Clustered Multi-Task Learning: A Convex Formulation
In multi-task learning several related tasks are considered simultaneously, with the hope that by an appropriate sharing of information across tasks, each task may benefit from the others. In the context of learning linear functions for supervised cl…
Authors: Laurent Jacob, Francis Bach, Jean-Philippe Vert
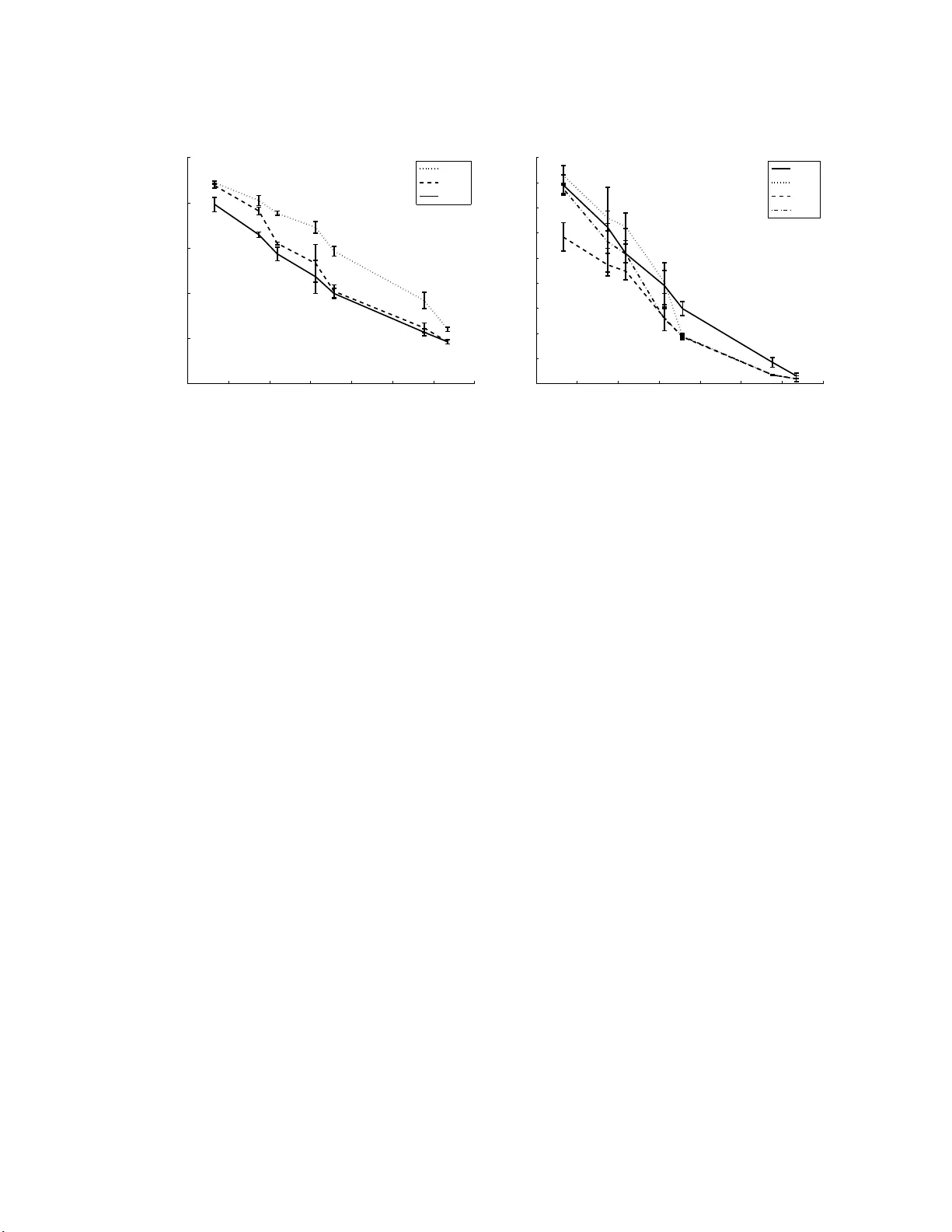
Clustered Multi-T ask Learning: a Con v ex F orm ulation Lauren t Jacob ∗ Mines P arisT ec h, CBIO Institut Curie, P aris, F-7524 8 F rance INSERM, U900 , P aris, F-75248 F rance laurent. jacob@mi nes-paristech.fr F rancis Bac h INRIA – WILLO W Pro ject T eam ´ Ecole Normale Sup ´ erieure, DI (CNRS/ENS/INRIA UMR 854 8) francis. bach@min es.org Jean-Philipp e V ert Mines P arisT ec h, CBIO Institut Curie, P aris, F-7524 8 F rance INSERM, U900 , P aris, F-75248 F r an ce jean-phi lippe.ve rt@mines-parist ech.fr Octob er 22, 2018 Abstract In m ulti-task learning several rela ted tasks are considered sim ultaneously , with the hop e that by an appropriate sharing of inf ormation across tasks, eac h task ma y b enefit from the ot hers . In the con text of le arnin g linear functions for su p ervised classification or regression, this can b e ac hieved by including a priori inf ormation ab out the weigh t vec tors asso ciated with the tasks, and ho w they are exp ected to b e related to eac h other. In this p ap er, w e assume that tasks are clustered into groups, whic h are u nkno wn b eforehand , and that tasks within a g roup hav e similar w eigh t v ectors. W e d esign a new sp ectral norm that en co des this a pr iori assum ption, without the prior kno wledge of the partition of tasks into groups, r esulting in a new con v ex optimization form ulation for m ulti-task learning. W e sho w in sim ulations on synthetic examples and on the iedb MHC-I bind ing dataset, that our approac h outp erforms w ell-kno wn con v ex metho ds for m ulti-task learning, as w ell as related n on conv ex metho ds d ed icated to the same p r oblem. ∗ T o whom corresp ondance should be address ed: 35, rue Sain t Honor ´ e, F-77300 F on tainebleau, F rance. 1 1 In tro duction Regularization has emerged as a dominan t theme in machin e learning and statistics, pro viding an intuitiv e and principled to ol for learning from high-dimensional data. In par t icular, regularization by squared Euclidean norms o r squared Hilb ert norms has b een thoroughly studied in v ar io us settings, leading to efficien t practical alg o- rithms based on linear algebra, a nd to v ery go o d theoretical understanding (see, e .g., [1, 2]). In recen t y ears, regularization by no n Hilb ert norms, suc h as ℓ p norms with p 6 = 2, has also generated considerable intere st for the inference of linear functions in sup ervised classification o r regression. Indeed, suc h norms can sometimes b o t h mak e the problem statistically and num erically b etter-b ehav ed, and imp ose v a rious a priori kno wledge on the problem. F or example, the ℓ 1 -norm (the sum of absolute v alues) imp oses some of the comp onen ts to b e equal to zero a nd is widely used to estimate sparse functions [3], while v arious com binations of ℓ p norms can b e defined to imp o se v ar io us sparsit y pa tterns. While mo st recen t w ork has f o cused on studying the prop erties of simple w ell- kno wn norms, w e take the opp osite approac h in this pap er. That is, assuming a giv en prior kno wledge, how can we design a norm that will enforce it? More precisely , w e consider the pro blem of m ulti-task learning, whic h has recen tly emerged as a ve ry promising researc h direction for v a r ious applic ations [4]. In m ulti- task learning sev eral related inference tasks are considered simultaneous ly , with the hop e that b y an appropriate sharing o f informa t ion across t a sks, eac h one ma y b enefit fro m the ot hers. When linear functions are estimated, eac h task is a sso ciated with a w eight v ector, and a common strategy to design multi-task learning algorithm is to tr a nslate some prio r hypothesis ab out how the tasks are related to eac h other in to constraints on the differen t w eigh t v ectors. F or example, suc h constrain ts are t ypically that the w eigh t v ectors of the diffe ren t ta sks belong (a) to a Euc lidean ball cen tered at the orig in [5], which implies no sharing of infor mat ion b etw een tasks apart from the size of t he differen t v ectors, i.e., the amount of regularization, (b) to a ball of unkno wn cen ter [5 ], whic h enforces a similarity b et w een the differen t w eigh t v ectors, or (c) to a n unkno wn lo w-dimensional subspace [6, 7]. In this pap er, w e consider a different prior h yp othesis tha t we b eliev e could b e more relev an t in some applications: t he h yp othesis that the diffe r e n t tasks ar e i n fact cluster e d into diffe r e n t gr oups, and that the weight ve c tors of tasks within a gr oup ar e simila r to e ach other . A k ey difference with [5 ], where a similar h yp othesis is studied, is tha t w e don’t assume that the groups ar e kno wn a priori, and in a sense our goal is b oth to identify the clusters and to use them for m ulti-task learning. An imp ortant situatio n that motiv ates this hy p o t hesis is the case where most of the tasks are indeed related to eac h other, but a few “outlier” ta sks are ve ry differen t, in whic h case it may b e b etter t o imp ose similarity o r low-dimens ional constraints only to a subset of the tasks (thus f o rming a cluster) rather than to all tasks. Ano t her situation of in terest is when one can exp ect a natural orga nization of the tasks in to 2 clusters, suc h as when one w an ts to mo del the preferences of customers a nd b eliev es that there are a few general ty p es of customers with similar preferences within eac h t yp e, although one do es not kno w b eforehand whic h customers b elong to whic h t yp es. Besides a n improv ed p erformance if t he h yp othesis turns out to b e correct, w e also exp ect this approach to b e able t o iden tify t he cluster structure among the tasks as a b y-pro duct of the inference step, e.g., to iden tify outliers or groups of customers, whic h can b e of in terest for further understanding of the structure of the problem. In o rder to t r anslate this hypothesis into a working a lgorithm, we follow the general strategy men tioned ab o v e whic h is to design a no r m or a p enalt y o v er the set of weigh ts whic h can b e used as regularization in classical inference algorithms. W e construct suc h a p enalt y b y first assuming that the partition of the tasks into clusters is kno wn, similarly to [5]. W e then attempt to optimize the ob jectiv e function of the inference algo rithm ov er the set of partitions, a strategy that has pro v ed useful in other contexts suc h as m ultiple k ernel learning [8]. This optimization problem o v er t he set o f partitions b eing computationally c hallenging, we prop ose a conv ex relaxation of the problem whic h results in an efficien t algorithm. 2 Multi-task learning with cluster e d tasks W e consider m related inference tasks that attempt to learn linear functions ov er X = R d from a training set of input/output pairs ( x i , y i ) i =1 ,...,n , where x i ∈ X and y i ∈ Y . In the case o f binary classification we usually tak e Y = {− 1 , +1 } , while in the case of regression w e t a k e Y = R . Eac h training example ( x i , y i ) is a sso ciated to a particular task t ∈ [1 , m ], and w e denote b y I ( t ) ⊂ [1 , n ] the set of indices of training examples asso ciated to the task t . Our goal is t o infer m linear f unctions f t ( x ) = w ⊤ t x , for t = 1 , . . . , m , asso ciated to the differen t tasks. W e denote b y W = ( w 1 . . . w m ) the d × m matrix whose columns are the successiv e ve ctors we w an t to estimate. W e fix a loss function l : R × Y 7→ R that quan tifies b y l ( f ( x ) , y ) the cost of predicting f ( x ) for the input x when the correct output is y . T ypical loss functions include the square error in regression l ( u , y ) = 1 2 ( u − y ) 2 or the hinge loss in binary classification l ( u, y ) = max(0 , 1 − u y ) with y ∈ {− 1 , 1 } . The empirical risk of a set of linear classifiers given in the matrix W is then defined as the a v erage loss o v er the tr a ining set: ℓ ( W ) = 1 n m X t =1 X i ∈I ( t ) l ( w ⊤ t x i , y i ) . (1) In the sequel, w e will often use the m × 1 v ector 1 comp o sed o f ones, the m × m pro jection matrices U = 11 ⊤ /m whose entries are all equal to 1 /m , as well as the pro jection matrix Π = I − U . 3 In o rder to learn simultaneously the m tasks, we follow the now w ell-established approac h whic h lo oks for a set o f w eigh t ve ctors W that minimizes the empirical risk regularized by a p enalty f unctional, i.e., w e consider t he problem: min W ∈ R d × m ℓ ( W ) + λ Ω( W ) , (2) where Ω( W ) can b e designed from prior know ledge to constrain some sharing of information b etw een tasks. F or example, [5] suggests to p enalize b oth the norms of the w i ’s and their v ariance, i.e., to consider a function o f the form: Ω var iance ( W ) = k ¯ w k 2 + β m m X i =1 k w i − ¯ w k 2 , (3) where ¯ w = ( P n i =1 w i ) /m is the mean w eigh t v ector. This p enalt y enforces a clus- tering of the w ′ i s to w ards their mean when β increases. Alternativ ely , [7] prop o se to p enalize the trace norm of W : Ω trace ( W ) = min( d,m ) X i =1 σ i ( W ) , (4) where σ 1 ( W ) , . . . , σ min( d,m ) ( W ) are the success ive singular v alues of W . This en- forces a low-rank solution in W , i.e., constrains the differen t w i ’s to liv e in a lo w- dimensional subspace. Here w e w ould lik e to define a p enalt y function Ω( W ) that enco des as prior kno wledge that tasks a r e clustered in to r < m gro ups. T o do so, let us first assume that w e kno w b eforehand the clusters, i.e., we hav e a part it io n of the set of tasks in to r groups. In that case w e can follo w an approac h prop osed b y [5] whic h for clarit y w e rephrase with our notations and slightly generalize no w. F or a giv en cluster c ∈ [1 , r ], let us denote J ( c ) ⊂ [1 , m ] the set of tasks in c , m c = |J ( c ) | the n um b er of t asks in the cluster c , and E the m × r binary matrix whic h describ es the cluster assignmen t fo r the m tasks, i.e., E ij = 1 if task i is in cluster j , 0 otherwise. Let us further denote b y ¯ w c = ( P i ∈J ( c ) w i ) /m c the av erage w eigh t v ector for the tasks in c , and recall tha t ¯ w = ( P m i =1 w i ) /m denotes the a v erage we ight v ector ov er all tasks. F ina lly it will b e con v enien t to intro duce the matrix M = E ( E ⊤ E ) − 1 E ⊤ . M can also b e written L − I , where L is the normalized Laplacian o f the gr aph G whose no des are the tasks connected by an edge if and only if they a r e in the same cluster. Then w e can define three semi-norms of interest on W that quan tify differen t orthogo na l asp ects: • A global p enalty , which measures on av erage how large the w eight v ectors are: Ω mean ( W ) = n k ¯ w k 2 = tr W U W ⊤ . 4 • A measure of b etw een-cluster v a riance, whic h quan tifies ho w close to eac h other the different clusters are: Ω betw e en ( W ) = r X c =1 m c k ¯ w c − ¯ w k 2 = tr W ( M − U ) W ⊤ . • A measure of within-cluster v ariance, whic h quantifies the compactness of the differen t clusters: Ω w ithin ( W ) = r X c =1 X i ∈J ( c ) k w i − ¯ w c k 2 = tr W ( I − M ) W ⊤ . W e note t ha t b oth Ω betw e en ( W ) and Ω w ithin ( W ) dep end on the particular c hoice of clusters E , or equiv alently of M . W e now pro p ose to consider the fo llowing general p enalt y function: Ω( W ) = ε M Ω mean ( W ) + ε B Ω betw e en ( W ) + ε W Ω w ithin ( W ) , (5) where ε M , ε B and ε W are three non-negativ e parameters that can balance the imp or- tance of the differen t compo nen ts o f t he p enalt y . Plugging this quadratic p enalt y in to (2) leads to the general optimization problem: min W ∈ R d × m ℓ ( W ) + λ t r W Σ( M ) − 1 W ⊤ , (6) where Σ( M ) − 1 = ε M U + ε B ( M − U ) + ε W ( I − M ) . (7) Here we use the notation Σ( M ) to insist o n the fact that this quadratic p enalt y dep ends on the cluster structure thro ugh the matrix M . Observing that the matrices U , M − U and I − M are orthogonal pro jections on to orthogonal supplemen tary subspaces, we easily get from (7) : Σ( M ) = ε − 1 M U + ε − 1 B ( M − U ) + ε − 1 W ( I − M ) = ε − 1 W I + ( ε − 1 M − ε − 1 B ) U + ( ε − 1 B − ε − 1 W ) M . (8) By choosing particular v alues for ε M , ε B and ε W w e can reco v er sev eral situatio ns, In par t icular: • F or ε W = ε B = ε M = ε , we simply reco v er the F rob enius norm of W , whic h do es not put any constrain t on the r elationship b etw een the differen t t a sks: Ω( W ) = ε tr W W ⊤ = ε m X i =1 k w i k 2 . 5 • F or ε W = ε B > ε M , w e recov er the p enalty of [5 ] without clusters: Ω( W ) = tr W ( ε M U + ε B ( I − U )) W ⊤ = ε M n k ¯ w k 2 + ε B m X i =1 k w i − ¯ w k 2 . In that case, a global similarit y b et w een tasks is enforced, in addition to the general constraint on their mean. The structure in clusters plays no role since the sum of the b et w een- and within-cluster v aria nce is indep endent of the particular c hoice of clusters. • F or ε W > ε B = ε M w e recov er the p enalt y of [5] with clusters: Ω( W ) = tr W ( ε M M + ε W ( I − M )) W ⊤ = ε M r X c =1 m c k ¯ w c k 2 + ε W ε M X i ∈J ( c ) k w i − ¯ w c k 2 . (9) In order to enforce a cluster h yp othesis on the tasks, w e therefore see that a natur a l c hoice is to ta k e ε W > ε B > ε M in (5). This would hav e the effect of p enalizing more the within-cluster v ariance than the b et w een-cluster v ariance, hence promoting compact clusters. Of course, a ma jor limita tion at this p oin t is that w e assumed the cluster structure kno wn a prio ri (through the matrix E , or equiv alen tly M ). In man y cases of interes t, w e w ould lik e instead to learn the cluster structure itself from the data. W e prop ose to learn the cluster structure in our fra mew ork by optimizing our ob jective function (6) b ot h in W and M , i.e., to consider the problem: min W ∈ R d × m ,M ∈M r ℓ ( W ) + λ t r W Σ( M ) − 1 W ⊤ , (10) where M r denotes the set o f matrices M = E ( E ⊤ E ) − 1 E ⊤ defined by a clustering of the m tasks in to r clusters and Σ( M ) is defined in (8) . Denoting b y S r = { Σ( M ) : M ∈ M r } t he corresp onding set of p o sitiv e semidefinite ma t rices, w e can equiv alen tly rewrite the problem a s: min W ∈ R d × m , Σ ∈S r ℓ ( W ) + λ t r W Σ − 1 W ⊤ . (11) The ob jectiv e function in (1 1) is join tly conv ex in W ∈ R d × m and Σ ∈ S m + , the set of m × m p ositiv e semidefinite matrices, ho w ev er t he (finite) set S r is not con v ex, making this problem in tractable. W e are now going to prop ose a con v ex relaxation of (11) b y optimizing o v er a con v ex set o f p ositiv e semidefinite matrices that con tains S r . 6 3 Con v ex relaxation In order to form ulate a con v ex relaxation of (11), let us first observ e that in the p enalt y term (5) the cluster structure only contributes t o the second and third terms Ω betw e en ( W ) and Ω w ithin ( W ), and that these p enalties only dep end on the cen tered v ersion of W . In terms of matrices, only the last tw o terms of Σ( M ) − 1 in (7) dep end on M , i.e. , o n the clustering, and these terms can b e re-written as: ε B ( M − U ) + ε W ( I − M ) = Π( ε B M + ε W ( I − M ))Π . (12) Indeed, it is easy to chec k tha t M − U = M Π = Π M Π, and that I − M = I − U − ( M − U ) = Π − Π M Π = Π( I − M )Π. In tuitiv ely , m ultiplying by Π on the righ t ( r esp. on the left) centers the ro ws ( r esp. the columns) of a matrix, and b oth M − U a nd I − M are ro w- and column-cen tered. T o simplify notat io ns, let us introduce f M = Π M Π. Plugg ing (12) in (7) and (10) , w e get the p enalty tr W Σ( M ) − 1 W ⊤ = ε M tr W ⊤ W U + ( W Π)( ε B f M + ε W ( I − f M ))( W Π) ⊤ , (13) in whic h, again, only the second part needs to b e optimized with resp ect to the clustering M . Denoting Σ − 1 c ( M ) = ε B f M + ε W ( I − f M ), one can express Σ c ( M ), using the fact that f M is a pro j ection: Σ c ( M ) = ε − 1 B − ε − 1 W f M + ε − 1 W I . (14) Σ c is c haracterized by f M = Π M Π, that is discrete b y construction, hence the non- con v exit y of S r . W e ha v e the natural constrain ts M ≥ 0 (i.e., f M ≥ − U ), 0 M I (i.e., 0 f M Π and tr M = r (i.e., tr f M = r − 1). A p ossible conv ex relaxatio n o f the discrete set of matrices f M is therefore { f M : 0 f M I , t r f M = r − 1 } . This giv es an equiv alen t conv ex set S c for Σ c , namely: S c = Σ c ∈ S m + : α I Σ β I , trΣ = γ , (15) with α = ε − 1 W , β = ε − 1 B and γ = ( m − r + 1) ε − 1 W + ( r − 1 ) ε − 1 B . Incorp ora ting the first part o f t he p enalty (13) into the empirical risk term b y defining ℓ c ( W ) = λℓ ( W ) + ε M tr W ⊤ W U , w e are now ready t o state our relaxation of (11): min W ∈ R d × m , Σ c ∈S c ℓ c ( W ) + λ trΠ W Σ − 1 c W ⊤ Π . (16) 3.1 Rein terpretat ion in terms of norms W e denote k W k 2 c = min Σ c ∈S c tr W Σ − 1 c W T the cluster norm (CN). F or any con v ex set S c , w e obtain a norm on W (that w e apply here to its cen tered v ersion). By 7 putting some differen t constrain ts o n the set S c , w e obtain differen t norms o n W , and in fa ct all previous m ulti-task form ulations ma y b e cast in this wa y , i.e. , b y c ho osing a sp ecific set of p ositiv e matrices S c ( e.g. , trace constrain t for the trace norm, a nd simply a singleton for the F rob enius norm). Th us, designing norms for m ulti-task learning is equiv alen t to designing a set of p ositiv e matrices. In this pap er, we hav e inv estigated a sp ecific set adapted fo r clustered-tasks, but other sets could b e designed in other situations. Note that w e ha v e selected a simple sp e ctr a l conv ex set S c in order to mak e the o ptimizatio n simple r in Section 3.3, but w e could also add some additional constrain ts that enco de the p oin t-wise p ositivity of the matrix M . Finally , when r = 1 (o ne clusters) a nd r = m (one cluster p er task), we get bac k the formulation of [5]. 3.2 Rein terpretat ion as a conv ex relaxation of K-means In this section we show that the semi-norm k Π W k 2 c that w e hav e designed earlier, can b e in terpreted a s a con v ex relaxation of K-means o n the tasks [9]. Indeed, giv en W ∈ R d × m , K- means aims to decomp o se it in the fo rm W = µE ⊤ where µ ∈ R d × r are cluster centers and E represen ts a par t it io n. Given the partition E , the matrix µ is found b y minimizing min µ k W ⊤ − E µ ⊤ k 2 F . T hus , a natural strat egy outlined b y [9], is to alternate b et w een optimizing µ , the partitio n E and the w eigh t ve ctors W . W e no w show that our conv ex norm is obtained when minimizing in closed form with resp ect t o µ and relaxing. By translation in v a riance, this is equiv alen t to minimizing min µ k Π W ⊤ − Π E µ ⊤ k 2 F . If w e add a p enalization on µ of the fo rm λ tr E ⊤ E µµ ⊤ , then a short calculation sho ws that the minim um with resp ect to µ (i.e., a fter optimization of the cluster cen ters) is equal to trΠ W ⊤ W Π(Π E ( E ⊤ E ) − 1 E ⊤ Π /λ + I ) − 1 = trΠ W ⊤ W Π(Π M Π /λ + I ) − 1 . By comparing with Eq. (14), w e see that our formulation is indeed a conv ex relax- ation of K-means. 3.3 Primal optimization Let us no w show in more details how (1 6) can b e solv ed efficien tly . Whereas a dual form ulation could b e easily deriv ed f ollo wing [8], a direct approach is to rewrite (16) as min W ∈ R d × m ℓ c ( W ) + min Σ c ∈S c trΠ W Σ − 1 c W T Π (17) whic h, if ℓ c is differentiable, can b e directly optimized by gradien t-based metho ds on W since k Π W k 2 c = min Σ c ∈S c trΠ W Σ − 1 c W T Π is a quadra tic semi-norm of W . This 8 regularization term trΠ W Σ − 1 c W ⊤ Π and its gradien t can b e computed efficien tly using a semi-closed fo r m. Indeed, since Σ c as defined in (1 5) is a sp ectral set (i.e., it do es dep end only on eigen v alues of cov ariance matrices), w e obtain a function of the singular v alues of Π W (or equiv alently the eigenv a lues of W ⊤ Π W ): min Σ c ∈S c trΠ W Σ − 1 c W ⊤ Π = min λ ∈ R m , α ≤ λ i ≤ β , λ 1 = γ , U ∈O m tr W U diag ( λ ) − 1 U ⊤ W ⊤ , where O m is the set of orthogonal matrices in R m × m . The optimal U is the matrix of the eigen ve ctors of W ⊤ Π W , and w e obtain the v alue of t he ob jectiv e function at the opt imum: min Σ ∈ S trΠ W Σ − 1 W ⊤ Π = min λ ∈ R m , α ≤ λ i ≤ β , λ 1 = γ m X i =1 σ 2 i λ i , where σ a nd λ are the v ectors con taining the singular v alues of Π W and Σ resp ec- tiv ely . No w, w e simply need t o b e able to compute t his f unction of t he singular v alues. The only coupling in this form ulation comes f r o m the trace constrain t. The Lagrangian corresp onding to t his constrain t is: L ( λ, ν ) = m X i =1 σ 2 i λ i + ν m X i =1 λ i − γ ! . (18) F or ν ≤ 0, this is a decreasing function of λ i , so the minim um on λ i ∈ [ α, β ] is reac hed for λ i = β . The dual function is then a linear non-decreasing function of ν (since α ≤ γ /m ≤ β from the definition of α, β , γ in (1 5), whic h reac hes it maxim um v alue (on ν ≤ 0 ) a t ν = 0 . Let us therefore now consider the dual for ν ≥ 0. (18) is then a conv ex function of λ i . Canceling its deriv ativ e with resp ect to λ i giv es that the minim um in λ ∈ R is reac hed for λ i = σ i / √ ν . No w this ma y not b e in the constrain t set ( α, β ), so if σ i < α √ ν then the minimum in λ i ∈ [ α, β ] of (18) is reached for λ i = α , and if σ i > β √ ν it is reac hed for λ i = β . Otherwise, it is reac hed for λ i = σ i / √ ν . Repo rting this in (18), the dual pr o blem is therefore max ν ≥ 0 X i,α √ ν ≤ σ i ≤ β √ ν 2 σ i √ ν + X i,σ i <α √ ν σ 2 i α + ν α + X i,β √ ν <σ i σ 2 i β + ν β − ν γ . (19) Since a closed for m for this expression is kno wn for eac h fixed v alue of ν , one can obtain k Π W k 2 c (and the eigen v alues of Σ ∗ ) b y Algorithm 1. The cancellation condition in Algorithm 1 is that the v alue canceling the deriv ativ e b elongs to ( a, b ), i.e. , ν = P i,α √ ν ≤ σ i ≤ β √ ν σ i γ − ( α n − + β n + ) ! 2 ∈ ( a, b ) , 9 Algorithm 1 Computing k A k 2 c Require: A, α , β , γ . Ensure: k A k 2 c , λ ∗ . Compute the singular v alues σ i of A . Order the σ 2 i α 2 , σ 2 i β 2 in a v ector I (with an additional 0 at the b eginning) . for all inte rv al ( a, b ) of I do if ∂ L ( λ ∗ ,ν ) ∂ ν is canceled on ν ∈ ( a, b ) then Replace ν ∗ in the dual function L ( λ ∗ , ν ) to get k A k 2 c , compute λ ∗ on ( a, b ). return k A k 2 c , λ ∗ . end if end for where n − and n + are the n um b er of σ i < α √ ν and σ i > β √ ν resp ectiv ely . In order to p erform the gradient descen t, we also need to compute ∂ k Π W k 2 c ∂ W . This can b e computed directly using λ ∗ , b y: ∀ i, ∂ k Π W k 2 c ∂ σ i = 2 σ i λ ∗ i and ∂ k Π W k 2 c ∂ W = ∂ k Π W k 2 c ∂ Π W Π . 4 Exp erimen ts 4.1 Artificial data W e generated syn thetic data consisting of t w o clusters of tw o t a sks. The tasks are v ectors o f R d , d = 30. F or each cluster, a center ¯ w c w as generated in R d − 2 , so that the tw o clusters b e orthog onal. Mor e precisely , eac h ¯ w c had ( d − 2) / 2 random features randomly dr awn from N (0 , σ 2 r ) , σ 2 r = 900, and ( d − 2) / 2 zero features. Then, eac h tasks t w as computed as w t + ¯ w c ( t ), where c ( t ) was the cluster of t . w t had the same zero feature a s its cluster cen ter, and the other features w ere drawn from N (0 , σ 2 c ) , σ 2 c = 16. The last t w o features w ere non-zero for all the tasks and dra wn from N (0 , σ 2 c ). F or each task, 200 0 p oints w ere generated and a normal no ise of v ariance σ 2 n = 15 0 w as added. In a first exp erimen t, we compared our cluster norm k . k 2 c with the single-t a sk learning given b y the F rob enius no r m, and with the trace norm, that corresp o nds to the assumption that the ta sks live in a low-dimens ion space. The multi-task k ernel approac h b eing a sp ecial case of CN, its p erformance will alw ay s b e b et w een the p erformance of the single task and the p erformance of CN. In a second setting, w e compare CN to alternative metho ds that differ in the w a y they learn Σ: • The T rue metric approach, t ha t simply plugs the actual clustering in E and 10 optimizes W using this fixed metric. This necessitates to know the true clus- tering a priori , and can b e tho ug h t of like a golden standard. • The k-me ans approach, that alternates b et we en optimizing the tasks in W giv en t he metric Σ and re-learning Σ by clustering the tasks w i [9]. The clustering is done by a k- means run 3 times. This is a non conv ex approac h, and differen t initia lization of k-means may result in differen t lo cal minima. W e also t ried one run of CN follo we d by a r un of T rue metric using the learned Σ repro jected in S r b y rounding, i.e. , by p erfo rming k-means on the eigen v ectors of the learned Σ ( R epr oje cte d approach), and a run o f k -me ans starting from the relaxed solution ( CNinit approa ch). Only t he first metho d requires to kno w the true clustering a priori, all the other metho ds can b e run without an y kno wledge of the clustering structure of the tasks. Eac h metho d w as run with differen t n um b ers of training p o in ts. The tra ining p oin ts we re equally separated b etw een the tw o clusters and for eac h cluster, 5 / 6th of the p oin ts were used for the first task and 1 / 6th for the second, in order to sim ulate a natura l setting w ere some tasks ha v e f ewer data. W e used the 2000 p oints o f eac h task to build 3 training folds, and the remaining p o ints w ere used for testing. W e used the mean R MSE across the tasks as a criterion, and a quadratic loss for ℓ ( W ). The results of the fir st exp erimen t are shown on Figure 1 (left). As exp ected, b oth m ulti-task appro a c hes p erform b etter than the approac h that learns each task indep enden tly . CN p enalization on the o ther hand alw a ys giv es b etter testing error than the trace nor m p enalization, with a stronger adv an tage when very few training p oin ts a r e a v ailable. When more training p oints b ecome av ailable, all the metho ds giv e more and more similar p erformances. In particular, with lar g e samples, it is not useful anymore to use a multi-task approach. Figure 1 (righ t) show s the results of the second exp erimen t. Us ing the true metric a lwa ys g ives the b est results. F or 28 training p oints, no metho d reco v ers the correct clustering structure, as display ed on Figure 2, although CN p erforms sligh tly b etter than the k-means approac h since the metric it learns is more diffuse. F or 50 training p oin ts, CN p erforms m uc h b etter than the k-means approac h, whic h completely fails to recov er the clustering structure as illustrated by the Σ learned for 28 and 50 training p oin ts on F igure 2. In the latter setting, CN pa rtially reco v ers the clusters. When more training p oin ts b ecome av a ila ble, the k-means approac h p erfectly recov ers the clustering structure and o utp erforms the relaxed a ppro ac h. The repro jected approach, on the other hand, p erforms alw ay s as w ell as the b est of the tw o other metho ds. The CNinit approach results are not display ed since the are the same as for t he repro j ected metho d. 11 3 3.5 4 4.5 5 5.5 6 6.5 10 15 20 25 30 35 Number of training points (log) RMSE Frob Trace CN 3 3.5 4 4.5 5 5.5 6 6.5 14 16 18 20 22 24 26 28 30 32 Number of training points (log) RMSE CN KM True Repr Figure 1: RMSE v ersus n um b er of t r a ining p oints f o r the tested metho ds. 4.2 MHC-I binding data W e a lso applied our metho d to the iedb MHC-I p eptide binding b enc hmark pro- p osed in [10]. This databa se con tains binding a ffinities of v arious p eptides, i.e. , short amino- acid sequences, with differen t MHC-I molecules. This binding pro cess is cen tral in t he imm une system, and predicting it is crucial, for example to design v accines. The a ffinities are thresholded to give a prediction problem. Eac h MHC-I molecule is considered as a task, and the goal is to predict whether a p eptide binds a molecule. W e used an ort ho g onal co ding of the a mino acids to represen t the p ep- tides and balanced the data b y k eeping only one nega tiv e example for eac h p ositiv e p oin t, resulting in 15 236 p o in ts inv o lving 35 differen t mo lecules. W e c hose a logistic loss for ℓ ( W ). Multi-task learning approach es ha v e already prov ed useful for this problem, see for example [11, 12]. Besides, it is we ll kno wn in the v accine design communit y that some molecules can b e group ed into empirically defined sup ertyp es kno wn to ha v e similar binding b ehav iors. [12] show ed in particular that the multi-task approaches w ere v ery useful for molecules with few known binders. F ollowing this observ ation, w e consider the mean error on the 10 molecules with less than 20 0 known lig ands, and rep o rt the results in T able 1. W e did not select the parameters b y inte rnal cross v a lidation, but c hose them among a small set of v a lues in order to av oid ov erfitting . More accurate results could arise from suc h a cross v alidation, in particular concerning the n um b er of clusters (here w e limited the c hoice to 2 or 10 clusters). The p o oling appro a c h simply considers one global prediction pro blem by p o oling together the data av ailable fo r a ll molecules. The results illustrate that it is b etter to consider individual mo dels than one unique p o oled mo del, ev en when few data 12 Figure 2: Recov ered Σ with CN (upp er line) and k-means (low er line) for 28, 50 and 100 p oin ts. T able 1: Prediction error fo r the 10 molecules with less tha n 200 training p eptides in ie db . Metho d P o oling F rob enius MT kernel T race norm Cluster Norm T est error 26 . 53% ± 2 . 0 11 . 62% ± 1 . 4 10 . 10 % ± 1 . 4 9 . 20% ± 1 . 3 8 . 71% ± 1 . 5 p oin ts ar e a v ailable. On the other hand, all the m ultitask approac hes improv e the accuracy , the cluster norm g iving the b est p erformance. Th e learned Σ, ho w ev er, did not reco v er the kno wn sup ertypes, although it may contain some relev ant infor- mation on the binding b eha vior of the molecules. F inally , the repro jection metho ds ( r e pr oje cte d and CNinit ) did not improv e t he p erformance, p otentially b ecause the learned structure was not strong enough. 5 Conclus ion W e hav e presen ted a conv ex approac h to clustered multi-task learning, based on the design of a dedicated norm. Promising results w ere presen ted on syn thetic examples and on the iedb dataset. W e are currently inv estigating more r efined con v ex relaxations and the natural extension to non- linear m ulti-task learning as w ell as the inclusion of sp ecific features on the tasks, whic h has show n to impro v e p erformance in other settings [6]. 13 References [1] G. W ahb a. Spline Mo dels for Observ ational Data , v olume 5 9 of CBMS-NSF R e gional C o nfer enc e S eries in Applie d Mathematics . SIAM, Philadelphia, 1 990. [2] F. Girosi, M. Jones, and T. P oggio. Regularization Theory and Neural Netw or ks Arc hitectures. Neur al Comput. , 7(2 ):219–269 , 199 5. [3] R. Tibshirani. Regression shrink age and selection via the lasso. J. Royal. Statist. So c. B. , 58(1):2 6 7–288, 1996. [4] B. Bakk er and T. Hesk es. T ask clustering and gating fo r ba y esian mu ltitask learning. J. Mach. L e arn. R es. , 4:83–9 9 , 2003. [5] T. Evgeniou, C. Micc helli, a nd M. Pon til. Learning m ultiple tasks with kernel metho ds. J. Mach. L e arn. R es. , 6:615– 637, 2005 . [6] J. Ab erneth y , F. Bac h, T. Evgeniou, and J.-P . V ert. Low -ra nk matrix f actor- ization with attributes. T ec hnical Rep ort cs/0611124 , arXiv, 2006. [7] A. Argyriou, T. Evgeniou, and M. P ontil. Multi-task feature learning. In B. Sc h¨ olk opf, J. Platt, and T. Hoffman, editors, A d v. Neur al. Inform. Pr o c ess Syst. 19 , pages 41–48, Cambridge, MA, 20 0 7. MIT Press. [8] G.R.G. Lanck riet, N. Cristianini, P . Bartlett, L. El Ghaoui, and M.I. Jor da n. Learning the Kernel Matrix with Semidefinite Programming. J. Mach. Le arn. Res. , 5:27 –72, 2004 . [9] Meghana Deo dhar and Joyde ep Gho sh. A framew ork for sim ultaneous co- clustering and learning fr o m complex data. In KDD ’07: Pr o c e e dings of the 13th ACM SI GKDD international c onfer enc e on Know le dge d i s c overy and data mining , pages 250–25 9, New Y ork, NY, USA, 200 7. AC M. [10] Bjo ern P eters, Huynh-Hoa Bui, Sune F rankild, Morten Nielson, Claus Lunde- gaard, Emrah Kostem, Derek Basc h, K asp er Lamberth, Mikk el Harndahl, W ar d Fleri, Stephen S Wilson, John Sidney , Ole Lund, Soren Buus, a nd Alessandro Sette. A comm unity resource b enc hmarking pr edictions of p eptide binding to MHC-I molecules. PL oS Comput Biol , 2 (6):e65, Jun 200 6. [11] Dav id Hec ke rman, Carl K a die, and Jennifer Listgart en. Lev eraging information across HLA a lleles/supertypes impro v es HLA-sp ecific epitop e prediction, 2006. [12] L. Jacob and J.- P . V ert. Efficien t p eptide-MHC-I binding prediction for alleles with few kno wn binders. Bioinformatics , 24(3):35 8–366, F eb 20 0 8. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment