Distance-based clustering of sparsely observed stochastic processes, with applications to online auctions
We propose a distance between two realizations of a random process where for each realization only sparse and irregularly spaced measurements with additional measurement errors are available. Such data occur commonly in longitudinal studies and onlin…
Authors: Jie Peng, Hans-Georg M"uller
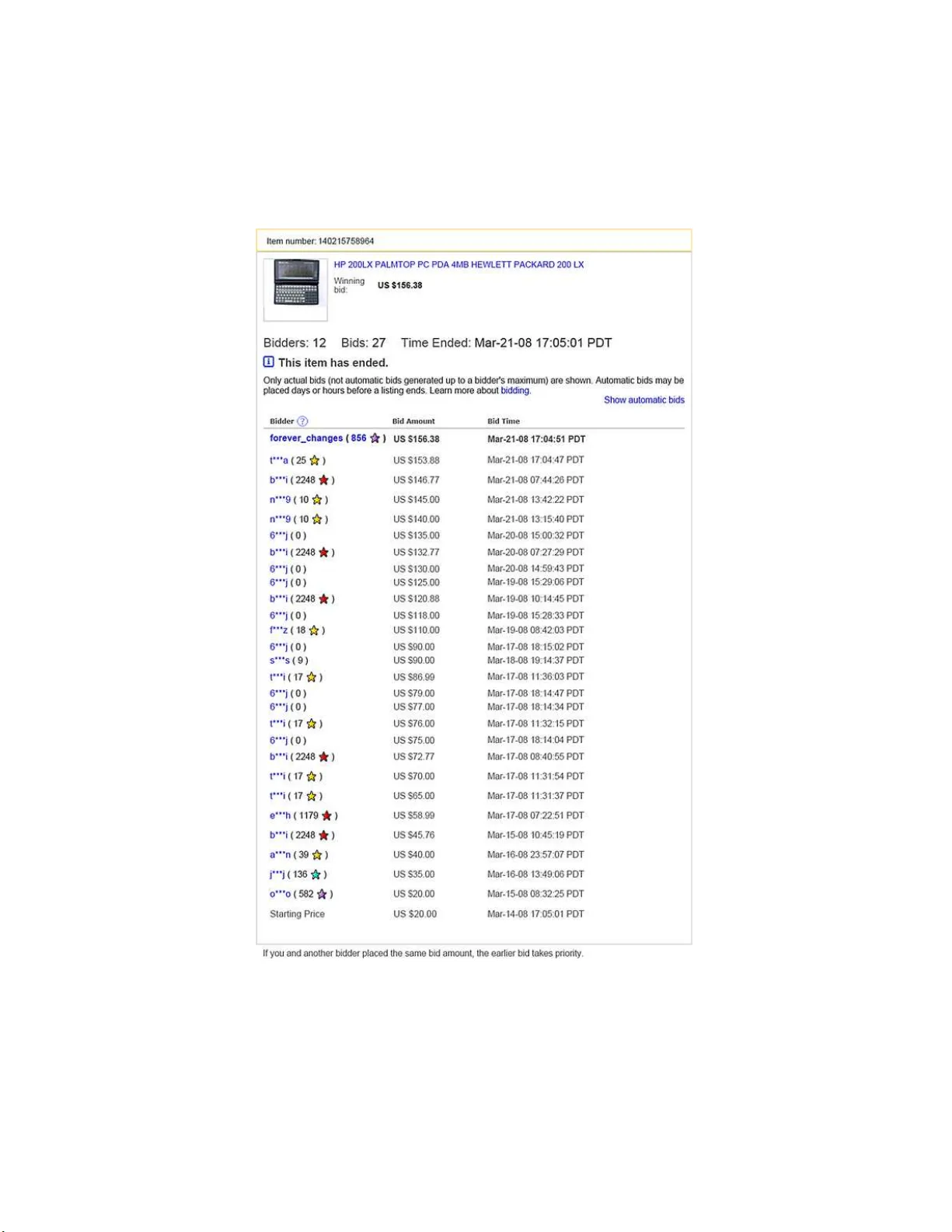
The Annals of Applie d Statistics 2008, V ol. 2, No. 3, 1056–1 077 DOI: 10.1214 /08-A OAS172 c Institute of Mathematical Statistics , 2008 DIST ANCE-BASE D CLUSTERING OF SP ARSEL Y OBSER VED STOCHASTIC PR OCE S SES, WITH APPLICA TIONS TO ONLINE A UC TIONS By Jie Peng and Hans-Georg M ¨ uller 1 University of California , Davis W e prop ose a distance b et w een tw o realizations of a random pro- cess where for eac h realization only sparse and irregularly spaced measuremen ts with additional measuremen t errors are a va ilable. Such data occu r commonly in longitudinal studies and online trading data. A distance measure then makes it p ossible to apply distance-based analysis suc h as classificatio n, clustering and multidimensional scal- ing for irregularl y sampled longitudinal data. Once a suitable dis- tance measure for sparsely sampled longitudinal tra jectories has b een found, we apply dista nce-based cl ustering meth ods to eBa y online auction data. W e identify six d istinct clusters of bidding patterns. Eac h of these bidding patterns is found to b e associated with a sp e- cific chance to obtain the auctioned item at a reasonable p rice. 1. In trod uction. The goal of cluste r analysis is to group a coll ection of su b jects in to clusters, suc h that those falling in to the same cluster are more similar to eac h other than those in different clusters. T herefore, a measure of similarit y or dissimilarit y b et w een sub jects is a necessary in- gredien t for clustering. A metric d efined on th e sub ject sp ace is one wa y to obtain dissimilarities, simply using the distance b et ween t wo sub jects as a measure of dissimilarit y . While one can readily c ho ose from a v ari- et y of w ell-kno wn metrics fo r the c ase of classical multiv ariate d ata, or for functional data that are in the form of con tin u ously observ ed tra jectories, finding a suitable distance measure for ir r egularly observ ed data ca n b e a c hallenge. One such situation wh ic h we study here occur s in the commonly encoun tered case o f ir r egularly and sparsely observed longitudinal data , with online auction data a prominent example [ Shmueli and Jank ( 2005 ), Jank and Shmueli ( 2006 ), Shmueli, Russo and Jank ( 2007 ), Liu and M ¨ uller Received Octob er 2007; rev ised April 2008. 1 Supp orted in part by NSF Grants DMS-03-54448 and DMS-05-05537. Key wor ds and phr ases. Bidder tra jectory, clustering of tra jectories, functional data analysis, metric in fun ction space, multidimensional scaling. This is an electronic reprint of the original article published by the Institute of Mathematical Statistics in The Annals of Applie d Statistics , 2008, V ol. 2, No. 3, 1056– 1077 . This reprint differs from the original in pagination and t y pog raphic deta il. 1 2 J. PENG AND H.-G. M ¨ ULLER ( 2008 )]. As an example, a s napshot of an eBa y auctio n history f or a P alm P erson al Digital Assista n t is sh own in Figure 1 . In this pap er the focu s is on a traditional clustering framew ork, where it is assumed that ea c h sub- ject b elongs to exac tly on e cluster. T here are alternati v e clustering id eas suc h as soft clustering [ Eroshev a and Fienberg ( 2005 )] or mixed m em b er- ship clustering [ Eroshev a, Fien b erg and Laffert y ( 2004 )]. F or example, in Eroshev a, Fien b erg and Joutard ( 2007 ), functional disabilit y d ata are ana- lyzed b y a grade of m em b ership mo del, which allo ws sub jects to ha v e partial mem b ership in s ev eral m ixture comp onen ts at the same time. Online auctions are generating in creasingly large amounts of data for whic h analysis to ols are still scarce and eBa y is one of the biggest online auction mark etplaces. The eBa y auction shown in Figure 1 is an example of the t yp e of single-item auctions on whic h we fo cus. These are 7-da y auctions set up as second-price auctions. eBa y uses a pro xy bidd ing system w here bidders s u bmit the maxim u m amoun ts that they are willing to pa y for the item b eing auctioned, referred to as WTP—wil lingness to p ay amounts , and the p r o xy syste m automatically increa ses eac h bidder’s bid by a minimum incremen t (whic h is relativ e to the current highest bid and set by eBa y), unt il either the bidder’s maxim um has b een r eac hed, or the b idder has the cu r ren t highest bid. During an auction, a bidder can sub m it as many WTP amounts as desired. The winning bidder is determined according to who has submitted the h ighest bid at the end of the auction. The price the winning bidder pa ys corresp onds to the second h ighest b id , plus an increment [ Shmueli and Jank ( 2005 )]. W e refer to the series of all WTP bids, includ ing the times within the auction at wh ic h these were submitted, as the “bid history” of a particular auction. It is notew orth y that consecutiv e WTP amoun ts can decrease and therefore are n ot constrained to b e monotone increasing, since all but the highest current WTP amoun ts are visible during an ongoing auction. F or studying bidding behavio rs in eBa y auctions, w e will fo cus here on the WTP amo unts, as these reflect the in ten tions of b idders and th erefore capture bidder b eha vior. A c haracteristic of on line auction data is that th e times w hen b ids are placed are sparsely lo cated within the time domain of an auction (7 da ys in our examples), as many bidders sub mit only very few bids (one or t w o) dur ing a give n auct ion, and the timing of their bids is irregular. It is wel l known that early and la te ph ases in an auction attract more bid ding activit y than the middle ph ase. The often frenzied b idding activit y at the end of an auction is referred to as bid sniping , and is caused b y the desire of bidd ers to win a giv en auctio n. Besides the ob jectiv e of winning, a main goal for most bidders is to w in the item b eing auctioned at the lo west p ossible price. The set of bids placed by an individu al bidder d uring a sp ecific auction consists of a few sn apshots, take n at the times the bidder places a b id, of an underlying b idder tra jectory whic h is a con tin uous function that corresp onds CLUSTERING OF STOCHASTIC PR OCESSES 3 Fig. 1. Snapshot of a seven-day eBay auction. to a sp ecific realiza tion of a sto chasti c pro cess and reflects the biddin g b e- ha vior. Our stud y is motiv ated b y th e go al to classify bidd er tra jectorie s based on the observed bidding activities. C lassifying b idder tra jectories is 4 J. PENG AND H.-G. M ¨ ULLER of in terest in order to i den tify differen t bidding strateg ies. Bidders aim at ac hieving a h igh chance of winn ing and/or winn ing the item at a lo w final price. Studying ho w d ifferen t strategies connect to these somewhat con- flicting aims may help to differen tiate v arious strategies in regard to th eir effectiv eness to ac hiev e th ese aims. As p oint ed out in Bapna et al. ( 2004 ), learning ab out bidding strategies also serv es to enhance the d esign of online auction systems. In a recen t p ap er b y Jank and S hm ueli ( 2008 ), the authors tak e a functional data view p oint and use curv e cluste ring tec hniques to group the p rice tra jectorie s of auctions. Their goal is to charac terize het- erogeneit y in th e price formation pr o cess of online auctions and understand sources that a ffect the pr ice dynamics. Therefore, the t ra jectories of inter- est in their study are d erived from th e ensemble of all bids p laced by all bidders who p articipate in a certain auction, while w e are in terested in th e study of individu al bidd er-sp ecific tra jectories and the clustering of these tra jectorie s. A fi rst step to differen tiate b et we en v arious bidding strategies is to d efine a distance b et w een the v arious observed b id ding b ehavio rs, in ord er to derive a dissimilarit y measure b et w een differen t bidding patterns. The distance is to b e based on the observ ed WTP bid s for one bidder (in one auction), and as t yp ical bidder tra jectories are observe d at only very few and irregular times, th is leads to the c hallenge to define a distance based on sp arse and irregularly ti med data . Similar p r oblems also arise in man y ot her t yp es of data from online en vironm en ts, such as user reviews and w eblog postings, where a single user migh t con tribu te a small n um b er of en tries for a sp ecific topic/ite m. Assu m ing that an in dividual’s bidd ing activit y is a r eflection of the realiza tion of an und erlying sto c hastic bid price pro cess, this c hallenge motiv ates the dev elopmen t of a metric on the sample space of a s tochas- tic p ro cess, where elemen ts of this space are realizations of the underlying pro cess with observ ations that consist of noisy measuremen ts and are made at sparse and irregular time p oin ts. On ce we hav e constructed a reasonable distance, w e ma y base clustering metho ds on the resulting distance matrix, for example, one may apply multi dimensional scaling or similar app roac hes. Implemen ting suc h a p ro cedure, w e find six distinct clusters of bidding pat- terns by analyzing the bids submitted durin g 158 seve n-da y auctions of Pal m M515 Personal Digital Assistan ts (for more d etails, see Section 3 ). Interest - ingly , the c hance of obtaining the auctioned item at a lo w price is closely asso ciated with the bidd in g pattern/strategy: If the goal of the b id der is to win the auctioned item a t a r easonable p r ice, the resulting probabilities to ac hiev e this goal sho w clear differences for th e v arious b idding strategies, and one can iden tify b etter and worse strategies. If the en tire t ra jectory of ea c h realized bid p r ice pro cess w ere observed, then the L 2 norm in the sp ace of squ are int egrable functions would pro vide a natural starting p oin t for defining a metric. How ev er, the L 2 distance i s CLUSTERING OF STOCHASTIC PR OCESSES 5 not readily calculable from the act ually a v ailable noisy , sparse and irregu- larly sampled measuremen ts of the bid price pro cess. Supp ose one observ es a square inte grable sto c hastic pro cess { X ( t ) : t ∈ T } at a random n umber of randomly lo cated p oin ts in T , with measuremen ts corru pted b y add itiv e i.i.d. r andom noise. Th e observ ations a v ailable from n indep endent realiza- tions of the pro cess are { Y il : 1 ≤ l ≤ n i ; 1 ≤ i ≤ n } with Y il = X i ( T il ) + ε il , (1.1) where { ε il } are i.i.d. with mean 0 and v ariance σ 2 . Since X is a squ are inte - grable sto chast ic pro cess, by Mercer’s theorem [cf. Ash ( 1972 )], there exists a p ositiv e semidefinite k ernel C ( · , · ) su c h that co v ( X ( s ) , X ( t )) = C ( s, t ) and w e hav e th e follo wing expansion of the p ro cess X i ( t ) in terms of the eigen- functions of the k ernel C ( · , · ): X i ( t ) = µ ( t ) + ∞ X k =1 ξ ik φ k ( t ) , (1.2) where µ ( · ) = E( X ( · )) is the mean function; the r an d om v ariables { ξ ik : k ≥ 1 } for eac h i are uncorrelated with zero mean and v ariance λ k ; P ∞ k =1 λ k < ∞ , λ 1 ≥ λ 2 ≥ · · · ≥ 0 are the eigen v alues of C ( · , · ); and φ k ( · ) are the corresp ond- ing orthonormal eigenfunctions. In the observed data model we assume that { T il : l = 1 , . . . , n i ; 1 ≤ i ≤ n } are randomly sampled from a (possibly unknown) distribution with a d en- sit y g on T . In the problems we stu d y , n i are t ypically small, reflecting that the observed data consist of sparse and noisy realizatio ns of a stoc hastic pro cess. W e will define a d istance b et wee n t wo su c h realizatio ns X i and X j based on the observ ed data as describ ed in the n ext section. This approac h is inspired by recen t devel opmen ts of fu nctional d ata analysis metho dology for longitudinal data, notably the work of Y ao, M ¨ uller and W ang ( 2005 ) where tra jectories are pr ed icted from sparse and noisy observ ations, wh ich recen tly w as adapted to online auctions [ Liu and M ¨ uller ( 2008 )]. Approac h es based on B-spline fitting with random co efficien ts which are suitable to fit similar data with random co efficien t mo dels ha v e b een prop osed b y Shi, W eiss and T aylo r ( 1996 ), Rice and W u ( 2001 ), and recen tly in the con- text of online auctions b y Reithinger et al. ( 200 8 ). F or an up-to-date in tro duction to functional data analysis, w e refer to the excelle n t b o ok by Ramsa y and Silv erman ( 2005 ). Descriptions of the r apidly ev olving in terface b et ween longitudinal and functional metho dology and functional mo d els for sparse longitudinal data can b e found in Rice and W u ( 2001 ), James, Hastie and S ugar ( 20 01 ), James and Sugar ( 2003 ), and the o vervie ws pro vided in Rice ( 2004 ), Zhao, Marron and W ells ( 2004 ) and M ¨ u ller ( 2005 ). Th e prop osed d istance is in tro d uced in the follo wing section. An ap- plication to the clustering of bidding p atterns in eBa y online auctions is the topic of Sectio n 3 , follo w ed by concludin g remarks. Pro ofs and auxiliary remarks can b e found in an Ap p endix . 6 J. PENG AND H.-G. M ¨ ULLER 2. A distance for sp arse and irregular data. W e prop ose a distance b e- t ween the random curves X i and X j based on the observe d data Y i = ( Y i 1 , . . . , Y in i ) T and Y j = ( Y i 1 , . . . , Y j n j ) T . The idea is to use the condi- tional exp ectatio n of the L 2 distance b et w een these tw o curves, given the data. Our analysis is conditional on the times of the measuremen ts { T il : l = 1 , . . . , n i ; 1 ≤ i ≤ n } and their n um b ers { n i : 1 ≤ i ≤ n } . 2.1. Definition and b asic pr op erties. The L 2 distance b et wee n t wo curves X i and X j is defined as D ( i, j ) = Z T ( X i ( t ) − X j ( t )) 2 dt 1 / 2 , and is not ca lculable in our situat ion, as only the sparse d ata Y i and Y j are observ ed. Therefore, we prop ose to use the conditional exp ectation of D 2 ( i, j ) , giv en Y i and Y j , as the squared d istance b et wee n X i and X j , ˜ D ( i, j ) = { E( D 2 ( i, j ) | Y i , Y j ) } 1 / 2 , 1 ≤ i, j ≤ n. (2.1) Note that as a f u nction of Y i , Y j , the ˜ D ( i, j ) s are r andom v ariables and ha ve the f ollo wing prop erties, the pro of of which is giv en in the App endix . Pr oposition 2.1. ˜ D sat isfies the fol lowing pr op erties: 1. ˜ D ( i, j ) ≥ 0 , ˜ D ( i, i ) = 0 and for i 6 = j , P ( ˜ D ( i, j ) > 0) = 1 ; 2. ˜ D ( i, j ) = ˜ D ( j, i ) ; 3. F or 1 ≤ i, j, k ≤ n , ˜ D ( i, j ) ≤ ˜ D ( i, k ) + ˜ D ( k , j ) . Therefore, ˜ D can b e viewe d as a metric on the sub ject space consisting of random realizations { X i ( · ) } of the u n derlying sto c hastic pro cess X ( · ). Since under mo d el ( 1.2 ), Parze v al’s identit y implies that the L 2 distance b et w een X i and X j can b e w ritten as D ( i, j ) = k X i − X j k 2 = ( ∞ X k =1 ( ξ ik − ξ j k ) 2 ) 1 / 2 , w e get ˜ D 2 ( i, j ) = E ∞ X k =1 ( ξ ik − ξ j k ) 2 | Y i , Y j ! . F or an in teger K ≥ 1, w e then define truncated v ersions of ˜ D as ˜ D ( K ) ( i, j ) = ( E K X k =1 ( ξ ik − ξ j k ) 2 | Y i , Y j !) 1 / 2 (2.2) CLUSTERING OF STOCHASTIC PR OCESSES 7 = ( K X k =1 v ar( ξ ik | Y i ) + v ar( ξ j k | Y j ) + (E( ξ ik | Y i ) − E( ξ j k | Y i )) 2 ) 1 / 2 . Note that it follo w s from these d efinitions that E( ˜ D 2 ( i, j )) = E( D 2 ( i, j )) and also for the tru ncated versions E( ˜ D ( K ) ( i, j ) 2 ) = P K k =1 2 λ k = E( D ( K ) ( i, j ) 2 ), so that these conditional exp ectat ions are unbia sed predictors of the corre- sp onding squared L 2 distances. 2.2. Estimation. In the follo wing w e discuss the estimatio n of the trun- cated v ersion of the distance ˜ D ( K ) ( i, j ) ( 2.2 ). Giv en an in teger K ≥ 1, let Λ ( K ) = diag { λ 1 , . . . , λ K } be the K × K diagonal matrix with diag onal ele- men ts { λ 1 , . . . , λ K } . F or 1 ≤ i ≤ n , 1 ≤ k ≤ K , let µ i = ( µ ( T i 1 ) , . . . , µ ( T in i )) T , ξ ( K ) i = ( ξ i 1 , . . . , ξ iK ) T , φ ik = ( φ k ( T i 1 ) , . . . , φ k ( T in i )) T and Φ ( K ) i = ( φ i 1 , . . . , φ iK ). Define ˜ ξ ( K ) i = Λ ( K ) (Φ ( K ) i ) T Σ − 1 Y i ( Y i − µ i ) , (2.3) where Σ Y i = co v ( Y i , Y i ) = ( C ( T il , T il ′ )) + σ 2 I n i . Note that ˜ ξ ( K ) is the b est linear unbiase d predictor (BLUP) of ξ ( K ) , since co v ( ξ ( K ) , Y i ) = Λ ( K ) (Φ ( K ) i ) T . Moreo v er, if we h a ve a finite-dimensional pro cess, such that f or some int eger K > 0, λ k = 0 for k > K in mo del ( 1.2 ), then (omitting upp er subscripts K ) Σ Y i = Φ i Λ(Φ i ) T + σ 2 I n i and ΛΦ T i (Φ i ΛΦ T i + σ 2 I n i ) − 1 = (Φ T i Φ i + σ 2 Λ − 1 ) − 1 Φ T i , so that ˜ ξ i = (Φ T i Φ i + σ 2 Λ − 1 ) − 1 Φ T i ( Y i − µ i ) , whic h also is the solution of the p enalized least-squares p r oblem min ξ ( Y i − µ i − Φ i ξ ) T ( Y i − µ i − Φ i ξ ) + σ 2 K X k =1 ξ 2 k /λ k . If one assu m es n ormalit y of the pro cesses in mo dels ( 1.1 ) and ( 1.2 ), that is, ξ ik ∼ N (0 , λ k ) and ε il i.i.d. ∼ N (0 , σ 2 ) and ind ep endence b et ween errors and pro cesses, the join t d istribution of { Y i , ξ ( K ) i } is m ultiv ariate normal w ith Y i ξ ( K ) i ∼ Normal µ i 0 , Σ Y i , Φ ( K ) i Λ ( K ) Λ ( K ) (Φ ( K ) i ) T , Λ ( K ) !! . (2.4) Therefore, the conditional d istribution of ξ ( K ) i giv en Y i is norm al with mean E( ξ ( K ) i | Y i ) = Λ ( K ) (Φ ( K ) i ) T Σ − 1 Y i ( Y i − µ i ) = ˜ ξ ( K ) i (2.5) and v ariance v ar( ξ ( K ) i | Y i ) = Λ ( K ) − Λ ( K ) (Φ ( K ) i ) T Σ − 1 Y i Φ ( K ) i Λ ( K ) . (2.6) 8 J. PENG AND H.-G. M ¨ ULLER F urthermore, ˜ ξ ( K ) b ecomes th e b est predictor of ξ ( K ) , and with ( 2.5 ) and ( 2.6 ), ( ˜ D ( K ) ( i, j )) 2 = tr(Λ ( K ) − Λ ( K ) (Φ ( K ) i ) T Σ − 1 Y i Φ ( K ) i Λ ( K ) ) (2.7) + tr(Λ ( K ) − Λ ( K ) (Φ ( K ) j ) T Σ − 1 Y j Φ ( K ) j Λ ( K ) ) + k Λ ( K ) (Φ ( K ) i ) T Σ − 1 Y i ( Y i − µ i ) − Λ ( K ) (Φ ( K ) j ) T Σ − 1 Y j ( Y j − µ j ) k 2 2 . Therefore, ˜ D ( K ) ( i, j ) can then b e estimated b y plugging in estimates for the mo del comp onents, that is, for mean curve µ ( · ), co v ariance k ernel C ( · , · ), first K eigen v alues { λ k : k = 1 , . . . , K } and corresp onding eigenfunctions { φ k : k = 1 , . . . , K } , as wel l as error v ariance σ 2 . Although ( 2.7 ) is derive d under the normalit y assumption, its exp ectat ion is alw a ys equal to the exp ectat ion of D ( K ) ( i, j ) 2 (whic h is P K k =1 2 λ k ), regardless of distributional assumptions. Assuming that mean, cov ariance and eigenfunctions are al l sm o oth, one can apply lo cal linear smo others [ F an and Gijb els ( 1996 )], p o oling observ a- tions for f unction and su rface estimation, fitting local lines in one dimension for estimat ing the mean function and lo cal planes in tw o dimensions f or estimatio n of the co v ariance k ernel [see Y ao, M ¨ uller and W ang ( 2005 ) for details]. Denoting the resu lting estimates of µ ( · ), C ( · , · ) by b µ ( · ), b C ( · , · ), the estimates of eigenfunctions and eige n v alues are giv en by the solutions ˆ φ k and ˆ λ k of th e eigen-e quations Z T b C ( s, t ) ˆ φ k ( s ) ds = ˆ λ k ˆ φ k ( t ) , where th is system of equations is s olved by discretizing the smo othed co v ari- ance [ Rice and Silv erman ( 1 991 )], f ollo w ed by a pro jection on the space of symmetric and nonnegativ e defin ite co v ariance surf aces [ Y ao et al. ( 2003 )]. The e stimate b σ 2 of σ 2 is obtained b y first su btracting b C ( t, t ) fr om a lo cal linear smo other of C ( t, t ) + σ 2 , denoted by b V ( t ), then av eraging o v er a sub- set of T [ Y ao, M ¨ uller and W ang ( 2005 )]. F urther details can b e found in the App endix . The estimate of ˜ D ( K ) ( i, j ) is then giv en by b D ( K ) ( i, j ) = { tr( b Λ ( K ) − b Λ ( K ) ( b Φ ( K ) i ) T b Σ − 1 Y i b Φ ( K ) i b Λ ( K ) ) + tr( b Λ ( K ) − b Λ ( K ) ( b Φ ( K ) j ) T b Σ − 1 Y j b Φ ( K ) j b Λ ( K ) ) (2.8) + k b Λ ( K ) ( b Φ ( K ) i ) T b Σ − 1 Y i ( Y i − b µ i ) − b Λ ( K ) ( b Φ ( K ) j ) T b Σ − 1 Y j ( Y j − b µ j ) k 2 2 } 1 / 2 , CLUSTERING OF STOCHASTIC PR OCESSES 9 where b Λ ( K ) = diag { ˆ λ 1 , . . . , ˆ λ K } ; b Φ ( K ) i = ( b φ i 1 , . . . , b φ iK ), and the ( l, l ′ ) en try of b Σ Y i is ( b Σ Y i ) l,l ′ = b C ( T il , T il ′ ) + b σ 2 δ ll ′ . T he compu ter co de to calculate ( 2.8 ) based on d ata is given as Supplementa ry material [ P eng and M ¨ uller ( 2008 )]. T o obtain fun ctional principal comp onen t scores for sp arse data, one can also use the matlab pac k age P ACE ( h ttp://anson.ucda vis.edu/˜m ueller/data/ programs.h tml ). The follo w in g result shows the consistency of these estimates for the target distance ˜ D ( i, j ) , pro viding some assurance that the estimated distance is close to the targeted one if enough comp onents are included and the num b er of observ ed random curv es is large enough. Theorem 2.1. Under the assumptions liste d in L emma A.2 in the App e ndix , lim K → + ∞ lim n → + ∞ b D ( K ) ( i, j ) = ˜ D ( i, j ) in pr ob ability . Pr oof. See App end ix . 2.3. Distanc e-b ase d sc aling. Multidimensional scaling (MDS) aims to find a pro jection of giv en original ob jects for whic h one has a distance matrix in to p -dimensional (Euclidean) s p ace for an y p ≥ 1, often c h osen as p = 2 or 3 whic h provides b est visualizatio n. T h e pro jected p oin ts in p -space rep- resen t the original ob jects (e.g., r andom curves) in such a wa y that their distances m atc h w ith the original distances or d issimilarities { δ ij } , accord- ing to some target crit erion. In our setting these original distances will b e the estimated conditional L 2 distances ( 2.8 ) b etw een the sparsely observe d random tra j ectories. V arious tec hniqu es exist for imp lemen ting the MDS pro jection, including metric and n onmetric scaling. In classical met ric scaling one treats dissimilariti es { δ ij } dir ectly as Eu - clidean distances and then uses th e sp ectral decomp osition of a doubly cen- tered matrix of d issimilarities [ Co x and Co x ( 2001 )]. It is well known that there is an equiv alence b et w een p rincipal comp onents analysis and classical scaling when dissimilarities are truly Eu clidean distances (if the su b jects are p oin ts in an Euclidean sp ace). Metric least squ ares scaling fi nds config- uration p oin ts { x i } in a p -dimensional space with distances { d ij } matc hing { δ ij } as closely as p ossible, by minimizing a lo ss function S , for example, S = P i 0, P ( | ˜ D 2 ( i, j ) − ˜ D ( K ) ( i, j ) 2 | > ǫ ) ≤ E( ˜ D 2 ( i, j ) − ˜ D ( K ) ( i, j ) 2 ) /ǫ = 2 ∞ X k = K +1 λ k /ǫ − → 0 . The result follo ws from Slutsky’s theorem. Pr oof of Theorem 2.1 . Note that | b D ( K ) ( i, j ) − ˜ D ( i, j ) | ≤ | b D ( K ) ( i, j ) − ˜ D ( K ) ( i, j ) | + | ˜ D ( K ) ( i, j ) − ˜ D ( i, j ) | . CLUSTERING OF STOCHASTIC PR OCESSES 21 By Lemma A.3 , for an y ǫ > 0 and an y δ > 0, there exists K 0 suc h that, for an y K ≥ K 0 , P ( | ˜ D ( K ) ( i, j ) − ˜ D ( i, j ) | ≥ ǫ/ 2) ≤ δ / 2 . By Lemma A.2 , for eac h K > 0 , there exists n 0 ( K ) > 0 suc h that, for an y n ≥ n 0 ( K ), P ( | b D ( K ) ( i, j ) − ˜ D ( K ) ( i, j ) | ≥ ǫ/ 2) ≤ δ / 2 . Therefore, for K ≥ K 0 , n ≥ n 0 ( K ), P ( | b D ( K ) ( i, j ) − ˜ D ( i, j ) | ≥ ǫ ) ≤ δ , whic h concludes the pro of. Ac kn o wledgment s. W e are grateful to W olfgang Jank for sh aring the eBa y auction data, and to one review er wh ose comment s led to man y im- pro v ements of th e pap er. SUPPLEMENT AR Y MA TERIAL Supplement A: eBa y cod es (DOI: 10.1214/ 08-A O AS172SUPP A ; .txt). Supplement B : R functions used for FPCA and conditional distance anal- ysis (DOI: 10.12 14/08- A OAS172SUPPB ; .txt). Th ese f unctions are us ed in eBa y co d es.txt. REFERENCES Ash, R. B. (1972). R e al Ana lysis and Pr ob ability . Academic Press, New Y ork. MR0435320 Bapna, R., Goes, P., Gupt a, A. and Jin, Y. (2004). User h eterogeneit y and its impact on electronic auction market design: An empirical exp loration. MI S Quarterly 28 21–43. Co x, T. and Cox, M. (2001). Multidimensional Sc al i ng . Chapman and H all/C RC, Lon- don. MR133544 9 Er oshev a, E. A. and Fienberg, S. E. (2005). Ba yesian mixed membership mo dels for soft clustering and classification. I n Cl assific ation—The Ubiquitous Chal lenge (C. W eihs and W. Gaul, eds.) 11–26. Springer, New Y ork. Er oshev a, E. A., Fienberg, S. E. and Jout ard, C. ( 2007). Describing disabilit y through individu al-lev el mixture mo d els for multiv ariate binary data. A nn. Appl. Statist. 1 502–537. Er oshev a, E. A., Fienberg, S. E. and Laffer ty, J. (2004). Mixed-membership mo dels of scientific publications. Pr o c. Natl. Ac ad. Sci. 101 5220–5227. F an, J. and Gijbels, I. (199 6). L o c al Polynomial Mo del l ing and Its Applic ations . Chap- man and Hall/CRC, London. MR138358 7 James, G., Hastie, T. G . and S ugar, C. A. (2001). Principal comp onent mo dels for sparse functional data. Biometrika 87 587–602. MR178981 1 James, G. and Su gar, C. A. (2003). Clustering for sparsely sampled functional data. J. Amer . Statist. Asso c. 98 397– 408. MR199571 6 Jank, W. and Shmu eli, G. (2006). F u n ctional data analysis in electronic commerce researc h. Statist. Sci. 21 155–166. MR232407 5 22 J. PENG AND H.-G. M ¨ ULLER Jank, W. and Shmue li, G. (2008). Studying heterogeneity of price evolution in eBay auc- tions v ia functional clustering. In Handb o ok on Information Series: Business Computing (C. Adomavicius and A. Gupta, eds.). Elsevier. T o app ear. Kearsley, A. J., T apia, R. A. and Tro sset, M. W . (1998). The solution of the metric STRESS and S STRESS problems in m ultidimensional scaling using Newton’s metho d. Comput. Statist. 13 369–396. Krusk al, J. B. (1964). Multidimensional scaling by optimizing go odn ess of fit to a non- metric hypothesis. Psychometrika 29 1–27. MR016971 2 Liu, B. and M ¨ uller, H. G. (20 08). F unctional data analysis for sparse auction data. In Statistic al Metho ds f or E-c ommer c e R ese ar ch (W. Jank and G. Shmueli, eds.). Wiley , New Y ork. M ¨ uller, H. G. (2005). F unctional mo delling and classi fication of longitudinal data. Sc and. J. Statist . 32 223–240. MR218867 1 Peng, J. and M ¨ uller, H.-G. (2008). Sup plemen t to “Distance-based clustering of sparsely observed sto c hastic pro cesses, with app lications to online auctions.” D OI: 10.121 4/08-A OAS172 SUPP A ; DOI: 10.1214 /08-A OAS172 SUPPB . Ramsa y, J. and Sil verman, B. (2005). F unctional Data Analysis . Springer, New Y ork. MR216899 3 Reithinger, F., Jank, W., Tutz, G. and Shmueli, G. ( 2008). Smo oth ing sparse and unevenly sampled curves using semiparametric mixed mod els: A n application to online auctions. J. R oy. Statist. So c. Ser. C 57 127–148. Rice, J. (2004). F unctional and longitudinal data analysis: Perspectives on smoothing. Statist. Sinic a 14 631–64 7. MR208796 6 Rice, J. and Sil v erman, B. (1991). Estimating th e mean and co v ariance structure non- parametrically when the data are cu rves . J. R oy. Statist. So c. Ser. B 53 233–243. MR109428 3 Rice, J. and Wu , C. (2001). Nonparametric mixed effects mo dels for uneq u ally sampled noisy curves. Biometrics 57 253–259. MR18333 14 Sammon, J. W. (1969). A nonlinear mapping for data structure analysis. IEEE T r ans. Computers 18 401– 409. Shi, M., Wei ss, R. E. and T a ylor, J. M. G. (1996). An analysis of paediatric CD4 counts for Acquired Immune Deficiency Synd rome u sing flexible random curve s. Appl. Statist. 45 151–163. Shmueli, G. and Jank, W. (2005). Visualizing online auctions. J. Comput. Gr aph. Statist. 14 299–319. MR216081 5 Shmueli, G., Russo, R. P. and Jank, W. (2007). The BARIST A: A mo del for bid arriv als in online auctions. Ann. Appl. Statist. 1 412–4 41. T akane, Y., Young, F. W. and DeLe euw, J. (1977). Nonmetric individual differences multi dimensional scal ing: An alternati ng least squares meth od with optimal s caling features. Psychometrika 42 7–67. Y ao, F., M ¨ uller, H. G., Clifford, A. J., Dueker, S. R., Fol lett, J., Lin, Y ., Buchholz, B. and Vogel, J. S. (2003). Shrink age estimation for functional princi- pal component sco res, with application to the population kinetics of plasma folate. Biometrics 59 676– 685. MR200427 3 Y ao, F., M ¨ uller, H. G . and W ang , J. L. (2005). F unctional data analysis for sparse longitudinal data. J. Amer. Statist . Asso c. 100 577–59 0. MR2160561 Zhao , X., Marron, J. S. and Wells, M. T. (2004 ). The functional data analysis view of longitudinal data. Statist. Si nic a 14 789–80 8. MR2087973 CLUSTERING OF STOCHASTIC PR OCESSES 23 Dep ar tmen t of St atis tics University of California Da v is, California 95616 USA E-mail: jie@wald.ucda vis.edu mue ller@wald.ucda vis.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment