Local antithetic sampling with scrambled nets
We consider the problem of computing an approximation to the integral $I=\int_{[0,1]^d}f(x) dx$. Monte Carlo (MC) sampling typically attains a root mean squared error (RMSE) of $O(n^{-1/2})$ from $n$ independent random function evaluations. By contra…
Authors: Art B. Owen
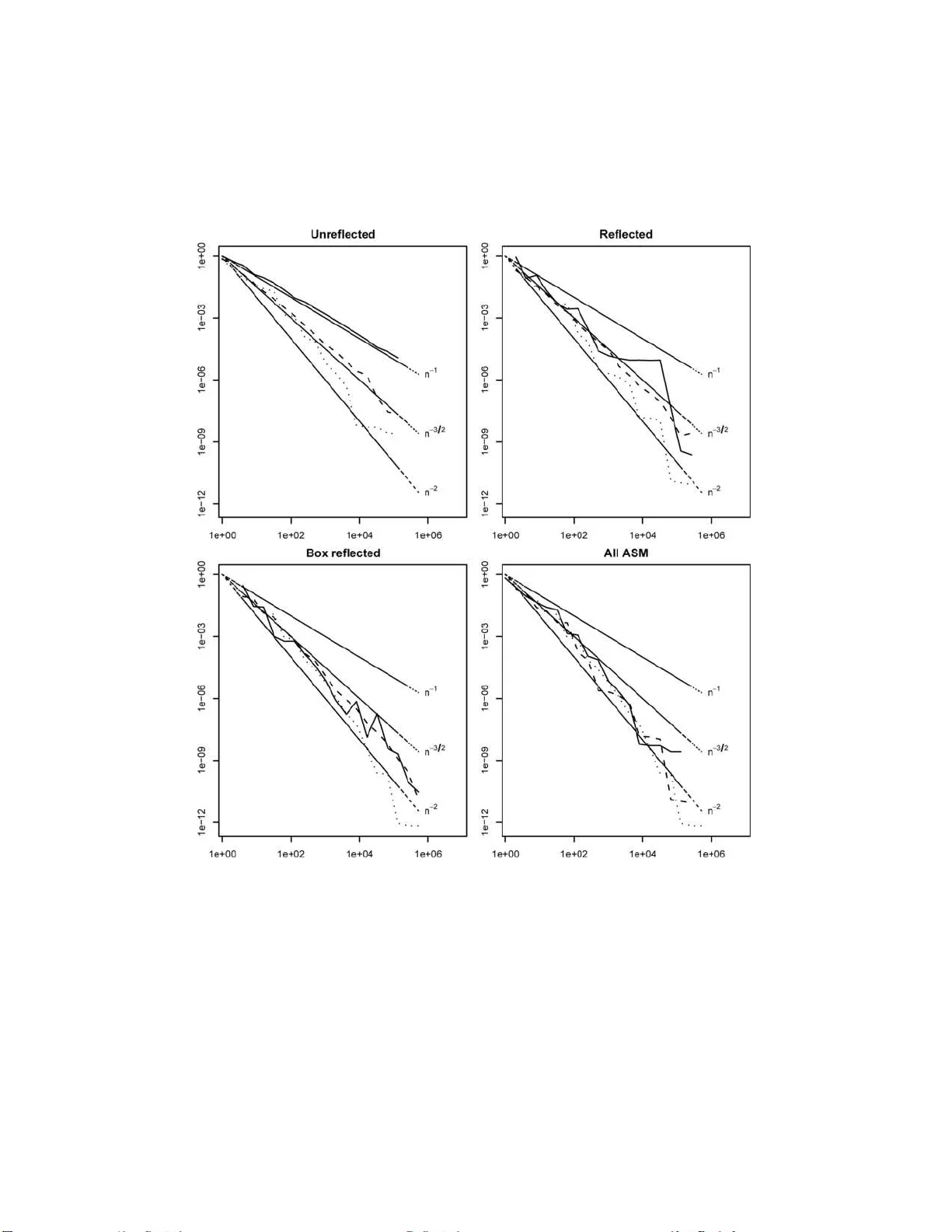
The Annals of Statistics 2008, V ol. 36, No. 5, 2319–23 43 DOI: 10.1214 /07-AOS548 c Institute of Mathematical Statistics , 2 008 LOCAL ANTITHETIC SAMPLING WITH SCRA MBLED NETS By Ar t B. O wen Stanfor d University W e consider the problem of computing an appro ximation to the integ ral I = R [0 , 1] d f ( x ) dx . Mon te Carlo (MC) sampling t yp ically at- tains a root mean squared error (RMSE) of O ( n − 1 / 2 ) from n in- dep endent random function ev aluations. By contrast, quasi-Monte Carlo ( QMC) sampling using carefully equispaced eval uation p oints can attain the rate O ( n − 1+ ε ) for any ε > 0 and ran d omized QMC (RQMC) can attain the RMSE O ( n − 3 / 2+ ε ), b oth und er mild cond i- tions on f . Classica l v ariance reduction meth od s for MC can b e adapted to QMC. Published results combining QMC with imp ortance sampling and with control v ariates hav e found w orthwhile improv ements, but no c hange in the error rate. This pap er extends the class ical v ari- ance reduction metho d of an tithetic sampling and combines it with RQMC. One such metho d is shown to bring a mod est impro vemen t in the RMSE rate, attaining O ( n − 3 / 2 − 1 /d + ε ) for an y ε > 0, for smo oth enough f . 1. In tro duction. Man y problems in science and engineering require m ul- tidimensional quadratures. There w e seek the v alue of an in tegral I = R [0 , 1] d f ( x ) dx . The integ rand f subsumes an y transformations necessary to accoun t for noncubic domains, or in tegratio n with resp ect to a n on uniform densit y . Mon te Carlo sampling is often emplo y ed for these problems. Its basic form uses an estimate ˆ I = (1 /n ) P n i =1 f ( x i ), wher e x i are s imulated indep en d en t draws from U [0 , 1] d . When f is in L 2 , then Mon te Carlo has a ro ot mean squ ared er r or (RMSE) at the familiar O ( n − 1 / 2 ) rate. Mon te Carlo in tegration can b e impr o v ed by the u se of v ariance reduc- tion metho d s. W ell-kno w n tec h niques include stratificatio n, imp ortance sam- pling, con trol v ariates and an tithetic sampling. T hese are d escrib ed in texts suc h as Glasserman [ 10 ] and Fishman [ 8 ]. Received Au gust 2007; revised August 2007. 1 Supp orted in part by N SF Gran ts DMS- 03-06612 and DMS-06-04939. AMS 2000 subje ct classific ations. Primary 65C05 ; secondary 68U20, 65D32. Key wor ds and phr ases. Digital n ets, monomial rules, randomized quasi-Monte Carlo, quasi-Monte Car lo. This is an electronic reprint of the or iginal ar ticle published by the Institute o f Mathematical Sta tistics in The Annals of Statistics , 2008, V o l. 36, No . 5, 23 19–2 343 . This reprint differs from the original in pagination a nd typog raphic detail. 1 2 A. B. O WEN In stratification, th e sample p oin ts x 1 , . . . , x n are made more uniformly distributed than they wo uld b e by chance. This idea of c ho osing p oin ts more uniformly th an they w ould b e by c hance under lies quasi-Mon te Carlo (QMC ) sampling wh ic h can b e thought of as an extreme v ersion of stratification. Deterministic QMC metho ds can attain an error rate of O ( n − 1+ ε ), while randomized versions can ac h iev e an RMSE of O ( n − 3 / 2+ ε ), b oth un der mild smo othness conditions on f , f or any ε > 0. It is in teresting to in v estigate wh ether v ariance reduction tec hniqu es from MC bring an y adv an tages to the QMC setting. Chelson [ 3 ] and S panier and Maize [ 27 ] ha ve inv estigated QMC with imp ortance sampling. Hic k ernell, Lemieux and Owen [ 12 ] hav e stud ied the com b ination of QMC with con- trol v ariates. Th is pap er considers a com bin ation of QMC with an tithetic sampling. An tithetic sampling imp ro v es Mon te Carlo b y exp loiting spatia l struc- ture in f . Eac h p oin t x ∈ [0 , 1] d is coupled with an other e x , commonly ob- tained a s e x = 1 − x in terpreted comp onen twise. In practic e, w e av erage e f ( x i ) = ( f ( x i ) + f ( e x i )) / 2 at n/ 2 p oin ts x i . If f ( x ) is linear in x , then e f ( x i ) = I and I can b e estimated w ithout error. When f ( x ) is nearly linear or nearly ant isymmetric [i.e., f ( x ) − I . = I − f ( e x )], then antithetic sampling can b ring a great reduction in RMSE, although the rate remains n − 1 / 2 . I n lo cal an tithetic samp ling, describ ed b elo w, the p oint e x is alw a ys close to x . Since smo oth fu nctions are lo cally linear in the T a ylor appro ximation sense, lo cal an tithetic sampling can b e m uc h b etter than antit hetic samp ling for small d . This pap er considers sev eral wa ys of com bin ing an tithetic samplin g and randomized d igital n ets. T h e main result is that one su ch metho d, a b o x folding scheme, reduces the RMSE to O ( n − 3 / 2 − 1 /d + ε ). T he improv ement in rate is mo dest and diminishes with d . But it compares f a v orably with or- dinary an tithetic samplin g whic h only c hanges the constant in the RMSE, and c hanges it for the w orse for s ome f . The other v ariance reduction meth- o ds fr om MC (con trol v ariates and imp ortance samplin g) on ly act on the constan t and do not improv e the RMSE rate when app lied to randomized QMC. The im p ro v ement w e find is the same factor n − 1 /d from classic results of Hab er [ 11 ]. Hab er get s an RMSE rate of O ( n − 1 / 2 − 1 /d ) for cubically stratified sampling and it imp ro v es to O ( n − 1 / 2 − 2 /d ) for a lo cally ant ithetic version of that s ampling. The outline of this pap er is as follo ws . Section 2 summ arizes bac kground information on scrambled n ets, whic h are a form of randomized quasi-Mon te Carlo sampling. Section 3 in tro duces some new notions of d -dimensional folding op erations used to in tro duce lo cal an tithetic p r op erties in to digital nets, and prop oses three sp ecific metho ds. Section 4 illustrates sev eral re- flection net samplin g sc hemes o n a t wo- dimens ional in tegrand studied by LOCALL Y ANTITHETIC SCRAMBLED NETS 3 [ 25 ]. The ro ot mean s q u ared errors seem to follo w a n − 2 rate. The next s ec- tions are devote d to sho wing that one of the metho ds, b o x folding, attains an RMSE of O ( n − 3 / 2 − 1 /d + ε ). S ection 5 recaps the v ariance for scrambled net quadrature of smo oth fu nctions. It corrects an error in the p ro of of the O ( n − 3 / 2 (log n ) ( d − 1) / 2 ) RMSE rate from [ 21 ]. It also extends th e pro of there to a wider collection of digital nets an d uses a w eak er sm o othness condition than the earlier pap er had. Sectio n 6 b uilds on Section 5 to prov e that the RMSE of the b o x folding sc heme is O ( n − 3 / 2 − 1 /d (log n ) ( d − 1) / 2 ) in d dimen- sions. More smo othness is required for th is r esult than for the unreflected scram bled nets. S ection 7 p resen ts the b o x folding sc heme as a h ybr id of a monomial cubatur e ru le with scram bled net sampling. Finally , it discusses ho w one might make use of these findings in higher d imensional p roblems of lo w effect ive dimension. 2. B ac kground and n otation. Scram b led nets are a particular form of randomized quasi-Mon te C arlo sampling. The monograph [ 17 ] by Nieder- reiter is the definitiv e source for quasi-Mon te Carlo sampling. Randomized quasi-Mon te Carlo sampling was surve ye d b y Lemieux and L’Ecuy er [ 15 ]. Scram bled nets were first p rop osed in [ 19 ]. W e use sup erscripts for comp onents, so x, x i ∈ [0 , 1] d ha v e comp onents x j and x j i resp ectiv ely f or j = 1 , . . . , d . The set { 1 , . . . , d } is abbr eviated 1 : d . If u ⊆ 1 : d , th en its complemen t { 1 ≤ j ≤ d | j / ∈ u } is written as − u . W e often hav e to extract and combine comp onents from one or more p oints in [0 , 1] d . When we extract the comp onen ts x j for j ∈ u ⊆ 1 : d , w e use x u to den ote the result. When x, z ∈ [0 , 1] d and we wan t to combine x u with z − u , we w r ite it as x u : z − u . Thus, x u : z − u is the p oint y ∈ [0 , 1] d with y j = x j for j ∈ u and y j = z j for j / ∈ u . 2.1. Quasi-Monte Carlo. Lik e plain Mon te Carlo, qu asi-Mont e Carlo sampling estimates an inte gral I = R [0 , 1] d f ( x ) dx b y the a v erage ˆ I = 1 n P n i =1 f ( x i ) tak en o ver p oin ts x i ∈ [0 , 1] d . QMC aims to b e b etter than rand om by select- ing x i to b e ev en more uniform ly distributed than rand om p oin ts t ypically are. T o qu an tify the nonuniformit y of x 1 , . . . , x n , consider th e lo cal discrep- ancy function δ ( x ) = 1 n n X i =1 1 x i ∈ [0 ,x ] − V ol([0 , x ]) (1) for x ∈ [0 , 1] d . The star discrepan cy of x 1 , . . . , x n is D ∗ n ( x 1 , . . . , x n ) = sup x ∈ [0 , 1] d | δ ( x ) | . (2) 4 A. B. O WEN When d = 1, then D ∗ n reduces to the Kolmogo rov– Smirn o v distance b et w een the empirical distribution of x i and the U [0 , 1] distribution. The Koksma– Hla w k a inequ ality [ 13 ] is | ˆ I − I | ≤ D ∗ n ( x 1 , . . . , x n ) k f k HK , (3) where k f k HK is the total v ariation of f in the sense of Hardy and K rause. It is p ossible to constru ct x i so that D ∗ n ≤ C d (log n ) d − 1 /n for n > 1. With suc h constru ctions, | ˆ I − I | = O ( n − 1+ ε ) holds f or all ε > 0 , un der the mild condition that k f k HK < ∞ . Thus, QMC has a far b etter asymptote than MC. 2.2. Digital nets. Digital nets attain their lo w discrepancy by b eing si- m ultaneously stratified f or many differen t stratifications of [0 , 1] d . Those stratifications are defined through hyper-rectangular subsets kno wn as ele- men tary inte rv als. This section d efines these elemen tary in terv als and some digital n ets and digital sequences. T hroughout we u se b to denote an inte ger base in w hic h to represent real n umbers, d to r epresent the dimen s ion, k j to rep r esen t some nonnegativ e in teger p ow ers of b and t j to repr esen t some nonnegativ e in teger translations. Definition 1. Let b ≥ 2 and d ≥ 1 b e in tegers. Let κ = ( k 1 , . . . , k d ) and τ = ( t 1 , . . . , t d ) b e d -ve ctors of in tegers for w hic h k j ≥ 0 and 0 ≤ t j < b k j . Then the set B κ,τ = d Y j =1 t j b k j , t j + 1 b k j is a base b elemen tary in terv al. If one fixes κ and v aries τ , th e sets B κ,τ pro vide a tiling of [0 , 1) d . The tilings of th e three illustrations in Figur e 1 are of this type. The vo lume of B κ,τ is b −| κ | , where | κ | = k 1 + · · · + k d . Th e closure of B κ,τ , defined by replacing the half op en interv als in Definition 1 b y closed in terv als, is denoted B κ,τ . Th e cen ter of B κ,τ and of B κ,τ is the p oin t c κ,τ with c j κ,τ = ( t j + 1 / 2) /b k j . When one o r more of the k j is 0 , then the corresp ondin g factors of B reduce to [0 , 1). Let u ⊆ 1 : d and let κ b e a vec tor of length | u | indexed by j ∈ u , with comp onent k j for j ∈ u . S imilarly , let τ ha ve comp onent s t j for j ∈ u . T hen B u,κ,τ ≡ Y j ∈ u t j b k j , t j + 1 b k j Y j / ∈ u [0 , 1) LOCALL Y ANTITHETIC SCRAMBLED NETS 5 will b e used b elo w. The cen ter of B u,κ,τ is the p oin t c u,κ,τ with c j u,κ,τ = t j + 1 / 2 b k j , j ∈ u , 1 2 , j / ∈ u . The elemen tary int erv al B κ,τ in Definition 1 has v olum e b −| κ | . Ideally it should get nb −| κ | of the sample p oint s x 1 , . . . , x n . If th at happ ens for one v ector κ , we ha v e a stratified samp le with one stratum for eac h τ . Digita l nets attain su c h stratification for multi ple κ simulta neously . Definition 2. F or in tegers m ≥ q ≥ 0 , b ≥ 2 and d ≥ 1, a sequence of p oints x 1 , . . . , x b m ∈ [0 , 1) d is a ( q , m, d )-n et in b ase b if ev ery b ase b elemen- tary interv al in [0 , 1) d of vol ume b q − m con tains pr ecisely b q p oints of th e sequence. The parameter q defines the qualit y of the n et, w ith smaller v alues im- plying b etter equidistrib ution, and q = 0 b eing the v ery b est wh en it is attainable. The m in T system [ 24 ] iden tifies the b est kno wn nets (smallest q ) giv en the v alues of m , d and b . T h e net prop erty is enough to ensur e lo w discrepancy: Theorem 1. If x 1 , . . . , x n ar e a ( q , m, d ) - ne t in b ase b , then n × D ∗ n ( x 1 , . . . , x n ) ≤ 1 ( d − 1)! ⌊ b/ 2 ⌋ log b d − 1 (log n ) d − 1 + O ( b q (log n ) d − 2 ) for n > 1 , wher e the i mplie d c onstant in the err or term dep ends only on b and d . Pr oof . This is from Theorem 4.10 of [ 17 ]. The m ultiple of (log n ) d − 1 can b e r educed somewh at when d = 2 and b is ev en, or wh en d = 3 , 4 and b = 2. Some constructions of digital nets are extensible. They let us increase n , k eeping the stratification prop ert y and retai ning the earlier fun ction ev alu- ations. Definition 3. F or in tegers q ≥ 0 , b ≥ 2, and d ≥ 1, an infi nite sequence of p oints x i ∈ [0 , 1) d for i ≥ 1 is a ( q , d )-sequ ence in base b if eve ry subse- quence x r b m +1 , . . . , x r b m + b m , for in tegers m ≥ q and r ≥ 0, is a ( q , m, d )-net in b ase b . 6 A. B. O WEN It is con v enient to work with the first n = λb m p oints of the sequence. Should they pr o v e inadequate, one can increase λ or, more generally , use e n = e λb e m ≥ n . T h e p oints of the new larger rule in clude all th ose of the previous ru le. Thus, ( q , d )-sequences provide extensible integ ration ru les. They automatica lly satisfy th e ( λ, q , m, d )-net p r op erty: Definition 4. F or in tegers m ≥ q ≥ 0, b ≥ 2, 1 ≤ λ < b and d ≥ 1, a sequence of p oin ts x 1 , . . . , x λb m ∈ [0 , 1) d is a ( λ, q , m, d )-net in base b if ev ery base b elemen tary inte rv al in [0 , 1) d of v olume b q − m con tains precisely λb q p oints of the sequence and n o b -ary b o x in [0 , 1) d of v olume b q − m − 1 con tains more than b q p oints of th e sequence. A r elaxe d ( λ, q , m, s )-n et in base b is as ab ov e, except that λ ≥ b is allo w ed and b oxe s of v olume b q − m − 1 ma y ha ve more than b q p oints of the sequence. 2.3. R andom digital scr ambles. In scram bled digital n et quadrature w e tak e a digital net a 1 , . . . , a n ∈ [0 , 1] d and apply a randomizing transf ormation to th is ensemble to pro duce p oin ts x 1 , . . . , x n ∈ [0 , 1] d with t w o p rop erties: eac h x i is individually U [0 , 1] d distributed, and x 1 , . . . , x n are collectiv ely a digital net with probabilit y 1. Th e fir st p rop erty makes the sample a v erage ˆ I = 1 n P n i =1 f ( x i ) an unbiased estimate of I . The second prop ert y means that ˆ I inherits th e go o d accuracy pr op erties of digital nets. Some such rand omized nets w ere p resen ted in [ 19 ] w h ere it w as also sho wn that scram bled digital sequences remain digital sequences with probability one. The original motiv ation for r an d omizing nets was that it allo wed ind e- p end ent replications for the p urp oses of estimating error. T hat randomiza- tion can imp ro v e the err or r ate was at first a su r prise, but is no w understo o d as an err or cancellation ph enomenon. Randomizations of nets typica lly use the same ran d om pro cedure on eac h p oint a i in order to yield the corresp onding x i , and so w e need only describ e the randomization of a s ingle p oin t a ∈ [0 , 1] d . F urthermore, the random- izations applied to comp onents a 1 through a j are t yp ically c h osen to b e statistica lly indep end ent. And so we only need to describ e the randomiza- tion of a single p oint a ∈ [0 , 1]. It is b ey ond the scop e of this article to exp lain ho w r an d omization of nets is able to ac hiev e the tw o defining prop erties. F or that one can consult the prop osal of Owen [ 19 ], it’s derandomization b y Matou ˇ sek [ 16 ], and the survey of Lemieux and L’Ecuy er [ 15 ]. W e can, ho wev er, lo ok at th e mechanics of some randomizations. T o scramble the p oint a ∈ [0 , 1), w e fi r st write it out in base b as a = P ∞ k =1 a ( k ) b − k , where a ( k ) ∈ { 0 , 1 , . . . , b − 1 } . Some v alues of a hav e t wo repre- sen tations, one end ing in infi nitely many zeros and the other ending in b − 1’s. LOCALL Y ANTITHETIC SCRAMBLED NETS 7 In such cases w e use the r epresen tation en d ing in zeros. F or this reason we d o not scramble the v alue a = 1 , and so scram bled nets actually pro duce p oint s x i ∈ [0 , 1) d from p oin ts a i ∈ [0 , 1) d . Th is presents no pr oblem. Th e standard net constructions yield p oint s in [0 , 1) d and R [0 , 1) d f ( x ) dx = R [0 , 1] d f ( x ) dx . The s cr ambled version of a is the p oint x = P ∞ k =1 x ( k ) b − k for d igits x ( k ) ∈ { 0 , 1 , . . . , b − 1 } obtained by rand om p ermutat ion sc hemes applied to the a ( k ) . In pr actice, the expansion of x is tr u ncated. There are b ! d istinct p ermutatio ns of { 0 , 1 , . . . , b − 1 } . In a u niform random p ermutatio n of this set, eac h p erm utation has probabilit y b ! . The metho d in [ 19 ] uses a great man y un if orm random p erm utations to scram ble a . One p ermutatio n is applied to the first digit yielding x (1) = π 1 ( a (1) ). F or the k th digit a ( k ) , one of b k − 1 indep en d en t u niform random p ermutatio ns is used to mak e x ( k ) , c hosen b ased on th e v alue of ⌊ b k − 1 a ⌋ . The original r an d omization is compu tationally bu r densome, requiring con- siderable storage. Matou ˇ sek [ 16 ] found an alternativ e and less costly scram- bling, by der an d omization. W e describ e that and several other scramblings here. Some more scram blings are describ ed in [ 23 ] f rom whic h the p ermuta- tion and s cram bling nomenclature used here is ta ke n. Definition 5. If b is a prime n umber , then a linear random p er mutation of { 0 , 1 , . . . , b − 1 } h as the form π ( a ) = h × a + g mo d b , where h ∈ { 1 , . . . , b − 1 } and g ∈ { 0 , 1 , . . . , b − 1 } are in dep end en t random v ariables uniformly dis- tributed o v er th eir resp ectiv e ranges. Linear p ermutations are restricted to pr ime b b ecause otherwise there are nonzero h for wh ic h h × a + g is not a p ermutat ion. F or example, consider b = 4 and h = 2. Linear p ermutati ons ha ve a generalizati on, via Galois field arithmetic, to b ases that are prim e p o w ers, bu t w e do not use th em here. Definition 6. F or a prime b ase b , an affine matrix scramble take s the form x ( k ) = C k + k X j =1 M k j a ( j ) mo d b, where C k and M k j are in { 0 , 1 , . . . , b − 1 } . W e will consider affine matrix scrambles in whic h the C k are indep en- den t uniformly distributed elemen ts of { 0 , 1 , . . . , b − 1 } , indep end en t of the elemen ts M k j . Suc h scrambles alw a ys ha v e x ∼ U [0 , 1] regardless of a and M k j . The matrix scram b les w e consider differ in the structure of th e matrix M . In eac h case M is lo wer triangular and inv ertible. Inv ertibilit y is required 8 A. B. O WEN so that distinct p oints a lead to d istin ct p oints x . The structur es that w e consider for M ca n b e repr esen ted as h 1 g 21 h 2 g 31 g 32 h 3 g 41 g 42 g 43 h 4 . . . . . . . . . . . . . . . , h 1 g 2 h 1 g 3 g 2 h 1 g 4 g 3 g 2 h 1 . . . . . . . . . . . . . . . , (4) h 1 h 1 h 2 h 1 h 2 h 3 h 1 h 3 h 3 h 4 . . . . . . . . . . . . . . . , where h ’s are samp led from { 1 , 2 , . . . , b − 1 } and g ’s are sampled from { 0 , 1 , . . . , b − 1 } . Within eac h matrix, entries with the same symbol are ident ical and en tries with d ifferen t s ym b ols are sampled indep en den tly . The matrices in ( 4 ) d escrib e resp ectiv ely , random linear scrambling of [ 16 ], I -binomial scram- bling of [ 30 ] and affine strip ed matrix (ASM) samp lin g from [ 23 ]. Random li near scram bling leads to the same sampling v ariance as the original n et scrambling in [ 19 ] (called “nested un iform scrambling”) but requires m uch less storage. I -binomial scrambling also leads to the same sampling v ariance but do es so w ith still less storage. The AS M scram b ling is not v ariance equiv alent to nested u n iform scram- bling. In th e ca se d = 1, ASM attains an RMSE of O ( n − 2 ), when f ′′ ( x ) is b oun ded, wh ic h is b etter than the rate O ( n − 3 / 2 ) from other scram bles, though not as goo d as the rate O ( n − 5 / 2 ) that Hab er’s method gets for d = 1. Our strateg y for impro ving randomized nets is to build in directly some d -dimensional versions of lo cally ant ithetic sampling. The lo cal ant ithetic sampling strategy is implemen ted b y adjoining to the s cr ambled n et certain reflections of sample p oin ts. 2.4. ANOV A. F or a function f ∈ L 2 [0 , 1] d , the ANO V A decomp osition is a v ailable to quantify the extent to w hic h f d ep ends primarily on low er dimensional pro jections of the in put space. In f ormally it is lik e em b ed d ing a r egular K d grid in [0 , 1] d , running an ANO V A on that grid and letting K → ∞ . The ANOV A of [0 , 1] d w as introd uced b y Ho effding [ 14 ], figures in the Efron –S tein in equalit y [ 6 ], and w as indep endently disco vered by Sob ol’ [ 26 ]. F or more details and the early h istory of the ANO V A decomp osition, see [ 29 ]. W e wr ite f ( x ) = P u ⊆ 1 : d f u ( x ), where f u ( x ) is a f unction of x that d ep ends on x only thr ough x u . T o get f u , w e su btract strict sub-effects f v for v ( u LOCALL Y ANTITHETIC SCRAMBLED NETS 9 and then av erage the residu al o v er x − u . Sp ecifically , f u ( x ) = Z f ( x ) dx − u − X v ( u f v ( x ) . (5) The ANO V A terms are orthogonal in th at R f u ( x ) f v ( x ) dx = 0 for sub sets u 6 = v . Letting σ 2 u = R f u ( x ) 2 dx , w e find that σ 2 = P | u | > 0 σ 2 u . 2.5. Smo othness and mixe d p artial derivatives. This section in tro d u ces our notion of smo othness for f and records some eleme ntary consequen ces of the defin ition for later use. Th e mixed p artial deriv ativ e of f tak en once with r esp ect to x j for eac h j ∈ u is den oted by ∂ u with the con v en tion th at ∂ ∅ f ( x ) = f ( x ). Definition 7. Th e real v alued fun ction f ( x ) on [0 , 1] d is sm o oth if ∂ u f ( x ) is con tin uous on [0 , 1] d for all u ⊆ 1 : d . Remark 1. There are | u | ! orders in which the mixed partial deriv ativ e ∂ u f ( x ) can b e in terpr eted. The co ntin uity conditions in Definition 7 are strong enough to ensu re th at all orderings giv e the same fun ction. Lemma 1. If f is smo oth, then ∂ u f u ( x ) is c ontinuous for al l u ⊆ 1 : d . Pr oof . The details are omitted to sa v e sp ace. The k ey is to pro ve by induction on | u | that ∂ u R f ( x ) dx − u = R ∂ u f ( x ) dx − u . W e also need a v ersion of the fundamental theorem of calculus. F or p oin ts a, b ∈ [0 , 1] d , define their r ectangular hull as the Cartesian pro duct rect[ a, b ] = d Y j =1 [min( a j , b j ) , max( a j , b j )] . F or d = 1 , if f has a con tin uous d eriv ativ e f ′ on the interv al rect[ c, x ], then f ( x ) = f ( c ) + R [ c,x ] f ′ ( y ) dy , with the in terpretation that R [ c,x ] means − R [ x,c ] when c > x . F or general d and smo oth f , w e hav e f ( x ) = X u ⊆{ 1 ,...,d } Z [ c u ,x u ] ∂ u f ( c − u : y u ) dy u . (6) Here R [ c u ,x u ] denotes ± R rect[ c u ,x u ] where the sign is n egativ e if and only if c j > x j holds f or an o dd num b er of in dices j ∈ u . Th e term for u = ∅ equals f ( c ) un der a natural con v enti on. 10 A. B. O WEN More generally , let w ⊆ { 1 , . . . , d } and sup p ose that ∂ u f is con tin uous f or u ⊆ w . Then f ( x ) = X u ⊆ w Z [ c u ,x u ] ∂ u f ( x − w : c w − u : y u ) dy u . (7) F or v ⊆ u ⊆ { 1 , . . . , d } , let ∂ u,v f denote the partial deriv ativ e of f u tak en once w ith resp ect to eac h x j for j ∈ v . That is, f u,v is f differentiat ed with resp ect to x j t wice for j in v and once for j in u − v . Definition 8. The real v alued function f ( x ) on [0 , 1] d is d oubly smo oth if ∂ u,v f ( x ) is con tinuous on [0 , 1] d for all v ⊆ u ⊆ 1 : d . 3. b -ary reflections and folds. Anti thetic samp ling is imp lemen ted via reflections about the cente r p oin t of [0 , 1] d . T o induce v arious lo cal an ti- thetic prop erties, we will u s e reflections of a p oint x ab out the cen ter of an elemen tary inte rv al con taining x . The case d = 1 is simplest. Th e p oin t x ∈ [0 , 1) b elongs to the in terv al [ tb − k , ( t + 1) b − k ), where t = t ( x ) = ⌊ b k x ⌋ . Th e center of this in terv al is c = c k ( x ) = ( t + 1 / 2) b − k . The k th order reflection of x is R k ( x ) = 2 c k ( x ) − x . The v alue k = 0 corresp ond s to the simple reflection 1 − x . If the b ase b expansion of x ∈ [0 , 1) is x = P ∞ ℓ =1 x ( ℓ ) b − ℓ with eac h x ( ℓ ) ∈ { 0 , 1 , . . . , b − 1 } , using trailing 0’s when x has t w o base b r epresen tations, then R k ( x ) = k X ℓ =1 x ( ℓ ) b − ℓ + ∞ X ℓ = k +1 ( b − 1 − x ( ℓ ) ) b − ℓ . (8) The reflection R k lea ves th e fi rst k digits of x unc hanged and it flips the trailing digits. By con ven tion, w e tak e R k (1) = lim x → 1 R k ( x ) = 1 − 1 /b k . Under this con- v en tion we find that lim k →∞ R k ( x ) = x holds uniformly in x . The reflection is nearly idemp oten t b ecause R k ( R k ( x )) = x u nless x = tb − k for an intege r t with 0 ≤ t < b k − 1. Note that a r eflection of a reflection is n ot generally a reflection. F or instance, wh en x is n ot of the form tb − k , then R 7 ( R 3 ( x )) flips digits 4 through 7 inclusive of x and lea v es all other digits unchange d. It is u seful to consid er tr an s formations in whic h some comp onents of x are reflected, while others get an iden tit y transform ation. F or s implicit y , we adopt the sp ecial v alue k = − 1, sometimes displa y ed simply as − , to den ote the iden tit y tr ansformation, so that R − 1 ( x ) = x for x ∈ [0 , 1]. Definition 9. F or the v ector κ = ( k 1 , . . . , k d ) with k j ∈ {− 1 , 0 , 1 , . . . } , the reflection R κ of x ∈ [0 , 1] d is defi ned by R κ ( x ) = z ∈ [0 , 1] d , where z j = R k j ( x j ) . (9) LOCALL Y ANTITHETIC SCRAMBLED NETS 11 Figure 1 illustrates some r eflections R (1 , 2) and R ( – , 2) for x ∈ [0 , 1) 2 with b = 2, as w ell as a b o x fold describ ed b elo w. Geometrical ly , a reflection of x has some comp onen ts symmetric ab out the cen ter of an elementa ry inte rv al con taining x and all other comp onents equal to the corresp onding ones of x . Recall th at th e cen ter of the elemen tary inte rv al B κ,τ is the p oin t c κ,τ = t 1 + 1 / 2 b k 1 , . . . , t d + 1 / 2 b k d . (10) F or a v ector κ = ( k 1 , . . . , k d ) with k j ≥ 0, the p oint x ∈ [0 , 1) d b elongs to the elemen tary in terv al B κ,τ for τ = τ ( κ, x ) = ⌊ b κ x ⌋ , with the multiplica tion and flo or op erators tak en comp onent wise. F or such κ , the reflection R κ ( x ) ma y b e written R κ ( x ) = 2 c κ,τ ( κ,x ) − x. Notice that R κ ( x ) has some p oin ts of discontin uity whenever max j k j ≥ 1 b ecause then c κ,τ ( κ,x ) jumps when x crosses the b oundary of certain base b elemen tary inte rv als. Definition 10. Let x 1 , . . . , x n ∈ [0 , 1) d and let R κ b e a b -ary refl ection. The folded sequence F κ ( x 1 , . . . , x n ) is the sequence z 1 , . . . , z 2 n ∈ [0 , 1) d with z i = x i for i = 1 , . . . , n and z i = R κ ( x i − n ) for i = n + 1 , . . . , 2 n . If F κ ( F κ ′ ( x 1 , . . . , x n )) and F κ ′ ( F κ ( x 1 , . . . , x n )) are b oth w ell defined , then they b oth ha ve the same p oints, but p ossibly in a d ifferen t order. In th is sense, folding is comm utativ e. If r folds ha v e b een app lied, then the sample size is 2 r n , p erh aps includin g some p oin ts multiple times. Fig. 1. This figur e il l ustr ates some b ase b = 2 digital r efle ctions as describ e d in the text. The left p anel shows 8 elementary intervals, one of which c ontains a solid p oi nt wi th i ts R (1 , 2) r efle ction. The c enter p anel shows 8 elementary intervals, one of which has a p oint with its R (3 , − ) r efle ction. The right p anel shows 4 elementary intervals, one of which includes a solid p oi nt x wi th the other thr e e p oints of its b ox r efle ction F (1 , − ) ( F ( − , 1) ( x )) . 12 A. B. O WEN F or foldin g to imp ro v e on a digital n et, it should p ro du ce a lo cal an ti- thetic pr op ert y within elemen tary interv als of v olum e comparable to b q − m . T o see why , consider the alternativ es, taking q = 0 for simplicit y . If reflections tak e place within elementa ry int erv als of v olume b − r ≪ b − m , then some ele- men tary interv als of v olume b − r ha v e tw o nearly identic al sampling p oint s, while most hav e none. Conv ersely , reflections within elemen tary interv als of v olume b − r ≫ b − m are n ot “local enough” to get th e b est error rate. In par- ticular, if r is constan t wh ile m → ∞ , then one cannot exp ect an imp ro v ed con v ergence rate, though the leading constant migh t b e b etter than without folding. F or κ = ( k 1 , . . . , k d ) with k j ∈ {− 1 , 0 , 1 , . . . } , let κ + ha v e comp onents k + j = max { k j , 0 } and put | κ + | = P d j =1 k + j . Then for x ∈ B κ + ,τ of v olume b −| κ + | , R κ ( x ) is in the closed elementa ry in terv al B κ + ,τ . F or reflectio ns of a digital net, w e should us e κ with | κ + | close to m − q . When the reflectio ns get finer as m increases, then the reflected scr ambled n ets will not ord in arily b e extensible. Here we pr esen t three metho ds for ind ucing lo cal antit hetic prop erties in some ( q , m, 2)-nets. T h ey are giv en in in creasing order with r esp ect to the n umb er of reflections required. 3.1. R efle ction nets. T he reflection net tak es the form F κ ( x 1 , . . . , x n ), where x 1 , . . . , x n is a ( λ, q , m, d )-net in base b and κ is a v ector of d nonn ega- tiv e in tegers summin g to q − m . The reflection net is a (relaxed) (2 λ, q , m , d )- net in b ase b . F or d = 2 and q = 0, w e use κ = ( k 1 , k 2 ), where eac h k j . = m/ 2, sp ecifically , k 1 = m + 1 2 and k 2 = m − k 1 . (11) These reflections treat eac h comp onen t of x n early equally , and r eflect within elemen tary inte rv als of volume 1 /n . 3.2. Box folde d nets. The asymptotic err or of scrambled n et quadrature from [ 21 ] is go verned by the norm of the m ixed partial deriv ativ e ∂ 1: d f . The reflection net ma y b e thought of as a v eraging the function e f ( x ) = ( f ( x ) + f ( R κ ( x ))) / 2 o ve r a sample of n v alues of a scrambled net. Th e function e f ( x ) has a mixed p artial d eriv ativ e almost ev erywhere, when f do es. If j ∈ u , then ∂ R κ ( x j ) /∂ x j = − 1 at almost all p oint s, and w e fi nd th at mixed partial deriv ative s of e f of o dd ord er largely cancel, while those of ev en order are av eraged. F or d = 2, the dominan t term in the error comes from ∂ { 1 , 2 } f , whic h is of eve n order and s o do es n ot ca ncel. Therefore, we consider another sc heme that a v erages e f ( x ) = 1 4 ( f ( x ) + f ( R ( k 1 , − ) ( x )) + f ( R ( − ,k 2 ) ( x )) + f ( R ( k 1 ,k 2 ) ( x ))) , LOCALL Y ANTITHETIC SCRAMBLED NETS 13 o v er n p oin ts, with k 1 and k 2 as in ( 11 ). T o constru ct these p oin ts, we app ly t w o folds as in F ( k 1 , − ) ( F ( − ,k 2 ) ( x 1 , . . . , x n )). T h e image F ( k 1 , − ) ( F ( − ,k 2 ) )( x ) is made up of 4 p oin ts, symmetric ab out the cen ter of a b ox co ntai ning x . One suc h quadru ple is shown in Figure 1 . 3.3. Monomial nets. A greedier reflection strategy folds together all of R (0 ,m ) , R (1 ,m − 1) , R (2 ,m − 2) , . . . , R ( m, 0) . When these m + 1 folds are applied to a (0 , m, 2)-net in base b , the resu lting p oints correctly in tegrate any f that is a sum of p iece-wise linear fun ctions linear w ithin elementa ry interv als of volume b m or large r. Suc h “monomial nets” extend the lo cal antit hetic prop erty of Hab er’s stratification schemes to all elementa ry interv als of v olume b − m , not jus t those from one vecto r κ . The cost is that the sample size is m u ltiplied by 2 m +1 , going fr om b m to 2(2 b ) m . When b = 2 the cost is 2 n 2 function ev aluations instead of n . F or b > 2, the cost gro ws su p erlinearly in n , but more slo wly than the square of n : 2(2 b ) m = 2(2 b ) log b ( n ) = 2 1+log b ( n ) n = 2 n 1+log b (2) . 4. E xample from Sloan and Jo e. T o illustrate the three lo cally an tithetic strategies for nets, we consider an inte grand s tudied by Sloan and Jo e [ 25 ], g ( x ) = x 2 exp( x 1 x 2 ) , x = ( x 1 , x 2 ) ∈ [0 , 1] 2 . This fu nction is b oun ded and has infin itely many con tin uous deriv ativ es. W e can exp ect it to ha ve all the smo othness that any of the refl ection tec hniqu es discussed ab ov e migh t b e able to exploit. Also, th ere are no sym metries or an tisymmetries that w ould mak e reflection metho ds exact f or this fun ction. This function has mean I = R 1 0 R 1 0 g ( x 1 , x 2 ) dx 1 dx 2 = e − 2 , and v ariance σ 2 = (3 − e )(7 e − 11) / 8. Using Mathematica, one can fi n d that the ANO V A mean squares for th e main effects are σ 2 { 1 } = 1 3 ((10 − e ) e − 15 + 2Ei(1) − 2Ei(2) + log (4)) and σ 2 { 2 } = (3 − e )( e − 1) / 2 , where Ei is the exp onen tial inte gral f u nction, Ei( z ) = − R ∞ − z t − 1 e − t dt. The relativ e v ariances (sensitivit y ind ices) of the ANO V A terms are σ 2 { 1 } σ 2 . = 0 . 072 9 , σ 2 { 2 } σ 2 . = 0 . 8561 and σ 2 { 1 , 2 } σ 2 . = 0 . 0710 . This function has a meaningfu lly large biv ariate term accoun ting for ab out 7 . 1 p ercen t of th e v ariance, and so it is not a nearly additiv e fu nction. 14 A. B. O WEN F or this pap er, we consider a scaled version of g , namely , f ( x ) = x 2 exp( x 1 x 2 ) e − 2 , x = ( x 1 , x 2 ) ∈ [0 , 1] 2 . (12) With this scaling, R f ( x ) dx = 1 and so absolute and relativ e errors coincide. All of the in tegration tec hn iques w e consider here are based on th e con- struction of (0 , m, 2) -nets giv en by F aure [ 7 ]. The bases u sed were b = 2 , 3 , 5 , 7. The p oin ts w ere either unscr ambled, AS M scrambled, or giv en a random linear scram bling. Nested uniform and I-Binomial scram bling w ere not tried b ecause they hav e the same v ariance as random lin ear s cram bling. F or eac h base and scram bling metho d , reflection nets, b o x nets and mono- mial n ets w ere tried. The monomial n ets did not p erform ve ry we ll, most lik ely b ecause of the sup erlinear (in n ) sample size that they required. In some in stances th ey w ere sligh tly b etter th an the original (0 , m, 2)-nets, but n ot n early as go o d as the other metho ds. F or the other metho ds, o v er v alues of n up to the first p o wer of b larger than 20 00, the b ase 2 metho ds were almost alwa ys th e b est. Accordingly , we wo rk with b = 2 and then extend the computations out to n = 2 17 . F or metho ds with reflections, the sample sizes go out to 2 18 , while for b o x folds, the sample sizes go to 2 19 . Figure 2 shows the error f or this fu nction with the m etho ds describ ed ab o v e. F or deterministic metho ds, the absolute error is sh o wn. F or random- ized metho d s, the ro ot m ean squared err or fr om 300 indep enden t rep lications is sho wn. The upp er left p anel sho ws, fr om top to b ottom, the error for u n- scram bled, random linear scram bled and ASM scrambled F aure p oin ts. The F au r e p oin ts lie very close to th e O ( n − 1 ) reference lin e, with no app aren t ev- idence of a logarithmic factor. The matrix scram bled p oin ts are close to the O ( n − 3 / 2 ) reference lin e. The ASM scram bled p oin ts seem to follo w O ( n − 3 / 2 ) at fi rst, then app r oac h the O ( n − 2 ) reference b efore lev eling out. The upp er righ t panel sh o ws the same three metho ds, with a r eflection incorp orated. Th e cu r v e for ASM scram bling k eeps crossing the n − 2 refer- ence line. The curve for random linear s cram bling lies just b elo w the n − 3 / 2 reference. T he cur v e for reflection without scrambling has a prominent fl at sp ot for n ≤ 32 , 768. Then it gets muc h b etter at 65 , 536. The lo wer left panel sho ws the three methods with b o x symmetry . Here the curv e for random linear scram bling lies b et we en the r eferences for n − 3 / 2 and n − 2 and ends up roughly parallel to the latter. Th e curve for ASM scram bling end s up b elo w the n − 2 reference line. The curv e for the b o x symmetrized F au r e sequence follo ws the one for r andom lin ear s cr ambling, but has an error that is not monotone in n . F or eac h kind of symmetry , th e ASM scrambling seems to giv e the b est results on this fun ction. The lo w er righ t panel sho ws all three ASM m etho ds. LOCALL Y ANTITHETIC SCRAMBLED NETS 15 Fig. 2. Shown ar e absolute err ors f or the F aur e se quenc e and sample RMSEs fr om 300 r eplic ations for scr am bl e d versions, in the quadr atur e example of Se ction 4 . The lower right p anel is for A SM scr ambli ng: unr efle cte d (solid), r efle cte d (dashe d) and b ox (dotte d). T he other p anels depict unscr amble d (solid), li ne arly scr amble d (dashe d) and ASM scr amble d (dotte d) r esults. A l l p anels have r efer enc e l ines pr op ortional to lab ele d p owers of n . F r om top to b ottom at the righ t of that panel they are for the original p oin ts, reflected p oints and b o xed p oints. F r om this example it is clear that reflection s trategies ha v e p oten tial to bring impro v emen ts and may ev en yield a rate b etter than O ( n − 3 / 2 ). There are also some p r ominen t flat sp ots and rev ersals in the err ors. In the next 16 A. B. O WEN sections we inv estigate b o x reflections and sh o w that it can impro v e th e error rate. 5. V ariance for scram bled digital nets. The err or rate analysis for b o x reflection of scram bled d igital nets builds on the analysis for unreflected scram bled nets. T h is section recaps some needed material for completeness, widens the generalit y , and corrects an error in the original pro of. W e b egin by recapping a base b Haar w a v elet m ultiresolution of f u nctions on [0 , 1) d . F or more details, see [ 20 ] and [ 21 ]. First define the u niv ariate mother wa vel ets for x ∈ R : ψ c ( x ) = b 1 / 2 1 ⌊ bx ⌋ = c − b − 1 / 2 1 ⌊ x ⌋ =0 , c = 0 , 1 , . . . , b − 1 . The familiar ( b = 2) Haar w a ve let decomp osition only needs one mother w a v elet because it has ψ 0 = − ψ 1 . The general s etting considered h ere r e- quires more than one mother w a ve let. Next, for n onnegativ e in tegers k and t < b k define dilated and translated ve rsions for x ∈ [0 , 1), ψ k tc ( x ) = b k / 2 ψ c ( b k x − t ) , = b ( k +1) / 2 1 ⌊ b k +1 x ⌋ = bt + c − b ( k − 1) / 2 1 ⌊ b k x ⌋ = t ≡ b ( k +1) / 2 N k ,t,c ( x ) − b ( k − 1) / 2 W k ,t ( x ) . The fun ctions N and W are indicators of rela tiv ely narro w and wide in- terv als resp ectiv ely , where the base b is understo o d . Eac h ψ k tc is a narro w rectangular sp ik e min us another one that is b times as wid e, but 1 /b times as high. The wa v elets for d ≥ 1 are tensor pro d ucts of f unctions of th e form ψ k tc . F or u ⊆ 1 : d , let κ b e a | u | -v ector of in tegers k j ≥ 0 for j ∈ u . S imilarly , let τ b e a | u | -v ector of nonnegativ e intege rs t j < b k j for j ∈ u . Notice that for κ to b e well defined a set u m us t b e un dersto o d, and τ dep end s s im ilarly on b oth u and κ . T o a v oid cluttered notation, we do not w rite κ ( u ) or τ ( u, κ ). The d v ariate Haar wa v elets in base b ta ke the form ψ uκτ γ ( x ) = Y j ∈ u ψ k j t j c j ( x j ) , with ψ {} ()() () ( x ) = 1 b y conv ent ion. The multiresolution of f ∈ L 2 [0 , 1) d is f ( x ) = X u X κ X τ X γ h ψ uk tg , f i ψ uk tg ( x ) , h ψ uk tg , f i = Z ψ uk tg ( x ) f ( x ) dx, where eac h summation is o ve r all p ossible v alues f or its argumen t, b eginning with all subsets u of { 1 , . . . , d } . LOCALL Y ANTITHETIC SCRAMBLED NETS 17 It is conv enient to write f ( x ) = P u P κ ν uκ ( x ), where ν uκ ( x ) = X τ X γ h ψ uκτ γ , f i ψ uκτ γ ( x ) . The f unction ν uk ( x ) is a s tep fu nction constant within elemen tary interv als of the form B u,κ,τ . If x 1 , . . . , x n are obtained b y making a nested uniform (or random linear or I-binomial) scram b le of p oints a 1 , . . . , a n ∈ [0 , 1) d in base b , then the v ariance of ˆ I = n − 1 P n i =1 f ( x i ) is 1 n X | u | > 0 X κ Γ u,κ σ 2 u,κ , (13) where σ 2 u,κ = Z ν u,κ ( x ) 2 dx, and the “gain co efficient s” are giv en by Γ u,κ = 1 n ( b − 1) | u | n X i =1 n X i ′ =1 Y j ∈ u ( b 1 ⌊ b k j +1 a j i ⌋ = ⌊ b k j +1 a j i ′ ⌋ − 1 ⌊ b k j a j i ⌋ = ⌊ b k j a j i ′ ⌋ ) . F r om the “multiresol ution ANO V A,” σ 2 = P u P κ σ 2 u,κ . Therefore, the v ari- ance of ordinary Mon te Carlo sampling h as the form ( 13 ) with all Γ u,κ = 1. The v ariance reduction from randomized nets arises from Γ u,κ ≪ 1 for some u and κ without allo wing Γ u,κ ≫ 1 for an y u and κ . In particular, if a 1 , . . . , a n are a ( λ, q , m, d )-net in base b , then Γ u,κ = 0 if m − q ≥ | u | + | κ | . Theorem 2. L e t a 1 , . . . , a n b e a (0 , m, d ) -net in b ase b ≥ 2 . Then 0 ≤ Γ u,κ ≤ b b − 1 min( d − 1 ,m ) ≤ b b − 1 b − 1 ≤ e . = 2 . 718 . L et a 1 , . . . , a n b e a ( λ, 0 , m, d ) - net in b ase b ≥ 2 . Then 0 ≤ Γ u,κ ≤ e + 1 . = 3 . 718 . L et a 1 , . . . , a n b e a ( λ, q , m, d ) -net in b ase b ≥ 2 . Then 0 ≤ Γ u,κ ≤ b q b b − 1 d − 1 . Pr oof . The fi rst part is fr om [ 20 ], the s econd is from [ 21 ], and the third is from [ 22 ]. Theorem 2 shows some upp er b ound s on gain coefficients for n ets. Sharp er, but more complicated b ounds are av ailable from intermediate stages of the pro ofs, particularly the ones in [ 22 ]. Still sharp er b ound s are a v ailable in [ 18 ] and in [ 31 ]. 18 A. B. O WEN 5.1. Scr amble d net varianc e for smo oth functions. There is an error in the wa y that the O ( · · · ) terms are gathered in Lemma 1 of [ 21 ]. This section repairs the pro of of the O ( n − 3 log( n ) d − 1 ) resu lt for th e v ariance of scram b led net integ rals of s m o oth functions. In the pro cess, a more general resu lt is obtained, using a w eak er definition of smo othness than in the original pap er, and co v ering nets with n on zero qu alit y parameter and relaxed v ersions of ( λ, q , m, d ) -nets. The pro of follo ws th e lines of [ 21 ]. Lemmas 2 and 3 here replace Lemmas 1 an d 2 there, resp ectiv ely . Lemma 2. Supp ose that f is a smo oth function on [0 , 1] d . F or b ≥ 2 and u ⊆ { 1 , . . . , d } , let κ and τ b e | u | - tuples of nonne gative i nte gers with c omp onents k j and t j < b k j for j ∈ u . Then |h f , ψ uκτ γ i| ≤ b − 1 b | u | b − (3 | κ | + | u | ) / 2 sup x ∈ B u,κ,τ | ∂ u f u ( x ) | . (14) Pr oof . F rom the defin itions, h f , ψ uκτ γ i = h f u , ψ uκτ γ i = b − ( | κ | + | u | ) / 2 Z f u ( x ) ψ uκτ γ ( x ) dx = b − ( | κ | + | u | ) / 2 Z f u ( x ) Y j ∈ u b k j +1 ( N k j t j c j ( x j ) − b − 1 W k j t j ( x j )) dx. (15) Next, f u ( x ) dep ends on x only through x u . Ap plying ( 7 ) to f u , w e ma y write f u ( x ) = X v ⊆ u Z [ c v uκτ ,x v ] ∂ v f u ( c − v uκτ : y v ) dy v . (16) If v 6 = u , then the corresp ond ing term in ( 16 ) do es not dep end on x u − v and is therefore orthogonal to N k j t j c j ( x j ) − b − 1 W k j t j ( x j ) for j ∈ u − v . Acc ord- ingly , we may replace f u in ( 15 ) b y the v = u term from ( 16 ). Also, the in tegrand in ( 15 ) v anishes for x / ∈ B uκτ . Putting these together, w e fi nd that b ( | κ | + | u | ) / 2 h f , ψ uκτ γ i equals Z Z [ c u uκτ ,x u ] ∂ u f u ( c − u uκτ : y u ) dy u Y j ∈ u b k j +1 ( N k j t j c j ( x j ) − b − 1 W k j t j ( x j )) dx ≤ sup x u ∈ B uκτ Z [ c u uκτ ,x u ] ∂ u f u ( c − u uκτ : y u ) dy u LOCALL Y ANTITHETIC SCRAMBLED NETS 19 × Z Y j ∈ u b k j +1 | N k j t j c j ( x j ) − b − 1 W k j t j ( x j ) | dx = (2 − 2 /b ) | u | sup x u ∈ B uκτ Z [ c u uκτ ,x u ] ∂ u f u ( c − u uκτ : y u ) dy u . By Lemma 1 , ∂ u f u is cont inuous, and so by the mean v alue theorem, there is a p oin t z ∈ B uκτ with Z [ c u uκτ ,x u ] ∂ u f u ( c − u uκτ : y u ) dy u = V ol(rect[ c u uκτ , x u ]) | ∂ u f u ( z ) | ≤ 2 −| u | b −| κ | | ∂ u f u ( z ) | . The f actor b −| κ | is the volume of a | u | -dimensional elemen tary int erv al con- taining b oth c u uκτ and x u . The factor 2 −| u | arises b ecause c u uκτ is at the center of this elementa ry inte rv al and x u is in some sub -interv al defined by c u uκτ and one of the corners of that elemen tary inte rv al. Finally , |h f , ψ uκτ γ i| ≤ (1 − 1 /b ) | u | b − (3 | κ | + | u | ) / 2 sup z ∈ B uκτ | ∂ u f u ( z ) | . Lemma 3. Under the c onditions of L emma 2 , σ 2 uκ ≤ 2 | u | b − 1 b 3 | u | b − 2 | κ | k ∂ u f u k 2 ∞ . (17) Pr oof . The supp orts of ψ uκτ γ and ψ uκτ ′ γ ′ are d isjoin t un less τ = τ ′ , and so ν 2 uκ ( x ) = X τ X γ X γ ′ h f , ψ uκτ γ ih f , ψ uκτ γ ′ i ψ uκτ γ ( x ) ψ uκτ γ ′ ( x ) . No w σ 2 uκ = Z ν 2 uκ ( x ) dx = X τ X γ X γ ′ h f , ψ uκτ γ ih f , ψ uκτ γ ′ i Z ψ uκτ γ ( x ) ψ uκτ γ ′ ( x ) dx = X τ X γ X γ ′ h f , ψ uκτ γ ih f , ψ uκτ γ ′ i Y j ∈ u (1 c j = c ′ j − b − 1 ) ≤ b − 1 b 2 | u | b − 3 | κ |−| u | X τ sup z ∈ B uκτ | ∂ u f u ( z ) | 2 X γ X γ ′ Y j ∈ u | 1 c j = c ′ j − b − 1 | ≤ b − 1 b 2 | u | b − 3 | κ |−| u | X τ sup z ∈ B uκτ | ∂ u f u ( z ) | 2 ! b − 1 X c =0 b − 1 X c ′ =0 | 1 c j = c ′ j − b − 1 | ! | u | 20 A. B. O WEN = 2 | u | b − 1 b 3 | u | b − 3 | κ | X τ sup z ∈ B uκτ | ∂ u f u ( z ) | 2 ≤ 2 | u | b − 1 b 3 | u | b − 2 | κ | k ∂ u f u k 2 ∞ . Theorem 3. L et x 1 thr ough x n b e the p oints of a r andomize d r elaxe d ( λ, q , m, d ) -net i n b ase b . Supp ose that as n → ∞ with λ and q fixe d, that al l of the gain c o e ffic i ents of the net satisfy Γ uκ ≤ G < ∞ . Then for smo oth f , V ( ˆ I ) = O (log n ) d − 1 n 3 . Pr oof . If | κ | + | u | ≤ m − q , then the d igital n et p rop erty of x 1 , . . . , x n yields Γ uκ = 0. Otherwise, w e hav e Γ uκ ≤ G , and so V ( ˆ I ) ≤ G n X | u | > 0 X | κ | > ( m − q −| u | ) + σ 2 uκ ≤ G n X | u | > 0 X | κ | > ( m − q −| u | ) + 2 | u | b − 1 b 3 | u | k ∂ u f u k 2 ∞ b − 2 | κ | ≤ G ′ n X | u | > 0 X | κ | > ( m − q −| u | ) + b − 2 | κ | , (18) where G ′ = G 2 | u | b − 1 b 3 | u | max | u | > 0 k ∂ u f u k 2 ∞ . Because w e are int erested in the li mit as m → ∞ , w e ma y supp ose that m > d + q . F or suc h large m , X | κ | > ( m − q −| u | ) + b − 2 | κ | = ∞ X r = m − q −| u | +1 b − 2 r r + | u | − 1 | u | − 1 , where the bin omial coefficient is the num b er of | u | -vect ors κ of nonnegativ e in tegers that sum to r . Making the sub stitution s = r − m + q + | u | , X | κ | > ( m − q −| u | ) + b − 2 | κ | = b − 2 m +2 q +2 | u | ∞ X s =1 b − 2 s s + m − q − 1 | u | − 1 ≤ λ 2 n 2 b 2 q +2 | u | ( | u | − 1)! ∞ X s =1 b − 2 s ( s + m − q − 1) | u |− 1 LOCALL Y ANTITHETIC SCRAMBLED NETS 21 ≤ λ 2 n 2 b 2 q +2 | u | ( | u | − 1)! ∞ X s =1 b − 2 s | u |− 1 X j =0 | u | − 1 j s j ( m − q − 1) | u |− 1 − j ≤ λ 2 n 2 b 2( q + | u |− 1) | u |− 1 X j =0 ( m − q − 1) | u |− 1 − j j !( | u | − 1 − j )! ∞ X s =1 b − 2( s − 1) s j ≤ λ 2 n 2 | u | b 2( q + | u |− 1) m | u |− 1 ∞ X s =1 b − 2( s − 1) s | u |− 1 = O ( n − 2 log( n ) | u |− 1 ) , (19) b ecause the infinite su m conv erges, m ≤ log b ( n ) and | u | ≤ d . The theorem follo ws up on substituting the b ound ( 19 ) into ( 18 ). 6. S cram bled net v ariance with b o x folding. This secti on inv estigates the effects of reflection sc hemes on scrambled n et v ariance. Reflections are written as R ρ , where ρ is a d vec tor of in tegers r j ≥ − 1 . As b efore, we let κ denote a s cale f or the m ultiresolution analysis. In Section 5.1 the coefficients h f , ψ uκτ γ i are b oun ded in terms of mixed partial deriv ativ es of f take n once with resp ect to eac h comp onent x j for j ∈ u . Refl ection is a p iece-wise differen tiable op eration. The fun ction R ρ ( x ) is d iscon tin uous at x if x j = tb − r j holds for some j with r j > 0 and some p os- itiv e in teger t < b r j . In the int erior of the pieces, r eflection of x j rev erses the sign of the deriv ativ e with resp ect to x j . This sign rev er s al can b e exploited to p ro duce a cancellation effect that redu ces a b ound on h f , ψ uκτ γ i . T o simplify some expressions, w e define the comp osite function f ρ b y f ρ ( x ) = f ( R ρ ( x )). At almost all p oin ts x ∈ [0 , 1] d the c hain r ule give s ∂ u f ρ ( x ) = ( − 1) sgn( ρ ) ∂ u f ( R ρ ( x )) , (20) where sgn( ρ ) = P d j =1 1 r j ≥ 0 coun ts the n umber of reflections in ρ . The factor ∂ u f ( R ρ ( x )) in the right-hand side of ( 20 ) is the partial deriv ative of f , ev aluated at the p oin t z = R ρ ( x ), and not the partial d eriv ativ e of f ◦ R ρ ev aluated at x , wh ic h app ears on the left-hand sid e. Definition 11. In d dimensions, a b o x foldin g sc heme is an a ve rage of 2 d reflections as describ ed b elo w . Start w ith ρ = ( r 1 , . . . , r d ), where ea c h r j ≥ 0. F or ℓ = 0 , . . . , 2 d − 1 , let ρ ℓ b e the d vecto r of in teger comp onents r ℓj ∈ { r j , − 1 } with r ℓj = r j if and only if the j th base 2 digit of ℓ is one. Then the b o x fold sc heme is e I = 1 2 d 2 d − 1 X ℓ =0 1 n n X i =1 f ρ ℓ ( x i ) = 1 n n X i =1 e f ( x i ) , where e f ( x ) = 2 − d P 2 d − 1 ℓ =0 f ρ ℓ ( x ). 22 A. B. O WEN Sometimes it is m ore co nv enient to index the reflections b y 2 d subsets v ⊆ { 1 , . . . , d } . Let v = v ( ℓ ) denote the s u bset where j ∈ v if and only if the j th binary d igit of ℓ is a one. T aking ρ v to mean ρ ℓ where v = v ( ℓ ), w e ma y write e f ( x ) = 2 − d P v ⊆ 1: d f ρ v ( x ). F rom the d efinition of v , w e find th at sgn( ρ v ) = ( − 1) | v | . T o get ANOV A comp onents of e f , we need the ANOV A comp onents of f ρ . Lemma 4 b elo w s h o ws that reflection comm utes w ith the op eration of taking ANO V A comp onents. Lemma 4. L et f b e an L 2 function on [0 , 1] d . L et f ρ ( x ) = f ( R ρ ( x )) , wher e ρ i s a d ve ctor of inte gers r j ≥ − 1 for j = 1 , . . . , d . L et u ⊆ { 1 , . . . , d } . Then f ρ u ( x ) = f u ( R ρ ( x )) . (21) Pr oof . The p r o of f ollo ws b y induction on | u | . The b oun ds for h f , ψ uκτ γ i in Section 5.1 made us e of different iabilit y of f , wh ich w e cannot assu m e for f ρ . Th e deriv ation as far as equation ( 15 ) do es follo w for f ρ and so h f ρ , ψ uκτ γ i equals b − ( | κ | + | u | ) / 2 Z f ρ u ( x ) Y j ∈ u b k j +1 ( N k j t j c j ( x j ) − b − 1 W k j t j ( x j )) dx. (22) The next step in the d eriv ation of b ounds for h f , ψ uκτ γ i requir ed ∂ u f at p oints of B uκτ , and ∂ u f ρ do es not necessarily exist. The setting is simp lest if th e s cale κ is finer than the reflection ρ . Supp ose that u = { 1 , . . . , d } and that k j ≥ r j for j = 1 , . . . , d . Th is sp ecifically includes cases with r j = − 1 that designate no refl ection for comp onent j . Th en , for smo oth f , ∂ u f ρ is uniformly cont inuous on the in terior of B uκτ . Letting c uκτ b e the cen ter of B uκτ as b efore, w e find that h f ρ , ψ uκτ γ i = Z Z [ c u uκτ ,x u ] ∂ u f ρ u ( c − u uκτ : y u ) dy u ψ uκτ γ ( x ) dx = ( − 1) sgn( ρ ) Z Z [ c u uκτ ,x u ] ∂ u f u ( c − u uκτ : R ρ ( y ) u ) dy u ψ uκτ γ ( x ) dx = ( − 1) sgn( ρ ) Z Z [ c uκτ ,x ] ∂ u f u ( R ρ ( y )) dy ψ uκτ γ ( x ) dx, (23) where at the last step we use u = 1 : d and − u = ∅ . LOCALL Y ANTITHETIC SCRAMBLED NETS 23 Lemma 5. Su pp ose that f is a doubly smo oth function on [0 , 1] d . L et ρ = ( r 1 , . . . , r d ) with inte gers r j ≥ 0 . T ake | ρ | = P d j =1 r j , and let e f b e define d by the b ox folding scheme o f Definition 11 . F or b ≥ 2 and u = { 1 , . . . , d } , let κ , τ and γ b e d -tuples of nonne gative inte gers with c omp onents k j ≥ r j , t j < b k j , and c j < b r esp e ctively, for j = 1 , . . . , d . Then |h e f , ψ uκτ γ i| ≤ b −| ρ | b − 1 b − d b − (3 | κ | + | u | ) / 2 k ∂ u,u f u k ∞ . (24) Pr oof . Because κ is on a fi ner scale than all of the refl ections ρ ℓ , equa- tion ( 23 ) holds for eac h of them. Therefore, h e f , ψ uκτ γ i = 1 2 d Z Z [ c uκτ ,x ] X v ⊆ 1: d ( − 1) | v | ∂ u f u ( R ρ v ( y )) dy ψ uκτ γ ( x ) dx. F or y ∈ [0 , 1] d , let k = k ( y ) ∈ [0 , 1] d b e the cente r p oint through which the reflection R ρ with ρ = ( r 1 , . . . , r d ) op erates on y . That is, k j = b − r j ( ⌊ b r j y j ⌋ + 1 / 2). Because κ is finer than ρ , the same cent er k app lies for all y ∈ [ c uκτ , x ]. Then the j th comp onen t of R ρ v ( y ) is 2 k j − y j if j ∈ v and is y j otherwise. Therefore, X v ⊆ u ( − 1) | v | ∂ u f u ((2 k − y ) v : y − v ) = V ol(rect[ y , 2 k − y ]) ∂ u,u f u ( z ) , where z = z ( y ) ∈ r ect[ y , 2 k − y ]. The volume of rect[ y , 2 k − y ] is at most b −| ρ | and so follo win g the argumen t from Lemma 2 , h e f , ψ uκτ γ i ≤ (1 − 1 /b ) − d b −| ρ | b − (3 | κ | + | u | ) / 2 k ∂ u,u f u k ∞ . The factor b −| ρ | in ( 24 ) under lies the imp r o v emen t that a b ox reflec- tion can bring. F or a scram bled ( λ, q , m , d )-net in b ase b , if we c ho ose ρ so th at | ρ | = m − q , then the co efficients h e f , ψ uκτ γ i with κ finer than ρ are O ( b − 3 | κ | / 2 −| ρ | ) instea d of O ( b − 3 | κ | / 2 ). Coarse terms with | κ | + | u | ≤ m − q do not con tribu te to the err or, so th e dominan t error terms h a v e | κ | + | u | = m − q + 1. In th e next theorem we will deal with those terms b y taking | ρ | = m − q . Cho osing | ρ | = m − q , the largest co ntributing co effi- cien ts are O ( b − 3 | κ | / 2 −| ρ | ) = O ( b − 3 m/ 2 − m ) = O ( n − 5 / 2 ) instead of O ( b − 3 | κ | / 2 ) = O ( b − 3 m/ 2 ) = O ( n − 3 / 2 ). F ollo wing the deriv ation in Section 5.1 , the terms σ 2 uκ are then of order O ( b − 3 m ) = O ( n − 3 ) in stead of O ( b − 2 m ) = O ( n − 2 ) and s o eac h of them contributes O ( n − 4 ) to the v ariance instead of O ( n − 3 ). The v ariance under b ox f olding do es not ge nerally end up as O ( n − 4+ ε ) th ough, b ecause th ere are also con tributions from terms κ where κ is not finer than ρ . 24 A. B. O WEN Theorem 4. L et x 1 thr ough x n b e p oints of a r andomize d r elaxe d ( λ, q , m, d ) -net in b ase b . Supp ose that the quality p ar ameter q r emains fixe d as n tends to infinity thr ough values λb m for fixe d λ and that none of the gain c o- efficients of the net is lar ger than G < ∞ . Then f or doubly smo oth f , under b ox folding by ρ = ( r 1 , . . . , r d ) wher e r j = ⌊ ( m − q ) /d ⌋ + 1 , j ≤ ( m − q ) − d ⌊ ( m − q ) /d ⌋ ⌊ ( m − q ) /d ⌋ , otherwise, we find that V ( e I ) = O (log n ) d − 1 n 3+2 /d as n → ∞ . Pr oof . First we consider co efficien ts h e f , ψ uκτ γ i for th e highest ord er subset u = { 1 , . . . , d } . Let w = w ( κ ) = { j ∈ u | k j ≥ r j } . If w = ∅ , then P j ∈ u k j ≤ P j ∈ u ( r j − 1) = m − q − d . Then | κ | + | u | = m − q , so th at Γ uκ = 0 b y the balance prop erty of the digita l net. Therefore, we restrict atten tion to w with | w | > 0 . Lemma 5 treated the case with w = u and with κ fi ner than ρ . F or x in the supp ort of ψ uκτ γ , the function e f is differenti able with resp ect to x j for j ∈ w . W e ma y app ly equation ( 7 ) to eac h f ρ v , k eeping only the ∂ w term b ecause the others are orth ogonal to ψ uκτ γ . Th e result shows th at 2 d h e f , ψ uκτ γ i is Z X v ⊆ 1 : d f ρ v u ( x ) ψ uκτ γ ( x ) dx = Z X v ⊆ 1: d Z [ c w wκτ ,x w ] ∂ w f ρ v u ( x − w : y w ) dy w ψ uκτ γ ( x ) dx = Z X v 1 ⊆− w Z [ c w wκτ ,x w ] X v 2 ⊆ w ∂ w f ρ v 1 ∪ v 2 u ( x − w : y w ) dy w ψ uκτ γ ( x ) dx, (25) after decomp osing v in to its in tersections v 1 and v 2 with w and − w resp ec- tiv ely . The s ummation in s ide of ( 25 ) ma y b e w ritten as X v 2 ⊆ w ( − 1) | v 2 | ∂ w f u ( R ρ v 1 ∪ v 2 ( x ) − w : R ρ v 1 ∪ v 2 ( y ) w ) = V ol (rect[ y w , 2 k w v 1 − y w ]) ∂ w ,w f u ( R ρ v 1 ∪ v 2 ( x ) − w : z w ) , where for j ∈ w , k j v 1 = b − r j ( ⌊ b r j y j ⌋ + 1 / 2) and z w ∈ rect[ y w , 2 k w v 1 − y w ]. Be- cause V ol (rect[ y w , 2 k w v 1 − y w ]) ≤ b − P j ∈ w r j , we fin d that b o x reflectio n results LOCALL Y ANTITHETIC SCRAMBLED NETS 25 in a co efficien t h e f , ψ uκτ γ i with an upp er b ound on th e ord er of b − P j ∈ w r j smaller than th e b ound for h f , ψ uκτ γ i . This coefficien t reduction is b − P j ∈ w r j = O ( b − m | w | /d ) = O ( n −| w | /d ). Be- cause we only n eed to consid er n onempt y w , the reduction is O ( n − 1 /d ). The effect is to reduce the b ound for σ 2 uκ b y O ( n − 2 /d ) and then the same coun ting argumen t as in T heorem 3 s h o ws that the con tribution of f u to the v ariance is O ((log n ) d − 1 /n 3+2 /d ). No w consider v ariance con tribution of f v for v ⊂ { 1 , . . . , d } with 1 ≤ | v | < d . T he sum (1 /n ) P n i =1 e f v ( x i ) is a b ox fold of a scrambled relaxed ( λb d −| v | , q , m, | v | )-net in base b for estimating the mean of the fu lly | v | - dimensional function g ( x v ) = f v ( x v : 0 − v ) obtained b y ignorin g th e − v com- p onents of x . Accordingly , it mak es a v ariance con tr ib ution that is O ((log n ) | v | − 1 /n 3+2 / | v | ). T h e v ariance of the sum cannot b e of higher order than O ((log n ) d − 1 /n 3+2 /d ). 7. D iscussion. In this pap er we ha v e seen that scrambled net quadrature can b e p rofitably com bined w ith ant ithetic sampling to redu ce v ariance. This result then fits in with the wo rk o f [ 12 ] wh o combined quasi-Mon te Carlo with control v ariates and [ 27 ] and [ 3 ] w ho b oth lo oke d at quasi-Mon te Carlo in combination with imp ortance sampling. The b est numerical results w ere for AS M scrambling combined with b ox reflections, bu t we h a v e n o theoretical results for th at combinatio n. The f oldings of scram bled nets studied h ere may also b e view ed as a h ybrid of digital nets and a monomial cubature rule. The 2 d -fold symmetry used b y b o x folding take s eac h sample p oint in the net and uses it to generate the p oints of a cubature. It is one of many cubatur e rules that migh t b e made to wo rk w ith digital nets. F or backg roun d an d catalogues of cubatur e rules, see [ 4 , 5 ] and [ 28 ]. The conclusions of T h eorems 3 and 4 b oth hold if λ and q are allo wed to fluctuate as n increases, so long as b oth r emain b elo w finite up p er b ounds. A larger imp ro v ement from lo cal antit hetic sampling may b e p ossible if w e can identify s < d inpu t v ariables that are muc h more imp ortant than the others, and apply refl ections only to them. In some cases we can ev en re-engineer the integrand to mak e a s m all n umb er of v ariables m uch more imp ortant than they are in the nominal enco ding. F or an example of suc h a tec h nique with an integ rand with resp ect to a high dimensional geometric Bro wnian motion, s ee [ 1 ] and [ 2 ]. Many more examples are presented in [ 9 ]. Ac kno wledgment s. I thank Harald Niederreiter, Christiane Lemieux, a referee and the Asso ciate Editor f or helpf ul comments. 26 A. B. O WEN REFERENCES [1] Acw or th, P., Bro adie , M. and Glasserman, P. (1997). A comparison of some Mon te Carlo tec hniques for option pricing. In Monte Carlo and Quasi-Monte Carlo Metho ds’96 (H. Niederreiter, P . H ellek alek, G. Larcher and P . Z interhof, eds.) 1–18. Springer, Berlin. [2] Ca flisch, R., Mor ok off, E. W. and Owen, A. B. (1997). V aluation of mort- gage back ed securities using Brow nian bridges to reduce effective d imension. J. Computational Financ e 1 27–4 6. [3] Ch elson, P. (1976). Quasi-random techniques for Monte Carlo metho ds. Ph.D. the- sis, The Claremon t Graduate School. [4] Cools, R. (1999). Monomial cubature rules since S troud: A compilation—part 2. J. Comput. Appl. Math. 112 21–27. MR172844 9 [5] Cools, R. and R abinow itz, P. (1993). Monomial cub ature rules since Stroud : A compilation. J. Comput. Appl. Math. 48 309–326. MR1252544 [6] Efron, B. and Stein, C. (1981 ). The jackknife estimate of v ariance. A nn. Statist. 9 586–596 . MR0615434 [7] F aure, H. (1982). Discr´ ep ance de suites associ´ ees ` a un syst` eme d e num ´ eration (en dimension s ). A cta Arith. 41 337–351 . MR0677547 [8] Fishm an, G. S. (2006). A Fi rst Course in Monte Carlo . Duxbury , Belmo nt, CA. [9] Fo x, B. L. (1999). Str ate gies for Quasi-Monte Carlo . Kluw er Academic, Boston. [10] Glasserman, P. ( 2004). Monte Carlo Metho ds in Financial Engine ering . Sp ringer, New Y ork. MR1999614 [11] Haber, S. (1970). Num erical ev aluation of multiple integrals. SIAM R ev. 12 481–526. MR0285119 [12] Hickernell, F. J., Lemieux, C. and Ow en, A. B. (2005). Control v ariates for quasi-Monte Car lo ( with discussion). Statist. Sci. 20 1–31. MR2182985 [13] Hla wka, E. (1961). F unktionen v on b eschr¨ ankter V ariation in der Theorie der Gle- ic hv erteilung. Ann. Mat. Pur a Appl. 54 325–333. MR0139597 [14] Hoeffding, W . (1948). A class of statistics with asymp totically normal distribution. Ann . Math. Statist. 19 293–32 5. MR0026294 [15] L’Ecuyer, P. and Le mieux, C. (2002). A survey of randomized quasi-Monte Carlo metho d s. In Mo deling Unc ertainty : An Examination of Sto chastic The ory, Meth- o ds, and Applic ations (M. Dror, P . L’Ecuyer and F. Szidarovszki, ed s.) 419–4 74. Kluw er A cademic, New Y ork. [16] Ma tou ˇ sek, J. (1998). Ge ometric Discr ep ancy : An Il lustr ate d Guide . Springer, H ei- delb erg. MR1697825 [17] Niede rre iter, H. (1992). R andom Numb er Gener ation and Quasi-Monte Carlo Metho ds . SIAM, Philadelphia. MR1172997 [18] Niede rre iter, H. and Pirsic, G . (2001 ). The microstructure of ( t, m, s )-n ets. J. Complexity 17 683–696. MR1881664 [19] Ow en, A. B. (1995). Randomly p ermuted ( t, m, s )-nets and ( t, s )-sequ ences. In Monte Carlo and Quasi-Monte Carlo Metho ds in Scientific Computing (H. Niederreiter and P . J.-S. Shiue, eds.) 299–3 17. Sp ringer, New Y ork. MR1445791 [20] Ow en, A. B. (1997). Monte Carlo v ariance of scram bled equidistribution quadratu re. SIAM J. Numer. Anal. 34 1884–1910. MR1472202 [21] Ow en, A. B. (1997). Scrambled net vari ance for integra ls of smooth functions. Ann. Statist. 25 1541–15 62. MR1463564 [22] Ow en, A. B. (1998). Scrambling Sob ol’ and Niederreiter–Xing p oints. J. Complexity 14 466–489. MR1659008 LOCALL Y ANTITHETIC SCRAMBLED NETS 27 [23] Ow en, A. B. (2003). V ariance with alternative scram b lings of digital nets. ACM T r ans. Mo deling and Computer Simulation 13 363–378. [24] Sch ¨ urer, R. and Schmid, W. C. (2006). MinT: A database for optimal net param- eters. In Monte Carlo and Quasi-Monte Carlo Metho ds 2004 (H. Niederreiter and D. T alay , eds.) 457–469. Springer, Berlin. MR2208725 [25] Slo an, I. H. and Joe, S. (1994). L attic e Metho ds f or Multiple Inte gr ation . Oxford Science Publications. MR1442955 [26] Sobol ’, I. M. (1967). The use of Haar series in estimating the error in th e com- putation of infinite-dimensional integrals. Dokl. A kad. Nauk SSSR 8 810–813. MR0215527 [27] Sp ani er, J. and Maiz e, E. H. (1994). Qu asi-random meth od s for estimating integra ls using relative ly small samples. SIAM R ev. 36 18–44. MR1267048 [28] Stroud, A. H. (1971). Appr oximate Calculation of Multiple I nte gr al s . Prentice-Hall, Englew oo d Cliffs, NJ. MR0327006 [29] T akemura , A. (1983). T ensor analysis of ANOV A decomp osition. J. Amer . Statist. Asso c. 78 894–9 00. MR0727575 [30] Tezuka, S. and F a ure, H. (2003). I- binomial scrambling of digital nets an d se- quences. J. Complexity 19 744–757. MR2040428 [31] Yue, R. X. and Hickernell, F. J. (2002). The discrepancy and gain co efficients of scram bled digital n ets. J. Com pl exity 18 135–1 51. MR1895080 Dep ar tment of S t at istics St a n ford University St a n ford, California 94305 USA E-mail: art@stat.stanford.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment