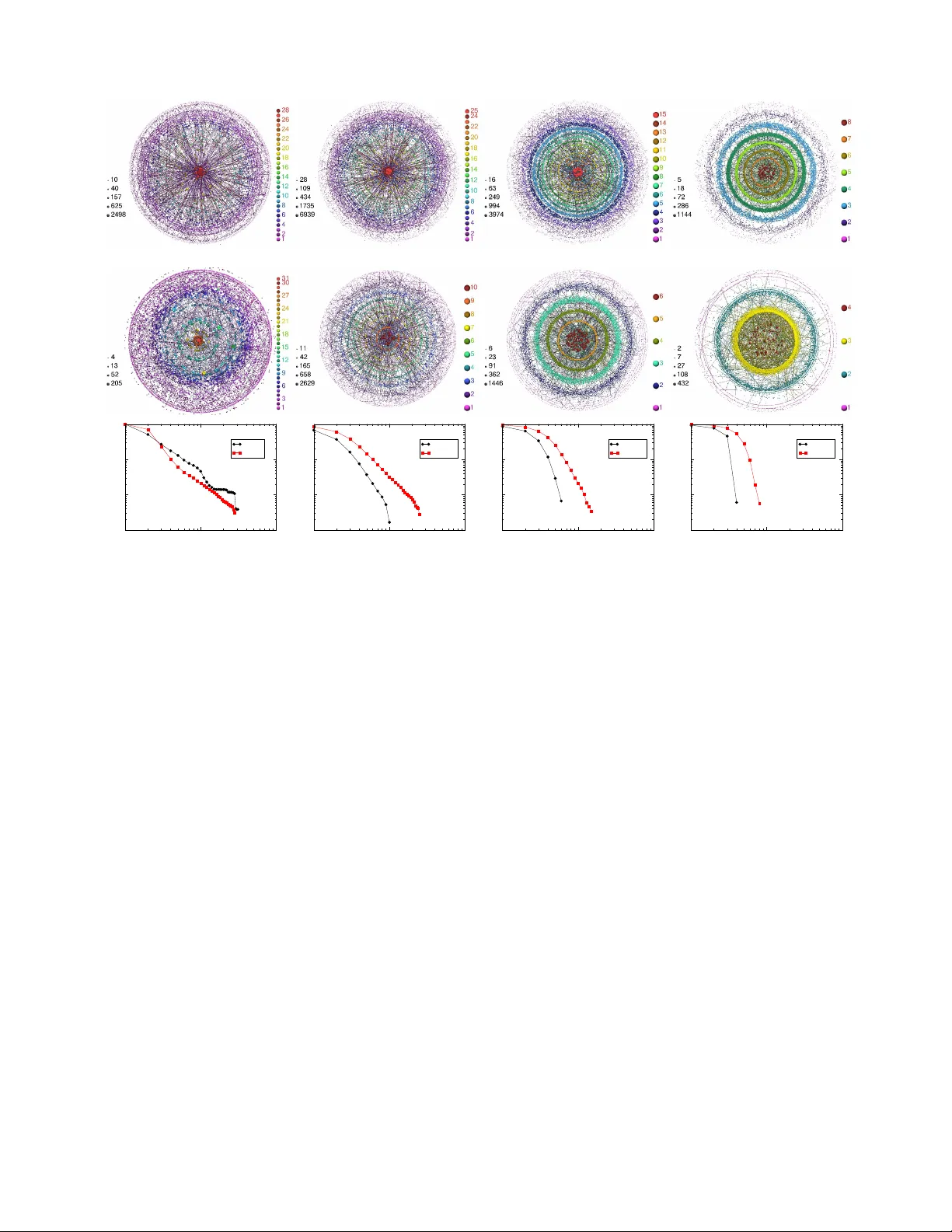
Na vigabilit y of complex net w orks Mari´ an Bogu ˜ n´ a, 1 Dmitri Kriouk ov, 2 and k c claffy 2 1 Dep artament de F ´ ısic a F onamental, Universitat de Bar c elona, Mart ´ ı i F r anqu` es 1, 08028 Bar c elona, Sp ain 2 Co op er ative Asso ciation for Internet Data Analysis (CAIDA), University of California, San Die go (UCSD), 9500 Gilman Drive, L a Jol la, CA 92093, USA Routing information through netw orks is a univ ersal phenomenon in b oth natural and manmade complex systems. When each node has full kno wledge of the global net work connectivit y , finding short comm unication paths is merely a matter of distributed computation. Ho wev er, in many real net works no des communicate efficiently even without such global in telligence. Here we show that the p eculiar structural characteristics of many complex net works supp ort efficient communication without global knowledge. W e also describ e a general mechanism that explains this connection b et ween netw ork structure and function. This mechanism relies on the presence of a metric space hidden b ehind an observ able net work. Our findings suggest that real netw orks in nature hav e un- derlying metric spaces that remain undiscov ered. Their discov ery would ha v e practical applications ranging from routing in the Internet and searching so cial netw orks, to studying information flows in neural, gene regulatory netw orks, or signaling pathw ays. I. INTR ODUCTION Net works are ubiquitous in all domains of science and tec hnology , and p ermeate man y aspects of daily h uman life [1, 2, 3, 4], esp ecially up on the rise of the informa- tion technology so ciety [5, 6]. Our growing dep endence on them has inspired a burst of activit y in the new field of net work science, k eeping researc hers motiv ated to solve the difficult c hallenges that net works offer. Among these, the relation b etw een netw ork structure and function is p erhaps the most important and fundamental. T ransp ort is one of the most common functions of net work ed sys- tems. Examples can b e found in man y domains: trans- p ort of energy in metab olic netw orks, of mass in fo o d w ebs, of p eople in transportation systems, of informa- tion in cell signalling pro cesses, or of bytes across the In ternet. In many of these examples, routing –or signalling of information propagation paths through a complex net- w ork maze– plays a determinant role in the transp ort prop erties of the system, in particular in such systems as the Internet or airp ort net works that hav e transp ort as their primary function. The observed efficiency of this routing process in real net works poses an intrigu- ing question: ho w is this efficiency achiev ed? When each elemen t of the system has a full view of the global net- w ork topology , finding short routes to target destinations is a well-understoo d computational pro cess. Ho wev er, in man y netw orks observ ed in nature, including those in so- ciet y and biology (signalling pathw a ys, neural netw orks, etc.), no des efficiently find intended communication tar- gets even though they do not p ossess an y global view of the system. F or example, neural net works would not function so well if they could not route sp ecific signals to appropriate organs or m uscles in the b o dy , although no neurone has a full view of global inter-neurone connec- tivit y in the brain. In this work, w e iden tify a general mec hanism that explains routing conductivit y , or navigabilit y of real net works based on the concept of similarity betw een no des [7, 8, 9, 10, 11, 12]. Sp ecifically , in trinsic char- acteristics of no des define a measure of similarity b e- t ween them, which we abstract as a hidden distance. T ak en together, hidden distances define a hidden metric sp ac e for a given net work. Our recen t work sho ws that these spaces explain the observed structural p eculiarities of several real net works, in particular so cial and tech- nological ones [13]. Here we show that this underlying metric structure can be used to guide the routing pro- cess, leading to efficient communication without global information in arbitrarily large netw orks. Our analysis rev eals that, remark ably , real net works satisfy the top o- logical conditions that maximise their navigabilit y within this framework. Therefore, hidden metric spaces offer explanations of tw o op en problems in complex netw orks science: the communication efficiency net works so often exhibit, and their unique structural c haracteristics. I I. NODE SIMILARITY AND HIDDEN METRIC SP A CES Our w ork is inspired by the seminal w ork of sociologist Stanley Milgram on the small world problem. The small w orld paradigm refers to the existence of short c hains of acquaintances among individuals in so cieties [14]. A t Milgram’s time, direct pro of of suc h a paradigm was im- p ossible due to the lack of large databases of so cial con- tacts, so Milgram conceiv ed an exp eriment to analyse the small world phenomenon in human so cial netw orks. Randomly chosen individuals in the United States were ask ed to route a letter to an unknown recipient using only friends or acquain tances that, according to their judge- men t, seemed most likely to kno w the in tended recipient. The outcome of the exp eriment revealed that, without an y global net work knowledge, letters reac hed the tar- get recipient using, on a verage, 5 . 2 in termediate p eople, demonstrating that so cial acquaintance net works w ere in- deed small worlds. The small w orld prop erty can b e easily induced b y 2 FIG. 1: How hidden metric spaces influence the structure and function of complex net works. The smaller the distance b etw een t wo no des in the hidden metric space, the more lik ely they are connected in the observ able net w ork topology . If no de A is close to no de B , and B is close to C , then A and C are necessarily close b ecause of the triangle inequality in the metric space. Therefore, triangle AB C exists in the netw ork topology with high probability , which explains the strong clustering observ ed in real complex net w orks. The hidden space also guides the greedy routing process: if node A w ants to reach no de F , it chec ks the hidden distances betw een F and its tw o neighbours B and C . Distance C F (green dashed line) is smaller than B F (red dashed line), therefore A forwards information to C . No de C then p erforms similar calculations and selects its neigh b our D as the next hop on the path to F . Node D is directly connected to F . The result is path A → C → D → F sho wn by green edges in the observ able top ology . adding a small n um b er of random connections to a “large w orld” netw ork [15]. More striking is the fact that so- cial netw orks are navigable without global information. Indeed, the only information that p eople used to make their routing decisions in Milgram’s experiment was a set of descriptiv e attributes of the destined recipien t, such as place of living and o ccupation. People then determined who among their contacts was “so cially closest” to the target. The success of the exp eriment indicates that so- cial distances among individuals –even though they may b e difficult to define mathematically– pla y a role in shap- ing the netw ork architecture and that, at the same time, these distances can be used to navigate the net w ork. Ho wev er, it is not clear how this coupling b etw een the structure and function of the net work leads to efficiency of the search pro cess, or what the minim um structural requiremen ts are to facilitate such efficiency [16]. In this work, we show how netw ork navigabilit y de- p ends on the structural parameters c haracterising the t wo most prominen t and common prop erties of real com- plex netw orks: (1) scale-free (p ow er-la w) node degree dis- tributions c haracterising the heterogeneit y in the n umber of connections that different no des hav e, and (2) cluster- ing, a measure of the num ber of triangles in the netw ork top ology . W e assume the existence of a hidden metric space, an underlying geometric frame that con tains all no des of the net w ork, shapes its top ology , and guides routing decisions, as illustrated in Fig. 1. No des are con- nected in the observ able topology , but a full view of their global connectivit y is not av ailable at any node. No des are also positioned in the hidden metric space and identi- fied by their co-ordinates in it. Distances b etw een no des in this space abstract their similarity [7, 8, 9, 10, 11, 12]. These distances influence b oth the observ able top ology and routing function: (1) the smaller the distance b e- t ween tw o no des in the hidden space, i.e., the more sim- ilar the tw o no des, the more lik ely they are connected in the observ able topology; (2) no des also use hidden dis- tances to select, as the next hop, the neighbour closest to the destination in the hidden space. Kleinberg intro- duced the term gr e e dy r outing to describe this forw arding pro cess [16]. Greedy routing and its mo difications hav e b een studied extensively in recen t computer science lit- erature [17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29] (see also Kleinberg’s review [30] and references therein). Ho wev er, most of these works do not study greedy rout- ing on scale-free topologies, which are kno wn as the com- mon signature of many large-scale self-evolving complex 3 net works [1, 2, 3]. W e use the class of net work mo dels developed in re- cen t work [13]. They generate netw orks with topologies similar to those of real netw orks –small-world, scale-free, and with strong clustering– and, sim ultaneously , with hidden metric spaces lying underneath. The simplest mo del in this class (the details are in Appendix A) uses a one-dimensional circle as the underlying metric space, in whic h no des are uniformly distributed. The mo del first assigns to each no de its exp ected degree k , drawn from a p o wer-la w degree distribution P ( k ) ∼ k − γ , with γ > 2, and then connects eac h pair of no des with connection probabilit y r ( d ; k , k 0 ) that dep ends b oth on the distance d b etw een the t wo no des in the circle and their assigned degrees k and k 0 , r ( d ; k , k 0 ) ≡ r ( d/d c ) = (1 + d/d c ) − α , (1) where α > 1 and d c ∼ kk 0 , whic h means that the probabilit y of link connection b e- t ween tw o no des in the netw ork decreases with the hid- den distance betw een them (as ∼ d − α ) and increases with their degrees (as ∼ ( k k 0 ) α ). These tw o prop erties hav e a clear interpretation. The connection cost increases with hidden distance, thus dis- couraging long-range links. How ev er, in making connec- tions, rich (w ell-connected, high-degree) no des care less ab out distances (connection costs) than po or nodes. F ur- ther, the char acteristic distanc e sc ale d c pro vides a cou- pling b etw een node degrees and hidden distances, and en- sures the follo wing three top ological characteristics that w e commonly see in real netw orks. First, pairs of richly connected, high-degree no des – hubs – are connected with high probabilit y regardless of the hidden distance b e- t ween them b ecause their c haracteristic distance d c is so large that any actual distance d b et ween them will b e short in comparison: regardless of d , connection proba- bilit y r in Eq. (1) is close to 1 if d c is large. Second, pairs of low-degree no des will not b e connected unless the hid- den distance d b etw een them is short enough to compare with the small v alue of their characteristic distance d c . Third, follo wing similar argumen ts, pairs comp osed of h ubs and low-degree nodes are connected only if they are lo cated at mo derate hidden distances. The parameter α in Eq. (1) determines the importance of hidden distances for node connections. The larger α , the more preferred are connections b etw een no des close in the hidden space. Consequen tly , the triangle inequal- it y in the metric space leads to stronger clustering in the net work, cf. Fig. 1. Clustering has a clear in terpre- tation in our approach as a reflection of the netw ork’s metric strength: the more p ow erful is the influence of the netw ork’s underlying metric space on the observ able top ology , the more strongly it is clustered. Although our to y model is not designed to exactly matc h any specific real netw ork, it generates graphs that are surprisingly similar to some real net w orks, suc h as the Internet at the autonomous system level or the USA airp ort netw ork. See App endix D for details. 10 3 10 4 10 5 network size (N) 3 4 5 6 7 8 average hop length ( τ ) α =1.5 α =2.5 α =3.5 α =4.5 2 2.2 2.4 2.6 2.8 3 degree exponent ( γ ) 0 5 10 15 average hop length ( τ ) α =1.5 α =2.5 α =3.5 α =4.5 γ =2.2 γ =2.5 FIG. 2: Av erage length of greedy-routing paths. The left plot shows the av erage hop length of successful paths, τ , as a function of the net work size N for differen t v alues of γ and α . Results for v alues of γ > 2 . 5 lo ok similar but with longer paths and are omitted for clarity . In all cases, the path length grows polylogarithmically with the netw ork size: the observed v alues of τ are fit w ell by τ ( N ) = A [log N ] ν (solid lines), where A and ν are some constants. The right plot shows τ as a function of γ and α for netw orks of fixed size N ≈ 10 5 . The effect of the tw o parameters on av erage path length is straightforw ard: paths are shorter for smaller exp onen ts γ and stronger clustering (larger α ’s). I I I. NA VIGABILITY OF MODELLED NETW ORKS W e use the mo del to generate scale-free net works with differen t v alues of p o wer-la w degree distribution expo- nen t γ and clustering strength α , cov ering the observed v alues in a v ast ma jority of do cumented complex net- w orks [1, 2, 3]. W e then simulate greedy routing for a large sample of paths on all generated netw orks, and com- pare the follo wing tw o navigabilit y parameters: 1) the a verage hop length τ from source to destination of suc- cessful greedy-routing paths, and 2) the success ratio p s , defined as the p ercen tage of successful paths. Unsuc- cessful paths are paths that get stuc k at no des without neigh b ours closer to the destination in the hidden space than themselves. These no des usually ha v e small degrees. See App endix B for simulation details. Fig. 2 sho ws the impact of the netw ork’s degree distri- bution and clustering on the a verage length τ of greedy routing paths. W e observe a straightforw ard dep endency: paths are shorter for smaller exponents γ and stronger clustering (larger α ’s). The dep endency of the success ratio (the fraction of successful paths) p s on the tw o top ology parameters γ and α is more intert wined. Fig. 3 sho ws that the effect of one parameter, γ , on the success ratio dep ends on the other parameter, the lev el of clus- tering. If clustering is weak (low α ), the p ercentage of successful paths decays with netw ork size N regardless of the v alue of γ (Fig. 3 top-left). Ho w ever, with strong clustering (large α ), the p ercentage of successful paths increases with N and attains a maximum for large net- w orks if γ . 2 . 6, whereas it degrades for large netw orks if γ > 2 . 6 (Fig. 3 bottom-left). Fig. 3 top-righ t shows this effect for netw orks of the same size ( N = 10 5 ) with differen t γ and α . The v alue of γ = 2 . 6 ± 0 . 1 maximises 4 10 2 10 3 10 4 10 5 0 0.1 0.2 γ=2.1 γ=2.2 γ=2.3 γ=2.4 γ=2.5 10 2 10 3 10 4 10 5 network size (N) 0.3 0.4 0.5 0.6 0.7 success probability (p s ) 2 2.2 2.4 2.6 2.8 3 degree exponent ( γ) 0 0.2 0.4 0.6 success probability (p s ) α=1.1 α=1.5 α=2.0 α=3.0 α=5.0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 clustering coefficient (C) 2 2.5 3 degree exponent ( γ ) 10 2 10 3 10 4 10 5 network size (N) 0 0.1 0.2 success probability (p s ) γ=2.6 γ=2.7 γ=2.8 γ=2.9 γ=3.0 α=1.1 α=5.0 navigable region non-navigable region Internet Web of trust Airports Metabolic FIG. 3: Success probabilit y of greedy routing. Left plots: success probability p s as a function of netw ork size N for differen t v alues of γ with w eak (top) and strong (b ottom) clustering. The top-right plot shows p s as a function of γ and α for net works of fixed size N ≈ 10 5 . In the b ottom- righ t plot, parameter α is mapp ed to clustering co efficient C [15] by computing C for eac h net work with given γ and α . F or each v alue of C , there is a critical v alue of γ = γ c ( C ) suc h that the success ratio in netw orks with this C and γ > γ c ( C ) decreases with the net work size ( p s ( N ) − − − − → N →∞ 0), while p s ( N ) reaches a constant v alue for large N in netw orks with γ < γ c ( C ). The solid line in the plot shows these critical v alues γ c ( C ), separating the low- γ , high- C navigable region, in which greedy routing remains efficient in the large-graph limit, from the high- γ , low- C non-na vigable region, where the efficiency of greedy routing degrades for large net works. The plot labels measured v alues of γ and C for several real complex net w orks. Internet is the global Internet top ology of autonomous systems as seen by the Border Gatew a y Proto col (BGP) [31]; Web of trust is the Pretty Go o d Priv acy (PGP) so cial net work of mutual trust relationships [32]; Metab olic is the netw ork of metab olic reactions of E. c oli [33]; and Airp orts is the netw ork of the public air transp ortation system [34]. the num ber of successful paths once clustering is ab ov e a threshold, α ≥ 1 . 5. These observ ations mean that for a fixed clustering strength, there is a critical v alue of the exp onen t γ (Fig. 3 b ottom-right) b elo w which netw orks remain navigable as their size increases, but ab ov e which their navigabilit y deteriorates with their size. In summary , strong clustering improv es b oth naviga- bilit y metrics. W e also find a delicate trade-off b etw een v alues of γ close to 2 minimising path lengths, and higher v alues – not exceeding γ ≈ 2 . 6 – maximising the p er- cen tage of successful paths. W e explain these findings in the next section, but w e note here that qualitatively , this navigable p ar ameter r e gion c ontains a majority of c omplex networks observe d in r e ality [1, 2, 3], as con- firmed in Fig. 3 (b ottom-right), where we juxtap ose few paradigmatic examples of communication, so cial, biolog- ical, and transp ortation netw orks vs. the identified na v- igable region of clustering and degree distribution exp o- nen t. Interestingly , pow er grids, which propagate elec- tricit y rather than route information, are neither scale- free nor clustered [15, 35]. IV. AIR TRA VEL BY GREED Y ROUTING AS AN EXPLANA TION W e illustrate the greedy routing function, and the structure of netw orks conductive to suc h routing, with an example of passenger air tra vel. Suppose we wan t to trav el from T okso ok Bay , Alask a, to Ibiza, Spain, b y the public air transp ortation netw ork. No des in this net- w ork are airports, and t w o airports are connected if there is at least one flight betw een them. W e trav el accord- ing to the greedy routing strategy using geograph y as the underlying metric space. A t eac h airp ort we choose the next-hop airp ort geographically closest to the desti- nation. Under these settings, our journey go es first to Bethel, then to Anchorage, to Detroit, ov er the Atlan tic to Paris, then to V alencia and finally to Ibiza, see Fig. 4. The sequence and sizes of airp ort hops reveal the struc- ture of our greedy-routing path. The path pro ceeds from a small airp ort to a lo cal h ub at a small distance, from there to a larger hub at a larger distance, and so on un- til w e reach Paris. A t that p oin t, when the distance to the destination becomes sufficien tly small, greedy routing leads us closer to our final destination by c ho osing not another hub, but a less connected neighbouring airp ort. W e observe that the na vigation pro cess has tw o, some- what symmetric phases. The first phase is a coarse- grained search, tra v elling longer and longer distances p er hop tow ard h ubs, th us “zo oming out” from the starting p oin t. The second phase corresponds to a fine-grained searc h, “zo oming in” onto the destination. The turning p oin t b et ween the t wo phases appe ars naturally: once we are in a hub near the destination, the probability that it is connected to a bigger hub closer to the destination sharply decreases, but at this p oint we do not need hubs an ywa y , and greedy routing directs us to smaller airp orts at shorter distances next to the destination. This zo om out/zo om in mec hanism works efficiently only if the coupling b etw een the airp ort net work top ol- ogy and the underlying geography satisfies the follow- ing t wo conditions: the sufficient hubs condition and the sufficient clustering condition. The first condition ensures that a netw ork has enough hub airp orts (high- degree no des) to provide an increasing sequence during the zoom out phase. This condition is fulfilled by the real airp ort net work and b y other scale-free netw orks with small v alues of degree distribution exp onen t γ , b ecause the smaller the γ , the larger the prop ortion of hubs in the netw ork. Ho wev er, the presence of many hubs do es not ensure that greedy routing will use them. Unlik e humans, who can use their kno wledge of airp ort size to selectively tra vel via h ub airp orts, greedy routing uses only one con- 5 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 distance to Ibiza (Km) 0.5 1 1.5 2 2.5 3 logarithm of airport degree Toksook bay Bethel Anchorage Detroit Paris Valencia Ibiza FIG. 4: Greedy routing in the airp ort netw ork. T op: the structure of the single greedy-routing path from T okso ok Bay to Ibiza. At each in termediate airp ort, the next hop is the airp ort closest to Ibiza geographically . Sizes of symbols representing the airp orts are prop ortional to the logarithm of their degrees. The b ottom left figure sho ws the c hanging distance to Ibiza (in the x axis) vs. the degree of the visited airp orts ( y axis, in logarithmic scale). Bottom righ t: the structure of greedy-routing paths b etw een a collection of airp orts in the USA [36]. W e include an airp ort pair in the collection if the distance betw een the airp orts is b etw een 3900 and 4100 kilometers. The num ber of airp ort pairs in this collection is 7620. W e use colour to indicate how often paths in the collection go through an airp ort of a giv en degree lo cated at a given geographical distance from the destination: blue/red indicates exp onentially less/more visits to those airp orts, or more sp ecifically , the color is the logarithm of the normalised density of visited airp orts. strain t at eac h hop: minimise distance to the destination. Therefore, the netw ork top ology must satisfy the second condition, which ensures that Bethel is larger than T ok- so ok Bay , Anc horage larger than Bethel, and so on. More generally , this condition is that the next greedy hop from a remote low-degree no de likely has a higher degree, so that greedy paths typically head first tow ard the highly connected netw ork core. But the netw ork metric strength is exactly the required property: preference for connec- tions betw een no des nearb y in the hidden space means that low-degree no des are less likely to hav e connectivity to distan t low-degree no des; only high-degree no des can ha ve long-range connection that greedy routing will ef- fectiv ely select. The stronger this coupling b etw een the metric space and top ology (the higher α in Eq. (1)), the stronger the clustering in the netw ork. T o illustrate, imagine an airp ort netw ork without suf- ficien t clustering, one where the airp ort closest to our 6 10 0 10 1 10 2 10 3 0 0.2 0.4 0.6 0.8 1 P up (k,d) 10 0 10 1 10 2 10 3 0 0.2 0.4 0.6 0.8 1 10 0 10 1 10 2 10 3 0 0.2 0.4 0.6 0.8 1 P up (k,d) 10 0 10 1 10 2 10 3 0 0.2 0.4 0.6 0.8 1 10 0 10 1 10 2 10 3 k 0 0.2 0.4 0.6 0.8 1 P up (k,d) 10 0 10 1 10 2 10 3 k 0 0.2 0.4 0.6 0.8 1 d =100 d =1000 d =10000 d =100000 α=5.0, γ=2.2 α=5.0, γ=2.5 α=5.0, γ=3.0 α=1.1, γ=2.2 α=1.1, γ=2.5 α=1.1, γ=3.0 FIG. 5: Probability that greedy routing tra v els to higher-degree no des. More precisely , the probabilit y P up ( k , d ) that the greedy-routing next hop after a no de of degree k lo cated at distance d from a destination has higher degree k 0 ≥ k and is closer to the destination. The distance legend in the right-bottom plot applies to all the plots. The results are for the large-graph limit N → ∞ . destination (Ibiza) among all airp orts connected to our curren t no de (T okso ok Bay , Alask a) is not Bethel, which is bigger than T okso ok Bay , but Nightm ute, Alask a, a nearb y airp ort of comparable size to T okso ok Bay . As greedy routing first leads us to Nightm ute, then to an- other small nearby airp ort, and then to another, we can no longer get to Ibiza in few hops. W orse, trav elling via these numerous small airp orts, we could reach one with no connecting flights heading closer to Ibiza. Our greedy routing w ould b e stuc k at this airp ort with an unsuccess- ful path. These factors explain why the most navigable top olo- gies correspond to scale-free net works with small expo- nen ts of the degree distribution, i.e., a large num ber of h ubs, and with strong clustering, i.e., strong coupling b e- t ween the hidden geometry and the observed top ology . V. THE STR UCTURE OF GREEDY-R OUTING P A THS W e observe the discussed zo om-out/zo om-in mecha- nism in analytical calculations and numerical simula- tions. Sp ecifically , we calculate (in App endix F) the FIG. 6: The structure of greedy-routing paths. W e visualise the results of our simulation of greedy routing in mo delled net works with different v alues of γ and α observed in real complex netw orks. The hidden distance b etw een the starting p oint and the destination is alwa ys approximately 10 4 , and the netw ork size N and num ber of attempted paths is alwa ys 10 5 for each ( γ , α ) com bination, but the num ber of successful paths and path hop-lengths v ary , cf. Figs. 2,3. All paths start and end at lo w-degree no des lo cated, resp ectively , in the left- and righ t-b ottom corners of the diagrams (see top left plot). F or each ( γ , α ) we depict a single typical path in blac k and, as in Fig. 4, use colour to indicate ho w often paths included a no de of a given degree lo cated at a given distance from the destination. The sim ulations confirm that only when γ is small and α is large do es the a v erage path structure follo w the zo om-out/zo om-in pattern that c haracterises successful greedy routing in real netw orks, e.g., in the airp ort netw ork in Fig. 4. probabilit y that the next hop from a no de of degree k lo cated at hidden distance d from the destination has a larger degree k 0 > k , in which case the path mo ves to ward the high-degree netw ork core, see Fig. 5. In the most na vigable case, with small degree-distribution exp onent and strong clustering, the probability of increasing the no de degree along the path is high at low-degree no des, 7 and sharply decreases to zero after reac hing a no de of a critical degree v alue, which increases with distance d . This observ ation implies that greedy-routing paths first propagate up to higher-degree no des in the netw ork core and then exit the core to ward low-degree destinations in the p eriphery . In contrast, with low clustering, paths are less likely to find higher-degree no des regardless of the distance to the destination. This path structure violates the zo om-out/zo om-in pattern required for efficient nav- igation. Fig. 6 sho ws the structure of greedy-routing paths in sim ulations, further confirming our analysis. W e again see that for small degree-distribution exp onents and strong clustering (upp er left and middle left), the routing pro cess quickly finds a w a y to the high-degree core, mak es a few hops there, and then descends to a lo w- degree destination. In the other, non-na vigable cases, the pro cess can almost never get to the core of high-degree no des. Instead, it wanders in the low-degree p eriphery increasing the probability of getting lost at low-degree no des. VI. DISCUSSION Our main motiv ation for this work comes from long- standing scalability problems with the Internet routing arc hitecture [37]. T o route information pac k ets to a giv en destination, Internet routers m ust comm unicate to main- tain a coherent view of the global Internet top ology . The constan tly increasing size and dynamics of the Internet th us leads to immense and quic kly growing communica- tion and information pro cessing ov erhead, a ma jor b ot- tlenec k in routing scalabilit y [38] causing concerns among In ternet exp erts that the existing Internet routing archi- tecture may not sustain even another decade [37]. Dis- co very of the In ternet’s hidden metric space would re- mo ve this b ottleneck, eliminating the need for the in- heren tly unscalable communication of top ology changes. Instead routers w ould b e able to just forw ard pack ets greedily to the destination based on hidden distances. In a similar manner, reconstruction of hidden metric spaces underlying other real netw orks may pro ve prac- tically useful. F or example, in so cial or communication net works (e.g., the W eb, ov erla y , or online so cial net- w orks) hidden spaces w ould yield efficient strategies for searc hing sp ecific individuals or con ten t based only on lo cal knowledge. The metric spaces hidden under some biological netw orks (suc h as neural, gene regulatory net- w orks, signalling or even protein folding [39] path wa ys) can b ecome a p ow erful to ol in studying the structure of information or signal flo ws in these netw orks, enabling in vestigation of such pro cesses without detailed global kno wledge of the net work structure or organisation. The natural question we thus face is how to proceed to- w ard discov ery of the explicit structure of hidden metric spaces underlying real netw orks. W e do not exp ect spaces underlying differen t netw orks to b e exactly the same. F or example, the similarity spaces of W eb pages [9] and Wikip edia editors [11] likely differ. How ev er, the main con tribution of this work establishes the gener al mec ha- nisms behind na vigabilit y of scale-free, strongly clustered top ologies that characterise many different real net w orks. The next step is to find the common properties of hid- den spaces that render them congruent with these mech- anisms. Sp ecifically , w e are in terested in what geometries of hidden spaces lead to such congruency [40]. In general, w e b eliev e that the presen t and future work on hidden metric spaces and net w ork na vigability will deep en our understanding of the fundamen tal la ws de- scribing relationships b et ween structure and function of complex netw orks. Ac knowledgmen ts W e thank M. ´ Angeles Serrano for useful comments and discussions. This work was supp orted in part b y DGES gran t FIS2007-66485-C02-02, Generalitat de Cataluny a gran t No. SGR00889, the Ram´ on y Ca jal program of the Spanish Ministry of Science, by NSF CNS-0434996 and CNS-0722070, by DHS N66001-08-C-2029, and by Cisco Systems. APPENDIX A: A MODEL WITH THE CIRCLE AS A HIDDEN METRIC SP A CE. In our mo del we place all no des on a circle by assign- ing them a random v ariable θ , i.e., their p olar angle, dis- tributed uniformly in [0 , 2 π ). The circle radius R gro ws linearly with the total num b er of nodes N , 2 π R = N , in order to keep the a verage density of no des on the cir- cle fixed to 1. W e next assign to each no de its exp ected degree κ drawn from some distribution ρ ( κ ). The con- nection probabilit y b etw een t wo no des with hidden co- ordinates ( θ , κ ) and ( θ 0 , κ 0 ) takes the form r ( θ , κ ; θ 0 , κ 0 ) = 1 + d ( θ , θ 0 ) µκκ 0 − α , µ = ( α − 1) 2 h k i , (A1) where d ( θ , θ 0 ) is the geo desic distance b etw een the tw o no de on the circle, while h k i is the av erage degree. One can show that the a verage degree of no des with hidden v ariable κ , ¯ k ( κ ), is prop ortional to κ .[41] This pro- p ortionalit y guaran tees that the shap e of the no de de- gree distribution P ( k ) in generated net works is appro x- imately the same as the shape of ρ ( κ ). The c hoice of ρ ( κ ) = ( γ − 1) κ γ − 1 0 κ − γ , κ > κ 0 ≡ ( γ − 2) h k i / ( γ − 1), γ > 2, generates random netw orks with a p o wer-la w de- gree distribution of the form P ( k ) ∼ k − γ , where γ is a mo del parameter that regulates the heterogeneity of the degree distribution in the netw ork. This parame- ter abstracts the heterogeneit y of node degrees in real net works, where degree distributions ma y not p erfectly 8 follo w p ow er laws, or may exhibit v arious forms of high- degree cut-offs [31, 42]. The sp ecific effects are less im- p ortan t than the ov erall measure of heterogenit y . W e note that instead of a circle in our mo del we could use an y isotropic space of any dimension [13]. APPENDIX B: NUMERICAL SIMULA TIONS. Our mo del has three independent parameters: ex- p onen t γ of p ow er-la w degree distributions, clustering strength α , and a verage degree h k i . W e fix the latter to 6, whic h is roughly equal to the av erage degree of some real netw orks of interest [31, 32], and v ary γ ∈ [2 . 1 , 3] and α ∈ [1 . 1 , 5], cov ering their observed ranges in do cu- men ted complex netw orks [1, 2, 3]. F or each ( γ , α ) pair, w e pro duce net w orks of differen t sizes N ∈ [10 3 , 10 5 ] gen- erating, for each ( γ , α, N ), a num b er of different netw ork instances—from 40 for large N to 4000 for small N . In eac h netw ork instance G , we randomly select 10 6 source- destination pairs ( a, b ) and execute the greedy-routing pro cess for them starting at a and selecting, at each hop h , the next hop as the h ’s neighbour in G closest to b in the circle. If for a giv en ( a, b ), this pro cess visits the same no de t wice, then the corresp onding path leads to a lo op and is unsuccessful. W e then av erage the measured v alues of path hop lengths τ and p ercentage of successful paths p s across all pairs ( a, b ) and netw orks G for the same ( γ , α, N ). Note that we are not concerned with the absolute v alues of the success ratio p s . Instead we use it as a me asur e of navigabilit y to compare netw orks with differen t ( γ , α, N ). F or this purp ose w e could use the success ratio of any (improv ed) mo dification of standard greedy routing. APPENDIX C: SHOR TEST P A TH VS. SHOR TEST TIME. All results derived in the present paper are ab out find- ing short paths across a net work top ology . The total ph ysical time from source to destination is implicitly as- sumed to b e proportional to the n um b er of hops. In real transp ortation systems, e.g. the Internet or the air- p ort net work, the finite capacity of no des implies that the end-to-end path latency may b e longer when inter- mediate no des are congested. While our results most cleanly apply to uncongested systems, there are obvious mo difications, such as choosing the second or third near- est rather than the nearest neighbor, that could still find nearly shortest paths while reducing and balancing load on the system. APPENDIX D: THE MODEL VS. REAL NETW ORKS: THE AUTONOMOUS SYSTEM LEVEL MAP OF THE INTERNET AND THE US AIRPOR T NETWORK The mo del we use in this work is not meant to repro- duce any particular system but to generate a set of gen- eral prop erties, like heterogeneous degree distributions, high clustering, and a metric structure lying underneath. Y et, despite its simplistic assumptions, the mo del gener- ates graphs that are surprisingly close to some real net- w orks of interest, in particular the Internet at the Au- tonomous System lev el (AS) [31, 43] and the netw ork of airline connections among airp orts within the United States during 2006 (USAN) [36]. In the case of the In- ternet, w e use tw o different data sets, the In ternet as view ed by the Border Gatewa y Proto col (BGP) [31] and the DIMES pro ject [43]. The BGP (DIMES) netw ork has a size of N ∼ 17446 ( N = 19499) ASs, av erage degree h k i = 4 . 7 ( h k i = 5), and av erage clustering C = 0 . 41 ( C = 0 . 6). The US Airp ort Net w ork is comp osed of US airp orts connected by regular fligh ts (with more than 1000 passengers p er year) during the year 2006. This re- sults in a net work of N = 599 airp orts, a verage degree h k i ∼ 10 . 8 and a verage clustering co efficient C = 0 . 72. Figs. 7 and 8 s ho w a comparison of the basic top olog- ical prop erties of these netw orks with graphs generated with the mo del. In the case of the AS map, w e use a truncated p ow er law distribution ρ ( κ ) ∼ κ − γ , κ < κ c with exp onent γ = 2 . 1 and κ c suc h that the maxim um degree of the netw ork is k c = 2400. F or the USAN, we use γ = 1 . 6 and a maxim um degree k c = 180, as observed in the real netw ork. As it can b e appreciated in b oth fig- ures, the matching of the mo del with the e mpirical data is surprisingly go o d except for very lo w degree v ertices. This is particularly interesting since we are not enforc- ing any mechanism to repro duce higher order statistics lik e the av erage nearest neighbours degree ¯ k nn ( k ) or the degree-dep enden t clustering co efficient ¯ c ( k ). This can b e understo o d as a consequence of the high heterogeneit y of the degree distribution that introduces structural con- strain ts in the net work [44, 45]. The airp ort netw ork differs in several wa ys from our mo delled netw orks: the distribution of airp orts in the geographic space is far from uniform; the airp ort degree distribution do es not p erfectly follow a p ow er law; and it exhibits a sharp high-degree cut-off. How ev er, the struc- ture of greedy paths is surprisingly similar to that in our mo delled netw orks in Fig. 6. The success ratio p s ≈ 0 . 64 and av erage length of successful paths τ ≈ 2 . 1 are also similar to those in our mo delled netw orks of the corre- sp onding size, clustering, and degree distribution exp o- nen t. These similarities indicate that the netw ork navi- gabilit y characteristics dep end on clustering and hetero- geneit y of the airp ort degree distribution, and less so on ho w p erfectly it follo ws a p ow er law. 9 10 0 10 1 10 2 10 3 10 4 k 10 -6 10 -4 10 -2 10 0 P(k) AS DIMES AS BGP Model γ =2.1 10 0 10 1 10 2 10 3 10 4 k 10 1 10 2 10 3 k nn (k) AS DIMES AS BGP Model 10 0 10 1 10 2 10 3 10 4 k 10 -3 10 -2 10 -1 10 0 c(k) AS DIMES AS BGP Model FIG. 7: Degree distribution P ( k ), av erage nearest neigh- b ours’ degree ¯ k nn ( k ), and degree-dep endent clustering co ef- ficien t ¯ c ( k ) generated by our mo del with γ = 2 . 1 and α = 2 compared to the same metrics for the real Internet map as seen by BGP data and the DIMES pro ject. APPENDIX E: HIERAR CHICAL OR GANIZA TION OF MODELED NETWORKS The routing process in our framew ork resem bles guided searc hing for a sp ecific ob ject in a complex collection of ob jects. Perhaps the simplest and most general wa y to mak e a complex collection of heterogenous ob jects searc hable is to classify them in a hierarchical fashion. By “hierarc hical,” we mean that the whole collection is split into categories (i.e., sets), sub-categories, sub-sub- categories, and so on. Relationships b etw een categories form (almost) a tree, whose leav es are individual ob jects in the collection [7, 8, 12, 40]. Finding an ob ject reduces to the simpler task of navigating this tree. k -core decomp osition [47, 48] is p ossibly the most suit- able generic to ol to exp ose hierarch y within our mo deled net works. The k -core of a netw ork is its maximal sub- graph such that all the no des in the subgraph hav e k or more connections to other no des in the subgraph. A no de’s coreness is the maxim um k such that the k -core 10 0 10 1 10 2 10 3 k 10 -4 10 -2 10 0 P(k) USAN Model γ =1.6 10 0 10 1 10 2 10 3 k 10 1 10 2 k nn (k) USAN Model 10 0 10 1 10 2 10 3 k 10 -1 10 0 c(k) USAN Model FIG. 8: Degree distribution P ( k ), av erage nearest neigh- b ours’ degree ¯ k nn ( k ), and degree-dependent clustering co effi- cien t ¯ c ( k ) generated b y our mo del with γ = 1 . 6, α = 5 and a cut-off at k c = 180 compared to the same metrics for the real US airp ort netw ork. con tains the node but the k + 1-core does not. The k -core structure of a net w ork is a form of hierarc h y since a k + 1- core is a subset of a k -core. One can estimate the quality of this hierarch y using prop erties of the k -core sp ectrum, i.e., the distribution of k -core sizes. If the maximum no de coreness is large and if there is a rich collection of comparably-sized k -cores with a wide sp ectrum of k ’s, then this hierarc hy is deep and w ell-developed, making it p oten tially more navigable. It is p o or, non-na vigable otherwise. In Fig. 9 we feed real and mo deled net works to the Large Netw ork visualization tool (LaNet-vi) [46] whic h utilizes no de coreness to visualize the net work. Fig. 9 sho ws that net w orks with stronger clustering and smaller exp onen ts of degree distribution p ossess stronger k -core hierarc hies. These hierarchies are directly related to how net works are constructed in our mo del, since no des with higher κ and, consequently , higher degrees ha v e generally higher coreness, as we can partially see in Fig. 9. 10 1 In ternet AS map (BGP) γ = 2 . 2 , α = 5 . 0 γ = 2 . 5 , α = 5 . 0 γ = 3 . 0 , α = 5 . 0 So cial net work (PGP) γ = 2 . 2 , α = 1 . 1 γ = 2 . 5 , α = 1 . 1 γ = 3 . 0 , α = 1 . 1 10 0 10 1 10 2 k 10 -3 10 -2 10 -1 10 0 S(k) PGP BGP 10 0 10 1 10 2 k 10 -3 10 -2 10 -1 10 0 S(k) ! =1.1 ! =5.0 10 0 10 1 10 2 k 10 -3 10 -2 10 -1 10 0 S(k) ! =1.1 ! =5.0 10 0 10 1 10 2 k 10 -3 10 -2 10 -1 10 0 S(k) ! =1.1 ! =5.0 FIG. 9: k -core decomp ositions of real and mo deled netw orks . The first tw o rows show LaNet-vi [46] netw ork visual- izations. All no des are color-co ded based on their coreness (righ t legends) and size-co ded based on their degrees (left legends). Higher-coreness no des are closer to circle centers. The third ro w shows the k -core sp ectrum, i.e., the distribution S ( k ) of sizes of no de sets with coreness k . The first column depicts tw o real netw orks: the AS-level Internet as seen by the Border Gatew ay Proto col (BGP) in [31] and the Pretty Goo d Priv acy (PGP) so cial net work from [32]. The rest of the columns show mo deled net works for different v alues of p ow er-law exponent γ in cases with weak ( α = 1 . 1) and strong ( α = 5 . 0) clustering. The net work size N for all real and mo deled cases is approximately 10 4 . Similarit y b etw een real netw orks and mo deled netw orks with low γ and high α is remark able. APPENDIX F: THE ONE-HOP PROP A GA TOR OF GREED Y ROUTING T o derive the greedy-routing propagator in this ap- p endix, we adopt a slightly more general formalism than in the main text. Sp ecifically , w e assume that no des liv e in a generic metric space H and, at the same time, ha ve intrinsic attributes unrelated to H . Contrary to normed spaces or Riemannian manifolds, generic metric spaces do not admit any co ordinates, but we still use the co ordinate-based notations here to simplify the ex- p osition b elow, and denote by x no des’ co ordinates in H and by ω all their other, non-geometric attributes, suc h as their exp ected degree κ . In other w ords, hidden v ari- ables x and ω in this general formalism represent some collections of no des’ geometric and non-geometric hidden attributes, not just a pair of scalar quan tities. Therefore, in tegrations ov er x and ω in what follo ws stand merely to denote an appropriate form of summation in eac h con- crete case. As in the main text, we assume that x and ω are inde- p enden t random v ariables so that the probabilit y densit y to find a no de with hidden v ariables ( x , ω ) is ρ ( x , ω ) = δ ( x ) ρ ( ω ) / N , (F1) where ρ ( ω ) is the probability density of the ω v ariables and δ ( x ) is the concen tration of no des in H . The total n umber of no des is N = Z H δ ( x ) d x , (F2) and the connection probability b etw een tw o no des is an in tegrable decreasing function of the hidden distance b e- t ween them, r ( x , ω ; x 0 , ω 0 ) = r [ d ( x , x 0 ) /d c ( ω , ω 0 )] , (F3) where d c ( ω , ω 0 ) a characteristic distance scale that de- p ends on ω and ω 0 . W e define the one-step propagator of greedy routing as the probability G ( x 0 , ω 0 | x , ω ; x t ) that the next hop after a no de with hidden v ariables ( x , ω ) is a no de with hid- den v ariables ( x 0 , ω 0 ), giv en that the final destination is lo cated at x t . 11 T o further simplify the notations b elo w, w e lab el the set of v ariables ( x , ω ) as a generic hidden v ariable h and undo this notation c hange at the end of the calculations according to the following rules: ( x , ω ) − → h ρ ( x , ω ) − → ρ ( h ) d x dω − → dh r ( x , ω ; x 0 , ω 0 ) − → r ( h, h 0 ) . (F4) W e b egin the propagator deriv ation assuming that a particular netw ork instance has a configuration given b y { h, h t , h 1 , · · · , h N − 2 } ≡ { h, h t ; { h j }} with j = 1 , · · · , N − 2, where h and h t denote the hidden v ari- ables of the curren t hop and the destination, respectively . In this particular netw ork configuration, the probability that the current no de’s next hop is a particular no de i with hidden v ariable h i is the probabilit y that the cur- ren t no de is connected to i but disconnected to all no des that are closer to the destination than i , Prob( i | h, h t ; { h j } ) = r ( h, h i ) N − 2 Y j ( 6 = i )=1 [1 − r ( h, h j )] Θ[ d ( h i ,h t ) − d ( h j ,h t )] , (F5) where Θ( · ) is the Heaviside step function. T ak- ing the av erage o ver all possible configurations { h 1 , · · · , h i − 1 , h i +1 , · · · , h N − 2 } excluding no de i , w e ob- tain Prob( i | h, h t ; h i ) = r ( h, h i ) 1 − 1 N − 3 ¯ k ( h | h i , h t ) N − 3 , (F6) where ¯ k ( h | h i , h t ) = ( N − 3) Z d ( h i ,h t ) d ( y , x t ) d y Z dω 0 δ ( y ) ρ ( ω 0 ) r d ( x , y ) d c ( ω , ω 0 ) . (F12) In the particular case of the S 1 mo del, we can express this propagator in terms of relative hidden distances in- stead of absolute co ordinates. Namely , G ( d 0 , ω 0 | d, ω ) is the probability that an ω -lab eled no de, e.g., a no de with exp ected degree κ = ω , at hidden distance d from the destination has as the next hop an ω 0 -lab eled no de at hidden distance d 0 from the destination. After tedious calculations, the resulting expression reads: 12 G ( d 0 , ω 0 | d, ω ) = 8 > > > > > < > > > > > : ( γ − 1) ω 0 γ " 1 (1+ d − d 0 µωω 0 ) α + 1 (1+ d + d 0 µωω 0 ) α # exp n (1 − γ ) µω α − 1 h B ( d − d 0 µω , γ − 2 , 2 − α ) − B ( d + d 0 µω , γ − 2 , 2 − α ) io ; d 0 ≤ d ( γ − 1) ω 0 γ " 1 (1+ d 0 − d µωω 0 ) α + 1 (1+ d + d 0 µωω 0 ) α # exp n (1 − γ ) µω α − 1 h 2 γ − 2 − B ( d 0 − d µω , γ − 2 , 2 − α ) − B ( d + d 0 µω , γ − 2 , 2 − α ) io ; d 0 > d , (F13) 10 -3 10 -2 10 -1 10 0 10 1 10 2 ω / d 1/2 0 0.2 0.4 0.6 0.8 1 P up ( ω , d) 10 -3 10 -2 10 -1 10 0 10 1 10 2 ω / d 1/2 0 0.2 0.4 0.6 0.8 1 P up ( ω , d) 10 -3 10 -2 10 -1 10 0 10 1 10 2 ω / d 1/2 0 0.2 0.4 0.6 0.8 1 P up ( ω , d) 10 -3 10 -2 10 -1 10 0 10 1 10 2 ω / d 1/2 0 0.2 0.4 0.6 0.8 1 P up ( ω , d) 10 -3 10 -2 10 -1 10 0 10 1 10 2 ω / d 1/2 0 0.2 0.4 0.6 0.8 1 P up ( ω , d) 10 -3 10 -2 10 -1 10 0 10 1 10 2 ω / d 1/2 0 0.2 0.4 0.6 0.8 1 P up ( ω , d) d=100 d=1000 d=10000 d=100000 α =5.0, γ =2.2 α =5.0, γ =2.5 α =5.0, γ =3.0 α =1.1, γ =2.2 α =1.1, γ =2.5 α =1.1, γ =3.0 FIG. 10: Probability P up ( ω /d 1 / 2 , d ). where we hav e defined function B ( z , a, b ) ≡ z − a Z z 0 t a − 1 (1 + t ) b − 1 dt, (F14) whic h is somewhat similar to the incomplete b eta func- tion B ( z , a, b ) = R z 0 t a − 1 (1 − t ) b − 1 dt . One of the informativ e quantities elucidating the struc- ture of greedy-routing paths is the probability P up ( ω , d ) that the next hop after an ω -lab eled no de at distance d from the destination has a higher v alue of ω . The greedy- routing propagator defines this probability as P up ( ω , d ) = Z ω 0 ≥ ω dω 0 Z d 0
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment