Comment: Microarrays, Empirical Bayes and the Two-Group Model
Comment on ``Microarrays, Empirical Bayes and the Two-Group Model'' [arXiv:0808.0572]
Authors: T. Tony Cai
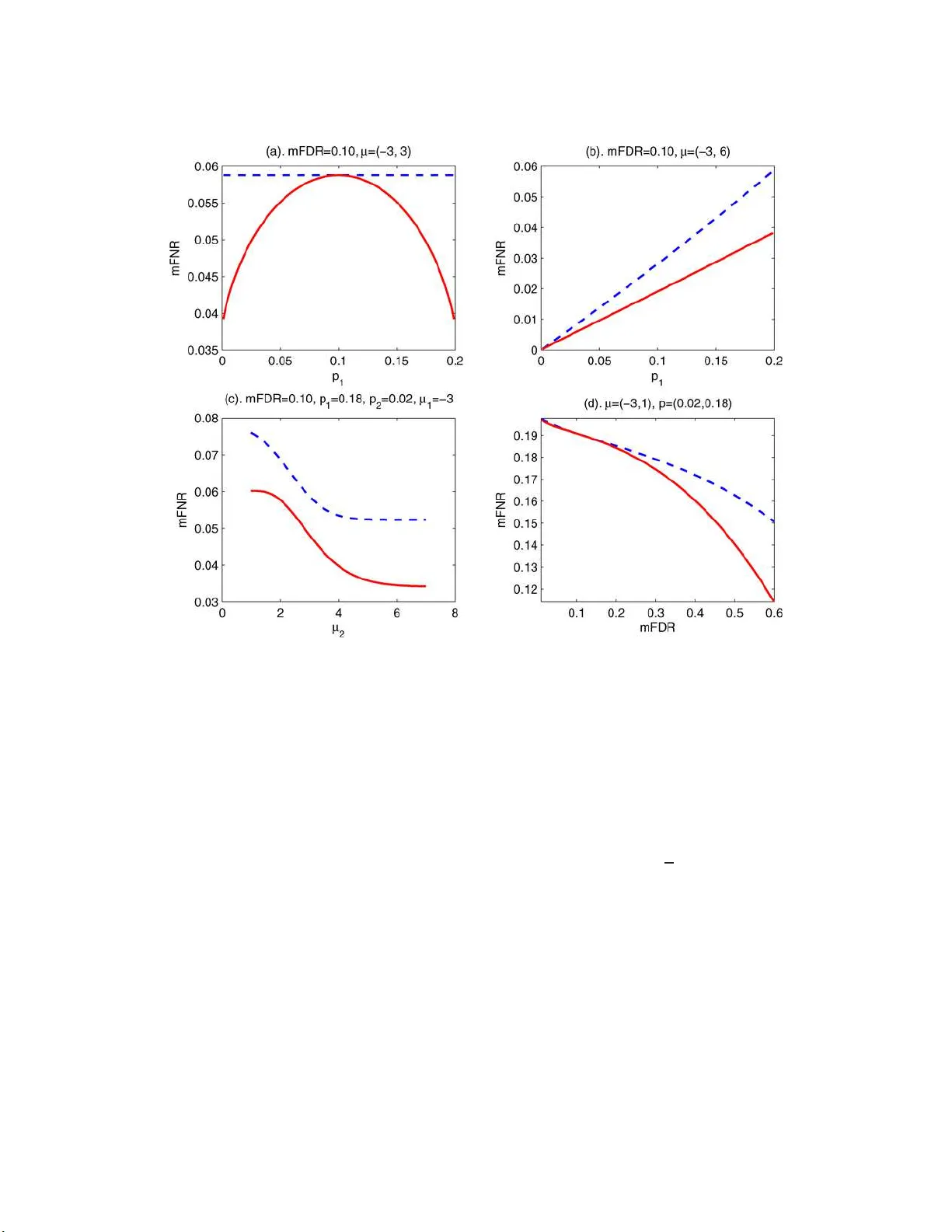
Statistic al Scienc e 2008, V ol. 23, No. 1, 29–3 3 DOI: 10.1214 /07-STS236C Main article DO I: 10.1214/07-STS236 c Institute of Mathematical Statisti cs , 2008 Comment: Microa rra ys, Empirical Ba y es and the Tw o- Group Mo del T. T ony Cai Professor Efron is to b e congratulated for his inno- v ativ e and v aluable con tributions to large-sc ale m ul- tiple testing. He has giv en u s a very interesting arti- cle with m uc h material for thought and exploration. The t w o-group m ixtu re mo del (2.1) p r o vides a con- v enien t and effectiv e fr amew ork for m u ltiple testing. The emp irical Ba yes app roac h leads naturally to the lo cal false disco v ery rate (Lfdr ) and giv es the Lfdr a useful Bay esian in terpretation. Th is and other r e- cen t p ap ers of Efron raised seve ral imp o rtant issu es in m ultiple testing su c h as theoretical null v ersus empirical null and the effects of correlation. Muc h researc h is needed to b etter understand these issues. Virtually all FDR con trolling pro cedur es in the literature are based on thresholdin g the ranked p - v alues. The difference among these metho ds is in the c h oice of the thr eshold. In multiple testing, t y p - ically one fir st u ses a p -v alue based metho d such as the Benjamini–Ho c hb er g p ro cedure f or global FDR con trol and th en uses the Lfdr as a measure of signif- icance for individual non null cases. S ee, for example, Efron ( 2004 , 2005 ). In what follo ws I w ill first dis- cuss the d ra wbac ks of using p -v alue in large-scale m ultiple testing and demonstr ate the fund amen tal role pla y ed by the Lfdr. I then discuss estimation of the null distr ibution and the prop ortion of th e non- n ulls. I will end w ith some comments ab ou t dealing with the dep endency . In the discussion I shall use the n otation giv en in T able 1 to s u mmarize the outcomes of a m ultiple testing pro cedu re. T. T ony Cai is Dor othy Silb erb er g Pr ofessor of Statistics, Dep artment of Statistics, The Wharton Scho ol, University of Penn sylvania, Philadelp hia, Pennsylvania 19104, USA (e-mail: tc ai@wharton.up enn .e du ) . This is an ele c tr onic reprint o f the o riginal article published by the Institute of Ma thema tical Statistics in Statistic al Scienc e , 20 08, V ol. 2 3, No. 1, 29 –33 . T his reprint differs fro m the o riginal in pag ination and t yp ogr aphic detail. With the notation giv en in the table, the false dis- co very rate (FDR) is then defin ed as FDR = E( N 10 /R | R > 0)Pr( R > 0). 1. THE USE OF p-V ALUES: V A LIDITY VERSUS EFFICIENCY In the classical theory of hypothesis testing the p -v alue is a f undamental quantit y . F or example, th e decision of a test can b e made by comparing the p - v alue with the pr esp ecified significance level α . In the more recent large-scale m ultiple testing litera- ture, p -v alue contin ues to pla y a central r ole. As men tioned earlier, nearly all FDR control ling pro- cedures sep arate the nonnull hyp otheses fr om the n ulls by thresholding the ordered p -v alues. A du al qu an tit y to the false disco very rate is the false nondisco ve ry rate FNR = E( N 01 /S | S > 0) × Pr( S > 0). In a decision-theoretica l fr amew ork, a natural goal in m ultiple testing is to find, among all tests wh ic h con trol th e FDR at a giv en level, the one which h as the sm allest FNR. W e sh all call an FDR p r o cedure valid if it controls the FDR at a presp ecified lev el α , and e fficient if it has the small- est FNR among all FDR p ro cedures at lev el α . Th e literature on FDR con trolling p ro cedures so far has fo cused virtu ally exclusively on the v alidit y; the ef- ficiency issu e has b een mostly unto uched. In a recen t article, Su n and Cai ( 2007 ) considered the m ultiple testing problem from a comp ound de- cision p oint of view. It is demonstrated that p -v alue is in fact n ot a fu ndament al qu an tit y in large-scale m ultiple testing; the lo cal false d isco very rate (Lfdr) is. Th resholding the ordered p -v alues d o es not in general lead to efficien t m ultiple testing pro cedures. The reason for th e inefficiency of the p -v alue meth- o ds can b e tr aced bac k to Copas ( 1974 ) where a w eigh ted classification problem w as considered. C o- pas ( 1974 ) show ed that if a symmetric classificatio n rule for d ic hotomies is admissib le, then it must b e ordered by the like liho o d r atios, which is equiv alent to b eing ord ered by the Lfdr. S un and Cai ( 2007 ) sho w ed that, under mild conditions, the multiple 1 2 T. T. CAI T able 1 Claimed nonsignificant Claimed significant T otal Null N 00 N 10 m 0 Nonnull N 01 N 11 m 1 T otal S R m testing p roblem is in fact equiv alen t to the w eigh ted classification pr oblem. I w ill discuss b elo w some of the fin dings in Su n an d Cai ( 2007 ) and dr a w con- nections to th e present p ap er b y Professor Efr on. The lo cal false discov ery r ate, defined in (2.7), w as first in tro d u ced in Efr on et al. ( 2001 ) as the a p osteriori probabilit y of a gene b eing in the null group giv en the z -score z . The results in Sun and Cai ( 2007 ) sho w that the Lfdr is a fu n dament al quantit y whic h can b e u sed directly for optimal FDR con trol. By u sing th e Lfdr dir ectly f or testing, the goals of global error con trol and individual case interpreta- tion are naturally unified . F or con v enience, in the follo wing we shall wo rk with the marginal false disco v ery rate mFDR = E( N 10 ) / E( R ) an d the marginal false n on d isco very rate mFNR = E( N 01 ) / E( S ). The mFDR is asym p - totical ly equiv alen t to the us ual FDR und er weak conditions, m FDR = FDR + O ( m − 1 / 2 ), where m is the num b er of hyp otheses. See Geno vese and W asser- man ( 2002 ). It is illustrativ e to first lo ok at an example in the so-called oracle setting, where in the tw o-group mixture m o del (2.6) the p r op ortion p 0 , the d ensit y f 0 of the null distribution and the density f of the marginal d istribution are assumed to b e known. In this case, b oth the optimal threshold for the p -v alues and the optimal threshold for the Lf d r v alues can b e calculate d for an y given m FDR leve l. W e shall call a testing p r o cedure with the optimal cutoff the or a- cle pr o c e dur e . Supp ose the z -v alues z 1 , . . . , z m come from a n ormal mixture distr ibution with f ( z ) = p 0 φ ( z ) + p 1 φ ( z − µ 1 ) + p 2 φ ( z − µ 2 ) , (1) where p 0 = 0 . 8, p 1 + p 2 = 0 . 2. T hat is, in the t w o- group mo del (2.6), the null distribution is N (0 , 1), the distribution of the nonnulls is a tw o-comp onent normal mixture, and the total prop ortion of the non- n ulls is 0 . 2. Figure 1 compares the p erf ormance of the p -v alue and Lfdr oracle pr o cedures (see Sun and Cai, 2007 ). In Figure 1 , p anel (a) plots the mFNR of the t w o oracle p ro cedures as a fun ction of p 1 in ( 1 ) where the mFDR leve l is set at 0 . 10, and the means un der the alternativ e are µ 1 = − 3 an d µ 2 = 3 . P anel (b) plots the m FNR as a f unction of p 1 in the same setting except that the alternative means are µ 1 = − 3 and µ 2 = 6. In p anel (c) w e c ho ose mFDR= 0 . 10, p 1 = 0 . 18, p 2 = 0 . 02, µ 1 = − 3 and plot th e mFNR as a function of µ 2 . Pa nel (d) p lots the mFNR as a function of the mFDR lev el w h ile holding µ 1 = − 3, µ 2 = 1, p 1 = 0 . 02, p 2 = 0 . 18 fi xed. It is clear from the plots that the p -v alue oracle pro cedur e is d ominated b y the Lfdr oracle pr o ce- dure. A t the same mFDR leve l, the mFNR of the Lfdr oracle pro cedure is uniformly smaller than the mFNR of the p -v alue oracle p r o cedure. The largest difference o ccurs when | µ 1 | < µ 2 and p 1 > p 2 , where the alternativ e d istribution is highly asymmetric ab out the n ull. When | µ 1 | = | µ 2 | , the mFNR r emains a constant for th e p -v alue oracle pro cedure, wh ile the m FNR for the Lfdr oracle p ro cedure can b e no- ticeably smaller when p 1 and p 2 are s ignifican tly dif- feren t, in whic h case the n onn ull distr ibution has a high d egree of asymmetry . The Lfdr oracle pr o ce- dure utilizes the distributional inform ation of the nonnulls, but th e p -v alue oracle pro cedu r e do es not. The Lfdr oracle pr o cedure ranks the relativ e im- p ortance of the test statistic s according to th eir like - liho o d ratios. An in teresting consequence of using the Lfdr statistic in m ultiple testing is that an ob- serv ation lo cated farther from the null (i.e., a larger absolute z -v alue or equiv alen tly a smaller p -v alue) ma y ha v e a lo w er significance lev el. It is therefore p ossible th at the test accepts a m ore “extreme” ob- serv ation while rejecting a less extreme observ ation, whic h imp lies that the rejection r egion is asymmet- ric. This is n ot p ossible for a testing pro cedure based on the in dividual p -v alues, whose r ejection region is alw a ys symmetric ab out th e null. This can b e seen from Figure 2 . Th e left panel compares the mFNR of the p -v alue oracle pr o cedure and Lfdr oracle p ro- cedure and the right panel compares the rejection region in the case of p 1 = 0 . 15. In this case the Lf dr pro cedur e r ejects a z -v alue of − 2 (Lfdr = 0.227, p - v alue = 0.046) but not a z -v alue of 3 (Lfd r = 0.543 , p -v alue = 0.003). More numerical r esults are giv en in Sun and Cai ( 2007 ). Th e results sho w that the Lfdr oracle pro cedure dominates the p -v alue pro cedur e in all configurations of the n onn ull hyp otheses. The difference b et we en the t w o pro cedur es can b e ev en more striking when th e alternativ e distribution f 1 is highly concen trated. In th is setting, it is p os- sible that the extreme p -v alues near b oth 0 and 1 COMMENT 3 Fig. 1. The c omp arison of the p -value (dashe d li ne) and z -value (solid line) or acle rules. actually all come f rom th e null distrib ution in s tead of the nonnull distrib ution! In suc h a case, thresh- olding the p -v alues f ails completely as a metho d for separating the nonn ull h yp otheses fr om the nulls. In con trast, the Lfdr can still b e effectiv e in distin- guishing b et ween the null and nonnull cases. In real applications, the p rop ortion p 0 and the densit y of th e marginal d istribution f are u nkno wn. With a large num b er of observe d z -v alues, b oth p 0 and f can b e estimated w ell from the d ata. In this regard, the large-scale nature of th e p roblem is a blessing. Th e n ull distrib ution is more subtle. If all the mathematica l assump tions are satisfied, the the- oretical n ull distribution is true and thus can b e u sed to compute the Lfdr v alues. Otherw ise, as argued con vincingly b y Efron in Section 5 of th e pr esent pa- p er, the empirical n ull distrib ution should b e used and it can b e estimated from the data. Among the three quanti ties, p 0 , f 0 and f , the m arginal den- sit y f is relativ ely easier to estimate than p 0 and f 0 . Optimal estimation of these quanti ties is a chal- lenging pr oblem. W e sh all discuss the estimation is- sue in the next section. Let us assume f or the mo- men t that we already hav e consisten t estimators ˆ p 0 , ˆ f 0 and ˆ f . Such consisten t estimators are pro vided, for example, in Jin and Cai ( 2007 ). Define the es- timated Lf dr by d Lfdr( z i ) = [ ˆ p 0 ˆ f 0 ( z i ) / ˆ f ( z i )] ∧ 1. S un and Cai ( 2007 ) in tro d uced the follo wing adaptive step-up pr o cedure: Let k = m ax ( i : 1 i i X j =1 d Lfdr ( j ) ≤ α ) , (2) then reject all H ( i ) , i = 1 , . . . , k . It was shown that the data-driv en pro cedu re ( 2 ) con- trols the mFDR at lev el α asymptotically and the mFNR lev el of the adaptiv e pro cedu re ( 2 ) is asymp- totical ly equal to the mFNR leve l ac h ieved by the Lfdr oracle pro cedure. In this sense, the adaptiv e pro cedur e ( 2 ) is asymptotically efficien t. Numerical studies in S un and Cai ( 2007 ) sh ow th at this adap- tiv e pro cedur e ou tp erforms th e step-u p pro cedure (Benjamini and Ho c h b erg, 1995 ) and the adaptive p -v alue based pr o cedure (Benjamini and Ho ch b erg, 2000 ; Geno v ese and W asserman, 2004 ). The numer- ical r esults are consisten t with the theoretical argu- 4 T. T. CAI Fig. 2. Symmetric r eje ction r e gi on versus asymmetric r ej e ction r e gion. In the mixtur e mo del ( 1 ), µ 1 = − 3 and µ 2 = 4 . Both pr o c e dur es c ontr ol the mFDR at 0. 10. men ts. Th ese results together show th at the L f dr, not the p -v alue, is a fu ndament al quant it y f or large- scale multiple testing. It is clear that the p erformance of the adaptiv e testing pro cedu re ( 2 ) dep ends to a certain extent on the estimation accuracy of the estimators ˆ p 0 , ˆ f 0 and ˆ f . This leads to th e estimation issue, wh ic h w ill b e discussed next. 2. ESTIMA TING THE NULL DISTRIBUTION AND THE PROPORTION OF THE NONNULLS As demonstrated con vincingly in this and other recen t pap ers of Efron, the tr u e null distribution of the test s tatistic can b e qu ite different from the the- oretical null and tw o seemingly close c hoices of the n ull distribution can lead to substantia lly different testing results. This d emonstrates that the problem of estimating the null dens it y f 0 is imp ortan t to si- m ultaneous m ultiple testing. In addition to the null densit y f 0 , the prop ortion of the nonnulls is another imp ortant quantit y . Con v ent ional metho ds for estimating the null pa- rameters are based on either moments or extreme observ ations. In the p resen t pap er, t wo metho ds, an- alytical and geometric, for estimating th e n ull den- sit y are d iscussed. In addition, Ef r on ( 2004 ) sug- gested an approac h w hic h u ses the cen ter and half width of the central p eak of the histogram for esti- mating th e parameters of the null distribution. These metho ds are con ve nient to u se. Ho we ve r, th e p rop- erties of these estimators are still mostly unknown. F or example, the analytical metho d app ears to b e quite sensitive to the choice of the in terv al [ a, b ]. It is interesti ng to unders tand h o w the c hoice of [ a, b ] affects the resulting estimator ˆ f 0 , and more imp or- tan tly the outcomes of the sub sequen t testing p r o- cedures. The three null density estimation metho ds men- tioned ab o ve rely h eavil y on the sp arsit y assum ption whic h means that the prop ortion of nonn ulls is small and most of the z -v alues near zero come from the n ulls. In the nonsp arse case these metho d s of esti- mating the null den s ities do not p erform we ll and it is not hard to s h o w th at the estimators are generally inconsisten t. COMMENT 5 Jin and Cai ( 2007 ) in tro du ced an alternativ e fre- quency d omain approac h f or estimating the null pa- rameters b y using the empirical c haracteristic func- tion and F ourier analysis. Th e appr oac h demons tr ates that the information ab out the n ull is well preserv ed in the h igh-frequency F ourier co efficients, wh ere the distortion of the nonnull effects is asymptotically negligible. Th e approac h integrate s the strength of sev eral factors, includ ing sparsit y and heteroscedas- ticit y , and p ro vides go o d estimates of the null in a m uc h br oader range of situations than existing ap- proac hes do. The resulting estimators are sho wn to b e uniformly consisten t o ve r a wide class of param- eters and ou tp erform existing metho d s in simula- tions. The appr oac h of Jin and Cai ( 2007 ) also yields a u niformly consistent estimator f or the p r op ortion of nonnull effects. In a tw o-comp onent normal mix- ture setting, Cai, Jin and Low ( 2007 ) prop osed an estimator of the prop ortion and deve lop ed a mini- max theory f or the estimation problem. Muc h researc h is still n eeded in this area. In par- ticular, it is of significant in terest to und erstand ho w well the null densit y can b e estimated and ho w the p erformance of the estimators affects the p er- formance of the sub sequent m ultiple testing pro ce- dures. 3. MODELING THE DEPENDENCY This pap er also raised the imp ortan t iss ue of the effects of correlation on outcomes of th e testing p ro- cedures. Observ ations arising from large- scale m ultiple comparison pr oblems are often dep end en t. F or example, differen t genes ma y cluster into group s along biological path w a ys and exh ib it high correla- tion in microarra y exp erimen ts. It is noted in this pap er th at correlation can considerably wid en or narro w the null distribu tion of the z -v alues, and so m ust b e accoun ted f or in d eciding whic h hyp otheses should b e r ep orted as nonnull. In fact, the notion of null d istribution itself b ecomes un clear in the d e- p end ent case. The fo cus of previous researc h on the effects of correlation h as b een exclusiv ely on the v alidit y of v arious multiple testing pr o cedures un der dep en- dency . F or example, Benjamini and Y ekutieli ( 2001 ) and W u ( 2008 ) sh ow ed that the FDR is control led at the n omin al level by the step-up pro cedur e (Ben- jamini and Ho ch b erg, 1995 ) and the adaptiv e p - v alue pro cedure (Benjamini and Ho c h b erg, 2000 ; Storey , 2002 ; Geno v ese and W asserman, 2004 ) u nder differen t dep endency assump tions. While the v alid- it y issue is imp ortant , the efficiency issue is arguably more imp ortant. In tuitiv ely it is clear that the dep end ency struc- ture among hypotheses is highly in f ormativ e in si- m ultaneous inference and can b e exploited to con- struct more efficien t tests. F or example, in compara- tiv e microarra y exp erim ents, it is found that c hanges in expr ession for genes can b e the consequence of regional du plications or d eletions, and significan t genes tend to app ear in clusters. Therefore, when deciding th e signifi cance leve l of a particular gene, the observ ations from its neigh b orh o o d should also b e tak en into accoun t. It is still an op en problem h o w to accommo date th e correlation for the construction of v alid and efficien t multi ple testing pro cedures. 4. CONCLUDING R EMARKS The tw o-group mixture mo del and the empirical Ba yes approac h together pro vide a usefu l general framew ork for multiple testing. T he Lfdr, not the p -v alue, is a fu ndament al qu an tit y for large-scal e m ultiple testing. The problem of estimating the null densit y and the prop ortion of the nonnulls is imp or- tan t to simultaneous m ultiple testing. T his pap er raises many imp ortan t qu estions and will definitely stim ulate new r esearc h in the fu ture. I th ank Pro- fessor Efron for his clear and imaginativ e work. A CKNO WLEDGMENT Researc h sup p orted in p art by NSF Gran t DMS- 06-04 954. REFERENCES Benjami ni, Y. and Hochberg, Y. (1995). Controlling the false d isco very rate: A p ractical and p ow erful approac h to multiple testing. J. R oy. Statist. So c. Ser. B 57 289–300. MR1325392 Benjami ni, Y. and Hochberg, Y. (2000). On the adap- tive control of the false discov ery rate in multiple t esting with indep en dent statistics. J. Educ ational and B ehavior al Statistics 25 60–83. Benjami ni, Y. and Ye kutieli, D. (2001). The control of the false d isco very rate under dep end ency . A nn. Statist. 29 1165–11 88. MR1869245 Cai, T., Jin, J. and Low, M. (2007). Estimation and con- fidence sets for sparse n ormal mixtures. Ann. Statist. 35 2421–24 49. Cop as , J. (1974). On symmetric compound decision rules for dichotomi es. Ann. Statist. 2 199–204. Efr on, B. (2004). Large-scale sim ultaneous hypoth esis test- ing: The choice of a null hypoth esis. J. Amer. Statist. As- so c. 99 96–104. MR2054289 6 T. T. CAI Efr on, B. (2005). Lo cal false disco very rates. Av ailable at http://w ww-stat.stanford.edu/˜brad/papers/F alse.pdf . Efr on, B. , Tibshirani , R. , Storey, J. and Tusher, V. (2001). Empirical Bay es analysis of a microarray exp eri- ment. J. Amer. Statist. Asso c. 96 1151–116 0. MR1946571 Genovese, C. and W asserman, L. (2002). Op erating char- acteristic and extensions of the false discov ery rate pro ce- dure. J. R oy. Statist. So c. Ser. B 64 499–517. Genovese, C. and W asserman, L. (2004). A stochastic pro- cess approach to false discov ery control . Ann. Statist. 32 1035–10 61. MR2065197 Jin, J. and Ca i, T. (2007). Estimating the null and the pro- p ortion of non- null effects in large-scale multiple compar- isons. J. Amer. Statist. Asso c. 102 495–50 6. MR2325113 Storey, J. (2002). A direct approac h to false discov ery rates. J. R oy. Statist. So c. Ser. B 64 479–498. MR1924302 Sun, W. and Cai , T. (2007). The oracle and compound deci- sion ru les for false disco very rate control. J. Amer. Statist. Asso c. 102 901–912. Wu, W. (2008). On false discov ery con trol u n der dep end en ce. Ann . Statist. 36 364–380.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment