iBOA: The Incremental Bayesian Optimization Algorithm
This paper proposes the incremental Bayesian optimization algorithm (iBOA), which modifies standard BOA by removing the population of solutions and using incremental updates of the Bayesian network. iBOA is shown to be able to learn and exploit unres…
Authors: Martin Pelikan, Kumara Sastry, David E. Goldberg
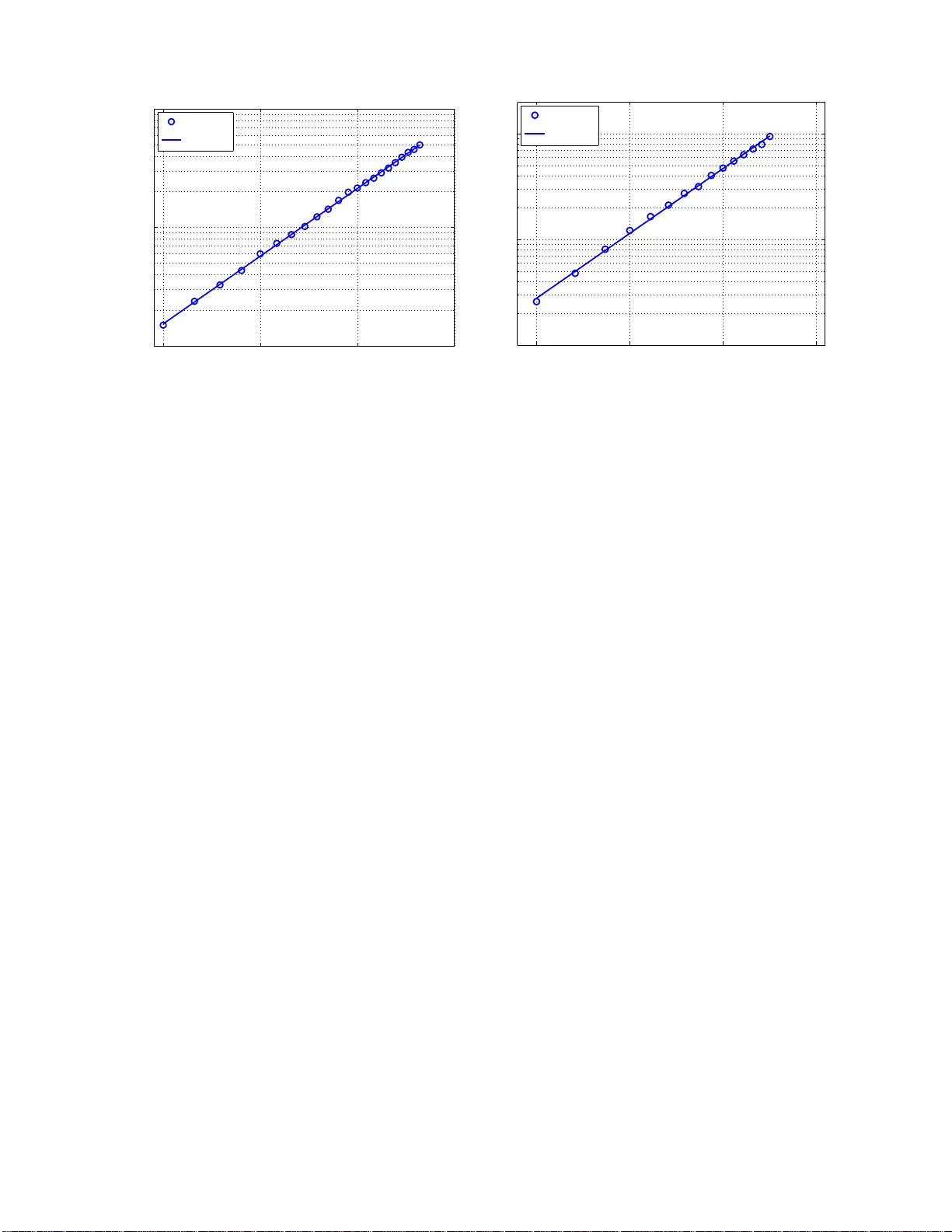
iBO A: The Incremental Ba y esian Optimization Algo rithm Ma rtin P elik an, Kuma ra Sastry , and D a vid E. Goldb erg MED AL Rep o rt No. 2008002 January 200 8 Abstract This pap er propo ses the incrementa l Bay e sian optimization alg orithm (iBO A), wh ich mo difies standard BO A b y removing the popul a tion o f so lutions and us i ng incremental up dates o f the Bay esian netw ork. iBO A is shown to b e able to learn and exploit unrestricted Ba yesian netw orks us i ng inc reme n tal techni q ues for up dating b oth the structure as w ell as the pa rameters of the probabilistic mo del. Thi s represents an imp ortant step tow ard the design of competen t incremental estim a tion of distribution algorithms that can sol ve difficul t nearly deco m p o sable pr obl ems scalab l y and reliab l y . Keyw o rds Ba yesian optimizatio n algorithm, incremental BOA, incremental mo del up d ate, estimation of d i stribution alg o- rithms, evolutionary com p utation. Missouri Esti mation of Distribution Algorithms Lab oratory (MEDAL) Department of Mathem a tics and Compu ter Scienc e University of Misso uri–St. Loui s One Uni versity Blvd., St. L o uis, MO 631 21 E-mail: medal@ cs.um sl.edu WWW: ht tp:// medal. cs.umsl.edu/ iBO A: The Incremen t al Ba y esian Optimizatio n A lgor ithm Martin P elik an Missouri Estimation o f Distribution Algor ithms Lab orato ry (MED AL) Dept. of Math and Computer Science, 320 CCB Univ ersit y of Missouri a t St. Louis One Univ ersit y Blvd., St. Lo uis, MO 6312 1 pelikan@cs. umsl.edu Kumara Sastry Illinois Genetic Algorithms Lab orator y (IlliGAL) Departmen t of Industrial and Enterpris e Systems Engineering Univ ersit y of Illinois at Urbana -Champaign, Urbana IL 61801 kumara@illi gal.ge.uiuc.edu Da vid E. Goldb erg Illinois Genetic Algorithms Lab orator y (IlliGAL) Departmen t of Industrial and Enterpris e Systems Engineering Univ ersit y of Illinois at Urbana -Champaign, Urbana IL 61801 deg@uiuc.ed u Abstract Keyw ords: Ba yesia n optimization algorithm, incremen tal BOA, incremen tal mo del up date, esti- mation of distribu tion algorithms, ev olutionary computation. 1 In tro duction Estimation of distribution algorithms (EDA s) [2, 21, 18, 24, 19, 28] replace standard v ariation op erators of genetic and evolutio nary algorithms b y b u ilding and sampling probabilistic mo dels of promising candid ate solutions. Al ready some of the earliest estimation of distribu tion algorithms (ED As) ha ve completely eliminated the need for main taining an explicit p opulation of candidate solutions used in most standard ev olutionary algorithms, and they up dated the pr obabilistic mo del incremen tally using only a few candidate s olutions at a time [2 , 13]. The main adv an tage of su ch incr emental ED As is that m emory complexit y is greatly r educed. One of the must successful resu lts of th is line of researc h w as the application of the compact genetic algorithm (cGA) [13] to a noisy problem with o v er one billion b its [11, 32]. Nonetheless, all incremental ED As prop osed in the past use either un iv ariate mo dels with n o int eractions b et w een th e v ariables or probabilistic mo dels in the form of a tree. This pap er pr op oses an incremen tal v ersion of the Ba yesian optimization algo rithm (BO A), whic h uses Ba ye sian n et w orks to mo d el promising solutions and samp le the new ones. The pr o- p osed algorithm is called the incr emental BO A (iBO A). While many of the ideas can b e adopted 1 from the work on other incremental ED As, the design of iBO A p oses one unique c hallenge—ho w to incremen tally up d ate a multiv ariate p robabilistic mo del w ithout either committing to a highly restricted set of str u ctures at the b eginning of the r un or having to main tain all p ossible m ulti- v ariate statistics that can b e usefu l throughout the run? W e p rop ose one solution to th is challe nge and outline another p ossible approac h to tac kling this problem. W e th en test iBO A on sev eral de- comp osable problems to v erify its robustness and scalabilit y on b oundedly difficult d ecomp osable problems. Finally , w e outline interesti ng topics for fu ture w ork in th is area. The pap er starts b y discussing related wo rk in section 2. Section 3 outlines the standard p opulation-based Ba y esian optimization algorithm (BOA). Sectio n 4 describ es the incremen tal BO A (iBO A). Section 5 presents an d discusses exp eriment al results. Section 6 outlines some of the most imp ortant c hallenges for future researc h in this area. Finally , section 7 summarizes and concludes the pap er. 2 Bac kground This section reviews some of the incremen tal estimation of distrib ution algorithms. Th roughout the section, w e assu me that candidate solutions are r epresen ted b y fi xed-length bin ary strings, although m ost of the metho ds can b e defin ed for fixed-length strings o v er an y fin ite alphab et in a straigh tforw ard manner. 2.1 P opulation-Based Incremen tal Learning ( P BIL) The p opulation-based increment al learning (PBIL) algorithm [2 ] wa s one of the fir st estimation of distribution algo rithm s and w as mainly inspir ed b y the equilibr ium genetic algo rithm (EGA) [17]. PBIL maint ains a pr obabilistic mo del of p r omising solutions in the form of a probabilit y vect or. The probability v ector considers only u niv ariate p robabilities and for eac h string p osition it stores the probabilit y of a 1 in that p osition. F or an n -bit string, the probabilit y v ector is thus a v ector of n probabilities p = ( p 1 , p 2 , . . . , p n ) w h ere p i enco des the probabilit y of a 1 in th e i -th p osition. Initially , all entries in the probabilit y v ector are set to 0 . 5, enco ding the uniform d istribution ov er all bin ary strings of length n . In eac h iteration of PBIL, a fix ed n umber N of binary str ings are fi r st generated from the current probability vect or; for eac h new string and eac h string p osition i , the bit in the i th p osition is set to 1 with probability p i from the curr ent p robabilit y vec tor (otherwise the bit is set to 0). The generated solutions are ev aluated and N best b est solutions are then selected from the new solutions based on the results of the ev aluation where N best < N . The selected b est solutions are then u sed to up date the probabilit y v ector. Sp ecifically , for eac h selecte d solution ( x 1 , x 2 , . . . , x n ), the probabilit y ve ctor p = ( p 1 , p 2 , . . . , p n ) is up d ated as follo ws: p i ← p i (1 − λ ) + x i λ for all i ∈ { 1 , . . . , n } , where λ ∈ (0 , 1) is the learning rate, t ypically set to some small v alue. If x i = 1, then p i is in creased; otherwise, p i is decreased. The rate of increase or decrease d ep ends on the learning rate λ an d the current v alue of the corresp onding probabilit y-v ector en try . In the original wo rk on PBIL [2], N = 200, N best = 2, and λ = 0 . 005. Although PBIL do es not m aintain an explicit p opulation of candidate solutions, the learning rate λ can b e used in a similar manner as the p opulation-size parameter of stand ard p opulation- based genetic and ev olutionary algorithms. T o simulate the effects of larger p opulations, λ should b e d ecreased; to sim ulate the effects of smaller p opulations, λ should b e increased. 2 2.2 Compact Genetic Algorithm (cGA) The compact genetic algorithm (cGA ) [13] also main tains a probabilit y v ector in s tead of a p opu- lation. Similarly as in PBIL, the initial pr obabilit y vecto r corresp onds to the u niform d istribution o v er all n -bit binary strings and all its entries are thus set to 0 . 5. In eac h iteration, cGA generates t w o cand id ate solutions from the current probabilit y vec tor. Th en, the tw o solutions are ev aluated and a tournament is executed b et wee n the t wo solutions. The winner w = ( w 1 , . . . , w n ) and the loser l = ( l 1 , . . . , l n ) of this tournament are then used to u p date the probabilit y v ector. Before presenting the u p date rule us ed in cGA, let us discuss the effect s of a s teady-state up date on th e univ ariate probab ilities of the probabilit y v ector in a p opu lation of size N where the winner replaces th e loser. If f or an y p osition i the w in ner con tains a 1 in this p osition and the loser con tains a 0 in the same p osition, the probabilit y p i of a 1 in this p osition wo uld increase by 1 / N . On the other h and, if the winner contai ns a 0 in this p osition and the loser con tains a 1, then the probab ility p i of a 1 in this p osition wo uld decrease b y 1. Finally , if the winner and the loser con tain the same bit in any p osition, the probabilit y of a 1 in this p osition would not c hange. This up d ate pro cedure can b e sim ulated ev en without an explicit p opu lation using the follo wing up date rule [13]: p i p i − 1 N if w i = 0 and l i = 1 p i + 1 N if w i = 1 and l i = 0 p i otherwise Although cGA do es not main tain an explicit p opulation, the parameter N serves as a replacemen t of th e p opu lation-size parameter (similarly as λ in PBIL). P erformance of cGA can b e exp ected to b e similar to that of PBIL, if b oth algo rithm s are set up similarly . F urthermore, cGA should p erform similarly to the simple genetic algorithm with uniform crosso v er with the p opulation size N . Ev en m ore closely , cGA r esem bles the univ ariate m arginal distribution algo rithm (UMD A) [21] an d the equilibrium genetic algorithm (EGA) [17]. 2.3 ED A with Optimal Dep endency T rees In the ED A with optimal dep endency trees [3 ], dep enden cy-tree mo d els are used and it is th us necessary to m ain tain not only the univ ariate pr obabilities bu t also the pairw ise probabilities for all pairs of string p ositions. T he p airwise pr obabilities are main tained using an arr a y A , which con tains a num b er A [ X i = a, X j = b ] f or ev ery pair of v ariables (string p ositions) X i and X j and ev ery com bination of assignments a and b of these v ariables. A [ X i = a, X j = b ] represents an estimate of the num b er of solutions with X i = a and X j = b . Initially , all en tries in A are initialize d to some constan t C init ; f or example, C init = 1000 ma y b e u s ed [3]. Giv en the array A , the marginal probabilities p ( X i = a, X j = b ) are estimated for ev ery pair of v ariables X i and X j and ev ery assignment of these v ariables as p ( X i = a, X j = b ) = A [ X i = a, X j = b ] P a ′ ,b ′ A [ X i = a ′ , X j = b ′ ] · Then, a d ep endency tree is built that maximizes the m utual information b etw een connected pairs of v ariables, where the mutual inf ormation b et w een an y tw o v ariables X i and X j is giv en b y I ( X i , X j ) = X a,b p ( X i = a, X j = b ) log P ( X i = a, X j = b ) p ( X i = a ) p ( X j = b ) 3 where marginal probabilities p ( X i = a ) and p ( X j = b ) are computed fr om the p airwise probabilities p ( X i = a, X j = b ). T he tr ee may b e built u sing a v arian t of Pr im ’s algorithm for fin ding m inim um spanning tr ees [30], minimizing the Ku llbac k-Liebler div ergence b etw een the empirical d istribution and th e dep endency-tree m o del [6]. New candidate solutions can b e generated from the probability distr ibution enco d ed b y the dep end en cy tree, wh ich is defined as p ( X 1 = x 1 , . . . , X n = x n ) = p ( X r = x r ) Y i 6 = r p ( X i = x i | X p ( i ) = x p ( i ) ) where r denotes the index of the root of the dep endency tree and p ( i ) d enotes the paren t of X i . The generation starts at the ro ot, the v alue of which is generated using its univ ariate probabilities P ( X i ), and then contin u es d o wn the tree by alw ays generating the v ariables the parents of whic h ha v e already b een generated. Eac h iteration of the d ep endency-tree ED A pro ceeds similarly as in PBIL. First, a dep endency tree is b uilt from A . Then, N candid ate solutions are generated from th e cur ren t dep endency tree and N best b est solutions are selected out of the generated candidates b ased on their ev aluation. The selected b est solutions are then used to u p date entries in the arra y A ; for eac h solution x = ( x 1 , . . . , x n ), the up date r ule is executed as follo w s: A [ X i = a, X j = b ] ← ( αA [ X i = a, X j = b ] + 1 if x i = a and x j = b αA [ X i = a, X j = b ] otherwise where α ∈ (0 , 1) is the deca y rate; for example, α = 0 . 99 [3]. The ab o v e u p date rule is similar to that u sed in PBIL. While b oth PBIL and cGA use a pr obabilistic mo del based on only u niv ariate p robabilities, the ED A with optimal d ep endency trees is capable of enco ding conditional dep endencies b et w een some pairs of string p ositions, enablin g the algorithm to efficien tly solv e some pr oblems th at are in tractable with PBIL and cGA. Nonetheless, using dep enden cy-tree mo dels is still insufficient to fully co ver multiv ariate d ep endencies; this ma y yield the ED A with optimal dep endency tr ees in tractable on m any decomp osable problems with m ultiv ariate interac tions [4, 27, 10, 34, 24]. 3 Ba y esian Optimization Algorithm (iBO A ) This section d escrib es the Ba y esian optimization algorithm (BO A). First, th e basic pro cedu re of BO A is d escrib ed. Next, the metho ds f or learning and samplin g Ba y esian netw orks in BO A are briefly review ed. 3.1 Basic BO A Algorithm The Ba y esian optimizatio n algo rithm (BO A) [26, 27] ev olv es a p opulation of candidate solutions represent ed b y fi xed-length ve ctors o v er a fin ite alphab et. In this pap er we assume th at candidate solutions are represen ted by n -bit binary strings, bu t none of the presen ted tec hniques is limited to only the binary alphab et. The fi r st p opulation of candidate s olutions is t ypically generated at random acc ordin g to the u niform distrib ution o v er all p ossible strin gs. Eac h iteration of BOA starts b y s electing a p opulation of pr omising candidate solutions f rom the current p opulation. An y selection metho d used in p opu lation-based ev olutionary algorithms can b e used; for example, we can use binary tournament selectio n. Then, a Bay esian net work is built 4 Figure 1: Basic pro cedu r e of the Ba y esian optimization algorithm (BO A). for th e selected solutions. New solutions are generated b y sampling th e pr obabilit y distr ib ution enco ded b y the learned Ba y esian net w ork. Finally , the new solutions are in corp orated into the original p op u lation; for example, this can b e done replacing the en tire old p opu lation with the n ew solutions. The pro cedure is term in ated when s ome p redefined termination criteria are reac hed; f or example, when a solution of sufficien t qualit y has b een reac hed or w h en the p opulation h as lost div ersit y and it is unlike ly that BO A will reac h a b etter solution than the solution that has b een found already . The pr o cedure of BOA is visualized in figure 1. 3.2 Ba y esian Netw orks A Ba y esian n et w ork (BNs) [23, 16] is defined by tw o comp onents: Structure. The structure of a Bay esian n et w ork f or n random v ariables is defin ed by an undirected acyclic graph where eac h no de corresp onds to one random v ariable and eac h edge defines a direct conditional d ep endency b et we en the connected v ariables. The sub s et of no d es fr om whic h there exists an edge to the no de are called the parents of th is no d e. P arameters. P arameters of a Bay esian n etw ork define conditional p robabilities of all v alues of eac h v ariable giv en any com bination of v alues of the p aren ts of this v ariable. A Ba y esian n et w ork defines the join t probabilit y distribution p ( X 1 , . . . , X n ) = n Y i =1 p ( X i | Π i ) , where Π i are the parent s of X 1 and p ( X i | Π i ) is th e conditional probabilit y of X i giv en Π i . Eac h v ari- able d irectly dep ends on its parent s. O n the other hand, the net w ork enco des many indep endence assumptions that ma y simplify the join t probabilit y distribution significan tly . Ba y esian net wo rks are more complex than decision trees d iscussed in section 2.3, allo w ing BOA to enco de arbitrary multiv ariate dep endencies. Th e estimatio n of Ba y esian net w orks algorithm (EBNA) [8] and the learnin g factorize d distribution algorithm (LFD A) [20] are also ED As based on Ba ye sian net w ork mo dels. 5 3.3 Learning Ba y esian N etw orks in BOA T o learn a Ba y esian netw ork fr om the set of selected solutions, w e m ust learn b oth the structure of th e net work as w ell as the p arameters (conditional and marginal probabilities). T o learn the parameters, th e maxim um like liho o d estimatio n defines th e conditional probabilit y that X i = x i giv en that the parent s are set as Π i = π i where x i and π i denote an y assignmen t of the v ariable and its parents: p ( X i = x i | Π i = π i ) = m ( X i = x i , Π i = π i ) m (Π i = π i ) , where m ( X i = x i , Π i = π i ) denotes the num b er of instances w ith X i = x i and Π i = π i , and m (Π i = π i ) denotes the num b er of instances w ith Π i = π i . T o learn the structure of a Ba yesia n net work, a greedy algorithm [14 ] is t ypically u s ed. In the greedy algorithm for n et w ork construction, the n et w ork is initialized to an empt y net w ork with no edges. Then, in eac h iteration, an edge that improv es the qualit y of the net w ork the most is added until the net w ork cann ot b e fur ther imp ro v ed or other user-sp ecified termination criteria are satisfied. There are sev eral appr oac hes to ev aluating the qualit y of a sp ecific net w ork structure. In this w ork, we use the Ba y esian inform ation criterion (BIC) [33] to score net w ork structures. BIC is a t wo-part minimum description length metric [12], where one part represents mo del accuracy , whereas the other part represents mo del complexit y measured by the n umb er of b its required to store mo del parameters. F or simplicit y , let us assume that th e solutions are binary str in gs of fixed length n . BIC assigns the net work s tr ucture B a score [33] B I C ( B ) = n X i =1 − H ( X i | Π i ) N − 2 | Π i | log 2 ( N ) 2 , where H ( X i | Π i ) is the conditional ent ropy of X i giv en its parent s Π i , n is the num b er of v ariables, and N is the p opulation size (the size of the trainin g data set). The conditional ent ropy H ( X i | Π i ) is giv en by H ( X i | Π i ) = − X x i ,π i p ( X i = x i , Π i = π i ) log 2 p ( X i = x i | Π i = π i ) , where th e sum r uns ov er all instances of X i and Π i . 3.4 Sampling Ba yesi an Netw orks in BOA The sampling can b e done using the pr ob ab ilistic logic sampling of Ba y esian net w orks [15], whic h pro ceeds in tw o steps. The first step compu tes an ancestral ord ering of the no des, wh er e eac h n o de is pr eceded by its parents. In the second step, the v alues of all v ariables of a n ew candidate solution are generated according to the computed order in g. S ince the algorithm generates the v ariables according to the ancestral ordering, wh en the algorithm attempts to generate the v alue of a v ariable, the parents of this v ariable m ust h a v e already b een generate d. Giv en the v alues of the parents of a v ariable, the distribution of the v alues of the v ariable is giv en b y the corresp ond in g conditional p robabilities. 6 Figure 2: Basic pro cedu r e of the incremen tal Ba y esian optimization algorithm (iBO A). 4 Incremen tal BO A (iBO A) This section outlines iBOA . First, the basic p ro cedure of iBO A is briefly outline. Next, the pro ce- dures used to u p date the structure and parameters of the mo d el are describ ed and it is d iscussed ho w to com bine these comp onen ts. Finally , the b enefits and costs of using iBO A are analyzed briefly . 4.1 iBO A: Basic Pro cedure The basic pro cedure of iBO A is similar to that of other incremental EDAs. The mo del is initialized to the prob ab ility vec tor that enco des the uniform distr ib ution o ver all bin ary strings; all entries in the probabilit y v ector are thus initialized to 0 . 5. In eac h iteration, several solutions are generated from the cur ren t m o del. Th en, the generated solutions are ev aluated. Give n the r esults of the ev aluation, the b est and the worst solution out of th e generated set of solutions are selected (the winn er and th e loser). The winn er and the loser are used to up d ate the parameters of the m o del. In some iterations, mo del structure is up d ated as we ll to reflect new dep enden cies th at are supp orted by the r esu lts of the p revious tourn amen ts. The b asic iBOA pro cedur e is visualized in figur e 2. There are t wo main differences b et ween BO A and iBO A in the w a y the mo del is up dated. First of all, the p arameters m ust b e up dated in cr ementally b ecause iBOA do es not main tain an exp licit p opulation of solutions. Second, the mo del s tructure also has to b e u p dated increment ally without using a p opulation of strin gs to learn th e stru cture from. The remainder of this sectio n discusses the details of iBOA pro cedure. Sp ecifically , w e discuss the c hallenges that must b e addressed in the d esign of the in cremen tal v ersion of BO A. T h en, we present sev eral appr oac h es to dealing with these challe nges and detail the most imp ortan t iBOA comp onents. 4.2 Up dating Param eters in iBOA The parameter up dates are done similarly as in cGA. Sp ecifically , iBO A main tains an arra y of marginal probabilities for eac h string p osition given other p ositions that the v ariable d ep ends on or th at the v ariable may dep end on. Let us denote the winner of the tournamen t (b est solution) b y w = ( w 1 , . . . , w n ) and the loser (worst solution) b y l = ( l 1 , . . . , l n ). A marginal probabilit y p ( X β (1) = x β (1) , . . . , X β k = x β ( k ) ) of order k w ith th e p ositions sp ecified by β ( · ), denoted by by 7 p ( X 1 , X 3 , X 5 ) p ( X 1 , X 3 , X 5 ) X 1 X 3 X 5 (b efore) (after) 0 0 0 0.10 0.10 0 0 1 0.05 0.04 0 1 0 0.20 0.20 0 1 1 0.10 0.10 1 0 0 0.15 0.15 1 0 1 0.20 0.20 1 1 0 0.05 0.05 1 1 1 0.15 0.16 P opulation size: N = 100 T ournamen t results: winner = 101110 loser = 010011 Figure 3: Up dating parameters in iBO A pro ceeds b y adding 1 / N to the marginal probabilit y consisten t with the winner and subtracting 1 / N f rom the marginal probabilit y consistent with the loser. Wh en th e winner and the loser b oth p oint to the same en try in the pr obabilit y table, the table remains the s ame. p ( x β (1) , . . . , x β ( k ) ) f or brevity , is up dated as follo ws : p ( x β (1) , . . . , x β ( k ) ) ← p ( x β (1) , . . . , x β ( k ) ) + 1 N if ∀ j : w β ( j ) = x β ( j ) and ∃ j : l β ( j ) 6 = x β ( j ) p ( x β (1) , . . . , x β ( k ) ) − 1 N if ∃ j : w β ( j ) 6 = x β ( j ) and ∀ j : l β ( j ) = x β ( j ) p ( x β (1) , . . . , x β ( k ) ) otherwise The ab o v e up date rule increases eac h marginal probabilit y by 1 / N if the sp ecific instance is consisten t with the w inner of the tournamen t bu t it is in consisten t with the loser. On the other h and, if th e instance is consisten t with the loser but n ot with the winner, th e pr obabilit y is decreased b y 1 / N . This corresp onds to replacing the winner by the loser in a p opu lation of N candidate solutions. F or any subset of v ariables, at most t wo marginal probabilities c h ange in eac h up date b ecause we on ly c hange marginal probabilities for the assignments consisten t with either the winner or the loser of the tournamen t. See figur e 3 for an example of the iBOA up date r ule for marginal probabilities. The conditional p robabilities can b e compu ted from th e m arginal ones. Th us, with the up d ate rule for the marginal p r obabilities, iBO A can main tain any marginal and conditional probabilities necessary for sampling and structural up dates. While it is straigh tforwa rd to initiali ze an y marginal probabilit y under the assumption of the uniform distribution and to up date the marginal probabilities using the results of a tournament, one question r emains op en—what m arginal p robabilities do we actually need to main tain when w e do not kn o w ho w the mo del str uctures will lo ok a priori? Since this question is closely r elated to structural u p dates in iBO A, w e discuss it next. 4.3 Up dating Mo del Struct ure in iBOA In all incremen tal ED As prop osed in the past, already at th e b eginnin g of the run it is clear what probabilities ha v e to b e mainta ined. I n cGA and PBIL, the only probabilities w e ha ve to mainta in are the univ ariate p robabilities for different string p ositions. In the dep end en cy-tree EDA, we also ha v e to mainta in pairwise p robabilities. But what probabilities do w e need to main tain in iBO A? This issue p oses a d ifficult challenge b ecause w e do not kn o w mo del structure a priori and th at is wh y it is not clear what conditional and marginal probabilities w e w ill n eed. 8 Let us firs t fo cus on structur al up dates and assume th at the cur ren t mo del is the probabilit y v ector (Ba y esian netw ork with no edges). T o decide on adding the firs t edge X i → X j based on the BIC metric or any other standard scoring metric, we n eed to ha v e p airwise marginal p robabilities p ( X i , X j ). In general, let us consider a string p osition X i with the set of parents Π i . T o d ecide on adding another parent X j to the current set of paren ts of X i using the BIC metric or an y other standard scoring metric, w e also need p robabilities p ( X i , X j , Π i ). If we kn ew the current set of parents of eac h v ariable, to ev aluate all p ossible edge additions, for eac h v ariable, w e wo uld need at most ( n − 1) marginal p robabilit y tables. O v erall, this would result in at most n ( n − 1) = O ( n 2 ) marginal probability tables to maintain. Ho we ver, s ince w e do not kno w what the set of parents of an y v ariable will b e, ev en if we restricted iBO A to con tain at most k parents for any v ariable, to consider all p ossible mo dels and all p ossible marginal probabilities, w e wo uld n eed to mainta in at least n k marginal probabilit y tables. Of course, main taining n k probabilit y tables for relativ ely large n will b e in tractable ev en for mo derate v alues of k . T his raises an imp ortan t question—can w e do b etter and store a more limited set of pr obabilit y tables without sacrificing m o del-building capabiliti es of iBO A? T o tac kle this c hallenge, for eac h v ariable X i , w e are going to main tain several probability tables. First of all, f or an y v ariable X i , we will main tain the probabilit y table for p ( X i , Π i ), w h ic h is necessary for sp ecifying the conditional probabilities in the cu r ren t mod el. Additionally , for X i , w e will main tain pr obabilit y tables p ( X i , X j , Π i ) for all X j that can b ecome paren ts of X i , which are necessary for adding a new paren t to X i . Th is will pr o vide iBO A not only with the probabilities required to sample new solutions, but also those required to mak e a new edge addition endin g in an arbitrary no de of the net w ork. Ov erall, the n umber of subsets for whic h the probabilit y table will b e mainta ined will b e u pp er b ound ed by O ( n 2 ), which is a significan t reduction fr om Ω ( n k +1 ) for any k ≥ 2. Nonetheless, we still must resolv e th e pr oblem of adding new marginal probabilities once w e mak e an edge addition. Sp ecifically , if we add an edge X j → X i , to add another edge ending in X i , w e will need to store p robabilities p ( X i , X j , X k , Π i ) where k d en otes the ind ex of any other v ariable that can b e added as a paren t of X i . While it is imp ossib le to obtain an exact v alue of these probabilities unless w e w ould main tain them from the b eginning of the run, one w a y to estimate these p arameters is to assume in d ep endence of X k and ( X i , X j , Π i ), resulting in the follo win g r ule to initialize the n ew marginal probabilities: p ( X i , X j , X k , Π i ) = p ( X k ) p ( X i , X j , Π i ) . (1) Once the new marginal probab ilities are initialized, they can b e u p dated after eac h new tourna- men t using the up date rule pr esen ted earlier. Although the ab ov e indep endence assumption may not hold in general, if the edge X k → X i is sup p orted b y future instances of iBO A, the edge will b e ev en tually added . While other approac hes to dealing with the c hallenge of in tro du cing new marginal probab ilities are p ossible, w e b eliev e that the str ategy p resen ted ab o v e should pro vide robust p erform ance as is also supp orted b y the exp eriments p resen ted later. A t the same time, after adding an edge X j → X i , we can eliminate probabilities p ( X i , Π i ) from the set of probabilit y tables, b ecause this probabilit y table will not b e necessary anymore. Initially , when the mo del con tains no edges, the marginal pr obabilities p ( X i , X j ) for all p airs of v ariables X i and X j m ust b e stored for the first roun d of stru ctural up date and up dated after eac h tournamen t. Later in the run , the marginal probabilities for eac h v ariable will b e c hanged based on the structure of the mod el and the results of the tournamen ts. An example sequence of mo del up dates with the corresp onding sets of marginal probabilit y tables f or a simple p roblem of n = 5 b its is sho wn in figur e 4. E ac h time a n ew m arginal probabilit y 9 Initial mo del: X 1 , X 2 , X 3 , X 4 , X 5 Probabilities stored: p ( X 1 ) , p ( X 2 ) , p ( X 3 ) , p ( X 4 ) , p ( X 5 ) , (for curren t str u cture) p ( X 1 , X 2 ) , p ( X 1 , X 3 ) , p ( X 1 , X 4 ) , p ( X 1 , X 5 ) , (for n ew parents of X 1 ) p ( X 2 , X 1 ) , p ( X 2 , X 3 ) , p ( X 2 , X 4 ) , p ( X 2 , X 5 ) , (for n ew parents of X 2 ) p ( X 3 , X 1 ) , p ( X 3 , X 2 ) , p ( X 3 , X 4 ) , p ( X 3 , X 5 ) , (for n ew parents of X 3 ) p ( X 4 , X 1 ) , p ( X 4 , X 2 ) , p ( X 4 , X 3 ) , p ( X 4 , X 5 ) (for new parents of X 4 ) p ( X 5 , X 1 ) , p ( X 5 , X 2 ) , p ( X 5 , X 3 ) , p ( X 5 , X 4 ) (for new parents of X 5 ) Added edge: X 3 → X 2 New m o del: X 1 , X 2 ← X 3 , X 3 , X 4 , X 5 Probabilities stored: p ( X 1 ) , p ( X 2 , X 3 ) , p ( X 3 ) , p ( X 4 ) , p ( X 5 ) , (for curren t str u cture) p ( X 1 , X 2 ) , p ( X 1 , X 3 ) , p ( X 1 , X 4 ) , p ( X 1 , X 5 ) , (for new paren ts of X 1 ) p ( X 2 , X 3 , X 1 ) , p ( X 2 , X 3 , X 4 ) , p ( X 2 , X 3 , X 5 ) , (for n ew parent s of X 2 ) p ( X 3 , X 1 ) , p ( X 3 , X 4 ) , p ( X 3 , X 5 ) , (for new paren ts of X 3 ) p ( X 4 , X 1 ) , p ( X 4 , X 2 ) , p ( X 4 , X 3 ) , p ( X 4 , X 5 ) (for new paren ts of X 4 ) p ( X 5 , X 1 ) , p ( X 5 , X 2 ) , p ( X 5 , X 3 ) , p ( X 5 , X 4 ) (for new paren ts of X 5 ) Added edge: X 2 → X 1 New m o del: X 1 ← X 2 , X 2 ← X 3 , X 3 , X 4 , X 5 Probabilities stored: p ( X 1 , X 2 ) , p ( X 2 , X 3 ) , p ( X 3 ) , p ( X 4 ) , p ( X 5 ) , (for curren t str u cture) p ( X 1 , X 2 , X 3 ) , p ( X 1 , X 2 , X 4 ) , p ( X 1 , X 2 , X 5 ) , (for n ew parent s of X 1 ) p ( X 2 , X 3 , X 4 ) , p ( X 2 , X 3 , X 5 ) , (for new paren ts of X 2 ) p ( X 3 , X 4 ) , p ( X 3 , X 5 ) , (for new paren ts of X 3 ) p ( X 4 , X 1 ) , p ( X 4 , X 2 ) , p ( X 4 , X 3 ) , p ( X 4 , X 5 ) (for new paren ts of X 4 ) p ( X 5 , X 1 ) , p ( X 5 , X 2 ) , p ( X 5 , X 3 ) , p ( X 5 , X 4 ) (for new paren ts of X 5 ) Figure 4: iBOA stores all marginal prob ab ilities for the curr ent s tr ucture and those required f or adding a new edge int o an y no de. Since some ed ges are disallo we d (du e to cycles), some p robabilities ma y b e omitted. In the ab o v e example, for clarit y , some marginal probabilities are rep eated (this w ould not b e done in the actual implementa tion). table is added, its v alues are in itialize d according to equation 1. 4.4 Sampling New Solutions There is n o difference b et ween the Ba y esian net wo rk learned in BOA and iBOA. T herefore, the same sampling algorithm as in BO A ca n b e used in iBO A. Sp ecifically , the v ariables are fi rst top ologica lly ordered and for eac h string, the v ariables are generated according to the generated ancestral ordering using the conditional probabilities stored in the mo d el as describ ed in section 3.4. 4.5 Strategies for Com bining Comp onen ts of iBOA There are sev eral strategies for com bin ing all the iBO A comp onen ts describ ed ab o v e together. This section briefly reviews and discusses sev eral of these strateg ies. The fir st approac h is to p erform con tinuous up dates of b oth the stru cture as well as the pa- rameters. After p erformin g eac h tournament, all pr obabilities will b e up dated first, and then the structure will b e up dated by add ing an y new edges that lead to an impr o v emen t of mo del qualit y . 10 Incremen tal B OA (iBOA) t := 0; B := probabi lity vector (no edges); p := margina l probabilities for B a ssuming uniform distrib ution; while (not done) { generate k solution s fro m B with probabiliti es p; evaluate the generated solutio ns; update p using the new solutio ns; update B using the new p; t := t+1; }; Figure 5: Pseud o co de of the incremen tal Ba yesian optimization algorithm (iBOA ). Mo d el structure is denoted b y B , marginal probabilities are denoted b y p . Dep ending on the v ariant of iBO A, some structural u p dates m a y b e skipp ed . The second app r oac h attempts to simulate BOA somewhat closer by up dating the structure only once in N iterations; only the pr ob ab ilities for sampling new solutions will b e up d ated in ev ery iteration of iBO A. This will significantly reduce the complexity of structural u p dates and impro ve the o v erall efficiency . While the mo d el stru cture will n ot b e up dated as frequently as in the fir s t appr oac h , the structural up d ates migh t b e more accurate b ecause of forcing the metric to use more data to mak e an adequate structural u p date. The third approac h remo ve s the steady-state comp onen t of iBO A and up d ates b oth the prob- abilities for samp lin g new solutions as we ll as th e mo del structure only once in every N iterations. That m eans that u n til th e next structural up d ate, the pr obabilit y d istribution enco ded by the cur- ren t m o del remains constan t, and it is only c hanged once new edges ha v e b een added to the new v alues after th e last N p arameter up dates. All ab o v e approac hes can b e im p lemen ted efficien tly , although in practice it app ears that the second appr oac h p erforms the b est. The b asic pro cedur e of iBOA is outlined in figure 5. 4.6 Benefits and Costs Clearly , the main b enefit of u sing iBO A instead of the stand ard BO A is that iBOA eliminates the p opulation and it will thus r educe the memory requiremen ts of BOA. T his can b e esp ecially imp ortant when solving extremely big and d iffi cu lt problems where the p opulations m a y b ecome v ery large. iBO A also provides the first increment al ED A capable of mainta ining multiv ariate probabilistic mod els built with the use of m ultiv ariate statistics. Nonetheless, eliminating the p opulation size also brings disad v an tages. First of all, it b ecomes difficult to effectiv ely maintai n div ersity using nic hin g, such as restricted tournament selecti on, b ecause nic hing tec hniques t ypically r equire an explicit p opulation of candidate solutions. While it migh t b e p ossib le to d esign sp ecialize d nic hing tec hniques th at directly promote div ersity by mo difying th e probabilistic m o del in some w a y , doing this seems to b e far fr om straigh tforwa rd. Second, w h ile iBO A red uces memory complexit y of BO A b y eliminating the p opulation, it still is necessary to store the probabilistic mo d el including all marginal probabilities required to mak e new edge additions. Since the marginal probability tables m a y require ev en more memory than the p opulation itself, th e memory sa vings will n ot b e as signifi cant as in cGA or PBIL. Nonetheless, as discussed in the section on futu re wo rk, this problem may b e alleviated by using lo cal stru ctures 11 in Ba yesia n net w orks, suc h as default tables or decision trees. 5 Exp erimen ts This section p r esen ts exp erimen tal results ob tained with iBO A on concatenated tr aps of order 4 and 5, and compares p erformance of iBO A to that of the standard BO A. 5.1 T est Pr oblems T o test iBO A, w e u sed t wo separable p roblems with fully deceptiv e sub problems based on the w ell-kno wn trap f unction: • T r ap-4. In tr ap-4 [1 , 7], the input string is first partitioned into indep endent groups of 4 b its eac h . This p artitioning is unkno wn to the algorithm and it do es n ot c hange durin g the run. A 4-bit fully deceptiv e trap function is applied to eac h group of 4 bits and the contributions of all tr ap functions are added tog ether to form th e fitness. The cont rib u tion of eac h group of 4 bits is computed as tr ap 4 ( u ) = 4 if u = 4 3 − u otherwise , (2) where u is the num b er of 1s in the input string of 4 bits. The task is to m aximize the f u nction. An n -bit trap-4 function h as one global optimum in the string of all 1s and (2 n/ 4 − 1) other lo cal optima. T raps of order 4 necessitate that all bits in eac h group are treated together, b ecause statisti cs of lo we r order are misleading. Since hBOA p erf orm ance is in v ariant with resp ect to the ordering of str ing p ositions [24], it do es not matter ho w the partitioning in to 4-bit groups is done, and thus, to make some of the results easier to u nderstand, w e assume that trap partitions are lo cated in cont iguous blo c ks of bits. • T r ap-5. In trap-5 [1, 7], th e input string is also partitioned in to indep endent groups but in this case eac h p artition contai ns 5 bits and th e cont rib ution of eac h partition is computed using th e trap of order 5: tr ap 5 ( u ) = 5 if u = 5 4 − u otherwise , (3) where u is the num b er of 1s in the input string of 5 bits. The task is to m aximize the f u nction. An n -bit trap-5 function h as one global optimum in the string of all 1s and (2 n/ 5 − 1) other lo cal optima. T raps of order 5 necessitate that all bits in eac h group are treated together, b ecause statistic s of lo wer order are misleading. 5.2 Description of Exp erimen ts Although iBO A do es n ot main tain an explicit p opulation of candidate solutions, it still u ses the parameter N wh ic h lo osely corresp onds to the actual p opulation size in the standard, p opulation- based BO A. Th us, while iBO A is p opulation-less, w e s till need to set an adequate p opulation size to ensu re that iBO A find s the global optim um r eliably . W e used the bisection metho d [31, 24] to estimate the min im um p opu lation size to reliably fi n d the global optim um in 10 out of 10 indep end en t runs. T o get more stable results, 10 ind ep endent bisection runs w ere rep eated for eac h problem size and th us the results for eac h problem size were a v eraged o v er 100 s u ccessful run s . 12 The num b er of generations w as upp er b ounded b y the num b er of bits n , based on the con vergence theory for BO A [22, 35, 10, 24] and preliminary exp eriments. F or iBO A, the num b er of generations is defin ed as the ratio of the n umber of iterations divided by the p opulation size. In iBO A, the n umb er of solutions in eac h tournament was set to k = 4 based on pr eliminary exp eriments, whic h sh o w ed that this v alue of k p erf ormed well. T o u s e select ion of similar strength in BOA, we used th e tourn amen t select ion with tournamen t size 4. Although these t wo metho ds are not equiv alen t, they s hould p erform similarly . I n b oth BOA and iBO A, BIC metric w as u sed to ev aluate competing net wo rk str u ctures in mo del building and the maxim um n umb er of paren ts w as not r estricted in an y wa y . I n iBO A, the mo del structure is up dated once in ev ery N iterations, while the sampling probabilities are up dated in eac h iteration. Finally , in BO A, the new p opulation of candidate solutions replaces the en tire original p opulation; wh ile this setting is not optimal (t ypically elitist replacemen t or restricted tournamen t r ep lacemen t w ould p erform b etter [24, 25]), it was still the metho d of c hoice to mak e the comparison fair b ecause iBOA do es n ot use any elitism or niching either. Although one of the p rimary goals of setting u p BO A and iBOA w as to mak e these algorithms p erform similarly , the comparison of these t w o algorithms is just a side pro duct of our exp erimen ts. The most imp ortan t goal was to pr ovide emp irical supp ort for the abilit y of iBO A to disco ver and m aintain a multiv ariate p robabilistic mo del without using an explicit p opu lation of candidate solutions. W e also tried the original cGA; h o w ev er, due to the us e of the s im p le mo del in the form of the probability v ector, cGA was not able to solv e problems of size n ≥ 20 ev en with extremely large p opulations and these resu lts we re th us omitted. 5.3 Results Figure 6 sh o ws the n umb er of ev aluations required by iBO A to reac h the global optim u m on concatenate d tr ap s of ord er 4 and 5. In b oth cases, the n umb er of ev aluations gro ws as a low-order p olynomial; for trap-4, the gro wth can b e appro ximated as O ( n 1 . 69 ), whereas for trap-5, the growth can b e approximat ed as O ( n 1 . 43 ). Wh ile the fact that the num b er of ev aluations required by iBO A scales worse on trap-5 than on trap-4 seems somewhat surprisin g, b oth cases are relativ ely close to the b ound predicted b y BOA scalabilit y theory [29, 24], w h ic h estimates the gro wth as O ( n 1 . 55 ). The lo w-order p olynomial p erformance of iBO A on trap-4 and trap-5 provides strong empirical evidence that iBO A is capable of fin ding an adequate p roblem decomp osition b ecause mo d els that w ould fail to captur e the most imp ortan t d ep endencies on the fu lly deceptiv e p roblems trap-4 and trap-5 would fail to solv e these problems scalably [4, 34, 10]. Figure 6 shows the n umb er of ev aluations requir ed by standard BO A to reac h the global op- tim um on concatenate d traps of order 4 and 5. In b oth cases, the num b er of ev aluations grows as a lo w-order p olynomial; for trap-4, the gro wth can b e appr o ximated as O ( n 1 . 69 ), whereas for trap-5, the gro w th can b e app ro ximated as O ( n 2 . 04 ). In b oth cases, we see that BOA p erforms w orse than predicted by scalabilit y theory [29, 24], whic h is most lik ely b ecause of u s ing an elitist replacemen t s trategy , w h ic h significant ly alleviate s the necessit y of ha ving acc ur ate mo dels in th e first few iteratio ns [24], and b ecause of the p otent ial for to o strong pr essure to wa rd s o verly s imple mo dels due to the u se of BIC m etric to score net wo rk structures. In any case, we can conclude that iBOA not on ly k eeps up with stand ard BO A, but without an elitist replacemen t s tr ategy or nic hing, it ev en outp erforms BOA with resp ect to the order of growth of the n umb er of function ev aluations with p roblem size. 13 16 32 64 128 10 3 10 4 10 5 Problem size Number of evaluations iBOA O(n 1.69 ) (a) T rap-4 15 30 60 120 10 4 10 5 Problem size Number of evaluations iBOA O(n 1.43 ) (b) T rap-5 Figure 6: Performance of iBO A on concatenated traps of order 4 and 5. 6 F uture W ork While the exp eriments confir med that iBO A is capable of learning multiv ariate mo dels incremen- tally without usin g a p opulation of candid ate solutions, the adv an tages of doing this are counter- balanced by the disadv anta ges. Most imp ortant ly , there are tw o issues that need to b e add r essed in future wo rk: (1) C omplexit y of mod el rep resen tation should b e improv ed usin g local s tructures in Ba y esian net wo rks, s u c h as d efault tables [9] or decision tr ees/graphs [5, 9]. (2) Elitist and div ersit y-pr eserv ation tec hniques should b e incorp orated int o iBO A to improv e its p erformance. Without addressin g these difficulties, th e adv anta ges of u sing iBO A instead of BOA are somewhat o v ershadow ed by the disadv antag es. 7 Summary and Conclusions This pap er prop osed an incremen tal v ersion of the Ba y esian optimization algorithm (BO A). The prop osed algorithm w as called the incr emental BO A (iBO A). Just lik e BO A, iBO A uses Ba y esian net w orks to mo del promising solutions and sample the new ones. Ho w ev er, iBOA do es not m aintain an explicit p opulation of candidate solutions; in s tead, iBO A p erf orms a series of small tournaments b et wee n solutions generated from the current Ba yesian net wo rk, and up dates th e mo del incre- men tally using the results of the tourn amen ts. Both th e structur e and parameters are up dated incremen tally . The m ain adv an tage of using iBO A rather than BO A is that iBO A do es not need to main- tain a p opulation of candidate solutions and its memory complexit y is thus reduced compared to BO A. Ho w ev er, without the p opulation, implementing elitist and div ersit y-pr eserv ation tec hniques b ecomes a c hallenge. F ur thermore, memory r equ ired to store the Ba y esian netw ork remains sig- nifican t and should b e addressed b y using lo cal structures in Ba y esian netw orks to represent the mo dels more efficien tly . Despite the ab o ve difficulties, this w ork represents the first step to ward the design of comp etent incrementa l EDAs, which can b uild and main tain multiv ariate probabilistic mo dels without us in g an explicit p op u lation of candidate solutions, red ucing memory requirements of s tandard multiv ariate estimation of distrib ution algorithms. 14 16 32 64 128 10 3 10 4 10 5 Problem size Number of evaluations BOA O(n 1.90 ) (a) T rap-4 15 30 60 120 10 3 10 4 10 5 Problem size Number of evaluations BOA O(n 2.04 ) (b) T rap-5 Figure 7: Performance of standard BOA on concate nated traps of ord er 4 and 5. Ac kno wledgmen ts This pro ject w as sp onsored b y the National Science F oun dation under CAREER grant ECS- 05470 13, b y the Air F orce Office of Scient ific Researc h, Air F orce Materiel Command , USAF, under gran t F A9550-06-1- 0096, and by th e Univ ersit y of Missouri in St. Louis through th e High P erformance Computing Collab oratory sp onsored b y Information T ec hnology Services, and the Researc h Aw ard and Researc h Board p r ograms. The U.S. Go v ernment is authorized to repro du ce and d istr ibute reprints for go v ernment pur- p oses n ot withstanding an y cop yright notation thereon. An y opinions, fi ndings, and conclusions or recommendations expressed in this material are th ose of the authors and do not necessarily r eflect the views of the National Science F oun dation, the Air F orce Office of Scientific Researc h, or the U.S. Go vernmen t. Some exp erimen ts w ere d one using the hBO A softw are develo p ed by Martin P elik an and Da vid E. Goldb erg at the Un iversit y of Illinois at Urbana-Champ aign and most exp er- imen ts we re p erform ed on the Beo wu lf cluster mainta ined by ITS at the Un iv ersit y of Missouri in St. Louis. References [1] D. H. Ac kley . An emp ir ical stud y of bit v ector f unction optimization. Genetic Algorithms and Simulate d Anne aling , pages 170–204 , 1987 . [2] S. Baluja. Population-based incremental learning: A metho d f or integ rating genetic searc h based function optimization and comp etitiv e learning. T ec h. Rep. No. C MU-CS-94-16 3, Carnegie Mellon Univ ersit y , Pittsburgh, P A, 1994. [3] S. Baluja and S. Da vies. Using optimal dep endency-trees for com bin atorial optimization: Learning the s tructure of the searc h sp ace. Pr o c e e dings of the International Confer enc e on Machine L e arning , pages 30–38, 1997 . 15 [4] P . A. N. Bosman and D. Thierens. Link age information pro cessing in distribution estimat ion algorithms. Pr o c e e dings of the Genetic and Evolutionary Computation Confer enc e (GECCO- 99) , I :60–6 7, 1999. [5] D. M. Chic k ering, D. Hec kerman, and C. Meek. A Bay esian approac h to learning Ba y esian net- w orks with lo cal structure. T echnical Rep ort MSR-TR-97-07 , Microsoft Researc h, R ed mond, W A, 1997. [6] C. Chow and C. Liu. Approximati ng discrete probabilit y d istributions with dep endence trees. IEEE T r ansactions on Informatio n The ory , 14:462–4 67, 1968 . [7] K. Deb and D. E. Goldb erg. Analyzing deception in trap f unctions. IlliGAL Rep ort No. 9100 9, Univ ersit y of Illinois at Urbana-Ch amp aign, Illinois Genetic Algorithms Lab oratory , Urbana, IL, 1991. [8] R. Etxeb erria and P . L arra ˜ naga. Global optimization using Ba yesian net wo rks. In A. A. O. Ro driguez, M. R. S . Ortiz, and R. S. Hermida, editors, Se c ond Symp osium on Artificial Intel- ligenc e (CIMA F- 99) , p ages 332–33 9, Habana, Cub a, 1999. Institud e of Cyb ernetics, Mathe- matics, and Ph ysics and Ministr y of Science, T ec hnology and En vironment. [9] N. F r iedm an an d M. Goldszmidt. Learning Ba y esian n etw orks with lo cal structure. In M. I. Jordan, ed itor, Gr aphic al mo dels , pages 421–459. MIT Pr ess, Cambridge, MA, 199 9. [10] D. E. Goldb erg. The design of innovation: L essons f r om and for c omp etent g enetic algorithms , v olume 7 of Genetic Algorithms and Evolutionar y Computa tion . Kluw er Academic Publish er s , 2002. [11] D. E. Goldb erg, K. Sastry , and X. Llor` a. T ow ard routine billion-v ariable optimization u sing genetic algorithms. Complexity , 12(3):27– 29, 2007. [12] P . Gr ¨ un wal d. The Minimum Description L ength Principle and R e asoning under Unc ertainty . PhD thesis, Univ ersity of Amsterdam, Amsterdam, Netherlands, 1998. [13] G. R. Harik, F. G. Lob o, and D. E. Goldb erg. Th e compact genetic algorithm. Pr o c e e dings of the International Confer enc e on Evolutionary Computation (ICEC-98) , pages 523– 528, 1998. [14] D. Hec k erman, D. Geige r, and D. M. Chic k ering. Learning Ba y esian n et w orks: Th e com bina- tion of kn o wledge and statistic al data. T ec hn ical Rep ort MSR-TR-94-09, Microsoft Researc h, Redmond, W A, 1994. [15] M. Henrion. Propagating uncertain t y in Ba yesia n net w orks by p robabilistic logic sampling. In J. F. Lemmer and L . N. Kanal, editors, Unc ertainty in Art ificial Intel ligenc e , pages 149–163. Elsevier, Ams terd am, London, New Y ork, 1988. [16] R . A. Ho wa rd and J. E. Matheson. Influ ence diagrams. In R. A. How ard and J . E. Matheson, editors, R e adings on the principles and applic ations of de cision analysis , v olume I I, pages 721–7 62. Strategic Decisions Gr ou p , Menlo P ark, CA, 1981. [17] A. Juels, S. Baluja, and A. Sinclair. The equilibriu m genetic algorithm and the r ole of crossov er, 1993. [18] P . Larra ˜ n aga and J. A. Lozano, editors. Estimation of Distribution A lgorithms: A N ew T o ol for Evolutionary Computation . Kluw er, Bosto n, MA, 200 2. 16 [19] J . A. Lozano, P . L arr a ˜ naga, I. In za, and E. Bengo etxea, editors. T owar ds a New Evolutionary Computation : A dvanc es on Estimation of Di stribu tion A lgorithms . Sp r inger, 2006. [20] H. M ¨ uhlen b ein and T. Mahn ig. FD A – A scalable ev olutionary algorithm for the optimization of additive ly decomp osed functions. Evolutionary Computation , 7(4):3 53–376, 199 9. [21] H. M ¨ uhlen b ein and G. P aaß. F r om recom bination of genes to the estimation of distributions I. Binary parameters. Par al lel Pr oblem Solving fr om Natur e , p ages 178–187, 1996. [22] H. M ¨ uhlenbein and D. S c hlierk amp -Voosen. Predictiv e m o dels for the b reeder genetic algo- rithm: I. Contin u ous parameter optimization. Evolutionary Comp utation , 1(1):25–4 9, 1993. [23] J . Pe arl. Pr ob abilistic r e asoning in intel ligent systems: Ne tworks of plausible infer enc e . Morgan Kaufmann, S an Mateo, CA, 1988. [24] M. Pe lik an . Hier ar chic al Bayesian optimization algorithm: T owar d a new gener ation of evolu- tionary algorithms . Spr inger, 2005. [25] M. P elik an and D. E . Goldb erg. Hierarc hical ba y esian optimizatio n algorithm. In M. P elik an, K. Sastry , and E. Can t ´ u-Pa z, editors, Sc alable Optimization via Pr ob abilistic Mo deling: F r om Algor ithms to Applic ations . Springer, 2006. [26] M. P elik an, D. E. Goldb erg, and E. Cant´ u-Paz. Lin k age problem, distribution estimation, and Ba y esian net wo rks . IlliGAL Rep ort No. 98013, Universit y of I llinois at Urb an a-Ch ampaign, Illinois Genetic Algorithms Lab oratory , Ur bana, IL, 1998 . [27] M. Pelik an, D. E. Goldb erg, and E. Cant´ u-P az. BO A: The Ba yesian optimization algorithm. Pr o c e e dings of the Genetic and Evolutionary Computation Confer enc e (GECCO-99) , I:525– 532, 1999. Also IlliGAL Rep ort No. 99003. [28] M. P elik an, K . Sastry , and E. Can t ´ u-Pa z, editors. Sc alable optimization via pr ob abilistic mo d- eling: Fr om algorithms to applic ations . Spr inger-V erlag, 2006. [29] M. P elik an, K. Sastry , and D. E. Goldb erg. Scalabilit y of the Ba y esian optimization algorithm. International Journal of Appr oximate R e asoning , 31(3):2 21–258, 2002. Also IlliGAL Rep ort No. 2001029. [30] R . Prim. Shortest connection n etw orks and some generali zations. Bel l Systems T e chnic al Journal , 36: 1389–140 1, 1957. [31] K . Sastry . Ev aluation-relaxation schemes for genetic and ev olutionary algorithms. Master’s thesis, Univ ersit y of Illinois at Urban a-Ch ampaign, Departmen t of General Engineering, Ur- bana, IL, 2001. Also IlliGAL Rep ort No. 20020 04. [32] K . S astry , D. E. Goldb erg, and X. Llor` a. T o wa rd s billion bit optimizatio n via efficien t genetic algorithms. IlliGAL Rep ort No. 2007007, Univ ersit y of Illinois at Urbana-Champaign, Illinois Genetic Algorithms Lab oratory , Urbana, IL, 2007. [33] G. Sc h warz. Estimating the d imension of a mo del. The Anna ls of Statistics , 6:461–4 64, 197 8. [34] D. T hierens. Scalabilit y problems of simple genetic algorithms. Evolutionary Computation , 7(4):3 31–352, 1999. 17 [35] D. Th ieren s , D. E. Goldb erg, and A. G. P ereira. Domino con ve rgence, drift, and the temp oral- salience structure of problems. Pr o c e e dings of the International Confer enc e on Evolutionary Computation (ICEC-98) , pages 535–540, 1998. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment