Bayesian Analysis of Marginal Log-Linear Graphical Models for Three Way Contingency Tables
This paper deals with the Bayesian analysis of graphical models of marginal independence for three way contingency tables. We use a marginal log-linear parametrization, under which the model is defined through suitable zero-constraints on the interac…
Authors: Ioannis Ntzoufras, Claudia Tarantola
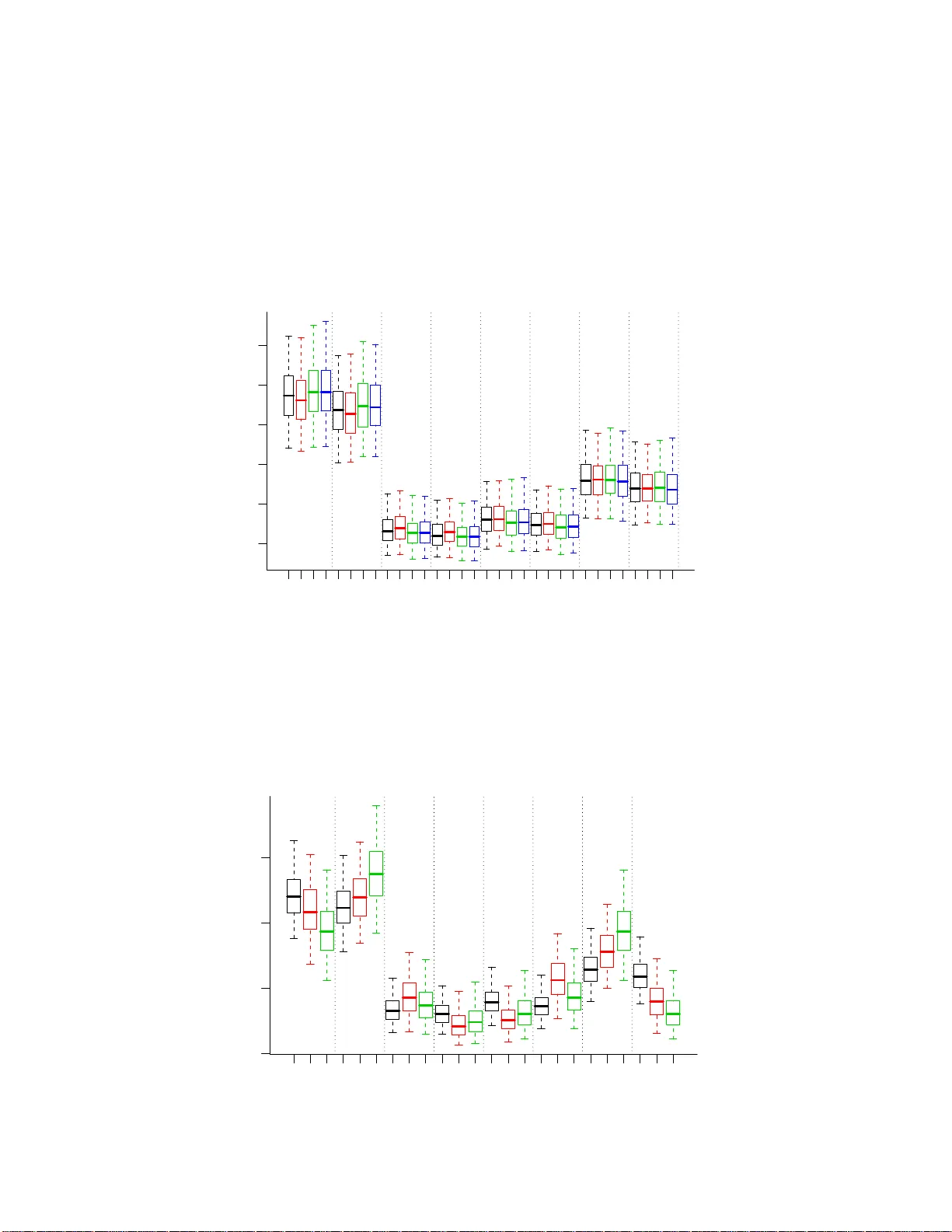
Ba y esian Analysis of Marginal Log-Linear Graphical Mo dels for Three W a y Con tingency T ables Ioannis Ntzoufras Departmen t of Statistics, Athen s Univ ersit y of Economics and Business , Greece. Claudia T aran tola ∗ Departmen t of Economics and Quantitativ e Metho ds, Univ ersit y of P a via, Italy July 27, 2021 Abstract This pap er deals with the B ay esian analysis of gr aphical mode ls of marg inal in- depe ndence for three wa y contingency tables. W e use a marginal log -linear parame- trization, under which the mo del is defined through suita ble zero-c o nstraints on the int era ction parameters calculated w ithin margina l distributions. W e undertake a com- prehensive Bayesian analysis of these mo dels, inv olving suitable choices of prior distri- butions, estimation, mo del determination, a s well as the allied computational issues. The methodolo gy is illustrated with reference to t wo real data sets. Keywor ds : Graphical mo dels, Marginal log-linear parametrization, Mo del selecti on, Mon te Carlo computation, Order d ecomp osabilit y , Po w er prior. ∗ Address for correspondence: C laudia T arantola, Department of Economics and Quan titative Metho ds, Universit y of Pa via, V ia S . F elice 7, 27100 Pa via, Italy . E-mail: claudia.tarantol a@unipv.it 1 1 In tro duction Graphical mo dels of marginal in dep endence w ere originally in tro duced by C o x and W er- m uth (1993) for the anal ysis of multiv ariate Gaussian distribu tions. They comp ose a family of m ultiv ariate distribu tions incorp orating the marginal indep end ences r epresen ted b y a b idirected graph. The no des in the graph corresp ond to a set of random v ariables and the bidirected edges represen t the pairwise asso ciations b et w een them. A missing edge from a p air of no des indicates that the corresp onding v ariables are marginally in- dep endent. The complete list of marginal indep end ences implied by a b idirected graph w ere studied by Kau er m ann (1996) and by Richardson (2003) using the so-called Mark o v prop erties. The analysis of the Gaussian case can b e easily p erformed b oth in classical and Ba yesian framew orks since marginal indep end ences corresp ond to zero constrain ts in the v ariance-co v ariance matrix. The situation is more complicated in the discrete case, where marginal indep end ences corresp ond to non linear constrain ts on the set of parameters. Only recen tly parameterizati ons for these mo dels ha v e b een prop osed by Lupparelli (2006 ), Lupparelli et al. (2008) and Drton and Richardson (2008). In this pap er we use th e pa- rameterizatio n p rop osed by Lup parelli (2006) and Lup parelli et al. (2008 ) based on the class of marginal log-linear mo dels of Bergsma and Rud as (2002). Eac h log-linear param- eter is calculated within the appropriate m arginal distrib ution and a graphical mo del of marginal ind ep endence is d efined b y zero constrain ts on sp ecific higher ord er log-linear parameters. Alternativ e parameteriza tions ha v e b een prop osed by Drton and Ric h ard- son (2008) b ased on the Mo ebius inv ersion and b y Lup parelli et al. (2008) b ased on m ultiv ariate logistic representat ion of the mo dels of Glonek and McCu llagh (1995 ). W e present a comprehen siv e Ba yesian analysis of discrete graphical mo d els of mar- 2 ginal ind ep endence, in v olving suitable c hoices of prior distributions, estimatio n, mo del determination as w ell as the allied computational issues. Here we fo cus on the thr ee wa y case wh er e th e join t p robabilit y of eac h mo del und er consideration can b e app ropriately factorized. W e work directly in terms of th e vect or of joint probabilities on whic h we imp ose the constrain ts implied by the graph . Then w e consider a minimal set of probability parameters expressing marginal/co nd itional indep endences an d su fficien tly describ e the graphical mo del of interest. W e introd u ce a conjugate prior distribu tion based on Diric hlet priors on the app ropriate probabilit y parameters. The prior distribution factorize similarly to the like liho o d. In ord er to mak e the p rior d istributions ‘compatible’ across mo dels we define all probabilit y parameters (marginal and conditional ones) of eac h mo del from the parameters of the joint distrib ution of the full table. In order to sp ecify the prior parameters of the Diric hlet p rior distrib u tion, we adopt ideas b ased on th e p ow er prior approac h of Ib rahim and Chen (2000) and Ch en et al. (2 000). The plan of the pap er is as follo ws. In Section 2 w e in tro duce grap h ical mo dels of marginal indep endence, w e establish th e notation, we presen t Marko v prop erties and we explain in detail th eir log-linea r parameterization. Section 3 illus trates a su itable factor- ization of the lik eliho o d fu n ction for all mo dels of m arginal ind ep endence in three-w a y tables. In S ection 4, we consider conjugate prior distributions, we present an imaginary data appr oac h for prior sp ecificatio n and we compare alternativ e pr ior set-ups. Section 5 pro vides p osterior m o d el and parameter distrib u tions whic h can b e easily calculated via conjugate analysis. Tw o illustrative examp les are p r esen ted in S ectio n 6. Finally , we end up with a d iscussion and s ome fi nal comments regarding our current research on the topic. 3 2 Preliminaries 2.1 Graphical Mo dels of Marginal Indep endence A bidirected graph G = ( V , E ) is c haracterized by a v ertex set V and an edge set E with the p rop ert y th at ( v i , v j ) ∈ E if and only if ( v j , v i ) ∈ E . W e d en ote eac h bidirected edge b y ( ← − → v i , v j ) = ( v i , v j ) , ( v j , v i ) and w e r epresen t it with a b idirected arro w. If a v ertex v i is adjacen t to another vertex v j , then v j is said to b e sp ouse of v i , and we write v j ∈ sp ( v i ). F or a set A ⊆ V , we defin e sp ( A ) = ∪ ( sp ( v ) | v ∈ A ). The degree d ( v ) of a vertex v is the cardinalit y of th e sp ouse set. A path connecting t wo vertic es, v 0 and v m , is a fi n ite sequence of distinct vertices v 0 , . . . v m suc h that ( v i − 1 , v i ) , i = 1 , . . . , m , is an edge of the graph. A ve rtex set C ⊆ V is connected if ev ery t w o vertexes v i and v j are joined b y a path in which ev ery vertex is in C. T w o sets A, B ∈ V are separated by a third set S ∈ V if an y path f rom a v ertex in A to a vertex in B con tains a v ertex in S . It can b e sho wn that, if a sub set of the n o d es D is not connected then there exist a un ique p artition of it in to maximal (with resp ect to inclusion) connected set C 1 , . . . , C r D = C 1 ∪ C 2 ∪ . . . ∪ C r . (1) The graph is used to represent marginal ind ep endences b et w een a set of discrete random v ariables X V = X v , v ∈ V , eac h one taking v alues i v ∈ I v . The cross- tabulation of v ariables X V pro duces a conti ngency table of d imension |V | w ith cell fre- quencies n = n ( i ) , i ∈ I where I = × v ∈V I v . Similarly f or an y marginal M ⊆ V , we denote with X M = X v , v ∈ M the set of v ariables which pro d uce the marginal table with frequencies n M = n M ( i M ) , i M ∈ I M where I M = × v ∈ M I v . Th e marginal cell coun ts are the su m of s p ecific elemen ts of the fu ll table and are giv en by 4 n M ( i M ) = X j ∈I M | i M n ( j ) where M = V \ M and I M | i M = { j ∈ I : j M = i M } . Therefore I M | i M refers to all cells of the f u ll table for whic h the v ariables of th e M marginal are constrained to the sp ecific v alue i M . A graphical mo del of m arginal in d ep endence is constructed via the follo w in g Mark o v prop erties. Definition 1 : Conne cte d Set Markov Pr op erty (R ichar dson, 2003). The distribution of a r andom ve c tor X V is said to satisfy the c onne cte d set Markov pr op erty if X C ⊥ ⊥ X V \ ( C ∪ sp ( C )) (2) whenever ∅ 6 = C ⊆ V is a c onne c te d set. A m ore exhaustive Marko v p r op ert y is the global Marko v p rop ert y , which requires all the marginal ind ep endences in (2 ), but also additional conditional indep enden ces. Definition 2 : Glob al Markov Pr op erty (Kauermann, 1996 and Richar dson, 2003). The distribution of a r andom ve ctor X V = { X v , v ∈ V } satisfies the Glob al Markov pr op erty if A is sep ar ate d fr om B by V \ ( A ∪ B ∪ C ) in G implies X A ⊥ ⊥ X B | X C , (3) with A , B and C disjoint subsets of V , and C may b e empty. Despite the global Mark o v prop ert y is more exh austiv e (in the sense that indicates b oth marginal and conditional indep endences), Drton and Ric h ardson (2008) p oin ted out that a d istribution satisfies the global Marko v p rop ert y if an d only if it satisfies the connected set Mark o v prop erty . 5 ¿F rom the global Marko v p rop ert y , w e directly d er ive that if t wo no des i and j are disconnected, th en X i ⊥ ⊥ X j that is th e v ariables are m arginal indep enden t. The same is true for any t wo sets A ⊂ V and B ⊂ V that are disconnected, implying that A ⊥ ⊥ B (are marginal in d ep endent ). This can b e easily generalized for any giv en disconn ected set D satisfying (1). Th en th e global Mark ov prop er ty for the bid irected graph G implies X C 1 ⊥ ⊥ X C 2 ⊥ ⊥ . . . ⊥ ⊥ X C r . According to Drton and R ichardson (2008), a discrete marginal graph ical mo del, as- so ciated to a bidirected graph G, is a family P ( G ) of joint d istributions for a catego rical random v ector X V satisfying th e global Mark o v p rop ert y (or equiv alently the connected set Mark o v pr op ert y). F ollo w ing the ab o ve , for ev ery not connected set D ⊆ V , it holds that P ( X D = i D ) = r Y k =1 P ( X C k = i C k ) (4) where C 1 , . . . , C r are the inclusion maximal connected sets satisfying (1). 2.2 A P arameterization for Marginal Log-Linea r Mo dels Lupparelli (2006 ) and Lupparelli et al. (2008) s ho w that it is p ossible to defin e a param- eterizatio n for any set X V of categorical v ariables, by usin g the marginal log-linear mo del b y Bersgma and Rudas (2002). Bergsma and Rudas (2 002) s u ggested to work in terms of log-linea r parameters λ obtained from a sp ecific set of marginal tables. They consider the follo win g mo del λ = C log M v ec( π ) (5) where π = π ( i ) , i ∈ I is the j oin t p robabilit y distribu tion of X V and v ec( π ) is a vec tor of dimension |I | obtained by rearran ging the elemen ts π in a r ev erse lexicographical ordering of the corresp ond ing v ariable lev els with the lev el of the firs t v ariable c hanging firs t (or 6 faster). F or example in a 2 × 2 table th e vec tor of p robabilities will b e giv en b y vec( π ) = π (1 , 1) , π (2 , 1) , π (1 , 2) , π ( 2 , 2) T . In this pap er we assume that the parameter v ector λ s atisfies sum -to-zero constrain ts and we in d icate with C the corresp on d ing con trast matrix. Finally M is the marginalization m atrix whic h sp ecifies from wh ich marginal we calculate eac h elemen t of λ . An algorithm for constructing C and M matrices is giv en in the App endix ( for add itional details see App endix A in Lu pparelli, 2006). 2.2.1 Prop erties of Marginal L og-Linear Parameters Let M ⊆ V b e a generic marginal, and indicate with S ( M ) the class of all su b sets of M and with E M ∈ S ( M ) the set of effects obtained from marginal M . Giv en M = { M 1 , M 2 , . . . , M |M| } the set of marginals used to calculate the log-linear parameters λ , we denote by λ M e = λ M e ( i e ) , i e ∈ I e , M ∈ M , the set of parameters for effect e ⊆ M estimated by the marginal M and b y λ M the set of all parameters estimated b y the same marginal. According to Bersgma and Rudas (2002), in ord er to obtain a w ell-defined param- eterizatio n, it is imp ortant to al lo cate the in teraction parameters λ among the c hosen marginals to get a c omplete and hier ar chic al set of p arameters. Definition 3 : Complete and hier ar chic al set of p ar ameters . A set of mar ginal lo g-line ar p ar ameters λ is c al le d hier ar chic al and c omplete if : i) The elements of M ar e or der e d in a non de cr e asing or der, which me ans that no mar ginal is a subset of any pr e c e ding one, i.e. M i 6⊆ M j if i > j (hier ar c hic al or dering). F urthermor e, we r e qui r e the last mar ginal i n the se q uenc e to b e the set al l vertic es under c onsider ation, ther efor e M |M| = V . 7 ii) F r om e ach mar ginal M i we c an c alculate only the effe cts that was not p ossible to get fr om the ones pr e c e ding it in the or dering under c onsider ation; henc e the sets E M i of the effe cts under c onsider ation ar e giv en by E M 1 = S ( M 1 ) and E M i = S ( M i ) \ ∪ i − 1 k =1 S ( M k ) for i = 1 , . . . , | M | . The ab o v e set of p arameters define a parametrization of the distribution on the con tin- gency table (see Bergsma and Rudas, 2002 , for a formal defin ition). It is called complete since eac h parameter is estimated fr om one and only one marginal and hierarc hical b e- cause the full set of parameters is generated by marginals in a non decreasing ordering (Bersgma and Ru das, 2002, p 143-1 44). F or ev ery complete and hierarchica l set of parameters, the inv erse tr an s formation of (5 ) alw a ys exists but it cannot b e analytically calculated (Lupparelli, 2006 , p. 39). Iterativ e pro cedures ha ve b een u sed to calc ulate π for any giv en v alues of λ and hence the like liho o d of the graph un der consideration (Rudas and Bergsma, 2004 and Lup parelli, 2006). An imp ortant p roblem w h en w orking with marginal log-linear parameters λ is that w e ma y end up with the d efinition of n on-existing joint m arginal probabilities. A w a y to a v oid this is to consider the parameters’ v ariation ind ep endence pr op ert y; see Bergsma and Ru das (2002) . A s et of parameters is v ariation indep end en t when the range of p os- sible v alues of one of them do es not dep end on the other’s v alue. Hence the joint range of the p arameters is the Cartesian pro duct of the separate ranges of the p arameters in- v olv ed. This p rop ert y ensures the existence of a common joint distr ibution derivin g fr om the marginals of the mo del und er consideration. Moreo ve r, v ariation indep end ence ensures strong compatibilit y wh ic h implies b oth compatibilit y of the marginals an d existence of a common join t distrib ution. Compatibilit y of the marginals means that f rom different distributions w e will end up to th e same distr ibution for the common paramete rs, for 8 example fr om marginals AB and AC we get the same marginal f or A. T o assu r e v aria- tion indep end ence of hierarc hical log-linear p arameters, a generaliza tion of the classical decomp osabilit y concept is needed. Definition 4 : De c omp osable set of Mar ginals . A class of inc omp ar able (with r esp e ct to inclusion) mar ginals M i s c al le d de c omp osable if it has at most two elements ( |M| ≤ 2 ) or if ther e i s an or dering M 1 , . . . , M |M| of i ts elements suc h that, for k = 3 , . . . , |M| ther e exist at le ast one j k < k for which the running interse ction pr op erty i s satisfie d, that is ∪ k − 1 i =1 M i ∩ M k = M j k ∩ M k . Definition 5 : Or der e d de c omp osable set of mar ginals . A class of mar ginals M is or- der e d de c omp osable if it has at most two elements or if ther e is a hier ar chic al or dering M 1 , . . . , M |M| of the mar ginals and, for k = 3 , . . . , |M| , the maximal elements (in terms of inclusion) of { M 1 , . . . , M k } form a de c omp osable set. The imp ortance of the ab o v e p rop ert y is du e to th e theorem 4 of Bergsma and Rudas (2002 ) wh er e they pr o ved that a set of complete and hierarc hical marginal log-linear pa- rameters is v ariation indep en den t if and only if the ordering of the marginals in v olv ed is ordered d ecomp osable. Hence order decomp osabilit y ensures the existence of a we ll defined join t probabilit y . 2.3 Construction of Marginal Log-Linear Gr aphical Mo dels Based on the resu lts of the previous su bsection, Lup parelli (2006) an d Lu p parelli et al. (2008 ) prop osed a strategy to construct a marginal log-linea r parametrization for th e family of d iscrete b idirected graph ical. Initially w e need to consider a set of a parameters λ deriv ed from a h ierarc hical ordering of the marginals in D ( G ) ∪ V ; where D ( G ) is the set of all disconnected comp onen ts of the 9 bidirected graph G . T h en, we m ust set the highest ord er log-linear inte raction parameters of D ( G ) equal to zero. More pr ecisely , w e n eed to consider the follo wing steps: i) Construct a h ierarc h ical ordering of th e marginals M i ∈ D ( G ). ii) App end the marginal M = V (corresp onding to the full table und er consideration) at the end of the list if it is not already includ ed. iii) F or every marginal table M i ∈ D ( G ) ∪ V estimate all parameters of effects in M i that ha ve not already estimated from the p r eceding marginals. iv) F or every marginal table M i ∈ D ( G ), set the highest order log-linear interactio n parameter equ al to zero; see Prop osition 4.3.1 in Lu pparelli (2006 ). In the three w a y case the log-li near p arameters the marginals are alw a ys obtained from a set of order of order decomp osable marginals, hence the parameters are v ariation indep endent. 3 Lik eliho o d Decomp osition In this pap er w e prop ose to u se a different app r oac h from the one by Rudas and Bergsma (2004 ) and Lup parelli (2006) in order to estimate the join t d istribution π of a graph G . W e imp ose the constraints implied by the graph G directly on the join t probabilities π . W e w ork w ith a min imal set of p robabilit y parameters π G expressing marginal/conditional indep enden ces and sufficientl y describ e th e graphical m od el G under inv estigation. By this w a y w e can alw a ys reconstruct the join t distribu tion π for a giv en graph G via π G and then simply calcula te th e marginal log-linear p arameters directly using (5). Here w e 10 fo cus on the three w ay case where the join t probability of eac h mo del can b e appropr iately factorized for any graph G . F or ev ery three w a y cont ingency ta ble eigh t p ossible graphical mo dels m od els exist whic h can b e represented by four d ifferen t t yp es of graphs: the indep endence, th e satu- rated, the edge and the gamma structure graph (see Figure 1 ). The indep endence graph is the one w ith the empty edge set ( E = ∅ ), the saturated is th e one con taining all p ossib le edges h E = ← − − → ( v , w ) : v 6 = w ∈ V i , an edge grap h is the one h a vin g only one single edge and a gamma structure graph is on e represent ed by a s in gle path of length t wo. I n a three w a y table, three ‘edge’ and three ‘gamma’ graphs are av ailable. A B C A B C A B C A B C (a) Ind ep endence Mo del (b) Saturated Mo del (c) Edge Mo del (d) Gamma Mod el Figure 1: Typ e of Graphs in Three W a y T ables F or the saturated mo del G S , we get all parameters fr om the full table, i.e. π G S = π . Th us , th e like liho o d is directly wr itten as f ( n | π , G S ) = Γ( N + 1) Q i ∈I Γ n ( i ) + 1 Y i ∈I π ( i ) n ( i ) where N = P i ∈I n ( i ) is the total sample size. The joint distrib utions for the indep en d ence and the edge mo dels can b e easily ex- pressed usin g the equation f ( n | π G , G ) = Γ( N + 1) Q i ∈I Γ n ( i ) + 1 Y d ∈D ( G ) Y i d ∈I d π d ( i d ) n ( i d ) 11 where π G = π d , d ∈ D ( G ) and π d = π d ( i d ) , i d ∈ I d is th e vec tor of p robabilities corresp onding to the table of the marginal d . The ab ov e equation derives d ir ectly fr om (4) since the graph is d isconnected. Finally , the d ecomp osition of the gamma s tr uctures is n ot as straight forward as in the previous case. In addition to sp ecific marginal probabilit y parameters we also need to use some conditional ones. Let u s denote by “ c ” the corner n od e, that is the v ertex with degree 2 and b y c = V \ c the end-p oin ts of the p ath. The set of d isconnected marginals is equ al to the end -p oin t v ertices of the graph, h ence c = D ( G ). T hen the lik eliho o d can b e written as f ( n | π G , G ) = Γ( N + 1) Q i ∈I Γ n ( i ) + 1 Y i c ∈I c Y i c ∈I c π c | c ( i c | i c ) n ( i c ,i c ) Y d ∈D ( G ) Y i d ∈I d π d ( i d ) n ( i d ) , where π G = π c | c , π d , d ∈ D ( G ) , here D ( G ) = V \ c and π c | c = π c | c ( i c | i c ) , i c ∈ I c , i c ∈ I c are all the cond itional probabilities of c give n c . The ab o v e f actorization can b e easily adopted to get maximum lik eliho o d estimates analyticall y and a void the iterativ e pro cedure used by Rudas and Bersgma (200 4) and Lup- parelli (2006) . I n this p ap er we w ork u s ing conjugate p riors on the appr opriate probability parameters of the ab o v e parametrization and then calculate the corresp onding log-linear parameters. 4 Prior distributions on cell probabilities 4.1 Conjugate Priors F or the sp ecification of the prior distribution of the pr ob ab ility parameter vec tor w e ini- tially consider a Diric hlet distribution with parameters α = α ( i ) , i ∈ I for the v ector of th e joint probabilities of th e full table π = π ( i ) , i ∈ I , w here I is the set of all cells 12 of the table under consideration. Hence, for the full table the pr ior d en sit y is giv en by f ( π ) = Γ ( α ) Q i ∈I Γ α ( i ) Y i ∈I π ( i ) α ( i ) − 1 = f D i ( π ; α ) (6) where f D i π ; α is the densit y fun ction of the Diric hlet distribution ev aluated at π with parameters α and α = P i ∈I α ( i ). Under th is set-up, the marginal prior of π ( i ) is a Beta d istribution with parameters α ( i ) and α − α ( i ), i.e. π ( i ) ∼ B eta α ( i ) , α − α ( i ) . The pr ior mean and v ariance of eac h cell is giv en by E π ( i ) = α ( i ) α and V π ( i ) = α ( i ) { α − α ( i ) } α 2 ( α + 1) . When no p r ior information is a v ailable then w e usu ally set all α ( i ) = α |I | resulting to E π ( i ) = 1 |I | and V π ( i ) = |I | − 1 |I | 2 ( α + 1) . Small v alues of α increase the v ariance of eac h cell probabilit y parameter. Usual c hoices for α are the v alues |I | / 2 (Jeffrey’s prior), |I | and 1 (corresp ondin g to α ( i ) equ al to 1 / 2, 1 and 1 / |I | resp ectiv ely); for details see Dellap ortas and F orster (1999 ). Th e c hoice of this prior parameter v alue is of prominent imp ortance for the mo del comparison due to the well kno wn sensitivit y of the p osterior m od el o dds and the Bartlett-Lindley paradox (Lindley , 1957, Bartlett, 1957). Here this effect is not so adverse, as for example in usual v ariable selection for generalize d linear mo dels, for t w o reasons. Firstly ev en if we consider the limiting case where α ( i ) = α |I | with α → 0, th e v ariance is fi nite and equal to ( |I | − 1) / |I | 2 . Secondly , the distributions of all mo dels are constructed from a common distribution of the f ull mo d el/ta ble making the prior distribu tions ‘compatible’ across different mo dels (Da wid and Laur itzen, 2000 and Ro v erato and Consonni, 2004). The mo del sp ecific prior distribu tions are defined by the constraint s imp osed b y the mo del’s graphical structure and the adopted fac torization. The prior distrib ution also 13 factorizes in same manner as th e lik eliho o d d escrib ed in section 3. T hus, the prior for the saturated mo del is the us u al Diric hlet (6). F or th e ind ep endence and ed ge mo dels th e prior is giv en by f π G G = Y d ∈D ( G ) Γ ( α ) Q i d ∈I d Γ α ( i d ) Y i d ∈I d π d ( i d ) α ( i d ) − 1 = Y d ∈D ( G ) f D i ( π d ; α d ) with parameter v ector π G = π d , d ∈ D ( G ) . W e d enote the ab o ve density whic h is a simple pr o d uct (o v er all disconnected sets) of Diric hlet distributions by f π G = f P D π d ; α d , d ∈ D ( G ) . (7) F or th e gamma stru cture th e prior is giv en by p π G = Y i c ∈I c Γ α ( i c ) Q i c ∈I c Γ α ( i c , i c ) Y i c ∈I c π c | c ( i c , i c ) α ( i c ,i c ) − 1 (8) × f P D π d ; α d , d ∈ D ( G ) with parameter v ector π G π c | c , π d , d ∈ D ( G ) . The fist part of equation (8), that is the pro duct for all lev el of c of Diric h let d istributions of the conditional p robabilities, can b e denoted by f C P D π c | c ; α . Then, the prior d en sit y (8) can b e wr itten as f π G = f C P D π c | c ; α f P D π d ; α d , d ∈ D ( G ) . (9) In order to make the prior d istributions ‘compatible’ across mo dels, we define the p rior parameters of π G from the corresp onding parameters of the prior distribu tion (6) imp osed on the p robabilities π of the full table; see Da wid and Lauritzen (2000), Rov erato and Consonni (2004). Let u s consider a marginal M ∈ M ( G ) f or whic h w e wish to estimate the probabilit y parameters π M = ( π M ( i M ) , i M ∈ I M ). The resu lting prior is π M ∼ D i α M , that is a 14 Diric hlet distribution with parameters α M = ( α M ( i M ) , i M ∈ I M ) giv en by α M ( i M ) = X j ∈I M | i M α ( j ) , see (i) of Lemma 7.2 in Da wid and Lauritzen (199 3, p.1304). F or example, consider a thr ee w a y table with V = { A, B , C } and the m arginal M = C . Then the pr ior imp osed on the parameters π C of th e marginal C is giv en b y π C ∼ D i α C with α C ( i C ) = |I A | X i A =1 |I B | X i B =1 α ( i A , i B , i C ) f or i C = 1 , 2 , . . . , |I C | , where π C = π C (1) , . . . , π C ( |I C | ) . F or the conditional distribution of M 1 | M 2 with M 1 6 = M 2 ∈ M ( G ) w e w ork in a similar wa y . The v ector π M 1 | M 2 ( ·| i M 2 ) = π M 1 | M 2 ( i M 1 | i M 2 ) , i M 1 ∈ I M 1 a p r iori follo ws a Diric hlet distribution π M 1 | M 2 ( ·| i M 2 ) ∼ D i α M 1 ∪ M 2 ( i M 1 ∪ M 2 ) , i M 1 ∪ M 2 ∈ I M 1 | i M 2 . The ab o ve s tr ucture derives from the decomp osition of a Diric hlet as a r atio of Gamma distributions; see also L emm a 7.2 (ii) in Da wid and Lauritzen (1993, p .1304 ). F or example, consider marginals M 1 = A and M 2 = B in a three wa y con tingency table with V = { A, B , C } . Then, for a sp ecific leve l of v ariable B , sa y i B = 2, π A | B ( ·| i B = 2) ∼ D i α AB ( · , 2) where α AB ( · , 2) = α AB (1 , 2) , α AB (2 , 2) , . . . , α AB ( |I A | , 2) and α AB ( i A , 2) = |I C | X i C =1 α AB C ( i A , 2 , i C ) . 4.2 Sp ecification of Prior Parameters Using I maginary Data. In order to sp ecify the prior parameters of the Diric hlet pr ior distrib u tion, we adopt ideas based on the p o w er prior appr oac h of Ib rahim and Chen (2000) and Chen et al. (2000) . 15 W e u s e their app roac h to adv o cate sensib le v alues for the Diric hlet pr ior parameters on the full table and the corresp ond ing indu ced v alues for the rest of the graphs as describ ed in the previous sub-section. Let us consider imaginary s et of d ata represen ted by the frequency table n ∗ = ( n ∗ ( i ) , i ∈ I ) of total sample size N ∗ = P i ∈I n ∗ ( i ) and a Diric hlet ‘pre-prior’ w ith all parameters equal to α 0 . Then the un normalized p rior distribution can b e obtained b y th e pro duct of th e like liho o d of n ∗ raised to a p o wer w multiplie d b y the ‘pre-prior’ distribu tion. Hence f ( π ) ∝ f ( n ∗ | π ) w × f D i π ; α ( i ) = α 0 , i ∈ I ∝ Y i ∈I π ( i ) w n ∗ ( i )+ α 0 − 1 = f D i π ; α ( i ) = w n ∗ ( i ) + α 0 , i ∈ I . (10) Using the ab o v e prior set u p, w e exp ect a priori to observ e a total num b er of w N ∗ + |I | α 0 observ ations. Th e parameter w is u sed to sp ecify the steepness of the prior dis- tribution and the weig ht of b elief on eac h pr ior observ ation. F or w = 1 then eac h imaginary observ ation has the same we ight as the actual observ ations. V alues of w < 1 will giv e less weig ht to eac h imaginary observ ation while w > 1 will incr ease the w eigh t of b eliev e on the prior/imaginary data. O verall the p r ior will account for the ( w N ∗ + |I | α 0 ) / ( w N ∗ + N + |I | α 0 ) of the total information used in the p osterior distri- bution. Hence for w = 1, N ∗ = N and α 0 → 0 then b oth th e prior and d ata will accoun t for 50% of the inf ormation u sed in the p osterior. F or w = 1 / N ∗ then α ( i ) = p ∗ ( i ) + α 0 with p ∗ ( i ) = n ∗ ( i ) / N ∗ , th e p rior data n ∗ will accoun t for inform ation of one data p oin t while the total weigh t of the pr ior w ill b e equal to (1 + |I | α 0 ) / (1 + N + |I | α 0 ). I f we furth er set α 0 = 0, then the prior d istr ibution (10) will account for information equiv alen t to a single observ ation. Th is p rior set-up will b e referred in this pap er as the unit information prior (UIP). When no information is 16 a v ailable, then w e m ay f u rther consider the choic e of equal cell fr equencies n ∗ ( i ) = n ∗ for the imaginary data in order to supp ort the simplest p ossible mo del u nder consid eration. Under this appr oac h N ∗ = n ∗ × |I | and w = 1 / N ∗ = 1 n ∗ ×|I | resulting to π ∼ D i α ( i ) = 1 / |I | , i ∈ I . The latter prior is equiv alen t to the one advocated by P erks (1947). It has th e n ice prop erty that th e pr ior on the marginal p arameters do es not dep end on the size of the table; for example, for a b in ary v ariable, this prior will assign a B eta (1 / 2 , 1 / 2 ) prior on the corresp ond ing marginal regardless the size of the table we work with (for example if w e work with 2 3 or 2 × 4 × 5 × 4 table). This p r op ert y is retained for any pr ior distrib ution of t yp e (10 ) with w ∗ = 1 / N ∗ , p ∗ ( i ) = 1 / |I | and α 0 ∝ 1 / |I | . 4.3 Comparison of Prior Set-ups Since P erks’ prior (with α ( i ) = 1 / |I | ) has a u nit inform ation interpretatio n, it can b e used as a y ardstic k in order to iden tify and interpret the effect of an y other prior distribution used. Prior d istribution with α ( i ) < 1 / |I | , or equiv alent ly α < 1, resu lts in larger v ariance than the one imp osed by our prop osed unit information prior and h ence it a p osteriori supp orts more p arsimonious mo dels. On the con trary , prior distributions with α ( i ) > 1 / |I | , or α > 1, result in lo we r prior v ariance and hence it a p osteriori s u pp ort mo dels with more complicated graph structure. So the v ariance ratio b etw een a Diric hlet p rior with α ( i ) = α/ |I | and Perks prior is equal to V R = V π i α ( i ) = α |I | V π i α ( i ) = |I | − 1 = 2 α + 1 . A comparison of th e in formation used from some standard c hoices is provided in T ab le 1. F rom this T able, we observe that Jeffreys’ pr ior v ariance is low er than the corresp onding P erks’ p rior reac hing a r eduction of ab out 60% an d 85% f or a 2 3 and a 2 × 3 × 4 table 17 T able 1: T able of Prior V ariance in Comparison to the Unit Information Prior (last r o w of the table) V ariance Ratio Pa rameter V [ π ( i )] General Equation 2 × 2 × 2 3 × 2 × 4 Jeffrey’s α ( i ) = 1 / 2 2 |I |− 1 |I | 2 {|I | +2 } 4 “ |I | +2 ” 0 . 4 0 . 15 Unit Exp. Cell α ( i ) = 1 |I |− 1 |I | 2 {|I | +1 } 2 “ |I | +1 ” 0 . 22 0 . 08 EBP α ( i ) = p ( i ) 1 2 p ( i ) “ 1 − p ( i ) ” |I | 2 |I |− 1 V [ π ( i )] 9 . 14 × “ V [ π ( i )] ” 25 . 04 × “ V [ π ( i )] ” UIP α ( i ) = p ∗ ( i ) 1 2 p ∗ ( i ) “ 1 − p ∗ ( i ) ” |I | 2 |I |− 1 p ∗ ( i ) “ 1 − p ∗ ( i ) ” 9 . 14 × p ∗ ( i ) “ 1 − p ∗ ( i ) ” 25 . 04 × p ∗ ( i ) “ 1 − p ∗ ( i ) ” PP with w = 1 / N ∗ α ( i ) = p ∗ ( i ) + α 0 S ( p ∗ ( i ) , α 0 , | I | ) a 2 |I | 2 |I |− 1 S ( p ∗ ( i ) , α 0 , | I | ) 18 . 28 × S ( p ∗ ( i ) , α 0 , 8) 50 . 08 × S ( p ∗ ( i ) , α 0 , 24) UIP-Perks’ α ( i ) = 1 / |I | |I |− 1 2 |I | 2 1 1 1 a S ( p ∗ ( i ) , α 0 , | I | ) = ` p ∗ ( i )+ α 0 ´` 1+ | I | α 0 − p ∗ ( i ) − α 0 ´ ` 1+ | I | α 0 ´ 2 ` 2+ | I | α 0 ´ 18 resp ectiv ely . T he r ed uction is even greater for the pr ior of the Unit Exp ected Cell mean ( α ( i ) = 1) reac hing 78% and 92% resp ectiv ely . Finally , we u se for comparison an Empirical Ba yes prior b ased on the UIP approac h. Hence w e set the im aginary d ata n ∗ ( i ) = n ( i ), w = 1 / N and α 0 = 0. Then the resulting prior parameters are giv en b y α ( i ) = p ( i ), where p ( i ) = n ( i ) / N is the samp le prop ortion. Under this set-up, th e prior v ariance for eac h π ( i ) is equ al to V [ π ( i )] = 1 2 p ( i ) 1 − p ( i ) . Th us the ab ov e pr ior assumes that we ha v e imaginary data with the same frequ ency table as the obs erv ed one but they accoun ts for information equ al to one data p oint (Emp irical UIP). 5 P osterior Mo del and P arameter Distributions Since the prior is conjugate to the likeli ho o d the p osterior can b e d eriv ed easily as fol- lo ws. F or the saturated mo del th e p osterior distribution is also a Dirichlet distribu tion π n , G S ∼ D i e α with parameters e α = e α ( i ) = α ( i ) + n ( i ) , i ∈ I . F or the indep end en ce and the edge structure the d ensit y of the p osterior distribu tion is is equiv alen t to (7), f ( π G n , G ) = f P D π G ; e α G with e α G = e α d , d ∈ D ( G ) and e α d = e α d ( i d ) = α d ( i d ) + n d ( i d ) , i d ∈ I d . Finally , for the gamma structure f ( π G | n , G ) = f C P D π c | c ; e α × f P D π d ; e α d , d ∈ D ( G ) i.e. a distribu tion with density equiv alent to the corresp ond ing prior (8) with parameters e α G = e α , e α d , d ∈ D ( G ) . ¿F rom the prop erties of the Diric h let distribution, it deriv es that eac h elemen t of π G follo w s a Beta distrib u tion with the appropriate parameters. 19 F or mo del choic e w e need to estimate the p osterior mo del p robabilities f ( G | n ) ∝ f ( n | G ) f ( G ), with f ( n | G ) marginal lik eliho o d of the m o d el and f ( G ) prior distrib ution on G . Here we restrict to the simple case where f ( G ) is uniform , hence the p osterior will dep end only on the m arginal likeli ho o d f ( n | G ) of the mo del und er consideration. The marginal lik eliho o d can b e calculated analytically since the ab o v e pr ior set-up is conjugate. F or th e saturated mo del the marginal lik eliho o d is give n by f ( n | G ) = K ( n ) × D K α D K e α where K ( n ) and D K ( α ) are given by K ( n ) = Γ( N + 1) Q i ∈I Γ n ( i ) + 1 and D K α = Γ P i ∈I α ( i ) Q i ∈I Γ α ( i ) . resp ectiv ely . F or th e ind ep endence and th e edge mo dels the marginal like liho o d is giv en by f ( n | G ) = K ( n ) Y d ∈D ( G ) D K α d D K e α d (11) where D K α d = Γ P i d ∈I d α d ( i d ) ! Q i d ∈I d Γ α d ( i d ) . Finally , for the gamma structure the marginal likelihoo d f ( n | G ) is giv en by f ( n | G ) = K ( n ) Y i c ∈I c D K α ( · , i c ) D K e α ( · , i c ) Y d ∈D ( G ) D K α d D K e α d . (12) where D K α ( · , i c ) = Γ P i c ∈I c α ( i c , i c ) ! Q i c ∈I c Γ α ( i c , i c ) . The p osterior distr ibution of the m arginal log-li near p arameters λ G can b e estimated in a straightfo rward manner us in g Mon te Carlo samples f rom the p osterior distribution of 20 π G . Sp ecifically , a samp le from the p osterior d istr ibution of λ G can b e generated b y the follo w in g steps. i) Generate a r an d om samp le π G, ( t ) ( t = 1 , . . . , T ) from the p osterior distribution of π G . ii) A t eac h iteration t , calculate the the full table of probabilities π ( t ) from π G, ( t ) . iii) The vect or of marginal log lin ear parameters, λ G, ( t ) , can b e easily obtained from π ( t ) via equation (5) which b ecomes λ G, ( t ) = C G log M G v ec π ( t ) where C G and M G are the contrast and marginalization m atrices un d er graph G . Note that some el ements of λ G will automati cally b e constrained to ze ro for all generated v alues d u e to the graphical structure of the mo del G and the w a y w e calculate log-linear parameters us ing the previous equation. Finally , w e can use the generated v alues λ G, ( t ) ; t = 1 , 2 , . . . , T to estimate summaries of the p osterior distrib ution f ( λ G | G ) or obtain plots f u lly d escribing this distribution. 6 Illustrativ e examples The metho d ology describ ed in the previous sections is n o w illustrated on t wo real data sets, a 2 × 2 × 2 and a 3 × 2 × 4 tables. In b oth example we compare th e results ob tained with our y ardstic k prior, th e UIP-Perks’ pr ior ( α ( i ) = 1 / | I | ), with those obtained usin g Jeffrey’s ( α ( i ) = 1 / 2), Unit Exp ected Cell ( α ( i ) = 1), and Em pirical Ba yes ( α ( i ) = p ( i )) priors. 21 6.1 A 2 × 2 × 2 T able: An tit o xin Medication Data W e consider a d ata set pr esen ted b y Healy (1988) regarding a study on the relationship b et we en patien t condition (more or less severe), assumption of ant ito xin (yes or not) and surviv al status (su rviv ed or not); see T able 2. In T able 3 we compare p osterior mo d el probabilities un d er the f our different p rior s et-ups. T able 2: An tito xin data Surviv al (S) Condition (C) An tito xin (A) No Y es More Sev ere Y es 15 6 No 22 4 Less Sev ere Y es 5 15 No 7 5 Under all prior assu m ptions the maximum a p osteriori mo del (MAP) is SC + A (w e omit the con v ent ional crossing (*) op erator b et we en v ariables for simplicit y), assuming the marginal ind ep endence of An tito x in fr om the remainin g t w o v ariables. Under Emp irical Ba ye s and UIP-Perks’ priors the p osterior distribution is concen trate on th e MAP mod el (it tak es in to acco unt 93 . 4% and 91 . 7% resp ectiv ely of the p oste- rior model probabilities). Th e p osterior distr ib utions under the Jeffreys’ an d the unit exp ected prior set-ups are more disp er s e, s upp orting th e three mo dels (SC+ A, AS+ SC and AS C) with p osterior weig hts h igher than 10% and accoun ting arou n d the 94% of th e p osterior mo del probabilities. Mod el AS + S C is also the mo del with the second highest p osterior pr obabilit y u nder UIP-P erks’ p rior but its weig ht is considerably lo w er than the corresp onding pr obabilit y of th e MAP m o d el. 22 T able 3: Po sterior mo d el probabilities (%) for the An tito xin data. Mo del A+S+C AS+C A C+S SC+A A S+A C AS+SC A C+SC ASC Prior Distri bution (1) (2) (3) (4) ( 5) (6) (7) (8) Jeffreys’ α ( i ) = 1 / 2 0.3 1 .5 0.2 59.7 0.1 21.7 3.0 13.4 Unit Exp ected Cell α ( i ) = 1 0.2 1.1 0.2 37.2 0.1 30.2 4.7 26.2 Empirical Bay es α ( i ) = p ( i ) 1.6 2.4 0.3 93.4 0.0 1.7 0.2 0.4 UIP-Perks’ α ( i ) = 1 / | I | 1.2 2.1 0.3 91.7 0.0 3.5 0.4 0.8 Figure 2 presen ts b o xplots summ arizing 2.5 %, 97.5% p osterior p ercen tiles and quan tiles of the join t p robabilities for th e MAP mo del (SC+ A) for the four prior set-ups. Since direct calculation fr om the p osterior distribu tion is not feasible, w e estimated the p osterior summaries via Monte Carlo simulatio n (1000 v alues). F rom this figure, we observ e min or differences b et w een the p osterior distrib utions obtained under the UIP-Perks’ and the empirical Ba ye s prior. More differences are observed b et w een Perks’ UIP and the p osterior distributions u nder the tw o other p rior set-ups. Differences are higher for the first tw o cell probabilities, i.e. f or π (1 , 1 , 1) and π (2 , 1 , 1). Similarly in Figure 3 w e present b o xplots p ro viding p osterior su mmaries for m o d els S C + A , AS + S C and AS C under th e UIP-P erks’ prior set-up. Th e fir st tw o mo dels are the ones with highest p osterior probabilities and all of their summaries ha ve b een calculate d usin g Monte Carlo simulation (1000 v alues). The saturated w as used mainly as reference mo del since it is th e only one f or whic h the p osterior d istributions are a v ailable analyticall y . F rom the figure we observ e that the p osterior distributions on the joint probabilities π of the full table are qu ite different highly dep ending on the assumed mo del structure. Finally , p osterior sum maries for th e pr obabilit y parameters π G and th e marginal log- linear p arameters λ G for mo dels S C + A , AS + S C and AS C (as describ ed ab o v e) un der 23 Figure 2: Antito xin data: Bo xp lots summarizing 2.5%, 97.5% p osterior p ercentile s and quan tiles of the join t probabilities π AB C ( i, j, k ) for the MAP m o d el (SC+ A) for all p rior set-ups (J=Jeffreys’, U=Unit Exp ected Cell, E=Emp irical Ba y es, P=Perks’) . 0.05 0.10 0.15 0.20 0.25 0.30 J U E P J U E P J U E P J U E P J U E P J U E P J U E P J U E P Prior 111 211 121 221 112 212 122 222 Cell Cell Probabilities Figure 3: Antito xin data: Boxplot s summarizing 2.5%, 97.5% p osterior p ercenti les and quan tiles of the join t p robabilities π AB C ( i, j, k ) for mo dels SC+A, AS+ SC and ASC (4, 6 and 8 resp ectiv ely) under the UIP-P erks’ prior set-up. 0.0 0.1 0.2 0.3 (4) (6) (8) (4) (6) (8) (4) (6) (8) (4) (6) (8) (4) (6) (8) (4) (6) (8) (4) (6) (8) (4) (6) (8) Model 111 211 121 221 112 212 122 222 Cell Cell Probabilities 24 the UIP-Pe rks ’ prior are provided in T ables 4 and 5 resp ectiv ely . All summaries of eac h elemen t of π G are obtained analytically b ased on the Beta distribu tion ind uced b y the corresp onding Dirichlet p osterior distribu tions of π G . P osterior summaries of λ G are esti- mated using the Mon te Carlo strategy (1000 v alues) discussed in section 5. As commen ted in this section, some elements of λ G for graphs S C + A and AS + S C are constrained to zero du e the wa y we hav e constructed our mo del. Hence for S C + A , the maximal in teraction terms for the d isconnected s ets AS , AC and AS C , i.e. p arameters λ AS (2 , 2), λ AC (2 , 2) and λ AS C (2 , 2 , 2), are constrained to b e zero for all generated obs erv ations. Sim- ilar is the picture for mo del AS + S C , but now only marginals AC and AB C corresp ond to disconnected sets implying th at λ AC (2 , 2) = λ AS C (2 , 2 , 2) = 0. 6.2 A 3 × 2 × 4 t able: Alcohol Data W e no w examine a w ell kn o w n data set presented b y K nuiman and S p eed (1988) regarding a small study held in W estern Au s tralia on the r elatio nsh ip b et wee n Alcohol intak e (A), Ob esit y (O) and High blo o d p ressure (H); see T able 6. In T able 7 w e rep ort p osterior mo del pr obabilities and corresp ond ing Log-marginal lik eliho o ds for eac h mo dels. Un der all prior set-ups the p osterior m od el probabilit y is concen trated on mo dels H+A+ O , HA+O and HO+A. Emp irical Ba y es and UIP-Perks’ supp ort the in dep endence mo d el (with p osterior model probabilit y of 0 . 878 and 0 . 807 resp ectiv ely) whereas Jeffreys’ and Unit Exp ected supp ort a more complex structure, HO+A (with p osterior mo d el pr obabilit y of 0 . 837 and 0 . 859 r esp ectiv ely). T o sa v e space we d o not rep ort here p osterior su mmaries for mo del parameters, they can b e foun d in a separate app endix on the web page: http://s tat-athens .aueb.gr/~jbn/papers/paper21.htm . 7 Discussion and Final Commen ts In this pap er we ha ve dealt with the Bay esian analysis of graphical mo d els of marginal asso- ciation for three w a y cont ingency tables. W e ha ve work ed using the probabilit y parameters of marginal tables required to fully s p ecify eac h m o d el. The pr op osed parametrizatio n and 25 T able 4: Poste rior summaries of mo del parameters f or mo d els S C + A , AS + S C and AS C in An tito xin d ata under the UIP-P erks’ p rior set-up; e a and e b are the parameters of the resulted Beta marginal p osterior d istribution. Mo del 4: S C + A Beta Posterio r Parameters Parameter Mean St.dev. Q 0 . 025 Q 0 . 975 e a e b π S C (1 , 1) 0.47 0.055 0.36 0.57 37.2 5 4 2.75 π S C (2 , 1) 0.13 0.037 0.06 0.21 10.2 5 6 9.75 π S C (1 , 2) 0.15 0.040 0.08 0.24 12.2 5 6 7.75 π A (1) 0.52 0.056 0.41 0.63 41.5 0 3 8.50 Mo del 6: AS + S C Parameter Mean St.dev. Q 0 . 025 Q 0 . 975 e a e b π S | AC (1 | 1 , 1 ) 0.71 0.096 0.51 0.88 15.1 2 6.1 2 π S | AC (1 | 2 , 1 ) 0.84 0.070 0.68 0.95 22.1 2 4.1 2 π S | AC (1 | 1 , 2 ) 0.25 0.094 0.09 0.46 5.12 15.12 π S | AC (1 | 2 , 2 ) 0.58 0.136 0.31 0.83 7.12 5.12 π A (1) 0.52 0.056 0.41 0.63 41.5 0 3 8.50 π C (1) 0.59 0.055 0.48 0.70 47.50 32.50 Mo del 8: AS C (Sa turated) Parameter Mean St.dev. Q 0 . 025 Q 0 . 975 e a e b π (1 , 1 , 1) 0.19 0.044 0.11 0.28 15.1 2 6 4.88 π (2 , 1 , 1) 0.28 0.050 0.18 0.38 22.1 2 5 7.88 π (1 , 2 , 1) 0.08 0.030 0.03 0.14 6.12 73.88 π (2 , 2 , 1) 0.05 0.025 0.01 0.11 4.12 75.88 π (1 , 1 , 2) 0.06 0.027 0.02 0.13 5.12 74.88 π (2 , 1 , 2) 0.09 0.032 0.04 0.16 7.12 72.88 π (1 , 2 , 2) 0.19 0.044 0.11 0.28 15.1 2 6 4.88 π (2 , 2 , 2) 0.06 0.027 0.02 0.13 5.12 74.88 26 T able 5: An tito xin data: P osterior summaries for lam b da for mo dels S C+A, AS+S C and ASC und er the UIP-Pe rks’ prior set-up Mo del 4: S C + A Parameter Marginal table Mean St.dev. Q 0 . 025 Q 0 . 975 λ ∅ M AS -1.429 0.0 32 -1 .513 -1.388 λ A (2) M AS -0.040 0.1 13 -0 .258 0.181 λ S (2) M AS -0.245 0.1 18 -0 .480 -0.021 λ AS (2 , 2) M AS 0.000 0.00 0 0.00 0 0.000 λ C (2) M AC -0.194 0.1 16 -0 .426 0.027 λ AC (2 , 2) M AC 0.000 0.00 0 0.00 0 0.000 λ S C (2 , 2) M AS C 0.460 0.13 4 0.19 9 0.735 λ AS C (2 , 2 , 2) M AS C 0.000 0.00 0 0.00 0 0.000 Mo del 6: AS + S C Parameter Ma rginal table Mean St.dev. Q 0 . 025 Q 0 . 975 λ ∅ M AC -1.418 0.0 25 -1 .483 -1.388 λ A (2) M AC -0.042 0.1 14 -0 .261 0.173 λ C (2) M AC -0.195 0.1 10 -0 .414 0.020 λ AC (2 , 2) M AC 0.000 0.00 0 0.00 0 0.000 λ S (2) M AS C -0.238 0.1 37 -0 .493 0.044 λ AS (2 , 2) M AS C -0.291 0.1 37 -0 .554 -0.019 λ S C (2 , 2) M AS C 0.437 0.13 7 0.17 8 0.712 λ AS C (2 , 2 , 2) M AS C -0.086 0.1 43 -0 .370 0.207 Mo del 8: AS C (Sa turated) Parameter Marginal table Mean St.dev. Q 0 . 025 Q 0 . 975 λ ∅ M AS C -2.325 0.0 79 -2 .504 -2.191 λ A (2) M AS C -0.106 0.1 34 -0 .379 0.152 λ S (2) M AS C -0.246 0.1 31 -0 .510 0.004 λ AS (2 , 2) M AS C -0.292 0.1 39 -0 .576 -0.033 λ C (2) M AS C -0.136 0.1 43 -0 .402 0.151 λ AC (2 , 2) M AS C -0.084 0.1 39 -0 .355 0.202 λ S C (2 , 2) M AS C 0.450 0.13 5 0.20 7 0.705 λ AS C (2 , 2 , 2) M AS C -0.074 0.1 43 -0 .368 0.209 27 T able 6: Alcohol Data Alcohol intak e (drinks/days) Ob esit y Hig h BP 0 1-2 3-5 6+ Lo w Y es 5 9 8 10 No 40 36 33 24 Av erage Y es 6 9 11 14 No 33 23 35 30 High Y es 9 12 19 19 No 24 25 28 29 T able 7: Alcohol data: P osterior mo del p robabilities and the corresp ond ing Log marginal lik eliho o ds; empt y cell in p osterior pr obabilities m eans that it is lo wer th an 0 . 0001 Po sterior mo del probabili ties (%) Mo del H+A+O HA+O HO+A AO+H HA+HO HA+AO HO+AO HAO Prior Distri bution (1) (2) ( 3) (4) (5) (6) (7) ( 8) Jeffreys’ 11.56 4.76 83.68 Unit Exp ected Cell 6.91 7.21 85.88 Empirical Bay es 87.81 0.07 12.12 Pe rks’ 80.67 0.15 19.18 Log-marginal likelihoo d for each m odel Mo del H+A+O HA+O HO+A AO+H HA+HO HA+AO HO+AO HAO Prior Distri bution (1) (2) ( 3) (4) (5) (6) (7) ( 8) Jeffreys ( α ( i ) = 1 / 2) -79.22 -80.11 - 77.24 - 87.73 -90.44 -100.93 -98.06 - 98.95 UEC ( α ( i ) = 1) -78.51 -78.47 - 75.99 - 84.70 -85.27 -93.99 -91.51 -91.46 Emprirical Bay es ( α ( i ) = p ( i )) -86.96 -94.10 - 88.94 -107.26 -124.75 -143.06 -137.91 - 145.04 Pe rks ( a ( i ) = 1 / | I | ) - 86.90 - 93.19 -88.33 -107.10 - 121.13 -139.89 -135.03 -141.33 28 the corresp onding decomp osition of the lik eliho o d simplifies the pr oblem and automati- cally imp oses the marginal indep end en ces represente d by the considered graph. By this w a y , the p osterior mo del probabilities and the p osterior d istributions for the used param- eters can b e calculated analytically . Moreo ve r, the p osterior distributions of the marginal log-linear p arameters λ G and the prob ab ilities π of the full table can b e easily obtained using simple Mont e Carlo sc hemes. This approac h a v oids th e prob lem of th e inv erse calcu- lation of π when the marginal asso ciation log-linear p arameters λ are av ailable wh ic h can b e only ac hieved via an iterativ e pr o cedu re; see Rud as and Bergsma (2004) and Lupp arelli (2006 ) for more details. An obvio us extension o f this w ork is to implement the same approac h in tables of higher dimension starting from four w ay tables. Although m ost of the mo dels in a four w a y continge ncy table can b e f actorize d and analyzed in a similar manner , t w o type of graphs (the 4-c h ain and the cordless four -cycle graphs ) cannot b e d ecomp osed in the ab o ve w a y . These mo dels are not Mark o v equiv alen t to an y d irected acyclic graph (D AG ). In f act eac h bidirected graph (whic h corresp onds to a marginal asso ciation mo d el) is equiv alent to a DA G, i.e. a conditional asso ciation mo del, with the same set of v ariables if and only if it do es not con tain an y 4-c hain, s ee P earl and W erm uth (1994). W e b eliev e that also in higher dimensional problems our approac h can b e app lied to b id irected graph s that admit a DA G represen tation. F or the graph th at do not fact orize, more soph isticated tec h niques m ust b e adopted in ord er to obtain the p osterior distribution of int erest and the corresp onding marginal lik eliho o d n eeded for the mo d el comparison (w ork in progress b y the authors). Another inte resting sub ject is ho w to obtain the p osterior distributions in the case that someone prefers to work d irectly w ith marginal log-linear parameters λ G defined b y (5). Using our approac h, w e imp ose a prior distribution on the probabilit y parameters π G . The prior of λ G cannot b e calculated analytically sin ce we cannot hav e the in ve rse expression of (5) in closed form. Nev er th eless, we can obtain a sample from the imp osed prior on λ G using a simple Monte Carlo sc heme. More s p ecifically , we can generate random v alues of π G from the Diric hlet based p rior set-ups d escrib ed in this pap er. W e calculat e the join t probabilit y vec tor π according to the factorization of the graph un der consideration and finally u s e (5) to obtain a s amp le from the imp osed p rior f ( λ G | G ). This will give us an idea of the pr ior imp osed on the log-linear p arameters. If pr ior information is expressed d irectly in terms of the lo g-linear parameters, see 29 e.g Knuiman and Sp eed (1988) and Dellap ortas and F ors ter (19 99), the prior and the corresp onding p osterior distribution of π G can b e obtained using t w o alte rn ativ e strategies. One p ossibility is to approximate the distribution imp osed on the elements of π G via Diric h let distributions with the parameters obtained in the follo wing w a y . Firstly w e generate r an d om v alues from the prior imp osed on the standard log- linear parameters for mo dels of conditional asso ciation. F or eac h set of generated v alues, we calculate the corresp onding probabilities π for the full table. Finally we obtain a sample for π G via marginalizatio n from eac h set of generated probabilities π . F or every element of π G , we use the corresp ondin g generated v alues to app ro ximate the imp osed pr ior b y a Diric hlet distribution with the parameters estimated us ing the moment-matc hing app roac h . Note that this appr oac h can only provide us a rough pictur e of the correct p osterior d istr ibution since the priors are only matc hed in terms of the mean and the v ariance wh ile their shap e can b e totally d ifferent d ue to the prop erties of th e Diric hlet distribution. Similar will b e the approac h if the prior d istributions f ( λ G | G ) for the marginal log- linear parameters λ G are a v ailable. The only prob lem h ere, in comparison to th e simpler approac h describ ed in the previous paragraph, is the calculation of π from eac h λ G . In order to ac hiev e that we need to use iterativ e pro cedures; see Rudas and Bergsma (2004) and Lupp arelli (2006). A second approac h is to directly calculate the pr ior d istribution imp osed on the pr ob- abilit y parameters π G starting fr om the p r ior f ( λ G | G ) using equation (5). Note th at the probabilities π of th e full table inv olv ed in (5 ) are simply a function of π G dep ending on the structur e G . Hence, the prior on π will b e giv en by f ( π G | G ) = f ( λ G | G ) ∂ λ G ∂ p G where p G is vec( π G ) after r emo vin g the last elemen t of eac h set of probability parameters and vec( π G ) refers to π G arranged in a ve ctor form . The elemen ts of the Jacobian are giv en b y ∂ λ G k ∂ p G l = col ( C ) X i =1 C k i |I | X j =1 M ij v ec( π ) j − 1 |I | X j =1 M ij ∂ vec( π ) j ∂ p G l where col ( C ) is the n umb er of column s of C matrix. F or the saturated mo del the ab o v e equation simplifies to ∂ λ G k ∂ p l = col ( C ) X i =1 C k i ( M il − M i |I | ) P |I | j =1 M ij v ec( π ) j 30 since vec( π ) j = p G j for j < |I | and v ec( π ) |I | = 1 − P |I |− 1 j =1 p G j . After ca lculating the corresp onding pr ior distribution f ( π G | G ), w e can work d irectly on π G using an MCMC algorithm to generate v alues fr om the resu lted p osterior. A sample of λ G can b e again obtained in a direct w ay using (5). When n o strong prior information is a v ailable, an indep enden ce Metrop olis algorithm can b e applied using as a p r op osal the Diric hlet distri- butions resulted fr om the lik eliho o d part. Otherwise more soph isticat ed tec hniques migh t b e n eeded. The authors are also exploring the p ossibilit y to extend the current w ork in this dir ection. Ac kno wledgmen t W e thank Monia Lu pparelli for f ruitful discussions and Gio v anni Marc hetti for p ro viding us the R fun ction inv.mlog it . This work w as partially supp orted b y MIUR, R OME, under pro ject PRIN 200513230 7 and Universit y of P a via. App endix 1. Construction of Matrix M Let M = { M 1 , M 2 , . . . , M |M| } b e the set of consider ed marginals. Let B b e a binary matrix of dimen sion |M| × |V | with elemen ts B iv indicating whether a v ariable v b elongs to a sp ecific marginal M i . The r o w s of B corresp ond to the marginals in M whereas the columns to th e v ariables. Th e v ariables follo w a r ev er s e orderin g, that is column 1 corresp onds to v ariable X |V | , column 2 to v ariable X |V |− 1 and so on. Matrix B has elemen ts B iv = 1 if v ∈ M i 0 otherwise. , for ev ery v ∈ V . The marginalization matrix M can b e constru cted us ing the follo win g rules. (a) F or eac h marginal M i , the probabilit y vec tor of the corresp ond ing marginal ta- ble is giv en by M i π ; where M i is calculated as a Kronec ker pro duct of matrices A iv M i = O v ∈V A iv 31 with A iv = I ℓ v if B iv = 1 1 T ℓ v if B iv = 0 where ℓ v is the n umb er of lev els for v v ariable, I ℓ v is the iden tit y matrix of dimension ℓ v × ℓ v and 1 ℓ v is a v ector of dimension ℓ v × 1 with all elements equ al to one. (b) Mat rix M is constructed by stac king all the M i matrices M = M 1 . . . M i . . . M | M | 2. Construction of Matrix C Firstly w e need to construct the design matrix X for the saturated mo del corre- sp onding to s um to zero constr aints. It h as has d imension Q v ℓ v × Q v ℓ v and can b e ob tained as X = O v ∈V R J ℓ v with J ℓ v ( r , c ) = 1 if c = 1 or r = c − 1 if r = 1 and c > 1 0 otherwise. In m atrix notation J ℓ v = 1 − 1 T ( ℓ v − 1) 1 ( ℓ v − 1) I ( ℓ v − 1) × ( ℓ v − 1) where 1 ( ℓ v − 1) is ( ℓ v − 1) × 1 v ector of ones wh ile I ( ℓ v − 1) × ( ℓ v − 1) is an identit y m atrix of d imension ( ℓ v − 1) × ( ℓ v − 1). The contrast matrix C can b e constru cted b y usin g the follo wing rules. (a) F or eac h margin M i construct the design matrix X i corresp onding to the sat- urated mo d el (using sum to zero constraints) and in ve rt it to get the contrast 32 matrix for the saturated mo del C i = X − 1 . Let C ∗ i b e a submatrix of C i ob- tained by deleting rows not corresp onding to elemen ts of E M i (the effects that w e wish to estimate from margin M i ) . (b) The con trast matrix C is obtained b y direct su m of the C ∗ i matrices as follo w C = M i : M i ∈ M C ∗ i that is it is a blo c k diagonal matrix with ( C ∗ 1 ; M i ∈ M ) as the blo c k s . F or example C ∗ i N C 2 = L 2 i =1 C ∗ i is the blo c k diagonal matrix with C 1 and C 2 as blo c ks. References [1] Bartle tt, M. S. (1957). A comment on Lindley’s statistical parado x. Bi ometrika , 44 , 533-5 34. [2] Bergsma, W. P . and Rud as, T . (2002 ). Marginal log-linear mo dels for categorical data. Anna ls of Statistics , 30 , 140-159. [3] Chen, M.H., Ibr ahim b, J.G. and Shao, Q. M. (2000) . P o wer prior distrib utions for generalized linear mo dels. J ournal of Statistic al Planning and Infer enc e , 84 , 121-13 7. [4] Co x, D. R. and W ermuth, N. (1993). Linear dep end encies r epresen ted by c hain graphs (with discussion). Statistic al Scienc e , 8 , 204-2 18, 247-277. [5] Da wid A.P . and Lauritzen S .L. (1993 ). Hyp er-Mark ov la ws in the statistical analysis of d ecomp osable grap h ical m o d els, Anna ls of Statistics , 21 , 1272-1317. [6] Da wid, A.P . and Lauritzen, S.L. (2000). Compatible pr ior distribu tions. I n Bayesian Metho ds with Applic ations to Scienc e P olicy and O fficial Statistics. The sixth world me eting of the International So ci e ty for Bayesian Analy sis (ed. E.I. George), 109-118. http://w ww.stat.cm u.edu/ISBA/index.html . [7] Dell ap ortas, P ., F orster, J.J. and Ntzoufras I. (2002). On Ba yesia n mo d el and v ariable selection using MCMC. Statistics and Computing , 12 , 27-36. [8] Drton, M. and Ric hardson, T. S. (2008). Binary mo dels for marginal ind ep endence. Journal of the R oyal Statistic al So ciety , Ser. B , 70 , 287-30 9. 33 [9] Glonek, G. J. N. and McCullagh, P . (1995). Multiv ariate logistic mo dels. Journal of the R oyal Statistic al So ciety , Ser. B, 57 , 533-546. [10] Healy , M.J.R. (1988). Glim: An Intr o duction , Claredon Press, Oxford, UK. [11] I b rahim J .G. and Chen M. H. (2000 ). Po wer Prior Distrib utions for Regression Mo d- els. Statistic al Scienc e , 15 , 46-60. [12] K auermann, G. (1996). On a d ualizatio n of graphical Gaussian mo dels. Sc andinavian Journal of Statistics , 23 , 105116. [13] K n uiman, M. W. and Sp eed, T. P . (1988). In corp orating prior information int o th e analysis of con tingency tables. Biometrics , 44 , 1061-1071 . [14] L in dley , D. V. (1957). A statistical parado x. Biometrika , 44, 187192 . [15] L u pparelli, M. (2006) . Gr aphic al mo dels of mar ginal i ndep endenc e for c ate goric al vari- ables . Ph. D. thesis, Universit y of Florence. [16] L u pparelli, M., Marc hetti, G. M., Bersgma, W. P . (200 8). P arameterization and fitting of b i-directed graph mo dels to categorical data. arXiv:0801.14 40v1 [17] Pearl, J. and W ermuth, N. (1994) . When can asso ciation graphs admit a causal in terpretation? In P . Cheesman and W. Oldf ord, eds., Mo dels and da ta, artific al intel ligenc e and statistics iv . Sprin ger, New Y ork, 205-21 4. [18] Perks, W. (1947). Some observ ations on inv er s e pr ob ab ility includ ing a new indiffer- ence rule. journal of the institute of actuaries 73, 285- 334. [19] Richardson, T. S. (2003). Marko v prop erty for acyclic directed mixed graphs. Sc an- dinavian J ournal of Statistics 30, 145-157 . [20] Rov erato A. and Consonn i G. (2004 ) Compatible Prior Distribu tions for D A G m o d els. Journal of the R oyal Statistic al So ciety series B, 66 , 47-61. [21] Ru das, T. and Bergsma, W. P . (2004). O n applications of marginal mo d els for cate- gorical data. Metr on L XI I, 1 25. 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment