Cognitive OFDM network sensing: a free probability approach
In this paper, a practical power detection scheme for OFDM terminals, based on recent free probability tools, is proposed. The objective is for the receiving terminal to determine the transmission power and the number of the surrounding base stations…
Authors: Romain Couillet, Merouane Debbah
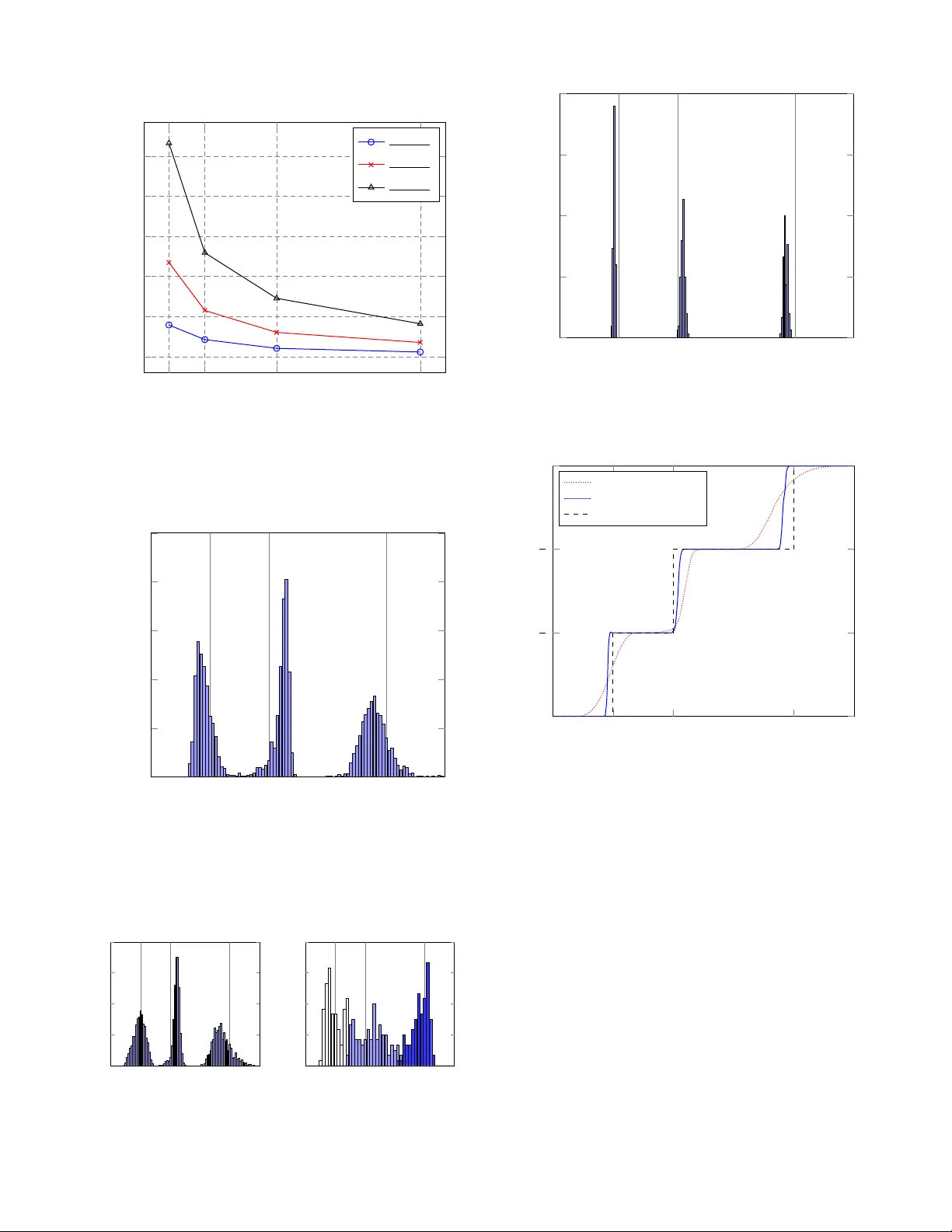
1 Cogniti v e OFDM network sensing: a free probability approach Romain Couillet ST -NXP W ireless - Supelec 505 Route des Lucioles 06560 Soph ia Anti polis, Franc e Email: romain.couillet@nxp.com M ´ erouane Debbah Alcatel-Lucent Chair , Supe lec Plateau de Moulon, 3 rue Joliot-Curie 91192 Gif sur Yvette, France Email: merouan e.debba h@supe lec.fr Abstract — In th is paper , a practical power detection scheme fo r OFDM terminals, based on recent fre e probability tools, is proposed. The objective is fo r the receiving terminal to determine the transmission power and the nu mber of the surrounding base stations in the network. Howev er , the system dimensions of the network model turn energ y detection in to an under-determined problem. The focus of this p aper is t hen twof old: (i ) discuss th e maximum amount of in for mation th at an OFDM terminal can gather from the surrounding base stations in the network, (ii) propose a practical solution for blind cell detection using th e free decon volution tool. The efficiency of this solution is measured through simulations, which show better performance than the classical p ower detection methods. I . I N T RO D U C T I O N The ever increasing deman d of hig h d ata rate has pushe d system designers to exploit the wireless channel medium to the smallest granular ity . In this respect, the ortho gonal frequ ency division multiplexing (OFDM) m odulation h as been c hosen as the next com mon standard in mo st wireless communication systems, e.g. WiMax [5], 3GPP-L TE [4 ]. OFDM converts a frequen cy selecti ve fading channel in to a set of flat fad- ing chann els [ 20], therefo re pr oviding a high flexibility in terms of p ower an d rate allocatio n. Future wireless networks therefor e tend to be based on highly load ed OFDM cells. Howe ver, in multiple cell en v ironme nts, inte r-cell in terferen ce is still the bottleneck factor whic h con siderably re duces th e network-wide capacity . Cooperation between base stations are envisioned to reach the capacity perfor mance o f the so- called br oa dcast chann el [13], but many problems (essen- tially of power allocation and user scheduling ) prevent those solutions to appe ar soon in practical standar ds. The refore, it is essential fo r mobile termin als to be ab le to d etermine which n eighbo ring cell provides the best quality of serv ice, so th at the termin al quick ly hands over this best perfor mance base station. Classically , only scarce and n arrow-band pilot sequences allow the ter minals to estimate the tra nsmission power o f the main surrou nding base stations, e.g. in 3 GPP- L TE, two sequen ces of the 0 . 7 MHz ba nd are available every 5 ms . Those synchr onization sequences are usually affected by fast channel fading and overlap data fr om other base stations; as a consequen ce numer ous occu rrences of those pilots need be accumulated to achieve a satisfying estimation of the base stations transmission p ower . The classical alterna ti ve to the pilot-aid ed ( also referred to as data-a ided ) p ower detection is to p erform a blind estimation fro m the in coming interferin g signals. This raises the fund amental cognitive radio que stion [2 3], [ 12], wh ich will be a n importan t top ic of th e presen t work: “ho w mu ch informa tion can a cogniti ve recei ver recover from the incoming signals?”. Th e response to th is q uestion answers two clas- sical concerns of eng ineers a nd system designers: (i) is the additional information brou ght by blind detection worth the computatio nal effort?, (ii) i s some gi ven blind detector solution far from providin g all the accessible informatio n?. It is clear in par ticular, from an in formatio n th eoretic v iewpoint, that the information rece i ved on the N OFDM subcarriers mu st ideally not be filtere d in order to pr ovide as much inform ation as p ossible on the problem a t hand, i. e. any filtering pro cess diminishes the a vailable inform ation in the Shannon’ s sense [1]. Theref ore, if as many as L consecutive OFDM symbols are received, the available inf ormation is c ontained in the received N × L matrix Y , with N typ ically large. As a consequen ce, since L cannot b e taken infin itely large, N / L is non tri vial. This leads to the study of large ran dom matrices problem s, which is currently a hot to pic in the wir eless commun ication co mmun ity [ 8]. This is in sharp con trast with classical p ower detection meth ods [10], [11] which are only asymptotically unb iased, i. e. these meth ods assume that on e of th e system d imensions is large with respec t to the others and this co ndition is n ecessary to en sure the c onv ergence of the u nderly ing algorith ms. Our purpo se is to r etrieve r elev an t infor mation on the base station transmission powers. It will be shown herea fter th at, depend ing on th e a priori knowledge of the receiv er , the essential part of the p ower inf ormation is, in most pr actical situations, contained in the eigenvalue distribution of the 2 matrix 1 L YY H . This naturally leads to the consideration of recent r esearch on random matrix theory (RMT) [8] and more specifically o n fre e deconv olution [1 6]. In particular, in [7], a similar stud y of terminal p ower detection in code division multiple access (CDMA) networks is derived from these to ols. Howe ver, the mo del in [7] only c onsiders flat fading ch annels and dod ges the difficulty of multi-p ath chann els; m oreover the structure of the CDMA encod ing matrix allows to easily recover the tr ansmitted signal variances, which is not the case of m ulti-cell OFDM in which m ultiple streams overlap with no dedicated code to separate them. W e p ropo se here first to discuss the o ptimal amou nt of informa tion which th e receiver can extract from the incoming data to blind ly retrieve the values of the powers transmitted b y all surround ing base stations, wh en the rece i ver’ s prior state of knowledge about the environment is very limited. From th is analysis, it will be observed th at the general problem is not very tractab le b oth in term s o f mathematical derivation an d therefor e in ter ms of practical implem entation. Seco ndly , we propo se a suboptimal but im plementable approa ch to so lve the cell detection prob lem, ba sed o n the free pr obability framework, fo r which we derive a novel sig nal detectio n algorithm for OFDM. The re mainder of the pape r is structu red as fo llows: In Section II, we in troduce the mod el of the mu ltiple cell OFDM network. I n Section III, we discuss the amount of infor mation about tran smitted p owers which can be collected by the terminal from the received matrix Y . The ob servation that all the n ecessary inform ation is contained in the eig en values of 1 L YY H leads to Section I V, in which we evaluate the classical energy detection meth ods, which assume L/ N → ∞ . In Sectio n V, we intr oduce some basic concep ts of random matrix theo ry [8], which a re n eeded to the u nderstand ing o f the subsequent sections. In Sec tion VI, we provide a novel algorithm to detect th e cell transmission powers. Simu lation results are th en provided in Section VII. A d iscussion on th e gains an d limitations of this n ovel meth od is carried out in Section VIII. Finally , in Section I X we draw our conclusion s. Notations: In the following, bo ldface lower case sym bols represent vector s, capital bold face characters den ote matrices ( I N is the size- N identity ma trix). The spaces M ( A , i, j ) and M ( A , i ) are the sets of i × j and i × i matr ices over the algebra A , respectively . The transpose and Herm itian transpose operator s are den oted ( · ) T and ( · ) H , respectively . The oper ator diag( x ) tur ns the v ector x in to a diagonal matrix. The function 1 ( · ) denotes th e indicator function . I I . D O W N L I N K M O D E L Consider a network of N B base stations and on e terminal equippe d with a single receiving antenn a. Th is scena rio is depicted in Figure 1. Assume m oreover th at the receiver is already connected to o ne serving base station , which we purpo sely exclude fr om the set of the N B surroun ding base stations since we already kn ow all informa tion abou t it. The network is assumed to be sync hronized in time and fr equency and to u se OFDM m odulation with a size N discr ete Fourier transform (DFT). Denote then M the m aximum number of P S f r a g r e p l a c e m e n t s s ( l ) 1 s ( l ) 2 s ( l ) 3 s ( l ) M Fig. 1. System Model base stations the receiver expects to de tect. Ideally N B ≤ M . In the following, for simplification, we assume that this condition is always fulfilled and we will only co nsider the parameter M , consider ing then a n etwork of M base stations, of which some co uld be of n ull power . Th e lin k between the terminal and th e base station k is modelled as a fast-fading complex f requen cy domain chann el h k = [ h k 1 . . . h kN ] T ∈ C N , coupled to a slow-fading path loss L k = 1 /P k with P k the mean receiv ed p ower origin ating from base station k . Th e terminal also receives additi ve white Gau ssian noise σ n ∈ C N with e ntries of variance σ 2 . T he base station k sends at time l the frequ ency-dom ain OFDM symb ol s ( l ) k = [ s ( l ) 1 k , . . . , s ( l ) N k ] T . Therefo re, the recei ved signal vector y ( l ) = [ y ( l ) 1 , . . . , y ( l ) N ] T at time l read s y ( l ) = M − 1 X k =0 P 1 2 k D k s ( l ) k + σ n ( l ) (1) with D k = dia g ( h k ) . This sum mation over the M cells can be rewritten y ( l ) = HP 1 2 θ ( l ) + σ n ( l ) (2) with θ ( l ) ∈ C M N the concatenated vector θ ( l ) = [ s ( l ) 1 , . . . , s ( l ) M ] T , H ∈ M ( C , N , M N ) the conc atenated m atrix of the D k , k ∈ { 1 , . . . , M } H = h 11 · · · 0 · · · h M 1 · · · 0 . . . . . . . . . · · · . . . . . . . . . 0 · · · h 2 N · · · 0 · · · h M N (3) and P ∈ M ( R , N ) th e diagon al matrix P = P 1 0 · · · 0 0 P 2 . . . . . . . . . . . . . . . 0 0 · · · 0 P M ⊗ I N (4) Now assum e th at the M ch annels ha ve a coher ence tim e of order (or more than) L times the OFDM symbol duration. The L samples y ( l ) , l = 1 , . . . , L , c an be concatenated into an N × L matrix Y = [ y ( 1 ) · · · y ( L ) ] to lead to the more general matrix expression of the r eceiv ed sign al Y Y = HP 1 2 Θ + σ N (5) where Θ ∈ M ( C , M N , L ) and N ∈ M ( C , N , L ) are the con- catenation matrices of th e L vectors θ ( l ) and n ( l ) , respectively . 3 I I I . P RO B L E M S TA T E M E N T The power detection pro blem consists in th e pre sent situa- tion to retrie ve the en tries of th e ma trix P fr om the rece iv e matrix Y . T he prior information at the receiver is no t s ufficient to find P in a straigh tforward manner . Inde ed, the chann el matrix H and the tr ansmitted signal Θ are un known and, worse, e ven th eir stochastic distribution are usually unkn own; in p articular, rec ent flexible multiple acce ss OFDM standar ds adapt their transmission rates to the channel quality so that the termina l ca nnot a priori assume to receive eithe r QPSK, 16 -QAM, 6 4 -QAM or any other type of modu lation. The a priori kn owledge I at the terminal is therefore limited to: ( i) the appr oximated back groun d covariance E[ nn H ] = σ 2 I , (ii) the fast-fading chan nel p ower E[ h H k h k ] = 1 , (iii) th e chan nel delay spread known to be lesser than th e cyclic prefix len gth, (iv) the transmitted signal covariance E[ θ H k θ k ] = I N . From this amou nt of prio r inform ation I , the most reli- able chan nel model 1 is obtain ed from the ma ximum entropy principle [14]. The latter states that the transmitted data Θ must be mode lled as a Ga ussian indep endent an d identically distributed process (i.i.d. ). As fo r the sh ort-term chann els h k , giv en a delay spread τ d (counted in integer n umber of time- domain samples), the time- domain representatio n of h k must be mo delled as a Gau ssian i.i.d. vector of length τ d ; ther efore, h k is to b e modelled as a Gaussian vector with cov ariance matrix the DFT of I τ d . Since little information about τ d is initially kn own to the receiver , the chan nels must be modelled as the marginal distribution of those Ga ussian p rocesses with τ d varying from 1 to the cyclic prefix length. Of course, this mo del migh t be very different fr om r eality and mig ht provide totally wrong results, as lon gly discussed in [1 5]. Howev er , this is the best on e can b lindly infer on the transmission scheme from the av ailable informa tion. The objective now is to determine what is the proba bility p ( P | I ) that a sequence of transmitted powers { P 1 , . . . , P M } fits the previous model kn owing I . From tho se probabilities, computed for all vectors in ( R + ) M , an estimate ˆ P of P can be designed which minimizes some erro r measure, e .g. ˆ P = E[ P | Y , I ] would be the min imum mean square erro r estimate of P . The prob ability p ( P | Y , I ) assigned to the info rmation ( P | Y , I ) can be written, thanks to Bayes’ rule p ( P | Y , I ) = p ( Y | P , I ) · p ( P | I ) p ( Y | I ) (6) in which ( P | I ) is th e a priori knowledge a bout P . It is classically assign ed a u niform d istribution over so me sub- space [0 , P max ] M for a m aximum rec eiv e power P max . As fo r p ( Y | P , I ) , it can b e expanded as p ( Y | P , I ) = Z Θ , H p ( Y | P , H , Θ , I ) p ( H | I ) p ( Θ | I )d H d Θ (7) in which all integrands are known from the max imum entropy model aforem entioned , 1 by “most reliable model”, we mean the model which satisfies the con- straints imposed by I and which is the most noncommittal regardi ng unknown system informati on. • p ( Θ | I ) is standard mu ltiv ariate i.i.d. Gaussian. • the compou nd chann el H is assigned a distribution p ( H | I ) = τ max X k =1 p ( H | τ d , I ) · p ( τ d | I ) (8) with τ d the channel delay spread, τ max the cyclic pr efix length, p ( τ d | I ) = 1 /τ max and p ( H | τ d , I ) with stan dard i.i.d. Gaussian diagonals. Howe ver, th e explicit com putation of ( 7) is very in volved and req uires advanced tools from ran dom matrix theor y . A similar calculus was p erform ed by the autho rs f or the simpler single-cell MIMO energy detector [31]. In the latter it was shown that, surprisingly , the standard i.i.d . Gau ssian model assigned to the main system pa rameters m akes the energy detection depen d only on the eig en value distribution of the receive ma trix Y . The multi-cell detection problem at han d is very similar in configu ration, a part for the chan nel marginal- ization of equa tion (8) whic h is not i.i.d. Gaussian. Since we cannot provide an optimal info rmation theoretical solu tion to our problem and since both aforem entioned pr oblems are very similar , it seems relev an t to concentrate on the close-to-o ptimal random m atrix theoretical appro ach. Some important infor mation can noneth eless be alre ady deduced from the integral form of equation (7). If the tran s- mission ch annels are extrem ely freq uency flat, i.e . for all k , h k 1 ≃ h k 2 . . . ≃ h kN , then { HP 1 2 Θ } ij = P k √ P k h k θ kj . Therefo re, even if the realizations o f N a nd Θ wer e perfectly known, o ne will have access at best to the variables √ P k h k , k = 1 , . . . , M , from which no reliable estimation of P k be drawn; in such a situation, the p osterior probab ility p ( P | Y , I ) is very b road and is m aximized on a large continuo us set of P 1 , . . . , P M . On an inf ormation theoretical viewpoint, this means th at the o ptimal in ference on P given Y and I cannot lead to any valuable information . In the random m atrix approa ch, the situatio n is even worse. If on e knew perf ectly the entries of HPH H , then nothin g at all can b e said ab out P 1 , . . . , P M . Indeed , { HPH H } ij = P k P k | h k | 2 (see Section VI fo r details) and the o nly piec e of informa tion which on e has about P 1 , . . . , P M is the sum P k P k | h k | 2 ; the l atter cannot lead to any estimate o f P when M > 1 an d the problem cannot be solved. This means that, given the limited prior informa tion of the terminal, it is impossible to come up with a reliable estimate of P when the channe ls are f requen cy flat. In the rem ainder o f this paper , we shall theref ore consider that the OFDM ch annels are very freq uency selecti ve 2 . In the following, we investigate the classical power detection techniqu es, which shall prove inefficient in this large n on-trivial matrix problem . I V . C L A S S I C A L P O W E R D E T E C T I O N Usual p ower detection conside rs the second o rder statistics of th e received signals. I n th e scalar case, i.e. y ( l ) reduces to a single value y ( l ) , it was proved [10] that the o ptimal detector with the aforemention ed state of knowledge at the terminal 2 note that this assumption ensures high effici ency of the network in terms of per -user outage capa city , which is very desirab le in the current trend for pack et-switch ed communications. 4 consists in evaluating 1 L ([ y (1) , . . . , y ( L ) ][ y (1) , . . . , y ( L ) ] H ) − σ 2 , with L > > 1 . W e show in what follows that this classical scheme can be simply extended to our network situation but that it is very in efficient for small L/ N ratios. Assuming that L/ N is very large, the expression of the normalized Gram matrix associated to Y reads YY H L − → L →∞ E 1 L ( HP 1 2 Θ + σ N )( HP 1 2 Θ + σ N ) H − → L →∞ HP 1 2 E ΘΘ H L P 1 2 H H + HP 1 2 L E h ΘN H i + 1 L E h NΘ H i P 1 2 H + E 1 L NN H − → L →∞ HPH H + σ 2 I N (9) the last line comes from th e f act that, N being finite, the N × N matrices 1 L NN H and 1 L ΘΘ H conv erge in distribution to an identity matrix, and the cross produ cts to null matrices. As a consequen ce, as will be de tailed in Section VI-B, one can estimate the values P k , k ∈ { 1 , . . . , M } from the moments { ( 1 L YY H − σ 2 I N ) k } , k ∈ { 1 , . . . , M } , wh en L is large co mpared with N . Our situa tion does not fall into this asymptotic L / N → ∞ co ntext. In present a nd f uture OFDM techn ologies, the number N of av ailable subcarr iers is large, e.g . of ord er a thousand subcarr iers, while L is limited in o ur model to the channel coh erence tim e or in general to the number of OFDM symbols the terminal is willing to memorize b efore treatin g informa tion. The refore, even if N and L ar e large, their ratio N / L is not in general close to zero. The fund amental asymptotic assumption is therefor e no long er satisfied. W e show in T able I that the non -trivial ratio N/ L im pairs significantly th e p erform ance of the classical power detection. The latter is the result of a simulation in which we applied the algo rithm that will be described in Section VI-B, based on th e sample mo ments o f 1 L ( YY H − σ 2 I N ) ( instead o f the sample mom ents of 1 L HPH H , whose cor respond ing results are shown between b rackets). Th e typical situation consid ered in this examp le is a thre e-base station scenario o f respective powers P 1 = 4 , P 2 = 2 an d P 3 = 1 an d a n oise lev el σ 2 = 0 . 1 , i.e. SNR = 10 dB , N = 2 56 and L is taken in a range from 256 to 3 2 , 7 68 . It turns out indeed that L need s to be large for this method to be satisfyin g. In this pr ecise example, this compels L/ N to be of o rder 6 4 , which is not acceptab le in our current system settings. Such problems inv olv ing large matrices with no n-trivial N /L r atios a re at the hear t o f a re cent field of research , known as rando m matrix theory (RMT), wh ich is a particular case of the more gen eral free pro bability theory intr oduced by V oiculescu [2 2]. In the subsequen t section, we pr ovide a quick introdu ction to impo rtant notions o f RMT which ar e necessary to handle the rest of the multiple cell detection study . V . R M T A N D F R E E D E C O N VO L U T I O N A. Ra ndom ma trix theory Definition 1: A ran dom matrix is a multi-variate ran - dom v ariable X = { X 11 , X 12 , . . . , X M N } f or a given N = 256 , P = { P 1 , P 2 , P 3 } = { 4 , 2 , 1 } L Estimated ˜ P [our algorithm] k P − ˜ P k 2 256 { 7 . 93 , 1 . 62 , − 2 . 5 } [ { 4 . 28 , 1 . 35 , 1 . 35 } ] 27 . 63 512 { 5 . 82 , 2 . 90 , − 1 . 7 } [ { 3 . 80 , 2 . 16 , 1 . 00 } ] 11 . 42 1024 { 4 . 26 , 3 . 60 , − 0 . 8 } [ { 3 . 62 , 2 . 37 , 0 . 94 } ] 5 . 87 2048 { 4 . 52 , 2 . 69 , − 0 . 2 } [ { 4 . 22 , 1 . 55 , 1 . 12 } ] 1 . 77 4096 { 4 . 20 , 2 . 65 , 0 . 18 } [ { 4 . 09 , 2 . 06 , 0 . 78 } ] 1 . 41 8192 { 4 . 10 , 2 . 28 , 0 . 58 } [ { 4 . 05 , 1 . 89 , 0 . 92 } ] 0 . 27 16384 { 3 . 97 , 2 . 42 , 0 . 89 } [ { 3 . 95 , 2 . 24 , 0 . 99 } ] 0 . 19 32768 { 4 . 07 , 1 . 95 , 0 . 99 } [ { 4 . 03 , 1 . 95 , 0 . 98 } ] 0 . 01 T ABL E I C L A S S I C A L M O M E N T - B A S E D M E T H O D ( M , N ) ∈ N 2 couple. As such, X is a m atrix who se entries X ij ∈ C M × N are ruled b y a joint pro bability distribution p ( X 11 , X 12 , . . . , X M N ) . Free pr obability is the study of rando m variables in non- commutative algeb ras, i.e. algebras in which the prod uct operation is non-c ommutative. The algeb ra of large He rmitian random ma trices is a particu lar case of those n on-com mutative algebras. In the f ollowing, we shall qualify fr ee any notion attached to the free prob ability (or RMT) framework while we shall q ualify c lassical any notion attached to th e cla ssical probab ility framework of commuta ti ve algebras. Similarly to the classical theory of pro bability , a free ex- pectation fun ctional φ can be d efined. For a given Her mitian random m atrix X , the free expectation read s φ ( X ) = lim N →∞ E [tr N X ] (10) and we can similarly define free moments m k , k ∈ N of a random m atrix. Those are m k = φ X k (11) Thanks to the trace pro perties, note that the free m oments are strongly linked to the eig en values λ i , i ∈ { 1 , N } of X , since m k can also be written m k = lim N →∞ 1 N N X i =1 λ k i (12) Indeed , denote X = Q Λ ΛQ Λ H with Λ = diag( { λ 1 , . . . , λ N } ) an d Q Λ unitary , X k = Q Λ Λ k Q Λ H . T aking the trace of X k leads to equation (12). The asy mptotic ( N , L → ∞ with N /L constant) marginal distribution o f the eigen values of X is called the empirical distribution of X and will b e de noted µ X . Its associated cumulative d istribution fun ction F X reads [8] F X ( λ ) = lim n →∞ 1 N N X i =1 1 ( λ i ≤ λ ) (13) Therefo re the free m oments are directly linked to the empirical d istribution of the matrix X , m k = lim N →∞ Z R + λ k µ X ( λ )d λ (14) which is the classical definitio n of mo ments associated to the distribution µ X . 5 0 0 . 5 1 1 . 5 2 2 . 5 3 0 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 x Densit y µ η c ( x ) c = 0 . 1 c = 0 . 2 c = 0 . 5 Fig. 2. Marchenk o-Pastur la w µ η c Interestingly , for mo st usua l 3 random ma trices A of large dimensions N , L → ∞ with N/L = c constant, the eigenv alu e density of X = 1 L AA H conv erges to a definite distribution. For instance, in our cu rrent p roblem, since the inpu t signals Θ and noise N ar e modelled as stand ard i. i.d. Gaussian, w e are interested in the so-called W ishart matrice s that we define hereafter Definition 2: An N × N ran dom matrix X = AA H , with A a rand om N × L matrix whose co lumns are zero mean Gaussian vectors with covariance matr ix Σ , is called a generalized Wis hart matrix of L degre es of freedom. This is denoted X ∼ W N ( L, Σ) (15) W ishar t matrices W N ( L, I N ) are known to h av e an e igen- value distribution which conv erges, whe n ( N , L ) grows to in- finity with a constant ra tio c = N /L , tow ards the Marchenko- Pastur law µ η c [8]. T he Marchenko-Pastur law is defined by µ η c = 1 − 1 c + δ ( x ) + p ( x − a ) + ( b − x ) + 2 π cx (16) with ( a, b ) = (1 − √ c ) 2 , (1 + √ c ) 2 . In Figure 2 we p rovide the distribution of µ η c for d ifferent values of c . Note that when c tends to 0 , i.e. when L/ N → ∞ , the Marchenko- Pastur law con verges to a sing le Dirac in 1 and we recover the classical law o f large num bers. Equiv alently to classical probab ility theory , many results of free pro bability in volve the distribution of sum , difference, produ ct and inverse of ran dom matr ices. The ch aracteristic function of a distribution, used to de riv e the distribution o f the sum of independen t co mmutative ran dom variables, has a free cou nterpar t called the R -Transform. The Mellin trans- form, used to derive the p roduct of indepen dent co mmutative random variables, also has a fre e counterp art, kn own as th e 3 by usual, we qualify matrices found in common wirel ess communication problems. S -Transform 4 . Giv en two large rand om Hermitian m atrices A an d B , whose sum is C = A + B and whose prod uct is D = AB , one can then deri ve the empirical distributions of C and D from th e empirical distributions of A and B , w hich we d enote µ C = µ A ⊞ µ B (17) µ D = µ A ⊠ µ B (18) Equation (17) is called a dditive free con volution and equation (18) is called multip licativ e free conv olution . Similarly , giv en only the d istributions of B , C and D , one can recover the distribution of A µ A = µ C ⊟ µ B (19) µ A = µ D µ B (20) in which equation (19) is called additive free dec onv olu tion and equation (20) is called multiplicative free d econv olution. B. F ree deco n volution for informatio n plus n oise mo del Our interest is to trea t a particu lar comm unication model, known as the information plus noise model , Definition 3: Given two N × L ( N / L → c ) large r andom matrices R (standing for an informative signal) and X (stand - ing for a n oise ad ditive signal) an d a scalar σ (the standa rd deviation of the noise proc ess), the mo del given by W = 1 L ( R + σ X )( R + σ X ) H (21) is called the information plus noise model. W e shall therefore call W an informa tion plu s noise matrix. It has been re cently shown [7] that the empirical distribution of 1 L RR H in the pr evious definition can be recovered from the empirical distributions of the matrices W an d XX H when X is Gaussian with i.i.d. en tries of zero m ean and v ariance 1 /L . This is giv en by µ 1 L RR H = (( µ W µ η c ) ⊟ δ σ 2 ) ⊠ µ η c (22) For more details about the demonstration of formula (22), refer to [ 16]. Thanks to th is RMT fr amew ork and th e f ree con volution tools, we can now address ou r multiple cell detectio n problem. V I . A P P L I C A T I O N O F F R E E D E C O N VO L U T I O N T O M U LT I P L E C E L L D E T E C T I O N A. Sig nal an d noise deconvolution In the m odel (5), th e N × N matrix 1 L YY H is an in- formation plu s noise matrix with N a Gaussian ran dom matrix. Th erefore, a ccording to eq uation (2 2), when N , L are sufficiently large, one ca n derive th e empir ical distribution 4 note that independe nce in the classical probability s ense is not enough in free probabilit y to deriv e the empiric al distribu tion of the sum , dif ference , product and in verse product of two random matri ces. This independe nce notion is ext ended to the asymptotic fr eeness concept [8] w hich is not a techni cal issue in our study . 6 µ 1 L HP 1 2 ΘΘ H P 1 2 H H from the emp irical d istribution µ 1 L YY H as follows µ 1 L HP 1 2 ΘΘ H P 1 2 H H = ( µ 1 L YY H µ η c ) ⊟ δ σ 2 ⊠ µ η c (23) where c = N / L , for N is of size N × L . Also, the m atrix Θ in equ ation (5) is modelled as standard i.i.d. Gaussian. Therefo re 1 L P 1 2 H H HP 1 2 ΘΘ H is a g eneralized W ishart matrix with covariance P 1 2 H H HP 1 2 . An alogou sly to (15), this can be written 1 L P 1 2 H H HP 1 2 ΘΘ H ∼ W N ( L, P 1 2 H H HP 1 2 ) (24 ) Then, the emp irical distribution of the covariance matrix P 1 2 H H HP 1 2 of the W ishart matrix 1 L P 1 2 H H HP 1 2 ΘΘ H can be recovered from the empirical distribution µ 1 L P 1 2 H H HP 1 2 ΘΘ H when the couple ( N , L ) tend s to infinity with a constant r atio c ′ = M N /L ( M is constant). Consequently , similarly to (20), µ P 1 2 H H HP 1 2 = µ 1 L P 1 2 H H HP 1 2 ΘΘ H µ η c ′ (25) The left side of equation (23) is slightly different fr om the desired expression in the rig ht side of equation (25). Still, thanks to the trace comm utativity p roperty , we have the link [8] µ 1 L P 1 2 H H HP 1 2 ΘΘ H = 1 M µ 1 L HP 1 2 ΘΘ H P 1 2 H H + 1 − 1 M δ 0 (26) This relation is due to the fact that the positive eigen- values o f 1 L HP 1 2 ΘΘ H P 1 2 H H are the same as those of 1 L P 1 2 H H HP 1 2 ΘΘ H (since their traces are identical and then all their m oments match). But th e rank o f both matrices differ an d then a cer tain amoun t of null eigenv alues mu st be intr oduced . Here, 1 L HP 1 2 ΘΘ H P 1 2 H H is o f full r ank ( N ) while 1 L P 1 2 H H HP 1 2 ΘΘ H is on ly o f rank N fo r a matrix size M N , h ence the M factor in eq uation ( 26). Finally , we similarly c onnect the left side of eq uation (25) to µ HPH H throug h µ P 1 2 H H HP 1 2 = 1 M µ HPH H + 1 − 1 M δ 0 (27) The emp irical distribution of HPH H was then der iv ed from the em pirical distribution of 1 L YY H . As a con sequence, the free moments d k = E[tr N ( HPH H ) k ] can be retrieved from the free momen ts m k = E[tr N ( 1 L YY H ) k ] . Surp risingly , it is shown in [16] that fo r all aforemen tioned fre e conv o lution operation s, the set o f the first k momen ts o f the [de]co n volved distributions can be re covered fro m the set of the k first moments of the operand s. This sub stantially reduces the com- putational effort, as is describe d in the following. Let us work in d etail all the steps to derive the mo ments d k from the momen ts m k . 1) first, the noise contribution to the signal Y is dec on- volved thanks to formula (23). The m ultiplicative conv o - lution (resp. d econv o lution) µ ( out ) of a distribution µ ( in ) and the March enko-Pastur law µ η c can be comp uted from all the m oments m ( in ) k . It is shown in [ 7] tha t c · m ( out ) k can be compu ted from th e moments/cu mulants transform (resp . cumu lants/moments transfor m) [8] o f the coefficients c · m ( in ) k , with c = N /L . As fo r additive conv olu tion (resp. deco n volution) µ ( add ) of two distribu- tions µ ( a ) and µ ( b ) , the f ree cumulan ts of µ ( add ) are the sum ( resp. difference) of th e cumulants o f µ ( a ) and µ ( b ) . From (23), the mo ments m ′ k of µ 1 L HP 1 2 ΘΘ H P 1 2 H H are obtained from the mo ments m k of µ 1 L YY H ; th erefore, in m athematical terms, this reads ( m ′ 1 , . . . , m ′ M ) = S 1 ( m 1 , . . . , m M , σ 2 ) (28) with S 1 = 1 c M c · M C 1 c C ( cm 1 , . . . , cm M ) − C σ 2 , . . . , σ 2 M (29) where the functio ns M ( · ) and C ( · ) stand respectively for the cumu lants/moments transform and the mo- ments/cumulan ts tr ansform th at b oth take as argument a vecto r of size k (the fir st k mo ments or cumulants, respectively) a nd outpu t a size k vector (th e fir st k cumulants or moments, respectively). Th e inner 1 c C ( c · ) operation multiplicatively deco n volve the Marc henko- Pastur law µ η c . T hen th e next C application tu rns the resulting mo ments into cumulants. T he ad ditiv e decon - volution o f δ σ 2 is then p erform ed thro ugh the cum ulant difference and the outp ut is turned back into the mo ment space throu gh the M app lication. The outer 1 c M ( c · ) is finally perfo rmed to m ultiplicatively c onv olve the result with µ η c . 2) the mo ments m ′′ k of µ 1 L P 1 2 H H HP 1 2 ΘΘ H are then gi ven throug h eq uation (26) by a simple scaling of the mo - ments m ′ k by 1 / M . This reads ( m ′′ 1 , . . . , m ′′ M ) = 1 M ( m ′ 1 , . . . , m ′ M ) (30) 3) the Marchenko-Pastur law µ η c ′ , c ′ = M N /L , is then deconv olved fr om µ 1 L P 1 2 H H HP 1 2 ΘΘ H accordin g to equation (25). This leads then to the mo ments m ′′′ k of µ P 1 2 H H HP 1 2 , ( m ′′′ 1 , . . . , m ′′′ M ) = 1 c ′ C ( c ′ d ′ 1 , . . . , c ′ d ′ M ) (31 ) 4) finally , th e resulting momen ts m ′′′ k are scaled by M to obtain th e d k coefficients, ( d 1 , . . . , d M ) = M ( m ′′′ 1 , . . . , m ′′′ M ) (32) Figure 3 summarizes these steps. Our final interest th ough is to find the d iagonal values of P . The d istribution of the cha nnel matrix H was mo delled in Section II by a m ixture of corr elated Gaussian sub channels. It is difficult, at this p oint o f kn owledge in free probability theory , to deconv olve the ef fect of H from the random ma trix HPH H . Only classical meth ods can help in this situation . Remarkably , it tu rns out that the matrix HPH H is diagonal HPH H = P k P k | h k 1 | 2 · · · 0 . . . . . . . . . 0 · · · P k P k | h kN | 2 (33) 7 For k ∈ { 1 , . . . , M } , c omputatio n of m k = E h tr L ( YY H ) k i Deconv o lution of the additive noise ( m ′ 1 , . . . , m ′ M ) = 1 M S 1 ( { m k } , σ 2 ) Retriev al o f th e d k ’ s ( d 1 , . . . , d M ) = M c ′ C ( c ′ m ′ 1 , . . . , c ′ m ′ M ) Fig. 3. m k to d k Block Diagram Therefo re the theoretical mome nts d k of µ HPH H are th e normalized traces of th e asympto tic dia gonal m atrices of entries, n ( HPH H ) k o ij = M X k =1 P k | h ki | 2 ! k δ j i (34) and then the p th order mom ent d p = E[tr N ( HPH H ) p ] of HPH H can then be equated for large N to d p = lim N →∞ 1 N N X j =1 M X k =1 P k | h kj | 2 ! p (35) In the f ollowing we provide a meth od to estimate the entries P k under the assump tion, which is nev er verified in practice, that the channels a re extremely frequ ency selecti ve, i.e. such that, fo r any k and any coup le j 6 = j ′ , the entries h k,j and h k,j ′ are independ ent. B. Estimation of th e p owers P k As alre ady co ncluded in Section III, if the channel delay spreads are very short, then the channel frequen cy resp onses { h k 1 , . . . , h kN } , k ∈ { 1 , . . . , M } , ar e stro ngly correlated and almost nothin g can be ded uced o n the entries of P . On the contrary , assume that the chann el delay spread is very large, and rewrite equatio n (35) as d p = ¯ d p + w p (36) = 1 N N X j =1 M X k =1 P k | h kj | 2 ! p + w p (37) with ¯ d p the p th sample order mome nt ( N < ∞ ) and w p some noise pro cess. The latter conver ges to 0 when N → ∞ and the channel frequ ency response is i.i.d. Gaussian. Howe ver, w hen N is finite or when the channel is less frequency selective, then w p is a bit more difficult to hand le. T o push th e computatio n for ward, we need first to de riv e the classical order p moment m ( h ) p of the v ariables | h kj | 2 , for any co uple ( k , j ) , in the complex ca se. This g iv es m ( h ) p = E [ | h kj | 2 p ] = 1 2 2 p p X i =0 C i p (2 i )!(2[ p − i ])! i !( p − 1)! (38) One can th en derive the g eneral expression for d p as d p = p ! 2 2 p X k 1 ,...,k M P i k i = p M Y i =1 ( k i X k =0 (2 k )!(2[ k i − k ])! ( k !) 2 ([ k i − k ]!) 2 ) P k i i (39) The complete deriv atio n of fo rmula (39) is provided in the append ix. 1) Bayesian a ppr o ach: Let K be some integer greater than or equa l to M . The no ise process w = [ w 1 , . . . , w K ] T , as already men tioned, is in gen eral difficult to analyze. W e shall consider in the following that one actually has a limited knowledge abou t w which reduc es to the covariance matrix C = E[ ww T ] gathered from p revious simulations 5 . Now , consider that th e set of prior informatio n I con tains the following elements: • the values o f P 1 , . . . , P M are real p ositiv e an d k nown not to b e larger than some value P max . • the typ ical err or variance C in the observed mom ents { d k } , k ∈ { 1 , . . . , M } , is k nown. In fact, th e exact covariance matrix C canno t be known since its computatio n req uires the exact k nowledge of P . Indeed , a few lines of calculu s of C = E h d − ¯ d H d − ¯ d i (40) with ¯ d = [ ¯ d 1 , . . . , ¯ d K ] T , lead to equ ation (41), which depends on P 1 , . . . , P M . Howe ver, let us first co nsider C known before we intro duce alternative solutions wh en C is u nknown. The objective is to infer on the set { P 1 , . . . , P M } giv en I and the ob served sample moments ¯ d . An err or measu re must be con sidered to come up with an estimate o f { P 1 , . . . , P M } . W e co nsider here th e estimate of P which minimizes th e mean quadra tic err or (MMSE). Th is MMSE estimate ˜ P is given by ˜ P = E P | ¯ d (42) = Z P P p ( P | ¯ d , I )d P (43) = Z P P p ( ¯ d | P , I ) p ( P | I ) R P p ( ¯ d | P , I ) p ( P | I )d P d P (44) Since the prio r information ( P | I ) is limited to the fact that all entries are upper-boun ded b y P max , p ( P | I ) sh ould be set unifor m on the space [0 , P max ] M accordin g to the max imum entropy principle. However , n ote that if { ˜ P 1 , . . . , ˜ P M } mini- mizes the M MSE then also does any p ermutation of this set. Therefo re, to have a cor rectly d efined problem (with a un ique solution), the set { P 1 , . . . , P M } must be order ed; we will then state in the following that P 1 ≤ P 2 ≤ P M . Ther efore the p rior p ( P k | I ) is taken un iformly on the set [0 , P k − 1 ] when P k − 1 is set, wh ich leads to p ( P | I ) = P max Q M − 1 i =1 P − 1 i . A lso, since only the error cov ariance matrix C in the observed sample moments ¯ d is known, the maxim um entropy princ iple requests that the p rocess w is assigned a Gau ssian distrib ution with 5 honesty woul d require tha t we actu ally deriv e the maximum ent ropy distrib ution of w but this would lead to in volv ed computation. 8 C a,b = − ¯ d a ¯ d b + X k 1 ,...,k M k ′ 1 ,...,k ′ M P i k i = a P j k j = b ( N − 1 ) a ! b ! N Y i,j 1 ≤ i ≤ a 1 ≤ j ≤ b P k i k i P k ′ j k ′ j m ( h ) k i m ( h ) k ′ j k i ! k ′ j ! + a ! b ! N Y i,j 1 ≤ i ≤ a 1 ≤ j ≤ b k i = k ′ j P 2 k i k i m ( h ) 2 k i ( k i !) 2 × Y i,j 1 ≤ i ≤ a 1 ≤ j ≤ b k i 6 = k ′ j P k i k i P k ′ j k ′ j m ( h ) k i m ( h ) k i k i ! k ′ j ! (41) variance C . Theref ore, equ ation (4 4) bec omes ˜ P = Z P 1 ≤ ... ≤ P M P e − w ( P ) H C − 1 w ( P ) R P 1 ≤ ... ≤ P M e − w ( P ) H C − 1 w ( P ) d P d P (4 5) where we denoted w = w ( P ) to remind the actual dependence of w in th e p owers P 1 , . . . , P M (throu gh the expression of d in equation (39)). Unfortu nately , the in tegration space of equ ation ( 45) m akes both integrals rather in volved to com pute. A way to prac tically computed ˜ P co nsists in turning the integrals into finite sums over thin sliced versions of the integration space. Also, as previously m entioned, the covariance matrix C is obviously unknown when trying to decipher the cell powers P 1 , . . . , P M . Howe ver, iterative m ethods can be con sidered in which C is initially defined as th e cov ariance matrix C init of an hyp othetic set o f p owers, say P 1 = P 2 = . . . = P M = P max / 2 . Then, runnin g the MMSE estimator with C init returns a first set P (1) 1 , . . . , P (1) M from which a r efined version of C can be ev alu ated ( from formu la (4 1)). Note that, in runn ing k instances o f the algor ithm, the sample mo ments ˜ d p can b e accumulated a nd the covariance matrix C has to be compute d as if as many as k N subcar riers we re actually used in the free deconv olution algorith m. This proc ess can be processed in a loop for a satisfying number of iterations. 2) Altern ative estimators: Other estimator s th an MMSE, such as m aximum- likelihood (ML), migh t b e conside red which take as an estimate the set P which minimizes w ( P ) H C − 1 w ( P ) . Howe ver , the measure associate d to the ML estimator does not suit the broa d a posteriori d istribution p ( P | ¯ d , I ) as will b e shown in simulation s. Indeed , a large estimation error is a s bad as a small estimation erro r in the ML context; theref ore, when the posterior p ( P | d , I ) is not peaky , large estimatio n errors are expected. T he MMSE estimator is, in this scenario, more appro priate. A zero-fo rcing method can also b e de riv ed. Fro m equ ation (39), if no thing wer e known abou t th e noise pro cess w p , one might naively consider solvin g th e system of M e quations (39), with p = 1 , . . . , M in the M un knowns P 1 , . . . , P M , in which d p is set equ al to the ob served ˜ d p . This can be solved by tur ning this system of equ ations into the eq uiv a lent system M X k =1 P k = Q 1 ( d 1 ) M X k =1 P 2 k = Q 2 ( d 1 , d 2 ) . . . = . . . M X k =1 P M k = Q M ( d 1 , . . . , d M ) (46) with Q k ∈ R [ d 1 , . . . , d k ] . This system can be so lved using the Newton-Girar d for - mulas [18]; the solutions P 1 , . . . , P M are foun d to be th e M roots o f an M th degree po lynom ial. This solution does not require an y kno wledge on the c ovariance matrix C , which does not h av e any significatio n in this context. Howev er , it often turns out that the roots P k are not all real, which makes the solution u seless in pr actice. Also, this zero- forcing metho d is very a wkward as it stron gly suffers from the presence of no ise. Especially , the large variance E[ | w M | 2 ] is consider ed equally to the typica lly very small variance E[ | w 1 | 2 ] , and therefo re the first sample mom ent ¯ d 1 is no t more impo rtant in the final computatio n than the last sample momen t ¯ d M 6 . V I I . S I M U L A T I O N A N D R E S U LT S In the follo wing, we use th e results that wer e p reviously derived in the case of a th ree-cell network that the ter minal wishes to track . The set o f cells studied alo ng this part are of relativ e powers P 1 = 4 , P 2 = 2 , P 3 = 1 . Before perfor ming the first simulation of the com plete algorithm , we present in Figure 4 the relative erro r in the estimation o f the momen ts ν k = tr N ( HPH H ) k from the free deco n volved sample mom ents ¯ d k . It is observed that ev en for N = 256 , L = 51 2 the m ean relative erro r in the computed third moments is of o rder 1% . This suggests that the free deconv olution techniqu e is very a ccurate ev en f or non-in finite values of N and L . The bottleneck approx imation in the estimation of P 1 , . . . , P M , as will be o bserved in the coming plots, therefor e lies in th e convergence of the entries h kj tow ards a Gaussian i.i.d. process, and not in the infinite matrix size assumption. In a first simulation, we stud y th e conv ergence properties of the p roposed scheme. W e consider a large OFDM sy stem with 6 this would be here again a dishonest considerati on as one at least knows that d M is m ore uncert ain than d 1 . 9 256 512 1 , 024 2 , 048 0 0 . 2 0 . 4 0 . 6 0 . 8 1 · 10 − 2 Num b er of sub carriers N relativ e error | ¯ d 1 − ν 1 | ν 1 | ¯ d 2 − ν 2 | ν 2 | ¯ d 3 − ν 3 | ν 3 Fig. 4. Relati ve error on recovere d moments ν k = tr N ( HPH H ) k from the free decon vol ution algor ithm, L = 2 N 1 2 4 0 0 . 02 0 . 04 0 . 06 0 . 08 0 . 10 Estimated p o w ers Densit y Fig. 5. Cell power detect ion, N = 2048 , L = 4096 , MMSE estimat e, Perfect kno wledge of C 1 2 4 0 0 . 02 0 . 04 0 . 06 0 . 08 Estimated p o w ers Densit y 1 2 4 0 0 . 02 0 . 04 0 . 06 0 . 08 Estimated p o w ers Densit y Fig. 6. Cell power detecti on, N = 512 , L = 1024 , MMSE estimate (lef t) and ML estimat e (right ), Perfect knowledg e of C 1 2 4 0 0 . 05 0 . 10 0 . 15 0 . 20 Estimated p o w ers Densit y Fig. 7. Cell po wer detection, N = 512 , L = 1024 , 10 a ccumulat ions, MMSE estimate , Perfec t knowle dge of C 1 2 4 0 1 3 2 3 1 Estimated p o w ers Cum ulativ e distribution No accum ulation 10 accum ulations Optimal estimation Fig. 8. Ce ll powe r detect ion CDF , N = 512 , L = 1024 , Perfect knowl edge of C N = 2048 subcarr iers an d L = 4096 sampling per iods under ideal Gaussian i.i.d . input symbo ls, un correlated Gaussian channel freq uency respo nses and Gau ssian add itiv e wh ite noise with signal to n oise ratio SNR = 20 dB . T he covariance matrix C is the exact covariance matrix. Figure 5 provid es the results o f this simu lation for thousan d channel realisations. It is observed that the distribution o f the eigenv alues is largely spread over the expected eigenv alu es. This is explained by the slow conver gence natu re of the compu ted d p tow ards the correspo nding m oments when N → ∞ . Also, it is ob served that th e peak ce nters ar e offset from the expected p owers. This is main ly due to th e fact that the MMSE estimator is meant to minimize th e mea n quadratic error averaged over all possible sets P 1 , P 2 , P 3 and not for the particular set selected here 7 . Also, the actually n on-Gaussian prop erty of the noise p rocess 7 it was observ ed in particula r from other simulations that cells of equal po wers are generally better estimat ed. 10 1 2 4 0 0 . 05 0 . 10 0 . 15 0 . 20 Estimated p o w ers Densit y Fig. 9. Cell po wer detecti on, N = 512 , L = 1024 , MMSE estimate, Recursi ve update of C , 10 steps w as well as the inexact results fro m the free deconv olution process contribute to the offset. Figure 6 provide s a comp arison between the results g iv en by the MMSE estimator and the ML e stimator when N = 512 an d L = 1 0 24 . It tu rns out, as discussed ear lier , that th e ML estimate is mo re largely spread ar ound the expected cell powers than the MMSE estimate. In the following, we perform more r ealistic simu lations in which input signals are QPSK modulated instead of co mplex Gaussian, an d with more realistic channels of length varying from 1 to N/ 4 symbols. T o red uce the v ariance o f the estimates, we also average the sample d p over ten channel realizations, which in practice requir es aro und 1 ms o f data to proc ess. I n Figure 7, we took N = 512 , L = 1024 and a Rayleigh ch annel o f le ngth N / 8 . The cov ariance matrix C is still the exact covariance matrix. Then a hund red r ealisations of this proc ess are run. Th e SNR is still SNR = 20 dB in this secon d experiment. The cumulative distribution f unction (CDF) of the detected p owers is presented in Figure 8 and compare d to th e CDF when no accum ulation is performed . The three thresholds correspond ing to the three d etected c ell powers ca n be observed, with a slight shift fro m the expected cell powers caused both by the non-exact Gaussian assumption on w and o n the n on-exact Gau ssian i.i. d. assumption on the channel frequen cy responses. Now we propose to examine the performance of the iterativ e cell p ower recovery . W e initially set C init to the cov ariance matrix of a set of cells of powers P 1 = P 2 = P 3 = 2 . 5 . Then ten iterations of the cell-po wer detector are run, with at each step a refinement of C . Note th at, since a t each step the sample moments ¯ d p are ac cumulated , th e en tries of the covariance matrix C are comp uted accordin gly , i.e. k accumulatio ns demand that C is compu ted from an effectiv e number k N sub carriers, as presented in Section VI. Figure 9 provides the results of the recursive algorithm, which p roves to perform s very accurately , with surpr isingly little dispersion around the detected powers com pared to Figu re 7. 1 2 4 0 1 3 1 6 1 Estimated p o w ers Cum ulativ e distribution i.i.d. Gaussian L TE-ETU L TE-EV A Optimal estimation Fig. 10. Cell po wer detection CDF in L T E channe ls, N = 512 , L = 1024 , 10 accumula tions, preset C Channel T ype RMS dela y spread Channel length EV A 357 ns N / 27 ETU 991 ns N/ 13 T ABL E II 3 G P P - LT E S TA N D A R D I Z E D S H O RT D E L AY C H A N N E L S Also, we test the r obustness of our algo rithm ag ainst prac- tical shor t channels, instead of high de lay spread c hannels. This is shown in Figure 10 which prop oses a compar ison between the id eal long chann el situation and the 3GPP-L TE [4] stand ardized E xtended V ehicular A (EV A) and E xtended T ypical Urb an (ETU) c hannels with para meters g iv en in T able II. Here we considered a m obile handset with N r = 2 anten nas, 256 subc arriers p er an tenna (an d then in total an effectiv e number of N = 512 subcarr iers), L = 1024 , SNR = 20 dB . The c ovariance m atrix C of the n oise pr ocess w is an approx imated matrix ob tained from intensive simulations on short chann els. Indeed, the covariance pa ttern is very different from the m atrices used in the Gaussian i.i.d. scenario and is difficult to derive an alytically; especially we noticed that the smaller the delay sprea d, the larger the un certainty on the higher moments, whic h tu rns C into an ill-condition ed matrix. The results are averaged over ten chan nel realizations. The CDF of the detected power d istribution f or those channels is provide d in Figure 10. The latter shows a r ather good behaviour in both ETU and E V A chan nels. Nonetheless their short delay spreads lead to a larger variance in the mean power estimation. Surprisingly , it turn s out that th e distribution of the in put signals s ( l ) does not impa ct the system p erforma nce as lo ng as it is i.i.d . with zero m ean and unit variance. T his is a known result in free deconv o lution which has no t been proven yet. Therefo re in our simulation s, QPSK modu lations showed the exact same behaviour as purely Gau ssian d istributed input signals. 11 V I I I . D I S C U S S I O N A. Data , p rior and c onver gence W e previously d escribed and simulated a recursive algo- rithm m eant to con verge to an accurate estimate of th e cell powers P 1 , . . . , P M , whose conver gence we did not prove yet. Actually , a m athematical as well a s a philosoph ical reasons for this convergence can be ad vanced. First, note that a large num- ber of iteration s lead to a smaller variance of w = d − ˆ d ( P ) , therefor e to smaller entries of the noise c ovariance matrix C . As a con sequence C − 1 has large entries and the exponential terms e − 1 2 ( d − ˆ d ( P )) T C − 1 ( d − ˆ d ( P )) in the MMSE integrals (45) are rele vant on ly when th e differences d − ˆ d ( P ) a re very small; this is, when ˆ d ( P ) ≃ d . Therefo re the accuracy in the entries of C − 1 is n ot of fun damental importan ce, as lon g as they are large en ough . Th e conver gence of the itera ti ve process is ensured by the accum ulated d ata d themselves; but of cou rse this convergence is accelerated with good appr oximation s of C . This obser vation is very gen eral in the Bayesian prob ability theory con text and h as been observed and analyzed tho roug hly by Jaynes [ 15]. Bayesian pr obabilities rely on a balance between priors and d ata . If the available data is scarce, then prior infor mation is very valuable; in o ur situation, as shown by simulation, if C wer e known, then e ven a sin gle chann el realization allows to app roxima tely recover the tran smitted powers. On th e contrar y , large amounts of d ata prev ail over prior information s o that even u nfortu nate prio rs may not badly alter the a posteriori pr obability; this explains why a precise estimation of C is n ot ma ndatory when large accum ulations of d ata ar e consider ed. Note th at in this case, ML estimates and MMSE e stimates show similar perform ance, since the posterior d istribution p ( P | Y , I ) is very peaky in the correct value for P . Howe ver, it is importan t to und erline the fact th at the offset problem, observed in simulatio n, in the estimation of P 1 , . . . , P M will not be redu ced by m ere data accum ulations. Indeed , the issue co mes here from the free deco n volution process which is not a ccurate for fi nite N . Therefo re, an appro- priate trade-off between large N an d many accumulations mu st be foun d: large N entail mo re accu rate f ree deconv olution processes at the expense o f compu tationally dema nding large matrix p rodu cts, while many accumulatio ns ensures a faster conv ergence ( to offset cell p owers) at a lower computation cost. Ano ther app roach consists in compu ting higher o rder moments to strengthen the cell power estimation. Howe ver, high order sam ple m oments have a large variance for finite N . Their impact on the fina l estimation might then be very limited since they are very un reliable. For instance we o bserved in simulations th at, for N = 51 2 , typical matrices C verify C 11 ≃ 1 e − 2 and C 33 ≃ 1 e 4 , which gives a million times more credit to the first o rder sample moment than to th e th ird order samp le m oment. Bring ing in the compu tation f ourth order mom ents with N = 512 would turn ou t n ot worth the computatio n increase. B. Ap plicability As reminded in the intro duction of this paper, usual cell power detection tech niques u se scar ce an d largely interfered synchro nization sequen ces. M uch time, but low compu tation, is then requ ired to detect cells with high efficiency . From the autho rs’ experience in the co ntext of 3GPP-L TE, many problem s arise when those p ilot seq uences are syn chron ized and the emitting cells ha ve equal p owers since both signals interfere to the detrimen t of th e decode r . In the previously derived sch eme, even cells of equal power can be counted and isolated . Indeed, if M cells are expected and the CDF of the estimated powers shows a large jump of 2 / M for a g iv en power P , then we can deduce that two cells have eq ual power P . It is th erefor e n ot necessary to enhanc e th e qua lity of the estimation to sep arate tho se two cells. Howe ver, some limitations can be f ound in th e applicab ility of this cog nitive scheme . Firstly , load ed cells are req uired to ensu re reliability of th e estimates; this r equires that the underly ing standards o ptimally r euse the allocated bandwidth . Secondly , if many cells are desired to b e de tected, th en very high ord er mome nts must be computed which , as discussed earlier are on ly re liable if the num ber of subcarrie rs N and the n umber of accumulation s are very large. High order moments also require very large matrix prod ucts, which migh t be too d emandin g to the embedd ed system processors. Also , under the limited state of k nowledge of the system mod el, neighbo ring cells can only b e de tected if the propag ation channels ar e very freq uency selectiv e. The flatter th e ch annels, the more num erous the accumulations requir ed to come up with a reliable estimation . The latter limitation is obviously the m ost constrainin g factor . I X . C O N C L U S I O N In this pape r , we pr ovided a practical way to blindly detect neighbo ring cells in a distributed OFDM network. Assumin g constant tran smission in those cells on a fairly large band - width, we showed that one can d etermine the ind ividual SNR of ev ery surrou nding cell provided that th e chann el delay spread is sufficiently large. This scheme is particularly suited for the future co gnitive OFDM systems which aim to r educe the amou nt of synchr onization sequences while keepin g track of the neighb oring cells. X . A C K N O W L E D G E M E N T This work was partially supporte d by the Europ ean Com- mission in the framework of the FP7 Network of Excellence in Wireless Com municatio ns NEWCOM++. A P P E N D I X Consider Gau ssian channels with independ ent fr equency responses h ij ( i ∈ { 1 , . . . , M } , j ∈ [1 , N ] ). Th en, for a g iv en 12 j , noise taken ap art, we denote d ( j ) p = M X i =1 P i | h ij | 2 ! p = X k 1 ,k 2 ,...,k M P m k m = p C k 1 p C k 2 p − k 1 . . . C k M p − k 1 − ... − k M − 1 M Y l =1 ( P i | h ij | 2 ) k l (47) where the pr oduct of the binom ial coefficients C k 1 p C k 2 p − k 1 . . . C k M p − k 1 − ... − k M − 1 is the multinomial coefficient p ! k 1 ! k 2 ! ...k M ! . Hence the simplified expression, when averaging d ( j ) p over j ∈ [1 , N ] ( with N → ∞ to ensure 1 N P j | h ij | 2 → E j [ | h ij | 2 ] ) d p = p ! X k 1 ,k 2 ,...,k M P m k m = p E j h Q M i =1 ( P i | h ij | 2 ) k i i Q M i =1 k i ! (48) The m oments of the com plex variable | h ij | 2 are deduced from the mome nts of a G aussian real variable by considering | h ij | 2 = ( h ℜ ij + i · h ℑ ij )( h ℜ ij − i · h ℑ ij ) (49) where the re al and imaginary parts h ℜ ij and h ℑ ij of h ij are standard Gaussian variables whose even moments are known E [( h ℜ ij ) 2 p ] = E [( h ℑ ij ) 2 p ] = (2 p )! 2 p p ! (50) hence equation (38). This results in d p = p ! 2 2 p X k 1 ,...,k M P i k i = p M Y i =1 ( k i X k =0 (2 k )!(2[ k i − k ])! ( k !) 2 ([ k i − k ]!) 2 ) P k i i (51) R E F E R E N C E S [1] C. E. Shannon, “ A m athemat ical theory of communications”, Bell System T echnica l Journal , vo l. 27, no. 7, pp. 379-423, 1948. [2] E. Bigli eri, J. Proakis, and S. Shamai, “Fa ding chann els: Information- theoret ic and communica tions aspects, ” IEEE Trans. on Inf. Theory , vol. 44, no. 6, pp. 2619-2692, Oct 1998. [3] J. H. W inters, “Smart Antennas for W irele ss Systems”, IEEE Personnal Communicat ions, vol . 5, no. 1, pp.23-27, Feb . 1998. [4] http://www .3gpp.org/ Highlight s/L T E/L TE.htm [5] http://wire lessman.org/ [6] K. Karakayal i, G. J. Foschini , R. A. V alenzue la, “Net work Coordinati on for Spectra lly Effic ient Communicat ions in Cellul ar Systems”, August 2006, IEEE W irele ss Communica tions Magazine (in vited). [7] Ø. Ryan, M. Debbah, “Free decon voluti on for signal processing applica- tions”, under re view , http://a rxi v .org/abs/c s.IT/0701025 [8] A. M. Tulino , S. V erd ´ u, “Rando m Matrix Theory and Wire less Commu- nicat ions”, No w Publishe rs, vol. 1, Issue 1, 2004. [9] P . Biane, “Free Probability for Probabili sts”, Quantum Probability Com- municati ons, W orld Scientist, 2003. [10] H. U rko witz, “Energy dete ction of unknown dete rministic signals, ” Proc. of the IEEE, vol. 55, no. 4, pp. 523-531, Apr . 1967 [11] V . I. Kostyle v , “Energy detection of a signal with Random Am plitude ”, Proc IEE E Int. Conf. on Communication s (ICC’02). New Y ork City , pp. 1606-1610, May 2002. [12] S. Haykin, “Cogniti ve Radio: Brai n-Empowe red W ireless Communica- tions”, IEEE Journal on Selected areas in Comm. , vol 23., no. 2, Feb 2005. [13] G. Caire and S. Shamai, “On the achie vable throughput of a mul tiante nna Gaussian broadcast channel” , IEEE Trans. on Information T heory , vol. 49, no. 7, pp. 1691-1706, 2003. [14] E. T . Jaynes, “Information Theory and Statist ical Mechanics”, Physical Re vie w , APS, vol. 106, no. 4, pp. 620-630, 1957. [15] E. T . Jaynes, “Probability Theory: The Logic of Science ”, Cambridge Uni versi ty Press, 2003. [16] Ø. Ryan, M. Debbah, “Multiplica ti ve free con voluti on and information- plus-noise type matrices”, Submit ted to J ournal Of Functional Analysis , 2008, http://www .ifi.uio.no/ ˜ oyvindry/ multfreecon v .pdf [17] Ø. Ryan, M. Debbah, “Channe l Capac ity E stimation using Free Prob- abili ty Theory”, IEEE Trans. on Signal Proce ssing, vol. 56, no. 11, pp. 5654-5667, Nov . 2008. [18] R. Seroul, D. O’Shea, “Programming for Mathema tician s”, Spri nger , 2000 [19] M. Hall J r . “Combinato rial Theory”, John Wi ley & Sons, Inc. New Y ork, NY , US A, 1998 [20] J.A. Bingham, “Multicarr ier modulati on for data transmission: An idea whose time has come, ” IEE E Comm. Mag., vol. 28, pp. 5-14, May 1990. [21] P . V iswanath , D. Tse and R. Laroia, “Opportunistic beamforming using dumb antennas”, IEEE Internationa l Symposium on Information Theory . IEEE. 2002, pp.449 [22] D. V . V oiculesc u and K. J. Dykema and A. Nica, “Free Random V ariable s”, Americ an Mathematica l Society , 1992. [23] J. Mitola, and Jr GQ Maguire, “Cognit i ve radio: making s oftwa re radios more personal ”, Personal Communications, IEE E [see also IEEE W ireless Communicat ions] 6(4), 13-18, 1999. [24] C.B. Papadia s, “Globally con ver gent blind s ource separat ion based on a multiuse r kurtosis maximizatio n criterion” , IEE E T rans. on Signal Processing, Dec. 2000, pp. 3508-3519. [25] J. V illares, “Symbol-rate Second-Order Blind Cha nnel Estimation in Coded Transmissions”, in Proc. ICASSP , Honolulu, Hawai i, April 2007. [26] C. Herzet , et al. , “Code-Aided Turb o Synchronizati on”, IEEE Proceed- ings, Special issue on turbo techniques, 2007. [27] H. Tri gui, D. T .M. Slock, “Cocha nnel interferen ce cancel lation within the current GSM standard”, IEEE ICUPC’98, Florence, Italy , Oct. 1998. [28] R. W . Thomas, L. A. DaSilva , A.B. MacK enzie,“Cogni ti ve networks”, DySP AN 2005 [29] E. V . Belmega, S. Lasaulce and M. Debbah, ”Decentra lized Hando vers in ce llular network s with cognit i ve terminals”, ISCCSP-2008 Malt a, 2008. [30] E. V . Belmega, S. Lasaulce and M. Debbah, ”Po wer Control in Dis- trib uted Multiple Access Channels with Coordina tion”, WNC3, 2008. [31] R. Couillet , M. Debbah, “Multi ple Antenna Cogniti ve Recei vers and Signal Detecti on”, Planned for s ubmission to IE EE T rans. on Information Theory .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment