Grammar-Based Random Walkers in Semantic Networks
Semantic networks qualify the meaning of an edge relating any two vertices. Determining which vertices are most "central" in a semantic network is difficult because one relationship type may be deemed subjectively more important than another. For thi…
Authors: Marko A. Rodriguez
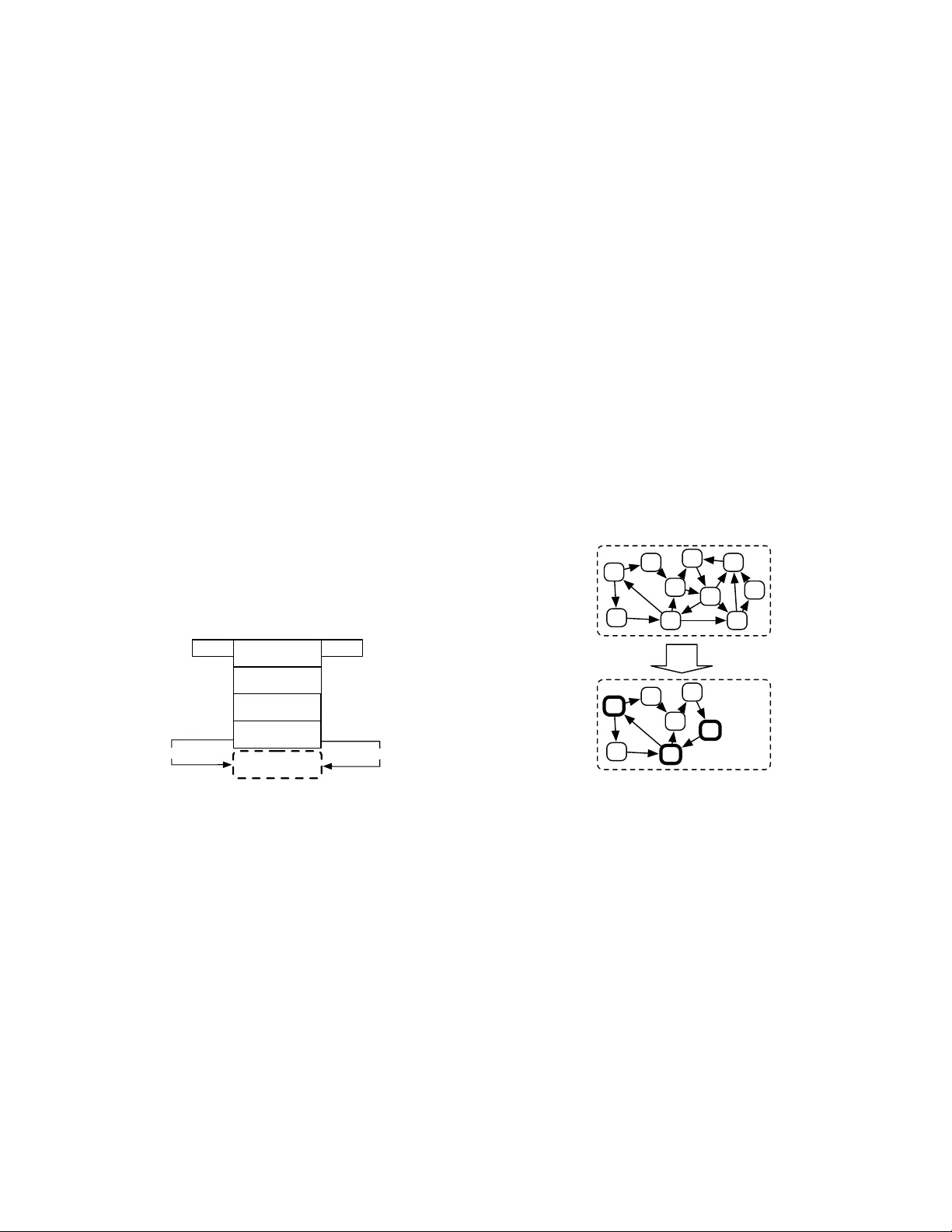
LA UR-06-7791 Grammar-Based Random W alk ers in Seman tic Net w orks ∗ Mark o A. Ro driguez Digital L ibr ary R ese ar ch and Prototyping T e am L os Alamos National L ab or atory L os A lamos, New Mexic o 87545 (Dated: Octob er 24, 2018) Seman tic netw orks qualify the meaning of an edge relating any tw o v ertices. Determining whic h v ertices are most “cen tral” in a semantic net work is difficult because one relationship t ype may b e deemed sub jectiv ely more imp ortant than another. F or this reason, research in to seman tic net w ork metrics has fo cused primarily on con text-based rankings (i.e. user prescrib ed con texts). Moreo v er, man y of the current semantic net work metrics rank semantic asso ciations (i.e. directed paths b etw een t w o vertices) and not the vertices themselves. This article presen ts a framework for calculating seman tically meaningful primary eigen v ector-based metrics suc h as eigen vector cen trality and P ageRank in semantic netw orks using a modified v ersion of the random w alk er model of Mark ov c hain analysis. Random walk ers, in the context of this article, are constrained by a grammar, where the grammar is a user defined data structure that determines the meaning of the final vertex ranking. The ideas in this article are presented within the context of the Resource Description F ramework (RDF) of the Semantic W eb initiativ e. I. INTR ODUCTION There exists a large collection of centralit y metrics that ha v e been used extensively to rank vertices in single- relational (or unlab eled) net works. An y metric for de- termining the centralit y of a vertex in a single-relational net w ork can b e generally defined b y the function f : G → R | V | , where a single-relational netw ork is denoted G 1 = ( V = { i, . . . , j } , E ⊆ V × V ) and the range of f is the rank v ector representing the centralit y v alue as- signed to each vertex in V [49]. The work in [10, 21, 47] pro vide reviews of the many p opular centralit y measures that are currently used to day to analyze single-relational net w orks. Of particular imp ortance to this article are those met- rics that use the primary eigenv ector of the net work to rank the v ertices in V (namely eigen v ector cen tralit y [9] and PageRank [33]). If A ∈ R | V |×| V | is the adjacency matrix representation of G 1 , then the primary eigen v ec- tor of A is π when A π = λπ , where λ is the greatest eigen v alue of all eigen v ectors of A and π ∈ R | V | [46]. The primary eigen v ector has b een applied extensiv ely to ranking vertices in all types of net works such as so- cial netw orks [9], sc holarly net works of articles [14] and journals [7], and technological net w orks such as the w eb citation net work [33]. In single-relational net w orks, de- termining the primary eigenv ector of the netw ork can be computed using the p ow er metho d whic h simulates the b eha vior of a collection of random walk ers trav ersing the net w ork [10]. Those vertices that ha v e a higher prob- abilit y of b eing tra v ersed by a random walk er are the ∗ Rodriguez, M.A., ”Grammar-Based Random W alk ers in Semantic Net works”, Knowledge-Based Systems, v olume 21, issue 7, pages 727-739, ISSN: 0950-7051, Elsevier, doi:10.1016/j.knosys.2008.03.030, LA-UR-06-7791, October 2008. most “central” or “imp ortan t” vertices. F or ap erio dic, strongly connected net w orks, π is the eigenv ector cen- tralit y ranking [9]. F or net w orks that are not strongly connected or are p erio dic, the netw ork’s top ology can b e altered such that a “telep ortation” netw ork can b e ov er- laid with G 1 to produce an irreducible and aperio dic net- w ork for whic h the p o w er metho d will yield a real v alued π . This is the metho d that was introduced by Brin and P age and is p opularly kno wn as the random web-surfer mo del of the P ageRank algorithm [33]. The P ageRank algorithm is one of the primary reasons for the (sub jec- tiv ely) successful rankings of web pages from the Go ogle searc h engine [25]. In a single-relational social net work, for example, the net w ork data structure can only represen t a single t yp e of relationship suc h as friendship. How ever, in a semantic net w ork (or m ulti-relational net work), the v ertices can be connected to each other b y a heterogeneous set of rela- tionships such as friendship, kinship, collab oration, com- m unication, etc. F or a semantic net w ork instance, there usually exists an ontology (or schema) which specifies ho w vertex types are related to one another. F or exam- ple, an ontology may say that a v ertex of type h uman can ha v e another vertex of type human as a friend, but a hu- man cannot hav e a vertex of t ype animal as a friend. An on tology is nearly analogous to the ob ject-sp ecifications of ob ject-oriented programming min us the metho d decla- rations [37] and lo osely related to the schema definitions of relational databases. The Resource Description F ramework (RDF) is a p op- ular data model for explicitly represen ting semantic net- w orks for the distribution and use amongst comput- ers [23, 28, 31]. The Resource Description F ramew ork Sc hema (RDFS) is a p opular ontology language for RDF [11]. An RDF net w ork can b e represented as a triple list G n ⊆ ( V × Ω × V ), where Ω is a set of edge labels denoting the semantic (or meaning) of the relationship b etw een the vertices in V and an y ordered triple h i, ω , j i ∈ G n 2 states that vertex i is related to vertex j by the seman- tic ω . The use of labeled edges complicates the meaning of the rank v ector returned by single-relational cen tral- it y measures b ecause some vertices ma y b e deemed more cen tral than others with respect to one edge label, but not with resp ect to another. F or example, the relation- ship isFriendOf may b e considered more relev ant than livesInSameCityAs . Therefore, due to the n um ber of w a ys by which tw o adjacent vertices can b e related and the fo cus on the seman tics of such relations, the aim of recen t seman tic net work metrics ha v e b een on ranking seman tic asso ciations [2, 26, 36, 44], not the vertices themselv es. A seman tic asso ciation b etw een vertices i and j is defined b y the ordered multi-set path q , where q = ( i, ω a , . . . , ω b , j ), i, j ∈ V , and ω a , ω b ∈ Ω [3]. If Q i,j is the set of all possible semantic asso ciations b et w een v ertices i and j in G n , then a path metric function is generally defined as f : Q V ,V → R | Q V ,V | , where the range of f denotes the ranking of eac h path in Q i,j . This article fo cuses on vertex ranking, not path rank- ing. Moreo v er, this article is primarily in terested in eigen v ector-based metrics suc h as eigenv ector cen trality [9] and P ageRank [33]. While eigenv ector-based metrics on semantic net w orks hav e been proposed to rank v er- tices, the algorithms rely on prescrib ed semantic net w ork on tologies and therefore, hav e not b een generalized to handle any seman tic netw ork instance [30, 38, 48]. This article presents a method for applying eigen v ector-based cen tralit y metrics to semantic netw orks such that the se- man tic net w ork’s on tology is resp ected. The proposed metho d extends the random w alk er mo del of Mark ov c hain analysis [22] to supp ort its application to seman- tic netw ork vertex ranking without altering the original data set or isolating subsets of the data set for analy- sis. This method is called the grammar-based random w alk er metho d. While the random walk er’s of Marko v c hain analysis are memoryless, grammar-based random w alk ers of seman tic net w orks utilize a user-defined gram- mar (or program) that instructs the grammar-based ran- dom w alk er to take particular ontological paths through the seman tic netw ork instance. Moreov er, a grammar- based random w alk er main tains a memory of its path in the netw ork and in the grammar in order for it to execute simple logic along its path. This simple logic allo ws the grammar-based random walk er to generate se- man tically complex eigen vector rankings. F or example, giv en a scholarly semantic net w ork and the grammar- based method, it is possible to calculate π ov er all author v ertices such that the authors indexed by π are located at some institution and they wrote an article that cites another article of a different author of the same institu- tion. The next section provides an o verview of the class of eigen v ector-based metrics for single-relational netw orks that use the random walk er mo del and then prop oses a metho d for meaningfully applying suc h metrics to se- man tic netw orks. The result is a vertex v aluing function generally defined as f : G × Ψ → R |⊆ V | where Ψ is a user defined grammar and π ∈ R |⊆ V | . I I. RANDOM W ALKERS IN SINGLE-RELA TIONAL NETWORKS The random w alker model comes from the field of Mark o v chain analysis. Marko v c hains are used to mo del the dynamics of a sto chastic system b y explicitly rep- resen ting the states of the system and the probability of transition b etw een those states [15, 32]. A Marko v c hain can b e represented by a directed weigh ted net- w ork G 1 = ( V , E , w ) where the set of vertices in V are system states, E ⊆ V × V are the set of directed edges representing the transitions b etw een states, and w : E → [0 , 1] is the function that maps eac h edge to a real w eigh t v alue that represen ts the state transition probabilit y [50]. The outgoing edge weigh ts of any state in the Marko v chain form a probability distribution such that P e ∈ Γ + ( i ) w ( i ) = 1 : | Γ + ( i ) | ≥ 1, where Γ + ( i ) ⊆ E is the set of outgoing edges of vertex i . The future state of the system at time n + 1 is based solely on the current state of the system at time n and its resp ective outgoing edges. Giv en that a Mark ov c hain can b e represented by a w eigh ted directed net w ork, one can envision a random w alk er moving from v ertex to vertex (i.e. state to state). A random w alker mo ves through the Marko v chain by c ho osing a new vertex according to the transition prob- abilities outgoing from its curren t vertex. This process con tin ues indefinitely where the long run b ehavior, or stationary distribution denoted π , of the random walk er mak es explicit the probability of the random walk er b e- ing lo cated at any one v ertex at some random time in the future. How ever, only ap erio dic, irreducible, and re- curren t Marko v chains can b e used to generate a π that is the stationary distribution of the chain [10]. If the Mark o v chain is ap erio dic then the random walk er do es not return to some previous vertex in a p erio dic manner. A Mark o v c hain is considered recurren t and irreducible if there exists a path from an y vertex to an y other vertex. In the language of graph theory , the w eigh ted directed net w ork representing the Marko v chain m ust b e strongly connected. If A ∈ R | V |×| V | is the w eigh ted adjacency matrix representation of G 1 and there exists a vertex v ector π ∈ R | V | where P i ∈ V π i = 1 and A π = λπ , where λ is the greatest eigenv alue of all eigen v ectors of A , then π is the stationary distribution of G 1 as well as the pri- mary eigen v ector of A [34]. The vector π represen ts the eigen v ector cen trality v alues for all vertices in V [9]. In the real world, p erio dicity is highly unlikely in most natural netw orks [10]. How ever, a strongly connected net w ork is not alwa ys guaranteed. If the netw ork is not strongly connected, then the problem of rank sinks and subset cycles is introduced and π is not a real v alued v ector. Therefore, man y netw orks require some manip- ulation to ensure strong connectivit y . F or example, the w eb citation netw ork, represented as G 1 = ( V , E ), is not 3 strongly connected [13] and therefore, in order to calcu- late π for the w eb citation net w ork, it is necessary to transform G 1 in to a strongly connected netw ork. One suc h metho d was introduced in [12, 33] where a proba- bilistic web citation netw ork is o verlaid with a fully con- nected w eb citation netw ork. In matrix form, the prob- abilistic adjacency matrix of the w eb citation net w ork, A ∈ R | V |×| V | , is created, where A i,j = ( 1 | Γ + ( i ) | if ( i, j ) ∈ E 1 | V | if | Γ + ( i ) | = 0 . In A , all rank sinks (i.e. v ertices with no out degree, absorbing v ertices) connect to every other vertex in V with equal probability . Next, the matrix B is created suc h that B ∈ R | V |×| V | and B i,j = 1 | V | for all i and j in V . B denotes a fully connected net w ork (i.e. a com- plete netw ork) where every v ertex is connected to every other vertex with equal probability . The comp osite ad- jacency matrix C = δ A + (1 − δ ) B , where δ ∈ (0 , 1] is a parameter weigh ting the contribution of eac h adjacency matrix, guarantees that there is some finite probabilit y that each v ertex in V is reachable b y ev ery other vertex in V . Therefore, the netw ork denoted by C is strongly con- nected and there exists a unique stationary distribution π such that C π = λπ . This method of inducing strong connectivit y is called P ageRank and has b een used ex- tensiv ely to rank v ertices in a unlab eled, single-relational net w orks [25]. The primary con tribution of this article is that it ports the eigen v ector-based algorithms of single-relational net- w orks ov er to the semantic netw ork domain. This article presen ts a metho d for calculating a seman tically mean- ingful stationary distribution within some subset of a se- man tic netw ork (called grammar-based eigen vector cen- tralit y) as w ell as how to implicitly induce strong con- nectivit y irresp ective of the netw ork’s topology (called grammar-based P ageRank). This general metho d is called the grammar-based random walk er mo del b ecause a random w alk er does not blindly mov e from vertex to v ertex, but instead is constrained by a grammar that en- sures that the stationary distribution is calculated in a “grammatically correct” subset of G n . Before discussing the grammar-based random w alk er metho d, the next sec- tion pro vides a brief review of semantic net works, on tolo- gies, and current standards for their represen tation. I I I. SEMANTIC NETWORKS A seman tic net w ork is also known as a m ulti-relational net w ork or directed lab eled netw ork. In a semantic net- w ork, there exists a heterogeneous set of v ertex t ypes and a heterogeneous set of edge types suc h that any t w o ver- tices in the netw ork can b e connected by zero or more edges. In order to mak e a distinction betw een tw o edges connecting the same vertices, a lab el denotes the mean- ing, or semantic, of the relationship. A seman tic net w ork can b e represented by the triple list G n ⊆ ( V × Ω × V ). A v ertex to v ertex relationship is called a triple b ecause there exists the relationship h i, ω , j i where i ∈ V is called the sub ject, ω ∈ Ω is called the predicate, and j ∈ V is called the ob ject. P erhaps the most p opular standard for represen ting se- man tic netw orks is the Resource Description F ramework (RDF) of the Semantic W eb initiativ e [23, 28]. There curren tly exists many applications to supp ort the cre- ation, query , and manipulation of RDF-based seman- tic netw orks. High-end, mo dern day triple-stores (RDF databases) can reasonably support on the order of 10 9 triples [1]. F or this reason, and due to the fact that RDF is b ecoming a common data mo del for v arious disciplines including digital libraries [4], bioinformatics [41], and computer science [39], all of the constructs of the grammar-based random walk er mo del will b e pre- sen ted according RDF and its ontology mo deling lan- guage RDFS. RDF iden tifies v ertices in a semantic net work b y Uni- form Resource Iden tifiers (URI) [5], literals, or blank no des (also called anonymous no des) and edge lab els are represen ted by URIs. An example RDF triple where all comp onen ts are URIs is h lanl:marko , lanl:hasFriend , lanl:johan i . In this triple, lanl is a namespace prefix that represents http://www.lanl.gov . This prefix con v en tion is used throughout the article to ensure brevit y of text and dia- gram clarity . Figure 1 is a graphic representation of the previous triple. lanl:marko lanl:johan lanl:hasFriend FIG. 1: A example triple in RDF. Another example of a triple where the ob ject is a literal is h lanl:marko , lanl:hasFirstName , "Marko" ∧ ∧ xsd:string i . In this triple, the literal "Marko" ∧ ∧ xsd:string is an XML sc hema datatype string ( xsd ) [6]. While a semantic netw ork instance is represented in pure RDF, a seman tic net w ork on tology is represen ted in RDFS (a language represented in RDF). A. On tologies Due the heterogeneous nature of the v ertices and edges in a semantic net w ork, an ontology is usually defined as w a y of sp ecifying the range of p ossible interactions be- t w een the vertices in the netw ork. On tologies articulate the relation b etw een abstract concepts and make no ex- plicit reference to the instances of those classes [45]. F or example, the on tology for the web citation net work can 4 b e defined by a single class representing the abstract con- cept of a w eb page and the single seman tic relationship represen ting a w eb link or citation (i.e. href ). This sim- ple ontology states that the netw ork represen ting the se- man tic mo del of the web is constrained to only instances of one class (a w eb page) and one relationship (a w eb link). Giv en the previous single triple represented in Figure 1, the seman tic netw ork ontology could b e represented as diagramed in Figure 2, where the lanl:hasFriend prop ert y m ust ha v e a domain of lanl:Human and a range of lanl:Human , where lanl:marko and lanl:johan are b oth lanl:Human s. lanl:marko lanl:johan lanl:hasFriend lanl:Human lanl:hasFriend rdfs:domain rdfs:range rdf:type rdf:type instance ontology FIG. 2: A example of the relationship betw een an ontology and its instance. Note that ontological diagrams can be abbreviated b y assuming that the tail of an edge is the rdfs:domain and the head of the edge is the rdfs:range . This abbreviated form is diagrammed in Figure 3. lanl:marko lanl:johan lanl:hasFriend lanl:Human lanl:hasFriend rdf:type rdf:type instance ontology FIG. 3: An abbreviation of the diagramed in Figure 2. In general, the relationship b etw een an ontology and its corresp onding seman tic netw ork instantiation is depicted in Figure 4 where the rdf:type prop ert y denotes that the v ertices in V are an instance of some abstract class in the on tology . Semantic Network Instance Ontology rdf:type FIG. 4: The relationship b etw een a semantic netw ork instance and its ontology . RDFS do es not provide a large enough vocabulary to describ e man y of the t yp es of relations needed for model- ing class interactions [24]. F or this reason, other mo del- ing languages, based on RDFS, ha v e b een dev eloped suc h as the W eb Ontology Language (OWL) [24, 29]. O WL allo ws a modeler to represen t restrictions on prop erties (e.g. cardinality) and provides a broader range of prop- ert y types (e.g. inv e rse relationships, functional relation- ships). Ev en though RDFS is limited in its expressiveness it will b e used as the mo deling language for describing the grammar-based random w alk er ontology . Note that it is trivial to map the presented concepts ov er to other mo deling languages suc h as O WL. F or a more in-depth review of on tology modeling languages, their history , and their application, please refer to [24] and [20]. The next section brings together the concepts of ran- dom walk ers, seman tic netw orks, and ontologies in order to formalize this article’s proposed grammar-based ran- dom w alk er mo del. IV. GRAMMAR-BASED RANDOM W ALKERS A grammar-based random w alk er mov es through a se- man tic net work in a manner that respects the labels of the edges connecting the netw ork’s vertices. The purp ose of the grammar-based random w alker is to iden tify the stationary distribution of some subset of the full seman- tic netw ork (i.e. the primary eigen vector of a sub-netw ork of the netw ork). Unlik e the random w alk ers of Marko v c hain analysis, a grammar-based random w alker do es not tak e an y outgoing edge from its current vertex, but in- stead, dep ending on the user defined grammar, tra v erses particular edges types to particular v ertex t yp es. An y designed grammar uses the constructs and algo- rithms defined by the grammar on tology (prefixed as rwr ). The grammar ontology defines rule classes, at- tribute classes, data structures, and prop erties that are in tended to b e com bined with instances and classes of G n to create a G n sp ecific grammar denoted Ψ. The rules of the grammar ultimately determine which v ertices in V are indexed by the returned rank vector π . The rank v ector π is created by a set of grammar-based random w alk ers P trav ersing through G n and ob eying Ψ. Figure 5 diagrams the relationship b etw een Ψ, P , G n , and their resp ectiv e ontologies. Note that Ψ, Ψ’s ontology , G n , and G n ’s ontology are all semantic net w orks and th us, can be represented b y the same seman tic net work data structure. How ever, in order to mak e the separation be- t w een the comp onents clear, each data structure will b e discussed as a separate semantic netw ork. Grammar Ψ Random Walker Population traverses traverses π Semantic Network G n P Grammar Ontology Network Ontology rdf:type rdf:type FIG. 5: The grammar-based random walk er architecture. 5 The meaning of the v ertex rank vector π of the grammar-based mo del, both semantically and theoreti- cally , dep ends primarily on the grammar used. Some Ψs will generate a π that is the stationary probability distri- bution of some subset of G n , while others will be more represen tativ e of a discrete form of the spreading acti- v ation models, where calculating the long run behavior of the random walk er is undesirable [16, 17, 18, 42]. In practice, determining whether π is a stationary distribu- tion of the analyzed subset of V is a matter of determin- ing whether the subset of G n that is tra v ersed b y P is strongly connected and the normalized π has conv erged to a stable set of v alues. An y grammar-based random w alk er implementation is a function generally defined as f : G × Ψ → R |⊆ V | . It is noted that there exists tw o related ontologies for mo deling the distribution of discrete entities in a seman- tic net w ork. These ontologies w ere inspirational to the ideas presented in this article. The mark er passing P etri net ontology of [19] and the particle sw arm ontology of [38]. How ev er, b oth ontologies w ere designed for a dif- feren t application space. The first is for P etri net algo- rithms while the latter w as defined sp ecifically for col- lectiv e decision making systems. Finally , the grammar- based mo del presen ted in [40] for calculating geo desics in a semantic netw ork combined with the grammar-based mo del presented in this article form a unified framework for porting many of the popular single-relational net w ork analysis algorithms ov er to the semantic net work domain (more sp ecifically , the RDF and Seman tic W eb domain). A. The Grammar-Based Random W alker On tology The complete grammar ontology is graphically rep- resen ted in Figure 6, where squares are rdfs:Class es and edge lab els are rdf:Property types. The tail of eac h edge is the rdfs:domain of the rdf:Property and the head is the rdfs:range . F or the purp ose of dia- gram clarity , the dashed edges denote a relationship of rdfs:subClassOf . Finally , note that the tw o dashed squares should b e instances or classes that are in G n or its on tology , resp ectively . The grammar ontology follows a conv ention similar to most ob ject orien ted programming languages [43] in that a rwr:Context (i.e. class) has a set of at- tributes (i.e. fields) and rules (i.e. metho ds). The gen- eral idea is that an y grammar instance Ψ is a col- lection of rwr:Context ob jects connected to one an- other by rwr:Traverse rules. rwr:Context s and their rwr:Traverse rules are an abstract mo del of what triples a grammar-based random walk er can trav erse in G n . The rwr:Is and rwr:Not attributes further constrain the types of v ertices that can be tra v ersed by the ran- dom walk er and are used for path “b ookkeeping” and path logic. The rwr:IncrCount and rwr:SubmitCounts rules determine which vertices in V should b e indexed b y π . Finally , the rwr:Reresolve rule is the means by rwr:Context rwr:hasAttributes rwr:hasRules rwr:Attributes rwr:hasAttribute rdf:Bag rwr:Rules rwr:Not rdfs:Container Membership Property rwr:Rule rwr:Submit Counts rwr:Incr Count rwr:Traverse rwr:Edge rwr:hasEdge rwr:Context xsd:int rwr:steps rwr:forResource rdfs:Resource rwr:hasObject rwr:Reresolve rwr:steps rwr:Is xsd:int rwr:steps rwr:Attribute rwr:Context rwr:hasSubject rwr:hasPredicate rwr:InEdge rwr:OutEdge rdf:Property rwr:probability rwr:Entry Context rwr:obeys rdf:Bag rdf:Seq rwr:Random Grammar rwr:inGrammar xsd:float FIG. 6: The complete grammar-based random w alk er on tol- ogy . whic h the random walk er is able to “telep ort” to other regions of G n . The rwr:Reresolve rule is used to mo del the P ageRank algorithm and therefore, is a mec hanism for guaranteeing that the subset of G n that is trav ersed is strongly connected and π is a stationary distribution. B. High-Lev el Overview of the Grammar-Based Mo del This section will provide a high-level o verview of the comp onen ts of the grammar diagrammed in Figure 6. Ψ is a user defined data structure that is created specifi- cally for G n and G n ’s resp ectiv e ontology . Any Ψ must ob ey the constrain ts defined b y the grammar on tology di- agrammed in Figure 6. A single grammar-based random w alk er (denoted p ∈ P ) “walks” both G n and Ψ in or- der to dynamically generate a vertex rank v ector denoted π . If the p -trav ersed subset of G n is strongly connected, then only a single random w alk er is needed to compute π [22]. When random w alker p ∈ P is at some rwr:Context in Ψ, the rwr:Context is “resolved” to a particular ver- tex in V . This is the relationship betw een Ψ and G n . F or example, if p is at some rwr:Context in Ψ that is rwr:forResource lanl:Human , then p must also be at some vertex in V that is of rdf:type lanl:Human . Th us, Ψ is an abstract representation of the legal ver- tices that p can trav erse in V . When p is at a 6 rwr:Context , p will execute the rwr:Context ’s collec- tion of rwr:Rule s, while at the same time respect- ing rwr:Context rwr:Attribute s. The collection of rwr:Rule s is an ordered rdf:Seq [11]. This means that p m ust execute the rules in their sp ecified se- quence. This is represented as the set of prop erties rdf: 1 , rdf: 2 , rdf: 3 , etc. (i.e. rdfs:subPropertyOf rdfs:ContainerMembershipProperty ). An y grammar-based random walk er p has three lo cal v ariables: • a reference to its path history in G n (denoted g p ) • a reference to its path history in Ψ (denoted ψ p ) • a lo cal vertex vector (denoted π p ∈ N |⊆ V | ) and a reference to a single global v ariable: • a global vertex vector (denoted π ∈ N |⊆ V | ) The path history g p is an ordered m ulti-set of vertices, edge lab els, and edge directionalities. If the random w alk er p tra v ersed the path dia- grammed in Figure 1 from left to right, then g p = { lanl:marko , lanl:hasFriend , + , lanl:johan } . Note that g p 0 = lanl:marko , g p 1 0 = lanl:hasFriend , g p 1 00 = +, and g p 1 = lanl:johan , where n 0 denotes the edge la- b el used to get to the vertex at time n and n 00 de- notes the direction that p trav ersed ov er that edge. In the grammar-based random walk er mo del, a random w alk er can, if stated in Ψ, opp ose an edge’s direction- alit y . F or example, if p had tra v ersed the edge dia- grammed in Figure 1 from right to left, then g p = { lanl:johan , lanl:hasFriend , − , lanl:marko } . A sim- ilar con ven tion holds for p ’s Ψ-history ψ p . Ho wev er, in ψ p the v ertices are rwr:Context s, the edge labels are the rdf:Property of the rwr:Edge c hosen, and the di- rectionalities are determined b y whether an rwr:OutEdge or rwr:InEdge was trav ersed. The “w alking” asp ect of p for b oth Ψ and G n is go v erned by the rwr:Traverse rule. When p exe- cutes a rwr:Traverse rule in Ψ, it selects a par- ticular rwr:Edge to trav erse. F or rwr:OutEdge s, a triple in G n is selected with the sub ject being its curren t lo cation g p n , and predicate and ob jects are instances of the resp ective resource sp ecified b y the rwr:OutEdge ( rwr:hasPredicate and rwr:hasObject ). F or rwr:InEdge s, a triple in G n is selected where g p n is the ob ject of the triple and the sub ject and predicate are instances of the resource specified by the rwr:InEdge ( rwr:hasPredicate and rwr:hasSubject ). The rwr:Context chosen is ψ p n +1 and the rdfs:Resource of the triple h ψ p n +1 , rwr:forResource , ? x i ∈ Ψ determines g p n +1 , where ? x is any class in G n ’s ontology or instance in G n ’s vertex set V . The newly chosen g p n +1 is called the resolution of ψ p n +1 . The rwr:IncrCount and rwr:SubmitCounts rules ef- fect the random walk er’s local vertex vector π p and the global vertex v ector π , respectively . The distinction b et w een π p and π is that π p is a temp orary counter that is not submitted to the global coun ter π until the rwr:SubmitCounts rule has b een executed. The walk er p do es not s ubmit its vertex counts un til it has determined that it is in a Ψ-correct subset of G n . The pro cess of mo ving p through a semantic netw ork and allowing it to incremen t a coun ter for sp ecific v ertices con tin ues until the ratio b et w een the v alues of the global π conv erge. Note that π does not provide a probabil- it y distribution, P i ∈ π π i 6 = 1. Instead, π represen ts the n um ber of times an indexed v ertex of π has b een counted b y a grammar-based random walk er. Therefore, to de- termine the probabilit y of b eing at an y one v ertex that is indexed b y π , π can b e normalized to generate a new vec- tor denoted π 0 ∈ R |⊆ V | , where π 0 i = π i P j ∈ π π j . If π 0 is the normalization of π then, when π 0 no longer changes with successiv e executions of the rwr:SubmitCounts rule, the pro cess is complete. More formally , if ∈ R is an ar- gumen t specifying the smallest change accepted for con- v ergence consideration, then the grammar-based random w alk er algorithm is complete when || π 0 n − π 0 m || 2 < , where n and m are the time steps of consecutiv e calls to rwr:SubmitCounts . How ev er, lik e Marko v chains, this conv ergence will only o ccur if the subset of G n that is trav ersed is strongly connected and ap erio dic. If the trav ersed subset of G n is not strongly connected or is perio dic, then the rwr:Reresolve rule can b e used to simulate grammar-based random walk er “telep orta- tion”. With the inclusion of the rwr:Reresolve rule, a grammar-based P ageRank can b e executed on G n . The next section will formalized each of the rwr:Rule s and rwr:Attribute s of the grammar on tology . V. THE RULES AND A TTRIBUTES OF THE GRAMMAR ONTOLOGY The follo wing rwr:Rule s and rwr:Attribute s are presen ted in a set theoretic form that b orrows m uc h of its structure from semantic query lan- guages such as SP AR QL [35]. The query triple h ? x, rdf:type , lanl:Author i ∈ G n will bind ? x to an y lanl:Author in the seman tic net w ork G n . The ? x no- tation represen ts that ? x is a v ariable that is b ound to an y vertex (i.e. URI) that matches the query pattern. The same query can return man y resources that bind to ? x . In such cases, the re sults are returned as a set. Th us X = { ? x | h ? x, rdf:type , lanl:Author i ∈ G n } de- notes the s et of all v ertices in V that are of rdf:type lanl:Author . The following subsections present eac h of the rwr:Rule s and rwr:Attribute s that a grammar-based random walk er must execute and resp ect during its jour- ney through b oth Ψ and G n . 7 A. En tering Ψ and G n Ev ery random walk er “w alks” b oth Ψ and G n in paral- lel. How ev er, b efore a walk er can w alk either data struc- ture, it m ust enter both Ψ and G n . The entry points of Ψ are rwr:EntryContext s and are represented b y the set s (Φ), where s (Φ) = { ? x | h ? x, rdf:type , rwr:EntryContext i ∈ Ψ } . The starting lo cation φ ∈ s (Φ) of p is chosen with prob- abilit y 1 | s (Φ) | . Once some φ is c hosen, ψ p 0 = φ (time n starts at 0). An entry lo cation into V can b e determined b y randomly selecting some vertex i ∈ s ( V | φ ), where s ( V | φ ) is the set of all i ∈ V giv en that i is a prop er resolution of the rwr:EntryContext φ . Th us, s ( V | φ ) = { ? i | h φ, rwr:forResource , ? z i ∈ Ψ ∧ ( h ? i, rdf:type , ? z i ∈ Ψ ∨ ? i =? z ) } , where type inheritance is strictly follow ed. F or instance, if i is an rdf:type of z then i is an instance of z or an instance of u where u is a rdfs:subClassOf z . This is subsumption in RDFS reasoning and will be used rep eat- edly throughout the remainder of this article. Giv en the set s ( V | φ ), the probabilit y of p choosing some i ∈ s ( V | φ ) is 1 | s ( V | φ ) | . The chosen v ertex i b e- comes the starting lo cation of p in G n and th us, g p 0 = i . Note that g p 0 0 = ∅ , ψ p 0 0 = ∅ , g p 0 00 = ∅ and ψ p 0 00 = ∅ since a random w alker en ters both Ψ and G n at a vertex without using an interv ening edge lab el or directionality . Figure 7 depicts how rwr:EntryContext s in Ψ are related to v ertices in G n . Ψ rwr:forResource rwr:forResource rdf:type rdf:type rdf:type rwr:EntryContext rdf:type rdf:type G n s ( V | ˆ φ ) s ( V | φ ) φ ˆ φ G n ontology FIG. 7: The relationship b etw een rwr:EntryContext s in Ψ, G n , and G n ’s ontology . B. The rwr:Not A ttribute Before presen ting the rwr:Traverse rule, it is im- p ortan t to discuss the tw o attributes that constrain the rwr:Traverse rule: namely , rwr:Not and rwr:Is . This subsection will discuss the rwr:Not attribute. The next section will discuss the rwr:Is attribute. The rwr:Not atttribute ensures that the random w alker p do es not tra- v erse an edge to a particular, previously seen v ertex in g p . Any rwr:Not attribute is the sub ject of a triple with a predicate rwr:steps and literal m ∈ N . The literal m denotes which vertex from m -steps ago p must av oid. In other words, p m ust not ha ve a g p n +1 that equals g p n − m . Th us, the rwr:Context ψ p n +1 cannot resolve to g p n − m . If M = { ? m | h ψ p n +1 , rwr:hasAttributes , ? x i ∈ Ψ ∧ h ? x, rwr:hasAttribute , ? y i ∈ Ψ ∧ h ? y , rdf:type , rwr:Not i ∈ Ψ ∧ h ? y , rwr:steps , ? m i ∈ Ψ } , then X ( p ) n +1 = [ m ∈ M g p n − m , where X ( p ) n +1 ⊆ V and X ( p ) n +1 ∩ g p n +1 = ∅ . The set X ( p ) n +1 is the set of v ertices in V that g p n +1 m ust not equal. The rwr:Not attribute is useful when p must not return to a vertex in V that has b een previously visited. Imagine that p is determining whether or not a particular article has at least tw o authors (or must trav erse an implicit coauthorship netw ork). Such an example is depicted in Figure 8, where the n umbered circles are the lo cation of p at particular time steps and author v ertices are only con- nected to their authored articles. If, at n = 1, p is located at lanl:marko then p will trav erse the lanl:wrote pred- icate to the lanl:DDD article. If p is chec king for another author that is not lanl:marko then p can only take the lanl:wrote predicate to lanl:dsteinbock . If lanl:DDD only had one author, then p w ould b e stuc k (i.e. halt) at lanl:DDD since no legal lanl:wrote predicate could b e trav ersed. A t which p oint, it is apparen t that the article has only one author. Moreo ver, by trav ersing to lanl:dstreinbock and not back to lanl:marko at n = 3, a coauthorship netw ork is implicitly tra v ersed. lanl:DDD lanl:marko lanl:dsteinbock lanl:wrote lanl:wrote 1 2 3 3 FIG. 8: An example situation for the rwr:Not attribute 8 C. The rwr:Is A ttribute Unlik e the rwr:Not attribute, the rwr:Is atttribute is used to ensure that the random walk er p do es, in fact, tra v erse an edge to a previously visited vertex in V . Any rwr:Is attribute is the sub ject of a triple with a predicate rwr:steps and literal m ∈ N . The literal m denotes whic h v ertex from m -steps ago p must tra v erse to. If this set of vertices returned b y the rwr:Is attribute is greater than 1, then p must trav erses to one of the vertices from the set. Th us, the random walk er p must hav e vertex g p n +1 equal some g p n − m . In other w ords, the rwr:Context ψ p n +1 m ust resolv e to some g p n − m . If M = { ? m | h ψ p n +1 , rwr:hasAttributes , ? x i ∈ Ψ ∧ h ? x, rwr:hasAttribute , ? y i ∈ Ψ ∧ h ? y , rdf:type , rwr:Is i ∈ Ψ ∧ h ? y , rwr:steps , ? m i ∈ Ψ } , then O ( p ) n +1 = [ m ∈ M g p n − m , where O ( p ) n +1 ⊆ V and g p n +1 ∈ O ( p ) n +1 . Again, unless O ( p ) n +1 = ∅ , one of the vertices in O ( p ) n +1 m ust be p ’s lo cation in G n at n + 1. The rwr:Is attribute is useful when p must search particular prop erties of a vertex and later return to the original vertex. F or instance, imagine the triple h lanl:LANL , rdf:type , lanl:Laboratory i ∈ G n as de- picted in Figure 9, where the num b ered circles represent the p ’s lo cation at particular time steps n . Assume that p is at the lanl:LANL vertex at n = 1 and p must chec k to determine if lanl:LANL is, in fact, a lanl:Laboratory . In order to do so, p m ust trav erse the rdf:type predi- cate to arrive at lanl:Laboratory at n = 2. A t n = 3, p should return to the original lanl:LANL vertex. With- out the rwr:Is attribute, p has the p otential for c hoosing some other lanl:Laboratory , suc h as lanl:PNNL . Once bac k at lanl:LANL , it is apparen t that lanl:LANL is a lanl:Laboratory and p can mov e to some other vertex at n = 4. lanl:Laboratory lanl:LANL lanl:PNNL rdf:type rdf:type 1 2 3 3 4 ... ... FIG. 9: An example situation for the rwr:Is attribute D. The rwr:Traversal Rule The rwr:Travere rule allo ws the random walk er p to tra v erse to a new rwr:Context in Ψ and a new v er- tex in V . If there exists some rwr:Context φ with the rwr:Traverse rule t , then when g p n = a and ψ p n = φ , the probabilit y of p trav ersing some outgoing triple from a or some incoming triple to a is 1 | Γ( a,p ) | , where if Y out = { ? y | h t, rdfs:hasEdge , ? y i ∈ Ψ ∧ h ? y , rdf:type , rwr:OutEdge i ∈ Ψ } , Y in = { ? y | h t, rdfs:hasEdge , ? y i ∈ Ψ ∧ h ? y , rdf:type , rwr:InEdge i ∈ Ψ } , Γ + ( a, p ) = [ y ∈ Y out {h a, ? ω , ? b i | h a, ? ω , ? b i ∈ G n ∧ h y , rwr:hasPredicate , ? w i ∈ Ψ ∧ ( h ? ω , rdfs:subPropertyOf , ? w i ∈ G n ∨ ? ω =? w ) ∧ h y , rwr:hasObject , ? x i ∈ Ψ ∧ h ? x, rdf:forResource , ? z i ∈ Ψ ∧ ( h ? b, rdf:type , ? z i ∈ G n ∨ ? b =? z ) ∧ ( O ( p ) n +1 = ∅ ∨ ? b ∈ O ( p ) n +1 ) ∧ ? b 6∈ X ( p ) n +1 } , Γ − ( a, p ) = [ y ∈ Y in {h ? b, ? ω , a i | h ? b, ? ω , a i ∈ G n ∧ h y , rwr:hasPredicate , ? w i ∈ Ψ ∧ ( h ? ω , rdfs:subPropertyOf , ? w i ∈ G n ∨ ? ω =? w ) ∧ h y , rwr:hasSubject , ? x i ∈ Ψ ∧ h ? x, rdf:forResource , ? z i ∈ Ψ ∧ ( h ? b, rdf:type , ? z i ∈ G n ∨ ? b =? z ) ∧ ( O ( p ) n +1 = ∅ ∨ ? b ∈ O ( p ) n +1 ) ∧ ? b 6∈ X ( p ) n +1 } , then Γ( a, p ) = Γ + ( a, p ) ∪ Γ − ( a, p ) . A t the completion of the trav ersal, g p n +1 = b , g p n +1 0 = ω , ψ p n +1 = x , and ψ p n +1 0 = w . If the edge w as chosen from Γ + ( a, p ) then g p n +1 00 = + and ψ p n +1 00 = +. If the edge w as c hosen from Γ − ( a, p ) then g p n +1 00 = − and ψ p n +1 00 = − . It is alwa ys the case that ∀ n : ψ p n 00 = g p n 00 . Note the relationship betw een G n and Ψ in the defini- tion of b oth Γ − ( a, p ) and Γ + ( a, p ). It is necessary that the rwr:hasPredicate ? w and the rwr:forResource ? z as defined in Ψ also exist in G n . It is through the rwr:Traverse rule that the relationship betw een Ψ and 9 G n is made explicit and demonstrates how Ψ constrains the path that p can tra v erse in G n . Figure 10 depicts an example of a tra v er- sal. In Figure 10, Γ − ψ ( a, p ) = {h j, ω , a i} and Γ + ψ ( a, p ) = {h a, ω , e i , h a, ω , f i} , where Γ ψ ( i ) = {h j, ω , a i , h a, ω , e i , h a, ω , f i} , and an y one triple is selected with 1 3 probabilit y . ω ω ω i j a Γ − ( a, p ) Γ + ( a, p ) e f g FIG. 10: An example of the set of edges allow ed for trav ersal b y p when g p n = a . E. The rwr:IncrCount and rwr:SubmitCounts Rules The purp ose of the rwr:IncrCount and rwr:SubmitCounts rules is to increment the lo cal v ertex rank vector π p and global vertex rank v ector π , resp ectively . While π p is a lo cal v ariable of p , only π is returned at the completion of the grammar-based random walk er algorithm. The reason for π p is to ensure that prior to incremen ting π , the vertices indexed by π p are in a grammatically correct region of G n as deter- mined by the grammar Ψ. F or example, if p is to index a particular lanl:Human , it will do so in π p . How ever, b efore that lanl:Human is considered legal according to Ψ, p ma y hav e to chec k to see if the lanl:Human is lanl:locatedAt the same lanl:University of some previously encoun tered lanl:Human . Th us, when p has submitted its π p to π , it will hav e guaranteed that all the appropriate asp ects of its incremented vertices in π p ha v e been v alidated by Ψ. This concept will b e made more salient in the example to follow in the next section. F ormally , if h φ, rdf:type , rwr:Context i ∈ Ψ, ψ p n = φ , g p n = i , and φ has the rwr:IncrCount rule, then π p i ( n +1) = π p i ( n ) + 1 . Next, if g p = i , ψ p = φ , h φ, rdf:type , rwr:Context i ∈ Ψ, and φ has the rwr:SubmitCounts rule, then π i ( n +1) = π i ( n ) + π p i ( n ) : ∀ i ∈ π p and π p i ( n +1) = 0 : ∀ i ∈ π p . As stated ab ov e, once π p has been submitted to π , the v alues of π p are set to 0. F. The rwr:Reresolve Rule The rwr:Reresolve rule is a w a y to “telep ort” the random walk er to some random vertex in V and is p erhaps the most complicated rule of the grammar-based random w alk er ontology . If there exists the rwr:Context φ , ψ p n = φ , φ has the rwr:Reresolve rule u , h u, rwr:probability , ? d i ∈ Ψ, and h u, rwr:steps , ? m i ∈ Ψ, then p will hav e a ( d · 100)% c hance of re-resolving its path from m steps ago to the curren t step n , where d = 0 . 15 in most PageRank im- plemen tations. If the random w alk er re-resolves, then the path from g p n − m to g p n is recalculated. In other w ords, a new path in G n is determined with resp ects to the rwr:Context s ψ p n − m to ψ p n suc h that no rules are executed and only those attributes specified by the rwr:obeys property are resp ected. F or example, suppose ψ p ( n − m ) → n = ( φ ( n − m ) , ω ( n − m )+1 0 , ± ( n − m )+1 00 , . . . , ω n 0 , ± n 00 , φ n ) and con text ψ p n has a rwr:Reresolve rule, where ψ p n = φ n . If the rwr:Reresolve rule rwr:obeys b oth the rwr:Is and rwr:Not attributes, then the grammar-based ran- dom w alk er p will re-resolve its history in G n . Thus it will recalculate g p n − m to g p n . The set of legal re-resolved paths from n − m steps ago to n is denoted Q ( n − m ) ,n . Giv en that the probability d is met, Q ( n − m ) ,n = { (? i, ? ω ( n − m )+1 0 , ± ( n − m )+1 00 , ? a, . . . , ? b, ? ω n 0 , ± n 00 , ? j ) | h ψ p ( n − m ) , rwr:forResource , ? x i ∈ Ψ ∧ ( h ? i, rdf:type , ? x i ∈ G n ∨ ? i =? x ) ∧ ( O ( p ) ( n − m ) = ∅ ∨ ? i ∈ O ( p ) ( n − m ) ) ∧ ? i 6∈ X ( p ) ( n − m ) ∧ ( h ? ω n 0 , rdfs:subPropertyOf , ψ p n 0 i ∈ G n ∨ ? ω ( n − m )+1 0 = ψ p ( n − m )+1 0 ) ∧ (( ± ( n − m )+1 00 = + ∧ (? i, ? ω ( n − m )+1 0 , ? a ) ∈ G n ) ∨ ( ± ( n − m )+1 00 = − ∧ (? a, ? ω ( n − m )+1 0 , ? i ) ∈ G n )) ∧ . . . ∧ (( ± n 00 = + ∧ (? b, ? ω n 0 , ? j ) ∈ G n ) ∨ ( ± n 00 = − ∧ (? j, ? ω n 0 , ? b ) ∈ G n )) ∧ ( h ? ω n 0 , rdfs:subPropertyOf , ψ p n 0 i ∈ G n ∨ ? ω n 0 = ψ p n 0 ) ∧ h ψ p n , rwr:forResource , ? y i ∈ Ψ ∧ ( h ? j, rdf:type , ? y i ∈ G n ∨ ? j =? y ) ∧ ( O ( p ) n = ∅ ∨ ? j ∈ O ( p ) n ) ∧ ? j 6∈ X ( p ) n } . The probability of p c ho osing some re-resolved path q ∈ Q ( n − m ) ,n is 1 Q ( n − m ) ,n , where g p k 00 = q k 00 , g p k 0 = q k 0 , and 10 g p k = q k for all k such that m ≤ k ≤ n . While the abov e equation is perhaps notationally tric ky , it has a relatively simple meaning. In short, p m ust recalculate (or re-resolv e) its path from m step ago to the present step n . This recalculation m ust follo w the exact same grammar path denoted in ψ p . Th us, if from m to n , p had ensured that its current v ertex is a lanl:Human that is lanl:locatedAt lanl:Laboratory then when p “telep orts”, the new v ertex at n will be guar- an teed to also b e a lanl:Human that is lanl:locatedAt a lanl:Laboratory . If there are no rank sinks, this rule guarantees a strongly connected net work; an y vertex can be reached b y any other vertex in the grammatically correct region of G n . Ho wev er, note that rank sinks are remedied b y the next rule. G. The Empty Rule Random walk er halting o ccurs when p arrives at some rwr:Context where no rule exists or there are no more rules to execute (e.g. when a rwr:Traverse rule do es not provide any transition edges – Γ( a, p ) = ∅ ). A t halt p oin ts, a new random walk er with an empt y π p and no G n or Ψ history (i.e. | g p | = 0 and | ψ p | = 0), enters G n at some rwr:EntryContext φ in Ψ and some i ∈ s ( V | φ ). The new random walk er executes the grammar. Note that the global rank vector π remains unchanged. The com bination of the empt y rule and the rwr:Reresolve rule are necessary to ensure that π is a stationary distribution. Both rules are used in conjunc- tion to supp ort grammar-based PageRank calculations. In order to demonstrate the aforementioned ideas, the next section presents a particular grammar instance de- v elop ed for a scholarly netw ork ontology and instance. VI. A SCHOLARL Y NETW ORK EXAMPLE This section will demonstrate the application of grammar-based random walk ers to a scholarly seman- tic netw ork denoted G n . Figure 11 diagrams the on tology of G n where the tail of the edge is the rdfs:domain and the head of the edge is the rdfs:range . The dashed lines represen t the rdfs:subClassOf re- lationship. This ontology represen ts the relation- ships b etw een lanl:Institution s, lanl:Researcher s, lanl:Article s, and their resp ective children classes. The first example calculates the stationary dis- tribution of the subset of G n that is semanti- cally equiv alent to the coauthorship netw ork re- sulting from lanl:ConferenceArticle s written b y lanl:Researcher s that are lanl:locatedAt a lanl:University only . The second example presents a grammar for calculating the stationary distribution ov er all v ertices in a seman tic net w ork irrespective of the edge lab els (i.e. an unconstrained grammar). The second lanl:Researcher lanl:Institution lanl:Article lanl:Journal Article lanl:Conference Article lanl:Graduate Student lanl:Professor lanl:University lanl:Scholarly Artifact lanl:locatedAt lanl:wrote lanl:cites lanl:Laboratory FIG. 11: An example scholarly ontology example is equiv alent to running the single-relational implemen tation of PageRank on a semantic netw ork. A. Conference Article Co-Authorship Grammar Ψ coaut Let Ψ coaut denote the grammar for generating a π for the subset of G n that is semantically equiv- alen t to the coauthorship net w ork resulting from lanl:ConferenceArticle s for all lanl:Researcher s from a lanl:University . Ψ coaut is diagrammed in Figure 12 where, for the sake of conv enience, the con- text names, without the #, denote the rdfs:Resource p oin ted to by the rwr:forResource prop erty of the resp ectiv e rwr:Context . The b olded + or − on the edges denotes whether the rwr:Edge is an rwr:OutEdge or rwr:InEdge , resp ectiv ely . The dashed square rep- resen ts an rwr:EntryContext . The stack of rules for eac h rwr:Context denotes the rdf:Seq of rules ordered from top to b ottom and rwr:Context attributes are also stac k ed (in no particular order) with their resp ective rwr:Context . lanl:Researcher_1 lanl:University_0 lanl:Conference Article_2 lanl:locatedAt lanl:wrote lanl:wrote rwr:Submit Counts_0 lanl:Researcher_3 lanl:locatedAt rwr:Traverse_0 rwr:Traverse_1 rwr:Traverse_2 rwr:Traverse_3 rwr:Incr Count_3 rwr:Not_3 rwr:Is_1 rwr:Incr Count_1 "1" "1" - + + Ψ coaut - FIG. 12: A grammar to calculate eigen vector cen tralit y on a conference article coauthorship netw ork of universit y re- searc hers. A single grammar-based random walk er p ∈ P will b egin its journey in G n at some v ertex i ∈ s ( V | lanl:University 0 ), where s ( V | lanl:University 0 ) = { ? i | h ? i, rdf:type , lanl:University i ∈ G n } 11 and the i ∈ s ( V | lanl:University 0 ) is chosen with probability 1 | s ( V | lanl:University 0 ) | . After a vertex in s ( V | lanl:University 0 ) is chosen, g p 0 = i and ψ p 0 = lanl:University 0 . There are 2 sequen tially or- dered rules at University 0 : rwr:SubmitCounts 0 and rwr:Traverse 0 . The first rule has no effect on π or π p b ecause for all i π p i (0) = 0. The rwr:SubmitCounts 0 rule is imp ortant on the next time around Ψ coaut . With the rwr:Traverse 0 rule, p randomly chooses a single v ertex w in W = { ? w | h ? w , lanl:locatedAt , i i ∈ G n ∧ h ? w , rdf:type , lanl:Researcher i ∈ G n } , where rwr:Is 1 requires that g p 1 = g p − 1 and g p − 1 = ∅ (i.e. O ( p ) 1 = ∅ ). The rwr:Is 1 attribute is imp ortan t the second time around Ψ coaut . A t time step 1, g p 1 = w and ψ p 1 = lanl:Researcher 1 . Researcher 1 has the rwr:IncrCount 1 rule and thus, π p w (1) = 1. After the rwr:IncrCount 1 rule is executed, p will execute the rwr:Traverse 1 rule. The random w alk er p will randomly choose some x in X = { ? x | h w , lanl:wrote , ? x i ∈ G n ∧ h ? x, rdf:type , lanl:ConferenceArticle i ∈ G n } . If x is prop erly resolved, then g p 2 = x and ψ p 2 = lanl:ConferenceArticle 2 . How ever, if w has not written a lanl:ConferenceArticle , then x = ∅ . A t which p oin t, the rwr:Traverse 1 rule fails and ( i, lanl:locatedAt , − , w ) is an ungrammatical path in G n according to Ψ coaut . If x = ∅ , a new random walk er (i.e. a p with no history and zero π p ) randomly c ho oses some en try p oin t in to Ψ coaut and G n and the pro cess b egins again. If, on the other hand, w has written some lanl:ConferenceArticle x , then p will randomly select a y in Y = { ? y | h ? y , lanl:wrote , x i ∈ G n ∧ h ? y , rdf:type , lanl:Researcher i ∈ G n ∧ ? y 6 = w } . Note the role of the rwr:Not 3 prop erty in Researcher 3 . rwr:Not 3 guarantees that the x lanl:ConfereneArticle was written by tw o or more lanl:Researcher s and that only those lanl:Researcher s that are not w are selected since X ( p ) 3 = { w } . Seman tically , this ensures that the subset of G n that is tra v ersed is a coauthorship netw ork. If y = ∅ , then ( i, lanl:locatedAt , − , w , lanl:wrote , + , x ) is an ungrammatical path with resp ects to Ψ coaut . If y 6 = ∅ , then g p 3 = y , ψ p 3 = Researcher 3 , and π p y (3) = 1. Finally , b ecause of the rwr:Traverse 3 rule, p randomly selects some z in Z = { ? z | h y , lanl:locatedAt , ? z i ∈ G n ∧ h ? z , rdf:type , lanl:University i ∈ G n } . Th us, g p 4 = z and ψ p 4 = University 0 . At this p oint in time, g p = ( i, lanl:locatedAt , − , w , lanl:wrote , + , x , lanl:wrote , − , y , lanl:locatedAt , + , z ) and g p is a Ψ coaut -correct and w and y are indexed b y π . The rwr:SubmitCounts 0 rule ensures that π w (4) = π p w (4) and π y (4) = π p y (4) . Finally , when rwr:SubmitCounts 0 has completed, π p w (4) = π p y (4) = 0. This process contin- ues un til the ratio b etw een the coun ts in π conv erge. A t n = 5, the rwr:Is 1 rule is imp ortant to en- sure that, after chec king if the y rwr:Researcher is rwr:locatedAt a rwr:University , p return to y b e- fore lo cating a rwr:ConferenceArticle written by y and con tin uing its trav ersal through the implicit coauthorship net w ork in G n as defined by Ψ coaut . What is pro vided b y π is the num b er of times a par- ticular vertex in V has b een visited ov er a given num b er of time steps n . If vertex i ∈ V was visited π i times then the probability of observing a random w alk er at i is n π i . Ho w ev er, giv en that P i ∈ V π i ≤ n because other vertices not indexed b y π exist on a Ψ coaut -correct path of G n , the probability of the random w alker b eing at vertex i when observing only those vertices indexed b y π is π 0 i = π i P j ∈ V π j : i ∈ V . Th us, X i ∈ V π 0 i = 1 . This step is called the normalization of π and is nec- essary for transforming the num b er of times a vertex in V is visited into the probabilit y that the v ertex is b eing visited at an y one time step. When || π 0 ( n ) − π 0 ( m ) || 2 ≤ , where m < n and m and n are consecutive π up date steps (i.e. consecutiv e rwr:SubmitCounts ), π has conv erged to a range acceptable by the ∈ R pro vided argumen t. Ho w ev er, π may never conv erge if the p -tra versed sub- set of G n is not strongly c onnected. F or instance, let the triple list A n b e defined as A n = {h ? i, lanl:coauthor , ? y i | ∧ h ? w , rdf:type , lanl:University i ∈ G n ∧ h ? i, lanl:locatedAt , ? w i ∈ G n ∧ h ? i, lanl:wrote , ? x i ∈ G n ∧ h ? x, rdf:type , lanl:ConferenceArticle i ∈ G n ∧ h ? y , lanl:wrote , ? x i ∈ G n ∧ h ? y , lanl:locatedAt , ? z i ∈ G n ∧ h ? z , rdf:type , lanl:University i ∈ G n ∧ ? i 6 =? y } . F urthermore, let V ∗ denote the set of unique lanl:Researcher vertices in A n and A ∈ R | V ∗ |×| V ∗ | b e a w eigh ted adjacency matrix where A i,y = ( 1 | Γ + ( i ) | if h i, lanl:coauthor , y i ∈ A n 1 | V ∗ | if | Γ + ( i ) | = 0 . 12 If A π 0 = λπ 0 where λ is the largest eigen v alue of the eigen v ectors of A , then π 0 is the stationary distri- bution of A and thus, the p -tra v ersed subset of G n giv en Ψ coaut is strongly connected. Ho w ev er, most coauthor- ship netw orks are not strongly connected [27] and there- fore, π 0 ma y not b e a stationary distribution. F or exam- ple, there may exists some lanl:University denoted R and lanl:locatedAt R are only t wo lanl:Researcher s, x and y , that hav e a coauthor relationship with resp ects to a particular lanl:ConferenceArticle . If the ran- dom w alk er p happens to enter G n at x , then the ran- dom w alk er will nev er lea v e the x/y comp onent. How- ev er, some new lanl:Researcher , and therefore some new lanl:University , can b e introduced into the prob- lem by re-resolving the lanl:ConferenceArticle unit- ing x and y such that p telep orts to some new researcher w at some other lanl:University S . This example is depicted in Figure 13, where the dashed line represents a telep ortation b y p . This telep ortation introduces the artificial relationship that x coauthored with w . Thus, when there exists a non-zero probabilit y of telep ortation at ev ery v ertex in V ∗ , the coauthorship net w ork becomes strongly connected. coauthor coauthor coauthor coauthor R S x y w z FIG. 13: T elep ortation required for connecting isolated com- p onen ts. In order to guarantee a strongly connected net work, it is possible to simulate the b eha vior of randomly c ho os- ing some new entry p oint with probabilit y δ ∈ (0 , 1] as an analogy to the metho d of inducing strong connectivity in [33]. The rwr:Reresolve rule is introduced to Ψ coaut at ConferenceArticle 2 where rwr:Reresolve 2 has a δ = 0 . 15, a rwr:steps of m = 2, and do es not rwr:obey an y rwr:Context attributes. Ψ coaut’ is diagrammed in Figure 14, where the "0.15" literal is the ob ject of the triple h rwr:Reresolve 2 , rwr:probability , "0.15" i ∈ Ψ coaut’ and the "2" literal is the ob ject of triple h rwr:Reresolve 2 , rwr:steps , "2" i ∈ Ψ coaut’ . With resp ects to G n , every time random walk er p encounters the rwr:ConferenceArticle 2 con text, it has a 15% chance of telep orting to some new lanl:Researcher_1 lanl:University_0 lanl:Conference Article_2 lanl:locatedAt lanl:wrote lanl:wrote rwr:Submit Counts_0 lanl:Researcher_3 lanl:locatedAt rwr:Traverse_0 rwr:Traverse_1 rwr:Traverse_2 rwr:Traverse_3 rwr:Incr Count_3 rwr:Not_3 rwr: Reresolve_2 rwr:Is_1 rwr:Incr Count_1 "0.15" "2" "1" "1" + - + Ψ coaut ! - FIG. 14: A grammar to calculate PageRank on a conference article coauthorship netw ork of univ ersity researchers. lanl:ConferenceArticle i in V such that Q n − 2 ,n = { (? w , ? x, − , ? y , ? z , + , ? i ) | ∧ h ? w , rdf:type , lanl:University i ∈ G n ∧ ? x = lanl:locatedAt ∧ h ? y , rdf:type , Researcher i ∈ G n ∧ ? z = lanl:wrote ∧ h ? i, rdf:type , lanl:ConferenceArticle i ∈ G n ∧ h ? y , ? x, ? w i ∈ G n ∧ h ? y , ? z , ? i i ∈ G n } . and a new path q ∈ Q n − 2 ,n is chosen with probability 1 | Q n − 2 ,n | . If q = ( w, x, − , y , z , + , i ), g p ( n − 2) → n = ( g p ( n − 2) → n with probabilit y 1 − d q 0 → 2 with probabilit y d. The rwr:Reresolve rule guaran tees that any confer- ence publishing researcher is reachable b y any other con- ference publishing univ ersit y researcher and thus, the coauthorship netw ork of conference publications by uni- v ersit y researchers is strongly connected. Theoretically , the rwr:Reresolve 2 rule ensures that there exists some h yp othetical triple list B n , suc h that B n = {h ? i, lanl:teleport , ? j i | ? i, ? j ∈ V ∗ } , where V ∗ is the set of lanl:Researcher s from A n . Let B ∈ R | V ∗ |×| V ∗ | b e a weigh ted adjacency matrix where for any entry in B , B i,j = 1 | V ∗ | . Ψ coaut’ is equiv alen t to computing π 0 for C where C = δ A + (1 − δ ) B and δ = 0 . 85. Therefore, π 0 generated from Ψ coaut’ is a stationary distribution. The eigen v ector centralit y or PageRank of the netw ork could ha v e b een calculated b y extracting the appropriate lanl:Researcher v ertices from V and generating the im- plicit lanl:ConferenceArticle coauthorship edge b e- t w een them. This was done with the netw ork A n and its “telep oration” netw ork B n , where A and B are the re- sp ectiv e adjacency matrices representations of these net- w orks. In this sense, the single-relational eigenv ector cen- tralit y or PageRank algorithm w ould generate the same 13 results. Ho w ev er, the grammar-based random walk er al- gorithm is differen t than the “isolation-based” metho d. In the grammar-based method, there is no need to gener- ate (i.e. make explicit) the implicit single-relational sub- set of G n and thus, create another data structure; the same G n can b e used for different eigenv ector calcula- tions without altering it. Th us, multiple different gram- mars can b e running in parallel on the same data set (on the same triple-store). F or more complex grammars that in v olv e rwr:Is and rwr:Not constraints ov er m ultiple cy- cles of a grammar, the query to isolate the sub-netw ork b ecomes increasingly long as recursions cannot be ex- pressed in the standard RDF query language SP ARQL [35]. B. Sim ulating Single-Relational P ageRank on a Seman tic Netw ork The grammar depicted in Figure 15 is denoted Ψ ∅ and is the grammar that calculates π on any seman tic net- w ork without consideration for edge directionality nor edge labels. Th us, this grammar is not constrained to the ontology of the semantic netw ork and can b e applied to an y G n instance. F urthermore, the rwr:Reresolve rule guaran tees that all v ertices are reac hable from all other vertices. Note that this grammar ensures that all v ertices in V are Ψ ∅ -correct. The presented grammar is equiv alen t to executing PageRank on an undirected single-relational represen tation of a semantic netw ork. rdfs:Resource_0 rwr:Submit Counts_0 rdfs:Resource rwr:T raverse_0 + rdfs:Resource - rwr:Incr Count_0 rwr:Reresolve_0 "0.15" "0" Ψ ∅ FIG. 15: A grammar to calculate an undirected single- relational netw ork PageRank on a semantic net w ork. VI I. ANAL YSIS What has b een presen ted th us far is an on tology for instan tiating an G n sp ecific grammar, the formalization of the rules and attributes that m ust b e resp ected by a grammar-based random walk er, and an eigenv ector cen tralit y and P ageRank example in volving a seman- tic scholarly net w ork. This section will briefly discuss the v arious p ermutations of G n that are tra v ersed by a grammar-based random walk er. As stated previously , only a subset of the complete seman tic netw ork G n is trav ersed b y any p ∈ P . Let G ψ ⊆ G n denote the graph tra versed by p according to Ψ. It is noted that only a subset of G ψ is considered Ψ-correct (i.e. grammatically correct according to Ψ). If p is unable to submit its π p to the global vertex vector π , then p has taken an ungrammatical semantic path in G n . On the other hand, if p contributes its π p to π , p has tak en a grammatical seman tic path (i.e. a Ψ-correct path). Let G ψ + ⊆ G ψ denote the subset of G ψ that is grammatically correct according to Ψ. Definition 1 (The Ψ -Correct Paths of G ψ + ) The p ath g p m → n in G n is c onsider e d gr ammatic al ly c orr e ct with r esp e cts to Ψ if and only if ψ p m is an rwr:EntryContext or an rwr:Context with an rwr:SubmitCounts rule, ψ p n is an rwr:Context with an rwr:SubmitCounts rule, and ther e exist some rwr:IncrCount rule at time k , such that m ≤ k ≤ n . The set of al l gr ammtic al ly c orr e ct p aths form the semantic network G ψ + , wher e G ψ + ⊆ G ψ ⊆ G n . The grammatically correct path g p m → n ensures that some v ertex in g p m → n w as v alidated by the grammar Ψ and indexed by π . Figure 16 demonstrates a subset of G n that is trav ersed b y P to generate G ψ + , where the b old lab eled v ertices are those indexed by π . G ψ + a a b b c c P G n FIG. 16: G ψ + as the Ψ-correct subset of G n . Note that the v ertices indexed by π are not nec- essarily all of the vertices encountered b y the ran- dom w alkers in G ψ + . Similar to the coauthor ex- ample presented previous, while a p ∈ P trav erses v ertices of type lanl:Article , lanl:University , and lanl:Researcher , only lanl:Resercher vertices are in- dex by π . Thus, those vertices indexed b y π form an “implied” netw ork. The G ψ + represen ted in Figure 16 has the implied netw ork G π as diagrammed in Figure 17. The probabilities on the edges are giv en b y branc hes b et w een the resp ective vertices in G ψ + . Theorem 1 If G ψ + is str ongly c onne cte d and ap erio dic, then π 0 is a stationary pr ob ability distribution. Pr o of. If G ψ + is strongly connected, then ev ery v ertex in G ψ + is reac hable from any other vertex. Given that π 14 0.5 0.5 0.5 1 0.5 G π a c b FIG. 17: G π as the implied netw ork of G ψ + . indexes a subset of the v ertices in G ψ + and the vertices in G π are reac hable by means of the edges in G ψ + , then the vertices indexed b y π are strongly connected. Thus, the normalization of π , π 0 , is a stationary probability distribution. Note that the ab o v e do es not generalize to G n . If G n is strongly connected, that do es not guaran tee that the grammar will permit the grammar-based random w alk er p to trav erse a subset of G n that is strongly connected. F or example, imagine the netw ork G n depicted in Figure 18. Even if G n is a strongly connected net work, the Ψ- correct subgraph of G n tra v ersed ma y not b e. G ψ + a c b FIG. 18: A strongly connected G n do es not guaran tee a strongly connected G ψ + . Finally , if the path distance b etw een the vertices in G π is equal in G ψ + , then π 0 is the primary eigen vector of the G π . How ever, this is not alw a ys the case. Figure 19 demonstrates that the timing betw een indexing the differen t vertices in the netw ork diagrammed in Figure 16 is different for different paths chosen by p . 1 2 3 4 5 a c b FIG. 19: The v ariability of index delay times for G π . Theorem 2 If the p aths in G ψ + b etwe en the vertic es in- dexe d by π ar e of e qual length, then π 0 is the primary eigenve ctor of G π . Pr o of. If the path lengths in G ψ + b et w een the v ertices index b y π are of equal length, then the in terv ening non- π v ertices in G ψ + can b e remov ed without interfer- ing with the relativ e timing of respective increments to the vertices in π . Given this netw ork manipulation, a single-relational eigen v ector cen trality algorithm on the single-relational netw ork G π w ould yield π 0 . Th us, π 0 is the primary eigenv ector of the netw ork G π . VI I I. CONCLUSION There is m uch disagreement to the high-level meaning of the primary eigenv ector of a netw ork. π has been as- so ciated with concepts such as “prestige”’, “v alue”, “im- p ortance”, etc. F or Mark o v c hain analysis, when vertices represen t states of a system, the meaning is clear; π de- fines the probabilit y that at some random time n , the system G 1 will b e at some particular state in V , where more “central” states (i.e. those with a higher π proba- bilit y) are more likely to b een seen. Ho w ev er, the application of π to more abstract con- cepts of cen tralit y such as “v alue” has b een applied in the area of the web citation netw ork. If the web is repre- sen ted as a Mark o v chain, then π i defines the probability that some random w eb surfer will b e at a particular web page i at some random time n . Do es this phenomena denote that web pages with a higher π probabilit y are more “v aluable” than those with lo w er π probabilities? F or the many of us who use Go ogle daily , it do es [12]. Ho w ev er, for other artifact netw orks, π can hav e a com- pletely differen t meaning. In journal usage netw orks, π tends to b e a comp onent whic h makes a distinction b etw een applied and theoreti- cal journals, not “v alue” or “prestige” [8]. On the other hand, the π calculated for a journal citation net work do es pro vide us with the notion of “prestige” [7]. This demon- strates that π has a differen t meaning dep ending on the seman tics of the edges trav ersed. In other words, differ- en t grammars provide different interpretations of π . Whether π represents “v alue” or some other dimen- sion of distinction, this article has provided a metho d for calculating v arious π vectors in subsets of the se- man tic netw ork G n b y means of a random walk er al- gorithm constrained to a grammar. F or researc hers with new ork-based data sets con taining heterogeneous en tity t yp es and heterogeneous relationship types, this article ma y pro vide a more in tuitiv e w ay of studying the v arious π s of G n . Ac kno wledgmen ts This work was funded by a grant from the Andrew W. Mellon F oundation and executed by the MESUR pro ject (h ttp://www.mesur.org). [1] Aasman, J., 2006, Al le gr o Graph , T echnical Rep ort 1, F ranz Incorp orated, URL www.franz.com/products/ allegrograph/allegrograph.datasheet.pdf . 15 [2] Aleman-Meza, B., C. Halaschek-Wiener, I. B. Arpinar, C. Ramakrishnan, and A. P . Sheth, 2005, IEEE Internet Computing 9 (3), 37, ISSN 1089-7801. [3] An yan wu, K., and A. Sheth, 2003, in Pro c e e dings of the Twelfth International World-Wide Web Confer enc e (Bu- dap est, Hungary). [4] Bax, M., 2004, in International Confer enc e on Ele ctr onic Publishing (ICCC2004) (Bras ´ ılia, Brazil). [5] Berners-Lee, T., , R. Fielding, D. Softw are, L. Masin- ter, and A. Systems, 2005, Uniform Resource Iden tifier (URI): Generic Syntax. [6] Biron, P . V., and A. Malhotra, 2004, XML Schema Part 2: Datatyp es Se c ond Edition , T echnical Rep ort, W orld Wide W eb Consortium, URL http://www.w3.org/TR/ xmlschema- 2/ . [7] Bollen, J., M. A. Ro driguez, and H. V an de Sompel, 2006, Scien tometrics 69 (3). [8] Bollen, J., and H. V an de Somp el, 2006, Scientometrics 69 (2). [9] Bonacic h, P ., 1987, American Journal of Sociology 92 (5), 1170. [10] Brandes, U., and T. Erlebac h (eds.), 2005, Network Anal- ysis: Metho dolgical F oundations (Springer, Berling, DE). [11] Bric kley , D., and R. Guha, 2004, RDF V o c abulary De- scription Language 1.0: RDF schema , T echnical Re- p ort, W orld Wide W eb Consortium, URL http://www. w3.org/TR/rdf- schema/ . [12] Brin, S., and L. P age, 1998, Computer Netw orks and ISDN Systems 30 (1–7), 107. [13] Broder, A., R. Kumar, F. Maghoul, P . Raghav an, S. Ra- jagopalan, R. Stata, A. T omkins, and J. Wiener, 2000, in Pr o c ee dings of the 9th International World Wide Web Confer enc e (Amsterdam, Netherlands). [14] Chen, P ., H. Xie, S. Maslov, and S. Redner, 2007, Jour- nal of Informetrics 1 (1), 8, URL physics/0604130 . [15] Ching, W.-K., and M. K. Ng, 2006, Markov Chains: Mo dels, Algorithms, and Applic ations (Springer, New Y ork, NY). [16] Cohen, P . R., and R. Kjeldsen, 1987, Information Pro- cessing and Management 23 (4), 255. [17] Crestani, F., 1997, Artificial In telligence Review 11 (6), 453. [18] Crestani, F., and P . L. Lee, 2000, Information Pro cessing and Management 36 (4), 585. [19] Gasevic, D., and V. Devedzic, 2006, Knowledge-Based Systems 19 , 220. [20] Gasevic, D., D. Djuric, and V. Dev edzic, 2006, Model Driven Ar chite ctur e and Ontolo gy Development (Spring- V erlag, Berlin, DE). [21] Getoor, L., and C. P . Diehl, 2005, SIGKDD Explorations Newsletter 7 (2), 3, ISSN 1931-0145. [22] H¨ aggstr¨ om, O., 2002, Finite Markov Chains and Algo- rithmic Applic ations (Cambridge Universit y Press). [23] Klyne, G., and J. J. Carroll, 2004, R esour c e Descrip- tion F r amework (RDF): Conc epts and Abstr act Syntax , T echnical Report, W orld Wide W eb Consortium, URL http://www.w3.org/TR/rdf- concepts/ . [24] Lacy , L. W., 2005, OWL: Repr esenting Information Us- ing the Web Ontolo gy L anguage (T rafford Publishing). [25] Langville, A. N., and C. D. Meyer, 2006, Go o gle’s PageR- ank and Beyond: The Scienc e of Se ar ch Engine R ankings (Princeton Universit y Press, Princeton, New Jersey). [26] Lin, S., 2004, in Sixteenth Confer enc e on Innovative Applic ations of Artificial Intel ligenc e , edited by D. L. McGuinness and G. F erguson (MIT Press), pp. 991–992. [27] Liu, X., J. Bollen, M. L. Nelson, and H. V an de Somp el, 2006, Information Processing and Management 41 (6), 1462, URL . [28] Manola, F., and E. Miller, 2004, RDF primer: W3C recommendation, URL http://www.w3.org/TR/ rdf- primer/ . [29] McGuinness, D. L., and F. v an Harmelen, 2004, OWL w eb ontology language ov erview, URL http://www.w3. org/TR/owl- features/ . [30] Mihalcea, R., P . T arau, and E. Figa, 2004, in Pr o c e e dings of the 20th International Confer enc e on Computational Linguistics (COLING 2004) (Switzerland, Genev a). [31] Miller, E., 1998, D-Lib Magazine URL http://dx.doi. org/hdl:cnri.dlib/may98- miller . [32] Mitrani, I., 1998, Prob abilistic Mo deling (Cambridge Uni- v ersit y Press, Cambridge, UK). [33] P age, L., S. Brin, R. Motw ani, and T. Winograd, 1998, The PageR ank Citation R anking: Bringing Or der to the Web , T echnical Rep ort, Stanford Digital Library T ech- nologies Pro ject. [34] P arzen, E., 1962, Sto chastic Pro c esses (Holden-Da y , Inc.). [35] Prud’hommeaux, E., and A. Seab orne, 2004, SP ARQL Query L anguage for RDF , T echnical Rep ort, W orld Wide W eb Consortium, URL http://www.w3.org/TR/2004/ WD- rdf- sparql- query- 20041012/ . [36] Rada, R., H. Mili, E. Bic knell, and M. Blettner, 1989, IEEE T ransactions on Systems, Man and Cyb ernetics 19 (1), 17. [37] Rodriguez, M. A., 2007, Gener al-Purp ose Computing on a Semantic Network Substr ate , T echnical Rep ort LA-UR- 07-2885, Los Alamos National Lab oratory , URL http: //arxiv.org/abs/0704.3395 . [38] Rodriguez, M. A., 2007, in 40th A nnual Hawaii In- ternational Confer enc e on Systems Scienc e (HICSS’07) (W aikoloa, Haw aii), URL http://dx.doi.org/10.1109/ HICSS.2007.487 . [39] Rodriguez, M. A., and J. Bollen, 2007, Mo deling Compu- tations in a Semantic Network Substr ate , T echnical Re- p ort LA-UR-07-3678, Los Alamos National Lab oratory , URL . [40] Rodriguez, M. A., and J. H. W atkins, 2007, Gr ammar- Base d Ge odesics in Semantic Networks , T echnical Rep ort LA-UR-07-4042, Los Alamos National Lab oratory . [41] Rutten b erg, A., T. Clark, W. Bug, M. Samw ald, O. Bo- denreider, H. Chen, D. Dohert y , K. F orsb erg, Y. Gao, V. Kashy ap, J. Kinoshita, J. Luciano, et al. , 2007, BMC Bioinformatics 8 (3), S2, ISSN 1471-2105, URL http: //www.biomedcentral.com/1471- 2105/8/S3/S2 . [42] Sa vo y , J., 1992, Information Pro cessing and Managemen t 28 (3), 389. [43] Sebesta, R. W., 2005, Conc epts of Pr o gramming L an- guages (Addison-W esley). [44] Sheth, A. P ., I. B. Arpinar, C. Halasc hek, C. Ramakr- ishnan, C. Bertram, Y. W arke, D. Av ant, F. S. Arpinar, K. An y an wu, and K. Ko c h ut, 2005, Journal of Database Managemen t 16 (1), 33. [45] So wa, J. F., 1987, Encyclop edia of Artificial Intel ligenc e (Wiley), chapter Semantic Netw orks. [46] T refethen, L. N., and D. Bau, 1997, Numeric al Line ar Algebr a (So ciety for Industrial and Applied Mathemat- ics). 16 [47] W asserman, S., and K. F aust, 1994, So cial Network Anal- ysis: Metho ds and Applic ations (Cambridge Univ ersity Press, Cambridge, UK). [48] Zh uge, H., and L. Zheng, 2003, in Pr o c e e dings of the Twelfth International World Wide Web Confer enc e (WWW03) (Budap est, Hungary). [49] The sup erscript 1 on G 1 denotes that the netw ork is a single-relational netw ork as opp osed to a semantic net- w ork which will b e denoted as G n . [50] Note that while the w eigh t function w do es in fact la- b el edges in E , the meaning of the edges are homogenous and th us, ω simply denotes the exten t to which the mean- ing is applied. Therefore, with respects to this article, a w eigh ted Marko v chain is considered a single-relational net w ork, not a semantic netw ork.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment