Detecting the overlapping and hierarchical community structure of complex networks
Many networks in nature, society and technology are characterized by a mesoscopic level of organization, with groups of nodes forming tightly connected units, called communities or modules, that are only weakly linked to each other. Uncovering this c…
Authors: Andrea Lancichinetti, Santo Fortunato, Janos Kertesz
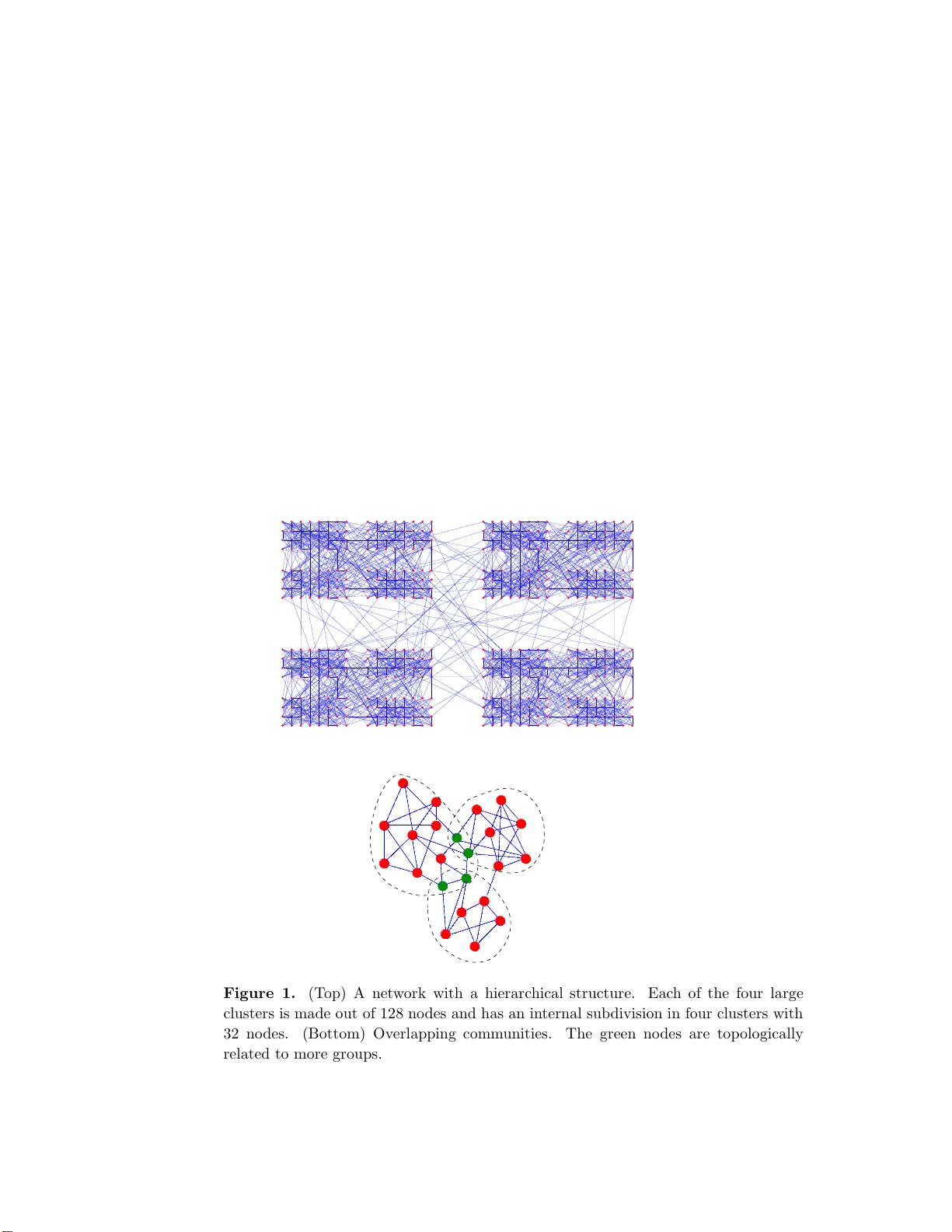
Detectin g the o v erlapping and hierarchical comm unit y structu re in complex net w orks Andrea Lancic hinetti Complex Net works Lagrange Labo ratory (CNLL), Institute for Scient ific Interchange (ISI), Viale S. Severo 65, 10133, T orino, Italy E-mail: arg.lan ci@gm ail.com San to F ortunato Complex Net works Lagrange Labo ratory (CNLL), Institute for Scient ific Interchange (ISI), Viale S. Severo 65, 10133, T orino, Italy E-mail: fortuna to@is i.it J´ anos Kert´ esz Department of Theoretical Physics, Buda pes t University of T echnology a nd Economics, Budafoki ´ ut 8, H1111, Budap est, Hungary E-mail: kertesz @phy. bme.hu Abstract. Many net works in nature, so ciety and tec hnolo g y are characterized b y a mesoscopic level of or ganization, with groups of no des forming tight ly connected units, called communi ties or modules , that are only weakly linked to ea ch other. Uncov ering this commun ity structure is one o f the most imp ortant problems in the field of complex netw orks. Net works often s how a hierar chical org anization, with communi ties embedded within other communities; moreover, no des can b e shar ed betw een differe nt communit ies. Here we present the first algorithm that finds both ov erlapping communities and the hierarchical structure. The metho d is ba sed o n the lo cal optimization of a fitness function. Commun ity structure is re vealed by p ea k s in the fitness histogram. The resolution can b e tuned b y a parameter enabling to in vestigate different hiera rchical levels of or ganization. T ests on real and ar tificial net works give excellen t r e s ults. P ACS num b ers: 89.75.-k, 89.75 .Hc, 05.40 -a, 89.7 5.Fb, 87 .23.Ge Dete cting the overlapping and hier ar chic a l c ommunity structur e in c omplex networks 2 1. In tr o duction The study of net w orks as the ”scaffold of complexit y” has prov e d v ery successful to understand b oth the structure and the function of many natural and ar t ificial systems [1, 2, 3, 4, 5]. A common feature of complex netw orks is c ommunity structur e [6, 7, 8, 9], i.e., the existence of groups of nodes suc h that no des within a group are m uc h more connected to eac h other than to the rest of the net work . Modules or comm unities r eflect top ological relationships b et w een elemen ts of the underlying system and represen t functional entitie s. E.g., comm unities ma y b e groups of related individuals in so cial net w orks [6, 10, 11], sets of W eb pag es dealing with the same topic [12], taxonomic categories in fo o d w ebs [13, 14], bio c hemical path w ays in metab olic net w orks [15, 16, 17], etc. Therefore the iden tification of comm unities is of cen tral imp ortance but it has remained a formidable t a sk. The solution is hamp ered b y the fact that the organization of net w orks at the ”mesoscopic”, mo dular lev el is usually highly non-trivial, for at least tw o reasons. First, there is often a whole hie rarch y of mo dules, b ecause comm unities are nested: Small comm unities build larger ones, whic h in turn group together to form ev en larger ones, etc. An example could be the o rganization of a large firm, and it has been argued that the complexit y of life can also b e mapp ed to a hierarch y of net w orks [18]. The hierarc hical form of or g anization can b e v ery efficien t, with the mo dules taking care of sp ecific functions of the system [19]. In the presence of hierarc h y , the concept of comm unit y structure b ecomes ric her, and demands a metho d that is able to detect all mo dular lev els, not just a single one. Hierarchic al clustering is a w ell-kno wn tec hnique in so cial net work a nalysis [20, 21], biolo g y [22 ] and finance [23]. Starting from a partition in whic h eac h no de is its o wn comm unit y , or all no des are in the same comm unity , one merges or splits clusters according to a top ological measure of similarit y b et w een no des. In this w ay one builds a hierarc hical tree of partitions, called dendr o gr am . Though this metho d naturally pro duces a hierarc hy of partitions, nothing is kno wn a priori a b out their qualities. The mo dularit y o f Newman and Girv an [24] is a measure of the quality of a partition, but it can iden tify a single partition, i.e. the one corresp onding t o the largest v alue of the measure. Only recen tly sc holars ha ve started to fo cus on the problem of iden tifying meaningful hierarc hies [19, 2 5]. A s econd difficult y is caus ed b y the fact that nodes often b elong to more than one m o dule, resulting in o v erlapping comm unities [17, 26, 27, 28, 29]. F o r ins tance p eople b elong to differen t so cial comm unities, dep ending on their families, friends, professions, hobbies, etc. No des b elonging to more than one comm unit y are a problem for standard metho ds and low er the qualit y of the detected mo dules. Moreo v er, this conceals imp ortan t information, and often leads to misclassifications . The problem o f o v erlapping comm unities was exp osed in [17], where a solution to it was also o ffered. The pro p osed metho d is based on clique p ercolation: A k -clique (a complete subgraph of k no des) is rolled o v er the netw ork b y using k − 1 common no des. This w a y a set of no des can b e reache d, whic h is iden tified as a comm unit y . One no de can participate Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 3 in more than one suc h unit, therefore ov erlaps naturally o ccur. The metho d how ev er is not suitable for the detection of hierarc hical structure, as o nce the size k of the clique is sp ecified, mostly a single mo dular structure can b e reco v ered. In Fig. 1 w e sho w distinct net w orks with hierarc hical structure and o v erlapping comm unities, t hough it should b e emphasize d that these features often o ccur sim ultaneously . In order to pro vide the most exhaustiv e information ab out the mo dular structure of a graph, a go o d algorithm should b e able to detect b oth o v erlapping comm unities and hierarc hies b etw een them. In this pa p er w e introduce a framew ork that accomplishes these t w o demands. The metho d p erforms a lo cal exploration of the net w ork, searc hing for the natural comm unit y of eac h no de. During the pro cedure, no des can b e visited man y times, no matter whether they ha v e b een assigned to a comm unit y or not. In this w a y , ov e rlapping comm unitie s are naturally reco v ered. The v ariation of a resolution parameter, dete rmining the av erage size of the comm unities, allo ws to explore all hierarc hical lev els of the netw ork. Powered by yFiles 0 0 1 1 0 0 1 1 0 0 0 1 1 1 0 0 1 1 00 00 11 11 00 00 00 11 11 11 0 0 1 1 00 00 11 11 00 00 11 11 0 0 1 1 0 0 1 1 0 0 0 1 1 1 00 00 11 11 0 0 1 1 0 0 0 1 1 1 00 00 11 11 0 0 1 1 0 0 1 1 0 0 0 1 1 1 00 00 11 11 0 0 0 1 1 1 0 0 1 1 0 0 0 1 1 1 00 11 0 0 0 0 1 1 1 1 00 00 00 00 00 11 11 11 11 11 00 00 00 00 00 00 11 11 11 11 11 11 000 000 000 111 111 111 000 000 000 000 000 000 000 111 111 111 111 111 111 111 00 00 00 00 00 00 11 11 11 11 11 11 000 000 000 111 111 111 00000 00000 00000 00000 00000 00000 00000 00000 11111 11111 11111 11111 11111 11111 11111 11111 0 0 0 1 1 1 000 000 000 000 111 111 111 111 00 00 11 11 00 00 00 00 00 00 00 11 11 11 11 11 11 11 00 00 00 00 00 11 11 11 11 11 00 00 00 11 11 11 00 00 11 11 000 111 0 0 0 0 1 1 1 1 000 000 000 111 111 111 000 000 111 111 0 0 0 1 1 1 00 11 0 0 0 1 1 1 00 00 00 00 11 11 11 11 00 00 00 00 11 11 11 11 000 000 111 111 00 11 0 0 0 0 1 1 1 1 0000 1111 00 00 00 00 00 00 11 11 11 11 11 11 0000 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111 1111 1111 1111 00 00 00 00 11 11 11 11 0000 0000 1111 1111 0 0 1 1 0000 0000 0000 1111 1111 1111 000 000 000 000 000 000 000 111 111 111 111 111 111 111 0 0 0 1 1 1 0 0 0 0 1 1 1 1 00 11 000 000 000 000 000 000 000 111 111 111 111 111 111 111 0000 0000 0000 1111 1111 1111 00 00 00 00 00 00 11 11 11 11 11 11 000000 000000 000000 111111 111111 111111 00 00 00 00 00 11 11 11 11 11 00 00 00 00 00 00 00 00 00 11 11 11 11 11 11 11 11 11 000 111 0 0 0 0 0 1 1 1 1 1 Figure 1. (T op) A netw ork with a hiera rchical structure. Ea ch o f the four large clusters is made out of 12 8 nodes and has an in ternal sub divisio n in four clusters with 32 no des. (Bottom) Overlapping co mm unities. The g reen no des are topo logically related to more groups. Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 4 2. The metho d The basic assumption b ehind our algorithm is that comm unities are essen tially lo cal structures, inv olving the no des b elonging to the mo dules themselv e s plus at most an extended neigh b orho o d of them. This is certainly plausible for large net w orks, where eac h no de do es not depend on most of its p eers. In the link graph of the WWW, for instance, one do es not ev en ha v e a p erception of how large the net w ork is, a nd topical comm unities are formed based only on partial information a b o ut the g raph. Similarly , so cial comm unities are lo cal structures without any reference to the h umankind a s a whole. Here a comm unity is a subgraph iden tified by the maximization of a prop ert y or fitness of its no des. W e ha v e tried sev eral options for the form of the fitness and obtained the b est results with the simple expression f G = k G in ( k G in + k G out ) α , (1) where k G in and k G out are the tota l intern al and external degrees of the no des of mo dule G , and α is a p ositiv e real-v alued parameter, controllin g the size of the commun ities. The intern al degree of a mo dule equals the double of the n um b er of inte rnal links of the mo dule. The external degree is the n um b er of links joining each mem b er of the mo dule with the rest of the g ra ph. The aim is to determine a subgraph starting from no de A suc h t hat the inclusion of a new no de, o r the elimination o f one no de from the subgraph w ould lo w er f G . W e call suc h subgraph the natur al c ommunity of no de A . This amoun ts to determine lo cal maxima fo r the fitness function for a give n α . The true maxim um for eac h no de trivially corresp onds to the whole net work , b ecause in this case k G out = 0 and the v alue of f G is the la rgest that the measure can p o ssibly attain for a giv en α . The idea of detecting comm unities b y a lo cal optimization of some metric has already b een applied earlier [26, 27, 30, 31]. It is helpful to in tro duce the concept o f no de fitness. Giv en a fitness function, the fitness of a no de A with resp ect to subgraph G , f A G , is defined as the v ariation of the fitness of subgraph G with and without no de A , i.e. f A G = f G + { A } − f G −{ A } . (2) In Eq. 2, the sym b ol G + { A } ( G − { A } ) indicates the subgraph o btained from mo dule G with no de A inside (outside). The natural comm unit y of a no de A is iden tified with the follow ing pro cedure. Let us supp ose that w e ha v e co v ered a subgraph G including no de A . Initially , G is iden tified with no de A ( k G in = 0). Each iteration o f the algorithm consists of the follo wing steps: (i) a lo op is p erformed ov er all neigh b oring no des of G not included in G ; (ii) the neigh b or with the largest fitness is added to G , yielding a lar g er subgraph G ′ ; (iii) the fitness of eac h no de of G ′ is recalculated; (iv) if a no de turns out to ha v e negativ e fitness , it is remo v ed from G ′ , yielding a new subgraph G ′′ ; Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 5 (v) if 4 o ccurs, rep eat from 3, otherwise rep eat from 1 for subgraph G ′′ . The pro cess stops when the no des examined in step 1 all ha v e negativ e fitness (F ig. 2). This pro cedure corresp onds to a sort of greedy optimization of the fitness function, as at eac h mov e one lo oks fo r the highest p ossible increase. Other recip es ma y b e a dopted as w ell. F or instance o ne could back track no des with negativ e fitness only when the cluster stops grow ing and/or include in the cluster the first neigh b oring no de that pro duces an increase fo the fitness. Such recipes may lead to higher fitness clusters in a shorter time, and deserv e in-depth in v estigations, whic h we leav e for future work. W e define a c over o f the graph as a set of clusters suc h that eac h no de is assigned to at le ast one cluster. This is an extension of the traditional concept o f graph partition (in whic h eac h no de b elongs to a single cluster), to accoun t for p ossible o v erlapping comm unities . In our case, detecting a co v er amoun ts to disco v ering the natural commun ity of eac h no de of the graph at study . T he straigh tforward w ay to ac hiev e this is to rep eat the ab ov e pro cedure for eac h single no de. This is, how ev er, computationally exp ensiv e. The natural comm unities of many no des often coincide, so most of the computer time is sp en t to redisco v er the same mo dules ov er and ov er. An economic w ay out can b e summarized a s follow s: (i) pic k a no de A at r a ndom; (ii) detect the natural comm unity of no de A ; (iii) pic k at ra ndom a no de B not yet assigned to any group; (iv) detect the natural comm unit y of B , exploring all no des regardless of their p o ssible mem b ership to other groups; (v) r ep eat from 3. The algo r ithm stops when all no des ha v e b een assigned to at le ast one g roup. Our recipe is justified b y the followin g argumen t. The no des of ev ery comm unity are either o v erlapping with other comm unities or not. The comm unity w as explored ab out a sp ecific no de; if one chose an y of the other no des one would either reco v er the same comm unit y or one of the p ossible o v erlapping comm unities. But t he latter can b e found as w ell if one starts from no des whic h are outside the commu nity at hand and non- o v erlapping with it. In this wa y one should recov er a ll mo dules, with out needing to start from ev ery no de. At the same time, ov erlappin g no des will b e co ve red during t he construction of eac h comm unit y they b elong to, as it is p ossible to include no des already assigned to other mo dules. Extensiv e n umerical tests sho w that the loss in accuracy is minimal if one pro ceeds as w e suggest rather than by finding the natural comm unit y of all no des. W e remark that the pro cedure has some degree of sto chastic ity , due to the r a ndom c hoice of the no de-seeds from whic h comm unities are closed. The issue is discuss ed in App endix App endix A. The parameter α tunes the resolution of the metho d. Fixing α means setting the scale at whic h w e are lo o king at the net work. Large v alues of α yield v ery small comm unities, small v alue s instead deliv er larg e mo dules. If α is small enough, a ll no des Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 6 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 0 1 1 1 Figure 2. Schematic example of natural co mm unity for a no de (sky-blue po in t in the figure) ac c ording to our definition. The blue no des a re the other members of the gr oup and hav e p ositive fitness within the group, while the red no des hav e all neg ative fitn ess with resp ect to the gro up. end up in the same cluster, the net work itself. W e hav e found that, in most cases, for α < 0 . 5 there is only o ne comm unity , for α > 2 one recov ers the smallest commun ities. A natural c hoice is α = 1, a s it is the ratio of the external degree to the total degree o f the comm unit y . This corresp onds to the so-called w eak definition of comm unit y in tro duced b y Radicc hi et al. [32]. W e found that in most cases the c ov er f ound for α = 1 is relev ant, so it gives useful information about the actual comm unit y structu re of the graph at hand. Stic king to a sp ecific v alue of α means constraining the resolution of the metho d, muc h like it happ ens b y optimizing Newman-Girv an’s mo dularity [33, 34 ]. Ho w ev er, one cannot know a priori how large the comm unities are, as this is one of the unkno wns of the problem, so it is necessary to compare co v ers obtained at differen t scales. By v arying the resolution p arameter one explores the whole hierarc h y of cov e rs of the graph, f rom the entire net w ork do wn to the single no des, leading to the most complete informatio n on the comm unit y structure o f the net w ork. Ho w ev er, the metho d giv es as w ell a natural w a y to rank co v ers based on their relev anc e. It is reasonable to think that a g o o d cov er of the net w ork is stable , i.e. can b e destroy ed only b y c hanging appreciably the v alue of α for whic h it w as reco v ered. Each cov er is deliv ered for α lying within some range. A stable co v er w ould b e indicated b y a large r a nge of α . What w e need is a quan titativ e index to lab el a co ve r P . W e shall adopt the av erage v alue ¯ f P of the fitness of its commun ities, i.e. ¯ f P = 1 n c n c X i =1 f G i ( α = 1) , (3) where n c is a gain the n umber of mo dules. The fitness m ust b e calculated f o r a fixed v alue of α (w e c ho ose α = 1 for simplicit y), suc h that iden tical (differen t) cov e rs can b e Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 7 recognized b y equal (differen t) v alues. W e shall deriv e the histogram of the ¯ f P -v alues of the cov e rs obtained fo r differen t α - v alues: stable co v ers are rev ealed b y pronounced p eaks in the r esulting fitness histogram. The higher the p eak, the more s table the co v er. In this w ay , cov ers can b e ranked based on their frequency . A similar concept of stabilit y has b een adopted in a recen t study where a resolution parameter was in tro duced in Newman-Girv an’s mo dularity [35]. A natural question is ho w to com bine hierarc hical comm unities with o v erlapping comm unities, as the usual meaning of hierarc hies seems incompatible with the existenc e of no des shared among comm unities. Ho w ev er, this is only apparen t and the same definition of h ierarch ical partitions can be extended to the c ase of ov erlappin g comm unities. W e sa y that tw o partitions C ′ and C ′′ are hier ar chic al ly or der e d , with C ′ higher than C ′′ , if all no des of each comm unit y of C ′′ participate (fully or partially) in a single comm unit y of partition C ′ . It is hard to estimate the computational complexit y of the algorithm, as it dep ends on the size o f the comm unities and the exten t of their o v erlaps, whic h in turn strongly dep end on the sp ecific netw ork at study along with the v alue of the par a meter α . The time to build a comm unit y with s no des scales appro ximately a s O ( s 2 ), due to the bac ktrac king steps. Therefore, a rough estimate of the complexit y for a fixed α -v alue is O ( n c < s 2 > ), where n c is the n um b er of mo dules of the deliv ered co ve r and h s 2 i the second momen t of the comm unity size. The square comes f ro m the lo op ov er all no des of a comm unit y to c hec k for their fitness after eac h mo v e. Th e w orst-case complexit y is O ( n 2 ), where n is t he n um b er o f no des of the net w ork, when comm unities are o f size comparable with n . This is in general not the case, so in most applications the algorithm runs m uc h faster and alm ost linearly when commu nities are small. The situation is sho wn in Fig. 3, where w e plot the time to r un the algorithm to completion for tw o differen t α -v alues as a function o f the n umber of no des for Erd¨ os-R ´ en yi graphs with a v erage degree 10: the complexit y go es f r o m quadratic to linear. The total complexit y of the algorithm to p erform the complete analysis of a netw ork d ep ends as w ell on the num ber of α -v alues required t o resolv e its hierarc hical structure. The hierarc h y of cov e rs can b e the b etter displa y ed, the larger the num ber of α -v alues used to run the algorithm. If the netw ork has a hierarc hical structure, as it often happ ens in real systems , the num ber of cov ers gro ws as log n . In this case, the n um b er of differen t α -v alues required to resolv e the hierarc hy is also o f the order of log n and the complete analysis can b e carried out v ery quic kly . W e note that eac h iteration o f the algorithm f o r a giv en α is indep enden t of the others. So, the calculation can b e trivially parallelized b y running differen t α -v alues on eac h computer. If large computer resources are not a v ailable, a cheap w a y to pro ceed could b e to start from a large α - v alue, for whic h the algorithm runs to completion in a v ery short t ime, and use the final cov er as i nitial configuration for a run at a sligh tly lo w er α - v alue . Since the corresp onding cov er is similar to the initial one, also the second run w ould b e completed in a short time a nd one can rep eat the pro cedure all the wa y to the left of the range of α . W e conclude that for hierarc hical net w orks our pro cedure has a w orst-case Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 8 0 500 1000 1500 2000 2500 3000 Number of nodes n 0 5 10 15 Time (s) α=0.9 α=1.6 T ~ n T ~ n 2 Figure 3. Computational complexit y o f the algo r ithm. The tw o curves show how the time to run the algorithm sca les w ith the size of the g raph for Erd¨ os-R´ enyi netw orks with average degr e e 10, for α = 0 . 9 and 1 . 6, r esp ectively . The co mplexit y ranges fro m quadratic for α = 0 . 9, for which communit ies a re sizeable, to linear for α = 1 . 6, for which communit ies are small. computational complexit y of n 2 log n . W e remark that, if it is true that sev eral algorithms now ada ys hav e a low er complexit y , none of them is capable to carry o ut a complete a nalysis of the hierarchic al comm unit y structure, as they usually deliv er a single partition. Therefore a fair comparison is not possible. Besides, other recipes for t he lo cal optimization of our o r other fitness f unctions ma y considerably low er the computational complexit y of the algorithm, whic h seems a promising researc h direction for the future. 3. Results W e extensiv ely tested o ur metho d on artificial net work s with built-in hierarc hical comm unit y structure. W e adopted a b enc hmark similar to that recen tly prop osed by Arenas et al. [36, 37], whic h is a simple extension of the classical b enc hmark prop osed b y Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 9 Girv an and Newman [6]. T here are 512 no des, arranged in 16 groups of 3 2 no des eac h. The 16 gro ups are ordered in to 4 sup ergroups. Ev ery no de has an av erage of k 1 links with the 31 part ners of its group and k 2 links with the 96 no des o f other three groups within t he same sup ergroup. In a ddition, eac h no de has a n um b er k 3 of links with the rest of the net work . In this wa y , tw o hierarc hical lev els emerge: one consisting of t he 16 small groups, and one of the supergroups with 128 no des each (Fig. 1top is an example). The degree of mixing of the fo ur sup ergroups is expressed b y the parameter k 3 , that w e tune freely . In principle w e could also tune the mixing o f the small comm unities, b y v aryin g the ratio k 1 /k 2 , but w e prefer to set k 1 = k 2 = 16, so that the micro-comm unities are “fuzzy”, i.e. very mixed with eac h other, and p ose a hard test to o ur metho d. W e ha v e to c hec k whether the built-in hierarc h y is reco v ered through the alg o rithm. This in general dep ends on the parameter k 3 . Therefore, w e considered differen t v alue s of k 3 : for each v alue w e built 10 0 realizations o f the net w ork. T o compare the built-in mo dular structure with the one deliv ered b y the algorithm w e adopt the normalize d mutual info rm ation , a measure of similarity b orrow ed from information theory , whic h has prov ed to b e reliable [38]. The extens ion of the measure to ov erlapping comm unities is not trivial and there are sev eral alternativ es. Our extension is discussed in App endix App endix B. In Fig. 4 we plot the a v erage v alue of the normalized mutual information as a function of k 3 for the t w o hierarc hical lev els. W e see that in b o th cases the results are ve ry goo d. The co ve r in the four sup ergroups or macro-commun ities is correctly iden tified for k 3 < 24, with ve ry few exceptions, and the algorithm starts to fail only when k 3 ∼ 32, i.e., when eac h no de has 32 links inside and 32 outside of its macro- comm unit y , whic h is then v ery mixed with the others. The p erformance is v ery go o d as we ll fo r the low er hierarc hical lev el: The mo dules are alw a ys w ell mixed with eac h othe r, as k 1 = k 2 = 16 for any v alue of k 3 , so it is remark able that the resulting mo dular structure found b y the algorithm is still so close to the built-in mo dular structure, up un til k 3 ∼ 32. The main problem with this t yp e of tests is that one do es not hav e indep enden t information ab o ut the co v ers, therefore it can b e judged only if they are reasonable or not. F ortunately , fo r a few net w orks, cov ers hav e b een iden tified b y sp ecial information on t he system itself and/or its history . In Fig. 5 w e sho w the fitness histograms corresp onding to some of these netw orks , often used to test alg orithms: Zachary’s k arate club [39] (top-left), Lusse au’s dolphins’ net w ork [40] (top-righ t) and the netw ork of American college fo otball teams [6] (b ottom-left). The so cial net w ork of k arate club mem b ers studied b y the so ciologist W a yne Zac hary has b ecome a b enc hmark for a ll metho ds of commu nity detection. The net w ork consists of 34 no des, whic h separated in t w o distinct groups due to a con trast b etw ee n one of the instructors and the administrator of the club. The question is whether one is able to detect the so cial fission of the net w ork. The second net w ork represen ts the so cial in teractions of b ottlenose dolphins living in Doubtful Sound, New Z ealand. The net w ork w as studied by the biologist David Lusseau, who divided the dolphins in tw o groups according to their age. The third example is the net w ork of American college fo otball teams. Here, there are 115 no des, represen ting the teams, and tw o no des are connected if Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 10 15 20 25 30 35 mixing parameter k 3 0.4 0.6 0.8 1 Normalized mutual information macro-communities micro-communities Figure 4. T est of the acc ur acy of our method on a hier archical benchmark. The normalized mutual information is used to compare the cover found by the algorithm with the natural cover of the net work at each level. A t the higher level (cir cles), the communi ties a r e four clusters including ea ch four clusters of 32 no des, for a total of 128 no des p er cluster. Our metho d finds the r ight clusters as long as they ar e not to o mixed with each other. A t the low er level (squares), the communities are 16 clusters of 3 2 no des each. The metho d p erforms very well, considering that each no de has as many links inside a s outside each micr o-communit y , for any v alue of k 3 . The da shed vertical line marks the graph configur ations for which the n umber o f links of each node within its macr o-communit y equals the nu mber of links connecting the no de to the other three macro-co mm unities. their teams play against each other. The teams are divided into 1 2 conferences. Games b et w een teams in the same conference are more f requen t than games b et w een teams of differen t conference s, so one has a natural co v er where the comm unities correspond to the conferences. The pronounced spik es in the histograms of Fig. 5 sho w that these net w orks indeed ha v e comm unit y structure. F or Zac hary’s netw ork w e find that t he most stable cov e r Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 11 0.3 0.4 0.5 0.6 0.7 0.8 0 500 1000 1500 2000 Frequency karate club 0.4 0.5 0.6 0.7 0.8 0.9 1 0 200 400 600 800 1000 dolphins 0.5 0.55 0.6 0.65 0.7 0.75 0.8 Fitness 0 500 1000 1500 2000 2500 3000 Frequency football 0.2 0.25 0.3 0.35 0.4 Fitness 0 1 2 3 random Figure 5. Analysis of real netw orks. The fitness histogra ms cor resp ond to Zachary’s k arate club (top-left), Lusseau’s dolphins’ netw ork (top-right) and the net w or k of American college fo otball teams (bottom-left). The highes t peaks indicate the b est cov ers, which coincide with the natural cov ers of the gra phs, except for Za chary’s k arate club, where it co rresp onds to the same split in four clusters found through mo dularity optimization. Howev er, the so cial cover in t wo of the netw ork is the third most relev an t cov er. In (bo ttom-right) we show the fitness histogram for a n Erd¨ os- R ´ enyi r a ndom g r aph with 10 0 no des a nd the same average degree of the netw ork of American college foo tball teams: there is no visible structure, as exp ected. consists of four clusters. Ev en if this is not what one w ould lik e to recov e r, w e stress that this co ve r is often found by other metho ds, lik e mo dularit y optimization, whic h indicates that it is top olo g ically meaningful. But our metho d can do b etter: The so cial split in t w o clusters (F ig . 6a) turns out to b e a higher hierarc hical lev el, giv en b y a pairwise merging of the four comm unities of the main co v er. In terestingly , w e found that the tw o groups are ov erlapping, sharing a few no des. F o r the dolphins’ net w ork the highest spik e correspo nds to Lus seau’s su b division of the animals’ p opulation in t w o comm unities, with some ov erlap b etw een the tw o gro ups (Fig. 6b). Similarly , the highest spik e in Fig. 5 (b ott o m-left) corresp onds to the natural partitio n of the teams Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 12 in conferences. Powered by yFiles 25 26 32 5 6 7 11 17 9 15 16 19 21 23 24 27 30 31 33 34 3 10 28 29 1 2 4 8 12 13 14 18 20 22 a Powered by yFiles 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 b Figure 6. (a) Zachary’s k arate club. W e show the hier archical levels corr esp onding to the cov er in tw o clusters (0 . 76 < α < 0 . 84). The nodes 3, 9, 1 0 , 1 4 and 31 are shar ed b et ween the tw o gro ups: such no des are o ften miscla ssified by traditional algorithms. The non-ov erla pping no des reflect the so cial fission o bserved by Zachary , which is illustrated b y the sq ua res and the circles in the figure. (b) Lusseau’s netw ork of bottlenose dolphins. The b est cover in tw o clusters that we found (0 . 7 7 < α < 0 . 82) agrees with the separ ation observed b y Lusseau (squares and circles in the figure). The no des 8, 20, 29, 31 and 40 a r e sha red betw een the tw o gro ups. T o c hec k ho w go o d our algo rithm p erforms as compared to other metho ds w e hav e analyzed the k a r a te, dolphins and American college fo otba ll netw orks with the clique p ercolation metho d (CPM) b y P alla et al. [17]. The v alues of the normalized mutual information o f the co v ers found b y the algorithm with resp ect to the real cov ers a re 0.690 (our metho d) and 0.170 (CPM) for t he k arate club, 0.781 (our metho d) and 0 .254 (CPM) for the dolphins’ net w ork, 0.754 (our metho d) and 0.697 (CPM) for the American college fo otball net w ork. So our metho d pro ve s sup erior to the CPM in these instances. On the other hand, the CPM performs b etter for netw orks with many c liques. An example is represen ted b y the w ord asso ciation netw ork built on the Univ ersit y of South Florida F ree Asso ciation Norms [41], a nalyzed in [17]. The CPM finds groups of w ords whic h correspo nd to w ell defined categories, w hereas with our metho d the categories are more mixed. An imp orta n t reason for this discrepancy is that o ur metho d recov ers D e t e c t i n g t h e o v e r l a p p i n g a n d h i e r a r c h i c a l c o m m u n i t y s t r u c t u r e i n c o m p l e x n e t w o r k s 1 3 0.8 1 1.2 1.4 α 0 0.05 0.1 0.15 0.2 0.25 Overlap karate club dolphins football Figure 7. F raction of ov erlapping no des as a function of α for the three real net works discussed in Fig. 5: Zachary’s k arate club and the netw orks of dolphins and American fo o tball teams. There is no unique pattern, the extent of the overlap do es not show a systematic v ariation with α . o v erlapping no des that usually lie at the b order betw een comm unities , whereas in the w ord asso ciation netw ork they often are cen tral no des of a comm unit y . F or instance , the word “color” is the cen tral h ub of the comm unit y of colors, but it also b elongs to other categories lik e “Astronom y” and “Ligh t”. W e p erformed tests o n many other real systems, including protein interac tion net w orks, scien tific collab oration net w orks, and other so cial netw orks . In all cases w e found reasonable cov ers . On the other hand, we found t hat random graphs hav e no natural commu nity s tructure, as cov ers are unstable (Fig. 5, b ottom-right). T his is remark a ble, as it is know n that other approac hes m ay find cov ers in random graphs as w ell [42], a problem tha t trigg ered an ongoing debate as to when a co v er is indeed relev ant [43]. In Fig. 7 w e study ho w the exten t of the o v erlap b etw ee n the comm unities dep ends on the resolution parameter α , for three real net w orks. F rom the figure it is not p ossible to infer a ny systematic dep endence of the o v erlap on α , the pattern is strongly dep enden t on the sp ecific graph top ology . W e conclude the section with an analysis o f the statistical prop erties of comm unit y Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 14 structure in graphs. Fig . 8 sho ws the distribution o f comm unit y sizes fo r a sample of the WWW link graph, corresp onding to the subset of W eb pages within the domain .gov . W e analyzed the largest connected compo nen t of the graph, consisting of 774 , 90 8 no des and 4 , 711 , 340 links. The figure refers to the cov er found for α = 1, whic h w as iden tified within less than 40 hours o f CPU time on a small PC. The distribution of comm unit y sizes is sk ew ed, with a tail that f o llo ws a p ow er law with exponen t 2 . 2 ( 1 ). The result is consisten t with previous analyses of comm unity size distributions on large graphs [44, 8, 17, 45], although this is the first result concerning the WWW. W e stress that w e ha v e not p erformed a complete analysis of this net w ork, b ecause it w ould require a lot of pro cessors t o carry out the high n um b er of ru ns at d ifferen t α -v a lues whic h are neces sary for a reliable analysis. Therefore, the distribution in Fig. 8 does not necess arily corresp ond to the most significan t cov er. How ev er, the α -v alues o f the most represen tativ e cov ers of a ll netw orks w e hav e considered turned o ut to b e close to 1, so the plot of F ig. 8 is lik ely to b e a fair appro ximation of the actual distribution. 10 0 10 1 10 2 10 3 10 4 10 5 Community size s 10 -8 10 -6 10 -4 10 -2 10 0 Probability density Web graph, domain .gov, α=1 Pr(s) ~ s -2.2 Figure 8. Distribution of communit y sizes for the link g raph co rresp onding to the domain .gov of the WWW. The res olution parameter α = 1. The distribution is clearly skew ed, in agr eement with previous findings on la rge graphs. Th e tail can b e well fitted by a p ow er law with exp onent 2 . 2(1) (dashed line in the figure). Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 15 4. Conclusions In th is pap er w e hav e presen ted the first metho d that unco v ers sim ultaneously b ot h the hierarc hical and the ov erlappin g c ommu nity structure of complex netw orks. The metho d cons ists in finding the lo cal maxim a of a fitness function b y lo cal, iterativ e searc h. The pro cedure enables eac h node to b e incl uded in m ore than one module, leading t o a natural description o f o v erlapping comm unities . Finally , b y tuning the resolution parameter α one can prob e the netw ork at diffe rent sc ales, exploring the p ossible hierarc hy of commun ity structure. The application of our metho d to a n um b er of constructed and empirical net w orks has giv en excellen t results. W e w ould lik e to emphasize that o ur metho d provide s a general fr amework , that yields a large class of algo r ithms. F or instance, o ne could c ho ose a differen t expression for the fitness function, another criterion to define the most me aningful cov er, o r a differen t optimization pro cedure of the fitness for a single cluster. The setup w e hav e tested pro v es to b e v ery reliable, but w e cannot exclude that differen t choic es yield ev en b etter results. In fact, the framew ork is so flexible that it can b e easily a dapted to the problem at hand: if o ne has hin ts ab out the top ology of the comm unities to b e found for a sp ecific system, this information can b e used to design a particular fitness function, accoun ting for the required features of the mo dules. Since the complete analysis of a net work’ s comm unit y structure can b e carried out sim ultaneously on man y computers, the upper size limit of trac table graphs can be pushed up considerably . Our metho d giv es the o pp ortunit y to study systematically the distribution of comm unit y sizes of large netw orks up to millions of no des, a crucial asp ect of the in ternal organization of a graph, whic h sch olars ha v e j ust b egun to examine. An in teresting b ypro duct of our tec hnique is the p ossibilit y of quan tifying the participation of ov erlapp ing no des in their comm uni ties b y the v alues of the ir (node) fitnes s with respect to eac h group they b elong to. Finally , w e w ould lik e to men tion that the metho d can b e naturally extended to w eigh ted net w orks, i.e. net w orks where links carry a w eigh t. There is no need to use any kind of thresholding [46], as the generalization of the fitness formula is straigh tforward: In Eq. 1 w e ha ve to replace the degree k with the corresponding strength s (expressin g the sum ov er the links’ w eigh ts). Applications to directed netw orks can also b e easily devised with suitable choic es of t he fitness function. O ur o wn function 1 could be extended to the directed case, in that one considers the inde gr e e of the no des of a subgraph: it is plausible to assume that t he total indegree of the no des of the subgraph due to links in ternal to the subgraph exceeds the total indegree pro duced by links coming from external no des, if the subgraph is a communi ty . 4.1. A cknow le dgments W e thank Marc Barth ´ e lem y for enlighte ning discussions and suggestions. W e also thank A. Arenas, S. G´ omez, A. P agnani, F. R adicc hi and J.J. Ramasco for a careful reading of the man uscript. JK thanks ISI for hospitalit y and ac kno wledges partial supp ort b y Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 16 OTKA K60456. App endix A. Dep endence on the random seeds The c hoice of the random seeds w here the c ommu nity e xploration starts may affect co v ers obtained for the same α -v alue. This means in principle that w e cannot rely on the fitness histogram f ound for a sp ecific c hoice of the seeds. W e hav e f o und that cov ers obtained for differen t seeds ar e quite close to eac h other, and that the most relev ant co v ers that emerge from the analysis are the same fo r an y choi ce of the seeds. What ma y dep end on the sp ecific seed adopted is the ranking of the cov ers . This can b e solve d b y p erforming some a dditional runs of the algorithm fo r differen t seeds in corresp ondence to the regions o f the α - range in whic h meaningful structures ha v e b een spo tted a fter the first scan. The final ranking of the cov ers is then more reliable than an y ranking obtained for a sp ecific choic e of the random seeds. Since the n um b er of relev ant p eaks is m uc h smaller than the num ber of no des n , the computational cost of the additional runs is negligible as compared to the total num ber of runs. App endix B. Comparing partitions The aim o f this section is to discuss the problem of comparing cov e rs. There are man y criteria in the literature (see [48]), but, to the b est of our kno wledge, the case of o v erlapping clusters has not been considered y et. Here, w e briefly d iscuss the issue within the framew ork of information theory [4 9]. The normaliz e d mutual information I nor m ( X : Y ) [38] is defined as I nor m ( X : Y ) = H ( X ) + H ( Y ) − H ( X , Y ) ( H ( X ) + H ( Y )) / 2 . (B.1) where H ( X ) ( H ( Y )) is the entrop y of the random v ariable X ( Y ) asso ciated to the partition C ′ ( C ′′ ), whereas H ( X , Y ) is the join t entrop y . This v ariable is in the range [0 , 1] and equals 1 only when the t w o partitions C ′ and C ′′ are exactly coinciden t. Another p ossible similarity measure is the variation of in formation V ( X , Y ) = H ( X | Y ) + H ( Y | X ) [43, 48]. One w ay to normalize V ( X , Y ) is V ′ nor m ( X , Y ) = 1 2 H ( X | Y ) H ( X ) + H ( Y | X ) H ( Y ) , (B.2) whic h can b e inte rpreted as the av erage relativ e lack of information to infer X giv en Y and vice v ersa. Thi s normalization will b e helpful in the f ollo wing. Let us now supp ose that a no de may b elong to more than one cluster. The mem b ership of the no de i is not a n um b er x i ∈ { 1, 2 . . . |C ′ |} a n ymore, but it mus t b e considered as a binary arra y of |C ′ | en tries, one for eac h cluster o f the partition C ′ (sa y ( x i ) k = 1 if the no de i is presen t in the C ′ k cluster, ( x i ) k = 0 o t herwise). W e can regard the k th en try of this arra y as the realization of a random v ariable X k = ( X ) k , whose probabilit y distribution is P ( X k = 1) = n k / N P ( X k = 0) = 1 − n k / N , (B.3) Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 17 where n k is the nu mber of no des in the cluster C ′ k of C ′ , i.e. n k = | C ′ k | . The same holds for the random v ariable Y l asso ciated to the cluster C ′′ l of C ′′ . It is p o ssible to define the join t distribution P ( X k , Y l ) P ( X k = 1 , Y l = 1) = | C ′ k ∩ C ′′ l | N , (B.4) P ( X k = 1 , Y l = 0) = | C ′ k | − | C ′ k ∩ C ′′ l | N , (B.5) P ( X k = 0 , Y l = 1) = | C ′′ l | − | C ′ k ∩ C ′′ l | N , (B.6 ) P ( X k = 0 , Y l = 0) = N − | C ′ k ∪ C ′′ l | N . (B.7) Again, w e w ant to define ho w similar C ′ and C ′′ are in terms of lac k of information ab out one cov er give n the other. In particular, we can define the amoun t of information to infer X k giv en a certain Y l H ( X k | Y l ) = H ( X k , Y l ) − H ( Y l ) . (B.8) In orde r to infer X k , w e can c hoo se one Y l among |C ′′ | p ossible candidates . In particular, if a cluster C ′′ b of C ′′ turns out to b e the same as C ′ k , w e hav e that H ( X k | Y b ) = 0, and w e w ould lik e to sa y that Y b is the b est c andidate to i nfer X k . So, in a set matc hing fashion, w e can decide t o consider only Y b and neglect all the other v ariables Y l . In particular, w e can define the conditional en trop y of X k with respect to all the comp onen ts of Y H ( X k | Y ) = min l ∈{ 1 , 2 ... |C ′′ |} H ( X k | Y l ) . (B.9) As in Eq. B.2 w e can nor malize H ( X k | Y ) dividing b y H ( X k ) H ( X k | Y ) nor m = H ( X k | Y ) H ( X k ) (B.10) and taking the av erage o v er k ev en tually leads to the definition of the normalized conditional en trop y of X with resp ect to Y H ( X | Y ) nor m = 1 |C ′ | X k H ( X k | Y ) H ( X k ) . (B.11) The express ion for H ( Y | X ) nor m can b e determined in the same w ay . So, w e can finally define N ( X | Y ) = 1 − 1 2 [ H ( X | Y ) nor m + H ( Y | X ) nor m ] . (B.12) The func tion N ( X | Y ) has the app ealing p rop ert y to be equ al to one if and only if X k = f ( Y l ) for a certain l , and vice v ersa. Unfort unately , this do es not imply that C ′ and C ′′ are equal. In particular, it ma y happ en that X k is the ne gative of Y l , i.e. | C ′ k ∩ C ′′ l | = 0 and | C ′ k ∪ C ′′ l | = N . (B.13) In this case w e do not need additional informatio n ab out X k if w e kno w Y l b ecause we are sure t hat if a no de b elongs to C ′′ l it do es not b elong t o C ′ k and vice vers a; nev ertheless the Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 18 t w o cov ers are not equal. In other w ords, taking the minim um in Eq. B.9 may not imply c ho osing a cluster C ′′ b v ery similar to C ′ k : a cluster whic h is close to the c omplementary of C ′ k can b e a go o d candidate a s w ell. T o a v oid this problem, w e add a constrain t in Eq. B.9: the o nly eligible Y l are those ones whic h are far from b eing the ne gatives of X k , i.e . those fulfilling the follo wing condition h [ P (1 , 1)] + h [ P (0 , 0)] > h [ P (0 , 1) ] + h [ P (1 , 0 )] , (B.14) where we used the short notation P (1 , 1) = P ( X k = 1 , Y l = 1) . . . and h ( p ) = − p log p . T o understand wh y this constrain t is appropriate, let us write explicitly the conditional en trop y (Eq. B.8) H ( X k | Y l ) = h [ P (1 , 1)] + h [ P (0 , 0)] + h [ P (0 , 1 ) ] + + h [ P (1 , 0)] − h [ P ( Y l = 1)] − h [ P ( Y l = 0)] . (B.15) In the case of C ′′ l equal to C ′ k w e hav e h [ P (1 , 1)] = h [ P ( Y l = 1)] and h [ P (0 , 0)] = h [ P ( Y l = 0)] , (B.16) while the mixing terms v anis h h [ P (0 , 1)] = 0 and h [ P (1 , 0)] = 0 . (B.17) On the other hand, if C ′′ l is the complemen tary t o C ′ k , the role of h ( P (1 , 1 )) and h ( P (0 , 0)) is play e d b y the mixing terms: h [ P (0 , 1)] = h [ P ( Y l = 1)] and h [ P (1 , 0)] = h [ P ( Y l = 0)] , (B.18) while h [ P (1 , 1)] = 0 and h [ P (0 , 0)] = 0 . (B.19) So, in the fo r mer case all the information quan tified b y H ( X k , Y l ) is used to enco de the p ositive cases i.e. H ( X k , Y l ) = h [ P (1 , 1)] + h [ P (0 , 0)], while in the latter it is used to enco de the mixing terms, i.e. H ( X k , Y l ) = h [ P (1 , 0)] + h [ P (0 , 1 )]. Then, the condition express ed b y Eq. B.14 means that more t han one half of H ( X k , Y l ) is used to enco de the p ositive cases, a nd so it excludes the clusters close to b eing complemen tary . If none of t he Y l fulfills Eq. B.14, we set H ( X k | Y ) = H ( X k ) . (B.20) All this assures that N ( X | Y ) = 1 if a nd only if the tw o co v ers C ′ and C ′′ are equal. T o sum up, all the pro cedure reduces t o : (i) for a giv en k , compute H ( X k | Y l ) for eac h l using the probabilities giv en b y Eqs. B.4 − B.7; (ii) compute H ( X k | Y ) from Eq. B.9 taking in to accoun t the constrain t giv en in Eq. B.14; note t hat if this condition is nev er fulfilled w e decided to set H ( X k | Y ) = H ( X k ); (iii) for eac h k , rep eat the previous step to compute H ( X | Y ) nor m according to Eq. B.11; (iv) rep eat all this for Y and put ev erything together in Eq. B.12. Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 19 References [1] Bar ab´ asi A-L and Alber t R 200 2 R ev. Mo d. Phys. 74 47 [2] Doro g ovtsev S N a nd Mendes J F F 200 3 Evolution of Networks: fr om biolo gic al nets t o the Internet and WWW (Oxford Univ ers it y Pre s s, Oxfo rd, UK) [3] Newman M E J 2003 S IAM R eview 45 167 [4] Pastor-Sator ras R and V es pignani A 200 4 Evolution and st ructur e of the Internet: A statistic al physics appr o ach (Cambridge University Press, Cam bridg e , UK) [5] Bo cca letti S, L a tora V, Moreno Y, Chav ez M and Hw ang D-U 2 006 Phys. R ep. 424 175 [6] Girv an M and Newman M E J 20 02 Pr o c . Natl. A c ad. Sci. 99 7821 [7] Newman M E J 2004 Eu r. Phys. J. B 38 321 [8] Danon L, Duch J, A re na s A and D ´ ıaz-Guilera A 20 07 L ar ge Sc ale Struct ur e and Dynamics of Complex Networks: F r om Information T e ch nolo gy to Financ e and Natur al Scienc e , eds. Caldarelli G and V espignani A (W orld Scientifi c, Singap ore) 93 [9] F o rtunato S and Ca stellano C 2009 in Encyclop e dia of Complexity and System Scienc e , ed. Meyers B (Springer, Heidelber g), arXiv:07 12.271 6 a t www.a rXiv.org [10] Luss e a u D and Newman M E J 200 4 Pr o c. R. So c. L ondon B 2 71 S477 [11] Adamic L and Glance N 2 005 Pr o c. 3 r d Int. Workshop on Link Disc overy (Information Sciences Inst., Univ of Southern California, Los Angeles), 36 [12] Flake G W, Lawrence S, Lee Giles C and Co etzee F M 2002 IEEE Computer 35 (3) 66 [13] P imm S L 1979 The or. Popul. Biol. 16 144 [14] Kr ause A E, F rank K A, Maso n D M, Ulanowicz R E and T a ylor W W 2003 N atur e 426 28 2 [15] Holme P , Huss M a nd J eong H 200 3 Bioinformati cs 19 532 [16] Guimer` a R and Amaral L A N 200 5 Natu r e 4 33 895 [17] Palla G, Der´ en yi I, F ark as I and Vicsek T 2 005 Natur e 435 8 14 [18] Oltv ai Z N and Ba r ab´ asi A-L 2002 Scienc e 298 763 [19] Claus et A, Mo ore C and Newman M E J 200 7 L e ct. Notes Comput. Sc. 4503 1 [20] W a sserman S and F aust K 1 9 94 So cial Network Analysis: Metho ds and Applic ations (Cam bridg e Univ ers it y Press, Cambridge, UK). [21] Scott J P 2 000 So cial Network Anal ysis (Sage Publications Ltd., London, UK). [22] E is en M B, Sp ellman P T, Brown P O and Botstein D 1998 Pr o c . Nat. A c ad. Sci. USA 95 148 63 [23] Mantegna R N 1999 Eur. Phys. J. B 11 19 3 [24] Newman M E J and Girv an M 2004 Phys. R ev. E 69 0261 1 3 [25] Sales -Pardo M, Guimer´ a R, Moreira A A and Amaral L A N 2007 Pr o c. N atl. A c ad. S ci. USA 104 15224 [26] Ba umes J, Goldb erg M, Krishna mo orty M, Mag don-Ismail M a nd P reston N 200 5 Pr o c. IA DIS Applie d Computing 200 5 (Eds. Guimar˜ aes N and Isa ´ ıas P T) 97 [27] Ba umes J, Goldberg M and Magdon-Isma il M 200 5 L e ct. Notes Comput. Sc. 3495 27 [28] Zha ng S, W ang R S and Zhang X S 200 7 Physic a A 374 48 3 [29] Nicos ia V, Mangioni G, Carchiolo V and Malger i M 20 0 8 eprint arXiv:0801 .1 647 a t www.a rxiv.org [30] Claus et A 2005 Phys. R ev. E 72 026 132 [31] Ba grow J and Bollt E 2005 Phys. R ev. E 72 046 108 [32] Radicchi F, Castellano C, Cecconi F, Lo reto V and Parisi D 2004 Pr o c. Natl. A c ad. Sci. USA 101 2658 [33] F ortunato S and Ba rth´ elem y M 2 007 Pr o c. Natl. A c ad. S ci. USA 104 36 [34] Kumpula J M, Sa r am¨ aki J, Ka ski K a nd Kert´ esz J 200 7 Eur. Phys. J. B 56 41 [35] Arena s A, F ern´ andez A and G´ omez S 2008 New J. Phys. 10 050 39 [36] Arena s A, D ´ ıaz-Guilera A and P´ erez-Vicente C J 2 006 Phys. R ev. L ett. 96 11410 2 [37] Arena s A, D ´ ıaz-Guilera A and P´ erez-Vicente C J 2 007 Physic a D 224 27 [38] Danon L, D ´ ıaz-Guilera A, Duc h J and Arenas A 200 5 J. Stat. Me ch. P09008 [39] Za chary W W 1977 J. of Anthr op ol. Re se ar ch 33 452 Dete cting the o v erlapping and hier ar chic al c ommunity structur e in c omplex n etworks 20 [40] Luss e a u D 20 03 Pr o c. R. So c. L ond on, Ser. B 270 S186 [41] Nelso n D L, McEnv oy C L and Schreiber T A 1998 The university of South Florida wor d asso cia tion, rhyme, and wor d fr agment norms [42] Guimer` a R, Sales-Pardo M and Amaral L A N 2004 Phys. Rev. E 70 025 101(R) [43] Ka rrer B , Levina E and Newman M E J 20 08 Phys. R ev. E 7 7 04611 9 [44] Guimer` a R, Danon L, D ´ ıaz- Guilera A, Giralt F and Arenas A 2 003 Phys. R ev. E 68 0651 0 3 [45] Claus et A, Newman M E J and Mo ore C 200 4 Phys. Rev . E 70 066111 [46] F ark a s I, ´ Abel D, Palla G and Vicsek T 2007 N ew J. Phys. 9 180 [47] Newman M E J 2004 Phys. R ev. E 69 066133 [48] Meila M 2 007 J . Multivariate Ana lysis 98 873 [49] Mac K ay D 2002 In formation The ory, Infer enc e & L e arning Algori thms (Cambridge Universit y Press, Cambridge, UK).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment