A review of the Statistical Mechanics approach to Random Optimization Problems
We review the connection between statistical mechanics and the analysis of random optimization problems, with particular emphasis on the random k-SAT problem. We discuss and characterize the different phase transitions that are met in these problems,…
Authors: Fabrizio Altarelli, Remi Monasson, Guilhem Semerjian
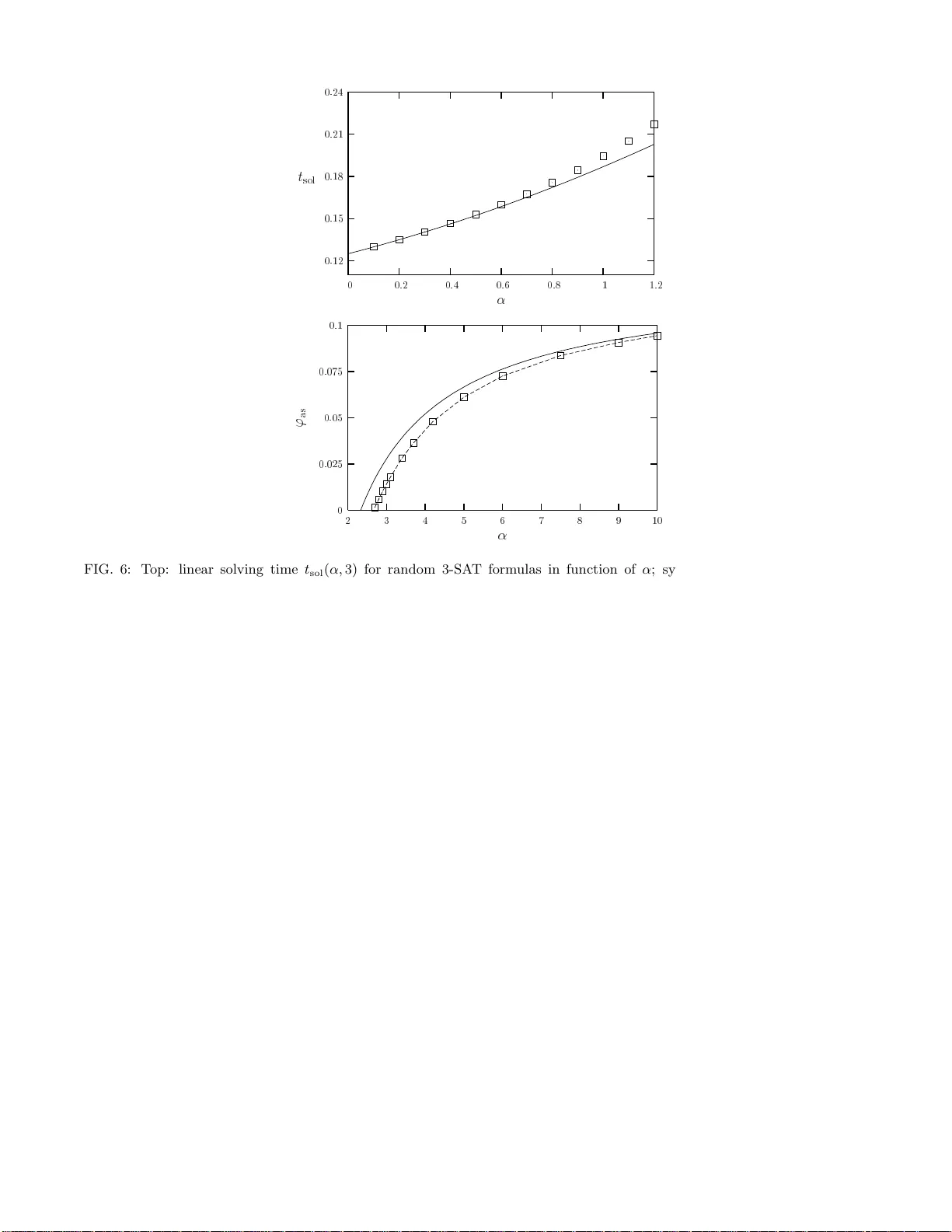
A review of the Statistical Mec hanics approac h to Random Optimization P roblems F abrizio Altarelli 1 , 2 , R´ emi Monasson 2 , Guilhem Semer jia n 2 and F rancesco Zamp oni 2 1 Dip artimento di Fisic a and CNR, Universit` a di R oma L a Sapienza, P. A. Mor o 2, 00185 R oma, Italy, 2 LPTENS, Uni t ´ e Mixte de R e cher che (UMR 8549) du CNRS et de l’ENS, asso ci´ ee ` a l’ UPMC Univ Paris 06, 24 R ue Lhomond, 7523 1 Paris Ce dex 05, F r anc e. W e review the connection b etw een statistical mechanics and t he analysis of random optimization problems, with particular emp hasis on the random k -S A T problem. W e discuss and characterize th e different phase transitions that are met in these problems, starting from b asic concepts. W e also discuss h o w statistical mechanics metho ds can b e used to investig ate the b ehavior of local search and decimation based algorithms. This p ap er has b e en written as a c ontribution to the “Handb o ok of Satisfiabili ty” to b e publishe d in 2008 by IOS pr ess. I. INTRO DUCTION The co nnection betw een the statistica l physics of disorder e d sys tems and optimizatio n problems in computer science dates bac k from tw ent y y e a rs at least [1]. In com bina torial optimization one is given a cost function (the length of a tour in the trav eling sa lesman problem (TSP ), the num b er of vio lated constr a ints in constraint satisfaction problems, . . . ) ov er a set of v a riables and loo ks for the minimal cost over a n allow ed range for those v ariables. Finding the true minimum may b e complicated, and requires bigger and bigger c o mputational efforts as the num b er of v a riables to be minimized o ver incr eases [2 ]. Statistical ph ysics is at first sigh t very different. The s cop e is to deduce the macr o scopic, that is, glo bal prop er ties of a physical sys tem, for instance a g as, a liquid or a s olid, from the knowledge of the energetic in ter actions o f its elementary comp onents (molecules, atoms or ions). Howev er, at very low temp eratur e, these elemen tary comp onents are ess entially forced to o ccupy the spatia l conformation minimizing the glo bal energy of the system. Hence low tempe rature statistical ph ysics c a n b e seen a s the search for minimizing a cost fun ction whose expressio n reflec ts the la ws of Na ture or, more hum bly , the degree o f accuracy r etained in its des cription. This problem is g enerally not difficult to solve for non disordered sy s tems where the lowest ener gy conformation are crystals in which comp onents are regular ly spaced from each other. Y et the presence of disorder , e.g. impurities, makes the problem very difficult and finding the conformation with minimal energy is a tr ue optimization problem. A t the b e ginning of the eigh ties, following the w or ks of G. Parisi and others on s ystems c a lled spin glasse s [1 ], impo rtant prog resses w ere made in the statistica l ph ysics of disordered systems. Tho se progresses made possible the quantitativ e study of the pr op erties of systems g iven some distribution of the disor der (for instance the lo cation of impurities) suc h as the av era ge minimal energy and its fluctuations. The application to o ptimiza tion problems was na tural and led to bea utiful studies on (a mong others ) the average prop er ties of the minimal tour leng th in the TSP , the minimal cos t in B ipartite Matc hing, for some sp ecific instance distributions [1]. Unfortunately statistical ph ysicists and computer scient ists did not es tablish clos e ties on a large scale at that time. The r eason could ha ve bee n of metho dologica l nature [3]. While physicists were making sta tistical statements, true for a given dis tribution of inputs, computer scie ntists were rather interested in so lving one (or several) particular instances o f a problem. The fo cus was thus o n efficient ways to do so, that is, re quiring a co mputational e ffort g rowing not to o quickly with the nu mber of data defining the instance. Knowing precisely the typical prop erties for a given, academic distr ibutio n of instances did not help muc h to so lve practical cases. A t the b eginning of the nineties practitionners in ar tificial intelligence r e alized that classes of rando m constraint satisfaction problems used as artificial b enchmarks for search alg orithms exhibited a brupt changes of b ehaviour when some control parameter were finely tuned [4]. The mo s t celebrated exa mple was ra ndom k -Satisfiability , where one lo oks for a so lution to a set o f random logica l cons traints ov er a se t of Bo olea n v a riables. It app e a red that, for la rge sets of v ariables, there was a critical v alue of the num b er of constr aints p er v a r iable b elow w hich ther e almost surely existed solutions, a nd a b ove which s olutions were a bsent. An imp or tant feature was that the p erfor ma nces of known search algorithms drastica lly worsened in the vicinity o f this c ritical ratio. In addition to its in trinsic mathematical int erest the rando m k -SA T problem was therefore worth to b e s tudied for ‘practical’ reaso ns. This critical phenomenon, s tr ongly reminiscent of phase transitio ns in co ndensed matter physics, led to a reviv al of the r esearch at the interface be tw een s ta tistical physics and computer scie nc e , which is still very a ctive. The pur po se of the present re v iew is to introduce the non physicist reader to some concepts required to understand the litera ture in the field and to presen t some ma jor results. W e shall in pa rticular discuss the re fined picture of the satisfiable phase put forward in sta tistical mechanics studies a nd the algorithmic approa ch (Survey Propaga tion, a n extension of Belief Propag ation used in co mm unication theory and statistical inference) this picture suggested. 2 While the pr esentation will mos tly fo cus on the k -Satisfiability problem (with r a ndom constraints) we will o cca- sionally discuss a nother computational problem, namely , linear sys tems o f Bo olean equations . A go o d reason to do so is that this pr oblem exhibits so me ess e n tial features e ncountered in random k -Satisfiability , while being tec hnically simpler to study . In addition it is clo sely r elated to erro r -corr ecting co des in communication theory . The chapter is divided into four main par ts . In Se c tio n I I we pr esent the basic statistical ph ysics concepts neces sary to understand the onset of phase transitions, and to characterize the nature of the phases . Those are illustrated on a s imple exa mple of decisio n problem, the so-calle d perceptro n problem. In Section II I w e r e view the scenario of the v ar ious phase tra nsitions taking place in ra ndo m k -SA T. Section IV a nd V pres ent the techniques used to study v arious type of alg orithms in optimization (lo c al search, backtracking pro cedures, message passing algo rithms). W e end up with some conclusive remar ks in Sec. VI. II. PHASE TRANSITIONS: BASIC CONCEPTS AND ILLUSTRA TION A. A simple de cision problem wi th a phase transition: the contin uous p erceptron F or p edago gical r easons we firs t discuss a simple e xample exhibiting several imp orta n t features we sha ll define mor e formally in the next subsection. Consider M p oints T 1 , . . . , T M of the N -dimensional space R N , their co ordinates being denoted T a = ( T a 1 , . . . , T a N ). The c ontin uous p er ceptron pro blem cons ists in dec iding the existence o f a v ector σ ∈ R N which has a p ositive sca lar pr o duct with all vectors linking the origin o f R N to the T ’s, σ · T a ≡ N X i =1 σ i T a i > 0 , ∀ a = 1 , . . . , M , (1) or in other words deter mining whether the M points b elong to the sa me half-space. The term contin uous in the name of the pro ble m emphasizes the domain R N of the v ar iable σ . This makes the proble m p olynomial from w o rst-case complexity p oint of view [5]. Suppo se now that the p oints a re chosen independently , identically , unifor mly on the unit hyperspher e, and ca ll P ( N , M ) = Pro bability that a s et of M randomly c hosen p oints belo ng to the same half-spa ce. This quantit y can b e computed exactly [6 ] (see also Chapter 5.7 of [5]) and is plotted in Fig. 1 as a function o f the ratio α = M / N for increasing sizes N = 5 , 20 , 1 00. Obviously P is a decr easing function of the num b er M of points for a g iven size N : increasing the num b er of constr a ints ca n only make more difficult the simultaneous satisfaction of all of them. More s ur prisingly , the figure s uggests that, in the lar ge s ize limit N → ∞ , the proba bilit y P reaches a limiting v alue 0 or 1 dep ending on whether the ra tio α lies, resp ectively , ab ove or below some ‘critical’ v alue α s = 2. This is confirmed by the analytica l expression of P o btained in [6], P ( N , M ) = 1 2 M − 1 min( N − 1 , M − 1) X i =0 M − 1 i , (2) from which one can easily show tha t, indeed, lim N →∞ P ( N , M = N α ) = ( 1 if α < α s 0 if α > α s , with α s = 2 . (3) Actually the a nalytical expr ession of P allows to desc rib e more accur a tely the drop in the probability as α incr eases. T o this aim we make a zo om o n the transition region M ≈ N α s and find from (2) that lim N →∞ P ( N , M = N α s (1 + λ N − 1 / 2 ) ) = Z ∞ λ √ 2 dx √ 2 π e − x 2 / 2 . (4) As it should the limits λ → ± ∞ gives ba ck the coar se descr iption of E q. (3) 3 0 1 2 3 4 ratio M/N 0 0,2 0,4 0,6 0,8 1 pobability p(M,N) N=5 N=20 N=100 FIG. 1: Probabilit y P ( N , M ) that M random p oints on the N -dimensional un it hypersph ere are lo cated in the same half-space. Symbols correspond to Co ver’s exact result [6], see Eq. (2), lines serve as guides to the eye. B. Generic definitions W e now put this simple example in a bro ader p ers pec tive a nd introduce some generic concepts that it illustra tes, along with the definitions of the pr o blems studied in the following. • Constraint Satisfaction Proble m (CSP) A CSP is a decisio n pro blem where an assignment (or co nfiguration) o f N v ariables σ = ( σ 1 , . . . , σ N ) ∈ X N is required to simultaneously sa tisfy M constraints. In the contin uous p erceptron the domain of σ is R N and the constraints imp ose the p ositivity of the scalar pro ducts (1 ). The instance o f the CSP , also called formula in the following, is s aid satisfiable if there exists a solution (a n assignment of σ fulfilling all the constraints). The k -SA T problem is a b o olean CSP ( X = { T rue , F a lse } ) where each constra int (cla use) is the disjunction (logica l OR) of k literals (a v aria ble or its negation). Similarly in k -XORSA T the literals a re combined by an eXclusive OR op eratio n, or eq uiv alently an addition mo dulo 2 o f 0 / 1 b o o lean v ar ia bles is r equired to ta ke a g iven v alue. The worst-case co mplexities o f these tw o proble ms are very different ( k -XORSA T is in the P co mplexity clas s for any k while k -SA T is NP-complete for any k ≥ 3), yet for the issues of this review we sha ll see that they present a lot of similar ities. In the following we use the statistical mechanics c onv ention and repres e n t b o olean v a riables by Is ing s pins , X = {− 1 , + 1 } . A k -SA T cla use will be defined by k indices i 1 , . . . , i k ∈ [1 , N ] and k v alues J i 1 , . . . , J i k = ± 1, such that the clause is unsatisfied b y the a ssignment σ if and only if σ i j = J i j ∀ j ∈ [1 , k ]. A k -X ORSA T clause is satisfied if the pro duct of the spins is equal to a fixed v a lue, σ i 1 . . . σ i k = J . • random C o nstraint Satisfaction Pr oblem (rCSP ) The set of instances o f most CSP can be turned in a probabilis tic space by defining a distribution over its constraints, as was done in the p erceptr on case by drawing the vertices T a uniformly on the hyp e rsphere. The random k -SA T formulas considered in the following are obta ined by choos ing for ea ch cla us e a independently a k -uplet o f distinct indices i a 1 , . . . , i a k uniformly over the N k po ssible o nes, a nd negating or not the corre s po nding literals ( J a i = ± 1) with equal proba bility one-half. The indices of r andom X ORSA T formulas are chosen similarly , with the constant J a = ± 1 uniformly . • thermo dynamic limit and phase trans itions These t wo terms are the physics jargo n for , r esp ectively , the lar ge size limit ( N → ∞ ) and for threshold phenomena as sta ted for instance in (3). In the thermo dynamic limit the typical b ehavior o f physical sys tems is controlled by a small num b er of para meters, for instance the tempera ture and pressure of a gas . At a phase transition thes e systems are drastically altered by a tiny change of a control parameter, think for instance at what happ ens to water when its temp eratur e crosses 100 o C . This cr itical v a lue of the temp era ture separates t wo qualita tively distinct phases, liquid and gas eous. F or random CSPs the role o f control parameter is usua lly play ed by the ratio of co nstraints p er v ariable, α = M / N , kept c o nstant in the thermo dynamic limit. Eq. (3) describ es a satisfiability tra nsition for the co n tinuous per ceptron, the critical v alue α s = 2 separa ting a sa tis fia ble phase at low α where instanc e s typically hav e solutions to a phase where they typically do not. Typically is used here as a synonym for with high probability , i.e. with a probability which g o es to one in the thermo dynamic limit. 4 • Finite Size Scaling (FSS) The re fined description of the neig h b orho o d of the critical v alue of α provided by (4) is known as a finite size scaling relation. More generally the finite size scaling hypothes is for a threshold phenomenon takes the form lim N →∞ P ( N , M = N α s (1 + λ N − 1 /ν ) ) = F ( λ ) , (5) where ν is called the FSS exp onent (2 for the co ntin uous p erce ptr on) and the scaling function F ( λ ) has limits 1 and 0 at resp ectively −∞ and + ∞ . This means that, for a larg e but finite size N , the transitio n window for the v alues of M / N wher e the pr obability drops from 1 − ǫ down to ǫ is, for arbitra ry sma ll ǫ , of width N − 1 /ν . Results of this fla vour are familiar in the study of random g raphs [7]; for instance the app ea rance o f a giant comp onent co nt aining a finite fra ction of the vertices of an Erd¨ os-R´ en yi random g raph happ ens on a windo w of width N − 1 / 3 on the av erage connectivity . FSS r elations are imp ortant, not only from the theor etical p oint of view, but also for pra ctical applications. Indeed numerical exp er iment s a r e always p e r formed o n finite-size instances while theoretical predictions o n phase tr a nsitions are usually true in the N → ∞ limit. F inite-size scaling relations help to bridge the ga p b etw een the tw o. W e shall review some FSS res ults in Sec. I II E. Let us emphasize that random k -SA T, a nd other r andom CSP , are exp ected to share so me features o f the co nt inuous per ceptron mo del, for instance the existence of a sa tisfiability thresho ld, but of course not its extreme analytical simplicity . In fact, despite an in tensive resear ch activity , the mere existence of a satisfia bility threshold fo r ra ndom SA T formulas remains a (widely accepted) conjecture. A s ignificant a chievemen t towards the resolution o f the conjecture was the proo f by F riedgut of the existence of a non-unifor m sha rp thr e shold [8]. There ex is ts also upp er [9] a nd low er [1 0] b ounds on the p ossible lo ca tion of this putative thr eshold, which b ecome almo st tight for lar ge v alues o f k [11]. W e r efer the reader to the c ha pter [1 2] o f this volume for mo re details on these issues . This difficulty to obtain tight results with the curr ent ly av ailable rigoro us techniques is a motiv ation for the use of heuristic statistical mechanics metho ds, that provide intu itions on why the standar d mathematical o nes r un in to trouble and how to amend them. In the rec e nt y ea rs imp ortant results fir s t conjectured by ph ysicis ts were indeed rig orously pro ven. Before describing in some generality the statistica l mechanics a pproach, it is instructive to study a simple v ar iation of the p erceptro n mo del for which the basic probabilistic techniques b ecome inefficient. C. The p erceptron problem contin ued: binary v ariabl es The binary p er ceptron problem co nsists in lo o king for solutio ns o f (1) on the hypercub e i.e . the domain of the v ariable σ is X N = {− 1 , +1 } N instead of R N . This decision problem is NP -complete. Unfortunately Cov er’s calcula- tion [6] cannot be extended to this ca se, though it is natura l to exp ect a similar satis fia bility thresho ld pheno meno n at an a pr iori distinct v a lue α s . Let us fir st try to study this p oint with basic pro babilistic to ols, namely the first a nd second moment metho d [13]. The former is a n a pplication of the Marko v inequa lit y , Prob[ Z > 0 ] ≤ E [ Z ] , (6) v alid for p ositive integer v alued random v aria bles Z . W e shall use it taking for Z the num b er of s o lutions of (1), Z = X σ ∈X N M Y a =1 θ ( σ · T a ) , (7) where θ ( x ) = 1 if x > 0, 0 if x ≤ 0. The exp ectation v alue of the num b er of solutions is easily co mputed, E [ Z ] = 2 N × 2 − M = e N G 1 with G 1 = (1 − α ) ln 2 , (8) and v anishes when N → ∞ if α > 1 . Hence, from Markov’s inequality (6), with hig h proba bilit y co nstraints (1) hav e no solution on the hypercub e when the ratio α exceeds unit y: if the thres ho ld α s exists, it must sa tis fy the b o und α s ≤ 1 . One can loo k for a low er b ound to α s using the second moment metho d, r elying on the inequality [13] E [ Z ] 2 E [ Z 2 ] ≤ Pro b[ Z > 0] . (9) The exp ectation v alue o f the s q uared num b er of solutions rea ds E [ Z 2 ] = X σ ,σ ′ ( E [ θ ( σ · T ) θ ( σ ′ · T )]) M (10) 5 since the v ertices T a are c hosen independently of eac h other. The exp ectation v alue on the right hand side of the ab ov e expre ssion is simply the probability that the vector p ointing to a r andomly chosen vertex, T , has po sitive scala r pro duct with b oth vectors σ , σ ′ . Elementary geometrica l consider ations r eveal that E [ θ ( σ · T ) θ ( σ ′ · T )] = 1 2 π ( π − ϕ ( σ , σ ′ )) (11) where ϕ is the r elative ang le betw een the tw o vectors. This angle ca n be alternatively parametr ized b y the overlap betw een σ and σ ′ , i.e. the no rmalized scalar pro duct, q = 1 N N X i =1 σ i σ ′ i = 1 − 2 1 N N X i =1 I ( σ i 6 = σ ′ i ) . (12) The last expr ession, in which I ( E ) denotes the indicator function of the even t E , reveals the tr aduction b etw een the concept of ov e r lap a nd the more traditional Hamming distanc e . The sum ov er vectors in (10) can then b e repla ced by a sum over ov erlap v alues with appr opriate combinatorial co efficients counting the num b er of pair s of vectors at a given ov erlap. The outcome is E [ Z 2 ] = 2 N X q = − 1 , − 1+ 2 N , − 1+ 4 N ,..., 1 N N 1+ q 2 1 2 − 1 2 π Arcos q M . (13) In the large N limit we can estimate this sum with the La place metho d, lim N →∞ 1 N ln E [ Z 2 ] = max − 1 0, a nd in consequence the left hand side of (9) v anishes. A p ossible scenario which explains this absence of concentration of the n umber of solutio ns is the following. As shown by the moment calculation the natural scaling o f Z is exp onentially lar ge in N (as is the total co nfiguration space X N ). W e shall th us denote s = (ln Z ) / N the random v aria ble o f or der one counting the log deg e neracy of the solutions. Supp ose s follows a la r ge deviation principle [14] that w e state in a very rough wa y as Pr ob[ s ] ≈ ex p[ N L ( s )], with L ( s ) a neg ative ra te function, assumed for simplicity to b e concave. Then the moments of Z ar e given, a t the leading exp onential o rder, by lim N →∞ 1 N ln E [ Z n ] = max s [ L ( s ) + ns ] , (16) and are controlled by the v alues of s such that L ′ ( s ) = − n . The moments o f lar g er a nd la rger order n are thu s dominated by the contribution of rar er and rar er instances with larger and lar ger n umbers of solutions. On the contrary the t ypical v a lue of the n umber of s o lutions is g iven by the maxim um o f L , rea ched in a v alue we denote s g ( α ): with high pr obability when N → ∞ , Z is co mprised b etw een e N ( s g ( α ) − ǫ ) and e N ( s g ( α )+ ǫ ) , fo r any ǫ > 0. F rom this reasoning it app ears that the relev ant quantit y to b e co mputed is s g ( α ) = lim N →∞ 1 N E [ln Z ] = lim N →∞ lim n → 0 1 n N ln E [ Z n ] . (17) This idea of computing moments of v anis hing or der is known in statistica l mechanics as the r eplica 1 metho d [1]. Its non-rigo rous implemen ta tion cons is ts in determining the moments o f int eger o rder n , which are then contin ued 1 The vocable r eplicas comes from the pr esence of n copies of the ve ctor σ in the calculation of Z n (see the n = 2 case in formula (10)). 6 tow ar ds n = 0. The outcome of such a co mputation fo r the binary p erceptron pro blem r eads [15] s g ( α ) = max q, ˆ q − 1 2 q (1 − ˆ q ) + Z ∞ −∞ D z ln(2 cosh( z p ˆ q )) (18) + α Z ∞ −∞ D z ln " Z ∞ z √ q/ (1 − q ) D y # , where Dz ≡ dz e − z 2 / 2 / √ 2 π . The entrop y s g ( α ) is a decrea sing function of α , which v anishes in α s ≃ 0 . 8 33. Numerical exp eriments supp ort this v alue for the critical ratio of the satisfia ble/unsatisfiable phas e transition. • the calculation o f the sec o nd moment is naturally re lated to the deter mination of the v alue of the overlap q betw een pa ir s of solutions (or equiv a lently their Hamming dista nc e , recall E q . (12)). This conclusion extends to the calculatio n o f the n th moment for a ny integer n , a nd to the n → 0 limit. The v alue o f q maximizing the r.h.s. of (18), q ∗ ( α ), repre sents the average ov e rlap b etw een tw o solutions of the same set of co nstraints (1). Actually the distr ibution of ov erlaps is highly concentrated in the large N limit a round q ∗ ( α ), in o ther words the (reduced) Hamming distance b etw een tw o solutions is, with high probability , equa l to d ∗ ( α ) = (1 − q ∗ ( α )) / 2. This distance d ∗ ( α ) ra nges from 1 2 for α = 0 to ≃ 1 4 at α = α s . Slig ht ly b elow the cr itica l ratio solutions a re still fa r aw ay from each other on the hyper c ube 2 . Note that the p erceptron pro blem is not as far as it co uld seem from the main s ub ject of this review. There exists indeed a natura l ma pping b etw een the binar y p er ceptron pr o blem a nd k -SA T. Assume the vertices T of the perceptron problem, instead of being dra wn on the hypers phere, ha ve coo rdinates that can take three v a lues: T i = − 1 , 0 , 1. Consider now a k -SA T for mu la F . T o each claus e a o f F we asso cia te the vertex T a with co o rdinates T a i = − J a i if v ar iable i app ears in c la use a , 0 other wise. Of course P i | T a i | = k : exactly k co o rdinates hav e non ze ro v alues for each vertex. Then r eplace co ndition (1) with N X i =1 σ i T a i > − ( k − 1 ) , ∀ a = 1 , . . . , M . (19) The scalar pr o duct is not required to b e positive any lo ng er, but to b e lar ger than − ( k − 1 ). It is an ea s y c heck that the p erceptr on problem admits a solutio n o n the hypercub e ( σ i = ± 1) if a nd only if F is satisfiable. While in the binar y p erc e ptr on mo del all co ordinates are non-v anishing, only a finite num b e r of them ta ke non z e ro v alues in k -SA T. F or this rea son k -SA T is called a diluted mo del in statistical physics. Also the direct application of the second moment metho d fails for the random k -SA T pro ble m; yet a r efined version of it w a s used in [11], which leads to asymptotically (at large k ) tight b o unds o n the lo ca tion of the satisfiability threshold. D. F rom random CSP to statistical mechanics of disordered syste ms The binary p erceptron example ta ught us that the n umber of solutions Z of a sa tisfiable random CSP usually scale s exp onentially with the size o f the problem, with larg e fluctuations that preven t the direct use of standa rd moment metho ds. This led us to the intro duction of the quenched entropy , as defined in (17). The computation techniques used to obtain (18 ) were in fa c t dev elop ed in an appare n tly different field, the statistical mechanics of dis ordered systems [1]. Let us review some basic concepts of statistical mechanics (for introductor y bo o ks see for example [16, 1 7]). A ph ysical system ca n b e mo deled by a space of configura tion σ ∈ X N , on which is defined a n ener gy function E ( σ ). F or instance usual magnets are describ ed by Ising spins σ i = ± 1, the energy b eing minimized when adjacent spins ta ke the same v a lue . The equilibrium prop erties of a physical sy stem at temper ature T ar e given b y the Gibbs-B oltzmann probability measur e on X N , µ ( σ ) = 1 Z exp[ − β E ( σ )] , (20) 2 This si tuation is very different from the con tinuous per ceptron case, where the t ypical o verlap q ∗ ( α ) reaches one when α tends to 2: a single solution is l eft right at the critical ratio. 7 where the inv er se temp eratur e β equals 1 /T a nd Z is a nor malization called partition function. The energy function E has a natural scaling , linear in the num b er N of v ariables (s uch a quantit y is sa id to b e e x tensive). In co nsequence in the thermo dynamic limit the Gibbs-Boltzmann measur e concentrates o n configuratio ns with a g iven energ y density ( e = E / N ), which dep ends on the conjuga ted pa rameter β . The num b er of such config urations is usually exp onentially large, ≈ exp[ N s ], with s called the en tropy density . The partition function is thus do mina ted by the contribution o f these configura tions, hence lim(ln Z / N ) = s − β e . In the a b ove presentation we s upp os ed the energy to b e a simple, known function of the configura tions. In fact some magnetic compounds, called spin-glas ses, are intrinsically disorder ed on a micro scopic scale. T his means that there is no hop e in describing exactly their micro scopic details , but that one should ra ther ass ume their ener gy to be itself a random function with a known distribution. Hop efully in the thermo dyna mic limit the fluctuations of the thermo dynamic o bserv ables as the energy and entrop y density v a nish, hence the prop erties o f a typical sample will be closely describ ed by the av erag e (o ver the distribution o f the ener gy function) of the entropy and energy dens ity . The random CSPs fit naturally in this line o f research. The energ y function E ( σ ) of a CSP is defined as the nu mber of constraints viola ted by the assig nmen t σ , in other words this is the cost function to b e minimized in the asso ciated optimization problem (MAXSA T for instance). Moreover the distribution of rando m instances o f CSP is the counterpart of the distribution o ver the microsco pic descr iption o f a disordered solid. The study o f the o ptimal configuratio ns of a CSP , a nd in par ticular the characterization of a satisfiability phase transition, is a chieved by taking the β → ∞ limit. Indeed, when this parameter increa ses (or equiv ale n tly the temper ature go es to 0), the law (2 0) fav or s the low e s t ener gy configurations. In particula r if the formula is satisfia ble µ bec omes the uniform measures ov er the solutions. Two imp orta n t features o f the formula can be deduced from the b ehavior of Z at larg e β : the ground-sta te energ y E g = min σ E ( σ ), which indicates how go o d a re the optimal config urations, and the ground state ent ropy S g = ln( |{ σ : E ( σ ) = E g }| ), whic h counts the degeneracy of these o ptimal c onfigurations . The satisfia bility of a formula is equiv alent to its g round-state energy b eing equal to 0. In the lar ge N limit these tw o thermo dyna mic quantities are supp o sed to concentrate around their mea n v alues (this is pr oven fo r E in [18]), we thus introduce the asso ciated typical densities, e g ( α ) = lim N →∞ 1 N E [ E g ] , s g ( α ) = lim N →∞ 1 N E [ S g ] . (21) Notice that formula (21) coincides with (17 ) in the satisfiable phase (where the gr ound state e ne r gy v anishes). Some cr iteria a r e needed to relate these ther mo dynamic q uantit ies to the (presumed to exist) satisfiability thresho ld α s . A firs t approa ch, used for insta nce in [19], consists in lo cating it a s the p oint wher e the gr ound-state e nergy density e g bec omes p ositive. The assumption underlying this reasoning is the abs e nce of an in termediate, typically UNSA T regime, with a s ub-extensive pos itive E g . In the discussio n of the bina ry per ceptron we used another criter ion, namely we r e cognized α s by the cancellation of the ground-state entropy density . This a rgument will b e true if the typical nu mber of solutions v anishes contin uously at α s . It is easy to realize that this is not the case for random k -SA T: a t any finite v a lue of α a finite fractio n exp[ − αk ] of the v ar iables do not app ear in any clause, which leads to a tr iv ial low er b ound (ln 2) exp[ − αk ] on s g . This quantit y is th us finite at the tr ansition, a larg e num b er of solutions dis app ear suddenly at α s . Even if it is wrong, the criterion s g ( α ) = 0 for the determination of the satisfiability transition is instructive for t wo reaso ns. First, it b ecomes asymptotically correct at la rge k (free v ar iables are very rare in this limit), this is why it works for the binary per ceptron of Sectio n I I C (which is, a s we hav e seen, close to k -SA T with k of order N ). Second, it will rea ppea r below in a r efined version: w e shall indeed deco mpo se the en tropy in tw o qualitatively distinct co ntributions, one of the t wo b eing indeed v a nishing at the satisfia bilit y tr a nsition. II I. PHASE TRANSITIONS IN RAND OM CSPS A. The cl ustering phenomenon W e hav e seen tha t the s tatistical physics appro ach to the pe r ceptron problem natura lly pr ovided us with information ab out the geometry of the spa ce o f its solutions . Mayb e one of the most imp ortant contribution of physicists to the field of r a ndom CSP was to s uggest the presence o f further phase tra nsitions in the satisfiable regime α < α s , affecting qualitatively the ge o metry (str uc tur e) of the set of solutions [20–22]. This subset of the configuration space is indeed thought to break down into “clus ters” in a part of the satisfia ble phase, α ∈ [ α d , α s ], α d being the thres hold v alue for the clustering transitio n. Clusters are mea nt as a partition of the set of s olutions having certain prop erties listed b elow. E ach clus ter co ntains an exp onential num b er of solutions , exp[ N s int ], and the clusters ar e themselves exp onentially numerous, exp[ N Σ]. The total e n tropy density thus decom- po ses into the sum of s int , the internal e n tropy of the clusters and Σ, enco ding the degener acy of thes e cluster s, usually termed complexity in this cont ext. F urthermor e, solutions inside a g iven cluster sho uld b e well-connected, while tw o 8 solutions of distinct clus ter s are well-separated. A p ossible definition for these notions is the following. Supp ose σ and τ ar e tw o solutions of a given cluster. Then one can construct a path ( σ = σ 0 , σ 1 , . . . , σ n − 1 , σ n = τ ) where any tw o successive σ i are sepa rated by a sub-extensive Hamming distance. On the contrary such a path do es not exist if σ and τ b elong to tw o distinct clusters. Clus tered co nfiguration s paces as des crib ed a bove hav e been o ften encountered in v arious contexts, e.g. neural netw orks [23] and mean-field s pin g lasses [24]. A v a s t b o dy of inv olved, yet non-rig orous, analytical techniques [1] hav e b een develop ed in the field of statistica l mechanics of disor dered systems to ta ckle such situations, some of them having b een justified rigoro usly [25–27]. In this literature cluster s a pp ea r under the name o f “pure states”, or “lumps” (se e fo r instance the chapter 6 of [25] for a r igoro us definition and pro of o f existence in a related mo de l). As we shall explain in a few lines, this clustering phenomenon has b een demonstrated rig orously in the case of r andom XORSA T instance s [2 8, 29 ]. F or r a ndom SA T insta nce s, where in fact the detailed picture of the satisfiable phase is thought to b e richer [2 2], there are some rigo rous results [30– 32] on the existence of clusters for large enough k . B. Phase transitions in random XORSA T Consider an instance F of the XORSA T problem [33], i.e. a list of M linear equations each inv o lving k out of N bo olean v ar iables, where the additions a re computed mo dulo 2 . The s tudy p erfor med in [28, 29] provides a detailed picture o f the clustering and s atisfiability transition sketc hed ab ov e. A crucial point is the construction of a core subformula according to the fo llowing a lgorithm. Let us denote F 0 = F the initial se t of equations, and V 0 the se t o f v ariables which app ear in at least one equation of F 0 . A se quence F T , V T is constructed recur sively: if there ar e no v ariables in V T which app ear in exactly one equa tio n of F T the algor ithm sto ps . Otherwise one of these “lea f v ariables” σ i is chosen ar bitr arily , F T +1 is co nstructed fr om F T by removing the unique equation in which σ i app eared, and V T +1 is defined as the s et of v aria bles which appe a r at least once in F T +1 . Let us ca ll T ∗ the num b er of steps perfor med befo re the algorithm stops , and F ′ = F T ∗ , V ′ = V T ∗ the remaining clauses a nd v aria ble s . Note first that despite the arbitrarines s in the choice of the removed leav es, the output subformula F ′ is unambiguously determined by F . Indeed, F ′ can be defined as the maximal (in the inclusion sense) subformula in whic h all pres ent v ar iables have a minimal o ccurrence num b er of 2, a nd is th us unique. In gra ph theo retic termino logy F ′ is the 2-cor e of F , the q -core of hypergr aphs being a g eneralizatio n o f the mor e familiar notion on gra phs, thoroug hly studied in random gra ph ensembles in [3 4]. Extending this study , relying o n the approximability o f this leaf remov a l pro cess b y different ial equations [35], it w as shown in [28, 29 ] that there is a thr eshold phenomenon at α d ( k ). F o r α < α d the 2-core F ′ is, w ith high probability , empt y , whereas it contains a finite frac tio n of the v a r iables and equations fo r α > α d . α d is e asily determined n umer ically: it is the smallest v a lue of α suc h that the equatio n x = 1 − exp[ − αk x k − 1 ] has a non-trivial solution in (0 , 1]. It turns out that F is satisfiable if and o nly if F ′ is, and that the num b er of solutions o f these tw o form ulas are related in an enlig h tening wa y . It is clear that if the 2-co re has no solution, there is no way to find o ne for the full formula. Supp ose on the co nt rar y that an a ssignment o f the v ariables in V ′ that s atisfy the equa tions of F ′ has b een found, and let us show how to construct a solution o f F (and count in how many p ossible ways w e can do this). Set N 0 = 1, and reintro duce step b y step the remo ved equations, starting fr om the last: in the n ’th step of this new pr o cedure we reintroduce the c la use which was remov e d at step T ∗ − n o f the leaf remov al. This r eintroduced clause has d n = | V T ∗ − n − 1 | − | V T ∗ − n | ≥ 1 leav es; their configura tion can b e c hosen in 2 d n − 1 wa ys to satisfy the reintroduced clause, irrespec tively of the previous choices, and we b o o kkeep this num b er of p oss ible extensions by setting N n +1 = N n 2 d n − 1 . Finally the total num b er of solutions of F compatible with the choice of the solution o f F ′ is o bta ined by adding the freedom of the v ar iables which app eared in no eq ua tions of F , N int = N T ∗ 2 N −| V 0 | . Let us underline that N int is indep endent of the initial satis fying assignment of the v a r iables in V ′ , as app ears clear ly from the desc r iption of the reconstructio n algorithm; this prop erty can b e traced bac k to the linear alg ebra s tructure of the problem. This suggests na turally the dec omp osition of the total num b er of solutions of F as the pr o duct o f the nu mber o f satisfying a ssignments of V ′ , call it N core , by the num b er of co mpatible full so lutions N int . In ter ms of the asso ciated entrop y densities this deco mpo sition is additive s = Σ + s int , Σ ≡ 1 N ln N core , s int ≡ 1 N ln N int , (22) where the quantit y Σ is the entrop y density a s so ciated to the core of the fo rmula. It is in fact muc h easier technically to c ompute the s tatistical (with r e sp e ct to the c hoice of the rando m for m ula F ) prop erties of Σ and s int once this decomp osition has b een done (the fluctuations in the num b er of so lutions is m uch smaller o nc e the non-core pa rt of the fo rmula has b een r e mov ed). The o utcome of the computatio ns [28, 29] is the determination of the threshold v alue α s for the app ear ance o f a solution of the 2-co re F ′ (and thus of the complete for mula), alo ng with explicit fo rmulas for the typical v alues of Σ and s . These tw o quantities a re plotted on Fig. 2. The satisfia bilit y thre shold co r resp onds 9 0.92 0.87 0.82 0.1 0 α s α d Σ s α s, Σ 1 0.75 0.5 0.25 0 1 0.8 0.6 0.4 0.2 0 FIG. 2: Complexity and total entropy for 3- XORSA T, in un its of ln 2. The inset presents an enlargemen t of the regime α ∈ [ α d , α s ]. T ABLE I: Critical connectivities for the dynamical, conden sation and satisfiabilit y transitions for k -S A T random formulas . α d [22] α c [22] α s [38] k = 3 3 . 86 3 . 86 4 . 267 k = 4 9 . 38 9 . 547 9 . 93 k = 5 19 . 16 20 . 80 21 . 12 k = 6 36 . 53 43 . 08 43 . 4 to the c a ncellation of Σ: the n umber of solutions of the core v anishes con tin uously a t α s , while the total en tro py remains finite b ecause of the free do m o f choice for the v ariable s in the non-co re pa rt of the formula. On top of the simplification in the a na lytical determination of the satisfiability thr e shold, this core decomp osition of a formula unv eils the c hange in the structure of the set of solutions that o ccur s at α d . Indeed, let us ca ll cluster all so lutions of F reconstructed fro m a common so lutio n of F ′ . Then one c a n show tha t this partition o f the solution set of F exhibits the pro p e rties exp osed in Sec. I I I A, na mely that solutions are well-connected inside a cluster a nd separated from o ne cluster to another. The num b er of cluster s is precisely equa l to the num b er of so lutions of the core subformula, it thus under go es a dra stic mo difica tion at α d . F or sma ller ratio of c o nstraints the core is typically empty , there is o ne sing le cluster co nt aining all s o lutions; when the thresho ld α d is reached there app ears an exponential nu mbers of clusters, the rate o f growth o f this ex po nent ial being giv en by the complexity Σ. Befo r e co nsidering the extension of this pictur e to r a ndom SA T pro blems, let us mention that further studies of the geometry o f the space of solutions of random XORSA T instances ca n be found in [3 6, 37]. C. Phase transitions in random SA T The p o ssibility of a clustering tr ansition in random SA T pr oblems was first studied in [2 0] by mea ns o f v ariationa l approximations. Later developments a llow ed the computation of the complexity and, from the conditio n of its cancellation, the estimation of the satisfiability threshold α s . This was fir st done for k = 3 in [2 1] and generalized for k ≥ 4 in [38], some of the v alues of α s th us computed ar e rep or ted in T a b. I. A systematic expa nsion of α s at lar ge k was also p erformed in [38]. SA T formulas do not sha re the linear algebra structure of X ORSA T, which makes the ana lysis of the clustering transition m uch more difficult, and leads to a r icher structur e of the satisfiable phas e α ≤ α s . The simple graph theoretic ar guments are not v alid an ymo re, one cannot extr act a co re subformula from which the par tition of the solutions into clusters follows directly . It is thus necessary to define them a s a par tition of the solutions such that ea ch cluster is well-connected and w ell-separ ated fro m the o ther ones. A second complica tio n aris es: there is no rea son for the clusters to contain all the same num b er of solutions, as was ensured by the linear str ucture of XORSA T. On the contrary , as w as obser ved in [20] and in [39] for the similar r andom C O L pro blem, one faces a v ariety of clusters with v arious internal entropies s int . T he complexity Σ b ecomes a function of s int , in other w ords the n umber of clusters of internal entropy density s int is typically e x po nent ial, growing at the leading order lik e exp[ N Σ( s int )]. Drawing the conse quences of these obse r v ations, a r efined picture of the satisfiable phase, and in particular the exis tence of a 10 new (so- called condensation) thresho ld α c ∈ [ α d , α s ], w as advocated in [22]. Let us brie fly sketc h so me o f these new features and their relationship with the previo us results of [21, 38]. Assuming the existence of a po sitive, concave, complexity function Σ ( s int ), contin uo usly v anishing o utside an interv al of internal entrop y densities [ s − , s + ], the to tal ent ropy density is g iven by s = lim N →∞ 1 N ln Z s + s − ds int e N [Σ( s int )+ s int ] . (23) In the thermo dyna mic limit the integral can b e ev a luated with the Laplac e metho d. Tw o qualitatively distinct situations can arise, whether the integral is dominated by a critica l p oint in the interior of the in terv al [ s − , s + ], or by the neighborho o d of the upp er limit s + . In the former ca se an ov erwhelming ma jority of the solutions ar e cont ained in a n exp o ne ntial num b er o f clusters , while in the latter the do minant contributions comes from a sub-exp onential nu mber of clusters o f internal en tropy s + , as Σ( s + ) = 0. The threshold α c separates the firs t reg ime [ α d , α c ] where the relev ant clusters are exp o nent ially numerous, from the seco nd, condensated situation for α ∈ [ α c , α s ] with a sub-exp onential num b er of dominant c lusters 3 . The computations of [21, 38] did not ta ke in to accoun t the distribution o f the v ario us internal entropies of the clusters, which explains the discrepancy in the estimation of the clustering threshold α d betw een [21, 38] and [22]. Let us how ever emphasize that this refinement of the picture do es not contradict the estimation of the satisfiability threshold of [21, 38]: the complex ity computed in these works is Σ max , the maximal v alue of Σ( s int ) r eached at a lo ca l maximum with Σ ′ ( s ) = 0, which indeed v anishes when the whole complexity function dis app ears. It is fair to say tha t the deta ils of the picture pro po sed by s ta tistical mechanics studies hav e r apidly evolv ed in the last years, and might s till b e improv ed. They rely indeed on self-consis ten t a ssumptions which are r ather tedious to chec k [40]. Some elements o f the clustering scena rio hav e howev er b een es ta blished rigo r ously in [30–32], at leas t for large enough k . In particular these works demons trated, fo r some v alues of k and α in the satisfiable reg ime, the existence of forbidden intermediate Hamming distances betw een pa irs o f configurations , which ar e either c lo se (in the same cluster) or far apart (in tw o distinct clusters). Note finally that the consequences of such distributions of clusters in ternal entropies w ere inv es tigated on a toy mo del in [4 1], and that yet another threshold α f > α d for the app ear ance of frozen v a riables constra ined to take the same v alues in all solutions of a g iven cluster was inv estigated in [42]. D. A glimpse at the computations The statistical mec hanics o f dis ordered s ystems [1] was first developed on so - called fully-connec ted mo dels , wher e each v a riable app ears in a n umber of co nstraints which div erges in the thermody namic limit. This is for instance the case of the p er ceptron problem discussed in Sec. I I. On the con trary , in a r a ndom k -SA T instance a v a riable is t ypically in volved in a finite num be r of clauses , one s pe a ks in this case of a diluted mo del. This finite connectivity is a so urce of ma jor technical complications. In particular the replica metho d, alluded to in Sec. I I C and applied to random k -SA T in [19, 20], turns out to be rather cumbersome for diluted mo dels in the presence of clustering [43]. The cavit y formalism [21, 44, 4 5], formally equiv alent to the re plica one, is mo r e a dapted to the diluted mo dels. In the following par a graphs we shall try to giv e a few hin ts at the strategy underlying the cavit y computations, that might hop efully eas e the rea ding of the original literature. The descr iption o f the random formula ensemble has tw o complementary asp ects: a g lobal (thermo dyna mic) one, which amounts to the computation of the typical energ y and n umber of optimal configura tions. A more am bitious description will also provide geometrica l information on the or ganization of this set of optimal configur ations inside the N - dimens io nal hyp e rcub e. As discusse d a bove these tw o asp ects a re in fact int erleaved, the clustering affecting bo th the thermo dynamics (by the deco mpo sition of the entrop y into the complexity and the internal entrop y) a nd the geometry of the configura tion spa ce. Let us for simplicit y concentrate on the α < α s regime and consider a satisfia ble formula F . Bo th thermo dynamic a nd geometric asp ects can b e studied in ter ms of the uniform pro bability law over the solutions of F : µ ( σ ) = 1 Z M Y a =1 w a ( σ a ) , (24) 3 This picture is expected to hold for k ≥ 4; for k = 3, the dominan t clusters are exp ected to be of sub-exp onen tial degeneracy in the whole clustered phase, hence α c = α d in this case. 11 1 2 3 4 5 6 7 FIG. 3: The factor graph representation of a small 3-S A T formula: ( x 1 ∨ x 2 ∨ x 3 ) ∧ ( x 3 ∨ x 4 ∨ x 5 ) ∧ ( x 4 ∨ x 6 ∨ x 7 ). where Z is the num b er of solutions of F , the pro duct r uns o ver its clauses, a nd w a is the indicator function of the even t “clause a is satisfie d by the assig nment σ ” (in fact this de p ends only on the configuration of the k v ar ia bles inv olved in the clause a , that we deno te σ a ). F or insta nce the (information theor e tic) e ntropy of µ is equal to ln Z , the log degenera cy of s olutions, and geometr ic pro p er ties can b e studied by computing av era ges with res p ect to µ of well-c hos en functions o f σ . A conv enient represe ntation o f such a la w is provided by factor g r aphs [46]. Thes e are bipartite gra phs with tw o t yp es of vertices (see Fig. 3 for an illustratio n): one v ar iable no de (filled circle) is a sso ciated to ea ch of the N Bo o lean v ariables , while the c la uses are repr esented by M constr aint no des (empt y square s). By conv ention we use the indices a, b, . . . for the c o nstraint no de s , i, j, . . . for the v ariables. An edge is drawn b etw een v ariable no de i and constraint no de a if a nd only if a dep ends o n i . T o precise further by which v alue of σ i the clause a gets satisfied o ne can us e t wo t yp e of linestyles, so lid and dashed on the figur e. A notation rep eatedly us ed in the following is ∂ a (resp. ∂ i ) for the neighbor ho o d of a constr aint (resp. v ariable) no de, i.e. the s e t of adjacent v ariable (r esp. constr aint) no des. In this context \ denotes the subtraction from a set. W e shall more precisely denote ∂ + i ( a ) (r esp. ∂ − i ( a )) the set of clauses in ∂ i \ a ag reeing (res p. disagre e ing) with a on the satisfying v alue of σ i , and ∂ σ i the set of clauses in ∂ i which are satisfied by σ i = σ . This gr aphical r epresentation naturally sug g ests a notion of distance b etw een v a riable no des i a nd j , defined as the minimal num b er o f constra int no des crosse d on a path of the factor gr aph linking no des i and j . Suppo se now that F is drawn fr om the random ensemble. The corresp onding r andom fa ctor graph enjoys several int eresting prop erties [7]. The degr e e | ∂ i | of a rando mly chosen v a riable i is, in the ther mo dynamic limit, a Poisson random v ariable of average αk . If instead of a no de one choo ses randomly an edge a − i , the outdegree | ∂ i \ a | of i has a gain a Poisson distr ibution with the same pa r ameter. More over the sig n of the literals b eing chosen uniformly , independently of the top olog y of the factor graph, the degr e es | ∂ + i | , | ∂ − i | , | ∂ + i ( a ) | and | ∂ − i ( a ) | are Poisson rando m v ariables of parameter αk / 2. Another imp ortant feature of these ra ndo m factor graphs is their lo cal tree-like character: if the p o rtion of the formula a t graph dis tance smaller than L of a randomly chosen v ar iable is e xp o sed, the proba bilit y that this subgra ph is a tree go es to 1 if L is k ept fixed while the size N go es to infinity . Let us for a seco nd forget ab out the r est of the gr aph and consider a finite fo rmula who se factor graph is a tree, as is the cas e for the example of Fig. 3. The pr o bability law µ of E q. (24 ) b ecomes in this case a r a ther simple ob ject. T ree str uctures are indeed naturally a menable to a recursive (dynamic progra mming) treatment, op era ting first on sub-trees which are then glued together . More precisely , for each e dg e b etw een a v ariable no de i and a co ns traint no de a one defines the amputated tree F a → i (resp. F i → a ) by removing all clauses in ∂ i a part fro m a (resp. removing only a ). The s e subtrees a re a sso ciated to pro bability laws µ a → i (resp. µ i → a ), defined as in Eq. (24 ) but with a pr o duct running o nly on the clauses present in F a → i (resp. F i → a ). The margina l law of the ro o t v ar iable i in these amputated probability measures can b e pa rametrized by a single real, as σ i can take only tw o v alues (that, in the Ising spin conv ention, are ± 1 ). W e thus define these fields, or messag es, h i → a and u a → i , by µ i → a ( σ i ) = 1 − J a i σ i tanh h i → a 2 , µ a → i ( σ i ) = 1 − J a i σ i tanh u a → i 2 , (25) where we recall that σ i = J a i is the v a lue of the literal i unsatisfying claus e a . A standard reasoning (see for instance [47]) allows to derive r ecursive equations (illustrated in Fig. 4) o n thes e message s , h i → a = X b ∈ ∂ + i ( a ) u b → i − X b ∈ ∂ − i ( a ) u b → i , (26) u a → i = − 1 2 ln 1 − Y j ∈ ∂ a \ i 1 − tanh h j → a 2 . 12 Because the factor gra ph is a tree this set of e quations has a unique solution which can b e efficiently determined: one start fro m the leaves (degr ee 1 v a r iable no des) which ob ey the b oundary condition h i → a = 0, and pr ogress es inw ar ds the graph. The law µ ca n b e co mpletely describ ed from the v alues o f the h ’s and u ’s solutio ns o f these equations for all edges of the gra ph. F or ins ta nce the marg inal pro bability of σ i can be written as µ ( σ i ) = 1 + σ i tanh h i 2 , h i = X a ∈ ∂ + i u a → i − X a ∈ ∂ − i u a → i . (27) In addition the entropy s of so lutions of such a tre e formula, can b e computed from the v alues of the messages h a nd u [47]. W e shall come back to the equations (26), a nd justify the denomination messages, in Sec. V C; these can b e int erpreted as the Belief P ropag ation [46, 48, 49] heuristic equations for lo o py factor graphs. The factor graph of random formulas is o nly lo c a lly tree-like; the simple co mputation sketched ab ov e has th us to be a mended in or de r to ta ke into acco unt the effect o f the distant, lo opy part of the formula. Let us call F L the fa ctor graph made of v ariable no des at graph distance sma ller than or equal to L fr o m an arbitra rily chosen v a riable no de i in a large r andom formula F , and B L the v aria ble no des at distance exa ctly L fro m i . Without los s of gener ality in the ther mo dynamic limit, w e can a ssume tha t F L is a tr ee. The cavit y metho d amounts to an hypo thesis o n the effect o f the distant part of the fac to r gr aph, F \ F L , i.e. on the b oundar y condition it induces on F L . In its simplest (so called replica s ymmetric) v ersion, that is believed to correctly des crib e the unclustere d situatio n for α ≤ α d , F \ F L is repla c ed, for each v ar iable no de j in the b oundary B L , by a fictitious co nstraint no de whic h sends a bias u ext → j . In other words the b oundary condition is fac torized on the v arious no des of B L ; such a simple descriptio n is exp ected to b e correct for α ≤ α d bec ause, in the amputated factor gra ph F \ F L , the distance b e t ween the v a riables of B L is t ypically large (of order ln N ), and these v a riables s hould thus b e weakly c o rrelated. These e x ternal biases are then turned into r andom v ariables to take into account the randomness in the construction of the factor graphs, and Eq. (26) acquires a distributional meaning. The messages h (resp. u ) are s uppo sed to b e i.i.d. random v ariables drawn fro m a commo n distribution, the degrees ∂ ± i ( a ) b eing tw o indep endent Poisson rando m v ariables of par ameter αk / 2. These distributional equa tions can b e numerically s olved by a p opula tion dynamics a lgorithm [44], also known as a par ticle repr esentation in the statistics litteratur e. The typical entropy density is then computed by av er aging s ov er these distributions o f h a nd u . This description fails in the pre s ence of clus tering, which induces corr elations betw een the v aria ble no des of B L in the a mputated factor graph F \ F L . T o take these correlations into account a refined version of the ca vity metho d (termed one s tep of replica symmetry br eaking, in short 1RSB) has b een developed. It relies on the h yp othesis that the partition of the solution space into clusters γ has nice decorr elation prop erties: o nc e decomp osed ont o this partition, µ restricted to a cluster γ behaves essentially as in the unclustered pha se (it is a pure state in statistical mechanics jargo n). Each directed edge a → i should thus b ear a family o f messa ges u γ a → i , one for each cluster , or alternatively a distribution Q a → i ( u ) of the messa ges with resp ect to the c ho ice of γ . The equations (26) a re thus promoted to re c ur sions b etw een distributions P i → a ( h ), Q a → i ( u ), which dep ends on a r e al m known as the P a risi breaking pa rameter. Its r ole is to select the s ize of the inv estig a ted clusters, i.e. the num b er of solutio ns they contain. The computation of the typical entropy density is indeed repla ced by a more detailed thermo dynamic p otential, Φ( m ) = 1 N ln X γ Z m γ = 1 N ln Z s + s − ds int e N [Σ( s int )+ ms int ] . (28) In this formula Z γ denotes the n umber o f solutions inside a cluster γ , and we used the hypothesis that at the leading order the num b er of c lus ters with internal entrop y densit y s int is g iven by ex p[ N Σ( s int )]. The complexity function Σ( s int ) can th us b e obtained from Φ( m ) by an inverse Legendre transform. F o r generic v alues of m this approach is computationally very demanding ; following the same s teps as in the r eplica symmetric version of the cavit y metho d one faces a dis tribution (with resp ect to the topo logy of the factor graph) o f distributions (with r e sp e ct to the choice of the clusters) of messa ges. Simplifications howev er arise for m = 1 and m = 0 [22]; the latter c ase corr esp onds in fact to the o riginal Sur vey Propa g ation appr oach o f [21]. As app ears clear ly in E q. (2 8), for this v alue of m a ll clusters are treated on a n equal fo oting and the dominant contribution comes fro m the most numerous clusters, indep endently of their s iz es. Moreov er , as we further explain in Sec. V C, the structure of the equations can b e gr eatly simplified in this case, the distribution ov er the cluster of fields b eing para metrized by a single nu mber. E. Finite Size Scali ng results As w e explained in Sec. I I B the thres ho ld phenomeno n ca n b e more precisely describ ed by finite size s caling relations. Let us mention some FSS re s ults a b o ut the transitions we just discussed. 13 ∂ a \ i i a u a → i j a i ∂ i \ a h i → a b h j → a u b → i FIG. 4: A schematic representation of Eq. (26). F or random 2- SA T, whe r e the sa tis fia bilit y pro p er t y is known [50] to exhibit a shar p thresho ld at α s = 1, the width of the transition window has b een deter mined in [51]. The range of α where the pr obability of satisfaction dro ps significantly is of or der N − 1 / 3 , i.e. the exp onent ν is equal to 3, a s for the ra ndo m graph p erco la tion. This similarity is not surprising , the pro of of [51] r elies indeed o n a mapping of 2-SA T formulas ont o r andom (directed) gra phs. The clustering tra nsition for XORSA T was first conjectured in [52] (in the related co ntext of err or-cor recting co des) then prov ed in [53] to b e desc r ib ed by P ( N , M = N ( α d + N − 1 / 2 λ + N − 2 / 3 δ )) = F ( λ ) + O ( N − 5 / 26 ) , (29) where δ is a subleading shift co rrection tha t has b een explicitly computed, and the scaling function F is, upto a m ultiplicative fa ctor o n λ , the same erro r function a s in Eq . (4 ). A g e neral r esult has b een proved in [54] on the width of transition windows. Under rather unrestrictive conditions one can show that ν ≥ 2: the tra nsitions cannot b e arbitrarily shar p. Roughly sp eaking the bound is v alid when a finite fractio n o f the clauses are not decisive for the pro p erty of the formulas studied, for instance cla us es containing a leaf v a riable ar e no t relev ant for the satisfia bility of a for mula. The num b er of these ir relev ant claus es is of o r der N and has thus natural fluctua tio ns of o rder √ N ; these fluctuations blur the tra nsition window which c a nnot b e sha rp er than N − 1 / 2 . Several studies (see for instance [33, 55, 5 6]) have attempted to de ter mine the transition window fro m numeric ev aluations of the pro bability P ( N , α ), for instance for the sa tis fia bilit y threshold of rando m 3-SA T [55, 56] and X ORSA T [33]. These studies are necessarily confined to small for mula sizes, as the typical computation cost of complete alg orithms g rows ex po nentially around the transition. In consequence the asymptotic re gime of the tr ansition window, N − 1 /ν , is often hidden by subleading corre c tions which ar e difficult to ev a luate, and in [55, 56] the rep orted v alues of ν w ere found to b e in con tradiction w ith the latter derived rigor ous b ound. This is not an iso lated c ase, nu merical studies ar e o ften plagued by uncontrolled finite-size effects, as for instance in the b o otstra p p erco la tion [5 7], a v ariation of the class ic al p erco lation problem. IV. LOCAL SEA RCH ALGORITHMS The following of this r eview will b e devoted to the study o f v ario us solving algor ithms for SA T formulas. Algorithms are, to some extent, similar to dy namical pro cess es studied in statistical ph ysics. In this c ontext the fo cus is how e ver mainly on sto chastic pro cesses that resp ect detailed balance with resp ect to the Gibbs- Boltzmann measur e [58], a condition whic h is rarely resp ected b y solving algorithms. P hysics inspired techniques can yet b e useful, a nd will emerge in three differen t w ays. The rando m walk algorithms cons idered in this Section a re stochastic proc esses in the space o f configurations (not fulfilling the detailed balance condition), moving by small steps where one or a few v ariables ar e mo dified. O ut-of-equilibrium physics (and in pa rticular growth pro c e sses) provide an in teresting view o n classical complete algorithms (DPLL), as shown in Sec . V B. Finally , the picture of the s atisfiable pha se put forward in Sec. I I I underlies the messa ge-passing pro cedures discussed in Sec. V C. A. Pure random walk sat, definition and results v al id for all instances Papadimitriou [59] prop o s ed the following a lg orithm, called Pure Random W alk Sat (PR WSA T) in the following, to solve k -SA T formulas: 1. Cho ose a n initial assignment σ (0) unifor mly at random and set T = 0. 14 2. If σ ( T ) is a solution o f the formula (i.e. E ( σ ( T )) = 0), output sol ution and stop. If T = T max , a threshold fixed befor ehand, output undetermined and stop. 3. Otherwise, pick unifor mly at ra ndom a cla use among those that a re UNSA T in σ ( T ); pick uniformly at r andom one of the k v aria bles o f this clause and flip it (reverse its sta tus from T rue to F alse and vice-v ersa ) to define the next assignment σ ( T + 1); set T → T + 1 a nd go back to step 2. This defines a sto chastic pro ce s s σ ( T ), a biased random walk in the space of configurations . The modification σ ( T ) → σ ( T + 1) in step 3 makes the selected clause satisfied; howev er the flip of a v ar iable i can turn prev iously satisfied clauses into unsatisfied o nes (those whic h were satisfied solely by i in σ ( T )). This algo r ithm is not complete: if it outputs a solution one is certain that the form ula was s atisfiable (and the current co nfiguration provides a certificate of it), but if no solution has b een found within the T max allow e d steps one cannot be sure that the for mula w a s unsa tisfiable. Ther e are how ever t wo r igorous results whic h makes it a probabilistically almost complete a lgorithm [6 0]. F or k = 2, it was shown in [59] that PR WSA T finds a solution in a time of o rder O ( N 2 ) with high probability for all satisfiable instances. Hence, one is almost cer tain that the formula was unsatisfiable if the output of the algor ithm is undetermined after T max = O ( N 2 ) steps. Sch¨ oning [6 1] prop osed the following v ar iation for k = 3. If the algorithm fails to find a solution b efore T max = 3 N steps, instea d of stopping and printing undetermined , it restarts from step 1, w ith a new random initial condition σ (0). Sch¨ oning pr oved that if after R restarts no solution has b een found, then the pro bability that the instance is satisfiable is upper-b ounded b y ex p[ − R × (3 / 4 ) N ] (asymptotically in N ). This means that a c o mputational cost of order (4 / 3) N allows to reduce the proba bility of er ror of the a lgorithm to a rbitrary small v alues. Note that if the time scaling o f this b ound is exp onential, it is also ex po nentially smaller than the 2 N cost o f an exha ustive enumeration. Improv e men ts o n the facto r 4 / 3 are rep orted in [62]. B. Typical b ehavior on random k -SA T instances The results quo ted ab ov e are true for a ny k -SA T instance. An in teresting pheno menology arises when one applies the PR WSA T algo r ithm to insta nces dr awn from the rando m k -SA T ensemble [63, 64]. Figure 5 displays the temp oral evolution of the num b er o f uns atisfied clauses during the e xecution o f the algor ithm, for tw o random 3-SA T instances of constraint ratio α = 2 and 3. The t wo cur ves are v e ry diff erent: a t lo w v alues of α the energy deca ys rather fast towards 0, until a p oint wher e the algorithm finds a solutio n and stops. O n the other hand, for larger v alues of α , the energy first decays tow a rds a strictly p ositive v alue, around which it fluctua tes for a lo ng time, un til a la rge fluctuation rea ches 0, signa ling the discovery of a so lution. A mor e detailed study with fo rmulas of incre a sing sizes reveals that a threshold v a lue α rw ≈ 2 . 7 (for k = 3) s harply sepa r ates this t wo dyna mical r egimes. In fac t the fraction of unsatisfie d clauses ϕ = E / M , expr essed in terms of the reduced time t = T / M , concentrates in the thermo dynamic limit aro und a deter ministic function ϕ ( t ). F or α < α rw the function ϕ ( t ) rea ches 0 at a finite v alue t sol ( α, k ), which means that the algo r ithm finds a solution in a linear num b er of steps, typically close to N t sol ( α, k ). On the contrary for α > α rw the reduced ener g y ϕ ( t ) reaches a p os itive v a lue ϕ as ( α, k ) as t → ∞ ; a solution, if any , ca n be found only through large fluctuations of the energ y which o ccur on a time scale exp onentially lar ge in N . This is an example of a metasta bilit y phenomenon, found in several other sto chastic pro cesses , for instance the co ntact pro cess [65]. When the threshold α rw is reached from below the so lving time t sol ( α, k ) diverges, while the height of the plateau ϕ as ( α, k ) v anishes when α rw is approa ched from ab ov e. In [63, 6 4] v arious statistica l mec hanics inspired techniques hav e b een applied to study analytically this phenomenol- ogy , some r esults are pres ented in Figure 6. The low α regime can b e tackled by a systematic ex pansion of t sol ( α, k ) in p ow er s of α . The first three terms of these s eries hav e b e e n computed, and are shown on the left panel to b e in go o d agreement with the numerical s im ulations. Another approa ch was followed to characterize the tr ansition α rw , and to compute (approximations of ) the asymp- totic fra ction of unsatis fie d clauses ϕ as and the intensit y of the fluctuations ar ound it. The idea is to pro ject the Marko vian evolution of the configuration σ ( T ) on a simpler observ able, the energy E ( T ). Obviously the Mark o- vian pr op erty is lost in this transformation, a nd the dynamics of E ( T ) is muc h more complex. One can how ever approximate it by assuming that all configurations of the same ener g y E ( T ) are equiproba ble at a given step of execution of the algor ithm. This rough approximation of the ev olution o f E ( T ) is found to concentrate aro und its mean v a lue in the thermo dynamic limit, as was constated numerically for the or iginal pro cess . Standard techniques allow to co mpute this av er age approximated evolution, which exhibits the thres hold b ehavior expla ined ab ov e at a v alue α = (2 k − 1 ) /k which is, for k = 3, slightly low er than the thresho ld α rw . The right panel of Fig. 6 confronts the results of this approximation with the numerical simulations; given the roug hness o f the hypothesis the a greement is rather satisfying, and is exp ected to impr ov e for larger v alues of k . 15 t ' 0.5 0.4 0.3 0.2 0.1 0 0.15 0.1 0.05 0 t ' 25 20 15 10 5 0 0.15 0.1 0.05 0 0 0.05 0.1 0.15 0 0.5 1 1.5 2 2.5 3 FIG. 5: F raction of unsatisfied constrain ts ϕ = E / M in function of reduced time t = T / M during the execution of PR WSA T on random 3-SA T form ulas with N = 500 v ariables. T op: α = 2, Bottom: α = 3. The rig o rous results on the b ehavior of PR WSA T on rando m instances are very few. Let us mention in pa r ticular [66], which prov e d that the solving time for rando m 3 - SA T for mulas is typically polynomia l up to α = 1 . 63, a r e sult in agreement yet weaker than the numerical results presented here . C. More p erforman t v ariants of the algorithm The threshold α rw for linear time s o lving of random instances b y P R WS A T was found above to b e muc h smaller than the sa tisfiability thr e s hold α s . It m ust how ever b e e mpha sized that PR WSA T is o nly the simplest example of a large family of lo c a l s earch algorithms, see for insta nce [6 7–71]. They all shar e the same structure: a solution is searched through a ra ndom walk in the space of configura tions, one v a riable being mo dified a t ea ch step. The choice of the flipped v ar ia ble is ma de accor ding to v ario us heur istics; the g o al is to find a compromise b etw een the greedines s of the walk which seeks to minimize lo ca lly the energy of the curr e n t a s signment, a nd the necessity to allow for moves increasing the energy in order to avoid the trapping in lo cal minima o f the ener gy function. A frequently encountered ingredient o f the heuristics, w hich is of a greedy nature, is the fo c using: the flipp ed v ariable neces sarily b elong s to a t least one unsatisfied claus e be fo re the flip, which thus b ecomes s a tisfied after the mov e. Mor e ov er , instea d of choosing randomly one of the k v aria bles of the unsatisfied clause , o ne can consider for each of them the effect o f the flip, and av o id v ariable s which, o nce flipp ed, will turn satisfied c la uses into uns atisfied o nes [6 7, 68]. Another way to implement the g reediness [6 9] consists in b o okkeeping the lowest ener gy found so far during the walk, and forbids flips which will raise the ener gy of the current assignment a b ov e the r egistered reco r d plus a tolerance thre shold. These demanding requirements hav e to b e balanced with noisy , random steps, allowing to escap e traps which are only lo cally minima of the ob jective function. These more elab ora ted heuristics are very num erous , and depend on pa rameters that are finely tuned to a chieve the best p erformance s , hence an exhaustive co mparison is out of the scop e of this r eview. Let us only men tion tha t some of these heuristics ar e rep orted in [69, 70] to efficiently find solutions o f larg e (up to N = 10 6 ) random for mulas of 3-SA T at ratio α very clos e to the satisfiability threshold, i.e. for α . 4 . 21. 16 t sol 1.2 1 0.8 0.6 0.4 0.2 0 0.24 0.21 0.18 0.15 0.12 ' as 10 9 8 7 6 5 4 3 2 0.1 0.075 0.05 0.025 0 FIG. 6: T op: linear sol ving time t sol ( α, 3) for ran d om 3-SA T formulas in function of α ; symb ols correspond to numerical sim ulations, solid line to the second order expansion in α obtained in [63 ]. Bottom: fraction of unsatisfied constraints reac hed at large time for α > α rw for random 3-SA T form ulas; symb ols correspond to numeric al simulatio ns, solid line to the approximate analytical computations of [63, 64]. V. DECIMA T ION BASED ALGORITHMS The alg orithms studied in the remaining of the review are of a very different nature compared to the lo cal search pro cedures describ ed ab ov e. Given a n initial formula F whose satisfiability has to b e decided, they pro ceed by assigning sequentially the v alue o f s ome o f the v ar iables. The for m ula can be simplified under such a partial assignment: clauses which are satisfied b y at lea st one of their literal can be remov e d, while litera ls unsatisfying a cla use are discarded from the c lause. It is instructive to consider the following thought e x pe r iment: supp os e o ne can consult an oracle who , given a formula, is able to compute the marginal pr obability of the v ar iables, in the uniform probability measure ov er the optimal ass ignments o f the for mu la. With the help of such an o racle it would b e p ossible to sample uniformly the optimal a ssignments o f F , by computing these marginals, s etting one una s signed v ar iable according to its marg inal, and then pr o ceed in the same way with the simplified fo r mula. A slightly less ambitious, yet still unrealistic, task is to find one optimal config uration (not necessar ily uniformly distributed) of F ; this can be p erfor med if the o racle is able to reveal, for each formula he is questioned a bo ut, whic h o f the unassig ned v a r iables take the same v a lue in all optimal assig nmen ts, and what is this v alue . Then it is enough to av oid setting incorr e c tly such a constra ined v a r iable to obtain at the end an optimal as signment. Of cours e such procedur es are not meant as practical algorithms; instead of these fictitious oracles one has to resort to simplified evidences gathered from the curren t for mula to guide the c hoice of the v a riable to as sign. In Sec. V A we consider a lgorithms ex plo iting bas ic informa tion on the num b er of o ccurr e nc e s of ea ch v a riable, and their behavior in the satisfiable regime of random SA T formulas. They are turned into complete algorithms by allowing for backtrac king the heuristic choices, as explained in V B. Finally in Sec. V C we s hall use more refined messag e-passing sub-pro cedures to provide the infor mation used in the assignment steps. 17 A. Heuristic search : the success-to-failure transition The first algor ithm we co nsider was int ro duced and ana lyzed by F ranco and his collab ora tors [72, 7 3]. 1. If a for mula co ntains a unit clause i.e. a clause with a single v a riable, this clause is s atisfied through a n appropria te assignment of its unique v a riable (propagation); If the formula contains no unit-clause a v ariable and its truth v alue ar e c hosen acco rding to so me heur istic rule (free choice). Note that the unit clause propa gation corres p o nds to the obvious answer an or acle would provide on such a for m ula. 2. Then the clauses in which the assig ned v aria ble appe ars are simplified: satisfied clauses a re remov ed, the other ones are reduced. 3. Resume fr om step 1. The pro cedure will end if one of tw o conditions is verified: 1. The fo r mula is completely empty (all cla uses hav e b een remov ed), and a s olution has be e n found ( success ). 2. A contradiction is generated from the pres ence of tw o opposite unit clauses. The a lgorithm halts. W e do not know if a solution exists and has not b een found or if ther e is no solution ( f ailure ). The simplest exa mple of heuristic is ca lled Unit Clause (UC) a nd consists in choos ing a v ariable unifor mly a t random among those that a re not yet set, and a ssigning it to true or f alse uniformly at rando m. Mor e so phisticated heuristics can take into account the num b er of o ccurrences of each v aria ble a nd o f its negatio n, the length of the claus e s in which each v a riable app ear s , or they can set more than o ne v ariable at a time. F or example, in the Generalized Unit Clause (GUC), the v ar iable is alwa ys chosen among those app ear ing in the sho r test clauses. Numerical ex p er iment s and theo ry show that the results of this pro cedure applied to random k - SA T formulas with ratios α and size N can b e class ifie d in tw o reg imes: • A t low ratio α < α H the search pro cedure finds a solution with p ositive pr obability (ov er the for mulas and the random c hoices of the algo r ithm) when N → ∞ . • A t high r a tio α > α H the probabilit y o f finding a solution v a nishes when N → ∞ . Notice that α H < α s : solutions do exist in the rang e [ α H , α s ] but are not found by this heuris tic. The ab ove algo rithm mo difies the formula as it pr o ceeds; during the ex e cution of the alg orithm the current formula will co nt ain cla uses of length 2 and 3 (we sp ecialize he r e to k = 3-SA T for the s ake of simplicity but hig her v a lues of k can b e considered). The s ub-formulas gener ated by the sea rch pr o cedure maint ain their statistical unifor mit y (conditioned o n the n umber of claus es of length 2 and 3). F ranco and collab ora tors used this fact to write down differential eq ua tions for the evolution of the densities o f 2- a nd 3-clause s as a function of the fraction t of elimina ted v ariables . W e do not repro duce those equations here, see [74] for a p edago gical rev ie w . Based on this analysis F riez e and Suen [75] were able to ca lculate, in the limit of infinite size, the pr obability of successful sear ch. The outcome for the UC heuristic is P (UC) success ( α ) = exp ( − 1 4 p 8 / 3 α − 1 arctan " 1 p 8 / 3 α − 1 # − 3 16 α ) (30) when α < 8 3 , and P = 0 for larger r atios. The probability P success is, as exp ected, a decr easing function of α ; it v anishes in α H = 8 3 . A similar ca lculation shows that α H ≃ 3 . 003 for the GUC heuristic [75]. F ranco e t a l’s a nalysis ca n b e r ecast in the following terms. Under the op era tion of the algo rithm the orig inal 3-SA T formula is turned int o a mixed 2 + p -SA T formula where p denotes the fraction of the clauses w ith 3 v ariables: there are N α · (1 − p ) 2 - clauses and N αp 3-clauses. As w e mentioned ear lier the simplicit y of the heuristics maintains a statistical uniformity over the for mulas with a given v alue of α a nd p . This constatation motiv ated the s tudy of the random 2 + p -SA T ensemble by statistical mechanics metho ds [20, 56], some of the results b eing later confir med by the rigoro us analysis of [76]. A t the heuristic level one exp ects the existence of a p dependent satisfiability threshold α s ( p ), int erp olating b etw ee n the 2-SA T k nown threshold, α s ( p = 0) = 1, and the c onjectured 3-SA T ca se, α s ( p = 1) ≈ 4 . 26 7. The upp erb o und α s ( p ) ≤ 1 / (1 − p ) is easily obtained: for the mixed formula to b e satisfiable, necessar ily the sub- formula obtained by retaining only the clauses of length 2 must be satisfiable as w ell. In fac t this b ound is tigh t for all v alues of p ∈ [0 , 2 / 5]. During the execution of the a lgorithm the ratio α and the fraction p are ‘dynamical’ parameters , changing with the fraction t = T / N of v ar iables a ssigned by the a lgorithm. They define the co ordinates 18 0.2 0.4 0.6 0.8 1 p H t L 1 2 3 4 Α H t L G G’ FIG. 7: T ra jectories generated by heuristic search acting on 3-S A T for α = 2 and α = 3 . 5. F or all heuristics, the starting p oint is on the p = 1 axis, with th e initial v alue of α as ordin ate. The cu rves that end at the origin corresp ond to UC, th ose ending on the p = 1 axis correspond to GUC. The thick line represents t h e satisfiabilit y th reshold: the part on the left of the critical p oint (2 / 5 , 5 / 3) is exact and coincides with the contradiction line, where contradictions are generated with high probabilit y , of equation α = 1 / (1 − p ), and which is plotted for larger v alues of p as well; th e part on the right of the critical p oint is only a sketc h. When th e tra jectories h it the satisfiability threshold, at p oin ts G for U C and G’ for GUC, they enter a region in which massiv e bac ktracking takes place, and th e tra jectory represen t s the evolution prior to backtrac king. The dashed part of the curves is “un physical” , i.e. th e tra jectories stop when the contra diction curve is reached. of the repre s ent ative p oint o f the instance at ‘time’ t in the ( p, α ) plane of Figur e 7. The motion of the r epresentativ e po int defines the s earch tra jectory of the a lgorithm. T r a jectories start from the p o int of co or dinates p (0) = 1 , α (0 ) = α and end up o n the α = 0 a x is when a so lution is found. The pro bability of success is po s itive as long as the 2-SA T subformula is satisfiable, tha t is, a s long as α · (1 − p ) < 1. In other words succ ess is p ossible provided the tra jector y do es not cross the c o ntradiction line α = 1 / (1 − p ) (Figure 7). The la rgest initial ratio α such that no cr ossing o cc ur s defines α H . Notice that the search tra jectory is a sto chastic o b ject. How ever F ranco has shown that the dev iations from its average lo c us in the pla ne v anish in the N → ∞ limit (co ncentration phenomenon). Lar ge deviations from the typical b ehavior can b e calculated e.g. to estimate the probability of success ab ove α H [77]. The pr ecise for m o f P success and the v a lue α H of the ra tio where it v anishes are spe c ific to the heuristic consider ed (UC in (30)). Howev er the b ehavior of the probability close to α H is largely independent of the heuristic (provided it preserves the unifor mity o f the s ubfor mulas genera ted): ln P success α = α H (1 − λ ) ∼ − λ − 1 / 2 . (31) This universality can loo sely b e interpreted by obse r ving that for α c lo se to α H the tra jectory will pass very close to the contradiction curve α · (1 − p ) = 1 , whic h c haracteriz e s the lo cus of the po ints wher e the probability that a v ariable is assigned b y the heur istics H v anishes (and all the v aria bles ar e ass igned by Unit Propa gation). The v alue of α H depe nd o n the “s ha p e ” o f the tra jectory far from this curve, a nd will therefore dep end on the heuristics, but the pr obability of succ e ss (i.e. of avoiding the contradiction curve) for v alues of α close to α H will only dep end on the lo cal b ehavior of the tra jectory clo se to the contradiction curve, a re g ion where most v aria ble s are assig ned through Unit Propag ation and not sensitive to the heuristics. The finite-size corr ections to equa tio n (3 0 ) are also universal (i.e. indep endent o n the heuristics): ln P success ( α = α H (1 − λ ) , N ) ∼ − N 1 / 6 F ( λN 1 / 3 ) , (32) where F is a universal scaling function which can b e exactly ex pr essed in ter ms of the Airy function [7 8]. This r esult indicates that right at α H the probability of success decr eases as a stretched exp onential ∼ ex p( − cst N 1 6 ). The expo nent 1 3 suggests that the critical scaling of P is related to random graphs. After T = t N steps of the pro cedure, the s ub-formula will co nsists of C 3 , C 2 and C 1 clauses o f length 3, 2 a nd 1 res p ectively (notice that these are extensive , i.e. O ( N ) quantities). W e can r e present the clause s of length 1 and 2 (which a re the relev a nt o nes to 19 understand the generation o f contradictions) as an o riented graph G in the following wa y . W e will hav e a vertex for each literal, and r epresent 1-clauses b y “mar king” the literal app earing in each; a 2-clause will b e repr esented by t wo directed edges, corr e sp o nding to the tw o implications equiv alent to the cla use (for example, x 1 ∨ ¯ x 2 is represented b y the directed edges ¯ x 1 → ¯ x 2 and x 2 → x 1 ). The av erage out-deg ree of the vertices in the gra ph is γ = C 2 / ( N − T ) = α ( t )(1 − p ( t )). What is the effect of the algor ithm on G ? The algorithm will pro ce ed in “r ounds”: a v a riable is set by the heuristics , and a ser ies of Unit P r opaga tio ns are p erfor med un til no more unit c la uses are left, at which p oint a new r ound starts. Notice that during a round, extensive quantities as C 1 , C 2 , C 3 are likely to v a ry b y b o unded a mo unt s and γ to v ar y by O ( 1 N ) (th is is the very reason that guara nt ees that these quantities are concentrated around their mean). A t each step of Unit Pr opagatio n, a marked literal (say x ) is a ssigned and remov e d from G , together w ith all the e dg es connected to it, and the “descendants” o f x (i.e. the literals at the end of outgoing edges) a re marked. Also ¯ x is remov ed tog ether with its edges, but its descendan ts are not marked. Ther efore, the marked v ertices “diffuse” in a connected comp onent of G following dir ected edges. Mor eov e r , a t each step new edges co rresp onding to clauses of length 3 that get simplified into clauses o f length 2 are added to the gra ph. When γ > 1 , G undergo es a dir ected p erco la tion transition, and a giant comp onent of size O ( N ) app ears, in which it is p ossible to go fr o m a ny vertex to any o ther vertex by following a directed path. When this happens, there is a finite pr obability that tw o opp osite literals x and ¯ x c a n b e re ached from some other literal y following a directed path. If ¯ y is selected by Unit Propaga tion, at some time both x and ¯ x will be mar ked, and this corresp onds to a contradiction. This s imple argument ex pla ins mo r e than just the conditio n γ = α · (1 − p ) = 1 for the failure o f the heuristic search. It can also b e us e d to explain the the exp onent 1 6 in the scaling (32), see [78, 79] for more details. B. Bac ktrac k-based search: the Davis-Put nam-Lov e l and-Logeman procedure The heuristic s earch pro cedure of the pr evious Sectio n ca n b e easily turned into a complete pro cedure for finding solutions or proving that fo rmulas are not sa tisfiable. When a contradiction is found the algor ithm now backtracks to the last as s igned v ariable (by the heuristic; unit clause propaga tions are merely consequences of pr evious assig nmen ts), inv ert it, and the sear ch resumes. If another c o ntradiction is found the algor ithm backtracks to the last-but-one assigned v ariable and so on. The algor ithm stops either if a so lution is found or all pos s ible backtrac ks hav e b een unsuccessful and a pro o f of unsatisfia bility is obtained. This a lg orithm was propo sed by Davis, Putnam, Loveland and Logemann and is referr ed to a s DPLL in the following. The history of the search pro cess can b e represented by a search tree, wher e the no des represent the v a riables assigned, and the desc e nding edg e s their v alues (Figure 8). The leav e s of the tree co rresp ond to solutions (S), or to contradictions (C). The ana lysis o f the α < α H regime in the previo us Section leads us to the co nclusion that search trees lo ok like Figure 8A a t sma ll r atios 4 . F or r atios α > α H DPLL is very likely to find a contradiction. Backtracking enters into play , and is r esp onsible for the dras tic slowing down of the algo rithm. The succes s-to-failure transition takes place in the non-ba cktrac king algorithm into a p olynomial- to-exp onential tra ns ition in DPLL. T he question is to compute the gr owth exp onent of the av er age tree size, T ∼ e N τ ( α ) , as a function of the ra tio α . 1. Exp onential r e gime: Unsatisfiable formulas Consider first the case o f unsatisfiable form ulas ( α > α s ) where all leaves carr y contradictions a fter DPLL ha lts (Figure 8B). DPLL builds the tr ee in a s equential manner, adding no des and edges o ne a fter the other, a nd completing branches through backtrac king steps. W e can think of the sa me se a rch tr ee built in a parallel wa y [80]. A t time (depth T ) our tree is comp osed of L ( T ) ≤ 2 T branches, each carrying a partia l assig nment ov er T v ar iables. Step T consists in as s igning one mor e v a riable to eac h branch, accor ding to DPLL r ule s , that is, thro ugh unit-propa gation or the heuristic rule. In the latter case we will sp eak o f a splitting ev ent, as t wo branches will emerge from this no de, corres p o nding to the t wo p oss ible v alues of the v ar iable assig ned. The p ossible consequences of this assignment are the emerg ence of a contradiction (which put a n end to the branch), or the simplificatio n of the attached formulas (the branch keeps gr owing). The n umber of bra nches L ( T ) is a stochastic v ar iable. Its a verage v alue can b e calculated as follows [81]. Let us define the average num b er L ( ~ C ; T ) of branches of depth T which b ea r a formula con taining C 3 (resp. C 2 , C 1 ) 4 A small amoun t of backtrac king may be necessary to find the solution si nce P success < 1 [75] , but the ov erall picture of a single branch is not qualitatively affected. 20 c c c c c c c c c c c c c c c c c c c S c G A C B S FIG. 8: Searc h trees generated by DPLL: A. linear, satisfiable ( α < α H ); B . exp on ential, un satisfiable ( α > α c ). C. exp onential, satisfiable ( α H < α < α c ); Lea ves are m arked with S (solutions) or C (contradictions). G is the h ighest no de to which DPLL backtrac ks, see Figure 7. equations of length 3 (resp. 2,1), with ~ C = ( C 1 , C 2 , C 3 ) Initially L ( ~ C ; 0) = 1 for ~ C = (0 , 0 , αN ), 0 otherwise. W e shall call M ( ~ C ′ , ~ C ; T ) the av erage nu mber o f branches descr ib e d by ~ C ′ generated fro m a ~ C bra nch once the T th v ariable is assigned [79, 8 0]. W e hav e 0 ≤ M ≤ 2 , the extr eme v alues co r resp onding to a contradiction and to a split r esp ectively . W e claim that L ( ~ C ′ ; T + 1) = X ~ C M ( ~ C ′ , ~ C ; T ) L ( ~ C ; T ) . (33) Evolution eq uation (33) co uld lo ok like somewhat s us picious at first sight due to its similar it y with the approximation we hav e sketc hed in Sec. I V B for the analys is of PR WSA T. Y et, thanks to the linea rity of exp ectatio n, the corre lations betw een the br anches (or b etter, the instanc e s ca rried by the branches) do not matter a s far as the av erag e num b er of branches is concerned. F or la rge N we exp ect that the n umber o f alive (not hit by a contradiction) bra nches grows exp onentially with the depth, or, equiv alently , X C 1 ,C 2 ,C 3 L ( C 1 , C 2 , C 3 ; T ) ∼ e N λ ( t )+ o ( N ) (34) The argument o f the exp onential, λ ( t ), can be found using partial differen tial equation techniques generalizing the ordinary differen tia l equa tion techniques of a single branch in the absence of backtracking (Section V A). Details can b e found in [81]. The outcome is that λ ( t ) is a function growing from λ = 0 at t = 0, reaching a maximum v alue λ M for s ome depth t M , and decr easing a t larg e r depths. t M is the depth in the tre e of Figure 8B wher e mos t contradictions are found; the num b er of con tradiction leav es is , to exp onential order , e N λ M . W e conclude tha t the logarithm of the av erage s ize of the tree we were lo ok ing for is τ = λ M . (35) F or large α ≫ α s one finds τ = O (1 / α ), in agreement with the a symptotic scaling of [82]. The calculation can b e extended to higher v alues of k . 2. Exp onential r e gime: Satisfiable formulas The a bove calculation holds for the unsatisfiable, exp o nential phase. How can w e understand the satisfiable but exp onential regime α H < α < α s ? The resolution tra jector y crosses the SA T/UNSA T cr itical line α s ( p ) at some po int G shown in Figure 7. Immediately after G the instance left by DP L L is unsatisfiable. A subtree with all its leav es carr ying co nt radictions will develop b e low G (Figure 8C). The size τ G of this subtree c an be easily calcula ted from the ab ov e theor y from the knowledge of the co or dinates ( p G , α G ) of G. Once this subtree has bee n built DPLL backtrac ks to G, flips the attached v a riable and will finally e nd up with a solution. Hence the (log of the) num b er of splits neces s ary will b e eq ua l to τ = (1 − t G ) τ G split [80]. Remark that our calcula tion gives the logarithm o f the av erage subtree size starting from the typical v a lue of G. Numeric al exp eriments show that the resulting v alue for τ coincides very ac curately with the most lik ely tree size for finding a solution. The r eason is that fluctuations in the sizes are mostly due to fluctuations of the hig hest ba cktrac king p oint G, tha t is, of the first part of the sea rch tr a jectory [77]. 21 C. Message passing al gorithms According to the thought exp eriment prop osed at the beg inning o f this Se c tio n v aluable information could be obtained from the knowledge o f the margina l pr obabilities of v ariables in the uniform measur e ov er o ptimal configu- rations. This is an inference problem in the g raphical mo del as s o ciated to the fo rmula. In this field messa ge pas sing techn iques (for instance Belief Propaga tion, or the min-sum algor ithm) ar e widely used to compute approximately such marg inals [4 6 , 48]. These numerical pro cedures in tro duce messages on the directed edges of the factor graph representation of the pro blem (recall the definitions g iven in Sec. II I D), which a re iteratively upda ted, the new v alue of a message b eing computed from the old v a lues of the incoming messag es (see Fig. 4). When the underlying gr aph is a tr e e , the message updates are guaranteed to conv er ge in a finite n umber of steps, and provide exact results. In the presence of cycle s the convergence of these recurrence equatio ns is no t guara nteed; they can howev er b e used heuristically , the iterations b eing rep eated until a fix e d p oint has b een reached (within a to le rance thres hold). Thoug h very few general r esults on the conv e rgence in pr esence of lo o ps are known [83] (see also [84] for low α random SA T formulas) these he ur istic pro cedures are often fo und to yield go o d approximation of the marginals on g eneric factor graph problems. The in terest in this approa ch for solving random SA T instances was trigger ed in the statistical mechanics communit y by the intro duction of the Sur vey Propa g ation algor ithm [21 ]. Since then several generaliza tions and re in terpretatio ns of SP hav e b een put forward, see for insta nce [85–90]. In the following para g raph we present three different message passing proce dures, whic h differ in the nature of the mess a ges pas sed b etw een nodes, following rather c lo sely the presentation o f [47] to which we refer the r eader for further details. W e then dis cuss how these pr o cedures hav e to be interleav e d with assignment (decimation) s teps in order to constitute a solver algorithm. Finally we shall review results obtained in a particular limit ca se (large α satisfiable formulas). 1. Definition of the message-p assing algorithms • Belief P ropag ation (BP) F or the sake of reada bilit y we rec all here the recursive equations (26) stated in Sec. I I I D for the uniform probability measure ov er the so lutio ns of a tree formula, h i → a = X b ∈ ∂ + i ( a ) u b → i − X b ∈ ∂ − i ( a ) u b → i , (36) u a → i = − 1 2 ln 1 − Y j ∈ ∂ a \ i 1 − tanh h j → a 2 . where the h and u ’s messa ges are r eals (po sitive for u ), para metrizing the marg inal probabilities (belie fs) for the v alue of a v aria ble in abse nce of some c o nstraint no des aro und it (cf. Eq. (25 )). These eq uations can be us e d in the heur istic wa y explained ab ov e for any formula, and cons titute the BP mes sage-pa s sing equations. Note that in the cours e o f the simplification pro cess the deg ree of the clauses change, we thus adopt here and in the following the na tural conv ention that sums (resp. pro ducts) ov e r empty sets of indices are equal to 0 (resp. 1). • W arning P ropag ation (WP) The ab ov e-stated version of the BP eq uations b ecome ill-defined for an uns a tisfiable formula, whether this was the case o f the original formula or b eca use of some wro ng a s signment steps; in particular the no rmalization constant o f Eq. (24) v anishes. A wa y to cur e this problem consists in intro ducing a fictitious inv erse temp era ture β a nd deriving the BP equations cor r esp onding to the regula rized Gibbs-Boltzmann probability law (20), tak ing as the energy function the num b er o f unsatisfied constraints. In the limit β → ∞ , in which the Gibbs- Boltzmann measure conce ntrates on the optimal a ssignments, one can single out a part of the informatio n conv e yed by the BP equations to obtain the simpler W arning Pro pagation rules. Indeed the messag es h, u a re at leading order prop ortiona l to β , with pro po rtionality co efficients we sha ll denote b h and b u . These messa ges are less infor ma tive than the ones of BP , yet simpler to handle. One finds indeed that instead of rea ls the WP mes sages are integers, more precisely b h ∈ Z and b u ∈ { 0 , 1 } . T he y ob ey the following re c ursive e q uations (with a structure similar to 22 the ones o f BP), b h i → a = X b ∈ ∂ + i ( a ) b u b → i − X b ∈ ∂ − i ( a ) b u b → i , b u a → i = Y j ∈ ∂ a \ i I ( b h j → a < 0) , (37) where I ( E ) is the indica tor function of the even t E . The interpretation of these equa tio ns go es as follows. b u a → i is equal to 1 if in a ll o ptimal assignments of the amputated formula in which i is only constrained b y a , i takes the v alue satisfying a . This happ ens if all o ther v aria bles of clause a (i.e. ∂ a \ i ) are re quired to take their v alues unsatisfying a , hence the form o f the right part of (37). In such a ca se we say that a sends a warning to v ar iable i . In the fir st part of (3 7 ), the messa ge b h i → a sent by a v ar ia ble to a clause is computed by po ndering the num b er of warnings sent by all other clauses; it will in particular be negative if a ma jor it y of cla uses req uir es i to take the v alue unsatisfying a . • Survey Propag ation (SP) The conv erg ence of B P and WP iterations is not ensured on lo opy gr aphs. In par ticular the clustering phe- nomenon describ e d in Sec. II I A is likely to sp o il the efficiency of these pro cedures. The Survey Propa g ation (SP) algorithm int ro duced in [21] ha s b een desig ned to deal with these clus tered space of configuratio ns . The underlying idea is that the simple iterations (of BP or WP t yp e) remain v alid inside eac h cluster of optimal assignments; for each o f thes e clusters γ and each directed edge o f the facto r g raph one ha s a messa ge h γ i → a (and u γ a → i ). One introduces on each edge a survey of these messages, defined as their proba bilit y distribution with resp ect to the choice o f the clusters. Then some hypotheses ar e made on the structure o f the c luster decomp o- sition in or der to write closed equations on the s ur vey . W e explicit now this a pproach in a version ada pted to satisfiable instances [47], ta king as the basic building blo ck the WP equations. This leads to a rather simple form of the survey . Indeed b u a → i can only ta ke tw o v alues, its proba bility distribution can thus b e parametrized by a single real δ a → i ∈ [0 , 1 ], the probability that b u a → i = 1. Similar ly the survey γ i → a is the probability that b h i → a < 0. The second part of (37) is readily tra nslated in probabilistic terms, δ a → i = Y j ∈ ∂ a \ i γ j → a . (38) The o ther part of the recur sion takes a slightly more complicated form, γ i → a = (1 − π − i → a ) π + i → a π + i → a + π − i → a − π + i → a π − i → a , with π + i → a = Q b ∈ ∂ + i ( a ) (1 − δ b → i ) π − i → a = Q b ∈ ∂ − i ( a ) (1 − δ b → i ) . (39) In this equatio n π + i → a (resp. π − i → a ) corre sp o nds to the pro bability that none of the clauses agr eeing (resp. disagreeing ) with a on the v a lue o f the literal of i sends a warning. F or i to b e constrained to the v alue unsatisfying a , a t least one of the cla us es of ∂ − i ( a ) should send a warning, a nd none of ∂ + i ( a ), which explains the form of the numerator of γ i → a . The denominator ar ises fr om the exclusion o f the ev ent that bo th clauses in ∂ + i ( a ) and ∂ − i ( a ) send messa ges, a contradictory even t in this v ersio n o f SP which is devised for s atisfiable formulas. F rom the s ta tistical mechanics p oint o f v iew the SP equa tions a rise from a 1RSB cavity calculatio n, as s ketched in Sec. I I I D, in the zero temp eratur e limit ( β → ∞ ) and v anishing Parisi parameter m , these tw o limits being either tak en sim ultaneously as in [21, 89] or successively [2 2]. One can th us compute, from the solution of the recursive equations on a single form ula, an estimatio n of its co mplexity , i.e. the n umber of its clusters (irresp ectively of their sizes). The mess age passing procedur e can also be adapted, at the pric e of technical complications, to unsatisfia ble clustered formulas [89]. Note a lso that the ab ov e SP equa tions have b een shown to corresp ond to the BP ones in an extended configur a tion spa ce where v a r iables can take a “joker” v alue [85, 86], mimic king the v ariable s which are not froze n to a single v alue in all the ass ignments of a g iven cluster. Heuristic int erp olatio ns b etw een the B P and SP e q uations hav e b een studied in [86, 8 7]. 23 2. Exploiting the information The information provided b y these mess age passing pro cedures can b e explo ited in order to s olve sa tis fia bilit y formulas; in the alg orithm sketched at the be g inning of Sec . V A the heuristic choice o f the ass igned v aria ble, and its truth v alue, can b e do ne according to the results of the mess age passing on the current formula. If BP were an exact inference alg orithm, one could choose any unass igned v ariable , c o mpute its ma r ginal acco rding to Eq. (27 ), and draw it a ccording to this proba bilit y . Of cours e B P is only an a pproximate pr o cedure, henc e a pr actical implementation of this idea sho uld privilege the v ariables with marginal probabilities closest to a deterministic law (i.e. with the larges t | h i | ), motiv a ted b y the intuition that these are the le ast s ub ject to the approximation error s of BP . Similar ly , if the message pa ssing pro cedure used at ea ch assig nmen t step is WP , one can fix the v ariable with the largest | b h i | to the v alue corresp onding to the s ig n of b h i . In the case of SP , the solution o f the message passing equations are used to compute, for each unass igned v ar iable i , a triplet of num b ers ( γ + i , γ − i , γ 0 i ) according to γ + i = (1 − π + i ) π − i π + i + π − i − π + i π − i , γ − i = (1 − π − i ) π + i π + i + π − i − π + i π − i , γ 0 i = 1 − γ + i − γ − i , with π + i = Q a ∈ ∂ + i (1 − δ a → i ) π − i = Q a ∈ ∂ − i (1 − δ a → i ) . (40) γ + i (resp. γ − i ) is int erpreted as the fra ction of clusters in which σ i = + 1 (r esp. σ i = − 1) in all solutions of the cluster, hence γ 0 i corres p o nds to the clusters in which σ i can tak e both v alues. In the version of [47], one then c ho ose the v ariable with the lar gest | γ + i − γ − i | , and fix it to σ i = +1 (resp. σ i = − 1 ) if γ + i > γ − i (resp. γ + i < γ − i ). In this wa y one tries to select an as s ignment pres erving the maximal num b er of clusters . Of co urse many v a riants o f these heur istic r ules ca n b e devis e d; for instance after each message pa ssing co mputation one can fix a finite fraction of the v aria bles (instead o f a single one), allows for so me a mount of ba cktrac king [91], or increase a soft bias instea d of assigning completely a v ariable [90]. Moreov er the tolerance on the level o f conv er gence of the messa ge pass ing itself can als o b e adjusted. All these implementation choices w ill affect the p erfor mances of the solver, in particular the maximal v alue of α up to which ra ndom SA T instances are solved efficiently , a nd thus ma kes difficult a precise statement ab o ut the limits o f these a lgorithms. In consequence we shall only rep o r t the impress ive result of [47], which presents an implementation [9 2] working for random 3-SA T instances up to α = 4 . 2 4 (very close to the conjectured satisfia bilit y threshold α s ≈ 4 . 26 7 ) for proble m sizes as la r ge a s N = 10 7 . The theoretical understanding of thes e mess age pa ssing inspired s olvers is still po o r compared to the alg o rithms studied in Sec. V A, which use muc h simpler he ur istics in their as signment steps. One difficulty is the description of the residual formula after an extensive num b er of v aria bles have b een a ssigned; b ecause of the cor relations b etw een successive s teps of the algo rithm this r esidual formula is not uniformly distr ibuted conditioned o n a few dynamical parameters , as was the case with ( α ( t ) , p ( t )) for the simpler he ur istics of Sec . V A. One v ersio n of BP guided decima tion could how ever b e studied a na lytically in [93], b y means of an analysis of the thought exper iment discussed a t the beg inning of Sec. V. The study of another simple messa ge passing algorithm is presented in the next pa ragr aph. 3. Warning Pr op agation on dense r andom f ormulas F eige prov ed in [94] a r emark able connection betw een the worst-c ase co mplexity of approximation problems and the str ucture of r andom 3-SA T at large (but independent of N ) v alues of the ratio α . He intro duced the follo wing hardness h yp othesis for r andom 3 -SA T formulas: Hypo thesis 1: Even if α is arbitr arily lar ge (but indep endent of N ), ther e is n o p olynomial t ime algorithm that on most 3-SA T formulas ou t puts UNSA T, and always outputs SA T on a 3-SA T formula that is satisfiable . and used it to derive hardnes s o f a pproximation res ults for v a rious computational problems. As we hav e s e en these instances are typically unsatisfia ble; the problem of interest is thus to recog niz e efficiently the rare satisfia ble insta nces of the distribution. A v a riant o f this problem was studied in [95], where WP was proven to be effectiv e in finding solutions of dense planted random form ula s (the plan ted distributio n is the uniform distribution conditioned on b eing satisfied by a given assignment). More prec isely , [95] prov e s that for α larg e e no ugh (but independent of N ), the following holds with probability 1 − e − O ( α ) : 1. WP conv erg es after at most O (ln N ) iter ations. 24 2. If a v aria ble i ha s b h i 6 = 0, then the sign of b h i is equal to the v a lue of σ i in the planted assignment. The num b er of such v ar iables is bigger than N (1 − e − O ( α ) ) (i.e. almos t a ll v ar ia bles can b e reconstructed from the v alues of b h i ). 3. Once these v ar iables are fixed to their cor rect assig nmen ts, the r emaining formula can b e satisfied in time O ( N ) (in fact, it is a tree formula). On the basis of non-r igorous statistical mechanics metho ds, these results were argued in [96] to remain true when the planted distribution is replaced by the uniform distribution conditioned on b eing sa tisfiable. In other words by iterating WP for a n um b er of iterations bigger than O (ln N ) one is able to detect the rar e satisfiable instances at la rge α . The argument is based on the similarity of structure betw een the tw o distributions at lar ge α , namely the exis tence of a s ingle, small cluster of s olutions wher e almost all v a riables are frozen to a given v alue. This corres p o ndence b et ween the tw o distributions of instances was proven rigo rously in [97], where it was also shown that a related p olynomial algo rithm s ucceeds with high probability in finding s olutions of the satisfiable distribution of large enough density α . These results indica te that a stronger form o f hypo thes is 1, obtained b y replacing always with with pr ob ability p (with resp ect to the uniform distributio n over the formulas and p oss ibly to some randomness built in the a lgorithm), is wrong fo r a n y p < 1. Ho wev er , the v alidity o f hypothesis 1 is still unknown for r andom 3-SA T instances. Nev er theles s, this result is int eresting b ecause it is one of the rare cases in which the p erformances of a message-pa ssing algorithm could be analyzed in full detail. VI. CONCLUSION This r eview was mainly dedicated to the random k - Satisfiability and k -Xor-Satisfia bilit y problems; the approach and results we presented how ever extend to other r andom decisio n problems, in particular rando m graph q -co lo ring. This pro blem consists in deciding whether ea ch vertex o f a gra ph can b e as signed one o ut of q p os sible co lors, without giving the same color to the t wo ex tremities of a n edge. When input gr a phs are randomly drawn fro m Er d¨ os-Renyi (ER) ensemble G ( N , p = c/ N ) a phase diagra m similar to the one of k -SA T (Section I I I) is obtained. There exists a colorable / uncolora ble phase transition for some critical a verage degree c s ( q ), with for instance c s (3) ≃ 4 . 69 [98]. The colo r able phase also exhibits the clustering and condensa tion transitions [99] we explained on the example of the k -Satisfiability . Actually what seems to matter here is rather the structure of inputs and the symmetry prop erties of the decision problem rather than its specific details . All the ab ov e considere d input mo dels share a common, underlying ER random graph structure. F ro m this p oint of view it would b e interesting to ‘esca pe ’ from the E R ensemble and consider more structur e d g raphs e .g. embedded in a low dimensional spac e. T o what extent the similarity b etw e en phase diagr ams cor r esp ond to similar behaviour in terms of har dnes s o f resolution is an op en question. Consider the case of ra re sa tisfiable insta nc e s for the r andom k -SA T and k - XORSA T well ab ove their sat/unsat thresholds (Section V). Both problems sha re v ery simila r statistical features. Howev er , while a simple messag e-passing algorithm allows one to ea sily find a (the) solution for the k -SA T pr oblem this algo rithm is inefficient for rando m k -XORSA T. Actually the lo cal o r decimation- ba sed algorithms of Sections IV and V are efficient to find solutio n to rare satisfable instances o f ra ndom k -SA T [100], but none of them works for r andom k -XORSA T (while the pro blem is in P!). This ex ample raises the impo rtant question of the relations hip b etw ee n the statistical prop erties of so lutions (or quasi- solutions) enco ded in the phas e diagram and the (average) computational har dness. V ery little is k nown ab out this crucial point; on in tuitive grounds one could exp ect the clustering phenomenon to preven t an efficient solving of for m ulas by lo cal sea r ch algorithms of the r andom walk type. This is indeed true for a particular class of sto chastic pro cesses [101], those which resp ect the so-ca lled deta iled balance conditions. This connection b etw een clustering and hardnes s of reso lutio n for lo cal search alg orithms is muc h less ob vious when the detailed balance conditions ar e not r esp ected, which is the case for most of the efficient v ariants of PR WSA T. [1] M. M ´ ezard, G. P arisi, and M. Virasoro, Spin glass the ory and b eyond (W orld Scientific, Singap ore, 1987). [2] C. Papadimitriou and K. Steiglitz, Combinatorial Optimi zation: Algorithms and C omplexity (Do ver, New Y ork, 1998). [3] Y. F u and P . W. Anderson, Journal of Physics A: Mathematical and General 19 , 1605 (1986). [4] D. Mitc hell, B. Selman, and H. Levesque (1992), no. 459 in Pro ceedings of the T enth National Conference on A rtificial Intellig ence. [5] J. Hertz, A. Krogh, and R. P almer, Intr o duction to the the ory of neur al c omputation , Santa F e Institute Stu dies in the Science of Complexity (Addison-W esley , Redwoo d city (CA), 1991). 25 [6] T. Cov er, I EEE T ransactions on Electronic Computers 14 , 326 (1965). [7] S. Janson, T. Lu czak, and A. Rucinsk i, R andom gr aphs (John Wiley and Sons, New Y ork, 2000). [8] E. F riedgut, Journal of the American Mathematical So ciety 12 , 1017 (1999). [9] O. Dub ois, Theoret. Comput. S ci. 265 , 187 (2001). [10] J. F ranco, Theoret. Comput. Sci. 265 , 147 (2001). [11] D. Achlioptas and Y. Peres, Journal of the A merican Mathematical So ciety 17 , 947 (2004). [12] Chapter r andom sat, this volum e . [13] N. Alon and J. Sp encer, The pr ob abil istic metho d ( John Wiley and sons, New Y ork, 2000). [14] A. Dembo and O . Zeitouni, L ar ge deviations. The ory and applic ations (Springer, Berlin, 1998). [15] W. Krauth and M. Mezard, J. Ph ysique 50 , 3057 (1989). [16] S. K. Ma, Statistic al Me chanics (W orld Scientific, Singap ore, 1985). [17] K. Huang, Statistic al Me chanics (John Wiley and Sons, New Y ork, 1990). [18] A. Broder, A. F rieze, and E. Up fal (1993), no. 322 in Proceedings of the F ourth An nual ACM-SIAM Symp osium on Discrete Algorithms. [19] R. Monasson and R. Zecchina, Phys. Rev. E 56 , 1357 (1997). [20] G. Biroli, R . Monasson, and M. W eigt, Eur. Phys. J. B 14 , 551 (2000). [21] M. M´ ezard and R. Zecchina, Phys. Rev. E 66 , 056126 (2002). [22] F. Krzak ala, A. Montanari , F. Ricci-T ersenghi, G. Semerjian, and L. Zdeb oro v a, Proceedings of the National Academy of Sciences 104 , 10318 (2007), http://www.pnas.o rg/cgi/reprin t /104/25/10318.pd f. [23] R. Monasson and D. O’Kane, Europhysics Letters 27 , 85 (1994). [24] T. R. Kirkp atric k and D. Thirumalai, Phys. Rev . B 36 , 5388 (1987). [25] M. T alagrand, Spin glasses: a chal lenge for mathematicians (Springer, Berlin, 2003). [26] D. Panc h enko and M. T alagrand, Probab. Theory Relat. Fields 130 , 319 (2004). [27] S. F ranz and M. Leone, J. Stat. Phys. 111 , 535 (2003). [28] M. M´ ezard, F. Ricci-T ersenghi, and R. Zecchina, J. Stat. Phys. 111 , 505 (2003). [29] S. Co cco, O. Dub ois, J. Mandler, and R. Monasson, Phys. Rev. Lett. 90 , 047205 (2003). [30] M. M´ ezard, T. Mora, and R. Zecchina, Physical Review Letters 94 , 197205 (pages 4) (2005). [31] H. Daud´ e, M. M ´ ezard, T. Mora, and R . Zecc hina (2005), arXiv:cond-ma t/0506053 . [32] D. Achlioptas and F. R icci-T ersenghi, Proceedin gs of th e thirty-eighth annual ACM symp osium on Theory of computing (2006), arXiv:cs.CC/0 611052 . [33] F. Ricci-T ersenghi, M. W eigt, and R. Zecchina, Phys. Rev. E 63 , 026702 (2001). [34] B. Pittel, J. Sp encer, and N. W ormald, J. Com b . Theory , Ser. B 67 , 111 (1996). [35] T. Kurtz, J. A ppl. Probab. 7 , 49 (1970). [36] A. Montanari and G. Semerjian, J. S tat. Phys. 124 , 103 ( 2006). [37] T. Mora and M. M´ ezard, Journal of Statistical Mec hanics: Theory and Exp eriment 2006 , P10007 (2006). [38] S. Mertens, M. M´ ezard, and R . Zecc hina, Ran d om Struct. Algorithms 28 , 340 (2006). [39] M. M´ ezard, M. Pa lassini, and O. Rivoire, Physica l Rev iew Letters 95 , 200202 (p ages 4) (2005). [40] A. Montanari, G. Pari si, and F. Ricci-T ersenghi, Journal of Physics A : Mathematical and General 37 , 2073 (2004). [41] T. Mora and L. Zdeb orov a ( 2007), arXiv:071 0.3804 . [42] G. Semerjian, J.Stat.Phys. 130 , 251 (2008). [43] R. Monasson, Journal of Physics A : Mathematical and General 31 , 513 (1998). [44] M. M´ ezard and G. Paris i, Eur. Phys. J. B 20 , 217 ( 2001). [45] M. M´ ezard and G. Paris i, J. Stat. Phys. 111 , 1 (2003). [46] F. R. K sc hischang, B. J. F rey , and H.-A. Lo eliger, I EEE T rans. In f. Theory 47 , 498 (2001). [47] A. Braunstein, M. M ´ ezard, and R. Zecchina, R andom Struct. Algorithms 27 , 201 (2005). [48] J. S. Y edidia, W. T. F reeman, and Y . W eiss, Ad v ances in Neural Information Pro cessing Systems 13 , 689 (2001). [49] J. S. Y edidia, W. T. F reeman, and Y . W eiss, in Exploring Ar tificial Intel ligenc e i n the New Mi l lennium (2003), p. 239. [50] W. F ern andez de la V ega, Theor. Comput . Sci. 265 , 131 (2001). [51] B. Bollob´ as, C. Borgs, J. T. Cha yes, J. H. Kim, and D. B. Wilson, Random Struct. Algorithms 18 , 201 (2001). [52] A. Amraoui, A . Montanari, T. R ichardso n, and R . Urbanke, arXiv:cs.IT/040 6050 ( 2004). [53] A. Dembo and A . Montanari, arXiv:math.PR/0702 007 (2007). [54] D. B. Wilson, Random Struct. Algorithms 21 , 182 (2002). [55] S. Kirkpatrick and B. Selman, Science 264 , 1297 (1994). [56] R. Monasson, R . Z ecchina, S. Kirk p atric k, B. S elman, and L. T roya nsky , Random Struct . A lgorithms 15 , 414 (1999). [57] P . De Gregorio, A. Lawlo r, P . Bradley , and K. D a wson, PNA S 102 , 5669 (2005). [58] L. Cugliandolo, in Slow r elaxations and none quilibrium dynamics in c ondense d matter , edited by J. L. Barrat, M. F eigel- man, J. Kurchan, and J. Dalibard ( Springer-V erlag, Les Houches, F rance, 2003). [59] C. Papadimitriou, in Pr o c e e dings of the 32th Annual Symp osium on F oundations of Computer Scienc e (1991), pp. 163–169. [60] R. Motw ani and P . Rav aghan, R andomize d algorithms (Cam bridge Un ivers ity Press, Cambridge, 1995). [61] U. Sch¨ oning, Algorithmica 32 , 615 (2002), I S SN 0178-4617 (print), 1432-0541 (electronic). [62] S. Baumer and R. Sch uler, Lecture Notes in Comput er Science 2919 , 150 ( 2004). [63] G. Semerjian and R. Monasson, Phys. R ev. E 67 , 066103 (2003). [64] W. Barthel, A . K . Hartmann, and M. W eigt, Phys. Rev. E 67 , 066104 (2003). [65] T. M. Liggett, Inter acting p article systems (Springer, Berlin, 1985). 26 [66] M. Alekhnovic h and E. Ben-S asson, SIA M Journal on Computing 36 , 1248 (2006). [67] B. S elman, H. A . Kautz, and B. Cohen, in Pr o c e e dings of the Twel fth Nat ional Confer enc e on A rtificial Intel ligenc e (AAAI’94) (S eattle, 1994), pp. 337–343. [68] D. McAllester, B. Selman, and H. Kautz, in Pr o c e e dings of the F ourte enth National C onf er enc e on Artificial Intel ligenc e (AAAI’97) (Providence, Rho de Island, 1997), pp. 321–326. [69] S. Seitz, M. Ala v a, and P . Orp onen , Journal of Statistical Mechanics: Theory an d Exp eriment 2005 , P06006 (2005). [70] J. Ardelius and E. Aurell, Physical Review E (Statistical, Nonlinear, and Soft Matter Ph ysics) 74 , 037 702 (pages 4) (2006). [71] M. Alav a, J. Ardelius, E. Aurell, P . K aski, S. K rishnamurth y , P . Orp onen , and S. Seitz (2007), arXiv:0711.490 2 . [72] M.-T. Chao and J. F ranco, S IAM J. Comput. 15 , 1106 (1986). [73] M.-T. Chao and J. F ranco, I n f. Sci. 51 , 289 (1990). [74] D. Achlioptas, Theor. Comput. Sci. 265 , 159 (2001). [75] A. F rieze and S. S uen, J. Algorithms 20 , 312 (1996). [76] D. Achlioptas, L. Kirousis, E. Kranakis, and D. Krizanc, Theor. Compu t . Sci. 265 , 109 (2001). [77] S. Co cco and R . Monasson, An n. Math. Artif. Intell. 43 , 153 (2005). [78] C. Deroulers and R. Monasson, Europhysics Letters 68 , 153 (2004). [79] R. Monasson, in Complex Systems , edited by J. P . Bouchaud, M. M ´ ezard, and J. Dalibard (Elsevier, Les Houches, F rance, 2007). [80] S. Co cco and R . Monasson, Phys. Rev. Lett. 86 , 1654 (2001). [81] R. Monasson, A gener ating function metho d for the aver age-c ase analysis of DPLL. , Lectu re Notes in Computer Science 3624, 402-413 (2005). (2005). [82] P . Beame, R. Karp, T. Pitassi, and M. Saks, SIAM Journal of Computing 31 , 1048 (2002). [83] S. T atikonda and M. Jordan, in Pr o c. Unc ertainty i n Artificial Intel l. (2002), vol . 18, p p. 493–500. [84] A. Montanari and D. Shah, in SOD A (2007), pp. 1255–12 64. [85] A. Braunstein and R. Zecchina, Journal of Statistical Mechanics: Theory and Exp erimen t 2004 , P06007 (2004). [86] E. Manev a, E. Mossel, and M. J. W ainw right, in SODA ’05: Pr o c e e dings of the sixte enth annual ACM-SIAM symp osium on Discr ete algorithms (So ciety for Industrial and Ap plied Mathematics, Philadelphia, P A, USA, 2005), p p. 1089–1098, ISBN 0-89871-585-7. [87] E. Aurell, U. Gordon, and S. K irk patric k, in NI PS (2004). [88] G. Pari si (2003), arXiv:cs.CC/03 01015 . [89] D. Battaglia, M. Kol´ a ˇ r, and R . Zecchina, Phys. Rev. E 70 , 036107 (2004). [90] J. Chav as, C. F u rt lehner, M. M´ ezard, and R. Z ecchina, Journal of S tatistical Mechanics: Theory and Exp eriment 2005 , P11016 (2005). [91] G. Pari si (2003), arXiv:cond-mat /0308510 . [92] URL http://www.ict p.trieste.it/ ~ zecchina/S P . [93] A. Monta nari, F. Ricci-T ersenghi, and G. Semerjian (2007), , to b e published in the Proceedin gs of the 45th Allerton Conference (2007). [94] U. F eige, in STOC (2002), pp. 534–543. [95] U. F eige, E. Mossel, and D . V ilenc hik, Complete c onver genc e of message p assing algorithms for some satisfiability pr ob- lems. , Lecture Notes in Computer Science 4110, 339-350 (2006). (2006). [96] F. Altarelli, R. Monasson, and F. Zamp on i, Journal of Physics A: Mathematical and Theoretical 40 , 867 (2007). [97] A. Co ja-Oghlan, M. Krivele vich, and D. Vilenchik, Why almost al l k-cnf formulas ar e e asy , to app ear (2007). [98] F. Krzak ala, A. Pa gnani, an d M. W eigt, Phys. R ev . E 70 , 046705 (2004). [99] L. Zdeb orov´ a and F. Krzak ala, Physical Review E (Statistical, Nonlinear, and S oft Matter Physics) 76 , 031131 (pages 29) (2007). [100] W. Barthel, A. K. Hartmann, M. Leone, F. Ricci-T ersenghi, M. W eigt, and R . Zecchina, Phys. R ev. Lett. 88 , 18870 1 (2002). [101] A. Montanari and G. Semerjian, J. S tat. Phys. 125 , 23 (2006).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment