Mining a medieval social network by kernel SOM and related methods
This paper briefly presents several ways to understand the organization of a large social network (several hundreds of persons). We compare approaches coming from data mining for clustering the vertices of a graph (spectral clustering, self-organizin…
Authors: Nathalie Villa (IMT), Fabrice Rossi (INRIA Rocquencourt / INRIA Sophia Antipolis), Quoc-Dinh Truong (IRIT)
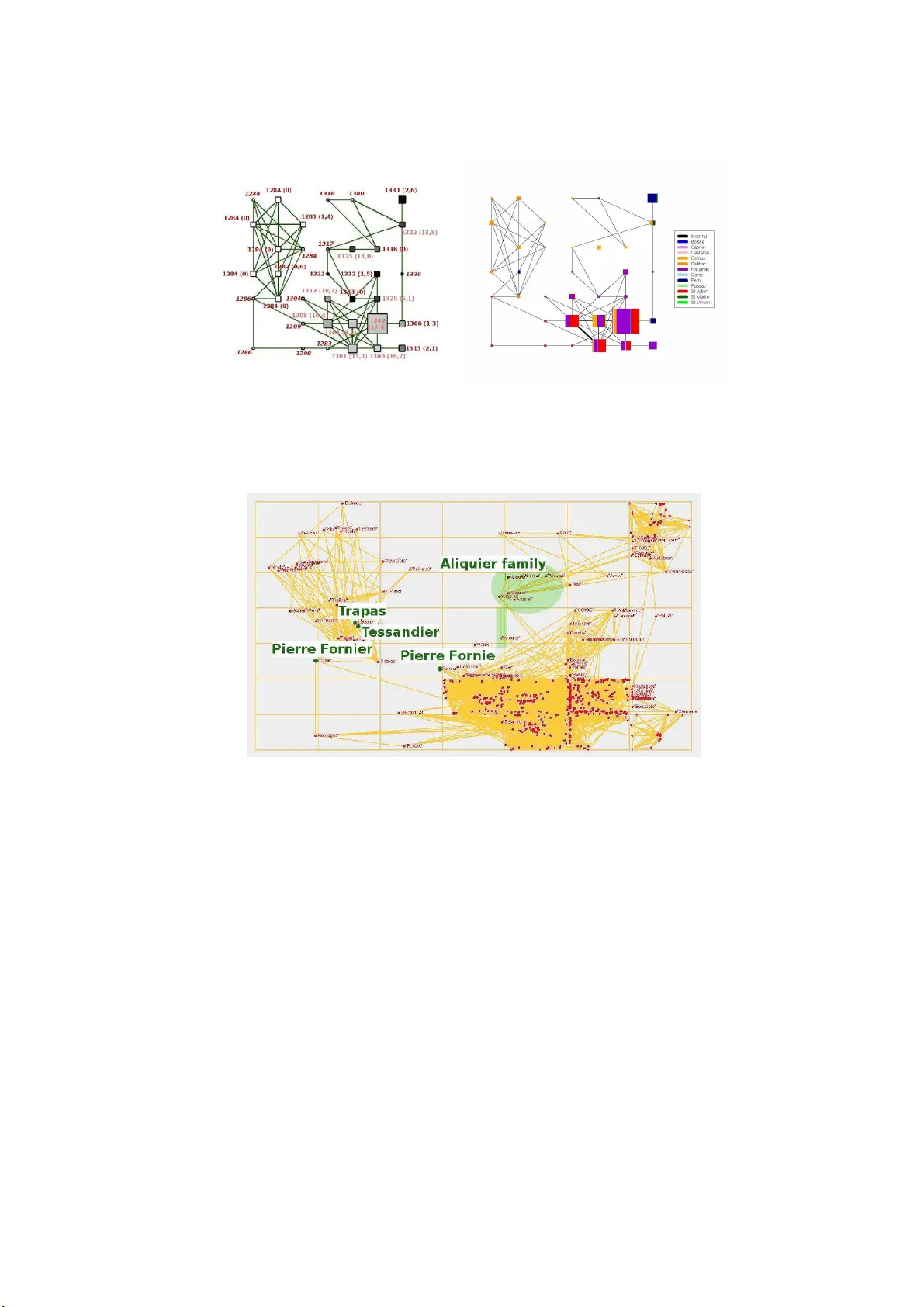
Mining a mediev al social network by k ernel SOM and rela ted met hods Nathalie Villa 1 , 2 , F abrice Rossi 3 & Quo c Dinh T ruong 4 1 IUT de Carcassonne, Univ ersit ´ e de P erpignan, P erpignan. F rance 2 Institut de Math ´ ematiques de T oulouse, Universit ´ e de T oulouse, T oulouse, F r ance nathalie.villa@math.univ-toulouse.fr 3 INRIA, Pro jet AxIS, Ro cquencourt, F r an ce fabrice.rossi@inria.fr 4 IRIT, Univ ersit´ e de T oulouse, T oulouse, F rance truong@univ-tlse2.fr Abstract - This p ap er briefly pr esents sever al ways to understand the or ganization of a lar ge so cial network (sever al hundr e ds of p ersons). We c omp ar e appr o aches c oming fr om data min- ing fo r clustering the vertic es o f a gr aph (sp e ctr al clustering, self- or ganizing a lgorithms. . . ) and pr ovide metho ds for r epr esenting th e gr ap h fr om these analysis. Al l these metho ds ar e il lustr ate d on a me dieval so cial netwo rk and the way they c an help to understand its or gani- zation is underline d. Key w ords - so cial netw ork, large graphs, SO M algorithm, graph drawing, clus- tering, spe ctral clustering, hea t kernel 1 In tro duction A large num b er of practical applications can b e mod eled through what is commonly called a “complex n et work”. Complex net w orks are relational data, that app ear in W orld Wide W eb studies, in so cial net w orks or in biol ogical s tudies (genes, proteins, metab olites interac tion net works) for example. This work is based on a historical database bu ilt from the arc hiv es of Lot, a small region in South W est of F rance. Th is database has already b een p r esen ted in [2]: in a tin y geographi- cal lo cation around Castelnau-Mon tratier, a large do cu m en tation has b een collected (see [9] for a complete p resen tation). This do cumentati on, made of ab out 1000 agrarian contract s (a v ailable at http://gra phcomp.u niv- tlse2.fr ) i s a v ery precious source of information ab out the p easan ts’ usual life in the m iddle ages where m ost of the written do cuments w ere concerned b y the well -educated part of the p opu lation. All the con tr acts are agrarian trans- actions: they men tion the name of the inv olv ed p easan t (or the p easan ts), th e names of the lord and the notary to wh om the p easan ts are related, some of the neigh b ors of th e p easan ts and v arious other in formations (suc h as the t yp e of tr an s action, the lo cation, the d ate, and so on). All the stud ied transactions w ere written b et w een 1260 and 1340 that is, just b efore the Hundr ed Y ears’ W ar but others concerned the p erio d just after this W ar. F rom this database, a relational n etw ork is bu ilt follo wing the advices pro vided b y the his- torians (see [4]). This so cial net w ork is describ ed by a weig hte d gr aph with 615 ve rtices (the MASHS 2008, C reteil p easan ts) and 4193 edges standing for the relations b et ween them. The edges are weigh ted b y th e num b er of relations foun d b et ween t wo giv en p easan ts. The obtained graph is d e- scrib ed in [4] where it is analyzed thr ough the comparison of an algebraic study and of a SOM algorithm. Th e collab oration b etw een mathematicians, computer scientists and his- torians inte nds to pro vide seve ral tools for historians to under s tand this complex and large net work. A part of the metho ds deve lop ed are coming f rom s tatistics and d ata min ing and will b e review ed and illustrated in this pap er. Comp lemen tary material could b e found in [4] and complemen tary studies of the database are av ailable in [3 , 2]. The pap er is organized as follo ws: Section 2 presents the p roblem of clustering the v ertices of a large graph an d exp lains h o w this problem can help to und erstand the structure of the graph. Sev eral metho ds are reviewe d and some of them, coming f r om w hat is called sp e ctr al clustering , a re illustrated on the m ediev al database. Section 3 explains ho w this clustering can b e used to pr o vid e a simplified repr esen tation of the graph. This leads us to use organization algorithms designed for graphs in order to classify and organize sim ultaneously the v ertices of the graph: kernel SOM, describ ed in section 4, target s such a du al ob jective . Finally , Section 5 in tends to represent the whole graph from this final organizing map. Examples of insigh ts on the d ata obtained b y the review ed metho d s are giv en at eac h step of the analysis. 2 Clustering the v ertices of the graph Large graphs representi ng complex net works are not easy to u n derstand. One wa y to simplify them, in order to u n derline the main tend ances of their structure, is to find dense subgraph s that ha v e few connections to eac h others. As emph asized by [13], r e ducing [the] level of c omplexity [of a network] to one that c an b e interpr ete d r e adily by the human eye, wil l b e invaluable in helping us to understand the lar ge- sc ale structur e of these new network data. But such a clustering of the ve rtices of a graph is facing the prob lem of relational data: there is no a priori d istance b etw een tw o vertic es and thus classical clustering algorithms, s uc h as, e.g., k -means, cannot b e directly u sed. A recent survey on clustering metho d s adapted to graphs is provided in [14]. Clustering th e v ertices of a graph is commonly ad d ressed by the u se of a diss imilarit y b et ween vertic es or by mappin g the graph on an euclidean space; then usual data min ing tools can b e u sed to fin d a con venien t clustering. Recen tly , sp e ctr al c lustering b ecame a successful metho d among th is kind of metho dologies (see [24] f or a v ery exhaustive tutorial on this sub ject): sp ectral clustering uses the prop erties of the L aplacian of the graph to understand its structure. Gi v en a w eighte d graph G w ith v ertices V = { x 1 . . . , x n } and edges we igh ted by ( w i,j ) i,j =1 ...,n ( w i,j = w j,i and w i,i = 0), the Laplacian is the matrix L suc h that L i,j = − w i,j if i 6 = j, d i = P n j =1 w i,j if i = j. The Laplacian app ears as a very con v enient to ol for under s tanding the graph as its eigen v alue decomp osition is directly related to the min cut problem (“Ho w to find a p artition of the v ertices that minimizes the n u m b er of cuts in the graph ?”, see [24]) and to the pr oblem of fin ding p erfect comm un ities, i.e., complete subgraph s those vertice s hav e exactly the same neigh b ors (see [4, 21]). More precisely , sp ectral clustering uses the eigen vec tors asso ciated with the smallest eigen v alues of the Laplacian to m ap the graph on an E uclidean space where a k -means algorithm is p erformed . Mining a mediev al so cial net w ork b y k ernel SOM and related metho ds But [4] notes that the sp ectral clustering metho d giv es equ al weigh ts to the first p eigen vect ors of the Laplacian, whereas the s maller the eigen v alue is, the more im p ortan t the corresp ond ing eigen ve ctor is. Moreo v er, only the firs t p eigen v alues are used and, hen ce, this appr oac h do es not u se the en tire structure of the graph . T o av oid these p roblems, one can u se a regularized v ers ion of the L aplacian: the heat ke rnel (also called the diffus ion ke rnel). The diffu sion matrix of the graph G for the parameter β > 0 is D β = e − β L and the d iffusion kernel is th e function K β : ( x i , x j ) ∈ V × V → D β i,j . Th is diffusion k ernel has b een in tensiv ely studied and used through the past yea rs (see [5, 10, 17, 15, 22], among others). One of its main desirable prop er ties comes from Aronsza jn ’s Theorem [1] th at states that th ere is a repro ducing k ernel Hilb ert space (RKHS), H β , called th e feature space, and a mappin g fu nction, φ β : V → H β suc h that for all i, j , h φ β ( x i ) , φ β ( x j ) i H β = K β ( x i , x j ) . (1) This last equation is commonly known as kernel trick and means that K β is simply a scalar pro du ct b etw een images by φ β of the v ertices of the graph. Similarly as sp ectral clustering, a k -means algorithm can b e p erformed on this mapping. This metho d is kno wn un der the name kernel k -me ans (see [16, 7, 6]). On a p ractical p oin t of view, partitions coming fr om sp ectral clustering and kernel k -means cannot b e directly compared b y the w a y of k -means error b ecause the m apping of the graph is not the same: the un derlined metrics are n ot comparable. T he same o ccurs for partitions coming from k er n els with differen t v alues of β . T o enable a comparison b et w een all these parti- tions, we use a qu alit y measure int ro du ced by [12], the q -mo dularity , Q mo dul = P k j =1 ( e j − a 2 j ) where k is the num b er of clusters, e j is the fraction of edges in the graph that connect tw o v ertices in cluster j and a j is the fr action of th e edges in the graph that connect to one v ertex in cluster j . This criterion do es not dep end on a m apping or a d issimilarit y on the graph and is easily interpretable in terms of probability of ha ving in/b et we en-clusters edges: a h igh q -mo d ularit y m eans that v ertices are clustered in to dense su bgraphs ha ving few edges b et w een them. T able 1 summarizes the main charac teristics of the partitions into 50 clusters of the m ediev al graph obtained b y th ese tw o app roac hes. Obvio usly , b oth partitions share common pr op er- ties: the q -mo du larit y is similar and the vertic es are concentrate d in a few num b er of large clusters. More than thr ee fourth of the ve rtices b elong to a cluster ha ving less than 7 vertic es and th e largest cluster cont ains more than one third of the vertic es of the whole graph. In conclusion, the partitions pr o vid ed by these tw o sim p le to ols ha ve to b e improv ed. Spec tr al clus tering Kernel k -means ( β = 0 . 0 5) q -mo dular ity 0.4195 0.4246 Num ber of cluster s of size 1 16 17 Maximum size of the clusters 268 242 Median of the cluster s’ size 2 2 3 r d q uartile of the c lus ters’ s ize 7 7 T able 1: Details ab out the p artitions obtained by sp ectral clustering and kernel k -means MASHS 2008, C reteil 3 Dra wing the graph F rom any p artition obtained by clustering th e graph, a simplified representat ion can b e ob- tained by assigning a given glyph to eac h cluster w here the su rface of the glyph is pr op ortional to the num b er of v er tices of the giv en cluster. At the same time, glyphs are connected to eac h others b y edges wh ose wid th is also p rop ortional to the total n um b er of w eight s b et ween the v ertices b elonging to the t w o corresp ondin g clusters. Glyphs can b e sp atially p ositioned b y a for c e dir e cte d algorithm that aims at pro v id ing an aesthetic repr esen tation of a graph b y assigning f orces amongst th e edges and no des (see [8]). Examples of suc h a repr esen tation are giv en in Figure 1 for the t w o partitions describ ed in section 2 1 . Figure 1: F o rce-directed algo rithms used for a simplified repre s entation coming from sp ectra l clustering (left) and kernel k -means (r ight) Both represen tations share common prop erties th at can b e seen as main structural prop erties of the graph: the net work has a star shap ed structur e with t wo main groups of cen tral p eople that can b e seen as a kind of “ric h club” (see [4]). Some tiny groups are totally isolated from this tw o m ain cen tral clusters and linked to other secondary clusters. T he t w o ma jor clusters are strongly linked to eac h others. Th ese pictures seem to giv e u nderstandable representa tions of the stru cture of the graph b ut, u nfortunately , the t wo main clusters r esp ectiv ely conta in ab out 250 and 100 vertice s, that is, more th an half of th e vertic es of the graph : then, these t wo clusters are almost as complex as the initial graph. 4 A clustering and organizing algorithm Sev eral ke rnelized ve rsions of SOM algorithm, that can p erform sim ultaneously the ob j ective s describ ed in sections 2 (clustering) and 3 (r ep resen tation), has b een d escrib ed in [11]. The present pap er uses a b atc h v ersion of the k ern el SOM (that generally con verges muc h f aster) prop osed in [4, 23]. The aim of self-organizing algorithms is to pro ject the initial d ata on a prior stru cture th at is generally a grid consisting in M neurons. A neigh b orho o d relatio nship is defined on the 1 All the graph figures hav e b een made with the free softw are T ulip, a v ailable at http://www .tulip- software.org/ Mining a mediev al so cial net w ork b y k ernel SOM and related metho ds grid and the pro jection intends to p reserve the initial top ology of the data on this grid. Th e batc h k ernel S OM is simply a batc h SOM p erformed on data th at h a ve b een mapp ed on a RKHS; the algorithm is rewritten by the wa y of the ke rnel tric k (Equation (1)). This algorithm has b een applied to the m ed iev al graph with a rectangular grid of size 7 × 7. The main c haracteristics of the obtained partition is summarized in T able 2. It is compared to the partition obtained b y using the batc h SOM on the rows of the k eigen v ectors asso ciated to the smallest eigen v alues (this last approac h has b een n amed “sp ectral S OM”). Spec tr al SO M Kernel SOM ( β = 0 . 0 5) q -mo dular ity 0.433 0.551 Final num b er of cluster s 29 35 Num ber of cluster s of size 1 11 13 Maximum size of the clusters 325 255 Median of the cluster s’ size 2 3 3 r d q uartile of the clusters ’ size 10 10 T able 2: Details ab out the clusterin g obtained by sp ectral SOM and batc h ke rnel SOM The corresp onding simplified representat ions, r esp ecting the top ology of the map, are pr o- vided in Figure 2 2 where an additional information is give n by the U-matrices (see [20]) that smo othly represen t the m ean distances (resp ectiv ely in the R k space generated by k eigen v ec- tors asso ciated to the smallest eigen v alues and in the feature space) b et w een the protot yp es of eac h cluster. Clearly , kernel SOM pr o vid es b etter clustering than sp ectral SOM (larger q -mo d ularit y , muc h less v ertices in the largest clus ter). It also seems to b e a little bit b etter than the sp ectral clustering and the kernel k -means (larger q -mo d ularit y , smaller num b er of tin y clusters - with less than 5 vertic es). In b oth cases, the simplified representat ions are well organized and easy to u nderstand . Compared to Figure 1, the represen tation pro vided by kernel SO M is very close to the one pro vided by a simple clus terin g follo w ed b y a force directed representat ion of the clusters: a large cluster has a central p osition and is su rround ed by smaller clusters. But looking at the u-matrix, the map is clearly divid ed in to th ree main part (top left, top right and b ottom righ t) w hic h , according to color leve ls, are d istan t to eac h others. This fact is clearly explained b y Figure 3 (left) where the significance of eac h cluster clearly app ears: the top left p art of the map is th e oldest cluster wh ereas the top right part is the y oun gest, with a con tinuous connexion of the dates on the map. Figure 3 (r ight) also pr o vid es some int eresting informations ab out the so cial net w ork : in particular, the top left p art of the map has an homogeneous geographical setting which is th e sm all village of Divilhac. This part of the map is only linked with th e large clusters at the b ottom right b y a sin gle p easan t. This p easan t do esn ’t liv e in this village b ut in the d ominan t village of the clusters to w hic h he is linked at the b ottom righ t of the map (St Julien 3 ). T h en, it seems that generational relationships an d geographical ones are v ery imp ortan t in th is n et work. Moreo v er, it is suprisin g to s ee how ev en large clus ters hav e a go o d homogeneit y of their geographical settings 2 Colored and high quality images can b e found at http://nathalie .vialaneix .free.fr/maths/article- normal.php3?id_a r t i c l e = 8 3 Readers interested by t h e lo cation of the v illages n amed in this pap er will find a approximate map at http://map s.google.c om/maps/ms?ie=UTF8&hl=fr&msa=0&msid=100355826667676777753.000001134e74760eae6cd&z=10 MASHS 2008, C reteil Figure 2 : Final map obtained by sp ectral SOM (top left) and cor resp onding smo o thed u-matrix (top r ight) and final map obta ined by batch kernel SOM (b ottom left) and corres po nding smo othed u-matrix (bo ttom right) (see the top right an d b ottom right clusters for example). 5 Represen ting the whole graph from the ke rnel Self-Organizing Map As the la yo ut used for Figure 2 h as b een built to b e well organized, it pro vides an in teresting starting p oin t for a readable presentat ion of the whole graph. In [19, 18], T ruong e t al. dev elop ed an energy mo del, in the spirit of f orce directed algorithms, b ut under lo cation constrain ts. This m o del in tends to represent grap h s that are already clustered. By applying this algorithm to the self-organizing map p r esen ted in Figure 2 , w e obtain the r epresent ation of Figure 4 where the names of some p easants in the sm allest clusters ha ve b een ad d ed. If it is obvious that the rep resen tation of the b ottom right part of the map still has to b e imp ro ved, some imp ortan t fac ts that seem to b e of in terest for historians ha v e b een emphasized: first of all th e p easan t that links the top left part of the m ap to the b ottom righ t one is “Pierre F ornie”. T his man is already kno w n by historians to b e a ma jor c h aracter. This name also app ear a bit appart fr om the main clusters and was identi fied b y h istorians as the s ame p eople (and n ot a namesak e) w hic h means that some am biguities still exist in the database (database correction is curr en tly un derwa y , partly due to this first analysis). Moreo v er, the p ers ons having a geographical setting different from th e r est of the top left part of the map (Pern and Ganic instead of Divilhac) are named T r apas and T essend ier. They also b elong to families kno wn for th eir dominan t p ositions. T hen, some clusters rou gh ly homogeneous on the geographical p oint of view are connected to similar clusters via imp ortant Mining a mediev al so cial net w ork b y k ernel SOM and related metho ds Figure 3: Mean dates of each clusters with standard deviatio n in pa r enthesis (left) and geogr aphical settings distr ibution of each cluster (r ight) Figure 4 : Representation of the whole mediev a l graph co ming from kernel SOM families that do n ot liv e in the same area and that can b e seen as imp ortan t links b et ween villages. Finally , the top right part of the map is linked to the b ottom right one by a single family named Aliquier family , this leads to id en tify this family as b eing v er y imp ortan t for the so cial cohesion of the net w ork. All these remarks h a ve h elp ed h istorians to u nderstand the organizatio n of the so cial n et work. Moreo v er, d ominan t families hav e b een identi fied th rough th is firs t study: the next ob jectiv e of this pro ject is to und erstand ho w they structured th e so ciet y and also ho w they hav e ev olve d through the hard break of the Hundr ed Y ears’ war. This work won’t hav e existed without th e AN R Graph-Comp’s team. The auth ors thank Bertrand Jouve, pro ject’s co ordinator, for this very interes ting su b ject and for all discussions ab out it. W e also w ant t o thank Romain Boulet, T aofiq Dk aki and Pascale Kuntz for helpful discussions, F abien Picarougne an d Bleuenn Le Goffic who entirely created and managed the d atabase and, of course, Floren t Hautefeuille, h istorian at UMR TRACE S (Universit y of T oulouse Le Mirail ), who p ro vides us helpful commen ts and analysis. MASHS 2008, C reteil References [1] N. A ronsza jn. Theory of reprod ucing kernels. T r ansactions of the Amer ic an Mathematic al So ciety , 68(3):337– 404, 1950. [2] R. Boulet, F. H autefeuille, B. Jouve, P . Kuntz, B. Le Goffic, F. Picarougne, and N. Villa. Sur l’analyse de r ´ eseaux de sociabilit´ e dans la so ci´ et ´ e paysanne m´ edi ´ ev ale. In M ASHS 2007 , Brest, F rance, 2007. [3] R. Boulet and B. Jouve. Partitionnemen t d’un r´ eseau de so ciabilit ´ e ` a fort co efficient de clustering. Re vue des Nouvel les T e chnolo gie de l’Inf ormation , 9:569–574, 2007. [4] R. Boulet, B. Jouve, F. Rossi, and N . Villa. Batch ke rnel SOM and related laplacian metho ds for social netw ork analysis. Neur o c omputing , 71(7-9):1257–1273, 2008. [5] F. Chung. Sp e ctr al Gr aph The ory . Number 92 in CBMS R egional Conference Series in Mathematics. American Mathematical Society , 1997. [6] I.S. Dhillon, Y . Gu an, and B. Kulis. K ernel k -means, sp ectral clustering and n ormalized cuts. In Pr o c e e dings of International Confer enc e on Know le dge Disc overy and Data Mining , 2004. [7] M. Filipp one, F. Camastra, F. Masulli, and S. Rov et t a. A survey of kernel and sp ectral meth od s for clustering. Pattern R e c o gniti on , 41:176–1 90, 2008. [8] T. F ruc hterma n and B. R eingold. Graph drawing by force-directed placement. Softwar e-Pr actic e and Exp erienc e , 21:1129–1164, 1991. [9] F. Haut efeuille. Structur es de l’habitat rur al et territoir es p ar oissiaux en b as-Quer cy et haut-Toulousain du VI I` eme au XIV` eme si` e cle . PhD th esis, U niversit y of T oulouse I I (Le Mirail), 1998. [10] R.I. Kondor an d J. Laffert y . D iffusion kernels on graphs and other discrete structures. In Pr o c e e dings of the 19th International Confer enc e on Machine L e arning , pages 315–322, 2002. [11] K.W. Lau, H. Yin, and S. Hubbard. Kernel self-org anising maps for classification. Neur o c omputing , 69:2033 –2040, 2006. [12] M.E.J. Newman. Mixing patterns in netw orks. Physic al Re view, E , 67:026126, 2003. [13] M.E.J. N ewman and M. Girv an. Finding and ev aluating communit y structure in n etw orks. Physic al R eview, E , 69:0261 13, 2004. [14] S.E. Schaeffer. Graph clustering. Computer Scienc e R eview , 1(1):27–64, Au gust 2007. [15] B. Sch¨ olk opf, K. Tsuda, and J.P . V ert. Kernel m etho ds in c omputational biolo gy . MIT Press, London , 2004. [16] J. Sh a w e-T aylor and N. Cristianini. Kernel metho ds f or p attern analysis . Cam bridge Universit y Press, Cam bridge, UK, 2004. [17] A.J. Smola and R . Kond or. Kernels and regularizatio n on graphs. In M. W armuth and B. Sch¨ ol kopf, editors, Pr o c e e dings of the Confer enc e on Le arning The ory (COL T) and Kernel W orkshop , 2003. [18] Q.D. T ruong, T. Dk aki, and P .J. Charrel. An energy mo del for the drawing of clustered graphs. In Pr o c e e dings of V` eme c ol lo que international VSST , Marrakec h, Maro c, 21-25 o ctobre 2007. [19] Q.D. T ru ong, T. Dk aki, and P .J. Charrel. Clustered graphs drawing. I n Pr o c e e dings of Stimulating Manufacturing Exc el lenc e in SME , Hammamet, T u nisie, 14-16 f ´ evrier 2008. [20] A. Ultsch and H. P . Siemon. Kohonen’s self organizing feature maps for ex ploratory d ata analysis. In Pr o c e e dings of International Neur al Network Confer enc e (INNC’90) , pages 305–30 8, 1990. [21] J. va n den Heuvel and S. Pejic. Using Laplacian eigen v alues and eigen vectors in the analysis of frequency assignmen t problems. Annals of Op er ations R ese ar ch , 107(1-4):349–368 , 2001. [22] J.P . V ert and M. Kanehisa. Extracting active p athw a ys from gene expression data. Bioi nformatics , 19:238i i–244ii , 2003. [23] N. Villa an d F. Rossi. A compariso n b etw een dissimi larit y SOM and k ernel SOM for clustering the vertices of a graph. In Pr o c e e dings of the 6th Workshop on Self-Or ganizing Maps (WSOM 07) , Bielefield, German y , Septemb er 2007. [24] U. vo n Luxburg. A tu torial on sp ectral clustering. Statistics and Computing , 17(4):395–416, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment