On the incidence-prevalence relation and length-biased sampling
For many diseases, logistic and other constraints often render large incidence studies difficult, if not impossible, to carry out. This becomes a drawback, particularly when a new incidence study is needed each time the disease incidence rate is inve…
Authors: ** Vittorio Addona, Masoud Asgharian, David B. Wolfson **
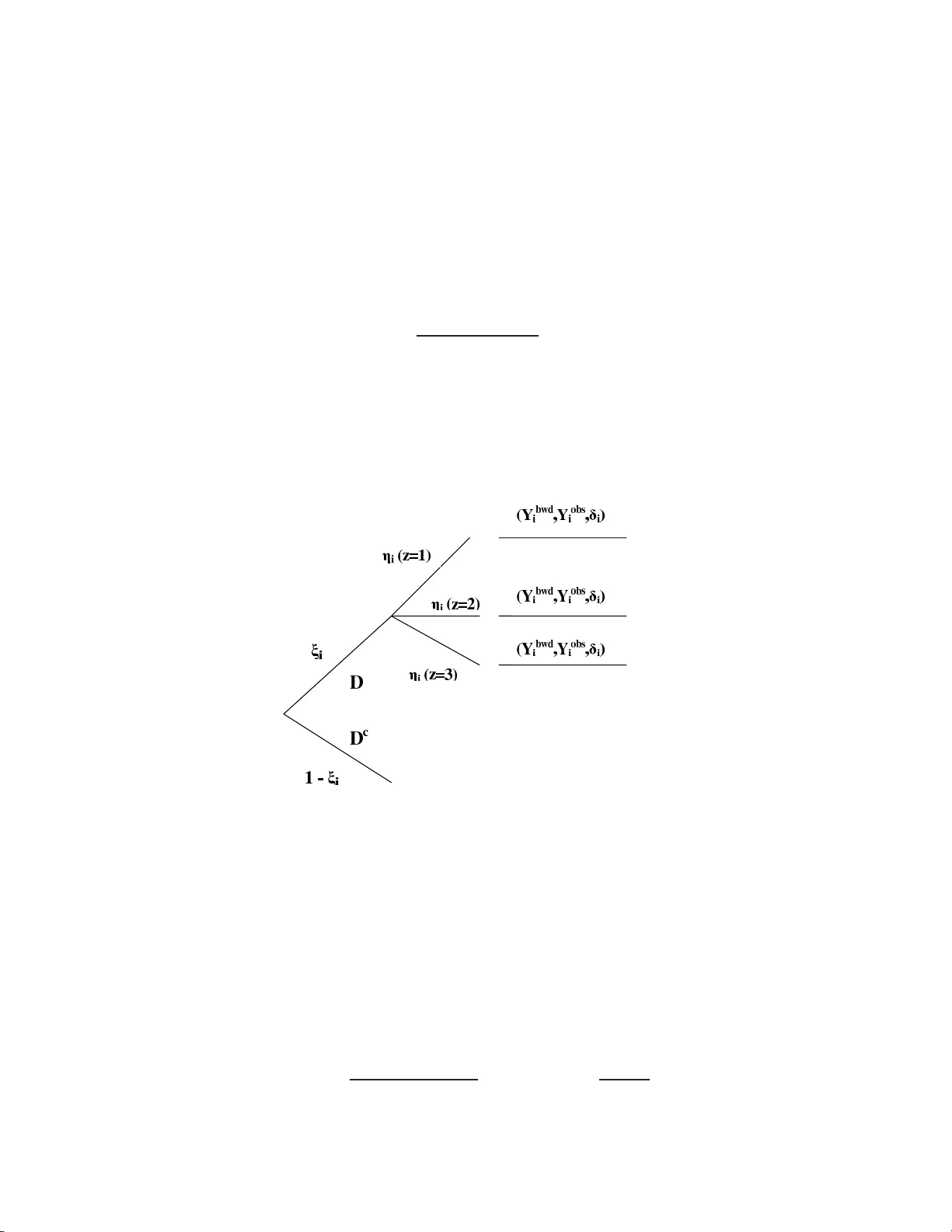
ON THE INCIDENCE-PRE V ALENCE RELA TION AND LENGTH-BIASE D SAMPLING VITTORIO ADDONA, MASOUD ASGHARIAN AND D A VID B. W OLFSON Mac alester Col le ge and McGil l University Abstract. F or many diseases, logistic a nd other constraints oft en render la rge in- cidence studies difficult, if not imp ossible, to car r y out. This b ecomes a drawbac k, particularly when a ne w incidence study is needed each time the disease incidence rate is inv estigated in a different p opulation. Ho wev er , by carrying out a prev a lent cohort study with follo w- up it is p ossible to estimate the incidence ra te if it is co n- stant. In this paper w e deriv e the max im um likelihoo d estimator (MLE) o f the overall incidence rate, λ , as well as age- spec ific incidence rates, b y ex plo iting the well known epidemiologic relatio nship, pre v alence = incidence × mean duration ( P = λ × µ ). W e establish the asymptotic distributions of the MLE s , provide approximate co nfidence int erv als fo r the par ameters, and p oint out that the MLE of λ is asymptotically most efficient. Moreov er, the MLE o f λ is the natur al estimator obtained by substituting the marginal maximum lik eliho o d es timators for P and µ , resp ectively , in the e x pression P = λ × µ . Our work is related to that of Ke iding (1991, 200 6), who, using a Marko v pro cess mo del, prop ose d estimators for the incidenc e ra te from a prev alent cohort s tudy without follow-up, under three differe nt scenarios . Howev er, each scenar io requir es as- sumptions that ar e b oth disease specific and depend on the av ailability of epidemiologic data at the p opulation level. With follow-up, we a r e able to r emov e these restr ictions, and our res ults a pply in a wide range of circumstances. W e apply our metho ds to data collected as part of the Canadian Study of Health and Ageing to estimate the incidence rate of demen tia amongst elderly Canadians. 1 Suppo rted in pa rt by FQRNT and NSERC of Cana da Key wor ds and phr ases : prev ale n t c o hort, r ig h t censoring, left truncation, incidence r ate, and nonpara- metric maximum likelihoo d estimator (NPMLE) 1 2 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON 1. Intr oduction In an incidence study , whose goa l is to estimate a disease incidence ra t e, a cohort of initially disease-free sub jects is follo w ed forw ard in time. T he sub jects are monitored closely and for those who deve lop the disease their approximate t imes of disease o nset are recorded. Often, as pa r t of an incidence study , these diseased sub j ects ar e follow ed un til “failure” or censoring. The data collected fro m suc h an incidence study may then b e used to dir ectly estimate b oth the disease incidence rate and the surviv al function for the time f rom onset to failure. The estimators o f the incidence rate a nd the surviv al function from suc h data a r e standard. F or many diseases, ho w ev er, logistic and other constrain ts often render large in- cidence studies difficult, if not imp ossible, t o carry out. This b ecomes a dra wbac k, particularly when a new incidence study is needed eac h time the disease incidence ra te is in ves tigated in a differen t p opulation. Nev ertheless, by carrying out a prev alen t co- hort study with f ollo w-up it is p ossible to estimate the incidence rate if it is constan t, th us av oiding the pro blems asso ciated with incidence studies. In this pap er we deriv e the maxim um likelihoo d estimator (MLE) of the ov erall incidence rate, λ , as we ll as age-sp ecific incidence rates f rom data collected as part of a prev alent cohort study with follo w-up. W e exploit the w ell kno wn epidemiologic relationship, prev alence = incidence × mean duration ( P = λ × µ ), to suggest that t he lik eliho o d b e derived as a function of the vec tor ( P , µ ). Once the MLE, ( ˆ P , ˆ µ ) of ( P , µ ), is obtained, t he MLE of λ = P µ follo ws b y in v ariance. A similar approach ma y b e used to find the MLEs of age sp ecific incidence rates. The asymptotic distributional prop erties of the estimators ma y b e obta ined b y mo difying previous results for the MLE of the surviv al f unction, based on surviv al data from a prev alen t cohort study with follow-up (see Section 4 ) . It is comforting that the MLE ˆ λ = ˆ P ˆ µ is, therefore, also t he na t ur a l ad ho c estimator of λ . In a medical setting, a prev alent cohort study with follow -up (W ang 1991) b egins with the identification, from a sampled cohort, of those with existing (prev alent) disease. The dates of onset for the diseased are ascertained and the diseased sub jects are f o llo wed forw ard in time un til failure o r censoring. Other da ta collected include the a ges at the time of recruitmen t, the fa ilure/censoring times of the sub jects who are f ollo w ed, and P = λµ AND LENGTH-BIASED S AMPLING 3 co v aria t es of in terest to the researc hers. There a re t w o main f eat ures of the data collected from suc h studies. First, the dates of disease onset of the prev alen t cases do not include the dates of o nset of those who died prior to the start of the prev alent cohort study; w e can only speculate as to the existenc e of suc h sub jects. Hence, direct use of the observ ed dates of onset from a prev alence study , in contrast to dates of onset from a n incidence study , leads to underestimation of t he tr ue incidence rate. Second, the o bserv ed failure/censoring in terv als are left-truncated and, if the underlying incidence pro cess is stationary , a s is the a ssumption here, t hey are length biased; those with longer surviv al in terv als ar e more lik ely to b e observ ed (Wicks ell 1925, Neyman 1955, Co x 1969, P atil and Rao 1978, and V ardi 1982, 1985). W e address these difficulties in deriving the MLE ( ˆ P , ˆ µ ) and hence the MLE ˆ λ , of the ov erall incidence rate. W e use a similar a pproac h to the estimation of age-sp ecific incidence rates. Keiding (1991, 2006) used a Mark o v pro cess model to deriv e carefully , the prev alence- incidence relationship, and prop osed three differen t scenarios whic h facilitate estimation of the (constant) a ge-sp ecific incidence rate when there ar e no follow-up da ta. In the first scenario it is assumed tha t there is non-differential morta lity fo r the diseased and non-diseased. In Biering-Sorensen and Hilden (1 984) this assumption is like ly to b e ten- able while in Keiding et al. (1989), it is proba bly not, since the disease under study is diab etes. In the second scenario, whic h Keiding in vok es in his 1989 pap er, no assump- tion o f non-differen tial mortality is made. It is either assumed that the incidence rate is small and that the difference b et w een t he in tensities f r o m the healthy and diseased states to death is kno wn or that the difference b etw een these tw o in tensities is small and kno wn. In the third scenario, it is assumed that the joint relativ e intens it y of the calendar time , age- and duration-sp ecific mortalit y is known. Under each scenario a parametric assumption m ust b e made, and in the last tw o scenarios certain p opulation parameters mus t b e kno wn. There fore, these estimators are strongly disease-sp ecific and also dep enden t on the av ailability of certain p opulation lev el data . These assumptions are needed to comp ensate for not ha ving follow-up inf o rmation. By f ollo wing-up the prev alen t cases we ar e able to a v oid these a ssumptions. Our main assumption is that the underlying incide nce pro cess is a stationary Poiss on pro cess , an ass umption that 4 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON Keiding also mak es. Sta tionarit y of the incidence rat e holds, roughly , for ma ny diseases: for example, amy otrophic lateral sclerosis (Sorenson et al. 2002), certain types of cancers (Jemal et al. 20 05), and sc hizophrenia ( F olnego vic and F o lnego vic-Smalc 1992 ). It may not, ho w ev er, b e tenable for an infectious disease. Diamond and McDonald (1991) also considered incidence rate estimation from prev alen t-case data, with no follow-up, again under different assu mptions. Ogata et al. (20 0 0) to ok an empirical Bay es approach to the analysis of r etrosp ectiv e incidence data. More recen tly Alio um et al. (2005) make HIV-AIDS-sp ecific mo del assumptions to estimate a general incidence rate. T o our kno wledge there is no literature that pro - vides a g eneral framew o r k for maxim um lik eliho o d estimation of a constan t underlying incidence rate when one has access only to prev alen t cohort surviv al data with fo llo w- up. The rest of this pap er is o rganized as follows: In Section 2 we pro vide a careful form ulation of a prev alen t cohort study with follow-up, pay ing pa rticular att ention to surviv al data. In Section 3 w e discuss the MLE fo r the underlying incidence rate. In Section 4 , we presen t the asymptotic pro p erties of the estimator, pa ving the wa y for computation of an appro ximate confidence in terv al fo r the underlying incidence rate. In Section 5 w e extend o ur results to include age- sp ecific incidence rates. In Section 6 w e apply our metho ds to data collected as pa r t of the Canadian Study of Health and Aging (CSHA), in o rder to estimate t he underlying age-sp ecific incide nce rates of deme n t ia amongst the elderly in Canada. 2. General se tup and not a t ion Let X 1 , X 2 , ..., X m b e m i.i.d. p ositive random v ariables represen ting the surviv al times of individuals from onset of a disease, sa y , to an end p oint of inte rest. Let the X i ’s ha v e surviv o r function S ( x ) = P ( X i > x ), cum ulative distribution function F ( x ), a nd probabilit y densit y function f ( x ). Define µ t o b e t he mean surviv al time; that is, µ = R ∞ 0 S ( x ) dx . Supp o se that τ 1 , τ 2 , ..., τ m are the m calendar times of onset corresp onding to X 1 , X 2 , ..., X m and let τ ∗ b e the calendar time of recruitmen t into a study . Individual i is observ ed in the study only if X i ≥ τ ∗ − τ i and, therefore, for i = 1 , 2 , ..., m , X i is left truncated with left truncation time T i = τ ∗ − τ i . Since the onset times are random, the P = λµ AND LENGTH-BIASED S AMPLING 5 truncation times are rando m v ariables, with distribution f unction denoted by G , a nd densit y g . Let Y 1 , Y 2 , ..., Y n b e t he observe d le ft truncated lif etimes, with n ≤ m . That is, P ( Y i > x ) = P ( X i > x | X i > T i ). W e b orro w terminology f r om renew al theory and write Y i = Y bw d i + Y f w d i , where Y bw d i is the time from onset to recruitmen t in to the study or the “back w a r d recurrence time”, and Y f w d i is the time from recruitmen t to fa ilure, or t he “ forw a r d recurrence time”. Also, let F LB represen t the distribution o f the Y i ’s, where the subscript, LB , is used to indicate that the Y i ’s are length-biased. Supp ose that individual i has censoring time C ∗ i = Y bw d i + C i , where C i , whic h w e call the “residual censoring t ime”, is the time fr o m recruitmen t until the individual is censored. W e assume that P( C ∗ i > T i ) = 1 (see W ang 1991 ) and we thus observ e only min( C ∗ i , Y i ). Often, ho w ev er, the bac kw ard recurrence times are fully observ ed, and w e assume this to b e the case here, so that the observ ed data a r e: ( Y bw d i , Y obs i , δ i ) i = 1 , 2 , ..., n where Y obs i = min ( Y f w d i , C i ) and δ i = I [ Y f w d i ≤ C i ] indicates whether sub ject i has b een follo w ed un til failure. Since C ∗ i and Y i share Y bw d i , the f ull surviv a l times, Y i , are info r mativ ely censored (V ardi 1989). It is still reasonable in many cases, how ev er, to assume that C i is indep enden t of b oth Y f w d i and Y bw d i , since indep endence b et w een C i and Y f w d i corresp onds to the usual ra ndom censoring assumption. In summary , w e differen tia te b et w een the p otential failure times, X i , some of whic h will not b e observ ed b ecause of left truncation, and the observ ed failure/censoring times ( Y bw d i + Y obs i ); these ar e ev en t times of the “long surviv ors”. 3. Point estima tion of the incidence ra te Under stationarit y w e assume the underlying incidence pro cess is a P o isson pro cess with constant in t ensity λ ( t ) ≡ λ . Hence, the truncation time distribution, G , is uniform, conditional on the n um b er of inciden t times in (0 , τ ∗ ) (Asgharian, W olfson, a nd Zhang 2006). W e b egin b y deriving the MLE of λ . W e then deriv e the MLE of the a ge-sp ecific incidence rates. The approac h depends on t he well-kno wn relationship, P = λ × µ where P is the time-indep enden t p oint prev alence, λ is the time-indep enden t underlying incidence rate, and µ is the mean duration of the disease (see Keiding 1991). 6 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON Let a random n umber of N prev alen t cases b e observ ed from a larg e group of s in- dividuals selected from screening. Fixing N at n , the realized num b er of prev alen t cases, Asgharian, M’Lan, and W olfson (2 002) and Asgharian and W olfson (20 05) deriv ed the unconditional NPMLE, ˆ S , of S under the assumption of stationarity . The y established its asymptotic prop erties and those of the NPMLE, ˆ µ = R ∞ 0 ˆ S ( x ) dx . Conditioning o n N = n , the lik eliho o d of the data is (1) L = L ( S, P ) = f (data , n ; S, P ) . W rite L ( S, P ) as L ( S | n ) L ( P ) = f (data; S | n ) f ( n ; P ), b y sufficiency of N for P . Now , in practice, the da ta of a prev alent cohort study with follo w-up a re collected in t wo stages. In stag e 1, a binary , 0- 1, random v ariable, sa y ξ , is measured o n eac h randomly selected sub ject to ascertain if the su b ject has exp erienced initiation of t he disease. In stage 2, w e observ e the triple ( Y bw d i , Y obs i , δ i ) i = 1 , 2 , ..., n o n diseased sub jects, indicated by ξ = 1. The follow ing tree diagram depicts our sampling sc heme: Figure 1. Sampling sc heme The full likelihoo d is: (2) L = s Y i =1 (1 − P ) 1 − ξ i " P dF ( y bw d i + y f w d i ) µ ! δ i Z ω ≥ y bwd i + c i dF ( ω ) µ ! 1 − δ i # ξ i , where P = P ( ξ = 1) is the time-indep enden t p oin t pr ev alence in the p opulation. F or the deriv ation of a similar lik eliho o d see Asgharian and W olfson (20 05). As is readily P = λµ AND LENGTH-BIASED S AMPLING 7 seen, the ab o v e lik eliho o d can b e factorized as (3) L = " s Y i =1 (1 − P ) 1 − ξ i P ξ i # " s Y i =1 dF ( y bw d i + y f w d i ) µ ! δ i Z ω ≥ y bwd i + c i dF ( ω ) µ ! 1 − δ i # ξ i Join t maximization of (2) with resp ect to S and P giv es the NPMLE ( ˆ S , ˆ P ) and hence the NPMLE ( ˆ µ, ˆ P ) where ˆ P = N/s is the usual p oint prev alence estimator of P . It follo ws, by in v ariance, that ˆ λ = ˆ P / ˆ µ is the unconditional NPMLE of λ . It is seen that ˆ λ , the MLE, is also the natural ad ho c estimator deriv ed from the r elat io n λ = P /µ , b y replacing P and µ b y t heir resp ectiv e natura l estimators. W ang (1991) derive d the NPMLE ˆ G of G , the truncating distribution, b y condi- tioning on the o bserv ed backw ard recurrence times. Although, under stationarity , G is uniform, and this observ a tion allow s one to informally assess stationarity , it do es not lead to a n estimate of λ , since λ is not uniquely determined b y G . 4. Inter v al e stima tion of the incidence ra te T o deriv e a n a symptotic confidence in terv al for λ w e b egin with the a symptotic prop erties of ( ˆ λ, ˆ P ) whic h in t ur n requires a careful examination of the likelih o o d (2). Iden tity (4) of Lemma 1, tho ug h simple, play s a k ey role in the deriv ation of an a symp- totic confidence in terv al fo r λ as it facilitates the transferral of the asymptotic pro p erties of ˆ µ and ˆ P to those of ˆ λ . Lemma 1. L et λ, P , and µ b e r esp e ctive l y, the time-in d ep endent underlying i n cidenc e r ate, the time-indep e n dent p oint pr evalenc e and the me a n dur ation of the dise ase. L et ˆ µ and ˆ P b e the unc onditional MLEs of µ and P r esp e ctively. Define ˆ λ = ˆ P ˆ µ , the MLE of ˆ λ . Then (4) ˆ λ − λ = 1 ˆ µµ [ µ ( ˆ P − P ) − P ( ˆ µ − µ )] . Pr o of. The result follows immediately fro m the definitions of λ and ˆ λ . Theorem 1 b elow , whic h draws on Lemma 1, essen tially sho ws that ˆ λ is consisten t and a symptotically Normal. W e state t his r esult and prov ide the main steps of t he pro o f 8 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON in the App endix. Suppo se γ = sup { t : F LB ( t ) = 0 } , and τ = inf { t : F LB ( t ) = 1 } . Then under mild conditions w e hav e, Theorem 1. S upp ose γ > 0 , τ < ∞ , and µ = R ∞ 0 xdF ( x ) < ∞ . Then as s → ∞ we have (a) | ˆ λ − λ | a.s. = O q log log s s (b) T = √ s ( ˆ λ − λ ) D → Z 1 − λZ 2 µ , wher e Z 1 ∼ N (0 , λµ [1 − λµ ]) and Z 2 ∼ N (0 , σ 2 µ /λµ ) ar e ind ep endent, σ 2 µ = µ 2 Z ∞ 0 Z ∞ 0 ψ ( u, v ) d 1 u d 1 v , and ψ ( u, v ) is the c ova ri a nc e function of the li m iting pr o c ess of ˆ S . The co v aria nce function ψ ( u, v ) has an in tracta ble form (see Asgharian et al. 2002 and Asgharian and W olf son 20 05). The asymptotic v ariance of T has consequen tly a rather complex form whic h precludes the p o ssibility of its direct estimation. Instead, w e obtain a confidence in t erv al fo r λ by b o otstrapping ˆ λ . 5. Estima ting the age-specific incide nce ra te F or man y diseases the incidence rate is age- dep endent, and estimators of age-sp ecific incidence rates are almost alwa ys sought b y epidemiologists. F ollowing the notatio n from Section 2, let τ ∗ represen t the calendar time o f recruitmen t, let X b e the time from onset to death, and τ o b e the calendar time of onset. Let D t b e the eve n t of b eing diseased and aliv e at time t , let A o b e the age at onset, and A t the age at calendar time t . W e assume that the distribution of X do es not change with calendar time, and that b ot h A o and A t are discrete r a ndom v ariables; the latter assumption can b e relaxed to include arbitrary random v ariables. Then, P ( D τ ∗ | A o = z ) = Z τ ∗ 0 P ( X ≥ τ ∗ − t, τ o = t | A o = z ) dt = Z τ ∗ 0 P ( X ≥ τ ∗ − t | τ o = t, A o = z ) dP τ o | A o ( t | z ) · P = λµ AND LENGTH-BIASED S AMPLING 9 On the other hand, we hav e dP τ o | A o ( t | z ) = P ( τ o ∈ ( t, t + dt ) , A o = z ) P ( A o = z ) = P ( τ o ∈ ( t, t + dt ) , A t = z ) P ( A o = z ) = dP τ o | A t ( t | z ) × P ( A t = z ) P ( A o = z ) · W e a lso note that P ( X ≥ τ ∗ − t | τ o = t, A o = z ) = P ( X ≥ τ ∗ − t | A o = z ) = S z ( τ ∗ − t ) · Ha ving a ssumed that dP τ o | A t ( t | z ) /dt = λ z only dep ends on z , w e obtain P ( D τ ∗ | A o = z ) = " Z τ ∗ 0 S z ( τ ∗ − t ) P ( A t = z ) dt # λ z P ( A o = z ) · W e t h us find the age-sp ecific incidence (5) λ z = P ( D τ ∗ , A o = z ) R τ ∗ 0 S z ( τ ∗ − t ) P ( A t = z ) d t . It follo ws by inv ariance that the MLE of λ z is (6) ˆ λ z = ˆ P ( D τ ∗ , A o = z ) R τ ∗ 0 ˆ S z ( τ ∗ − t ) P ( A t = z ) dt , where ˆ P ( D τ ∗ , A o = z ) is the observ ed pro p ortion in the recruited cohort who are diseased and with a ge-at-onset z . Note that to find ˆ S z w e b egin by r estricting our a t t ention to the length-biased surviv a l/censoring times of t he prev alen t cases, whose o nset o ccurred at age z . Then ˆ S z is the MLE of S z , based on these length- biased data, as deriv ed b y Asgharian et al. (20 02) and Asgharian and W olfson (2005). It is assumed that the p opulation age distribution { P ( A t = z ) } z , ma y b e routinely obtained from census data. Since census data are usually only up da ted ev ery five years, a reasonable assu mption is that P ( A t = z ) is piec ewise constan t a s a function of t . Ho wev er, as we shall see in Section 6 it migh t b e p ossible to make the eve n stronger assumption that P ( A t = z ) = P ( A = z ), is roughly indep enden t o f t , without affecting ˆ λ z substan tially . An alternative whic h requires more intens iv e mo deling, is to replace 10 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON the step function P ( A t = z ) by a smo oth function of t . W e suggest that the extra effort w ould probably result in v ery small improv emen t if an y . Since, in Section 6, the p o pulation a g e distribution is assumed to b e constan t we restrict our atten tio n to this case. Then equation (5 ) reduces to (7) λ z = P ( D τ ∗ , A o = z ) µ z P ( A = z ) , where P ( A = z ) is the prop ortion o f sub jects in age category z , and µ z represen ts the mean surviv a l time in a ge category z . The information contained in t he observ ations, for the case of three age categor ies ( z = 1 , 2 , 3), may b e illustrated throug h the follo wing tree diagram, Figure 2. Illustration of information con ta ined in the observ at ions where η z ( i ) = 1 , if A o = z for the i-th sub ject , 0 , Otherwise . The full likelihoo d, for the g eneral case z = 1 , 2 , ..., l is, (8) L a = " s Y i =1 (1 − P ) 1 − ξ i P ξ i # " s Y i =1 n dF ( y bw d i + y f w d i ) µ δ i Z ω ≥ y bwd i + c i dF ( ω ) µ 1 − δ i l Y z =1 P ( A o = z ) η z ( i ) o ξ i # . P = λµ AND LENGTH-BIASED S AMPLING 11 Using equation (7), (9) ˆ λ z = ˆ P ( D τ ∗ , A o = z ) ˆ µ z P ( A = z ) , is the MLE of λ z , where ˆ µ z is the MLE of µ z deriv ed fr o m ˆ S z . 6. Estima ting the incide nce ra te of dementia In 1991 , 10,263 elderly Canadians (65 y ears o r older), living at home or in a n institution, w ere screened for demen tia (CSHA w orking group 1994). This phase of the study was kno wn as CSHA-1. At the time of CSHA-1, 821 sub jects w ere classified as hav ing either p ossible Alzheimer’s disease, probable Alzheimer’s disease, or v ascular demen tia. Henceforth, b y the term demen tia we mean ha ving exactly one of these three conditions since t hey constitute the v ast ma jority o f demen tias. The approx imate dates of onset w ere derive d in a hierarc hical fashion from the answ ers to three questions (W olfson et al. 2001). In 1996, the second phase of the study , CSHA-2, w as completed. CSHA-2 included the ascertainmen t of the dat e of death o r right censoring for those cases iden tified at CSHA-1. These are the data up on whic h w e shall base o ur estimates of the ov erall and ag e- sp ecific incide n t rates of demen tia. Ho wev er, additional data w ere, in fact, collected as part of the CSHA with t he goal o f estimating the a g e-sp ecific incidence r a tes of demen tia among elderly Canadians. The sub jects who w ere deemed not to hav e demen tia at CSHA-1 w ere re-ev aluated fo r dementia at CSHA-2. Assuming that these incidence rates had remained constant, they were estimated using the inciden t cases observ ed b et we en CSHA-1 and CSHA-2. There w ere nev ertheless, difficulties with these “incide n t ” data since it could not b e asce rtained with ce rtain t y whether t ho se who had died b et w een CSHA-1 and CSHA-2 had b ecome inciden t cases with demen tia. In this pap er we, therefore, re-estimated the incidence rates without relying on the “inciden t” cases that o ccurred b et w een CSH A-1 and CSHA-2. The ass umption of a roughly constant incidence rate for demen tia has b een previous ly c hec k ed in sev eral w ays and has b een deemed to b e reasonable (see Asgharia n et al. 2002, Asgharian et al. 2006 and Addona a nd W olfson 2006 ). 12 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON Age Gr o up Range SD CV 65-74 59.8 - 6 2.7% 1.36% 0.022 75-84 29.1 - 3 1.3% 1.03% 0.034 85+ 8.2 - 8.9 % 0.34% 0.040 T able 1. Range, standard deviation, and co efficien t o f v ariation for the p ercen tage of Canadians (aged 65 a nd older) in eac h age group 6.1. Estimating the o verall incidence rate of demen tia. The NPMLE, ˆ S ( x ), yields ˆ µ ≈ 4.75 y ears or 57 mo nths. Since the CSHA data did not constitute a ra ndom sample of all sub jects o v er the age o f 65 in Canada, w e used the age-standardized prev alence estimate instead o f simply , ˆ P = N s . This giv es an estimate for P o f 0.066 (CSHA w orking group 1994), whic h leads to a p oin t estimate, ˆ λ = 0.0139, or 13 .9 p er 1,000 p erson-y ears. T o obtain an in terv al estimate for λ , w e follow ed the b o ot stra p pro cedure and sampled with replacemen t from the 10,263 screened sub jects to obtain 10,00 0 b o otstrap samples of the same size. W e obta ined a confidence interv al for λ of [12 . 52 , 15 . 28] cases p er 1,00 0 p erson-y ears. 6.2. Estimating the age-sp ecific incidence rate of demen tia. Three ag e groups w ere considered for the CSHA data: 65-74, 75-84, and 85 + y ears o ld. The 821 cases of demen tia were sub divided a s follows: 16 4 had onset b et w een 65 and 74 y ears old, 381 had onset b et w een 75 and 84 y ears old, and 27 6 w ere 8 5 or o lder when they had onset. The estimated mean surviv al t imes in years we re 7.97, 5.16 , a nd 3 .50, for the 65 -74, 75-84, and 85+ g roups, resp ectiv ely . T o use equation (9), w e require an approximately stable age distribution ov er the p erio d co v ering the onset times. W e consulted data from four Canadian censuses cov ering 1976- 1991 to assess this assumption. Figure 3 shows the progression of the p ercen tage of the Canadian p opulation aged 65 and older in eac h of the three a g e groups (St a tistics Canada 2006). Using data fro m the 19 76, 198 1, 198 6 , and 1991 censuses, w e also computed some measures of v ariabilit y for the p ercen tage in eac h of the three age groups. The se are presen ted in T able 1. P = λµ AND LENGTH-BIASED S AMPLING 13 1976 1981 1986 1991 0 10 20 30 40 50 60 70 Year Percentage (%) Figure 3. P ercen tage of Canadian p opulation aged 65 and older in 6 5-74 (circles), 75-84 (diamonds), and 85+ (t r iangles) age groups Ha ving v erified t ha t the age distribution is ro ug hly stable fo r this time p erio d, w e pro- ceeded with the age-sp ecific incidence estimation using the 199 1 census da t a. Amongst those 65 ye ars o r older in 1991, 59.8% were in the 65- 74 gro up, 31.3 % we re in the 75-8 4 group, a nd 8.9% w ere in the 85+ gr o up (Statistics Cana da 20 06). The resulting age- sp ecific incidence rate estimates a re presen ted in T able 2. In 1976, a mong st t ho se 65 y ears or older, 62.7% w ere in the 6 5-74 group, 29.1% w ere in the 7 5-84 group, and 8.2 % w ere in the 85+ gro up (Statistics Canada 2006 ). W e also estimated the age-specific incidence rates based o n the census age distribution dat a from 1976 to take in to a ccoun t small c hanges in the p opulation age distribution that might hav e o ccurred ov er the p e- rio d from 1976 to 1991. When the age distribution c hanges, this approac h prov ides a simple f ramew ork f o r inv estigating robustness of the a ge-sp ecific incidence rate estimator to departures from the assumption of constancy of the age distribution. F or comparative purp oses, the ag e-sp ecific incidence rate estimates based on t he 1976 census data a re also giv en in T able 2. 14 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON Age Gr o up ˆ λ z (1991) 95% CI (1991) ˆ λ z (1976) 95% CI (1976) 65-74 3.35 [2.72 , 3.99] 3.20 [2.58 , 3.82] 75-84 22.99 [19.92 , 26.04] 24.69 [21.26 , 28.13] 85+ 85.86 [70.52 , 101 .20] 93.39 [7 7 .00 , 109.7 7 ] T able 2. Age-sp ecific incidenc e rat e estimates p er 1,000 person-years using 1991 and 197 6 Canadian census da ta 6.3. Discussion of demen tia incidence rate estimates. Sub jects w ere not prosp ec- tiv ely monitor ed b et w een CSHA-1 and CSHA-2. It was thu s difficult to ascertain whether those who had died in this time p erio d had had onset of Alzheimer’s disease (p ossible or probable). As a result, incidence rates of Alzheimer’s disease rep o r t ed from the CSHA w ere underestimates of the true incidence r ates a mongst elderly Canadia ns since they w ere based only on sub jects who surviv ed until the end of CSHA-2 in 19 96. The CSHA incidence rate estimates of Alzheimer’s disease w ere 7.4 and 5 .9 p er 1,000 p erson-y ears f o r w omen and men resp ectiv ely (CSHA working gro up 2 0 00), g iving a crude estimated incidence rate for me n and w omen comb ined of 6.7 p er 10 0 0 p erson y ears. Using the CSHA data, H ´ eb ert et al.(200 0) estimated the incidence rat e of v as- cular demen tia to b e 3.79 p er 1,00 0 p erson-years. Therefore the CSHA ov erall (under-) estimated rate for demen tia was appro ximately 6.7 + 3.79 = 10.49 per 1000 p erson y ears. Direct comparison with our r esults is difficult. Our ov erall estimate (for p ossi- ble or probable Alzheimer’s, or v ascular demen tia) of 13.9 p er 1,000 p erson-years seems to b e consisten t with these previous estimates o btained fro m the CSHA. An analogous comparison of the ag e-sp ecific incidence estimates rev eals tha t they to o are consisten t with those already obtained from the CSHA. Note that the sligh t ly different p oint esti- mates for the ag e-sp ecific incidence rates, particularly in the 85+ categor y , should not b e in terpreted as meaning that incidence rates declined or increased b et w een 1976 and 1991. They simply pro vide a ra ng e of p ossible v alues for the estimate dep ending on what is t ak en a s the p opulation ag e distribution. P = λµ AND LENGTH-BIASED S AMPLING 15 7. Concluding remarks Sim ulatio ns, whose results a re not rep orted in this pap er, suggest tha t our meth- o ds work w ell for mo derate sample sizes; the asymptotic distribution o f the estimated incidence rates we re close to Normal, the p oint estimates w ere close to their true v alues and the confidence interv als reasonably narro w for a range of parameter c hoices. Our estimator of the incidence rate dep ends on the estimator ˆ S , for the surviv a l function S . W e prop ose that the most efficien t estimator for S , under the assumption of a constant incidence rate, should b e used. The estimator, ˆ S , used in this pap er is more efficien t than the w ell-known estimator of S for general left truncation data ( W ang 1991) whic h do es not inv ok e stationarity o f the incidence pro cess (Asgharian et al. 200 2). Indeed, it is p ossible to sho w that the es timators w e presen t for the incidence rates (o v erall and age-sp ecific) are asymptotically most efficien t. This follo ws from Asgharian and W olfson (2 0 05, Theorem 3 ) and V an der V aart (1998, Theorem 25.47, page 3 87). If the largest observ ed failure time is censored, ˆ S is left undefined b ey ond this p oin t b y most authors. Consequen tly ˆ µ is not w ell- defined in this situation. F ortunately , in our example, the la r g est surviv al time is a true failure time. Ad ho c “fixes” are av ailable, but pro duce biased estimators. The CSHA data used for illustration is based on an initial cohort of 10,263 sub j ects obtained as a stratified cluster sample whereb y a fixed n um b er of institutionalized (ab out 10%) and non-institutionalized (ab out 90%) sub jects w ere sampled. In addition, those o v er 85 y ears old w ere ov er-sampled. W e do not take in to accoun t the sampling sc heme in our estimated incidence rates or in the asymptotic distributions of our estimators. T o do so requires dev elopmen t of new theory allo wing for within cluster dep endence, whic h is a topic for further study and is not directly p ertinen t to our metho ds. A cknowledgments This researc h was supp o rted in part by the Natur a l Sciences and Engineering Re- searc h Council of Canada (NSER C) and Le F onds Qu ´ eb ´ ecois de la rec herche sur la na ture et les tec hnologies (F QRNT). The data rep orted in this article w ere collected as part of the CSHA. The core study w a s funded by the Seniors’ Indep endence Researc h Program, 16 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON through the National Health Researc h and Developme n t Program (NHRDP) of Health Canada Pro ject 6606- 3954-MC(S). Additional funding w as provide d by Pfizer Canada Incorp orated through the Medical Researc h Council/Pharmaceutical Man uf a cturers As- so ciation of Canada Health Activit y Program, NHRD P Pro ject 6 6 03-1417- 302(R), Ba y er Incorp orated, and the British Columbia Health Researc h F oundatio n Pro jects 38 (93 - 2) and 34 (96-1 ) . The study w as co ordinated through the Univ ersit y of Ottaw a and t he Division of Ag ing and Seniors, Health Canada. W e would also like to thank the referees and Asso ciate Editor for their useful commen ts and suggestions which help ed g reatly enhance our pap er. Appendix W e provid e a roa d map o f the pro of o f Theorem 1 and giv e further details ab out steps (iv) and (v) b elow. Roa d map of the pro of: (i) Establish the asymptotic b eha vior of ˆ F LB . (ii) Establish the asymptotic b eha vior of ˆ F using (i). (iii) Establish the asymptotic b eha vior of ˆ µ using (ii). (iv) Establish the independence of ˆ µ and ˆ P . (v) Establish the asymptotic b eha vior o f ˆ λ using (4), (iii) , and (iv). The deriv ation of (i) is similar to it s coun terpart giv en b y Asgharian and W olfson (2005), and those of (ii) and (iii) are similar to their counterparts in Asgharian et al. (20 02). The expressions, how ev er, a r e sligh tly differen t in view of the differen t sampling sc heme under consideration here. W e therefore ske tc h the pro of of steps (iv) and (v). Step(iv): In this step w e justify the inde p endence of ˆ P a nd ˆ F , and hence of ˆ P a nd ˆ µ . This indep endence is suggested b y the lik eliho o d factorizatio n (3). Theorem 2 sho ws that this is in fa ct the case. F irst, observ e that it follo ws from (2) that ˆ P = N s is the NPMLE of P . W e hav e (10) Π s = √ s ( ˆ P − P ) D → N 0 , P (1 − P ) . P = λµ AND LENGTH-BIASED S AMPLING 17 Theorem 2. L et R × D 0 [0 , t ] b e endow e d with the top olo gy induc e d by k ( a, x ) k = | a | +sup s ∈ [0 ,t ] | x ( s ) | . Under the as s ump tions of The or em 1 (Π s , U N ) D → ( W , U ) in R × D 0 [0 , t ] , wher e U is given in The or em 1 and W ∼ N (0 , P (1 − P )) is indep endent of U . Pr o of. It follows f r om Theorem 7.2.1 and Lemma 7.2.1 of Cs ¨ o rgo and Rev esz (1981) that k ( Π s , U N ) − (Π s , U [ sP ] ) k P − → 0 as s → ∞ It remains to show that Π s and U [ sP ] are indep enden t. This follows from the fact that ˆ P is a partial ancillary for F LB , while { ( Y bw d i , Y obs i , δ i ) , i = 1 , 2 , · · · , [ sP ] } is pa rtially sufficien t for F LB . Step(v): In t his final step w e com bine the results of steps (i) thro ug h (iii), in Theorem 1, to yield the asymptotic b eha viour of ˆ λ . Pr o of of T he or em 1. P art (a) f ollo ws from Lemma 1, part (b) o f Theorem 1 of Asgharian et a l. (2002), and the asymptotic prop erties of the sample pro p ortion in Bi- nomial sampling. Part ( b) follows from part (c) of Theorem 1 of Asgharian et al. (200 2), (10), and the iden tity (4). Reference s 1. Addona, V. a nd W olf son, D . B. (20 06). A formal t est fo r the stationarity of the incidence rate using data from a prev alen t cohort study with follow-up. Lifetime Data A nalysis 12 , No. 3, 267-28 4. 2. Alioum A., Commenges D., Thi ´ ebaut R., a nd Dabis F. (2005). A m ultistate ap- proac h for estimating the incidence of human immunodeficiency virus b y using data from a prev a lent cohort study . Applie d Statistics 54 , P art 4, 739-752. 18 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON 3. Asgharian, M., M’Lan, C.E. and W olfson, D. B. (2002). Length-biased sampling with right censoring: an unconditional approac h. Journal of the A meric an Statistic al Asso ciation 97 , No.457, 201-209. 4. Asgharian, M., and W olfson, D.B. (20 0 5). Asymptotic b ehaviour of the unconditional NPMLE of the length-biased surviv or function from right censored prev alen t cohort data. The Annals of Statistics 33 , No.5, 2 109-2131 . 5. Asgharian, M., W olfson, D. W. and Z hang, X. (20 06). Chec king stationarity of the incidence rate using prev alen t cohort surviv a l data. Statistics in Me dicine 25 , 1 751-1767 . 6. Biering-Sorensen, F., and Hilden, J. (198 4 ). Repro ducibilit y of the history o f low- bac k trouble. Spine 9 , No.3, 2 80-286. 7. Co x, D .R. (196 9). Some sampling problems in techn ology . In New Developm e nts in Survey Sa mpling . Edited by Johnson and Smith. Wile y , 506-5 27. 8. Csorgo, M. and Rev esz (1981). Str ong Appr oximation in Pr ob ability and Statistics . Academic Press, New Y ork. 9. CSHA w orking group, (1994). Canadian study of health and aging: study metho ds and prev alence of demen tia. Journal of the Cana d ian Me dic al Asso ciation 150 , 89 9-913. 10. CSHA w orking group (2000). The incidence of demen tia in Canada. Neur olo gy 55 , 66-73. 11. Dia mond, I.D., a nd McDonald, J.W. (1 9 91). Analysis of current-status data. In Demo gr aphic Appli c ations of Event History A nalysis Edited by T russell, J., Hankinson, R., and Tilton, J. chapter 12. Oxford: Oxford Unive rsit y Press. 12. F olnegov ic, Z. a nd F olnego vic-Smalc, V. (199 2). Sc hizophrenia in Croat ia: inter- regional differences in prev alence and a commen t on cons tan t incidence. Journal o f Epidemiolo gy and Com munity He alth 46 , 248-255 . 13. H ´ eb ert, R., Lindsa y , J., V erreault, R., Ro c kw o o d, K., Hill, G., and Dub ois, M- F.(2000). V ascular demen tia: Incidence and risk factors in the Canadia n Study of Health and Aging. Str oke 31 , 1487- 1493. 14. Jemal, A., Murra y , T., W ard, E., Sam uels, A., Tiw ari, R .C., Ghafo or, A., F euer, E.J., and Th un, M.J. (2005). Cancer Statistics, 2 0 05. CA: A Canc er Journal fo r Clini- cians 55 , 10- 30. P = λµ AND LENGTH-BIASED S AMPLING 19 15. Keiding, N. (200 6). Eve n t history analysis and the cross-section. Statistics in Me dicine 25, 2 343-2364 . 16. Keiding, N. (1991). Age-sp ecific incidence and prev alence: A statistical p ersp ectiv e (with discussion). Journal of the R oyal Statistic al So ciety, Serie s A 154 , No.3, 37 1-412. 17. Keiding, N., Holst, C. and Green, A. (1989). Retrosp ectiv e estimation o f diab etes incidence f r o m informatio n in a curren t prev alen t p o pulation and historical mortality . A meric an Journal o f Epidemiol o gy 130 , 588-60 0 . 18. Neyman, J. (1955). Statistics-serv an t of all sciences. Sc ienc e , V ol.122 , no . 3 166, 401-406 . 19. Ogata, Y., Katsura, K., Keiding, N., Holst, C. a nd Green, A. (2000) . Empirical Ba y es age- p erio d-cohort analysis of r etrosp ectiv e incidence data. Sc an d inavian Journal of Statistics 27 , 41 5 -432. 20. P atil, G.P . and Rao, C.R. (1978). W eigh ted distributions a nd sized-biased sampling with applications to wildlife p opulations and h uman families. B iometrics 34 , 179 - 189. 21. Sorenson, E.J., Stalk er, A.P ., K urla nd, L.T., and Windebank, A.J. (20 0 2). Am y- otrophic la t eral sclerosis in Olmsted Coun ty , Minnesota, 1925 to 1998 . Neur o l o gy 59 , 280-282 . 22. Statistics Canada (2006) Census of P opulation, Statistics Canada cata logue no . 97- 551-XC B2006005 : Age G roups and Sex for the P opulation of Canada, Provinc es and T erritories, 1921 t o 2006 Censuses. Ottaw a: Statistics Canada. 23. V an der V aart , A. W.(1998 ). Asymptotic Statistics . Cambridge Series in Statistics and Probabilistic Mathematics. Cam bridge Univ ersit y Press, Cam bridg e, UK. 24. V ardi, Y. (1982). Nonpara metric estimation in the presence of length bias. Th e A nnals o f Statistics 10 , 616-6 20. 25. V ardi, Y. (19 85). Empirical distributions in selection bias mo dels. The Annals of Statistics 13 , 17 8 -205. 26. V a r di, Y. (1989 ). Multiplicativ e censoring, rene w al pro cesses , decon v olution and decreasing densit y: nonparametric estimation. Biometrika 76 , No.4, 75 1 -761. 27. W ang, M-C. (1 9 91). Nonparametric estimation from cross-sectional surviv a l data. Journal of the Americ a n Statistic al Asso ciation 86 , No.4 13, 1 30-143. 20 VITTORIO ADD ONA, MASOU D ASGH ARIAN A ND DA V ID B. WOLFSON 28. Wic ksell, S.D . (1925). The Corpuscle Problem: A Mathematical Study of a Biomet- ric Problem. Bio metrika 17 , No.1, 84- 99. 29. W olfson, C., W olfson, D.B., Asgharian, M., M’Lan, C.E., Ø stb y e, T., Ro c kw o o d, K. and Hogan, D.B.(2 001). A reev alua tion of the duration of surviv al a fter the o nset of demen tia. New England Journal of Me dicine 344 , No.15, 1111- 1116. dep ar tment of Ma thema tics and Computer Science, Macalester College, 1600 Grand A ve., St. P a ul, MN , 55105 E-mail addr ess : a ddona@ macale ster.edu dep ar tment of ma thema tics and st a tistics, McGill U niversity, Burnside Hall , 805 Sherbrooke S treet West, Mo ntreal, Quebec, CAN ADA H3A 2K6 E-mail addr ess : a sghari an@mat h.mcgill.ca E-mail addr ess : d avid@m ath.mc gill.ca
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment