Conditionally Gaussian Hypermodels for Cerebral Source Localization
Bayesian modeling and analysis of the MEG and EEG modalities provide a flexible framework for introducing prior information complementary to the measured data. This prior information is often qualitative in nature, making the translation of the avail…
Authors: Daniela Calvetti, Harri Hakula, Sampsa Pursiainen
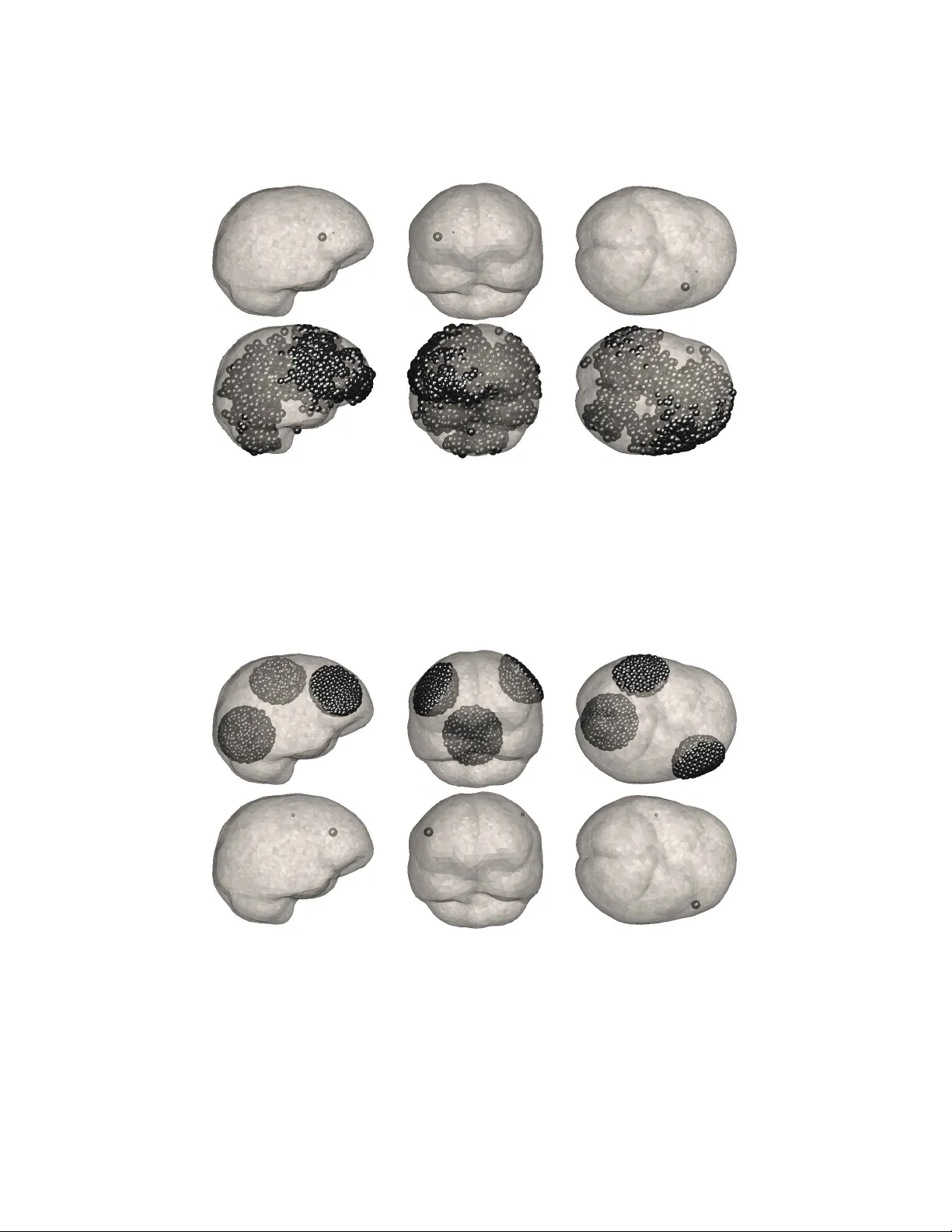
CONDITIONALL Y GA USSIAN HYPERMODELS F OR CEREBRAL SOUR CE LOCALIZA TION DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO Abstract. Ba y esian modeling and analysis of the MEG and EEG modalities provide a flexible framew ork for introducing prior information complementary to the measured data. This prior information is often qualitative in nature, making the translation of the av ailable information into a computational model a challenging task. W e prop ose a generalized gamma family of hyperpriors which allo ws the impressed curren ts to be focal and w e advocate a fast and ef- ficient iterative algorithm, the Iterative Alternating Sequential (IAS) algorithm for computing maxim um a posteriori (MAP) estimates. F urthermore, we sho w that for particular choices of the scalar parameters sp ecifying the hyperprior, the algorithm effectively approximates p opular regularization strategies such as the Minim um Curren t Estimate and the Minim um Support Estimate. The connection b et ween priorconditioning and adaptive regularization metho ds is also p oin ted out. The p osterior densities are explored by means of a Marko v Chain Monte Carlo (MCMC) strategy suitable for this family of hypermo dels. The computed exp erimen ts suggest that the known preference of regulariza- tion methods for superficial sources o v er deep sources is a prop ert y of the MAP estimators only , and that estimation of the p osterior mean in the hierarc hical model is b etter adapted for localizing deep sources. 1. Introduction The h uman brain con tains approximately 10 11 exitable neurons whose resting state is characterized b y a cross-membrane v oltage difference. Electromagnetic sig- nals propagate as p erturbations of this voltage difference, or action potentials, along the axons and are transferred across the synaptic gaps b y neurotransmitters, creat- ing a p ost-synaptic p oten tial in the receiving neurons. The p ost-synaptic p otential ma y b e relatively stable o ver a p eriod of milliseconds and, b eing well localized, it can b e mo delled mathematically as current dip ole. The neurons are organized in bundles, and when thousands of neighboring neurons are sim ultaneously in the p ost-synaptic excitation state, the net effect of the p ost-synaptic p oten tials gives rise to a lo calized curren t appro ximately parallel to the neuron bundle. This el- emen tary impressed source current drives an Ohmic v olume curren t in the brain tissue, and the net electromagnetic field can b e registered on or outside the skull. Imaging of the neuronal activity based on the registered electric voltage (EEG) or on the magnetic field (MEG) has b ecome a standard researc h to ol in clinical and cognitiv e studies. F urthermore, when coupled to functional imaging metho ds, 2000 Mathematics Subject Classific ation. Primary 92C55; Secondary 65C05, 74S05. Key wor ds and phr ases. Electroencephalography/Magnetoencephalography (EEG/MEG), Marko v chain Monte Carlo (MCMC), Finite element methods (FEM). 1 2 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO MEG and EEG ha ve a great p oten tial to gather pertinent information ab out the coupling b et ween neuronal activit y and cerebral hemo dynamics. The adv an tage of electromagnetic brain imaging mo dalities is their go o d tempo- ral resolution, about a millisecond, while their spatial resolution is limited b y v arious factors, including weak signal-to-noise ratio, am biguities in the source estimation due to the non-uniqueness of the inv erse source problem [25] and uncertainties in the mo del. F or example, while EEG suffers from lack of kno wledge of the electric conductivit y distribution and anisotropy of the head, MEG is known to b e less affected b y that [9, 34]. F or b oth modalities, the anisotropy of the white matter ma y result in a strong bias of the volume curren ts, an effect that should b e taken in to accoun t in a detailed mo del. The prop erties of the solutions to electromagnetic in v erse source problems de- p end on the a priori information implemented in the algorithm. One piece of information that may certainly improv e the spatial resolution, if prop erly incorp o- rated in the algorithm, is the fo cal nature of the impressed currents. In fact, since the electric and magnetic fields outside the skull dep end linearly on the impressed curren ts, but the comp onen t of the source b elonging to the significantly nontrivial n ull space of the forward map has no effect on the data, the determination of a ph ysiologically meaningful solution must b e based on complementary information. The implemen tation of feasible selection criteria has led to different solutions. F or example, setting the null space component to zero gives the minimum norm esti- mate (MNE) [12], while minimization of the current, or ` 1 norm of the source results in the minimum curr ent estimate (MCE) [31]. Solutions such as the Low Resolu- tion Electromagnetic T omography (LORET A) [22] are based on the assumption of smo othness of the source. In [13], the localization is pursued b y lo cal m ultip ole expansions of the fields. Low-dimensional parametric mo dels, for example those using only a few current dip oles [8, 19, 11], lead to lo calized solutions but limit the n umber of p ossible source configurations. Prior anatomical information such as the lo cation of the sulci has b een shown to improv e the p erformance of the lo calization [2]. Ba yesian metho ds are widely used in EEG/MEG to implement p ertinen t prior information such as anatomic constraints or functional information based on other imaging mo dalities [2, 14, 27, 30]. An additional lev el of flexibility to Bay esian mo delling is provided by hierarchical mo dels that allow uncertain ties in the prior mo del itself [1, 21, 26]. In particular, the mo del hierarc h y is a p o w erful to ol for including prior information that is qualitative rather than quan titative [7]. The connection b et ween classical regularization metho ds and Bay esian Maxi- m um A Posteriori (MAP) estimates is well known. In particular, the Gaussian mo dels lead to a MAP estimate that coincides with the standard Tikhono v regu- larized solution with a quadratic p enalt y , while non-Gaussian models are needed for non-quadratic penalties that are often more useful but computationally more c hallenging. In this work, we construct a c onditional ly Gaussian hierarc hical para- metric mo del that has the computational adv an tages of Gaussian prior mo dels but leads to a ric h class of MAP estimators that hav e the desirable qualitative prop- erties of n umerous commonly used non-Gaussian mo dels. Using the conditional normalit y , we construct a fast, efficient and simple MAP estimation algorithm, and sho w that with prop er choices of the few mo del parameters, the algorithm can b e in terpreted as a fixed p oin t iteration for solving the minimum norm estimate, the CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 3 minim um current estimate and, more generally , the minimum ` p estimate, while with a different choice, the algorithm approximates the minimum supp ort estimate (MSE) [20]. Hence, our approach puts these methods in a unified framework. The estimation algorithms require the solution of large linear systems, the sys- tem size dep ending on the discretization of the mo del. When a realistic three- dimensional mo del is used as in the present paper, iterative linear systems solvers are indisp ensable. It is common practice to improv e the p erformance of the itera- tiv e solv ers by preconditioners [24]. Recen tly , the authors introduced the concept of prior c onditioner [6], a preconditioner that is based on the prior mo del rather than on linear algebraic prop erties of the system matrix. It is shown in this ar- ticle that the priorconditioning based on the conditionally Gaussian hierarc hical mo dels yields an effective implementation of adaptive regularization similar to the F OCUSS (F OCal Underdetermined System Solver) algorithm [10]. A well-kno wn feature of many regularization based source lo calization algo- rithms, including the minimum norm and minimum current estimates, is their ten- dency to fav or surface sources, leading sometimes to a gross misplacement of deep sources. T o suppress this bias, differen t w eighting metho ds hav e b een prop osed to fa vor deep sources ov er the shallo w ones, see, e.g., [16] for a recent account. F rom the statistical p oin t of view, ho wev er, a depth dependent prior cov ariance which comp ensates for the preference of the lik eliho o d to wards superficial sources app ears rather dubious, since there is no reason to believe a priori that a deep source should ha ve high er v ariance than a sup erficial one. In this article, we confirm with n umeri- cal exp erimen ts that surface biasing may be a prop ert y of the MAP estimate, while Mark ov Chain Mon te Carlo (MCMC) sampling based posterior mean estimates ma y lo calize better deep sources without requiring w eight compensation. This result re- inforces the concept, well kno wn to the Ba y esian statistics comm unity , that the mo de of the posterior distribution may do a p oor job at represen ting the distribu- tion, demonstrating that the Bay esian form ulation of the inv erse problem is muc h more than “yet another w a y to regularize an ill-p osed problem”, as is sometimes incorrectly stated. Preliminary testing of the inv ersion algorithms and the MCMC sampling is done using a simple geometry with constant conductivity , mo delling the distributed cur- ren ts by a field of current dip oles. Subsequently , numerical exp erimen ts with a realistic three dimensional head mo del, with different electric conductivities in the scalp, skull, cerebrospinal fluid and the brain tissue are also presented. The volume curren t calculations are carried out with a finite element algorithm developed for this purp ose. The distributed curren ts are represen ted by Raviart-Thomas elemen ts that are a reasonable substitute for singular dip oles in the FEM context. 2. F or w ard model, EEG and MEG W e start by introducing the notations to b e used in the sequel and review some basic facts concerning the forward mo del, which is based on the standard approach using the quasi-static approximation of Maxw ell’s equations [25]. W e denote by D ⊂ R 3 the head with b oundary surface S and scalar conductivity distribution σ > 0. If we let J denote the impressed current densit y in D , the total current densit y , consisting of the impressed curren t and the Ohmic volume current, is J tot = J + σ E , where E is the electric field induced b y the current. Under the quasi-static appro ximation, we ma y a ssume that E is conserv ative, E = −∇ u . Neglecting the 4 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO electric displacement current in the Maxw ell-Amp ` ere equation, the total curren t densit y is div ergence free, leading to the Poisson equation for the electric p oten tial, (1) ∇ · ( σ ∇ u ) = ∇ · J , ∂ u ∂ n S = 0 , where the Neumann b oundary condition follows from the assumption that the con- ductivit y v anishes outside D . The magnetic field B outside the head induced b y the total current is, according to the Biot-Sav art law, obtained as (2) B ( x ) = µ 0 4 π Z D J tot × x − y | x − y | 3 dy , x ∈ R 3 \ D . The computation of the magnetic field therefore consists of t wo steps: the n umerical solution of the P oisson equation (1) to find u and thus the total electric current densit y J tot = J − σ ∇ u , and the computation of the integral yielding the magnetic field B (2). Each of these steps p oses computational challenges. The solution of the b oundary v alue problem (1) can be formally expressed in terms of the Neumann Green’s function G N of the diffusion op erator ∇ · σ ∇ , (3) u ( x ) = Z D G N ( x, y ) ∇ · J ( y ) dy . W e assume that the electric p oten tial is measured at lo cations x ` , 1 ≤ ` ≤ L on the surface S of the head. The approximation of the impressed curren t b y a finite linear com bination J = P K k =1 α k j k of basis curren ts j k , 1 ≤ k ≤ K , leads to a discrete mo del u ` = u ( x ` ) = K X k =1 Z D G N ( x ` , y ) ∇ · j k ( y ) dy α k = K X k =1 M e `k α k , 1 ≤ ` ≤ L, where the matrix M e ∈ R L × K is the ele ctric le ad field matrix . Similarly , assume that outside the head at p oin ts x n , 1 ≤ n ≤ N , the pro jection of the magnetic field in given directions e n is measured. Substituting the expression (3) in the Biot-Sa v art la w and representing the impressed current in the basis j k , we hav e the discrete mo del v n = e n · B ( x n ) = K X k =1 α k e n µ 0 4 π Z D j k ( y ) − σ ( y ) ∇ Z D G N ( y , z ) ∇ · j k ( z ) dz × x n − y | x n − y | 3 dy = K X k =1 M m nk α k , 1 ≤ n ≤ N , where the matrix M m ∈ R N × K is the magnetic le ad field matrix . The EEG inv erse source problem is to estimate the v ector α ∈ R K from the noisy observ ations of the v oltage potential u ∈ R L , while in the MEG in v erse source problem the data consist of the noisy observ ations of the magnetic field comp onen t v ector v ∈ R N . CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 5 In our mo del, we assume that the current elemen ts j k that constitute the basis for the distributed current are either dip oles or dip ole-lik e vector-v alued elemen ts. 3. Imaging in the Ba yesian framew ork In the Bay esian framework, inv erse problems are recast in the form of statistical inference [6, 15]. The lac k of information ab out an y of the quantities app earing in the form ulation of the problem is expressed b y mo delling them as random v ariables, and the av ailable information is enco ded in the probabilit y densities. In the electromagnetic inv erse source problem, the goal is to estimate the co ef- ficien t v ector α from the observ ations b = M α + e, where M is either the electric or magnetic lead field matrix and e is noise that, for simplicit y , is mo delled here as additive. Although not necessary , we assume that the noise is white Gaussian with kno wn v ariance σ 2 , whic h w e assume kno wn, leading to a likelihoo d mo del of the form π ( b | α ) ∝ exp − 1 2 σ 2 k b − M α k 2 . W e consider prior mo dels that are conditionally Gaussian and of the form π prior ( α | θ ) ∝ exp − 1 2 k D − 1 / 2 θ α k 2 − 1 2 K X j =1 log θ j , where D θ is a diagonal matrix, D θ = diag ( θ 1 , . . . , θ K ), and the logarithmic term comes from normalizing of the prior density by the determinan t of D − 1 / 2 θ . The p osterior densit y conditional on θ is, b y Ba y es’ form ula, π ( α | b, θ ) ∝ π prior ( α | θ ) π ( b | α ) ∝ exp − 1 2 σ 2 k b − M α k 2 − 1 2 k D − 1 / 2 θ α k 2 − 1 2 K X j =1 log θ j . Assuming the v ariance vector θ known and fixed, the MAP estimate for α , α MAP = argmin 1 2 σ 2 k b − M α k 2 + 1 2 k D − 1 / 2 θ α k 2 , is the classical Tikhono v regularized solution with a penalty defined b y the diagonal matrix D . It is known that if θ has equal entries, this solution is smeared out ev en if the data corresp onds to a fo cal input. T o improv e the lo calization, non- quadratic p enalties, for example the ` p -norm, p < 2, of the co efficien t vector α , ha ve b een prop osed. Here, w e take a differen t approach assuming instead that the v ariance v ector θ is unknown, and thus making its estimation a part of the inv erse problem. The v ariance v ector θ is mo delled as a random v ariable, and av ailable a priori information concerning it is expressed by a hyperprior π hyper ( θ ). The prior probabilit y densit y of the pair ( α, θ ) is then π prior ( α, θ ) = π hyper ( θ ) π prior ( α | θ ) , 6 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO and, according to Ba y es’ formula, the p osterior probability density , conditioned on the observ ation b alone, b ecomes π ( α, θ | b ) ∝ π hyper ( θ ) π prior ( α | θ ) π ( b | α ) . This implies that in the present form ulation w e need to estimate b oth α and its prior v ariance vector θ . 4. Hypermodels: MCE, minimum ` p and beyond Prior densities require quantitativ e information ab out the unknown, e.g., an estimate for its mean and its dynamical range, which is in turn related to the prior v ariance. The flexibility of hypermo dels lie in their abilit y to imp ort qualitative information into the estimation pro cess, see [5, 7, 4, 6]. In this article, we assume that the only a priori information concerning the impressed curren t is that it should consist of few fo cal sources. In statistical terms, such information can b e expressed b y the following three statements: (1) Nearb y source curren t elements, should not b e, a priori, m utually dep en- den t, to fav or the fo calit y; (2) No lo cation preference for the activity should b e given a priori; (3) Most of the dip ole-lik e sources should be silent, while few of them could ha ve large amplitude. T o enco de these conditions into the hyperprior, we observ e first that sto c hastic dep endence among the v ariances θ k w ould couple the dynamical ranges of the cor- resp onding co efficien ts α k . Therefore, it is reasonable to assume that the v ariances θ k are m utually indep enden t. On the other hand, without prior knowledge ab out the lo cation of the active sources, it is also reasonable to assume a priori that the v ariances are equally distributed. F urthermore, we wan t to allow the distribution of the v ariances to fav or small v alues while p ermitting rare large outliers which cor- resp ond to large amplitude of the source. Among the wealth of distributions that meet these requirements, we choose the parametric family of distributions, known as the gener alize d gamma distribution , θ k ∼ GenGamma( r , β , θ 0 ), defined as π hyper ( θ ) = π hyper ( θ ; r, β , θ 0 ) ∝ K Y k =1 θ rβ − 1 k exp − θ r k θ r 0 = exp − K X k =1 θ r k θ r 0 + ( r β − 1) K X k =1 log θ k ! . (4) In particular, we remark that by c ho osing r = 1, we hav e the gamma distribution , θ k ∼ Gamma( β , θ 0 ) = GenGamma(1 , β , θ 0 ), π hyper ( θ ) ∝ K Y k =1 θ β − 1 k exp − θ k θ 0 = exp − K X k =1 θ k θ 0 + ( β − 1) K X k =1 log θ k ! , while with r = − 1, we obtain θ k ∼ InvGamma( β , θ 0 ) = GenGamma( − 1 , β , θ 0 ) whic h is the inverse gamma distribution , and π hyper ( θ ) ∝ K Y k =1 θ − β − 1 k exp − θ 0 θ k = exp − K X k =1 θ 0 θ k − ( β + 1) K X k =1 log θ k ! . F or gamma and in verse gamma distributions, the parameters β and θ 0 are re- ferred to as shap e p ar ameter and sc aling p ar ameter , resp ectiv ely . A discussion of the similarities and differences of these tw o distributions, in particular with regard CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 7 to the frequency of o ccurrence and v alue of outliers, can b e found in [5], where w e also prop ose the follo wing Iterative Alternating Sequential (IAS) algorithm for computing the MAP estimate, ( α MAP , θ MAP ) = argmax π ( α, θ | b ) : IAS MAP estimation algorithm: (1) Initialize θ = θ 0 and set i = 1; (2) Up date α b y defining α i = argmax { π ( α | b, θ i − 1 ) } ; (3) Up date θ by defining θ i = argmax { π ( θ | b, α i ) } ; (4) Increase i by one and repeat from 2. until conv ergence. In the algorithm, follo wing Ba yes’ form ula, the conditional posterior probabilities are obtained as π ( α | b, θ i − 1 ) ∝ π ( α, θ i − 1 | b ) and π ( θ | b, α i ) ∝ π ( α i , θ | b ), i.e., alternatingly the vector α or the vector θ in the expression for the p osterior density set to the current estimate. The IAS algorithm has b een previously applied to image and signal deblurring [6, 5, 7], and it is found to give a fast and stable algorithm that is easy to implement. Before discussing ho w to organize the computations for different choices of the h yp erprior parameter r in (4), p oin ting out connections with kno wn algorithms as appropriate, w e w an t to point out a difference betw een our approac h and previously prop osed ones. In the literature of Bay esian hierarc hical models, the gamma distribution is often suggested as a hyperprior for the precision, or inv erse of the v ariance, because of its conjugacy prop ert y . This corresp onds to the inv erse gamma distribution for the v ariance. The conjugacy property is useful, e.g., when v ariational Ba yes metho ds, or v ariants of the closely related EM algorithm, are used and analytic marginal in tegrals are desired (Rao-Blackw ellization), see, e.g., [17]. Relev an t references for the MEG problem are [26, 33]. Interestingly , in [26] the gamma hyperprior for the precision was suggested but the c onnection with the regularization metho ds was not p ointed out. W e emphasize that our approach neither needs the conjugacy , nor do es it tak e adv antage of it. In fact, as we will show b elo w, the IAS algorithm yields fast, efficient and explicit estimators with a large range of parameter v alues corresp onding to non-conjugate mo dels. The generalized gamma distribution is c hosen here solely on the basis that it allo ws rare outliers. Gamma distribution and Minimum Current Estimate. Consider the p oste- rior density of the pair ( α, θ ) when the h yp erprior is the gamma distribution π ( α, θ | b ) ∝ exp − 1 2 σ 2 k b − M α k 2 − 1 2 k D − 1 / 2 θ α k 2 − 1 θ 0 K X k =1 θ k + β − 3 2 K X k =1 log θ k ! . T o solve the first maximization problem in the IAS MAP estimation algorithm, set θ = θ i − 1 and let the up dated α j b e the minimizer of the negative of the log- p osterior, (5) α i = argmin 1 2 σ 2 k b − M α k 2 + 1 2 k D − 1 / 2 θ i − 1 α k 2 , 8 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO whic h is the least squares solution of the linear system (6) σ − 1 M D − 1 / 2 θ i − 1 α = σ − 1 b 0 . Subsequen tly , setting α = α i , the updated v alue of θ can b e found b y differen tiating the log-posterior with resp ect to θ and setting the deriv ative equal to zero. The resulting equation is a second order equation 1 2 α 2 j /θ 2 j − 1 /θ 0 + η /θ j = 0 , η = β − 3 / 2 , α j = α i j , for the p ositiv e ro ot, whose analytic expression is θ i j = 1 2 θ 0 η + q η 2 + 2 α 2 j /θ 0 . In particular, if we let η = 0, w e hav e θ i j = | α i j | p θ 0 / 2, and, by substituting this in (5), we obtain α i = argmin 1 2 σ 2 k b − M α k 2 + 1 √ 2 θ 0 K X k =1 α 2 k | α i − 1 k | ! , whic h is also a fixed p oin t iterate of the minimization problem whose solution is the Minimum Current Estimate (MCE) [31] α MC = argmin k b − M α k 2 + δ K X k =1 α 2 k | α k | ! , δ = r 2 θ 0 σ 2 . Observ e that, b y choosing β > 3 / 2 in the hyperprior, we av oid the problem of dividing b y comp onen ts α i − 1 k near or equal to zero. This hence provides a natural regularization metho d for solving the Minim um Curren t Estimate problem. Generalized gamma distribution and ` p –estimates. The c hoice of the h y- p erprior from the family of generalized gamma distributions leads to the posterior mo del π ( α, θ | b ) ∝ exp − 1 2 σ 2 k b − M α k 2 − 1 2 k D − 1 / 2 θ α k 2 − 1 θ r 0 K X k =1 θ r k + r β − 3 2 K X k =1 log θ k ! . The up dating of α given the current v alue θ i − 1 requires solving the system (6) as in the case of gamma h yp erprior, while the updating formula for the v ariance parameter c hanges. Setting the deriv ative of the logarithm of the p osterior density equal to zero leads to the algebraic equation 1 2 α 2 j /θ 2 j − r θ r − 1 j /θ r 0 + ( r β − 3 / 2) /θ j = 0 , α j = α i j . This equation do es not hav e, in general, a closed form solution, although when r β = 3 / 2 the solution is simply θ i j = ( θ r 0 α 2 j / 2 r ) 1 / ( r +1) . CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 9 As in the case of the gamma distribution, after substituting this solution into the ob jective function in (5) w e notice that the up dated α i is a fixed point iterate of the ` p –p enalized regularization problem, α p = argmin k b − M α k 2 + δ K X k =1 | α k | p ! , δ = 2 σ 2 2 r θ r 0 1 / ( r +1) , with r = p/ (2 − p ). It is known that when 0 < p < 1, i.e., 0 < r < 1, this solution, lik e the MCE solution, tends to minimize the support of the estimated curren t, th us yielding a goo d localization of the focal activit y . On the other hand, letting r → ∞ , or, equiv alen tly , p → 2, the MAP estimate approaches the Tikhono v regularized solution with a quadratic p enalt y . The in termediate case 1 < p < 2 is related to the analysis presented in [1]. In v erse gamma distribution and Minimum Supp ort Estimate. The p oste- rior density for the inv erse gamma h yp ermodel is of the form π ( α, θ | b ) ∝ exp − 1 2 σ 2 k b − M α k 2 − 1 2 k D − 1 / 2 θ α k 2 − θ 0 K X k =1 1 θ k − β + 3 2 ! K X k =1 log θ k ! . Once again, the up dated v alue α i is found by solving (6) keeping θ fixed to the curren t v alue θ i − 1 , while θ j is the zero of the deriv ativ e of the logarithm of the p osterior whic h satisfies 1 2 α 2 j /θ 2 j + θ 0 /θ 2 j − κ/θ j = 0 , with κ = β + 3 / 2, and α j = α i j , and can b e expressed as θ i j = 1 2 α 2 j + θ 0 /κ. By interpreting this algorithm as a fixed p oin t step of a regularization sc heme with a nonlinear p enalt y term, we can reformulate it as the following minimization problem α = argmin k b − M α k 2 + δ K X k =1 ( α k ) 2 ( α k ) 2 + 2 θ 0 ! , δ = 4 κσ 2 , whose solution is the Minimum Support Estimate (MSE) [20]. In [6, 5, 7], the authors hav e sho wn that, in the context of traditional image pro cessing, the corre- sp onding p enalt y is related to the Perona-Malik functional [23]. Higher order inv erse gamma distributions. The gamma and in v erse gamma distributions are standard mo dels in hierarc hical Bay esian metho ds and the MAP estimates correspond to known regularizing sc hemes. The com bination of the gen- eralized gamma distribution and the IAS algorithm provide mo dels that are com- putationally tractable and lead to new estimators. As an example, if we c ho ose 10 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO r = − q , where q > 1 is an in teger, the p osterior distribution is π ( α, θ | b ) ∝ exp − 1 2 σ 2 k b − M α k 2 − 1 2 k D − 1 / 2 θ α k 2 − θ q 0 K X k =1 1 θ q k − q β + 3 2 ! K X k =1 log θ k ! . The algebraic equation for up dating θ k is q θ q 0 + 1 2 x 2 k θ q − 1 k − q β + 3 2 θ q k = 0 , i.e., θ k is a positive ro ot of a polynomial of order q , and can b e computed in a stable w ay b y considering the companion matrix. 5. Hyperpriorconditioners Direct computation of the least squares solution of the linear system (6), which yields the up dated α , b ecomes prohibitiv ely slow when the dimensionalit y of the problem is large, as is the case in the applications that we are considering here. Iterativ e metho ds are the metho d of choice for the solution of large scale linear sys- tems. In the case of linear discrete ill-p osed problems, this approach is particularly attractiv e b ecause of the inherent regularizing prop erties of iterative solvers when equipp ed with suitable stopping criteria. Iterativ e linear system solvers start from a given appro ximate solution and pro ceed to determine a sequence of improv ed appro ximate solutions. Assume, for the momen t, that in the pro cess of up dating α we introduce the c hange of v ariable w = D − 1 / 2 θ c α where θ c is the curren t v alue for θ , and express the solution of the optimization step in the form (7) w + = argmin 1 2 σ 2 k b − M D 1 / 2 θ c w k 2 + 1 2 k w k 2 , α + = D 1 / 2 θ c w + . W e remark that while in the statistical framework a suitable choice of the matrix D θ c mak es the change of v ariable equiv alent to whitening the random v ariable α , in the context of iterative linear systems solvers, this transformation amounts to preconditioning. Since in our problem the choice of the matrix D 1 / 2 θ c is dictated b y the selection of the prior, following [6] we refer to it as priorconditioner, to emphasize the connection b et ween the n umerical p erformance and the statistical setting. After the change of v ariables, the solution of the least squares problem (7) for up dating α coincides with the standard Tikhonov regularized solution for solving the preconditioned linear system (8) σ − 1 M D 1 / 2 θ c w = σ − 1 b, α = D 1 / 2 θ c w . It has b een sho wn in the literature that iterative Krylov subspace metho ds suc h as CGLS (see [24]) with early stopping of the iterations ma y giv e results of comparable qualit y to Tikhonov regularization but are computationally muc h more efficient. The in tro duction of a suitable right priorconditioner, which in the Bay esian framew ork is related to the prior of the unkno wn of primary in terest, to bias the iterates tow ards a desirable subspace, has b een shown to impro ve the qualit y of the CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 11 computed solution, in particular when the num ber of iterations is limited by either high computational costs or a large noise level in the data [6]. In general, statistically inspired preconditioners, which conv ey into the linear system solv er prior b eliefs ab out the solution, are constructed from the co v ariance matrix of the prior. In the application considered here, how ev er, the prior is a function of unknown parameters, whose distribution is, in turn, given by the hy- p erprior. Since the parameters of the prior are themselv es part of the estimation problem, they are updated at eac h iteration step. T o ensure that the solution of the minimization problem (5) uses the most up to date information ab out the problem, as so on as θ c b ecomes a v ailable, we update the priorconditioning matrix D 1 / 2 θ c , then pro ceed to compute a new estimate of α . W e remark that the idea of up dating the preconditioner to tak e adv an tage of newly acquired information ab out the linear systems w as already prop osed in the con text of a Flexible Generalized MINimal RESidual (FGMRES) scheme [24], al- though the motiv ation for the up dating were quite different. In the Ba yesian par- adigm w e can view priorconditioning in the context of h yp ermodels as priorcondi- tioning c onditione d on the presen t estimate of the prior parameters. Finally , it is of interest to notice that the alternating up dating scheme where the least squares problem is solved with preconditioned iterative metho ds (8) includes as a sp ecial case an algorithm previously proposed in the literature, based on adaptive w eighting of the ` 2 –norm. In fact, when the h yp erprior is the gamma distribution with β = 3 / 2, the IAS is essen tially the FOCUSS algorithm discussed, e.g. in [10]. While in the F OCUSS algorithm the regularization is obtained by passing from (8) to the normal equation corresp onding to (7), here w e adv o cate regularization by truncated iteration. The connections b et ween the minimum current estimate and F OCUSS from the empirical Bay esian p oint of view hav e b een p oin ted out also in [33]. 6. MCMC and regions of interest A great adv antage of the Ba yesian approac h o ver differen t regularization schemes is that starting from the p osterior densit y , we can compute a n umber of differen t es- timates and furthermore quan tify their reliability . The uncertaint y quan tification, ho wev er, usually requires sequen tial sampling tec hniques which are computation- ally considerably more in tensive than optimization based computation of single estimates, in particular when applied to a detailed three dimensional mo del. V arious dimension reduction metho ds ha ve been proposed in the literature to mak e the MCMC sampling viable. A common approach is to restrict the source sampling either to the surface of the brain or to a thin cortical lay er, see, e.g., [26]. In MEG, a further reduction of the dimensionalit y of mo del ma y be ac hieved by restricting the sampling to the cortical regions with a non-radial normal v ector, see, e.g., [1]. These mo del reductions are not applicable for us, since we consider b oth EEG and MEG and the p ossibilit y of reco v ering deep sources with the MCMC sampling. F ortunately , in applications where w e are interested in lo cal sources, it is often sufficien t to restrict the sampling to a muc h smaller Region Of Interest (ROI), around the p oten tially activ e area. The selection of the ROI can b e based on prior information about the expected activit y: for example, the primary resp onse to a visual stimulus is expected to o ccur in the o ccipital lob e. Alternativ ely , the R OI 12 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO can b e selected around an estimated fo cus of activity . Note that the concept of R OI does not exclude the p ossibilities of restricting the sampling to a p ortion of the cortical lay er, as is done in the cited articles, or of sampling ov er the whole brain, if the computing resources are not an issue. Once the ROI has b een identified, w e collect the indices of the source basis v ectors j k whose supp ort is in the ROI in the index vector I ROI , and the remaining ones in the vector I 0 . W e then partition the vectors α and θ accordingly , in tro ducing the notation α ROI = α ( I ROI ), α 0 = α ( I 0 ), θ ROI = θ ( I ROI ) and θ 0 = θ ( I 0 ). W e can now p erform MCMC sampling ov er the ROI, fixing the outside cur- ren t v alues and prior v ariance to prescrib ed v alues α 0 , θ 0 , using the conditional distribution, π ( α ROI , θ ROI | α 0 , θ 0 , b ) ∝ π ([ α ROI , α 0 ] , [ θ ROI , θ 0 ] | b ) . Eviden tly , α 0 = 0 is the most natural choice, corresp onding to the assumption that no activity outside the R OI app ears. The MCMC algorithm that w e prop ose is an indep endence sampling metho d, where α ROI and θ ROI are up dated sequentially by a pro cedure analogous to that of the IAS estimation algorithm. The updating of α ROI is done using the conditional normality of the p osterior, while the up dating of θ ROI is done via a full scan Gibbs sampler [6, 15, 17]. MCMC sampling over ROI: (1) Initialize α 0 ROI , θ 0 ROI and set i = 1. Define M , the desired sample size. (2) Dra w α i ROI from the Gaussian density π ( α ROI | θ i − 1 ROI , α 0 , θ 0 , b ) ∝ π ([ α ROI , α 0 ] , [ θ i − 1 ROI , θ 0 ] | b ) . (3) Dra w θ i ROI comp onen twise with a Gibbs sampler from the densit y π ( θ ROI | α i ROI , α 0 , θ 0 , b ) ∝ π ([ α i ROI , α 0 ] , [ θ ROI , θ 0 ] | b ) . (4) If i = M , stop; otherwise increase i by one and repeat from 2. In the practical implementation of the algorithm we up date α ROI b y defining a matrix G and its partitioning, G = σ − 1 M D − 1 / 2 θ i − 1 = G ROI G 0 , where G ROI con tains the columns of G with indices in I ROI and G 0 the remaining columns. The up dated α i ROI is obtained b y solving, in the least squares sense, the linear system G ROI α ROI = σ − 1 b 0 − G 0 α 0 + w , w ∼ N (0 , I ) . The up dating of θ k , k ∈ I ROI , is p erformed by drawing from the one-dimensional probabilit y densit y π k ( θ k ) ∝ exp − α 2 k 2 θ k − θ k θ 0 r + r β − 3 2 log θ k b y the in v erse cumulativ e distribution metho d [6, 15]. Hence, the sampling tec h- nique just outlined takes adv antage of the conditional normality of the prior and of the mutual indep endence of the v ariances, similarly to the IAS algorithm. CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 13 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 Figure 1. MAP estimates of the current (top ro w) and of the v ariance of the prior (b ottom row) at different depth in the ROI. The h yperprior is the gamma distribution. The true curren t dipole used for generating sim ulated data is shown as a hallo w arro w, and the ROI is marked on the sup erficial lay er. d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 Figure 2. MAP estimates of the current (top ro w) and of the v ariance of the prior (b ottom row) at different depth in the ROI. The hyperprior is the inv erse gamma distribution. The true current dip ole used for generating sim ulated data is shown as a hallow arro w, and the ROI is mark ed on the sup erficial lay er. 7. Computed experiments In this section w e apply the metho dology derived ab o ve to inv erse source prob- lems by first considering an example with a simplified planar geometry using a traditional singular dip ole mo del, then applying it to a realistic conductivity mo del for the h uman head. In the latter case, both the MEG and EEG mo dalities are considered. Since the finite element metho d (FEM) is needed to solv e the poten- tial distribution, w e use FEM basis functions also for representation of the curren t densit y . MEG in planar geometry . Consider a half space as a local mo del for the hu- man head. The half space mo del is particularly appropriate to illustrate the depth 14 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 Figure 3. P osterior mean estimates of the current (top row), of the v ariance of the prior (center row), and of the v ariance of the norm of the current estimated ov er the sample (b ottom row). The h yp erprior is the gamma distribution. d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 d = 0 d = 0.5 d = 1 d = 1.5 d = 2 d = 2.5 d = 3 d = 3.5 d = 4 Figure 4. P osterior mean estimates of the current (top ro w), of the v ariance of the prior (center ro w) and the v ariance of the norm of the current estimated ov er the sample (b ottom row). The h yp erprior is the inv erse gamma distribution. resolution with different hypermo del parameters and with different statistical esti- mators. The magnetic field component p erp endicular to the surface is recorded in a rectangular array of observ ation p oin ts x ` ab o ve the surface z = 0. W e represent CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 15 Figure 5. Sample histories of the components θ j and k q j k for the gamma hyperprior (top row) and the in verse gamma (b ottom ro w), where j is the index of the comp onen t of maximum v alue of θ C M . the current density as a linear combination of p oin t-wise current dip oles, J ( y ) = K X j =1 δ ( y − y k )( α 1 k e 1 + α 2 k e 2 ) = K X j =1 δ ( y − y k ) q k , where e 1 and e 2 are orthogonal basis v ectors parallel to the plane z = 0. In this example we ignore the volume currents, which is tantamoun t to setting σ = 0. More generally , assuming a conductivit y density that dep ends only on the depth [25], we arrive at a particularly simple magnetic lead field mo del, b ` = µ 0 4 π K X k =1 2 X j =1 e 3 · ( e j × ( x ` − y k )) | x ` − y k | 3 α j k , or b = M m 1 M m 2 α 1 α 2 , with α = [ α 1 ; α 2 ] ∈ R 2 K . When writing the conditional prior, we iden tify the v ariances θ 1 k and θ 2 k of the t wo mutually p erpendicular dip oles whose lo cations coincide, and the unknown v ariance θ 1 k = θ 2 k = θ k is a vector of length K . The 16 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO p osterior densit y then b ecomes π ( α, θ | b ) ∝ exp − 1 2 σ 2 k b − M α k 2 − 1 2 K X j =1 k q k k 2 θ k − K X k =1 θ k θ 0 r + r β − 3 2 K X k =1 log θ k ! , with k q k k 2 = ( α 1 k ) 2 + ( α 2 k ) 2 . W e use the IAS algorithm to calculate the MAP estimate, and MCMC sampling ov er the R OI to estimate the CM and obtain a measure of its uncertaint y . The geometry of our model consists of a rectangular array of 10 × 10 vertical magnetometers 2 cm ab o ve the half space, with a distance b et ween adjacent mag- netometers of 1 cm. The dip oles are lo cated b elo w the magnetometers in nine horizon tal lay ers, each con taining a 10 × 10 rectangular array of dip oles. The depth of these la y ers v aries from zero (superficial sources) to 4 cm, with a distance b et w een the lay ers of 0.5 cm. Since the MAP estimation algorithm is tantamoun t to fixed p oin t iteration with lo calizing p enalties, w e expect goo d p erformance at detecting fo cal sources of kno wn depth. It is well known [11, 16, 31] that when the depth of the source is unknown, the minimum current and minimum norm estimates due to their tendency to bias to- w ards sup erficial sources ma y lead to gross misplacemen ts of the deep fo cal sources. W e e xpect the same b eha vior from the MAP estimates of our hypermo del. W e test this b y generating synthetic data in which a single dip ole source is placed 3.5 cm b elo w the surface of the half space. The standard deviation in the likelihoo d mo del w as assumed to b e 5% of the maxim um noiseless signal. In this simulation, we did not add artificial noise to the data, since we are only interested in the mo del bias, not in the noise sensitivit y . The MAP estimates for the dip ole fields as well as for the prior v ariance θ with mo del parameter v alues r = 1 (gamma) and r = − 1 (inv erse gamma) are sho wn in Figures 1 – 2. When r = 1, we use the v alues θ 0 = 10 − 7 and β = 3 for the scaling parameter and the shap e parameter, while when r = − 1, we set θ 0 = 10 − 5 and β = 3. In b oth cases we p erform 15 iterations with the IAS algorithm. As exp ected, b oth h yp ermodels fav or sup erficial sources, with a relatively go od lo calization in the horizontal direction, i.e., the MAP estimate of the activity is ab o ve the true source. The ma jor differences b et w een the tw o hypermo dels are in the con v ergence rate and in the fo calit y of the MAP estimate. With the inv erse gamma h yp ermodel the iterative algorithm conv erges faster than with the gamma h yp ermodel, in particular for non-sup erficial sources, and seeks to explain the data with fewer active sup erficial dip oles. T o reduce the dimensionalit y of the sampling space, we select the R OI to be a cylinder with a 6 × 6 cm 2 square base around the estimated sup erficial fo cal activit y , shown in Figure 1 – 2, containing 9 × 6 × 6 = 324 dip oles. F or each h yp erparameter model we generate a sample of size M = 50 000, conditional on the curren ts v anishing outside the ROI, and calculate estimates of the p osterior means of the vectors α and θ , α j CM = 1 M P M i =1 α j,i , j = 1 , 2, and θ CM = 1 M P M i =1 θ i , and of the posterior v ariance of the dip ole amplitudes, V ar( k q k k ) = 1 M P M i =1 ( α 1 ,i − α 1 CM ) 2 + ( α 2 ,i − α 2 CM ) 2 . CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 17 T able 1. The domains of the head mo del and resp ectiv e conductivities. La yer Conductivit y scalp 0.33 skull 0.0042 cerebrospinal fluid 1 brain 0.33 Figure 3 displays the plots of the posterior mean of the curren t and the estimates of the prior v ariance, and the p osterior v ariance of the amplitude with the gamma h yp erprior, while Figure 4 shows the analogous results for the in v erse gamma hy- p erprior. The results with the tw o hyperpriors are qualitativ ely very different. The p osterior mean of the current for the gamma h yperprior mo del is biased to w ards the surface and is very similar to the MAP estimate, while the in verse gamma h yp ermodel has a go od depth resolution, with an error b etw een the true and the estimated source depth of 0.5 cm. The observ ation that the gamma hyperprior leads to a p osterior densit y that is qualitatively closer to the Gaussian prior, whose mean and maximum coincide, is in line with the fact that, as r → ∞ , the MAP estimate approac hes the minimum norm, or Tikhono v regularized, solution. The latter corresp onds to an ` 2 prior mo del. The sample histories of single components k q j k = (( α 1 j ) 2 +( α 2 j ) 2 ) 1 / 2 and θ j rev eal an in teresting feature of the posterior densit y . Figure 5 shows the sample histories of the comp onen ts corresp onding to the maximum v alue of θ CM . The sample histories with the gamma hyperprior exhibit go od mixing, while those corresponding to the in verse gamma distribution seem to suggest a bimo dal p osterior density . Note that the p osterior mean of the prior v ariance θ is in go o d agreement with the p osterior v ariance of the current amplitude, implying that the reliability of the p osterior mean current in this geometry could b e assessed directly from the mean of the v ariance parameter θ . EEG/MEG in realistic geometry. T o v alidate the h yperprior mo dels in a more realistic geometry , we p erformed EEG and MEG tests with a realistic human head mo del, based on MRI data. W e assume that b oth electric and magnetic fields are measured outside the skull at 31 different locations, as shown in Figure 6. This mo del is partitioned in to four domains of constant electric conductivit y: scalp, skull, cerebrospinal fluid (CSF), and brain, as illustrated in Figure 6. Anisotropies in the brain as well as p ossible electro conductiv e differences b et ween the gra y and the white matter are ignored. The electric and magnetic lead field matrices for this setup were constructed using the complete electro de model and a Finite Elemen t Metho d (FEM), describ ed in the App endix, under the assumption that all electro de contact imp edances are equal to one. The FEM mesh was generated in t wo stages. The meshes for the skull and the brain domains w ere generated first using triangular elemen ts. The meshes for the scalp and CSF domains w ere then generated by p ositioning prism elemen ts, eac h to b e subsequently divided into three tetrahedral elements, b et w een the brain and the skull surface. The total num ber of tetrahedral elemen ts in the head mesh is 108 914. The electric conductivities of the domains are giv en in T able 1. These v alues are as in [32]. 18 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO Figure 6. Sagittal, coronal, and axial pro jections (left to right) of the head mo del (top row) and the conductivity distribution inside it (b ottom row). The electric field is measured using 31 contact electro des marked by dark grey surface patches. The 31 mag- netic field measurement locations are indicated by the lighter dark spheres ov er the patches. Figure 7. Sagittal, coronal, and axial pro jections (left to right) of the reference curren t density (top ro w) and of the region of interest (b ottom ro w). Lo west order H (div)-conforming Raviart-Thomas elements were applied for the source current density . In these elements, basis functions are linear ov er the tetra- hedron, v anish at one of the vertices, and hav e a constant direction normal to the CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 19 Figure 8. Sagittal, coronal, and axial pro jections (left to right) of the MAP estimate from EEG data of the current for the gamma h yp ermodel (top row) and of the inv erse gamma hypermo del (b ot- tom row). T o improv e the readability of the three dimensional plots, only the curren t elemen ts whose amplitude is ab o ve 5% of the maximum of the amplitudes in the estimate w ere plotted. Figure 9. Sagittal, coronal, and axial pro jections (left to right) of the CM estimate from EEG data of the current for the gamma h yp ermodel (top row) and for the in verse gamma h yp ermodel (bot- tom row). face opp osite to the v ertex where they v anish [3]. F or a curl-free current density , e.g. a dipole source, it is necessary to use H (div)-conforming elemen ts [18], i.e. elemen ts in which basis functions and their divergences are square in tegrable. Basis functions 20 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO Figure 10. Sagittal, coronal, and axial pro jections (left to righ t) of the MAP estimate from MEG data of the curren t for the gamma h yp ermodel (top row) and for the in verse gamma h yp ermodel (bot- tom row). Figure 11. Sagittal, coronal, and axial pro jections (left to righ t) of the CM estimate from MEG data of the curren t for the gamma h yp ermodel (top row) and for the in verse gamma h yp ermodel (bot- tom row). for H (div)-conforming elements can be in terpreted to represent dip ole-lik e curren ts [29]. The electric p oten tial u was mo delled using Lagrange elemen ts [3]. Quadratic Lagrange elemen ts and a fifteen p oin t Gauss quadrature rule [3] w ere emplo y ed to generate sim ulated, noiseless reference data, while the exploration of the p osterior w as done using linear Lagrange elements and a four p oin t Gauss quadrature to CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 21 Figure 12. Sagittal, coronal, and axial pro jections (left to righ t) of the MAP estimate from EEG data of the v ariance of the prior for the gamma h ypermo del (top row) and for the in v erse gamma h yp ermodel (bottom row). In the top ro w, lo cation of the comp o- nen ts of θ larger than 5% of the maxim um v alue are marked with a bubble. In the b ottom row only elemen ts whose v alues w ere greater than or equal to 85% of the maxim um w ere plotted, indicating that the estimated v ariance is nearly maximal ov er the entire brain. Figure 13. Sagittal, coronal, and axial pro jections (left to righ t) of the CM estimate from EEG data of the v ariance of the prior for the gamma h ypermo del (top row) and for the in v erse gamma h yp ermodel (b ottom row). The thresholding level is set to 5% in this plot. sp eed up the com putation. The resulting forw ard mo delling error for the electric 22 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO Figure 14. Sagittal, coronal, and axial pro jections (left to righ t) of the MAP estimate from MEG data of the v ariance of the prior for the gamma hypermo del (top row) and inv erse gamma hypermo del (b ottom row). The thresholding in the visualization is as in Fig- ure 12. Figure 15. Sagittal, coronal, and axial pro jections (left to righ t) of the CM estimate from MEG data of the v ariance of the prior for the gamma h ypermo del (top row) and for the in v erse gamma h yp ermodel (bottom row). Here, the visualization threshold is set to 5%. lead field matrix in the brain domain w as appro ximately 3 % in the F rob enius norm [3], and approximately 2 % for the magnetic lead field matrix. The reference current density used to generate the reference data, sho wn in Figure 7, corresp onds to the case where we hav e three dip ole-lik e source curren ts, one positioned deeply , approximately 2.5 cm under the occipital lob e, and the other CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 23 Figure 16. Sagittal, coronal, and axial pro jections (left to righ t) of the sample based estimates of the p osterior v ariance from EEG data for the gamma hypermo del (top row) and for the in verse gamma h yp ermodel (b ottom row). The visualization threshold is set at 5% here. Figure 17. Sagittal, coronal, and axial pro jections (left to righ t) of the sample based estimates of the p osterior v ariance from MEG data for the gamma hypermo del (top row) and for the in verse gamma h yp ermodel (b ottom row). The visualization threshold is set to 5%. t wo on the surface la yer modelling the cortex. The source on the right of the fron tal lob e is almost tangential to the surface, and the source close to the left central sulcus is almost normal to the surface. 24 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO Figure 18. Sample histories of the comp onen t corresp onding to the maximum of the p osterior mean estimate of the curren t esti- mate from the EEG data and the gamma hypermo del (top left) and with the inv erse gamma hypermo del (b ottom left). In the righ t column w e show the corresp onding plots obtained from the MEG data and the gamma distribution (top righ t) or the inv erse gamma distribution (b ottom right). As in the planar geometry example, the standard deviation in the likelihoo d mo del is assumed to b e 5% of the maximum noiseless signal. In this case, to sim ulate real situations, the noise is added to the generated data. The MAP estimate with the IAS algorithm and p osterior mean by MCMC sam- pling ov er the ROI are computed, corresp onding to tw o different h yp erprior models (gamma, inv erse gamma) and to the EEG and MEG recording mo dalities. In these examples, the scaling and shap e parameter v alues are held constant at θ 0 = 10 − 7 and β = 1 . 55 and up to 20 iterations of the IAS metho ds were allow ed to compute the MAP estimates. The ROI consisted of three disjoin t sets containing together 5 982 elements, see Figure 7. Corresp onding to each com bination of hyperprior mo del and recording mo dalit y , an MCMC sample of size M = 50 000 is generated, assuming that impressed currents differ from zero only inside the ROI. In Figures 8 – 9, the MAP and p osterior mean estimates of the current v ector α using the EEG data are sup erimposed with three different pro jections (sagittal, coronal, and axial) of the brain. The top ro w corresp onds to the gamma h yp erprior and the b ottom row to inv erse gamma. Interestingly , the MAP estimate with the gamma distribution is more fo cal than with the inv erse gamma, while with the p osterior mean, the inv erse gamma yields more fo cal estimates. The same b eha vior is also seen in the estimates based on the MEG data, see Figures 10 – 11. Although fo cal, the estimate obtained from the EEG data is unable to locate all the sources. The preference for finding the right cortical source while missing CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 25 the left cortical source may b e related to the orien tation of the dip oles and the p ositioning of the electro des in the simulation. Unlik e in the case of the planar geometry , when using a realistic head mo del the deep source in the MAP estimates is not driven to the surface, indicating that there is enough geometric information in the three dimensional p ositioning of the electro des or magnetometers to resolve the depth. The MAP and p osterior mean estimates of the v ariance vector θ of the prior are sho wn in Figures 12 – 13 using the EEG data and in Figures 14 – 15 for the MEG data. The results are in full agreement with the corresponding estimates for the curren ts. Finally , based on the MCMC sampling, we estimate the p osterior v ariances V ar( α ) of the curren t v ector. The estimated v ariances are visualized in Figures 16 – 17. In terestingly , even when the p osterior estimates are blurry , the p osterior v ariances are relativ ely fo cal, giving additional information of the lik ely p ositions of the sources. T o monitor the performance of the MCMC sampler, in Figure 18 we ha v e plotted the sample histories of the comp onen ts of α and θ corresp onding to the index of maxim um v alue of the conditional mean estimate. In the realistic geometry , we do not encounter effects that would suggest multimodality of the distribution, and the mixing and conv ergence seem, by visual inspection, satisfactory . 8. Discussion In this article, we consider the MEG/EEG inv erse problems of lo calizing few fo cal sources in the framework of Bay esian hierarchical mo dels. It is sho wn that b y using a conditionally Gaussian prior com bined with generalized gamma distri- butions as hyperpriors, a rich family of p osterior densities ensues, and it is p ossible to generate numerous estimates, some of which are closely related to previously prop osed, regularization based estimators. W e prop ose a simple and effective numerical algorithm, the Iterativ e Alternating Sequen tial (IAS) algorithm for computing the MAP estimate sim ultaneously for the curren t densit y and its v ariance. The v ersatilit y of this approac h is confirmed b y its abilit y of producing an efficient fixed p oin t implemen tation of sev eral w ell kno wn fo- cal reconstruction methods based on non-quadratic p enalties or non-Gaussian prior distributions. Particular instances, that correspond to a choice of few scalar param- eters in the h yp ermodel, include the minimum current estimate, the ` p -regularized estimate and the limited supp ort functional estimate. F urthermore, the efficient n umerical implementation using iterative solvers gives also a natural in terpreta- tion in the statistical framework for the FOCUSS algorithm when applied to the MEG/EEG imaging problem. Compared to the empirical Bay es metho ds proposed in the literature such as evidence maximization, or Automatic Relev ance Determi- nation (ARD), Exp ectation Maximization (EM) and v ariational metho ds [26, 33], the IAS algorithm is very fast, easy to implemen t and does not require sophisti- cated minimization methods, nor do es it lead to intractable in tegral expressions. As sho wn in this article, explicit expressions for the iterative minimization steps can be found with n umerous c hoices of the h yp erprior parameters without requiring conjugacy prop ert y of the hyperprior. The different choices of the h ypermo del parameter lead to algorithms that be- ha ve qualitativ ely similarly with resp ect to the MAP estimation: when the depth 26 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO resolution due to the measurement geometry is p oor, as is the case in the lo cal half space mo del, sup erficial fo cal sources are lo calized well, while deep sources are biased tow ards the surface. The MCMC analysis of the posterior distributions, ho wev er, reveals a qualitative difference betw een the h yp ermodels with different v alues of the hypermo del parameter r . In the case where r = 1, corresp onding to the gamma h yp ermodel, the MAP estimate coincides with the minimum current estimate and, lik e the p osterior mean estimate, is biased to wards sup erficial sources. With r = − 1, yielding the in v erse gamma hypermo del, the MAP estimate is also biased tow ards sup erficial sources, but the p osterior mean is not. This qualitativ e difference may b e interpreted by saying that the smaller the parameter r , the less Gaussian the mo del, and in the limit as r → ∞ we obtain the minimum norm solution. Note that for Gaussian distributions, the p osterior mean and the MAP estimates coincide. F rom the p oin t of view of Bay esian mo delling paradigm, the qualitatively differ- en t b eha vior of solutions corresp onding to differen t hyperpriors ma y seem strange, since in none of the cases any a priori preference to sup erficial sources is given. The explanation is related to the parameter v alues in the h yp erpriors. The scal- ing parameter θ 0 in the gamma distribution w as chosen very small in our example with planar geometry to obtain go o d lo calization in the tangential direction. Since the mean of the gamma distribution is θ 0 β , this c hoice of θ 0 fa vors small curren t dip oles in the conditional mean, and the energetically easiest w ay to ac hieve this is to place all the currents on the surface. The mean of the inv erse gamma distribution, θ 0 / ( β − 1), is also a small num ber for this choice of θ 0 , but since this distribution allo ws significan tly larger outliers, it has no difficulty in letting few large dip oles in the low er la y ers explain the data. F or c ompleteness, we also p erformed MCMC runs with the gamma distribution with considerably larger scaling parameter v al- ues. The result suggest that when the scaling parameter is large enough to allo w dip oles of the correct size in the low er la yers where the true dip ole lies, the fo cal prop erties of the p osterior mean are lost. W e conclude that the findings are in line with the Bay esian philosophy and seem to suggest that the inv erse gamma prior is more suitable for deep sources. When using a three-dimensional more realistic geometry , the question of depth resolution b ecomes more delicate since the geometry starts to play a significan t role, and measurements from different directions p ossibly contribute to the depth resolution more than the prior. The computed results obtained with the realistic head mo del are in go od agree- men t with the planar case results, suggesting that the p osterior mean estimate is most effectiv e in combination with the inv erse gamma prior. The MAP estimate, on the other hand, is most effective when applied in connection with the gamma prior. In general, for the inv erse gamma hypermo del the p osterior mean estimation pro duced b etter results with larger v alues of the scaling parameter θ 0 than MAP estimation, while for the gamma hypermo del, MAP estimates w ere sup erior to CM estimates with larger θ 0 v alues. In these mo del b oth estimate types were found to b e more sensitive to the choice of the shap e parameter β than in the case of the planar geometry , with large v alue of β leading to blurred estimates and ultimately to in visibilit y of the deep source curren t. The hyperparameter v alues θ 0 = 10 − 7 and β = 1 . 55, used in the realistic case, w ere chosen based on visual inspection. CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 27 F uture extensions of this w ork include a hierarc hical extension of the model where the v alues of the hypermo del parameters will b e chosen based on the data, and the extension of the formalism to include time dep enden t sources with a longitudinal correlation structure. 9. Appendix: Complete electrode model and FEM f or EEG/MEG This app endix describes briefly how the electric and magnetic lead field matrices can b e constructed through the complete electro de mo del [28] and the FEM for a realistic three dimensional head, denoted here by Ω. The complete electro de model assumes that a set of con tact electro des e 1 , e 2 , . . . , e L with contact imp edances z 1 , z 2 ,. . . , z L is attached to the b oundary ∂ Ω. The electro de p oten tial v alues are collected into a vector U = ( U 1 ,U 2 , . . . ,U L ) and the electric p oten tial field u satisfies the equation (9) ∇ · ( σ ∇ u ) = ∇ · J , in Ω , as well as the b oundary conditions (10) σ ∂ u ∂ n ∂ Ω \∪ ` e ` = 0 , Z e ` σ ∂ u ∂ n ds = 0 , u + z ` σ ∂ u ∂ n e ` = U ` , with ` = 1 , 2 , . . . , L . Additionally , the Kirc hoff ’s v oltage la w P L ` =1 U ` = 0 is as- sumed to hold. The weak form of (9) and (10) can b e formulated by requiring that u ∈ H 1 (Ω) = { w ∈ L 2 (Ω) : ∂ w/∂ r i ∈ L 2 (Ω) , i = 1 , 2 , 3 } and J ∈ H (div; Ω) = { w ∈ L 2 (Ω) 3 : ∇ · w ∈ L 2 (Ω) } . These function spaces are thoroughly discussed e.g. in [18]. The finite element discretized fields corresp onding to u ∈ H 1 (Ω) and J p ∈ H (div;Ω) can be defined as u T = P N u i =1 ζ i ψ i and J T = P N J i =1 α i w i , resp ectiv ely . Here, the functions ψ 1 , ψ 2 , . . . , ψ N u ∈ H 1 (Ω) and w 1 , w 2 , . . . , w N J ∈ H (div; Ω) are, resp ectiv ely , scalar and vector v alued finite element basis functions, defined on a shap e regular finite element mesh T [3], and the coefficients form the coordinate v ectors ζ = ( ζ 1 , ζ 2 , . . . , ζ N u ) T and α = ( α 1 , α 2 , . . . , α N J ) T . F urthermore, since the sum of the electro de p oten tials is assumed to b e zero in the complete electro de mo del, it is required that U = ( U 1 ,U 2 ,. . . ,U L ) T = R ˜ ζ , where ˜ ζ is a vector and R ∈ R L × ( L − 1) is a matrix with entries R 1 ,j = − R j +1 ,j = 1 for j = 1 , 2 , . . . , L − 1, and otherwise R i,j = 0. The vectors α, ζ and ˜ ζ are link ed through a symmetric and positive definite linear system of the form (11) B C C T G ζ ˜ ζ = F α 0 , 28 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO in which the submatrix entries are given by F i,k = Z Ω ( ∇ · w k ) ψ i d Ω , B i,j = Z Ω σ ∇ ψ i · ∇ ψ j d Ω + L X ` =1 1 z ` Z e ` ϕ i ϕ j dS, C i,j = − 1 z 1 Z e 1 ϕ i dS + 1 z j +1 Z e j +1 ϕ i dS, G i,j = 1 z j Z e j dS + δ i,j z j +1 Z e j +1 dS, where δ i,j denotes the Kroneck er delta. The system (11) arises from the Ritz- Galerkin discretization [3] of the weak form of (9) and (10). Similarly , a discretized v ersion of the Biot-Sav art law (2) can b e expressed as B = W α − V ζ , where B is a v ector containing the magnetic field v alues at the measurement lo cations, and the matrices are defined by W i, 3( j − 1)+ k = Z Ω e k · w j × ( r i − r ) | r i − r | 3 d r , and V i, 3( j − 1)+ k = Z Ω e k · σ ∇ ψ j × ( r i − r ) | r i − r | 3 d r , with r j denoting the j th measuremen t lo cation and e k denoting the k th natural basis vector. The dep endences of U and B on the v ector α are describ ed b y the electric and magnetic lead field matrices M e and M m , respectively . These matrices are giv en b y M e = R ( C T B − 1 C − G ) − 1 C T B − 1 F , M m = W − V ( B − C G − 1 C T ) − 1 F , as can b e verified through straigh tforw ard linear algebra manipulations. Note that these expressions are v alid only if a set of contact electrodes is attached to the head during the magnetic field measuremen t. References [1] T. Auranen, A. Nummenmaa, M. S. H ¨ am ¨ al ¨ ainen, I. P. J ¨ a ¨ askel ¨ ainen, J. Lampinen, A. Veht ari, and M. Sams , Bayesian analysis of the neur omagnetic inverse pr oblem with ` p -norm priors , NeuroImage, 26 (2005), pp. 870–884. [2] S. Baillet and L. Garner o , A Bayesian appr o ach to intro ducing anatomo-functional priors in the EEG/MEG inverse pr oblem , IEEE T rans. BME, 44 (1997), pp. 374–385. [3] D. Braess , Finite elements , Cambridge Universit y Press, Cambridge, UK, 2001. [4] D. Cal vetti and E. Somersalo , A unifie d Bayesian fr amework for algorithms to r e cover blo cky signals , (2007). Adv anced Signal Pro cessing Algorithms, Arc hitectures and Imple- mentations XVII, edited by F ranklin T. Luk, Proc. of SPIE V ol. 6697 (SPIE 2007), pap er no. 6697–4 (10 pages). [5] , Gaussian hyp ermo dels and r e c overy of blo cky obje cts , Inv erse Problems, 23 (2007), pp. 733–754. [6] , Intr o duction to Bayesian scientific c omputing – ten le ctur es on subjective c omputing , Springer V erlag, New Y ork, 2007. [7] , Hyp ermo dels in the Bayesian imaging fr amework , (2008). T o app ear in In v erse Prob- lems. CONDITIONALL Y GAUSSIAN HYPERMODELS FOR CEREBRAL SOURCES 29 [8] J. C. de Munck, B. W. v an Dijk, and H. Spekrejse , Mathematic aldip oles ar e ade quate to describ e re alistic genr ators of human br ain activity , IEEE T rans. BME, 35 (1988), pp. 960– 966. [9] N. G. Genc ¸ er and C. E. Acar , Sensitivity of EEG and MEG me asur ements to tissue c onductivity , Ph ys. Med. Biol., 49 (2004), pp. 701–717. [10] I. F. Gorodnitsky and B. D. Rao , Sp arse signal r e c onstruction fr om limite d dat using FOCUSS: a r e-weighted minimum norm algorithm , IEEE T rans. Signal Proc., 45 (1997), pp. 600–616. [11] M. S. H ¨ am ¨ al ¨ ainen, R. Hari, R. Ilmoniemi, J. Knuutila, and O. V. Lounasmaa , Magne- to enc ephalo gr aphy – The ory, instrumentation and applications to nonivasive studies of the working human brain , Rev. Mo d. Phys., 65 (1993), pp. 413–498. [12] M. S. H ¨ am ¨ al ¨ ainen and R. Ilmoniemi , Interpr eting measur e d magnetic fields of the br ain: estimates of curr ent distributions , (1984). Rep ort TKK-F-A559 Low T emp erature Lab ora- tory , Helsinki Universit y of T echnology , SF-02150 Esp oo, Finland. [13] K. Jerbi, S. Baillet, J. C. Mosher, G. Nol te, L. Garnero, and R. M. Leahy , L o c aliza- tion of re alistic c ortic al activity in MEG using curr ent multip oles , NeuroImage, 22 (2004), pp. 779–793. [14] S. C. Jun, J. S. George, J. P ar ´ e-Blagoev, S. M. Plis, D. M. Ranken, D. M. Schmidt, and C. C. Wood , Sp atiotemp or al Bayesian infer enc e dip ole analysis for MEG neur oimaging data , NeuroImage, 28 (2005), pp. 84–98. [15] J. Kaipio and E. Somersalo , Statistical and c omputational inverse pr oblems , Springer V er- lag, New Y ork, 2004. [16] F. H. Lin, T. Witzel, S. P. Ahlfors, S. M. Stufflebeam, J. W. Belliveau, and M. S. H ¨ am ¨ al ¨ ainen , Assessing and impr oving the sp atial ac cur acy in MEG sour c e lo calization by depth-weighte d minimum-norm estimates , NeuroImage, 31 (2006), pp. 160–171. [17] J. S. Liu , Monte Carlo strate gies in scientific computing , Springer V erlag, New Y ork, 2001. [18] P. Monk , Finite Element Metho ds for Maxwel l’s Equations , Clarendon Press, Oxford, UK, 2003. [19] J. C. Mosher, P. S. Lewis, and R. M. Leahy , Multiple dip ole mo del ling and loc alization fr om sp atiotemp or al MEG data , IEEE T rans. BME, 39 (1992), pp. 541–557. [20] S. Nagarajan, O. Por tniaguine, D. Hw ang, C. R. Johnson, and K. Sekihara , Contr ol le d Supp ort MEG imaging , NeuroImage, 33 (2006), pp. 878–885. [21] A. Nummenmaa, T. A uranen, M. S. H ¨ am ¨ al ¨ ainen, I. P. J ¨ a ¨ askel ¨ ainen, J. Lampinen, M. Sams, and A. Veht ari , Hier ar chic al Bayesian estimates of distribute d MEG sour c es: The or etic al asp e cts and c omp arison of variational MCMC metho ds , NeuroImage, 35 (2007), pp. 669–685. [22] R. D. P ascual-Marqui , Review of metho ds for solving the EEG inverse problem , Int. J. Bioelectromagnetism, 1 (1999), pp. 75–86. [23] P. Perona and J. Malik , Sc ale-sp ac e and e dge detection using anisotropic diffusion , IEEE T rans. Pattern Anal. Mach. Intell., 12 (1990), pp. 629–639. [24] Y. Saad , Iter ative Metho ds for Sp arse Line ar Systems , So ciet y for Industrial and Applied Mathematics, Philadelphia, P A, 2003. [25] J. Sar v as , Basic mathematical and ele ctr omagnetic c onc epts of the biomagnetic inverse prob- lem , Phys. Med. Biol., 32 (1987), pp. 11–22. [26] M. Sa to, T. Yoshika, S. Kajihara, K. Toy ama, N. Goda, K. D. Ka w a to, and M. Ka w a to , Hierar chic al Bayesian estimation for MEG inverse pr oblem , NeuroImage, 23 (2004), pp. 806–826. [27] D. M. Schmidt, J. S. George, and C. C. Wood , Bayesian infer enc e applied to the ele ctr o- magnetic inverse problem , Human Brain Mapping, 7 (1999), pp. 195–212. [28] E. Somersalo, M. Cheney, and D. Isaacson , Existenc e and uniqueness for ele ctr o de mo dels for electric curr ent c ompute d tomo gr aphy , SIAM J. Appl. Math., 52 (1992), pp. 1023–1040. [29] O. T anzer, S. J ¨ ar venp ¨ a ¨ a, J. Nenonen, and E. Somersalo , Repr esentation of bio ele ctric curr ent sour ces using Whitney elements in finite element method , Phys. Med. Biol., 50 (2005), pp. 3023–3039. [30] N. J. Trujillo-Barreto, E. auber t V ´ asquez, and P. A. V ald ´ es-Sosa , Bayesian model aver aging in EEG/MEG imaging , NeuroImage, 21 (2004), pp. 1300–1319. [31] K. Uutela, M. S. H ¨ am ¨ al ¨ ainen, and E. Somersalo , Visualization of magneto enc ephalo- gr aphic data using minimum curr ent estmates , NeuroImage, 10 (1999), pp. 173–180. 30 DANIELA CAL VETTI, HARRI HAKULA, SAMPSA PURSIAINEN, AND ERKKI SOMERSALO [32] P. Wen, F. He, and K. Sammut , A pseudo-c onductivity inhomo gene ous he ad mo del for c omputation of EEG , Pro ceedings of the 20th Ann ual In ternational Conference of the IEEE Engineering in Medicine and Biology Society , 20 (1998). [33] D. Wipf, R. Ramirez, J. P almer, S. Makeig, and B. Rao , Analysis of empiric al b ayesian metho ds for neur o electr omagnetic sour c e lo c alization , in Adv ances in Neural Information Processing Systems 19, B. Sch ed., 2007. [34] C. H. Wol ters, A. Anw andter, X. Tricoche, D. Weinstein, M. A. K och, and R. S. McLeod , Influence of tissue c onductivity anisotr opy on EEG/MEG field and r eturn curr ent c omputation is a r e alistic he ad mo del: A simulation and visualization study using high- r esolution finite element mo deling , NeuroImage, 30 (2006), pp. 813–826. D. Cal vetti: Dep ar tment of Ma thema tics, Case Western Reser ve University, 10900 Euclid A venue, Cleveland, OH 44106, USA E-mail address : daniela.calvetti@case.edu H. Hakula: Institute of Ma thema tics, Box 1100, FI-02015 Helsinki University of Tech- nology, Finland E-mail address : harri.hakula@tkk.fi S. Pursiainen: Institute of Ma thema tics, Box 1100, FI-02015 Helsinki University of Technology, Finland E-mail address : sampsa.pursiainen@tkk.fi E. Somersalo: Dep ar tment of Ma thema tics, Case Western Reser ve University, 10900 Euclid A venue, Cleveland, OH 44106, USA E-mail address : erkki.somersalo@case.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment