Least angle and $ell_1$ penalized regression: A review
Least Angle Regression is a promising technique for variable selection applications, offering a nice alternative to stepwise regression. It provides an explanation for the similar behavior of LASSO ($\ell_1$-penalized regression) and forward stagewis…
Authors: Tim Hesterberg, Nam Hee Choi, Lukas Meier
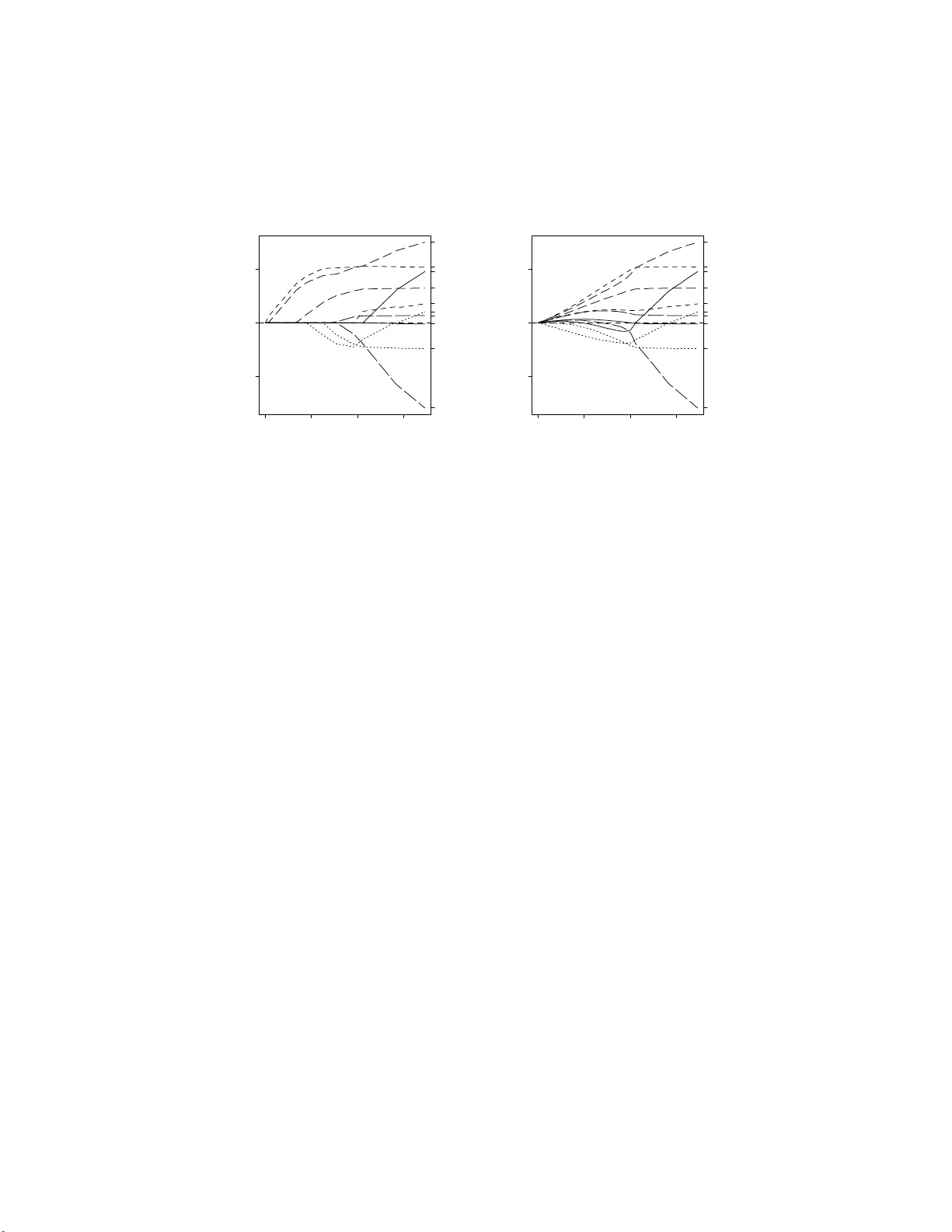
Statistics Surve ys V ol. 2 (2008) 61–93 ISSN: 1935-7516 DOI: 10.1214/ 08-SS035 Least angle and ℓ 1 p enalized regression : A review ∗ † Tim Hesterb erg , Nam Hee Choi , Luk as Meier , and Chris F raley § Insighftul Corp. ‡ , Unive rsity of Michigan, ETH Z ¨ urich, Insightful Corp. Abstract: Least Angle Regression is a promising tec hnique for v ar iable selection applications, offering a nice alternative to stepwise r egression. It prov ides an explanation for the similar b ehavior of LASSO ( ℓ 1 -p enalized regression) and forward stagewise regression, and provides a fast imple- men tation of both. The idea has caught on r apidl y , and spark ed a great deal of researc h in terest. In this pa per, we giv e a n o v erview of Least Angle Regression and the current state of related research. AMS 2000 sub ject cla ssifications: Pr imary 62J07; second ary 69J99. Keywords and phrases: lasso, regression, regularization, ℓ 1 penalty, v ari- able selection. Receiv ed F ebruary 2008. Con ten ts 1 In tro duction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 2 History . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 2.1 Significance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 3 2.2 LARS and Earlier Methods . . . . . . . . . . . . . . . . . . . . . 64 2.2.1 Step wise and All-Subsets Regression . . . . . . . . . . . . 6 5 2.2.2 Ridge Regressio n . . . . . . . . . . . . . . . . . . . . . . . 66 2.2.3 LASSO . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 7 2.2.4 F orw ard Stagewise . . . . . . . . . . . . . . . . . . . . . . 68 2.2.5 Least Angle Regr ession . . . . . . . . . . . . . . . . . . . 6 9 2.2.6 Comparing LAR, LASSO and Stagewise . . . . . . . . . . 72 3 LARS Extensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72 3.1 Exploiting Additional Structure . . . . . . . . . . . . . . . . . . . 73 3.1.1 Ordered Predictor s . . . . . . . . . . . . . . . . . . . . . . 73 3.1.2 Unknown Pr edictor Groups . . . . . . . . . . . . . . . . . 7 3 3.1.3 Known Predictor Groups . . . . . . . . . . . . . . . . . . 74 3.1.4 Order Restrictions . . . . . . . . . . . . . . . . . . . . . . 75 3.1.5 Time Series and Multiresponse Data . . . . . . . . . . . . 7 6 3.2 Nonlinear mo dels . . . . . . . . . . . . . . . . . . . . . . . . . . . 77 ∗ This work was supported by NIH SBIR Phase I 1R43GM0743 13-01 and Phase II 2R44GM07431 3-02 a w ards. † This paper was accepte d b y Grace W ahba, Associate Editor for the IMS. ‡ no w at Google, Inc. § corresponding author (fraley@insigh tful.com) 61 Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 62 3.3 Other Applications . . . . . . . . . . . . . . . . . . . . . . . . . . 8 0 3.4 Computational Issues . . . . . . . . . . . . . . . . . . . . . . . . 80 4 Theoretical Pr op erties and Alternative Regularization Approaches . . 81 4.1 Criteria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 1 4.1.1 The Pr ediction Problem . . . . . . . . . . . . . . . . . . . 82 4.1.2 The V ariable Selection P roblem . . . . . . . . . . . . . . . 82 4.2 Adaptiv e LASSO a nd related metho ds . . . . . . . . . . . . . . . 83 4.3 Dant zig selector . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 5 5 Soft ware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86 6 Conclusions and F uture W ork . . . . . . . . . . . . . . . . . . . . . . . 8 6 References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87 1. In tro duction “I’v e got all these v ariables, but I don’t know whic h ones to u se.” Classification and r egressio n problems with larg e num b ers of candidate pr e- dictor v a r iables o ccur in a wide v ariety of scientific fields, increasingly so with improv emen ts in data collection tec hnologies. F or example, in microar r ay a nal- ysis, the num b er of predictor s (genes) to b e ana lyzed t ypically far exceeds the n um ber of observ ations. Goals in model selection include: • accurate pre dictio ns , • int erpretable mo dels—determining which predictors ar e meaningful, • stability—small changes in the data s hould no t result in large c hanges in either the subset of predictor s used, the asso ciated coefficients, or the predictions, and • av oiding bias in hypothesis tests during or after v ariable selection. Older metho ds, such as stepwise regress io n, all- subsets regr ession and ridge re- gression, fall short in one or more of these criteria . Mo dern pr o cedures such as bo osting ( F reund a nd Schapire , 19 97 ) forward sta gewise reg r ession ( Hastie et al. , 2001 ), and LASSO ( Tibshirani , 1996 ), improv e s tabilit y and pr e dictio ns . Efron et al. ( 2004 ) show that there ar e stro ng connectio ns b etw een these mo dern metho ds and a metho d they call le ast angle r e gr ession , and develop an algorithmic fra mework that includes all of these metho ds and provides a fast implemen tation, for which they use the term ‘LARS’. LARS is potentially revo- lutionary , o ffering in terpretable mo dels, stability , accurate predictions, gra phica l output that sho ws the key tr a deoff in model complexit y , and a simple data-bas e d rule for determining the o ptimal lev el of complexit y that near ly avoids the bias in hypothesis tests. This idea has caught on rapidly in the academic communit y—a ‘Go ogle Sch olar’ search in May 2 0 08 shows ov er 400 citatio ns of Efron et al. ( 2004 ), and ov er 1000 citations of Tibshira ni ( 1996 ). Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 63 W e explain the impor tance of LARS in this introduction and in Section 2.1 and compa re it to older v ar iable selection or p enalized regressio n metho ds in Section 2 .2 . W e describ e extensions in Section 3 , alterna te approa ches in Sec- tion 4 , a nd list some av aila ble soft w are in Section 5 . 2. History 2.1. Signi fic anc e In 19 9 6 one o f us (Hesterberg) a sked Brad Efron for the most important prob- lems in sta tistics, fully expecting the answ er to inv olv e the bo o tstrap, giv en Efron’s status as inv en tor. Instead, E fron named a single problem, variable s ele c- tion in r e gr ession . This entails selecting v a r iables from among a s et o f ca ndidate v aria bles, estimating parameters for those v ariables, and inference—hypotheses tests, standard err ors, and confidence interv als. It is hard to a rgue with this assessment. Regression, the problem of estimating a r elationship b etw een a resp onse v ariable a nd v arious predictors (explanatory v aria bles, cov aria tes) is of paramount imp or tance in statistics (particularly when we include “classification” pro blems, where the resp onse v ar iable is ca tegorica l). A large fraction of r egressio n problems require some sor t o f choice of pre dicto r s. Efron’s work has long been stro ngly grounded in solving r eal pr oblems, many of them from biomedical consulting. His answer reflects the imp ortance o f v ariable selection in pr a ctice. Classical to ols for ana lyzing regress ion results, such as t statistics for judging the significance of individual predictors, are based o n the assumption that the set of predictors is fixed in adv ance. When instea d the s et is c hosen adaptively , incorp orating those v ariables that g ive the best fit for a pa rticular s et of data, the classical too ls are biased. F or example, if there are 10 candidate predictors, and we select the single o ne that gives the bes t fit, ther e is ab o ut a 40 % chance that tha t v ariable will be judged significant at the 5 % level, when in fact all predictors are independent of the resp onse and each o ther. Similar bias holds for the F test for comparing tw o models ; it is based on the assumption that the t wo mo dels are fixed in adv ance, r ather than chosen adaptively . This bias affects the v ar iable selection pro cess itself. F ormal s e le c tio n pro ce- dures such a s stepwise regr ession and all-subsets regres s ion are ultimately ba sed on statistics related to the F s tatistics for comparing mo dels. Informal se lection pro cedures, in whic h an analyst picks v aria bles that give a go o d fit, are similarly affected. In the preface to the s e cond edition of Subset Sele ction in R e gr ession (Miller 2002), Allan Miller noted that little prog ress had b een ma de in the previous decade: What has happened in this field since the firs t edition w as publi shed in 1990? The short answer is that there has b een very little progress. The i ncrease in the sp eed of computers has b een used to apply subset selection to an increasing range of mo dels, linear, nonlinear, generalized linear m odels, to regression metho ds whic h are m ore robust against outliers than least squares, but w e still know very l ittle about the prop erties of Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 64 the parameters of the b est-fitting mo dels cho sen b y these methods. F r om tim e-to-time simulation studies ha v e been published, e.g. Adams ( 1990 ), H urvich and Tsai ( 1990 ), and Roeck er ( 1991 ), whic h ha ve sho wn, for instan ce, that prediction errors us ing ordinary least squares ar e f ar to o small, or that nominal 95% confidence regions only include the true parameter v alues in p erhaps 50% of cases. Problems ar ise not o nly in selecting v ariables, but also in estimating co effi- cient s for those v ar iables, a nd pro ducing predictions. The co efficients and pr e - dictions are biased as well a s unstable (small changes in the da ta may re s ult in large c hanges in the set of v ariables included in a mo del and in the corr esp onding co efficients a nd predictions). Miller ( 2002 ) notes: As far as estimation of regression co efficien ts i s concerned, there has been essen tially no progress. Least angle re g ression Efron et al. ( 2004 ), and its LASSO and forward s ta ge- wise v ar iations, offer stro ng promise for pro ducing interpretable mo dels, ac c u- rate predictions, a nd approximately un biased inferences. 2.2. LARS and Earlier Metho ds In this sec tio n we discuss v arious methods for regres sion with many v ariables, leading up to the original LARS pap er ( Efron et al. , 2004 ). W e b egin with “pure v aria ble selection” methods such as stepwise regressio n and all- subsets regres - sion that pic k predicto r s, then es timate coefficients fo r those v ariables using standard criter ia such as lea st-squares or maxim um likelihoo d. In other words, these methods fo cus on v aria ble selection, and do nothing sp ecial a bo ut estimat- ing co efficients. W e then mov e on to ridge regression, which do es the conv erse—it is not concerned with v ariable selection (it uses all candidate predictors), and instead modifies how c o efficient s are es timated. W e then discuss LASSO, a v ari- ation of ridge regressio n that mo difies co efficient estimation s o a s to reduce some co efficients to zer o, effectiv ely pe r forming v ar iable selection. F ro m ther e we mov e to forward stagewise regres sion, an incremen tal v ersion o f stepwise r e - gression that gives results very simila r to LASSO. Finally we turn to least angle regress io n, which connects all the methods. W e write LAR fo r least angle regression, and LARS to include LAR as well as LASSO or forward stagewise as implemented by least-a ngle metho ds. W e use the terms predictors, cov ar iates, and v ariables interchangeably (except we use the la tter only when it is clear we are discussing pr edictors r ather tha n res po nse v aria bles). The e x ample in this section in volv es linear regre s sion, but most of the text applies as well to logistic, surviv al, and other nonlinear regre s sions in which the predictors ar e combined linearly . W e note where there are differences b etw een linear reg r ession and the nonlinear cases. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 65 T a ble 1 Diab e tes St udy: 442 p atients wer e me asur e d on 10 b aseline variables; a pr e diction mo del is desir e d f or the r esp onse variable Y , a me asur e of dise ase pr o gr ession one ye ar after b aseline. Pr e dictors include age, sex, b o dy mass index, aver age blo o d pr ess ur e, and si x differ ent blo o d serum me asur ements. One go al is to cr e ate a m o del that pr e dicts the r esp onse f r om the pr e dictors ; a se c ond is to find a smal ler subset of pr e dictors that fits wel l, suggesting that those variables ar e imp ortan t f actors in dise ase pr o gr ession. Pa tien t Age Sex BMI BP S1 S2 S3 S4 S5 S6 Y 1 59 2 32.1 10 1 157 93.2 38 4.0 4.9 87 151 2 48 1 21.6 87 1 83 103.2 70 3.0 3.9 69 75 3 72 2 30.5 93 1 56 93.6 41 4.0 4.7 85 141 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442 36 1 19 .6 71 250 133 .2 97 3.0 4.6 92 57 2.2.1 . Stepwise and A l l-Su bsets R e gr ession W e b eg in our description of v ario us regression metho ds with s tep wise and all- subsets reg ression, which focus on selecting v aria bles for a mo del, rather than on how coefficients are estimated once v aria bles are selected. F orward stepwise regression b egins b y selecting the single predictor v ar iable that pro duces the b est fit, e.g. the smallest residual sum of squar es. Another predictor is then added that pr o duces the best fit in combinati on with the first, follow ed by a third that pro duces the best fit in co mbi nation with the first tw o, and so o n. This pro cess contin ues until some stopping criteria is reached, based e.g. on the num ber of pr edictors and lack of improvemen t in fit. F or the diabe tes data shown in T able 1 , single be s t predictor is BMI; subsequen t v ariables selected are S5, BP , S1, Sex , S2, S4 , and S6. The pro cess is unstable, in that re la tively small changes in the data might cause one v ariable to b e selected instead of a nother, after which subsequent choices may be completely different. V aria tio ns include backw ard stepwise regress ion, which starts with a lar ger mo del and sequentially removes v aria bles that con tribute least to the fit, and Efroymson’s procedur e ( Efroymson , 1 960 ), whic h combines forward and back- ward steps. These algo rithms are greedy , making the b est change at each step, re gardless of future effects. In contrast, a ll-subsets reg ression is exhaustive, considering all subsets of v ariables of each size, limited by a maximum n um ber o f b est sub- sets ( F urniv a l and Wilson, Jr. , 19 74 ). The adv an tage ov er stepwise pro cedures is that the b est set of tw o predictor s need no t include the pr edicto r that was bes t in isolation. The disadv antage is that biases in inference are ev en g r eater, beca use it co nsiders a muc h greater num ber of pos sible mo dels. In the case of linear r egressio n, computations for these stepwise and all- subsets pro c e dur es can be acco mplished using a single pass through the da ta . Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 66 This improv es sp eed substantially in the usual case in where are many mor e observ ations than pr edictors. Consider the model Y = X β + ǫ (1) where Y is a vector of length n , X a n n b y p matrix, β a v ector of length p containing reg ression co efficients, and ǫ assumed to be a v ector of indep endent normal noise terms. In v aria ble selection, when some pr e dicto r s are no t included in a mo del, the corres p o nding terms in β ar e set to zer o. There ar e a n um ber of wa ys to compute regr ession co efficient s and erro r s ums of squa res in b oth stepwise and all subsets r e g ression. One poss ibilit y is to use the cro ss-pro duct matrices X ′ X , X ′ Y , and Y ′ Y . Another is to use the QR decompos ition. Both the cross-pr o duct a nd QR implementations can b e computed in a single pas s through the data, and in both cases there are efficien t up dating algorithms for adding or deleting v a riables. Ho wev er, the QR appro ach has b etter numerical prop erties. See e.g. Thisted ( 19 88 ); Monahan ( 20 01 ); Miller ( 2 002 ) for further information. F or nonlinear regr essions, the computations are it erative, a nd it is not possible to fit all models in a single pas s through the data. Those p o ints car r y ov er to LARS. The origina l L ARS algor ithm computes X ′ X and X ′ Y in one pass through the da ta ; using the QR factorization would be more stable, a nd could a lso be done in one pass. LARS for nonlinear regre ssion requires m ultiple pa sses through the data for each step, hence sp eed beco mes m uch mor e of an issue. 2.2.2 . Ridg e R e gr ession The ad-ho c nature and instability of v a riable selection methods has led to o ther approaches. Ridge regres sion ( Miller , 2002 ; Drap er and Smith , 1998 ), includes all predictors, but with typically smaller coefficients than they w ould ha v e under ordinary least sq uares. The co e fficients minimize a p enalized sum of squar es, k Y − X β k 2 2 + θ p X j =1 β 2 j . (2) where θ is a po sitive s c a lar; θ = 0 co r resp onds to ordinary least-s q uares r egres- sion. In practice no penalty is applied to the in tercept, and v ariables are scaled to v ar iance 1 so that the p enalty is inv a riant to the scale of the original data. Figure 1 shows the co efficients fo r ridge re gression graphically as a function of θ ; these shr ink as θ increa ses. V ariables most co rrelated with other v ariables are affected most, e.g. S1 and S2 hav e cor relation 0.90. Note that as θ increases , the co efficient s a pproach but do not equal zero . Hence, no v ariable is ever exc luded fro m the mo del (except when co efficients cross zero for s maller v alues of θ ). In contrast, the use o f an ℓ 1 pena lt y do es reduce terms to zero. This yields LASSO, which w e consider next. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 67 theta beta −500 0 500 0.0 0.1 1.0 10.0 AGE SEX BMI BP S1 S2 S3 S4 S5 S6 Fig 1 . Co efficients for ridge r e gr ession (standar dize d variables) 2.2.3 . LASSO Tibshirani ( 19 96 ) pr op osed minimizing the residual sum of squares, sub ject to a cons tr aint on the s um o f a bsolute v alues o f the re g ression co efficients, P p j =1 | β j | ≤ t . This is e q uiv alent to minimizing the sums o f squares of residuals plus an ℓ 1 pena lt y on the regressio n co efficients, k Y − X β k 2 2 + θ p X j =1 | β j | . (3) A s imilar formulation was prop osed by Chen et al. ( 1998 ) under the name b asis pursu it , for denoising using overcomplete w a velet dictionar ies (this corre- sp o nds to p > n ). Figure 2 shows the resulting co efficients. F or co mparison, the rig ht panel shows the co efficients fro m ridge r egressio n, plotted on the same sca le. T o the right, where the p enalties are small, the tw o pro cedures g ive close to the same results. More in teresting is what happens star ting from the left, as all co e fficients start at zero and p enalties are relaxed. F o r ridge regr ession all coe fficients imme- diately beco me no nzero. F or L ASSO, co efficients b eco me nonzero o ne a t a time. Hence the ℓ 1 pena lt y results in v a riable selection, a s v ariables with co efficients of zero a re effectiv ely omitted from the mo del. Another impo rtant difference o ccurs for the predictors that ar e most signif- icant. Whereas an ℓ 2 pena lt y θ P β 2 j pushes β j tow ard zero with a force pro- po rtional to the v alue of the co efficient, an ℓ 1 pena lt y θ P | β j | exerts the s a me force o n all nonzero co efficients. Hence for v ariables that are mo st v aluable, that clearly should b e in the mo del and where shrink age tow ard zero is less desirable, an ℓ 1 pena lt y shrinks less. This is imp or tant for pro viding accurate predictions of future v alues. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 68 sum( |beta| ) Standardized Coefficients 0 1000 2000 3000 −500 0 500 LASSO AGE SEX BMI BP S1 S2 S3 S4 S5 S6 sum( |beta| ) Standardized Coefficients 0 1000 2000 3000 −500 0 500 Ridge Regression AGE SEX BMI BP S1 S2 S3 S4 S5 S6 Fig 2 . Co efficients for LASSO and Ridge Re gr ession ( ℓ 1 and ℓ 2 p enalties). In this case, BMI (b o dy mass index) and S5 (a blo o d s erum measur e ment) app ear to be most impo rtant, follow ed by BP (blo o d pres sure), S3, Sex, S6, S1, S4, S2, and Age. Some curious features are apparent. S1 a nd S2 enter the mo del relatively late, but when they do their c o efficient s grow rapidly , in o p- po site directions. These t w o v aria bles ha ve strong p ositive corre la tion, so these terms lar gely ca ncel out, with little effect on predictions for the obser ved v al- ues. The collinearity b etw een these tw o v ar iables has a n um ber of undesir a ble consequences—rela tively small changes in the data can hav e str ong effects on the co efficien ts, the co efficients are unstable, predictions for new data may b e unstable, pa rticularly if the new data do not fo llow the same r elationship be- t ween S1 and S2 found in the tra ining data, and the c a lculation of co efficients may b e n umerically inaccurate. Also, the S3 co efficient c hanges direction when S4 enters the mo del, ultimately ch anging sign. This is due to high (negative) correla tio n be tw een S3 a nd S4. 2.2.4 . F orwar d St agewise Another pro cedure, forward stag ewise re g ression, app e a rs to b e very different from LASSO, but turns out to have similar behavior. This pro cedure is motiv ated by a desir e to mitigate the nega tive eff ects of the greedy b ehavior of stepwise regr ession. In s tep wise reg ression, the most useful predictor is added to the mo del at each step, a nd the co efficient jumps from zero to the the least-squar es v alue. F orward stagewise picks the sa me firs t v ar iable as for ward stepwise, but changes the corresp onding co efficient only a small amount. It then pic ks the v aria ble with hig hest correla tio n with the curr ent residuals (pos s ibly the same Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 69 v aria ble as in the previous step), and takes a small step for that v ariable, and contin ues in this fashion. Where one v ariable has a clear initial adv an tage ov er other v a riables there will be a num ber of steps taken for that v ariable. Subsequently , once a num ber of v ariables are in the mo del, the pro cedure tends to alter nate b etw een them. The resulting co efficients are more s table than those for step wise. Curiously , an idealized version of forward sta gewise reg ression (with the step size tending tow ard zero) has v ery similar b ehavior to LASSO despite the ap- parent differences. In the diab etes example, the t w o methods give identical re- sults un til the eight h v aria ble enters, after whic h there are small differences ( Efron et al. , 200 4 ). There a re a lso strong connections betw een forward stagewise r egressio n and the b o osting algor ithm popular in machine lea rning ( Efron et al. 200 4 ; Hastie et al. 2001 ). T he difference is not in the fitting metho d, but rather in the predictors used; in stag ewise the pr edictors are typically determined in ad- v ance, while in b o osting the next v ar iable is typically determined on the fly . 2.2.5 . L e ast A ngle R e gr ession Least a ngle re g ression ( Efron et al. , 2004 ) can be view ed as a version of s ta gewise that uses mathematical formulas to acce lerate the computations. Rather than taking many tiny steps with the fir st v ar iable, the appropriate num ber of steps is determined algebr a ically , until the second v ariable b egins to en ter the mo del. Then, rather than ta k ing alterna ting steps betw een those tw o v ariables un til a third v aria ble e nters the model, the metho d jumps right to the appropria te sp o t. Figure 3 shows this pr o cess in the case of 2 predictor v ariables, for linear regress io n. O X2 X1 A B C D E Fig 3 . The LAR algorithm in the c ase of 2 pr e dictors. O is the pr e diction b ase d solely on an inter c ept. C = ˆ Y = ˆ β 1 X 1 + ˆ β 2 X 2 is the or dinary le ast-squar es fit, the pr oje ction of Y onto the subsp ac e sp anne d by X 1 and X 2 . A is the forwar d ste pwise fit after one step; the se c ond step pr o c e e ds to C . Stagewise takes a numb er of tiny steps fr om O to B , then takes steps alternating b etwe en the X 1 and X 2 dir e ctions, eventual ly r e aching E ; i f al l owe d to c ont inue it would r e ach C . LAR jumps fr om O to B in one step, wher e B is the p oint such that B C bise cts the angle AB D . A t the se c ond step it jum ps to C . LASSO fol lows a p ath f r om O to B , then fr om B to C . Her e LAR agr e es with LASSO and stagewise (as the step size → 0 f or stagewise). In higher dimensions additional c onditions ar e ne e de d for exact agr e ement to hold. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 70 The first v ariable c hosen is the o ne that ha s the smallest a ngle b etw een the v aria ble a nd the r esp onse v ar iable; in Figure 3 the angle C O X 1 is smaller than C O X 2 . W e pro ce e d in that direction as long as the angle b etw een that pr edictor and the vector of res iduals Y − γ X 1 is smaller than the a ng le b etw ee n other predictors and the residuals. E ven tually the angle fo r another v a r iable will equal this ang le (once we reach p o int B in Figure 3 ), a t which p oint we b egin mo ving tow ard the direction of the least-squares fit based on both v ariables. In higher dimensions we w ill reach the p oint at whic h a third v a r iable has an equal angle, and joins the model, etc. Expressed another way , the (absolute v alue o f the) cor relation b etw een the residuals and the firs t predictor is grea ter than the (absolute) correla tio n for other predictor s. As γ increases, another v ariable will even tually have a co r rela- tion with the r esiduals equaling that of the active v a riable, and join the model as a s econd active v aria ble. In higher dimensions additional v ariables will ev en- tually join the mo del, when the cor relation b etw e e n all active v ar iables and the residuals drops to the levels o f the a dditional v ar iables. Three remark able prop erties of LAR There ar e three r emark able things ab out LAR. First is the sp eed: Efron et al. ( 2004 ) no te that “The entire seq uence of LARS s teps with p < n v aria bles r e q uires O ( p 3 + np 2 ) co mputations — the cost of a least squares fit o n p v ariables.” Second is that the ba sic LAR algorithm, based o n the geometry o f angle bisection, can be used to efficien tly fit L ASSO and stagewise mo dels , with cer tain mo difications in higher dimensions ( Efron et al. , 2004 ). This pr ovides a fast a nd relatively simple w ay to fit LASSO and sta g ewise mo dels. Madigan and Ridgeway ( 200 4 ) commen ts that LASSO has had little impact on statistical practice, due to the inefficiency of the original LASSO and com- plexit y of more recent algo rithms ( Osb or ne et al. , 2000a ); they add that this “efficient, simple algorithm for the LASSO a s well as algo rithms for stagewise regress io n and the new least ang le regression” are “an impo rtant cont ribution to statistical computing”. Third is the a v ailability of a simple C p statistic for cho osing the num ber of steps, C p = (1 / ˆ σ 2 ) n X i =1 ( y i − ˆ y i ) 2 − n + 2 k (4) where k is the n um ber of steps and ˆ σ 2 is the estimated residual v a riance (es - timated from the saturated model, as s uming that n > p ). This is based on Theorem 3 in Efron et al. ( 20 04 ), which indicates that after k steps of LAR the degrees of freedom P n i =1 cov ( ˆ µ i , Y i ) /σ 2 is approximately k . This provides a simple stopping rule, to stop after the num ber of s teps k that minimizes the C p statistic. Zou et al. ( 20 07 ) extend that result to LASSO, sho wing an unbiased rela - tionship b etw een the num b er o f terms in the mo del a nd deg rees of freedom, and discuss C p , AIC and BIC criterion for mo del selection. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 71 Steps Mean RSS 0 5 10 15 20 20 25 30 35 LAR OLS Stepwise Steps sum(beta^2) 0 5 10 15 20 0 5 10 15 20 LAR OLS Stepwise Fig 4 . Effe ct of LAR steps on r esidual varianc e and pr e diction err or. The left p anel shows the r esidual sum of squar es for LAR, or dinary le ast-squar es with fixed pr e dictor or der, and stepwise r e gr ession. The right p anel shows P p i =1 β 2 j ; this me asur e s how much less ac cur ate pr e dictions ar e t han for the true mo del. The figur es ar e b ase d on a simulation with 10,000 r eplic ations, with n = 40, p = 20, ortho gonal pr e dictors with norm 1, β j = 1 ∀ j , and r esidual varianc e 1. The promise of a fast effectiv e wa y of c ho osing the tuning parameter, based on C p , AIC or BIC, is imp or ta nt in practice. While figures suc h as Figure 2 a re attractive, they b ecome unwieldy in high dimensio ns. In any case, for prediction one must ultimately choose a sing le v alue of the p enalty parameter. Still, there are some q ues tions about this C p statistic ( Ishw a ran 2004 ; Loub es and Mass a rt 200 4 ; Madigan and Ridge way 2 004 ; Stine 2 004 ), a nd some suggest other selection c r iteria, esp ecially cross-v a lidation. Cross-v alidation is slo w. Still, a fas t approximation for the tuning para meter could sp eed up cross -v alida tio n. F o r example, s uppo se there ar e 1000 predictor s, and C p suggests that the optimal n um ber to include in a mo del is 20; then when doing cross-v alidation o ne might stop after s ay 40 steps in every iteration, rather 1000. Note that ther e are different definitions of degrees of freedom, a nd the one used here is a ppropriate for C p statistics, but that k do es not mea sure other kinds of degr ees o f fr eedom. In particular, neither the av e rage dro p in residual squared err or, nor the exp ected prediction er ror are linear in k (under the null h yp othesis that β j = 0 for all j ). Figure 4 shows the b ehavior o f those quan tities. In the left panel we s e e that the residual sums of squares drop mo re quickly for LAR than for or dinary least squa res (OLS) with fixed prediction o rder, suggesting that b y o ne meas ure, the effectiv e degr ees of freedom is greater than k . In the right panel, the sums of squares o f co efficients mea sures how muc h worse predictions ar e than using the true parameter s β j = 0; here LAR increases more slowly than for OLS, suggesting effective degr ees of freedom less than k . These tw o effects balance out for the C p statistic. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 72 In contrast, stepwise reg ression has e ffective degrees o f freedom greater than the n um ber of steps; it ov erfits when there is no true signal, and prediction errors suffer. These results ar e encourag ing. It appea rs that LAR fits the data more clos ely than OLS, with a smaller pena lt y in prediction e r rors. While in this example there is only noise and no sig nal, it suggests that LAR may hav e relatively high sensitivit y to signal and low sensitivit y to noise. 2.2.6 . Comp aring LAR , LAS S O and Stagewise In general in hig her dimensions na tive LAR and the least a ngle implementation of LASSO and stag ewise give results that are similar but not identical. When they differ, LAR has a sp eed adv an tage, becaus e LAR v ar iables are added to the mo del, never r emov ed. Hence it will reach the full least-s quares solution, using all v aria bles, in p steps. F o r LASSO, and to a grea ter extent for stagewise, v a riables can leav e the mo del, and p ossibly r e-enter later, m ultiple times. Hence they may take more than p steps to re ach the full mo del (if n > p ). Efron et al. ( 200 4 ) test the three procedur es for the diab etes data using a quadratic model, co nsisting of the 10 ma in effects, 45 tw o-wa y interactions, and 9 squares (excluding the binary v ariable Sex). LAR takes 64 steps to reach the full mo del, LASSO tak es 103, a nd stagewise takes 255. E ven in other situations, when stopping shor t of the satura ted model, LAR has a sp eed adv antage. The three metho ds hav e interesting deriv atio ns. LASSO is regression with an ℓ 1 pena lt y , a relatively simple concept; this is also known as a form of regula riza- tion in the mac hine learning comm unit y . Stagewise is closely related to bo os ting, or “slow lea rning” in machine learning ( Efr o n et al. , 2004 ; Hastie et al. , 20 07 ). LAR has a simpler interpretation than the original der iv ation; it can be viewed as a v ar iation of Newton’s metho d (Hesterb erg and F raley 2006 a, 200 6 b), which makes it eas ier to extend to some nonlinear mo dels such as generalized linear mo dels ( Rosset a nd Zhu , 20 04 ). 3. LARS Extensions In this sec tio n we re v iew extensions to LARS and other contributions desc r ib ed in the litera tur e . W e introduce LARS ex tensio ns that accoun t for specific struc- tures in v ariables in Section 3.1 , e x tensions to nonlinear mo dels in Section 3.2 , extensions in other settings in Section 3.3 , and computational issues in Sec- tion 3.4 . Ridge regres sion and LASSO optimize a criterion that includ es a penalty term. A num ber o f authors develop other p enalty approaches, including SCAD ( F an and Li , 20 01 ), adaptive L ASSO ( Zou , 2006 ), r elaxed LASSO ( Meinshausen , 2007 ), and the Dantzig selector ( Candes and T ao , 20 07 ). Some o f these may be considered as alternatives r ather than extensions to LARS, so we defer this discussion until Section 4 . Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 73 3.1. Expl oiting A dditional Structur e Some kinds of data hav e structure in the predictor v ar ia bles—they may b e ordered in some meaningful wa y (such as mea surements ba s ed on intensit y at successive w av elengths of light in pr o teomics) o r come in groups, either known (such a s groups of dumm y v ar iables for a facto r ) or unknown (suc h as r e la ted genes in microar ray analysis). There may b e order restrictions (such as main effects b efore interactions). When there is a group of stro ngly cor related predictors, LASSO tends to select only one predictor from the group, but we may pr efer to s elect the whole group. F o r a sequence of or dered predictors , w e may wan t the differences b etw ee n successive co e fficients to b e small. 3.1.1 . Or der e d Pr e dictors Tibshirani et al. ( 2005 ) prop ose the fuse d LA SSO for a sequence o f predictors . This uses a combination of a n ℓ 1 pena lt y on co efficients and an ℓ 1 pena lt y on the difference b etw een adjacent coefficients: k Y − X β k 2 2 + θ 1 p X j =1 | β j | + θ 2 p X j =2 | β j − β j − 1 | . This differs from LASSO in that the additional ℓ 1 pena lt y on the difference betw een successive co efficients enco urages the co efficient pr ofiles β j (a function of j ) to be locally flat. The fused LASSO is useful for problems s uc h as the analysis of pr oteomics data, wher e there is a natural ordering of the pr edictors (e.g. measurements on different wa v elengths) and co efficient s for nea rby pr edic- tors should nor mally b e simila r ; it tends to give lo cally- constant co e fficients. Estimates can be o btained via a quadratic progra mming approa ch for a fixed pair ( θ 1 , θ 2 ), or by pathwise coor dinate optimization ( F riedman et al. , 2007a ). 3.1.2 . Unknown Pr e dictor Gr oups Zou and Hastie ( 200 5 b ) prop ose the elastic net 1 for a pplica tions with unknown groups of pr edictors. It in volv es b oth the ℓ 1 pena lt y from LASSO and the ℓ 2 pena lt y from ridge regression: k Y − X β k 2 2 + θ 1 p X j =1 | β j | + θ 2 p X j =1 β 2 j (5) They sho w that strictly co nv ex p e na lt y functions hav e a grouping effect, while the LASSO ℓ 1 pena lt y does not. A bridge r egressio n ( F rank and F riedman , 1993 ) ℓ q norm p enalty with 1 < q < 2 is str ictly conv ex and has a gr ouping ef- fect, but do es not pro duce a spa rse so lution ( F an and Li , 2 001 ). This motiv ates 1 R pac k age elas ticnet is av ailable. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 74 Zou and Hastie ( 2005 b ) to use the elastic net pena lt y ( 5 ), which is strictly con- vex when θ 2 > 0, and can also pro duce sparse solutions . The elastic net is useful in the analys is of micro array data, as it tends to bring related genes into the mo del as a g roup. It also appear s to give better predictions than LASSO when predictors are corr elated. In high dimensio na l settings ( p ≫ n ) elastic net al- lows selecting more than n predictors , while LASSO do es not. Solutions can be computed efficien tly using an a lg orithm based on LARS; for g iv en θ 2 , formula ( 5 ) can be in terpreted as a LASSO problem. 3.1.3 . Known Pr e dictor Gr oups In some cases it is appropriate to select o r drop a group of v ariables simultane- ously , for exa mple a set of dummy v ariables that repr esent a multi-lev el factor. Similarly , a set of ba s is functions for a p olynomial or spline fit should b e treated as a g r oup. Y uan and Lin ( 2006 ) prop ose gr oup LASSO to handle g roups of predictors (see also ( Ba kin , 1999 )). Supp ose the p pr edictors are divided in to J groups of siz e s p 1 , . . . , p J , and let β j be the corresp onding sub-vectors of β . Group LASSO minimizes k Y − X β k 2 2 + θ p X j =1 k β j k K j , (6) where k η k K = ( η T K η ) 1 / 2 is the elliptical norm determined by a positive definite matrix K . This includes LASSO as a s pe c ia l case, with p j = 1 for all j and each K j the one-dimensiona l identit y matrix. Y uan and Lin ( 2006 ) use K j = p j I p j , where I p j is the p j -dimensional identit y matrix. The mo dified penalty in ( 6 ) encourages spa r sity in the num b er of groups included, rather than the n um ber of v ar iables. Lin and Zhang ( 2006 ) let the g roups of pr edictors co rresp ond to sets of basis functions for smo o thing splines, in whic h the p enalty k β j k K j would give the square-r o ot o f the in tegrated squared s e c o nd deriv ative of a spline function (a linear co mbi nation of the ba sis functions). Their r esulting COSSO (COmp onent Selection and Smoo thing O pe rator) is an alternative to MARS (F riedman 19 91). Y uan and Lin ( 2006 ) note that group LASSO do es not hav e piecewise linear solution pa ths, and define a gr oup LARS that do e s . Gro up LARS replaces the correla tio n criterio n in the original LARS with the av erage squar ed correla tion betw een a gr oup of v ariables and the current residual. A g roup of v ariables that has the highest average squar ed correla tion with the residual is added to the active set. Park and Hastie ( 2006b ) mo dify group LARS, repla cing the av e r age squared correlation with the av e r age a bsolute correlation to prev ent s e le c ting a large group with only few o f its comp onents b eing co rrelated with the residuals. The Comp osi te Absolute Penalties (CAP) a pproach, pro po sed by Zhao et al. ( 2008 ), is simila r to group LASSO but uses ℓ γ j -norm instead of ℓ 2 -norm, a nd Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 75 the equiv a lent of an ℓ γ 0 norm for co mb ining group p enalties: k Y − X β k 2 2 + θ J X j =1 ( k β j k γ j ) γ 0 (7) where γ j > 1 for gr o up e d v ariable selection. F or exa mple, when γ j = ∞ , the co efficients in the j th group are encour a ged to b e of equal size, w hile γ j = 2 do es not imply any information but the grouping infor mation. An obvious g eneralization that could apply to many of the metho ds, bo th in group ed and ungroup ed settings, is to include constant factors in the p enalties for v ariables or g roups to penalize differen t ter ms different amounts. Y uan and Lin ( 2006 ) include co nstant terms p j depending on degrees of freedom—terms with more degre e s of freedom ar e p enalized mo re. Similar co ns ta nt s could b e used to reflec t the desirability of p enalizing different terms differen tly . F or example, some terms kno wn fro m previous exp er ie nce to b e imp ortant could b e left un- pena lized or p enalized using a small co efficient , while a larg er n um ber of terms being screened as p o s sible contributors could b e ass ig ned higher p enalties. Main effects co uld be p enalized by sma ll a mounts and higher-order in teractions p e- nalized more. 3.1.4 . Or der Restric tions Besides gro up structure, we may wan t to incorpo rate order restrictio ns in v ari- able selection pro cedures. F or example, a higher o rder term (e.g. an interaction term X 1 X 2 ) should b e selected o nly when the corre s po nding lower or der ter ms (e.g. main effects X 1 and X 2 ) are present in the mo del. This is the mar ginality principle in linear mo dels ( McCullagh and Nelder , 19 89 ) and heredity principle in design o f exp eriments ( Hamada and W u , 199 2 ). Although it is not a strict rule, it is usually b etter to enforce o rder restriction, b ecause it helps the resulting mo dels to b e in v aria n t to scaling and transformation of predictors. Efron et al. ( 2004 ) s uggest a tw o-step pro cedure to enforce o rder res tr ictions: first a pply LARS only to main effects, and then to p ossible in teractions be- t ween the main effects selected from the fir st s tep. T urlach ( 2004 ) shows that the t w o-step pro cedure ma y miss impo rtant main effects at the first step in some nont rivial cases a nd propo ses an ex tended version of LARS: when the j th v aria ble has the highest co rrelation with the residual, that v a riable and a set of v ar iables o n which it dep ends enter the mo del together. Y uan et al. ( 20 0 7 ) prop ose a similar extension to LARS that account s for the num b er o f v ar ia bles that ent er the mo del together: they look at the scaled correlations betw een the resp onse and the linear space spanned b y the set of v ar iables that should be selected together. Choi and Z hu ( 2006 ) discuss re- pa rameterizing the in terac- tion co efficients to incor po rate order restrictions, and the CAP approach ( 7 ) of Zhao et al. ( 2008 ) c a n be used for the same purp ose b y assigning overlapping groups (e.g. gro ups for each main effect a nd a nother tha t includes in teractions and all main effects). Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 76 There is another type o f order res triction called w eak heredity or marg ina lit y principle: a higher order term can be selected only when at leas t one of the corresp o nding low er order terms is present in the mo del. Y uan et al. ( 2007 ) extend LARS to this case by lo oking at the scaled c o rrelations betw een the resp onse and the linear space spanned by each eligible set of predictors ; in contrast to the strong her edit y ca s e, the co mbination of an int eraction and just one (rather than b o th) of the co rresp onding main effects w ould b e eligible. 3.1.5 . Time Series and Multir esp onse D ata The fused LASSO intro duced in Section 3.1.1 is for problems with a sequence of o r dered predictor s. Some problems, howev er, c o ntain natural orderings in re- sp o nse v ariables as well. A go o d example would b e time-course data, in which the data consist of multiple o bs erv a tio ns over time; either re sp o nses o r predic- tors, or both, could v ar y o v er time. F or such cas es, w e co uld simply fit a mo del at each time p oint, but it would be more efficient to com bine the information from the entire dataset. As an illustration, consider linear r egressio n with multiple resp onses at N different time points t 1 , . . . , t N and fixed pre dictors X : Y ( t r ) = X β ( t r ) + ǫ ( t r ) , r = 1 , . . . , N . (8) where Y ( t r ) ∈ R n , β ( t r ) ∈ R p , ǫ ( t r ) ∈ R n , and X is a n × p design matrix. By assuming that adjacent time p oints are related and similar, we c o uld apply the fused LASSO to this pro blem by p enalizing the difference b etw een the co effi- cient s of successive time points, | β j ( t r ) − β j ( t r − 1 ) | . But it co uld be c hallenging to sim ultaneously fit a mo del with all N p parameters when the num b er of time po int s N is large. Meier a nd B ¨ uhlmann ( 2007 ) pro po se smo othe d LASSO to solv e this pr ob- lem. They assume that adjacent time points are more related than distant time po int s, and incorp orate the information from differen t time points by applying weigh ts w ( · , t r ) satisfying P N s =1 w ( t s , t r ) = 1 in the criter io n below for parame- ter estimation at time-point t r : N X s =1 w ( t s , t r ) k Y ( t s ) − X β ( t r ) k 2 2 + θ p X j =1 | β j ( t r ) | . (9) The weight s w ( · , t r ) should hav e lar ger v a lues a t the time p oints near t r so that the r esulting estimates can reflect mor e information from neighbor ing p oints. Problem ( 9 ) can b e solved a s an ordinary LASSO problem by using t he smoothed resp onse e Y ( t r ) = P N s =1 w ( t s , t r ) Y ( t s ). T urlach et al. ( 2005 ) and Simil¨ a a nd Tikk a ( 2006 ) also address the multi- ple respo nse problem with differen t approaches. T urlach et al. ( 2 005 ) extend LASSO to select a co mmon subset of predictors for predicting multip le resp onse v aria bles using the following criterion: N X r =1 k Y ( t r ) − X β ( t r ) k 2 2 + θ p X j =1 max r =1 ,...,N | β j ( t r ) | . (10) Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 77 W e note that this is equiv alent to a sp ecia l case (with γ j = ∞ ) of the CAP approach ( Zhao et al. , 2008 ) that was introduced in Section 3.1.3 for gro up e d v aria ble selection. On the o ther hand, Simil¨ a a nd Tikk a ( 2006 ) extend t he LARS algorithm b y defining a new cor relation cr iterion betw een the residua ls and the predictor, k ( Y − ˆ Y ) T x j k γ ( γ = 1 , 2 , ∞ ) where Y = ( y ( t 1 ) , . . . , y ( t N )) is an n × N matrix. They note that their metho d is very similar to group LARS ( Y uan and Lin , 2006 ) when γ = 2. Both of their pr o cedures differ from the smo othed LASSO in that a ll co efficients corresp onding to one predictor ar e estimated as either zero or nonzero as a group — if a predictor is selected, its co efficients at differen t time p oints are all no nzero, in co nt rast to the smo o thed LASSO which ma y hav e different nonzero co efficients at different times. In ( 8 ), the predictors X a re the same f or different time p oints, but in some ap- plications bo th X and y can v ar y over time. Balakrishna n and Madigan ( 20 07 ) combine ideas from group LASSO ( Y ua n and Lin , 20 06 ) and fused LASSO ( Tibshirani et al. , 2005 ), a iming to select impor ta n t g roups of corr elated time- series predicto rs. W a ng et al. ( 2007b ) co nsider autoregressive erro r mo dels that in volv e tw o kinds of co efficients, regres s ion co efficients and autoreg r ession co- efficient s. By applying tw o separa te ℓ 1 pena lties to r egressio n co efficients and autoregr e s sion co efficients, they achiev e a spars e mo del that includes b oth im- po rtant pr edictors and a utoregress ion terms. 3.2. Nonline ar mo dels The original LARS metho d is for linea r regr ession: E ( Y | X = x ) = f ( x ) = β 0 + β 1 x 1 + . . . + β p x p , (11) where the regres s ion function f ( x ) has a linea r relationship to the predictors x 1 , . . . , x p through the co efficients β 1 , . . . , β p . The pr oblem can also b e viewed as the minimization o f a s um-o f-squares criterion min β k Y − X β k 2 2 , with a dded v ariable or model selection considerations. The LASSO extension gives an efficien t solution for the case of an ℓ 1 pena lt y term o n reg ression co ef- ficien ts: min β k Y − X β k 2 2 + θ p X j =1 | β j | . (12) The num ber of s o lutions to ( 12 ) is finite for θ ∈ [0 , ∞ ), and predictor selection is a utomatic since the so lutions v a ry in the n um ber and lo cation of nonzero co efficients. The or iginal LARS metho ds a pply to quite general mo dels of the form E ( Y | X = x ) = f ( x ) = β 0 + β 1 φ 1 ( x ) + . . . + β M φ M ( x ) , (13) Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 78 where φ m are (nonlinear) functions of the origina l predictors X . The φ m could, for example, include higher-order terms a nd interactions such as x 2 i or x i x j , nonlinear transfor ma tions such a s log ( x i ), piecewise p olyno mia ls, splines and kernels. The use of nonlinear basis functions φ j ( x ) allows the use of linear metho ds for fitting nonlinear relationships betw een y a nd the predictors x j . As long as the φ m are predetermined, the fundamen tal structure of the problem is linear and the original LARS metho ds are applicable. F o r example, Av alos et al. ( 2 0 07 ) consider additive mo dels where each additiv e co mpo nen t φ j ( x ) = φ j ( x j ) is fitted b y cubic splines. T hey discuss the extension of L ASSO to those mo dels b y imp o sing the ℓ 1 pena lt y on the co efficient s of the linea r part to get a s parse mo del. A drawbac k is that the resulting mo del may no t ob ey o rder restrictions; for example it may drop a linear term while keeping the corr esp onding higher order terms. Another example is kernel regres sion, in whic h φ m ( x ) = K λ ( x m , x ) ( m = 1 , . . . , n ), where K is a kernel function belo nging to a repro ducing kernel Hilbert space (RKHS), and λ is a h yper pa rameter that regulates the scale of the kernel function K . By impo sing an ℓ 1 pena lt y on the coefficients with the squared error loss function, the resulting mo del has a sparse r e pr esentation based on a smaller num ber of k ernels s o tha t predictions can b e computed more efficien tly . W ang et al. ( 2007 a ) discuss a pa th-following a lgorithm ba sed o n L ARS to fit solutions to this ℓ 1 regularized k ernel regress ion model, as well as a sepa rate path-following algorithm for estimating the optimal kernel hyper pa rameter λ . Guigue et al. ( 2006 ) and Gunn and Kandola ( 2002 ) c o nsider LASSO extensions to more flexible kernel regress ion mo dels, in which each kernel function K λ ( x m , · ) is replaced by a weigh ted sum of multiple kernels. More g enerally , the sum-of-squa res loss function in ( 12 ) ca n b e r eplaced by a more g eneral conv ex lo ss function L , min β L ( y , φ ( x ) β ) + θ n X j =1 | β j | , (14) although solution strategies b ecome more c o mplicated. Rosset and Zhu ( 2007 ) extend the LARS-LASSO algo r ithm to use Hub er’s loss function by specifying mo difications when the solution path hits the knots b etw een the linear part and quadratic par t. Huber’s loss is als o co nsidered in Roth ( 2004 ) for ℓ 1 regularized kernel regress ion based on iteratively reweigh ted least square s (IRLS). When L is ǫ -insensitive loss, L ǫ ( y , ˆ y ) = P n i =1 max(0 , | y i − ˆ y i | − ǫ ), the problem b ecomes an ℓ 1 regularized Suppor t V ecto r Machine (SV M). Path-following algo r ithms for this problem a re discussed in Zhu et al. ( 2003 ) and Hastie et al. ( 2004 ). In sev eral impo rtant applications, including genera lized linear models and Cox prop or tional hazards mo dels, some function of the reg ression function f ( x ) is linearly as so ciated with the pa rameters β : g ( E ( Y | X = x )) = g ( f ( x ) ) = β 0 + β 1 x 1 + . . . + β p x p . (15) Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 79 Several author s discuss extensions of LARS to these mo dels: generalized lin- ear models ( Lokhorst , 199 9 ; Roth , 2004 ; Madigan and Ridgeway , 2004 ; Rosset , 2005 ; P ark and Hastie , 2007 ; Keer thi and Shev ade , 2007 ) and Co x regres s ion ( Tibshirani , 1997 ; Gui and Li , 200 5 ; Park and Hastie , 20 07 ). 2 Some authors fo cus on the sp ecial ca se o f a binary re s po nse (logistic regres- sion). The function g in ( 15 ) has a parametric form and is linearly related to predictors x . Zhang et al. ( 2004 ) consider a nonparametric framework called Smo othing Spline ANOV A and extend LASSO b y using the p enalized neg a- tiv e Bernoulli log- likelihoo d with an ℓ 1 pena lt y on the co e fficients of the basis functions. Shi et al. ( 2008 ) consider a tw o-step pro cedure to efficient ly explore po ten tial high order interaction patterns for predicting the binary r e sp o nse in high dimensional data where the num ber of pre dicto rs is very large. They first fo c us on to binary (or dichotomized) predictors, and imp ose a n ℓ 1 pena lt y on the co efficients of the basis functions for main effects and higher-or der in terac- tions of those binary predictors to achiev e a spars e representation. They then use only the s elected basis functions to fit a fina l linear logistic mo del. The preceding para graphs discuss applications with particular loss functions; some authors pro p o se general strateg ies for LASSO pr oblems with genera l con- vex lo ss functions. Rosset and Zhu ( 2007 ) discuss conditions under which co ef- ficien t paths are piecewise linear. Rosset ( 2005 ) discusses a method fo r track- ing curved co efficient paths for which the computational req uirement s severely limit its suitability for lar ge problems. Kim et al. ( 2005b ) prop ose a g radient approach 3 that is particularly useful for high dimensions due to computation- ally a ffordability; it re quires only a univ aria te optimization at each iteration, and its co nv ergence rate is independent of the data dimension. W ang and Leng ( 2007 ) suggest using approximations to loss functions that a re quadratic func- tions of the co e fficients, so that s o lutions can then b e computed using the LARS algorithm. Bo osting is another technique that can b e used to a pproximately fit ℓ 1 reg- ularized mo dels. Efron et al. ( 2004 ) showed that forward s tagewise reg ression can b e viewed as a version of b o o s ting for linear regress ion with the squared error loss, producing a similar result to LASSO when the step size approa ches zero. F or general lo ss functions, Zhao and Y u ( 2007 ) approximate the LASSO solution path b y incorp orating forward stag ewise fitting a nd ba ckward steps. F riedman ( 20 06 ) discusses a gra dien t b o o sting based metho d that can b e ap- plied to gener al pena lt y functions as well as general loss functions. Some of the a pproaches in tro duced in Section 3.1 for group ed and ordere d predictors hav e also b een extended to nonlinear mo dels . Park and Hastie ( 200 7 ) extend a path-following algorithm for ela stic net to gener alized linear mo dels for a fix e d θ 2 in ( 5 ). They note that a dding an ℓ 2 pena lt y is especially useful for logistic regres sion since it preven ts k β k 1 from growing to infinit y as the r egular- ization parameter θ decrease s to zero, a common problem that arises in ℓ 1 fitting to separable data. Park and Hastie ( 2006b ) propo se a path-following algorithm 2 S-PLUS and R pack ages glmpat h and glars are av ailable, for b oth GLMs and Co x re- gression. 3 R-pac k age glas so is av ailable. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 80 for group LASSO in expo nent ial family models. Kim et al. ( 20 06 ) use a gradi- ent pro jection metho d to extend group LASSO to general loss functions, and Meier et al. ( 2008 ) 4 discuss an a lgorithm for group LASSO for logistic regression mo dels. 3.3. Other Applic ati ons Robust Regressi on Rosset and Zh u ( 2007 ) and Ow en ( 2006 ) extend LASSO b y replacing the squa red error loss by Huber’s loss. In the linear reg ression case this a lso yields piecewise- linear solution paths, a llowing for fas t solutions. Khan et al. ( 2007 ) extend LAR b y replacing corr elations with robust correlation estimates. Subset of Observ atio ns LARS can be used for cho o sing an imp ortant subset of observ ations as well as for selecting a subset of v aria bles. Silv a et al. ( 20 05 ) apply LARS for selecting a represent ative subset of the data for use as landmarks to reduce computational expense in nonlinear manifold models. Principal Comp onen t and Discriminant Analysis Jolliffe et al. ( 20 03 ) and Zou et al. ( 2006 ) apply ℓ 1 pena lties to get s parse loadings in pr incipal com- po nent s. T rendafilov and Joilliffe ( 2007 ) discuss ℓ 1 pena lties in linear discrimi- nant ana lysis. Gaussian Graphical Mo dels A num ber of author s discuss using ℓ 1 pena l- ties to estimate a spars e in v erse cov ar iance matrix (or a sparse graphical mo del). Meinshausen and B ¨ uhlmann ( 20 06 ) fit a LASSO model to each v ar iable, using the others as predictors , then set the ij term of the in verse cov ariance matrix to zero if the coefficient of X j for predicting X i is zero, or the con v erse. Man y au- thors ( Y uan , 2008 ; Ba nerjee et al. , 2008 ; Dahl et al. , 20 08 ; Y uan and Lin , 200 7a ; F riedman et al. , 2 0 07b ) discuss efficien t methods for optimizing the ℓ 1 -p enalized likelih o o d, using in terio r-p oint or blo ckwise co ordinate-descent approaches. This work has yet to be extended to handle nonlinear relationships betw een v aria bles, such a s ( 13 ). 3.4. Computati onal Issues There are three primary computation issues: sp eed, memory usa ge, and numer- ical accura cy . The original LAR algorithm for linear regression as described in Efron et al. ( 2004 ) and implemen ted in Efron and Has tie ( 2003 ) 5 is remark ably fast and memory efficien t in the p < n ca se, a s noted in Section 2.1 . Mino r mo difica- tions allow computing the LASSO and for ward stag e wis e cases. Ho wev er, the 4 R-pac k age grpl asso is av ailable. 5 S-PLUS and R pac k age lars is av ailable. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 81 implemen tations use cr oss-pro duct matrices, whic h ar e notorious for n umerical inaccuracy with highly correlated predictors. F raley and Hesterb erg ( 20 07 ) (see also Hesterb erg and F raley 2006 a,b) de- velop L ARS implement ations based on QR deco mpo sitions 6 . This reduces the roundoff error by a facto r equa l to the condition num ber of X relative to the original a lg orithm. One v ar iation uses o nly a single pass thro ugh the data for an initial factoriza tion, after whic h it requires stor age O ( p 2 ), indep endent of n ; in contrast the original LARS implementation is in tended for in-memory datasets, and makes m ultiple passes through the data. F u ( 199 8 ) prop oses a sho oting algor ithm to solve LASSO for a s p ecified v a lue of the pena lt y parameter θ . The algor ithm is a specia l case of a co ordinate descent method that cycles through the c o ordinates, optimizing the cur rent one and keeping the remaining co ordinates fixed. Using a (predefined) g rid of pena lt y parameter s, the co efficient pa ths ca n be computed efficiently , esp ecially in very hig h-dimensional settings, by mak ing use of the pr e ceding solution as starting v alues. Other co o rdinate-wise optimization techniques ha ve shown their succes s with other pena lt y types and also for nonlinear mo dels ( Genkin et al. 2007 ; Y uan and Lin 2006 ; Meier et al. 2008 ; F riedman et al. 2007a , b ). Osb orne et al. ( 2000a ) prop ose a descent algorithm for a LASSO problem with a sp ecified v alue of the p enalty parameter θ , as well as a homotopy method for the piecewise linear so lution path in the linear r e g ression case that is rela ted to the LAR implementation of Efron et al. ( 200 4 ). In Osb or ne et al. ( 2000 b ), an algorithm based on LASSO and its dual is prop osed that yields new insig ht s and an improv ed metho d for estimating standard errors of reg r ession parameters. Nonlinear regress ion In the linea r regress ion case the solution path is piece- wise linear, and each step direction and jump siz e can be computed in closed- form s o lution. In the nonlinear case paths are cur ved, so that itera tive metho ds are needed for computing a nd up dating directions and determining the ends o f each curve, requiring multiple passes through the data. Hence the algor ithms are muc h slow er than in the linear ca se. 4. Theoretical Prop erties and Alternativ e Regularization Approac hes In this section we discuss some theoretica l pr op erties of LASSO, a nd illus- trate how some alternative re g ularization approaches addres s the drawbac ks of LASSO. 4.1. Cr i teria It is imp ortant to distinguish betw een the goals o f prediction accura cy and v aria ble selection. If the main in terest is in finding a n interpretable model or 6 S-PLUS and R pac k age sclars i s a v ailable. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 82 in identifying the “true” underlying mo del a s closely a s p ossible, predictio n accuracy is o f seconda r y impor ta nce. An example would be netw ork mo deling in biology . O n the other ha nd, if prediction is the fo cus of in terest, it is usually acceptable for the selected mo del to contain s ome extra v ariables, as long as the co efficients o f those v ariables are small. 4.1.1 . The Pr e diction Pr oblem Greenshtein a nd Ritov ( 200 4 ) study the prediction prop erties of LASSO t ype estimators. F o r a high-dimensional setting, where the n um ber of parameters can grow a t a p o lynomial rate in the sample size n and the true pa rameter vector is sparse in an ℓ 1 -sense, they sho w that E [( Y − x T ˆ β n ) 2 ] − σ 2 P − → 0 ( n → ∞ ) for a suitable choice of the penalty par ameter θ = θ n (and other mild conditions), where σ 2 is the error v ariance. There a re no s trict conditions on the design matrix X . This r isk consistency pr op erty is also called “p er s istency”. 4.1.2 . The V ariable Sele ction Pr oble m An impor tant theoretical question is: “Is it p ossible to determine the true mo del, at least asymptotically?” The answer is “ Y es, but with some limita- tions”. Meinshausen and B¨ uhlmann ( 2006 ) show that LASSO is co nsistent for v aria ble selection if and only if a neig hborho o d stability condition is fulfilled. Zhao and Y u ( 2006 ) made this condition more explicit and used the term “ir- representable condition” for it. Under other assumptions, both sources show that LASSO is co nsistent for model selection, e ven if p = p n is allowed to gr ow (at a certain rate) a s n → ∞ . The irre pr esentable co ndition r equires that the correla tio n b etw een relev a nt and irrelev an t predictors not b e to o large (w e call a predictor relev a nt if the corr e s po nding (true) coefficient is nonzero and ir- relev a nt otherwise). Unfortunately , the theory assumes that the r e gularization parameter θ follows a certain rate, which is impractical for applications. Even so, the result implies that the true mo del is so mewhere in the solution path with high pro bability . In practice, people often c ho ose θ to b e pr e diction optimal (or use some other criteria like C p ). Meinshausen and B¨ uhlmann ( 2006 ) a nd Leng et al. ( 2006 ) illustrate some sit- uations wher e a prediction o ptimal selection of θ leads to estimated mo dels that contain not o nly the true (relev a nt ) pr edictors but also some noise (irrelev an t) v aria bles. F or exa mple, consider a high-dimensional situation with an under ly- ing sparse mo del, that is where most v a r iables a re ir relev a n t. In this case a lar ge v alue o f the reg ularization penalty parameter θ would b e r equired to identify the true mo del. The corr esp onding co efficien ts are biased significantly tow ard zero, and the estimator will have bad prediction per formance. In co nt rast, a pre- diction optimal θ is smaller; in the resulting mo del, the relev a nt co efficients will Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 83 not be shrunken to o muc h, while the noise v ariables still hav e small coefficients and hence do not hav e a large effect o n prediction. Recent ly it has b een s hown that LASSO is consistent in an ℓ q -sense, for q ∈ { 1 , 2 } . This means that k ˆ β n − β k q P − → 0 ( n → ∞ ) , (16) ( Meinshausen and Y u 2008 ; Zhang a nd Huang 2007 ; Bunea et al. 2 007 ; v an de Geer 2008 ); for a high-dimensional setting and a suitable sequence θ n , of- ten under mu ch fewer restrictions than needed for mo del selection co nsistency . F or fixed dimension p , this con v ergence result implies that co e fficients corre - sp o nding to the relev ant pr edictors will be non-zero with high proba bility . The conclusion is that the sequence of mo dels found using LASSO con tains the true mo del with hig h probability , along with so me noise v ariables. This sugges ts that LASSO b e used as a ‘v ariable filtering’ metho d. When there are a very large num ber of pr e dicto rs, a s ing le regularization pa rameter θ is not sufficient for selecting v a riables and co e fficient estimatio n. LASSO may be used to select a small set of predictors , follow ed b y a second step (LASSO or otherwise) to selec t co efficient s for thos e predictors, and also to p erfor m additional v a riable selection in s ome cases. 4.2. A daptive LASSO and r elate d metho ds One example of a t w o-step metho d is r ela xe d LAS SO ( Meinshausen , 20 07 ) 7 . It w orks roughly a s follows: Calculate the w ho le path of LASSO solutions and iden tify the different s ubmo dels along the path. F or each submo del, use LASSO again, but with a smaller (or no) penalty parameter φθ , where φ ∈ [0 , 1], i.e. no mo del selection ta kes place in the sec o nd step. By definition, relaxed LASSO finds the sa me s ets of submo dels as LASSO, but estimates the co efficients using less shr ink age : Model selection a nd shrink age es timation are now controlled b y t wo different parameters. The hop e is that the true model is somewher e in the first LASSO s o lution path. Relaxing the p enalty may give b etter par ameter estimates, with less bias tow ard zer o. If we use φ = 0 in the s econd step, this is exactly the LARS/OLS h ybrid in Efron et al. ( 2004 ). In mo st cases , the estimator can be constructed at little additional cost by extr ap olating the cor resp onding LASSO paths. Empir- ical a nd so me theoretical results show the s uper iority over the o rdinary LASSO in ma n y situations. Meinshausen ( 20 07 ) shows that the c onv ergence rate of E [( Y − x T ˆ β n ) 2 ] − σ 2 is mostly unaffected by the nu mber of predictors (in con- trast to the ordinary LASSO) if the tuning parameter s θ and φ are chosen by cross-v alidation. Mo reov er, the conjecture is that a prediction-optimal c hoice of the tuning pa rameters leads to c o nsistent mo del selection. Another tw o-step metho d is adaptive LAS SO ( Zou , 200 6 ). It needs an initial estimator ˆ β init , e.g. the least-squa r es estimator in a classical ( p < n ) situation. 7 R pac k age rela xo is av ailable. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 84 W eights can then b e constructed based on the imp ortance of the differen t pre - dictors. F or example, if the co efficient of the initial estimator is rather la rge, this would seem to indicate that the co rresp onding v aria ble is quite impor ta nt , and the corr esp onding coefficient shouldn’t be pe na lized muc h. Co nv ersely , a n unimpor tant v ariable should be p enalized mo r e. The second step is a re weighted LASSO fit, us ing a pena lt y of the form θ p X j =1 ˆ w j | β j | , where ˆ w j = 1 / | ˆ β init, j | γ for some γ > 0. Note that the weigh ts are constructed in a ‘data ada ptiv e’ w ay . As with relaxed LASSO, the idea is to reduce bias by applying less shrink ag e to the imp ortant predictor s . F ro m a theoretical point of view, this leads to consistent mo del selection, under fewer restrictions than for LASSO. If θ = θ n is chosen at an appro priate rate it c an b e shown that lim n →∞ P [ ˆ A n = A ] = 1 , where ˆ A n is the estimated model s tructure and A is the true underlying model structure. As in all pe na lt y metho ds, the choice of the penalty par ameter θ is an issue, but prediction-optimal tuning para meter selection giv es goo d empirical results. Besides mo del selec tio n prop er ties, adaptive LASSO enjo ys ‘o r acle prop er - ties’: it is a symptotically a s efficien t a s lea st squares reg ression using the p er fect mo del (all re le v an t predictors and no others) as identified b y an or acle: √ n ( ˆ β n, A − β A ) → N (0 , σ 2 ( C AA ) − 1 ) ( n → ∞ ) , where C AA is the submatrix o f C = lim n →∞ 1 n X T X corr esp onding to the active set. Implemen tation of the ada ptiv e LASSO estimator is easy: After a res caling of the co lumns of the design ma trix with the corresp onding weigh ts, the problem reduces to a n ordinary LASSO pro blem. Huang et al. ( 2008 ) dev elop so me the- ory ab out the adaptive LASSO in a high- dimensional setting. Sev eral authors discuss a pplying the adaptiv e idea to other LASSO mo dels and prov e their or- acle prop erties: W ang a nd Leng ( 2006 ) for group LASSO, W ang et al. ( 2007b ) for a uto r egressive error mo dels, Ghosh ( 2007 ) for elastic net, and Zhang and Lu ( 2007 ) and Lu and Zhang ( 2007 ) fo r Cox’s propor tional hazards mo del. A predecesso r o f the adaptive LASSO is the nonnega tive garr ote ( Breima n , 1995 ). It r escales an initial estimator by minimizing k Y − p X j =1 x j ˆ β init,j c j k 2 2 + θ p X j =1 c j , sub ject to c j ≥ 0 for all j . Indeed, the ada ptive LASSO with γ = 1 and the nonnegative garrote ar e almost identical, up to some sign cons tr aints ( Zou , Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 85 2006 ). The nonneg ative gar rote is for exa mple also studied in Gao ( 199 8 ) and B ¨ uhlmann a nd Y u ( 2006 ). More recently , Y ua n and Lin ( 2007b ) prov ed s o me consistency results and show ed that the solution path is piecewise linear a nd hence can b e computed efficien tly . The a b ov e methods try to reduce the bias of the estimates for the relev an t predictors by applying less shr ink age whenever the corr espo nding co e fficients are large. This raises the question of whether we could achiev e s imilar behavior with a suitably c hosen p enalty function. F an and Li ( 20 01 ) propo se the SCAD (smo othly clippe d absolute deviation) p enalty , a non-co nv ex pena lt y that p enal- izes large v alues less heavily . It also enjoys or acle proper ties. The main drawbac k is the co mputational difficulty o f the cor resp onding non-con v ex optimization problem. Zou and Li ( 2008 ) mak e a co nnection b et ween (adaptive) LASSO and SCAD. They use an iterative algorithm based on a linea r a pproximation of the SCAD pena lt y function (or other p enalties). In a n approximation step, an (adaptive) LASSO problem is so lved, and hence a sparse so lution is obta ined. This solution is then used for the next approximation step, and s o on. Ho w ever, it is not nec- essary to use mo r e than one itera tion: their One-Step (one iteration) estimato r is asymptotically as efficien t as the final solution, and hence also enjo ys oracle prop erties. Conv ersely , adaptive LASSO ca n also be itera ted: the co efficients can b e used to build new weigh ts ˆ w j , a nd new co efficient s can b e calcula ted using these weigh ts, and the iteration ca n be rep ea ted. B ¨ uhlmann and Meier ( 200 8 ) and Candes et al. ( 2007 ) find that doing m ultiple s teps can improv e estimation error and spa rsity . 4.3. Dantzi g sele ctor Candes and T ao ( 2007 ) prop os e a n alternativ e v ariable selection method called Dantzig sele ctor , b y optimizing min β k X T ( Y − X β ) k ∞ sub ject to k β k 1 ≤ t. They discuss an e ffective bo und on the mean squared er ror of β , and the result can be understo o d as a deterministic v ersion of ( 16 ). This pr o cedure, whic h can be implemented via linear progra mming, may b e v aluable in high dimen- sional settings. In contrast, Tibshirani ( 1996 ) originally prop os e d a quadr atic progra mming so lution for LASSO, though the LAR implemen tation is more efficient . How ev er, Efron et al. ( 2007 ) a nd Meinshausen et al. ( 2007 ) argue that LASSO is pre fer able to the Danzig selector for tw o r easons: implementation and p er for- mance. Althoug h Dantzig selector has a piecewise linear s o lution pa th ( Rosset and Zhu , 20 07 ), it contains jumps and many more steps, making it difficult to desig n a n efficient path-following alg orithm like the LARS imple- men tation of LASSO. F urthermore, in their num erical results, they show that Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 86 LASSO perfor ms as well a s or better than Dan tzig selector in t erms of prediction accuracy and mo del selection. 5. Soft w are There are a num ber of S-P LUS and R pack ag es related to LARS, including: brdgru n ( F u , 200 0 ), e lasti cnet ( Zou and Hastie , 2005a ), glars ( Insight ful Corp or tation , 200 6 ), glas so ( Kim et al. , 2005a ), gl mpath ( Park a nd Hastie , 20 06a ), grp lasso ( Meier et al. , 2 008 ), la rs ( Efron a nd Hastie , 2003 ), lass o2 ( Lokhorst et al. , 199 9 ), relaxo ( Meinshausen , 200 7 ). 6. Conclusions and F uture W ork LARS has considerable promise, offering sp eed, interpretabilit y , relatively stable predictions, nea rly un biased inferences, and a nice graphical presen tation of co- efficient paths. But considerable work is re quired in order to realize this promise in practice. A n um ber of differen t approaches hav e b een sugges ted, both for lin- ear and nonlinear mo dels ; further study is needed to deter mine their adv antages and drawbac ks. Also v arious implementations o f so me of the appro aches ha v e been prop osed that differ in sp eed, numerical stability , and accuracy; these also need further as sessment. Alternate penalties suc h as the elastic net and fused LASSO ha ve adv antages for certain kinds of data (e.g. microarrays and proteomics). The original LARS methodo logy is limited to cont in uous or binar y cov ar iates; gr oup ed LASSO and LAR o ffer an e x tension to facto r v ariables o r o ther v ariables with multiple de- grees of freedom such as p olynomial and spline fits. W o rk is needed to further in vestigate the prop erties of these metho ds, a nd to extend them to nonlinear mo dels. F urther w ork is also needed to address some practical co nsiderations, includ- ing order restrictions (e.g. main effects sho uld be included in a mo del b efore in teractions, or linear ter ms b efore quadra tic), forcing certain terms into the mo del, a llowing unpena lized terms, o r applying differen t lev els of p enalties to different predictors based on an analyst’s knowledge. F or exa mple, when esti- mating a treatmen t effect, the treatment term should b e forced into the mo del and estimated without p enalty , while co v aria tes should be optiona l and p enal- ized. Additional work is needed on choosing tuning pa rameters suc h as the mag- nitude of the ℓ 1 pena lt y parameter in LASSO and other metho ds, the num ber of steps for LAR, and the multiple tuning parameters for elastic net and fused LASSO. Clos ely related is the question of statistical inference: is a larger mo del significantly better than a simpler mo del? W o r k is needed to inv estigate and compare mo del-se lec tio n methods including C p , AIC, BIC, cross- v alidation, and empirical Bay es. W ork is also needed to develop estimates of bias, standar d err or, and confi- dence int erv a ls , for predictions, co efficient s, and linear co mb inations of co effi- cient s. Are predictions sufficiently close to nor mally-distributed to allow for the Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 87 use of t confidence in terv als? Do es it even make sense to compute standar d er- rors? Co efficients are definitely not no rmally distributed, due to a p oint mas s at zero; but when co efficient s are sufficiently large , might t interv als still b e useful, and how w ould one compute the standard erro rs? The signal-to-no ise ra tio needs to be examined for the prop osed methods, and alternatives compared. Evidence for a go o d s ignal-to-no ise ra tio would provide a strong imp etus for their adoption by the s tatistical communit y . Speed is a lso an issue, particularly for no nlinea r mo dels, and especially when cross v alidation is used for mo del selec tio n o r bo o tstrapping is used for infer- ences. In the linear r egressio n case the cross -pro duct ma trices or QR decomp o - sition req uired for computations can b e ca lculated in a single pass through the data. In co ntrast, for nonlinear mo dels, fitting each subset of predictors requires m ultiple passes. Developmen t of fast metho ds for nonlinear mo dels is highly desirable. Finally , to truly realize the pr omise of these methods be yond the domain o f academic resear ch, w ork is needed on usa bilit y issues. Implementations must b e robust, n umerical and g raphical diagnostics to in terpret regression mo del output m ust be developed, a nd in terfaces must be targeted to a broad base of user s. W e close on a p ositive note, with comment s in the literature ab out LARS: Knight ( 2004 ) is impressed by the r obustness of LASSO to small changes in its tuning pa rameter, re la tive to more classical stepwise subset selection metho ds, and notes “What s e e ms to make the LASSO sp ecial is (i) its abilit y to pro duce exact 0 estimates a nd (ii) the ‘fact’ that its bias seems to b e more co nt rollable than it is for other metho ds (e.g., ridge regres sion, whic h naturally ov ershrinks large effects) . . . ” Loub es and Mass a rt ( 20 0 4 ) indicate “It seems to us that it solves pra ctical questions of crucia l interest and raises very in teresting theoret- ical ques tio ns . . . ”. Segal et al. ( 2003 ) write “The developmen t of lea st angle regress io n (LARS) ( Efron et al. , 2 004 ) which can rea dily be sp ecialized to pro- vide all LASSO solutions in a highly efficient fashion, represents a ma jor break- through. LARS is a less gr eedy v ersion of standard forward s election schemes. The simple yet elegant manner in which LARS can b e adapted to yield LASSO estimates a s well as detailed description of prop erties o f pro cedure s , degrees o f freedom, and attendant algorithms are pro vided b y Efron et al. ( 200 4 ).” The pro cedure has enormous p otential, which is eviden t in the amount of effort dev oted to the area b y suc h a larg e num ber of authors in the short time since publication of the seminal paper. W e hop e that this article provides a sense of that v alue. Additional information, including softw a re, ma y b e found a t www.in sight ful.com/lars References Adams, J. L. (19 90) A computer exp eriment to ev aluate reg r ession strategies. In Pr o c e e dings of the Statistic al Computing Se ction , 55–62. America n Statistical Asso ciation. Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 88 Av alos, M., Gr a ndv alet, Y. and Am broise, C. (2007) Parsimonious additive mo d- els. Computational Statistics and Data Analysis , 51 , 2851–28 70. MR23456 10 Bakin, S. (19 9 9) A daptive r e gr ession and mo del sele ction in data mining pr ob- lems . Ph.D. thesis, The Australian Nationa l Universit y . Balakrishna n, S. and Madigan, D. (2 007) Finding predictiv e r uns with laps. International Confer enc e on Machine L e arning (ICML) , 41 5 –420 . Banerjee, O ., El Ghaoui, L. and d’Aspremont, A. (2008) Mo del selectio n through sparse maximum likelihoo d estimation for m ultiv a riate Gaussia n or binary data. Journal of Machine L e arning R ese ar ch . (to app ear). Breiman, L. (1995) Better subset regressio n using the nonnegativ e gar rote. T e ch - nometrics , 37 , 37 3–38 4 . MR13657 20 B ¨ uhlmann, P . and Meier, L. (2008) Discussion of “One-step sparse estimates in nonconcav e pena lized likelih o o d models” by H. Zo u and R. Li. Annals of Statistics . (to a ppea r). B ¨ uhlmann, P . and Y u, B. (2006 ) Spar se b o osting. Journal of Mach ine L e arning R ese ar ch , 7 , 1001–1 024. MR22743 95 Bunea, F., Tsybako v, A. and W eg k amp, M. H. (2007) Sparsit y o racle inequalities for the La sso. Ele ct ro nic Journal of Statistics , 1 , 16 9–194 . MR23121 49 Candes, E . and T ao , T. (2007 ) The Dantzig selector: statistical estimatio n when p is muc h larer than n . Annals of Statistics , 35 , 2 3 13–2 351. MR2 38264 4 Candes, E. J ., W akin, M. and Boyd, S. (2 0 07) Enhancing sparsity b y reweigh ted L1 minimization. T ech. rep., California Institute of T echnology . Chen, S., Do no ho, D. and Saunders, M. (1998 ) A tomic decomp osition by basis pursuit. SIAM Journal on Scientific Computing , 20 , 3 3 –61. MR16390 94 Choi, N. H. and Zh u, J. (200 6) V a riable selectio n with strong hered- it y/margina lity constraints. T ech. rep., Departmen t of Statistics, Univ ersit y of Michigan. Dahl, J ., V a ndenberghe, L. and Royc ho wdh ury , V. (2008) Cov aria nce selection for non-chordal gra phs via chordal embedding. Optimization Metho ds and Softwar e . (to app ear). Drap er, N. R. and Smith, H. (199 8) Applie d r e gr ession analysi s . Wiley , 3 rd edn. MR16143 35 Efron, B. and Has tie, T. (200 3) LARS softwar e for R and Splus . http:/ /www- s tat.stanford.edu/ ~ hastie /Pape rs/LA RS . Efron, B., Hastie, T., Jo hnstone, I. and Tibshirani, R. (2004) Least a ngle re- gression. Annals of Statistics , 32 , 407– 451. MR206016 6 Efron, B., Hastie, T. a nd Tibshirani, R. (2007 ) Discuss ion o f “the Dantzig selector” by E. Candes and T. T an. Annals of Statistics , 35 , 2358 –236 4. MR23826 46 Efroymson, M. A. (196 0) Multiple r egressio n analysis. In Mathematic al Metho ds for Digital Computers (eds. A . Ralston and H. S. Wilf ), v ol. 1, 191–2 03. Wiley . MR01179 23 F an, J. and Li, R. (200 1) V aria ble selection via nonconcav e penalized likeliho o d and its o r acle prop er ties. Journal of the A meric an Statistic al Asso ciation , 96 , 1348– 1360 . MR19465 81 F raley , C. and Hesterb erg, T. (2007) Lea st-angle regr ession and L a sso for large Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 89 datasets. T ech. r ep., Insightful Corpo ration. F rank, I. E. and F riedman, J. H. (1 993) A statistical view of some chemometrics regress io n to o ls, with discussio n. T e chno metrics , 3 5 , 109– 148. F reund, Y. and Schapire, R. E. (1997) A decision-theore tic generalization of online lea rning and a n a pplication to b o osting. Journal of Computer and System Scienc es , 5 5 , 119– 139. MR14730 55 F riedman, J. (2006) Herding lambdas: fast a lgorithms for p enalized regressio n and classification. Man uscript. F riedman, J. H. (19 9 1) Muliv ar iate adaptive regression splines. Annals of St atis- tics , 19 , 1 – 67. MR10918 42 F riedman, J. H., Hastie, T., H¨ ofling, H. and Tibshirani, R. (2007a) Path wise co ordinate optimization. A nnals of Applie d Statistics , 1 , 302 –332. F riedman, J. H., Hastie, T. and Tibshirani, R. (2007 b) Sparse in v erse cov a riance estimation with the gra phica l lasso. Biostatistics . (published online Decem ber 12, 20 0 7). F u, W. (1998) Penalized r e gressions : the Bridg e versus the La sso. Journal of Computational and Gr aphic al S t atistics , 7 , 39 7 –416 . MR16467 10 F u, W. (2000) S -PLUS p ackage br dgrun for shrinkage estimators with bridge p enalty . http://l ib.st at.cmu.edu/S/brdgrun.shar . F urniv a l, G. M. a nd Wilson, Jr., R. W. (1974) Reg ression by leaps and b ounds. T e chnometrics , 16 , 49 9–51 1. Gao, H.-Y. (19 98) W avelet s hrink ag e denoising using the non-negative ga rrote. Journal of Computationa l and Gr aphic al St atistics , 7 , 469 –488. MR16656 66 Genkin, A., Lewis , D. D. a nd Madiga n, D. (2007) Lar ge-scale Ba yesian log istic regress io n for text categor iza tion. T e chnometric s , 49 , 291–3 04. Ghosh, S. (200 7) Adaptive ela stic net: An improvemen t of e la stic net to achiev e oracle prop erties. T ech. rep., Departmen t of Mathematical Sciences, Indiana Univ ersity-Purdue Universit y , Indianap olis. Greenshtein, E. and Ritov, Y. (2004) P ersistency in high dimensional linear predictor-selection and the virtue of over-parametrization. Bernoul li , 10 , 971– 988. MR21080 39 Gui, J. and Li, H. (2005) Penalized Cox regr ession a na lysis in the hig h- dimensional a nd low-sample size settings, with a pplications to microar r ay gene expressio n data. Bioinforma tics , 21 , 30 01–3 0 08. Guigue, V ., Ra kotomamonjy , A. and Canu, S. (2006) Kernel basis pursuit. R evue d’Intel ligenc e A rtificiel le , 20 , 757–7 74. Gunn, S. R. and Kandola, J. S. (20 02) Structural modeling with spar s e k ernels. Machine L e arning , 10 , 581– 591. Hamada, M. a nd W u, C. (19 92) Analysis of des igned exp eriments with co mplex aliasing. Journal of Quality T e chnolo gy , 24 , 130–1 37. Hastie, T., Rosset, S., Tibshirani, R. and Zh u, J . (2 004) The entire regular iz a tion path for the support vector ma chine. Journal of Mach ine L e arning R ese ar ch , 5 , 1391 –141 5 . 3/5/ 04. MR2248021 Hastie, T., T aylor, J., Tibshira ni, R. and W a lther, G. (2007) F orward sta gewise regress io n and the mono tone las s o. Ele ctr onic Journal of S tatistics , 1 , 1–29. MR23121 44 Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 90 Hastie, T., Tibshir ani, R. and F riedman, J. (200 1) The Elements of Statis- tic al L e arning: Data Mining, Infer enc e and Pr e diction . Spring er V erlag. MR18516 06 Hesterb erg, T. and F raley , C. (2006a) Least angle regression. Pro p o sal to NIH, http:/ /www. insightful.com/lars . Hesterb erg, T. and F raley , C. (20 06b) S-PLUS and R pack age for least a ngle regress io n. In Pr o c e e dings of the Americ an Statistic al Asso ciation, Statist ic al Computing S e ction [CD-R OM] , 20 54–20 61. Al exandria, V A: American Sta tis- tical Asso ciation. Huang, J., Ma, S. and Zhang, C.-H. (2008) Adaptive La sso for sparse high- dimensional regr ession models. Statisic a Sinic a . (to app ear ). Hurvich, C. M. and Tsai, C.-L. (1990) The imp act of mo del selection on inference in linear reg r ession. The Americ an Statistician , 44 , 21 4–21 7 . Insightf ul Corp or tation (2006) GLARS: Gener alize d L e ast Angle Re gr ession softwar e for R and S-PLUS . http://ww w.ins ightful.com/lars . Ishw a ran, H. (2004) Discussion of “Lea st Angle Regress ion” b y Efron et al. Annals of Statistics , 32 , 4 5 2–45 8. MR2 06016 6 Jolliffe, I., T renda filov, N. and Uddin, M. (20 03) A mo dified principal co mpo nent tech nique based on the LASSO. Journal of Computational and Gr aphic al Statistics , 12 , 5 31–5 47. MR20 02634 Keerthi, S. and Shev ade, S. (2007) A fast tracking algo rithm for gener alized lars/las so. IEEE T r ansactio ns on Neur al Networks , 18 , 1826– 1830 . Khan, J. A., V an Aelst, S. and Zama r, R. H. (20 07) Robust linear mo del se - lection based on lea st angle regres sion. Journal of the Americ an Statistic al Asso ciation , 102 , 1289–1 299. Kim, J., Kim, Y. and K im, Y. (2005a) glasso: R-p ackage for Gr adient LASS O algorithm . http:/ /idea .snu. ac.kr/Research/glassojskim/glasso.htm . R pack age version 0.9, ht tp:// idea. snu.ac.kr/Research/glassojskim/ glasso .htm . Kim, J., Kim, Y. and Kim, Y. (200 5b) Gradien t LASSO algorithm. T echnical rep ort, Seoul Nationa l Universit y . Kim, Y., Kim, J. and Kim, Y. (2006) B lo ckwise sparse regres s ion. Statistic a Sinic a , 16 , 375–39 0. MR22672 40 Knight, K. (20 04) Discussion of “Least Angle Regression” b y Efron et al. Annals of Statistics , 32 , 458 –460 . MR2060 166 Leng, C., Lin, Y. and W ahba, G. (2006) A note on the LASSO and r elated pro cedures in mo del selection. Statistic a S inic a , 1 6 , 1273 –128 4 . MR23274 90 Lin, Y. a nd Z hang, H. (20 06) Comp onent selectio n a nd smo othing in m ul- tiv aria te nonpar ametric regr e s sion. Annals of Statistics , 34 , 22 72–2 297. MR22915 00 Lokhorst, J. (1999) The LASSO and Generalised Linea r Mo dels. Honor s Pro ject, The Universit y of Adelaide, Australia. Lokhorst, J., V enables, B. and T urlach, B. (19 99) L asso2: L1 Constr aine d Estimation R outines . http:/ /www. maths.uwa.edu.au/ berwi n/sof tware/ lasso. html . Loub es, J. a nd Ma ssart, P . (2004) D iscussion of “least ang le r egressio n” by Efron Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 91 et al. Annals of Statistics , 32 , 46 0–46 5. MR206 0166 Lu, W. and Zhang , H. (2007) V a r iable selection for prop ortional o dds mo del. Statistics in Me dicine , 2 6 , 3771 –378 1 . Madigan, D. and Ridgew ay , G. (200 4) Discussio n of “ least angle regressio n” by Efron et al. A nnals of Statistics , 32 , 465– 4 69. MR20601 66 McCullagh, P . and Nelder, J. A. (1989) Gener alise d Line ar Mo dels . London: Chapman and Hall. Meier, L. and B ¨ uhlmann, P . (2007) Smoo thing ℓ 1 -p enalized estimators for high- dimensional time-co urse data. Ele ctr onic Journal of St atistics , 1 , 59 7–61 5. MR23690 27 Meier, L., v an de Geer, S. and B ¨ uhlmann, P . (20 08) The group lasso for logistic regress io n. Journ al of the R oya l Statistic al So ciety, S eries B , 70 , 53 –71. Meinshausen, N. (20 07) Las so with relaxation. Co mputational Statistics and Data Anal ysis , 52 , 37 4–393 . Meinshausen, N. and B¨ uhlm ann, P . (2006) High dimensional gr aphs a nd v ariable selection with the lasso. Annals of Statistics , 34 , 1436– 1 462. MR22783 63 Meinshausen, N., Rocha, G. a nd Y u, B. (20 07) A tale of three cousins: Las so, L2Bo osting, and Dantzig. Annals of Statistics , 35 , 2373–2 384. MR23826 49 Meinshausen, N. and Y u, B. (2008) Lasso -type rec overy of sparse represen tations for high-dimensional data. A nnals of Statistics . (to app ear ). Miller, A. (2002) Subset Sele ction in R e gr ession . Chapman & Hall, se c ond edn. MR20011 93 Monahan, J. F. (2001) Numeric al Metho ds of Statistics . C a mbridge Univ ersit y Press. MR1813 549 Osb orne, M. R., Presnell, B. and T urlach, B. A. (2000a) A new a ppr oach to v ari- able selection in least squar es problems. IMA J ourn al of Numeric al Analysi s , 20 , 389 – 403. MR17732 65 Osb orne, M. R., Presnell, B. and T urlach, B. A. (2000b) On the LASSO and its dual. J ou rn al of Computational and Gr ap hic al Statistics , 9 , 319–3 37. MR18220 89 Owen, A. (2006) A robus t hybrid of la s so and ridge r egressio n. F rom the web. Park, M. Y. and Hastie, T. (2006a ) glmp ath: L1 R e gularization Path for Gener al ize d Line ar Mo dels and Pr op ortional Hazar ds Mo del . URL http:/ /cran .r- project.org/src/contrib/Descriptions/glmpath.html . R pack age version 0.91. Park, M. Y. and Hastie, T. (20 06b) Regularization path algorithms for detecting gene interactions. T ech. rep., Department of Statistics, Stanford Universit y . Park, M.-Y. and Hastie, T. (20 07) An L 1 regulariza tion-path algor ithm for generalized linear models. Journal of the R oyal Statistic al So ciety Series B , 69 , 659 – 677. MR23700 74 Ro eck er, E. B. (1991) Prediction error and its estimation for subset-selected mo dels. T e chnometrics , 33 , 459– 468. Rosset, S. (2005) F ollowing curv ed r egularized o ptimization solution paths. In A dv anc es in Neur al Information Pr o c essing Systems 17 (eds. L. K. Saul, Y. W eiss and L. Bottou), 1153–11 60. Cambridge, MA: MIT Pres s. Rosset, S. a nd Zhu, J. (2004) Discussion of “Least Angle Regres sion” by E fron Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 92 et al. Annals of Statistics , 32 , 46 9–47 5. MR206 0166 Rosset, S. and Zhu, J. (2007) Piecewise linear regularized solution paths. A nnals of Statistics , 35 , 101 2–10 30. MR2341 696 Roth, V. (2004) The genera lized LASSO. IEEE T r ansactions on Neur al Net- works , 15 , 16– 28. Segal, M. R., Dahlquist, K. D. and Conklin, B. R. (200 3) Regression a pproaches for microarr ay da ta analysis. Journal of Computational Biolo gy , 10 , 96 1–98 0. Shi, W., W ahba, G., W r ight, S., Lee, K., Klein, R. and K lein, B. (2008 ) Lasso- patternsearch a lgorithm with application to ophthalmology a nd genomic data. Statistics and Its Interfac e . (to appea r). Silv a, J., Mar ques, J. and Lemos, J. (2005) Selecting landmark p oints for spar se manifold lear ning. In A dvanc es in Neura l Information Pr o c essing Systems 18 (eds. Y. W eiss, B. Sch¨ olkopf and J. P latt), 1241–12 48. Ca mb ridge, MA: MIT Press. Simil¨ a, T. a nd Tikk a, J. (2006) Common subset selection of inputs in multire- sp o nse r egressio n. In IEEE International Joint Confer enc e on Neu r al N et- works , 1908 –191 5 . V anco uver, Cana da. Stine, R. A. (200 4) Discussion of “ Least Ang le Reg r ession” by Efron et al. Annals of Statistics , 32 , 4 7 5–48 1. MR20601 66 Thisted, R. A. (19 8 8) Elements of Statistic al Computing . Chapman and Hall. MR09404 74 Tibshirani, R. (1 9 96) Regr ession shrink a g e and selection via the lasso. Journal of the R oyal Statistic al So ciety, S eries B , 58 , 26 7–28 8. MR13792 42 Tibshirani, R. (1997) The lasso metho d for v ariable selection in the Cox mo del. Statistics in Me dicine , 1 6 , 385– 395. Tibshirani, R., Sa unders, M., Rosset, S., Zh u, J. and Knight , K . (20 0 5) Spar sity and smo o thness via the fused la s so. Journal of t he R oyal Statistic al So ciety, Series B , 67 , 91– 108. MR21366 41 T rendafilov, N. and Jo illiffe, I. (2007) Dlass: V ariable selection in discriminant analysis via the lass o . Computational Statistics and Data A nalysis , 51 , 3718– 3736. MR236 4486 T urlach, B. A. (2004 ) Discussion o f “Lea s t Angle Regression” by Efro n et al. Annals of Statistics , 32 , 4 8 1–49 0. MR2 06016 6 T urlach, B. A., V enables, W. N. and W right, S. J. (20 05) Simultaneous v ariable selection. T e chnome trics , 4 7 , 349– 363. MR2164706 v an de Geer, S. (2008 ) H igh-dimensional generalized linear mo dels and the lasso. Annals of Statistics , 36 , 6 1 4–64 5. W ang, G., Y eung, D.-Y. a nd Lochovsky , F. (2007a) The kernel path in kernelized LASSO. In International Confer enc e on Artificial Intel ligenc e and Statistics . San Juan, Puer to Rico. W ang, H. and Leng, C. (2006) Improving group ed v aria ble selection via agla sso. T ech. rep., Peking Univ ersit y & National University of Singa po re. W ang, H. a nd L e ng , C. (2007 ) Unified LASSO estimation via least squar es approximation. Journal of the Americ an Statistic al Asso ciati on , 102 , 1039 – 1048. W ang, H., Li, G. and Tsai, C. (2007b) Reg ression co efficient and autoregressive Hesterb er g et al./LARS and ℓ 1 p enalize d r egr ession 93 order shrink ag e and selection via the lasso . Journal of the R oy al St atistic al So ciety, Series B , 69 , 63–7 8 . MR23015 00 Y uan, M. (2008) Efficient computation of the ℓ 1 regularized solution path in Gaussian graphical mo dels . Journal of Computational and Gr aph ic al St atis- tics . (to appea r ). Y uan, M., Jos eph, R. and Lin, Y. (2007) An efficient v ar iable selection approach for analyzing desig ned e xpe r iment s. T e chnometrics , 49 , 430 –439 . Y uan, M. and Lin, Y. (20 06) Mo del selection and estimation in regr ession with group ed v ariables. Journal of t he Roy al Statistic al So ciety, Series B , 68 , 49–68 . MR22125 74 Y uan, M. and Lin, Y. (2007a) Model selection and estimation in the Gaussian graphical mo del. Bio metrika , 9 4 , 19–3 5. MR2367824 Y uan, M. and Lin, Y. (2007b) On the non-negative garrote estimator. Journal of the R oyal Statistic al So ciety, S eries B , 69 , 14 3–16 1. MR232 5 269 Zhang, C.-H. and Huang, J. (20 07) The sparsity and bias of the las so selection in high-dimensiona l linear regres s ion. Annals of S tatistics . T o app ear . Zhang, H. and Lu, W. (2007 ) Adaptive Lasso for Cox’s prop or tional hazards mo del. Biometrika , 94 , 691–7 03. Zhang, H., W ahba, G., Lin, Y., V o elker, M., F er ris, M., Klein, R. a nd Klein, B. (2004) V ariable selection and model building via lik elihoo d basis pursuit. Journal of the A meric an Statistic al Asso ciation , 99 , 65 9 –672 . MR20909 01 Zhao, P ., Ro cha, G. and Y u, B. (2008 ) Gr o up e d a nd hierarchical model selectio n through comp osite a bsolute p enalties. A nnals of Statistics . (to app e a r). Zhao, P . and Y u, B. (200 6) On mo del selection co nsistency of Lasso. J ournal of Machine L e arning Rese ar ch , 7 , 2 5 41–2 567. MR22744 49 Zhao, P . and Y u, B. (2007) Stag e wise Lasso. Journal of Machine L e arning R ese ar ch , 8 , 2701–2 726. Zhu, J., Rosset, S., Hastie, T. and Tibs hir ani, R. (2003) 1-norm s upp or t v ector machines. In A dvanc es in N eur al Information Pr o c essing Systems 16 , 49 –56. MIT Press. NIPS 2003 Pro ceeding s . Zou, H. (20 06) The adaptive L a sso and its or acle prop erties. Journal of the Ameri c an St atistic al Asso cia tion , 101 , 1 418– 1429. MR22794 69 Zou, H. and Hastie, T. (2005a) elasticnet: Elastic Net Re gu larization and V ari- able Sele ction . R pack a ge version 1 .0-3. Zou, H. and Hastie, T. (2 005b) Regulariza tion and v ariable selection via the elastic net. J ournal of the R oyal Statistic al So ciety, Series B , 67 , 301– 320. MR21373 27 Zou, H., Hastie, T. and Tibshirani, R. (2006) Sparse principal comp onent analysis. J ournal of Computational and Gr aphic al Statistics , 15 , 265 –286. MR22525 27 Zou, H., Hastie, T. and Tibs hir ani, R. (20 0 7) O n the “Degree s of F reedom” of the Lasso . Annals of Statistics , 35 , 2173–2 192. MR23639 67 Zou, H. and Li, R. (2008) One-step spar se estimates in nonconcave penalized likelih o o d mo dels. A nnals of S tatistics . (to a ppea r).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment