Lasso-type recovery of sparse representations for high-dimensional data
The Lasso is an attractive technique for regularization and variable selection for high-dimensional data, where the number of predictor variables $p_n$ is potentially much larger than the number of samples $n$. However, it was recently discovered tha…
Authors: Nicolai Meinshausen, Bin Yu
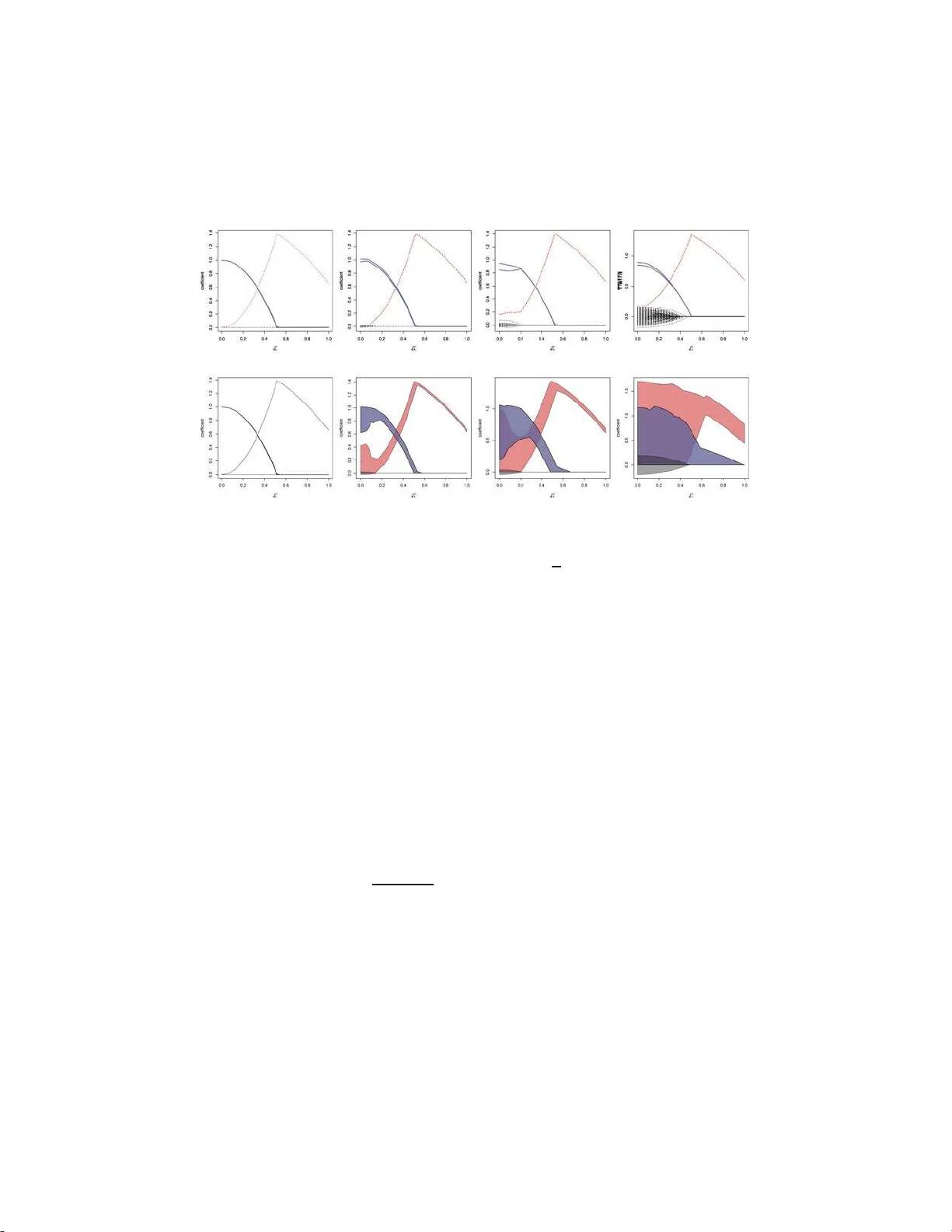
The Annals of Statistics 2009, V ol. 37, No. 1, 246–270 DOI: 10.1214 /07-A O S582 c Institute of Mathematical Statistics , 2009 LASSO-TYPE RECO VER Y OF SP ARSE REPRESENT A TIONS F OR HIGH-DIMENSIONAL DA T A By Nicolai Meinshausen 1 and Bin Yu 2 University of Oxfor d and University of California, Berkeley The Lasso is an attractive tec h nique for regularization and v ari- able selectio n for high-dimensional data, where the n umber of pre- dictor v ariables p n is p otentiall y muc h larger than the number of samples n . How ever, it w as recently disco vered that the sparsit y p at- tern o f the Lasso estimator can only be asymptotical ly identica l to the true sparsit y pattern if the desi gn matrix satisfies the so-called irr epr esentable c ondition . The latter condition can easily b e violated in the presence of h ighly correlated v ariables. Here w e examine the b eha vior of the Lasso estimators if th e irr ep- r esentable c ondition is relaxed. Ev en though the Lasso cannot reco ver the correct sparsity pattern, we sho w that the estimator is still con- sisten t in the ℓ 2 -norm sense for fi xed designs under conditions on (a) the num b er s n of nonzero comp onents of th e vector β n and (b) the minimal singular v alues of design matrices that are indu ced b y se- lecting small subsets of va riables. F urthermore, a rate of con verg ence result is obtained on th e ℓ 2 error w ith an appropriate choic e of the smoothing parameter. The rate is shown to b e optimal un der the condition of b ounded maximal and minimal sparse eigen v alues. Our results imply that, with h igh probabilit y , all imp ortant v ariables are selected. The set of selected v ariables is a meaningful reduction on the original set o f va riables. Finally , our results a re illustrated wi th the detection of closely adjacen t frequencies, a problem encountered in astrophysi cs. 1. In tro du ction. The Lasso was in tro duced by [ 29 ] and h as since b een pro v en to b e v ery p opular and w ell studied [ 18 , 35 , 41 , 42 ]. Some r easons for the p opularit y might b e that the en tire regularization path of the Lasso can b e computed efficien tly [ 1 1 , 25 ], that Lasso is able to hand le more pr edictor Received December 2006; revised December 2007. 1 Supp orted by DFG (Deutsche F orsch ungsgemeinsc haft). 2 Supp orted in part by a Guggenheim fello wship and Grants NS F DMS- 06-0516 5 (06- 08), NSF DMS-03-036508 (03-05) and A RO W911NF-05-1-0104 (05-07). AMS 2000 subje ct classific ations. Primary 62J07; secondary 62F07. Key wor ds and phr ases. Shrink age estimation, lasso, high-dimensional data, sparsity. This is a n electronic reprint of the o riginal ar ticle published by the Institute of Mathematica l Statistics in The Annals of Statistics , 2009, V ol. 3 7, No. 1, 24 6–27 0 . This r eprint differs fr o m the orig inal in pagination and typog raphic detail. 1 2 N. MEIN S HAUSEN AND B. YU v ariables than samples a nd p ro duces sparse mo d els wh ic h are easy to int er- pret. Sev eral extensions and v ariations ha ve b een pr op osed [ 5 , 21 , 36 , 40 , 42 ]. 1.1. L asso-typ e estimation. The Lasso estima tor, as int ro duced b y [ 29 ], is giv en b y ˆ β λ = arg min β k Y − X β k 2 ℓ 2 + λ k β k ℓ 1 , (1) where X = ( X 1 , . . . , X p ) is the n × p matrix whose columns consist of the n -dimensional fixed predictor v ariables X k , k = 1 , . . . , p . The v ector Y con- tains the n -dimensional set of real-v alued observ ations o f th e resp onse v ari- able. The distribution of Lasso-t yp e estimators has b een studied in Knight and F u [ 18 ]. V a riable se lection and prediction p rop erties of the Lasso h a ve b een studied extensive ly for h igh-dimensional data with p n ≫ n , a frequen tly en- coun tered chall enge in mo dern statistical applications. Some studies Bunea, Tsybak o v and W egk amp, for example, [ 2 ], Gr eenshtein and Rito v, for exam- ple, [ 13 ], v an de Geer, for example, [ 34 ] ha v e fo cused mainly on the b eh avio r of prediction loss. Muc h recen t w ork aims at understanding the Lasso esti - mates from the point of view of model selec tion, including Candes and T ao [ 5 ], Donoho, Elad and T emly ako v [ 10 ], Meinshausen and B ¨ uhlmann [ 23 ], T ropp [ 30 ], W ain wright [ 35 ], Z h ao and Y u [ 41 ], Z ou [ 42 ]. F or the Lasso e sti- mates to b e close to the mo d el selection estimates when th e data dimensions gro w, all the aforemen tioned pap ers assumed a sparse mo d el and used v ari- ous c onditions that require the ir r elev ant v ariables to b e not to o co rrelated with the relev an t ones. Incoherence is the terminology used in the determin- istic setting of Donoho, Elad and T emly ak o v [ 10 ] and “irrepresen tabilit y” is used in the sto c hastic setting (linear mo del) of Zh ao and Y u [ 41 ]. Here we fo cus exclusiv ely on the prop erties of the estimate of the co efficien t v ector under squ ared error loss and try to unders tand th e b eha vior of the estimate under a relaxe d irr epr esentable c ondition (hence we are in the sto c hastic or linear mo d el set ting). The aim is to see whether the Lasso still giv es meaningful models in th is case. More discussions on the connectio ns with other w orks w ill b e co v ered in Section 1.5 after notions are introdu ced to sta te explicitly what the irrepre- sen table condition is so that th e discus s ions are cl earer. 1.2. Line ar r e gr e ssion m o del. W e assume a linear mo del for th e obser- v ations of the resp onse v ariable Y = ( Y 1 , . . . , Y n ) T , Y = X β + ε, (2) where ε = ( ε 1 , . . . , ε n ) T is a v ector c on taining indep enden tly and iden tically distributed noise with ε i ∼ N (0 , σ 2 ) for all i = 1 , . . . , n . The assump tion of LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 3 Gaussianit y could b e relaxed and replaced with exponentia l tail b ounds on the noise if, add itionally , p r edictor v ariables are assumed to b e b ounded. When t here is a questio n o f noniden tifiabilit y for β , for p n > n , we defin e β as β = arg min { β : E Y = X β } k β k ℓ 1 . (3) The ai m is to reco v er the v ector β as w ell as possible from noisy obser- v ations Y . F or the equ iv alence b etw een ℓ 1 - and ℓ 0 -sparse solutions see, for example, Donoho [ 8 ], Donoho and Elad [ 9 ], F uchs [ 12 ], Grib on v al and Nielsen [ 14 ], T ropp [ 30 , 31 ]. 1.3. R e c overy of the sp arsity p attern and the irr epr e sentable c ondition. There is empirical evidence that man y signals in high-dimensional s p aces allo w for a sparse represen tation. As an example, wa v elet coefficient s of images often exhibit exp onen tial deca y , and a relativ ely small subset of all w av elet co efficien ts allo w a go o d app ro ximation to the original image [ 17 , 19 , 20 ]. F or conceptual simplicit y , we assu me in our regression setting that th e v ector β is sparse in the ℓ 0 -sense and man y co efficien ts of β are iden tically zero. The corresp onding v ariables ha ve th u s no influence on the resp ons e v ariable and could b e safely remov ed. Th e sparsit y pattern of β is und ers to o d to b e the sign fu nction of its entrie s, with sign( x ) = 0 if x = 0, sig n( x ) = 1 if x > 0 and sign( x ) = − 1 if x < 0. The sparsit y pattern of a v ector might th u s lo ok lik e sign( β ) = (+1 , − 1 , 0 , 0 , +1 , +1 , − 1 , +1 , 0 , 0 , . . . ) , distinguishing whether v ariables ha ve a p ositiv e, negat iv e or n o infl uence at all on t he r esp onse v ariable. It i s o f inte rest wh ether the spars ity pattern of the Lasso estimator is a go o d approximat ion to the tru e sp arsit y pattern. If these sparsit y patterns agree asymptotically , th e estimator is said to b e sign c onsistent [ 41 ]. Definition 1 (Sign c onsistency). An estimat or ˆ β λ is sign c onsistent if and only if P { sign( β ) = sign( ˆ β ) } → 1 as n → ∞ . It w as sho wn indep endently in Zhao and Y u [ 41 ] and Zou [ 42 ] in the lin- ear mo del case and [ 23 ] in a Gaussian Graphical Mo del setting that sign c onsistency requires a condition on the design matrix. The assump tion w as termed neighb orho o d stability in Meinshausen and B ¨ u hlmann [ 23 ] and irr e p- r esentable c ondition in Zhao and Y u [ 41 ]. Let C = n − 1 X T X. The d ep endence on n is neglected notatio nally . 4 N. MEIN S HAUSEN AND B. YU Definition 2 (Irrepr esen table condition). Let K = { k : β k 6 = 0 } b e the set of relev ant v ariables and let N = { 1 , . . . , p } \ K b e the set of noise v ari- ables. The s u b-matrix C H K is understo o d as the matrix obtained fr om C b y keeping r ows with ind ex in t he set H and columns with index in K . The irr epr esentable c ondition is fulfilled if k C N K C − 1 K K sign( β K ) k ℓ ∞ < 1 . In Zhao and Y u [ 41 ], an additional str ong irr epr esentable c onditio n is de- fined wh ic h r equires that the ab ov e elemen ts are not merely smaller than 1 but are uniformly b ound ed a w ay from 1. Zhao and Y u [ 41 ], Zou [ 42 ] and Meinshausen and B ¨ uhlmann [ 23 ] show that the L asso is sign consistent only if the irr epr esentable c ondition holds. Pr oposition 1 (Sign consistency). A ssume that the irr epr e sentable c on- dition or neighb orho o d stability is not fulfil le d. Then ther e exists no se que nc e λ = λ n such that the estimator ˆ β λ is sign c onsistent. It is w orth n oting that a sligh tly stronger condition has b een used in T ropp [ 30 , 31 ] in a deterministic study of L asso’s model selectio n properties where 1 − C N K C − 1 K K is called ER C (exact reco very co efficien t). A p ositiv e ER C implies the irr ep r esen table condition f or all β v alues. In practice, it migh t be difficult to v erify whether the condition is ful- filled. This led v arious au th ors to prop ose interesting extensions to the Lasso [ 22 , 39 , 42 ]. Before giving up on the Lasso alto gether, ho w ever, w e wa n t to examine i n this p ap er in what sense the original Lasso pro cedure still giv es sensible results, ev en if the irr epr e sentable c ondition or, equiv alen tly , neigh- b orho o d stability is not fu lfilled. 1.4. ℓ 2 -c onsistency. The aforementi oned studies sho wed that if the ir- r epr esentable c ondition is not fu lfi lled, the Lasso cannot select the correct sparsit y patte rn. In this pap er we show that the Lasso selects in t hese cases the non zero entries of β and some not-to o-many additional zero ent ries of β un der r elaxed conditions t han the irrepresen table condition. The nonzero en tries of β are in any case in cluded in the selecte d m o del. Moreo ver, the size of the estimated co efficien ts allo ws to separate the few truly zero and the many nonzero co efficien ts. Ho w ever, we n ote that in extreme cases, wh en the v ariables are linearly d ep endent, even these relaxed conditions will b e violate d. In these s ituations, it is not sensible to use the ℓ 2 -metric on β to assess Lasso. Our main result sho ws the ℓ 2 -consistency of the La sso, ev en if the irr ep- r esentable c ondition is violated. T o b e precise, an estimator is said to b e ℓ 2 -consisten t if k ˆ β − β k ℓ 2 → 0 as n → ∞ . (4) LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 5 Rates of con verge nce results w ill also b e d eriv ed and un der the condition of b ounded maximal and minimal sparse eigen v alues, the rate is seen op- timal. An ℓ 2 -consisten t estimator is attractiv e, as imp ortant v ariables are c hosen with high probabilit y and falsely c hosen v ariables ha v e v ery small co efficients. The b ottom line will b e that eve n if the sparsity pattern of β cannot b e reco vered by the Lasso, we can still obtain a go o d approximat ion. 1.5. R elate d work. Prediction loss for high-dimensional r egression un der an ℓ 1 -p enalt y has b een studied for quadratic loss function in Greenshte in an d Rito v [ 13 ] and for general Lipsc hitz loss functions in v an de Geer [ 34 ]. With a f o cus on aggreg ation, similarly in teresting results are derived in Bun ea, Tsybak o v and W egk amp [ 3 ]. Both v an de Geer [ 34 ] and Bun ea, Tsybako v and W egk amp [ 3 ] o btain impressiv e results for random design and sharp b ound s for t he ℓ 1 -distance b et ween the v ector β and it s Lasso estimate ˆ β λ . In the cur ren t manuscript, w e f o cus on the ℓ 2 -estimatio n lo ss on β . As a consequence, w e can derive consistency in t he sense of ( 4 ) u nder the condi- tion that s n log p n /n → 0 f or n → ∞ (ignoring l og n factors). An implication of our work is thus that the sparsit y s n is allo w ed to gro w almost as fast as the sample size if one is inte rested to obtain con v ergence in ℓ 2 -norm. In con trast, the r esults in [ 3 , 34 ] require s n = o ( √ n ) to obtain con verge nce in ℓ 1 -norm. The r ecen t ind ep endent wo rk of Zh an g and Huang [ 38 ] shows that the subspace span n ed b y the v ariables selected by Lasso is close to an optimal subspace. The results also imp ly that imp ortant v ariables are c hosen with high pr obabilit y and pr ovides a tigh t bound on the ℓ 2 -distance b et we en th e v ector β and its Lasso estimator. A “partial Riesz condition” is employ ed in [ 38 ], whic h is rather similar to our notion of i nc oher ent design , d efined further belo w in ( 6 ). W e w ould lik e to compare the r esults of this man u script briefly with resu lts in Donoho [ 8 ] and C an d es and T ao [ 5 ], as b oth of these pap ers deriv e b ounds on the ℓ 2 -norm distance b et w een β and ˆ β for ℓ 1 -norm constrained estimators. In Do noho [ 8 ] t he desig n is random and the random predictor v ariables are assumed to b e indep endent . The results are thus n ot directly comparable to t he results deriv ed here for general fixed designs. Nevert heless, results in Meinshausen and B ¨ uhlmann [ 23 ] s uggest that the irr epr esentable c ondition is with high probabilit y fulfilled for indep end en tly normal distributed predictor v ariables. The results in Donoho [ 8 ] can th us not d irectly be used to study the b eha vior of th e Lasso under a violated irr epr e sentable c ondition , whic h is our goal in the curren t manuscript. Candes and T ao [ 5 ] study the prop erties of the so-called “Dan tzig selec- tor,” whic h is v ery similar to the Lasso, and deriv e b ounds on the ℓ 2 -distance b et ween the ve ctor β and the pr op osed estimator ˆ β . The results are derived 6 N. MEIN S HAUSEN AND B. YU under the c ondition of a Uniform Unc ertainty P rinciple (UUP), whic h w as in tro duced in Candes and T ao [ 4 ]. T he UUP is related to our assumptions on s p arse eigen v alues in this man u script. A comparison b et w een th ese t w o assumptions is gi v en after the f ormulation ( 10 ) of the UUP . The b ounds on the ℓ 2 -distance b et ween the true co efficien t ve ctor β and its Lasso estima- tor (obtained in the cur ren t m anuscript) or, resp ectiv ely , “Dan tzig selector” (obtained in [ 5 ]) are quite similar in nature. This comes ma yb e as no surpr ise since the form ulation of the “Da n tzig selector” i s quite s imilar to the Lasso [ 24 ]. Ho we v er, it do es not seem straigh tforward to translate the b ounds obtained for the “Dan tzig selecto r” in to b ound s for the Lasso estimator and vice ve rsa. W e emplo y also somewhat differen t conditions b ecause there could b e situations of d esign matrix a rising i n statistical pr actice w here the dep endence b et ween the predictors is stronge r than what is allo w ed by the UUP , but wo uld satisfy our cond ition of “incoheren t design” to b e defined in the next section. It would certainly b e of in terest to stu d y the connection b et ween th e Lasso and “Dan tzig selector” further, as th e solutions s h are man y similarities. Final not e: a recen t fol lo w-up wo rk [ 1 ] pro vides simil ar b ounds as in this pap er for b oth Lasso and Dantz ig selectors. 2. Main assumptions and resu lts. First, w e in tro duce the n otion of sp arse eigenvalues , whic h will pla y a crucial role in providing b ounds for the con ver- gence rates of the Lasso estimator. Thereafter, the assumptions are explained in det ail and the main results are given. 2.1. Sp arse eigenvalues. T he notion of sp arse eige nvalues is n ot new and has b een used b efore [ 8 ]; we merely int end to fixate notation. The m-sp arse minimal eig e nvalue of a matrix is the minimal eigen v alue of an y m × m - dimensional submatrix. Definition 3. The m-sp arse minimal eigenvalue and m-sp arse maximal eigenvalue of C are defined as φ min ( m ) = min β : k β k ℓ 0 ≤⌈ m ⌉ β T C β β T β and φ max ( m ) = max β : k β k ℓ 0 ≤⌈ m ⌉ β T C β β T β . (5) The minimal eigen v alue of the unrestricted matrix C is equiv alen t to φ min ( p ). If the n um b er of predictor v ariables p n is larger than s amp le size, p n > n , this eigen v alue is zero, as φ min ( m ) = 0 for any m > n . A crucial factor con tribu ting to the con vergence of the Lasso estimator is the b eh avior of the smallest m-sp arse e i genvalue , where the num b er m of v ariables o v er whic h the minimal eig en v alues is computed is roughly t he same order as the sparsit y s n , or the num b er of nonzero comp onents, of the true underlying ve ctor β . LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 7 2.2. Sp arsity multipliers and inc oher ent designs. As apparent from the in teresting d iscus s ion in Cand es and T ao [ 5 ], one cannot allo w arbitrarily large “c oherence” b et we en v ariables if one still hop es t o reco v er the co rrect sparsit y patte rn. Assume that there are t wo v ectors β and ˜ β so that the signal can b e r ep r esen ted b y either vec tor X β = X ˜ β and b oth vec tors are equally sparse, sa y k β k ℓ 0 = k ˜ β k 0 = s n and are not iden tical. W e ha v e no hop e of distinguishing b et we en β and ˜ β in suc h a case: if indeed X β = X ˜ β and β and ˜ β are not identica l, it follo ws that the m in imal sparse eigen v alue φ min (2 s n ) = 0 v anishes as X ( β − ˜ β ) = 0 and k β − ˜ β k ℓ 0 ≤ 2 s n . I f the minimal sparse eige n v alue of a selec tion of 2 s n v ariables is zero, we ha v e no hop e of reco v ering the true sparse underlying vect or from noi sy o bserv ations. T o defi n e our assumption ab out sufficien t conditions f or reco very , we need the definition of inc oher ent design . As mo tiv ated by the exa mple ab ov e, w e w ould need a lo we r b ound on the minimal eigen v alue of at least 2 s n v ariables, where s n is again the num b er of nonzero co efficien ts. W e no w introdu ce the concepts of sp arsity multiplier a d inc oher ent design to mak e this requirement a bit more general, as m in imal eigen v alues are allo wed to conv erge to zero slo wly . A design is called inc oher ent in the follo wing if minimal sparse eigen v alues are not deca ying to o fast, in a sense made precise in the definition b elo w. F or notational simplicit y , let in the foll o wing φ max = φ max ( s n + min { n, p n } ) b e the maximal eige n v alue of a selection of at most s n + min { n, p n } v ariables. A t the cost of more inv olv ed p ro ofs, o ne could also work wit h the m aximal eigen v alue of a smaller selection of v ariables in stead. Eve n though w e do not assum e an u pp er b oun d for the q u an tit y φ max , it would not b e very restrictiv e to do so for the p n ≫ n setting. T o b e sp ecific, assume multiv ariate normal p redictors. If the maximal eigenv alue of the p opulation co v ariance matrix, whic h is induced b y s electing 2 n v ariables, is b ounded from ab o ve b y an arb itrarily large constan t, it follo ws b y Theorem 2.13 in Da vid son and Szarek [ 7 ] or Lemma A3.1 in Pa ul [ 26 ] that the cond ition n u m b er of the induced sample co v ariance matrix observ es a Gaussian tail b ound. Using an en tropy b ound for the p ossible num b er of subsets wh en c h o osing n out of p n v ariables. The maximal eige n v alue of a se lectio n of 2 min { n, p } v ariables is th u s b ounded from a b o v e b y some constan t, with probabilit y conv erging to 1 f or n → ∞ und er the cond ition that log p n = o ( n κ ) for some κ < 1, and the assumption of a b oun ded φ max , ev en though not needed, is th us ma yb e not o v erly restrictiv e. As the maximal sparse eigen v alue is t ypically gro w ing only v ery slo wly as a f unction of the num b er of v ariables, th e fo cus w ill b e on the deca y of the smallest sparse eigen v alue, whic h is a muc h more pressing problem for high-dimensional data. 8 N. MEIN S HAUSEN AND B. YU Definition 4 (Incoheren t designs). A design is called inc oher ent if there exists a p ositiv e sequence e n , the so-call ed sp arsity multiplier sequen ce, suc h that lim inf n →∞ e n φ min ( e 2 n s n ) φ max ( s n + min { n, p n } ) ≥ 18 . (6) Our main result will require inc oher ent design . The constan t 18 could quite p ossibly b e improv ed up on. W e will a ssume for the follo wing that the m u ltiplier sequence is the smallest. Belo w, w e giv e s ome simple examples under whic h the condition of inc oher ent design is fulfilled. 2.2.1. Example: b lo ck designs. Th e first example is ma yb e not o verly realistic but gives, h op efully , some in tuition for the condition. A “block design” is understo o d to ha ve the structure n − 1 X T X = Σ(1) 0 · · · 0 0 Σ(2) · · · 0 · · · · · · · · · · · · 0 0 · · · Σ( d ) , (7) where the matrice s Σ(1) , . . . , Σ( d ) are of dimension b (1 ) , . . . , b ( d ), resp ec- tiv ely . The minimal and maximal eigen v alues o v er all d sub-matrices are denoted b y φ block min := min k min u ∈ R b ( k ) u T Σ( k ) u u T u , φ block max := max k max u ∈ R b ( k ) u T Σ( k ) u u T u . In our s etup , all constan ts are allo wed to dep end on the samp le size n . The question arises if simple b ounds can b e found under which the design is inc oher ent in the sense of ( 6 ). The blo ck ed sp arse eigenv alues are trivial lo wer and u p p er b ound s, resp ectiv ely , for φ min ( u ) a nd φ max ( u ) for all v alues of u . Cho osing e n suc h that e 2 n s n = o ( n ), the condition ( 6 ) of inc oher ent design requires then e n φ min ( e 2 n s n ) ≫ φ max ( s n + min { n, p n } ). Using φ min ( e 2 n s n ) ≥ φ block min and φ max ≤ φ block max , it is su fficien t if there exists a sequence e n with e n = o ( φ block max /φ block min ). T ogether with the requirement e 2 n s n = o ( n ), the condition of inc oher ent design is fulfilled if, for n → ∞ , s n = o n c 2 n , (8) where the condition n umb er c n is giv en b y c n := φ block max /φ block min . (9) Under increasingly stronger assumption on the sparsity , the condition num- b er c n can thus gro w almost as fast as √ n , while still allo w ing for inc oher ent design . LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 9 2.2.2. Mor e e xamples of inc oher e nt designs. Consid er t wo more exam- ples of incoheren t design: • The condition ( 6 ) of inc oher ent design is fulfilled if the minimal eigen v alue of a selection of s n (log n ) 2 v ariables is v anishing slo wly for n → ∞ so that φ min { s n (log n ) 2 } ≫ 1 log n φ max ( s n + min { p n , n } ) . • The condition is also fulfilled if the minimal eigen v alue of a selection of n α s n v ariables is v anishing slowly for n → ∞ so that φ min ( n α s n ) ≫ n − α/ 2 φ max . These results can b e deriv ed from ( 6 ) b y c ho osing the sparse m u ltiplier sequences e n = log n and e n = n α/ 2 , resp ectiv ely . Some more scenarios of inc oher ent design can be seen to satisfy ( 6 ). 2.2.3. Comp arison with the uniform u nc ertainty principle. Candes and T ao [ 5 ] use a Uniform U nc ertainty Principle (UUP) to discuss the con ver- gence of the so-called Dantzig sele ctor . T he UUP can only b e fulfi lled if the minimal eigen v alue of a selection of s n v ariables is b ounded from b elo w by a constant, where s n is again the n u m b er of nonzero co efficien ts of β . In the original v ersion, a necessary conditio n for UUP is φ min ( s n ) + φ min (2 s n ) + φ min (3 s n ) > 2 . (10) A t t he same time, a b ound on the maximal eigen v alue is a condition f or th e UUP in [ 5 ], φ max ( s n ) + φ max (2 s n ) + φ max (3 s n ) < 4 . (11) This UUP co ndition is differen t f rom our incoherent design condition. In some sense, the UUP is weak er than i nc oher ent design , as the minimal eigen- v alues are calculate d o ver only 3 s n v ariables. In another sense, UUP is quite strong as it d emands, in form ( 10 ) and assuming s n ≥ 2, that al l p airwise correlatio ns betw een v ariables b e less than 1 / 3! Th e condition of inc oher ent design is w eak er as the eigen v alue can b e b ounded from b elo w by an arbi- trarily small constan t (as opp osed to the large v alue implied b y the UUP). Sparse eig en v alues can ev en con v erge slo wly to z ero in our setti ng. T aking the example of blo c k d esigns from fu rther ab o v e, inc oher ent de- sign allo wed for t he conditio n n umb er ( 9 ) to gro w almost as fast as √ n . In con trast, if the sparsit y s n is larger than the maximal blo c k-size, the UUP requires that th e condition n um b er c n b e b ounded from ab o ve by a p ositiv e constan t. Using its f orm ( 10 ) and the corresp onding b oun d ( 11 ) for the max- imal eigen v alue, it implies sp ecifically that c n ≤ 2, whic h is clearly stricter than t he conditio n ( 8 ). 10 N. MEIN S HAUSEN AND B. YU 2.2.4. Inc oher ent designs and the irr epr esentable c ondition. On e might ask in what sense the notion of inc oher ent design is m ore general than the irr epr esentable c ondition . A t fir st, it migh t seem lik e we are simply replac- ing the strict co ndition of irr epr esentable c ondition b y a similarly strong condition o n the design matrix. Consider fi rst the classical case of a fi xed num b er p n of v ariables. If the co v ariance matrix C = C n is conv erging to a p ositiv e d efinite matrix for large sample sizes, the design is automaticall y i nc oher ent . On the other h and, it is easy to violate the irr epr esentable c ondition in this case; for examples, see Zou [ 42 ]. The notion of inc oher ent designs is o nly a real r estriction in the h igh- dimensional case with p n > n . Ev en then, it is clear that the notion of inc oher enc e is a relaxati on from irr epr esentable c ondition , as the irr epr e- sentable c ondition can easily b e violated ev en though all sparse e igen v alues are boun ded we ll a w a y from zero. 2.3. Main r esult for high-dimensional data ( p n > n ). W e first state our main result. Theorem 1 (Conv ergence in ℓ 2 -norm). Assume the inc oher ent design c ondition ( 6 ) with a sp arsity multiplier se quenc e e n . If λ ∝ σ e n √ n log p n , ther e e xists a c onstant M > 0 such t hat, with pr ob ability c onver ging to 1 for n → ∞ , k β − ˆ β λ n k 2 ℓ 2 ≤ M σ 2 s n log p n n e 2 n φ 2 min ( e 2 n s n ) . (12) A pro of is giv en in S ection 3 . It can b e seen from the pr o ofs that nonasymp - totic boun d s could b e obtained with essen tially the same results. If we c ho ose the smallest p ossible m u ltiplier sequence e n , one obtains not only the required lo w er b ound e n ≥ 18 φ max /φ min ( e 2 n s n ) fr om ( 6 ) but also an upp er bound e n ≤ K φ max /φ min ( e 2 n s n ) . Plugging this into ( 12 ) yields the probabilistic boun d, for some p ositiv e M , k β − ˆ β λ n k 2 ℓ 2 ≤ M σ 2 s n log p n n φ 2 max φ 4 min ( e 2 n s n ) . It is no w easy to see that the con verge nce rate is essenti ally optimal as long a s the relev an t eigen v alues are b ounded. Corollar y 1. Assume that ther e exist c onstants 0 < κ min ≤ κ max < ∞ such that lim inf n →∞ φ min ( s n log n ) ≥ κ min and (13) lim sup n →∞ φ max ( s n + min { n, p n } ) ≤ κ max . LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 11 Then, for λ ∝ σ √ n log p n , ther e exists a c onstant M > 0 such that, with pr ob ability c onver ging to 1 for n → ∞ , k β − ˆ β λ n k 2 ℓ 2 ≤ M σ 2 s n log p n n . The p ro of of this follo w s from Theorem 1 by choosing a constan t sp arsity multiplier sequence, for example, 20 κ max /κ min . The rate of conv ergence ac h iev ed is essen tially optimal. Ignoring the log p n factor, it corresp onds to the rate that co uld b e ac hiev ed with maxim u m lik eliho o d estimation if the true u nderlying sparse mo del w ould b e known. It is p erhaps also worth while to mak e a remark ab out the p enalt y p aram- eter sequence λ and its, maybe unusual, reliance on the sparsit y multiplie r sequence e n . If b oth the relev an t minimal and maximal sparse eigen v alues in ( 6 ) are b ounded from b elo w and ab o v e, as in C orollary 1 ab ov e, the sequence e n is simp ly a constant . An y deviation fr om the usually optimal sequence λ ∝ σ √ n log p n o ccurs th us only if the minimal sp arse eigen v al- ues are d eca ying to zero for n → ∞ , in wh ich case th e p enalt y parameter is increased sligh tly . The v alue of λ can b e computed, in theory , without kno wledge ab out the true β . Doing so in practice would not b e a trivia l task, how ev er, as the spars e eigen v alues would ha v e to b e kno wn . Moreo ver, the noise lev el σ wo uld ha v e to b e est imated from data, a difficult task for high-dimensional d ata with p n > n . F rom a pr actical p ersp ectiv e, we mostly see the results as i mplying that the ℓ 2 -distance can b e small for som e v alue of the p enalt y paramete r λ along the solution pat h. 2.4. Numb er of sele cte d variables. As a result of separate in terest, it is p erhaps n otew orth y that b ound s on the n um b er of sel ected v ariables are deriv ed for the pro of of Th eorem 1 . F or the setting of Corollary 1 ab ov e, where a constan t sp arsity multiplier ca n b e c hosen, Lemma 5 implies that, with high probabilit y , at most O ( s n ) v ariables are selected b y the Lasso estimator. The selected su bset is hence of the same order of magnitude as the set o f “truly n onzero” coefficien ts. I n g eneral, with high pr obabilit y , no more than e 2 n s n v ariables are selected. 2.5. Sign c onsistency with two-step p r o c e dur es. It fol lo ws from our re- sults ab ov e that the Lasso estimator can b e mo d ified to b e sign c onsistent in a t w o-step p ro cedure ev en if the irr epr esentable c ondition is relaxe d. All one n eeds is the assum p tion that nonzero co efficient s of β are “sufficient ly” large. One p ossibilit y is hard-thresholding of the obtained co efficien ts, n e- glecti ng v ariables w ith v ery sm all co efficien ts. T his effect h as already b een observ ed emp irically in [ 33 ]. Other p ossibilities in clude soft-thresholding and relaxatio n metho ds suc h as the Gauss–Dan tzig selector [ 5 ], the relaxed Lasso [ 22 ] with an additional t hresholding ste p or the adaptiv e Lasso of Zou [ 42 ]. 12 N. MEIN S HAUSEN AND B. YU Definition 5 (Hard-thresholded Lasso estimator). Let, for eac h x ∈ R p , the qu an tit y 1 {| x | ≥ c } b e a p n -dimensional vec tor which is, comp onen t wise, equal to 1 if | x k | ≥ c and 0 otherwise. F or a giv en sequence t n , the hard- thresholded Lasso estimator ˆ β ht,λ is d efined as ˆ β ht,λ = ˆ β λ 1 { ˆ β λ ≥ σ t n q log p n /n } . The sequence t n can b e c hosen freely . W e start with a corollary that follo ws directly fr om Theorem 1 , stating that the hard-thresholded Lasso estimator (unlike the un -thresholded estimator) is sign c onsistent under regularit y assum ptions that are w eake r than the irr epr esentable c onditio n needed for sign-consistency of the ordinary La sso esti mator. Corollar y 2 (Sign consistency b y hard thresholding). A ssume the in- c oher ent design assumptio n ( 6 ) holds and the sp arsity of β fulfil ls s n = o ( t 2 n e − 4 n ) for n → ∞ . Assume furthermor e min k : β k 6 =0 | β k | ≫ σ t n q log p n /n, n → ∞ . Under a c hoic e λ ∝ σ e n √ n log p n , the har d-thr esholde d L asso estima tor of Definition 5 is then sign-c onsistent and P { sign( ˆ β ht,λ ) = sign( β ) } → 1 as n → ∞ . The pro of follo ws from the results of Theorem 1 . Th e b ound ( 12 ) on the ℓ 2 -distance, derived fr om Th eorem 1 , giv es then trivially the ident ical b ound on th e squared ℓ ∞ -distance b etw een ˆ β λ and β . Th e result follo w s b y observing that 1 / φ max = O (1) a nd the fact that ℓ ∞ error is a small er order of th e lo we r b ound on the size of nonzero β ’s due to assumptions of incoheren t design and s n = o ( t 2 n e − 4 n ). W hen choosing a suitable v alue of the cut-off parameter t n , one is faced with a trade-off. Cho osing larger v alues of the cut-off t n places a stricter conditio n on the minimal nonze ro v alue o f β , while s m aller v alues of t n relax this a ssumption, yet require the vec tor β to b e sparser. The result mainly implies that sign-c onsistency can b e ac hieved with the hard-thresholded Lasso estimator u n der muc h wea k er consistency require- men ts than w ith the ordinary Lasso estima tor. As discussed previo usly , the ordinary L asso e stimator is only sign consistent if the irr epr esentable c ondi- tion or, equiv alen tly , neighb orho o d stability is fulfilled [ 23 , 41 , 42 ]. This is a considerably stronger assumption than the incoherence assum ption ab o ve. In either case, a similar assumption on the rate of deca y of the minimal nonzero co mp onents is needed. In conclusion, ev en though one cannot ac hiev e sign c onsistency in gen- eral with ju st a single Lasso estimation, it can b e ac h iev ed in a t w o-stage pro cedure. LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 13 3. Pro of of Theorem 1 . Let β λ b e the estimator under the absence of noise, that is, β λ = ˆ β λ, 0 , where ˆ β λ,ξ is defined as in ( 15 ). The ℓ 2 -distance can then b e b oun ded by k ˆ β λ − β k 2 ℓ 2 ≤ 2 k ˆ β λ − β λ k 2 ℓ 2 + 2 k β λ − β k 2 ℓ 2 . T h e fi rst term on the r igh t-hand side represents the v ariance of the est imation, while the second term represen ts the bias. The bias con tribution follo ws directly from Lemma 2 b elo w. The b ound on the v ariance term fo llo ws b y Lemma 6 b elo w. De-noise d r esp onse. Before starting, it is useful to define a d e-noised resp onse. Define for 0 < ξ < 1 the de-noised ve rsion of the resp onse v ariable, Y ( ξ ) = X β + ξ ε. (14) W e can regulat e the amoun t of noise w ith the paramet er ξ . F or ξ = 0, only the signal is retained. The original observ ations with the full amount of noise are reco v ered for ξ = 1 . Now co nsider for 0 ≤ ξ ≤ 1 the e stimator ˆ β λ,ξ , ˆ β λ,ξ = arg min β k Y ( ξ ) − X β k 2 ℓ 2 + λ k β k ℓ 1 . (15) The ordinary Lasso estimate is reco ve red un der the full amoun t of noi se so that ˆ β λ, 1 = ˆ β λ . Using the notation from the p revious results, we can write for th e estimate in the absence of noise, ˆ β λ, 0 = β λ . Th e definition of the de-noised version of the Lasso estimator w ill b e helpfu l for the p ro of as it allo ws to c haracterize the v ariance of t he e stimator. 3.1. Part I of pr o of: bias. Let K b e the set of nonzero elements of β , that is, K = { k : β k 6 = 0 } . The cardinalit y of K is again d enoted by s = s n . F or the follo wing, let β λ b e the estimator ˆ β λ, 0 under the abs en ce of noise, as defi n ed in ( 15 ). Th e solution β λ can, for eac h v alue of λ , b e wr itten as β λ = β + γ λ , where γ λ = arg min ζ ∈ R p f ( ζ ) . (16) The function f ( ζ ) is give n b y f ( ζ ) = n ζ T C ζ + λ X k ∈ K c | ζ k | + λ X k ∈ K ( | β k + ζ k | − | β k | ) . (17) The v ector γ λ is the bias of the Lasso estimator. W e d erive first a b ound on the ℓ 2 -norm o f γ λ . Lemma 1. Assume inc oher ent design as in ( 6 ) with a sp arsity multiplier se quenc e e n . The ℓ 2 -norm of γ λ , as define d in ( 16 ), is then b ounde d for sufficiently lar ge values of n by k γ λ k ℓ 2 ≤ 17 . 5 λ n √ s n φ min ( e n s n ) . (18) 14 N. MEIN S HAUSEN AND B. YU Pr oof. W e write in the follo wing γ instead of γ λ for notational s im- plicit y . L et γ ( K ) b e the vecto r with co efficien ts γ k ( K ) = γ k 1 { k ∈ K } , that is, γ ( K ) is the bias of the truly n onzero co efficien ts. Analogo usly , le t γ ( K c ) b e th e b ias of the truly zero co efficients with γ k ( K c ) = γ k 1 { k / ∈ K } . Clearly , γ = γ ( K ) + γ ( K c ). The v alue of the function f ( ζ ) , as defined in ( 17 ), is 0 if setting ζ = 0. F or th e true solution γ λ , it follo ws h ence th at f ( γ λ ) ≤ 0 . Hence, using that ζ T C ζ ≥ 0 for an y ζ , k γ ( K c ) k ℓ 1 = X k ∈ K c | ζ k | ≤ X k ∈ K ( | β k + ζ k | − | β k | ) ≤ k γ ( K ) k ℓ 1 . (19) As k γ ( K ) k ℓ 0 ≤ s n , it follo ws that k γ ( K ) k ℓ 1 ≤ √ s n k γ ( K ) k ℓ 2 ≤ √ s n k γ k ℓ 2 and hence, using ( 19 ), k γ k ℓ 1 ≤ 2 √ s n k γ k ℓ 2 . (20) This resu lt will b e u sed fur ther b elo w. W e use now again th at f ( γ λ ) ≤ 0 [as ζ = 0 yields the upp er b ound f ( ζ ) = 0]. Using the previous resu lt that k γ ( K ) k ℓ 1 ≤ √ s n k γ k ℓ 2 , and ignoring the n on n egativ e term k γ ( K c ) k ℓ 1 , it fol lo ws that nγ T C γ ≤ λ √ s n k γ k ℓ 2 . (21) Consider n o w the t erm γ T C γ . Bound ing this term fr om b elo w and plug- ging the r esult in to ( 21 ) will yield the desired upp er b ound o n the ℓ 2 -norm of γ . Let | γ (1) | ≥ | γ (2) | ≥ · · · ≥ | γ ( p ) | b e the ordered en tries of γ . Let u n for n ∈ N b e a sequence of p ositiv e integ ers, to b e c h osen later, and define the set of the “ u n -largest co efficien ts” as U = { k : | γ k | ≥ | γ ( u n ) |} . Define analogously to ab o ve the vect ors γ ( U ) and γ ( U c ) by γ k ( U ) = γ k 1 { k ∈ U } and γ k ( U c ) = γ k 1 { k / ∈ U } . The quantit y γ T C γ can b e written as γ T C γ = k a + b k 2 ℓ 2 , where a := n − 1 / 2 X γ ( U ) and b := n − 1 / 2 X γ ( U c ). Then γ T C γ = k a + b k 2 ℓ 2 ≥ ( k a k ℓ 2 − k b k ℓ 2 ) 2 . (22) Before pro ceeding, we need to b ound the norm k γ ( U c ) k ℓ 2 as a fun ction of u n . Assume f or the moment th at the ℓ 1 -norm k γ k ℓ 1 is iden tical to some ℓ > 0. Then it holds for ev ery k = 1 , . . . , p that γ ( k ) ≤ ℓ/k . Hence, k γ ( U c ) k 2 ℓ 2 ≤ k γ k 2 ℓ 1 p X k = u n +1 1 k 2 ≤ (4 s n k γ k 2 ℓ 2 ) 1 u n , (23) ha ving used the result ( 20 ) from ab o ve that k γ k ℓ 1 ≤ 2 √ s n k γ k ℓ 2 . As γ ( U ) has b y definition only u n nonzero coefficien ts, k a k 2 ℓ 2 = k γ ( U ) T C γ ( U ) k 2 ℓ 2 ≥ φ min ( u n ) k γ ( U ) k 2 ℓ 2 (24) ≥ φ min ( u n ) 1 − 4 s n u n k γ k 2 ℓ 2 , LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 15 ha ving used ( 23 ) an d k γ ( U ) k 2 ℓ 2 = k γ k 2 ℓ 2 − k γ ( U c ) k 2 ℓ 2 . As γ ( U c ) has at most min { n, p } nonzero co efficient s and using again ( 23 ), k b k 2 ℓ 2 = k γ ( U c ) T C γ ( U c ) k 2 ℓ 2 ≤ φ max k γ ( U c ) k 2 ℓ 2 ≤ φ max 4 s n u n k γ k 2 ℓ 2 . (25) Using ( 24 ) and ( 25 ) in ( 22 ), toget her with φ max ≥ φ min ( u n ), γ T C γ ≥ φ min ( u n ) k γ k 2 ℓ 2 1 − 4 s s n φ max u n φ min ( u n ) . (26) Cho osing for u n the sp arsity multiplier sequence, as defin ed in ( 6 ), times the sparsit y s n , so that u n = e n s n it holds that s n φ max / ( e n s n φ min ( e n s n )) < 1 / 18 and hence also that s n φ max / ( e n s n φ min ( e 2 n s n )) < 1 / 18, since φ min ( e 2 n s n ) ≤ φ min ( e n s n ). Thus the r igh t-hand side in ( 26 ) is b oun ded from b elo w by 18 φ min ( e n s n ) k γ k 2 ℓ 2 since (1 − 4 / √ 18) ≤ 17 . 5. Using the last result toget her with ( 21 ), wh ic h says that γ T C γ ≤ n − 1 λ √ s n k γ k ℓ 2 , it follo ws that for large n , k γ k ℓ 2 ≤ 17 . 5 λ n √ s n φ min ( e n s n ) , whic h completes the p r o of. Lemma 2. Under the assumptions of The or em 1 , the bias k γ λ k 2 ℓ 2 is b ounde d by k γ λ k 2 ℓ 2 ≤ (17 . 5) 2 σ 2 s n log p n n e 2 n φ 2 min ( e 2 n s n ) . Pr oof. T h is is an immediate consequence of Lemma 1 . Plugging the p enalt y sequence λ ∝ σ √ n log p n e n in to ( 18 ), the results f ollo ws b y the in- equalit y φ min ( e n s n ) ≥ φ min ( e 2 n s n ), ha ving used that, b y its definitio n in ( 6 ), e n is n ecessarily larger than 1. 3.2. Part I I of pr o of: varianc e. T h e pro of f or the v ariance part needs t wo steps. First, a b ound on t he v ariance is deriv ed, wh ic h is a fun ction of the num b er of activ e v ariables. In a second step, the num b er of activ e v ariables will b e b ounded, taking into account also the b ound on the bias deriv ed ab ov e. V arianc e of r estricte d OLS. Before considering the Lasso estimator, a trivial b oun d is sho wn for the v ariance of a restricted OLS estimation. Let ˆ θ M ∈ R p b e, for ev ery subset M ⊆ { 1 , . . . , p } with | M | ≤ n , the restricted OLS-estimator o f the n oise ve ctor ε , ˆ θ M = ( X T M X M ) − 1 X T M ε. (27) 16 N. MEIN S HAUSEN AND B. YU First, w e b ound the ℓ 2 -norm of th is estimator. The resu lt is useful for b oun d- ing the v ariance of the fi nal estimator, based on th e derived b ound on the n um b er of activ e v ariables. Lemma 3. L et m n b e a se quenc e with m n = o ( n ) and m n → ∞ for n → ∞ . If p n → ∞ , it holds with pr ob ability c onver ging to 1 for n → ∞ max M : | M |≤ m n k ˆ θ M k 2 ℓ 2 ≤ 2 log p n n m n φ 2 min ( m n ) σ 2 . The ℓ 2 -norm of the restricted estimator ˆ θ M is thus b ounded uniform ly o ve r all set s M with | M | ≤ m n . Pr oof of Lemma 3 . It follo ws direc tly fr om the definition of ˆ θ M that, for e v ery M with | M | ≤ m n , k ˆ θ M k 2 ℓ 2 ≤ 1 n 2 φ 2 min ( m n ) k X T M ε k 2 ℓ 2 . (28) It remains to b e sh o wn that, fo r n → ∞ , w ith p robabilit y con ve rging to 1, max M : | M |≤ m n k X T M ε k 2 ℓ 2 ≤ 2 log p n σ 2 m n n. As ε i ∼ N (0 , σ 2 ) for all i = 1 , . . . , n , it h olds w ith p robabilit y conv erging to 1 for n → ∞ , by Bonferroni’s inequalit y that max k ≤ p n | X T k ε | 2 is b ounded from ab o ve b y 2 log p n σ 2 n . Hence, w ith p robabilit y con vergi ng to 1 for n → ∞ , max M : | M |≤ m n k X T M ε k 2 ℓ 2 ≤ m n max k ≤ p n | X T k ε | 2 ≤ 2 log p n σ 2 n m n , (29) whic h completes the p r o of. V arianc e of estimate is b ounde d by r estricte d OLS varianc e. W e show that the v ariance of the Lasso estimator can b e b ounded b y the v ariances of restricted OLS estimators, u sing b ound s on the num b er of activ e v ariables. Lemma 4. If, for a fixe d value of λ , the numb er of active variables of the de-noise d estimators ˆ β λ,ξ is for every 0 ≤ ξ ≤ 1 b ounde d by m , then sup 0 ≤ ξ ≤ 1 k ˆ β λ, 0 − ˆ β λ,ξ k 2 ℓ 2 ≤ max M : | M |≤ m k ˆ θ M k 2 ℓ 2 . (30) Pr oof. T h e key in the p r o of is that the solution path of ˆ β λ,ξ , if increas- ing the v alue of ξ fr om 0 to 1, can b e expressed piecewise in terms of the restricted OLS solution. It will b e ob vious f r om the pro of that it is suffi cient to sho w the claim for ξ = 1 in the term o n the r.h.s. of ( 30 ). LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 17 The set M ( ξ ) of activ e v ariables is the set with maximal absolute gradien t, M ( ξ ) = { k : | G λ,ξ k | = λ } . Note that the estimato r ˆ β λ,ξ and also the gradient G λ,ξ k are con tinuous func- tions in b oth λ and ξ [ 11 ]. Let 0 = ξ 1 < ξ 2 < · · · < ξ L +1 = 1 b e the p oin ts of discon tinuit y of M ( ξ ). A t these lo cations, v ariables either join the activ e set or are dropp ed from the activ e set. Fix some j w ith 1 ≤ j ≤ J . Denote by M j the set of activ e v ariables M ( ξ ) for an y ξ ∈ ( ξ j , ξ j +1 ). W e sho w in t he follo wing that the solution ˆ β λ,ξ is for all ξ in the int erv al ( ξ j , ξ j +1 ) giv en b y ∀ ξ ∈ ( ξ j , ξ j +1 ) : ˆ β λ,ξ = ˆ β λ,ξ j + ( ξ − ξ j ) ˆ θ M j , (31) where ˆ θ M j is the restricted OLS esti mator of noise, as defined in ( 27 ). The lo cal effect of increased noise (larger v alue of ξ ) on the estimator is thus to shift the co efficien ts of the activ e set of v ariables along t he least squ ares direction. Once ( 31 ) is sho w n , the claim follo ws by piecing together the piecewise linear parts and using con tin uity of the solution as a function of ξ to obtain k ˆ β λ, 0 − ˆ β λ, 1 k ℓ 2 ≤ J X j =1 k ˆ β λ,ξ j − ˆ β λ,ξ j +1 k ℓ 2 ≤ max M : | M |≤ m k ˆ θ M k ℓ 2 J X j =1 ( ξ j +1 − ξ j ) = max M : | M |≤ m k ˆ θ M k ℓ 2 . It thus remains to sh ow ( 31 ). A n ecessary and su ffi cien t condition for ˆ β λ,ξ with ξ ∈ ( ξ j , ξ j +1 ) to b e a v alid solution is that for al l k ∈ M j with nonzero co efficient ˆ β λ,ξ k 6 = 0 , the gra dien t is equal to λ times t he n egativ e sign, G λ,ξ k = − λ sign( ˆ β λ,ξ k ) , (32) that for all v ariables with k ∈ M j with zero coefficien t ˆ β λ,ξ k = 0 the gradien t is equal in absolute v alue to λ | G λ,ξ k | = λ (33) and for v ariables k / ∈ M j not in the ac tiv e set, | G λ,ξ k | < λ. (34) These conditions are a consequence of the requir ement that the subgradient of the loss function cont ains 0 fo r a v alid so lution. 18 N. MEIN S HAUSEN AND B. YU Note that the gradien t of the activ e v ariables in M j is u nc h anged if re- placing ξ ∈ ( ξ j , ξ j +1 ) by some ξ ′ ∈ ( ξ j , ξ j +1 ) and replacing ˆ β λ,ξ b y ˆ β λ,ξ + ( ξ ′ − ξ ) ˆ θ M j . That is, for all k ∈ M j , ( Y ( ξ ) − X ˆ β λ,ξ ) T X k = { Y ( ξ ′ ) − X ( ˆ β λ,ξ + ( ξ ′ − ξ ) ˆ θ M j ) } T X k , as the difference of b oth s ides is equal to ( ξ ′ − ξ ) { ( ε − X ˆ θ M j ) T X k } , and ( ε − X ˆ θ M j ) T X k = 0 for all k ∈ M j , as ˆ θ M j is th e OLS of ε , regressed on the v ariables in M j . Equalities ( 32 ) and ( 33 ) are th u s fulfilled for the solution and it remains to show that ( 34 ) also holds. F or sufficien tly small v alues of ξ ′ − ξ , inequalit y ( 34 ) is clearly fulfilled for con tinuit y r easons. Note that if | ξ ′ − ξ | is large enough suc h that for one v ariable k / ∈ M j inequalit y ( 34 ) b ecomes an equalit y , then th e set of activ e v ariables c hanges and th us either ξ ′ = ξ j +1 or ξ ′ = ξ j . W e hav e thus shown that the solution ˆ β λ,ξ can for all ξ ∈ ( ξ j , ξ j +1 ) be written as ˆ β λ,ξ = ˆ β λ,ξ j + ( ξ − ξ j ) ˆ θ M j , whic h pro v es ( 31 ) and thus completes the pr o of. A b ound on the numb er of active variables. A decisiv e part in the v ari- ance o f the estimator is d etermined by t he num b er of selected v ariables. Instead of directly b ound in g the num b er of select ed v ariable s, we derive b ound s for the num b er of active variables . As any v ariable with a n onzero regression co efficient is also an active variable , these b oun ds lead trivially to boun d s for the num b er of selecte d v ariables. Let A λ b e the set of active variables , A λ = { k : | G λ k | = λ } . Let A λ,ξ b e the set of active variables of th e de-noised estimator ˆ β λ,ξ , as defined in ( 15 ). The n umb er of sele cted v ariables (v ariables with a nonzero co efficient) is at most as larg e as the num b er of active variables , as an y v ariable with a n onzero estimated co efficien t has to b e an active varia ble [ 25 ]. Lemma 5. F or λ ≥ σ e n √ n log p n , the maximal numb er sup 0 ≤ ξ ≤ 1 |A λ,ξ | of active variables is b ounde d, with pr ob ability c onver ging to 1 for n → ∞ , by sup 0 ≤ ξ ≤ 1 |A λ,ξ | ≤ e 2 n s n . Pr oof. Let R λ,ξ b e the residuals of the de-noised estimator ( 15 ), R λ,ξ = Y − X ˆ β λ,ξ . F or any k in the |A λ,ξ | -dimensional space sp anned by the active variables , | X T k R λ,ξ | = λ. (35) LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 19 Adding up, it follo ws that f or all 0 ≤ ξ ≤ 1, |A λ,ξ | λ 2 = k X T A λ,ξ R λ,ξ k 2 ℓ 2 . (36) The residuals can for all v alues 0 ≤ ξ ≤ 1 b e written as the sum of t w o terms, R λ,ξ = X ( β − ˆ β λ,ξ ) + ξ ε. Equalit y ( 36 ) can no w b e transf ormed in to the inequalit y , |A λ,ξ | λ 2 ≤ ( k X T A λ,ξ X ( β − ˆ β λ,ξ ) k ℓ 2 + ξ 2 k X T A λ,ξ ε k ℓ 2 ) 2 (37) ≤ ( k X T A λ,ξ X ( β − ˆ β λ,ξ ) k ℓ 2 + k X T A λ,ξ ε k ℓ 2 ) 2 . (38) Denote b y ˜ m the supremum of |A λ,ξ | o ver all v alues of 0 ≤ ξ ≤ 1. Using the same argument as in the deriv ation of ( 29 ), the term sup 0 ≤ ξ ≤ 1 k X T A λ,ξ ε k 2 ℓ 2 is of ord er o p ( ˜ mn log p n ) as long as p n → ∞ for n → ∞ . F or s u fficien tly large n it holds thus, using λ ≥ σ e n √ n log p n , th at sup 0 ≤ ξ ≤ 1 k X T A λ,ξ ε k ℓ 2 / ( ˜ mλ 2 ) 1 / 2 ≤ η for an y η > 0. Dividing by λ 2 , ( 37 ) imp lies then, with probabilit y con v erg- ing to 1, ˜ m ≤ sup 0 ≤ ξ ≤ 1 ( λ − 1 k X T A λ,ξ X ( β − ˆ β λ,ξ ) k ℓ 2 + η √ ˜ m ) 2 . (39) No w tur ning to the right- hand s ide, it trivially h olds for an y v alue of 0 ≤ ξ ≤ 1 that |A λ,ξ | ≤ min { n, p } . On the other hand , X ( β − ˆ β λ,ξ ) = X B λ,ξ ( β − ˆ β λ,ξ ) , where B λ,ξ := A λ,ξ ∪ { k : β k 6 = 0 } , as the difference ve ctor β − ˆ β λ,ξ has n onzero en tries only in the set B λ,ξ . Th us k X T A λ,ξ X ( β − ˆ β λ,ξ ) k 2 ℓ 2 ≤ k X T B λ,ξ X B λ,ξ ( β − ˆ β λ,ξ ) k 2 ℓ 2 . Using additio nally |B λ,ξ | ≤ s n + min { n, p } , it follo ws that k X T A λ,ξ X ( β − ˆ β λ,ξ ) k 2 ℓ 2 ≤ n 2 φ 2 max k ( β − ˆ β λ,ξ ) k 2 ℓ 2 . Splitting the d ifference β − ˆ β λ,ξ in to ( β − β λ ) + ( β λ − ˆ β λ,ξ ), where β λ = ˆ β λ, 0 is again the p opulation ve rsion of the Lasso estimator, it h olds for any η > 0, using ( 39 ), that with probabilit y con v erging to 1 for n → ∞ , ˜ m ≤ nλ − 1 φ max k β − β λ k ℓ 2 + nλ − 1 φ max sup 0 ≤ ξ ≤ 1 k ˆ β λ, 0 − ˆ β λ,ξ k ℓ 2 + η √ ˜ m 2 . (40) Using Lemmas 3 and 4 , the v ariance term n 2 φ 2 max sup 0 ≤ ξ ≤ 1 k ˆ β λ, 0 − ˆ β λ,ξ k 2 ℓ 2 is b ounded b y o p { n ˜ m log p n φ 2 max /φ 2 min ( ˜ m ) } . Define, implicitly , a sequence ˜ λ = σ √ n log p n ( φ max /φ min ( ˜ m )) . F or any sequence λ w ith lim inf n →∞ λ/ ˜ λ > 0, the term n 2 λ − 2 φ 2 max sup 0 ≤ ξ ≤ 1 k ˆ β λ, 0 − ˆ β λ,ξ k 2 ℓ 2 is then of order o p ( ˜ m ). Using furthermore the b ound on the bias from Lemma 1 , it h olds with p robabilit y 20 N. MEIN S HAUSEN AND B. YU con ve rging to 1, for n → ∞ for an y sequence λ w ith lim in f n →∞ λ/ ˜ λ > 0 and an y η > 0 that ˜ m ≤ ( n λ − 1 φ max k β − β λ k ℓ 2 + 2 η √ ˜ m ) 2 ≤ 17 . 5 φ max √ s n φ min ( e n s n ) + 2 η √ ˜ m 2 . Cho osing η = 0 . 013 implies, for an inequ alit y of th e form a 2 ≤ ( x + 2 η a ) 2 , that a ≤ (18 / 17 . 5) x . Hence, c ho osing this v alue of η , it fol lo ws from the equation abov e that, with probabilit y con v erging to 1 for n → ∞ , ˜ m ≤ 18 2 φ 2 max s n φ 2 min ( e n s n ) = e 2 n s n 18 φ max e n φ min ( e n s n ) 2 ≤ e 2 n s n , ha ving used the definition of the sp arsity multiplier in ( 6 ). W e can no w see that the requiremen t on λ , namely lim inf n →∞ λ/ ˜ λ > 0, is fulfilled if λ ≥ σ e n √ n log p n , whic h complet es the pr o of. Finally , we u se L emm as 3 , 4 and 5 to sho w the b ound on the v ariance of the esti mator. Lemma 6. Under the c onditions of The or em 1 , with pr ob ability c onver g- ing to 1 for n → ∞ , k β λ − ˆ β λ k 2 ℓ 2 ≤ 2 σ 2 s n log p n n e 2 n φ 2 min ( e 2 n s n ) . The proof follo ws immediately from Lemmas 3 and 4 when inserting t he b ound on the n umb er of activ e v ariables o btained in Lemma 5 . 4. Numerical il lustration: frequency detect ion. In s tead of extensive nu- merical simula tions, w e w ould lik e to illustrate a few asp ects of Lasso-t yp e v ariable selection if the irr epr esentable c ondition is not f ulfilled. W e are not making clai ms that the Lasso is sup erior to ot her met ho ds for high- dimensional data. W e merely wan t to d ra w atten tion to the fact that (a) the Lasso migh t not b e able to select the correct v ariables b ut (b) comes nev ertheless close to the true vec tor in an ℓ 2 -sense. An illustrativ e example is frequency detection. I t is of int erest in some areas of the ph ysical sciences to accurately detect and resolv e frequency com- p onents; t wo e xamples are v ariable stars [ 27 ] and detection of gravi tational w av es [ 6 , 32 ]. A nonp arametric approac h is often most s uitable for fi tting of the inv olv ed p erio d ic functions [ 15 ]. Ho wev er, we assume here for simplicit y that the observ ations Y = ( Y 1 , . . . , Y n ) at time p oint s t = ( t 1 , . . . , t n ) are of the form Y i = X ω ∈ Ω β ω sin(2 π ω t i + φ ω ) + ε i , LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 21 where Ω c on tains the set of fu ndamen tal frequencies inv olv ed, and ε i for i = 1 , . . . , n is indep endently and iden tically distributed noise with ε i ∼ N (0 , σ 2 ). T o simplify the pr ob lem ev en more, we assume that the ph ases are kno wn to b e zero, φ ω = 0 for all ω ∈ Ω . O th erw ise one migh t lik e to emplo y the Group Lasso [ 37 ], grouping together the sine and cosine part of identica l frequencies. It is of in terest to resolv e closely adjacen t sp ectral lines [ 16 ] and we will w ork in this set ting in the follo wing. W e choose for the exp erimen t n = 200 eve nly spaced obs erv ation times. Th ere are supp osed to b e t w o closely adjacen t frequencies w ith ω 1 = 0 . 0545 and ω 2 = 0 . 0555 = ω 1 + 1 / 300, b oth en tering w ith β ω 1 = β ω 2 = 1. As we hav e the inf ormation that the phase is zero for all frequencies, the predictor v ariables are giv en by all sine-functions with fr equencies ev enly sp aced b et ween 1 / 20 0 and 1 / 2, with a spacing of 1 / 600 b et ween adjacent frequencies. In the c hosen setting, the irr e pr esentable c ondition is violated for the frequency ω m = ( ω 1 + ω 2 ) / 2. Even in the absence of noise, th is r esonanc e fr e quency is included in th e Lasso-estimate for all p ositiv e p enalt y param- eters, as can b e seen from the results fu rther b elo w. As a consequence of a violated irr epr esentable c ondition , the largest p eak in the p erio dogram is in general obtained for the r esonanc e fr e quency . In Figure 1 we show the p erio dogram [ 28 ] und er a mo derate noise lev el σ = 0 . 2. The p erio dogram sho w s the amount of energy in eac h frequency , and is defi n ed through the function ∆ E ( ω ) = X i Y 2 i − X i ( Y i − ˆ Y ( ω ) i ) 2 , where ˆ Y ( ω ) is the least squares fit of the observ ations Y , using only sine and cosine fu nctions with frequency ω as tw o p redictor v ariables. There is clearly a p eak at frequency ω m . As can b e seen in the close-up around ω m , it is not immediately ob vious from the p erio dogram that there are two frequencies at frequencies ω 1 and ω 2 . As said ab ov e, the irr epr esentable c ondition is violated for the r esonanc e fr e quency and it is of in terest to se e whic h frequencies are p ic k ed up by the Lasso estimator. The r esults are s ho wn in Figures 2 and 3 . Figure 3 highlight s that the t wo true frequen cies are with high probabilit y pic ked up by t h e Lasso. Th e r esonanc e fr e quency is also selected with high probabilit y , n o matter ho w the p enalt y is chose n. This result could b e exp ected as the irr epr esentable c ondition is vio lated and the estimat or can thus not b e sign c onsistent . W e exp ect fr om th e theo retical results in this m an u s cript that the co efficien t of the falsely selected r esonanc e fr e quency is very small if the p enalt y parameter is c hosen correctly . And it can indeed b e seen in Figure 2 that the co efficien ts of the tru e fr equencies are muc h larger than th e coefficien t of the r esonanc e fr e quency for an appropriate c hoice of the p enalt y parameter. 22 N. MEIN S HAUSEN AND B. YU Fig. 1. The ener gy log ∆ E ( ω ) for a n oise level σ = 0 . 2 is shown o n the left for a r ange of fr e quencies ω . A close-up of the r e gion ar ound the p e ak i s shown on the right. The two fr e quencies ω 1 and ω 2 ar e m arke d with solid vertic al lines, while the r esonanc e fr e quency ( ω 1 + ω 2 ) / 2 is shown with a br oken v ertic al line. These results r einforce our conclusion that the Lasso migh t not b e able to pic k up the correct sp arsit y pattern, but deliv ers nev ertheless useful ap- pro ximations as falsely selected v ariables are c hosen only wit h a ve ry small co efficient; this b eha vior is t ypical and exp ected f rom the r esults of Theorem 1 . F alsely selected co efficien ts can th u s b e remo v ed in a second step, eit her b y thresholding v ariables with small co efficien ts or u sing other relaxation tec hniques. In an y case, it is reassuring to kn ow that all imp ortan t v ariables are included in the Lasso estimate . 5. Concluding r emarks. It has recen tly b een disco ve red that the Lasso cannot reco ver the correct sparsit y pattern in certain circumstances, ev en not asymptotically for p n fixed and n → ∞ . Th is sh eds a little doubt on whether the Lasso is a go o d metho d for ident ification of sparse mo dels for b oth lo w- and high-dimensional data. Here we ha v e sho wn that the Lasso can conti n ue to deliv er go o d appro x- imations to sparse co efficien t v ectors β in the sense that the ℓ 2 -difference k β − ˆ β λ k ℓ 2 v anishes for large sample sizes n , ev en if it fails to disco ver the correct sparsit y pattern. The conditions n eeded for a goo d appro ximation in the ℓ 2 -sense are w eak er than the irr epr esentable c ondition needed for sign c onsistency . W e p oin ted out th at the correct spars ity pattern could b e reco v- ered in a t wo-sta ge pro cedu re when the true co efficien ts are n ot to o small. The fir st step consists in a regular Lasso fit. V ariables with small absolute co efficients a re then remo v ed fr om the mo del in a sec ond step. W e deriv ed p ossible scenarios under w hic h ℓ 2 -consistency in the sense of ( 4 ) can b e ac hiev ed as a fun ction of the sparsit y of the v ector β , the n um b er LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 23 Fig. 2. A n example wher e the L asso is b ound to sele ct wr ong variables, whi le b eing a go o d appr oximation to the true ve ctor in the ℓ 2 -sense. T op r ow: The noise level incr e ases fr om left to right as σ = 0 , 0 . 1 , 0 . 2 , 1 . F or one run of the si m ulation, p aths of the estimate d c o efficients ar e shown as a function of the squar e r o ot √ λ o f the p enalty p ar ameter. The actual ly pr esent signal fr e quencies ω 1 and ω 2 ar e shown as solid lines, the r esonanc e fr e- quency as a br oken line, and al l other f r e quencies ar e shown as dotte d lines. Bottom r ow: The shade d ar e as c ontain, for 90% of al l simulations, the r e gularization p aths of the signal fr e quencies (r e gion with solid b or ders), r esonanc e fr e quency (ar e a with br oken b or ders) and al l other fr e quencies (ar e a with dotte d b oundaries). The p ath of the r esonanc e fr e quency displays r everse shr inkage as i ts c o efficient ge ts, in gener al, smal ler for smal ler values of the p enalty. As exp e cte d fr om the the or etic al r esults, i f the p enalty p ar ameter is chosen c orr e ctly, i t i s p ossible to sep ar ate the signal and r esonanc e f r e quencies for sufficiently l ow noise levels by just r etaining lar ge and ne gle cting smal l c o efficients. It is also app ar ent that the c o efficient of the r esonanc e fr e quency is smal l for a c orr e ct choic e of t he p enalty p ar ameter but very seldom identic al l y zer o. of samples and the n umber of v ariables. Un der the condition that sparse minimal eigen v alues are not d eca ying too fast in some sen s e, the requiremen t for ℓ 2 -consistency is (ignoring log n factors) s n log p n n → 0 as n → ∞ . The rate of con vergence is actually optimal with an appropr iate c hoice of the tuning p arameter λ and und er the condition of b ounded maximal and minimal sparse eigen v alues. T his rate is, apart f rom logarithmic factor in p n and n , identic al to what could b e achie v ed if the true sparse mo del would b e kno wn . If ℓ 2 -consistency is ac hiev ed, the Lasso is selecting all “sufficiently large” co efficien ts, and p ossibly s ome other unw an ted v ariables. “Sufficien tly large” means h ere that the squ ared size of the co efficien ts is deca ying slo wer than t he r ate n − 1 s n log p n , again ig noring loga rithmic fact ors in the samp le size. The num b er of v ariables can th us b e narr o wed do wn considerably with 24 N. MEIN S HAUSEN AND B. YU Fig. 3. The top r ow shows the ℓ 2 -distanc e b etwe en β and ˆ β λ sep ar ately f or the signal fr e quencies (solid blue line), r esonanc e fr e quency (br oken r e d line) and al l other f r e quencies (dotte d gr ay li ne). It is evident that the distanc e i s quite smal l f or al l thr e e c ate gories simultane ously if the noise level is sufficiently low (the noise level is again incr e asing fr om left to right as σ = 0 , 0 . 1 , 0 . 2 , 1 ). The b ottom r ow shows, on the other hand, the aver age numb er of sele cte d variables (with nonzer o estimate d r e gr ession c o efficient) i n e ach of the thr e e c ate gories as a function of the p enalty p ar ameter. It is imp ossible to cho ose the c orr e ct mo del, as the r esonanc e fr e quency is always sele cte d, no matter how l ow the noise level and no matter how the p enalty p ar ameter is chosen. This il lustr ates that sign c onsistency do es not hold i f the irr epr esentable c ondition i s vi olate d, even though t he estimate c an b e close to the true ve ctor β in the ℓ 2 -sense. the Lasso in a m eaningfu l w a y , k eeping all imp ortan t v ariables. The siz e of the reduced subset can b e b ounded with high probabilit y by the n um b er of tru ly imp ortan t v ariables times a factor that d ep ends on the deca y of the sp arse eigen v alues. This factor is often simply the squared log arithm of the sample size. Our conditions are similar in spirit to those in related aforemen tioned wo rks, but expand the groun d to co v er p ossibly cases with more d ep endent predictors than U UP . These results sup p ort that the Lasso is a useful mod el identifica tion method for high-dimensional data. Ac kn o wledgment s. W e w ould lik e to thank Noureddine El Karoui and Debashis Paul for p oin ting out in teresting connections to Random Matrix theory . Some results of this manuscript h av e b een p r esen ted at the Ob er- w olfac h workshop “Qualitativ e Assu mptions and Regularizat ion for High- Dimensional Data.” Finally , we w ould lik e to thank the tw o referees and the AE for their helpful commen ts that ha v e led to an impro vemen t o v er our previous results. LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 25 REFERENCES [1] B ickel, P., Rito v, Y. and Tsybako v, A. (2008). Sim ultaneous a nalysis of La sso and Dantzig selector. Ann. Statist. T o app ear. [2] B unea, B., Tsybak o v, A. and Wegkamp, M. (2007). Aggregation for Gaussian regressio n. Ann. Statist. 35 1674–1 697. MR235110 1 [3] B unea, F., Tsybak ov, A. and Wegkamp, M. (2006). S parsit y or acle inequalities for the Lasso. Ele ctr on. J. Statist. 169–194 . MR231214 9 [4] C andes, E. and T ao, T. (2005a ). D eco ding by linear programming. IEEE T r ans. Inform. The ory 51 4203–4215. MR224315 2 [5] C andes, E. and T ao, T. (2005b). The Dantzig selector: Statistical estimation when p is muc h larger than n . A nn. Statist. 35 2313–235 1. MR238264 4 [6] C ornish, N. and C ro wder, J. (2005). LISA data analysis using Mark o v chain Mon te Carlo metho ds. Phys. R ev. D 72 43005. [7] Da vidson, K. and Szare k, S. ( 2001). Local operator theory , random ma trices and Banach spaces. In Handb o ok on the Ge ometry of Banach Sp ac es 1 (W. B. J ohnson and J. Li ndenstrauss, eds.) 317–366 . North -Holland, Amsterdam. MR186369 6 [8] Donoho, D. (2006). F or most large underdetermined systems of linear equations, the mi nimal l 1 -norm so lution is also the sparsest solution. Comm . Pur e Appl. Math. 59 797–829 . MR2217606 [9] Donoho, D. and Elad, M. (2003). Optimally sparse rep resentation in general (nonorthogonal) dictionaries via ℓ 1 -minimization. Pr o c. Natl. A c ad. Sci. USA 100 2197–220 2. MR1963681 [10] Donoho, D., Elad, M. and Teml y ak ov, V. (2006). Stable reco very of sparse ove r- complete represen t ations in the presence of noise. IEEE T r ans. Inform. The ory 52 6–18. MR2237332 [11] Efr on, B ., Hastie, T . , Johnstone, I. and Ti bshi ra ni, R. (2004). Least angle regressio n. Ann. Statist. 32 407–45 1. MR206016 6 [12] Fuchs, J. (2005). Recov ery of exact sparse rep resentations in the presence of b ounded noise. IEEE T r ans. Inform. The ory 51 3601–3608. MR223752 6 [13] Greenshtein, E. and Ritov, Y. (2004). Pers istence in high-dimensional p redic- tor selection a nd the virtue of ov er-parametrization. Bernoul li 10 971–98 8. MR210803 9 [14] Gribonv al, R. and Nielsen, M . (2003). Sparse representations in unions of b ases. IEEE T r ans. Inform. The ory 49 3320–3325 . MR204581 3 [15] Hall, P., Reimann, J. and Rice, J. (2000). Nonp arametric estimation of a p erio dic function. Biometrika 87 545–557 . MR178980 8 [16] Hannan, E. and Quin n , B. (1989). The resolution of closely adjacent sp ectral lines. J. Time Ser. Anal. 10 13–31. MR100188 0 [17] Joshi, R., Cr ump, V. and Fischer, T. (1995). Image subband co ding using arith- metic coded t rellis co dedquantization. IEEE T r ansactions on Cir cuits and Sys- tems for Vide o T e chnolo gy 5 515–523. [18] Knight, K. and Fu, W. (2000). Asymptotics for Lasso-type estimators. A nn. Statist. 28 1356–1378 . MR1805787 [19] LoPresto, S., Ramchandran, K. and Orchard, M. (1997). Image co ding based on mixture mo deling o f wa velet coefficients and a f ast estimation-quantization framew ork. In Pr o c. Data Compr ession Confer enc e 221–230. [20] Malla t, S. (1989). A theory for multiresol ution signal decomp osition: The wa velet represen tation. IEEE T r ans. Pattern Anal. Machine Intel l igenc e 11 674–693 . 26 N. MEIN S HAUSEN AND B. YU [21] Meier, L. , v a n de Geer, S. and B ¨ uhlmann, P. (2008). The group Lasso for logisti c regressio n. J. R oy. Statist. So c. Ser. B 70 53–71. [22] Meinshausen, N. (2007). Relaxed Lasso. Comput. Statist. Data Anal. 52 374–393. [23] Meinshausen, N. and B ¨ uhlmann, P. (2006). High-dimensional graphs and v ariable selection with the Lasso. Ann. Statist. 34 1436–1 462. MR2278363 [24] Meinshausen, N., Rocha, G. and Yu, B. (200 7). A tale of three cousins: Lasso, L2Boosting and Dan tzig. Ann. Statist. 35 2373–2 384. MR238264 9 [25] Osborne, M., Presnell, B. and Turlach, B. (2000). On the Lasso and its dual. J. Comput. Gr aph. Statistics 9 319–337. MR182208 9 [26] P aul, D. (2007). Asymptotics of sample eigenstructure for a large-dimensional spik ed co v ariance mo del. Statist. Sinic a 17 1617–1642 . MR239986 5 [27] Pojmanski, G. (2002). The All Sky Au t omated Su rvey . Catalog of V ariable Stars. I. 0 h–6 Quarter of the Southern Hemisphere. A cta Astr onomic a 52 397–427. [28] Scargle, J. (1982). Studies in astrono mical time series analysis . II. Statistical as- p ects of sp ectral analysis of un evenly spaced data. Astr ophysic al J. 263 835. [29] Tibshirani, R. (1996). Regression shrink age and selection via the Lasso. J. R oy. Statist. So c. Ser. B 58 267–288. MR137924 2 [30] Tro pp, J. (2004). Greed is go o d : Algorithmic results for sparse app ro ximation. IEEE T r ans. I nf orm. The ory 50 2231–2 242. MR209704 4 [31] Tro pp, J. (2006 ). Just relax: Con vex progr amming methods for identifying sparse signals in noise. IEEE T r ans. Inform. The ory 52 1030–1051 . MR223806 9 [32] Umst ¨ atter, R., Christense n , N., Hendr y, M., Meyer, R., Simha, V., Ve itch, J., Vigeland , S. and Wo an, G. (2005). LISA source confusion: Identification and charac terization of signals . C l assic al and Q uantum Gr avity 22 901. [33] V ald ´ es-Sosa, P., S ´ anchez-Bornot, J., Lage-Castellanos, A., Vega- Hern ´ andez, M., B osch-Ba y ard, J., Melie-Garc ´ ıa, L. and Canales- Ro dr ´ ıguez, E. (2005). Estimating brain functional connectivity with sparse multi v ariate autoregression. Philos. T r ans. Ro y. So c. B: Biolo gic al Scienc es 360 969–98 1. [34] v an de Gee r, S. (2006). H igh-d imensional generaliz ed linear mo dels and the Lasso. An n. Statist. 36 614–645. MR239680 9 [35] W ain wrig h t, M. (2006). Sharp thresholds for high-dimensional and noisy recov ery of sparsit y. Av ailable at arXiv:math.ST/060 5740 . [36] Yuan, M. and Lin, Y. (2006a). M odel selection and estimation in regression with grouped v ariables. J. R oy. Statist. So c. Ser. B 68 49–67. MR2212574 [37] Yuan, M. and Lin, Y. (20 06b). M odel selection and estimati on in regression with grouped v ariables. J. R oy. Statist. So c. Ser. B 68 49–67. MR221257 4 [38] Zhang, C.-H. and Huang, J. (2006). The sparsity and bias of the Lasso selectio n in high-dimensional linear regression. Ann. Statist. 36 1567–15 94. MR243544 8 [39] Zhang, H. and Lu, W. (2007). Adaptive-Lasso for Co x ’s prop ortional hazards mo del. Biometrika 94 691–703 . [40] Zhao , P. and Yu, B. (2004). Stagewise Lasso. J. Machine L e arning R ese ar ch 8 2701–2 726. MR238357 2 [41] Zhao , P. and Yu, B . (2006). On mo del selection consistency of Lasso. J. Machine L e arning R ese ar ch 7 2541–2563. MR227444 9 [42] Zou, H. (2006). The adaptive Lasso and its oracle prop erties. J. A mer. Statist. Asso c. 101 1418–142 9. MR227946 9 LASSO-TYPE RECOVER Y OF SP ARSE REPRESENT A TIONS 27 Dep ar tment of S t a tistics University of Oxford 1 South P arks Ro ad O xford OX1 3TG United Kingdom E-mail: meinshausen@stats.o x.ac.uk Dep ar tment of S t a tistics UC Berkeley 367 Ev ans Hall Berkeley, California 94720 USA E-mail: yu@stat.berkeley .edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment