Adaptive Base Class Boost for Multi-class Classification
We develop the concept of ABC-Boost (Adaptive Base Class Boost) for multi-class classification and present ABC-MART, a concrete implementation of ABC-Boost. The original MART (Multiple Additive Regression Trees) algorithm has been very successful in …
Authors: Ping Li
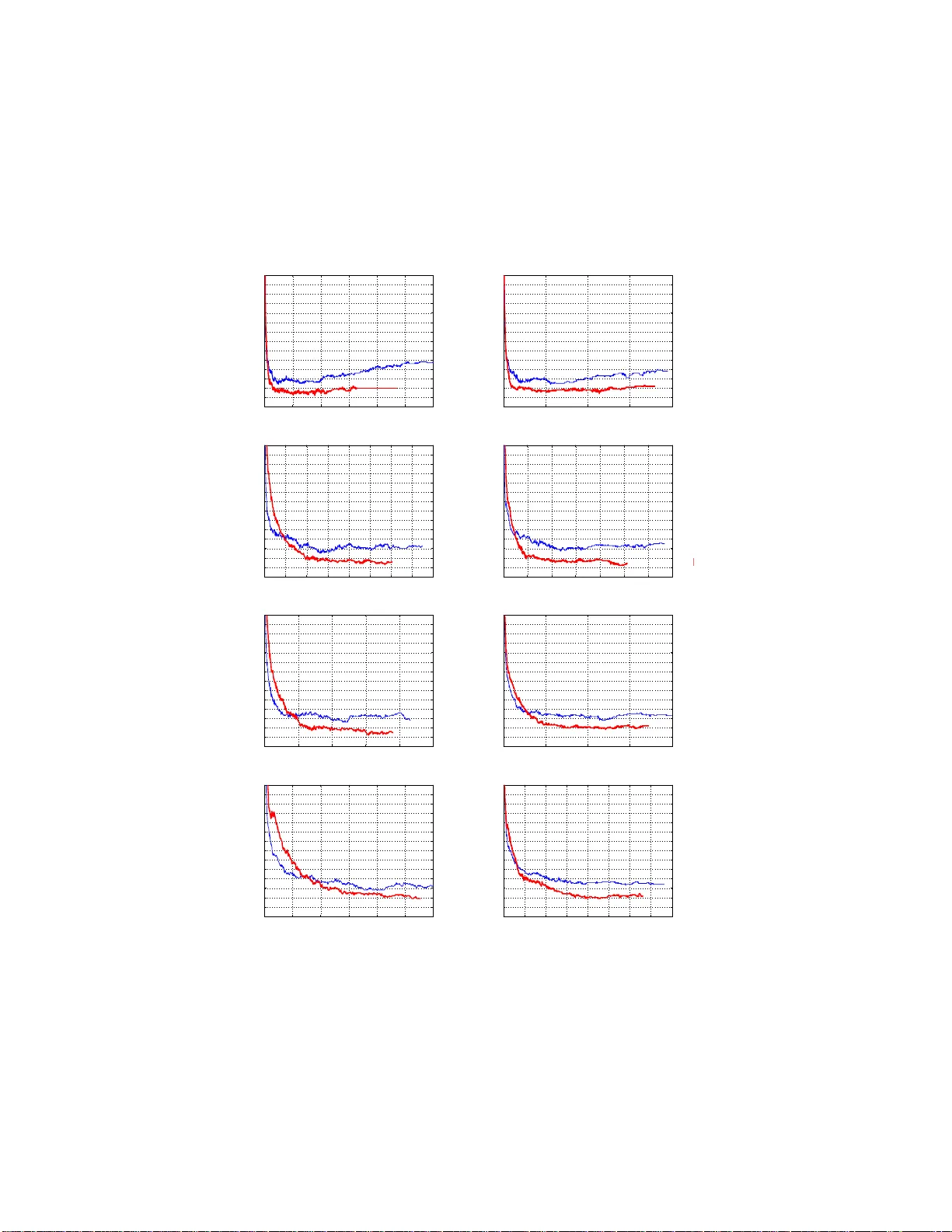
Adapti ve Base Class Boost for Multi-class Classifica tion Ping Li Department of Statistical Science Faculty of C omputin g and Information Science Cornell Unive rsity Ithaca, NY 14853 pingli@cornell. edu First draft July 2008. Re vised October 2008 Abstract W e 1 de velop the concept of ABC -Boost ( A daptive B ase C lass Boost) for multi-class classifi cation and present ABC -MAR T , a concrete implementation of ABC -Boost. The original MAR T ( M ultiple A dditiv e R egression T rees) algo rithm has been very successful in lar ge-scale ap plications. For binary classifi cation, ABC-MAR T re- cov ers MAR T . For multi-class classification, ABC-MAR T considerably improve s MAR T , as ev aluated on se veral public data sets. 1 Introd uction Classification is a basic task in machin e learning . A training data set { y i , X i } N i =1 consists of N f eature vectors (samples) X i , an d N class lab els, y i , i = 1 to N . Here y i ∈ { 0 , 1 , 2 , ..., K − 1 } and K is the numb er of classes. The task is to predict the class labels. This study focu ses on multi-class class ification ( K ≥ 3 ). Many classification algorithms are based on b oosting [7, 2, 3, 5, 4], which is regarded on e of most signifi- cant breakthrough s in machine learning. MAR T[4] ( M ultiple A dditive R egression T rees) is a successful boosting algorithm , es pecially for large-scale applications in industry pra ctice. For example, the re gression-b ased r ank- ing metho d d ev eloped in Y ahoo![1, 9] used an underlying lear ning algorith m b ased on MAR T . M cRank [ 6], the classification-based ranking method, also used MAR T as the under lying learning proc edure. This study propo ses ABC -Boost ( A daptiv e B ase C lass Boost) for multi-class c lassification. W e present ABC - MAR T , a concrete implementa tion of ABC-Boost. ABC-Boost is based on the fo llowing two ke y ideas: 1. For multi-class classification, popu lar loss functions for K classes usually assume a constraint[5, 4, 8] such that only the values for K − 1 classes are needed . Therefo re, we can choose a base class and deri ve algorithm s only for K − 1 classes. 2. At each boosting step, although the base class is not explicitly trained, it will implicitly benefit f rom the training on K − 1 classes, d ue to the constrain t. Thus, we ada ptively choose the b ase class wh ich h as the “worst” performan ce. The idea of assuming a constraint on the l oss functio n and using a base class may not be at all surprising. For binary ( K = 2 ) classification, a “sum- to-zero” constraint on the loss functio n is automatically conside red so that we only need to train the alg orithm for one (instead of K = 2 ) class. For mu lti-class ( K ≥ 3 ) classification, the sum-to -zero constraint on the loss fu nction is also ubiqu itously adopted[5, 4, 8]. In particular, the multi-class Logitboost [5] algorithm was deri ved by explicitly a veraging ov er K − 1 ba se classes. 1 The first draft was submitted to IEEE ICDM on July 07, 2008. Although the submission was not accepted, the author appreciat es two of the revie wers for their informati ve comments. In partic ular , the author appreciat es that one of the revie wer considered this work ”will be one of the state of the art. ” In this revi sion, we follo wed that revie wer’ s suggestion by adding more exper iments. 1 The loss fu nction adop ted in our ABC-MAR T is the same as in MAR T[4] and Logitb oost [5]. All thre e algo- rithms assume th e “sum-to-zero ” constraint. Howev er , we obtain different fi rst an d second deriv ativ es of the loss function , from MAR T[4] and Logitboost [5]. See Section 3 fo r details. In terms of implementation, our pr oposed ABC -MAR T differs from the original MAR T algorithm only in a fe w li nes of code. Since MAR T is known to be a successfu l a lgorithm, much of our work is de voted to the empirical compa risons of ABC-MAR T with MAR T . Our e xperimen t results on pub licly available data sets will demonstra te that ABC-MAR T cou ld considerably improves MAR T . Also, ABC-MAR T redu ces both the training and testing time by 1 /K , which may be quite beneficial when K is small. W e notice that data sets in industry applicatio ns are often qu ite large (e. g., several million samples[6]). Pub- licly available data sets (e.g., UCI repository), ho wev er , ar e mo stly small. In our study , th e Covertype data set from the UCI repository is reasonab ly large with 581,01 2 observations. W e first re view the original MAR T algorithm and functiona l gradient boosting[4]. 2 Re view MAR T and Func tional Gradient Boos ting The MAR T a lgorithm is the m arriage of the fu nctional gradient boosting and regre ssion trees. Given the training data set { y i , x i } N i =1 and a loss functio n L , [4] adopted a “greed y stage wise” approach to build an additiv e function F ( M ) , which is a sum of M terms, F ( M ) ( x ) = M X m =1 ρ m h ( x ; a m ) , (1) such that, at each stage m , m = 1 to M , { ρ m , a m } = argmin ρ, a N X i =1 L y i , F ( m − 1) ( x i ; a , ρ ) . (2) Here the functio n h ( x ; a ) is the “b ase lear ner” or “weak learner . ” In gener al, (2) is still a difficult op timization problem . [4] app roximately conducted steepest descent in the function s pace, by solving a least squar e problem a m = argmin a ,ρ N X i =1 [ − g m ( x i ) − ρh ( x i ; a )] 2 , (3) where − g m ( x i ) = − ∂ L ( y i , F ( x i )) ∂ F ( x i ) F (( x ))= F ( m − 1) (( x )) (4) is the negati ve gradient ( the steepest descent direction) in the N -dim ensional data space at F ( m − 1) ( x ) . For obtaining another coefficient ρ m , a line search is perfo rmed: ρ m = argmin ρ N X i =1 L y i , F ( m − 1) ( x i ) + ρh ( x i ; a m ) . (5) A gen eric “grad ient boosting ” algorithm is described in Alg. 1, for any dif ferentiable loss function L . For multi-class classification, [4] prop osed MAR T , which implemented Line 5 in Alg. 1 by regression trees and Lin e 7 by a one-step Newton upda te within each terminal node of the trees. 2.1 The Loss Function and Multiple Logistic Prob ability Model in MAR T For multi-class classification, MAR T adopted the follo wing ne ga tive multino mial log-lik elihood loss , which is also the loss functio n in Logitboost [5]: L = N X i =1 L i = N X i =1 ( − K − 1 X k =0 r i,k log p i,k ) (6) 2 Algorithm 1 A generic gradien t boosting algorithm [4, Alg. 1 ]. 1: F x = argmin ρ P N i =1 L ( y i , ρ ) 2: For m = 1 to M D o 3: For k = 0 to K − 1 Do 4: ˜ y i = − h ∂ L ( y i ,F ( x i )) ∂ F ( x i ) i F (( x ))= F ( m − 1) (( x ))) , i = 1 to N . 5: a m = argmin a ,ρ P N i =1 [ ˜ y i − ρh ( x i ; a )] 2 6: ρ m = argmin ρ P N i =1 L y i , F ( m − 1) ( x i ) + ρh ( x i ; a m ) 7: F x = F x + ρ m h ( x ; a m ) 8: End 9: End where r i,k = 1 if y i = k and r i,k = 0 otherwise. Apparen tly , P K − 1 k =0 r i,k = 1 for any i . Here p i,k is the probab ility that the i th obser vation belongs to class k : p i,k = Pr ( y i = k | X i ) . (7) MAR T adopted the following logistic probability model[4] F i,k = log p i,k − 1 K K − 1 X s =0 log p i,s , (8) or equiv alently[4], p i,k = e F i,k P K − 1 s =0 e F i,s . (9) Apparen tly , the model (8) implies P K − 1 k =0 F i,k = 0 , the sum-to- zero constraint. In fact, si nce P K − 1 k =0 p i,k = 1 , the mod el only has K − 1 d egrees of fr eedom. Some constrain t on F i,k is n ecessary in ord er to o btain a uniq ue solution. For binary ( K = 2 ) classification, the sum-to-z ero constraint is autom atically enforced. 2.2 The Original MAR T Alg orithm Alg. 2 describes the MAR T algorithm for multi-class classification using ne g ative multinomial log-likelihood loss (6) and multi-class logistic model (9). Algorithm 2 M AR T[4, Alg. 6 ]. Note that in Line 6, th e term p i,k (1 − p i,k ) re places th e equ iv alent ter m | r i,k − p i,k | (1 − | r i,k − p i,k | ) in [4, Alg. 6] 0: r i,k = 1 , if y i = k , and r i,k = 0 othe rwise. 1: F i,k = 0 , k = 0 to K − 1 , i = 1 to N 2: For m = 1 to M D o 3: For k = 0 to K − 1 Do 4: p i,k = exp( F i,k ) / P K − 1 s =0 exp( F i,s ) 5: { R j,k,m } J j =1 = J -terminal node regression tree fro m { r i,k − p i,k , x i } N i =1 6: β j,k,m = K − 1 K P x i ∈ R j,k,m r i,k − p i,k P x i ∈ R j,k,m (1 − p i,k ) p i,k 7: F i,k = F i,k + ν P J j =1 β j,k,m 1 x i ∈ R j,k,m 8: End 9: End . MAR T f ollows the gener ic paradigm of f unctiona l gradient bo osting Alg. 1. At each stage m , M AR T solves the mean square problem (Line 5 in Alg. 1 ) by regression trees. MAR T builds K regression trees at ea ch boo sting step. W e elaborate in more detail on serv al ke y componen ts of MAR T . 3 2.2.1 The Functional Gradient (Pseudo Response) MAR T perform s grad ient d escent in th e fu nction spa ce, u sing the gradie nt evaluated at th e func tion values. F or the i th data point, using the ne gative multinomial log-likelihood loss (6), i.e., L i ( F i,k , y i ) = − K − 1 X k =0 r i,k log p i,k (10) and the proba bility mode l (9 ), [4] showed ∂ L i ∂ F i,k = − ( r i,k − p i,k ) . (11) This explains the term r i,k − p i,k in Line 5 of Alg. 2. 2.2.2 The Second Derivative and One-Step Newton Update While only the first derivati ves were u sed for building the structure o f the tr ees, MAR T used the secon d deri vati ves to update the values of the term inal nodes by a one-step Ne wton procedure. [4] showed ∂ 2 L i ∂ F 2 i,k = p i,k (1 − p i,k ) , (12) which explains Line 6 in Alg. 2. (11) and (12) were also der i ved in the Logitb oost [5]. Howe ver , in this paper we actually obtain different first and second deriv ativ es. 2.2.3 K T rees for K Classes For ea ch i , the re ar e K fun ction values, F i,k , k = 0 to K − 1 , and co nsequently K g radients. MAR T builds K regression tress at each boosting step. Ap parently , the constraint P K − 1 k =0 F i,k = 0 will no t hold. Note that o ne can actually r e-center the F i,k at the end of every bo osting step so that the sum-to-zer o con straint is satisfied after training. That is, one can insert a line F i,k ← F i,k − 1 K K − 1 X s =0 F i,s , (13) after L ine 8 in Alg. 2 to make P K − 1 k =0 F i,k = 0 . Howe ver , we ob serve that this re-centering step makes n o difference in our experiments. W e believe the sum-to-zero constraint should be en forced before the training instead of after the training, at e very boosting step. The case K = 2 is an exception . Because th e two pseudo respo nses, r i,k =0 − p i,k =0 and r i,k =1 − p i,k =1 are identical with signs flip ped (i.e., P 1 k =0 F i,k = 0 au tomatically h olds), there is n o need to build K = 2 tress. In fact, [4] p resented the b inary classification alg orithm sepa rately [4, Alg . 5 ], which is the sam e as [ 4, Alg. 6] by letting K = 2 , althoug h the pr esentations were somewhat different. Line 6 o f Alg. 2 co ntains a factor K − 1 K . For binary classification , it is clear th at the factor 1 2 comes fro m th e mathematical deri v ation. For K ≥ 3 , we believ e th is f actor in a w ay appro ximates the constraint P K − 1 k =0 F i,k = 0 . Because MAR T builds K tree s while there are only K − 1 degrees of freedom, a factor K − 1 K may help reduce the influence. 2.2.4 Three M ain Parameters: J , ν , and M Practitioners like MAR T par tly becau se th is gre at algorithm h as only a few parameter s, which ar e not very sen- siti ve as long as they fall in some “reason able” r ange. It is often f airly easy to identify the ( close to) o ptimal parameters with limited tuning. This is a huge advantage, especially for large data sets. 4 The numbe r of terminal nodes, J , deter mines the capacity of the base learner . MAR T sug gested J = 6 often might be a good choice. The shrinkage parameter, ν , should be large enoug h to m ake a sufficient p rogress at ea ch b oosting step and small enough to a void o ver-fitting. Also, a very small ν m ay require a large number of boosting steps, which may be a pr actical co ncern f or r eal-world app lications if the tr aining and/o r testing is time-con suming. [4 ] sugg ested ν ≤ 0 . 1 . The numb er of b oosting steps, M , in a sen se is largely determ ined by th e com puting time o ne c an afford. A common ly-regarded mer it of boosting is that ov er-fitting can be largely a voided for reasonable J and ν and hence one mig ht simply let M be as large as p ossible. Howe ver , for small data sets, the train ing loss (6) m ay r each the machine accuracy before M can be too large. 3 ABC-Boost and ABC-MAR T W e re- iterate the two k ey componen ts in dev eloping ABC-Boost (Adaptive Base Cl ass Boost): 1. Using the popular constraint in the loss function, we can ch oose a base class and d erive the boosting algorithm for only K − 1 classes. 2. At each boosting step, we can adaptively choose the base class which has the “worst” perform ance. ABC-MAR T is a concrete im plementation of ABC-Boost by using the n e gative multinom ial log-likelihood loss (6), the m ulti-class lo gistic model ( 9), and the p aradigm of functional g radient b oosting. Apparen tly , ther e are other possible im plementation s of ABC-Boost. For example, one can imp lement an “ ABC-Logitboo st. ” Th is study focuses on ABC-MAR T . Since MAR T has been p roved to be successful in large-scale industry applications, demonstra ting that ABC-MAR T may con siderably improve MAR T will be appealing. 3.1 The Multi-class Logistic Model with a Fixed Base W e first derive some basic fo rmulas nee ded for developing ABC-MAR T . W ithout loss of g enerality , we assume class 0 is the base class. Lemma 1 provides the first and second deriv ati ves of the class pro babilities p i,k under the multi-class logistic model (9) and the sum-to-z ero constraint P K − 1 k =0 F i,k = 0 [5, 4, 8]. Lemma 1 ∂ p i,k ∂ F i,k = p i,k (1 + p i, 0 − p i,k ) , k 6 = 0 (14) ∂ p i,k ∂ F i,s = p i,k ( p i, 0 − p i,s ) , k 6 = s 6 = 0 (15) ∂ p i, 0 ∂ F i,k = p i, 0 ( − 1 + p i, 0 − p i,k ) , k 6 = 0 (1 6) Proof: Note that F i, 0 = − P K − 1 k =1 F i,k . Henc e p i,k = e F i,k P K − 1 s =0 e F i,s = e F i,k P K − 1 s =1 e F i,s + e P K − 1 s =1 − F i,s ∂ p i,k ∂ F i,k = e F i,k P K − 1 s =0 e F i,s − e F i,k e F i,k − e − F i, 0 P K − 1 s =0 e F i,s 2 = p i,k (1 + p i, 0 − p i,k ) . The other derivatives can be obtained similarly . Lemma 1 helps deriv e the deri vati ves of the loss function, presented in Lemma 2. 5 Lemma 2 ∂ L i ∂ F i,k = ( r i, 0 − p i, 0 ) − ( r i,k − p i,k ) , (17) ∂ 2 L i ∂ F 2 i,k = p i, 0 (1 − p i, 0 ) + p i,k (1 − p i,k ) + 2 p i, 0 p i,k . (18) Proof: L i = − K − 1 X s =1 ,s 6 = k r i,s log p i,s − r i,k log p i,k − r i, 0 log p i, 0 . It first derivative is ∂ L i ∂ F i,k = − K − 1 X s =1 ,s 6 = k r i,s p i,s ∂ p i,s F i,k − r i,k p i,k ∂ p i,k F i,k − r i, 0 p i, 0 ∂ p i, 0 F i,k (19) = K − 1 X s =1 ,s 6 = k − r i,s ( p i, 0 − p i,k ) − r i,k (1 + p i, 0 − p i,k ) − r i, 0 ( − 1 + p i, 0 − p i,k ) = − K − 1 X s =0 r i,s ( p i, 0 − p i,k ) + r i, 0 − r i,k = ( r i, 0 − p i, 0 ) − ( r i,k − p i,k ) . And the second derivative is ∂ 2 L i ∂ F 2 i,k = − ∂ p i, 0 ∂ F i,k + ∂ p i,k ∂ F i,k = − p i, 0 ( − 1 + p i, 0 − p i,k ) + p i,k (1 + p i, 0 − p i,k ) = p i, 0 (1 − p i, 0 ) + p i,k (1 − p i,k ) + 2 p i, 0 p i,k . Note th e the first and secon d d eriv ati ves we d eriv es differ from (1 1) and (1 2), which are the d eriv ati ves used in Logitboost [5] and MAR T[4]. 3.2 ABC-MAR T Alg. 3 pr ovides th e pseud o c ode f or ABC-MAR T . C ompare d with MAR T (Alg. 2), we use dif ferent gradien ts to build the trees and different second der iv a ti ves to up date th e values o f ter minal nodes. In a ddition, there is a proced ure (Line 10 ) for selecting the b ase class, denoted b y b , which ha s th e “worst” (i.e., largest) trainin g loss (6). At each boosting step, we only need to build K − 1 tr ees because the constraint P K − 1 k =0 F i,k = 0 is enforced . 3.3 ABC-MAR T Recovers MAR T when K = 2 Note tha t th e f actor K − 1 K does n ot appear in ABC -MAR T (Alg. 3 ). Interestingly , when K = 2 , ABC-MAR T recovers MAR T . For e xample, consider K = 2 , r i, 0 = 1 , r i, 1 = 0 , then ∂ L i ∂ F i, 1 = (1 − p i, 0 ) − (0 − p i, 1 ) = 2 p i, 1 , ∂ 2 L i ∂ F 2 i, 1 = 4 p i, 0 p i, 1 . In other words, the first ( second) deriv ativ e is twice (fo ur times) of the first ( second) d eriv ati ve in MAR T . Using the one- step Newton up date ( Line 6 in Alg. 3), the factor 1 2 (which appe ared in MAR T) is recovered. Note th at scaling the first deriv ati ves does not affect the tree structures. 6 Algorithm 3 ABC-MAR T . 0: r i,k = 1 , if y i = k , r i,k = 0 othe rwise. Cho ose a random base b 1: F i,k = 0 , p i,k = 1 K , k = 0 to K − 1 , i = 1 to N 2: For m = 1 to M D o 3: For k = 0 to K − 1 , k 6 = b , Do 4: { R j,k,m } J j =1 = J -terminal node regression tree fro m {− ( r i,b − p i,b ) + ( r i,k − p i,k ) , x i } N i =1 5: β j,k,m = P x i ∈ R j,k,m − ( r i,b − p i,b )+( r i,k − p i,k ) P x i ∈ R j,k,m p i,b (1 − p i,b )+ p i,k (1 − p i,k )+2 p i,b p i,k 6: F i,k = F i,k + ν P J j =1 β j,k,m 1 x i ∈ R j,k,m 7: End 8: F i,b = − P k 6 = b F i,k , i = 1 to N . 9: p i,k = exp( F i,k ) / P K − 1 s =0 exp( F i,s ) , k = 0 to K − 1 , i = 1 to N 10: b = argmax k L ( k ) , where L ( k ) = P N i =1 − log ( p i,k ) 1 y i = k , k = 0 , 1 , ..., K − 1 . 11: End 3.4 MAR T Appr ox imately “A v erages” All Base Classes when K ≥ 3 In a sense, MAR T did consider the averaging affect from all K − 1 b ase classes. For t he first der i vati ves, the following equality holds, X b 6 = k {− ( r i,b − p i,b ) + ( r i,k − p i,k ) } = K ( r i,k − p i,k ) , (20) because X b 6 = k {− ( r i,b − p i,b ) + ( r i,k − p i,k ) } = − X b 6 = k r i,b + X b 6 = k p i,b + ( K − 1)( r i,k − p i,k ) = − 1 + r i,k + 1 − p i,k + ( K − 1 )( r i,k − p i,k ) Recall : K − 1 X k =0 r i,k = 1 , K − 1 X k =0 p i,k = 1 = K ( r i,k − p i,k ) . In other words, the gradient used in MAR T is the a veraged gradient of ABC-MAR T . Next, we can sho w that, for the second deri vati ves, X b 6 = k { (1 − p i,b ) p i,b + (1 − p i,k ) p i,k + 2 p i,b p i,k } ≈ ( K + 2 )(1 − p i,k ) p i,k , (21) with equality holdin g only when K = 2 , becau se X b 6 = k { (1 − p i,b ) p i,b + (1 − p i,k ) p i,k + 2 p i,b p i,k } =( K − 1)(1 − p i,k ) p i,k + 2 p i,k X b 6 = k p i,b + X b 6 = k (1 − p i,b ) p i,b =( K + 1)(1 − p i,k ) p i,k + X b 6 = k p i,b − X b 6 = k p 2 i,b ≈ ( K + 1)(1 − p i,k ) p i,k + X b 6 = k p i,b − X b 6 = k p i,b 2 =( K + 1)(1 − p i,k ) p i,k + (1 − p i,k ) p i,k =( K + 2)( r i,k − p i,k ) . 7 Thus, e ven the second deri vati ve used in MAR T may be approximately viewed as the a veraged second deri va- ti ves in ABC-MAR T . It appears th e factor K − 1 K in MAR T may b e reasonably r eplaced by K K +2 (both equal 1 2 when K = 2 ). This, of c ourse, will not m ake a rea l difference because the c onstant (eith er K − 1 K or K K +2 ) can be absorbed into the shrinkag e factor ν . 4 Evaluations The goal of the ev aluation study is to co mpare ABC-MAR T (Alg. 3) with MAR T (Alg. 2) fo r multi-class classification. The experim ents were co nducted on one fairly large data set ( Covertype ) p lus fiv e small data sets ( Letter , P endig its, Zipcode, Optdig its , and Isolet ); see T able 1. 2 T ab le 1: Our exper iments wer e ba sed o n six publicly av a ilable d ata sets. W e rando mly split the Covertype d ata set into a training set and test set. For all other data sets, we used the standard (default) training and test sets . Data set K # training samples # test samples # featu res Covertype 7 29050 6 29050 6 54 Letter 26 16000 4000 16 Pendigits 10 7494 3498 16 Zipcode 10 7291 2007 256 Optdigits 10 3823 1797 64 Isolet 26 6218 1559 617 In general, a com prehensive and fair co mparison of two classification algorithm s is a non-trivial task. In o ur case, howe ver , the compariso n task appears quite easy because AB C-MAR T and MAR T dif fer only in a fe w lines of code and their underly ing base learner s can be completely identical. Ideally , we h ope that ABC-MAR T will im prove MAR T , f or every set o f reasonab le parameters, J an d ν . For the five small data sets, we experiment with every combin ation of nu mber o f terminal no des J and shrink age ν , where J and ν are chosen from J ∈ { 4 , 6 , 8 , 10 , 12 , 14 , 1 6 } , ν ∈ { 0 . 0 4 , 0 . 06 , 0 . 08 , 0 . 1 } . For the fi ve small data sets, we let the num ber of boosting steps M = 1000 0 . Howe ver , the experimen ts usually terminated well before M = 10000 becau se the machine accuracy was reached. For t he Covertype data s et, since it is fairly l arge, we only e xperimen ted with J = 6 , 10 , 20 and ν = 0 . 04 , 0 . 1 and we limited M to be 160 00, 11500, 6000, for J = 6 , 10 , 20 , respecti vely . 4.1 Summary of Experiment Results The test misclassification err or is a direct m easure o f per forman ce. MAR T and ABC-MAR T output K class probab ilities p i,k , k = 0 to K − 1 , for each observ ation i . T o obtain the class labels, we adopt the commonly used rule k ′ = argmax k p i,k . (22) W e defin e R err , the “relative improvement of test mis-classification errors, ” as R err = mis-classification errors of MAR T − mis-classification errors of ABC-MAR T mis-classification errors of MAR T × 100 (%) . (23) Since we experim ented with a series of p arameters, J , ν , an d M , we report th e overall “best” (i.e., smallest) mis-classification errors in T able 2. Later , we will also report the more detailed mis-classification errors for e very combinatio n of J and ν , in Sections 4.2 to 4.7. 2 All dat a sets are publicly av ailabl e. The Zipcode data se t is downloa ded from http:/ /www- stat.stanford.edu/ ˜ tibs/ElemStatL earn/data.html and all other data sets can be found from the UCI reposito ry . 8 T ab le 2: Summar y of t est mis-classification error s. Data set MA R T ABC-MAR T R err (%) P -value Covertype 11133 10203 8.4 4 . 4 × 10 − 11 Letter 135 111 17.8 0.060 Pendigits 123 104 15.5 0.100 Zipcode 111 98 11.7 0.178 Optdigits 56 41 26.8 0.061 Isolet 8 4 69 17.9 0.107 T ab le 2 also p rovides the “ P - value” of the one-sided t -test. The idea is to model th e test err or rate (i.e., the test mis-classification error s divided by the number of test samp les) as a bino mial prob ability and the n co nduct the t -test using the no rmal approximatio n of th e difference of two binomial probab ilities. W e can see that fo r the Covertype data set, the improvement o f ABC-MAR T over MAR T is highly significant (the P -value is nearly zero) under this test. For the fi ve small data sets, the P -values are also reasonably small. W e shall mention that th is t - test is very stringent when the erro r rate is small. In fact, we do not often see papers which calculated the P -values when comparin g different classification algorithms. Next, we present the detailed experime nt results on the six data sets. 4.2 Experiments on the Cov ertype Data Set T ab le 3 summarize s the test mis-classification err ors along with the re lati ve improvements ( R err ), for every combinatio n of J ∈ { 6 , 1 0 , 20 } and ν ∈ { 0 . 0 4 , 0 . 1 } . For each J and ν , the smallest test mis-classification errors, separately for ABC-MAR T and MAR T , are the lowest points in the curves in Figure 2. T ab le 3: Covertype . The test mis-classification errors. The correspondin g relative improvements ( R err , % ) of ABC-MAR T are included in parenth eses. (a) MAR T ν = 0 . 04 ν = 0 . 1 J = 6 20756 15959 J = 10 15862 12553 J = 20 13630 11133 (b) ABC- MAR T ν = 0 . 04 ν = 0 . 1 J = 6 17185 (17. 2) 14230 (10.8) J = 10 13064 (17. 6) 11487 (8. 5) J = 20 11595 (14. 9) 10203 (8. 4) T o report th e experiments in a m ore informative m anner, Fig ure 1, Figure 2, and Figure 3, respectively , pre sent the trainin g loss, the test m is-classification er rors, and th e relative improvements, for the co mplete history of M boosting steps (iterations) . Figure 1 indicates that ABC-MAR T reduces the trainin g loss (6) considerably and consistently f aster than MAR T . Figur e 2 demonstrates that ABC-MAR T exhibits consid erably and con sistently smaller test mis-classification errors than MAR T . Figure 3 illustrates that th e r elativ e improvements of ABC-MAR T over MA R T , in terms of the mis-classification errors, m ay be consid erably larger than the nu mbers rep orted in T able 3 if we stop the trainin g earlier . This phe- nomeno n may be qu ite beneficial for real- world large- scale app lications when either th e training or te st time is part of the per forman ce me asure. For example, real-tim e app lications (e.g., searc h engines) may no t be able to afford to use mode ls with a very large number of boosting steps. 9 1 4000 8000 12000 16000 10 3 10 4 10 5 10 6 Train: J = 6 ν = 0.1 Iterations Training loss ABC 1 4000 8000 12000 16000 10 4 10 5 10 6 Train: J = 6 ν = 0.04 Iterations Training loss ABC 1 4000 8000 12000 10 3 10 4 10 5 10 6 Train: J = 10 ν = 0.1 Iterations Training loss ABC 1 4000 8000 12000 10 4 10 5 10 6 Train: J = 10 ν = 0.04 Iterations Training loss ABC 0 2000 4000 6000 10 3 10 4 10 5 10 6 Train: J = 20 ν = 0.1 Iterations Training loss ABC 0 2000 4000 6000 10 4 10 5 10 6 Train: J = 20 ν = 0.04 Iterations Training loss ABC Figure 1: Covertype . Th e training loss, i.e., (6). The curves labeled “ ABC” corresp ond to AB C-MAR T . 10 1 4000 8000 12000 16000 1 2 3 4 5 x 10 4 Test: J = 6 ν = 0.1 Iterations Test misclassifications ABC 1 4000 8000 12000 16000 1 2 3 4 5 x 10 4 Test: J = 6 ν = 0.04 Iterations Test misclassifications ABC 1 4000 8000 12000 1 2 3 4 5 x 10 4 Test: J = 10 ν = 0.1 Iterations Test misclassifications ABC 1 4000 8000 12000 1 2 3 4 5 x 10 4 Test: J = 10 ν = 0.04 Iterations Test misclassifications ABC 1 2000 4000 6000 1 2 3 4 5 x 10 4 Test: J = 20 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 1 2 3 4 5 x 10 4 Test: J = 20 ν = 0.04 Iterations Test misclassifications ABC Figure 2: Covertype . Th e test mis-classifi cation erro rs. 11 1 4000 8000 12000 16000 0 5 10 15 20 25 Test: J = 6 ν = 0.1 Iterations Test relative improvement (%) 1 4000 8000 12000 16000 0 5 10 15 20 25 Test: J = 6 ν = 0.04 Iterations Test relative improvement (%) 1 4000 8000 12000 0 5 10 15 20 25 Test: J = 10 ν = 0.1 Iterations Test relative improvement (%) 1 4000 8000 12000 0 5 10 15 20 25 Test: J = 10 ν = 0.04 Iterations Test relative improvement (%) 1 2000 4000 6000 0 5 10 15 20 25 Test: J = 20 ν = 0.1 Iterations Test relative improvement (%) 1 2000 4000 6000 0 5 10 15 20 25 Test: J = 20 ν = 0.04 Iterations Test relative improvement (%) Figure 3: Covertype . The relati ve improvements, R err ( % ). 12 The next fi ve subsections are respecti vely de voted to presen ting the experiment results of fi ve small data sets. The results exhibit similar characteristics across data sets. 4.3 Experiments on the Letter Data Set T ab le 4 summarizes the test mis-classification error s along with the relati ve improvements for e very combination of J ∈ { 4 , 6 , 8 , 10 , 12 , 14 , 16 } an d ν ∈ { 0 . 04 , 0 . 0 6 , 0 . 08 , 0 . 1 } . T ab le 4: Le tter . Th e test mis-classification erro rs. The corresp onding relative improvements ( R err , % ) of ABC- MAR T are includ ed in par entheses. (a) MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 176 178 177 17 3 J = 6 154 16 0 156 158 J = 8 151 14 5 151 154 J = 1 0 141 14 1 147 1 44 J = 1 2 150 14 4 144 1 40 J = 1 4 143 14 7 144 1 46 J = 1 6 138 14 7 142 1 35 (b) ABC- MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 155 (11.9) 143 (19.7 ) 148 (16.4) 144 (16.8) J = 6 140 (9.1) 141 (11.9 ) 130 (16 .7) 121 (23.4) J = 8 132 (12.6) 126 (13.1 ) 124 (17. 9) 117 (24.0) J = 10 131 (7.1) 119 (15.6 ) 116 ( 21.1) 115 (20.1) J = 12 125 (16.7) 124 (13.9 ) 119 (17.4) 119 (15.0) J = 14 117 (18.2) 118 (19.7 ) 123 (14. 6) 112 (23.3) J = 16 117 (15.2) 113 (23.1 ) 113 (20.4) 111 (17.8) Figure 4 again indicates that ABC -MAR T reduces the training loss (6) considerably and co nsistently faster than MAR T . Since this is a small data set, the training loss could appro ach zer o e ven when the numb er of boosting steps is not too large. Figure 5 again demo nstrates that ABC-MAR T exh ibits co nsiderably and consistently smaller test mis-classification errors than MAR T . 13 1 2000 4000 6000 8000 10000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 4 ν = 0.1 Iterations Training loss ABC 1 2000 4000 6000 8000 10000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 4 ν = 0.04 Iterations Training loss ABC 1 2000 4000 6000 8000 10000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 8 ν = 0.1 Iterations Training loss ABC 1 2000 4000 6000 8000 10000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 8 ν = 0.04 Iterations Training loss ABC 1 2000 4000 6000 8000 10000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 12 ν = 0.1 Iterations Training loss ABC 1 2000 4000 6000 8000 10000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 12 ν = 0.04 Iterations Training loss ABC 1 2000 4000 6000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 16 ν = 0.1 Iterations Training loss ABC 1 2000 4000 6000 8000 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Train: J = 16 ν = 0.04 Iterations Training loss ABC Figure 4: Letter . Th e training loss, i.e., (6). The curves labeled “ ABC” correspo nd to AB C-MAR T . 14 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 4 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 4 ν = 0.04 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 8 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 8 ν = 0.04 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 12 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 12 ν = 0.04 Iterations Test misclassifications ABC 1 2000 4000 6000 100 120 140 160 180 200 220 240 Test: J = 16 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 100 120 140 160 180 200 220 240 Test: J = 16 ν = 0.04 Iterations Test misclassifications ABC Figure 5: Letter . The test mis-classification errors. 15 4.4 Experiments on the P endigits Data Set T ab le 5: Pen digits . The test mis-classification errors. The correspon ding relative improvements ( R err , % ) of ABC-MAR T are included in parenth eses. (a) MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 144 14 5 142 148 J = 6 137 13 4 136 135 J = 8 133 13 4 132 128 J = 1 0 123 13 1 127 1 30 J = 1 2 135 13 6 134 1 33 J = 1 4 129 13 1 130 1 33 J = 1 6 132 12 9 130 1 34 (b) ABC- MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 112 (22. 2) 109 (24 .8) 110 (2 2.5) 112 ( 24.3) J = 6 114 (16. 8) 114 (14 .9) 111 (1 8.4) 109 ( 19.3) J = 8 112 (15. 8) 107 (20 .1) 111 (1 5.9) 105 ( 18.0) J = 10 105 (14. 6) 105 (19 .8) 107 (1 5.7) 109 ( 16.2) J = 12 104 (23. 0) 106 (22 .1) 104 (2 2.4) 105 ( 21.1) J = 14 107 (17. 1) 106 (19 .1) 104 (2 0.0) 107 ( 19.5) J = 16 106 (19. 7) 107 (17 .1) 106 (1 8.5) 107 ( 20.1) 16 1 1000 2000 3000 4000 5000 6000 100 120 140 160 180 200 220 240 Test: J = 4 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 100 120 140 160 180 200 220 240 Test: J = 4 ν = 0.04 Iterations Test misclassifications ABC 1 500 1000 1500 2000 100 120 140 160 180 200 220 240 Test: J = 8 ν = 0.1 Iterations Test misclassifications ABC 1 1000 2000 3000 4000 100 120 140 160 180 200 220 240 Test: J = 8 ν = 0.04 Iterations Test misclassifications ABC 1 200 400 600 800 1000 100 120 140 160 180 200 220 240 Test: J = 12 ν = 0.1 Iterations Test misclassifications ABC 1 500 1000 1500 2000 2500 3000 100 120 140 160 180 200 220 240 Test: J = 12 ν = 0.04 Iterations Test misclassifications ABC 1 200 400 600 800 100 120 140 160 180 200 220 240 Test: J = 16 ν = 0.1 Iterations Test misclassifications ABC 1 500 1000 1500 2000 2500 100 120 140 160 180 200 220 240 Test: J = 16 ν = 0.04 Iterations Test misclassifications ABC Figure 6: P endigits . Th e test mis-classification errors. 17 4.5 Experiments on the Zipcode Data Set T ab le 6: Zipcode . The test mis-classification erro rs. (a) MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 130 12 6 129 127 J = 6 123 12 2 123 126 J = 8 120 12 2 121 123 J = 1 0 118 11 8 119 1 18 J = 1 2 117 11 7 116 1 18 J = 1 4 119 12 0 119 1 17 J = 1 6 118 11 1 116 1 16 (b) ABC- MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 0 8 ν = 0 . 1 J = 4 116 (10. 8) 114 (9.5) 116 (1 0.1) 111 ( 12.6) J = 6 110 (10. 6) 111 (9.0) 109 (11.4) 108 (14.3) J = 8 109 (9.2 ) 102 (16.4) 111 (8.3) 1 06 (13.8) J = 10 106 (10. 2) 103 (12.7) 103 (13.4) 104 (11.9) J = 12 105 (10. 3) 102 (12.8) 103 (11.2) 98 (16.9) J = 14 106 (10. 9) 104 (13.3) 103 (13.4) 105 (10.3) J = 16 104 (11. 9) 103 (7.2) 102 (12.1) 104 (10.3) 18 1 2000 4000 6000 8000 10000 90 100 110 120 130 140 150 160 Test: J = 4 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 90 100 110 120 130 140 150 160 Test: J = 4 ν = 0.04 Iterations Test misclassifications ABC 1 500 1000 1500 2000 2500 3000 90 100 110 120 130 140 150 160 Test: J = 8 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 90 100 110 120 130 140 150 160 Test: J = 8 ν = 0.04 Iterations Test misclassifications ABC 1 500 1000 1500 90 100 110 120 130 140 150 160 Test: J = 12 ν = 0.1 Iterations Test misclassifications B ABC 0 1000 2000 3000 4000 90 100 110 120 130 140 150 160 Test: J = 12 ν = 0.04 Iterations Test misclassifications ABC 1 400 800 1200 90 100 110 120 130 140 150 160 Test: J = 16 ν = 0.1 Iterations Test misclassifications ABC 1 500 1000 1500 2000 2500 3000 90 100 110 120 130 140 150 160 Test: J = 16 ν = 0.04 Iterations Test misclassifications ABC Figure 7: Zipco de . The test mis-classification err ors. 19 4.6 Experiments on the Optdigits Data Set T ab le 7: Optdigits . The test mis-classification erro rs . (a) MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 58 57 57 59 J = 6 60 57 59 57 J = 8 60 60 57 61 J = 1 0 59 59 58 59 J = 1 2 57 58 56 61 J = 1 4 57 59 58 56 J = 1 6 59 58 59 57 (b) ABC- MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 45 (22.4 ) 41 (28.1) 44 (22.8) 42 (28.8) J = 6 47 (21.7 ) 48 (15.8) 47 (20.3) 45 (21.1) J = 8 49 (18.3 ) 49 (18.3) 49 (14.0) 46 (24.6) J = 1 0 55 (6.8) 54 (8.5) 50 (13. 8) 49 (16.9) J = 1 2 56 (1.8) 55 (5.2) 50 (10. 7) 51 (16.4) J = 1 4 55 (3.5) 53 (10.2 ) 50 (13.8) 47 (16.1) J = 1 6 57 (3.4) 54 (6.9) 53 (10. 2) 53 (7.0) 20 1 1000 2000 3000 4000 40 50 60 70 80 90 Test: J = 4 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 10000 40 50 60 70 80 90 Test: J = 4 ν = 0.04 Iterations Test misclassifications ABC 1 500 1000 1500 40 50 60 70 80 90 Test: J = 8 ν = 0.1 Iterations Test misclassifications ABC 1 1000 2000 3000 4000 40 50 60 70 80 90 Test: J = 8 ν = 0.04 Iterations Test misclassifications ABC 0 200 400 600 800 1000 40 50 60 70 80 90 Test: J = 12 ν = 0.1 Iterations Test misclassifications ABC 1 500 1000 1500 2000 2500 40 50 60 70 80 90 Test: J = 12 ν = 0.04 Iterations Test misclassifications ABC 1 200 400 600 800 40 50 60 70 80 90 Test: J = 16 ν = 0.1 Iterations Test misclassifications ABC 1 500 1000 1500 2000 40 50 60 70 80 90 Test: J = 16 ν = 0.04 Iterations Test misclassifications ABC Figure 8: Optdig its . The test mis-classification errors. 21 4.7 Experiments on the Isolet Data Set T ab le 8: Isolet . The test mis-classification erro rs. (a) MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 84 84 85 84 J = 6 84 84 85 85 J = 8 87 89 86 85 J = 1 0 88 87 84 84 J = 1 2 88 91 85 86 J = 1 4 94 93 90 91 J = 1 6 93 91 90 88 (b) ABC- MAR T ν = 0 . 04 ν = 0 . 06 ν = 0 . 08 ν = 0 . 1 J = 4 74 (11.9 ) 74 (11.9 ) 74 (12.9 ) 72 (14 .3) J = 6 76 ( 9.5) 71 (1 5.5) 69 (18.8) 71 (16.5 ) J = 8 72 (17.2 ) 74 (16.9 ) 73 (15.1 ) 73 (14 .1) J = 10 72 (18.2 ) 76 (12.6 ) 75 (10.7 ) 71 (15 .5) J = 12 78 (11.4 ) 74 (18.7 ) 75 (11.8 ) 72 (16 .3) J = 14 74 (21.3 ) 72 (22.6 ) 71 (21.1 ) 79 (13 .2) J = 16 79 (15.1 ) 75 (17.6 ) 76 (15.6 ) 79 (10 .2) 22 1 2000 4000 6000 60 80 100 120 140 160 180 200 Test: J = 4 ν = 0.1 Iterations Test misclassifications ABC 1 2000 4000 6000 8000 60 80 100 120 140 160 180 200 Test: J = 4 ν = 0.04 Iterations Test misclassifications ABC 1 400 800 1200 1600 60 80 100 120 140 160 180 200 Test: J = 8 ν = 0.1 Iterations Test misclassifications ABC 1 1000 2000 3000 60 80 100 120 140 160 180 200 Test: J = 8 ν = 0.04 Iterations Test misclassifications B ABC 1 200 400 600 800 1000 60 80 100 120 140 160 180 200 Test: J = 12 ν = 0.1 Iterations Test misclassifications ABC 1 500 1000 1500 2000 60 80 100 120 140 160 180 200 Test: J = 12 ν = 0.04 Iterations Test misclassifications ABC 1 100 200 300 400 500 600 60 80 100 120 140 160 180 200 Test: J = 16 ν = 0.1 Iterations Test misclassifications ABC 1 400 800 1200 1600 60 80 100 120 140 160 180 200 Test: J = 16 ν = 0.04 Iterations Test misclassifications ABC Figure 9: Isolet . The test mis-classification errors. 23 5 Discussion Retrospectively , the id eas behind ABC-Boost a nd ABC-MAR T a ppear simple an d intuitive. Our experiments in Section 4 have demon strated t he effecti veness of ABC-MAR T and its considera ble improvements ov er MAR T . The tw o key components of ABC-Boost are: (1 ) developing boosting algorithms by assuming one base class ; (2) adaptively cho osing the base class so that, at each boosting step, the “worst” class will be selected. W e believe both compon ents contribute critically to the good performance of ABC-MAR T . Note that assuming the sum-to-zero constraint on the loss function and the base class is a ubiquitously adopted strategy[5, 4, 8]. Our contribution in this p art is the different set of derivati ves of the loss fu nction (6), co mpared with the classical work[5, 4]. One may ask two q uestions. 1: Can we use the MAR T deriv ativ es (11) and (12 ) an d ad aptively cho ose the base? 2: Can we u se ABC-MAR T deriv ati ves and a fixed base? Neith er will achieve a good performan ce. T o demonstrate this point, we consider three alternati ve boosting algorithms and present their training and test results using the P end igits data set ( K = 10 ). 1. MART derivatives + ada ptively choo sing the worst base . It is th e same as ABC-MAR T excep t it u ses the deriv ati ves of MAR T . In Figure 10, we label the correspon ding curves by “Mb . ” 2. ABC-MART derivatives + a fixed b ase class chosen according to MART tr aining loss . In the experimen t with MAR T , we find “class 1” exhibits the overall largest train ing loss. T hus, we fix “class 1” as the base and re-train using the deri vati ves of ABC -MAR T . In Figure 10, we label the correspon ding curves by “b1. ” 3. ABC-MART derivatives + a fixed base class chosen acco r ding to MART test mis-classification err o rs . In the experiment with MAR T , we find “class 7” exhibits the overall largest error . W e fix “class 7” as the base and re-train using the deri vati ves of ABC -MAR T . In Figure 10, we label the correspon ding curves by “b7. ” Figure 10 demonstrate that none of the alternative boosting algorithms could outperfor m ABC-MAR T . 1 400 800 1200 1600 10 −16 10 −12 10 −8 10 −4 10 0 10 4 Iterations Training loss Train: J = 10, ν = 0.1 ABC M b7 b1 Mb 1 400 800 1200 1600 100 120 140 160 180 200 220 240 Iterations Test misclassifications Test: J = 10, ν = 0.1 ABC M b7 b1 Mb Figure 10: P endigits . The trainin g lo ss an d test mis-classification error s of thre e altern ativ e bo osting algo rithms (labeled by “Mb”, “b1”, and ”b7”), together with the results of ABC-MAR T and MAR T (labeled by “M”). 6 Conclusion W e pr esent the general idea of ABC-Boost and its concrete implementation named ABC-MAR T , for mu lti-class classification (with K ≥ 3 classes). T wo key co mponen ts o f ABC-Boost include: (1) By enforcing the (commonly used) co nstraint on the loss fu nction, we can de riv e bo osting algorith ms fo r K − 1 class using a base class ; (2 ) W e adaptively ch oose the current “worst” class as the b ase class, at each boosting step . Both componen ts are critical. Our experiments on a fairly large data s et and fiv e sma ll d ata sets demonstrate that ABC-MAR T co uld considerab ly improves the o riginal MAR T a lgorithm, wh ich has a lready been highly successfu l in large-scale industry application s. 24 Ackno wledgement The author thanks T on g Zhang for providing valuable comments to this manuscript. In late June 200 8, the author visited Stanf ord University and Google in Mo untain V iew . During th at visit, the autho r had th e op portun ity of presenting to Professor Friedman and Pro fessor Hastie the algorithm and some experiment results of ABC-MAR T ; and the author hig hly appreciates th eir comm ents and encou ragemen t. Also, th e au thor would like to express h is gratitude to Phil Long (Google) and Cun-Hu i Zhang for the helpful discussions of this work, and to Rich Caruana who suggested the author to test the algorith m on the Covertype data set. Refer ences [1] Da vid Cossock and T ong Zhang. Subset ranking using regression. In COL T , pages 605– 619, 2006. [2] Y oav Freund. Boosting a weak learning algorith m by majority . Inf. Comput. , 121 (2):25 6–285 , 1995. [3] Y oav Freund and Rob ert E. Schapire. A decision -theoretic generalizatio n of o n-line learning and a n applica- tion to boo sting. J . Comput. Syst. Sci. , 55(1):11 9–139 , 19 97. [4] Jerome H. Fr iedman. Greedy function approxima tion: A gradient boosting machine. The Annals of Statistics , 29(5) :1189– 1232, 2 001. [5] Jerome H. Fried man, Tre vor J. Hastie, and Rob ert Tibshirani. A dditive logistic regression: a statistical v iew of boosting. The Ann als of Statistics , 28(2):337 –407, 2000. [6] Ping Li, Christopher J.C. Burges, and Qiang W u. Mcrank : Lea rning to rank using classification and gr adient boosting. In NIPS , V anco uver , BC, Canada, 2008. [7] Robert Schapire. The strength of weak learnab ility . Machine Learning , 5(2) :197–2 27, 1990. [8] T on g Zha ng. Statistical a nalysis of some multi- category large margin classification methods. J ournal of Machine Learning Resear ch , 5:122 5–125 1, 2 004. [9] Zhaohui Z heng, Keke Chen, Gordo n Sun, and Hong yuan Zha. A r egression framework for learn ing ranking function s using relative relev a nce judg ments. In SIGIR , pages 287– 294, Amsterdam, The Netherland s, 2007 . 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment