Identification of information tonality based on Bayesian approach and neural networks
A model of the identification of information tonality, based on Bayesian approach and neural networks was described. In the context of this paper tonality means positive or negative tone of both the whole information and its parts which are related t…
Authors: D.V. L, e
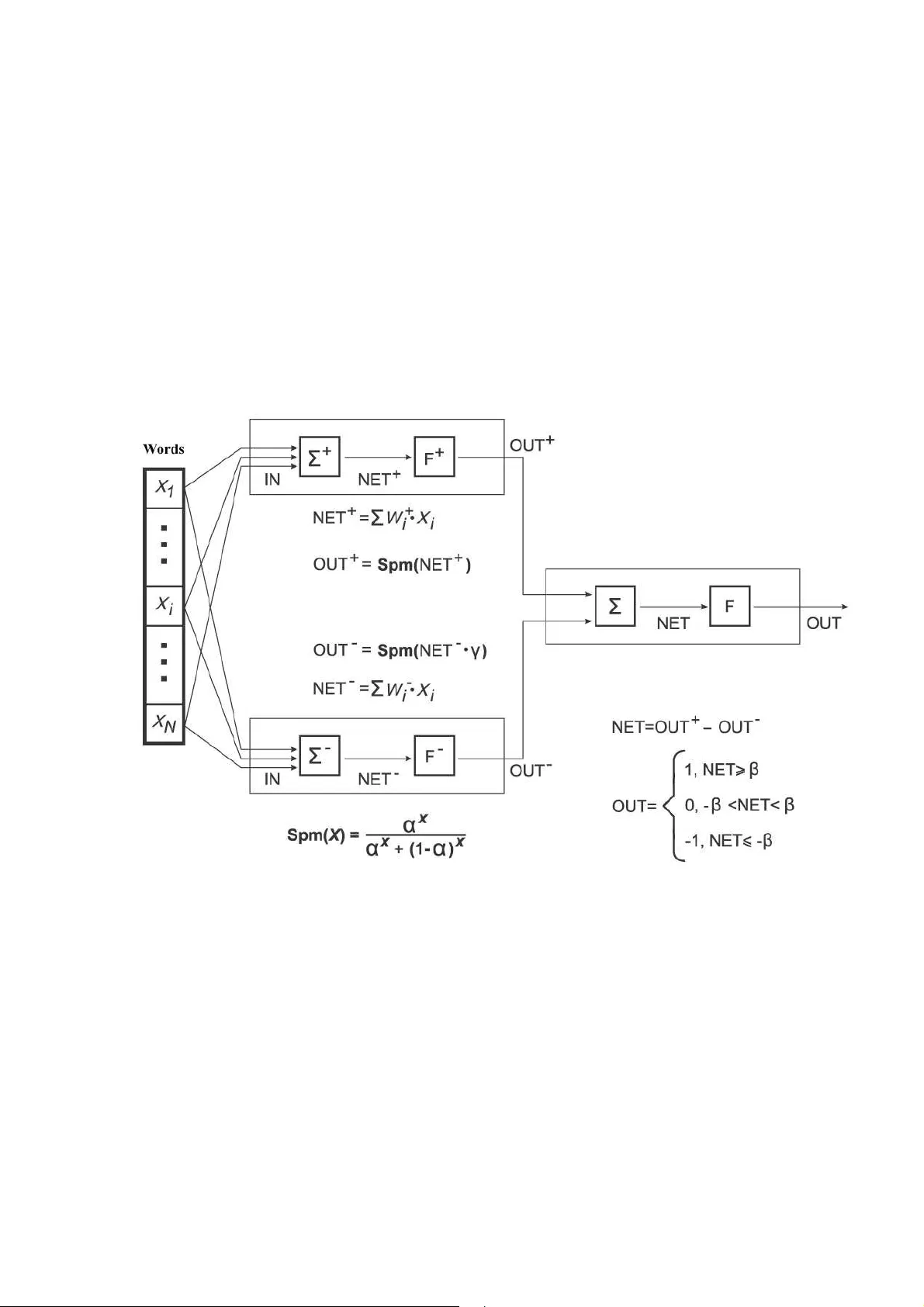
1 Identification of information tonali ty based on Bayesian approach and neural networks D.V. Lande ElVisti Information center, Kiev, Ukraine A model of the identification of information tonality, based on Bayesian approach and neural netw orks was described. In the conte xt of this paper t onality means positive or negative tone of both t he whole i nformation and its parts which are related to particular concepts. The me thod, its application is prese nted in the paper, is based on statistic re gularities c onnected with the presenc e of d efinite lexemes in the texts. A distinctive f eature of the method is i ts simplicity and versatilit y. At present ideologically similar approaches are widely used to control spam. Key words: information flows, Bay esian theorem, Internet, text file, tonality, neural network, emotional tone Tonality issue The pace of development, d ynamics and bodies of information space of the Internet transform it into i nformation flow [1]. Studying the flow of news i nformation, published on t he pages of Web-sites, s hould use an absolutely new mechanisms, as the conv entional methods ca nnot always cove r eve n the representative part of this flow (nothing to sa y about the whole flow). A traditional exp ert estimation of text information appears to b e inefficient for super large and supe r dynamic text files. One of the aspects of the analysis of text information from current information flows, namely, the estimation of text t onality, is considered in this paper. In the context of this paper text tonality refers t o positive, negative or neutral emotional tone of both the whole information and its separate parts, related to particular concepts such as persons, organiz ations, brands etc. The s ystem "VAA L" [2] is t he best known in the sphere of automati on of the process of text tonality identification; it is oriented on an e motional-ligical anal ysis. This system is based on making a frequenc y word list, its analysis as to the availabilit y of particular words which allow, with some probability, to determine ps ych- linquist ic categories Another approach, orient ed on the use of linguistic algorithms, statistic text anal ysis, which takes into consideration modal characteristics of t he situation, modus meanings and author 's attitude to a described situation, is a promising one; however, it is quite re source-consuming and not versatile enough. Besides, the n ature of t he majorit y of ele ctronic publications makes it possibl e to estimate text tonality, its emotional tone directl y by it s vocabulary, which is close to th e approa ches used in the system "VAAL". The method, its applicati on is presented in the paper, is based on sta tistic regularities connected with the pres ence of definite lexemes in t he tex ts, naïve Bayesian approach and neural networks (realization of two-layer perceptron). A distinctive feature of t he method is i ts simplicit y and versatility, the accuracy of the estimation being regulated parametricall y in a rather wide range. At present ideolog ically similar approaches are widel y used to control spam and they yield g ood results [3, 4]. However, it i s necessary to mention th at the task of t he identi fication of information tonalit y is more complicated than that of spam based on the text analysis. To id entify spam implies two hypotheses (spam, not spam); when we identif y tonalit y three aspects are involved: emotional positive, negative, neutra l tone, and quite frequentl y there is a necessit y to check the combination of these hypotheses (for example, to determine the level of text "expressiveness"). On the othe r hand, unlike the p roblem of spam i dentification whe re estima tion of i ndividual documents can b e clos e t o one-valued, in case of tonalit y identification even various people-ex perts 2 do not always agree. Here the situation approach es the estimation level o f relevanc y-pertinency in information search. Bayesian approach to the estimation of info rmation tonality As the suggested approach is close t o the on e which is used in Bayesian anti-spam filt ers, let us first consider the app lication of Ba yesian theorem to solve spam problems. Ba yesian method envisages the use of an estimation t ool – two bodies of el ectronic letters: one of them is made of spam, the other on e – of usual letters. Word frequency is calculated fo r each body, then weight estimation is m ade (from 0 to 1), which characterizes conditional probabilit y th at the information with this word is spam. Meanings of the weight s, close to ½, ar e not considered in integrated calculation, and the words with such weights are ignored and removed fro m dictionaries. According to t he method, suggested by Paul Gr aham, i f information contains n words with weight meanings w 1 ...w n , the estimation of conditional probabili ty, that a letter is spam, which is based on the data from estimation bodies, is calculated with help of a formul a: . ( 1 ) = + − ∏ ∏ ∏ i i i w Spm w w (1) This formula is explained with the followi ng con siderations. I t is assumed that S is an ev ent which means that a l etter is spam, А is an eve nt which means that a letter has wo rd t . Then i n accordance with Bayesian formula, it is true: ( | ) ( ) ( | ) . ( | ) ( ) ( | ) ( ) = + P A S P S P S A P A S P S P A S P S (2) If it is not clear ini tially whether a letter is sp am or not, then based on t he ex perience, it is suggested that P S = λ P(S) , and it comes from (2) that: ( | ) ( | ) . ( | ) ( | ) = + λ P A S P S A P A S P A S (3) Further, formula (3) i s generalized in the foll owing wa y. It is assumed that A 1 and A 2 are events which mean that a letter contains words t 1 and t 2 . Another assu mption i s that these events are not dependent (this i s exactly wh y the method is called "n aïve" Ba yesian). Cond itional probabilit y that the letter, containing bot h words ( t 1 and t 2 ), is spam, is equal to: 1 2 1 2 1 2 1 2 1 2 1 2 1 2 ( | ) ( | ) ( | & ) ( | ) ( | ) ( | ) ( | ) ( ) ( ) . ( ) ( ) ( 1 ( ))( 1 ( )) = + λ = + λ − − P A S P A S P S A A P A S P A S P A S P A S p t p t p t p t p t p t (4) Formula (1) is the generalizati on of formula (4) in case of a randomiz ed number of words and λ =1. We h ave to m ention that th e meaning λ =1 is the most widel y us ed in anti-spam filt ers. O n the one hand, it simpl ifies calculations, but on the other hand, it distorts realit y and reduces quality performance of these programs considerabl y. 3 In pra ctice, bas ed on t he dictionaries/lists of words, which are constantl y modified, meaning Spm is calculated for each messa ge. If it exceeds some threshold level, the information is considered to be spam. When information tonalit y i s estimated, h ypothesis space will c ontain: H -1 – tonality is negative, H 0 – tonality is neutral and H 1 – tonality i s positive, H 1 - to nality i s not positive. W ords, which are typical for these documents, are picked from a document bod y with positive tonality. From them words t with meaning p (t | H 1 ), ex ceeding ½, for ex ample 0.6, are picked. Such wo rds are called tone-colored or simpl y tonal, having estimating semantics. To simpli fy the model, le t us assume that for all chosen terms wei ght will b e the same, equal to α (it can change when teaching the model). The n formula (1) will look like: ( ) . ( 1 ) α = α + λ − α x x x Spm x (5) where х – the nu mber of wei ght y words fro m the point of view o f t onali ty in t he i nformat ion message, α – wei ght. As it is s een from Fig. 1 ( α = 0.6, λ = 1), the av ailabili ty of 10 wo rds, t ypical for p ositiv e tonalit y, guarantees th at th e informati on mess age wil l posses s the sam e propert y. Fig. 1. A plot of a funct ion Spm(x) To estimate a h ypothesis about n egative t onalit y o f i nformatio n ( H -1 ), a li st of words with "negative tonality" and the s ame formula (5) can be us ed. Besid es, as pos itive and negativ e tonaliti es are somewhat a ntagonism s, a final deci sion about info rmation t onality is m ade taki ng i nto consideratio n a differen ce of meanin gs of wei ght hypothesis estimat ion H 1 and H -1 . A t hreshol d meaning o f this qu antit y - β is defined in the pro cess of adjust ing (teachin g) th e system. It is necess ar y to make one more remark, p ro mpted b y practic al exp erience. Ne gative informati on tonalit y in the Internet is almost always exp ressed mor e vividly than a posit ive one.To compare tonalities while calculatin g t he weight of negative tonalit y, m eanin g х in fo rmula (5) is decreased sl ightl y through m ultip lying it b y empirical ly defined co nstan t γ ∈ 0 , 1 . In some cases the docu ments, whi ch have high weight mean ings of bot h positive and negative tonali ty, presen t certain inter est for anal ysists. The differen ce of these weights m a y be minim al, i.e., the document may be char acteriz ed as neu tral. In add ition, it will get a characte ristic of "exp ressive" tonal it y. 4 Model of neural network The realiz ation of a giv en algori thm will b e presented in th e form of neural network [ 5] (Fig. 2). The fi rst layer of this network co ntains two neurons – determ inan ts of weight meanin gs of positi ve and negative ton alit y (po sitive and neg ative neurons). We can assum e that the n umber of dentrites of each neuron is equal to that of layers from the diction ary o f a natu ral langua ge. Input signals – meani ngs x 1 …x n , which correspon d to input words come to a neuron entr y. In th is case x i = 1, if t he w ord with nu mber i entered, then x i = 0. Weight meanin gs (s ynapse wei ghts), whi ch correspond to these w ords, are equ al to w + 1 …w + n for a pos itive neuron and w - 1 …w - n – for a n egative one. It is these we ght meanin gs that can chan ge in the process of teachin g p erceptron. Th e adders calculate t he meani ngs of N ET + and NET - , corres pondin gly. Neuron conductance is calculated with formula (5), t he ar gument is m enaing NET + for a po sitive neuron and γ NET - fo r a negative on e. Both neu rons, via axon s/neurites , give gradient m eanings, OU T + and OUT - , which are input signals for a n euron of the second level, whos e adder cal culates th e differen ce OUT + an d OUT - , and conductanc e function giv es a gradi ent result as it is s hown in Fig. 2. Fig. 2. A two-la yer percept ron wh ich determi nes text ton ality Practical application of the approach A sug gested model i s re aliz ed i n th e conten t-minit oring InfoStre am s y stem , whi ch is used t o implem ent th e tasks of gatherin g news i nformat ion from open web-sites , its systematizat ion and ensuring th e access to it in retrieval/sear ch regim es. At present this system covers 350 0 so urecs – over 6 0000 uniqu e n ews in formation wi thin 24 hours. To navi gate in t hese inform ation resour ces and to specif y inqui ries, a mechan ism of inform a tion portrait was worked o ut; it is a m ulti-aspect selection of choosi ng parameters b ased on the in itiall y m ade requ est/inq uiry. In th e informati on portrait the m eanin g of inform ation tonal ity is us ed as one o f t he param eters, the sp ecificat ion of which makes it pos sible to sin gle out pu blication s of negative or posi tive t onali ty, co rrespond ing to the to pics, defined b y the initi ally enter ed in quiry. An other feature of InfoSt ream s ystem is t o monito r the appea rance dynamics of the conc epts, which correspond to the inquiries entered by the users. The m essa ges, ma rked with pos itive or ne gat ive t onalit y, form se gments of green or r ed col or on a corresp ondin g diagram . 5 From text tonality to concept tonality A su ggested algo rithm is used as an instrum ent to identi fy gen eral inform ation tonali ty, while tonali ty of separat e co ncepts, covered b y t he m essage, does not alwa ys corresp ond to the tonalit y of the whole informati on. W e can assu me (accordin g to experts -anal ysts, such assumpti on is q uite justified in p ractice) that when a lar ge info rmation channel corres pond ing to som e inq uiry is anal y zed, an emotional tone of a target concept will coincide with t he integral estimati on of the informati on channel. More ac curate results can be received when a fragment, e.g. a para grap h, cont aining a concept of int erest, a se ntence or ev en a part of the senten ece, is estim ated rathe r t han the who le informati on. It is cl ear, t hat such app roach do es not ensur e ac curacy in ever y case, and the in formation being divid ed into small parts m ay lose th e who leness o f its m eaning. H owever, w e stress again, that fo r represen tativ e in formatio n chann els relating to a tar get con cept, a s uggested method olog y appears to b e not o nly "tran sparent" bu t also qu ite effici ent du e to stati stic regul arities. Reference 1. Braichevski i, S.M . Lande, D.V. Ur gent asp ects of curr ent inform ation flo w // S cientific and technical in formation processi ng / - Al lerton press , inc. – Vol 32 , part 6. -20 05. – P. 18-31 . 2. VAAL Pro ject. http ://www.v aal.ru/ 3. Graham P. A Plan for Spam . http ://paulgraham. co m/spam .html, August 200 2. 4. Graham P. Better Bayesian Fil terin g. http://p aulgraham.co m/better.h tml, J anuar y 2003. 5. Ha ykin, S. Neural N etworks: A C ompreh ensive Foundation. - New York: Macmill an, 1994.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment