Online Coordinate Boosting
We present a new online boosting algorithm for adapting the weights of a boosted classifier, which yields a closer approximation to Freund and Schapire's AdaBoost algorithm than previous online boosting algorithms. We also contribute a new way of der…
Authors: Raphael Pelossof, Michael Jones, Ilia Vovsha
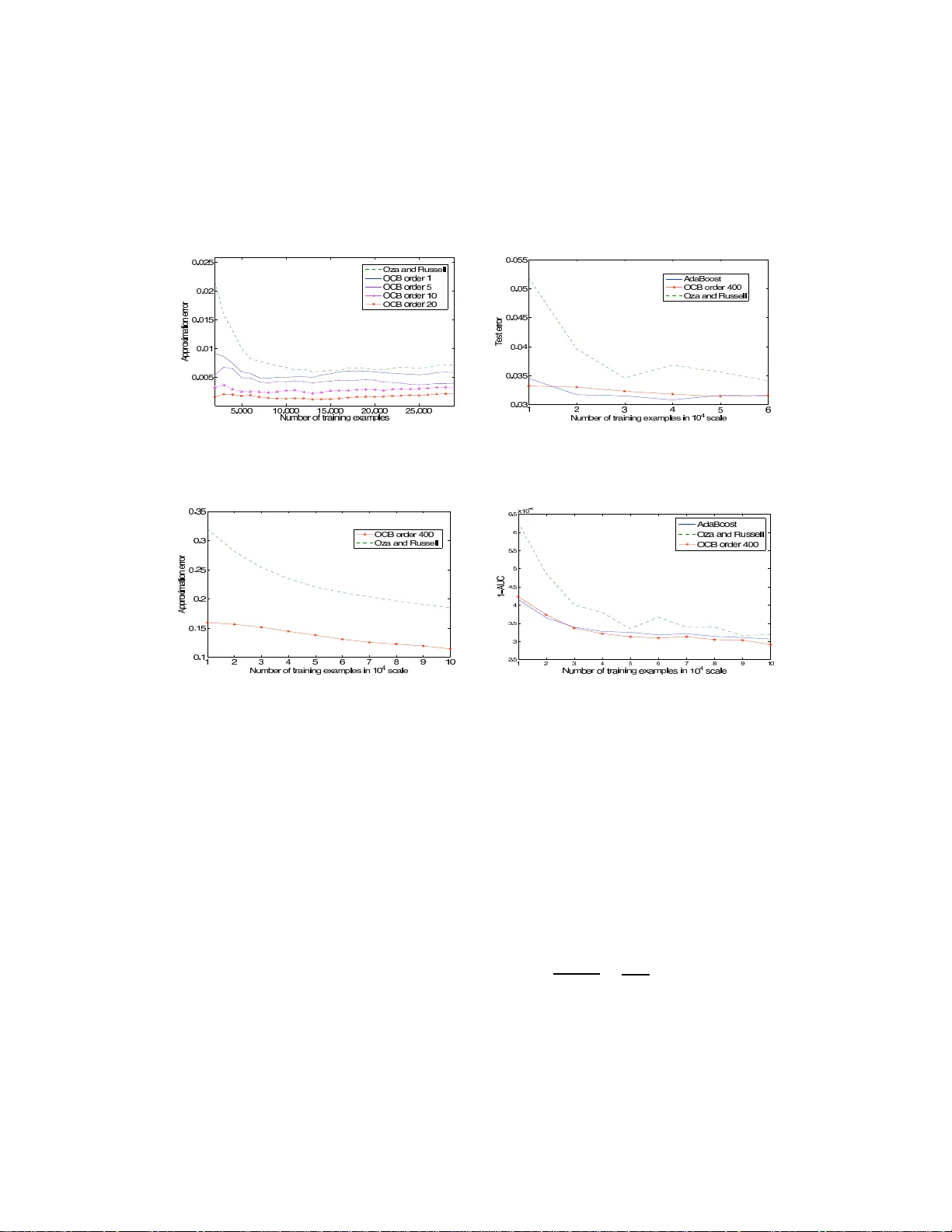
Online Coordi nate Boosting Raphael Pelossof Departmen t of C omputer Science Columbia Univ ersity 2960 Broadway , New Y ork, NY 10027 pelossof@cs. columbia.ed u Michael Jones Mitsubishi Electric Research Labs 201 Broadway , Camb ridge, MA 02139 mjones@merl. com Ilia V ovsha Columbia Univ ersity 2960 Broadway , Ne w Y ork, NY 10027 iv2121@colum bia.edu Cynthia Rudin Columbia Univ ersity Center for Computatio nal Learning Systems Interchu rch Cen ter , 47 5 Ri verside Drive MC 77 17 New Y ork , NY 10115 rudin@ccls.c olumbia.edu Abstract W e present a ne w online boosting algorithm for adapting the weights o f a boosted classifier , which yields a closer approximation to Freund and Schap ire’ s AdaBoost algorithm than pr evious online boosting algorithms. W e als o contribute a new way of deriving the online algor ithm that ties togeth er previous online b oosting work . W e assume that the weak h ypotheses were selected befor ehand, an d only the ir weights are upd ated during online boo sting. The upd ate r ule is d eriv ed b y mini- mizing AdaBoo st’ s loss whe n viewed in an incr emental form . The equation s show that optimization is computationally e x pensive. Ho wev e r , a fast online approx ima- tion is possible. W e compar e ap prox imation er ror to b atch AdaBoost on syn thetic datasets and generalization error on face datasets and the MNIST dataset. 1 Intr o duction Most practical algorithms for object detection or classification require tr aining a classifier that is general enoug h to work in alm ost any en vironmen t. Such generality is often no t needed on ce the classifier is used in a real ap plication. A face d etector, for example, may be ru n on a fixed cam era data stre am a nd therefore no t see mu ch variety in non -face patches. Thus, it would be de sirable to ad apt a classifier in an on line fashion to achieve greater accu racy for specific environmen ts. I n addition, the target con cept migh t shift as time prog resses and we would like the classifier to adapt to the cha nge. Finally , th e stream may be extremely large w hich deems batch -based algorithms to be ineffecti ve for training. Our goal is to create a fast an d accurate o nline learning a lgorithm that can ada pt an existing boosted classifier to a new en vironm ent and co ncept change. T his paper looks at the core problem that must be solved to meet this g oal which is to develop a fast and accur ate sequen tial on line lear ning alg o- rithm. W e u se a trad itional online learnin g approac h, w hich is to assume that the f eature mappin g is selected beforeh and and is fixed wh ile trainin g. The p aradigm allows us to adapt ou r algorith m easily to a new environmen t. The alg orithm is deriv ed by lo oking at the minim ization of AdaBoost’ s exponential loss function whe n training AdaBoost with N training exam ples, th en ad ding a single example to the tra ining set, and r etraining with th e new set of N + 1 examples. The eq uations show that an online algorithm that exactly replicates batch AdaBoost is not possible, since the up- date requ ires computing the classification results of the fu ll dataset by all the weak hy potheses. W e show that a simple an d app roximatio n that avoids this costly com putation is po ssible, resulting in a 1 fast o nline algorithm. Ou r experiments show that by gr eedily m inimizing the appro ximation err or at each coord inate we are able to approximate b atch AdaBoost better th an Oza and Ru ssell’ s algorith m. The pap er is organ ized as follows, in section 2 we d iscuss related work. In section 3 we present AdaBoost in exact in cremental f orm, then we derive a fast approx imation to this fo rm, an d d iscuss issues that arise when implementing the approxima tion as an algorith m. W e also com pare our algo- rithm with Oza and Russell’ s alg orithm [8]. W e conclude with experiments and a short discussion in section 4. 2 Related W o rk The prob lem o f adapting the weigh ts of existing classifiers is a topic of o ngoin g research in v ision [3, 4, 9, 13]. Huan g et al’ s [3] work is most clo sely related to our work. They proposed an incremen tal learning algorithm to update the weight of each weak hyp othesis. Their final classifier is a conv ex combinatio n o f an o ffline model an d an online model. The ir offline mod el is tr ained so lely on of fline examples, and is based on a similar app roxima tion to ours. Ou r m odel com bines bo th their mo dels into one unif orm mod el, wh ich d oes no t differentiate between offline and on line examples. This allows us to continuo usly adapt regard less of wh ether or not the examples were seen in th e offline or online part of the training. Also, by lo oking at the change in example weights as a single example is added to th e training set, we are able to com pute an exact update to the weak hypo theses w eights, in an online manner, that does not requ ire a line search as in Huang et al’ s work. Our online algor ithm stems from an approx imation to AdaBoost’ s loss min imization as the training set grows one example at a time. W e use a multiplicativ e u pdate rule to adapt the classifier weights. The multiplicativ e update for online algorithm s was first propo sed by Littlestone [7] with the W in - now alg orithm. Ki v inen and W ar muth [6] extended the update rule of Littlestone to achieve a wider set of classifiers by inco rporatin g positiv e and negati ve weigh ts. Freund and Schapir e [2] con verted the onlin e learning pa radigm to b atch learnin g with multiplicative weight updates. Their Ad aBoost algorithm keeps two sets of weights, one on the data and o ne o n th e weak hyp otheses. Ad aBoost updates the examp le weigh ts at each trainin g round to fo rm a harder pr oblem for the next rou nd. This type of sequential reweighting in an online setting, where o nly o ne e x ample is kept at any time, was later propo sed b y Oza and Russell [8]. They update the weight of each weak hy pothesis se- quentially . At each iteration, a weak hypothesis classifi es a weighted example, where the example’ s weight is der iv e d from the perfo rmance of th e cu rrent co mbination of weak hypoth eses. L ike our algorithm , Oza and Russell’ s alg orithm has a seq uential u pdate f or the weights o f the we ak hy pothe- ses, howev er , unlike ours, their s in cludes feature selection. Ou r algorithm is also derived from the more recent AdaBoo st f ormulatio n [11]. W e show how the Online Coordin ate Boo sting algorithm weight update rule can be reduced to Oza and Russell’ s update rule with a fe w si mple modifications. Both our and Oza and Russell’ s algo rithms store fo r each class ifier an approxima tion of the sums of example we ights that were co rrectly an d incorr ectly cla ssified by each weak hyp othesis. They ca n be seen as alg orithms for estimating the weighted erro r rate of e ach weak hyp othesis u nder memor y an d speed co nstraints. Another alg orithm that can be seen th is way is Bradley a nd Sch apire’ s FilterBoost algorithm [1]. FilterBoost uses nonmo noton ic adaptive sampling to gether with a filter to sequ entially estimate the edge, an affine transformation of the weighted err or, of each weak hypoth esis. When the edg e is estimated with high p robability the a lgorithm u pdates its classifier and continu es to select and train the ne xt w eak hypoth esis. Unlike o ur and Oza an d Russell’ s algo rithm, FilterBoost cannot adapt already selected weak hypo theses weig hts to drifting concepts. 3 Online Coordinate Boosting W e would like to m inimize batch Ad aBoost’ s bound on th e error using a fast u pdate ru le as exam- ples are presented to our algorithm. Let ( x 1 , y 1 ) , .., ( x N +1 , y N +1 ) be a stream of labeled examples x i ∈ R M , y i ∈ {− 1 , 1 } , and let a c lassifier b e defined by a linear com bination of weak hypo the- ses H ( x ) = sig n ( P J j =1 α j h j ( x )) , where the weigh ts ar e real-valued α j ∈ R and each weak hypoth esis h j is p reselected and is binary h j ( x ) ∈ {− 1 , 1 } . W e use the ter m co or d inate as the index of a weak hyp othesis. Let m ij = y i h j ( x i ) be d efined as the margin which is eq ual to 1 for correc tly classified examples and -1 for incorrec tly classified examples by weak hypo thesis j . 2 Throu ghout tr aining, AdaBoo st maintains a weig hted distribution over the examples. The weigh ts at each tim e step are set to minimize the classification error according to batch AdaBoo st [1 0]. Adding a single example to the training set chan ges the weig hts of the examples, and the weig hts of the en tire classifier . A daBoost define s the weight o f example i as d iJ = e − P J − 1 j =1 α j m ij , which implies d iJ = d i,J − 1 e − α J − 1 m i,J − 1 . Furthermore , the weigh t of a weak h ypothesis J is d efined as α J = 1 2 log W + J /W − J , wh ere the sum s of corre ctly and incorr ectly classified examples b y we ak hypoth esis j are defined by W + J = P i : m iJ =+1 d iJ and W − J = P i : m iJ = − 1 d iJ correspo ndingly . W e define 1 [ ] as the indicator function . W e use superscrip t to indicate tim e, which in the batch setting is the numb er of examples in the training set, and in the on line setting is the index of the last examp le. T o improve legibility , if we drop the superscript fr om an equ ation, th e time index is assum ed to b e N + 1 . Theref ore, wh en adding the N + 1 example, the w eights of t he other examp les will chan ge fro m d N iJ to d N +1 iJ and the weights o f eac h weak hyp othesis from α N J to α N +1 J . W e denote the change in a weak hypoth esis weights as ∆ α N J = α N +1 J − α N J . 3.1 AdaBoost in exact incremental f orm AdaBoost’ s loss fu nction Z J +1 = P i d iJ e − α J m iJ bound s the tr aining erro r . It has been sh own [10, 11] that m inimizing this l oss tends to lo wer g eneralization erro r . W e are m otiv ated to minimize a fast and accura te approx imation to the same loss f unction, as each example is presented to our a lgorithm. Similarly to AdaBoo st, we fix a ll the coord inates up to co ordinate J , and seek to m inimize th e approx imate lo ss at the J th coord inate. T he optim ization is don e b y findin g th e u pdate ∆ α N J that minimizes AdaBoo st’ s approx imate lo ss with the addition of the last example. M ore for mally , we are given the previous we ak hy potheses weights α N 1 , .., α N J and their updates so far ∆ α N 1 , .., ∆ α N J − 1 and wish to co mpute the update ∆ α N J that minimizes Z J +1 . The resulting u pdate rule is the change we would get in coor dinate J ’ s weight if we trained batch AdaBo ost with N examples an d th en added a n ew example and retrained with the larger set of N + 1 exam ples. Look ing at the deri vati ve of batch AdaBoost’ s loss functio n w hen adding a new e xa mple, we get the update rule for ∆ α N J : Z J +1 = N +1 X i =1 d iJ e − α N +1 J m iJ = N +1 X i =1 d iJ e − ( α N J +∆ α N J ) m iJ (1) ∂ Z J +1 ∂ ∆ α N J = − N +1 X i =1 d iJ e − ( α N J +∆ α N J ) m iJ m iJ (2) = X i : m iJ = − 1 d iJ e ( α N J +∆ α N J ) − X i : m iJ =+1 d i,J e − ( α N J +∆ α N J ) (3) = − W N +1 J e ( α N J +∆ α N J ) − + W N +1 J e − ( α N J +∆ α N J ) . (4) Setting the deriv ative to zer o and solving for ∆ α N J we get: ∆ α N J = 1 2 log + W N +1 J − W N +1 J − α N J . = α N +1 J − α N J . (5) The update ∆ α N J that minimizes Z J +1 is depende nt on two qu antities + W N +1 J and − W N +1 J . These are the sum s of weights of examp les that were r espectively classified correctly an d in correctly by weak hypoth esis J + 1 , wh en training with N + 1 examp les. W e rewrite the se sums in an incremental form . The incre mental form is derived by separating the weight of the last example that was added to each of the sum s from the rest of th e sum. This will allow us later on to comp ute a fast incremental approximatio n to them, resu lting in our online algo- rithm. W e comb ine the analysis of both sums by incorpo rating th e parameter σ ∈ {− 1 , +1 } , which represents the sign of the margin of the examp les being group ed by the cumu lativ e sum. Formally , we will b reak the se subsets to subsets over N weights { d 1 J , .., d N J } , and the weigh t of the last ex- 3 ample d N +1 ,J which is added to the approp riate su m using the function g σ J = d N +1 ,J 1 [ m N +1 ,J = σ ] : σ W N +1 J = X i : m iJ = σ d iJ = X i σ J d iJ + g σ J = X i σ J J − 1 Y j =1 e − α N +1 j m ij + g σ J (6) = X i σ J J − 1 Y j =1 e − ( α N j +∆ α N j ) m ij + g σ J = X i σ J d N iJ J − 1 Y j =1 e − ∆ α N j m ij + g σ J . (7) W e define the subsets o f examp les as i σ J = { i | ( m iJ = σ ) ∧ ( i ≤ N ) } . W e pa rtition th e ind ices o f the first N examples to two su bsets: a subset of corre ctly classified examples, wh ere σ = +1 , and incorrectly classified examples, where σ = − 1 . 3.2 A fast approximation to the incremental f or m Equation 7 is a sum p rodu ct e x pression which is co stly to comp ute and requir es that the margins of all previous examples be stored . I n order to m ake th is an online a lgorithm which stor es o nly one example in the memor y , we appro ximate e ach term in the produc t with a term that is independ ent of all of the margins m ij . This typ e of approxim ation en ables us to separate the sum of th e weights from the produc t terms, which r esults in a faster approximate update rule: σ W N +1 J = X i σ J d N iJ J − 1 Y j =1 e − m ij ∆ α N j + g σ J (8) ≈ σ W N J J − 1 Y j =1 ( q σ j J e − ∆ α N j + (1 − q σ j J ) e ∆ α N j ) + g σ J (9) where q σ j J ∈ R . The transition f rom eq uation 8 to 9 is done in two steps. The term s in th e p roduct are app roximate d by new terms that are inde penden t of i . Given this independ ence, the sum of weighted examples ca n be grou ped to the cu mulative sum of previous weigh ts. Equation 9 is very similar to Huan g et al’ s offline loss function. Howe ver , by greedily solving the appro ximation error equations, we show that the u pdate to the mod el should take into accou nt all th e examp les, and n ot just the offline o nes as in [3]. Since o ur approx imation incurs erro rs, we would like to find for each we ak h ypoth esis the p arameters q σ j J that minimize the app roxima tion error . Eq uation 9 can b e r ewritten in two eq uiv alen t forms to show t wo types of errors: σ W N +1 J ≈ X i σ J d N iJ J − 1 Y j =1 ( e ∆ α j + q σ j J ( e − ∆ α j − e ∆ α j )) + g σ J (10) = X i σ J d N iJ J − 1 Y j =1 ( e − ∆ α j + (1 − q σ j J )( e ∆ α j − e − ∆ α j )) + g σ J . (11) The equi valent app roxima tion forms gi ve us a w ay to compute the e xact error for any choice of m ij . Howe ver, the exact er ror expression ma y h av e 2 J terms and exactly m inimizing it may be costly . Instead, by taking a g reedy approach and looking at a p art of the er ror terms we are able to minimize the appr oximation error at each c oordin ate. W e formu late the problem as follows: nature cho oses a set of margins m ij and the b ooster chooses q σ 1 J , .., q σ j J to minimize the ap prox imation error of the boosted cla ssifier at each co ordinate. Let δ j = e − ∆ α j − e ∆ α j , then for each wea k h ypothesis, if nature choses th e margin m ij = − 1 , acco rding to 1 0, the sq uared erro r at coo rdinate j is ( q σ j J ) 2 δ 2 j . If natu re chooses a m argin m ij = +1 , th en accordin g to 11, the squ ared erro r at coord inate j is (1 − q σ j J ) 2 δ 2 . W e loo k at squared error to av oid negative er rors. Regardless of the choice of margin, we can only make one type of error since the margins ar e binary . Theorem 1 gives us the solution for param eters q σ j J using a gree dy minimization of the weighted squared approx imation error at each coord inate. 4 Theorem 1. Let the weigh ted squar ed ap pr oximatio n err o r at coo r din ate j and s ign σ be defined b y ǫ σ j J = X i σ J d N iJ 1 [ i : m ij = − 1] ( q σ j J ) 2 δ 2 j + 1 [ i : m ij =+1] (1 − q σ j J ) 2 δ 2 j . (12) Then, the minimizer q σ j J of the weighted appr ox imation err or at coor dina te j is: q σ j J = P i σ J ∧ i + j d N iJ P i σ J d N iJ . (13) Pr oof. Using a g reedy ap proach and looking at the weighted squ ared appr oximation error at a single coordin ate j given th e weights of the examp les at coordinate J , we solve for q σ j J . Since the error function is conve x , we can take deriv ati ves and solve to find the global minimum : ∂ ǫ σ j J ∂ q σ j J = 2 δ 2 j X i σ J d N iJ 1 [ i : m ij = − 1] q σ j J − 1 [ i : m ij =+1] (1 − q σ j J ) . (14) W e solve fo r q σ j J by sett ing the deri vati ve to zero. W e can d ivide by δ j since all the example weigh ts are positiv e and therefore δ j 6 = 0 . q σ j J = P i : i σ J ∧ m ij =+1 d N iJ P i : i σ J ∧ m ij = − 1 d N iJ + P i : i σ J ∧ m ij =+1 d N iJ = P i σ J ∧ i + j d N iJ P i σ J d N iJ . (15) Theorem 1 has a very natu ral interpretation . T he minimizer q σ j J can be seen as th e weighted prob a- bility of weak hypothesis j produ cing a positi ve margin and weak h ypothesis J pro ducing a margin σ (either positive or negative.) 3.3 Implementing the approximation as an algorithm Initialization: The recursiv e f orm of equation 9 requir es us to define a setting for σ W N 0 . Let σ W N 0 = | i σ 1 | be the c ount of examples with a σ margin with th e first weak hy pothesis.Th is is equiv a lent to setting th e initial weight of each examp le to on e, wh ich gives all the examples equal weig ht b efore being classified by the first weak hypo thesis. W eight updates: Theorem 1 sh ows tha t calculatin g the error minimizer requir es keepin g sums of weights which in volve two weak hypoth eses j an d J . Similarly to our appro ximation o f the sums of weights σ W N +1 J , we need to ap proxim ate q σ j J as examples are presented the the online algorithm. Applying the sam e approx imation to estimate q σ j J yields th e a similar op timization p roblem, howev e r the appr oximation err or minimizers for this pr oblem in volves thr ee margins. W e av oid calculatin g this new minimizer , and instead use the same correction we used for σ W N +1 J (see Algorithm 1.) Running time: R etraining AdaBo ost for each new example would r equire O ( N 2 J ) opera tions, as the classifier need s to be fully trained fo r eac h examp le. By using our approx imation we can train the classifier in O ( N J 2 ) , where th e p rocessing of each example takes O ( J 2 ) . A tra deoff between accuracy and spee d can b e established b y only com puting the last K terms o f the p roduc t, and assuming that th e others are equ al to one. This speedu p r esults in run ning time complexity O ( N J K ) , wh ere K will b e d efined as the order of th e algo rithm. Algor ithm 1 shows the Online Coordinate Boosting algorithm with order K . 3.4 Similarity to Oza and Russell’ s Online alg orithm Let us compare Oza and Russell’ s algorithm [8] to our algorithm. E xcludin g featu re selection, there are two steps in their algorithm . The first adds the examp le weigh t to the appropr iate cumulative sum, an d the secon d reweights the example. Step on e is ide ntical to th e ad dition that ou r algorith m perfor ms if we ass ume that all the te rms in the produ ct in eq uation 9 are e qual to one, or equi valently 5 Algorithm 1 K-order Online Coordinate Boosting Input: Example classifications M ∈ {− 1 , 1 } N × J where m ij = y i h j ( x i ) Order paramenter K Smoothing parameter ǫ Option 1: Initialize α j = 0 , ∆ α j = 0 whe re j = 0 , .., J . W + j k = ǫ, W − j k = ǫ whe re j, k = 0 , .., J Option 2: Initialize using AdaBoost on a small set. for i = 1 to N do d = 1 for j = 1 to J do j 0 = max(0 , j − K ) π + j = Q j − 1 k = j 0 W + jk W + jj e − ∆ α k + (1 − W + jk W + jj ) e ∆ α k π − j = Q j − 1 k = j 0 W − jk W − jj e − ∆ α k + (1 − W − jk W − jj ) e ∆ α k for k = 1 to j do W + j k ← W + j k π + j + d 1 [ m ik =+1] · 1 [ m ij =+1] W − j k ← W − j k π − j + d 1 [ m ik = − 1] · 1 [ m ij = − 1] end for α i j = 1 2 log W + jj W − jj ∆ α j = α i j − α i − 1 j d ← de − α i j m ij end for end for Output: α N 1 , .., α N J that ∆ α j = 0 . At step two, r eweighting the example, Oza a nd Russell b reak th e update ru le to two cases, one for each type of margin: m ij = +1 : d ← d W + j + W − j 2 W + j = d + d W − j W + j 2 (16) m ij = − 1 : d ← d W + j + W − j 2 W − j = d + d W + j W − j 2 . (17) The two cases can be consolidated to on e case when we intr oduce the margin into the equ ations. Interestingly , this u pdate r ule smo oths the examples weights by taking the av erage betwee n the o ld weight and the new upd ated weight that we would get by AdaBoost’ s exponential re weigh ting [11 ] : d ← d + d W + j W − j − m ij 2 = d + de − 2 α j m ij 2 . (18) If we do not perfo rm co rrection s to the W’ s, a nd on ly a dd the we ight of the last example to them, we red uce our algor ithm to a f orm similar to Oza and Russell’ s algorithm . Since Oz a and Russell use an older Ada Boost update rule, when put in an online framework, the weights in their alg orithm are squared and av eraged compared to our weights. 4 Experiments and Discussion W e tested ou r alg orithm against m odified versions of Oza a nd Russell’ s o nline alg orithm.T he only modification was the removal o f the weak hypo thesis selectio n proc ess. Instead we fixed a p rede- fined set o f ordere d weak hypotheses. Three experimen ts were conducted , th e first w ith ra ndom 6 data, the secon d with the MNIST dataset, an d the thir d with a face dataset. Thr ough out all our experiments we initialized ou r alg orithm with the cu mulative weig hts that were produce d by run- ning AdaBoost on a small part of the trainin g set. W e n eeded to initialize our algorith m to avoid divide-by-zero error s when o nly ma rgins of o ne ty pe h ave been seen fo r sma ll num bers of train ing examples. W e similar ly initialized Oza and Russell’ s algorithm, howe ver, sin ce our training sets are large, it had little influence on their algorithm’ s performance compared to a non-initialized run. (a) Synthetic: A verage approximation error as the number of training examples is increased. Concept drift e very 10 K examples. A verag ed over 5 runs. Accuracy imp rov es with higher order . (b) MNIST: C ombined classifier test error as the number of training examp les is increased. OCB and AdaBoost achiev e lowe r test error rates than Oza and Russell’ s algorithm. (c) Face data: A ve rage normalized approximation error as the number of training examples is in- creased. A veraged over 10 permutation s of the training set. OCB best approximates AdaBoost. (d) Face data: A verage 1-A UC as the number of training examples is increased. OCB and AdaBoost hav e almost identical performance on 100K t est set. Figure 1: A pprox imation a nd T est error experiments Synthetic data: T he synthetic experiment w as set u p to test the adaptation of our algorithm to con- cept cha nge, and th e effects of the alg orithm’ s ord er on its approx imation er ror . W e created syn thetic data by ran domly generating mu ltiple margin matrices M t which contain margins m ij . Each matrix was created o ne colu mn at a time wh ere we d raw a ran dom num ber between zer o and one fo r each column. Th e rand om numb er gives us the pro bability of the weak hypothesis classifying a n example correctly . T o simula te co ncept drift, each matrix M t was ge nerated by perturb ing the p robab ilities of the previous matr ix by a small amou nt and sampling new margins accord ingly . W e con sider th e normalized appr oximation error of the classifier learned b y the onlin e algorithms and the equiv a- lent boo sted classifier . Let the nor malized approxim ation error between AdaBoo sts’ s weight vector and ano ther weight vector be d efined by e rr ( α ada , α ) = 0 . 5 k α ada k α ada k 1 − α k α k 1 k 1 . W e co mpared the approx imation erro r fo r each exam ple th at was presen ted to the online a lgorithms with th e e quiv a- lently train ed ba tch classifier . T he experim ent was repeated 5 time s with dif ferent margin gen eration probab ilities. Each experimen t comprised of three M t matrices of size 10 , 000 × 20 , thereby simu- lating concept drift ev ery 1 0 , 000 examples. Figure 1 (a) shows th e average a pprox imation er ror as the num ber of training examples is increased. Increasing our algorithm ’ s order sho ws improvement in p erforma nce. Howe ver, we have witn essed that a tradeo ff exists when train ing large classifiers, where the app roximatio n deteriorates as the order is incr eased too much. The tra deoff exists since q σ j J is a greedy error minimizer, and mig ht not optimally minimize the total approximatio n erro r . Face data: W e co nducted a f rontal face classification experiment u sing the features f rom an existing 7 0 1 2 3 4 5 6 7 8 9 AdaBoost 0.31 0.19 0.8 0.89 0.9 1.0 0.47 0.79 1.6 2 1.29 OCB 0.33 0.18 0.78 0.93 0.87 0.9 8 0.49 0.82 1.61 1.3 Oza 0.35 0.27 0.79 1.05 0.85 1.0 2 0.55 0.97 1.82 1.36 T able 1: MNIST test error in % for each classifier one-v s-all 0 1 2 3 4 5 6 7 8 9 OCB 0.07 0.1 0.04 0.04 0.04 0.04 0.06 0.05 0.04 0.03 Oza 0.1 0.1 0.0 9 0.09 0.1 0.09 0 .1 0.1 0.1 0. 09 T able 2: MNIST appr oximation error for each class ifier one-v s-all face detector . These weak hy potheses are thresholded bo x filter decision stumps. T he trained face detector con tains 1520 weak h ypoth eses, which were learn ed u sing b atch AdaBoost with r esampling [5, 12]. Using the existing set of weak hy potheses, we compared the different online algorithms for approx imation and generaliza tion error on n ew tr aining and test sets. Both o ur training and test sets consist o f 93 , 000 non-face images co llected fro m the web , and 7 , 000 han d labeled f rontal faces all of size 24 × 24 .W e created 10 permu ted training sets b y reor dering the exam ples in the original training set 1 0 times. T he experimental results were averaged over the 10 sets. This was do ne to verify that ou r algorithm is robust to any o rdering . Our algorithm was in itialized with the cu mulative sums of weights obtained by training AdaBoost with th e first 5000 examples in eac h train ing set. Initializing Oza ’ s algor ithm did n ot impr ove its perfo rmance. W e com pared the online algo rithms to Ad aBoost’ s while trainin g for e very 10 , 00 0 examples. T he tr aining r esults in figure 1(d) show that o ur on line algorith m with or der 40 0 achieves better av erage A UC rates than Oza a nd Russell’ s algorithm . W e com pare average A UC since th ere ar e far less positiv es in the test set. Figure 1(c) shows that our av erage app roxima tion of AdaBoost’ s we ak hypoth eses weig hts is also b etter . W e found that setting an order of 400 with f rontal face classifiers of size 1520 works well. MNIST data: Th e MNIST dataset consists o f 28 × 28 images of the digits [0 , 9] . The dataset is split into a train ing set which inc ludes 6000 0 images, and a test set which includ es 10 , 0 00 im- ages. All the digits are represented approx imately in equal amount in each set. S imilarly to the face d etector, we train ed a classifier in an offline manner with sampling to find a set of weak hy - potheses. When training we n ormalized the images to hav e zer o m ean and unit variance. W e used h j ( x ) = s ig n ( k x j − x k 2 − θ ) as o ur weak hy pothesis. The we ak learner fo und for every boosting round the vector x j and thresho ld θ that cr eate a weak hy pothesis which minimizes the train ing error . As candidates for x j we used all th e examples that were sampled fro m the trainin g set at that boosting r ound . W e p artitioned the multi-class pro blem into 1 0 one- versus-all prob lems, a nd defined a meta-r ule for deciding the dig it numb er as the ind ex of the classifier that produced th e highest vote. The gen eralization and app roximatio n error r ates for each classifier can be seen in tables 1 an d 2 . Th e p erform ance of the com bination ru le u sing ea ch o f the m ethods can b e seen in figure 1(b). Ag ain, we found that order 400 p erform s well. Concluding remarks: W e sh owed that by d eriving an onlin e appro ximation to AdaBoo st we wer e able to create a more acc urate on line algor ithm. Nevertheless, the r elationship between proximity of w eak hyp othesis weights an d g eneralization needs to be furth er studied. One of the drawbacks of the algorithm is that it usually n eeds to be initialized with Ad aBoost o n a small tra ining set. W e are in vestigating adaptive weight norma lization, which may allow for a better initialization scheme. W e are also trying to connec t FilterBoo st’ s filtering framework and feature selection with OCB to improve p erform ance an d speed. Refer ences [1] Joseph K Bradley and Ro bert E. Scha pire. Filterboost: Regression and classification on large datasets. In Neural Information Pr ocessing Systems , pages 185–192 . MIT Press, 2008. [2] Y oav Freund and Robert E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Jou rnal of Computer and System Sciences , 55(1):119–139 , 1997. [3] C. H uang, H. Ai, T . Y amashita, S. L ao, and M. Kawade. Incremental learning of boosted face detector . In Interantion al Confer ence on Computer V ision , pages 1–8, 2007 . 8 [4] Omar Javed , S aad Ali, and Mubarak Shah. Online detection and classificati on of moving objects using progressi vely improving d etectors. In Computer V ision and P attern Recog nition , pages I: 696–701, 2005. [5] Michael Jones and Paul V iola. Face recognition using boosted local features. In MERL T echnical Report TR2003-25 , 2003. [6] Jyrki Ki vinen and Manfred K. W armuth. Exponentiated gradient versus gradient descent for linear pre- dictors. Information and Computation , 132(1):1–63 , 1997. [7] Nick Littlestone. Learning quickly when ir relev ant attributes abound: A new linear-threshold algorithm. Mach ine Learning , 2(4):285–318 , 1988. [8] N. Oza and S. Russell. Online bagging and boosting. In Artificial Intelli gence and Statistics , pages 105–11 2. Mor gan Kaufmann, 2001. [9] Minh-T ri Pham and T at-Jen Cham. Online learning asymmetric boosted cl assifiers for object detection. In Computer V isi on and P attern Reco gnition . IEEE Computer Society , 2007. [10] R obert E. Scha pire, Y oav Freund , Peter Bartlett, a nd W ee S . Lee. B oosting the margin: a ne w e xplanation for the effecti veness of voting metho ds. Annals of Statistics , 26(5):1651–16 86, 1998. [11] R obert E. Schapire and Y oram Singer . Improved boosting algorithms using confiden ce-rated predictions. Mach ine Learning , 37(3):297–33 6, 1999. [12] Paul V iola and Michael Jones. Rapid object detection using a boosted cascade of si mple features. In Computer V ision and P attern Recognition , 2001. [13] B . Wu and R. Nev ati a. Improving part based object detection by unsuperv ised, online boosting. In Computer V ision and P attern Recognition , pages 1–8, 2007. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment