Information In The Non-Stationary Case
Information estimates such as the ``direct method'' of Strong et al. (1998) sidestep the difficult problem of estimating the joint distribution of response and stimulus by instead estimating the difference between the marginal and conditional entropi…
Authors: Vincent Q. Vu, Bin Yu, Robert E. Kass
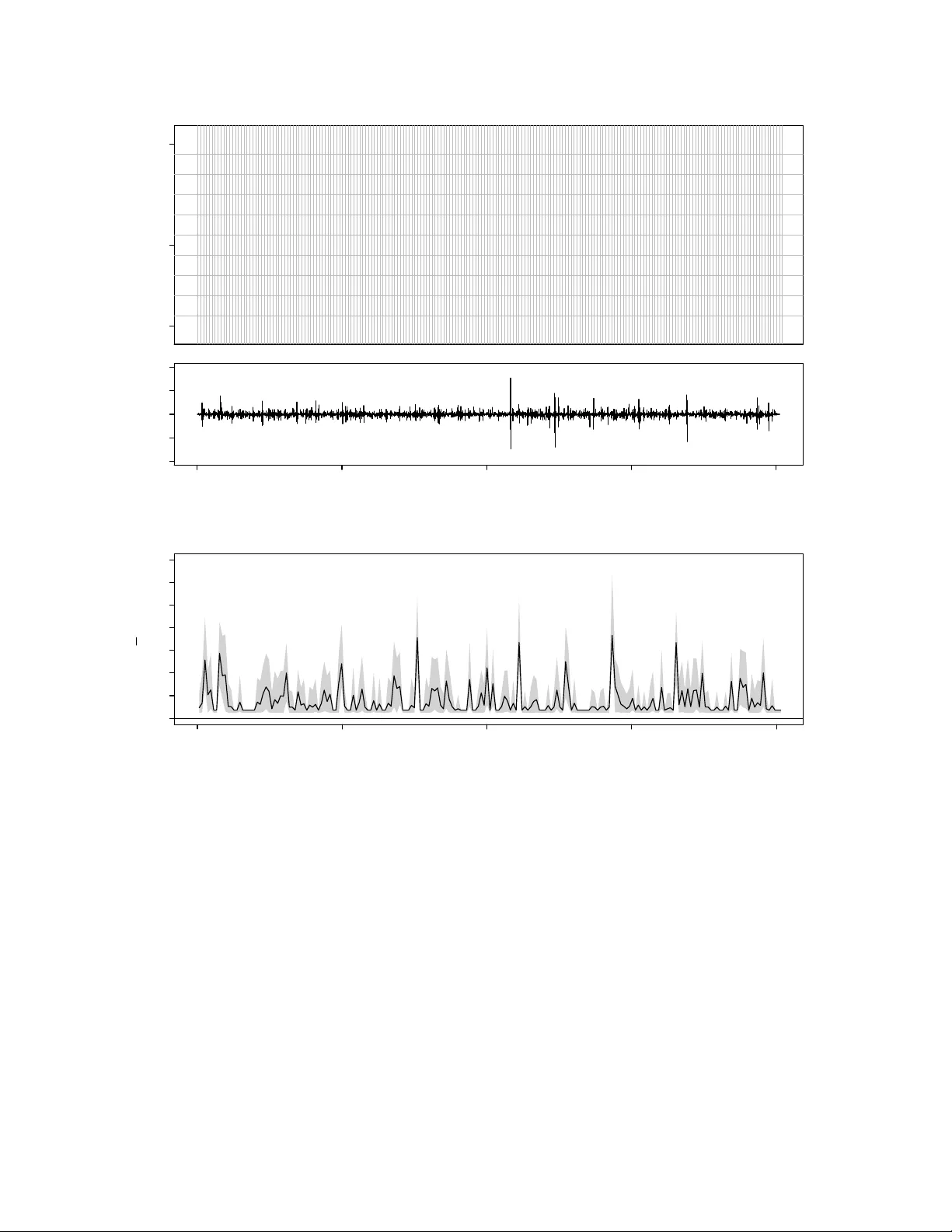
Information In The Non-Stationary Case Vincen t Q. V u † , Bin Y u † , Rob ert E. Kass ‡ { vqv, binyu } @stat.berkeley.edu, kass@stat.cmu.edu † Departmen t of Statistics, Univ ersit y of California, Berk eley ‡ Departmen t of Statistics and Cen ter for the Neural Basis of Cognition, Carnegie Mellon Universit y No v em b er 15, 2021 Abstract Information estimates such as the “direct metho d” of Strong et al. (1998) sidestep the difficult problem of estimating the join t distribution of resp onse and stim ulus by instead estimating the difference betw een the marginal and conditional en tropies of the resp onse. While this is an effectiv e estimation strategy , it tempts the practitioner to ignore the role of the stimulus and the meaning of mutual information. W e show here that, as the num b er of trials increases indefinitely , the direct (or “plug-in”) estimate of marginal en tropy con verges (with probability 1) to the en trop y of the time-a v eraged conditional distribution of the resp onse, and the direct estimate of the conditional en tropy conv erges to the time-a v eraged en tropy of the conditional distribution of the resp onse. Under join t stationarity and ergo dicit y of the resp onse and stimulus, the difference of these quan tities conv erges to the mutual information. When the stim ulus is deterministic or non-stationary the direct estimate of information no longer esti- mates m utual information, which is no longer meaningful, but it remains a measure of v ariability of the resp onse distribution across time. 1 In tro duction Information estimates are used to characterize the amount of information that a spik e train con tains ab out a stimulus [15, 4]. They are motiv ated by information theory [14] and widely b eliev ed to estimate the m utual information (or m utual information rate) betw een stim ulus and spike train resp onse. They are frequently calculated using data from exp erimen ts where the stimulus and resp onse are dynamic and time-v arying [8, 12, 13, 11]. F or m utual information to b e prop erly defined, see for example [5], the stimulus and re- sp onse must b e considered random, and when the estimates are obtained from time-a verages, they should also b e stationary and ergo dic. In practice these assumptions are usually tacit, and information estimates, such as the dir e ct metho d prop osed by [15], can b e made without explicit consideration of the stim ulus. This can lead to misinterpretation. The purp ose of this note is to sho w that the direct method information estimate can b e rein terpreted as the a v erage div ergence across time of the conditional resp onse distribution from its o v erall mean; in the absence of stationarity and ergo dicity: 1. information estimates do not necessarily estimate mutual information, but 2. p oten tially useful in terpretations can still b e made b y referring back to the time-v arying div ergence. Although our results are sp ecialized to the direct method with the plug-in entrop y estimator, they should hold more generally regardless of the choice of entrop y estimator. 1 The fundamen tal issue concerns stationarity: metho ds that assume stationarit y are un- lik ely to be appropriate when stationarity app ears to b e violated. In the non-stationary case, our second result should b e of use, as would b e other metho ds that explicitly consider the dynamic and non-stationary nature of the stimulus and resp onse; see for instance [2]. 1 See [16] for a recen t review of existing en tropy estimators. 1 W e b egin with a brief review of the direct metho d and plug-in entrop y estimator. This is follow ed by results showing that the information estimate can b e recast as a time-av erage. This characterization leads us to the interpretation that the information estimate is actually a measure of v ariability of the stim ulus conditioned resp onse distribution. This observ ation is first made in the finite num ber of trials case, and then formalized b y a theorem describing the limiting b ehavior of the information estimate as the n um b er of trials tends to infinity . F ollowing the theorem is discussion ab out the in terpretation of the limit, and examples that illustrate the in terpretation with a prop osed graphical plot. 2 Review of the direct metho d In the direct metho d a time-v arying stimulus is c hosen b y the exp erimen ter and then rep eat- edly presented to a sub ject o v er m ultiple trials. The observ ed resp onses are conditioned by the same stim ulus. Tw o types of v ariation in the resp onse are considered: 1. v ariation across time (p otentially related to the stimulus), and 2. trial-to-trial v ariation. Figure 1(a) sho ws an example of data from such an exp erimen t. The upp er panel is a raster plot of the resp onse of a Field L neuron of an adult male Zebra Finch during syn thetic song stim ulation. The low er panel is a plot of the audio signal corresp onding to the natural song. Details of the exp erimen t can b e found in [8]. Let us consider the random pro cess { S t , R k t } represen ting the v alue of the stim ulus and resp onse at time t = 1 , . . . , n during trial k = 1 , . . . , m . The resp onse is made discrete b y dividing time in to bins of size dt and then considering wor ds (or patterns) of spik e coun ts formed within in terv als (o verlapping or non-o v erlapping) of L adjacen t time bins. The num ber of spikes that o ccur in eac h time bin b ecome the letters in the w ords. R k t 2 corresp onds to these w ords, and ma y b elong to a countably infinite set (b ecause the num b er of spik es in a bin is theoretically un b ounded). In the raster plot of Figure 1(a) the time bin size is dt = 1 millisecond, and the v ertical lines demarcate non-ov erlapping words of length L = 10 time bins. Giv en the resp onses { R k t } , the direct metho d considers t w o different en tropies: 1. the total entr opy H of the resp onse, and 2. the lo cal noise entr opy H t of the resp onse at time t . The total entrop y is asso ciated with the stimulus conditioned distribution of the resp onse across all times and trials. The lo cal noise entrop y is associated with the stim ulus conditioned distribution of the resp onse at time t across all trials. These quantities are calculated directly from the neural resp onse, and the difference b etw een the total entrop y and the av erage (o v er t ) noise en tropy is what [15] call “the information that the spike train provides ab out the stim ulus.” H and H t dep end implicitly on the length L of the words. Normalizing b y L and consid- ering large L leads to the total and lo cal en trop y rates that are defined to b e lim L →∞ H ( L ) /L and lim L →∞ H t ( L ) /L , resp ectiv ely , when they exist. The direct metho d of [15] prescrib ed an extrap olation for estimating these limits, ho wev er they do not necessarily exist when the stim ulus and resp onse pro cess are non-stationary . When there is stationarity , estimation of en tropy for large L is p oten tially difficult, and extrap olation from a few small choices of L can b e susp ect. Since we are primarily in terested in the non-stationary case, we do not address these issues and refer the reader to [9, 7] for larger discussion on the stationary case. F or notational simplicity , the dep endence on L will b e suppressed in the remainder of the text. 3 The plug-in entrop y estimate [15] proposed estimating H and H t b y plug-in with the corresp onding empirical distributions: ˆ P ( r ) := 1 mn n X t =1 m X k =1 1 { R k t = r } (1) and ˆ P t ( r ) := 1 m m X k =1 1 { R k t = r } . (2) Note that ˆ P is also the a verage of ˆ P t across t = 1 , . . . , n . So the direct metho d plug-in estimates 2 of H and H t are ˆ H := − X r ˆ P ( r ) log ˆ P ( r ) , (3) and ˆ H t := − X r ˆ P t ( r ) log ˆ P t ( r ) , (4) resp ectiv ely . The direct metho d plug-in information estimate is ˆ I := ˆ H − 1 n n X t =1 ˆ H t . (5) 3 Results The direct metho d information estimate is not only the difference of entropies shown in (5), but also a time-a v erage of div ergences. The empirical distribution of resp onse across all trials 2 [15] used the name naive estimates . 4 and times (1) is equal to the av erage of ˆ P t o v er time. That is ˆ P ( r ) = n − 1 P n t =1 ˆ P t ( r ) and so ˆ I = ˆ H − 1 n n X t =1 ˆ H t (6) = 1 n n X t =1 X r ˆ P t ( r ) log ˆ P t ( r ) − X r " 1 n n X t =1 ˆ P t ( r ) # log ˆ P ( r ) (7) = 1 n n X t =1 X r ˆ P t ( r ) log ˆ P t ( r ) − 1 n n X t =1 X r ˆ P t ( r ) log ˆ P ( r ) (8) = 1 n n X t =1 X r ˆ P t ( r ) log ˆ P t ( r ) ˆ P ( r ) . (9) The quantit y that is a veraged ov er time in (9) is the Kullback-Leibler div ergence b et w een the empirical time t resp onse distribution ˆ P t and the av erage empirical resp onse distribution ˆ P . Since the same stim ulus is rep eatedly presen ted to the sub ject, and there is no evolution in the resp onse, o ver multiple trials, the follo wing r ep e ate d trial assumption is natural: Conditional on the stimulus { S t } the m trials { S t , R 1 t } , . . . , { S t , R m t } are inde- p enden t and iden tically distributed (i.i.d.). Under this assumption 1 { R 1 t = r } , . . . , 1 { R m t = r } are conditionally i.i.d. for each fixed t and r . F urthermore, the law of large n um b ers guaran tees that as the n um b er of trials m increases the empirical resp onse distribution ˆ P t ( r ) con verges to its conditional exp ected v alue for each fixed t and r . Thus ˆ P t ( r ) and ˆ P ( r ) can b e viewed as estimates of P t ( r | S 1 , . . . , S n ), defined b y P t ( r | S 1 , . . . , S n ) := P ( R k t = r | S 1 , . . . , S n ) = E { ˆ P t ( r ) | S 1 , . . . , S n } , (10) and ¯ P ( r | S 1 , . . . , S n ), defined b y ¯ P ( r | S 1 , . . . , S n ) := 1 n n X t =1 P t ( r | S 1 , . . . , S n ) , (11) 5 resp ectiv ely . ¯ P is av erage resp onse distribution across time t = 1 , . . . , n conditional on the en tire stimulus { S 1 , . . . , S n } . So the quantit y that is a v eraged ov er time in (9) should b e viewed as a plug-in estimate of the Kullbac k-Leibler divergence b et w een P t and ¯ P . W e emphasize this b y writing ˆ D ( P t || ¯ P ) := X r ˆ P t ( r ) log ˆ P t ( r ) ˆ P ( r ) . (12) This observ ation will b e formalized by the theorem of the next section. F or now w e summarize the ab ov e with a prop osition. Prop osition 1. The information estimate is the time-aver age ˆ I = 1 n P n t =1 ˆ D ( P t || ¯ P ) . This decomp osition of the information estimate is analogous to the decomp osition of m u- tual information that [6] call the “sp ecific surprise,” while “sp ecific information” is analogous to the alternativ e decomp osition, ˆ I = 1 n n X t =1 [ ˆ H − ˆ H t ] . (13) An imp ortan t difference is that here the stim ulus itself is a function of time and the decom- p ositions are given in terms of time-dep endent quan tities. It is p ossible that these quantities can rev eal dynamic asp ects of the stimulus and resp onse relationship. This will b e explored further in Sections 3.2 and 3.3. 3.1 What is b eing estimated? There are tw o directions in whic h the amoun t of observ ed resp onse data can b e increased: length of time n , and num ber of trials m . The information estimate is the av erage of ˆ D ( P t || ¯ P ) o v er time, and may not necessarily conv erge as n increases. This could b e due to { S t , R k t } b eing non-stationary and/or highly dep enden t in time. Even when con v ergence ma y occur, 6 the presence of serial correlation in ˆ D ( P t || ¯ P ) (see the auto correlation in panel (b) of Figures 2 for example) can mak e assessments of uncertain t y in ˆ I difficult. Assuming that the stim ulus and resp onse pro cess is stationary and not to o dep enden t in time could guaran tee con vergence, but this could b e unrealistic. On the other hand, the rep eated trial assumption is appropriate if the same stimulus is rep eatedly presented to the sub ject ov er m ultiple trials. It is also enough to guarantee that the information estimate con verges as the num b er of trials m increases. W e pro v e the following theorem in the app endix. Theorem 1. Supp ose that P t has finite entr opy for al l t = 1 , . . . , n . Then under the r ep e ate d trial assumption lim m →∞ ˆ I = H ( ¯ P ) − 1 n n X t =1 H ( P t ) = 1 n n X t =1 [ H ( ¯ P ) − H ( P t )] = 1 n n X t =1 D ( P t || ¯ P ) with pr ob ability 1, and in p articular the fol lowing statements hold uniformly for t = 1 , . . . , n with pr ob ability 1: 1. lim m →∞ ˆ H = H ( ¯ P ) , 2. lim m →∞ ˆ H t = H ( P t ) , and 3. lim m →∞ ˆ D ( P t || ¯ P ) = D ( P t || ¯ P ) for t = 1 , . . . , n , wher e D ( P t || ¯ P ) is the Kul lb ack-L eibler diver genc e define d by, D ( P t || ¯ P ) := X r P t ( r | S 1 , . . . , S n ) log P t ( r | S 1 , . . . , S n ) ¯ P ( r | S 1 , . . . , S n ) , and H ( P ) is the entr opy of the distribution P , define d by H ( P ) := − X r P ( r ) log P ( r ) . 7 Note that if stationary and ergo dicit y do hold, then P t for t = 1 , . . . , n is also station- ary and ergo dic 3 . So its av erage, ¯ P ( r ), is guaranteed by the ergo dic theorem to conv erge p oin t wise to P ( R 1 1 = r ) as n → ∞ . Moreov er, if R 1 1 can only take on a finite n um b er of v alues, then H ( ¯ P ) also conv erges to the marginal en tropy H ( R 1 1 ) of R 1 1 . Lik ewise, the a v- erage of the conditional entrop y H ( P t ) also con verges to the exp ected conditional entrop y: lim n →∞ H ( R 1 n | S 1 , . . . , S n ). So in this case the information estimate do es indeed estimate m utual information. Ho w ever, the primary consequence of the theorem is that, in the absence of stationarit y and ergo dicit y , the information estimate ˆ I do es not necessarily estimate m utual information. The three particular statemen ts sho w that the time-v arying quantities [ ˆ H − ˆ H t ] and ˆ D ( P t || ¯ P ) con v erge individually to the appropriate limits, and justify our assertion that the information estimate is a time-a verage of plug-in estimates of the corresp onding time-v arying quan tities. Th us, the information estimate can alwa ys b e viewed as an estimate of the time-av erage of either D ( P t || ¯ P ) or [ H ( P ) − H ( P t )]–stationary and ergo dic or not. 3.2 The information estimate measures v ariabilit y of the resp onse distribution The Kullbac k-Leibler Div ergence D ( P t || ¯ P ) has a simple in terpretation: it measures the dissimilarit y of the time t resp onse distribution P t from its o v erall av erage ¯ P . So as a function of time, D ( P t || ¯ P ) measures how the conditional resp onse distribution v aries across time, relative to its ov erall mean. This can b e seen in a more familiar form by considering the leading term of the T aylor expansion, D ( P t || ¯ P ) = 1 2 X r [ P t ( r | S 1 , . . . , S n ) − ¯ P ( r | S 1 , . . . , S n )] 2 ¯ P ( r | S 1 , . . . , S n ) + · · · . (14) 3 P t and ¯ P are stim ulus conditional distributions, and hence random v ariables p otentially dep ending on S 1 , . . . , S n . 8 Th us, its av erage is in this sense a measure of the av erage v ariability of the resp onse distri- bution. It is, of course, p ossible that characteristics of the response are due to confounding factors rather than the stimulus. F urthermore, the presence of additional noise in either pro cess would weak en a measured relationship b et w een stimulus and resp onse, compared to its strength if the noise were eliminated. Setting these concerns aside, the v ariation of the resp onse distribution P t ab out its av erage pro vides information ab out the relationship b et w een the stimulus and the resp onse. In the stationary and ergo dic case, this information ma y b e av eraged across time to obtain mutual information. In more general settings av erag- ing across time may not provide a complete picture of the relationship b etw een stim ulus and resp onse. Instead, we suggest examining the time-v arying D ( P t || ¯ P ) directly , via graphical displa y as discussed next. 3.3 Plotting the div ergence The plug-in estimate ˆ D ( P t || ¯ P ) is an obvious c hoice for estimating D ( P t || ¯ P ), but it turns out that estimating D ( P t || ¯ P ) is akin to estimating entrop y . Since the trials are conditionally i.i.d., the co verage adjustment method describ ed in [17] can b e used to impro ve estimation of D ( P t || ¯ P ) ov er the plug-in estimate. The app endix contains the details of this. Figures 1 and 2 show the resp onses of the same Field L neuron of an adult male Zebra Finc h under t wo differen t stim ulus conditions. Details of the exp erimen t and the statistics of the stimuli are described in [8]. Panel (a) of the figures sho ws the stimulus and response data. In Figure 1 the stimulus is synthetic and stationary b y construction, while in Figure 2 the stimulus is a natural song. P anel (b) of the figures sho ws the cov erage adjusted estimate of the divergenc e D ( P t || ¯ P ) plotted as a function of time. 95% confidence interv als w ere formed b y b ootstrapping entire trials, i.e. an entire trial is either included in or excluded from a b ootstrap sample. 9 The information estimate going along with eac h Divergence plot is the av erage of the solid curve representing the estimate of D ( P t || ¯ P ). It is equal to 0.77 bits (p er 10 millisecond w ord) in Figure 1(b) and 0.76 bits (p er 10 millisecond word) in Figure 2(b). Although the information estimates are nearly iden tical, the tw o plots are very different. In the first case, the stimulus is stationary b y construction and it app ears that the time- v arying div ergence is to o. Its fluctuations app ear to b e roughly of the same scale across time, and its lo cal mean is relatively stable. The av erage of the solid curv e seems to b e a fair summary . In the second case the stimulus is a natural song. The isolated bursts of the time-v arying div ergence and relativ ely flat regions in Figure 2(b) suggest that the resp onse pro cess (and the divergence) is non-stationary and has strong serial correlations. The lo cal mean of the div ergence also v aries strongly with time. Summarizing D ( P t || ¯ P ) b y its time-av erage hides the time-dep endent features of the plot. More interestingly , when the div ergence plot is compared to the plot of the stimulus in Figure 2, there is a striking coincidence b et ween the lo cation of large isolated v alues of the estimated div ergence and visual features of the stim ulus wa v eform. They tend to coincide with the b oundaries of the bursts in the stimulus signal. This suggests that the spik e train ma y carry information ab out the onset/offset of bursts in the stim ulus. W e discussed this with the Theunissen Lab and they confirmed from their STRF mo dels that the cell in the example is an offset cell. It tends to fire at the offsets of song syllables–the bursts of energy in the stimulus wa veform. They also suggested that a word length within the range of 30–50 milliseconds is a b etter match to the length of correlations in the auditory system. W e regenerated the plots for words of length L = 40 (not shown here) and found that the isolated structures in the div ergence plot b ecame ev en more pronounced. 10 4 Discussion Estimates of m utual information, including the plug-in estimate, may be viewed as measures of the strength of the relationship b etw een the resp onse and the stimulus when the stimulus and resp onse are jointly stationary and ergo dic. Man y applications, ho wev er, use non- stationary or even deterministic stim uli, so that mutual information is no longer w ell defined. In such non-stationary cases do estimates of m utual information b ecome meaningless? W e think not, but the purp ose of this note has b een to p oin t out the delicacy of the situation, and to suggest a viable interpretation of information estimates, along with the divergence plot, in the non-stationary case. In using sto c hastic pro cesses to analyze data there is an implicit practical ackno wledg- men t that assumptions cannot b e met precisely: the mathematical formalism is, after all, an abstraction imp osed on the data; the hop e is simply that the v ariabilit y display ed b y the data is similar in relev an t resp ects to that display ed b y the presumptive sto c hastic pro cess. The “relev ant resp ects” inv olv e the statistical prop erties deduced from the sto chastic assump- tions. The p oin t we are trying to make is that highly non-stationary stimuli make statistical prop erties based on an assumption of stationarity highly susp ect; strictly sp eaking, they b ecome void. T o b e more concrete, let us reconsider the snipp et of natural song and resp onse display ed in Figure 2. When w e lo ok at the less than 2 seconds of stimulus amplitude giv en there, the stim ulus is not at all time-inv arian t: instead, the stimulus has a series of well-defined bursts follow ed b y p erio ds of quiescence. Perhaps, on a v ery muc h longer time scale, the stim ulus would lo ok stationary . But a go o d sto c hastic mo del on a long time scale w ould lik ely require long-range dep endence. Indeed, it can b e difficult to distinguish non-stationarit y from long-range dep endence [10], and the usual statistical prop erties of estimators are know n to breakdo wn when long-range dep endence is presen t [3]. Giv en a short in terv al of data, v alid 11 statistical inference under stationarit y assumptions b ecomes highly problematic. T o av oid these problems w e ha v e proposed the use of the divergence plot, and a recognition that the “bits p er second” summary is no longer m utual information in the usual sense. Instead we w ould sa y that the estimate of information measures magnitude of v ariation of the resp onse as the stimulus v aries, and that this is a useful assessmen t of the exten t to whic h the stimulus affects the resp onse as long as other factors that affect the resp onse are themselv es time- in v ariant. In other deterministic or non-stationary settings the argumen t for the relev ance of an information estimate should b e analogous. Under stationarity and ergo dicity , and indefinitely many trials, the stim ulus sets that affect the resp onse—whatev er they are— will b e rep eatedly sampled, with appropriate probability , to determine the v ariabilit y in the resp onse distribution, with time-inv ariance in the resp onse b eing guaranteed by the join t stationarit y condition. This b ecomes part of the in tuition b ehind mutual information. In the deterministic or non-stationary settings information estimates do not estimate mutual information, but they may remain in tuitiv e assessmen ts of strength of effect. Ac kno wledgmen ts The authors thank the Theunissen Lab at the Univ ersit y of California, Berkeley for pro- viding the data set and helpful discussion. They also thank an anon ymous reviewer for commen ts that greatly improv ed the manuscript. V. Q. V u was supported by a NSF VIGRE Graduate F ellowship and NIDCD gran t DC 007293. B. Y u w as supp orted by NSF grants DMS-03036508, DMS-0605165, DMS-0426227, AR O gran t W911NF-05-1-0104, NSFC gran t 60628102, and a fellowship from the John Simon Guggenheim Memorial F oundation. This w ork b egan while Kass w as a Miller Institute Visiting Research Professor at the Universit y of California, Berk eley . Supp ort from the Miller Institute is greatly appreciated. Kass’s w ork w as also supp orted in part b y NIMH gran t RO1-MH064537-04. 12 A App endix A.1 Co v erage adjusted estimate of D ( P t || ¯ P ) The main idea b ehind cov erage adjustmen t is to adjust estimates for p otentially unobserved v alues. This happ ens in tw o places: estimation of P t and estimation of D ( P t || ¯ P ). In the first case, unobserv ed v alues affect the amount of weigh t that ˆ P t , defined in (2) in the main text, places on observ ed v alues. In the second case unobserv ed v alues corresp ond to missing summands when plugging ˆ P t in to the Kullbac k-Leibler div ergence. [17] gives a more thorough explanation of these ideas. Let N t ( r ) := m X k =1 1 { R k t = r } . (15) The sample cov erage, or total P t -probabilit y of observed v alues r , is estimated b y ˆ C t defined b y ˆ C t := 1 − # { r : N t ( r ) = 1 } + . 5 m + 1 . (16) The num ber in the numerator of the fraction refers to the num b er of singletons—patterns that were observed only once across the m trials at time t . Then the co v erage adjusted estimate of P t is the follo wing shrunken v ersion of ˆ P t : ˜ P t ( r ) = ˆ C t ˆ P t ( r ) . (17) ¯ P is estimated b y simply a v eraging ˜ P t : ˜ P ( r ) = 1 n n X t =1 ˜ P t ( r ) . (18) The cov erage adjusted estimate of D ( P t || ¯ P ) is obtained by plugging ˜ P t and ˜ P into the Kullbac k-Leibler divergence, but with an additional weigh ting on the summands according 13 to the in v erse of the estimated probabilit y that the summand is observ ed: ˜ D ( P t || ¯ P ) := X r ˜ P t ( r ) { log ˜ P t ( r ) − log ˜ P ( r ) } 1 − (1 − ˜ P t ( r )) m . (19) The additional w eigh ting is to correct for p oten tially missing summands. (This is also explained in detail in [17].) Confidence interv als for D ( P t || ¯ P ) can b e obtained by b o otstrap sampling entire trials, and applying ˜ D to the b o otstrap replicate data. A.2 Pro ofs W e will use the following extension of the Leb esgue Dominated Con vergence Theorem in the pro of of Theorem 1. Lemma 1. L et f m and g m for m = 1 , 2 , . . . b e se quenc es of me asur able, inte gr able functions define d on a me asur e sp ac e e quipp e d with me asur e µ , and with p ointwise limits f and g , r esp e ctively. Supp ose further that | f m | ≤ g m and lim m →∞ R g m dµ = R g dµ < ∞ . Then lim m →∞ Z f m dµ = Z lim m →∞ f m dµ. Pr o of. By linearity of the in tegral, lim inf n →∞ Z ( g + g m ) dµ − lim sup n →∞ Z | f − f m | dµ = lim inf n →∞ Z ( g + g m ) − | f − f m | dµ. Since 0 ≤ ( g + g m ) − | f − f m | , F atou’s Lemma implies lim inf n →∞ Z ( g + g m ) − | f − f m | dµ ≥ Z lim inf n →∞ ( g + g m ) − | f − f m | dµ. The limit inferior on the inside of the right-hand integral is equal to 2 g b y assumption. 14 Com bining with the previous t w o displa ys and the assumption that R g m dµ → R g dµ giv es lim sup n →∞ | Z f dµ − Z f m dµ | ≤ lim sup n →∞ Z | f − f m | dµ ≤ 0 . Pr o of of The or em 1. The main statemen t of the theorem is implied by the three num bered statemen ts together with Prop osition 1. W e start with the second num bered statemen t. Under the repeated trial assumption, R 1 t , . . . , R m t are conditionally i.i.d. given the stimulus { S t } . So Corollary 1 of [1], can b e applied to show that lim m →∞ ˆ H t = lim m →∞ − X r ˆ P t ( r ) log ˆ P t ( r ) (20) = − X r P t ( r | S 1 , . . . , S n ) log P t ( r | S 1 , . . . , S n ) (21) = H ( P t ) (22) with probability 1. This prov es the first n um b ered statement. W e will use Lemma 1 to pro ve the first num bered statement. F or each r the la w of large n um b ers asserts lim m →∞ ˆ P t ( r ) = P t ( r | S 1 , . . . , S n ) with probabilit y 1. So for eac h r , lim m →∞ − ˆ P t ( r ) log ˆ P ( r ) = − P t ( r | S 1 , . . . , S n ) log ¯ P ( r | S 1 , . . . , S n ) (23) and lim m →∞ − ˆ P t ( r ) log ˆ P t ( r ) = − P t ( r | S 1 , . . . , S n ) log P t ( r | S 1 , . . . , S n ) (24) with probability 1. Fix a realization where (20 – 24) hold and let f m ( r ) := − ˆ P t ( r ) log ˆ P ( r ) 15 and g m ( r ) := − ˆ P t ( r )[log ˆ P t ( r ) − log n ] . Then for eac h r lim m →∞ f m ( r ) = − P t ( r | S 1 , . . . , S n ) log ¯ P ( r | S 1 , . . . , S n ) =: f ( r ) and lim m →∞ g m ( r ) = − P t ( r )[log P t ( r ) − log n ] =: g ( r ) . The sequence f m is dominated b y g m b ecause 0 ≤ − ˆ P t ( r ) log ˆ P ( r ) = f m ( r ) (25) = − ˆ P t ( r )[log n X u =1 ˆ P u ( r ) − log n ] (26) ≤ − ˆ P t ( r )[log ˆ P t ( r ) − log n ] (27) = g m ( r ) (28) for all r , where (27) uses the fact that log x is an increasing function. F rom (20) w e also hav e that lim m →∞ P r g m ( r ) = P r g ( r ). Clearly , f m and g m are summable. Moreo ver H ( P t ) < ∞ b y assumption. So X r g ( r ) = X r − P t ( r ) log P t ( r ) + log n X r P t ( r ) = H ( P t ) + log n < ∞ (29) and the conditions of Lemma 1 are satisfied. Thus lim m →∞ X r − ˆ P t ( r ) log ˆ P ( r ) = lim m →∞ X r f m ( r ) = X r f ( r ) = X r − P t ( r ) log ¯ P ( r ) . (30) 16 Av eraging ov er t = 1 , . . . n gives ˆ H = lim m →∞ X r − ˆ P ( r ) log ˆ P ( r ) = X r − ¯ P ( r ) log ¯ P ( r ) = H ( ¯ P ) . (31) for realizations where (20 – 24) hold. This prov es the first n um b ered statemen t b ecause the probabilit y of all such realizations is 1. F or the third n um b ered statement we b egin with the expansions ˆ D ( P t || ¯ P ) = X r ˆ P t ( r ) log ˆ P t ( r ) − ˆ P t ( r ) log ˆ P ( r ) . (32) and D ( P t || ¯ P ) = X r P t ( r ) log P t ( r ) − P t ( r ) log ¯ P ( r ) . (33) The second n um b ered statement and (30) imply lim m →∞ X r ˆ P t ( r ) log ˆ P t ( r ) − ˆ P t ( r ) log ˆ P ( r ) = X r P t ( r ) log P t ( r ) − X r P t ( r ) log ¯ P ( r ) (34) with probability 1. This prov es the third n um b ered statement. References [1] Andr´ as Antos and Ioannis Konto yiannis. Conv ergence prop erties of functional estimates for discrete distributions. R andom Structur es and Algorithms , 19:163–193, 2001. [2] Riccardo Barbieri, Loren M. F rank, David P . Nguyen, Michael C. Quirk, Victor Solo, Matthew A. Wilson, and Emery N. Brown. Dynamic analyses of information enco ding in neural ensem bles. Neur al Computation , 16(2):277–307, 2004. [3] Jan Beran. Statistics for long-memory pr o c esses . Chapman & Hall Ltd., 1994. 17 [4] Alexander Borst and F r ´ ed ´ eric E. Theunissen. Information theory and neural co ding. Natur e Neur oscienc e , 2(11):947–957, 1999. [5] T. Cov er and J. Thomas. Elements of Information The ory . Wiley , New Y ork, 1991. [6] M Dew eese and M Meister. Ho w to measure the information gained from one sym b ol. Network: Computation in Neur al Systems , Jan 1999. [7] Y un Gao, Ioannis Konto yiannis, and Elie Bienensto ck. F rom the entrop y to the statisti- cal structure of spik e trains. Information The ory, 2006 IEEE International Symp osium on , pages 645–649, July 2006. [8] Anne Hsu, Sarah M N W o olley , Thane E F remou w, and F r ´ ed ´ eric E Theunissen. Mo du- lation p o w er and phase sp ectrum of natural sounds enhance neural enco ding p erformed b y single auditory neurons. J. Neur o. , 24(41):9201–9211, 2004. [9] Matthew B Kennel, Jonathon Shlens, Henry D I Abarbanel, and E J Chichilnisky . Estimating en tropy rates with ba y esian confidence in terv als. Neur al Computation , 17(7):1531–1576, 2005. [10] H Kunsc h. Discrimination b et ween monotonic trends and long-range dependence. Jour- nal of Applie d Pr ob ability , 23(4):1025–1030, Jan 1986. [11] S Niren b erg, S M Carcieri, A L Jacobs, and P E Latham. Retinal ganglion cells act largely as indep enden t enco ders. Natur e , 411(6838):698–701, Jun 2001. [12] Daniel S. Reich, F erenc Mechler, and Jonathan D. Victor. F ormal and attribute-sp ecific information in primary visual cortex. Journal of Neur ophysiolo gy , 85(1):305–318, 2001. [13] P amela Reinagel and R. Clay Reid. T emp oral coding of visual information in the thalam us. Journal of Neur oscienc e , 20(14):5392–5400, 2000. 18 [14] C. E. Shannon. A mathematical theory of comm unication. Bel l System T e chnic al Journal , 27:379–423, 1948. [15] S. P . Strong, Roland Kob erle, Rob de Ruyter v an Steveninc k, and William Bialek. En trop y and information in neural spike trains. Physic al R eview L etters , 80(1):197–200, 1998. [16] Jonathon D. Victor. Approac hes to information-theoretic analysis of neural activity . Biolo gic al The ory , 1:302–316, 2006. [17] Vincen t Q. V u, Bin Y u, and Rob ert E. Kass. Cov erage adjusted entrop y estimation. Statistics in Me dicine , 26(21):4039–4060, 2007. 19 time (msec) trial number 1 5 10 | | | || | | | | | | | | | | | | | | | | | | | | | | | | | | || | | | | | | | | | | | | | | | | | || || || | | | | | | | | | | || | | | | | | | | | | | | | | | | | | | | | | | | | | | | || | | | | | | | || | | | | | | | | | | || | | | | | | | | | | | | | | | | | | || | | | | | | | | | | | | | | || || | | || | | | | | | | | | | | | | | | | | | | || | | | | | | | | | | | | | | | || | || | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | || | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | || | | | | | | | | | | | || | | | | | | | | | | | | | || | | | | | || | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | || | | | | | || | | 0 500 1000 1500 2000 −1.0 0.0 1.0 time (msec) stimulus amplitude (a) Stimulus and resp onse 0 500 1000 1500 2000 0 1 2 3 4 5 6 7 time (msec) D ~ ( ( P t , , P ) ) (bits) (b) Divergence plot Figure 1: (a) Raster plot of the resp onse of the a Field L neuron of an adult male Zebra Finc h (ab o v e) during the presen tation of a synthetic audio stimulus (b elow) for 10 rep eated trials. The vertical lines indicate b oundaries of L = 10 millisecond (msec) words formed at a resolution of dt = 1 msec. The data consists of 10 trials, each of duration 2000 msecs. (b) The cov erage adjusted estimate (solid line) of D ( P t , ¯ P ) from the resp onse shown ab o ve with 10 msec words. P oint wise 95% confidence in terv als are indicated b y the shaded region and obtained by b o otstrapping the trials 1000 times. The information estimate, 0.77 bits (p er 10msec word, or 0.077 bits/msec), corresp onds to the av erage v alue of the solid curv e. 20 time (msec) trial number 1 5 10 | | | | | | | | | | | | | | | | | | | | | | | | || | | | | | | | | | | | | ||| | | | | || | | | | | | | | | | | || | | | | | || | | | | | | | | || | | | | | | | | | || | | | || | | | | | | | | | | | || | | | | | | | | | | | | | | | | || || | | | | | || || | | || | | | | | | | | | | | || | | | ||| | | | |||| | | || | | | | | | | | | || | | | | | | | | | ||| | | || | | | || | || | | | | | | | | | | || | | | | | | | | | | || | | | | | || | | | ||| ||| | | | || | | | | | | | | | | | | | | | || | | | | | ||| | | | | | | | | | | | || | | | | | | | | | | | || | | | || | | | | | | | || | | || | | | | | | || | | | | || | | | | | | | | | | | | || | | | | || 0 500 1000 1500 −1.0 0.0 1.0 time (msec) stimulus amplitude (a) Stimulus and resp onse 0 500 1000 1500 0 1 2 3 4 5 6 7 time (msec) D ~ ( ( P t , , P ) ) (bits) (b) Divergence plot Figure 2: (a) Same as in Figure 1, but in this set of trials the stimulus is a consp ecific natural song. (b) The co v erage adjusted estimate (solid line) of D ( P t , ¯ P ) from the response sho wn ab o v e. P oin t wise 95% confidence interv als are indicated by the shaded region and obtained by b o otstrapping the trials 1000 times. The information estimate, 0.76 bits (p er 10 msec w ord or 0.076 bits/msec), corresponds to the a v erage v alue of the solid curve. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment