Fountain Codes and Invertible Matrices
This paper deals with Fountain codes, and especially with their encoding matrices, which are required here to be invertible. A result is stated that an encoding matrix induces a permutation. Also, a result is that encoding matrices form a group with …
Authors: Mikko Malinen
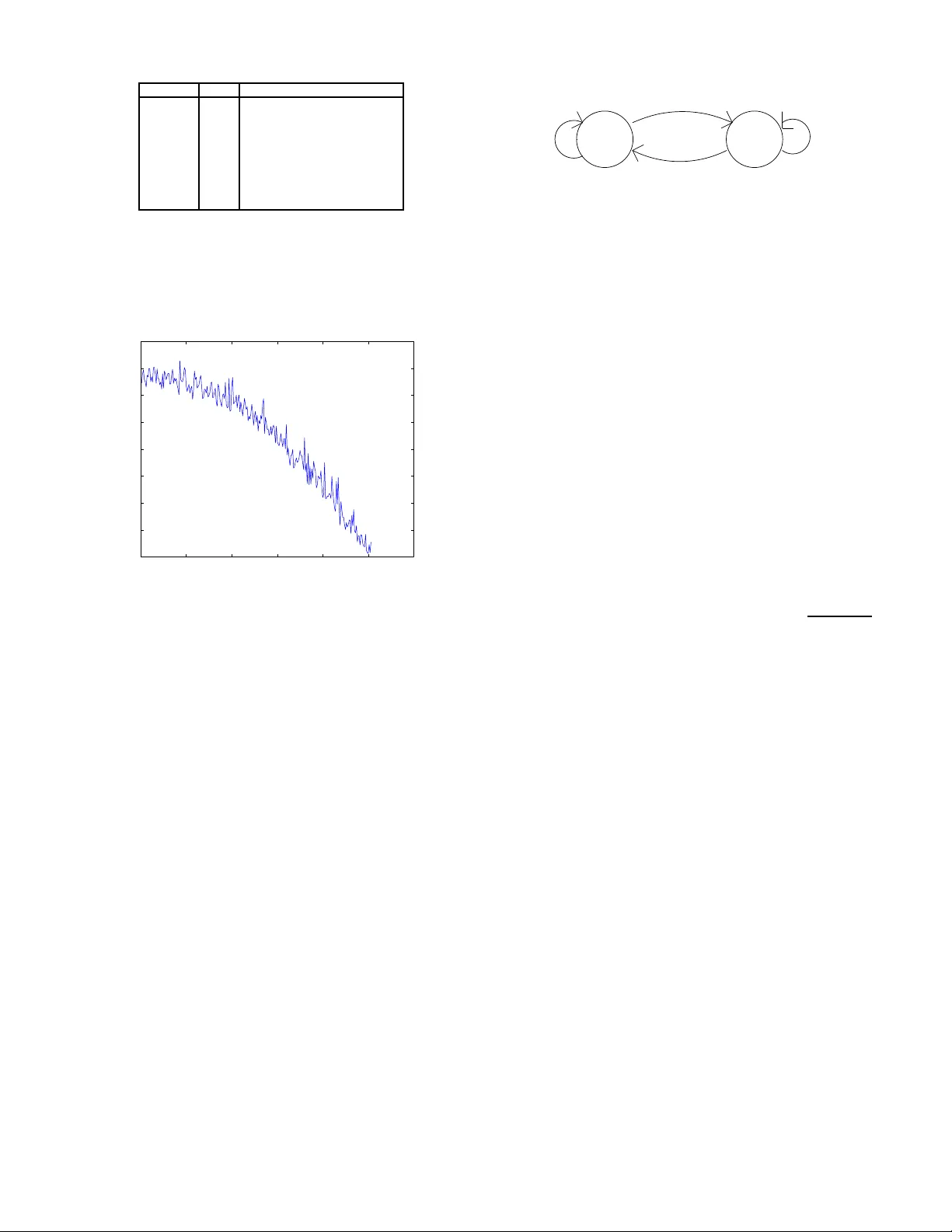
1 F ountain Codes and In v ertible Mat rices Mikko Malinen, Student Membe r , IEEE. Abstract —This paper deals with Fountain codes, and especially with their encoding ma trices, which are re quired here to b e in vertible. A result is stated that an encoding matrix in duces a permutation. Also, a r esult is that encoding matrices f orm a g roup with multiplication operation. An encoding is a transfo rmation, which reduces the entropy of an ini tially high-entropy i nput vector . A special encoding matrix, wi th wh ich the entropy reduction is more effective than with matrices created b y the Ideal Soliton distribution is f ormed. Experime ntal results with entropy r eduction are shown. Index T erms —Entropy-reducing transfo rmation, F ountain codes, gro up, Ideal Soliton distribution, permutation. I . I N T R O D U C T I O N F OUNT AI N codes were first men tioned in [1] . L T -co des [3] are first pra ctical Fountain codes. In Foun tain cod es we h av e k input sy mbols and n o utput symb ols. W e call an encodin g graph a bipartite g raph w here on the o ther side are the inpu t symbols and on th e other side the ou tput symbo ls. There are edges wh ich mark the connections betwee n the input symb ols and the output sy mbols. W e call the d egree of an outpu t symbol the numb er of inp ut symb ols the output symbol is c onnected to. The degree distribution ρ ( i ) tells the probab ility that an ou tput symb ol h as i connection s. W e call an encodin g matrix R a k × k matrix where an element r lm is 1 if the m :th input symbol affects (has a connec tion) to the l :th outpu t symbol and 0 if it has not. Gene rally , R may have rank < k , but here we r estrict the treatment to ma trices which have full ran k, i.e. all the rows are line arly indepen dent. These matrices are in vertible. This way the nu mber o f output symbols n e quals the n umber of inp ut symb ols k . Fountain codes for which the m atrix R is of full ran k are always decodab le. The outpu t bits ar e calculated by y = R x, where y is o utput bits in vector form, x is inp ut bits in vector form and th e mu ltiplication is do ne mod ulo 2 as is the idea in Fountain coding . The d ecoding is done by x = R − 1 y . I I . E N C O D I N G M AT R I X I N D U C E S A P E R M U TA T I O N Our first result (Result 1) is that when there a re two different inputs x (1) and x (2) , the two ou tputs y (1) and y (2) are always different. This is due to th e fact that wh en decodin g y ( i ) we end up to an unique x ( i ) . From the Result 1 follows the n ext r esult: By multiplying an in put vector x sev eral times by the encodin g matr ix, we end up b ack to x at som e point. Each m ultiplication results to different ou tput un til we en d u p to x . Dep ending on the choice of the initial input we end u p to different cycles. Thus, in pr inciple, we co uld m ake deco ding o f an o utput by multiply ing the outp ut, length o f the cycle - 1 times. Of course, we h av e to know the length of the cycle. If we number th e d ifferent length k vectors by 1 , 2 , ..., 2 k we can say th at an encod ing matrix R in duces an unique p ermutation . W e can use the list pre sentation of a permutation [2] , pp. 52-64 , to express the permu tation. From the list pr esentation can be seen that th ere are s ! d ifferent possible perm utations of s elements. This c ould be u sed as th e upper b ound for th e number o f d ifferent encoding matr ices. However , it turns out that 2 k ! (we have 2 k elements) grows faster than th e total number of different 0- 1 matrices 2 ( k 2 ) (in a k × k matrix there are k 2 elements). Thu s this uppe r b ound is p ractically useless. W e may also conclud e that in vertible 0-1 matrices o f size k × k do not ind uce all possible p ermutation s of size 2 k . I I I . E N C O D I N G M A T R I C E S F O R M A G RO U P One result is th at encoding matrices ( in vertible 0-1 matrices) form a group with mo dulo 2 m ultiplication oper ation. Namely , two such matr ices mu ltiplied is also such a matrix. The re is a un it elemen t, a unit matrix. Also, the in verse element is the in verse matrix . And the multiplicatio n is associati ve. I V . E N T RO P Y - R E D U C I N G T R A N S F O R M AT I O N S Next, we come to entropy con siderations. W e state a result, that when all different inp ut vectors are m ultiplied by an encodin g m atrix, the entropy rem ains the same o n average. This is due to the fact that if the entro py would ch ange, we cou ld compress the input vector below what the in itial entropy in dicates. Even if the e ntropy increased o n the a verage, we cou ld reduc e the en tropy by using the in verted matrix. Howe ver , accord ing to our exp erimental r esults, if th e entropy is ”big”, i.e., the number of 0’ s and 1’ s a re near th e same, the entro py decreases on the average when multiplied by an encodin g matrix. Th is we have calculated o n a 8 bit lo ng inp ut and th e Ideal So liton degree d istribution as d escribed in [3] . As we shall see later , we can constru ct a special enco ding matrix with almost all distribution weigth on d egree 2 with which the redu ction in entropy is dem onstrated also on large input len gths. For the first mentioned 8 bit long input, with 4 zeros and 4 o nes we give the pr obabilities of z ero in outpu t in T able I ( ρ ( i ) is the Ideal Soliton degree distribution): The two last co lumns m ultiplied with each oth er and summ ed results in 0.4 7321 prob ability of zero in outp ut. This is lower than the 0.5 prob ability at the input. One may think that there is so me o ther d egree distribution with even better r eduction in entropy or that there exists some degree distribution that giv es the b est red uction. It can be seen fr om the T able I th at 2 degre e i ρ ( i ) Probability of zero in output 1 1/8 0.5 2 1/2 0.42857 3 1/6 0.5 4 1/12 0.52857 5 1/20 0.5 6 1/30 0.42857 7 1/42 0.5 8 1/56 1 T ABLE I I D E A L S O L I T O N D E G R E E P R O B A B I L I T I E S A N D P RO B A B I L I T I E S O F Z E RO I N O U T P U T F O R A 8 - B I T L E N G T H I N P U T W I T H E Q U A L N U M B E R O F Z E RO S A N D O N E S 0 50 100 150 200 250 300 −6 −5 −4 −3 −2 −1 0 1 2 Fig. 1. Savi ng in bits (vertic al direct ion) when transformation is applied to input of length 30204 with dif ferent reduced number of ones in the input (horizont al directi on) degree i = 2 gives the lowest p robability of zero in the outpu t, 0.428 57. W e used this d egree an d formed a special in vertible encodin g matrix R : r lm = 1 , when m = l or m = l + 1 r lm = 0 , otherwise . For exam ple, a 4 × 4 en coding matrix R would b e: R = 1 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1 . There is a single 1 in the last row at the last column . T hese matrices are in vertible and thus suitable for en coding and decodin g. W e r an simulations with inpu t length 30204 and 61408 . W e used different initial pro portion s of zero s and o nes in input. W e calculated th e effect of the entropy chang e to the optim al representation of the b its. In Fig ure 1 we see the sa ving in bits as the function o f un ev eness of 0’ s and 1’ s at the in put. The inpu t vector length is 302 04 bits. At the left border there a re 0 on es less than zeros in input. Near the righ t border there ar e 250 on es less in inp ut th an in the left borde r . W ith each h orizontal value ten sim ulations wer e ma de, with random ly placed ones, and the av erage was taken. W e see that for horizon tal values 0 ..90 th e needed numb er of bits in 0.5 0 1 0.5 0.5 0.5 Fig. 2. A stochastic process defined by a Marko v chain. representin g th e o utput is lower than the neede d num ber of bits nee ded in rep resenting the in put. Th e reduc tion is at most near 1 bit. With larger hor izontal values the entro py inc reases and mo re b its are need ed to repre sent the ou tput. In princip le, we got similar results with input vector length 61408. The space saving is still a t most less th an one bit on average. The results rise some co njectures which we presen t here. Conjectur e 1: The space sa ving using this tran sformation is on av erage less than one b it, even when applied to hig h- entropy input. Let u s consider a stochastic pro cess defined by the Markov chain in Figure 2. The average entropy of a finite length realization o f this process can be ca lculated with the help of a binomial pro bability de nsity fu nction multiplied by entro py function . It would b e tempting to think that the av erage entropy equals to the entro py calcu lated from the pro portion s of 0’ s and 1’ s when the nu mber of on es is decr eased b y the stan dard deviation of the associated binom ial distribution. T he standard deviation of a bin omial distribution is σ = p np (1 − p ) . But, according to our calculation s, this is not the case. T hese entropies differ . Conjectur e 2: The tran sformatio n described above can not reduce on av erage the entropy of a realization of the stoch astic process described ab ove below th e a verage entropy of the same process. V . C O N C L U S I O N S Fountain cod es and espe cially th eir inv ertible encod ing matrices w ere dealt with. Encod ing matrices ind uces a un ique permutatio n on k bit strin gs. E ncoding matrices with mu ltipli- cation operation form a gr oup. E ncoding matr ices sampled from th e I deal Soliton degre e distribution redu ce entro py at least in a spec ial case. A special transfo rmation matrix model was for med and different inpu t vector s were used in simulation s which showed reduc tion in entropy when the initial entropy was high. Although some entropy reduction was possible, it was on av erage less than on e bit from tens of thousand s o f bits, so in practice this th is meth od may n ot b e applicable. Howe ver , mo re re search is still needed to show if Conjecture 1 hold s. R E F E R E N C E S [1] J. Byers, M. Luby , M. Mitzen macher, and A. Rege, ”A digital fountain appr oach to reliable distribution o f bulk d ata”, in Pr oc. ACM SI GCOMM ’98 , V an couver, BC, Canad a, Jan. 1998, pp. 56-6 7 3 [2] D. L. Kreh er and D. R. Stinson, Comb inatorial Algorithms, Generation, Enu meration and S ear ch , CRC Press LLC, Boca Raton, FL, 19 99 [3] M. Luby , ”L T -codes”, in Pr o c. 4 3r d An nu. IEEE Symp. F ou ndation s of Compu ter Science (FOCS) , V an couver, BC, Canada, Nov . 2002 , p p. 271- 280
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment